Embed Size (px)
Citation preview

Computer ArchitectureLecture 1: Introduction and Basics

Where we are
How does an assembly program end up executing as digital logic?
What happens in-between? How is a computer designed
using logic gates and wires to satisfy specific goals?
Programming
CO
“C” as a model of computation
Digital logic as a model of computation
Programmer’s view of a computer system works
HW designer’s view of a computer system works
Architect/microarchitect’s view:How to design a computer that
meets system design goals.Choices critically affect both
the SW programmer and the HW designer
2

Levels of Transformation
MicroarchitectureISA (Architecture)
Program/LanguageAlgorithmProblem
LogicCircuits
Runtime System(VM, OS, MM)
Electrons
“The purpose of computing is insight” (Richard Hamming)We gain and generate insight by solving problemsHow do we ensure problems are solved by electrons?
3

The Power of Abstraction Levels of transformation create abstractions
Abstraction: A higher level only needs to know about the interface to the lower level, not how the lower level is implemented
E.g., high-level language programmer does not really need to know what the ISA is and how a computer executes instructions
Abstraction improves productivity No need to worry about decisions made in underlying levels E.g., programming in Java vs. C vs. assembly vs. binary vs. by
specifying control signals of each transistor every cycle
Then, why would you want to know what goes on underneath or above?
4

Crossing the Abstraction Layers As long as everything goes well, not knowing what happens
in the underlying level (or above) is not a problem.
What if The program you wrote is running slow? The program you wrote does not run correctly? The program you wrote consumes too much energy?
What if The hardware you designed is too hard to program? The hardware you designed is too slow because it does not provide the
right primitives to the software?
What if You want to design a much more efficient and higher performance
system?5

Crossing the Abstraction Layers
Two key goals of this course are
to understand how a processor works underneath the software layer and how decisions made in hardware affect the software/programmer
to enable you to be comfortable in making design and optimization decisions that cross the boundaries of different layers and system components
6

An Example: Multi-Core Systems
CORE 1
L2 CAC
HE 0
SHA
RED
L3 CA
CH
E
DR
AM
INTER
FAC
E
CORE 0
CORE 2 CORE 3L2 C
ACH
E 1
L2 CAC
HE 2
L2 CAC
HE 3
DR
AM
BA
NK
SMulti-CoreChip
*Die photo credit: AMD Barcelona
DRAM MEMORY CONTROLLER
7

Unexpected Slowdowns in Multi-Core
Memory Performance HogLow priority
High priority
(Core 0) (Core 1)
8

A Question or Two Can you figure out why there is a disparity in slowdowns if
you do not know how the processor executes the programs?
Can you fix the problem without knowing what is happening “underneath”?
9

Why the Disparity in Slowdowns?
CORE 1 CORE 2
L2 CACHE
L2 CACHE
DRAM MEMORY CONTROLLER
DRAM Bank 0
DRAM Bank 1
DRAM Bank 2
Shared DRAMMemory System
Multi-CoreChip
unfairnessINTERCONNECT
matlab gcc
DRAM Bank 3
10

DRAM Bank Operation
Row Buffer
(Row 0, Column 0)
Row
dec
oder
Column mux
Row address 0
Column address 0
Data
Row 0Empty
(Row 0, Column 1)
Column address 1
(Row 0, Column 85)
Column address 85
(Row 1, Column 0)
HITHIT
Row address 1
Row 1
Column address 0
CONFLICT !
Columns
Row
s
Access Address:
11

DRAM Controllers
A row-conflict memory access takes significantly longer than a row-hit access
Current controllers take advantage of the row buffer
Commonly used scheduling policy [Rixner 2000]*(1) Row-hit first: Service row-hit memory accesses first(2) Oldest-first: Then service older accesses first
This scheduling policy aims to maximize DRAM throughput
*Rixner et al., “Memory Access Scheduling,” ISCA 2000.*Zuravleff and Robinson, “Controller for a synchronous DRAM …,” US Patent 5,630,096, May 1997.
12

The Problem Multiple threads share the DRAM controller DRAM controllers designed to maximize DRAM throughput
DRAM scheduling policies are thread-unfair Row-hit first: unfairly prioritizes threads with high row buffer locality
Threads that keep on accessing the same row Oldest-first: unfairly prioritizes memory-intensive threads
DRAM controller vulnerable to denial of service attacks Can write programs to exploit unfairness
13

// initialize large arrays A, B
for (j=0; j<N; j++) {index = rand();A[index] = B[index];…
}
A Memory Performance Hog
STREAM
- Sequential memory access - Very high row buffer locality (96% hit rate)- Memory intensive
RANDOM
- Random memory access- Very low row buffer locality (3% hit rate)- Similarly memory intensive
// initialize large arrays A, B
for (j=0; j<N; j++) {index = j*linesize;A[index] = B[index];…
}
streaming random
14

What Does the Memory Hog Do?
Row Buffer
Row
dec
oder
Column mux
Data
Row 0
T0: Row 0
Row 0
T1: Row 16T0: Row 0T1: Row 111T0: Row 0T0: Row 0T1: Row 5
T0: Row 0T0: Row 0T0: Row 0T0: Row 0T0: Row 0
Memory Request Buffer
T0: STREAMT1: RANDOM
Row size: 8KB, cache block size: 64B128 (8KB/64B) requests of T0 serviced before T1
15

Now That We Know What Happens Underneath
How would you solve the problem?
What is the right place to solve the problem? Programmer? System software? Compiler? Hardware (Memory controller)? Hardware (DRAM)? Circuits?
Two other goals of this course: Enable you to think critically Enable you to think broadly
MicroarchitectureISA (Architecture)
Program/LanguageAlgorithmProblem
LogicCircuits
Runtime System(VM, OS, MM)
Electrons
16

If You Are Interested … Further Readings Onur Mutlu and Thomas Moscibroda,
"Stall-Time Fair Memory Access Scheduling for Chip Multiprocessors"Proceedings of the 40th International Symposium on Microarchitecture(MICRO), pages 146-158, Chicago, IL, December 2007. Slides (ppt)
Sai Prashanth Muralidhara, Lavanya Subramanian, Onur Mutlu, Mahmut Kandemir, and Thomas Moscibroda, "Reducing Memory Interference in Multicore Systems via Application-Aware Memory Channel Partitioning"Proceedings of the 44th International Symposium on Microarchitecture(MICRO), Porto Alegre, Brazil, December 2011. Slides (pptx)
17

Takeaway Breaking the abstraction layers (between components and
transformation hierarchy levels) and knowing what is underneath enables you to solve problems
18

Another Example DRAM Refresh
19

DRAM in the System
CORE 1
L2 CAC
HE 0
SHA
RED
L3 CA
CH
E
DR
AM
INTER
FAC
E
CORE 0
CORE 2 CORE 3L2 C
ACH
E 1
L2 CAC
HE 2
L2 CAC
HE 3
DR
AM
BA
NK
SMulti-CoreChip
*Die photo credit: AMD Barcelona
DRAM MEMORY CONTROLLER
20

A DRAM Cell
A DRAM cell consists of a capacitor and an access transistor It stores data in terms of charge in the capacitor A DRAM chip consists of (10s of 1000s of) rows of such cells
wordline
bitli
ne
bitli
ne
bitli
ne
bitli
ne
(row enable)

DRAM Refresh DRAM capacitor charge leaks over time
The memory controller needs to refresh each row periodically to restore charge Activate each row every N ms Typical N = 64 ms
Downsides of refresh-- Energy consumption: Each refresh consumes energy-- Performance degradation: DRAM rank/bank unavailable while refreshed-- QoS/predictability impact: (Long) pause times during refresh-- Refresh rate limits DRAM capacity scaling
Add more rows, need to refresh more rows Reduce the cell size: difficult to maintain charge due to leaky access
transistors22

Refresh Overhead: Performance
8%
46%
Liu et al., “RAIDR: Retention-Aware Intelligent DRAM Refresh,” ISCA 2012. 23

Refresh Overhead: Energy
15%
47%
Liu et al., “RAIDR: Retention-Aware Intelligent DRAM Refresh,” ISCA 2012. 24

How Do We Solve the Problem? Do we need to refresh all rows every 64ms?
What if we knew what happened underneath and exposed that information to upper layers?
25

Underneath: Retention Time Profile of DRAM
Liu et al., “RAIDR: Retention-Aware Intelligent DRAM Refresh,” ISCA 2012. 26

Taking Advantage of This Profile Expose this retention time profile information to
the memory controller the operating system the programmer? the compiler?
How much information to expose? Affects hardware/software overhead, power consumption,
verification complexity, cost
How to determine this profile information? Also, who determines it?
27

Takeaway Breaking the abstraction layers (between components and
transformation hierarchy levels) and knowing what is underneath enables you to solve problems and design better future systems
Cooperation between multiple components and layers can enable more effective solutions and systems
30

Objectives of this course Teach/enable/empower you you to:
Understand how a processor works Implement a simple processor (with not so simple parts) Understand how decisions made in hardware affect the
software/programmer as well as hardware designer Think critically (in solving problems) Think broadly across the levels of transformation Understand how to analyze and make tradeoffs in design
31

What Will You Learn Computer Architecture: The science and art of
designing, selecting, and interconnecting hardware components and designing the hardware/software interface to create a computing system that meets functional, performance, energy consumption, cost, and other specific goals.
Traditional definition: “The term architecture is used here to describe the attributes of a system as seen by the programmer, i.e., the conceptual structure and functional behavior as distinct from the organization of the dataflow and controls, the logic design, and the physical implementation.” Gene Amdahl, IBM Journal of R&D, April 1964
32

Computer Architecture in Levels of Transformation
Read: Patt, “Requirements, Bottlenecks, and Good Fortune: Agents for Microprocessor Evolution,” Proceedings of the IEEE 2001.
MicroarchitectureISA (Architecture)
Program/LanguageAlgorithmProblem
LogicCircuits
Runtime System(VM, OS, MM)
Electrons
33

Levels of Transformation, Revisited
MicroarchitectureISA
Program/LanguageAlgorithmProblem
Runtime System(VM, OS, MM)
User
A user-centric view: computer designed for users
The entire stack should be optimized for user
LogicCircuitsElectrons
34

What Will You Learn? Fundamental principles and tradeoffs in designing the
hardware/software interface and major components of a modern programmable microprocessor Focus on state-of-the-art (and some recent research and trends) Trade-offs and how to make them
How to design, implement, and evaluate a functional modern processor Semester-long lab assignments A combination of RTL implementation and higher-level simulation Focus is on functionality (and some focus on “how to do even better”)
How to dig out information, think critically and broadly How to work even harder!
35

Course Goals Goal 1: To familiarize those interested in computer system
design with both fundamental operation principles and design tradeoffs of processor, memory, and platform architectures in today’s systems. Strong emphasis on fundamentals and design tradeoffs.
Goal 2: To provide the necessary background and experience to design, implement, and evaluate a modern processor by performing hands-on RTL and C-level implementation. Strong emphasis on functionality and hands-on design.
36

Computer ArchitectureLecture 2: Fundamental Concepts and ISA

Agenda for Today Why study computer architecture?
Fundamental concepts
ISA
2

Review: Comp. Arch. in Levels of Transformation
Read: Patt, “Requirements, Bottlenecks, and Good Fortune: Agents for Microprocessor Evolution,” Proceedings of the IEEE 2001.
MicroarchitectureISA (Architecture)
Program/LanguageAlgorithmProblem
LogicCircuits
Runtime System(VM, OS, MM)
Electrons
3

Review: Levels of Transformation, Revisited
MicroarchitectureISA
Program/LanguageAlgorithmProblem
Runtime System(VM, OS, MM)
User
A user-centric view: computer designed for users
The entire stack should be optimized for user
LogicCircuitsElectrons
4

What Will You Learn? Fundamental principles and tradeoffs in designing the
hardware/software interface and major components of a modern programmable microprocessor Focus on state-of-the-art (and some recent research and trends) Trade-offs and how to make them
How to design, implement, and evaluate a functional modern processor Semester-long lab assignments A combination of RTL implementation and higher-level simulation Focus is on functionality (and some focus on “how to do even better”)
5

Course Goals Goal 1: To familiarize those interested in computer system
design with both fundamental operation principles and design tradeoffs of processor, memory, and platform architectures in today’s systems. Strong emphasis on fundamentals and design tradeoffs.
Goal 2: To provide the necessary background and experience to design, implement, and evaluate a modern processor by performing hands-on RTL and C-level implementation. Strong emphasis on functionality and hands-on design.
6

A Note on Hardware vs. Software This course is classified under “Computer Hardware”
However, you will be much more capable if you master both hardware and software (and the interface between them) Can develop better software if you understand the underlying
hardware Can design better hardware if you understand what software
it will execute Can design a better computing system if you understand both
This course covers the HW/SW interface and microarchitecture We will focus on tradeoffs and how they affect software
7

Why Study Computer Architecture?
8

What is Computer Architecture?
The science and art of designing, selecting, and interconnecting hardware components and designing the hardware/software interface to create a computing system that meets functional, performance, energy consumption, cost, and other specific goals.
We will soon distinguish between the terms architecture, and microarchitecture.
9

An Enabler: Moore’s Law
Moore, “Cramming more components onto integrated circuits,”Electronics Magazine, 1965. Component counts double every other year
Image source: Intel 10

Number of transistors on an integrated circuit doubles ~ every two years
Image source: Wikipedia 11

Why Study Computer Architecture? Enable better systems: make computers faster, cheaper,
smaller, more reliable, … By exploiting advances and changes in underlying technology/circuits
Enable new applications Life-like 3D visualization 20 years ago? Virtual reality? Personal genomics?
Enable better solutions to problems Software innovation is built into trends and changes in computer architecture
> 50% performance improvement per year has enabled this innovation
Understand why computers work the way they do12

Computer Architecture Today (I) Today is a very exciting time to study computer architecture
Industry is in a large paradigm shift (to multi-core and beyond) – many different potential system designs possible
Many difficult problems motivating and caused by the shift Power/energy constraints Complexity of design multi-core? Difficulties in technology scaling new technologies? Memory wall/gap Reliability wall/issues Programmability wall/problem
No clear, definitive answers to these problems13

Computer Architecture Today (II) These problems affect all parts of the computing stack – if
we do not change the way we design systems
No clear, definitive answers to these problems
MicroarchitectureISA
Program/LanguageAlgorithmProblem
Runtime System(VM, OS, MM)
User
LogicCircuitsElectrons
14

Fundamental Concepts
15

What is A Computer? Three key components
Computation Communication Storage (memory)
16

What is A Computer? We will cover all three components
Memory(programand data)
I/O
Processing
control(sequencing)
datapath
17

The Von Neumann Model/Architecture Also called stored program computer (instructions in
memory). Two key properties:
Stored program Instructions stored in a linear memory array Memory is unified between instructions and data
The interpretation of a stored value depends on the control signals
Sequential instruction processing One instruction processed (fetched, executed, and completed) at a
time Program counter (instruction pointer) identifies the current instr. Program counter is advanced sequentially except for control transfer
instructions
When is a value interpreted as an instruction?
18

The Von Neumann Model/Architecture Recommended reading
Burks, Goldstein, von Neumann, “Preliminary discussion of the logical design of an electronic computing instrument,” 1946.
Stored program
Sequential instruction processing
19

The von Neumann Model (of a Computer)
CONTROL UNIT
IP Inst Register
PROCESSING UNIT
ALU TEMP
MEMORY
Mem Addr Reg
Mem Data Reg
INPUT OUTPUT
20

The Dataflow Model (of a Computer) Von Neumann model: An instruction is fetched and
executed in control flow order As specified by the instruction pointer Sequential unless explicit control flow instruction
Dataflow model: An instruction is fetched and executed in data flow order i.e., when its operands are ready i.e., there is no instruction pointer Instruction ordering specified by data flow dependence
Each instruction specifies “who” should receive the result An instruction can “fire” whenever all operands are received
Potentially many instructions can execute at the same time Inherently more parallel
21

von Neumann vs Dataflow Consider a von Neumann program
What is the significance of the program order? What is the significance of the storage locations?
Which model is more natural to you as a programmer?
v <= a + b; w <= b * 2;x <= v - wy <= v + wz <= x * y
+ *2
- +
*
a b
z
Sequential
Dataflow
22

More on Data Flow In a data flow machine, a program consists of data flow
nodes A data flow node fires (fetched and executed) when all it
inputs are ready i.e. when all inputs have tokens
Data flow node and its ISA representation
23

Data Flow Nodes
24

ISA-level Tradeoff: Instruction Pointer
Do we need an instruction pointer in the ISA? Yes: Control-driven, sequential execution
An instruction is executed when the IP points to it IP automatically changes sequentially (except for control flow
instructions) No: Data-driven, parallel execution
An instruction is executed when all its operand values are available (data flow)
Tradeoffs: MANY high-level ones Ease of programming (for average programmers)? Ease of compilation? Performance: Extraction of parallelism? Hardware complexity?
25

ISA vs. Microarchitecture Level Tradeoff A similar tradeoff (control vs. data-driven execution) can be
made at the microarchitecture level
ISA: Specifies how the programmer sees instructions to be executed Programmer sees a sequential, control-flow execution order vs. Programmer sees a data-flow execution order
Microarchitecture: How the underlying implementation actually executes instructions Microarchitecture can execute instructions in any order as long
as it obeys the semantics specified by the ISA when making the instruction results visible to software Programmer should see the order specified by the ISA
26

Let’s Get Back to the Von Neumann Model
But, if you want to learn more about dataflow…
Dennis and Misunas, “A preliminary architecture for a basic data-flow processor,” ISCA 1974.
Gurd et al., “The Manchester prototype dataflow computer,” CACM 1985.
27

The Von-Neumann Model All major instruction set architectures today use this model
x86, ARM, MIPS, SPARC, Alpha, POWER
Underneath (at the microarchitecture level), the execution model of almost all implementations (or, microarchitectures) is very different Pipelined instruction execution: Intel 80486 uarch Multiple instructions at a time: Intel Pentium uarch Out-of-order execution: Intel Pentium Pro uarch Separate instruction and data caches
But, what happens underneath that is not consistent with the von Neumann model is not exposed to software Difference between ISA and microarchitecture
28

What is Computer Architecture? ISA+implementation definition: The science and art of
designing, selecting, and interconnecting hardware components and designing the hardware/software interface to create a computing system that meets functional, performance, energy consumption, cost, and other specific goals.
Traditional (only ISA) definition: “The term architecture is used here to describe the attributes of a system as seen by the programmer, i.e., the conceptual structure and functional behavior as distinct from the organization of the dataflow and controls, the logic design, and the physical implementation.” Gene Amdahl, IBM Journal of R&D, April 1964
29

ISA vs. Microarchitecture
ISA Agreed upon interface between software
and hardware SW/compiler assumes, HW promises
What the software writer needs to know to write and debug system/user programs
Microarchitecture Specific implementation of an ISA Not visible to the software
Microprocessor ISA, uarch, circuits “Architecture” = ISA + microarchitecture
MicroarchitectureISAProgramAlgorithmProblem
CircuitsElectrons
30

ISA vs. Microarchitecture What is part of ISA vs. Uarch?
Gas pedal: interface for “acceleration”
Internals of the engine: implement “acceleration”
Implementation (uarch) can be various as long as it satisfies the specification (ISA) Add instruction vs. Adder implementation
Bit serial, ripple carry, carry lookahead adders are all part of microarchitecture
x86 ISA has many implementations: 286, 386, 486, Pentium, Pentium Pro, Pentium 4, Core, …
Microarchitecture usually changes faster than ISA Few ISAs (x86, ARM, SPARC, MIPS, Alpha) but many uarchs Why?
31

ISA Instructions
Opcodes, Addressing Modes, Data Types Instruction Types and Formats Registers, Condition Codes
Memory Address space, Addressability, Alignment Virtual memory management
Call, Interrupt/Exception Handling Access Control, Priority/Privilege I/O: memory-mapped vs. instr. Task/thread Management Power and Thermal Management Multi-threading support, Multiprocessor support
32

Microarchitecture Implementation of the ISA under specific design constraints
and goals Anything done in hardware without exposure to software
Pipelining In-order versus out-of-order instruction execution Memory access scheduling policy Speculative execution Superscalar processing (multiple instruction issue?) Clock gating Caching? Levels, size, associativity, replacement policy Prefetching? Voltage/frequency scaling? Error correction?
33

Property of ISA vs. Uarch? ADD instruction’s opcode Number of general purpose registers Number of ports to the register file Number of cycles to execute the MUL instruction Whether or not the machine employs pipelined instruction
execution
Remember Microarchitecture: Implementation of the ISA under specific
design constraints and goals
34

Design Point A set of design considerations and their importance
leads to tradeoffs in both ISA and uarch Considerations
Cost Performance Maximum power consumption Energy consumption (battery life) Availability Reliability and Correctness Time to Market
Design point determined by the “Problem” space (application space), or the intended users/market
MicroarchitectureISAProgramAlgorithmProblem
CircuitsElectrons
35

Application Space Dream, and they will appear…
36

Tradeoffs: Soul of Computer Architecture
ISA-level tradeoffs
Microarchitecture-level tradeoffs
System and Task-level tradeoffs How to divide the labor between hardware and software
Computer architecture is the science and art of making the appropriate trade-offs to meet a design point Why art?
37

Why Is It (Somewhat) Art?
MicroarchitectureISA
Program/LanguageAlgorithmProblem
Runtime System(VM, OS, MM)
User
We do not (fully) know the future (applications, users, market)
LogicCircuitsElectrons
38

Why Is It (Somewhat) Art?
MicroarchitectureISA
Program/LanguageAlgorithmProblem
Runtime System(VM, OS, MM)
User
And, the future is not constant (it changes)!
LogicCircuitsElectrons
39

Lecture 3: ISA Tradeoffs

Design Point A set of design considerations and their importance
leads to tradeoffs in both ISA and uarch Considerations
Cost Performance Maximum power consumption Energy consumption (battery life) Availability Reliability and Correctness Time to Market
Send degraded image when battery is running low Design point determined by the “Problem” space
(application space), or the intended users/market
MicroarchitectureISAProgramAlgorithmProblem
CircuitsElectrons
2

Application Space Dream, and they will appear…
3

Tradeoffs: Soul of Computer Architecture
ISA-level tradeoffs
Microarchitecture-level tradeoffs
System and Task-level tradeoffs How to divide the labor between hardware and software
Computer architecture is the science and art of making the appropriate trade-offs to meet a design point Why art?
4
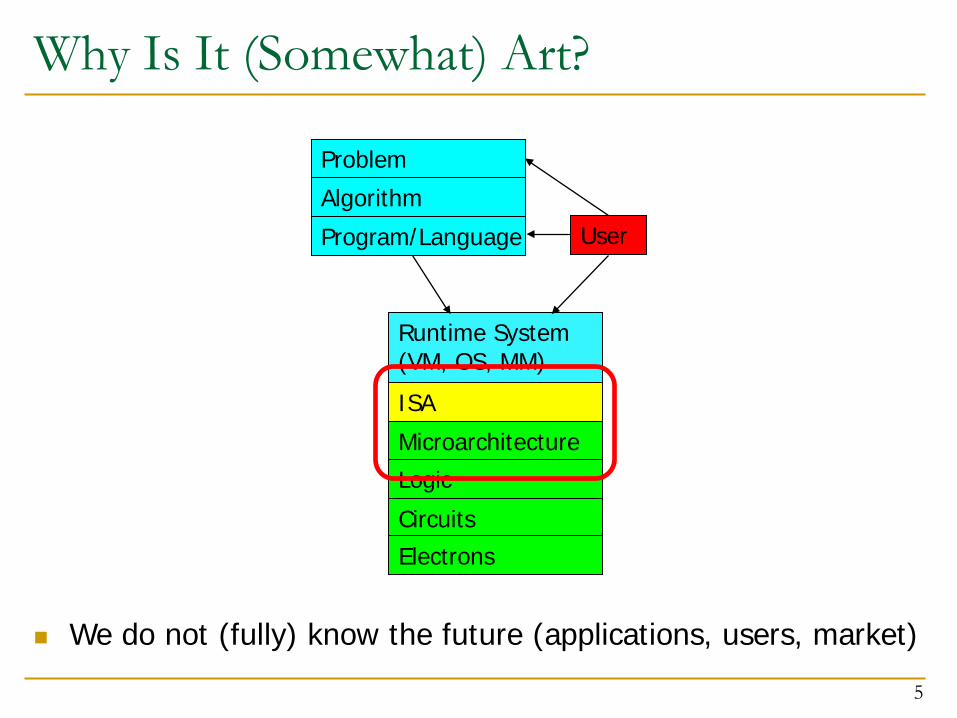
Why Is It (Somewhat) Art?
MicroarchitectureISA
Program/LanguageAlgorithmProblem
Runtime System(VM, OS, MM)
User
We do not (fully) know the future (applications, users, market)
LogicCircuitsElectrons
5

Why Is It (Somewhat) Art?
MicroarchitectureISA
Program/LanguageAlgorithmProblem
Runtime System(VM, OS, MM)
User
And, the future is not constant (it changes)!
LogicCircuitsElectrons
6

ISA Principles and Tradeoffs
7

Many Different ISAs Over Decades X86 [software compatibility well maintained over the years] PDP-x: Programmed Data Processor (PDP-11) [DEC] VAX [Virtual Address Extension]
DEC abandoned VAX and moved to Alpha IBM 360 CDC 6600 SIMD ISAs: CRAY-1, Connection Machine
ADD operation on million elements VLIW ISAs: Multiflow, Cydrome, IA-64 (EPIC)
ADD, MULTIPLY – multiple operations encoded as a single instruction
Can do multiple operations together at the same time
8

Many Different ISAs Over Decades PowerPC, POWER RISC ISAs: Alpha, MIPS, SPARC, ARM What are the fundamental differences?
E.g., how instructions are specified and what they do E.g., how complex are the instructions
9

Instruction Basic element of the HW/SW interface Consists of
opcode: what the instruction does operands: who it is to do it to Example from Alpha ISA:
Uniform Decode characteristic Same bits in the instruction specify the same things across
instructions – opcode is always bits 31-26 Nice and beautiful decoder that looks at just these bits
10
ARM
11

Set of Instructions, Encoding, and Spec Example from LC-3b ISA
http://www.ece.utexas.edu/~patt/11s.460N/handouts/new_byte.pdf
x86 Manual
Why unused instructions? Aside: concept of “bit
steering” A bit in the instruction
determines the interpretation of other bits
12

Bit Steering in Alpha
13

What Are the Elements of An ISA? Instruction sequencing model
Control flow vs. data flow Tradeoffs?
Instruction processing style Specifies the number of “operands” an instruction “operates” on and
how it does so 0, 1, 2, 3 address machines
0-address: stack machine (push A, pop A, op) 1-address: accumulator machine (ld A, st A, op A) 2-address: 2-operand machine (one is both source and dest) 3-address: 3-operand machine (source and dest are separate)
Tradeoffs? Larger operate instructions vs. more executed operations Code size vs. execution time vs. on-chip memory space
[e.g. For a stack machine, instruction size is small, but may need more operations]
14

An Example: Stack Machine+ Small instruction size (no operands needed for operate instructions)
Simpler logic Compact code
+ Efficient procedure calls: all parameters on stack No additional cycles for parameter passing
-- Computations that are not easily expressible with “postfix notation” are difficult to map to stack machines
Cannot perform operations on many values at the same time (only top N values on the stack at the same time)
Not flexible
15

An Example: Stack Machine (II)
Koopman, “Stack Computers: The New Wave,” 1989.http://www.ece.cmu.edu/~koopman/stack_computers/sec3_2.html
16

An Example: Stack Machine Operation
Koopman, “Stack Computers: The New Wave,” 1989.http://www.ece.cmu.edu/~koopman/stack_computers/sec3_2.html
17

Other Examples PDP-11: A 2-address machine
PDP-11 ADD: 4-bit opcode, 2 6-bit operand specifiers Why? Keep 16 bits to specify an instruction [code size less] Disadvantage: One source operand is always clobbered with
the result of the instruction How do you ensure you preserve the old value of the source?
X86: A 2-address (memory/memory) machine Alpha: A 3-address (load/store) machine MIPS, ARM: 3-address
18

What Are the Elements of An ISA? Instructions
Opcode Operand specifiers (addressing modes)
How to obtain the operand?
Data types Definition: Representation of information for which there are
instructions that operate on the representation Integer, floating point, character, binary, decimal, BCD Doubly linked list, queue, string, bit vector, stack
VAX: INSQUEUE and REMQUEUE instructions on a doubly linked list or queue; FINDFIRST
Digital Equipment Corp., “VAX11 780 Architecture Handbook,”1977.
X86: SCAN opcode operates on character strings; PUSH/POP
Why are there different addressing modes?
19

Data Type Tradeoffs Benefit of having more or high-level data types in the ISA?
Programs can run much faster If you have a string copy instruction, no loads and stores
What is the disadvantage? Extra hardware cost
Think compiler/programmer vs. microarchitect If data type is high level, fits programmer need Compiler sees a linked list operation, maps it to instruction Microarchitecture becomes complex
Example: Early RISC architectures vs. Intel 432 Early RISC: Only integer data type Intel 432: Object data type, capability based machine
20

What Are the Elements of An ISA? Memory organization
Address space: How many uniquely identifiable locations in memory
Addressability: How much data does each uniquely identifiable location store Byte addressable: most ISAs, characters are 8 bits Bit addressable: Burroughs 1700. Why? 64-bit addressable: Some supercomputers. Why? 32-bit addressable: First Alpha Food for thought
How do you add 2 32-bit numbers with only byte addressability? How do you add 2 8-bit numbers with only 32-bit addressability? Big endian vs. little endian? MSB at low or high byte.
Support for virtual memory21

Some Historical Readings If you want to dig deeper
Wilner, “Design of the Burroughs 1700,” AFIPS 1972.
Levy, “The Intel iAPX 432,” 1981. http://www.cs.washington.edu/homes/levy/capabook/Chapter
9.pdf
22

What Are the Elements of An ISA? Registers
How many Size of each register
Why is having registers a good idea? Memory is slow, keep data close to the processor for faster
operation Because programs exhibit a characteristic called data locality A recently produced/accessed value is likely to be used more
than once (temporal locality) Storing that value in a register eliminates the need to go to
memory each time that value is needed
23

Programmer Visible (Architectural) State
M[0]M[1]M[2]M[3]M[4]
M[N-1]Memoryarray of storage locationsindexed by an address
Program Countermemory addressof the current instruction
Registers- given special names in the ISA
(as opposed to addresses)- general vs. special purpose
Instructions (and programs) specify how to transformthe values of programmer visible state
24

Aside: Programmer Invisible State Microarchitectural state Programmer cannot access this directly
E.g. cache state E.g. pipeline registers
25

Evolution of Register Architecture Accumulator
a legacy from the “adding” machine days
Accumulator + address registers need register indirection initially address registers were special-purpose, i.e., can only
be loaded with an address for indirection eventually arithmetic on addresses became supported
General purpose registers (GPR) all registers good for all purposes grew from a few registers to 32 (common for RISC) to 128 in
Intel IA-6426

Instruction Classes Operate instructions
Process data: arithmetic and logical operations Fetch operands, compute result, store result Implicit sequential control flow
Data movement instructions Move data between memory, registers, I/O devices Implicit sequential control flow
Control flow instructions Change the sequence of instructions that are executed
27

What Are the Elements of An ISA? Load/store vs. memory/memory architectures
Load/store architecture: operate instructions operate only on registers E.g., MIPS, ARM and many RISC ISAs
Memory/memory architecture: operate instructions can operate on memory locations E.g., x86, VAX and many CISC ISAs
28

What Are the Elements of An ISA? Addressing modes specify how to obtain the operands
Absolute LW rt, 10000use immediate value as address
Register Indirect: LW rt, (rbase)use GPR[rbase] as address
Displaced or based: LW rt, offset(rbase)use offset+GPR[rbase] as address
Indexed: LW rt, (rbase, rindex)use GPR[rbase]+GPR[rindex] as address
Memory Indirect LW rt ((rbase))use value at M[ GPR[ rbase ] ] as address
Auto inc/decrement LW Rt, (rbase)use GRP[rbase] as address, but inc. or dec. GPR[rbase] each time
29

What Are the Benefits of Different Addressing Modes?
Another example of programmer vs. microarchitect tradeoff
Advantage of more addressing modes: Enables better mapping of high-level constructs to the
machine: some accesses are better expressed with a different mode reduced number of instructions and code size Think array accesses (autoincrement mode) Think indirection (pointer chasing) Sparse matrix accesses
Disadvantage: More work for the compiler More work for the microarchitect
30

ISA Orthogonality Orthogonal ISA:
All addressing modes can be used with all instruction types Example: VAX
(~13 addressing modes) x (>300 opcodes) x (integer and FP formats)
Who is this good for? – for compiler Who is this bad for? – for microarchitect
31

Is the LC-3b ISA Orthogonal?
32

LC-3b: Addressing Modes of ADD
33

LC-3b: Addressing Modes of of JSR(R)
34

What Are the Elements of An ISA? How to interface with I/O devices
Memory mapped I/O A region of memory is mapped to I/O devices I/O operations are loads and stores to those locations
Special I/O instructions IN and OUT instructions in x86 deal with ports of the chip
Tradeoffs? Which one is more general purpose?
35

What Are the Elements of An ISA? Privilege modes
User vs supervisor Who can execute what instructions?
Exception and interrupt handling What procedure is followed when something goes wrong with an
instruction? What procedure is followed when an external device requests the
processor? Vectored vs. non-vectored interrupts (early MIPS)
Virtual memory Each program has the illusion of the entire memory space, which is greater
than physical memory
Access protection
36

Complex vs. Simple Instructions Complex instruction: An instruction does a lot of work, e.g.
many operations Insert in a doubly linked list Compute FFT String copy
Simple instruction: An instruction does small amount of work, it is a primitive using which complex operations can be built Add XOR Multiply
37

Complex vs. Simple Instructions Advantages of Complex instructions
+ Denser encoding smaller code size better memory utilization, saves off-chip bandwidth, better cache hit rate (better packing of instructions)
+ Simpler compiler: no need to optimize small instructions as much
Disadvantages of Complex Instructions- Larger chunks of work compiler has less opportunity to
optimize (limited in fine-grained optimizations it can do)- More complex hardware translation from a high level to
control signals and optimization needs to be done by hardware
38

ISA-level Tradeoffs: Semantic Gap Where to place the ISA? Semantic gap
Closer to high-level language (HLL) Small semantic gap, complex instructions
Closer to hardware control signals? Large semantic gap, simple instructions
RISC vs. CISC machines RISC: Reduced instruction set computer CISC: Complex instruction set computer
FFT, QUICKSORT, POLY, FP instructions? VAX INDEX instruction (array access with bounds checking)
39

ISA-level Tradeoffs: Semantic Gap Some tradeoffs (for you to think about)
Simple compiler, complex hardware vs. complex compiler, simple hardware Caveat: Translation (indirection) can change the tradeoff!
Burden of backward compatibility
Performance? Optimization opportunity: Example of VAX INDEX instruction:
who (compiler vs. hardware) puts more effort into optimization?
Instruction size, code size40

X86: Small Semantic Gap: String Operations
An instruction operates on a string Move one string of arbitrary length to another location Compare two strings
Enabled by the ability to specify repeated execution of an instruction (in the ISA) Using a “prefix” called REP prefix
Example: REP MOVS instruction Only two bytes: REP prefix byte and MOVS opcode byte (F2 A4) Implicit source and destination registers pointing to the two
strings (ESI, EDI) Implicit count register (ECX) specifies how long the string is
41

X86: Small Semantic Gap: String OperationsREP MOVS (DEST SRC)
How many instructions does this take in ARM and MIPS?42

Small Semantic Gap Examples in VAX FIND FIRST
Find the first set bit in a bit field Helps OS resource allocation operations
SAVE CONTEXT, LOAD CONTEXT Special context switching instructions
INSQUEUE, REMQUEUE Operations on doubly linked list
INDEX Array access with bounds checking
STRING Operations Compare strings, find substrings, …
Cyclic Redundancy Check Instruction EDITPC
Implements editing functions to display fixed format output
Digital Equipment Corp., “VAX11 780 Architecture Handbook,” 1977-78.43

Small versus Large Semantic Gap CISC vs. RISC
Complex instruction set computer complex instructions Initially motivated by “not good enough” code generation
Reduced instruction set computer simple instructions John Cocke, mid 1970s, IBM 801
Goal: enable better compiler control and optimization
RISC motivated by Memory stalls (no work done in a complex instruction when
there is a memory stall?) When is this correct?
Simplifying the hardware lower cost, higher frequency Enabling the compiler to optimize the code better
Find fine-grained parallelism to reduce stalls44

How High or Low Can You Go? Very large semantic gap
Each instruction specifies the complete set of control signals in the machine
Compiler generates control signals Open microcode (John Cocke, circa 1970s)
Gave way to optimizing compilers
Very small semantic gap ISA is (almost) the same as high-level language Java machines, LISP machines, object-oriented machines,
capability-based machines
45

A Note on ISA Evolution ISAs have evolved to reflect/satisfy the concerns of the day
Examples: Limited on-chip and off-chip memory size Limited compiler optimization technology Limited memory bandwidth Need for specialization in important applications (e.g., MMX)
Use of translation (in HW and SW) enabled underlying implementations to be similar, regardless of the ISA Concept of dynamic/static interface Contrast it with hardware/software interface
46

Effect of Translation One can translate from one ISA to another ISA to change
the semantic gap tradeoffs
Examples Intel’s and AMD’s x86 implementations translate x86
instructions into programmer-invisible microoperations (simple instructions) in hardware
Transmeta’s x86 implementations translated x86 instructions into “secret” VLIW instructions in software (code morphing software)
Think about the tradeoffs
47





























