Embed Size (px)
Citation preview

Neurocomputing 73 (2010) 2793–2796
Contents lists available at ScienceDirect
Neurocomputing
0925-23
doi:10.1
� Corr
E-m
journal homepage: www.elsevier.com/locate/neucom
Letters
Conceptual collaborative filtering recommendation: A probabilisticlearning approach
Jae-won Lee a, Han-Joon Kim b,�, Sang-goo Lee a
a School of Computer Science and Engineering, Seoul National University, Republic of Koreab School of Electrical and Computer Engineering, The University of Seoul, Republic of Korea
a r t i c l e i n f o
Article history:
Received 8 April 2009
Received in revised form
16 March 2010
Accepted 4 April 2010
Communicated by R.W. Newcombmatch with domain concepts, whereas conventional collaborative filtering uses an exact match to find
Available online 4 May 2010
Keywords:
Information retrieval
Collaborative filtering
Probabilistic learning
Concept
Recommendation systems
12/$ - see front matter & 2010 Elsevier B.V. A
016/j.neucom.2010.04.005
esponding author. Tel.: +822 2210 5632; fax
ail address: [email protected] (H.-J. Kim).
a b s t r a c t
Collaborative filtering is one of the most successful and popular methods in developing recommenda-
tion systems. However, conventional collaborative filtering methods suffer from item sparsity and new
item problems. In this paper, we propose a probabilistic learning approach that solves the item sparsity
problem while describing users and items with domain concepts. Our method uses a probabilistic
similar users. Empirical experiments show that our method outperforms the conventional ones.
& 2010 Elsevier B.V. All rights reserved.
1. Introduction
As the amount of information items on the Web, such as music,movie, image, and web pages, has grown explosively, it becomeshighly important to find the items that are relevant to users’preferences. When a user does not know exact keywords fortarget items, recommendation systems can be more useful ratherthan information search systems. A recommendation systemperforms to present information items that are likely of interest tothe user, and it predicts the rate that a user would give to an itemby utilizing user preference. In developing recommendationsystems, one of the most successful and popular methodologiesis ‘collaborative filtering’.
Collaborative filtering (CF) is to predict the preferences of anactive user from the preference data of his/her similar users. Thus,it is critical to exactly compute the similarity between users.Currently, the Pearson correlation coefficient and cosine similarityare widely used in conventional systems [1,3,8,9].
However, despite its success and popularity, conventional CFmethods have two drawbacks. One is ‘item sparsity’ problem,which means that as the number of items in database increases,the density of each user’s records with respect to these items willdecrease [5]. When similar users have rated different items, it ishard to figure out that those users have similar preferences. Theother one is ‘new item’ or ‘cold start’ problem, which means that it
ll rights reserved.
: +822 2249 6802.
is impossible to recommend new or recently added items untilthey are rated by other users.
Our paper focuses on a probabilistic learning framework forsolving the ‘item sparsity’ problem while describing a conceptualcollaborative filtering method that associates users and itemswith concepts. The ‘item sparsity’ problem cannot be avoided aslong as a CF system uses the similarity measures such as Pearsoncorrelation coefficient and cosine similarity. This is because such aCF system requires an exact match to compute the similaritybetween users only with explicit feedback on items such as users’scores and purchase logs [4]. In contrast, in our work, items andusers are semantically represented as a set of domain conceptswith the probabilistic framework, and we thus achieve to avoidthe item sparsity problem and to improve the precision ofrecommendation.
2. Conceptual collaborative filtering
2.1. Concept representation
For concept representation, the proposed learning frameworkexploits the concept hierarchy of a comprehensive web directorysuch as the Open Directory Project (refer to http://dmoz.org).Thus, a concept (or category) can be described with webdocuments that are classified into the concept.
Definition 1 (Concepts). Let C ¼ fc1, . . . ,ci, . . . ,cng be a set ofconcepts, and n be the total number of concepts. Then, the

J.-w. Lee et al. / Neurocomputing 73 (2010) 2793–27962794
concept ci is defined as the average of web document term vectorsunder ci as follows:
ci ¼1
jDci j
Xd
cijADci
dci
j where Dci ¼ fdci
1 , . . . ,dci
j , . . . ,dci
jDci jg ð1Þ
where Dci is the set of web documents that belong to the conceptci, and dci
j is the jth document in Dci . Each web document dci
j isrepresented as the weighted term vector dci
j ¼/w1, . . . ,wm, . . . ,wjV jS where V denotes the set of index terms and eachweight wm for the index term tm is calculated by using thetraditional information retrieval metrics: term frequency (TF) andinverse document frequency (IDF) [2].
To reduce the number of terms used, we remove the stopwords(such as articles, propositions, and conjunctions) which do not help todescribe the concepts, and also use the Porter stemming algorithm [6]to transform inflected words to their stem or root forms.
2.2. Probabilistic learning framework
In terms of probabilistic learning, to recommend the item ik tothe user ui can be regarded as estimating the conditionalprobability pðikjuiÞ.
1 That is, the system recommends severalitems argsmaxfik A I0 ,ngpðikjuiÞ to the user ui, where n is the numberof recommended items, in which argsmaxfxAX,ngFðxÞ denotes thetop-n values of x for sorted values of F(x), assuming that thevalues of x are discrete.2 The probability pðikjuiÞ measures howmuch an active user ui likes ikA I0 although the user ui has not yetaccessed the item ik.
The collaborative filtering recommendation is to predict a user’spreference for items by using preference information of his/hersimilar users, and thus, pðikjuiÞ needs to contain the random variablesut to represent all the (target) users other than ui. By applying the lawof total probability to pðikjuiÞ, it is written as follows:
argsmaxfik A I0 ,ng
pðikjuiÞ ¼ argsmaxfik A I0 ,ng
Xut AU
pðikjutÞ � pðuijutÞ � pðutÞ
¼ argsmaxfik A I0 ,ng
Xut AU
pðikjutÞ � pðuijutÞ ð2Þ
where U is a set of users within which ui is an active user and ut is asimilar user of ui. I
0
is a set of items that the only similar user (i.e., ut)has accessed. p(ut) is the user probability that any random user ut isselected, and for simplicity’s sake, it is assumed to be equivalent for allusers; that is, pðutÞ ¼ 1=number of total users. Thus, by the definitionof argsmax in Section 2.2, we can remove p(ut) in Eq. (2). And, pðikjutÞ
is the probability that a randomly chosen item from items that theuser ut has accessed is the item ik. It is estimated as accessðut ,ikÞ=accessðutÞ, where access(ut,ik) is the access count of the user ut for theitem ik, and access(ut) is the total access counts of the user ut. Theaccess count can be replaced with click-through count, rating score, orpurchase counts depending on the properties of items. As for pðuijutÞ,we interpret it as the probability that any random user from userssimilar to the user ut is the user ui, and thus we think that thisprobability can express the degree of similarity between two users.
As we intend to associate users with concepts, the probabilitypðuijutÞ is re-written with regard to the concept cj as follows:
pðuijutÞ ¼Xcj AC
pðuijcjÞ � pðut jcjÞ � pðcjÞ ¼ pðutjuiÞ ð3Þ
1 Normally, discrete probability distributions are characterized by a prob-
ability mass function, p such that Pr(X¼x)¼p(x), where X is a random variable and
x is a value (i.e., event) for X.2 In comparison with argsmaxfxAX,ngFðxÞ, argmaxxAX FðxÞ is the value of x for
which F(x) has the largest value.
where pðuijcjÞ is the probability that a randomly chosen user fromusers related to the concept cj is the user ui. Actually, Eq. (3) canplay a role of a similarity function since it is symmetric (i.e.,pðuijutÞ equals pðut juiÞ). In the context of collaborative filtering,users can be represented with the items that they selected (orbought), and thus we join the factor of the item ik into pðuijcjÞ byapplying both the law of total probability and Bayes’ theorem asfollows:
pðuijcjÞ ¼Xik A I
pðuijikÞ � pðcjjikÞ � pðikÞ
¼Xik A I
pðikjuiÞ � pðuiÞ
pðikÞ�
pðikjcjÞ � pðcjÞ
pðikÞ� pðikÞ
¼Xik A I
pðcjÞ � pðuiÞ
pðikÞ� pðikjcjÞ � pðikjuiÞ ð4Þ
where I denotes a set of items that an active user ui has accessed.And, p(cj), p(ui), and p(ik) are the prior probability for the conceptcj, the user ui, and the item ik, respectively, and they are assumedto be equivalent for all the value of related random variables.Consequently,
pðuijcjÞpXik A I
pðikjcjÞ � pðikjuiÞ ð5Þ
where pðikjcjÞ is the probability that a randomly chosen item fromitems related to the concept cj is the item ik. pðikjuiÞ is similar topðikjutÞ in Eq. (2). The problem is how to estimate pðikjcjÞ. Supposean itemset I¼ fi1, . . . ,ilg be a set of items and ik ¼/wk1, . . . ,wkjV jSwhere wkm is the weighted value of term tm. We want to associatean item with a concept, and thus each value of wkm (i.e., pðtmjikÞ) isused to defined pðikjcjÞ, which is written as the followingproportional equation as in Eq. (5).
pðikjcjÞpX
tm A ik
pðtmjikÞ � pðtmjcjÞ ð6Þ
where pðtmjikÞ can be estimated by computing wðik,tmÞ=wðikÞ,where w(ik,tm) denotes the term weight of tm in ik and w(ik)denotes the total weight sum of all terms in ik. Similarly, pðtmjcjÞ isestimated by computing wðcj,tmÞ=wðcjÞ, where w(cj,tm) denotes theterm weight of tm in cj and w(cj) denotes the total weight sum ofall terms in cj. Note that each of concepts is described bydocuments within each of web categories.
Finally, the probability pðikjuiÞ for recommending the item ikto the user ui is re-written by combining Eqs. (3), (4) and (6) withEq. (2) as follows:
argsmaxfik A I0 ,ng
pðikjuiÞ ¼ argsmaxfik A I0 ,ng
Xut AU
pðikjutÞ � pðuijutÞ ¼ argsmaxfik A I0 ,ng
Xut AU
pðikjutÞ
�Xcj AC
Xik A I
Xtm A ik
pðtmjikÞ � pðtmjcjÞ
0@
1A� pðikjuiÞ
8<:
9=;
24
�Xik A I0
Xtm A ik
pðtmjikÞ � pðtmjcjÞ
0@
1A� pðikjutÞ
8<:
9=;
35 ð7Þ
As a result, we build the prediction model for recommendation,which is composed of pðijuÞ, pðtjiÞ, and pðtjcÞ with the past trainingdata.
3. Experiments
In our experiment, we have extracted 11,584 concepts fromthe Open Directory Project (ODP) whose domain is limited tomusic; that is, categories under the category /Top/Arts/Music
in ODP. The 9394 users’ click-through logs from Last.fm are
J.-w. Lee et al. / Neurocomputing 73 (2010) 2793–2796 2795
crawled for experiments. Among the users, we have assigned 50users to active users. In addition, 22,216 music meta-data areused as items. For evaluation, we introduce two performancemeasures: Precisionk and InverseRankPrecisionk.
Precisionk ¼number of items the user selects in the top�k items
k
InverseRankPrecisionk ¼
Pki ¼ 1
1
rank according to user’s preferencePk
i ¼ 1
1
i
Precisionk is for examining whether they are relevant to the user’spreferences for top-k items retrieved, and it represents howmuch the system reflects the user’s general preference. And,InverseRankPrecisionk is similar to ‘mean reciprocal rank’ [7], and itrepresents how much the system reflects the user’s main
Fig. 1. Changes in Precisionk and I
Fig. 2. Changes in Precisionk and Inve
preferences because it gives more weights to higher ranked itemsselected. The closer InverseRankPrecisionk reaches 1.0, the moresearch results are adapted to the user’s main preferences. Forcomparison, we use Pearson correlation coefficient based CF andCosine similarity based CF, which are denoted as PCF and CCF,respectively, and our proposed method is denoted as SCF.
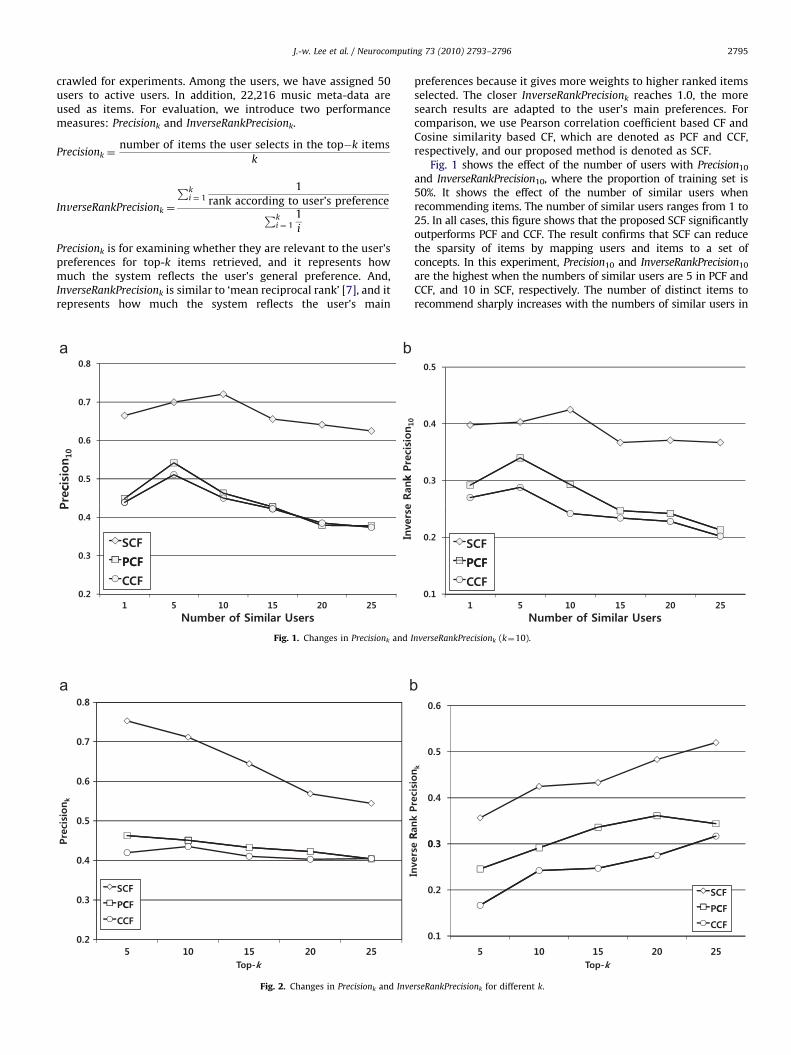
Fig. 1 shows the effect of the number of users with Precision10
and InverseRankPrecision10, where the proportion of training set is50%. It shows the effect of the number of similar users whenrecommending items. The number of similar users ranges from 1 to25. In all cases, this figure shows that the proposed SCF significantlyoutperforms PCF and CCF. The result confirms that SCF can reducethe sparsity of items by mapping users and items to a set ofconcepts. In this experiment, Precision10 and InverseRankPrecision10
are the highest when the numbers of similar users are 5 in PCF andCCF, and 10 in SCF, respectively. The number of distinct items torecommend sharply increases with the numbers of similar users in
nverseRankPrecisionk (k¼10).
rseRankPrecisionk for different k.

J.-w. Lee et al. / Neurocomputing 73 (2010) 2793–27962796
PCF and CCF, whereas the number of distinct items slowly increasesin SCF. Therefore, the numbers of similar users of PCF and CCF aresmaller than that of SCF. As for PCF and CCF, even though there is alittle difference in Precision10 of PCF and CCF, InverseRankPrecision10
of CCF is fairly lower than that of PCF in our experiments. This isbecause the Pearson correlation coefficient of PCF considers thedifferences in users’ preference scales.
Fig. 2 shows the changes in Precisonk and InverseRankPrecisionk
from varying k when the number of similar users is 10. Since theaverage number of items that a user has accessed is 50 and theproportion of training set is 50% in our experiments, we increase k
from 5 to 25. This figure also shows that the proposed SCF providesmuch better performance than PCF and CCF. To be noted is thatPrecisonk of SCF, PCF and CCF decrease as the value of k increases, buttheir InverseRankPrecisionk increase as the value of k increases. Thebigger value of InverseRankPrecisionk means that the users can locatetheir preferred items among higher ranked items. This result suggeststhat SCF is more effective method that can accommodate users’ mainpreferences in developing the collaborative filtering systems.
4. Summary
Our contribution in this paper is the first attempt to aprobabilistic learning framework for collaborative learningecommendation. The basic idea behind our approach is toestimate the item recommendation probability, pðijuÞ, by applyingthe law of total probability and Bayes’ theorem. By associatingusers and items with a set of concepts, we achieve to improve theprecision of recommendation and to solve ‘item sparsity’ problemof the conventional CF. Through intensive experiments, wedemonstrate that our conceptual CF method is more precise thanconventional CF methods. Currently, we are investigating a hybridcollaborative filtering method that combines semantic collabora-tive filtering with content based filtering.
Acknowledgments
This research was supported by the MKE (The Ministry ofKnowledge Economy), Korea, under the ITRC (InformationTechnology Research Center) support program supervised by theNIPA (National IT Industry Promotion Agency) (Grant numberNIPA-2010-C1090-1031-0002).
References
[1] H.J. Ahn, A new similarity measure for collaborative filtering to alleviate thenew user cold-starting problem, Information Science: An International Journal178 (1) (2008) 37–51.
[2] R. Baeza-Yates, B. Ribeiro-Neto, Modeling, in: Modern Information Retrieval,Addison Wesley, Boston, MA, 1999.
[3] J. Breese, D. Heckerman, C. Kadie, Empirical analysis of predictive algorithmsfor collaborative filtering, in: Proceeding of the 14th Annual Conferenceon Uncertainty in Artificial Intelligence, Wisconsin, United States, 1998,pp. 43–52.
[4] T.Q. Lee, Y. Park, Y. Park, A time based approach to effective recommendersystems using implicit feedback, Expert Systems with Applications: AnInternational Journal 34 (4) (2008) 3055–3062.
[5] B. Mobasher, X. Jin, Y. Zhou, Semantically enhanced collaborative filtering onthe web, Lecture Notes in Artificial Intelligence, vol. 3209, Springer, Berlin,2004, pp. 57–76.
[6] M.F. Porter, An algorithm for suffix stripping, in: Readings in InformationRetrieval, Morgan Kaufmann, San Francisco, 1997, pp. 313–316.
[7] D. Radev, H. Qi, H. Wu, W. Fan, Evaluating web-based question answeringsystems, in: Proceeding of the Third International Conference on LanguageResources and Evaluation, Las Palmas, Spain, 2002.
[8] P. Resnick, N. Lacovou, M. Suchak, P. Bergstrom, J. Riedl, GroupLens: an openarchitecture for collaborative filtering of netnews, in: Proceeding of the 1994ACM Conference on Computer Supported Cooperative Work, Chapel Hill,United States, 1994, pp. 175–186.
[9] J. Wang, A.P. de Vries, M.J. Reinders, Unifying user-based and item-basedcollaborative filtering approaches by similarity fusion, in: Proceeding of the29th Annual International ACM SIGIR Conference on Research and Develop-ment in Information Retrieval, Seattle, United States, 2006, pp. 501–508.
Jae-won Lee received the B.S. degree in Informationand Telecommunication Engineering from SoongsilUniversity, Seoul, Korea, in 2003, and the M.S. degreein Computer Science and Engineering from SeoulNational University, Seoul, Korea, in 2006. He iscurrently a Ph.D. candidate at School of ComputerScience and Engineering in Seoul National University,Seoul, Korea. His research interests include machinelearning, ontology, and personalized search.
Han-joon Kim received the B.S. and M.S. degrees inComputer Science and Statistics from Seoul NationalUniversity, Seoul, Korea in 1994 and 1996 and thePh.D. degree in Computer Science and Engineeringfrom Seoul National University, Seoul, Korea in 2002,respectively. He is currently an associate professor atthe School of Electrical and Computer Engineering,University of Seoul, Korea. His current research inter-ests include text mining, machine learning, andintelligent information retrieval.
Sang-goo Lee received the B.S. degree in ComputerScience from Seoul National University at Seoul, Korea,in 1985. He also received the M.S. and Ph.D. inComputer Science from Northwestern University atEvanston, Illinois, USA, in 1987 and 1990, respectively.He is currently a professor in School of ComputerScience and Engineering at Seoul National University,Seoul, Korea. He has been the director of Center fore-Business Technology at Seoul National University,since 2001. His current research interests includee-Business technology, database systems, productinformation management, and ontology.

![Inducing semantic relations from conceptual spaces: adata ...orca.cf.ac.uk/90101/1/main.pdf · rules capturing probabilistic dependencies [3] or using matrix factorisation [4]. A](https://img.pdfslide.us/doc/110x75/5fe39a17fd4e890a280aa925/inducing-semantic-relations-from-conceptual-spaces-adata-orcacfacuk901011mainpdf.jpg)








![H2E: A Privacy Provisioning Framework for Collaborative Filtering … · 2019-09-10 · collaborative filtering, content-based filtering, and hybrid filtering [3]. Content-based filtering,](https://img.pdfslide.us/doc/110x75/5f2811153d39b70bb31af3b8/h2e-a-privacy-provisioning-framework-for-collaborative-filtering-2019-09-10-collaborative.jpg)


















