Embed Size (px)
Citation preview

1
Computer Analysis of Chinese Learner English
Gui ShichunYang Huizhong
HKUST 2001.6

2
1. Background
1.1 Corpus linguistics as an outcome of modern technologies (high-speed CPUs, big-sized rams and hard-disks, and scanners).
(Sinclair 1991)

3
1.2 Three approaches to linguistic study
• Different procedures for obtaining data about a language:
1.2.1 Introspection• Linguists as their own informants,
• judging the ambiguity, acceptability, and other properties of utterances against their own intuitions.

4
• Linguistic analysis based on invented examples:
• Flying planes can be dangerous.• Sincerity may scare the boy.
• John is eager to please.• John is easy to please.
• A competence-based approach

5
1.2.2 Elicitation
• A carefully planned intensive field investigation
• using controlled methods for eliciting judgments about sentences or elements they contain.
• Subjects are asked to identify errors, to rate the acceptability of sentences, to make judgments of perception or comprehension, and to carry out a variety of analytical procedures.
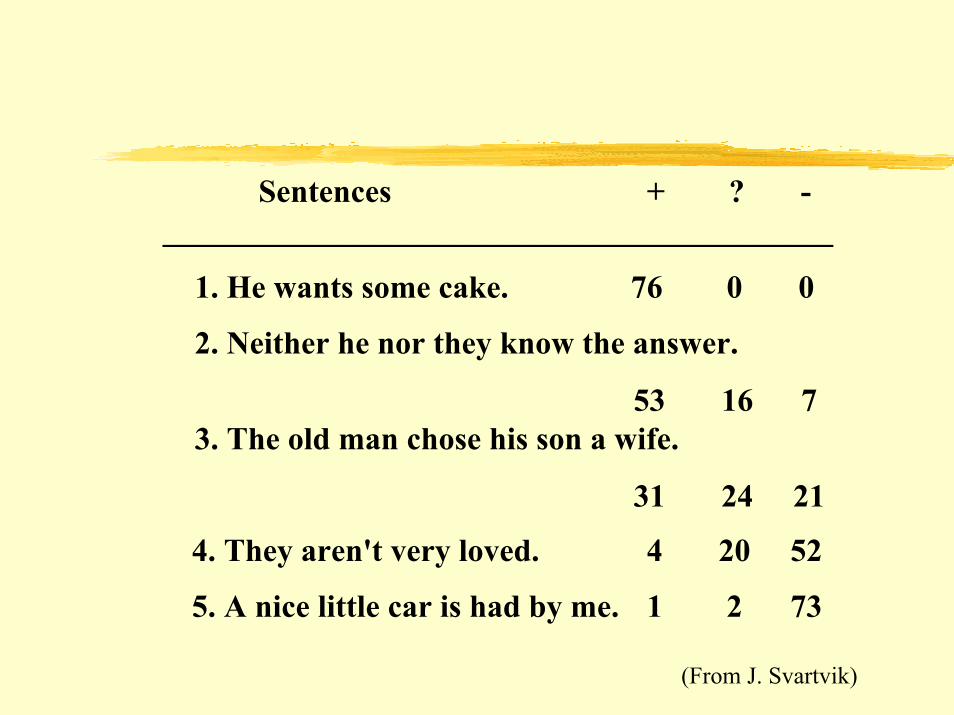
6
Sentences + ? -__________________________________________
1. He wants some cake. 76 0 0
2. Neither he nor they know the answer.
53 16 7 3. The old man chose his son a wife.
31 24 21
4. They aren't very loved. 4 20 52
5. A nice little car is had by me. 1 2 73
(From J. Svartvik)

7
• Field investigations help to yield objective and reliable conclusion.
• People's views vary on the acceptability of certain language forms.
• Time and manpower limits the scale of investigation.
• Informants' judgments may be subject to prompts, which influence the validity of the study.
• Partly performance-based and partly competence-based approach.

8
1.2.3 A corpus-based approach
• A representative sample of language, compiled for the purpose of linguistic analysis.
• Representativeness, randomness and size of sampling.

9
• Corpus data
• authenticity of data, • large size of text, and• not subject to subjective judgments.
• A performance-based approach

10
1.3 Sharply opposed positions on the appropriate data for linguistic study
• The critical problem for grammatical theory today is not paucity of evidence but rather the inadequacy of present theories of language to account for masses of evidence that are hardly open to serious question.
(Chomsky, 1965, Aspects of the Theory of Syntax)
• “The Corpus, if natural, will be so skewed that the description would be no more than a mere list.”
(Chomsky, 1962)

11
• Invented sentences based on native speaker's intuitions about well-formedness• Merit:
May reveal the depth of abstractness and complexity of native speakers' knowledge of their language.
• Problems:Only narrow aspects of human linguistic competence can be revealed by such methods.A strange notion of data: one normally expects a scientist to develop theories to describe and explain some phenomena which already exist, independently of the scientist, not to make up the data afterwards, in order to illustrate the theory.

12
• The nature of data for linguistics: Language should be studied in attested, authentic instances of use (not as intuitive, invented sentences); language should be studied as whole texts (not as isolated sentences or text fragments); andtexts must be studied comparatively across text corpora.
(Stubbs, 1996, Text and Corpus Analysis)
• The ability to examine large text corpora in a systematic manner allows access to a quality of evidence that has not been available before.
(Sinclair, 1991, Corpus, Concordance, Collocation)

13
1.4 Corpus linguistics as a new research paradigm
• The orientation of much linguistic research is undergoing change.
• There are calls for fresh approaches.
• This study will hopefully lead to a better understanding of the complexities of natural languages.
• We are working with real language data.

14
1.5 Characteristics of corpus-based research
• Empirical.
• A large and principled collection of natural texts.
• Extensive use of computer analysis.
• Qualitative as well as quantitative technique.
• Assumption that language is probabilistic in nature.
(Biber et al.,1998)

15
1.6 The revival of corpus linguistics
• McEnery & Wilson (1996) summarised the growth of linguistic studies by using the corpus-based approach as shown in the table below.
Date Studies
To 1965 101966~1970 201971~1975 301976~1980 801981~1985 1601986~1991 320

16
1.7 Corpus linguistics and EFL
Using computerized language data for teaching hasbecome so popular that it is now variously described as 'coming of age', 'becoming mainstream', 'the flower of the decade', etc., leading to the rise of computer learner corpus (CLC) researches.
Leech (1997) emphasises the implications of corpus linguistics for language teaching.

17
2. Computer Learner Corpora
2.1 Learner corpora are powerful tools for inter-language studies.
• Learner corpora provide a more complete picture of inter-language, namely the totality of the learner performance.
• Learner corpora put the variables affecting the learner performance under control and allow for conditioned queries.
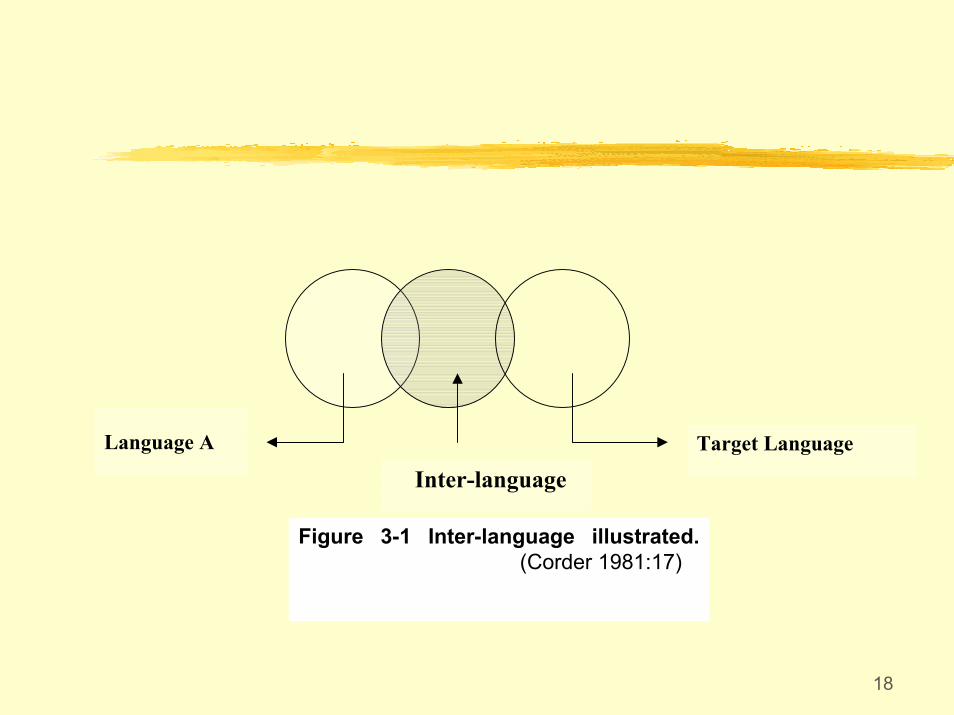
18
Target Language
Inter-languageLanguage A
Figure 3-1 Inter-language illustrated.(Corder 1981:17)

19
2.2 Inter-language studies
Inter-language is a system ever approximating the norm of the target language.
Inter-language is dynamic, developmental, and characterized by variations.
Inter-language is the learners' transitional competence.

20
2.3 Significance of inter-language studies
• Understand language learning.
• Learners observe, make hypotheses, and experiment in the learning process
• Inter-language is the learners' attempted communication in the target language with their own hypotheses.
• Understand learner strategies in the TL production.
• Learners adopt every possible contributory strategy to meet their communicative needs.
• Such strategies are not errors to be prevented.

21
2.4 Contrastive studies
Learner corpora are accessible for different types of contrastive studies:
Native speakers VS. Non-native learners.
Native learners VS. Non-native learners.
Non-native learners of different mother tongues.
Non-native learners of different language proficiency.
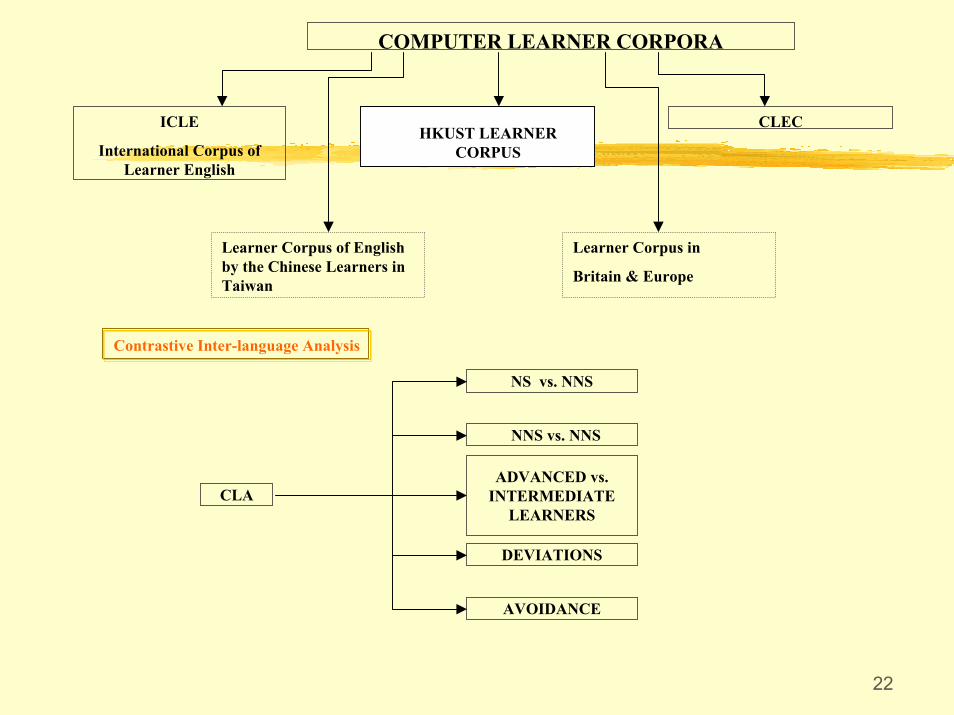
22
COMPUTER LEARNER CORPORA
CLECHKUST LEARNER
CORPUS
ICLE
International Corpus of Learner English
Learner Corpus of English by the Chinese Learners in Taiwan
Learner Corpus in
Britain & Europe
Contrastive Inter-language Analysis
NS vs. NNS
CLA
NNS vs. NNS
ADVANCED vs. INTERMEDIATE
LEARNERS
DEVIATIONS
AVOIDANCE
23
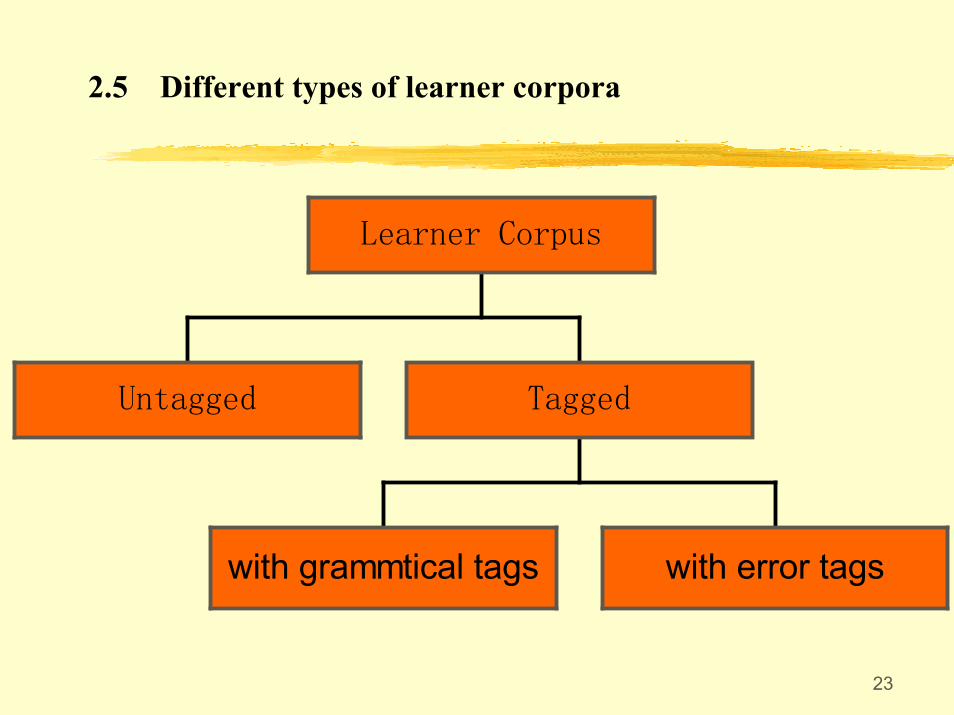
2.5 Different types of learner corpora
Untagged
with grammtical tags with error tags
Tagged
Learner Corpus

24
3. Chinese Learner English Corpus (CLEC)
3.1 Design and Procedure of CLEC
• CBACLE (Corpus-based Analysis of Chinese Learner English) is an ongoing project in the Ninth Five-Year Plan of the National Foundation of Social Sciences.
• Phase one is to develop CLEC (Chinese Learner English Corpus). Phase two is to conduct a series of studies based on the corpus.

25
• The project is undertaken by teachers of English in various universities across three cities (Guangzhou, Shanghai, XinXiang) under the general directorship of Professor Gui Shichun of Guangdong University of Foreign Studies and Professor Yang Huizhong of Shanghai Jiaotong University.

26
3.2 Goals of the Research Project
• A contrastive study of CLEC with the other corpora of English speakers, such as Brown (American English), LOB (British English), and sometimes with their updated versions Frown andFlob (by Freiburg U), AHI (American Heritage Intermediate, 5 million words of American English), and JDEST (a corpus of academic English, 4.5 million words).
• A quantitative and qualitative study of Chinese learners' errors of English.
27
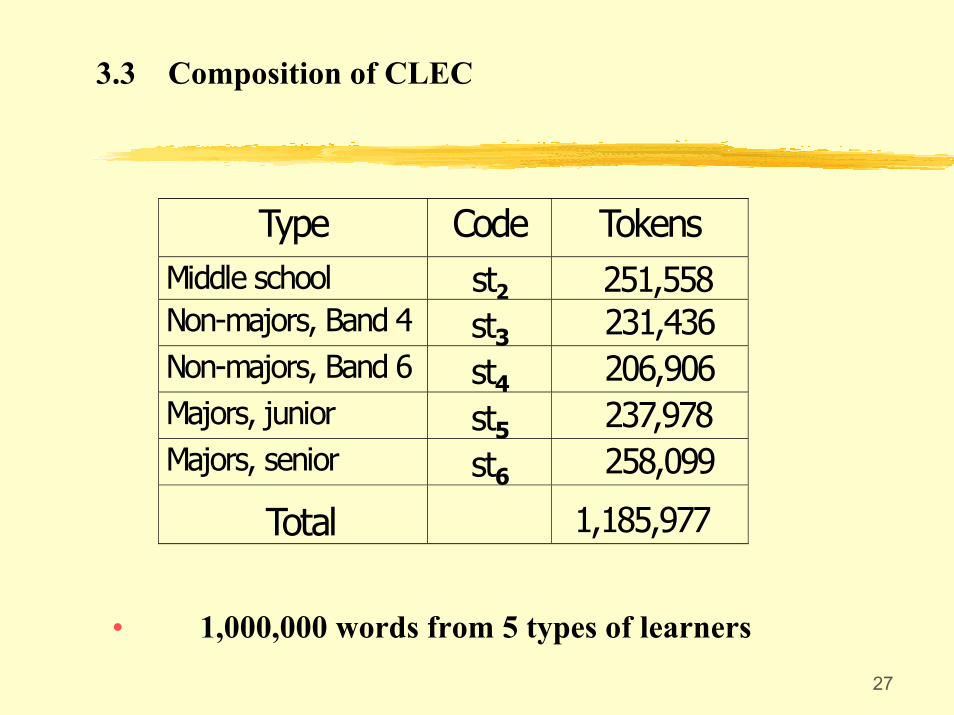
3.3 Composition of CLEC
• 1,000,000 words from 5 types of learners
Type
Code TokensMiddle school st2 251,558Non-majors, Band 4 st3 231,436Non-majors, Band 6 st4 206,906Majors, junior st5 237,978Majors, senior st6 258,099
Total
1,185,977
28
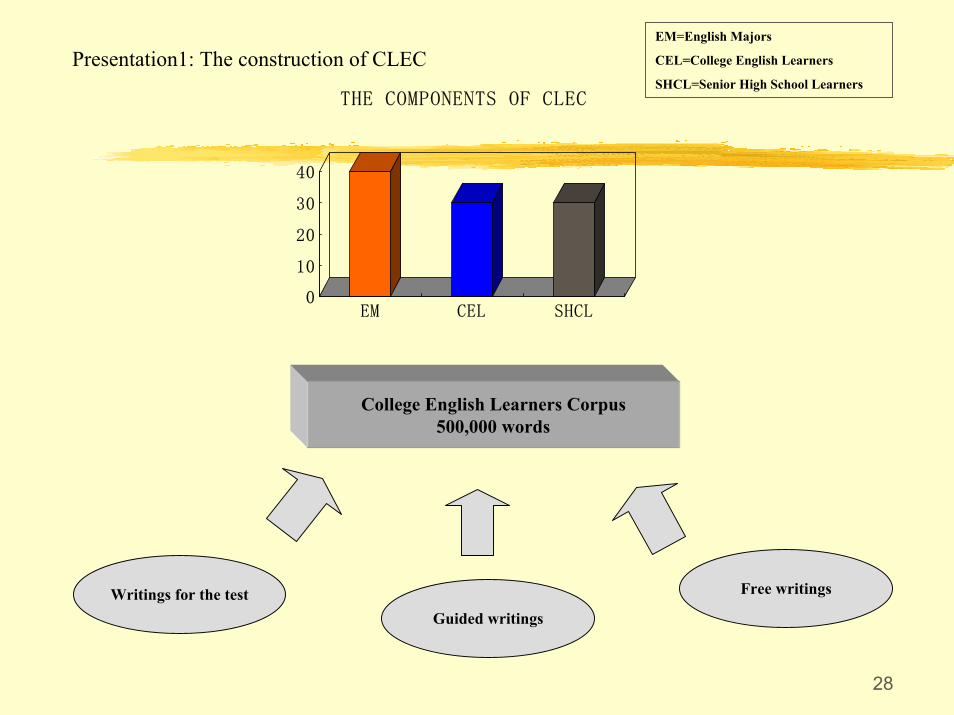
Presentation1: The construction of CLEC
0
10
20
30
40
EM CEL SHCL
THE COMPONENTS OF CLEC
EM=English Majors
CEL=College English Learners
SHCL=Senior High School Learners
College English Learners Corpus500,000 words
Free writingsWritings for the testGuided writings
29
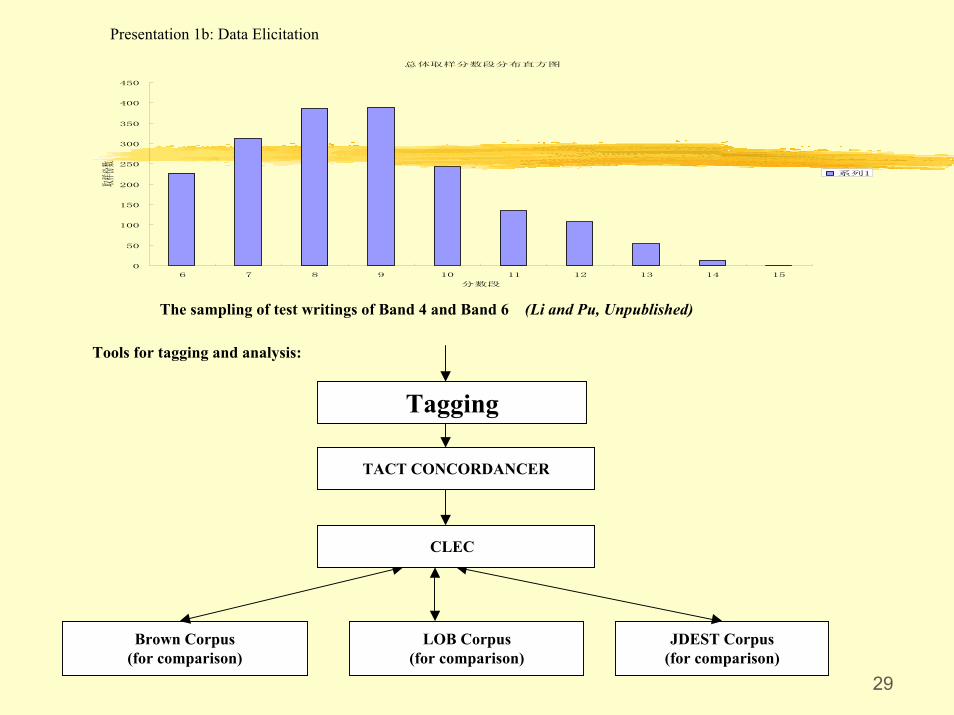
Presentation 1b: Data Elicitation
总体取样分数段分布直方图
0
50
100
150
200
250
300
350
400
450
6 7 8 9 10 11 12 13 14 15
分数段
取样份
数
系列1
The sampling of test writings of Band 4 and Band 6 (Li and Pu, Unpublished)
Tools for tagging and analysis:
Tagging
TACT CONCORDANCER
Brown Corpus(for comparison)
LOB Corpus(for comparison)
JDEST Corpus(for comparison)
CLEC
30
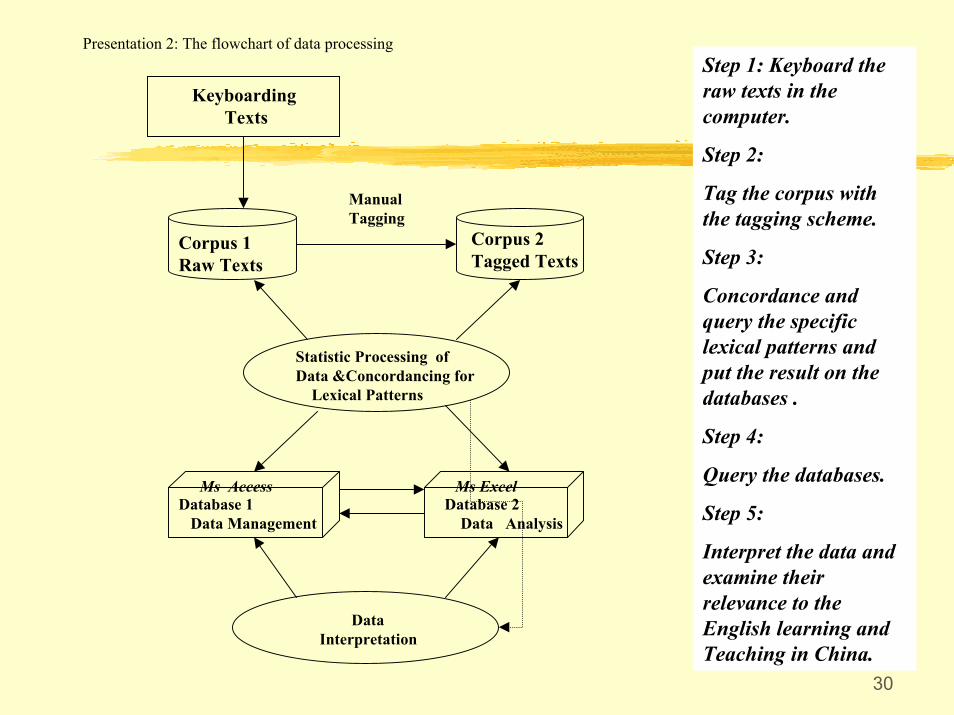
Presentation 2: The flowchart of data processingStep 1: Keyboard the raw texts in the computer.
Step 2:
Tag the corpus with the tagging scheme.
Step 3:
Concordance and query the specific lexical patterns and put the result on the databases .
Step 4:
Query the databases.
Step 5:
Interpret the data and examine their relevance to the English learning and Teaching in China.
KeyboardingTexts
Corpus 1Raw Texts
Corpus 2Tagged Texts
Statistic Processing of Data &Concordancing for
Lexical Patterns
Database 1Data Management
Database 2Data Analysis
DataInterpretation
Ms Access Ms Excel
Manual Tagging

31
3.4 Principles of tagging the errors
• Concise but logical and systematic scheming.
• Detailed categorisation of more common grammatical errors and rough for those with lower frequency of occurrence. The error marking scheme has 61 items under 11 categories (word form, verb phrase, noun phrase, pronoun, adjective, adverb, preposition, conjunction, word usage, collocation, syntax ) .
• Openness.
• Exclusion of stylistic errors.
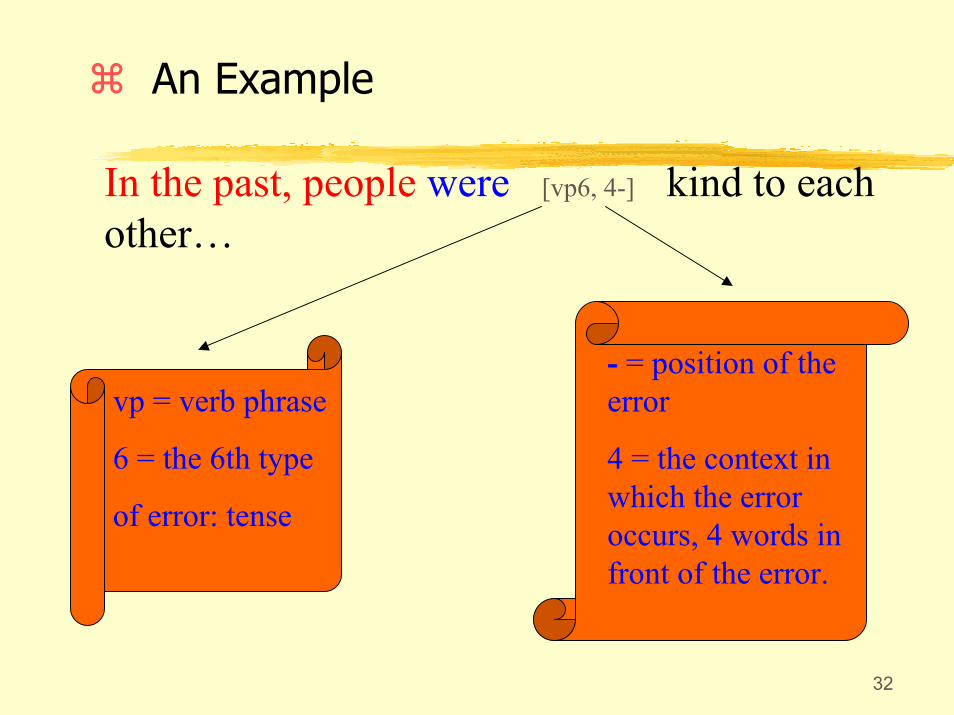
32
An Example
In the past, people were [vp6, 4-] kind to each other…
vp = verb phrase
6 = the 6th type
of error: tense
- = position of the error
4 = the context in which the error occurs, 4 words in front of the error.
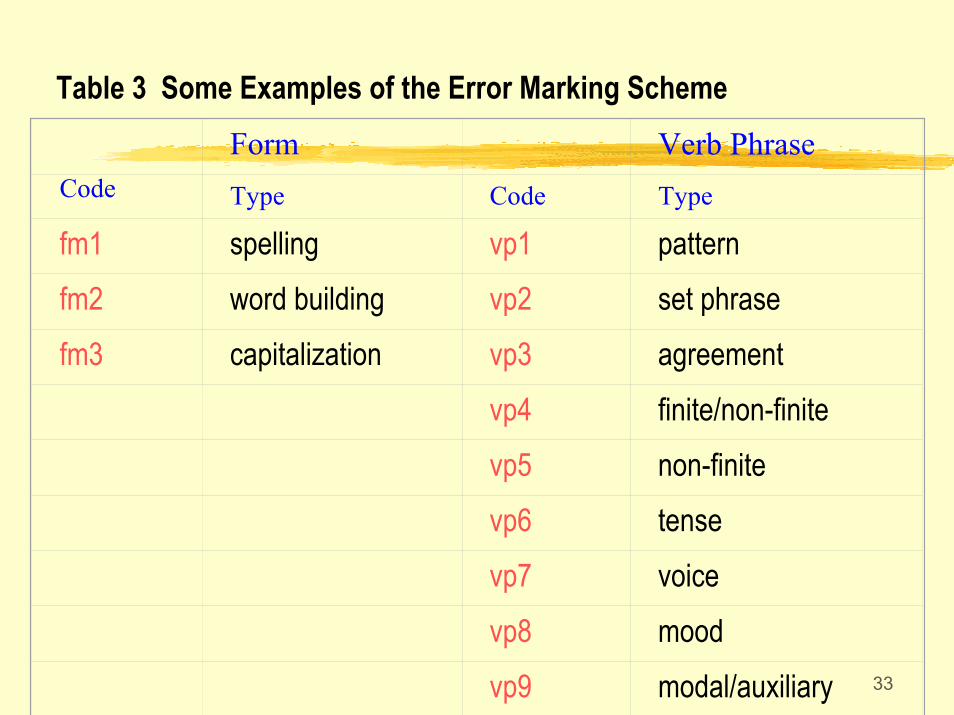
33
Table 3 Some Examples of the Error Marking Scheme
CodeForm Verb PhraseType Code Type
fm1 spelling vp1 patternfm2 word building vp2 set phrasefm3 capitalization vp3 agreement
vp4 finite/non-finitevp5 non-finitevp6 tensevp7 voicevp8 moodvp9 modal/auxiliary
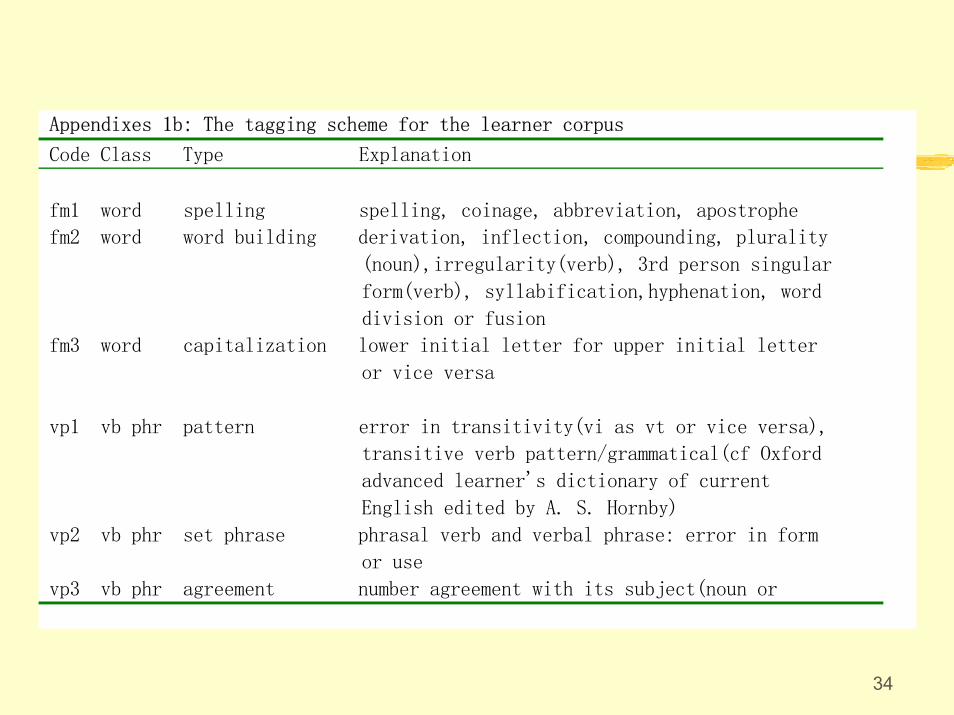
34
Appendixes 1b: The tagging scheme for the learner corpus
Code Class Type Explanation
fm1 word spelling spelling, coinage, abbreviation, apostrophe
fm2 word word building derivation, inflection, compounding, plurality
(noun),irregularity(verb), 3rd person singular
form(verb), syllabification,hyphenation, word
division or fusion
fm3 word capitalization lower initial letter for upper initial letter
or vice versa
vp1 vb phr pattern error in transitivity(vi as vt or vice versa),
transitive verb pattern/grammatical(cf Oxford
advanced learner's dictionary of current
English edited by A. S. Hornby)
vp2 vb phr set phrase phrasal verb and verbal phrase: error in form
or use
vp3 vb phr agreement number agreement with its subject(noun or
35
Figure4-3: The Tagging-with-Word Toolbar (Li Wenzhong, 1997)
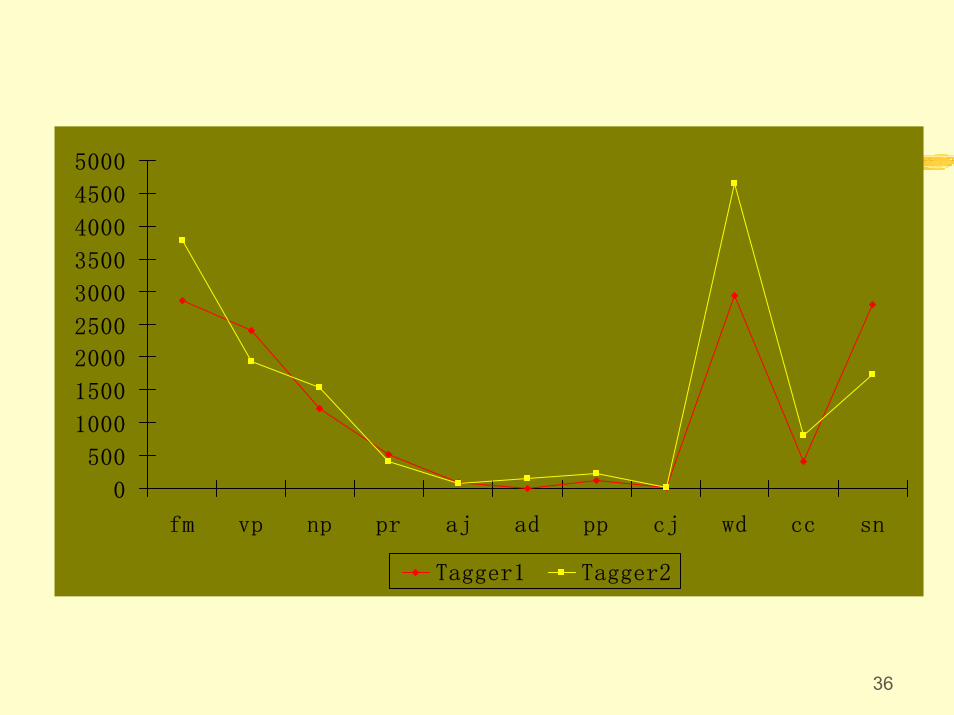
36
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
fm vp np pr aj ad pp cj wd cc sn
Tagger1 Tagger2

37
4. Statistical features
4.1 Compiling the rank list
• Word.
nHDppppH iiii
log//)log()log(
2 =ΣΣ−Σ=
• Frequency.
• D (Dispersion) Value

38
• U: the estimated frequency-per-million tokensderived from with an adjustment for D.
min)1()[/1000000( fDFDNU −+=
)4(log10 += USFI
• SFI: Standard Frequency Index
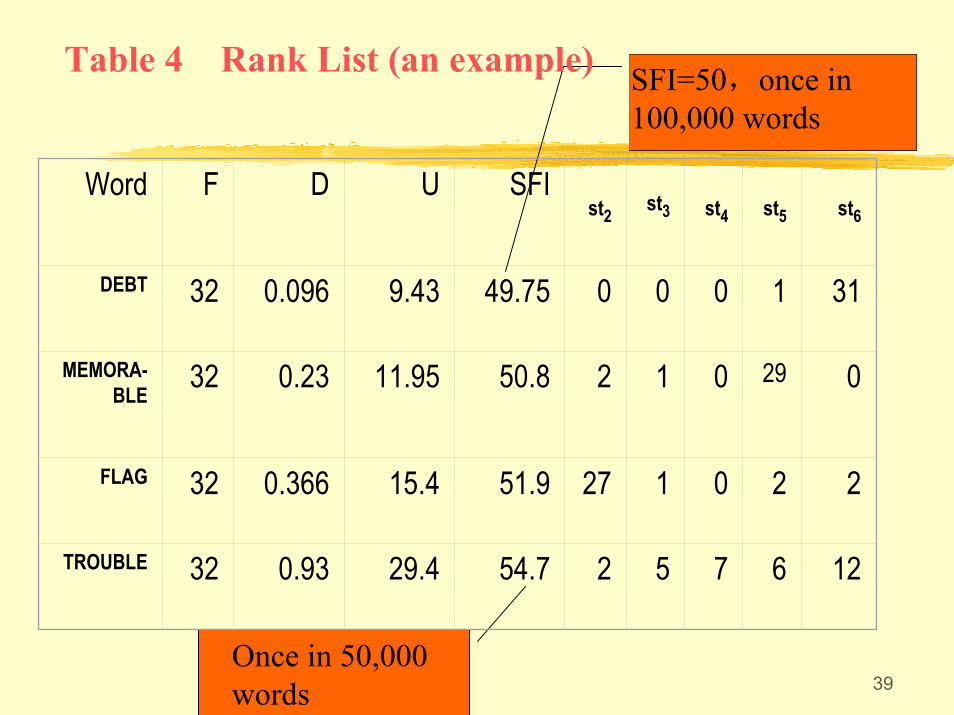
39Once in 50,000 words
Word F D U SFIst2 st3 st4 st5 st6
DEBT 32 0.096 9.43 49.75 0 0 0 1 31
MEMORA-BLE
32 0.23 11.95 50.8 2 1 0 29 0
FLAG 32 0.366 15.4 51.9 27 1 0 2 2
TROUBLE 32 0.93 29.4 54.7 2 5 7 6 12
Table 4 Rank List (an example) SFI=50,once in 100,000 words

40
• Trimming the CLEC.
• Misspellings (such as *abilitical, *abilitities, *abilitys, *abillities, *ablelity, *ablity, *abtilities).
• Chinese proper nouns.
• After these trimmings, the total number of types decreased from 23,633 to 14,598. Altogether 8,675 types have been deleted.

41
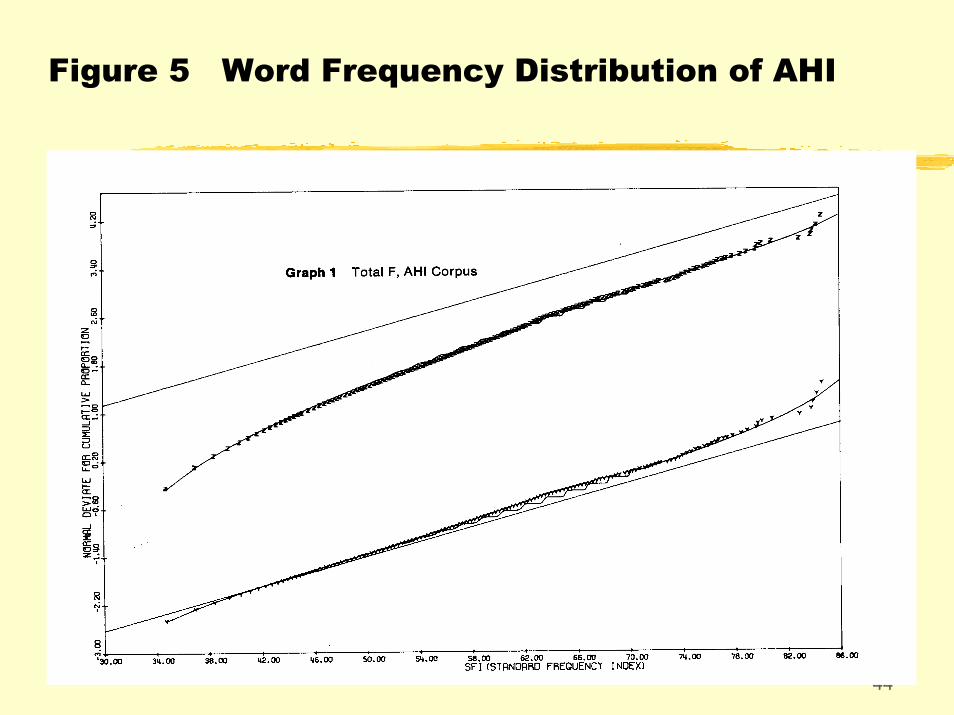
• To justify the contrastive studies, we need to check the lognormality of CLEC. This is done by plotting the cumulative proportions of the sample (in terms of tokens) against the logarithms of the corresponding word-type frequencies. The plot should follow the cumulative normal curve.
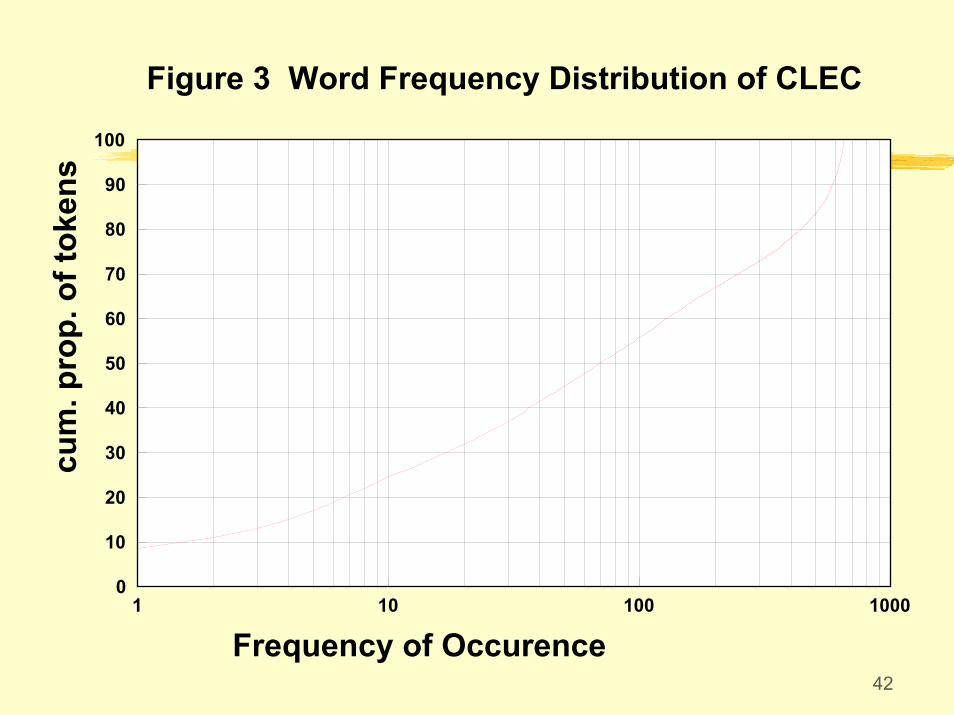
42
1 10 100 10000
10
20
30
40
50
60
70
80
90
100
Figure 3 Word Frequency Distribution of CLEC
Frequency of Occurence
cum
. pro
p. o
f tok
ens
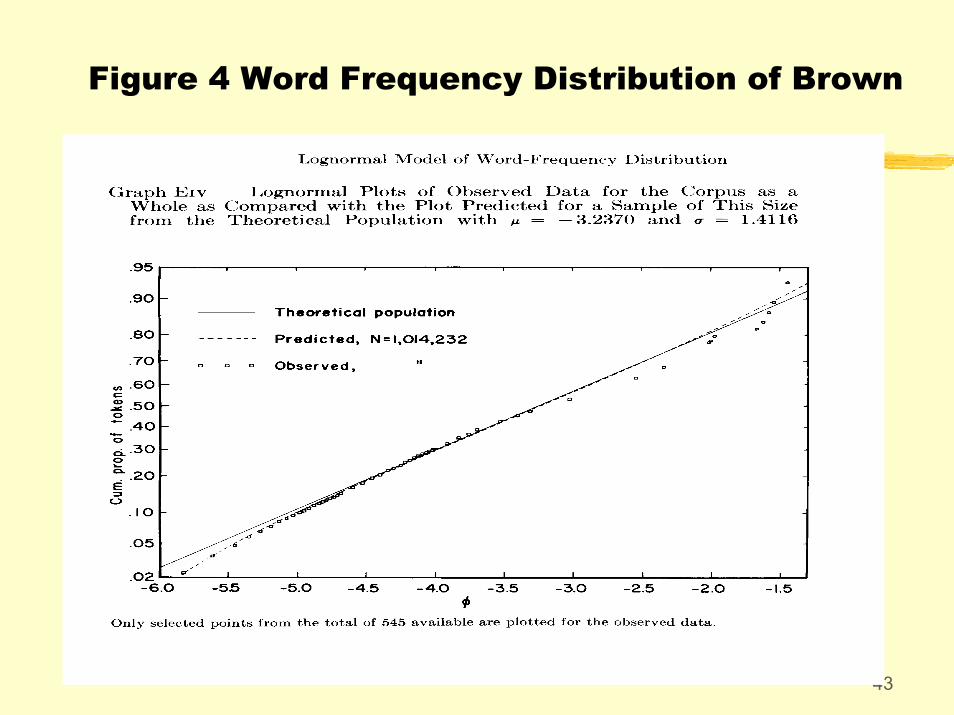
43
Figure 4 Word Frequency Distribution of Brown
44
Figure 5 Word Frequency Distribution of AHI

45
4.2 Some basic findings
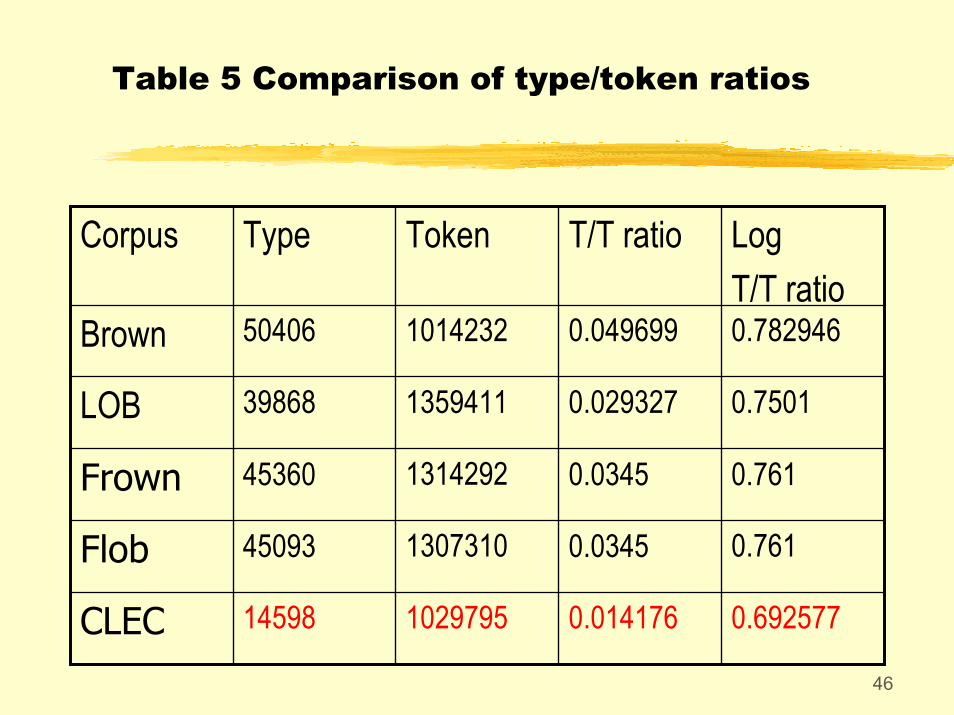
• The TTR (Type/Token Ratio) of CLEC is much smaller than those of native speakers' corpora, showing that the Chinese learners have a limited vocabulary. The more proficient the learners, the greater their vocabulary range. The vocabulary of College English students appears to be smaller due to the constraint of topics, because their written works were chosen from examination papers.
46
Table 5 Comparison of type/token ratios
0.6925770.014176102979514598CLEC
0.7610.0345130731045093Flob
0.7610.0345131429245360Frown
0.75010.029327135941139868LOB
0.7829460.049699101423250406Brown
Log T/T ratio
T/T ratioTokenTypeCorpus
47
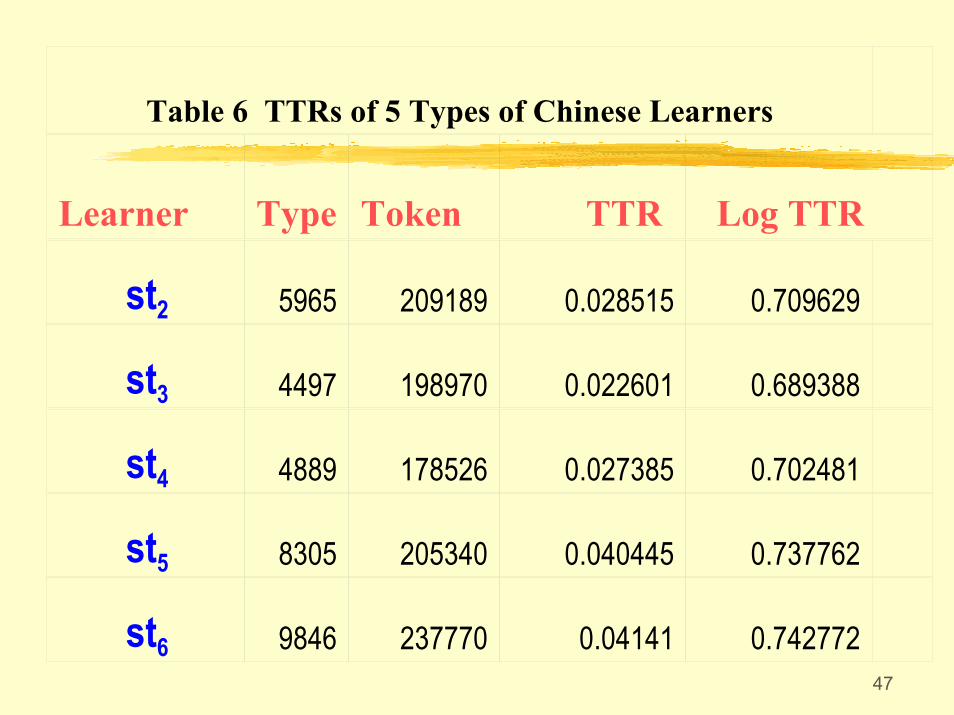
Table 6 TTRs of 5 Types of Chinese Learners
Learner Type Token TTR Log TTR
st2 5965 209189 0.028515 0.709629
st3 4497 198970 0.022601 0.689388
st4 4889 178526 0.027385 0.702481
st5 8305 205340 0.040445 0.737762
st6 9846 237770 0.04141 0.742772

48
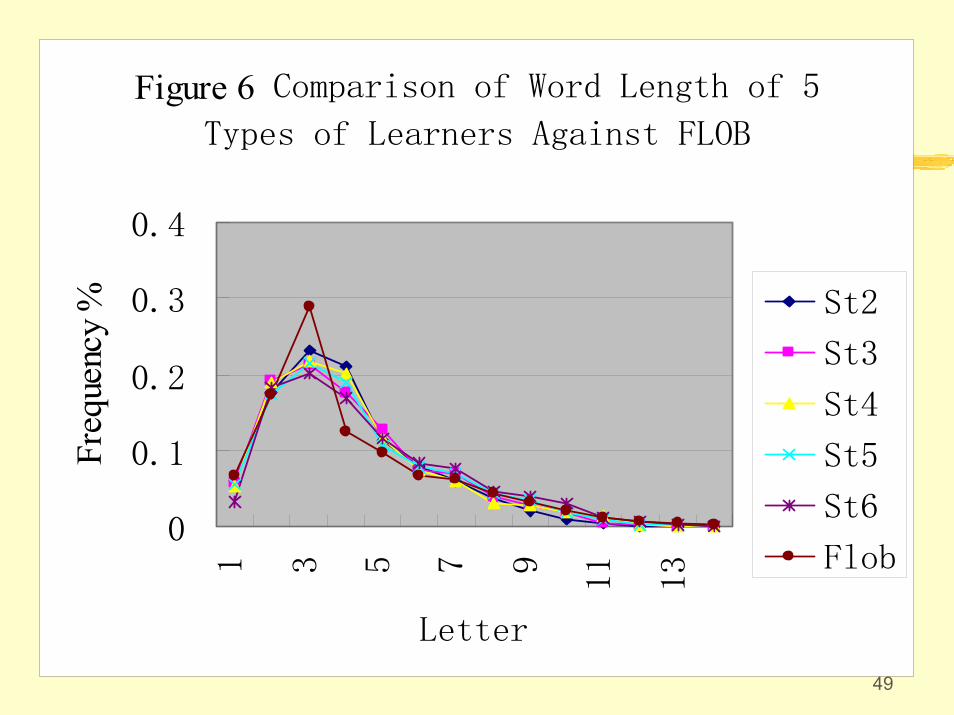
The average word length of CLEC follows the general pattern of the other corpora with 3-letter words on the top of the list. But 4-letter words come the second instead of 2-letter words. CLEC(4.26) stands in the middle of Frown(4.28) and FLOB(4.23). The more proficient the learners are, the longer the words they use.
49
Figure 6 Comparison of Word Length of 5Types of Learners Against FLOB
0
0.1
0.2
0.3
0.41 3 5 7 9
11
13
Letter
Freq
uenc
y % St2
St3
St4
St5
St6
Flob
50
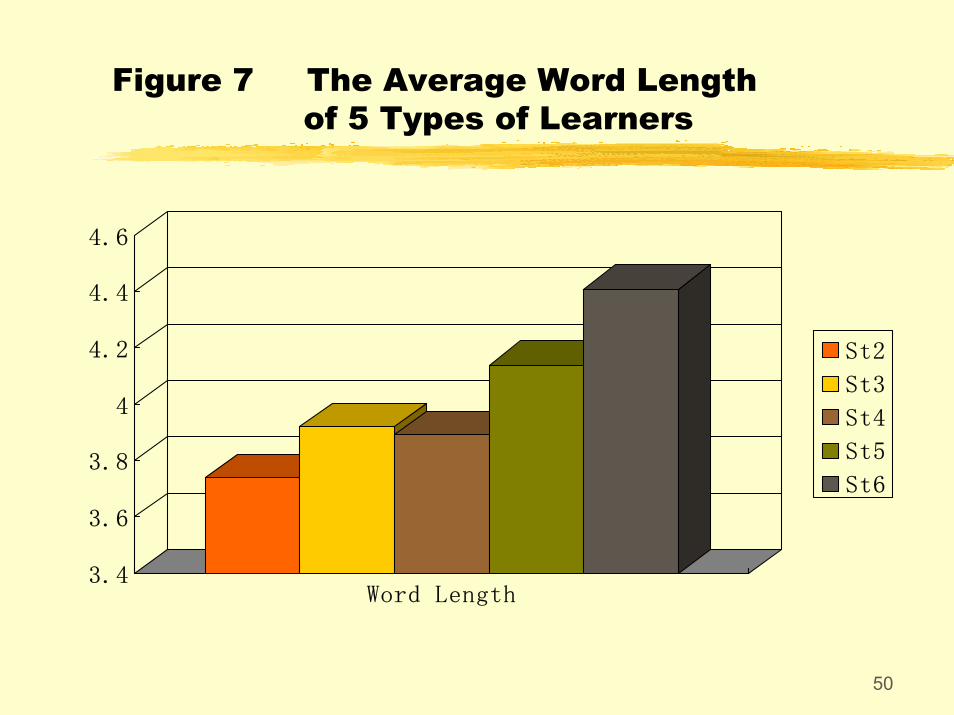
Figure 7 The Average Word Length of 5 Types of Learners
3.4
3.6
3.8
4
4.2
4.4
4.6
Word Length
St2
St3
St4
St5
St6

51
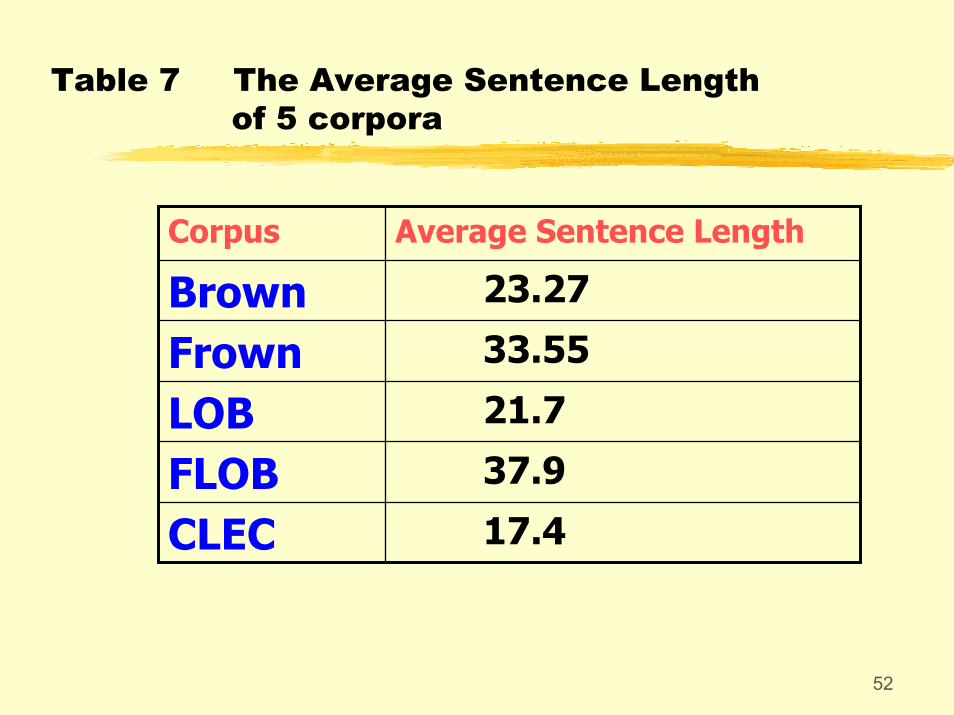
The average length of sentences of CLEC is much shorter than that of the English speakers', though their general tendency seems to be using longer sentences. One interesting discovery is that college English learners seem to be using longer sentences than the other types of Chinese learners.
52
Table 7 The Average Sentence Lengthof 5 corpora
17.4CLEC37.9FLOB21.7LOB33.55Frown23.27Brown
Average Sentence LengthCorpus
53
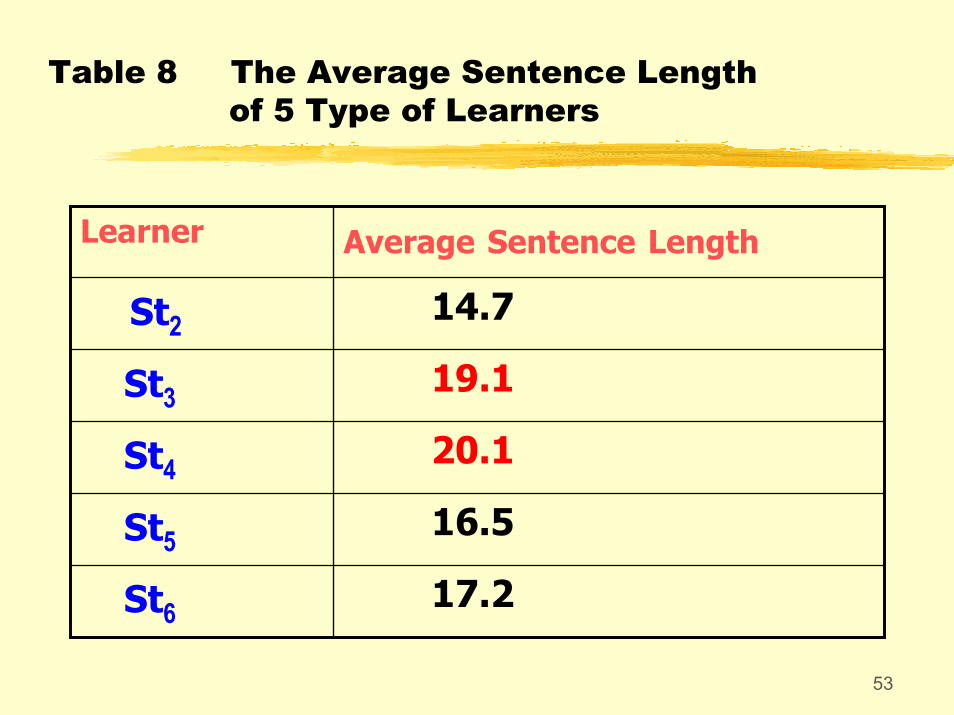
Table 8 The Average Sentence Length of 5 Type of Learners
17.2St6
16.5St5
20.1St4
19.1St3
14.7St2
Average Sentence LengthLearner

54
5. Features of Learner Vocabulary
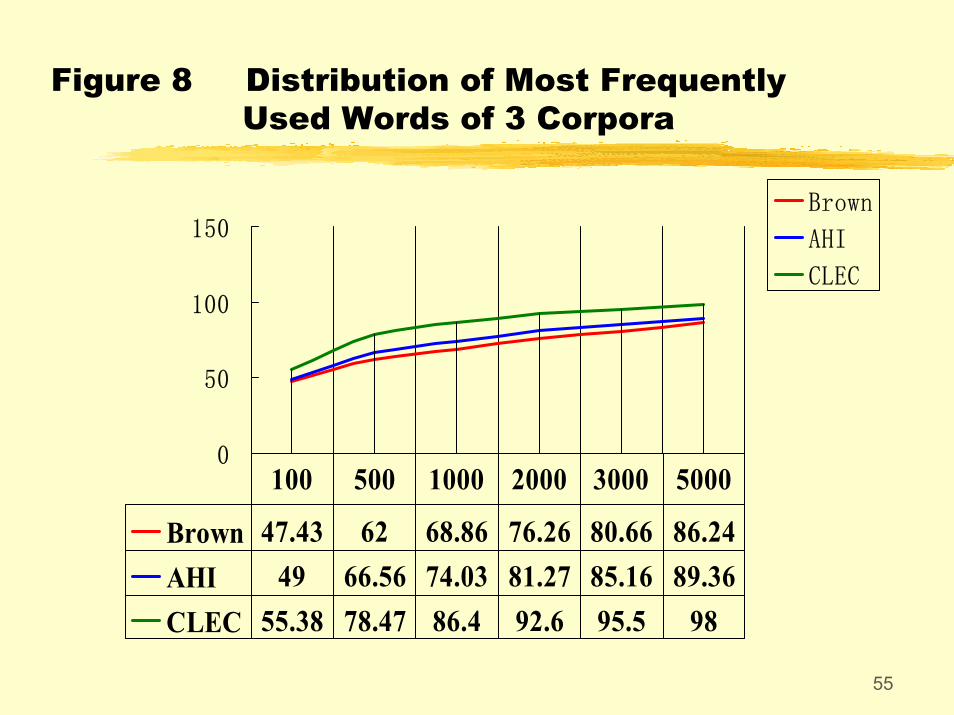
5.1 Over-use of frequently used words as a result of a limited vocabulary. This is demonstrated by the distribution table of most frequently used words of CLEC, Brown and AHI.
55
Figure 8 Distribution of Most Frequently Used Words of 3 Corpora
0
50
100
150Brown
AHI
CLEC
Brown 47.43 62 68.86 76.26 80.66 86.24AHI 49 66.56 74.03 81.27 85.16 89.36CLEC 55.38 78.47 86.4 92.6 95.5 98
100 500 1000 2000 3000 5000

56
5.2 Under-use and over-use of words. CLEC was compared to Flob using Wordsmith (Mike Scott). Most of the over-used words (915) are related to their personal and school activities. Among the under-used words(927) were 3rd person pronouns (she, he, his, her, him, he'd, he's), some prepositions(of, by, within, off, as, with, over, between) and some verbs (had, was, been, were, might). This in a way shows the influence of Chinese.

57
5.3 Over-use leads to misuse. Following Biber(2000), we look at the usage of great, big andlarge in CLEC, and found great was greatly over-used. Then we look at the collocations of great with one word to the right, there are 22 collocates that occurred over 10 times in CLEC. In Flob, there were only 2 collocates (deal, 34; Britain, 16); whereas in Frown, only one (deal, 30).
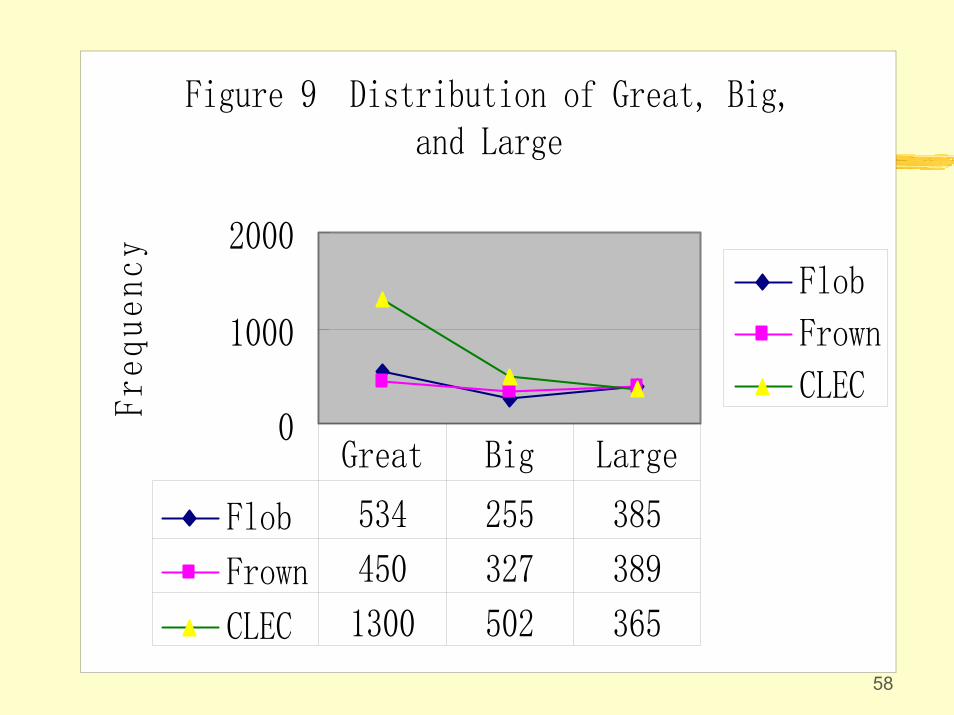
58
Figure 9 Distribution of Great, Big,and Large
0
1000
2000
Frequency
Flob
Frown
CLEC
Flob 534 255 385
Frown 450 327 389
CLEC 1300 502 365
Great Big Large

59
5.4 Collocation
• Collocations are co-occurrence of words.
• They are recurrent.
• They are syntactically and semantically constrained.
• They are usage restricted.
• They are arbitrary and domain-dependent.
• Some collocations are culturally loaded.

60
• Collocations are characterised by syntactic patterning and meaning associations.
• Collocations are on a scale on which at one end are free collocations, and at the other are fixed. It is the collocations in the middle area, the semi-fixed collocations, are most problematic.
• Unsuccessful L1 transfer has been identified as the major cause for improper collocations.
• The learners have greater problems in Verb + Nouncollocations than in other patterns.
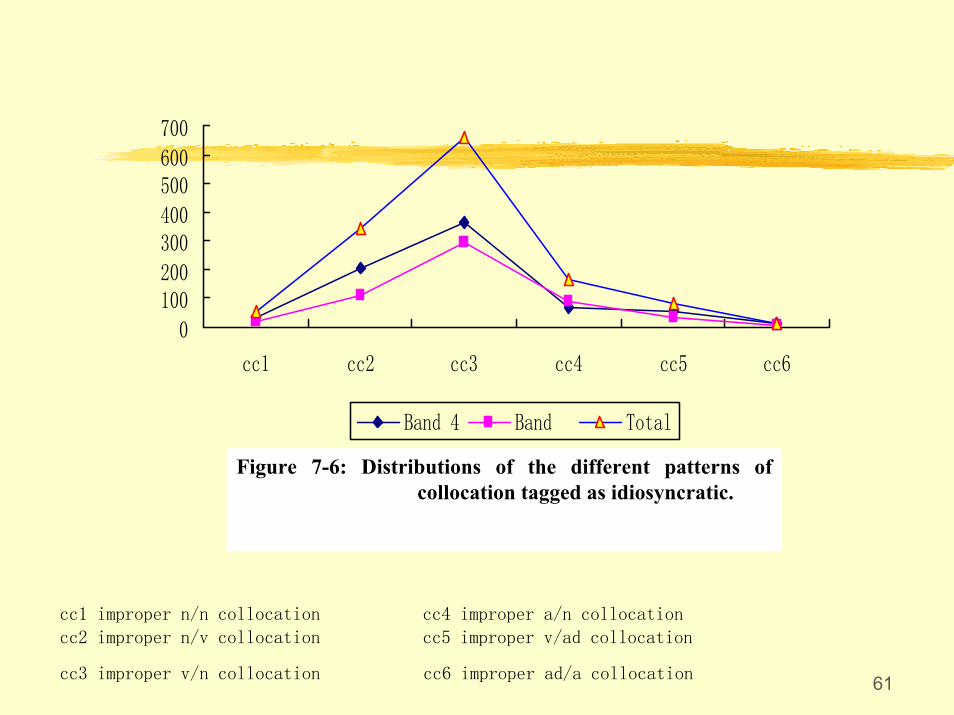
61
0
100200
300400
500600
700
cc1 cc2 cc3 cc4 cc5 cc6
Band 4 Band Total
Figure 7-6: Distributions of the different patterns ofcollocation tagged as idiosyncratic.
cc1 improper n/n collocation cc4 improper a/n collocation
cc2 improper n/v collocation cc5 improper v/ad collocation
cc3 improper v/n collocation cc6 improper ad/a collocation

62
• The inappropriacy of the collocations is interpreted as the learner strategies in the attempted communication in the TL, such as
• Transfer;
• substitution;
• avoidance; and
• repetition.
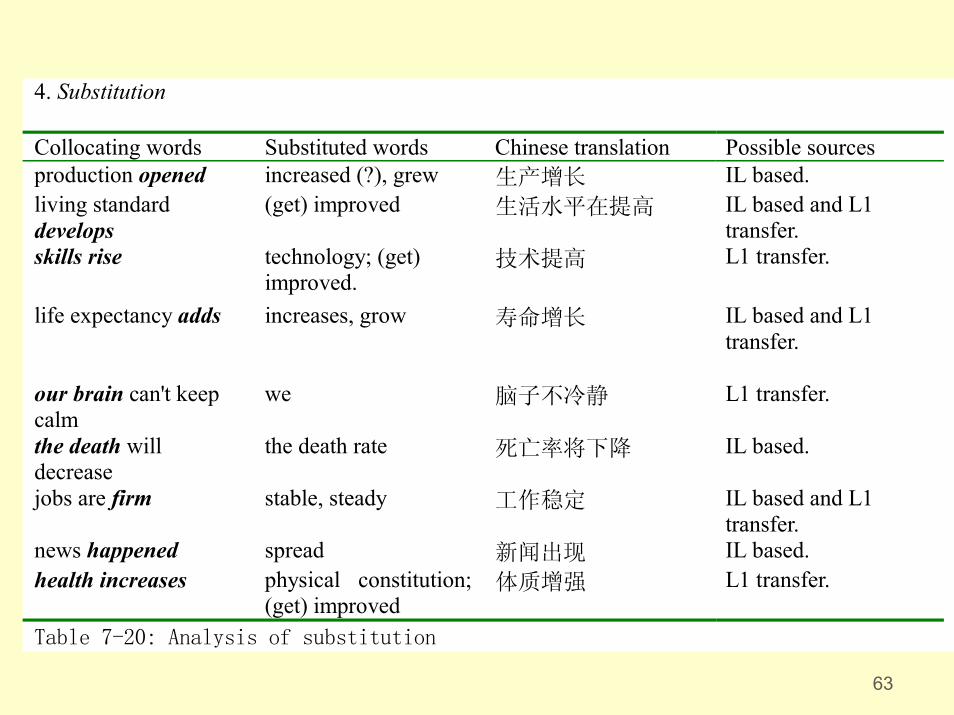
63
4. Substitution
Collocating words Substituted words Chinese translation Possible sourcesproduction opened increased (?), grew 生产增长 IL based.living standarddevelops
(get) improved 生活水平在提高 IL based and L1transfer.
skills rise technology; (get)improved.
技术提高 L1 transfer.
life expectancy adds increases, grow 寿命增长 IL based and L1transfer.
our brain can't keepcalm
we 脑子不冷静 L1 transfer.
the death willdecrease
the death rate 死亡率将下降 IL based.
jobs are firm stable, steady 工作稳定 IL based and L1transfer.
news happened spread 新闻出现 IL based.health increases physical constitution;
(get) improved体质增强 L1 transfer.
Table 7-20: Analysis of substitution
64
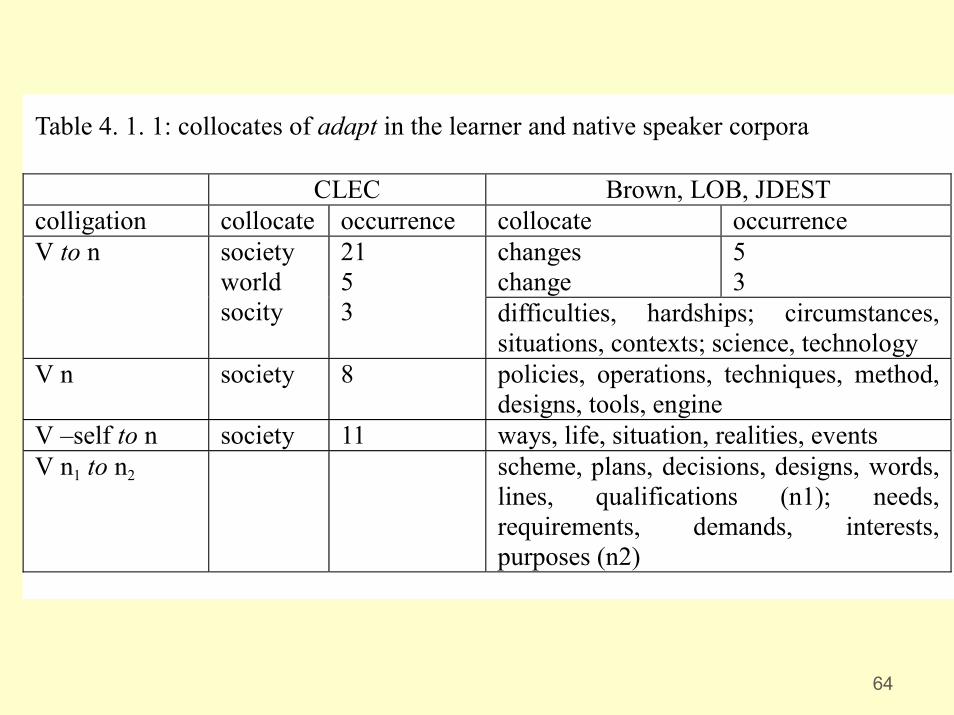
Table 4. 1. 1: collocates of adapt in the learner and native speaker corpora
CLEC Brown, LOB, JDESTcolligation collocate occurrence collocate occurrence
changeschange
53
V to n societyworldsocity
2153 difficulties, hardships; circumstances,
situations, contexts; science, technologyV n society 8 policies, operations, techniques, method,
designs, tools, engineV –self to n society 11 ways, life, situation, realities, eventsV n1 to n2 scheme, plans, decisions, designs, words,
lines, qualifications (n1); needs,requirements, demands, interests,purposes (n2)

65
5.5 Coinages and creativity
• Coinages are created in a systematic manner.
• Coinages are the indicator of the learners' use of productive strategies with their TL vocabulary knowledge available.
• Intermediate learners are most active creators of new forms.
• Learners demonstrate great needs for explicit word formation knowledge.
• Learners tend to over-generalise word formation rules in derivation and transfer their L1 in compounding.
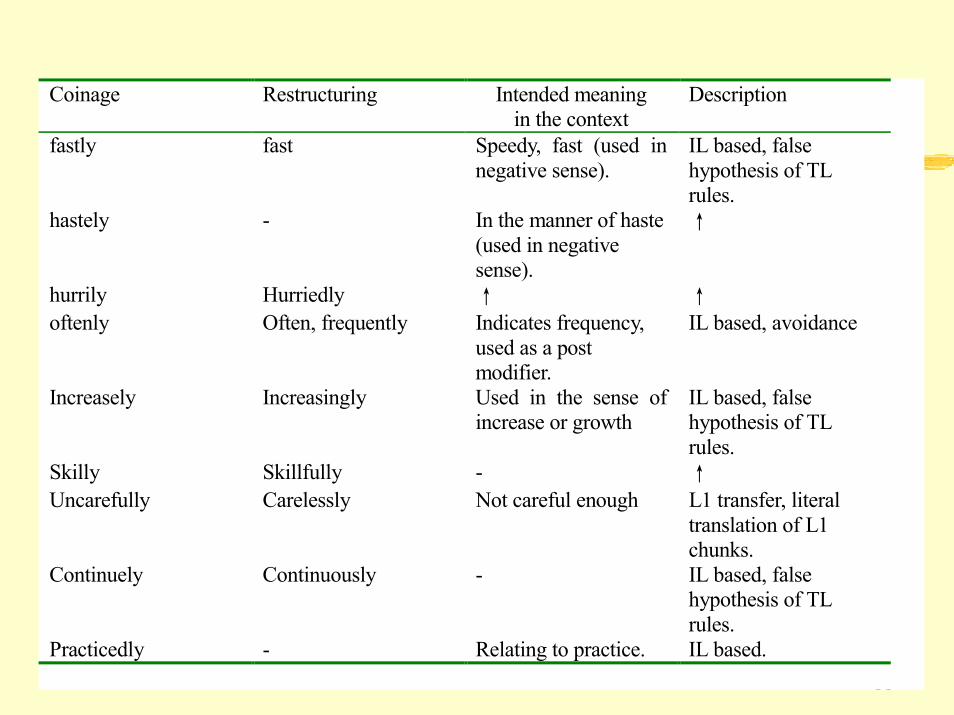
66
Coinage Restructuring Intended meaningin the context
Description
fastly fast Speedy, fast (used innegative sense).
IL based, falsehypothesis of TLrules.
hastely - In the manner of haste(used in negativesense).
↑
hurrily Hurriedly ↑ ↑oftenly Often, frequently Indicates frequency,
used as a postmodifier.
IL based, avoidance
Increasely Increasingly Used in the sense ofincrease or growth
IL based, falsehypothesis of TLrules.
Skilly Skillfully - ↑Uncarefully Carelessly Not careful enough L1 transfer, literal
translation of L1chunks.
Continuely Continuously - IL based, falsehypothesis of TLrules.
Practicedly - Relating to practice. IL based.
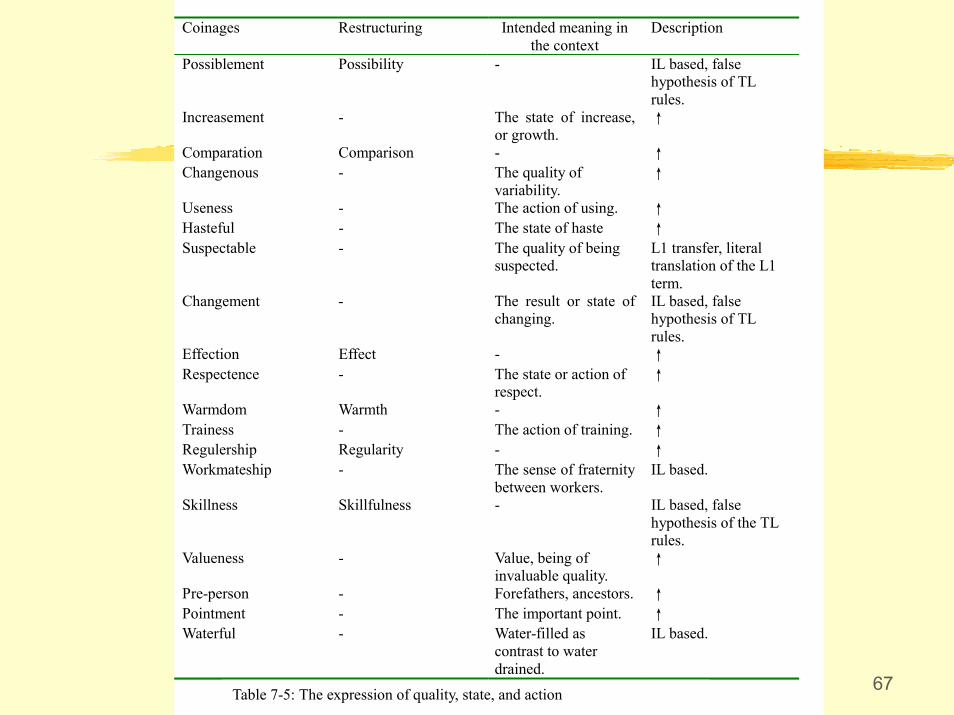
67
Coinages Restructuring Intended meaning inthe context
Description
Possiblement Possibility - IL based, falsehypothesis of TLrules.
Increasement - The state of increase,or growth.
↑
Comparation Comparison - ↑Changenous - The quality of
variability.↑
Useness - The action of using. ↑Hasteful - The state of haste ↑Suspectable - The quality of being
suspected.L1 transfer, literaltranslation of the L1term.
Changement - The result or state ofchanging.
IL based, falsehypothesis of TLrules.
Effection Effect - ↑Respectence - The state or action of
respect.↑
Warmdom Warmth - ↑Trainess - The action of training. ↑Regulership Regularity - ↑Workmateship - The sense of fraternity
between workers.IL based.
Skillness Skillfulness - IL based, falsehypothesis of the TLrules.
Valueness - Value, being ofinvaluable quality.
↑
Pre-person - Forefathers, ancestors. ↑Pointment - The important point. ↑Waterful - Water-filled as
contrast to waterdrained.
IL based.
Table 7-5: The expression of quality, state, and action

68
Coinages Restructuring Intended meaning inthe context
Description
Successer - The person whosucceeds in somefield.
IL based or L1transfer.
Colleger - A college student. IL based, falsehypothesis of the TLrules.
Takers - The people who do ajob.
↑
Disearsers - The people who havediseases or patients.
↑
Typeier Typist - ↑Societor - The person who is
worker as contrast to acollege student.
↑
Statists Statistician - ↑Failurer A failure A person who fails. ↑Sporters Sportsman - AvoidanceChallenger - A person who
challenges.IL based, falsehypothesis of the TLrules.
Funder - The person ororganization thatprovides funds.
IL based.
Constructors - The person whoconstructs or developsa concrete building, oran abstract system.
IL based, falsehypothesis of the TLrules.
Servicer - A person who doesservices (oftentermporarily).
↑
Table 7-6: The expression of identity, actors, doers, executors of the actions.

69
2. Compounding
Coinages Restructuring Intended meaning inthe context
Description
Workmates - Fellow workers Both IL based or L1transfer.
Advertise-man - The person who isengaged in the designof advertisement.
L1 transfer. (cf.Guanggaoren).
Oilman - The person who sellsoil.
IL based.
Man-at-home - The person who likesstaying with family.
IL based.
Family-teacher Home tutor - L1 transfer. (cf.Jiajiao).
House-teacher Home tutor - ↑
Table 7-8: The expression of professions

70
3. Back formationCoinages Restructuring Intended meaning in
the contextDescription
Solute Solve To provide solution.Back formed fromsolution.
IL based.
Revoluting Revolutionize Back formed fromrevolution.
↑
Comprehense Comprehend Back formed fromcomprehension.
↑
Table 7-11: Back formation
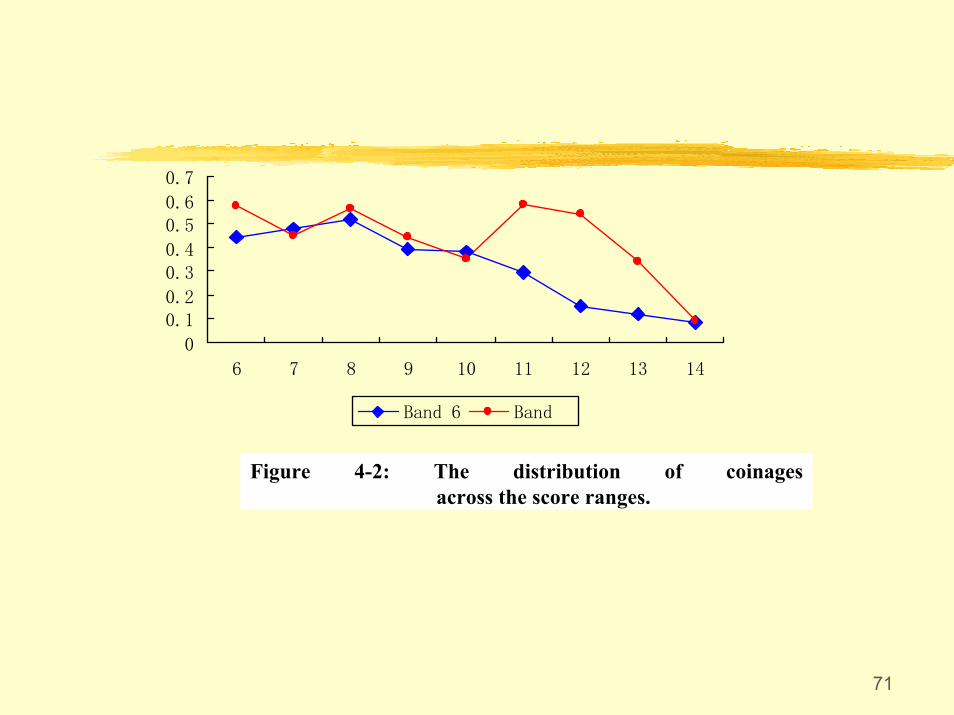
71
0
0.10.2
0.30.4
0.50.6
0.7
6 7 8 9 10 11 12 13 14
Band 6 Band
Figure 4-2: The distribution of coinages across the score ranges.

72
6. Error Distribution
• Statistical Analysis of Chinese Learner Errors in English
• A horizontal investigation of errors in terms of error types.
• A vertical investigation of errors in terms of learners.

73
6.1 Horizontal Investigation
• 71,046 errors were identified in the corpus of 1,185,977 tokens. The percentage of errors is 6%.
• Of the 11 categories of errors, word forms, word usage, syntax, and verb phrase constitute the greatest proportion, about 5%.
• The D (dispersion) value is 0.914, showing the errors are well distributed among 5 types of students.
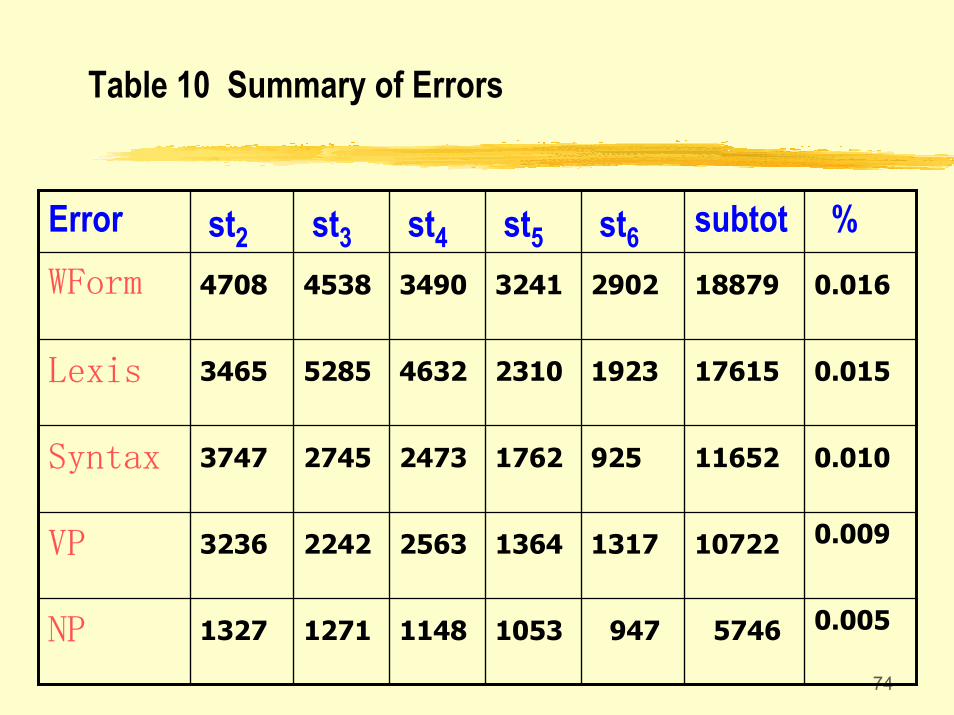
74
Table 10 Summary of Errors
0.00557469471053114812711327NP
0.0091072213171364256322423236VP
0.010116529251762247327453747Syntax
0.0151761519232310463252853465Lexis
0.0161887929023241349045384708WForm
%subtotst6st5st4st3st2Error
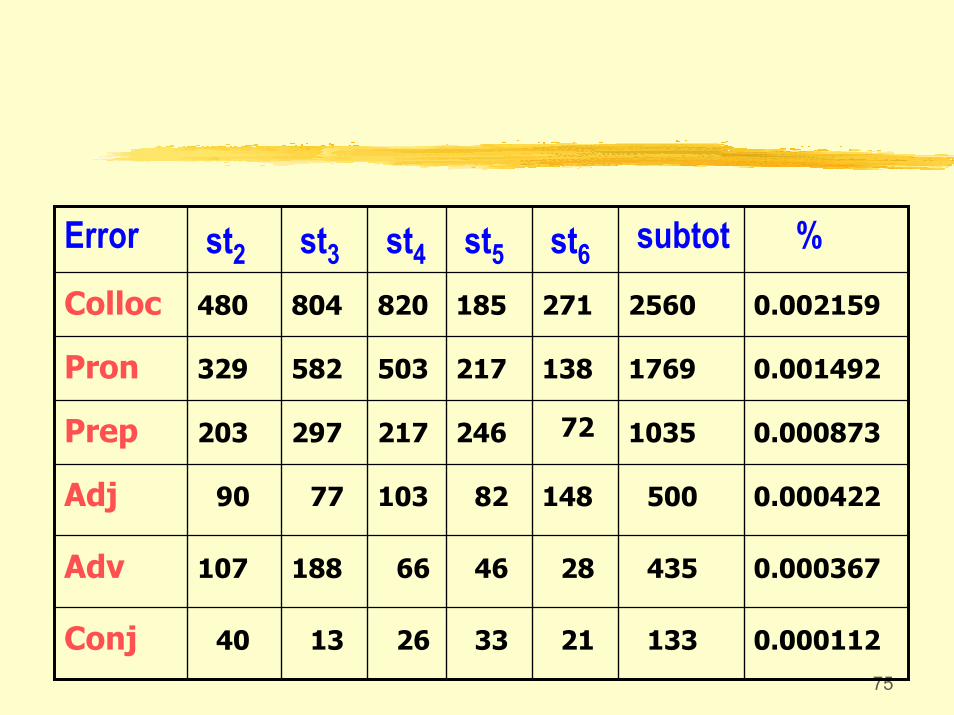
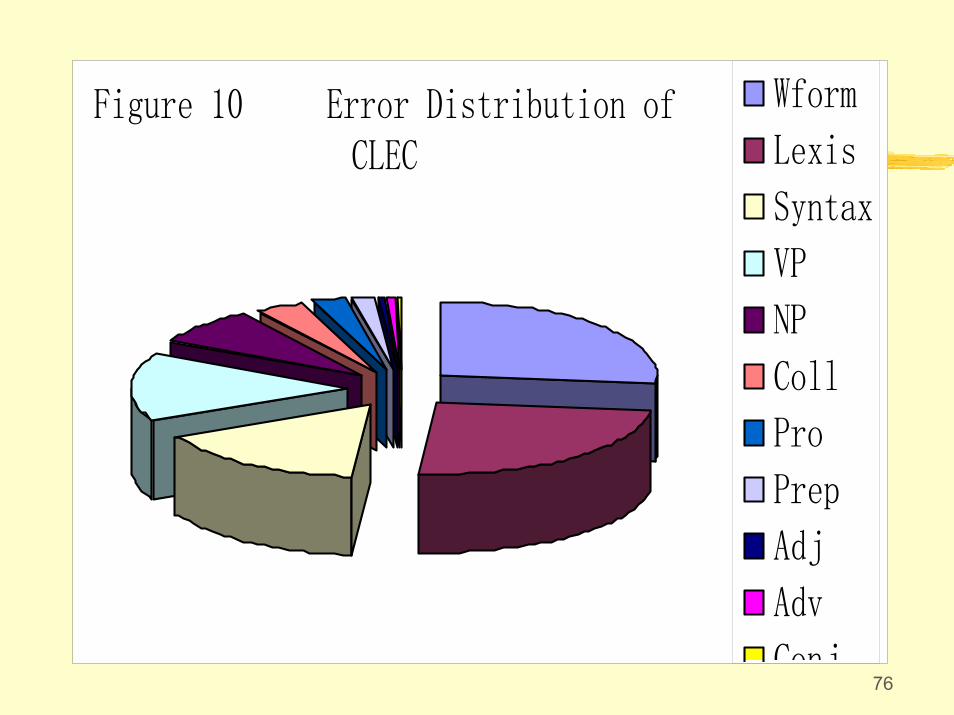
75
0.000367435284666188107Adv
0.0001121332133261340Conj
0.000422500148821037790Adj
0.000873103572246217297203Prep
0.0014921769138217503582329Pron
0.0021592560271185820804480Colloc
%subtotst6st5st4st3st2Error
76
Figure 10 Error Distribution ofCLEC
Wform
Lexis
Syntax
VP
NP
Coll
Pro
Prep
Adj
Adv
Conj

77
Factor analysis shows that the 11 categories of errors can be grouped under 3 factors. Factor 1 (word form, syntax, verb phrase, noun phrase, & conjunction, 37% ) can be interpreted as the syntactic factor, Factor 2 (Lexis, collocation, pronoun, adverb, & conjunction, 32% ) the semantic factor, and Factor 3 (Preposition, adjective, & adverb, 26%) the functional factor.
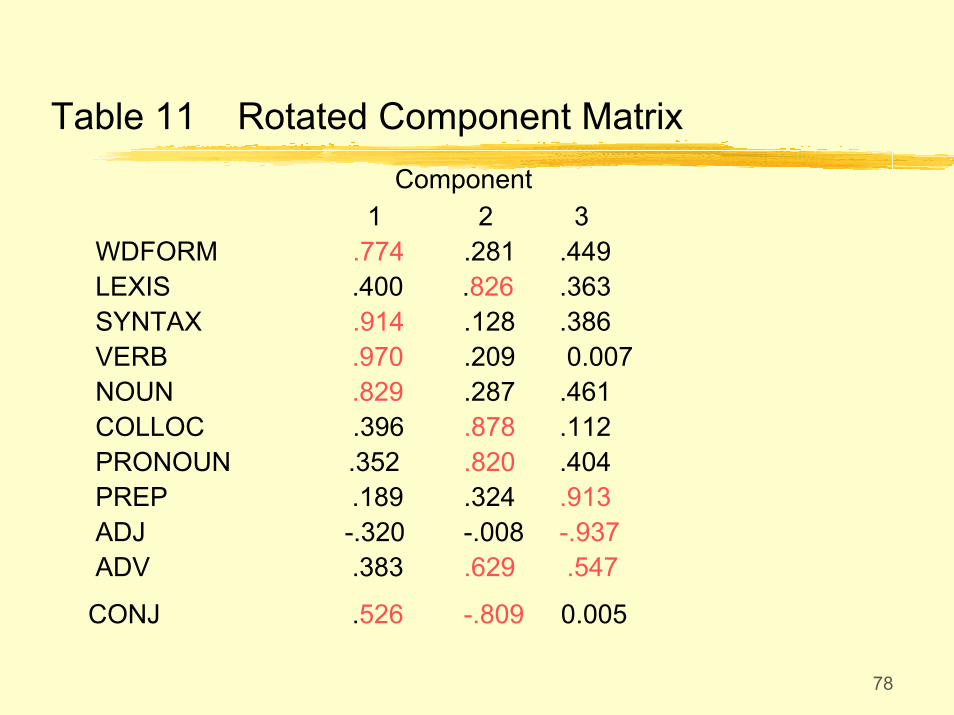
78
Table 11 Rotated Component MatrixComponent
1 2 3WDFORM .774 .281 .449LEXIS .400 .826 .363SYNTAX .914 .128 .386VERB .970 .209 0.007NOUN .829 .287 .461COLLOC .396 .878 .112PRONOUN .352 .820 .404PREP .189 .324 .913ADJ -.320 -.008 -.937ADV .383 .629 .547
CONJ .526 -.809 0.005

79
6.2 Vertical Investigation
• Vertical investigation looks at the 5 types of students representing different levels of language development.
• Factor analysis shows the 5 types of Chinese learners belong to one single group.
• Cluster analysis further shows their hierarchical relation.
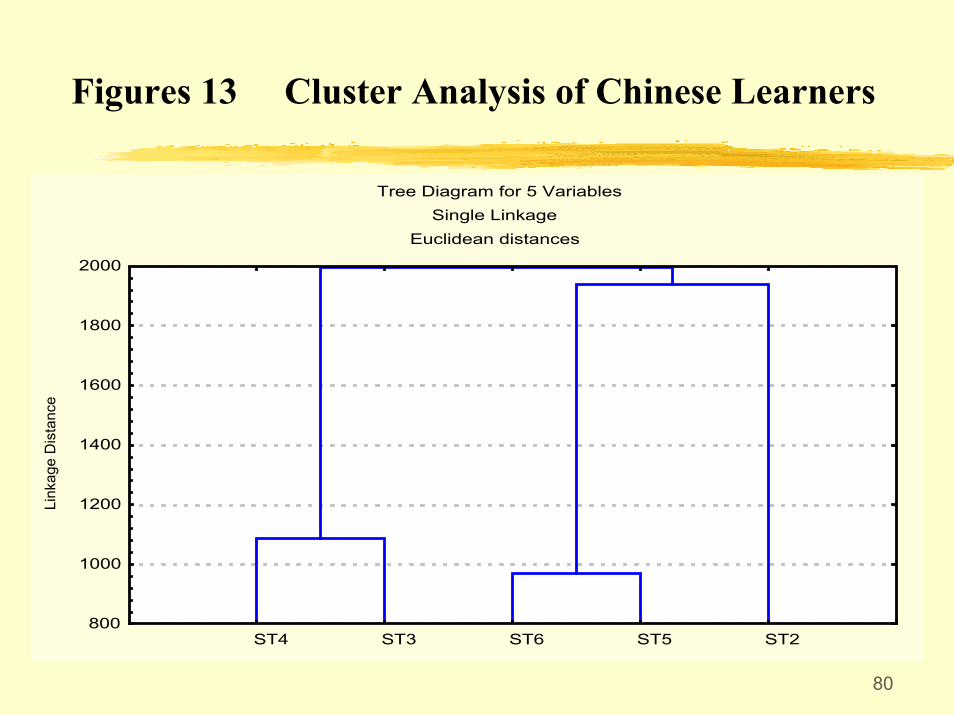
80
Figures 13 Cluster Analysis of Chinese Learners
Tree Diagram for 5 VariablesSingle Linkage
Euclidean distances
Link
age
Dis
tanc
e
800
1000
1200
1400
1600
1800
2000
ST4 ST3 ST6 ST5 ST2

81
• The general tendency is that the more proficient the learners are, the less errors they make. But there are also fluctuations in their development of the target language.
• As a whole, st3 and st4 commit more lexical errors than st2, and st4 commit more errors in verb phrases than st3. St3 learners also make morecollocational errors.
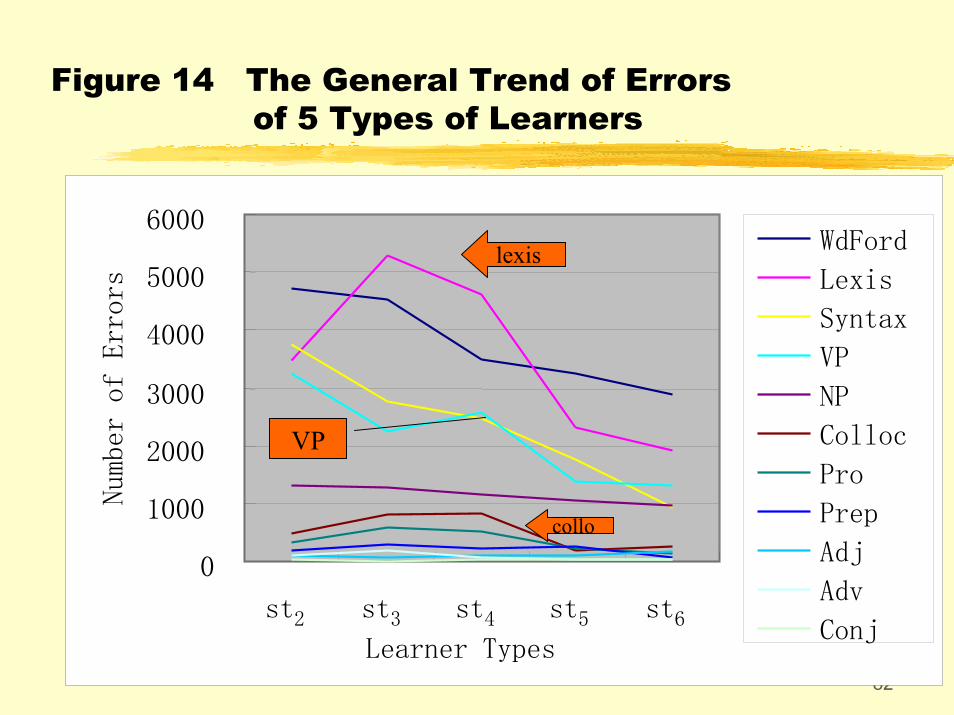
82
Figure 14 The General Trend of Errors of 5 Types of Learners
0
1000
2000
3000
4000
5000
6000
st2 st3 st4 st5 st6Learner Types
Number of Errors
WdFord
Lexis
Syntax
VP
NP
Colloc
Pro
Prep
Adj
Adv
Conj
lexis
collo
VP

83
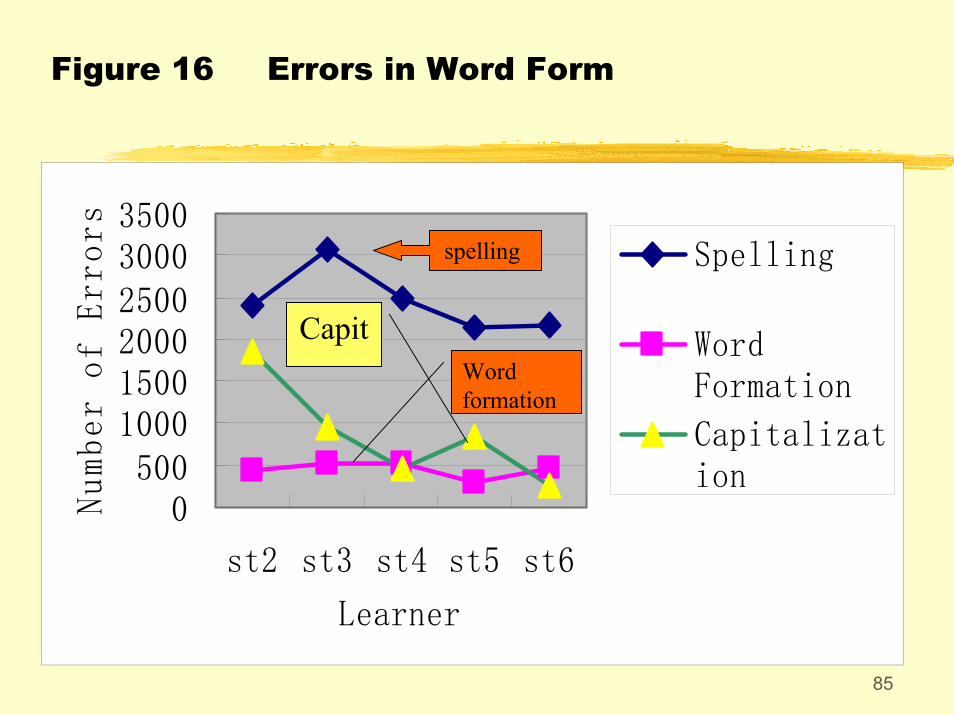
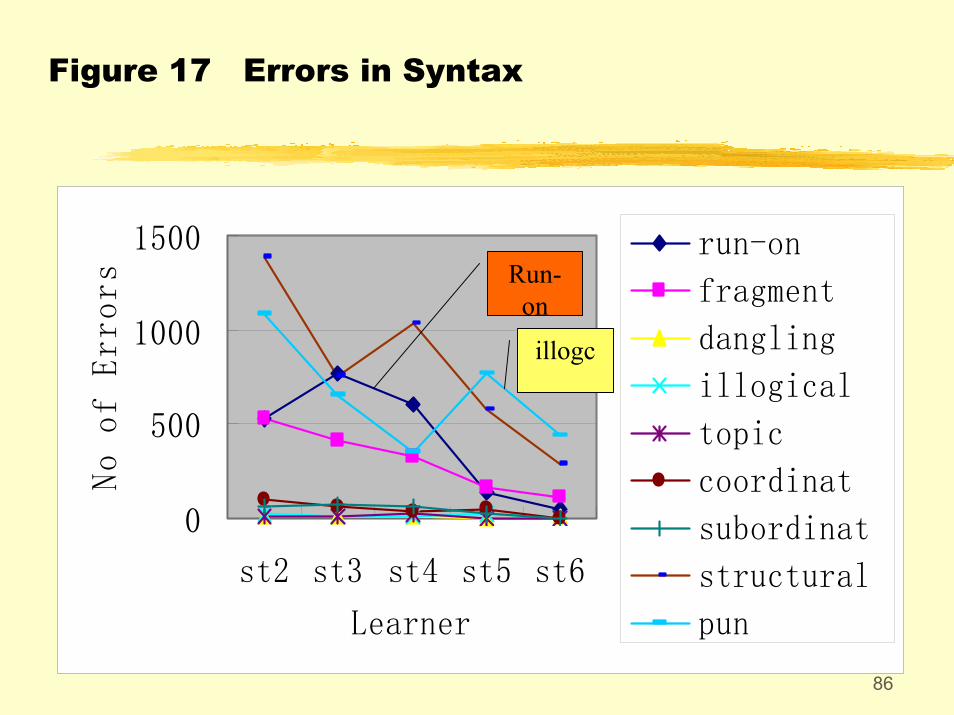
Some more “abnormalities”:St2 commit more errors in tense, and st4 more errors in agreement.St3 and st4 commit more errors in spellings and word formation.St3 and st4 tend to use more run-on sentences, and st5 and st6 tend to use illogical comparisons.St3 and st4 tend to use the wrong lexical words and parts of speech.
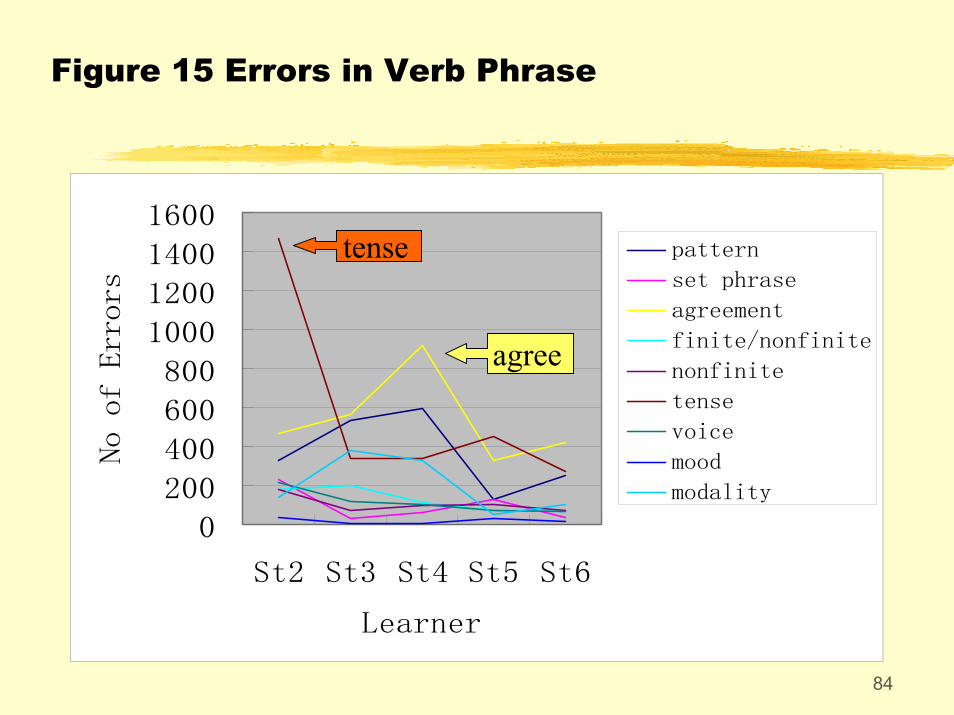
84
Figure 15 Errors in Verb Phrase
0
200
400
600
800
1000
1200
1400
1600
St2 St3 St4 St5 St6
Learner
No of Errors
pattern
set phrase
agreement
finite/nonfinite
nonfinite
tense
voice
mood
modality
tense
agree
85
Figure 16 Errors in Word Form
0500
100015002000250030003500
st2 st3 st4 st5 st6
Learner
Number of Errors
Spelling
WordFormation
Capitalization
spelling
Word formation
Capit
86
Figure 17 Errors in Syntax
0
500
1000
1500
st2 st3 st4 st5 st6
Learner
No of Errors
run-on
fragment
dangling
illogical
topic
coordinat
subordinat
structural
pun
Run-on
illogc

87
7. Some Concluding Remarks
• Contrastive study is possible because CLEC and the other corpora follows the same lognormal model.
• The corpus approach provides us with an interface between the quantitative method that relies on figures, and the qualitative method that relies on words. It is essential to integrate the two methods.

88
• In terms of log type/token ratio, average word length, and average sentence length, the figures of the Chinese learners are lower than that of the native speakers'. The more proficient the learners, the closer they are to the native speakers' of English.
• The first 5000 words, which occupy 36% of the types, constitute 98% of the tokens. This implies the learners are using a smaller vocabulary on a greater number of occasions, or over-using the frequently-used words. This may cause their misuse, especially of polysemous words.

89
• The implication is that we should pay more attention to the teaching of frequently-used words (especially polysemous words and word usage) rather than to simply increasing the vocabulary range of the students.
• Chinese students have difficulties in both lexis and syntax. They are all weak in spelling. Apart from lexis, the three types of errors decrease with the language development of the students.

90
• Among the lexis errors, 40% of them are related to misuse (substitution), then wrong parts of speech (17%), and redundancy (14%). Lexis errors may not be closely related to the students' levels, they may be more dependent on the writing tasks.
• We have paid more attention to the sampling of student types, than to the sampling of topics.

91
• Vocabulary knowledge involves the knowledge of the sound system, syntactic functions, semantic relations of individual words of the TL.
• Vocabulary acquisition is essential to learning success.
• Collocation is one of the important component of vocabulary knowledge.
• Collocations, particularly the semi-fixed collocations, create special problems for the Chinese learners of English.

92
• Implications for EFL vocabulary learning:
• Words learned in isolation may be the sourceof problems.
• Equivalence between L1 and the TL words is bleak and may cause unsuccessful transfer.
• Learners should learn word by chunks.
• Implications for EFL teaching:
• Words must be delivered in association and collocation with adequate context.
• Explicit vocabulary instruction is necessary.

93
• The CLEC corpus is restricted to the written language only.
• The corpus can only reflect the productive, not the receptive ability of the students.
• Consistency of tagging remains a problem. And the error marking scheme needs to be improved.

94
The CLEC corpus is now accessible onthe Internet (www.eclass.com.cn or www2.gdufs.edu.cn).
Professor Gui's email address [email protected]
My email address is [email protected]

95
Thank you for your attention !
-----------------------------------------------------------------Professor Yang HuizhongChairman, National College English Testing Committee of ChinaShanghai Jiao Tong University
------------------------------------------------------------------------





























