Embed Size (px)
Citation preview

Digital Signal Processing 24 (2014) 124–134
Contents lists available at ScienceDirect
Digital Signal Processing
www.elsevier.com/locate/dsp
Context-aware Discriminative Vocabulary Tree Learning for mobilelandmark recognition
Zhen Li ∗, Kim-Hui Yap
School of Electrical and Electronic Engineering, Nanyang Technological University, 639798, Singapore
a r t i c l e i n f o a b s t r a c t
Article history:Available online 18 September 2013
Keywords:Mobile landmark recognitionContent and context integrationWeighted hierarchical clustering
Recently, mobile landmark recognition has become one of the emerging applications in mobile media,offering landmark information and e-commerce opportunities to both mobile users and business owners.Existing mobile landmark recognition techniques mainly use GPS (Global Positioning System) locationinformation to obtain a shortlist of database landmark images nearby the query image, followed byvisual content analysis within the shortlist. This is insufficient since (i) GPS data often has large errors indense build-up areas, and (ii) direction data that can be acquired from mobile devices is underutilized tofurther improve recognition. In this paper, we propose to integrate content and context in an effective andefficient vocabulary tree framework. Specifically, visual content and two types of mobile context: locationand direction, can be integrated by the proposed Context-aware Discriminative Vocabulary Tree Learning(CDVTL) algorithm. The experimental results show that the proposed mobile landmark recognitionmethod outperforms the state-of-the-art methods by about 6%, 21% and 13% on NTU Landmark-50, PKULandmark-198 and the large-scale San Francisco landmark dataset, respectively.
© 2013 Elsevier Inc. All rights reserved.
1. Introduction
Recent years have witnessed the phenomenal growth in the us-age of mobile devices. Nowadays, most mobile phones in use havethe camera feature. The built-in camera and network connectiv-ity of current mobile phones makes it increasingly appealing forthe users to snap pictures of landmarks, and obtain relevant in-formation about the captured landmarks. This is particularly usefulin applications such as mobile landmark identification for touristsguide, mobile shopping, and mobile image annotation. An illustra-tion of a mobile recognition system for tourist guide is shown inFig. 1. The mobile user captures a landmark image but he/she hasno idea about the landmark. Then the user uploads it to the serverand, in a moment, the related information of the captured image isreturned to the mobile user, e.g. the landmark name, the locationin the map, the description of the landmark, recent events, etc.The returned shortlist contains the best matched images and mul-tiple images corresponding to the same category are only shownwith best matched one. In such a way, the user will probably findthe correct landmark category by simply scrolling the screen in afew times. Landmark recognition (e.g. [1–3]) is closely related tolandmark classification [4] and landmark search [5] problems, andcan be broadly categorized into non-mobile and mobile landmarkrecognition systems.
* Corresponding author.E-mail addresses: [email protected] (Z. Li), [email protected] (K.-H. Yap).
1051-2004/$ – see front matter © 2013 Elsevier Inc. All rights reserved.http://dx.doi.org/10.1016/j.dsp.2013.09.002
In recent years, a number of non-mobile landmark vision sys-tems have been developed [6,4], which focused on learning astatistical model for mapping image content features to classifi-cation labels. In [6], a scalable vocabulary tree (SVT) is generatedby hierarchically clustering local descriptors as follows: (1) an ini-tial k-means clustering is performed on the local descriptors ofthe training data to obtain the first-level k-clusters, (2) the sameclustering process is applied recursively to each cluster at the cur-rent level. This will lead to the formation of a hierarchical k-meansclustering structure, also known as a VT in this context. Based onthe VT, the high-dimensional histograms of image local descrip-tors can be generated, which enables efficient image recognition.In [4], non-visual information such as textual tags and temporalconstraints are utilized to improve the performance of contentanalysis.
However, these landmark recognition methods underutilize theunique features of mobile devices, such as location, direction andtime information. These context information can be easily acquiredfrom mobile devices, which can further enhance the performanceof content analysis without introducing much additional computa-tional cost. In the mobile landmark recognition scenario, utilizingeither content or context analysis alone is suboptimal. GPS locationis able to help discriminate visually similar landmark categoriesthat are far away from each other. However, location informationshould not be used alone due to the GPS error. As such, the con-text information must be used in conjunction with visual contentanalysis in mobile landmark recognition.

Z. Li, K.-H. Yap / Digital Signal Processing 24 (2014) 124–134 125
Fig. 1. Illustration of mobile landmark recognition prototype.
Fig. 2. Proposed framework for mobile landmark recognition.
In order to further enhance the performance, it is therefore im-perative to combine the context information with content analysisin mobile systems. In [7], the content of mobile images is analyzedbased on local descriptors, and the user interaction as a sourceof context information is considered. In [8–11,1], the GPS loca-tion information is utilized to assist in content-based mobile imagerecognition. In these methods, the content analysis is essentiallyfiltered by a pre-defined area centered at the logged GPS loca-tion of the query image. With the aid of the location information,the challenge in differentiating similar images that are captured indifferent areas can be reduced substantially. Recent works in [5,12] demonstrate that GPS can be utilized to improve SVT-basedmobile landmark recognition [6]. In these systems, the candidateimages for the query image are obtained from the landmark imagedatabase by using GPS information. This is done by selecting thoselandmark images that are located close to the mobile device whentaking the query image. Visual content analysis is then performedin the GPS-based shortlist for the final recognition. This approachmakes it easy to differentiate visually similar images of differentlandmark categories that are far away from each other.
However, the approach of performing content analysis withinthe GPS-based shortlist still has some drawbacks that make it non-ideal in real applications: (1) it is elusive to determine the optimalsearch radius since the GPS error of the captured image may varysignificantly from open areas (about 30 meters) to dense build-up
areas (up to 150 meters). In the event that GPS error of the cap-tured image is too large, the correct landmark category may befiltered out, which will result in wrong recognition, and (2) direc-tion information is not utilized to further improve the recognitionperformance, which can be easily acquired from the digital com-pass on mobile devices.
In order to circumvent the approach of performing contentanalysis within a GPS-based shortlist as in most existing mobilerecognition systems as well as to have the flexibility of incorpo-rating different types of context, we propose to integrate variouscontent and context information by Context-aware DiscriminativeVocabulary Tree Learning (CDVTL). As compared to the well-knownapproach of using SVT built upon SIFT descriptors [6], we im-prove the recognition performance by incorporating various con-text descriptors. Context information adopted in this work includeslocation information (obtained through built-in GPS or WiFi local-ization) and direction information (obtained from digital compass).
2. Overview of the proposed mobile landmark recognition
In this paper, we present a context-aware mobile landmarkrecognition framework as shown in Fig. 2, which enables efficientmobile landmark recognition in both context-aware and context-agnostic environments.
In Fig. 2, the application on the mobile device provides theuser interface which can upload the photo along with its context

126 Z. Li, K.-H. Yap / Digital Signal Processing 24 (2014) 124–134
Fig. 3. Typical images from NTU landmark dataset. (a) Administrative building, (b) Nanyang auditorium, (c) Cafe express.
information such as GPS and direction to the server, while allthe feature extraction and recognition tasks are processed in theserver side. In such a way, both feature extraction and recognitionare fast and the efficiency is independent to the computationalcapacities of different mobile devices. The battery energy is alsosaved by avoiding the computation on the mobile devices. More-over, this architecture makes it easier to migrate the mobile imagerecognition across different mobile platforms. In this work, a pro-totype for context-aware mobile image recognition is developedand its efficiency is validated using the developed Android appli-cation.
The recognition procedure is different from the traditional mo-bile image recognition pipeline: confine the candidate imagesto a radius of several hundred meters centered at the locationof the mobile device, and then perform content-based recogni-tion within the shortlist. This pre-filtering is less than ideal be-cause it is elusive to determine the search range centered atthe logged location and the range should not be a constant.In this work, the pre-filtering by location is circumvented, thatis, image content descriptors and context information are pre-combined without the pre-filtering step. The proposed frameworkhas achieved superior recognition precision with low computa-tional cost comparing with some state-of-the-art mobile visionsystems to recognize landmarks from university-scale to city-scalelandmark datasets.
We also propose a Context-aware Discriminative VocabularyTree Learning (CDVTL) algorithm that can be embedded in the pro-posed framework. In landmark recognition scenarios, the locationinformation can be more important within a region with a radiusof hundreds of meters, while less reliable in a region within onehundred meters due to the GPS error. In contrast, image contentdescriptors are usually more discriminative in small regions forlandmark recognition. In addition, for regions of the same scale,the image content descriptors may not be the same discriminative,e.g. it is more discriminative in suburban areas but less discrim-inative in build-up areas. In view of these observations, for eachcodeword in each level of the hierarchical clustering when train-ing the vocabulary tree, we introduce a weighting scheme whichevaluates the relative discriminative power between the contextinformation and the image content descriptors. Intuitively, a smallregion with visually distinct landmarks is supposed to yield moreweighting for image descriptors and less weighting for location,and vice versa. In this work, we use 128-D SIFT as the contentdescriptor, and 2-D GPS location (longitude and latitude) and 1-Ddirection as the context descriptors. The context descriptors areconcatenated to each of its SIFT descriptor to form a 130-D (onlyGPS is available) or 131-D (both GPS and compass are available)hybrid descriptors, where SIFT, GPS and direction components havetheir respective weights.
In order to demonstrate the effectiveness of combining contentand context features for image recognition, we randomly selected60 images from the categories “Administrative building”, “Nanyangauditorium” and “Cafe express” in NTU landmark dataset. It is atypical dataset to compare different methods although the classifi-
cation on this small-scale dataset is relatively easier than that onthe whole dataset. The example images for the 3 landmarks areshown in Fig. 3(a)–(c), respectively, and are briefed as categories1, 2 and 3 here. We can notice that categories 1 and 2 are vi-sually very similar, however, they are different buildings far awayfrom each other. In contrast, categories 2 and 3 are located nearbysharing similar GPS coordinates, however, they are visually dissim-ilar.
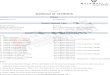
In Fig. 4(a)–(b), we show 2D feature for the purpose of illus-tration, where different shapes indicate the feature extracted fromdifferent categories. In Fig. 4(a), the average pixel values in R andB channels are adopted as the 2D content feature for each image,which are clustered by using K -means clustering. By observing theVoronoi graph, we can see that the 2D content features are notwell partitioned between category 1 and category 2 because theimages are visually similar, while the content features from cat-egory 3 are well separated from categories 1 and 2. In Fig. 4(b),the 2D GPS coordinates of images are clustered by K -means clus-tering. By observing the Voronoi graph, we can observe that the2D GPS features are not well partitioned between categories 2 and3 because the images are geometrically nearby, while the GPS fea-ture from category 1 is distinguished. In Fig. 4(c), the 4D compositefeature is formed by concatenating the 2D R–B feature and 2D GPScoordinates, and is also clustered by K -means clustering. In orderto illustrate the clustering results, the 4D composite feature is onlyshown in 2D geometrical point of view in Fig. 4(c). For visualiza-tion, the feature points allocated to different clusters are markedby different colors. We can observe that the feature points are cor-rectly grouped into their own category. In contrast, in Fig. 4(a)and (b), the feature points are not well grouped into their owncategory overall. Therefore, by considering both the content andcontext information, we can obtain a better representation of themobile image for the subsequent recognition.
Using K -means as the flat clustering method in each layerof hierarchical clustering, a VT is generated from the compositecontent–context image features. VT trees are illustrated In Fig. 5,where the gray level of each node indicates the weight for GPScomponent (the darker the higher). In Fig. 5(a), the traditionalVT-based mobile landmark recognition [5,12] is shown, where thecoarse clusters are partitioned by location first, and the finer clus-ters are obtained by soly visual content descriptors. However, asshown in Fig. 4, this scheme is not optimal. In Fig. 5(b), GPS isconsidered together with content feature in each cluster in eachlevel, and the weight for each component is generally non-zerovalues. For example, in the coarse cluster I, the visual content isimportant and location is less useful, so the node I has very lowlocation weight; in the cluster III, location weight is high since itcan perfectly separate the patterns; while in the cluster II, contentand GPS weights are almost equal so the node is gray. We can no-tice that the existing mobile vision systems based on VT matchingare essentially a special case of content–context weighing in theproposed hybrid recognition framework.
Z. Li, K.-H. Yap / Digital Signal Processing 24 (2014) 124–134 127
Fig. 4. Clustering of content feature, context feature and composite feature. (a) Clustering by content descriptors alone, (b) clustering by location coordinates alone, (c) clus-
tering by hybrid RB–GPS descriptors with a proper weighting scheme.3. Context-aware discriminative vocabulary tree learning
3.1. Related work
Towards scalable near-duplicate mobile landmark recognition,the Scalable Vocabulary Tree (SVT) model [6] is well exploited inthe state-of-the-art works [12,13,5,14]. In these works, the SVTis constructed within a region by filtering out the database im-ages that are far away from the query image. An SVT T is con-structed by hierarchically clustering of local descriptors, whichconsists of C = B L codewords, where B is the branch factorand L is the depth. Let each node vl,h ∈ T in the tree repre-
sent a visual codeword, where l ∈ {0,1, . . . , L} indicates its level,and h ∈ {1,2, . . . , B L−l} is the index of its node in its level.A query image q is represented by a bag of Nq local descrip-tors Xq = {xq,i}, i ∈ Nq . Each xq,i is traversed in T from the rootto a leaf to find the nearest node, resulting in the quantizationT (xi) = {vl,h
i }Ll=1. Thus, a query image is eventually represented
by a high-dimensional sparse Bag-of-Words (BoW) histogram Hq =[h1q, . . . ,hCq] obtained by counting the occurrence of its descrip-tors on each node of T .
The database images are denoted by {dm}Mm=1. Following the
same VT quantization procedure, the local descriptors {y j} in dm

128 Z. Li, K.-H. Yap / Digital Signal Processing 24 (2014) 124–134
Fig. 5. VT nodes and the associated weights for location. (a) Nister’s method, (b) a better solution.
are mapped to a high-dimensional sparse Bag-of-Words (BoW) his-togram Hd = [h1d, . . . ,hCd].
The images with highest similarity score sim(q,dm) betweenquery q and database image dm are returned as the retrieval set,where similarity sim(q,dm) is defined in [6] as
sim(Hq,Hdm ) =∥∥∥∥ Hq · w
‖Hq · w‖ − Hdm · w
‖Hdm · w‖∥∥∥∥ (1)
where w = [w1, w2, . . . , wC ], wi = ln MMi
, and Mi is the numberof images in the database with at least one descriptor vector paththrough node i.
Since the vocabulary tree is very large, the number of imageswhose descriptors are quantized to a particular node is normallyzero. Therefore, inverted index files attached to leaf nodes allow avery efficient implementation of this voting procedure. In [6] thescalability is addressed by only comparing those database imagesindexed by each non-zero codeword for the given query image.
3.2. Node-wise content and context weighting
As mentioned in our contributions, for each VT node we intro-duce a weighting factor that evaluates the relative discriminativepower between the context information and the image contentdescriptors. Given a set of training data {(xl
i, ti)}, i = 1, . . . , N ,l = 1, . . . , K , where xl
i ∈ R Dl represents the i-th vector in the l-thtype of feature (SIFT descriptor, GPS location, direction, etc.), Dl isthe dimensionality of the l-th type of feature. ti is the multioutputslabel vector, that is, if the original class label is p, the expectedoutput vector is ti = [0, . . . ,0,1,0, . . . ,0]T with only the p-th el-ement of ti = [ti,1, . . . , ti,m]T being one, while the rest of the el-ements are set to zero. Due to the nonlinear separability of thesetraining data in the input space, in most cases, one can map thetraining data xl
i from the input space to a feature space Z througha nonlinear mapping φ : xi → φ(xi). As such, the distance betweentwo different classes in the feature space Z is 2
‖w‖ , where w is thecoefficient vector in the feature space. To maximize the separatingmargin and to minimize the training errors, ε i , is equivalent to
minw,ε,α,η
=K∑
l=1
{1
2
∥∥wl∥∥2
2 + 1
2C · 1
N
N∑i=1
∥∥αlεli
∥∥22 + 1
2Dη2
}(2)
subject to
φ(xl
i
)wl = tT
i − (εl
i
)T, i = 1,2, . . . , N (3)
and
1T α = 1 − η (4)
where εi = [εi,1, . . . , εi,m]T is the training error vector with re-spect to the training sample xl
i , αl is the weight for the l-th typeof descriptor, η is the slack factor for the sum of weights, and Cis a user-specified parameter and provides a tradeoff between thedistance between two different classes and the training error. Inthis work, we do not aim to tune C for every dataset in order toachieve a better generalization, so we default C = 1. The first twoterms in the objective function is the balance of error minimizationand generalization. The additional third term is the regularizationthat requires that the weights summing to unity, which it can re-strict the search space to achieve efficient optimization. Based onthe KKT theorem [15], the above optimization function is equiva-lent to solving the following dual optimization problem:
L =K∑
l=1
{1
2
∥∥wl∥∥2
2 + 1
2C · 1
N
N∑i=1
∥∥αlεli
∥∥22 + 1
2Dη2
}
−K∑
l=1
N∑i=1
m∑j=1
βi, j(φ(xl
i
)wl
j − ti, j + εli, j
) − r(1T α − 1 + η
)(5)
The KKT optimality conditions are as follows:
∂L
∂ wlj
= 0 → wlj =
N∑i=1
βli, jφ
(xl
i
)T → wl = ΦTl βl (6)
∂L
∂εli
= 0 → βli = C · 1
Nα2
l εli → βl = C · 1
Nα2
l εl (7)
∂L
∂βli
= 0 → ΦTl wl − T + εl = 0 (8)
∂L
∂αl= 0 → C · 1
Nαl
N∑i=1
∥∥εli
∥∥22 − r = 0 → αl = r
C · 1N ‖εl‖2
2
(9)
where αi = [αi,1, . . . ,αi,m]T and α = [α1, . . . ,αN ]T . By substitut-ing (6) and (7) into (19), we have
wl = ΦTl
(NI
Cα2l
+ ΦlΦTl
)−1
T (10)
The output function is
Yl = Φl · wl = ΦlΦTl
(NI
Cα2l
+ ΦTl Φl
)−1
T (11)
Since we expect that 1T α = 1, from (9) and (8), we can cal-culate the normalized weighting factor α∗
l for the l-th type offeature:

Z. Li, K.-H. Yap / Digital Signal Processing 24 (2014) 124–134 129
α∗l = αl∑
l αl= 1
‖T − Yl‖22
/∑l
(1
‖T − Yl‖22
)(12)
Different solutions to the above optimization can be obtainedfor the purpose of efficiency of huge sizes of the training set. Ifthe number of training data is very large, for example, it is muchlarger than the dimensionality of the feature space, we have analternative solution. From (6) and (7), we have the following equa-tions:
βl = C · 1
NΦT
l α2l εl (13)
εl = N
C
(ΦT
l α2l
)+wl (14)
ΦTl wl + N
Cα2l
(ΦT
l
)+wl = T (15)
ΦTl
(Φl + NI
Cα2l
(ΦT
l
)+)
wl = ΦTl T (16)
wl =(
NI
Cα2l
+ ΦTl Φl
)−1
ΦTl T (17)
From (6) and (8), we have
ΦTl Φlβ
l + NI
Cα2l
βl − T = 0 (18)
βl =(
ΦTl Φl + NI
Cα2l
)−1
T (19)
And then from (17) we have
εl = T − Φl · wl =[
I − Φl
(NI
Cα2l
+ ΦlΦTl
)−1
ΦTl
]T (20)
and predicted class label matrix is
Yl = Φl · wl = Φl
(NI
Cα2l
+ ΦTl Φl
)−1
ΦTl T (21)
We have φ(x) = [G(a1,b1,x), . . . , G(aD ,bD ,x)] where G(a,b,x)
is a nonlinear piecewise continuous function. According to [16], al-most all nonlinear piecewise continuous functions can be used forthe feature mapping φ(x). So the parameters {(ai,bi)}D
i=1 used inφ(x) can be very diversified and here they are randomly generated.In this work, we adopt the Sigmoid function:
G(a,b,x) = 1
1 + exp(−(a · x + b))(22)
In order to achieve high computational efficiency, if the sizesof the training data in the feature space Φl are very large, onemay prefer to apply solutions (21) in order to reduce computa-tional costs; otherwise, one may prefer to use either solutions (11)or (21).
3.3. Context-aware weighted hierarchical clustering
Under the proposed framework, a simple way to integrate thecontent and context information is that, various types of descrip-tors (128-D SIFT, 2-D GPS and/or 1-D direction) are pre-combinedto generate hybrid descriptors with equal weight of each type ofdescriptors. Then the traditional hierarchical K -means algorithmis applied directly to the hybrid descriptors as in [6]. This tenta-tive strategy is expected to improve the recognition relative to SVTmatching based on content descriptors, however, it can be furtherimproved by assigning optimal weights for each type of descriptors
respectively. Therefore, the clustering algorithm has to considera weighting vector associated with each hybrid content–contextdescriptor in the computation of cluster centers. We develop a di-verse hierarchical clustering with a weighted K -means embeddedas the subroutine clustering algorithm, which is composed of thefollowing steps in Algorithm 1.
Algorithm 1 Context-aware Discriminative Vocabulary Tree Learn-ing.
Input: Descriptors of database images and their labels: Z = {(xpm,ym)}, where xp
mcan be SIFT, GPS or direction descriptors for an image.Output: The vocabulary tree T consisting of C = BL visual codewords vl,h ∈ T ,where l ∈ {0,1, . . . , L} indicates its level, and h ∈ {1,2, . . . , BL−l} is its index in itslevel.(1) Set the branch factor B , the depth L; Initialize a vocabulary tree by using thetraditional hierarchical K -means clustering; Set the current level l = L. (2) Applythe following weighted K -means procedure to the descriptors that are assigned tothe current cluster:
• Calculate the weight αl for the l-th type of feature using (12);• Compute the cost function: E(V) = ∑n
i=1∑D
j=1∑
vl,h∈V μ j(xi, j − vl,hj )2, where
D = ∑Pp=1 D p is the sum of the dimensionalities of all types of features, and
μ j is the weighting for each dimension as follows: μ = [[ α1D1
, . . . ,α1D1
]D1×1, . . . ,
[ αPD P
, . . . , αPD P
]D P ×1]D×1;• Repeat the pattern assignment and cluster center update until convergence
with the weighted distance measure: d(x,v) = ∑Dj=1 μ j(x j − v j)
2;
• Repeat the above clustering procedure in level l until all vl,h,h = 1, . . . , B L−l ,have been partitioned to B clusters;
• l ← l − 1. Repeat the clustering procedure in each level recursively until l = 0.
4. Experimental results
4.1. Datasets
4.1.1. NTU landmark datasetFor the purpose of validating the effectiveness of the proposed
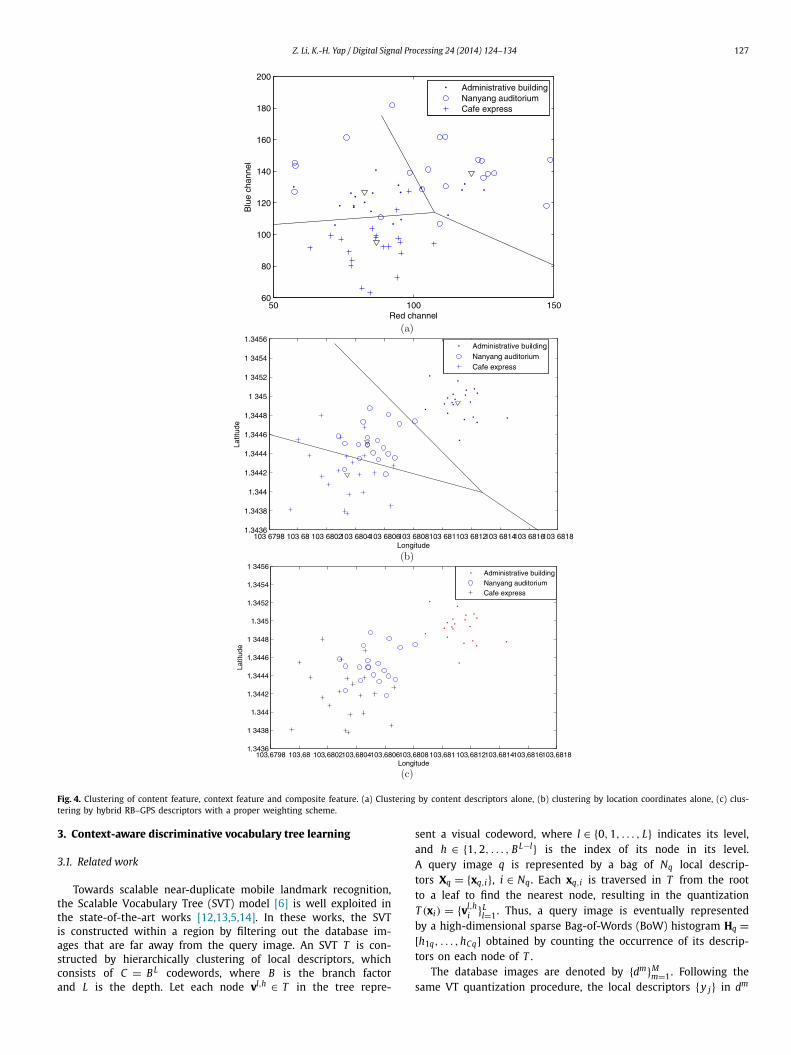
schemes for mobile image recognition, we require a data set of la-beled and geo-tagged photos. Therefore we constructed a landmarkdatabase called NTU Landmark-50 dataset [1] consisting of 3622training images and 534 testing images for 50 landmark categoriesfrom the campus in Nanyang Technological University (NTU), Sin-gapore. We consider choosing NTU campus for collecting mobileimages mainly because it facilitates: (i) collecting a large num-ber of images in a confined geographic area for validation of thesystem in domain-specific application, (ii) evaluating the systemperformance in terms of recognition accuracy and processing time,and (iii) testing the performance of incorporating direction infor-mation. The landmark images are captured using camera phonesequipped with GPS receiver and digital compass. The volunteerswere instructed to take photos around the NTU campus, at theirleisure, as if they were traveling in NTU campus with their ownmobile cameras. Different image acquisition conditions are usedwhen capturing the images, such as camera settings, capturingtime, illumination, weather changes, and changes in viewpoints,scale and occlusion. Sample images of NTU Landmark-50 datasetare given in Fig. 6(a), and the geospatial distribution of the land-marks is given in Fig. 6(b). From the figure, it can be seen that thelandmarks spread across the whole campus of NTU, with certainareas having a higher concentration of landmarks. The numbers ofthe training and testing images for each landmark are mostly uni-form. There are on average 70 images for training and 10 imagesfor testing for each landmark.
4.1.2. PKU landmark datasetWe also test our proposed algorithms on the mobile landmark
benchmark from MPEG CDVS requirement subgroup [13], which
130 Z. Li, K.-H. Yap / Digital Signal Processing 24 (2014) 124–134
Fig. 6. Sample images and geospatial distribution of the images in NTU Landmark-50 dataset. (a) Sample images, (b) geospatial distribution of the image-wise locations.
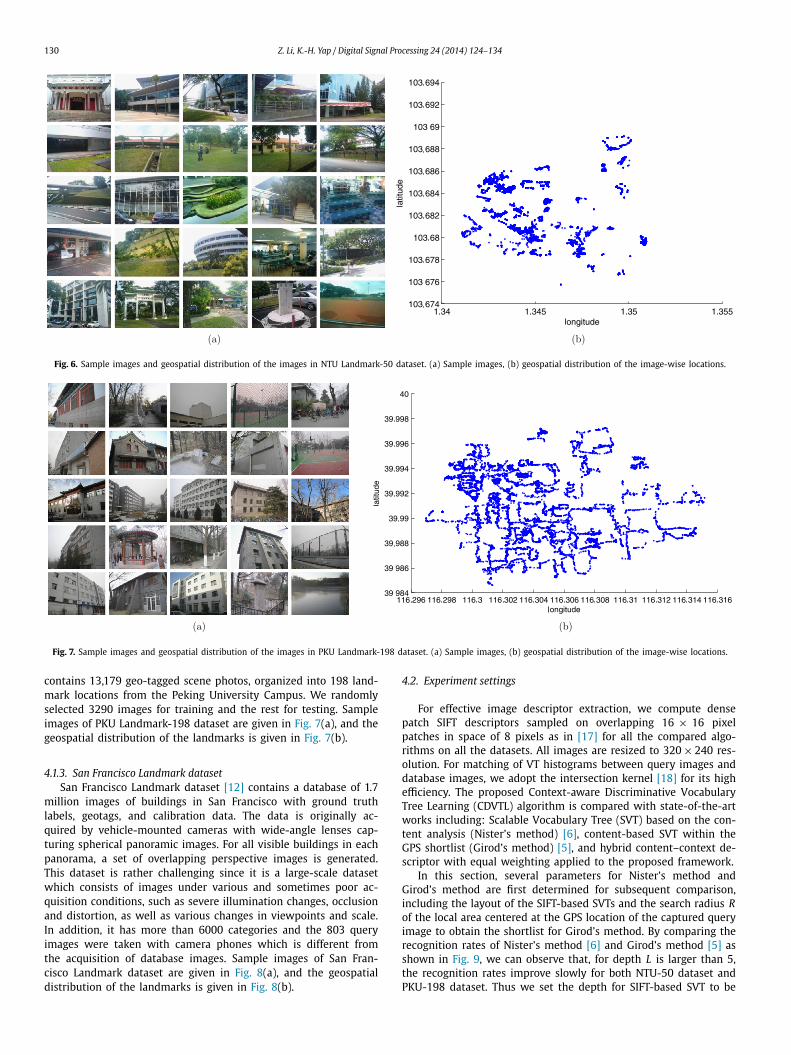
Fig. 7. Sample images and geospatial distribution of the images in PKU Landmark-198 dataset. (a) Sample images, (b) geospatial distribution of the image-wise locations.
contains 13,179 geo-tagged scene photos, organized into 198 land-mark locations from the Peking University Campus. We randomlyselected 3290 images for training and the rest for testing. Sampleimages of PKU Landmark-198 dataset are given in Fig. 7(a), and thegeospatial distribution of the landmarks is given in Fig. 7(b).
4.1.3. San Francisco Landmark datasetSan Francisco Landmark dataset [12] contains a database of 1.7
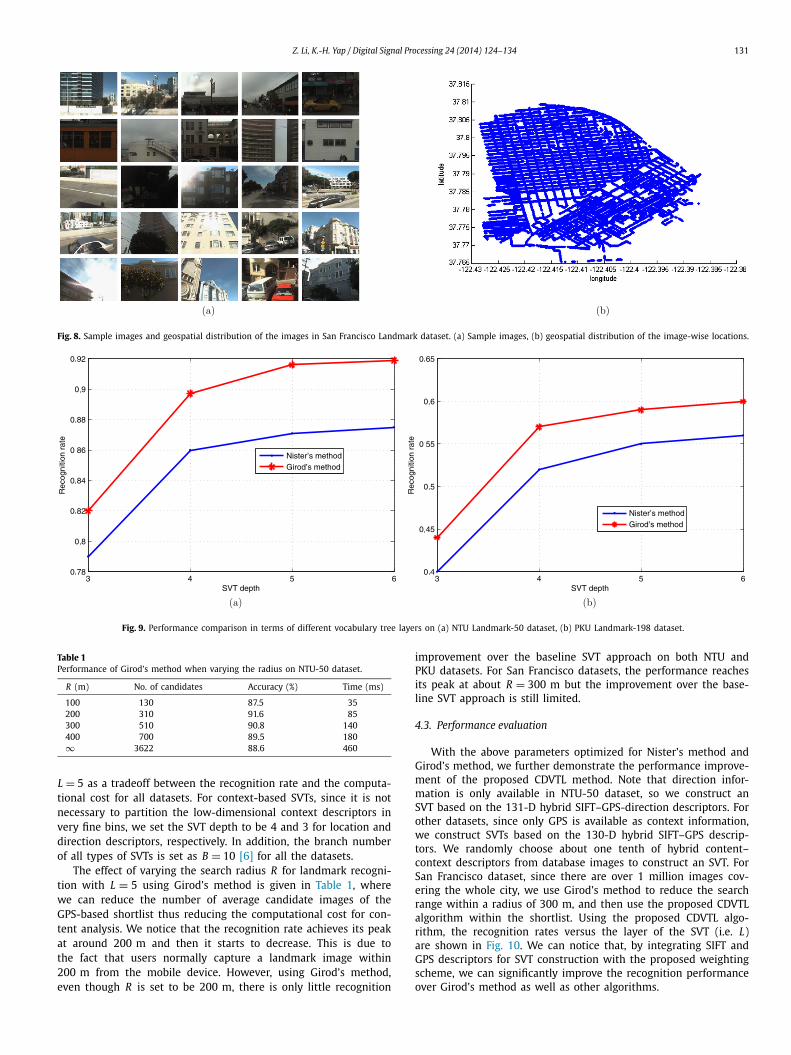
million images of buildings in San Francisco with ground truthlabels, geotags, and calibration data. The data is originally ac-quired by vehicle-mounted cameras with wide-angle lenses cap-turing spherical panoramic images. For all visible buildings in eachpanorama, a set of overlapping perspective images is generated.This dataset is rather challenging since it is a large-scale datasetwhich consists of images under various and sometimes poor ac-quisition conditions, such as severe illumination changes, occlusionand distortion, as well as various changes in viewpoints and scale.In addition, it has more than 6000 categories and the 803 queryimages were taken with camera phones which is different fromthe acquisition of database images. Sample images of San Fran-cisco Landmark dataset are given in Fig. 8(a), and the geospatialdistribution of the landmarks is given in Fig. 8(b).
4.2. Experiment settings
For effective image descriptor extraction, we compute densepatch SIFT descriptors sampled on overlapping 16 × 16 pixelpatches in space of 8 pixels as in [17] for all the compared algo-rithms on all the datasets. All images are resized to 320 × 240 res-olution. For matching of VT histograms between query images anddatabase images, we adopt the intersection kernel [18] for its highefficiency. The proposed Context-aware Discriminative VocabularyTree Learning (CDVTL) algorithm is compared with state-of-the-artworks including: Scalable Vocabulary Tree (SVT) based on the con-tent analysis (Nister’s method) [6], content-based SVT within theGPS shortlist (Girod’s method) [5], and hybrid content–context de-scriptor with equal weighting applied to the proposed framework.
In this section, several parameters for Nister’s method andGirod’s method are first determined for subsequent comparison,including the layout of the SIFT-based SVTs and the search radius Rof the local area centered at the GPS location of the captured queryimage to obtain the shortlist for Girod’s method. By comparing therecognition rates of Nister’s method [6] and Girod’s method [5] asshown in Fig. 9, we can observe that, for depth L is larger than 5,the recognition rates improve slowly for both NTU-50 dataset andPKU-198 dataset. Thus we set the depth for SIFT-based SVT to be
Z. Li, K.-H. Yap / Digital Signal Processing 24 (2014) 124–134 131
Fig. 8. Sample images and geospatial distribution of the images in San Francisco Landmark dataset. (a) Sample images, (b) geospatial distribution of the image-wise locations.
Fig. 9. Performance comparison in terms of different vocabulary tree layers on (a) NTU Landmark-50 dataset, (b) PKU Landmark-198 dataset.
Table 1Performance of Girod’s method when varying the radius on NTU-50 dataset.
R (m) No. of candidates Accuracy (%) Time (ms)
100 130 87.5 35200 310 91.6 85300 510 90.8 140400 700 89.5 180∞ 3622 88.6 460
L = 5 as a tradeoff between the recognition rate and the computa-tional cost for all datasets. For context-based SVTs, since it is notnecessary to partition the low-dimensional context descriptors invery fine bins, we set the SVT depth to be 4 and 3 for location anddirection descriptors, respectively. In addition, the branch numberof all types of SVTs is set as B = 10 [6] for all the datasets.
The effect of varying the search radius R for landmark recogni-tion with L = 5 using Girod’s method is given in Table 1, wherewe can reduce the number of average candidate images of theGPS-based shortlist thus reducing the computational cost for con-tent analysis. We notice that the recognition rate achieves its peakat around 200 m and then it starts to decrease. This is due tothe fact that users normally capture a landmark image within200 m from the mobile device. However, using Girod’s method,even though R is set to be 200 m, there is only little recognition
improvement over the baseline SVT approach on both NTU andPKU datasets. For San Francisco datasets, the performance reachesits peak at about R = 300 m but the improvement over the base-line SVT approach is still limited.
4.3. Performance evaluation
With the above parameters optimized for Nister’s method andGirod’s method, we further demonstrate the performance improve-ment of the proposed CDVTL method. Note that direction infor-mation is only available in NTU-50 dataset, so we construct anSVT based on the 131-D hybrid SIFT–GPS-direction descriptors. Forother datasets, since only GPS is available as context information,we construct SVTs based on the 130-D hybrid SIFT–GPS descrip-tors. We randomly choose about one tenth of hybrid content–context descriptors from database images to construct an SVT. ForSan Francisco dataset, since there are over 1 million images cov-ering the whole city, we use Girod’s method to reduce the searchrange within a radius of 300 m, and then use the proposed CDVTLalgorithm within the shortlist. Using the proposed CDVTL algo-rithm, the recognition rates versus the layer of the SVT (i.e. L)are shown in Fig. 10. We can notice that, by integrating SIFT andGPS descriptors for SVT construction with the proposed weightingscheme, we can significantly improve the recognition performanceover Girod’s method as well as other algorithms.
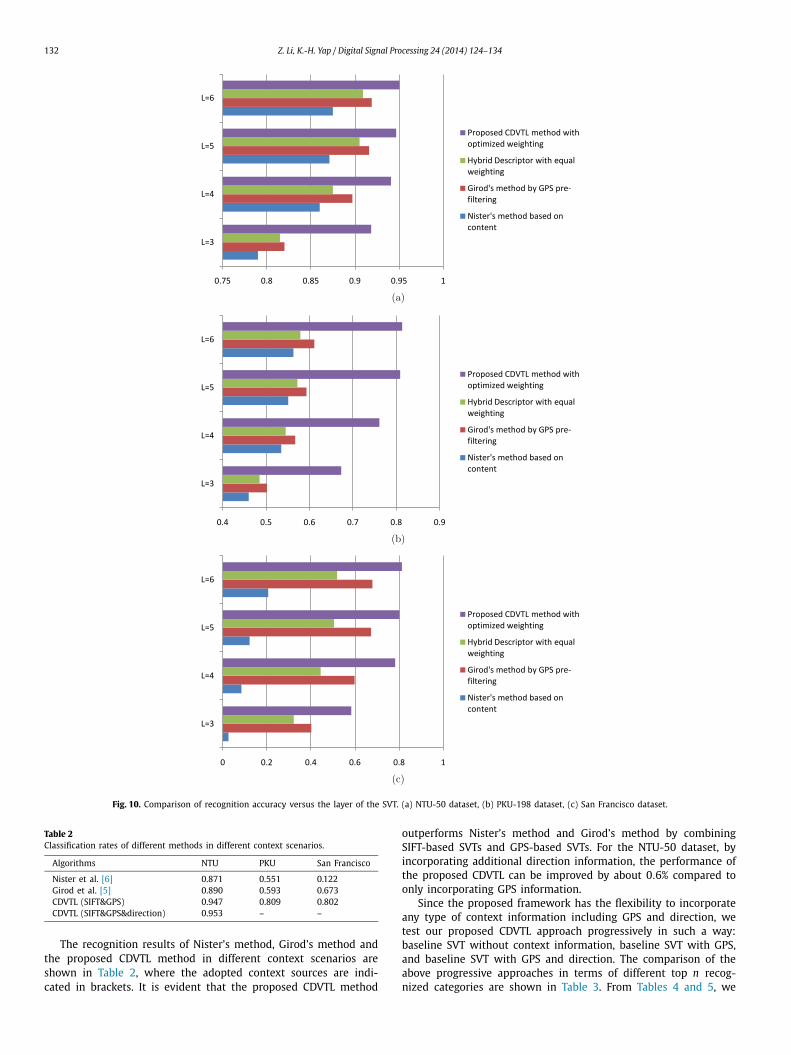
132 Z. Li, K.-H. Yap / Digital Signal Processing 24 (2014) 124–134
Fig. 10. Comparison of recognition accuracy versus the layer of the SVT. (a) NTU-50 dataset, (b) PKU-198 dataset, (c) San Francisco dataset.
Table 2Classification rates of different methods in different context scenarios.
Algorithms NTU PKU San Francisco
Nister et al. [6] 0.871 0.551 0.122Girod et al. [5] 0.890 0.593 0.673CDVTL (SIFT&GPS) 0.947 0.809 0.802CDVTL (SIFT&GPS&direction) 0.953 – –
The recognition results of Nister’s method, Girod’s method andthe proposed CDVTL method in different context scenarios areshown in Table 2, where the adopted context sources are indi-cated in brackets. It is evident that the proposed CDVTL method
outperforms Nister’s method and Girod’s method by combiningSIFT-based SVTs and GPS-based SVTs. For the NTU-50 dataset, byincorporating additional direction information, the performance ofthe proposed CDVTL can be improved by about 0.6% compared toonly incorporating GPS information.
Since the proposed framework has the flexibility to incorporateany type of context information including GPS and direction, wetest our proposed CDVTL approach progressively in such a way:baseline SVT without context information, baseline SVT with GPS,and baseline SVT with GPS and direction. The comparison of theabove progressive approaches in terms of different top n recog-nized categories are shown in Table 3. From Tables 4 and 5, we
Z. Li, K.-H. Yap / Digital Signal Processing 24 (2014) 124–134 133
can observe that, incorporating the context information will pro-gressively improve the recognition performance.
Typical cases for the improved recognition are shown in Fig. 11,where the top 3 matched categories are shown for each method.The top categories are obtained by finding the first categories in
Table 3Recognition rates by CDVTL with various context scenarios on NTU dataset.
Information available top 1 top 3 top 5
SIFT GPS Direction
� × × 0.871 0.913 0.925� � × 0.947 0.954 0.958� � � 0.953 0.959 0.961
Table 4Recognition rates by CDVTL with various context scenarios on PKU dataset.
Information available top 1 top 3 top 5
SIFT GPS
� × 0.551 0.634 0.652� � 0.809 0.851 0.872
Table 5Recognition rates by CDVTL with various context scenarios on San Francisco dataset.
Information available top 1 top 3 top 5
SIFT GPS
� × 0.122 0.136 0.143� � 0.810 0.822 0.833
the top recognized image list. In such a way, the user will prob-ably find the correct landmark category out of the top recognizedcategories. In Fig. 11(a) and (b), a query image in “Nanyang Lake”is tested for comparison of the proposed method and Nister’smethod. Using Nister’s method which only utilizes content infor-mation, the first and the third recognized images in the returnedlist are actually located far away from where the query image istaken. By using the proposed CDVTL method which incorporateslocation and direction information, the recognized images in thereturned list are all well matched to the query image. In Fig. 11(c)and (d), a query image for “Wells Fargo” is tested for compari-son of the proposed method and Girod’s method. Since Girod’smethod utilizes GPS information to obtain candidate images thatare located near the query image and then perform content-basedrecognition, the recognized images in the returned list are locatednearby the query image. However, the recognition result can befurther improved by assigning optimal weights for SIFT descriptorsand GPS locations using the proposed CDVTL algorithm. By usingthe proposed method, we first filter out database images locatedfar away, and then use the proposed CDVTL algorithm, resulting inmuch better recognized images.
4.4. Computational cost
As to the computational cost, combination of content and con-text analyses will need more time than using content or contextanalysis alone. However, since the mobile user will normally not besure whether using content or context information alone is better,
Fig. 11. A typical case of top matched category list. (a) NTU query using Nister’s method, (b) NTU query using the proposed method, (c) San Francisco query using Girod’smethod, (d) San Francisco query using the proposed method.

134 Z. Li, K.-H. Yap / Digital Signal Processing 24 (2014) 124–134
Table 6Average computational cost.
NTU PKU San Francisco
Nister et al. [6] 0.460 0.538 –Girod et al. [5] 0.085 0.0850 2.852CDVTL (SIFT&GPS) 0.472 0.540 2.882CDVTL (SIFT&GPS&direction) 0.473 0.541 2.889
the proposed adaptive content and context combination approachis more reliable, effective and convenient.
The computational cost is shown in Table 6. It is noticedthat the proposed recognition scheme shows a dramatic improve-ment over Nister’s baseline SVT approach, however, the increasein recognition time per image is as trivial as about 0.013 s.Although using Girod’s method, the recognition time is greatlyreduced by filtering out the database images located far awayfrom the query image in the first stage. However, the proposedscheme improves the recognition rate over Girod’s method byabout 6%–21%, which is significant. For San Francisco dataset, sincewe use Girod’s scheme in the first stage and then use the pro-posed CDVTL scheme, the recognition time is only slightly higherthan Girod’s scheme, while the traditional content analysis alonewill not return the result within one hour. Therefore we can con-clude that proposed recognition scheme has a good practical utilityin landmark recognition systems. The computational cost includesboth feature extraction time and the recognition by combiningcontent and context information. The feature extraction step israther efficient: we can SIFT descriptor within 0.2 second andcontext information within 0.002 second for each query image,while the recognition time dominates the total online computa-tional cost.
The hardware setting is given as follows: Windows XP, CPU P42.66 GHz, and 4 GB RAM. The current implementation is carriedout mainly by MATLAB2009a, and we can expect it to be furtheraccelerated several times by C code. So the proposed method isaffordable in real applications.
5. Conclusions
We proposed a new mobile landmark recognition frameworkthat can integrate various mobile content and context informa-tion by Context-aware Discriminative Vocabulary Tree Learning(CDVTL). As compared to content analysis based on GPS shortlistthat is adopted in most existing mobile landmark recognition sys-tems, the proposed CDVTL scheme can significantly improve therecognition performance while not introducing much additionalcomputational cost. In addition, the proposed content and contextintegration framework has the flexibility to incorporate any typesof content and context information when they are available in themobile device. Future work may include integrating other contextinformation (e.g. time) to further improve the recognition perfor-mance.
References
[1] K. Yap, T. Chen, Z. Li, K. Wu, A comparative study of mobile-based landmarkrecognition techniques, IEEE Intell. Syst. 25 (1) (2010) 48–57.
[2] T. Chen, K. Wu, K. Yap, Z. Li, F. Tsai, A survey on mobile landmark recognitionfor information retrieval, in: International Conference on Mobile Data Manage-ment: Systems, Services and Middleware, 2009, pp. 625–630.
[3] T. Chen, Z. Li, K. Yap, et al., A multi-scale learning approach for landmarkrecognition using mobile devices, in: International Conference on Information,Communications and Signal Processing, 2009, pp. 1–4.
[4] Y. Li, D. Crandall, D. Huttenlocher, Landmark classification in large-scale imagecollections, in: IEEE 12th International Conference on Computer Vision, 2009,pp. 1957–1964.
[5] B. Girod, V. Chandrasekhar, D. Chen, et al., Mobile visual search, IEEE SignalProcess. Mag. 28 (4) (2011) 61–76.
[6] D. Nister, H. Stewenius, Scalable recognition with a vocabulary tree, in: IEEEComputer Society Conference on Computer Vision and Pattern Recognition,vol. 2, 2006, pp. 2161–2168.
[7] Y. Li, J. Lim, Outdoor place recognition using compact local descriptors andmultiple queries with user verification, in: Proceedings of the 15th Interna-tional Conference on ACM Multimedia, 2007, pp. 549–552.
[8] G. Fritz, C. Seifert, L. Paletta, A mobile vision system for urban detection withinformative local descriptors, in: IEEE International Conference on ComputerVision Systems, 2006, pp. 30–38.
[9] C. Tsai, A. Qamra, E. Chang, Y. Wang, Extent: Inferring image metadata fromcontext and content, in: IEEE International Conference on Multimedia andExpo, 2005, pp. 1270–1273.
[10] N. O’Hare, C. Gurrin, G. Jones, A. Smeaton, Combination of content analysisand context features for digital photograph retrieval, in: The 2nd EuropeanWorkshop on the Integration of Knowledge, Semantics and Digital Media Tech-nology, 2005, pp. 323–328.
[11] J. Lim, Y. Li, Y. You, J. Chevallet, Scene recognition with camera phones fortourist information access, in: IEEE International Conference on Multimediaand Expo, 2007, pp. 100–103.
[12] D. Chen, G. Baatz, K. Koser, et al., City-scale landmark identification on mobiledevices, in: IEEE Conference on Computer Vision and Pattern Recognition, 2011,pp. 737–744.
[13] R. Ji, L. Duan, J. Chen, et al., Pkubench: A context rich mobile visual searchbenchmark, in: 18th IEEE International Conference on Image Processing, 2011,pp. 2545–2548.
[14] X. Wang, M. Yang, T. Cour, et al., Contextual weighting for vocabulary treebased image retrieval, in: IEEE International Conference on Computer Vision,2011, pp. 209–216.
[15] P. Gill, W. Murray, M. Wright, Practical Optimization, vol. 1, Academic Press,1981.
[16] G. Huang, L. Chen, Enhanced random search based incremental extreme learn-ing machine, Neurocomput. 71 (16) (2008) 3460–3468.
[17] J. Zhang, M. Marszalek, S. Lazebnik, C. Schmid, Local features and kernels forclassification of texture and object categories: A comprehensive study, Int. J.Comput. Vis. 73 (2) (2007) 213–238.
[18] M. Swain, D. Ballard, Color indexing, Int. J. Comput. Vis. 7 (1) (1991) 11–32.
Zhen Li is working toward a PhD in electrical engineering at NanyangTechnological University, Singapore. His research interests include content-and context-based multimedia understanding and processing. He has amaster degree in measurement technology and instrumentation fromHarbin Institute of Technology, China.
Kim-Hui Yap is an associate professor in the School of Electrical andElectronic Engineering at Nanyang Technological University, Singapore. Hismain research interests include image and video processing, media con-tent analysis, computer vision, and computational intelligence. He has aPhD in electrical engineering from the University of Sydney, Australia.