Embed Size (px)
Citation preview

Computacion y Metodos NumericosP56, libre eleccionNotas de clase y tareas
M. Araceli Garın
Prof. Titular de Economıa Aplicada
Dpto. Economıa Aplicada III
Fac. CC. Economicas y Empresariales
Bilbao


Indice general
1. Nociones basicas sobre algoritmos 11.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2. ¿Que es un algoritmo? Medidas de eficiencia . . . . . . . . . . 21.3. Complejidad. Complejidad computacional . . . . . . . . . . . 51.4. Complejidad agebraica y analıtica . . . . . . . . . . . . . . . 61.5. Precision numerica . . . . . . . . . . . . . . . . . . . . . . . . 71.6. Analisis de Algoritmos. Lımites de complejidad . . . . . . . . 10
2. Introduccion al lenguaje de programacion C (I) 132.1. Nociones sobre trabajo en el Sistema Operativo UNIX. El
editor vi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2. Compilado, ejecucion y depuracion de programas en C . . . . 202.3. Variables escalares, subindicadas (arrays) y constantes . . . . 21
2.3.1. Nombres de variables . . . . . . . . . . . . . . . . . . . 222.3.2. Tipo y tamano de datos . . . . . . . . . . . . . . . . . 23
2.4. Un ejemplo. El primer programa en C . . . . . . . . . . . . . 262.5. Operadores y funciones standard mas usuales . . . . . . . . . 30
2.5.1. Funciones mas usuales . . . . . . . . . . . . . . . . . . 312.6. Ambito de definicion y validez de las variables. Variables ex-
ternas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.7. Precedencia y orden de evaluacion entre operadores . . . . . . 39
3. Introduccion al lenguaje de programacion C (II) 413.1. Declaraciones. Tipos de datos escalares: enteros, caracter, de
coma flotante y enumeracion . . . . . . . . . . . . . . . . . . 413.2. Conversiones de tipo . . . . . . . . . . . . . . . . . . . . . . . 453.3. Nociones sobre representacion de datos e implicaciones sobre
la precision numerica . . . . . . . . . . . . . . . . . . . . . . . 483.3.1. Errores de redondeo en computacion . . . . . . . . . . 513.3.2. Error de cancelacion . . . . . . . . . . . . . . . . . . . 52
4. Introduccion al lenguaje de programacion C (III) 554.1. Sentencias de control de flujo: for, if , do, while, switch. Ejem-
plos de uso . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
i

ii Indice general
4.2. Funciones: anatomıa y uso . . . . . . . . . . . . . . . . . . . . 644.3. Convenciones sobre el paso de argumentos . . . . . . . . . . . 654.4. Clases de almacenamiento . . . . . . . . . . . . . . . . . . . . 684.5. Recursion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 714.6. Funciones definidas en stdio y math . . . . . . . . . . . . . . 72
5. Algoritmos iterativos 795.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 795.2. Resolucion de ecuaciones . . . . . . . . . . . . . . . . . . . . . 81
5.2.1. Metodo de biseccion . . . . . . . . . . . . . . . . . . . 815.2.2. Metodo de Newton-Raphson . . . . . . . . . . . . . . 835.2.3. Metodo de la secante . . . . . . . . . . . . . . . . . . . 855.2.4. Regula Falsi . . . . . . . . . . . . . . . . . . . . . . . . 87
5.3. Comparacion de los distintos ordenes de convergencia . . . . 885.3.1. Convergencia del metodo de biseccion . . . . . . . . . 885.3.2. Convergencia del metodo de Newton-Raphson . . . . . 905.3.3. Convergencia del metodo de la secante . . . . . . . . . 935.3.4. Convergencia del metodo de regula falsi . . . . . . . . 95
5.4. Teorıa general de los metodos iterativos. Iteracion del puntofijo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.5. Generalizacion a sistemas de ecuaciones . . . . . . . . . . . . 995.5.1. Metodo de Newton-Raphson . . . . . . . . . . . . . . 1015.5.2. Metodo de Gauss-Seidel . . . . . . . . . . . . . . . . . 102
5.6. Ejercicios de aplicacion . . . . . . . . . . . . . . . . . . . . . . 103
6. Metodos de ordenacion 1056.1. Analisis teorico: orden de complejidad optimo alcanzable para
algoritmos internos . . . . . . . . . . . . . . . . . . . . . . . . 1056.2. Metodos simples de complejidad O(n2): comparacion, inser-
cion, burbuja . . . . . . . . . . . . . . . . . . . . . . . . . . . 1086.2.1. Metodo de comparacion (seleccion) . . . . . . . . . . . 1086.2.2. Metodo de insercion . . . . . . . . . . . . . . . . . . . 1106.2.3. Metodo de intercambio (burbuja) . . . . . . . . . . . . 111
6.3. Metodos de complejidad O(nlogn): Quicksort y Heapsort . . . 1136.3.1. Heapsort . . . . . . . . . . . . . . . . . . . . . . . . . 113
6.4. Quicksort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
7. El lenguaje de programacion C (IV) 1257.1. Direccionamiento indirecto. Punteros: variables que contienen
la ubicacion en memoria de otras variables . . . . . . . . . . . 1257.2. Punteros y funciones: paso de argumentos de referencia ha-
ciendo uso de punteros . . . . . . . . . . . . . . . . . . . . . . 1287.2.1. Punteros y arrays . . . . . . . . . . . . . . . . . . . . . 131
7.3. Algebra de punteros . . . . . . . . . . . . . . . . . . . . . . . 134

Indice general 1
7.4. Punteros a caracteres . . . . . . . . . . . . . . . . . . . . . . . 1377.5. Ejemplos de utilizacion de punteros . . . . . . . . . . . . . . . 139
8. El lenguaje de programacion C (V) 1498.1. Tipos de datos definidos por el usuario: estructuras . . . . . . 1498.2. Operaciones con estructuras . . . . . . . . . . . . . . . . . . . 1518.3. Punteros a estructuras y estructuras ligadas. Arboles binarios.
Ejemplos de uso . . . . . . . . . . . . . . . . . . . . . . . . . 158
9. Solucion de sistemas de ecuaciones lineales 1679.1. Metodos directos para la resolucion de sistemas de ecuaciones
lineales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1689.1.1. Sistemas triangulares . . . . . . . . . . . . . . . . . . . 168
9.2. Eliminacion gaussiana . . . . . . . . . . . . . . . . . . . . . . 1699.3. Estabilidad numerica y su mejora. Pivotado total y parcial.
Complejidad algorıtmica . . . . . . . . . . . . . . . . . . . . . 1729.4. La variante de Gauss-Jordan . . . . . . . . . . . . . . . . . . 176
10.Solucion de sistemas de ecuaciones lineales sin inversion dela matriz de coeficientes 17910.1. La descomposicion LU . . . . . . . . . . . . . . . . . . . . . . 17910.2. Escenas compactas en la eliminacion gaussiana: metodos de
Doolittle, Crout y Choleski . . . . . . . . . . . . . . . . . . . 184
11.Simulacion (I). Generacion de numeros aleatorios 18911.1. Numeros aleatorios y Metodo de Montecarlo. Integracion numeri-
ca . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19011.2. Otras aplicaciones . . . . . . . . . . . . . . . . . . . . . . . . 19511.3. Generacion de observaciones pseudoaleatorias uniformes . . . 19511.4. Generadores multiplicativos: eleccion del multiplicador, modu-
lo y semilla . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
12.Simulacion (II). Generacion de variables no uniformes 20512.1. Metodo de inversion. Ejemplos . . . . . . . . . . . . . . . . . 20512.2. Metodo de rechazo. Ejemplos . . . . . . . . . . . . . . . . . . 20712.3. Metodo de transformacion. Ejemplos . . . . . . . . . . . . . . 21012.4. Metodos especıficos . . . . . . . . . . . . . . . . . . . . . . . . 211

2 Indice general

Capıtulo 1
Nociones basicas sobre algoritmos
1.1. Introduccion
Es evidente que las matematicas son utilizadas de una forma u otra enla mayorıa de las areas de la ciencia y la industria.
Durante el siglo XX avanzados metodos y modelos matematicos han sidoaplicados en distintas areas como la medicina, la economıa o las ciencias so-ciales. A menudo, las aplicaciones generan problemas matematicos que porsu complejidad no pueden ser resueltos de manera exacta. Uno entonces, serestringe a casos especiales o modelos demasiado simplificados que puedanser analizados. En la mayoria de los casos, se reduce el problema a un pro-blema lineal, por ejemplo, una ecuacion diferencial, la funcion objetivo en unproblema de optimizacion, etc. Tal aproximacion puede ser muy efectiva yexplicar conceptos y puntos de vista que al menos cualitativamente puedenser aplicados al problema inicial. Sin embargo, a veces, tal aproximacion noes suficiente o incluso puede inducir a error.
La alternativa que nosotros plateamos aqui, es la de tratar un problemamenos simplificado, utilizando el potencial del calculo numerico. La cantidadde trabajo dependera del grado de precision demandada.
Con la utilizacion del ordenador, desarrollado en los ultimos cincuentaanos, las posibilidades de utilizar metodos numericos han crecido enorme-mente.
Desarrollar un metodo numerico, significa en la mayorıa de los casos, laaplicacion de un pequeno numero de ideas generales y relativamente simples.Dichas ideas han de ser combinadas de forma intuitiva con un conocimiento
3

4 1 · Nociones basicas sobre algoritmos
del problema que puede ser obtenido de distintas formas fundamentalmentecon metodos del analisis matematico.
A lo largo de la asignatura ilustratremos la utilizacion de las ideas ge-nerales que se esconden detras de los metodos numericos que resuelven losproblemas mas habituales. Normalmente dichos problemas aparecen comosubproblemas o detalles computacionales de problemas mas grandes y com-plejos.
En este capıtulo comenzamos presentando conceptos y terminologıa basi-ca en el desarrollo de posteriores capıtulos.
1.2. ¿Que es un algoritmo? Medidas de eficiencia
Por problema numerico entenderemos una clara e inambigaa descrip-cion de una relacion funcional entre datos (inputs) -es decir, variables in-dependientes en el problema- y resultados (outputs). Datos y resultados, queconstituyen un conjunto finito de cantidades reales. La relacion funcionalpuede, por su parte, estar implıcita o explıcitamente representada.
Por algoritmo entenderemos un procedimiento formado por un con-junto finito de reglas que especifican una secuencia finita de operaciones,mediante las cuales se obtiene la solucion de un problema, o bien, de unaclase especıfica de problemas.
Analizaremos algunos aspectos de esta ultima definicion:
1. Cada paso de un algoritmo debe estar definido de manera precisa y sinambiguedad. Las acciones a llevar a cabo deben estar rigurosamenteespecificadas en cada paso.
2. El algoritmo debe llegar a la solucion del problema en un numerofinito de pasos. La restriccion general de necesitar un numero finitode pasos, en ocasiones no es suficiente, ya que dicho numero aunquefinito puede llegar a ser muy elevado. Un algoritmo util, debe requerirno solo un numero finito, sino ademas un numero razonable de pasoshasta obtener la solucion del problema.
3. Cada algoritmo posee cero o mas datos y proporciona uno o mas resul-tados. Los datos (inputs) pueden ser definidos como cantidades, quele son dados al algoritmo inicialmente, antes de ser ejecutado, y losresultados (outputs), tambien definidos como cantidades, tienen algu-

1.2 · ¿Que es un algoritmo? Medidas de eficiencia 5
na relacion con los datos y son proporcionados cuando se completa laejecucion del algoritmo.
4. Es preferible que un algoritmo sea aplicable en la resolucion de cual-quier miembro de una clase de problemas y no unicamente en unproblema aislado. Esta propiedad de generalidad es, aunque no nece-saria, siempre deseable en un algoritmo.
5. Finalmente, aclarar que quiza la nocion de algoritmo es muy general.A lo largo de la asignatura nos dedicaremos al estudio de algoritmosdisenados para ser ejecutados en un ordenador. Un algoritmo de estetipo, debe ser implementado en un lenguaje de programacion y a lalarga constituir un programa o conjunto de programas.
Como hemos mencionado, para un problema numerico dado se puedenconsiderar distintos algoritmos.
Ejemplo 1.1 Determinar la raız real mas grande de la ecuacion:
x3 + a2x2 + a1x+ a0 = 0
con coeficientes reales a0, a1, a2 es un problema numerico. El vector de datoses (a0, a1, a2). El resultado es el valor de la raız buscada x, que esta implıci-tamente definida en funcion de los datos. Existen distintos algoritmos parala resolucion de este problema, basados en el metodo de Newton Rapson, elde biseccion, el de la secante, etc.
Ejemplo 1.2 El problema de resolver la ecuacion diferencial
d2x
d2y= x2 + y2
con condiciones de contorno y(0) = 0, y(5) = 1, no es, de acuerdo con ladefinicion dada arriba un problema numerico. En este problema los datos(input) se reducen a una funcion y, que no puede ser especificada simple-mente por un conjunto finito de numeros. El problema es entonces un pro-blema matematico, que puede ser aproximado por un problema numerico, enel sentido de que el resultado sera un conjunto de valores que aproximarana la funcion y(x), para x = h, 2h, 3h, ....
Medidas de eficiencia
Es muy facil inventar algoritmos. En la practica, sin embargo, uno noquiere solo algoritmos, quiere buenos algoritmos. El objetivo entonces, esinventar buenos algoritmos y probar que dichos algoritmos son buenos. La

6 1 · Nociones basicas sobre algoritmos
“bondad” de un algoritmo puede ser valorada de acuerdo con varios crite-rios. Uno de los mas importantes es el tiempo que tarda en ejecutarse. Haytambien, distintos aspectos dentro del criterio que controla el tiempo. Unode ellos, es el tiempo de ejecucion requerido por distintos algoritmos para laresolucion de un mismo problema en un ordenador concreto. Esta medidaempırica, esta fuertemente relacionada con el programa y con la maquinautilizada en la implementacion del algoritmo. Un cambio en un programapuede no representar un cambio significativo en el algoritmo correspondientey, sin embargo, afectar a su rapidez de ejecucion. Ademas, si dos programasson comparados, primero en una maquina y luego en otra, ambas compara-ciones pueden generar diferentes conclusiones.
Ası, mientras la comparacion de programas corriendo en ordenadoreses una importante fuente de informacion, los resultados estaran siempreafectados tanto por las caracterısticas de la maquina como por la destrezay habilidad del programador.
Una alternativa util a esta medida empırica, es la realizacion de un anali-sis matematico de la dificultad intrınseca de la resolucion computacional delproblema. Juiciosamente utilizado, tal analisis proporciona una importantemedida de evaluacion del costo de ejecucion de un algoritmo.
El tiempo de proceso de un algoritmo es una funcion del tamano del pro-blema computacional a resolver. Sin embargo, suponiendo que tenemos unprograma de ordenador que eventualmente acaba, la resolucion de un proble-ma solo requiere de suficiente tiempo y suficiente memoria para almacenarinformacion.
De mayor interes son los algoritmos que pueden ser aplicados a unacoleccion de problemas de un cierto tipo. Para estos algoritmos, el tiempo yel espacio de memoria requeridos por un programa, variara con el ejemploparticular a ser resuelto. Veamos por ejemplo la siguiente clase de problemas.
1. Encontrar el mayor elemento en una secuencia de n numeros enteros.
2. Resolver un conjunto de ecuaciones lineales Ax = b, donde A es unamatriz real nxn y b es un vector real de longitud n.
3. Ordenar en orden decreciente un vector de n numeros enteros distintos.
4. Evaluar un polinomio de grado n, Pn(x) = b−n∑k=0
akxk en x = x0.
En cada uno de estos problemas, el parametro n proporciona una medidadel tamano del problema, en el sentido de que, o bien el tiempo requerido

1.3 · Complejidad. Complejidad computacional 7
para resolver cada problema o el espacio de memoria requerido por el algo-ritmo, o ambos a la vez, crecen con n.
1.3. Complejidad. Complejidad computacional
Para medir el coste de ejecucion de un programa, definiremos una funcionde complejidad (o costo) F , donde F (n) es una medida del tiempo requeridopara ejecutar el algoritmo sobre un problema de tamano n, o una medida delespacio de memoria requerido para tal ejecucion. De esta forma, hablaremosde la complejidad en cuanto a tiempo o de la complejidad en cuanto amemoria del algoritmo. Tambien podemos referirnos a cualquiera de las dos,simplemente como funcion de complejidad (o costo) del algoritmo.
En general, el costo de obtencion de una solucion crece de acuerdo conel incremento del tamano del problema, n. Si el valor n es muy pequeno,incluso un algoritmo ineficiente tardara poco en ejecutarse, de manera quela eleccion de un algoritmo para un problema pequeno no es crıtico (a menosque el problema sea resuelto muchas veces). En la mayorıa de los casos, sinembargo, al incrementar n, se llega a una situacion, en la que el algoritmono puede ejecutarse en un periodo razonable de tiempo. Este punto se ilus-tra en la siguiente tabla, donde puede verse como crecen las funciones decomplejidad de determinados algoritmos, al crecer n.
F (n) n = 10 n = 102 n = 103 n = 104
log2n 3.3 6.6 10 13.3n 10 102 103 104
nlog2n 0,33 · 10 0,7 · 102 104 1,3 · 105
n2 102 104 106 108
n3 103 106 109 1012
2n 1024 1,3 · 1030 > 10100 > 10100
n! 3 · 106 > 10100 > 10100 > 10100
n: tamano del problemaF (n): funcion de complejidad temporal
En la practica es importante controlar el comportamiento del algorit-mo para valores grandes de n, es decir, el comportamiento asintotico de lafuncion de complejidad.

8 1 · Nociones basicas sobre algoritmos
La complejidad asintotica es el crecimiento en el lımite de la funcionde complejidad cuando crece el tamano del problema n. De esta forma, lafuncion asintotica (temporal o espacial) determina el tamano maximo delproblema a ser resuelto por el algoritmo.
En estos terminos diremos que la complejidad del algoritmo es O(nlogn)y leeremos “de orden n logaritmo (en base dos) de n”, si el tiempo de procesodel algoritmo para un ejemplo de tamano n es proporcional a nlogn, o encualquier caso no supera esta cantidad. A lo largo de diferentes capıtulos,hablaremos en los siguientes terminos, todos ellos para decir lo mismo:
1. La complejidad temporal del algoritmo es de orden nlogn, que puedeser expresado como O(nlogn).
2. El algoritmo es ejecutado en un tiempo O(nlogn).
3. La cantidad de trabajo requerida por el algoritmo es proporcional anlogn, o es O(nlogn).
1.4. Complejidad agebraica y analıtica
Entenderemos por algoritmo numerico, un algoritmo que resuelve unproblema en el que el contenido numerico es esencial. Hay muchos ejemplosde algoritmos numericos entre los que se encuentran los siguientes:
1. El calculo de las raices de una ecuacion no lineal, o bien de un sistemade ecuaciones no lineales.
2. La evaluacion de un polinomio en un valor dado, etc.
Los algoritmos no numericos, resuelven problemas y la solucion de losmismos, aunque en ocasiones se representa por un numero (o conjunto denumeros), es de naturaleza no numerica. Dos importantes ejemplos de pro-blemas no numericos son, la ordenacion de un conjunto de elementos des-ordenados (si es un conjunto de numeros, en orden creciente o decreciente,mientras que si es un conjuntos de letras o palabras, en orden alfabetico) y labusqueda de un elemento en un conjunto. En los Temas 5 y 6 del programaanalizaremos algoritmos para resolver estos problemas.
En el analisis de la complejidad computacional de los algoritmos numeri-cos es conveniente distinguir entre la medida de complejidad algebraica y

1.5 · Precision numerica 9
analıtica, donde ambas representan ramas de la propia complejidad com-putacional. En el caso de los algoritmos no numericos, la complejidad esunicamente abgebraica.
Los objetivos de la complejidad algebraica son multiples. Por una parteintenta estimar el numero de operaciones aritmeticas requeridas por un algo-ritmo. Ademas intenta estimar el numero mınimo de operaciones necesariopara resolver un problema dado. Tambien intenta describir un algoritmo oalgoritmos que resuelvan un problema en un numero mınimo de operaciones.La evaluacion de un polinomio en uno o varios valores dados y la resolucionde ecuaciones o sistemas de ecuaciones lineales mediante metodos directosson ejemplos de problemas que pueden ser estudiados en terminos de sucomplejidad algebraica. Un aspecto importante de los algoritmos que sonutilizados para resolver estos problemas, es el numero finito de pasos queson necesarios hasta la obtencion de la solucion del problema. Esto implica,evidentemente, que el numero de operaciones aritmeticas necesarias tambienes finito.
Por otra parte, la complejidad analıtica resuelve la cuestion de cuantacomputacion ha de ser desarrollada hasta obtener un resultado con un deter-minado grado de precision y se centra mas en los procesos computacionalesque en cierto sentido nunca terminan. Los procesos iterativos son un evi-dente ejemplo. En este caso, el proceso es interrumpido en un punto y, siel valor actual del resultado satisface el problema con un margen de erroracotado, dicho resultado se toma como solucion del problema, en otro casola computacion continua hasta obtener un resultado satisfactorio. En estecaso, uno estima el numero de operaciones aritmeticas por paso en cada ite-racion y un “buen” algoritmo en terminos de su complejidad computacionales definido como aquel que requiere el menor numero total de operacionesaritmeticas para alcanzar un resultado, con un nivel de precision prefijado.
1.5. Precision numerica
En el analisis de algoritmos que resuelven problemas numericos, la pre-cision de los resultados obtenidos es otro importante criterio a la hora dedistinguir entre un buen y un mal algoritmo. La necesidad de examinar laprecision de los calculos matematicos viene del hecho de considerar que unordenador es una maquina finita, que es capaz de representar los numerosunicamente en un numero finito de posiciones. La mayorıa de los numeros,incluso si son enteros, si son muy grandes para ser representados en el or-denador, se redondean y solo una aproximacion finita a dicho numero esalmacenada en el ordenador. Esto implica que si no se tiene cuidado, algu-

10 1 · Nociones basicas sobre algoritmos
nos algoritmos numericos implementados en un ordenador pueden produciraproximaciones al verdadero valor de la solucion, bastante imprecisas.
Aunque todavıa no hemos introducido el concepto de error de redondeo(lo haremos en el Capıtulo 3), con el siguiente ejemplo vamos a ver como loserrores de redondeo pueden destrozar el resultado de un calculo si se eligeun mal algoritmo.
Ejemplo 1.3 Vamos a analizar el problema de computar para n =0, ..., 8, la integral:
yn =∫ 1
0
xn
x+ 5dx
Vamos a utilizar un procedimiento iterativo basado en una relacion derecurrencia. En general las relaciones de recurrencia son ubicuas en es-tadıstica computacional y probabilidad. En la mayorıa de los casos surgende considerar el primero y el ultimo de una cadena de eventos. Este ejemplosera el primero en ilustrar este principio.
En nuestro caso la relacion de recurrencia viene dada por:
yn =1n− 5yn−1
y se sigue directamente de la identidad:
yn =∫ 1
0
xn−1(x+ 5− 5)x+ 5
dx =∫ 1
0xn−1dx− 5
∫ 1
0
xn−1
x+ 5dx =
1n− 5yn−1
En teorıa esta relacion de recurrencia permitira crear un proceso iterativoy computar yn a partir del valor inicial y0 =
∫ 10
dxx+5 = [ln(x+ 5)]10 = ln6−
ln5 = 0,182.
y1 = 1− 5y0 ≈ 0,09
y2 =12− 5y1 ≈ 0,05
y3 =13− 5y2 ≈ 0,083 extrano que y3 > y2
y4 =14− 5y3 ≈ −0,165 absurdo!!
La razon del absurdo resulta ser un error de redondeo ε en y0 cuya mag-nitud puede ser como mucho de 5 · 10−4. Dicho valor es multiplicado por -5

1.5 · Precision numerica 11
en el calculo de y1, que entonces tiene un error de −5ε. Dicho error produceun error en y2 de 25ε, etc. De esta forma el error en y4 es 625ε que puedealcanzar el valor 625 · 5 · 10−4 = 0,3125.
Si se comienza en y0 utilizando mas decimales, lo que sucede es que seretrasa la aparicion del absurdo.
Este algoritmo es un ejemplo de un fenomeno denominado inestabili-dad numerica. Podremos evitar dicha inestabilidad numerica eligiendo unalgoritmo mas adecuado.
Otra forma de explicar dicha inestabilidad numerica es utilizando cono-cimientos de analisis matematico. En este caso sabemos que, para n mode-radamente grande, la mayorıa de la masa de la integral se agrupa en tornoa x = 1. Por lo tanto, una buena aproximacion de yn−1 serıa:
yn−1 ≈ 11 + 5
∫ 1
0xn−1dx =
16n
Es decir:
yn ≈ 1n− 5
6n=
1n(1− 5
6)
Por lo tanto perdemos precision porque en cada iteracion restamos dosnumeros del mismo signo y parecida magnitud.
Una solucion al problema en este caso, puede ser utilizar la formula derecurrencia en la otra direccion.
yn−1 =15n
− yn5
Pero necesitamos un valor inicial. Podemos ver directamente de la de-finicion que yn decrece cuando n crece. Se puede suponer entonces que yndecrece suavemente cuando n es grande. De manera que y10 ≈ y9, de donde:
y9 + 5y9 ≈ 110, y9 ≈ 1
60≈ 0,017
De este modo:
y8 =145
− y9
5≈ 0,019

12 1 · Nociones basicas sobre algoritmos
y7 =140
− y8
5≈ 0,021
y6 ≈ 0,025y5 ≈ 0,028y4 ≈ 0,034y3 ≈ 0,043y2 ≈ 0,058y1 ≈ 0,088y0 ≈ 0,182 Correcto!!
Este mismo algoritmo hacia atras puede elegir como valor inicial y10 = 0.La aproximacion inicial es distinta pero el error se divide por 5 en cadaiteracion y a partir de y7 se obtienen los mismos resultados.
Aunque en este caso la solucion ha sido elegir una formula de recursionhacia atras, esto no supone siempre una mejor alternativa.
En adelante utilizaremos el termino metodo numerico para denotarun procedimiento util en algunos casos para aproximar un problema ma-tematico con un problema numerico, y en otros para resolver un problemanumerico. Especificar la formula de recursion que permite resolver una su-cesion de integrales, es proporcionar un metodo numerico. Ası, un metodonumerico es mas general que un algoritmo y hace menos enfasis en detallescomputacionales.
1.6. Analisis de Algoritmos. Lımites de compleji-dad
Es conveniente distinguir entre el analisis de un algoritmo en particulary el analisis de una clase de algoritmos. En el analisis de un algoritmo enconcreto deberıamos probablemente investigar sus caracterısticas mas im-portantes tales como su complejidad temporal, cuantas veces es convenienteejecutar cada parte del algoritmo y la complejidad espacial, esto es, cuantamemoria va a ser necesaria. En el analisis de una clase de algoritmos, porotra parte, estudiaremos la clase de algoritmos que resuelven un problemaparticular e intentaremos seleccionar el “mejor” algoritmo de la clase capazde hacerlo. Si tal algoritmo no se encuentra, entonces intentaremos estable-cer lımites de la complejidad de los algoritmos de dicha clase.

1.6 · Analisis de Algoritmos. Lımites de complejidad 13
Analisis del primer tipo han sido realizados desde los comienzos de la pro-gramacion en ordenador. Analisis del segundo tipo, comienzan a realizarse,salvo raras excepciones, mucho tiempo despues. Es facil ver que analisis delsegundo tipo son bastante mas potentes y utiles ya que permiten estudiarvarios algoritmos simultaneamente.
Lımites de Complejidad
El analisis de la complejidad esta relacionado entre otras cosas con laobtencion de lımites superiores e inferiores de la ejecucion de un algoritmo ouna clase de algoritmos que resuelve una clase de problemas. La existenciade lımites de la complejidad de algunos algoritmos nos puede servir comobase para la clasificacion de algunos problemas.
Hay algunos problemas para los que los lımites de complejidad de suresolucion pueden ser determinados utilizando teoremas apropiados, sin lanecesidad de construir el algoritmo para el problema. En algunos de estoscasos las demostraciones de los teoremas no son constructivas en el sentidode que no indican la forma de construir un algoritmo para la resolucion delproblema y ni siquiera nos dicen si es posible su construccion. Para otros pro-blemas ha sido posible acotar su complejidad, pero no se conoce algoritmocapaz de alcanzar dicha cota. Un ejemplo de este caso es la multiplicacionde matrices, donde una cota superior mınima de O(n2) es facilmente visua-lizada y sin embargo el mas rapido de todos los metodos conocidos tieneuna complejidad de O(n2,496). Este intervalo sugiere que la cota O(n2) noes alcanzada en la practica.
Otros problemas son tales que se conoce la cota inferior de su com-plejidad, se pueden construir algoritmos que satisfacen dichas cotas y sinembargo dichos algoritmos son numericamente inestables. Metodos rapidosde multiplicacion de matrices pertencen a esta categorıa.
Finalmente, hay problemas para los cuales los lımites inferiores de com-plejidad son conocidos y los algoritmos que alcanzan dichas cotas puedenconstruirse y ademas son numericamente estables.

14 1 · Nociones basicas sobre algoritmos

Capıtulo 2
Nociones sobre arquitectura de
ordenadores
2.1. Introduccion
Las aplicaciones de un ordenador caen, en su mayorıa, dentro de losgrupos:
1. Calculo numerico.
2. Almacenamiento, recuperacion procesamiento y analisis de datos o in-formacion.
El primer punto ha sido la causa por la que se invento y desarrollo elordenador. Sin embargo el segundo punto es el que ha experimentado unmayor desarrollo en los ultimos anos y ya domina en todos los campos de latecnologıa informatica. Estamos sin duda en la era de la gestion informaticade la informacion. Facturacion y control de grandes companıas, edicion ycomposicion editorial de las paginas en los periodicos, busqueda de sıntomasen grandes bases de datos que ayudan al diagnostico de enfermedades, noson mas que algunos ejemplos en los que interviene un ordenador.
El unico lımite existente proviene del numero de personas expertas enun determinado campo, que posean la habilidad y conocimientos necesariospara aplicar la informatica a ese campo.
15

16 2 · Nociones sobre arquitectura de ordenadores
2.1.1. Representacion binaria de la informacion
Las operaciones que realiza internamente un ordenador no son, en prin-cipio, demasiado complicadas. Desde hace siglos se sabe que un conmutadoral tener dos estados (abierto y cerrado) puede representar los numeros 0 y1. Si disponemos de muchos conmutadores, podremos representar grandescantidades de ceros y unos. Por otra parte podremos representar los numerosen base 2 en lugar de utilizar la base de numeracion decimal como hacemosnormalmente. Los numeros expresados en base dos solamente utilizan losdıgitos 0 y 1, ası que podemos representar un determinado numero por me-dio del estado de una serie de conmutadores. Por ejemplo, el 372 se puederepresentar en base decimal
372 = 3(102) + 7(10) + 2(100)
pero tambien podemos escribirlo como
372 = 1(28) + 0(27) + 1(26) + 1(25) + 1(24) + 0(23) + 1(22) + 0(21) + 0(20) == 1(256) + 0(128) + 1(64) + 1(32) + 1(16) + 0(8) + 1(4) + 0(2) + 0(1)
o bien
(372)2 = (101110100)2
es decir necesitaremos nueve posiciones para representar el numero 372.
Ademas de numeros podemos representar otros tipos de datos en codigobinario, por ejemplo, cada una de las letras del abecedario. Podemos con-vertir de forma aproximada, la informacion contenida en una imagen, enuna serie de puntos cuyos valores de posicion color e intensidad podremoscodificar y procesar o transmitir a traves de lıneas telefonicas.
2.2. Memoria, dispositivos de entrada/salida, uni-
dad central de proceso o CPU
En sus mas remotos orıgenes cada uno de los conmutadores que consti-tuıan un ordenador era un dispositivo electromecanico conocido como rele.El resultado fue una maquina monstruosa en tamano, ruido y consumo. Elsiguiente paso fue sustituir los ruidosos y poco fiables reles por calurosas y,tambien, poco fiables valvulas de vacio, que, por lo menos eran mas rapidas.A continuacion se introdujo el transistor, lo que supuso un gran avance (yaestamos en los anos sesenta). Pero lo que ha hecho posible la revolucioninformatica ha sido la aparicion de los circuitos integrados.

2.2 · Memoria, dispositivos de entrada/salida, unidad central de proceso o CPU17
Existe un circuito basico formado por dos transistores llamado flip-flopo biestable. Este circuito posee dos estados de funcionamiento estable. Siasignamos el valor 1 a uno de estos estados y el 0 al otro, de nuevo tendremosnuestro sistema de representacion de numeros binarios. El estado en el quese encuentra el circuito puede medirse (lectura) o alterarse (escritura).
Gracias a la microelectronica se pueden colocar varias decenas de mi-les de circuitos dentro de un chip. Las tecnicas que permiten un grado deempaquetamiento tan elevado de denominan tecnologıa VLSI (Very LargeScale of Integration). El tamano resultante no suele superar el centımetrocuadrado, lo que da idea del grado de miniaturizacion del proceso. Estosavances tecnologicos han hecho posible que los ordenadores actuales seanmucho mas rapidos, fiables, y baratos que sus antecesores.
La memoria principal de un ordenador consiste en varios millones de cir-cuitos elementales biestables capaces de almacenar un cero o un uno. Cadaunidad de informacion binaria es un bit. Sin embargo, no suele accedersede forma individual a un bit, sino que suelen agruparse de ocho en ocho,formando un byte. La unidad de informacion que se transfiere a o desde lamemoria principal recibe el nombre de palabra. En los ordenadores perso-nales la longitud de una palabra suele ser de 8, 16 o 32 bits, mientras queen los grandes puede oscilar entre 12 y 64, o mas, bits. Los detalles sobrela construccion y organizacion de la memoria principar de un odenador nosuelen tener demasiada importancia a la hora de escribir un programa. Losdos unicos puntos importantes a considerar son los siguientes:
1. Hay dos valores asociados con cada elemento de memoria: Su contenidoque sera su dato o instruccion en codigo binario y la direccion de esaposicion de memoria, que nos permite acceder a ella.
2. El tamano de la palabra de cualquier ordenador es finito. Esto signi-fica que dispondremos solamente de un numero finito de dıgitos pararepresentar las cantidades durante su calculo. Ası los numeros cuyarepresentacion binaria sea ilimitada, seran truncados al guardarse enuna direccion de memoria. Nos estamos refiriendo a los numeros cuyarepresentacion binaria (no decimal) tiene infinitos decimales. Por ejem-plo 0.1, tiene una representacion periodica en base 2. La longitud de lamemoria ocupada por una dato nos limitara la precision de los calculosnumericos y es una caracterıstica importante de cada ordenador.
El tiempo de acceso (tiempo necesario para leer informacion almacena-da en una direccion determinada) es un parametro de importancia crucialen el funcionamiento de un ordenador. Una suma se suele realizar en me-nos tiempo del necesario en buscar los sumandos en memoria. El tiempo

18 2 · Nociones sobre arquitectura de ordenadores
de acceso en una memoria de gran tamano es del orden de 5 · 10−7 segun-dos. Este tiempo aunque es extraordinariamente pequeno, puede reducirsecolocando los datos e instrucciones mas recientes en otra memoria mas pe-quena y rapida, es la memoria cache. La idea es que los terminos utilizadosultimamente tienen grandes probabilidades de ser necesarios de nuevo. Lamemoria principal recibe el nombre de memoria de acceso aleatorio (randomaccess memory, o RAM). Con este termino se indica que el tiempo de accesoa una determinada posicion de memoria es practicamente independiente desu direccion.
En una RAM la informacion no se guarda de forma secuencial, aunquepuede ser comodo imaginar las direcciones ordenadas consecutivamente.
La memoria principal no es el unico sitio en el que se almacena la in-formacion; existen otros lugares donde a cambio de unos tiempos de accesomayores se pueden conservar grandes cantidades de informacion. Estos dis-positivos reciben el nombre de memoria secundaria o memoria masiva, ysuelen consistir en cintas magneticas, discos fijos, diskketes, cd’s, etc. Losdatos de la memoria secundaria no son accesibles directamente, sino quedeberan pasar a la memoria principal.
La seccion del ordenador que realiza las operaciones con los datos, si-guiendo las instrucciones almacenadas en la memoria principal, es la unidadcentral de proceso (central processing unit, o CPU). La CPU realiza dostipos de tareas:
1. Control y observacion del sistema completo. Este consta de todos losdispositivos de entrada y salida de informacion del ordenador juntocon el trafico de informacion interna al ordenador.
2. Ejecucion de las instrucciones recibidas desde la memoria principal.
La CPU consta de dos secciones que realizan cada una de estas funciones.La unidad de control se encarga de la realizacion de las tareas de control,mientras que la unidad de proceso de datos e instrucciones sera la respon-sable de ejecutar las ordenes elementales que forman el programa. Estasordenes consisten principalmente en operaciones aritmeticas y de compa-racion entre dos datos. Esta segunda seccion recibe el nombre de unidadaritmetico-logica (arithmetic-logic unit, o ALU).
La unidad de control es la responsable de la busqueda de la siguienteinstruccion y del calculo de las direcciones de los datos, ası como del alma-cenamiento de ambos en registro de acceso inmediato. Las instrucciones setraen de la memoria principal en el orden indicado por el programa. Si hay

2.3 · Lenguaje de maquina, lenguajes de ensamblado, lenguajes de alto nivel19
que realizar alguna operacion con los datos, estos se transfieren a la ALUjunto con la orden de sumarlos, restarlos, compararlos, etc. La unidad decontrol, se encarga, una vez realizada la operacion, de colocar el resultadoen la memoria principal.
Recuerda que todos los elementos procesados en la CPU, datos e instruc-ciones, estan escritos en codigo binario. Esta es la unica forma de comunica-cion que puede entender el ordenador. Los programas escritos de esta formareciben el nombre de programas en lenguaje maquina o microprogramas.
Dos de los errores mas comunes son el de realizar una serie de opera-ciones con datos que no se han introducido en la memoria principal y elde ejecutar un programa que carece de las instrucciones para la impresionde los resultados. Practicamente todos los programas constan de tres fases:introduccion de los datos, procesamiento e impresion de los resultados. Losdispositivos de entrada mas comunes son el teclado y los discos magneticos.Los resultados de un programa pueden presentarse en una pantalla o en unaimpresora o bien guardarse en un disco. Los dispositivos mas comunmen-te usados, especialmente en los ordenadores personales, son el teclado y lapantalla.
Todos los componentes fısicos tales como la CPU, las memorias principaly secundaria y los dispositivos de entrada E/S forman parte del llamadohardware del ordenador. El conjunto de programas forman el software.
Nota 2.1. La metafora del enano computador Lee atentamente esteartıculo que te servira para comprender mejor lo descrito en esta seccion.
2.3. Lenguaje de maquina, lenguajes de ensambla-do, lenguajes de alto nivel
Como se ha comentado anteriormente, la definibilidad de un algoritmoexige especificar de modo riguroso y sin ambiguedades las acciones a realizar.Para ello se han creado los lenguajes de programacion definidos formalmentepara especificar algoritmos. La transcripcion del algoritmo en sentencias deun lenguaje de programacion se denomina “codificacion” y constituye el“programa” informatico. Un lenguaje de programacion esta formado por unconjunto de codigos que permiten describir los algoritmos y sus datos, demanera que, por una parte, se puedan ejecutar por un ordenador; y por otra,su descripcion sea comprensible por el usuario.
El lenguaje de programacion es un medio de comunicacion entre el hom-

20 2 · Nociones sobre arquitectura de ordenadores
bre y el ordenador. Para describir al ordenador un metodo para resolverun problema, es necesario formalizarlo adecuadamente para que lo puedaentender.
Dado que la circuiterıa del ordenador solo acepta, e interpreta ceros yunos, el lenguaje binario es la base del “lenguaje maquina”. Como la palabralo dice, el “lenguaje maquina” es particular de cada ordenador en concretoy aunque su base sea binaria existen entre unos y otros grandes diferencias.
Interesa precisar dos hechos:
1. Un ordenador solo entiende y acepta su propio lenguaje de maquina.
2. La utilizacion de un lenguaje mas evolucionado y por lo tanto los pro-gramas escritos en ese lenguaje, exigira la existencia de un “traductor”(escrito en el propio lenguaje maquina”) para que convierta estos pro-gramas al lenguaje maquina.
Logicamente el lenguaje maquina es muy incomodo de utilizar. Por unaparte hay que conocer los codigos de todas las operaciones, y por otra, hayque disponer de las direcciones que los datos toman en la memoria central.
Todo ello obligo a las empresas informaticas a desarrollar una forma deprogramacion mas sencilla y plantearon distintas formas de automatizarla.
Un primer paso fue utilizar bases numericas superiores a dos para larepresentacion de las instrucciones, en la entrada y la salida del ordenador:octal, decimal, hexadecimal, etc.
Pero la verdadera evolucion la marcaron dos aspectos:
a) La simbolizacion.
b) La utilizacion de lenguajes intermedios.
Al igual que se ha descrito en el artıculo del enano computador, en elordenador real se numeran las direcciones de memoria. Ello presenta unagran inconveniente en la programacion, por el hecho de que el programadordebe conocer en todo momento la ubicacion de sus datos en la memoriacentral.
Los lenguajes “simbolicos” obvian este inconveniente al permitir reem-plazar los codigos de operacion y las direcciones numericas de memoria porsımbolos que representan esos codigos y direcciones.

2.3 · Lenguaje de maquina, lenguajes de ensamblado, lenguajes de alto nivel21
Los nombres simbolicos de las direcciones de memoria exigen la observan-cia de determinadas reglas de formacion, por ejemplo: limitacion del numerode caracteres, obligacion de que aparezca un caracter en particular, etc.
Las instrucciones escritas de manera simbolica deben ser transcritas eninstrucciones en lenguaje maquina, ya que los sombolos no pueden ser serinterpretados directamente por el ordenador. Por ello es necesario crear unastablas de correspondencia a fin de traducir estos sımbolos en codigo deoperacion y direcciones numericas. Esta funcion la desarrolla un progra-ma particular que se denomina traductor. Por lo tanto, todos los lenguajesintermedios necesitan la presencia de un traductor, cuya funcion es la detraducir el programa fuente en el programa-maquina, dando como resultadoun programa objeto que es directamente ejecutable por el ordenador.
Entre los lenguajes intermedios mas importantes tenemos:
1.- Los lenguajes de ensamblaje o ensambladores.
2.- Los lenguajes autocode.
El lenguaje ensamblador es muy proximo a la maquina, y en el cadaorden corresponde directamente a una instruccion en codigo maquina, o ala descripcion de un dato elemental tal como se presenta en la memoria delordenador.
La accion del ensamblador consiste en traducir todos los elementos simboli-cos del programa fuente, tanto los codigos de operacion como las direccionesde memoria. Con respecto a los codigos de operacion, el ensamblador com-para cada sımbolo encontrado en el programa con los existentes en una tablapreestablecida, cargada en memoria en el momento del ensamblaje. Cuandose produzca la correspondencia, el codigo simbolico sera sustituido por sucorrespondiente numerico de la tabla. Para las direcciones, el proceso es al-go diferente. En una primera pasada, el ensamblador crea en memoria unatabla, asignando una direccion real a cada direccion simbolica que encuen-tra. En la segunda pasada, el ensamblador reexamina cada instruccion yreemplaza los sımbolos por las direcciones correspondientes de la tabla. Esentonces preciso que el ensamblador lea, por lo menos, dos veces el programafuente para obtener el programa en lenguaje maquina (programa objeto).
La funcion del ensamblador no se reduce a estas operaciones que seacaban de indicar. Tambien se encarga de reservar zonas de memoria, decargar algun dato inmediato en la memoria del ordenador, etc.
Por su parte el lenguaje autocode tambien es un lenguaje muy proximo

22 2 · Nociones sobre arquitectura de ordenadores
al lenguaje maquina. Se diferencia del ensamblador por la introduccion de lamacro-instruccion. Se denomina ası porque en el momento de la traducciongenera varias instrucciones de codigo maquina.
La nocion de macroinstruccion esta ligada al concepto de subprograma,procedimiento o rutina. Supongamos que en un programa se desea leer datosen diferentes puntos del mismo. Lo logico serıa disponer de un conjuntode instrucciones independientes del resto del programa (macro-instruccion),que nos realice esta operacion de lectura, y poder llamar a esta macro-instruccion, cuando lo precisemos.
En el lenguaje autocode, la tecnica de ensamblaje es esencialmente lamisma que en el ensamblador. Al ensamblador del autocode se le denominamacroensamblador.
El autocode presenta ademas, con respecto al ensamblador, la ventajade poder utilizar subprogramas ya existentes en el sistema, definidos por elprogramador o por otro usuario del equipo.
Los lenguajes intermedios se suelen utilizar, bien porque las operacionesque se desean programar no son posibles con los lenguajes mas evoluciona-dos, o bien porque los programas a construir son de ejecucion permanentey precisan una gran optimizacion tanto de memoria como de tiempo de eje-cucion. Es es el caso de algunos sistemas operativos y procesadores basicos.
La llegada de los lenguajes de alto nivel marca una etapa importante en laevolucion de los lenguajes intermedios. Mientras que estos estan orientadosa la maquina, los de alto nivel van orientados al problema. Esto ultimoexplica que la estructura de los lenguajes evolucionados sea completamentediferente al de los de ensamblaje, estando los primeros mucho mas proximosal lenguaje natural. Los lenguajes evolucionados tienden a una universalidadde empleo, permitiendo ser procesados, casi, con independencia del tipo deordenador.
Tomando como criterio el tipo de aplicacion, se distinguen dos categorıas:
1. Lenguajes de proposito general: que permiten resolver, en principiocualquier tipo de problema. Se dividen en dos grupos dependiendo defin para el que han sido desarrollados.
a) Lenguajes definidos para aplicaciones tecnico-cientıficas: FOR-TRAN, ALGOL y BASIC que fueron los primeros en ser des-arrollados, entre 1954 y 1958, y el PASCAL y el lenguaje C quese desarrollaron posterioremente, en 1970 y 1972 respectivamente,son los mas representativos en esta categorıa.

2.3 · Lenguaje de maquina, lenguajes de ensamblado, lenguajes de alto nivel23
b) Lenguajes de gestion, como el COBOL, RPG, etc. El COBOLha sido basicamente estudiado y pensado para programar aplica-ciones de gestion. Hoy en dıa en la explotacion y tratamiento degrandes bases de datos, se emplea ORACLE, ACCES, etc
2. Lenguajes especializados: que han sido disenados para un tipo especialde aplicacion (por ejemplo, manejo de maquina herramienta, diseno,ensenanza asistida, etc). Son a tıtulo de ejemplo el CAD, GPSS, SI-MULA, LISP, entre otros. Dentro de una especializacion mas cercana,S-plus o R.
En los lenguajes de alto nivel se sustituye el traductor (ensamblador omacroensamblador) por el compilador, y la traduccion se denomina compi-lacion.
Un compilador, es pues, un traductor de programas escritos en un len-guaje de alto nivel. El compilador es un programa complejo (normalmenteescrito en ensamblador) que tiene como mision traducir expresiones y sen-tencias, escritas en un lenguaje de alto nivel, en instrucciones que comprendae interprete el ordenador. Mas adelante, veremos con mas detalle la formade compilar un programa escrito en C.

24 2 · Nociones sobre arquitectura de ordenadores

Capıtulo 3
Introduccion al lenguaje de programacion
C (I)
C es un lenguaje de programacion de uso general. Ha sido y es utilizadopara escribir programas numericos, programas de procesamiento de textos ybases de datos. Dentro de los lenguajes de alto nivel, es clasificado como unlenguaje de relativo bajo nivel, esto es, trabaja con la misma clase de objetosque la mayorıa de los ordenadores: caracteres, numeros y direcciones, quepueden ser combinados con los operadores aritmeticos y logicos, utilizadosnormalmente en las maquinas. No contiene elementos de alto nivel, quedeberan siempre ser aportados por funciones llamadas explıcitamente.
De igual forma, las sentencias de control de flujo en C son sencillas,secuenciales, de seleccion, de iteracion, bloques y subprogramas, pero nomultiprogramacion, paralelismo sincronizacion o corrutinas.
La ausencia de estas caracterısticas es lo que da ventajas al lenguaje. Ces relativamente pequeno, puede escribirse en poco espacio y aprenderse confacilidad. Por el contrario es tremendamente versatil y portatil, es decir sepuede hacer casi cualquier cosa y ejecutar sin cambios en una amplia va-riedad de maquinas. Los compiladores se escriben facilmente. Exceptuandolos programas que necesariamente dependen en alguna forma de la maqui-na, como el compilador, ensamblador y depurador, el software escrito enC es identico en casi cualquier maquina que soporte a C. El lenguaje esindependiente de cualquier arquitectura de la maquina en particular.
El sistema operativo UNIX esta escrito en su mayor parte en lenguajeC. Los programas en C tienden a ser lo suficientemente eficientes como paraque no haya que escribirlos en lenguaje ensamblador. De hecho, casi todaslas aplicaciones de UNIX estan escritas en C.
25

26 3 · Introduccion al lenguaje de programacion C (I)
En nuestro caso, hemos optado por describir la situacion del sistemaUNIX, de la HP9000 de nuestro Centro de Calculo, pues dicho entorno detrabajo es el habitual de la mayorıa de programadores de C.
Muchas de las ideas principales de C provienen de un lenguaje mucho masantiguo pero aun vigente: el lenguaje BCPL inventado por Martin Richars.La influencia de BCPL le llega indirectamente a traves del lenguaje B, escritopor Ken Thompson en 1970 para el primer sistema UNIX.
En C los objetos fundamentales son caracteres, enteros de varios ta-manos y numeros en punto flotante. Existe tambien una jerarquıa de tiposde datos derivados, creados con apuntadores, arreglos estructuras, unionesy funciones.
C posee las construcciones fundamentales de control de flujo para es-cribir programas bien estructurados: agrupamiento de sentencias, toma dedecisiones (if), ciclos (bucles), con comprobacion de la condicion de termi-nacion al principio (while, for) o al final (do) y seleccion entre un conjuntode casos posibles (switch). C incluye apuntadores o punteros y capacidadaritmetica de direcciones.
Mostraremos estos y otros elementos esenciales del lenguaje C en este ylos siguientes capıtulos.
3.1. Nociones sobre trabajo en el Sistema Opera-
tivo UNIX. El editor vi
UNIX es un sistema operativo con las siguientes caracterısticas:
a. Interactivo: El sistema acepta peticiones, las procesa en formade dialogo con el usuario.
b. Multiusuario: El sistema permite atender a varios usuariosde forma simultanea. Para ello, utiliza la tecnica denominada detiempo compartido.
c. Multiprogramado: El sistema es capaz de realizar mas de unatarea para cada uno de los diversos usuarios.
Basicamente consta de los siguientes elementos:
1. KERNEL: Constituye el nucleo central del S.O., con entre otras fun-ciones:

3.1 · Nociones sobre trabajo en el Sistema Operativo UNIX. El editor vi27
a) Control de los recursos del ordenador, asignandolos entre los dis-tintos usuarios.
b) Planificacion de la ejecucion de los distintos programas realizadospor los usuarios.
c) Control de los dispositivos de hardware (discos, impresoras,..).
d) Mantenimiento del sistema de archivos.
2. SHELL: Es la capa externa al nucleo. Su mision es la de proporcionarun interface entre el usuario y el S.O. Se puede decir que el SHELL es:
a) Un interprete de comandos.
b) Un lenguaje de programacion.
c) Un controlador de procesos.
3. HERRAMIENTAS Y UTILIDADES: Son un conjunto de programasque se entregan con el S.O. y que realizan tareas mas complicadas yde diversa ındole. Por ejemplo:
a) Manipulacion de ficheros.
b) Manipulacion del contenido de los ficheros.
c) Edicion de textos.
d) Compilaciones de programas.
e) Gestion de ventanas.
4. COMANDOS: Son un conjunto de expresiones prefijadas que permi-ten dar ordenes al S.O.. UNIX es un sitema operativo orientado acomandos: hay que escribir las ordenes. Windows es por el contrarioun sistema visual: hay que seleccionar iconos.
a) Claves de acceso a tu cuenta personal. Normalmente hay un su-pervisor del sistema que tiene acceso a todas las cuentas. Losusuarios tienen unicamente acceso a su cuenta personal.login: etpgamaapassword: ara2411
b) Estructura del arbol de directorios:
Como todo sistema operativo, maneja ficheros los cuales son almace-nados en distintas divisiones del disco duro, denominados directorios.Tanto los directorios como los ficheros poseen un nombre.
Ficheros: guardan datos, programas, etc..
Nombre de ficheros:

28 3 · Introduccion al lenguaje de programacion C (I)
- Se pueden usar como maximo 14 caracteres (en versiones modernas,incluso mas).
- Hay caracteres prohibidos (/, ?, ’, ”)
- Para trabajar con distintos ficheros:
Ejemplo 1: p* denota todos ficheros cuyo nombre comienza por p
Ejemplo 2: p?pe denota todos los ficheros cuyo nombre comienza porp, luego cualquier cosa (incluso nada) y luego pe.
Usualmente los nombres de ficheros tienen lo que se llama extension.Por ejemplo, los ficheros fuente en FORTRAN tienen extension .f, enC tienen extension .c, etc..
Directorios: guardan ficheros u otros directorios. No guardan infor-macion como tal, sino que sirven para estructurar dicha informacion.
(0) Raız: se denota por /.
(1) bin: guarda los comandos del sistema.
(2) etc: guarda los sistemas de arranque.
(3) lost+found: se va guardando lo que el sistema va perdiendo.
(4) mnt: montaje del arbol. Depende del mismo arbol y es quien orga-niza el arbol (utilidades del montaje,...).
(5) users: todos los usuarios del sistema estan aquı.
- Cada cuenta tiene el nombre de un usuario que cuelga de aquı.
- Cada usuario puede hacer lo que quiera por debajo, pero con unlımite de espacio (p.e. en mi caso 10 megas). Todo lo demas es accesible,dependiendo de los correspondientes permisos. Es posible leer o inclusocopiar, ficheros existentes en directorios ajenos a la cuenta del usuario.
- En mi caso etpgamaa es el directorio del usuario (directorio home),que coincide con el nombre de la cuenta a la que accedo.

3.1 · Nociones sobre trabajo en el Sistema Operativo UNIX. El editor vi29
/
bin etc ls.+fd. users
pract
p9mnu
p9mnuaa p9mnuga · · · p9mnups
Estructura de comandos:
...>orden -[opciones] [parametros]
([] puede no estar. Las opciones siempre empiezan con un guion). UNIXdiferencia minusculas y mayusculas. La mayorıa de las ordenes son enminusculas. Para separar las distintas componentes (orden, opciones,parametros , se usan espacios en blanco (solo aquı, y en ningun si-tio mas se usa y esto es la clave de numerosos errores que se suelencometer).
Comandos para manejar el arbol de directorios
pwd, mkdir, rmdir, cd
a) ...>pwdDonde estoy, dame el directorio activo.
b) ...>mkdir nombre-de-directorioCrea un directorio que se llame nombre-de-directorio.Ejemplo 3:...>mkdir docencia metnuCrea ambos directorios.
c) ...>rmdir nombre-de-directorioBorra el directorio que se llame nombre-de-directorio. Para ellose requieren dos condiciones: tiene que estar vacio y no tiene queestar activo (no estar en el ni por debajo de el).Ejemplo 4:...>rmdir docencia metnuBorra ambos directorios.
d) ...>cd nombre-de-directorioCambia al directorio nombre-de-directorio.

30 3 · Introduccion al lenguaje de programacion C (I)
Ejemplo 5:...>cd .. (Sube uno hacia arriba)Ejemplo 6:...>cd (Sube hasta el raız)Ejemplo 7:...>cd /users/etpgamaa/docencia/metnu
5. Comandos para manejar ficheros:
cat,ls,rm, cp, mv, chmod, lp,vi
a) >cat nombre-de-fichero visualiza el fichero nombre-de-fichero, pe-ro no lo modifica (similar al comando TYPE de MS-DOS). Labusqueda la realiza en el directorio activo. Si el fichero no esta endicho directorio, me dira que no lo encuentra. Si en mi directoriotengo creados dos subdirectorios: Programas y Datos, me encuen-tro en este ultimo y quiero que me ensene un fichero que esta enProgramas, hay que dar el camino:...>cat /users/etpgamaa/programas/nombre-de-ficheroEsto es dar el path absoluto. Otro modo de hacerlo es dar el pathrelativo....>cat ../Programas/nombre-de-ficheroLa orden .., sube un paso hacia arriba.Ademas dicho comando permite concatenar:...>cat pepe ana > alumnos existen tres ficheros pepe, ana y alum-nos que contiene la union de pepe y ana....>cat pepe ana > alumnos mantiene el fichero alumnos (existen-te) y le anade el contenido de pepe y ana....>cat p* > pruebas une todos los ficheros que empiezan por pcreando uno de nombre pruebas.
b) >ls [-opciones] [directorios] lista el contenido del directorio en elque estoy.
• Sin opciones ni parametros: informacion completa deldirectorio actual.• ...>ls -l /users/etpgamaa informacion completa de di-cho directorio.• ...>ls -R -l /users/etpgamaa informacion completa yrecursiva de todos los dicrectorios. El resultado de esto:
- - - - - - - - - - n.-enlaces propiet. grupo tamano fecha n.-fichero(1) (2) (3) (4) (5) (6) (7) (8) (9) (10)
(1)Tipo de fichero:- fichero ordinario (Programa, texto, datos).d directorio.

3.1 · Nociones sobre trabajo en el Sistema Operativo UNIX. El editor vi31
c,s,w,r controladores de dispositivos de e/s (impresora, modem,cd-rom,...)Permisos: aparece en tres bloques de tres.(2) Propietario(3) Otros usuarios del mismo grupo que el propietario(4) Todos los demas usuarios del sistemaEn cada grupo de tres:r Lectura: se puede ver pero no modificar.w Escritura: se puede modificar.x Ejecucion. (La tienen los ejecutables).(5)N.-enlaces: numero de lugares (directorios) desde los que esaccesible el fichero (frente a lo que sucede con el MS-DOS, unfichero en UNIX es accesible desde distintos lugares).(6)Propietario(7)Grupo: grupo del propietario(8)Tamano: memoria que ocupa el fichero.(9)Fecha: Fecha y hora de la ultima modificacion del fichero.(10)N.-fichero: nombre del fichero.
c) >rm [-opciones] ficheros o directorios borra los ficheros indicados.Puede tener como opciones:
• -r: borrado recursivo dentro de un directorio. • -i: pe-ticion de confirmacion.Ejemplo 8: ...>rm -r * borra todo lo que hay en el direc-torio. Es conveniente pedir confirmacion.Ejemplo 9: ...>rm pepe ana borra los ficheros pepe y ana.Ejemplo 10: ...>rm p* borra todos los ficheros cuyo nom-bre empieza por p.
d) >cp fichero-origen fichero-destino copia el fichero-origen en elfichero-destino, machacando cualquier contenido que tuviera esteultimo y manteniendo intacto el fichero-origen. Si hay cambio dedirectorio hay que indicar el camino.Ejemplo 11: ...>cp pepe /users/etpgamma/alumnos/pepe.1
e) >mv fichero-origen fichero-destino Frente al comando cp, estecomando no mantiene el fichero-origen, su contenido esta unica-mente en el fichero-destino. (Es similar al comando RENAME deMSDOS).
f ) >chmod [modo] fichero/directorio cambia los permisos de acceso.modo: (1) usuario, (2) operador, (3) permiso(1) u=user (2) + anadir (3) r lectura
g=group - quitar w escriturao=other = asignar x ejecuciona=all

32 3 · Introduccion al lenguaje de programacion C (I)
Ejemplo 12: ...>chmod g+w pepe ana anade a la gente del grupoel permiso de escritura sobre los ficheros pepe y ana.Ejemplo 13: ...>chmod g+wx o-rwx pepeEjemplo 14: ...>chmod g=rx pepe
g) >lp pepe imprime el fichero pepe.
h) >vi pepe crea el fichero pepe. Es el comando de edicion de textosen UNIX. Puede estar en modo COMANDO, para posicionarse,moverse, abrir lıneas nuevas, eliminar lıneas, etc. pulsando la teclaESCAPE. Tambien puede estar en modo EDICION, para escribir.Se entra en modo EDICION tecleando i o a.Para salir: ESCAPE :wq sale guardando; ESCAPE :q! abandona.
Otros comandos:
date, who, passwd
a) >date dame la fecha que tiene registrada la maquina.
b) >who informame de los actuales usuarios del sistema.
• Sin opciones ni parametros: usuarios conectados.• ...>who -a todos los usuarios.• ...>who am i solo de mi mismo.
c) >passwd Sentencia para cambiar el password (palabra de paso).Aparece:Old password:New password:Re-enter new password:
Para desconectarse en la terminal: CTRL+D o teclear EXIT
3.2. Compilado, ejecucion y depuracion de progra-mas en C
En entornos UNIX, los programas se editan utilizando los editores delsistema. En nuestra maquina el de uso habitual es vi.
Todo el texto o codigo de un programa se almacena en un fichero de ex-tension .c, denominado fichero fuente. Para compilar el programa, se invocaal compilador desde el prompt de sistema operativo, utilizando el comandocc, seguido del nombre completo del fichero fuente. Por ejemplo:
$ cc programa1.c

3.3 · Variables escalares, subindicadas (arrays) y constantes 33
Si el fichero fuente contiene errores, aparecen por pantalla todos ellos.Hay que volver al programa fuente y subsanar dichos errores. Se vuelve acompilar el programa. Si dicho programa no tiene errores, el compilador creael fichero objeto, que tiene el mismo nombre que el fichero fuente, pero conextension .o. Si el fichero fuente era unico, la sentencia cc produce tambien ellinkaje, y crea ademas del fichero objeto el fichero ejecutable, que por defectose llama a.out. Si solo queremos que cree el objeto, hay que especificarlo:
$ cc -c programa1.c
Si queremos que el ejecutable tenga otro nombre (por ejemplo programa),hay que especificarlo tambien:
$ cc -o programa programa1.c
Si existen distintos ficheros fuente, programa1.c, programa2.c, progra-ma3.c, se pueden compilar todos ellos, crear los correspondientes programasobjeto y linkarlos de manera que tengamos un unico ejecutable de nombreprograma.
$ cc -o programa programa1.c programa2.c programa3.c
Para ejecutar el programa, basta escribir su nombre
$ programa
En C existe ademas lo que se denomina en ingles debugger. Un debugeres un depurador de codigo. No genera codigo, sino que realiza una com-probacion muy estricta de tantos aspectos de un programa como puedanser comprobados durante la compilacion. Detecta inconsistencias en los ti-pos de datos, uso incongruente de argumentos, variables no utilizadas o noinicializadas, problemas potenciales de portabilidad, etc.
La forma de depurar un programa en nuestro entorno es mediante lasentencia lint.
$ lint programa1.c
3.3. Variables escalares, subindicadas (arrays) yconstantes
La sentencia

34 3 · Introduccion al lenguaje de programacion C (I)
j = 5 + 10;
significa lo siguiente: suma los valores 5 y 10 y asigna el resultado a la varia-ble denominada j. En la lectura de la sentencia anterior, estamos suponiendoconocidos todos los sımbolos involucrados. Sabemos que 5 y 10 son valoresenteros, que + e = son operadores y que j es una variable, lo cual significaque su valor puede cambiar. Para el ordenador, sin embargo, todos estossignos son una mera combinacion de ceros y unos. Para que dicha expresiontenga sentido para un ordenador, hay que decirle previamente el significadode cada uno de los sımbolos mencionados. Esta es una de las funciones delcompilador.
Las variables y las constantes son los objetos basicos que se manipulan enun programa. Como sus propios nombres indican una constante es un valorque nunca cambia, mientras que una variable puede representar distintosvalores. Una variable consigue su variabilidad representando una posicion,una direccion de memoria.
La variable j esta localizada en alguna posicion, por ejemplo en la 2486.De manera que la sentencia anterior, para el ordenador significa: suma losvalores 5 y 10 y coloca su resultado en la posicion de memoria 2486.
La sentencia,
j = j − 2;
es entendida entonces como: coge el contenido de la posicion 2486 de lamemoria, restale la constante 2 y almacena el resultado de nuevo en dichaposicion de memoria.
Variable Direccion2482
j 24862490
Memoria· · · ·· · · ·· · · ·
4 bytes
Las declaraciones iniciales en un programa indican las variables que sevan a utilizar, establecen su tipo y tal vez las inicializan, es decir las dan unvalor inicial.
3.3.1. Nombres de variables
En el lenguaje C, se puede poner nombre casi a cualquier cosa: variables,constantes, funciones, e incluso localizaciones en un programa. Los nombres

3.3 · Variables escalares, subindicadas (arrays) y constantes 35
pueden contener letras, numeros, o el caracter barra baja , pero debencomenzar por una letra o por dicho caracter. Hay algunas otras restriccionesen los nombres de las variables y constantes simbolicas.
El lenguaje C diferencia entre mayusculas y minusculas, de manera que:var, Var, VAR
son nombres diferentes.
No se pueden elegir como nombres las palabras reservadas. (Hay unalista de ellas en casi cualquier manual de C). En general no existe lımiteen cuanto al numero de caracteres que puede tener un nombre en C. Al-gunos compiladores antiguos lo fijan en 8 caracteres, otros en 31. Es buenacostumbre por la portabilidad del programa, intentar que los ocho primeroscaracteres de cada nombre sean unicos.
3.3.2. Tipo y tamano de datos
La primera clasificacion que se puede hacer en cuanto al tipo de datos enC es, como simples y compuestos. Dentro de los datos simples, tenemos:
1. Numericos, que a su vez pueden ser:
a) enteros: int o long (dependiendo de su tamano)
b) reales (en punto flotante): float o double.
2. Caracter, que a su vez pueden ser:
a) simples: char
b) cadenas: char*
3. Punteros: representan direcciones de memoria.
Dentro de los datos compuestos, dependiendo de su composicion:
1. Arrays: secuencia (vector) de datos simples del mismo tipo.
2. Estructuras: composicion de datos de distinto tipo.
Variables Numericas
Todas las variables hay que declararlas antes de usarlas en el programa,es decir, dar su nombre, tipo y contenido. Por ejemplo:

36 3 · Introduccion al lenguaje de programacion C (I)
int x;
int lower, upper, step;
float factorial;
El contenido de la variables no es necesario darlo al principio del progra-ma, pero sı antes del uso de dicha variable.
int x=0;
float factorial=1,0E-5 (que es lo mismo que 0.00001);
Variables Caracter
Las declaraciones son:
char respuesta;
char* nombre;
si ademas las inicializamos:
char respuesta=‘s’; (la s es el valor simple que representa inicialmente lavariable respuesta)
char* nombre =”Jaime ”; (es una cadena de caracteres)
Cuando se inicializa ası, el ordenador entiende:
(‘J’‘a’‘i’‘m’‘e’‘\0’)
Nota: ‘s’ representa el caracter simple s; mientras que ”s”es entendidocomo una cadena de caracteres dada por (‘s’ ‘\0’).
Variables Subindicadas (arrays)
EJEMPLO 1
int tabla [10];
define un vector de elementos enteros con 10 posiciones, (tabla [j], j=0,9).
tabla2 5 200 520 3 0 1 850 1230 580 1 2 3 4 5 6 7 8 9

3.3 · Variables escalares, subindicadas (arrays) y constantes 37
Se inicializarıa:
int tabla={2, 5, 200, 520, 3, 0, 1, 850, 1230, 58};
tabla[3]=520;
x=tabla[9]; /* el valor de la variable x es 58*/
EJEMPLO 2
char nombre [20];
define un vector de elementos de tipo caracter con 20 posiciones, (nombre[j],j=0,19).
nombre· · ·
0 1 19
La inicializacion es:
char nombre[20]=”Jaime”;
o bien;
char nombre[20]={‘J’ ,‘a’,‘i’,‘m’,‘e’,‘\0’};
EJEMPLO 3
int tabla2 [10][20]; /* es una matriz 10x20 */
define una matriz de 10 filas y 20 columnas, de elementos enteros.
La inicializacion para una casilla, serıa:
tabla2 [1][3]=800;
tabla2
0 · ·1 800 · ·
· ·· ·
9 · ·0 3 19
Variables Estructura
EJEMPLO 4

38 3 · Introduccion al lenguaje de programacion C (I)
struct persona
{ char nombre [20];
struct fecha
{ int dia, mes, a~no; } fnacimiento;
int sueldo;
} empleado;
Todo esto define una estructura para cada persona. La variable es em-pleado y esta compuesta por tres tipos de datos: el nombre (de tipo caracter),la fecha de nacimiento (a su vez una estructura compuesta por tres datosenteros), y el sueldo (una variable escalar de tipo entero).
Para inicializar esto:
empleado.nombre=”Pepito”;
empleado.fnacimiento.mes=10;
empleado.fnacimiento.ano=72;
empleado.sueldo=150000;
O bien:
empleado={ ”Pepito”, { 3,10,72},150000};
O agrupando los datos para la estructura fnacimiento:
empleado.fnacimiento={3, 10, 72};
3.4. Un ejemplo. El primer programa en C
El siguiente programa imprime la tabla de conversion de temperatu-ras Fahrenheit a grados centıgrados o Celsius, utilizando la formula: C =(5/9)(F − 32).
0 -17.820 -6.740 4.4

3.4 · Un ejemplo. El primer programa en C 39
60 15.6... ...260 126.7280 137.8300 148.9
El programa es
/* imprime la tabla Fahrenheit-Celsius
para f=0,20,...,300 */
main()
{
int lower, upper, step;
float fahr, celsius;
lower=0; /* lımite inferior de la tabla de temperaturas*/
upper=300; /* lımite superior */
step=20; /*tama~no del incremento */
fahr=lower;
while (fahr<=upper){
celsius=(5.0/9.0) * (fahr-32.0);
printf("%4.0f %6.1f\n", fahr, celsius);
fahr=fahr+step;
}
}
Las dos primeras lıneas de programa son un comentario que, en este casoexplica lo que hace el programa. El compilador prescinde de los caracterescomprendidos entre /∗ y ∗/.
A continuacion comienza el cuerpo de programa, donde aparece la fun-cion main. Todos los programas en C deben tener una funcion main enalgun sitio. Normalmente main hara uso de otras funciones para efectuar sutrabajo. El cuerpo del programa esta dentro de unas llaves, que encierran elbloque de todas las sentencias de que consta este.
A continuacion aparece la lista de definiciones de las variables a utilizar(su tipo) y su inicializacion (valor inicial). Como hemos visto anteriormenteel tipo int implica que las variables de la lista son enteros; float indica puntoflotante, es decir numeros que poseen parte fraccionaria. La precision, tantode int como de float depende de la maquina que se este utilizando. En elCapıtulo 4 se especifican mas detalles al respecto.
Las sentencias o proposiciones individuales se terminan con punto y co-ma. Cada lınea de la tabla se calcula de la misma forma, para lo cual se utiliza

40 3 · Introduccion al lenguaje de programacion C (I)
un ciclo (bucle) que se repite una vez por cada lınea. Este es el propositode la sentencia while. Se examina la condicion encerrada entre parentesis.Si es cierta (fahr es menor o igual que upper), se ejecuta el cuerpo del ciclo(todas las sentencias encerradas entre llaves). A continuacion se vuelve aevaluar la condicion y si es cierta se ejecuta de nuevo el cuerpo del ciclo.Cuando la condicion es falsa, finaliza el ciclo y el control del programa pasaa la sentencia que lo sigue.
Mas adelante hablaremos de las reglas que rigen la conversion entre en-teros y punto flotante. Por ahora basta observar, que tanto la asignacionfahr = lower; como la comprobacion while(fahr <= upper) trabajan co-mo se esperaba: la variable de tipo int es convertida a float antes de realizarla operacion.
En el ejemplo tambien se muestra como funciona la funcion printf .printf es una funcion con formatos de conversion de uso general que de-tallaremos mas adelante. Su primer argumento es una cadena de caracteresque imprimir, indicando cada signo % el lugar en que ha de sustituirse cadauno de los restantes (segundo, tercero,...) argumentos y en que forma hade ser impreso. Por ejemplo, en la sentencia escrita en el programa la es-pecificacion de conversion %4,0f indica que se ha de imprimir un numeroen punto flotante que ocupe un espacio de a lo sumo cuatro caracteres, sindıgitos despues del punto decimal. %6,1f pide otro numero que ocupara alo sumo 6 posiciones, con un dıgito despues del punto decimal. Despues dela especificacion de formato y separadas por comas, aparecen las variablescuyos valores se van a imprimir.
Para terminar, hay que senalar que printf no forma parte del lenguaje.En C no se define ni la entrada ni la salida. Es unicamente una funcionutil de la biblioteca estandar de funciones de entrada/salida habitualmenteaccesible desde los programas en C.
Evidentemente, hay muchas formas de escribir un programa en C. Elsiguiente es una modificacion del anterior:
/* imprime la tabla Fahrenheit-Celsius */
main()
{
int fahr;
for (fahr=0; fahr<= 300; fahr=fahr+20)
printf("%4d %6.1f\n", fahr, (5.0/9.0)*(fahr-32));
}
El programa anterior produce el mismo resultado, pero su aspecto esdiferente. Se han eliminado la mayorıa de las variables. La variable fahr

3.4 · Un ejemplo. El primer programa en C 41
permanece como int, hasta que en la propia funcion printf se realiza laconversion %4d.
Se ha utilizado una nueva expresion iterativa, la proposicion for. Constade tres partes separadas por punto y coma. La primera se ejecuta una solavez, antes de entrar en el ciclo propiamente dicho. La segunda es el criterioo condicion que controla la ejecucion. Esta condicion se evalua; si es cierta,se ejecuta el cuerpo del ciclo, y a continuacion se ejecuta la tercera parteque es la parte de reinicializacion y se vuelve a evaluar la condicion. El ciclotermina cuando la condicion se torna falsa. Como en while el cuerpo delciclo puede ser una sola sentencia o un grupo de ellas colocadas entre llaves.
La decision de utilizar un while o un for es arbitraria.
Una ultima observacion es la siguiente. Es una mala costumbre sepultaren el interior del programa numeros como 0, 300 o 20 en el caso del programaanterior. Siendo difıcil cambiarlos sistematicamente si la ocasion lo merece.Para ello se utilizan en C las sentencias #define y las constantes simboli-cas. Mediante la construccion #define, al comienzo del programa se puededefinir un nombre simbolico como una determinada cadena de caracteres ydarlas un valor.
#include <stlib.h>
#include <stdio.h>
#define LOWER 0
#define UPPER 300
#define STEP 20
/* imprime la tabla Fahrenheit-Celsius */
main()
{
int fahr;
for (fahr=LOWER; fahr<= UPPER; fahr=fahr+STEP)
printf("%4d %6.1f\n", fahr, (5.0/9.0)*(fahr-32));
exit(0);
}
Las tres cantidades definidas son constantes y por lo tanto no puedenaparecer en las declaraciones. Observese ademas que no hay punto y comadespues de las definiciones.

42 3 · Introduccion al lenguaje de programacion C (I)
3.5. Operadores y funciones standard mas usuales
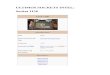
Los operadores son las herramientas mediante las cuales se construyenlas expresiones que manipulan los datos. Una clasificacion inicial puede serla siguiente:
1. Unitarios: − (menos unitario,−x representa la negacion de x) y + (masunitario, +x representa el valor de x, esta disponible en compiladoresANSI). Por ejemplo, si m es igual a 5, −m es igual a -5. No hay queconfundir estos operadores con los operadores binarios aritmeticos dediferencia y suma.
2. Aritmeticos: + (suma), − (diferencia y tambien existe el − unitario;p.e. −x representa la negacion de x), ∗ (producto), / (cociente), %(division entera: x%y produce el resto de dividir x entre y, y porlo tanto es cero, si x es divisible entre y). El operador % no puedeutilizarse con datos de tipo float o double (reales).
Ejemplo 1: j = 3−−x, es interpretado como j = (3−(−x)). El primer− senala una resta, el segundo es un − unitario.
Ejemplo 2: 3/4 da como resultado el valor 0, puesto que es una divisionentera (la parte fraccional se trunca). Si queremos realizar la division,hay que escribir 3,0/4,0.
3. Relacionales: == (igual), ! = (distinto), > (mayor que), < (menorque), >= (mayor o igual que), <= (menor o igual que).
4. Asignacion: = (Usado en inicializaciones), + = (suma-asignacion),− = (resta-asignacion), ∗ = (multiplica-asignacion), / =(divide-asignacion),% = (resto-asignacion).
Ejemplo 3: a = b pon el valor de b en a.
Ejemplo 4: a+ = b pon el valor de a+ b en a.
Ejemplo 5: a− = b pon el valor de a− b en a.
Ejemplo 6: a∗ = b pon el valor de a ∗ b en a.
Ejemplo 7: a/ = b pon el valor de a/b en a.
Ejemplo 8: a% = b pon el valor de a%b en a.
El termino de la izquierda en las anteriores expresiones (a), puedereferirse a una posicion de memoria.
5. Logicos: && (and), || (or), ! (not).Ejemplo 9: a&&b vale 1 si a y b son no nulos, vale 0 en otro caso.
Ejemplo 10: a||b vale 1 si a o b son no nulos, vale 0 en otro caso.

3.5 · Operadores y funciones standard mas usuales 43
Ejemplo 11: !b vale 1 si b es nulo, vale 0 en otro caso.
6. Acceso a miembros (Operadores de memoria): [] (usado en declaracio-nes de arrays) , · (usado en declaraciones de estructuras), → (acceso aestructuras , cuando se dispone del puntero), () (para pasar parame-tros en funciones, & (pon un objeto en una direccion de memoria), ∗(obten el objeto situado en esa direccion de memoria).
Ejemplo 12: &x obtiene la direccion de x.
Ejemplo 13: ∗x obtiene el objeto situado en la direccion x.
Ejemplo 14: x[5] obtiene el valor del vector x en la posicion 5.
Ejemplo 15: x.y obtiene el valor del miembro y en la estructura x.
Ejemplo 16: p → y obtiene el valor del miembro y en la estructurapunteada por p.
7. Operadores de incremento y decremento: C dispone de dos operadoresun poco raros, que incrementan y decrementan el valor de las variables.El operador ++ le suma 1 a su operando; el operador −− le resta 1. Lacaracterıstica especial de estos operadores es que pueden ser utilizadoscomo prefijos (antes de la variable, como en ++n) o bien como sufijos(despues de la variable, n − −). En los dos casos ++ aumenta (−−disminuye) en 1 el valor de la variable n, pero la expresion + + nincrementa n antes de utilizar su valor, mientras que n + + lo hacedespues de que se ha empleado su valor. Por ejemplo, si n = 5:
x = ++ n; pone un 6 en x (incrementa primero el valor de n), pero
x = n++; pone un 5 (toma primero el valor de n).
8. Operador condicional ? : que resulta ser una version abreviada de laexpresion if...else.... Por ejemplo: z = (x < y)?x : y), comprueba six < y, en cuyo caso asigna z = x, si x ≥ y, la asignacion que hace esz = y.
9. Operadores para la manipulacion de bits: >>, <<, &, |, ∧, ∼.
10. Operador cast, de conversion de tipo.
11. Operador sizeof, que devuelve el tamano en bytes, de datos o expre-siones.
3.5.1. Funciones mas usuales
Una funcion es una coleccion de componentes del lenguaje agrupadasbajo un mismo nombre. Si la funcion esta bien disenada, debe representar

44 3 · Introduccion al lenguaje de programacion C (I)
un pequeno numero de operaciones, que son indicadas por el nombre dela funcion. A menudo, una funcion aparece unas pocas lıneas mas abajode donde se la llama una sola vez, para clarificar una parte del programa.Vamos a mostrar los mecanismos para la definicion de funciones escribiendola funcion power(m,n) que eleva el entero m a la potencia representada porel entero positivo n.
/* prueba de la funcion power */
main()
{
int i;
for (i=0; i< 10; ++i)
printf("%d %d %d\n",i,power(2,i), power(-3,i));
}
power(x,n) /* elevar x a la n-esima potencia */
int x,n;
{
int i,p;
p=1;
for(i=1; i<=n; ++i)
p=p * x;
return(p);
}
Las funciones aparecen en cualquier orden, y en uno o mas archivosfuente. Por el momento supondremos que estan en el mismo archivo, por loque se mantiene lo que hemos aprendido sobre ejecucion de programas enC.
En la lınea de impresion se llama dos veces a la funcion power. En cadallamada se pasan dos argumentos a power, que cada vez devuelve un enteroque se formatea e imprime. Los argumentos de la funcion power se declaranpara que se conozca su tipo. La declaracion de los argumentos se realizaentre la lista de argumentos y la llave de apertura. Cada declaracion debeacabar con un punto y coma. Los nombre de los argumentos en power soncompletamente locales a la funcion. Esto tambien se aplica a las variables iy p: la i de power no tiene nada que ver con la i de main.
El valor que calcula power se devuelve al programa principal main me-diante la sentencia return. Puede aparecer cualquier expresion entre losparentesis de una sentencia return. Una funcion no tiene por que devolverun valor; una sentencia return sin expresion devuelve el control al programaprincipal aunque no le devuelve un valor util.

3.5 · Operadores y funciones standard mas usuales 45
En C todos los argumentos se pasan por valor. Esto significa que la fun-cion recibe los valores de sus argumentos en variables temporales, en lugarde recibir sus direcciones. La diferencia principal es que en C la funcionllamada no puede alterar el valor de una variable de la funcion que llama,unicamente puede cambiar el valor de su copia privada y temporal. Esto esuna ventaja y permite escribir programas mas compactos, con pocas varia-bles externas, ya que los argumentos se tratan como variables locales a larutina llamada, si estan debidamente inicializadas. Veamos una version depower que utiliza este hecho.
power(x,n) /* elevar x a la n-esima potencia. Version 2 */
int x,n;
{
int p;
for(p=1; n>=0; --n)
p=p * x;
return(p);
}
El argumento n se utiliza como variable temporal, siendo decrementadahasta que llega a ser 0. Cualquier cosa que hagamos con n dentro de powerno tendra ningun efecto sobre el argumento. Cuando sea necesario, es po-sible hacer que una funcion modifique el valor de una variable en la rutinallamante. Trataremos esto con mas detalles cuando hablemos de direccionesde memoria y paso de argumentos por referencia.
En C como en otros lenguajes de programacion existen cientos de fun-ciones prefabricadas almacenadas en librerıas. Algunas de las standard, apa-recen a continuacion:
Funcion Descripcionfgetc() Lee un caracter de un ficherofopen() Abre un ficherofclose() Cierra un ficherotime() Calcula el tiempo actualsin() Calcula el seno de un angulolog() Calcula el logaritmo de un numero
Como hemos visto tambien es posible crear nuevas funciones. Por ejem-plo, podrıamos definir una funcion para calcular el cuadrado de un numeroentero. Serıa un caso particular de la funcion power:
int square(int num)
{

46 3 · Introduccion al lenguaje de programacion C (I)
int answer;
answer=num*num;
return answer;
}
La funcion main()
Por otro lado, todo programa ejecutable debe contener una funcion espe-cial denominada main(), que indica donde comienza la ejecucion. Por ejem-plo para invocar a la funcion square(), que eleva un numero al cuadrado,deberıamos escribir:
#include <stdlib.h>
int main(void)
{
extern int square(int);
int solution;
solution=square(5);
exit(0);
}
Este pequeno programa asigna el cuadrado de 5 a la variable denominadasolution. Las reglas de utilizacion de esta funcion son las mismas que lasde cualquier otra. Sin embargo, no hemos declarado el tipo de datos quedevuelve, ni los argumentos. Adoptaremos por ahora, que dicha funcionmain() genera un valor y trabaja con dos argumentos. Analizaremos estedetalle en el Tema 5.
La funcion exit() causa el final del programa, devolviendo el controlal sistema operativo. Si el argumento de exit() es el cero, significa que elprograma termina sin errores. Argumentos distintos del cero, denotan erroresen la ejecucion. La llamada de exit() dentro de una funcion main() haceexactamente lo mismo que la sentencia return. Es decir exit(0); es lo mismoque return 0;. Se debe incluir cualquiera de las dos, dentro de cada funcionmain().
Si se usa exit() debe incluirse al comienzo del programa el fichero stdlib.h,que es donde esta almacenada dicha funcion.

3.5 · Operadores y funciones standard mas usuales 47
En el caso anterior declaramos dos nombres en main(). El primero esla funcion square(), que vamos a llamar. La palabra extern indica que di-cha funcion esta definida en cualquier sitio, posiblemente en otro ficherofuente. La otra variable solution, es un entero que nosotros utilizamos paraalmacenar el valor que devuelve la funcion square().
La siguiente sentencia es en la que se invoca a la funcion square(). Elargumento que aparece entre parentesis, indica que es el valor pasado comoargumento a dicha funcion, esto es, es el valor del que se va a calcular elcuadrado. El operador de asignacion =, indica que el resultado que devuelvedicha funcion sera almacenado en la variable solution.
La funcion printf()
El programa anterior es correcto pero poco operativo. Una de las razoneses que no nos deja ver su salida. Una solucion para este problema es utilizarla funcion printf().
#include <stdio.h> /*Fichero donde se encuentra printf()*/
#include <stdlib.h>
int main(void)
{
extern int square(int);
int solution;
solution=square(27);
printf("El cuadrado de 27 es %d \n", solution);
exit(0);
}
Senalar que hemos tenido que anadir en la cabecera el fichero stdio.h,donde se encuentra la funcion de Input/Output printf(). Aunque describire-mos dicha funcion con mas detalle en otro capıtulo, senalar que el sımbolo%d indica que el argumento que va a imprimir es un entero decimal. Lasecuencia \n indica a dicha funcion que salte de lınea (newline).
Si tienes almacenado el programa anterior en un fichero de nombre poten-cia2.c y la funcion square() en otro denominado square.c, podrıas compilarambos programas mediante la sentencia:

48 3 · Introduccion al lenguaje de programacion C (I)
$ cc -o potencia2 potencia2.c square.c
que crea un ejecutable con nombre potencia2. Basta a continuacion queteclees
$ potencia2
y obtentras
El cuadrado de 27 es 729
En la sentencia que aparece utilizada la funcion printf(), se utilizan dosargumentos, el primero ademas de incluir un pequeno texto, especifica elformato de la variable que se va a imprimir. Ası %d, indica que la variablesolution es un entero decimal. Hay otros especificadores para otros tipos dedatos, por ejemplo:
Caracter Especificacion%s Vector caracter%x Entero Hexadecimal%f Dato real (punto flotante)%o Entero octal
La version general de la funcion printf(), debe contener tantas especifi-caciones de formato como variables se van a imprimir:
printf(”Imprime tres valores: %d, %d, %d”, num1, num2, num3);
La funcion scanf()
Todavıa el programa anterior es poco operativo, ya que permite calcularunicamente el cuadrado del numero 27. Para obtener el cuadrado de otronumero, habrıa que modificar el fichero fuente potencia2.c, volver a compilary volver a ejecutar. Esto se puede evitar con el uso de la funcion scanf().Dicha funcion realiza el trabajo contrario al de printf(), mientras esta escribela salida del programa en la pantalla, la funcion scanf() lee el valor del datointroducido mediante el teclado y se lo asigna a una variable. Si anadimosesta posibilidad al programa anterior:
#include <stdio.h> /*Fichero donde se encuentra printf()*/
#include <stdlib.h>
int main(void)
{

3.5 · Operadores y funciones standard mas usuales 49
extern int square(int);
int solution;
int input_val;
printf("Introduce un valor entero:");
scanf("%d", &input_val);
solution=square(input_val);
printf("El cuadrado de %d es %d\n", input_val, solution);
exit(0);
}
Ahora hemos declarado una nueva variable input val, que sirve para al-macenar el valor entero introducido por el teclado, luego pasamos este valorcomo argumento a square(). La expresion &input val, significa ”la direccionde memoria de la variable imput val”. En realidad, la funcion scanf() alma-cena el valor introducido directamente en dicha direccion de memoria. Laejecucion del programa tendra el aspecto:
$ potencia2
Introduce un valor entero: 22
El cuadrado de 22 es 484
Hemos visto que la funcion scanf() realiza la tarea contraria a printf().Su sintaxis es similar. La diferencia es que en la funcion scanf(), los nombresde variables, van precedidas del sımbolo &. Esto hace que el sistema lea eldato de la terminal y lo coloque en una direccion de memoria.
Sentencias #include
Esta sentencia hace que el compilador lea texto de otros ficheros, almismo tiempo que lee el fichero que esta compilando. Una sentencia de estetipo puede tener dos estructuras:
#include < fichero >
y
#include “fichero”

50 3 · Introduccion al lenguaje de programacion C (I)
En el primer caso, el compilador busca en algun lugar designado por elsistema operativo. En el segundo caso, el compilador busca en el directoriodonde se encuentre el fichero que esta compilando.
Sentencias #define
Sirven para asociar una constante a una variable, que ocupa una direc-cion de memoria. Por ejemplo:
#define var 1 34
asigna el valor 34 a la variable var 1, de manera que las sentencias
j = 1 + 34;
j = 1 + var 1;
dan el mismo resultado.
3.6. Ambito de definicion y validez de las varia-
bles. Variables externas
Las variables de main son privadas o locales a main. Lo anterior tam-bien es valido para las variables de otras funciones. Cada variable local deuna rutina comienza a existir cuando se llama a la funcion, y desaparececuando la funcion acaba. Por esta razon, tales variables reciben el nombrede automaticas.
Las variables automaticas aparecen y desaparecen con la invocacion dela funcion, por eso no conservan su valor entre dos llamadas sucesivas, y seles ha de dar un valor a la entrada de la funcion.
Como alternativa es posible definir variables externas a todas las fun-ciones; esto es, variables globales a las que puede acceder cualquier funcionmediante su nombre. Las variables externas son accesibles globalmente; porello pueden usarse en lugar de listas de argumentos para comunicar datosentre funciones. Ademas mantienen sus valores, ya que existen permanente-mente en lugar de aparecer y desaparecer, incluso despues de que finalizanlas funciones que las cambian.
Una variable externa ha de definirse fuera de las funciones. Esto lesasigna memoria real. La variable ha de ser declarada en toda funcion que

3.7 · Precedencia y orden de evaluacion entre operadores 51
quiera acceder a ella; esto puede hacerse mediante una declaracion externexplıcita, o en forma implıcita a traves del contexto. Veamos un ejemplo:
#include <stdio.h>
/* definicion de la variable global var1 */
int var1=50;
main(){ /* comienzo del programa */
printf("%d\n", var1); /* escribe 50 */
{ /* var1 y var2 variables locales al bloque 1 y 2*/
int var1=100, var2=200;
printf("%d %d\n", var1, var2); /* escribe 100 y 200 */
{ /* bloque 2*/
int var1=0;
printf("%d %d\n", var1, var2); /* escribe 0 y 200 */
}
printf("%d\n", var1); /* escribe 100 */
}
printf("%d\n", var1); /* escribe 50 */
} /* final de programa*/
3.7. Precedencia y orden de evaluacion entre ope-radores
Los operadores tiene dos propiedades, precedencia y asociatividad. Lasdos estan estrechamente relacionadas. Veamoslas en un ejemplo:
La expresion 2+ 3 ∗ 4 evaluada por la maquina es 14, igual que 3 ∗ 4+2.Sin embargo la maquina hace la cuenta siempre en el mismo orden. Primeroevalua 3 ∗ 4 y luego al resultado le suma un 2. Esto se resume diciendo queel operador ∗ tiene una precedencia mas alta que el operador +. Si se quiereestablecer otro orden hay que utilizar parentesis. Por ejemplo, 3,0− 4,0/8,0da como resultado 2,5, distinto al de la expresion (3,0 − 4,0)/8,0 que da−0,125.
Por otra parte, la expresion de asignacion x = y = 3, es asociativa dederecha a izquierda, es decir se evalua comenzando por la derecha. En primerlugar se asigna un 3 a la variable y, y posteriormente se asigna este mismovalor a la variable x. Un operador puede ser asociativo de derecha a izquierdao de izquierda a derecha.
52 3 · Introduccion al lenguaje de programacion C (I)
En la siguiente tabla aparecen clasificados los operadores de acuerdo asu precedencia y asociatividad.
Clase de Operador Operadores en la clase Asociatividad PrecedenciaPrimario () [] → · Izda. a dcha. AltaUnitario cast
sizeof& (direccion en memoria) Dcha. a izda.∗ (de referencia)− +∼ ++ −− !
Aritmetico multiplicativo ∗ / % Izda. a dcha.Aritmetico aditivo + − Izda. a dcha.Manipulacion de bytes << >> Izda. a dcha.Relacional de desigual. < <= > >= Izda. a dcha.Relacional de igual. == ! = Izda. a dcha.Manipulacion de bytes & Izda. a dcha.Manipulacion de bytes ∧ Izda. a dcha.Manipulacion de bytes | Izda. a dcha.Logico && Izda. a dcha.Logico || Izda. a dcha.Condicional ? : Dcha. a izda.Asignacion = + = − = ∗ =
/ = % = >> n = <<= Dcha. a izda.& = ∧ = Baja

Capıtulo 4
Introduccion al lenguaje de programacion
C (II)
Un tipo de dato es una interpretacion que da el compilador a una cadenade bits. En el tema anterior vimos una clasificacion de datos como simples (oescalares) y compuestos (o agregados). Hay ademas un tipo de dato -void-que no es ni simple ni compuesto. En este tema vamos a describir los tiposde datos escalares y el tipo void.
4.1. Declaraciones. Tipos de datos escalares: ente-
ros, caracter, de coma flotante y enumeracion
Todas las variables deben ser declaradas antes de utilizarlas, aunque cier-tas declaraciones se realizan implıcitamente por el contexto. La declaracionle dice al compilador como interpretar y almacenar una serie de bytes. Paradeclarar la variable j como entera, debemos escribir:
int j;
La palabra int es una palabra reservada que especifica que el dato esde tipo entero. Hay nueve palabras reservadas para especificar los tipos dedatos simples o escalares. Los cinco dados por: char, int, float, double,enum son tipos basicos. Los otros: short, long, signed y unsigned sonmodificaciones calificadoras de datos simples.
53

54 4 · Introduccion al lenguaje de programacion C (II)
char un byte (octeto) capaz de contener un caracter del juego decaracteres de la instalacion local
int un entero, normalmente del tamano de los enteros de lainstalacion local
float un numero en punto flotante de precision normaldouble un numero en punto flotante de doble precision
Ademas hay una serie de calificadores que se aplican a los enteros: short,long, signed y unsigned. short y long se refieren a diferentes tamanos delos numeros. Algunos compiladores dedican cuatro bytes para almacenar unentero, mientras que otros solo dedican dos. Por otra parte el tamano de unbyte tampoco es constante. En la mayorıa de las maquinas un byte son ochobits, pero hay excepciones.
Si no tienes interes en el tamano del entero dentro de la maquina, puedesusar int. En otro caso debes especificar short o long. En la mayorıa de lasmaquinas short int es un entero que ocupa dos bytes, mientras que longint es un entero que ocupa cuatro bytes.
short int j;
long int k;
es lo mismo que
short j;
long k;
El numero de bits utilizados para representar un entero determina elrango de valores que pueden ser almacenados en ese tipo.
Tipo Tamano (en bytes) Rango de valoresint 4 −231 a 231 − 1
short int 2 −215 a 215 − 1long int 4 −231 a 231 − 1
unsigned short int 2 0 a 216 − 1unsigned long int 4 0 a 232 − 1
signed char 1 −27 a 27 − 1unsigned char 1 0 a 28 − 1
Consideremos por ejemplo un entero short int (16 bits). Cada bit repre-senta un valor de 2 elevado a la potencia n, donde n representa la posicion

4.1 · Declaraciones. Tipos de datos escalares: enteros, caracter, de coma flotante y enumeracion55
del bit:
215 214 213 212 211 210 29 28 27 26 25 24 23 22 21 20
Por ejemplo para expresar el numero decimal 9 = 23 + 20 = 8 + 1.
0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1
Ademas en C existe la posibilidad de declarar una variable como nonegativa (unsigned). Para hacer esto se utiliza el calificador unsigned:
unsigned int k;
unsigned short j;
unsigned long m;
En los compiladores standard ANSI, existe la posibilidad de declarar alos enteros signed, es decir, con valores positivos o negativos. Un calificadorde este tipo parece superfluo, dado que por defecto una variable no declaradacomo unsigned, deberıa ser signed. La diferencia esta en las variables de tipocaracter, que pueden ser signed o unsigned por defecto. La mayorıa de loscompiladores utilizan signed char por defecto.
Vamos a ver ahora que la notacion cientıfica usual
123,45e−7
o bien
0,12E3
tambien es valida para valores float. Toda constante en punto flotante setoma por defecto como double, por lo que la notacion e sirve tanto parafloat como para double. Si queremos declarar e inicializar una variable enpunto flotante
float eps = 1.5e-5;
(le estamos asignando a la variable real eps el valor inicial 0,000015 = 1,5 ∗10−5).
Hay una notacion para constantes octales y hexadecimales: un cero queencabece una constante int indica octal; el grupo 0x (o bien OX) indica he-

56 4 · Introduccion al lenguaje de programacion C (II)
xadecimal. Por ejemplo, el decimal 31 de puede escribir como 037 en octal, ocomo 0x1f (0X1F ) en hexadecimal. Las constantes octales o hexadecimalespueden acabar en L para hacerlas long. (Ver tabla de conversion ASCII,para las equivalencias entre los distintos tipos de representacion).
Una constante caracter es un unico caracter escrito entre apostrofos. Elvalor numerico de una constante caracter es el valor numerico del caracter enel conjunto de caracteres de la representacion. Por ejemplo, en el conjuntode caracteres ASCII, el caracter cero, ‘0’, es 48, diferente del valor numerico0. Las constantes caracter pueden participar en las operaciones numericascomo cualquier otro numero, aunque es mas frecuente encontrarlas en com-paraciones con otros caracteres.
Ciertos caracteres no imprimibles se representan como constantes caractermediante secuencia de escape como \n (nueva lınea), \t (tabulador); \0 (nu-lo), \\ (barra invertida), \′ (apostrofo), etc. Aunque aparecen como doscaracteres, en realidad son solo uno. La constante ′\0′ representa el caractercon valor nulo.
El tipo de dato de enumeracion enum, es particularmente util, cuandoquieres crear un unico conjunto de valores que pueden ser asociados conuna variable. En el siguiente ejemplo, vamos a declarar dos variables deenumeracion llamadas color e intensidad. A color le vamos a poder asignaruno de los cuatro valores constantes rojo, azul, amarillo, verde. A intensidadle vamos a poder asignar los valores brillante, media, oscura. La declaracionserıa:
enum rojo, azul, amarillo,verde color;
enum brillante, media, oscura intensidad;
Este tipo de dato no forma parte de la version de C dada por Kernighan yRitchie, por lo que la implementacion puede variar de un compilador a otro.Un buen compilador, sin embargo, darıa senal de problemas ante sentenciascomo:
color=brillante;
intensidad= azul;
color=1;
color=azul+verde;

4.2 · Conversiones de tipo 57
El tipo de dato void
Tampoco forma parte de la version de C dada por Kernighan y Ritchie.El tipo dato void, tiene dos importantes usos. El primero es indicar queuna determinada funcion no devuelve un valor. Por ejemplo, puedes ver unafuncion definida como:
void func (a, b)
int a, b;
{
.
.
}
Esto indica que la funcion no devuelve ningun valor. Tambien podıamoshaberlo utilizado en la llamada de func()
extern void func();
Esto informa al compilador de que no se puede asignar el valor de retornode dicha funcion, por ejemplo:
num=func(x,y);
darıa un error.
El otro uso de void es declarar un puntero generico. Lo veremos con masdetalle, mas adelante.
4.2. Conversiones de tipo
Los operandos de tipos diferentes que aparecen en una expresion se con-vierten a un mismo tipo de acuerdo con unas cuantas reglas. Las unicasconversiones que se realizan automaticamente son las que tiene sentido, co-mo la conversion de un entero a punto flotante antes de sumar dicho enterocon un numero en punto flotante. (Por ejemplo: 3+2.5=5.5).
Por otra parte no estan permitidas expresiones que carecen de sentido,por ejemplo, utilizar un numero en punto flotante como subındice.
Ademas los caracteres y los enteros (char e int) se mezclan en expresionesaritmeticas: todo char de una expresion se convierte automaticamente en int.

58 4 · Introduccion al lenguaje de programacion C (II)
Ejemplo 4.1: Uso de la funcion atoi() que convierte una cadena dedıgitos en su valor numerico correspondiente.
atoi(s) /* convierte el caracter s en entero*/
char s[];
{
int i,n;
n=0;
for(i=0; s[i] >= ‘0’ && s[i] <= ‘9’; ++i)
n=10*n+s[i]-‘0’;
return(n);
}
La comparacion
s[i] >=‘0’ && s[i]<=‘9’
determina si el caracter que hay en s[i] es un dıgito. Si lo es, el valor numeri-co del dıgito es s[i] - ‘0’. Esto ultimo funciona correctamente solo si ‘0’, ‘1’,...etc., son positivos y estan en orden creciente, y solo si hay dıgitos entre loscaracteres ‘0’ y ‘9’. Afortunadamente esto es cierto para todos los juegos decaracteres ordinarios.
Por definicion, toda aritmetica en la que intervienen valores de tipo chare int, se realiza convirtiendo los valores char al tipo int. Las variables yconstantes de tipo char son esencialmente identicas, en cuanto al tipo, a losvalores int en contextos aritmeticos. Por ejemplo, s[i]-‘0’, es una expresionentera con un valor entre ‘0’ y ‘9’ segun sea el caracter almacenado en s[i],y dicha expresion se puede utilizar como subındice.
Por ultimo la sentencia
n=10*n+s[i]-‘0’;
expresa el valor del dıgito s[i]-‘0’, en sistema decimal (base diez).
Otro ejemplo de conversion de char a int, es la funcion lower(), que asignaa cada letra mayuscula su correspondiente minuscula. (Valido para caracte-res ASCII). Si el caracter no es una letra mayuscula, la funcion devuelve lamisma letra sin alteraciones.
lower(c) /* convierte c en minuscula, solo para ASCII */
int c;

4.2 · Conversiones de tipo 59
{
if( c >= ‘A’ && c <= ‘Z’)
return(c+‘a’- ‘A’);
else
return(c);
}
Esta funcion actua correctamente en ASCII, ya que las letras mayusculasy minusculas correspondientes estan situadas a una distancia fija, conside-radas como valores numericos, y ademas el alfabeto es continuo, es decir, nocontiene ningun otro caracter entre dichas letras.
Otra utilidad de la conversion automatica de tipos esta relacionada conexpresiones como i > j y expresiones logicas que utilizan && y ||, en las quese ha establecido que devuelvan el valor 1, en caso de que el resultado seacierto y el valor 0 en caso contrario.
Las conversiones automaticas se realizan de acuerdo con las siguientesreglas. Si un operador como + o ∗ con dos operandos (un operador binario)tiene los operandos de distinto tipo, el de tipo ”inferior”es ascendido al tipo”superior”, antes de realizar la operacion. El resultado es de tipo ”superior”.En general los operandos que intervienen en una operacion, son convertidosal tipo del operando de precision mas alta.
Las reglas de conversion se resumen en las siguientes:
char y short se convierten en int, y float se convierte en double.
Si algun operando es de tipo double, el otro se convierte en doubley el resultado es double.
Si no se aplica la regla anterior, y si algun operando es de tipolong, el otro se convierte en long y el resultado es long.
Si no se aplica la regla anterior y algun operando es de tipounsigned, el otro se convierte en unsigned y el resultado es detipo unsigned.
Si no se puede aplicar ninguna de las reglas anteriores, los ope-randos deben ser de tipo int y el resultado es de tipo int.
En C la aritmetica del punto flotante se realiza en doble precision. Lasconversiones tambien tienen lugar en las asignaciones; el valor de la partederecha se convierte al de la izquierda, que es el tipo del resultado. Defloat a int la conversion provoca un truncamiento de la parte fraccionaria.De double a float, un redondeo. Los enteros de mayor magnitud (long) se

60 4 · Introduccion al lenguaje de programacion C (II)
convierten en tipo short o en caracteres (char) por eliminacion de los bitsde orden superior.
Los argumentos de una funcion son expresiones y por ello las reglas deconverion de tipo tambien se aplican con ellos. Concretamente, char y shortse convierten en int y float se vuelve double. A esto se debe el que hayamosdeclarado los argumentos de la funcion como int y double, incluso cuandose llama a la funcion con char y float.
Por ultimo se puede forzar la conversion explıcita de tipo coaccionada”deuna expresion, mediante una construccion denominada cast. En la construc-cion
(nombre de tipo) expresion
la expresion se convierte al tipo citado mediante las anteriores reglas de con-version. Por ejemplo, la rutina sqrt() espera que se le pase un argumento detipo double, con lo cual transmitira mensajes de error si recibe argumentosde otro tipo. Si n es entero,
sqrt((double) n)
convierte n al tipo double antes de pasarselo a sqrt. El operador cast tienela misma precedencia que cualquier otro operador unitario, segun vimos enla tabla del tema anterior.
4.3. Nociones sobre representacion de datos e im-
plicaciones sobre la precision numerica
El ordenador digital representa los numeros en base 2, de manera quecada numero se almacena en un numero finito de dıgitos binarios. Hay dosformas de almacenar estos numeros, en punto fijo y en punto flotante.
La representacion en punto fijo es la que utilizamos normalmente. Porejemplo: −30,421 o 0,3245 son representaciones en punto fijo. Como hemosdicho, el numero de dıgitos de cada numero que almacena un ordenador esfinito n = n1 +n2, donde n1 son los dıgitos de la parte entera y n2 los de lafraccionaria.
n1 n2
−30,421 − 0030 4210000.3245 0000 324500

4.3 · Nociones sobre representacion de datos e implicaciones sobre la precision numerica61
n1 = 4, n2 = 6 son valores fijos del ordenador. De esta forma hay valoresque se pueden representar de forma exacta y otros que no. Por ejemplo,el numero 31,8923467, en un ordenador con n1 = 4 y n2 = 6 puede serrepresentado como
0031 892346
representacion que se denomina corte. O bien
0031 892347
en cuyo caso, la representacion se denomina redondeo. En general la re-presentacion de numeros en punto fijo es muy poco util, se utiliza solopara operaciones elementales (calculadoras,..). Por ejemplo, los errores derepresentacion de numeros como: 35420,87 o 0,00000056, son brutales. Enel primer caso, el ordenador aproximarıa por 9999 y en el segundo por 0.
Para calculos mas ambiciosos, el ordenador debe operar en punto flotan-te.
La representacion en punto flotante de un numero x es x = ax10b con0,1 ≤ |a| < 1 y b entero.
Por ejemplo:
342,17 (en punto fijo) 0,34217x103 (en punto flotante)
x = (±.α1α2...αn)x10±bm...b0
donde (±.α1α2...αn) se denomina mantisa y ±bm...b0 es el exponente. Lanotacion a emplear sera:
,34217E3
El numero de dıgitos en la mantisa se denominan dıgitos significativos.El numero 0,0001423 = ,1423E-3 tiene cuatro dıgitos significativos. Con lacondicion α1 > 0, la representacion anterior es unica.
En la representacion numerica en punto flotante, es necesario reservarun numero de dıgitos para la mantisa (t) y un numero para el exponente (e).Si t = 4 y e = 2, el numero 0,00143 se puede expresar 0,00143 = ,1430E-2.Los valores de t y e son caracterısticos de cada ordenador.

62 4 · Introduccion al lenguaje de programacion C (II)
Por ejemplo, si t = 12 y e ∈ (−500, 500) el rango de valores a representaren pantalla es ±,999999999999E±499.
Existen valores que no se pueden representar de forma exacta. Para re-presentar estos numeros se pueden emplear dos tecnicas de aproximacion:corte y redondeo.
Para t = 4: x = 3,87184 = 0,387184E1
fl(x) = 0,3871E1 corte (*)
fl(x) = 0,3872E1 redondeo.
Sea A el conjunto de numeros maquina (representables de forma exactapara un cierto valor de t). A es un conjunto finito.
Para cualquier numero x, fl(x) ∈ A. Esta aplicacion debe cumplir
|x− fl(x)| ≤ |x− y| ∀y ∈ A (4.1)
(observar que la aproximacion por corte (*) no satisface esta condicion).
Si a = ±.α1α2...αtαt+1... |a| = .α1...αt+1... y su representacion por re-dondeo a′ es:
a′ =
{.α1α2...αt si αt+1 ≤ 4.α1α2...αt + 10−t si αt+1 ≥ 5
fl(x) = signo(x)xa′x10e y esta aplicacion sı satisface (4.1).
Si x �= 0
∣∣∣∣x− fl(x)x
∣∣∣∣ =∣∣∣∣ |a|10e − a′10e
|a|10e∣∣∣∣ =
∣∣∣∣ |a| − a′
|a|∣∣∣∣ ≤ 5 · 10−(t+1)
|a| ≥ 10−1≤ 5 · 10−t (4.2)
Es decir ||a|−a′| ≤ 5 ·10−(t+1). Esta segunda cantidad se denomina errorabsoluto. No da idea de la proximidad de los numeros. Por ejemplo:
Si x1 = 5437,43215 y x2 = 5437,43214, |x1 − x2| = 0,00001.
Si y1 = 0,00005 y y2 = 0,00004, |y1 − y2| = 0,00001.
La diferencia es la misma y solo en el primer caso dirıamos que x1 esuna buena aproximacion de x2.

4.3 · Nociones sobre representacion de datos e implicaciones sobre la precision numerica63
∣∣∣x1−x2x1
∣∣∣ = 0,183910341 · 10−8.
|y1−y2y1| = 0,2 > 5 · 10−5.
La cantidad (4.2) se denomina error relativo, que esta acotado comovemos por 5 · 10−t.
Si x−fl(x)x = ε, fl(x) = x(1− ε) con |ε| ≤ eps. eps se denomina precisiondel ordenador.
Por ejemplo si escribimos 3,1415 y decimos que tiene cuatro dıgitos sig-nificativos correctos, significa que su error relativo es < 5 · 10−5.
4.3.1. Errores de redondeo en computacion
Sean por ejemplo x = 0,845E7 e y = 0,324E − 2. El resultado de sumarestos dos numeros es
845000 00.00324
845000 0.00324con t = 8.
x⊕ y = x y en general si |y| < eps10 |x| ⇒ x⊕ y = x.
Se puede decir que en general la suma, resta, division y multiplicacionde numeros maquina no son operaciones asociativas y tampoco distributivasuna con respecto a la otra. El resultado de una serie de operaciones dependedel orden en que se realicen.
Ejemplo 4.2 (t = 8) a = 0,023371258E − 4, b = 0,33678429E2 yc = −0,33677811E2. Veamos que (a⊕ b)⊕ c �= a⊕ (b⊕ c).
0.000023 37125833.67842933.678452 371258
no aparece si t = 8 (= a⊕ b)-33.677811
0.000641 371258 (a⊕ b)⊕ c = 0,641E − 3
Por otra parte: b⊕ c = 0,000618. (b⊕ c)⊕ a = 0,64137E − 3.

64 4 · Introduccion al lenguaje de programacion C (II)
Ejemplo 4.3 En sumas que involucran sumandos de distinta maginitud,el orden es importante. Si sumamos de manera exacta estos tres numeros:(t = 8)
0.000000070.0000000933.00000016
Si t = 8 = 0,30000001E1
Sin embargo si los sumamos en disntinto orden:
30.000000070.000000093.0000000
= 0,3000000E1
Este tipo de errores es caracterıstico de la suma de series.∑∞i=1 ai ≈∑n
i=1 ai.
En las series convergentes el termino general tiende a 0 y los terminosvan de mayor a menor. El error relativo a la hora de sumar los terminospequenos es mınimo si los terminos se suman de menor a mayor; de esaforma, el valor de la suma va aumentando y se va aproximando al tamanode los ultimos sumandos (los primeros terminos en la serie). Luego una serieconvergente hay que sumarla siempre en orden regresivo.
4.3.2. Error de cancelacion
Aparece cuando restamos dos numeros del mismo signo y muy proximos:x− y, x ≈ y.
Por ejemplo, con t = 8:
0.76545421 E1-0.76545264 E10.00000157 E1
Hemos pasado de tener 8 dıgitos significativos correctos a tener 3, luegohemos perdido 5 dıgitos correctos.

4.3 · Nociones sobre representacion de datos e implicaciones sobre la precision numerica65
Ejemplo 4.4 Para resolver: ax2 + bx+ c = 0
x1
x2= −b±√
b2−4ac2a
Si ac << b2 ⇒ |b2 − 4ac| ≈ b2 y uno de los signos ± da un error decancelacion.
La forma de evitarlo serıa:
x1 = −signo(b) · |b|+√b2 − 4ac2a
x2 =c
ax1
Con t = 5, al resolver: x2 + 111,1x+ 1,2121 = 0
De la primera forma: x1 = −111,10, x2 = −0,01000.
De la segunda: x1 = −111,10, x2 = −0,010910, esta ultima mas proximaal valor real.
Las raıces serıan (con t = 9): x1 = −111,09909..., x2 = −0,01091008...
Recuerda la relacion de recurrencia utilizada en el Ejemplo 1.3. Repre-senta, sin duda, un caso mas en el que se pierde precision al restar dosnumeros del mismo signo y magnitd comparable. Debes extremar precau-ciones cuando utilices relaciones de recurrencia que envuelvan restas.

66 4 · Introduccion al lenguaje de programacion C (II)

Capıtulo 5
Introduccion al lenguaje de programacion
C (III)
Las sentencias o proposiciones de control de flujo de un lenguaje especi-fican el orden en que se realizan las computaciones.
5.1. Sentencias de control de flujo: for, if , do, whi-le, switch. Ejemplos de uso
Una expresion como x=0 o i++ o printf() se convierte en una proposi-cion cuando va seguida de punto y coma, como en
x=0;i++;printf(...);
En el lenguaje C, el punto y coma es un terminador de sentencia, yno un separador. Con las llaves se agrupan declaraciones y sentencias enuna proposicion compuesta o bloque, y son sintacticamente equivalentes auna proposicion simple. Las llaves que rodean las proposiciones multiplesdespues de if, else, while, o for son otro ejemplo. Nunca se pone punto ycoma despues de la llave derecha que cierra un bloque.
If-Else
La proposicion if-else sirve para tomar decisiones. Formalmente la sinta-xis es
67

68 5 · Introduccion al lenguaje de programacion C (III)
if (expresion)
proposicion-1
else
proposicion-2
donde la parte else es opcional. Se evalua la expresion; si es cierta (es decir,si tiene un valor distinto de cero), se ejecuta la proposicion-1. Si es falsa,(expresion es cero) y existe parte else, se ejecuta proposicion-2. Un if sim-plemente comprobara el valor numerico de una expresion; por ello puedenaplicarse abreviaciones. Lo mas elemental es escribir
if (expresion)
en lugar de
if (expresion !=0)
Dado que la parte else de un if-else es opcional, hay ambiguedad cuandose omite un else en una secuencia de if anidados. Esto se resuelve asociandoel else al if sin el else mas cercano. Por ejemplo:
if (n > 0)
if(a > b)
z=a;
else
z=b;
La parte else se asocia con el if mas interior, como se indica en el sangrado.Si no fuera ası, hay que utilizar llaves, como en:
if (n > 0){
if(a > b)
z=a;
}
else
z=b;
Else-if
La construccion
if (expresion)
proposicion

5.1 · Sentencias de control de flujo: for, if , do, while, switch. Ejemplos de uso69
else if (expresion)
proposicion
else if (expresion)
proposicion
else
proposicion
es la forma mas general de escribir una decision multiple. Las expresiones seevaluan en orden; si alguna es cierta, se ejecuta la proposicion asociada conellas y se acaba la cadena. El codigo para una proposicion puede ser simpleo un bloque entre llaves.
La ultima parte else maneja el caso ”ninguno de los anteriores”, o el dedefecto, cuando no se sustituye ninguna de las otras condiciones. Si no hayaccion explıcita para el defecto, se puede omitir el ultimo else.
Ejemplo 5.1: Vamos a ver un programa que decribe una funcion debusqueda binaria, que decide si un valor concreto x aparece en un arregloordenado v de dimension n. Los elementos de v estan ordenados en ordencreciente. La funcion devolvera la posicion (un numero entre 0 y n − 1) six esta en v, y un -1 si no esta.
binary(x,v,n) /* buscar x en v[0],...,v[n-1]*/
int x, v[], n;
{
int low, high, mid;
low=0;
high=n-1;
while( low<= high){
mid=(low+high) / 2.;
if(x < v[mid])
high = mid-1;
else if(x > v[mid])
low = mid+1;
else /* encontrado */
return(mid);
}
return(-1);
}
La decision basica es si x es menor, mayor o igual que el elemento centralv[mid] en cada paso.
Switch

70 5 · Introduccion al lenguaje de programacion C (III)
La proposicion switch es una herramienta especial para decisiones multi-ples que comprueba si una expresion iguala uno entre varios valores cons-tantes, y se bifurca a partir de ellos.
int switch_example( char input_arg )
{
switch (input_arg)
{
case ‘A’: return 1;
case ‘B’: return 2;
case ‘C’: return 3;
case ‘D’: return 4;
default : return -1;
}
}
La misma funcion puede ser escrita con proposiciones if-else:

5.1 · Sentencias de control de flujo: for, if , do, while, switch. Ejemplos de uso71
int switch_example( char input_arg )
{
if (input_arg ==‘A’)
return 1;
else if(input_arg == ‘B’)
return 2;
else if(input_arg == ‘C’)
return 3;
else if(input_arg == ‘D’)
return 4;
else
return -1;
}
La expresion switch debe de ir seguida de un parentesis que encierra otraexpresion. Esta ultima expresion debe de ser entera, es decir, puede ser char,long o short; pero no double, float o long double. En la version de Kernighamy Ritchie, debe ser una expresion int. La proposicion default, es opcional.
Ejemplo 5.2:
/* Programma que imprime mensajes de error, basados en el
* valor de la variable error_code. La funcion es declarada
* void porque no devuelve ningun valor*/
#include <stdio.h>
#define ERR_INPUT_VAL 1
#define ERR_OPERAND 2
#define ERR_OPERATOR 3
#define ERR_TYPE 4
void print_error (int error_code )
{
switch (error_code)
{
case ERR_INPUT_VAL:
printf("Error: Valor inicial no valido.\n");
break;
case ERR_OPERAND:
printf("Error: Operando no valido.\n");
break;
case ERR_OPERATOR:
printf("Error: Operador no valido.\n");
break;
case ERR_TYPE:
printf("Error: Dato incompatible.\n");
break;
default:
printf("Error: Codigo de error desconocido %d\n",
error_code");
break;
}

72 5 · Introduccion al lenguaje de programacion C (III)
}
La proposicion break, hace que se produzca una salida inmediata de lainstruccion switch.
Iteraciones while y for
En
while ( expresion )
proposicion
se evalua una expresion. Si es cierta (si no es cero), se ejecuta la proposiciony se vuelve a evaluar la expresion. El ciclo continua hasta que la expresionvale cero, momento en que la ejecucion continua despues de la proposicion.
La sintaxis en la proposicion for es:
for ( expr1; expr2; expr3 )
proposicion
que es equivalente a:
expr1;
while ( expr2 )
{
proposicion
expr3;
}
Ejemplo 5.3: La siguiente funcion devuelve el factorial del argumento:
long int factorial ( long val)
{
int j, fact=1;
for (j=2; j <= val; j++)
fact=fact*j;
return fact;
}
que escrita mediante la proposicion while es:

5.1 · Sentencias de control de flujo: for, if , do, while, switch. Ejemplos de uso73
long int factorial ( long val)
{
int j, fact=1;
j=2;
while (j <= val)
{
fact=fact*j;
j++;
}
return fact;
}
Gramaticalmente las tres componentes de un for son expresiones. Mascomunmente, expr1 y expr3 son asignaciones o llamadas a funcion y expr2es una expresion de relacion. Pueden omitirse cualquiera de las tres, aunquedeben mantenerse los puntos y coma. Si la comprobacion expr2 no esta sesupone que es cierta.
La eleccion entre un ciclo while o for suele ser una cuestion de gusto.
Otro operador de C es la coma ”,”que casi siempre encuentra aplicacionen la sentencia for. Una pareja de expresiones separadas por una coma seevalua de izquierda a derecha, y el tipo del resultado es el mismo que el deoperando derecho. Por tanto en una proposicion for es posible situar variasexpresiones en cada una de sus partes.
Iteraciones do-while
Las iteraciones while y for comparten la util caracterıstica de comprobarla condicion de terminacion al comienzo en lugar de hacerlo al final. El tercertipo de iteracion en C, do-while, hace la comprobacion al final, despues dela pasada sobre le cuerpo del ciclo. Y este se ejecuta al menos una vez. Lasintaxis es
do
proposicion
while ( expresion);
Primero se ejecuta la proposicion y luego se evalua la expresion. En casode ser cierta se ejecuta de nuevo y ası sucesivamente. La ejecucion terminacuando la expresion resulta falsa.
Break
A veces es necesario tener la posibilidad de salir de un ciclo por un lugardistinto al de las comprobaciones del comienzo o del final. La sentencia break

74 5 · Introduccion al lenguaje de programacion C (III)
proporciona una salida forzada de for, while y do, en la misma forma quede switch. Una sentencia break obliga a una salida inmediata del ciclo (oswitch) mas interior.
Continue
La proposicion continue esta relacionada con break, pero se usa me-nos. Obliga a ejecutar la siguiente iteracion del ciclo (for, while, do), quela contiene. En while y do, significa que la parte de comprobacion se eje-cute inmediatamente; en for, el control pasa a la etapa de reinicializacion(continue se aplica solo a ciclos, no a switch).
Ejemplo 5.4:
for (i=0; i < N; i++){
if (a[i] < 0) /*salta los elementos negativos*/
continue;
.....; /* trata los positivos */
}
Notar que cada vez que se ejecuta la sentencia continue, el cuerpo delfor se abandona, iniciandose la ejecucion del mismo para un nuevo valor dei.
Saltos (goto) y etiquetas
El lenguaje C contiene la infinitamente seductora sentencia goto, juntoa las etiquetas a las que saltar. Formalmente goto no es necesario nunca ysiempre se puede evitar. Sin embargo en algunas (pocas) ocasiones, puederesultar util. El uso mas normal consiste en abandonar el proceso en algunaestructura profundamente anidada, tal como la salida de dos ciclos a la vez.La proposicion break, no resulta efectiva en este caso, ya que solo abandonael ciclo interno.
for(...)
for(...){
...
if (desastre)
goto error;
}
...
error: arregla el desatre
Ejemplos de uso

5.1 · Sentencias de control de flujo: for, if , do, while, switch. Ejemplos de uso75
/******* Fichero salir.c *************/
#include <stdio.h>
main()
{
int c,f ;
int m[4][4]={2,4,3,1,2,-1,5,-1,-1,2,4,2,1,-1,-1,0};
for (f=0;f<=3;f++)
for(c=0; c<=3; c++)
if(m[f][c]==-1)
goto salir;
salir:
if(f<4 && c<4)
printf("(%d, %d)\n", f,c);
}
/***********Fichero salir2.c********/
#include <stdio.h>
main()
{
int c,f ;
int m[4][4]={2,4,3,1,2,-1,5,-1,-1,2,4,2,1,-1,-1,0};
for (f=0;f<=3;f++)
for(c=0; c<=3; c++)
if(m[f][c]==-1)
{
printf("(%d, %d)\n", f,c);
break;}
if(f<4 && c<4)
printf("(%d, %d)\n", f,c);
}
/**************Fichero salir 3.c ********/
#include <stdio.h>
main()
{
int c,f ;
int m[4][4]={2,4,3,1,2,-1,5,-1,-1,2,4,2,1,-1,-1,0};
for (f=0;f<=3;f++)
for(c=0; c<=3; c++)
if(m[f][c]==-1)
printf("(%d, %d)\n", f,c);
if(f<4 && c<4)
printf("(%d, %d)\n", f,c);

76 5 · Introduccion al lenguaje de programacion C (III)
}
Objetivo de los tres programas anteriores:
1. salir.c: lee la matriz por filas y en cuanto encuentra un −1, nos da suposicion y acaba.
2. salir2.c: lee la matriz por filas. Cuando encuentra en una fila el valor−1, nos da su posicion y salta de fila.
3. salir3.c: nos indica la posicion de todos los −1 de la matriz.
5.2. Funciones: anatomıa y uso
Las funciones dividen grandes trabajos de computacion en partes masbreves y aprovechan la labor realizada por otras personas en lugar de par-tir de cero. Los programas escritos e C normalmente constan de una grancantidad de pequenas funciones en lugar de pocas y grandes. Un programapuede residir en uno o mas ficheros fuente en cualquier forma conveniente;los archivos fuente pueden compilarse por separado y enlazarse junto confunciones de biblioteca compiladas con antelacion.
En cuanto a sintaxis, hay dos formatos para definir una funcion. La nuevasintaxis conocida como forma prototipo viene a ser
/* Prototipo de definicion de una funcion*/
int func_def(int a, int b, int c);
{
.
.
que es equivalente en la forma tradicional; a
/* Forma tradicional de definicion de una funcion*/
int func_def( a, b, c)
int a,b,c;
{
.
.
Es decir en la nueva sintaxis, dentro del parentesis que recoge la listade argumentos, aparecen a la vez sus declaraciones, mientras que tradicio-

5.3 · Convenciones sobre el paso de argumentos 77
nalmente, dichas declaraciones aparecıan a continuacion. Posteriormente, elcuerpo de la funcion aparece entre llaves.
El nombre de la funcion debera ir precedido de un tipo, si la funciondevuelve un valor no entero. Si la funcion no devuelve ningun valor, seespecifica el tipo void.
Un programa es entonces un conjunto de definiciones de funciones. Lacomunicacion entre las funciones se efectua (en este caso) a traves de ar-gumentos y valores devueltos por la funcion. Tambien se pueden realizarmediante variables externas.
Las funciones aparecen en cualquier orden en el fichero fuente, y el ficherofuente puede estar dividido en varios ficheros. Sin embargo, las funciones sonindivisibles.
La sentencia return es el mecanismo para devolver un valor desde lafuncion llamada a su llamador; return puede ir seguido de una expresion.
return (expresion);
Tanto la expresion, como los parentesis de esta son opcionales. Una fun-cion puede contener cualquier numero de sentencias return. Si no hay sen-tencia return, el control del programa vuelve al programa llamador, cuandose alcanza la llave } que cierra el cuerpo de la funcion. En este caso el valordevuelto es indefinido.
float f()
{
float f2;
int a;
char c;
f2=a; /* OK, convierte a float */
return a; /* OK, convierte a float */
f2=c; /* OK, convierte a float */
return c; /* OK, convierte a float */
}
5.3. Convenciones sobre el paso de argumentos
Hemos visto en el apartado anterior, los aspectos relacionados con ladefinicion de una funcion. A lo largo de un programa, se van utilizando

78 5 · Introduccion al lenguaje de programacion C (III)
funciones, mediante su llamada o alusion.
Una alusion a una funcion es una declaracion de una funcion que esta de-finida en cualquier sitio, generalmente en otro fichero distinto. El propositogeneral de una alusion es decir al compilador que tipo de valor devuelve lafuncion, y declarar el numero y tipo de argumentos que toma dicha funcion.Se considera por defecto que todas las funciones devuelven un valor entero.No es necesario declarar funciones que devuelven valores enteros, sin em-bargo es una buena costumbre declarar todas las funciones que van a serllamadas.
En general hay dos tipos de alusiones: prototipo y no-prototipo. Unaalusion no-prototipo a una funcion declara el tipo de retorno de la funcion,pero no el numero o tipo de argumentos que emplea:
extern old_function();
Las alusiones prototipo permiten anadir el numero y tipo de argumentoempleado:
extern int new_function(int j, float x);
Para declarar una funcion que no toma argumentos se emplea el tipovoid.
extern int f(void);
Tıpicamente aparecen las declaraciones de las funciones en la cabeceradel programa, junto a las declaraciones de las variables y antes de la llamadaa la correspondiente funcion.
Una llamada a una funcion es la invocacion a dicha funcion. En estepunto el programa pasa el control a la correspondiente funcion. La sintaxisgeneral es
nombre_funcion ( argumento1, argumento2,...,argumentok);
En las llamadas de una funcion debe haber el mismo numero de argu-mentos que en su declaracion. En cuanto al tipo, puede haber conversionesautomaticas, con la consiguiente falta de precision. Si la conversion no esposible, el compilador manda mensajes de error. Por ejemplo:

5.3 · Convenciones sobre el paso de argumentos 79
{
extern void f(int *);
float x;
f(x); /* ilegal, no se puede convertir un float a un
puntero*/
...
Sin embargo en:
{
extern void f(float, short);
double x;
long j;
f(j,x); /* se convierte un long a float y double a short */
...
A menos que en la declaracion de la funcion aparezca que el tipo deretorno es void, las funciones siempre devuelven un valor de retorno, que essustituıdo por la llamada a la funcion. Por ejemplo, si f() devuelve un 1, lasentencia
a=f()/3;
es equivalente a
a=1/3;
En el lenguaje de programacion C, la funcion llamada recibe una copiatemporal, privada, de cada argumento. Esto significa que la funcion no puedealterar el valor del argumento original en la funcion que la llama. En unafuncion, cada argumento es una variable temporal inicializada con el valorcon el que se llamo la funcion.
Cuando aparece el nombre de un arreglo como argumento de una funcion,se pasa la direccion de comienzo del mismo; no se copian los elementos. Lafuncion puede alterar el valor de elementos del arreglo subindexando a partirde esta posicion. Ello hace que el arreglo se pase por referencia. Mas adelanteveremos el uso de apuntadores para alterar el valor de argumentos que nosean arreglos.

80 5 · Introduccion al lenguaje de programacion C (III)
5.4. Clases de almacenamiento
Hemos comentado ya algun aspecto sobre el ambito definicion y validezde las variables. Una variable puede ser limitada a un bloque, a un fichero,a una funcion o a una declaracion de una funcion prototipo.
Hay cuatro tipos de ambito de validez de las variables en C: local obloque, global o fichero, funcion y estructura.
Por defecto todas las variables llevan asociada una clase de almacena-miento que determina su accesibilidad y existencia. La clase de almacena-miento puede alterarse con los calificadores:
1. auto (almacenamiento automatico, de ambito local).
2. register (almacenamiento en un registro, de ambito local).
3. static (local, global o funcion).
4. extern (global o funcion).
Variables declaradas a nivel externo (fuera de toda definicionde funcion)
Las funciones y variables externas que constituyen un programa en Cno tienen que ser compiladas todas a la vez. El texto fuente del programapuede mantenerse en varios archivos, y puede enlazarse.
El ambito de validez de una variable externa abarca desde el punto desu declaracion en un archivo fuente hasta el fin del archivo.
Se pueden utilizar los calificadores static o extern o ninguno. La declara-cion extern es obligatoria si se ha de hacer referencia a una variable externaantes de su definicion o si esta definida en un archivo fuente que no es aquelen el que se usa.
Es importante distinguir entre la declaracion de una variable externa ysu definicion. Una declaracion da a conocer las propiedades de una variable(su tipo, tamano, etc.); una definicion produce tambien una asignacion dememoria. Si las lıneas:
int sp;double val[MAXVAL];

5.4 · Clases de almacenamiento 81
aparecen fuera de cualquier funcion definen las variables externas sp y val,obligan a asignar memoria y sirven de declaracion al resto del archivo. Laslıneas:
extern int sp;extern double val[];
declaran para el resto del archivo fuente que sp es un entero y val un arreglodouble (cuyo tamano se fija en otro lugar), pero no crean las variables ni lesasignan memoria. Solo debe de haber un definicion de una variable externaentre todos los archivos que constituyen el programa fuente. Los otros archi-vos deberan contener declaraciones extern para acceder a el. La declaracionde una variable externa inicializa la variable a 0 por defecto, o a un valorespecificado. Si se utiliza el calificador static, solo se puede acceder a elladesde el propio fichero fuente.
Variables declaradas a nivel interno (dentro de un bloque)
Pueden ser:
1. no declarada o auto: en este caso solo es visible dentro del bloque. Hayque inicializarlas explıcitamente.
2. extern a nivel interno, hace accesible la variable a modulos a los cualesno lo es.
3. static: las variables estaticas constituyen la tercera clase de almacena-miento ademas de las extern y las automaticas, ya tratadas. El califi-cativo static se puede utilizar a nivel externo o interno. Las variablesinternas estaticas son locales a una funcion en la misma forma que lasautomaticas, pero a diferencia de estas, su existencia es permanente,en lugar de aparecer y desaparecer al activar la funcion. Se iniciali-zan por defecto a 0. El almacenamiento estatico, interno o externo, seespecifica al prefijar la declaracion normal con la palabra static. Lavariable es externa si se define fuera de las funciones e interna si sedefine dentro de una funcion.
4. register es la cuarta y ultima clase de almacenamiento. Una decla-racion register avisa al compilador de que la variable en cuestionsera muy usada. Si es posible, la variable register sera almacenadaen los registros de la maquina, lo que producira programas cortos yrapidos. Este tipo de almacenamiento es valido para los tipos int chary punteros. La declaracion es del tipo:

82 5 · Introduccion al lenguaje de programacion C (III)
register int x;register char c;
La parte int puede omitirse; register solo se aplica a variables automati-cas y a los parametros formales de una funcion. La declaracion sera:
f(c,n)register int c,n;{
register int i;...}
Solo unas pocas variables en cada funcion se pueden mantener en re-gistros. La declaracion se ignora si hay declaraciones excesivas o nopermitidas. Una variable register ha de ser inicializada explıcitamen-te.
Ejemplo de uso
main()
{
extern int var1;
static int var2;
register int var3=0;
int var4=0;
var1+=2;
printf("%d %d %d %d\n", var1, var2, var3, var4);
funcion_1();
}
int var1=5;
funcion_1()
{
int var1=15;
static var2=5;
var2+=5;
printf("%d %d \n", var1, var2);
}
¿Que valores se imprimen en el programa anterior?
Solucion: 7 0 0 0
15 10

5.5 · Recursion 83
(Si se llamase otra vez a la funcion funcion 1, var2 entrarıa valiendo 10).
extern int var;
main()
{
var++;
printf("%d \n", var); /* escribe 6*/
funcion_1();
}
int var=5;
funcion_1()
{
var++;
printf("%d \n", var); /*escribe 7*/
funcion_2();
}
---------------------------
/* En otro fichero*/
extern int var;
funcion_2()
{
var++;
printf("%d \n"; var); /* escribe 8*/
}
5.5. Recursion
Una funcion recursiva es una funcion que se llama a sı misma. Por ejem-plo:
printd(int n) /* imprime n en decimal (recursiva) */
{
int i;
if ( n < 0 ){
putchar (‘-’);
n=-n;
}
if(( i=n/10)!= 0)
printd(i);
putchar(n % 10+‘0’);
}

84 5 · Introduccion al lenguaje de programacion C (III)
Cuando una funcion se llama a sı misma recursivamente, cada invocacioncrea una nueva copia de todas las variables automaticas, que es independien-te de la anterior. Por tanto, en printd(), la primera vez n=123. Pasa 12 ala segunda printd. La segunda printd pasa 1 a la tercera. La tercera toma nigual a 1, hace i = 0 y escribe 1. En la vuelta hacia arriba la segunda printdescribe un 2 y la primera escribe un 3.
La recursividad generalmente no ahorra memoria pues ha de mantenerseuna pila con los valores que estan siendo procesados. Tampoco sera masrapida, pero el codigo recursivo es mas compacto y a menudo mas senci-llo de escribir y comprender. Esta especialmente pensado para estructurasdefinidas recursivamente, como los arboles, que veremos mas adelante.
Nota: Trata de escribir la funcion anterior, sin emplear su recursividad.
5.6. Funciones definidas en stdio y math
En stdio.h se encuentran las funciones I/O. Dicho fichero contiene lasdeclaraciones prototipo de todas las funciones I/O. Algunas de ellas son:
printf()
#include <stdio.h>
int printf (const char *formato[,argumento 1,...],...);
Salida con formato. Escribe los datos formateados en la cadena de salidastandard (stdout). El primer argumento es un vector caracter que puede con-tener texto y expresiones de control de formato. Los siguientes argumentosrepresentan los datos a ser escritos.
Ejemplo de uso
#include <stdio.h>
main()
{
int a,b,c;
a=20;b=350;c=1991;
printf ("\n Los resultados son:\n");
printf ("a=%6d\t b=%6d\t c=%6d\n",a,b,c);
}

5.6 · Funciones definidas en stdio y math 85
Resultado:
Los resultados son:
a = 20 b = 350 c = 1991
scanf()
#include <stdio.h>
int scanf (const char *formato[,argumento 1,..]...);
Entrada con formato. Lee datos de stdin en la forma especificada porun vector de formato. La sintaxis y semantica de scanf() es la inversa de lade printf(), donde el argumento representa un puntero a la variable que sequiere leer. Vimos esta funcion en el primer capıtulo dedicado a C.
Ejemplo de uso
#include <stdio.h>
main()
{
int a;float b; char c;
scanf ("%d %f %c", &a,&b, &c);
}
Resultado:
Lee de la pantalla, por ejemplo: 5 23.4 b y lo almacena en las variablescorrespondientes: a, b, c.
getchar()
#include <stdio.h>
int getchar (void);
Entrada de caracteres. La funcion getchar() lee del fichero estandar depantalla (stdin) un caracter y avanza una posicion. Cuando llega al final delfichero lee el caracter EOF.
Ejemplo de uso
#include <stdio.h>
main()
{

86 5 · Introduccion al lenguaje de programacion C (III)
int car;
car=getchar();
}
Resultado:
Lee un caracter y lo almacena en la variable car.
putchar()
#include <stdio.h>
int putchar (int c);
Salida de caracteres. Escribe su argumento en la cadena de salida stan-dard (stdout) y devuelve el caracter escrito. La expresion putchar (c), esequivalente a putc(c, stdout).
Ejemplo de uso
#include <stdio.h>
main()
{
int car=4;
putchar(car);
}
Resultado:
Escribe en pantalla el valor 4.
Funciones estandar de entrada/salida. Manipulando ficheros
Permiten escribir y leer datos a, y desde ficheros y dispositivos. La E/S,en el procesamiento de ficheros, se realiza a traves de un buffer o memoriaintermedia. Esta tecnica, implementada en software, hace las operaciones deentrada y salida mas eficientes. Dependiendo de los datos que se deseen leero escribir se utilizan las siguientes funciones:
1. Datos leıdos o escritos caracter a caracter:
fgetc(), fputc()
2. Datos leıdos o escritos palabra a palabra (palabra maquina=valorint(normalmente 2 bytes):

5.6 · Funciones definidas en stdio y math 87
fgetw(), fputw()
3. Datos leıdos o escritos como cadena de caracteres:
fgets(), fputs()
4. Datos leıdos o escritos con formato:
fscanf(), fprintf()
5. Datos de longitud fija (estructuras o arrays) leıdos como registros obloques:
fread(), fwrite()

88 5 · Introduccion al lenguaje de programacion C (III)
Abrir y cerrar ficheros
fopen()
#include <stdio.h>
FILE *fopen (const char *nombrefichero, const char *modo de
acceso);
Abre el fichero identificado por nombrefichero y asocia una cadena condicho fichero. El segundo argumento es un puntero a una cadena de carac-teres que identifica el tipo de acceso al fichero.
fclose()
#include <stdio.h>
int fclose (FILE *cadena);
Cierra el fichero asociado con la cadena especificada. Dicha funcion de-vuelve un cero, si termina satisfactoriamente y un elemento nocero (EOF)si sucede algun error.
Salidas y entradas con formato
fprintf()
#include <stdio.h>
int fprintf (FILE *pf, const char *formato[,arg]...);
Escribe sus argumentos (arg) en el fichero apuntado por pf, con el formatoespecificado. La descripcion del formato es la misma que en printf.
fscanf()
#include <stdio.h>
int fscanf (FILE *pf, const char *formato[,arg]...);
Lee sus argumentos (arg) del fichero apuntado por pf, con el formatoespecificado. Cada formato debe ser un puntero a una variable en la quequeremos almacenar el valor leıdo.
Ejemplo de escritura en un fichero de nombre resul

5.6 · Funciones definidas en stdio y math 89
/* Este fichero realiza el mismo calculo que primos.c, pero escribe*/
/* el resultado en un fichero*/
/* Calculo de numeros primos mediante la criba de Eratostenes*/
#include <stdio.h>
main()
{
FILE *presul;
presul = fopen ("resul", "w");
if(presul != NULL)
{
#define SIZE 1000
char flags[SIZE+1];
int i, k, primo, cuenta;
cuenta = 0;
for(i=0; i<=SIZE; i++) /* contador */
flags[i]=1; /* inicio de la tabla a 1 */
for(i=0; i<=SIZE; i++) {
if(flags[i]) { /*primo encontrado */
primo=i+i+3;
fprintf (presul, "%d\n" , primo);
for (k=i+primo; k<= SIZE; k+= primo)
flags[k]=0; /* quitar todos los multiplos */
cuenta++;
}
}
fprintf (presul, "Hay %d numeros primos\n ", cuenta);
}
}
Nota: Extrae el algoritmo del programa anterior.
Funciones definidas en math.h
En < math.h > se encuentran las funciones matematicas, divididas entres grupos: trigonometricas e hiperbolicas, exponenciales y logarıtmicas ymiscelaneas. Todas ellas operan con valores en double.

90 5 · Introduccion al lenguaje de programacion C (III)
Dentro de las trigonometricas, se encuentran: acos(), asin(), atan(),cos(), cosh(), sin(), sinh(), tan(), tanh().
Dentro de las exponenciales y logarıtmicas: exp(), log(), log10(), sqrt()entre otras.
Por ultimo dentro de las miscelaneas: fabs(), fmod(), son quizas las masutilizadas.

Capıtulo 6
Algoritmos iterativos
6.1. Introduccion
Las raıces de la ecuacion no lineal f(x) = 0 no pueden obtenerse ge-neralmente de forma exacta. Por ello, si queremos resolver ecuaciones nolineales, nos veremos obligados a utilizar metodos aproximados. Estos meto-dos se basan en ideas como la aproximacion sucesiva o la linearizacion. Talesmetodos son iterativos, esto es, comienzan en una aproximacion inicial a laraız y producen una sucesion x0, x1,..., xn,... que presumiblemente convergea la raız deseada.
En determinados metodos, es suficiente (en terminos de convergencia)conocer un intervalo [a, b] en el que se encuentra la raız buscada. Otrosmetodos requieren de una aproximacion inicial que este cerca de la raızdeseada, ello hace que converjan mas rapidamente.
Por simplicidad, nos dedicaremos a estudiar el problema de determinaruna raız real simple, p, de la ecuacion f(x) = 0; es decir, supondremos quep ∈ R y f ′(p) �= 0.
Al final del capıtulo, describiremos someramente algunos procedimientospara la resolucion de sistemas de ecuaciones no lineales. Veremos que aunquelos metodos utilizados para la resolucion de ecuaciones no lineales son gene-ralizables a la resolucion de sistemas de ecuaciones, todos ellos presuponenel conocimiento de una buena aproximacion de la raız. Se sabe muy poco,de como resolver el problema si no se dispone de informacion a priori de lalocalizacion de las raıces.
Una forma de obtener un aproximacion inicial a la raız de una ecuacion
91

92 6 · Algoritmos iterativos
Figura 6.1: y = senx− x2
4 , x ∈ [π2 , 2]
1.6 1.7 1.8 1.9
-0.1
0.1
0.2
0.3
f(x) = 0, es mediante su representacion grafica. Para ello, se pueden con-siderar las abscisas de los puntos de interseccion de la grafica de la funciony = f(x) con el eje X.
A veces es aconsejable sustituir la ecuacion dada por otra ecuacion equi-valente (es decir con las mismas raıces), ϕ(x) = ψ(x), donde las funcionesϕ y ψ son mas sencillas que f . Se representan entonces las graficas de lasfunciones y = ϕ(x) e y = ψ(x), y las raıces buscadas seran entonces lasabscisas de los puntos de interseccion de dichas graficas.
Ejemplo 6.1 Obtener una aproximacion de la raız real positiva que tienela ecuacion:
x2
4− senx = 0
Expresando la ecuacion de forma equivalente: x2
4 = senx. Si se repre-sentan graficamente las curvas y = x2
4 e y = senx, se observa que una raızqueda en el intervalo (π2 , 2), posiblemente cerca de x = 1,9.
Otra posibilidad es dar valores a la funcion f(x) y observar los cambiosde signo de los resultados obtenidos.

6.2 · Resolucion de ecuaciones 93
x x2
4 senx(calculado en radianes) f(x)1.6 0.64 0.9996 ¡01.8 0.81 0.974 ¡02.0 1.0 0.909 ¿0
De esta forma se puede concluir que p ∈ (1,8, 2,0).
En general, un resultado existente en este sentido es el siguiente:
Teorema del Valor Intermedio Si una funcion f(x) ∈ C[a, b] y k esun numero cualquiera entre f(a) y f(b), entonces existe c ∈ (a, b), tal quef(c) = k.
Corolario Si una funcion f(x) ∈ C[a, b] y f(a) · f(b) < 0, la ecuacionf(x) = 0 tiene al menos una raız en el intervalo (a, b). Es decir, existe almenos un numero p ∈ (a, b), tal que f(p) = 0.
La raız p sera unica si f ′(x) existe y mantiene el signo en el intervalo(a, b).
6.2. Resolucion de ecuaciones
A lo largo de esta seccion mostraremos distintos metodos de resolucionde la ecuacion f(x) = 0. El problema consiste en encontrar los valores de lavariable x que satisfacen la ecuacion f(x) = 0, para una funcion f dada.
El primer metodo basado en el Teorema del Valor Intermedio, se deno-mina metodo de biseccion, de busqueda binaria o metodo de Bolzano.
6.2.1. Metodo de biseccion
Sea f(x) una funcion continua en el intervalo (a0, b0) tal que f(a0)f(b0) <0. Determinaremos entonces, una secuencia de intervalos (a1, b1) ⊃ (a2, b2) ⊃(a3, b3)..., tales que todos ellos contendran en su interior una raız de la ecua-cion f(x) = 0. Supongamos en particular que f(a0) < 0 y f(b0) > 0 (estono supone ninguna limitacion puesto que en otro caso se podrıa considerar−f(x) = 0). Los intervalos Ik = (ak, bk), k = 1, 2, ... son determinados demanera recursiva de la siguiente forma. El punto medio del intervalo Ik−1
es:
mk =12(ak−1 + bk−1)

94 6 · Algoritmos iterativos
Podemos suponer que f(mk) �= 0, puesto que en otro caso, tendrıamosdeterminada la raız de la ecuacion. Computamos f(mk) y tenemos:
(ak, bk) =
{(mk, bk), si f(mk) < 0(ak,mk), si f(mk) > 0
De la construccion de (ak, bk) se sigue inmediatamente que f(ak) < 0y f(bk) > 0, y ademas cada intervalo Ik contiene una raız de la ecuacionf(x) = 0.
Despues de n pasos, tenemos la raız dentro del intervalo (an, bn) de lon-gitud:
bn − an =12(bn−1 − an−1) =
122
(bn−2 − an−2) = ... =12n
(b0 − a0)
Tenemos ademas que mn+1 es un estimador de la raız que buscamos, y
p = mn+1 ± dn, dn =1
2n+1(b0 − a0)

6.2 · Resolucion de ecuaciones 95
Algoritmo
Tolerancia = TOL. Numero de iteraciones= NUMITE. Valoresiniciales a0, b0.
Paso 1: Sea i = 1
Paso 2: Mientras que i ≤ NUMITE, hacer:
Paso 3: mi = ai−1 + 12(bi−1 − ai−1)
Paso 4: Si f(mi) = 0, o∣∣∣ bi−1−ai−1
2
∣∣∣ < TOL, STOP. La raızbuscada es mi.
Paso 5: Si f(mi) < 0, ai = mi, bi = bi−1.
Si f(mi) > 0, ai = ai−1, bi = mi.
Hacer i = i+ 1, e ir al Paso 3.
Paso 6: SALIDA. Despues de NUMITE iteraciones el procesoha terminado sin exito.
Ejemplo 6.2 El metodo de biseccion aplicado a la ecuacion x2
4 −senx = 0con I0 = (1,5, 2), genera la secuencia de intervalos:
k ak−1 bk−1 mk f(mk)1 1.5 2 1.75 ¡02 1.75 2 1.875 ¡03 1.875 2 1.9375 ¿04 1.875 1.9375 1.90625 ¡05 1.90625 1.9375
6.2.2. Metodo de Newton-Raphson
La idea basica del metodo de Newton Raphson para la resolucion de unaecuacion f(x) = 0, ha sido descrita en la introduccion del tema. A partirde una aproximacion inicial x0, se computa una secuencia x1, x2, ..., xn, ...donde xn+1 se determina como explicamos a continuacion:
Sea f(x) una funcion continuamente diferenciable dos veces en el inter-valo [a, b], es decir f ∈ C2[a, b]. Sea x0 una aproximacion de la raız p, tal quef ′(x0) �= 0 y |x0 − p| pequeno. Si consideramos el desarrollo de Taylor hastagrado dos, alrededor de x0:
f(x) = f(x0) + (x− x0)f ′(x0) +(x− x0)2
2f ′′(ψ(x)),

96 6 · Algoritmos iterativos
donde ψ(x) esta entre x y x0. Como f(p) = 0:
0 = f(x0) + (p− x0)f ′(x0) +(p − x0)2
2f ′′(ψ(p)), (6.1)
El metodo de Newton Rapson se deriva suponiendo que el termino cua-dratico de la anterior expresion es practicamente nulo y que:
0 ≈ f(x0) + (x− x0)f ′(x0), (6.2)
Es decir, la funcion f(x) es aproximada por su tangente en el punto(xn, f(xn)), y xn+1 es la abscisa del punto de interseccion de la tangentecon el eje X. Luego para determinar xn+1 tenemos que resolver la siguienteecuacion:
f(xn) + (xn+1 − xn)f ′(xn) = 0 (6.3)
El metodo de Newton-Raphson es definido por la siguiente formula ite-rativa:
xn+1 = xn + hn, hn =−f(xn)f ′(xn)
(6.4)
Algoritmo
Tolerancia = TOL. Numero de iteraciones= NUMITE. Valorinicial x0.
Paso 1: Sea i = 1.
Paso 2: Mientras que i ≤ NUMITE, hacer:
Paso 3: xi = x0 − f(x0)f ′(x0)
Paso 4: Si |xi − x0| < TOL, STOP. La raız buscada es xi.
Paso 5: Hacer x0 = xi, i = i+ 1, e ir al Paso 3.
Paso 6: SALIDA. Despues de NUMITE iteraciones el procesoha terminado sin exito.
Ejemplo 6.3 Dada f(x) = senx − x2
4 , f ′(x) = cosx − x2 . Queremos
determinar una raız positiva con cinco decimales correctos, i.e. TOL = 0,5 ·10−5. Dado el Ejemplo 2, tomamos, x0 = 1,5.

6.2 · Resolucion de ecuaciones 97
i xi f(xi) f ′(xi) h(xi)0 1.5 0.434995 -0.67926 0.640391 2.14039 -0.303197 -1.60948 -0.188382 1.95201 -0.024372 -1.34805 -0.018263 1.93393 -0.000233 -0.00018 0.000184 1.93375 0.000005 -1.32191 < 0,5 · 10−5
La raız buscada es entonces p = 1,93375. Solo han sido necesarias 4 ite-raciones, incluso teniendo en cuenta que la aproximacion inicial es bastantemala. Vemos tambien que |hi| decrece mas y mas rapidamente hasta que loserrores de redondeo empiezan a dominar. Sin embargo, cuando uno esta lejosde la raız, se puede evitar trabajar con tantos decimales. En el ejemplo ante-rior, es unicamente necesario trabajar con f(xn) con tantos decimales comodeberıan ser correctos en xn+1. En este caso, la derivada ha sido calculadacon una innecesaria precision. Entonces no es necesario calcular f ′(xn) contanta precision como f(xn). Como la precision de f(xn) es la que nos dicecomo xn se aproxima a la raız, se podrıa utilizar f ′(x2) en las iteracionesi = 3 o 4.
6.2.3. Metodo de la secante
El metodo de Newton Raphson es una tecnica extremadamente poderosa,pero tiene una dificultad grande: la necesidad de conocer el valor de laderivada de f en cada aproximacion de la raız. Habitualmente la expresionde f ′(x) es todavıa mas complicada y necesita mas operaciones aritmeticaspara su calculo que f(x).
El metodo de la secante trata de evitar este problema, aproximando elvalor de la derivada f ′(xn) por el cociente incremental f(xn)−f(xn−1)
xn−xn−1. Esto ge-
nera el siguiente metodo. Calcular, a partir de dos aproximaciones iniciales,x0 y x1, la secuencia x2, x3, ..., a partir de la formula iterativa:
xn+1 = xn + hn, hn = −f(xn) · xn − xn−1
f(xn)− f(xn−1), f(xn) �= f(xn−1)
La interpretacion geometrica de este metodo es que xn+1 se calcula comola abscisa del punto de interseccion entre la secante a traves de (xn−1, f(xn−1))y (xn, f(xn)) y el eje de las X. Senalar que el metodo de la secante a diferen-cia del metodo de Newton Raphson requiere de dos aproximaciones iniciales,pero solo se requiere de una evaluacion de la funcion en cada paso.
Los valores iniciales x0 y x1, son los extremos del intervalo de referenciaen el que se encuentra la raız buscada, de manera que se cumple: f(x0) ·

98 6 · Algoritmos iterativos
f(x1) < 0. Como en el metodo de biseccion consideraremos, por simplicidadque f(x0) < 0 y f(x1) > 0. En caso de suceder lo contrario resolveremos laecuacion −f(x) = 0.
Nota: La ecuacion de la secante que pasa por (xn−1, f(xn−1)) y por(xn, f(xn)) es:
x− xn−1
xn − xn−1=
y − f(xn−1)f(xn)− f(xn−1)
En el punto de interseccion con el eje X, y = 0, de donde se deduce laformula iterativa anterior.
Algoritmo
Tolerancia = TOL. Numero de iteraciones= NUMITE. Valoresiniciales x0 y x1.
Paso 1: Sea i = 2.
Paso 2: Mientras que i ≤ NUMITE, hacer:
Paso 3: xi = xi−1 − f(xi−1)(xi−1−xi−2)
(f(xi−1)−f(xi−2))
Paso 4: Si |xi − xi−1| < TOL, STOP. La raız buscada es xi.
Paso 5: Hacer i = i+ 1, e ir al Paso 3.
Paso 6: SALIDA. Despues de NUMITE iteraciones el procesoha terminado sin exito.
Ejemplo 6.4 Tomamos de nuevo la ecuacion f(x) = senx− x2
4 . Quere-mos determinar una raız positiva con cinco decimales correctos, i.e. TOL =0,5 · 10−5. Tomamos, x0 = 1, x1 = 2. f(1) = 0,5915 > 0, f(2) = −0,0907 <0. Por lo tanto trabajaremos con g(x) = −f(x) = x2
4 − senx.
i xi g(xi) h(xi)0 1 -0.591471 2 0.0907032 1.86704 -0.084980 -0.132963 1.93135 -0.003177 0.064314 1.93384 0.000114 0.002495 1.93375 -0.000005 -0.000096 1.93375
Este ejemplo, proporciona la misma precision con el mismo numero deiteraciones en el metodo de Newton-Raphson que en el de la secante. Esto

6.2 · Resolucion de ecuaciones 99
puede ser debido a que una de las aproximaciones x1, estaba muy cerca dela raız. Cuando |xn− xn−1| es pequeno, el cociente (xn−xn−1)
f(xn)−f(xn−1) sera deter-minado en general con una pobre precision relativa. Si por ejemplo, elegimoslas aproximaciones iniciales x0, x1 muy cerca de p, los errores de redondeopueden hacer que |xn − p| sea grande. El analisis de errores que haremosposteriormente nos dira que el metodo de la secante proporciona en generaluna secuencia tal que |xn − xn−1| >> |xn − p|.
Una analisis mas minucioso muestra que la contribucion dominante alerror relativo de hn proviene del error cometido en el calculo de f(xn), unapobre precision en el otro factor, resulta ser de menor importancia.
Senalar, sin embargo, que la ecuacion de recurrencia anterior puede serexpresada de la forma:
xn+1 =xn−1f(xn)− xnf(xn−1)
f(xn)− f(xn−1), f(xn) �= f(xn−1)
de manera que se puede obtener una cancelacion cuando xn ≈ xn−1 yf(xn)f(xn−1) > 0.
El metodo de Newton-Raphson o el de la secante se utilizan frecuente-mente para refinar las respuestas obtenidas mediante otras tecnicas, comoel metodo de biseccion. El motivo es que dan convergencia rapida, peronecesitan una buena primera aproximacion.
6.2.4. Regula Falsi
El metodo de regula falsi o de la falsa posicion entra dentro de los meto-dos de interpolacion, muy utiles a la hora de determinar los ceros de unafuncion real f(x) cualquiera. A diferencia del metodo de Newton-Raphson,en los metodos de interpolacion no se necesita calcular la derivada de f , yademas convergen mas rapidamente.
En este sentido, se puede considerar tambien como una variante delmetodo de la secante. En el metodo de regula falsi, se elige en cada iteracionla secante entre (xn, f(xn)) y (x′n, f(x′n)), donde n′ es el mayor ındice, n′ < n,para el cual f(xn)f(x′n) < 0.
Las aproximaciones iniciales x0 y x1, deben ser elegidas tambien, demanera que f(x0) ·f(x1) < 0. La ventaja del metodo de regula falsi, al igualque el de biseccion, es que es siempre convergente para funciones continuasf(x). En contraste con el metodo de la secante, sin embargo, el metodo

100 6 · Algoritmos iterativos
de regula falsi es un metodo de primer orden (convergencia lineal). Esto loprobaremos mas adelante.
El metodo de regula falsi es considerado un buen metodo siempre que nose utilice en un entorno muy proximo de la raız. Puede ser utilizado comoparte de un metodo hıbrido que tendrıa buenas propiedades cerca de la raız.
El planteamiento es similar al del metodo de biseccion donde a partirde un intervalo inicial [a0, b0] = [x0, x1], (f(x0) · f(x1) < 0), se determinaen cada iteracion un intervalo [an, bn], de forma que f(an) · f(bn) < 0. Elintervalo [an, bn] contiene entonces al menos un cero de f(x), y los valoresan se determinan de manera que convergen hacia uno de estos ceros. Engeneral se sigue la siguiente formula iterativa:
xn = an − f(an)bn − an
f(bn)− f(an)= (6.5)
=bnf(an)− anf(bn)f(an)− f(bn)
(6.6)
El hecho de que f(an) · f(bn) < 0, hace que f(an) · f(bn) �= 0, luego xnesta bien definido. Ademas, satisface an < xn < bn o bn < xn < an. En estecaso, a menos que f(xn) = 0, se define:
an+1 = xn, bn+1 = bn, si f(xn) · f(an) > 0an+1 = an, bn+1 = xn, si f(xn) · f(an) < 0
El algoritmo termina cuando f(xn) = 0.
Ejercicio 1
Intenta especificar el algoritmo para el metodo de regula falsi, y probarlocon la ecuacion dada en los Ejemplos 1,2,3 y 4 anteriores. Comenta losresultados que obtienes.
6.3. Comparacion de los distintos ordenes de con-
vergencia
6.3.1. Convergencia del metodo de biseccion
El metodo de biseccion, aunque conceptualmente claro, tiene inconve-nientes importantes. Converge muy lentamente, (es decir NUMITE puede

6.3 · Comparacion de los distintos ordenes de convergencia 101
ser muy grande antes de que |xn − p| sea suficientemente pequeno) y, masaun, una buena aproximacion intermedia puede ser desechada sin que nosdemos cuenta. Sin embargo, no debemos olvidar una propiedad importantedel metodo, y es que se trata de un metodo que converge siempre a unasolucion.
Definicion 1 Diremos que la sucesion {αn}∞n=1 converge a α con rapidezde convergencia O(βn), donde {βn}∞n=1 es otra sucesion con βn �= 0 para cadan, si
|αn − α||βn| ≤ K, para n suficientemente grande
donde K es una constante independiente de n. Esto se indica escribiendoαn = α+O(βn), o bien αn → α con una rapidez O(βn).
Teorema 2 Sea f ∈ C[a, b], tal que f(a) · f(b) < 0. El procedimiento debiseccion genera una sucesion xn que aproxima a p con la propiedad
|xn − p| ≤ 12n
(b− a), n ≥ 1. (6.7)
Demostracion: para cada n ≥ 1, tenemos
bn − an =1
2n−1(b− a), y p ∈ (a, b)
Ya que xn = 12 (an + bn), para todo n, se sigue que
|xn − p| = |12(an + bn)− p| ≤ |1
2(an + bn)− an| = 1
2(bn − an) = 2−n(b− a).•
De acuerdo con la definicion de rapidez de convergencia, la desigualdad(6.7) implica que {xn}∞n=1 converge a p y esta acotada por una sucesion queconverge a 0 con una rapidez de convergencia O(2−n). Es importante hacernotar que teoremas como este, unicamente acotan superiormente los errores,que en la practica pueden ser muy inferiores.
Ejemplo 6.5 Determinar aproximadamente el numero de iteracionesnecesarias para resolver la ecuacion f(x) = x3 + 4x2 − 10 = 0 con unaprecision de 10−5, tomando como intervalo inicial [a, b] = [1, 2].
Se trata de encontrar n tal que:
|xn − p| = 10−5 ≤ 12n
(b− a) = 2−n (6.8)

102 6 · Algoritmos iterativos
Tomando logaritmos (en base diez, pues la tolerancia esta dada en base 10),tenemos que
log10(10−5) = −5 ≤ log10(2−n)
−nlog102 ≥ −5 ⇒ n ≤ 5log102
≈ 16,6
Segun la expresion anterior se requieren como mucho 16 iteraciones paraobtener una aproximacion con precision 10−5.
Otra caracterıstica a senalar de este metodo es que su velocidad de con-vergencia es completamente independiente de la ecuacion a resolver.
6.3.2. Convergencia del metodo de Newton-Raphson
Definicion 2 Sea {xn}∞n=0 una sucesion que converge a p y en = xn−p,para cada n ≥ 0. Si existen dos numeros positivos λ y α tales que
limn→∞|xn+1 − p||xn − p|α = limn→∞
|en+1||en|α = λ
entonces se dice que {xn}∞n=0 converge a p con orden α, con una constantede error asintotico λ, o que la convergencia es de orden α.
Si α = 1, el metodo se denomina lineal o de primer orden. Si α = 2, elmetodo se denomina cuadratico o de segundo orden.
Teorema 3 Sea f ∈ C2[a, b]. Si f(a) · f(b) < 0, y f ′(x) y f ′′(x) sonno nulas y conservan el signo para a ≤ x ≤ b, entonces, a partir de unaaproximacion inicial x0 ∈ [a, b] que satisface f(x0) · f ′′(x0) > 0, es posibleutilizando el metodo de Newton (formula (6.2)), calcular una raız unica, p,de la ecuacion f(x) = 0 con cualquier grado de precision.
Por esta razon, al aplicar el metodo de Newton-Raphson, se debe aplicarla siguiente regla: para el punto inicial x0 elıjase el extremo del intervalo(a, b) asociado con una ordenada del mismo signo que el de f ′′(x0).
Teorema 4 Sea f ∈ C(−∞,∞), f(a) · f(b) < 0, f ′(x) �= 0 para a ≤ x ≤b. Si f ′′(x) existe en cualquier punto y conserva el signo, entonces puedetomarse cualquier valor c ∈ [a, b] como valor inicial x0 al utilizar el metodode Newton para hallar una raız de la ecuacion f(x) = 0, que caiga en elintervalo [a, b]. Se puede tomar, por ejemplo, x0 = a o x0 = b.

6.3 · Comparacion de los distintos ordenes de convergencia 103
Notese que en la formula iterativa (6.3) esta claro que cuanto mayor seael valor numerico de f ′(x) en un entorno de la raız, tanto menor sera lacorreccion que ha de anadirse a la aproximacion n-esima para obtener laaproximacion (n+1). El metodo de Newton, es por lo tanto, muy convenientecuando la grafica de la funcion tiene una gran pendiente en un entorno de laraız dada, pero si el valor numerico de la derivada es pequeno, las correcionesseran entonces mayores, y calcular la raız mediante este procedimiento puedeser un proceso largo o a veces imposible. Es decir: no utilices el metodo deNewton para resolver una ecuacion f(x) = 0, si la curva y = f(x) es casihorizontal en un entorno del punto de interseccion con el eje X.
La obtencion de la formula iterativa del metodo de Newton, a partir de laserie de Taylor, resalta la importancia de una buena aproximacion inicial. Lahipotesis necesaria para pasar de (6.1) a (6.2) es que el termino que contienea (p − x0)2 puede ser eliminado. Esto, no se cumple a menos que x0 seauna buena aproximacion de p. El siguiente resultado ilustra la importanciateorica de la eleccion de x0.
Teorema 5 Sea f ∈ C[a, b]. Si p ∈ [a, b] es tal que f(p) = 0, f ′(p) �= 0,entonces existe un δ > 0, tal que, el metodo de Newton-Raphson generauna sucesion {xn}∞n=1 que converge a p, para cualquier aproximacion inicialx0 ∈ [p− δ, p + δ].
Bajo las anteriores condiciones, vamos a obtener una formula que rela-cione los errores absolutos de dos aproximaciones sucesivas. Obtendremosentonces una relacion entre en = xn − p y en+1. Utilizando el desarrollo deTaylor, en un entorno de la raız:
0 = f(p) = f(xn) + f ′(xn)(p − xn) +12f ′′(ψn)(p− xn)2, (6.9)
donde ψn, esta entre p y xn. Dividiendo por f ′(xn) y despejando p:
p = xn − f(xn)f ′(xn)
− 12· f
′′(ψn)f ′(xn)
(p − xn)2, (6.10)
y teniendo en cuenta la expresion (6.4), tenemos
p− xn+1 = −12· f
′′(ψn)f ′(xn)
(p− xn)2, (6.11)
Entonces
en+1
e2n=
12· f
′′(ψn)f ′(xn)
(6.12)

104 6 · Algoritmos iterativos
y cuando xn → p,
en+1
e2n→ 1
2· f
′′(p)f ′(p)
(6.13)
Como en+1 es proporcional al cuadrado de en, y de acuerdo con la De-finicion 2, se dice que el metodo de Newton-Raphson tiene convergenciacuadratica, o que es un metodo de segundo orden.
Un razonamiento intuitivo que demuestra el teorema anterior es el si-guiente:
Supongamos que I es un intervalo en torno a p, tal que
12· |f
′′(y)||f ′(x)| ≤ m, ∀x, y ∈ I (6.14)
Si xn ∈ I de (6.12), se tiene que |en+1| ≤ me2n ⇔ |men+1| ≤ (men)2.
Supongamos que |me0| < 1 y que el intervalo [p− |e0|, p+ |e0|] ⊆ I. Porinduccion podemos ver que xn ∈ I ∀n y |en| ≤ 1
m(me0)2n.
Por este motivo, puede probarse que el metodo de Newton-Raphson siem-pre converge (a una raız simple) si x0 ha sido elegido lo suficientemente cercade la raız p. (Si |me0| = m|x0 − p| < 1).
Sin embargo en la practica p es desconocido y la condicion anterior esdifıcil de comprobar. El teorema que damos a continuacion da un criteriomas practico a la hora de demostrar la convergencia.
Teorema 6 Sea x0 una aproximacion inicial y definimos xn y hn talesque xn+1 = xn + hn, hn = −f(xn)
f ′(xn) . Sea I0 el intervalo (x0, x0 + 2h0) ysupongamos que
2|h0|M ≤ |f ′(x0)|, M = maxx0∈I0
|f ′′(x)| (6.15)
Entonces, xn ∈ I0, n = 1, 2, ..., y limn→∞xn = p, donde p es la unicaraız de f(x) = 0 en I0.
Otro criterio que en ocasiones es mas facil de aplicar, viene dado por elsiguiente resultado.
Teorema 7 Supongamos que f ′(x) �= 0 y f ′′(x) no cambia de signo en

6.3 · Comparacion de los distintos ordenes de convergencia 105
el intervalo [a, b], y que f(a) · f(b) < 0. Si∣∣∣∣ f(a)f ′(a)
∣∣∣∣ < b− a,
∣∣∣∣ f(b)f ′(b)
∣∣∣∣ < b− a (6.16)
entonces el metodo de Newton-Raphson converge a partir de una aproxima-cion inicial x0 ∈ [a, b].
6.3.3. Convergencia del metodo de la secante
Para probar la convergencia del proceso, consideraremos que la raızesta separada y la segunda derivada f ′′(x) tiene signo constante en el in-tervalo [a, b] = [x0, x1].
Supongamos que f ′′(x) > 0 para a ≤ x ≤ b. La curva y = f(x) en estecaso sera convexa hacia abajo y por lo tanto estara localizada por debajode la secante que pasa por (a, f(a)), (b, f(b)). Si hemos supuesto en la des-cripcion del metodo, f(a) < 0, el extremo b esta fijo y las aproximacionessucesivas:
x0 = a, xn+1 = xn − f(xn)(b− xn)
f(b)− f(xn), n = 0, 1, 2... (6.17)
forman una secuencia monotona creciente y acotada:
x0 < x1 < ... < xn < xn+1 < ... < p < b (6.18)
Resumiendo:
1. El extremo fijo es aquel para el cual el signo de la funcion f(x) coincidecon el signo de su segunda derivada f ′′(x).
2. Las aproximaciones sucesivas caen en el lado de la raız p, donde elsigno de la raız es opuesto al signo de su segunda derivada f ′′(x).
En cualquier caso, cada aproximacion xn+1 esta mas proxima a la raızp, que la precedente xn.
Supongamos que p = limn→∞xn, a < p < b. Dicho lımite existe, puestoque la sucesion es monotona y esta acotada. Tomando lımites en la expresion(6.17),
p = p− f(p)(b− p)
f(b)− f(p), (6.19)

106 6 · Algoritmos iterativos
de donde f(p) = 0. Como p es la unica raız de f(x) = 0 en el intervalo (a, b),se deduce que p = p.
Se trata de un metodo que no converge globalmente. Al igual que en elcaso del metodo de Newton, tenemos convergencia local.
El siguiente resultado nos permite obtener el orden de convergencia.
Teorema 8 (de interpolacion) Sea f ∈ C[a, b], p, xn−1, xn, xn+1 ∈[a, b], tales que:
1. f ′(x) �= 0 ∀x ∈ [a, b]
2. f(p) = 0
3. xn+1 = xn − f(xn) · xn−xn−1
f(xn)−f(xn−1)
Entonces ∃ψ, ν ∈ (a, b) (ψ, ν entre p, xn−1, xn, xn+1), tal que:
(p − xn+1) =f ′′(ψ)2f ′(ν)
(p − xn)(p− xn−1). (6.20)
Tenemos entonces que, para n suficientemente grande, bajo las hipotesisdel teorema anterior:
|en+1| ≈ C|en||en−1|, C = |f ′′(ψ)|2|f ′(ν)|
Intentamos determinar el orden de convergencia, haciendo uso de la si-guiente conjetura:
|en+1| ≈ K|en|a, |en| ≈ K|en−1|a, ¿a?
Sustituyendo en la ecuacion anterior:
K|en|a ≈ C|en|K− 1a |en| 1a
Esta relacion se mantiene solo si:
a = 1 +1a⇔ a =
12(1±
√5)
C = K1+ 1a = Ka
La raız a = 12 (1−
√5) = −0,618 puede ser ignorada, pues |en+1| ≈ K|en|a
y en dicho caso el error cometido en la iteracion n+1 serıa superior al erroren la iteracion n (o lo que es lo mismo el metodo no serıa convergente).

6.3 · Comparacion de los distintos ordenes de convergencia 107
Por lo tanto |en+1| ≈ C1a |en|a, a = 1
2(1 +√5) = 1,618.
6.3.4. Convergencia del metodo de regula falsi
Para probar la convergencia del metodo de regula falsi, supondremos porsimplicidad que f ′′(x) existe y que para algun valor i,
ai < bi, f(ai) < 0, f(bi) > 0 (6.21)
f ′′(x) ≥ 0,∀x ∈ [ai, bi] (6.22)
Con estas hipotesis, o f(xi+1) = 0 o f(xi+1) · f(ai) > 0, y entoncesai < ai+1 = xi < bi+1 = bi.
Ademas es facil ver que las formulas (6.21), (6.22) son validas para todoi ≥ i0 si lo son para i0. Entonces, bi = b, para i ≥ i0 y las ai forman unasucesion monotona creciente y acotada, por lo tanto es convergente, es decirexiste p = limn→∞ai. Por el hecho de ser f continua y por (6.21) y (6.22),se tiene
f(b) > 0, f(p) ≤ 0 (6.23)
Ademas tomando lımites en (6.6)
p =bf(p)− pf(b)f(p)− f(b)
(6.24)
que implica (p− b)f(p) = 0.
Pero p �= b, y entonces f(p) = 0.
En el caso particular que estamos analizando, (6.22), se ve claramenteque las sucesivas iteraciones matienen fijo el extremo b, de manera que,utilizando esto en la misma relacion obtenida para el metodo de la secante:
limn→∞|en+1||en| = C ′ (6.25)
puesto que:
p− xn+1 =f ′′(ψ)2f ′(ψ)
(p− xn)(p − xn−1) (6.26)

108 6 · Algoritmos iterativos
Si xn = b;
|en+1||en| → | f
′′(ψ)2f ′(ψ)
(p− b)| = C ′ (6.27)
Entonces α = 1 y tenemos convergencia lineal. El metodo de regula falsi,es en general un metodo de primer orden. Es convergente siempre que f seacontinua.
6.4. Teorıa general de los metodos iterativos. Ite-
racion del punto fijo
El metodo de Newton-Raphson y el de la secante pueden ser conside-rados como casos especiales de un metodo iterativo mas general. Sea xn+1
determinado por el valor de una funcion y de su derivada en m puntosxn, xn−1, ..., xn−m+1 y sea
xn+1 = ϕ(xn, xn−1, ..., xn−m+1)
Llamaremos a ϕ funcion de iteracion.
Ejemplo 6.6 En el metodo de Newton-Raphson:
ϕ(x) = x− f(x)f ′(x)
, m = 1
En el de la secante:
ϕ(x) = x− f(x) · x− y
f(x)− f(y), m = 2
La teorıa general de los procesos iterativos es mas simple cuando m = 1.En este caso tenemos:
xn+1 = ϕ(xn)
que se denomina metodo de iteracion uni-punto o del punto fijo. Nos dedi-caremos a continuacion al estudio de este tipo de procesos.
Supongamos ahora que tenemos una sucesion {xn} generada a partirde cierto valor inicial x0, y que limn→∞xn = p. Si ϕ es continua, p =

6.4 · Teorıa general de los metodos iterativos. Iteracion del punto fijo 109
limn→∞xn+1 = limn→∞ϕ(xn) = ϕ(p); es decir el valor p es una raız de laecuacion x = ϕ(x).
Es decir, para construir un metodo iterativo para la resolucion de f(x) =0, podemos intentar escribir dicha expresion de la forma x = ϕ(x), lo cualdefine un metodo de iteracion: xn+1 = ϕ(xn).
Ejemplo 6.7 Sea la ecuacion: x3−x−5 = 0 que puede ser escrita como
x = ϕ1(x) = x3 − 5; x = ϕ2(x) = 3√x+ 5; x = ϕ3(x) = 5
x2−1
es decir el metodo iterativo puede no ser unico.
Tampoco podemos asegurar que todos ellos sean convergentes. Una con-dicion suficiente para la convergencia la da el siguiente resultado:
Teorema 9 Supongamos que la ecuacion x = ϕ(x) tiene una raız p, yque en el intervalo
J = {x : |x− p| ≤ ρ}
ϕ′(x) existe y satisface la condicion
|ϕ′(x)| ≤ m < 1
Entonces, para todo x0 ∈ J :
1. xn ∈ J , n = 0, 1, 2, 3....
2. limn→∞xn = p.
3. p es la unica raız en J de x = ϕ(x).
Demostracion:
1. Por induccion: sea x0 ∈ J y supongamos que xn−1 ∈ J . Por el teoremadel valor medio,
xn − p = ϕ(xn−1)− ϕ(p) = ϕ′(ψ)(xn−1 − p), ψ ∈ J
|xn − p| ≤ m|xn−1 − p| ≤ mρ < ρ ⇒ xn ∈ J

110 6 · Algoritmos iterativos
2. Utilizando la desigualdad anterior repetidas veces:
|xn − p| ≤ m|xn−1 − p| ≤ ... ≤ mn|x0 − p|
Como m < 1, se tiene el resultado.
3. Supongamos finalmente que x = ϕ(x) tiene otra raız, β, en J . β �= p.Entonces:
p− β = ϕ(p)− ϕ(β) = ϕ′(ψ)(p − β), ψ ∈ J
|p− β| ≤ m|p− β| < |p − β|,
lo cual es absurdo.•
En el Teorema 9, hemos partido de suponer la existencia de una raız p.El teorema puede ser modificado y utilizado para probar la existencia deuna raız de la ecuacion x = ϕ(x).
Teorema 10 Sea J un intervalo cerrado en el cual ϕ′(x) existe y sa-tisface la desigualdad |ϕ′(x)| ≤ m < 1. Entonces la sucesion {xn} definidacomo xn+1 = ϕ(xn), x0 ∈ J satisface los apartados 1,2 y 3 del Teorema 9 si
x1 ± m
1−m|x1 − x0| ∈ J
El metodo iterativo xn+1 = ϕ(xn) es en general un metodo de primerorden, a menos que ϕ(x) sea elegida de manera especial. Si ϕ(x) es α vecesdiferenciable y sus derivadas continuas ϕ ∈ Cα, en un entorno de p, dondep = ϕ(p), y ϕ(j)(p) = 0, j = 1, ..., α − 1, ϕ(α)(p) �= 0. De acuerdo con elteorema de Taylor tenemos:
xn+1 = ϕ(xn) = p+1α!ϕ(α)(ψ)(xn − p)α, ψ ∈ (xn, p)
Si limn→∞xn = p,
limn→∞|en+1||en|α =
1α!
|ϕ(α)(p)| �= 0, εn = xn − p (6.28)
Luego el metodo de iteracion es de orden α para p.

6.5 · Generalizacion a sistemas de ecuaciones 111
Este argumento da una demostracion alternativa del hecho de que elmetodo de Newton-Raphson sea al menos de segundo orden para raıcessimples, ya que:
ϕ(x) = x− f(x)f ′(x)
ϕ′(x) =f(x) · f ′′(x)(f ′(x))2
= 1− [(f ′(x))2 − f(x) · f ′′(x)](f ′(x))2
Si p es una raız simple, f ′(p) �= 0 ⇒ ϕ′(p) = 0
6.5. Generalizacion a sistemas de ecuaciones
Algunos de los metodos que hemos visto para resolver ecuaciones no li-neales simples, pueden ser generalizados a sistemas de ecuaciones no lineales.
Consideremos un sistema general de n ecuaciones no lineales con nincognitas.
fi(x1, ..., xn) = 0, i = 1, ..., n
Un metodo de iteracion uni-punto para la resolucion de este sistemapuede ser construıdo escribiendo el sistema de la forma:
xi = ϕi(x1, ..., xn), i = 1, ..., n
que sugiere el metodo iterativo:
x(k+1)i = ϕi(x
(k)1 , ..., x(k)
n ), i = 1, ..., n
La similitud formal al caso n = 1 es mas facil de ver si utilizamos notacionvectorial.
x = (x1, ..., xn)t, ϕ(x) = (ϕ1(x), ..., ϕn(x))t
El metodo iterativo puede entonces describirse como:
x(k+1) = ϕ(x(k)), k = 0, 1, ...

112 6 · Algoritmos iterativos
Un criterio de convergencia similar al descrito en el Teorema 9 puedeutilizarse en este caso.
Supongamos que p = ϕ(p) y que las derivadas parciales
dij(x) =∂ϕi∂xj
(x), 1 ≤ i, j ≤ n
existen para x ∈ R, R = {x : ||x − p|| < ρ}. Sea D(x) una matriz nxncuyos elementos son dij(x). En este caso una condicion suficiente para queel metodo de iteracion anterior converja para cada x0 ∈ R es que para algunaeleccion de la norma se cumpla
||D(x)|| ≤ m < 1, x ∈ R (6.29)
Nota: Normas de vectores:
Lp: ||x||p = (|x1|p + ...+ |xn|p)1p , 1 ≤ p ≤ ∞
p = 2 (norma euclıdea) ||x||2 = (|x1|2 + ...+ |xn|2) 12
p = ∞ ||x||∞ = maxi=1,...,n |xi|Norma matricial: ||A||∞ = maxi=1,..,n
∑nj=1 |aij |
Definicion 3 Se dice que ϕ es una funcion de contraccion cuando ||D(x)|| ≤m < 1, x ∈ R, puesto que
en este caso dicha condicion implica la desigualdad
||ϕ(x) − ϕ(y)|| ≤ m||x− y||,∀x, y ∈ R
Una condicion necesaria para que el proceso iterativo anterior converjaes que el radio espectral de D(p) sea menor o igual que 1. La velocidad deconvergencia depende linealmente de m y tenemos
||x(k+1) − p|| = ||ϕ(x(k))− ϕ(p)|| ≤ m||x(k) − p||, k = 0, 1, ...
Nota: En algunas aplicaciones nos puede interesar resolver unsistema de la forma
x = a+ hϕ(x)

6.5 · Generalizacion a sistemas de ecuaciones 113
donde a es un vector constante y h es un parametro 0 < h << 1.Si ϕ(x) tiene derivadas parciales acotadas, entonces el criteriode convergencia anterior, (6.29), se satisface siempre para h su-ficientemente pequeno y el metodo de iteracion es:
x(k+1) = a+ hϕ(x(k)), k = 0, 1, ...
6.5.1. Metodo de Newton-Raphson
Para n = 1 hemos deducido este metodo a partir de la formula de Taylor:
f(x) = f(xk) + (x− xk)f ′(xk) +O(|x− xk|2)
Si nos olvidamos del ultimo termino, obtenemos para f(x) = 0 el metodoiterativo:
f(xk) + (xk+1 − xk)f ′(xk) = 0, k = 0, 1, ...
Utilizando la formula de Taylor en dimension n:
f(x) = f(x(k)) + f ′(x(k))(x− x(k)) +O(||x− x(k)||2)donde f ′(x) es una matriz nxn, el jacobiano de f , denotado en ocasionespor J , cuyos elementos son
f ′ij(x) =
∂fi∂xj
(x), 1 ≤ i, j ≤ n
De esta forma el metodo de Newton-Raphson en dimension n es:
f(x(k)) + (x(k+1) − x(k))f ′(x(k)) = 0, k = 0, 1, ...
Este es un sistema de ecuaciones lineal para x(k+1) y si f ′(x(k)) es nosingular puede ser resuelto como veremos mas adelante.
El metodo de Newton en dimension n es de segundo orden, es decir existeuna constante C = C(ρ), tal que, ∀x(k), ||x(k) − p|| ≤ ρ, y se tiene
||x(k+1) − p|| ≤ C||x(k) − p||2
Desigualdad que se sigue directamente de:
x(k+1) = f(x(k)) = p+12!f (2)(ψ)||x(k) − p||2, ψ ∈ (x(k), p)

114 6 · Algoritmos iterativos
De aqui se puede demostrar su convergencia supuesto que x(0) este losuficientemente cerca de p.
Como hemos visto cada iteracion del metodo de Newton-Raphson re-quiere la resolucion de un sistema de ecuaciones lineales el cual, cuando n esgrande puede ser difıcil de resolver. Ademas en cada paso hay que calcularlos n2 elementos de f ′(x(k)). Esto es imposible de hacer a menos que dichoselementos tengan una forma funcional sencilla.
Existen metodos derivados de este, que proponen estimar f ′(x), como elmetodo de la secante que lo aproxima por un cociente de diferencias. Unaaproximacion utilizada en le practica es:
∂fi∂xj
(x) ≈ ∆ij(x, h) =fi(x+ hjej)− fi(x)
hj
donde ej = (0, ..., j, ..,0) y h es un parametro n-dimensional con componenteshj �= 0, j = 1, ..., n.
6.5.2. Metodo de Gauss-Seidel
Otro metodo de resolucion de un sistema no lineal f(x) = 0 consiste enutilizar la i-esima ecuacion a resolver para obtener x(k+1)
i , i = 1, 2, ..., n. Deesta forma en cada iteracion se utiliza la ecuacion no lineal de dimensionuno:
fi(x(k+1)1 , ..., x
(k+1)i−1 , xi, x
(k)i+1, ..., x
(k)n ) = 0
para obtener x(k+1)i .
Ejemplo de aplicacion Sea un sistema no lineal de dimension n = 3.
f1(x1, x2, x3) = 0f2(x1, x2, x3) = 0f3(x1, x2, x3) = 0
En k = 0:
i = 1: f1(x1, x(0)2 , x
(0)3 ) = 0 → x
(1)1
i = 2: f2(x(1)1 , x2, x
(0)3 ) = 0 → x
(1)2
i = 3: f3(x(1)1 , x
(1)2 , x3) = 0 → x
(1)3

6.6 · Ejercicios de aplicacion 115
En k = 1:
i = 1: f1(x1, x(1)2 , x
(1)3 ) = 0 → x
(2)1
i = 2: f2(x(2)1 , x2, x
(1)3 ) = 0 → x
(2)2
i = 3: f3(x(2)1 , x
(2)2 , x3) = 0 → x
(2)3
· · ·
6.6. Ejercicios de aplicacion
Como aplicacion de los metodos anteriores, puedes intentar resolver lassiguientes ecuaciones:
1. x = tg(x) en [1, 2].
2. x3 − x+ 1 = 0 en [−2, 2].
3. x− senx− 0,25 = 0 en [1, 2].
4. e−3 = xe−x en [0, 1].
5. (1 + x)senx− 1 = 0 en [0,5, 1].
6. senx− x+ 2 = 0 en [2, 3].
Si tienes muchas inquietudes, intenta resolver el sistema:
x = 1 + h2(ey√x + 3x2)
y = 0,5 + h2tang(ex + y2)x0 = 1, y0 = 0,5
Prueba con valores de h = 0,1 o 0.01.

116 6 · Algoritmos iterativos

Capıtulo 7
Metodos de ordenacion
7.1. Analisis teorico: orden de complejidad optimo
alcanzable para algoritmos internos
Definicion 1
Un orden parcial en un conjunto S es una relacion R, tal que para cadaa, b, c en S:
1. aRa es verdad (R es reflexiva).
2. aRb y bRa implican a = b (antisimetrica).
3. aRb y bRc implican aRc (transitiva).
La relacion R = ” ≤ ” entre enteros y la relacion R = ” ⊆ ” entreconjuntos son dos ordenes parciales.
Un orden total o lineal en un conjunto S es un orden parcial en el queademas se cumple que para cada dos elementos a, b ∈ S o bien aRb o bRa.La relacion ≤ sobre enteros es un orden total (lineal), ⊆ sobre conjuntos nolo es.
El problema de la ordenacion puede ser planteado como sigue. Dada unasucesion de n elementos a1, ..., an elegidos de un conjunto con orden total,que usualmente denotaremos por ≤, vamos a encontrar una permutacion πde esos n elementos que describira la secuencia dada en forma no decrecienteaπ(1), ..., aπ(n), tal que aπ(i) ≤ aπ(i+1), para 1 ≤ i ≤ n − 1. Usualmentedaremos la secuencia ordenada en lugar de la permutacion de ordenacion π.
117

118 7 · Metodos de ordenacion
1 [tnpos=r]a < b 2 [tnpos=r]b < c 4 [tnpos=r]Orden:a b c5 [tnpos=r]a < c 8 [tnpos=r]Orden: a c b 9 [tnpos=r]Orden:c a b 3 [tnpos=r]a < c 6 [tnpos=r]Orden: b a c
7 [tnpos=r]b < c 10 [tnpos=r]Orden: b c a 11 [tnpos=r]Orden: c b a
Figura (a)
Los metodos de ordenacion son clasificados como internos, donde losdatos residen en la propia memoria del ordenador, o externos (los datos estanprincipalmente fuera de la memoria, almacenados en mecanismos como cd’so cintas).
Otra clasificacion posible surge atendiendo a la estructura de los ele-mentos que van a ser ordenados. La diferencia esta en si los elementos sonnumeros enteros con un rango fijo, o por el contrario son elementos de losque no se conoce nada de su estructura en particular. Esta segunda clase dealgoritmos tiene como operacion basica la comparacion entre distintos paresde elementos. Con algoritmos de esta naturaleza veremos que se necesitanal menos nlogn comparaciones para ordenar una secuencia de n elementos.
Arboles de decision
Vamos a considerar un algoritmo en el que en cada paso se realiza unabifurcacion (ramificacion en dos ramas) depeniendo de una comparacionrealizada entre dos elementos. La representacion usual para un algoritmode este tipo es un arbol binario denominado arbol de decision. Cada verticeinterior representa una decision. Es test que representa el nodo raız es elprimero en realizarse, y luego el control pasa a uno de sus hijos, dependiendode la respuesta. En general, el control continua pasando de cada vertice auno de sus hijos, la eleccion en cada caso depende del resultado del test,hasta que se llega a un final de rama (hoja). El resultado del algoritmo seobtiene cuando se alcanza dicho nodo (final de rama).
Ejemplo 1 Vamos a ilustrar mediante un arbol de decision el algoritmode ordenacion de tres elementos a, b y c en orden alfabetico. Los tests estanindicados a la derecha del un cırculo que respresenta el nodo correspondiente.El control se mueve hacia la izquierda si la respuesta es ”si”, y hacia laderecha si la respuesta es ”no”.
La complejidad computacional (en cuanto a tiempo), de un arbol de de-

7.1 · Analisis teorico: orden de complejidad optimo alcanzable para algoritmos internos119
cision es la altura del arbol, como una funcion del tamano del problema.Normalmente deseamos contar el maximo numero de comparaciones nece-sarias para encontrar el camino de la raız a un vertice de abandono (numerobifurcaciones). Es de destacar que el numero total de vertices en el arbolpuede ser mucho mayor que su altura. En cualquier caso, podemos probarun buen resultado acerca de la altura de un arbol de decision que ordena nelementos.
Lema 1 Un arbol binario de altura h tiene a lo sumo 2h hojas.
Demostracion: Por induccion sobre h. Se necesita simplemente obser-var que un arbol binario de altura h esta compuesto por una raız y a losumo dos subarboles de altura a lo mas h− 1.
Teorema 2 Cualquier arbol de decision que orden n elementos tiene dealtura al menos log2n!.
Demostracion: Como el resultado de la ordenacion de n elementospuede ser una de las n! permutaciones de los datos, debe haber al menosn! hojas en el arbol de decision. Por el Lema 1, la altura debe ser al menoslog2n!.
Corolario 1 Cualquier algoritmo que ordene mediante comparacionesrequiere al menos cnlogn comparaciones para ordenar n elementos, parac > 0 y n suficientemente grande.
Demostracion: Para n > 1:
n! ≥ n(n− 1)(n − 2)...(�n2�)≥(n
2
)n2
de manera que
logn! ≥ n
2log
(n
2
)≥ n
4logn para n ≥ 4
De la aproximacion de Stirling podemos obtener una aproximacion masprecisa de n! como
(ne
)n, de manera que n(log2n− log2e) = nlog2n− 1,44n,resulta ser una buena aproximacion inferior del numero de comparacionesnecesarias para ordenar n elementos.

120 7 · Metodos de ordenacion
7.2. Metodos simples de complejidad O(n2): com-
paracion, insercion, burbuja
7.2.1. Metodo de comparacion (seleccion)
Es uno de los metodos de ordenacion mas simples y trabaja de la si-guiente forma:
1. Encontrar el elemento mas grande del vector.
2. Intercambiarlo con el elemento de la ultima posicion.
3. Encontrar el segundo mayor elemento.
4. Intercambiarlo con el elemento de la anteultima posicion.
5. Continuar con dicho proceso hasta obtener el vector ordenado.
Tambien se denomina algoritmo de seleccion porque trabaja repetida-mente seleccionando el actual mayor elemento.
Algorithm selectsort
for index := n to 2,−1, do
largest := index
for loop := index − 1 to 1,−1, do
if k(loop) > k(largest) then largest := loop endif
enddo
//intercambio de posiciones de los dos elementos//
temp := k(largest)
k(largest) := k(index)
k(index) := temp
enddo
Para estimar el numero de comparaciones es importante senalar que elalgoritmo se reduce a dos ciclos que estan anidados y la comparacion serealiza una vez en cada paso del ciclo interior. El ciclo interior tiene j − 1pasos por cada paso j en el ciclo exterior y hay n − 1 pasos en el cicloexterior, luego el numero de comparaciones requerido por el algoritmo es:
(n− 1) + (n− 2) + ...+ (2) + (1) =n(n− 1)
2

7.2 · Metodos simples de complejidad O(n2): comparacion, insercion, burbuja121
Este numero es constante sea cual sea la ordenacion inicial de los ele-mentos.
En el algoritmo, el numero de veces que los elementos cambian sus po-siciones esta dado por el numero de veces Sn, que se ejecuta la sentencialargest := loop. Este numero Sn, depende de la ordenacion inicial de loselementos y puede describirse por sus valores mınimo, maximo y medio.Si el vector inicial esta ordenado, dicha sentencia no se ejecuta nunca ySn,min = 0. Si el vector inicial esta ordenado en el orden decreciente, encada paso del ciclo exterior se intercambian dos elementos y la longitud delvector desordenado es reducida en uno en cada paso. Esto nos da el maximovalor para Sn,max, que es:
(n− 1) + (n− 3) + ...+ 1 =
{n2
4 si n es par(n2−1)
4 si n es impar
Para determinar el numero medio de elementos intercambiados hay quesenalar que:
1. Si el algoritmo comienza con una permutacion aleatoria de 1, 2, ..., n,entonces el primer paso en el ciclo externo genera una permutacionaleatoria de 1, ..., n−1 seguida por n, ya que la permutacion q1, ..., qn−1, nes producida por cada uno de los datos.
n q2 q3 · · · qn−1 qnq1 n q3 · · · qn−1 qn· · · · · ·q1 q2 q3 · · · qn−1 n
2. La ocurrencia de cada permutacion de 1, 2, ..., n−1 en k(1), k(2), ..., k(n−1) es igualmente probable y el numero medio de veces que se ejecutala sentencia largest := loop durante el primer paso del ciclo externoviene dada por Hn − 1 = 1
2 + 13 + ...+ 1
n .
En general, el valor medio de Sn, Sn satisface la relacion de recurrenciaSn = Hn − 1 + Sn−1, de manera que
Sn =n∑j=2
Hj − (n − 1) = (n + 1)Hn − 2n
Nota: Hemos utilizado el resultado∑nj=1Hj = (n+1)Hn−n, H1 = 1,
que puede ser probado por induccion.

122 7 · Metodos de ordenacion
En resumen, el numero de comparaciones entre elementos es
n(n− 1)2
= O(n2)
y el numero de intercambios es:
min = 0
media = (n + 1)Hn − 2n = O(nlogn) (Notar que Hn ≈ log2n, para ngrande)
max =
{n2
4 si n es par(n2−1)
4 si n es impar= O(n2)
La complejidad total del algoritmo es entonces O(n2) y queda determi-nada por el numero de operaciones.
7.2.2. Metodo de insercion
Los metodos de ordenacion por insercion estan basados en la siguienteidea:
Sea un vector ordenado de n elementos distintos
k(1) < k(2) < ... < k(n)
Queremos insertar un elemento X en el vector anterior comparandolocon los elementos del vector y situandolo en su posicion moviendo despueslos elementos posteriores un lugar a la derecha. Un algoritmo que realizaesto se denomina algoritmo de insercion.
Si queremos aplicar un algoritmo de este tipo a la ordenacion de unvector de n elementos, tendremos que ir considerando elemento a elementoy situandolo en su propio lugar en un vector ya ordenado.
Un posible algoritmo serıa:
Algorithm insertsort
k(0) := minvalue
for i := 2 to n, do
pivot := k(i)

7.2 · Metodos simples de complejidad O(n2): comparacion, insercion, burbuja123
j := i
while k(j − 1) > pivot do
k(j) := k(j − 1)
j := j − 1
enddo
k(j) := pivot
enddo
El algoritmo anterior requiere n(n−1)2 movimientos de elementos en el
peor caso. Esta alta complejidad es debida a que cada pasada del ciclo internoproduce unicamente intercambios entre elementos adyacentes. Esto producemuchos movimientos redundantes de elementos, porque, si por ejemplo, elelemento mas pequeno esta situado en el extremo contrario del vector hacenfalta n pasos para moverle a la posicion que le corresponde.
Una modificacion de este algoritmo es el que se denomina Shellsort. (Verpor ejemplo pag. 231 y ss. de [9]).
7.2.3. Metodo de intercambio (burbuja)
Otra familia de algoritmos de ordenacion por comparacion esta basadaen la idea de que cada comparacion entre dos elementos debe ser seguidasistematicamente por el intercambio de pares de elementos desordenados,hasta que no aparezcan mas pares a ordenar.
El algoritmo trabaja de la siguiente manera: dada una secuencia deelementos desordenados k(1), ..., k(n), generalmente no todos distintos; elmetodo de la burbuja los ordena intercambiando elementos adyacentes, si esnecesario, en sucesivas pasadas. Cuando no es necesario ningun intercambiomas, la secuencia esta ordenada.
Algorithm bubblesort
repeat
pivot := 1
for k := 2 to n do
if A(k − 1) > A(k) then
temp := A(k − 1)
A(k − 1) := A(k)
A(k) := temp
pivot := k − 1
endif
enddo

124 7 · Metodos de ordenacion
until pivot = 1
Ejemplo 2Vamos a ver como ordena la secuencia 3 4 2 1 7
3 4 23 2 4 13 2 1 4 7 pasada 1, pivot=43 22 3 12 1 3 4 7 pasada 2, pivot=32 11 2 3 4 7 pasada 3, pivot=1
Hay tres cantidades involucradas en el tiempo de desarrollo del metodode la burbuja: el numero de comparaciones, el numero de intercambios yel numero de pasadas a traves de los datos. Para estimar dichas cantida-des podemos ver que el algoritmo se ha implementado utilizando dos ciclosanidados. Un paso del ciclo exterior corresponde a una pasada a traves delvector inicial, de manera que el numero de pasadas corresponde al numerode pasos ejecutados en el ciclo exterior.
Si los elementos estan ordenados, la pasada inicial sera tambien la ultimay no haran falta intercambios de elementos. Entonces el valor mınimo parael numero de comparaciones, el numero de intercambios y el numero depasadas son n− 1, 0 y 1 respectivamente.
Si los datos iniciales estan en orden inverso, entonces en la primera pasa-da se colocara el elemento mas grande en su propia posicion, y se utilizarann − 1 comparaciones y n − 1 intercambios. La segunda pasada colocara elsegundo mayor elemento en su posicion y utilizara para ello n− 2 compara-ciones y n− 2 intercambios. Continuando con este argumento, concluiremosque este metodo requiere de n(n−1)
2 comparaciones e intercambios y n pasa-das.
El analisis de valores del numero medio de comparaciones, pasadas eintercambios no es facil de realizar. El motivo es que dicho calculo requierede una interesante herramienta matematica como son las tablas de inversion.(Ver por ejemplo pag. 220 y 223 de [9]). En cualquier caso podemos concluirque la complejidad del metodo de la burbuja en media no es mejor queO(n2).

7.3 · Metodos de complejidad O(nlogn): Quicksort y Heapsort 125
23 [tnpos=r]A(1) 19 [tnpos=r]A(2) 11 [tnpos=r]A(4) 1 [tnpos=r]A(8) 2 [tnpos=r]A(9)7 [tnpos=r]A(5) 4 [tnpos=r]A(10) 6 [tnpos=r]A(11)10 [tnpos=r]A(3) 5 [tnpos=r]A(6)
3 [tnpos=r]A(7)
Figura (b)
7.3. Metodos de complejidad O(nlogn): Quicksorty Heapsort
7.3.1. Heapsort
Es un elegante metodo de ordenacion que utiliza la idea de una repeti-da seleccion de elementos. Fue inventado por Williams y Floyd (1964). Elproceso consiste en dos etapas: los primeros n pasos construyen un vectorcon estructura de ”monton”(o pila) y los siguientes n extraen los elementosen orden decreciente y construyen la secuencia ordenada final, situada dederecha a izquierda en un vector. En la etapa de creacion del monton, lainformacion relativa al orden de los elementos que es obtenido despues decada comparacion es implementada en forma de estructura de datos amon-tonados. Veamos esto con el siguiente ejemplo.
Consideremos un vector A(1 : n). Asociamos a este vector una estructurade arbol binario. Un arbol binario puede representarse graficamente de dife-rentes formas. Normalmente se representa como si creciese hacia abajo, y elnodo mas alto, A(1), se denomina raız. Una forma usual de numerar todoslos nodos es de izquierda a derecha en cada nivel, de manera que si A(k) esel nodo raız de un subarbol, A(2k) y A(2k+1) son los dos nodos inmediatoscolocados detras de el, que son llamados nodos hijos. Inversamente A(k) esel nodo padre de A(2k) y A(2k + 1).
Definimos la raız de un arbol como el nodo que esta en el nivel 1. Si A(k)esta en el nivel i, A(2k) y A(2k+1) estan en el nivel i+1. Un nodo que notiene hijos se denomina nodo terminal (hoja), y si no es un nodo terminal, esun nodo interno o de bifurcacion. El numero de nodos que hay que recorrerdesde la raız hasta el nodo A(j), se denomina longitud del camino hastaA(j). El nodo raız es un nodo de longitud 1, sus hijos estan a una longitud2 y ası sucesivamente. En general un nodo de nivel i tiene un camino delongitud i hasta la raız.

126 7 · Metodos de ordenacion
Definicion 2
Una pila o monton es un arbol binario con nodos A(1) a A(n) inclusive,el cual tiene todos sus nodos terminales al mismo nivel, o en dos nivelesadyacentes a lo sumo; y tiene la propiedad de que el valor de un nudo padrees mayor o igual que los valores de los hijos.
A(k) ≥ max(A(2k), A(2k + 1)),para 1 ≤ k ≤ �n2�, n ≥ 2
La secuencia de elementos en el camino de la raız a un nodo terminalesta linealmente ordenada. Por ejemplo: 23 > 19 > 11 > 1. El elemento masgrande en un subarbol es siempre la raız de ese arbol. El algoritmo heapsortfunciona de la siguiente forma: dado un vector desordenado de tamano n:A(1 : n), el algoritmo en una primera parte construye la pila o monton yluego sistematicamente selecciona la raız actual y situa dicho elemento enla ultima posicion del vector A.
Algorithm createheap A(1 : n)
for r := �n2� to 1, −1 do
k := r
10 if A(k) < max(A(2k),A(2k + 1)) then
index :=ındice del mayor elemento de A(2k), A(2k + 1) (si solohay un hijo, el ındice del mayor elemento es el de ese hijo)
temp := A(k)
A(k) := A(index)
A(index) := temp
if(index ≤ n2) (index no es una hoja)
k := index
goto 10
endif
endif
enddo
Ejemplo 3
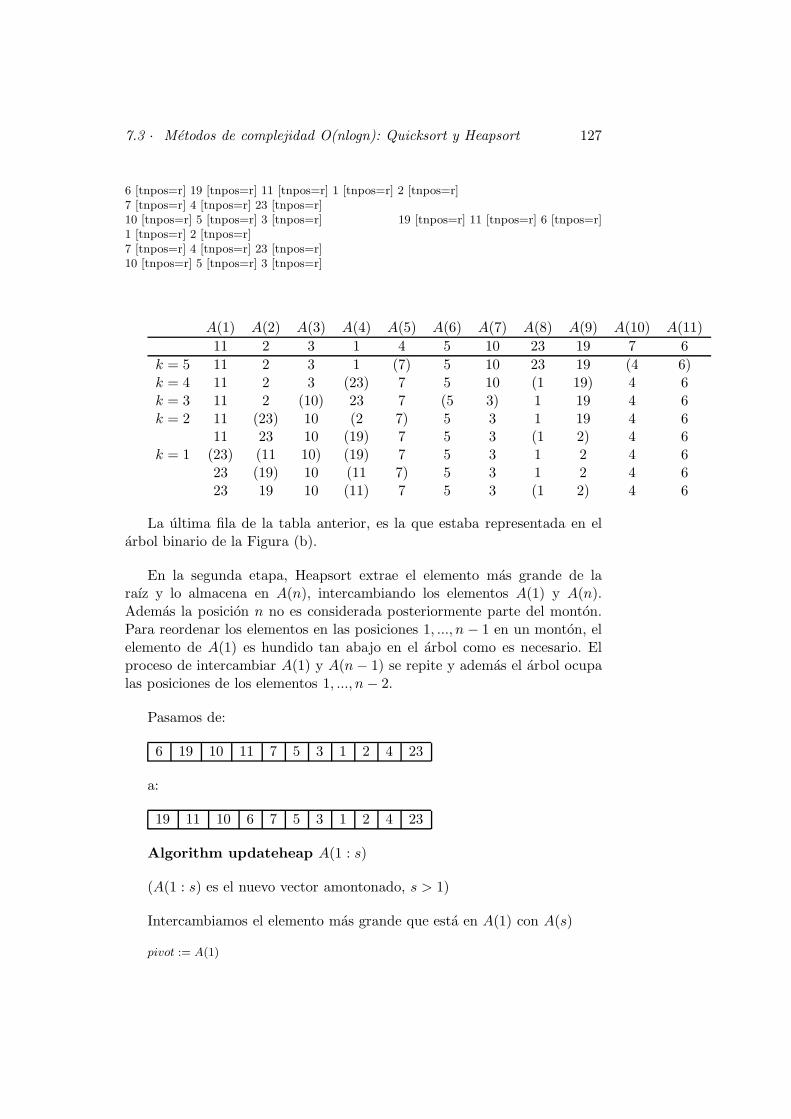
7.3 · Metodos de complejidad O(nlogn): Quicksort y Heapsort 127
6 [tnpos=r] 19 [tnpos=r] 11 [tnpos=r] 1 [tnpos=r] 2 [tnpos=r]7 [tnpos=r] 4 [tnpos=r] 23 [tnpos=r]10 [tnpos=r] 5 [tnpos=r] 3 [tnpos=r] 19 [tnpos=r] 11 [tnpos=r] 6 [tnpos=r]1 [tnpos=r] 2 [tnpos=r]7 [tnpos=r] 4 [tnpos=r] 23 [tnpos=r]10 [tnpos=r] 5 [tnpos=r] 3 [tnpos=r]
A(1) A(2) A(3) A(4) A(5) A(6) A(7) A(8) A(9) A(10) A(11)11 2 3 1 4 5 10 23 19 7 6
k = 5 11 2 3 1 (7) 5 10 23 19 (4 6)k = 4 11 2 3 (23) 7 5 10 (1 19) 4 6k = 3 11 2 (10) 23 7 (5 3) 1 19 4 6k = 2 11 (23) 10 (2 7) 5 3 1 19 4 6
11 23 10 (19) 7 5 3 (1 2) 4 6k = 1 (23) (11 10) (19) 7 5 3 1 2 4 6
23 (19) 10 (11 7) 5 3 1 2 4 623 19 10 (11) 7 5 3 (1 2) 4 6
La ultima fila de la tabla anterior, es la que estaba representada en elarbol binario de la Figura (b).
En la segunda etapa, Heapsort extrae el elemento mas grande de laraız y lo almacena en A(n), intercambiando los elementos A(1) y A(n).Ademas la posicion n no es considerada posteriormente parte del monton.Para reordenar los elementos en las posiciones 1, ..., n − 1 en un monton, elelemento de A(1) es hundido tan abajo en el arbol como es necesario. Elproceso de intercambiar A(1) y A(n− 1) se repite y ademas el arbol ocupalas posiciones de los elementos 1, ..., n − 2.
Pasamos de:
6 19 10 11 7 5 3 1 2 4 23
a:
19 11 10 6 7 5 3 1 2 4 23
Algorithm updateheap A(1 : s)
(A(1 : s) es el nuevo vector amontonado, s > 1)
Intercambiamos el elemento mas grande que esta en A(1) con A(s)
pivot := A(1)

128 7 · Metodos de ordenacion
A(1) := A(s)
A(s) := pivot
k := 1
while 2k < (s − 1) do
index := ındice mas grande de A(2k), A(2k + 1)
if A(k) < A(index) then
//intercambiar A(k) con A(index)//
pivot := A(index)
A(index) := A(k)
A(k) := pivot
k := index
else goto fin
endif
enddo
fin. Return (A)
El algoritmo Heapsort completo se implementa como sigue:
Algoritmo Heapsort
createheap A(1:n)
for s := n to 2,−1 do
updateheap A(1 : s)
enndo
Numero de comparaciones necesario en Heapsort
El primer algoritmo createheap consta de dos ciclos que estan anidados.El ciclo exterior tiene n
2 pasos, mientras que el interior no se realiza masveces que la altura, h, que tiene el monton considerado. Ademas en cadapaso del ciclo interior se realizan al menos dos comparaciones. El numero decomparaciones necesarias es O(n2 · h) = O(nh).
El algoritmo updateheap contiene unicamente un ciclo. Se realiza unacomparacion por cada paso del ciclo y el ciclo se realiza al menos el numerode veces que corresponde a la altura del monton. Es decir el numero de

7.4 · Quicksort 129
comparaciones es O(h), donde h representa la altura del monton. Si el arboltiene n elementos y en cada nodo se produce una bifurcacion, h ≈ log2n.
El numero total de comparaciones requeridas por el algoritmo completoheapsort es:
O(nh) + (n− 1)O(h) = O(nlog2n) + nO(log2n) = O(nlogn)
El numero de intercambios de elementos requerido por heapsort paracualquier vector inicial, es tambien O(nlogn).
7.4. Quicksort
Supongamos un vector de elementos desordenado K(1), ...,K(n). Quick-sort trabaja particionando el vector en dos partes y ordenando cada una delas partes independientemente. La posicion exacta de la particion dependede los datos. En la etapa en la que se realiza la particion, el vector se ordenade manera que se mantienen las siguientes condiciones:
1. El elemento que particiona K(k), esta en su propia posicion.
2. Todos los elementos K(1), ...,K(k−1) son menores o iguales queK(k).
3. Todos los elementos K(k+1), ...,K(n) son mayores o iguales queK(k).
Esto puede ser implementado facilmente utilizando la siguiente estrate-gia. Declarar dos punteros i, j con i = 1, j = n inicialmente. CompararK(i) con K(j),K(j − 1), ...,K(s) hasta enontrar un elemento K(s) menorque K(i). Intercambiar ambos elementos, incrementar i por 1 y continuarla comparacion despues de incrementar el valor de i y hasta que se produz-ca otro intercambio. Despues del intercambio disminuir j en 1 y continuarla comparacion hasta que se produzca otro intercambio. Despues de dichointercambio incrementar i y ası sucesivamente hasta que i = j.
Para un mejor desarrollo del algoritmo, se produce un intercambio in-cluso cuando para i �= j, K(i) y K(j) son elementos con el mismo valor.Cuando los punteros i, j alcanzan la misma posicion, dicha posicion deter-mina la particion del vector en dos subvectores. Cada uno de los dos vectoreses ordenado independientemente. Esto significa que despues de cada parti-cion del vector, una de las partes necesita ser almacenada temporalmentemientras Quicksort ordena la otra parte. Esto requiere de alguna memoriaauxiliar por parte del algoritmo.

130 7 · Metodos de ordenacion
Una descripcion completa del algoritmo serıa la siguiente:
Algorithm Quicksort (r, s)
i := r
j := s + 1
pivot := K(i)
if s > 1 then
repeat
repeat j := j − 1 until K(j) ≤ pivot
repeat i := i + 1 until K(i) ≥ pivot
if i < j
temp := K(i)K(i) := K(j)K(j) := temp
endif
until j ≤ i
K(r) := K(j)
K(j) := pivot (el elemento que determina la particion esta en la posicion j)
endif
if r < s then
quicksort(r, j − 1)
quicksort(j + 1, s)
endif
Tiempo medio requerido por Quicksort
Antes de calcular el tiempo medio de ejecucion de un algoritmo, vamosa determinar cual es la distribucion de probabilidad de los datos. Para al-goritmos de ordenacion, una hipotesis natural, y que nosotros haremos, esque cada permutacion de la secuencia a ordenar es igualmente probable ala hora de aparecer como datos. Bajo esta hipotesis, facilmente se puedeacotar inferiormente el numero de comparaciones necesarias para ordenaruna secuencia de n elementos.

7.4 · Quicksort 131
El metodo general es asociar con cada hoja del arbol de decision ν, laprobabilidad de alcanzar dicha hoja, para unos datos dados. Si conocemosla distribucion de probabilidad de los datos, se pueden determinar las pro-babilidades de cada una de las hojas. Entonces, se puede calcular el numeroesperado de comparaciones realizado por un algoritmo de ordenacion parti-cular, evaluando sobre todas las hojas del arbol de decision, la suma
∑i pidi,
donde pi es la probabilidad de alcanzar la hoja i y di su altura. Esta sumaes la altura esperada de un arbol de decision.
Teorema 3 Bajo la hipotesis de que todas las permutaciones de la se-cuencia de n elementos son igualmente probables, cualquier arbol de decisionque ordene n elementos tiene una altura esperada de al menos logn!.
Demostracion: Sea D(T ) la suma de las alturas de las hojas de unarbol binario T . Sea D(m) el valor mas pequeno de D(T), elegido de entretodos los arboles T con m hojas. Demostraremos por induccion sobre m,que D(m) ≥ mlogm. Para m = 1 el resultado es trivial. Supongamos quees cierto para valores de m menores que k y consideremos un arbol T conk hojas. T esta formado por una raız y por un arbol a la izquierda Ti con ihojas y un arbol a la derecha Tk−i con k− i hojas (la raız de T no pertenecea ninguno de los dos subarboles Ti ni Tk−i), para algun i, 1 ≤ i ≤ k.Claramente
D(T ) = i+D(Ti) + (k − i) +D(Tk−i)
Ademas, la suma mınima esta dada por
D(k) = min1≤i≤k{k +D(i) +D(k − i)}
De la hipotesis inductiva, tenemos:
D(k) ≥ k +min1≤i<k[ilogi + (k − i)log(k − i)] = k +min1≤i<kf(i)
Derivando f ′(i) = 0, se deduce que i = k2 con f ′′(k2 ) > 0. El mınimo se
alcanza en i = k2 ; luego:
D(k) ≥ k + klogk
2= k + klogk − klog2 = klogk
Concluımos entonces que D(m) ≥ mlogm, ∀m ≥ 1.
Recordemos del Teorema 2, que un arbol de decision T que ordene nelementos cualesquiera tiene al menos n! hojas. Mas aun, tiene exactamente

132 7 · Metodos de ordenacion
n! hojas con probabilidad 1n! cada una, y las restantes con probabilidad
0. Podemos eliminar de T todos los nodos antecesores solo de hojas conprobabilidad 0, sin cambiar la altura esperada de T . Tenemos entonces unarbol T ′ con n! hojas, cada una de probabilidad 1
n! . Como D(T ′) ≥ n!logn!,la altura esperada de T ′ y por lo tanto de T es al menos 1
n!n!logn! = logn!.•
Corolario 2 Cada algoritmo de ordenacion mediante comparaciones rea-liza al menos cnlogn comparaciones en media, para alguna constante c > 0.
Veremos ahora que el algoritmo Quicksort tiene un tiempo medio de eje-cucion acotado inferiormente por cnlogn para alguna constante c. El hechosignificativo es que el tiempo de ejecucion para el peor caso en dicho algo-ritmo es cuadratico. Sin embargo no es un hecho importante en la mayorıade los casos.
Teorema 4 El algoritmo Quicksort ordena una secuencia de n elementosen un tiempo esperado de O(nlogn).
Demostracion: Sea una secuencia de n elementos a1, ..., an. Por simpli-cidad supongamos que todos los elementos en S son distintos. Esta hipotesismaximizara los tamanos de los vectores resultantes de su particion.
Sea T (n) el tiempo medio necesario por Quicksort para ordenar una se-cuencia de n elementos. Claramente T (0) = T (1) = b para alguna constanteb.
Supongamos que despues de la primera particion hemos creado dos vec-tores en S. Denotamos por T (s) y T (n − s), respectivamente, los tiemposmedios requeridos por Quicksort para ordenar cada uno de los dos vectores.Como s es iguamente probable al resto de valores entre 1 y n, y el tiemponecesario para obtener la primera particion es cn, donde c es una constante,1 < c < 2 (se sigue del hecho de que se necesitan n comparaciones y ≤ nintercambios), tenemos:
T (0) = T (1) = b
T (n) =1n
n∑s=1
(T (s) + T (n− s)) + cn, n ≥ 2
=1n{n∑s=1
T (s) +n−1∑j=0
T (j)} + cn
=1n{n−1∑s=1
T (s) +n−1∑j=0
T (j) + T (n)}+ cn

7.4 · Quicksort 133
=2n
n−1∑s=1
T (s) +1nT (n) + cn
o escrito de otro modo:
(n− 1)T (n) = 2n−1∑s=1
T (s) + cn2, 1 < c < 2
Expresion que nos da una relacion de recurrencia. Si la escribimos paran+ 1.
nT (n+ 1) = 2n∑s=1
T (s) + c(n+ 1)2, 1 < c < 2
(n− 1)T (n) = 2n−1∑s=1
T (s) + cn2
restando la segunda de la primera, se obtiene:
nT (n+ 1)− (n− 1)T (n) = 2T (n) + c(2n + 1)
o lo que es lo mismo:
nT (n+ 1) = (n + 1)T (n) + c(2n + 1)
T (n+ 1)n+ 1
=T (n)n
+ c(2n+ 1)n(n+ 1)
que escrita recursivamente:
T (n+ 1)n+ 1
=T (n)n
+ c(2n+ 1)n(n+ 1)
=T (n)n
+ c(1
(n + 1)+
1n)
T (n)n
=T (n− 1)n− 1
+ c(1n+
1n− 1
)· · ·
T (2)2
=T (1)1
+ c(12+ 1)
De donde:
T (n+ 1)n+ 1
=b
1+ c
[(1
n+ 1+
1n+ ...+
12
)+(1n+
1n− 1
+ ...+ 1)]
=
= b+ c
[(Hn+1 − 1) + (Hn+1 − 1
n+ 1)]=
= b+ 2cHn+1 − cn+ 2n+ 1

134 7 · Metodos de ordenacion
Si y solo si:
T (n+ 1) = (n+ 1)b+ 2c(n + 1)Hn+1 − c(n + 2) ⇔
T (n) = nb+ 2cnHn − c(n+ 1)
Donde:
Hn ≈ logen =∞∑n=1
1n+ 1
de manera que:
T (n) ≈ nb− c(n+ 1) + 2cnlogen = O(nlogn)
Notar que:
k = logen ⇔ ek = n
l = log2n ⇔ 2l = n
2 < e, luego n = 2l < el, de donde k < l y por tanto logen < log2n.•

Capıtulo 8
El lenguaje de programacion C (IV)
Los apuntadores o punteros son variables que contienen la direccion deotra variable. Son frecuentemente utilizados en C, puesto que son, en ocasio-nes, la unica forma de expresar algunos calculos, mediante codigo compactoy eficiente.
Los apuntadores se han comparado con la proposicion goto, como unamanera de crear programas imposibles de entender. Esto es completamentecierto cuando se emplean sin cuidado. Sin embargo, con disciplina se puedenemplear para conseguir claridad y simplicidad. Este es el aspecto que vamosa intentar desarrollar en este tema.
8.1. Direccionamiento indirecto. Punteros: varia-bles que contienen la ubicacion en memoria
de otras variables
Puesto que un puntero contiene la direccion de un objeto, se puede acce-der al objeto “indirectamente” a traves de el. Sea x una variable de tipo int,y px un puntero. El operador unitario & devuelve la direccion de un objeto,por lo que la proposicion
px = &x;
asigna la direccion de x a la variable px; ahora se dice que px “apunta a” x.El operador & solo se puede aplicar a variables y elementos de un arreglo(array). Construcciones como &(x+ 1) o &3 son ilegales. Tambien es ilegalobtener la direccion de una variable register.
135

136 8 · El lenguaje de programacion C (IV)
El operador unitario ∗ toma su operando como una direccion para obte-ner su contenido. Si y tambien es de tipo int,
y=*px;
asigna a y el contenido de cualquier parte a la que apunte px. La secuencia
px = &x;y = *px;
asigna a y el mismo valor de x.
Tambien es necesario declarar las variables que intervienen, la forma dehacerlo es:
int x,y;
int *px;
Esta ultima declaracion se entiende como un mnemotecnico. Se quiereindicar que la combinacion ∗px es de tipo int, es decir si px aparece enel contexto ∗px, ello equivale a una variable int. La sintaxis en la declara-cion de una variable imita a la sintaxis de las expresiones en las que puedeaparecer la variable. Este razonamiento es util cuando aparecen expresionescomplicadas. Por ejemplo:
double atof(), *dp;
indican que atof() y ∗dp toman valores de tipo double si aparecen enuna expresion. Hay que senalar que en la declaracion de un apuntador serestringe el tipo de los objetos a los que puede apuntar. Los apuntadorespueden aparecer en expresiones. Si px apunta al entero x, entonces ∗pxpuede aparecer en cualquier contexto que pudiera hacerlo x.
A un puntero se le puede sumar o restar un entero. En el caso del ejemploanterior, px ha sido declarado como un puntero a un entero x. La expresion
y=*px+1;
asigna a y una unidad mas que x. La expresion

8.1 · Direccionamiento indirecto. Punteros: variables que contienen la ubicacion en memoria de otras variab
printf("%d\n", *px);
imprime el valor actual de x; y
d=sqrt((double)*px);
asigna a d la raiz cuadrada de x, variable que es convertida a double parapoder utilizar sqrt.
En expresiones como
y=*px+1;
los operadores unitarios ∗ y & tienen mayor precedencia que los opera-dores aritmeticos, por lo que al evaluar la expresion se toma el valor delobjeto al que apunta px y se le suma 1, y el resultado es asignado a y. Masadelante veremos el significado de ∗(px+ 1).
Tambien pueden aparecer referencias a apuntadores en la parte izquierdade una asignacion. Si px apunta a x, entonces
*px=0;
pone x a 0, y
*px+=1;
incrementa en 1 el valor de x, al igual que
(*px)++;
En este ultimo ejemplo se necesitan los parentesis. En otro caso, se in-crementarıa en 1 px y no el objeto al que apunta, ya que los operadoresunitarios como ∗ y ++ se evaluan de derecha a izquierda.
Ademas como los apuntadores son variables, se pueden manipular igualque cualquier variable. Si py es otro apuntador a enteros,
py=px;
copia el contenido de px en py, con lo que se consigue que ahora pyapunte al mismo objeto que px.

138 8 · El lenguaje de programacion C (IV)
8.2. Punteros y funciones: paso de argumentos dereferencia haciendo uso de punteros
Cuando hablamos de las funciones en C, dijimos que los argumentos sepasaban por valor. Tambien es cierto que no hay forma directa de hacer quela funcion llamada altere una variable de la funcion que la llama. ¿Que hacerentonces cuando realmente queremos modificar alguno de los argumentos?
Por ejemplo, un programa de clasificacion podrıa intercambiar dos ele-mentos no ordenados con una funcion llamada swap. La llamada serıa
swap (a,b);
y la definicion (incorrecta, como veremos) serıa:
swap(x,y)
int x,y;
{
int temp;
temp=x;
x=y;
y=temp;
}
Pero, por defecto de la llamada “por valor”, la funcion swap no puedemodificar los argumentos a y b. Sin embargo hay una forma de hacerlo, quepermite conseguir el fın deseado. En la llamada a la fucion swap se utilizanapuntadores a los valores que se desea cambiar:
swap (&a,&b);
El operador & devuelve la direccion de una variable, por lo que &a es unapuntador a a. En la definicion (correcta) de la funcion swap se tienen quedeclarar los argumentos como apuntadores, a traves de los cuales se accedea los operandos reales.
swap(px,py) /* intercambio de *px y *py */
int *px,*py;
{
int temp;
temp=*px;

8.2 · Punteros y funciones: paso de argumentos de referencia haciendo uso de punteros139
*px=*py;
*py=temp;
}
Los apuntadores como argumentos suelen emplearse en el caso de funcio-nes que devuelven mas de un valor simple. Podrıa decirse que swap devuelvedos valores: los nuevos valores de sus argumentos.
Ejemplo: Consideremos una funcion getint() que realice la conversionde una cadena de caracteres en valores enteros, sin formato y un entero porllamada. getint debe devolver el valor hallado o una indicacion de fin dearchivo, si no hay caracteres. Dichos valores hay que devolverlos en objetosindependientes, puesto que en otro caso, el valor empleado para EOF, podrıacoincidir con el del entero hallado en la entrada.
Una solucion consiste en que getint devuelva EOF si detecta el fin defichero o cualquier otro valor, para indicar un entero normal. El valor numeri-co del entero hallado se devuelve a traves del argumento, que debera ser unapuntador a un entero. Esta organizacion diferencia la indicacion de fin dearchivo y los valores numericos.
Con las siguientes sentencias se consigue llenar un array con valoresenteros llamando a getint:
int n, v, array[SIZE];
for (n=0;n<SIZE && getint(&v)!=EOF;n++)
array[n]=v;
Cada llamada deja en v el entero hallado. Observa que es imprescindibleescribir &v en lugar de v, como argumento de getint. Si se utiliza v se puedecometer un error de direccionamiento puesto que getint supone que se lepasa un puntero como argumento. La definicion de getint es la siguiente:
getint(pn) /* toma el siguiente entero de la entrada */
int *pn;
{
int c, sign;
while((c=getch())==’ ’|| c==’\n’ || c==’\t’)
; /* salta espacios en blanco */
sign=1;
if(c==’+’ || c==’-’)
{ /* registra signo */
sign= (c==’+’) ? 1: -1;
c=getch();
}

140 8 · El lenguaje de programacion C (IV)
for(*pn=0; c>=’0’ && c<=’9’; c=getch())
*pn=10* *pn + c - ’0’;
*pn *= sign;
if(c != EOF)
ungetch(c);
return ();
}
∗pn se utiliza en getint como cualquier variable de tipo int.
Nota: ¿Que hacen getch y ungetch? A menudo se da el casode que un programa que lee no puede determinar si ha leıdosuficiente hasta que ha leıdo demasiado. Un ejemplo es la reco-leccion de los caracteres que constituyen un numero: mientras nose encuentra el primer caracter que no sea dıgito se sabe que elnumero no esta completo. Pero entonces el programa habra leıdoun caracter de mas para el que no esta preparado.
El problema estarıa resuelto si fuera posible “desleer” el caracterno deseado. Entonces, cada vez que un programa leyera un caracterde mas, podrıa devolverlo a la entrada y el resto del codigo secomportarıa como si nunca hubiera sido leıdo. Afortunadamen-te es facil simular la devolucion de un caracter con solo escribirun par de funciones cooperantes. getch toma un caracter de laentrada y ungetch lo devuelve, para que la siguiente llamadade getch pueda encontrarlo de nuevo. La forma de funcionar essencilla. ungetch situa el caracter devuelto en un buffer compar-tido (un arreglo de caracteres). getch lee en el buffer, si contienealgo. Llama a getchar si el buffer esta vacıo. Tambien debe deexistir una variable ındice que recuerda la posicion siguiente delcaracter en el buffer. Ya que el buffer y el ındice son compartidospor getch y ungetch y deben conservar sus valores entre llama-das, deberan ser externos a ambas. Una forma de escribir getchy ungetch y sus variables compartidas es:
#define BUFSIZE 100
char buf[BUFSIZE]; /* buffer para ungetch */
int bufp=0; /* sigue posicion libre en buf */
getch() /* lee un (posiblemente devuelto) caracter */
{
return ((bufp > 0) ? buf[--bufp] : getchar());
}
ungetch(c) /* devuelve un caracter */

8.2 · Punteros y funciones: paso de argumentos de referencia haciendo uso de punteros141
int c;
{
if(bufp > BUFSIZE)
printf("ungetch: demasiados caracteres \n");
else
buf[bufp++]=c;
}
8.2.1. Punteros y arrays
En C existe entre punteros y arrays un relacion tal que, cualquier opera-cion que pueda realizarse mediante la indexacion de un array se puede reali-zar tambien con punteros. La version con estos sera mas rapida en terminosgenerales, pero para los no iniciados, mas difıcil de entender.
La declaracion
int a[10];
define un array de tamano 10, es decir un bloque con diez objetos conse-cutivos denominados a[0], a[1], ..., a[9]. La notacion a[i] significa que el ele-mento del array se encuentra a i posiciones del comienzo. Si pa es un punteroa un entero, declarado como
int *pa;
entonces la asignacion
pa=&a[0];
hace que pa apunte al elemento 0 de a; es decir, pa contiene la direccionde a[0]. Ahora la asignacion
x=*pa;
copiara el contenido de a[0] en x.
Si pa apunta a un elemento particular de un arreglo a, entonces, pordefinicion pa+1 apunta al siguiente elemento, y en general pa−i al elementosituado i posiciones antes que pa, y pa + i apunta al elemento situado iposiciones despues. Si pa apunta a a[0], entonces

142 8 · El lenguaje de programacion C (IV)
*(pa+1)
se refiere al contenido de a[1], pa+ i es la direccion de a[i] y ∗(pa+ i) esel contenido de a[i]. Estos comentarios son ciertos cualquiera que sea el tipode variables del array a. Y por extension, toda la aritmetica de punterosestablece que el incremento se adecua al tamano en memoria del objetoapuntado. En pa+ i, i se multiplica por el tamano de los objetos a los queapunta pa antes de ser sumado a pa.
La correspondencia entre indexacion y aritmetica de punteros es eviden-temente muy estrecha. El compilador convierte toda referencia a un array enun puntero al comienzo del arreglo. El efecto es que el nombre de un arrayes una expresion de tipo puntero. Este hecho tiene algunas implicacionesmuy utiles. Puesto que el nombre de un arreglo es sinonimo de la posiciondel elemento cero, la asignacion
pa=&a[0]
se puede escribir ası
pa=a
Del mismo modo, una referencia a a[i] se puede escribir tambien como∗(a+ i). Al aplicar & a los dos lados de esta equivalencia se deduce tambienque &a[i] y a + i tambien son identicas. a + i es la direccion del i-esimoelemento de a. Por otra parte, si pa es un puntero, en las expresiones puedeaparecer como un subındice: pa[i] es identico a ∗(pa+ i). En suma, cualquierexpresion en que aparezca un array y un subındice se puede escribir como unpuntero y un desplazamiento y viceversa, incluso en la misma proposicion.
Sin embargo, hay una diferencia entre el nombre de un array y un pun-tero, que hay que tener en cuenta. Un puntero es una variable, por lo queoperaciones como pa = a y pa++ son correctas. Pero el nombre de un arrayes una constante, no una variable; de manera que expresiones como a = pao a++ son ilegales.
Cuando se pasa el nombre de un array a una funcion, se pasa la direcciondel comienzo del array. En la funcion, este argumento es una variable, por loque el nombre de un array como argumento es un puntero, o sea una variableque contiene una direccion. Podemos ver esto en el siguiente ejemplo:
strlen(s) /* regresa la longitud de la cadena s */

8.2 · Punteros y funciones: paso de argumentos de referencia haciendo uso de punteros143
char *s;
{
int n;
for (n = 0; *s != ’\0’; s++)
n++;
return n;
}
Es perfectamente legal incrementar s, puesto que es un puntero; s + +no modifica la cadena de caracteres s, no hace mas que incrementar la copiaprivada de la direccion.
Las definiciones de parametros
char s[];
y
char *s;
son completamente equivalentes; la forma como debe escribirse dependedel tipo de expresiones en las que aparece. Cuando se pasa el nombre de unarray a una funcion, la funcion puede establecer a su conveniencia si va amanejar un array o un puntero, y hacer las manipulaciones de acuerdo conesto. Incluso puede emplear los dos tipos de operaciones si le parece claro yconveniente.
Tambien es posible pasar parte de un arreglo a una funcion, pasando unpuntero al comienzo del subarreglo. Por ejemplo si a es un array
f(&a[2]);
y
f(a+2);
pasan a la funcion f la direccion del elemento a[2], ya que &a[2] y a+2son expresiones de tipo puntero que apuntan al tercer elemento de a. En f ,la declaracion de los argumentos podrıa ser

144 8 · El lenguaje de programacion C (IV)
f(arr)int arr[];{...}
o bien
f(arr)int *arr;{...}
8.3. Algebra de punteros
El lenguaje C es consistente y formal en su manejo de la aritmetica dedirecciones; la integracion de punteros, arrays y aritmetica de direccioneses una de sus principales virtudes. Veremos a continuacion algunas de suspropiedades, escribiendo un rudimentario administrador de memoria. Haydos rutinas: alloc(n) devuelve un puntero p a n caracteres consecutivos;free(p) libera la memoria adquirida de esa manera, para poder ser utiliza-da posteriormente. Las rutinas son rudimentarias, en el sentido de que lasllamadas a free deben hacerse en orden inverso a las llamadas a alloc. Esdecir, la memoria administrada por alloc y free es una pila, o estructuraultima-en-entrar, primera-en-salir. La biblioteca estandar de C tiene funcio-nes analogas que no tienen las restricciones anteriores. Sin embargo, muchasaplicaciones solo necesitan una sencilla funcion alloc que les proporcione pe-quenas zonas de memoria de tamano impredecible y en instantes tambienimpredecibles.
La realizacion mas sencilla consiste en que alloc devuelve trozos de ungran array de caracteres que llamaremos allocbuf . Este array es exclusivo dealloc y free. Puesto que se trabaja con punteros y no con subındices, nin-guna otra rutina necesita conocer el nombre del array, por lo que se declaracomo externo y estatico, es decir, local al archivo fuente que contenga allocy free e invisible fuera de el. En aplicaciones practicas, el array no necesitanombre; en lugar de ello se puede obtener pidiendo al sistema operativo unazona libre de memoria.
En cuanto a la manipulacion del array allocbuf , se empleara un punteroal primer elemento libre, llamado allocp. Cuando se le piden a alloc n ca-

8.3 · Algebra de punteros 145
racteres, se comprueba si hay espacio suficiente en allocbuf (el comienzo deun bloque libre) y se incrementa su valor en n para que apunte a la nuevazona libre. free(p) le da el valor p a allocp, si p se encuentra en allocbuf .
#define NULL 0 /* valor del puntero para devolver errores */
#define ALLOCSIZE 1000 /* tama~no del area disponible */
static char allocbuf[ALLOCSIZE]; /* espacio para alloc */
static char *allocp = allocbuf; /* siguiente posicion libre */
char *alloc(n) /* devuelve puntero a n caracteres */
int n;
{
if (allocp + n <= allocbuf+ALLOCSIZE){ /* se encontro */
allocp += n;
return (allocp - n); /* p anterior */
}
else /* no hubo espacio suficiente */
return (NULL);
}
free(p) /* p apunta al area libre */
char *p;
{
if(p >= allocbuf && p < allocbuf+ ALLOCSIZE)
allocp = p;
}
En general un apuntador se puede inicializar como cualquier otra varia-ble, aunque normalmente los valores significativos son NULL o una expre-sion en que aparezcan direcciones de objetos del tipo apropiado definidaspreviamente.
La declaracion
static char *allocp = allocbuf;
define allocp como un puntero a caracteres y lo inicializa para que apuntea allocbuf, que es la zona libre cuando comienza el programa. Esto se podıahaber hecho escribiendo
static char *allocp = &allocbuf[0];
ya que el nombre del array es la direccion del elemento cero.
La pregunta

146 8 · El lenguaje de programacion C (IV)
if (allocp + n <= allocbuf+ALLOCSIZE)
comprueba si hay espacio suficiente para satisfacer la peticion de n ca-racteres; si lo hay, el nuevo valor de allocp serıa como maximo una posicionmas alla del fin de allocbuf . Si la peticion se puede satisfacer, alloc devuelveun apuntador. En caso contrario, alloc debe devolver alguna indicacion deque no tiene espacio.
El lenguaje C garantiza que un apuntador que apunte a datos validosnunca tendra valor cero. Se puede emplear para senalar una condicion anor-mal: en este caso, indica que no hay espacio. Se escribe NULL en lugar decero, para indicar que es un valor especial para punteros. En general no tienesentido asignar enteros a punteros, el cero es un caso especial.
Preguntas como las aparecidas en las sentencias if , del ejemplo anterior,muestran diferentes facetas de la aritmetica de punteros. Los punteros sepueden comparar en ciertas circunstancias. Si p y q apuntan a miembros deun mismo array, se pueden utilizar relaciones como <,>,=, etc.
Tambien se pueden utilizar relaciones como == y ! =. Todo punterose puede comparar con igualdad o desigualdad con el valor NULL. No sepueden comparar punteros a distintos arreglos. (Esto puede funcionar en al-gunas maquinas, lo que puede hacer que nuestro programa deje de funcionarmisteriosamente cuando lo trasladamos de maquina).
Ademas se pueden sumar o restar un puntero y un entero. La construc-cion
p + n
significa el n-esimo objeto a partir del que apunta p. Esto es cierto in-dependientemente del objeto al que apunte p. Si p y q apuntan a miembrosdel mismo array, tambien se pueden restar: p− q es el numero de elementosentre p y q. Esto nos permite escribir otra version de la funcion strlen:
strlen(s) /* regresa la longitud de la cadena s */
char *s;
{
char *p = s;
while (*p != ’\0’)
p++;
return (p-s);
}
En esta version p se inicializa con s, es decir, apunta al primer caracter.En la iteracion while se examina cada caracter hasta encontrar el \0. Puesto

8.4 · Punteros a caracteres 147
que \0 es cero y la iteracion while comprueba solo si la expresion es cero,se puede omitir la comprobacion explıcita, y escribir la iteracion como
while (*p)
p++;
Como p apunta a caracteres, p + + actualiza p para que apunte al si-guiente caracter cada vez, y p − s indica el numero de caracteres tratados,es decir la longitud de la cadena. Si estuviesemos apuntando a float, queocupan mas memoria que los char y si p fuese un puntero a float, p + + seposicionarıa en el siguiente float.
No se pueden hacer mas operaciones con punteros de las senaladas aquı.No se permite sumar dos punteros, multiplicarlos, dividirlos, sumarles valo-res float o double, etc.
8.4. Punteros a caracteres
Vamos a analizar inicialmente dos funciones de la biblioteca estandar deC, string.h. La primera strcpy(s, t) que copia la cadena t en la cadena s. Laversion con arrays es:
strcpy(s,t) /* copia t a s */
char s[], t[];
{
int i;
i = 0;
while((s[i] = t[i]) != ’\0’)
i++;
}
Mientras que la version con punteros es:
strcpy(s,t) /* copia t a s */
char *s, *t;
{
while((*s = *t) != ’\0’)
{
s++;
t++;
}
}
Como los argumentos se pasan por valor, strcpy puede usar s y t conabsoluta libertad. Son punteros que recorren el array caracter a caracter

148 8 · El lenguaje de programacion C (IV)
hasta que el \0 con que termina t se ha copiado a s. La tercera version mascompacta es:
strcpy(s,t) /* copia t a s */
char *s, *t;
{
while(*s++ = *t++)
;
}
Por una parte se ha introducido los incrementos de s y de t en la parte decomprobacion de la iteracion. El valor de ∗t++ es el caracter al que apuntabat antes de ser incrementado; el operador sufijo ++ no se aplica hasta que seha obtenido ese caracter. De la misma manera el caracter se almacena en laantigua posicion donde apuntaba s antes de ser incrementado. Este caracteres tambien el valor que se compara con \0 para controlar la iteracion. Elefecto neto es la copia de los caracteres de t a s hasta copiar el \0 final.
Por otra parte se ha eliminado la comparacion explıcita con \0 por re-sultar redundante.
La segunda rutina que vamos a examinar es strcmp(s, t), que comparalas cadenas de caracteres s y t, y devuelve un valor entero negativo, cero opositivo, segun que s sea lexicograficamente menor, igual o mayor que t. Elvalor se obtiene al restar los caracteres de la primera posicion donde s y tdifieren.
strcmp(s,t) /* devuelve <0 si s<t, =0 si s=t, >0 si s>t */
char s[], t[];
{
int i;
i = 0;
while(s[i] == t[i])
if(s[i++] == ’\0’)
return 0;
return(s[i]-t[i]);
}
La version con punteros es:
strcmp(s,t) /* devuelve <0 si s<t, =0 si s=t, >0 si s>t */
char *s, *t;
{
for( ; *s == *t; s++, t++ )
if(*s == ’\0’)
return 0;
return(*s - *t);
}

8.5 · Ejemplos de utilizacion de punteros 149
Generalmente se ha visto que en la mayor parte de las computadorasse puede asignar un puntero a un entero y viceversa, sin que se altere elpuntero. Lamentablemente esto ha conducido a abusar de rutinas que de-vuelven punteros que pasan posteriormente a otras rutinas. En ocasiones seomiten declaraciones, de manera que el codigo resultante sigue funcionan-do aunque arriesgadamente, puesto que su funcionamiento depende de laparticular arquitectura del ordenador empleado.
8.5. Ejemplos de utilizacion de punteros
Vamos a considerar como primer ejemplo, el problema de la conversionde la fecha, del dıa del mes a dıa del ano y viceversa. Por ejemplo, el 1 deMarzo es el dıa 60 en un ano no bisiesto, y el 61 de uno bisiesto. Veremosdos funciones: day of year, que realizara la primera operacion y month day,que convertira un dıa del ano, en mes y dıa.
Ambas funciones necesitan de la misma informacion inicial, una tablacon los dıas que tiene cada mes (treinta dıas tiene Junio, Septiembre,...).Puesto que el numero de dıas del mes de Febrero varıa entre anos bisiestosy no bisiestos, mantendremos dicha informacion en el siguiente array de dosfilas:
static int day_tab[2][13]={{0,31,28,31,30,31,30,31,31,30,31,30,31},{0,31,29,31,30,31,30,31,31,30,31,30,31}};
La primera funcion sera:
day_of_year(year, month, day) /* calcula el dıa del a~no
* a partir de mes y dıa */
int year, month, day;
{
int i, bisiesto;
bisiesto= year % 4==0 && year % 100 != 0 || year % 400 == 0;
for(i=1; i < month ; i++)
day += day_tab[bisiesto][i];
return (day);
}
month_day(year, yearday, pmonth, pday) /* calcula mes, dıa

150 8 · El lenguaje de programacion C (IV)
* a partir del dıa y a~no */
int year, yearday, *pmonth, *pday;
{
int i, bisiesto;
bisiesto= year % 4==0 && year % 100 != 0 || year % 400 == 0;
for(i=1; yearday > day_tab[bisiesto][i]; i++)
yearday -= day_tab[bisiesto][i];
*pmonth= i;
*pday=yearday;
}
El array day tab ha de ser externo a ambas funciones para poder serutilizado por ambas.
day tab es el primer array bidimensional con el que trabajamos. En reali-dad, en C, un array bidimensional es por definicion un array unidimensional,en el que cada elemento vuelve a ser un array. Los subındices se escribencomo
day_tab[i][j]
en lugar de
day_tab[i,j]
empleado en la mayorıa de los demas lenguajes. Por otra parte, los ele-mentos se almacenan por filas, es decir, el subındice mas a la derecha varıamas rapidamente cuando se accede a los elementos por orden de almacena-miento. La inicializacion se realiza listando los valores entre llaves. Cada filase inicializa mediante la correspondiente sublista. En este caso se ha comen-zado con una columna de ceros, para que los ındices correspondientes a losdistintos meses varıen entre 1 y 12.
En el caso de tener que transferir un array a una funcion, la declaraciondel argumento en la funcion debera incluir el numero de columnas. El numerode filas es irrelevante, pudiendose utilizar un apuntador para declarar estedato. Son posibles las siguientes declaraciones de f :
f(day_tab)
int day_tab[2][13];
{
...
}

8.5 · Ejemplos de utilizacion de punteros 151
O bien:
int day_tab[][13];
o tambien
int (*day_tab)[13];
que indica que el argumento es un apuntador a un array de 13 ente-ros. Los parentesis son necesarios puesto que los corchetes [] tienen mayorprecedencia que el operador de indireccion *. Sin parentesis, la declaracion
int *day_tab[13];
declara un array de 13 apuntadores a enteros, como veremos en el si-guiente ejemplo.
Vamos a ver ahora un ejemplo de un programa que ordene un conjuntode lıneas de texto en orden alfabetico, version reducida de la utilerıa sort deUNIX.
La dificultad del ejemplo estriba en el hecho de trabajar con lıneas detexto, de longitud variable, que exigen ser comparadas y movidas en mas deuna sola operacion, a diferencia de lo que sucede con un numero entero. Senecesita por lo tanto una representacion eficiente de los datos, que funcionecorrectamente con lıneas de texto de longitud variable.
Utilizaremos en este caso un array de punteros. Si las lıneas a ordenar sealmacenan una tras otra en un gran array de caracteres, se podra acceder acada lınea a traves de un puntero a su primer caracter. Los punteros puedenalmacenarse a su vez en un array. Se pueden comparar dos lıneas con solopasar sus punteros a strcmp. Cuando tengamos que intercambiar dos lıneasdesordenadas, se intercambiaran los punteros en el arreglo y no las lıneas.
Como siempre es mejor dividir el programa principal en funciones quesigan esta division y que la rutina principal controle las cosas.
Si comenzamos pensando en la entrada de datos, la rutina de entradaha de recoger y guardar los caracteres de cada lınea y construir un arrayde punteros a las lıneas. Tambien tiene que contar el numero de lıneas deentrada, pues esta informacion sera necesaria para el proceso de ordenacion

152 8 · El lenguaje de programacion C (IV)
y el de salida. La funcion de entrada devolvera un -1, si existen demasiadaslıneas. La funcion de salida solo tiene que imprimir las lıneas en el orden enel que aparecen los correspondientes punteros.
#define NULL 0
#define MAXLINES 100 /* numero maximo de lıneas a ordenar */
main() /* ordena las lıneas */
{
char *lineptr[MAXLINES]; /* punteros a las lıneas de texto */
int nlines; /* numero de lıneas leıdas */
if((nlines = readlines (lineptr, MAXLINES)) >= 0)
{
sort(lineptr, nlines);
writelines(lineptr, nlines);
}
else
printf(" Demasiadas lıneas a ordenar\n ");
}
Veamos las definiciones de las funciones utilizadas
#define MAXLEN 1000
readlines (lineptr, maxlines) /* lee lıneas de entrada */
char *lineptr[];
int maxlines;
{
int len, nlines;
char *p, *alloc(), line[MAXLEN];
nlines=0;
while((len=getline(line, MAXLEN)) > 0)
if(nlines >= maxlines)
return -1;
else if((p=alloc(len) == NULL)
return -1;
else{
line[len-1] = ’\0’; /* quita el caracter nueva lınea */
strcpy(p, line);
lineptr[nlines++]=p;
}
return nlines;
}
El caracter nueva lınea al final de cada lınea se elimina, pues no afectaa la forma de ordenar.

8.5 · Ejemplos de utilizacion de punteros 153
writelines(lineptr, nlines) /* escribe lıneas */
char *lineptr[];
int nlines;
{
int i;
for(i = 0; i < nlines; i++)
printf("%s \n", lineptr[i]);
}
la novedad es la declaracion de lineptr.
char *lineptr[LINES];
indica que lineptr es un array de LINES elementos, cada uno de loscuales es un puntero a un caracter y ∗lineptr[i] tiene acceso a un caracter.
Una vez que la entrada y salida estan controladas, podemos procedera su ordenacion. El metodo elegido en este caso, no ha sido desarrolladopreviamente en teorıa, se denomina Shellsort.
sort(v,n) /* ordena las cadenas v[0],...v[n-1] *
* en orden creciente */
char *v[];
int n;
{
int gap, i,j;
char *temp;
for( gap = n/2; gap > 0; gap /= 2)
for(i = gap; i < n; i++)
for(j = i - gap; j >= 0; j -=gap){
if(strcmp(v[j], v[j+gap]) <= 0)
break;
temp=v[j];
v[j]=v[j+gap];
v[j+gap]=temp;
}
}
Debido a que los elementos de v son punteros, tambien debe serlo temp.Podrıa mejorarse el programa sustituyendo el metodo de ordenacion Shellpor ejemplo por Quicksort. Intentalo como ejercicio.
El programa anterior ha sido implementado, junto con las funciones re-adlines, writelines, sort, getline y alloc. El resultado es el fichero siguiente:
#include<stdio.h>

154 8 · El lenguaje de programacion C (IV)
#include<string.h>
#define NULL 0
#define MAXLINES 100 /*numero maximo de lineas a ordenar */
#define MAXLEN 1000
main(){
char *lineptr[MAXLINES];
int nlines; /* numero de lineas leidas */
if((nlines=readlines(lineptr, MAXLINES))>=0)
{
sort(lineptr, nlines);
writelines(lineptr, nlines);
}
else
printf("Demasiadas lineas a ordenar\n ");
}
readlines(lineptr, maxlines) /* lee las lineas de la entrada */
char *lineptr[];
int maxlines;
{
int len, nlines;
char *p, *alloc(), line[MAXLEN];
nlines=0;
while((len=getline(line,MAXLEN))>0)
if(nlines >= maxlines)
return (-1);
else if ((p=alloc(len)) == NULL)
return (-1);
else{
line[len-1]=’\0’; /* quita el caracter nueva linea */
strcpy(p,line);
lineptr[nlines++]=p;
}
return (nlines);
}
writelines(lineptr,nlines) /*escribe lineas */
char *lineptr[];
int nlines;
{
int i;
for (i=0; i < nlines; i++ )
printf("%s\n", lineptr[i]);
}
sort(v,n) /*ordena las cadenas v[0],...v[n-1] en orden creciente */
char *v[];
int n;
{
int gap,i,j;
char *temp;

8.5 · Ejemplos de utilizacion de punteros 155
for(gap=n/2; gap>0; gap/=2)
for(i=gap; i<n; i++)
for(j=i-gap; j>=0; j-=gap){
if(strcmp(v[j],v[j+gap])<=0)
break;
temp=v[j];
v[j]=v[j+gap];
v[j+gap]=temp;
}
}
getline(s,lim) /* para la cadena s da su longitud */
char s[];
int lim;
{
int c,i;
i=0;
while(--lim>0 && (c=getchar())!= EOF && c!= ’\n’)
s[i++]=c;
if(c==’\n’)
s[i++]=c;
s[i]=’\0’;
return(i);
}
#define ALLOCSIZE 1000 /*tama~no del area disponible */
static char allocbuf[ALLOCSIZE];
static char *allocp=allocbuf;
char *alloc(n) /*devuelve apuntador a cadena de caracteres */
int n;
{
if(allocp+n<=allocbuf+ALLOCSIZE){
allocp+=n;
return(allocp-n);
}
else
return(NULL);
}
Observaciones sobre E/S
La entrada y salida del programa anterior estan sin especificar. Unaopcion a utilizar desde el sistema operativo, es direccionar la entrada desdeun fichero, por ejemplo lineas.txt. Para ello basta teclear
$ a.out<lineas.txt
Si ademas queremos que la salida se escriba en un fichero, basta direc-cionar la salida del programa a dicho fichero:

156 8 · El lenguaje de programacion C (IV)
$ a.out<lineas.txt>salida.txt
Por ejemplo si en lineas.txt, aparecen los nombres de los alumnos deMetodos Numericos del curso 98-99. El fichero salida.txt resultante sera:
Beato UnaiBlanco Maria IsabelCao Rosa MariaCaracena Jose AntonioFuente Rosa Maria de laGomez Pedro AlbertoGuisasola AinhoaHerran BelenJuan Mario deMorillo AlbertoNunez DavidQuintela MonicaRivas SilviaRuiz Diego
Otra forma de hacer lo mismo, esta vez desde dentro del programa, esla que aparece a continuacion:
/* este es el programa en el fichero fordena.c */
/* ordena alfabeticamente cadenas de caracteres */
/* que lee del fichero lineas.txt */
/* la salida va al fichero salida.txt */
#include<stdio.h>
#include<string.h>
#define MAXLINES 500
#define MAXLENGTH 100
main(){
char *lineptr[MAXLINES];
char linea[MAXLINES][MAXLENGTH];
int c,i,n;
FILE *fp;
FILE *fresul;
fp=fopen("lineas.txt","r");
fresul=fopen("salida.txt", "a");
i=1;
while((lineptr[i] = fgets(&linea[i][0], MAXLENGTH,fp))
!= NULL && (i<MAXLINES))

8.5 · Ejemplos de utilizacion de punteros 157
i++;
n=i-1;
for(i=1; i<=n; i++)
{
printf("%s", lineptr[i]);
}
sort(lineptr+1, n);
fprintf(fresul,"\n\n Lineas ordenadas lexicograficamente: \n\n");
for (i=1; i<=n; i++)
{
fprintf(fresul, "%s", lineptr[i]);
}
return 0;
}
sort(lineptr, n)
char *lineptr[];
int n;
{
int gap,i,j;
char *temp;
for ( gap=n/2; gap >0; gap/=2)
for (i=gap; i<n; i++)
for (j=i-gap; j>=0; j-=gap){
if(strcmp(lineptr[j],lineptr[j+gap])<=0)
break;
temp=lineptr[j];
lineptr[j]=lineptr[j+gap];
lineptr[j+gap]=temp;
}
}
El cambio de la entrada de datos a un programa tambien es invisible si laentrada proviene de la salida de otro programa a traves de una interconexion,(pipe). En este caso, la linea de comando
$ prog1.out |prog2.out
ejecuta los programas prog1.out y prog2.out, y conecta la salida estandarde prog1.out con la entrada estandar de prog2.out.
En la practica muchos programas leen de un solo archivo y escriben en ununico archivo. Para estos programas, la entrada/salida mediante getchar(),putchar() y printf es totalmente adecuada.
Ademas varios archivos se pueden unir usando por ejemplo la utilerıacat de UNIX. Ello hace innecesario aprender a acceder a los archivos desde

158 8 · El lenguaje de programacion C (IV)
dentro del programa.
Por ejemplo, con un sencillo programa como el siguiente:
#include<stdio.h>
main()
{
int c;
while((c=getchar())!=EOF)
putchar(issuper(c) ? tolower(c) :c );
}
se traduce la entrada a minusculas. Las funciones issuper y tolower sonmacros definidas en stdio.h, que convierten en mayuscula y minusculas, res-pectivamente, el caracter leıdo. Con la lınea de comando:
$ cat lineas.txt lineas2.txt | lower.out> output
se unen los ficheros lineas.txt y lineas2.txt y se ejecuta sobre el ficherounido, el programa lower.out. La salida aparece en el archivo output.

Capıtulo 9
El lenguaje de programacion C (V)
9.1. Tipos de datos definidos por el usuario: es-
tructuras
Una estructura es un conjunto de diversas variables, posiblemente dedistinto tipo, agrupadas bajo un mismo nombre, lo que hace mas eficientesu manejo.
Las estructuras ayudan a organizar datos complicados, particularmen-te en programas grandes, puesto que permiten considerar como unidad unconjunto de variables relacionadas, en lugar de tratarlas como unidades in-dependientes.
Una fecha tiene por ejemplo varios componentes, dıa, mes, ano, dıa delano y nombre del mes. Estas cinco variables se pueden agrupar bajo unaestructura como la siguiente:
struct date {
int day;
int month;
int year;
int yearday;
char mon_name[4];
};
La palabra clave struct introduce la declaracion de una estructura, queno es mas que un conjunto de declaraciones encerradas entre llaves. Op-cionalmente se puede anadir un nombre despues de la palabre clave struct(como el date en el ejemplo anterior). A dicho nombre se le denomina nom-bre de la estructura y se puede emplear en declaraciones posteriores como
159

160 9 · El lenguaje de programacion C (V)
abreviatura de la estructura.
Los elementos o variables citados en una estructura se denominan miem-bros. Un miembro de una estructura, la propia estructura y una variableordinaria pueden tener el mismo nombre; siempre que se puedan distinguira traves del contexto.
La llave de cierre que termina la declaracion de la lista de miembrospuede ir seguida de una lista de variables
struct{...} x, y, z;
en el sentido de que x, y, z son declaradas las tres como estructuras delmismo tipo y se reserva la memoria correspondiente.
Si la declaracion de una estructura no va seguida de una lista de variables,no se reserva memoria, y se considera unicamente descrita una plantilla dela estructura. Posteriormente se puede utilizar dicha plantilla, para definirestructuras del mismo tipo. Por ejemplo, una vez construıda la plantilla dela estructura date,
struct date d;
declara la variable d como una estructura de tipo date. Si la variableestructura es de tipo externa o estatica, se puede inicializar de la siguienteforma:
struct date d={4 ,7 ,1776, 186, "Jul"};
Si nos queremos referir a un elemento de la estructura, tenemos queutilizar una construccion de la forma
nombre_de_estructura.miembro
El operador miembro de estructura ”·conecta el nombre de la estructuray el del miembro. Para dar un valor a la variable bisiesto a partir de laestructura date se hara:
bisiesto=d.year % 4 == 0 && d.year % 100 != 0|| d.year % 400 == 0;

9.2 · Operaciones con estructuras 161
o para comprobar el nombre del mes:
if (strcmp (d.mon_name, "Aug") == 0) . . .
o para convertir a minuscula el primer caracter del nombre del mes:
d.mon_name[0] = lower(d.mon_name[0]);
Por otra parte las estructuras se pueden anidar. Un registro de la nominapuede ser por ejemplo:
struct person{char name[NAMESIZE]; /* dimension = tama~no del nombre */char address[ADRSIZE];long zipcode;long ss_number;double salary;struct date birthdate;struct date hiredate;
};
La estructura persona tiene dos fechas. Si declaramos la variable empcomo una estructura del mismo tipo:
struct person emp;
entonces
emp.birthdate.month
se refiere al mes de nacimiento. El operador de miembro de una estruc-tura es asociativo de izquierda a derecha.
9.2. Operaciones con estructuras
Con una variable declarada como una estructura pueden realizarse lassiguientes operaciones:

162 9 · El lenguaje de programacion C (V)
1. Tomar su direccion mediante el operador &.
2. Acceder a uno de sus miembros.
3. Asignar una estructura a otra con el operador de asignacion.
Esta ultima operacion es posible solo en las nuevas versiones de C, perono en el C estandar. En general si se desean hacer programas portables, hayque tener cuidado con lo que no se puede hacer en C estandar.
Si queremos copiar una estructura como una unidad, o pasarla comoargumento a una funcion, tendremos que utilizar punteros.
Por otra parte, las estructuras automaticas no se pueden inicializar, solopueden inicializarse estructuras externas o estaticas.
Como ejemplos de uso, volveremos a escribir las funciones de conversionde fechas que vimos en el Tema 8, utilizando estructuras. Como no es po-sible pasar una estructura a una funcion como argumento, pasaremos lascomponentes por separado, o bien pasaremos un puntero a la estructura.
La primera alternativa emplea day of year igual que se escribio en elTema 8.
d.yearday = day_of_year(d.year, d.month, d.day);
La otra alternativa es pasar un puntero. Si hemos declarado hiredate(fecha de contrato) como una estructura del tipo date, es decir:
struct date hiredate;
hay que modificar la funcion day of year, para que su argumento sea unpuntero y no una lista de variables. La modificacion puede ser:
day_of_year (pd) /* convertir en dia del a~no */
struct date *pd;
{
int i, day, bisiesto;
day = pd -> day;
bisiesto=pd -> year % 4 == 0 && pd -> year % 100 != 0
|| pd -> year % 400 == 0;
for (i=1; i< pd -> month; i++)
day += day_tab[bisiesto][i];
return (day);
}

9.2 · Operaciones con estructuras 163
con lo que la llamada a la funcion serıa:
d.yearday = day_of_year(&hiredate);
La declaracion
struct date *pd;
especifica que pd es un puntero a una estructura de tipo date. La notacionpd− >year sirve para describir el operador de acceso al miembro de unaestructura. En este caso apunta al miembro denominado year. Puesto quepd apunta a una estructura, el miembro year se puede referenciar mediante
(*pd).year
pero dada la frecuencia con la que se emplean los punteros a estructu-ras, se ha introducido la notacion − > mas abreviada que la anterior. En(∗pd).year hacen falta los parentesis, ya que la precedencia del operador demiembro de estructura es mayor que la del operador *. Tanto − > como ·son asociativos de izquierda a derecha, de manera que
p -> q -> membemp.birthdate.month
equivalen a
(p -> q) -> memb(emp.birthdate).month
Podemos modificar en el mismo sentido, la funcion month day para uti-lizar estructuras:
month_day (pd) /* convertir a mes y dia */
struct date *pd;
{
int i, bisiesto;
bisiesto=pd -> year % 4 == 0 && pd -> year % 100 != 0
|| pd -> year % 400 == 0;
pd -> day = pd -> yearday;
for (i=1; pd -> day > day_tab[bisiesto][i]; i++)
pd -> day -= day_tab[bisiesto][i];
pd -> month =i;
}

164 9 · El lenguaje de programacion C (V)
Los operadores de estructuras − > y · junto con los parentesis y los cor-chetes tienen la maxima precedencia entre todos los operadores. Por ejemplo,dada la declaracion
struct{int x;int *y;
} *p;
la sentencia
++p -> x
incrementa x en lugar de p, ya que los parentesis implıcitos son ++(p− >x). Se deben utilizar parentesis para alterar el orden de aplicacion de losoperadores. (+ + p)− > x incrementa p antes de acceder a x, mientras que(p++)− > x lo incrementa despues. En este ultimo caso, no se necesitarıanparentesis ¿verdad?
Las estructuras tienen una aplicacion bastante util en arrays de variablesrelacionadas entre sı. Vamos a analizar un ejemplo de aplicacion en estesentido.
Considerese un programa que intenta contar las veces que aparece unapalabra clave de C. En tal programa necesitarıamos un array de caracterespara almacenar los nombres de las distintas palablas claves y otro paracontar el numero de ocurrencias.
Una posibilidad consistirıa en mantener dos arreglos en paralelo keywordy keycount
char *keyword[nkeys];int keycount[nkeys];
Sin embargo el hecho de que los dos arreglos se vayan a manipular enparalelo indica otra posible organizacion. Cada palabra clave es en realidadun par:
char *keyword;int keycount;

9.2 · Operaciones con estructuras 165
y se necesita un array de pares. Se puede entonces declarar una estructurade la forma
struct key {char *keyword;int keycount;}keytab[nkeys];
que define un array keytab de estructuras de este tipo y le asigna me-moria. Cada elemento del array es una estructura. Otra posible definiciones:
struct key {char *keyword;int keycount;};
struct key keytab[nkeys];
La estructura keytab puede inicializarse de una vez para siempre con elconjunto de nombres de las palabras clave de C. En cuanto al numero deocurrencias, se inicializa en todas ellas a 0.
struct key {
char *keyword;
int keycount;
} keytab[]={
"break", 0,
"case", 0,
"char", 0,
"continue", 0,
/* . . . */
"unsigned", 0,
"while", 0
};
Los inicializadores se agrupan por pares. Tambien se podrıan agruparentre llaves los inicializadores en cada fila.
{"break", 0},{"case", 0},. . .

166 9 · El lenguaje de programacion C (V)
Estas llaves no son necesarias si los inicializadores son variables simpleso cadenas de caracteres y si ademas estan todos presentes. La dimension delarray en el caso de que esten todos presentes la calcula el compilador y [] sedeja vacıo.
Escribimos a continuacion el programa que cuenta palabras clave. Se de-fine inicialmente keytab. El programa principal lee datos llamando repetida-mente a getword que busca en keytab mediante una funcion que implementaun algoritmo de busqueda binaria. (Dicha funcion de busqueda necesita quelas palabras clave en keytab esten ordenadas en orden creciente, o lo que eslo mismo en orden alfabetico).
#define MAXWORD 20
main() /*cuenta palabras clave de C */
{
int n, t;
char word[MAXWORD];
while ((t = getword(word,MAXWORD))!= EOF)
if(t == LETTER)
if ((n = binary(word, keytab, NKEYS)) >= 0)
keytab[n].keycount++;
for (n=0; n < NKEYS; n++)
if(keytab[n].keycount > 0)
printf("%4d %s\n",
keytab[n].keycount, keytab[n].keyword);
}
binary(word, tab, n) /*busca palabra en tab[0]...tab[n-1]*/
char *word;
struct key tab[];
int n;
{
int low, high, mid, cond;
low = 0;
high = n-1;
while (low <= high){
mid = (low+high) / 2;
if ((cond = strcmp(word, tab[mid].keyword)) < 0)
high = mid - 1;
else if (cond > 0)
low = mid + 1;
else
return(mid);
}
return(-1);
}

9.2 · Operaciones con estructuras 167
La funcion getword la veremos un poco mas adelante. De ella solo sabe-mos por ahora, que devuelve LETTER cada vez que encuentra una palabra,y copia la palabra en su primer argumento word.
La constante NKEY S es el numero de palabras que caben en keytab.Esta cantidad puede determinarse al contar las palabras clave en la tabla,pero es mas comodo y seguro que esta cantidad se calcule automaticamente,puesto que ademas dicha lista puede variar. Una posibilidad es utilizar elhecho de que el tamano del array se conoce en el momento de la compilacion.El numero de elementos es
tamano de keytab (40) / tamano de struct key (2)
C tiene un operador unitario llamado sizeof que calcula el tamano decualquier objeto en el momento de la compilacion. La expresion sizeof(objeto)devuelve un entero igual al tamano del objeto especificado. Dicho objetopuede ser una variable, un array o una estructura, el nombre de un tipobasico como int o double, o el nombre de una estructura. En nuestro caso,el numero de palabras clave se obtiene de la siguiente manera.
#define NKEYS (sizeof(keytab) /sizeof(struct key)) /% (20) %/
Vamos a describir ahora la funcion getword. Dicha funcion devuelve laconstante LETTER si el sımbolo es una palabra (cadena de letras y dıgitosque comienza con una letra, o bien un unico caracter). Si se alcanza el finaldel archivo, la funcion devuelve EOF.
getword(w, lim) /* leer la siguiente palabra */
char *w;
int lim;
{
int c, t;
if(type(c = *w++ = getch()) != LETTER){
*w = ’\0’;
return (c);
}
while (--lim >0) {
t = type(c = *w++ =getch());
if (t != LETTER && t != DIGIT) {
ungetch(c);
break;
}
}
*(w-1) = ’\0’;
return(LETTER);
}

168 9 · El lenguaje de programacion C (V)
getword utiliza las rutinas getch y ungetch que vimos en el Tema 8.Cuando acaba la recoleccion de una cadena alfanumerica se llama a la rutinaungetch para devolver el ultimo caracter leıdo, que sera el siguiente en serprocesado en la proxima llamada.
getword llama a type para determinar el tipo de caracter de entrada.La funcion type descrita a continuacion, es valida solo para el conjunto decaracteres ASCII.
type(c) /*devuelve el tipo de un caracter ASCII*/
int c;
{
if(c >= ’a’ && c <= ’z’ || c >= ’A’ && c <= ’Z’)
return LETTER;
else if (c >= ’0’ && c <= ’9’)
return DIGIT;
else
return c;
}
Las constantes simbolicas LETTER y DIGIT pueden tener cualquiervalor que no entre en conflicto con un caracter alfanumerico o EOF; laselecciones obvias son:
#define LETTER ’a’#define DIGIT ’0’
El programa correspondiente esta implementado y su nombre es cuenta.c.
9.3. Punteros a estructuras y estructuras ligadas.
Arboles binarios. Ejemplos de uso
Vamos a volver a escribir un programa en C que cuente palabras clave.Esta vez vamos a utilizar punteros en lugar de ındices del array. Hay quecambiar main y binary, que quedarıan de la siguiente forma:
main() /*cuenta palabras clave de C */
{
int t;
char word[MAXWORD];
struct key *binary(), *p;
while ((t = getword(word,MAXWORD))!= EOF)
if(t == LETTER)

9.3 · Punteros a estructuras y estructuras ligadas. Arboles binarios. Ejemplos de uso169
if ((p = binary(word, keytab, NKEYS)) != NULL)
p->.keycount++;
for (p = keytab; p < keytab + NKEYS; p++)
if(p -> keycount > 0)
printf("%4d %s\n", p->keycount, p ->keyword);
}
struct key *binary(word, tab, n) /*busca palabra en
tab[0]...tab[n-1]*/
char *word;
struct key tab[];
int n;
{
int cond;
struct key *low = &tab[0];
struct key *high = &tab[n-1];
struct key *mid;
while (low <= high){
mid = low + (high-low) / 2;
if ((cond = strcmp(word, mid -> keyword)) < 0)
high = mid - 1;
else if (cond > 0)
low = mid + 1;
else
return(mid);
}
return(NULL);
}
En la nueva version se aprecian varios cambios. La declaracion de binaryindica que devuelve un puntero a una estructura de tipo key, en lugar deun entero; esta declaracion hay que hacerla en main y en binary. Si binaryencuentra la palabra, devuelve un puntero a ella, en caso contrario devuelveNULL.
Ademas el acceso a los elementos de keytab se hace a traves de punteros.Esto provoca bastante cambio en binary: el calculo del elemento central nopuede hacerse como antes
mid = (low+high)2
ya que la suma de los punteros no produce ningun tipo de respuesta util(tampoco dividir por 2), que de hecho es ilegal. El calculo hay que cambiarlopor
mid = low + (high−low)2
que hace que mid apunte al elemento situado en la mitad de low y high.

170 9 · El lenguaje de programacion C (V)
Tambien hay que observar los inicializadores de low y high. Se puedeinicializar un puntero con la direccion de un objeto definido previamente,que es en este caso lo que se hace.
En main se tendra:
for (p = keytab; p < keytab + NKEYS; p++)
Si p es un puntero a una estructura, cualquier operacion aritmetica quese realice con el tendra en cuenta el tamano de la estructura, por lo quep + + incrementa p en la cantidad adecuada para acceder al siguiente ele-mento del arreglo de estructuras. No se debe suponer que el tamano de unaestructura es la suma de los tamanos de cada uno de los miembros, ya quelos requerimientos de alineacion de los diferentes objetos pueden ocasionarhuecos en la estructura.
Por ultimo hay que comentar algo sobre el formato de un programa.Cuando una funcion devuelve un tipo complicado como
struct key *binary(word, tab, n)
puede ser difıcil encontrar el nombre de la funcion. Una forma alternativade escribirlo, quiza mas clara puede ser
struct key *binary(word, tab, n)
Vamos a analizar por ultimo el siguiente ejemplo. Supongase que se de-sea contar el numero de ocurrencias de todas las palabras de algun texto.Dado que de entrada no se conoce la lista de palabras, no se pueden ordenarpara utilizar un algoritmo de busqueda binaria. Tampoco serıa correcta unabusqueda lineal de cada palabra encontrada, puesto que serıa un procedi-miento muy lento. ¿Como podemos organizar nuestros datos para controlareficientemente una lista de palabras arbitrarias?
Una solucion es mantener en todo momento las palabras ordenadas, co-locando en su sitio cada palabra que llega. Esto no es posible hacerlo, des-plazando las palabras en un array lineal, pues se emplearıa mucho tiempo.Lo que sı podemos utilizar es una estructura de datos denominada arbolbinario.
El arbol va a contener un nodo por cada palabra diferente, en cada nodotendremos:

9.3 · Punteros a estructuras y estructuras ligadas. Arboles binarios. Ejemplos de uso171
un puntero a los caracteres de la palabra
un contador del numero de ocurrencias
un puntero a su hijo izquierdo (que es un nodo)
un puntero a su hijo derecho (que tambien es un nodo)
Ningun nodo puede tener mas de dos hijos, pero puede tener uno oninguno. La estructura del arbol esta definida, de manera que: dado unnodo, el subarbol izquierdo contiene palabras que son (lexicograficamente)menores que la palabra del nodo, y el subarbol derecho contiene palabras queson mayores que la palabra del nodo actual. Para averiguar si una palabra yaesta en el arbol, se comienza comparando dicha palabra con la almacenadaen el nodo raız del arbol.
Si coinciden, es que la palabra ya esta en el arbol, en este caso se ac-tualiza el contador de ocurrencias. Si la palabra es menor, se continua labusqueda por el subarbol izquierdo; si la palabra es mayor, es investigadaen el subarbol derecho. Si no existe descendiente en la direccion examinadaes que la palabra no esta en el arbol, y su lugar es el del descendiente queno existe.
Este proceso de busqueda es claramente recursivo, puesto que la busque-da en cualquier nodo se realiza de igual manera en cualquiera de sus hijos.
La estructura de cada nodo, puede estar definida de la siguiente manera:
struct tnode{ /* el nodo*/
char *word; /* puntero a los caracteres */
int count;
struct tnode *left; /*hijo izquierdo */
struct tnode *right; /*hijo derecho */
};
Es ilegal que una estructura contenga un elemento que sea ella misma,pero la sentencia
struct tnode *left; /*hijo izquierdo */
declara left como un puntero a un nodo, no como un nodo en sı.
El codigo del programa es muy corto ya que utiliza funciones que han sidodefinidas anteriormente. Dichas funciones son getword que lee la siguientepalabra de la entrada y alloc que obtiene memoria para las palabras.

172 9 · El lenguaje de programacion C (V)
El programa principal lee palabras llamando a getword y las anade alarbol mediante la funcion tree que luego veremos:
#define MAXWORD 20
main() /* cuenta frecuencia de palabras*/
{
struct tnode *root, *tree();
char word[MAXWORD];
int t;
root=NULL;
while(( t=getword(word, MAXWORD))!= EOF)
if(t == LETTER)
root = tree(root, word);
treeprint(root);
}
main presenta una palabra a comparar comenzando por la raız del arbol.En cada etapa, dicha palabra se compara con la almacenada en el nodoy se prosigue la busqueda por el subarbol derecho o izquierdo medianteuna llamada recursiva a tree. Pueden darse dos posibilidades, si la palabracoincide con una que esta en el arbol, se incrementa el contador, mientrasque si se encuentra un puntero nulo, esto quiere decir que hay que crear yanadir un nodo al arbol. Si se crea un nodo, tree devuelve su puntero parapoder instalarlo en el nodo padre.
struct tnode *tree(p,w) /*introduce w en p o a continuacion de p */
struct tnode *p;
char *w;
{
struct tnode *talloc();
char *strsave();
int cond;
if(p == NULL)
{ /* llega una nueva palabra */
p=talloc();
p->word = strsave(w);
p->count = 1;
p->left = p->right = NULL;
}
else if ((cond = strcmp(w, p->word)) == 0)
p->count++; /*palabra repetida */
else if (cond < 0) /* las menores va al izdo.*/
p->left=tree(p->left, w);
else
p->right=tree(p->right, w);/*las mayores al dcho. */
return (p);
}
La memoria para crear el nuevo nodo se obtiene llamando a la rutinatalloc, adaptacion de la rutina alloc vista anteriormente. Devuelve un pun-

9.3 · Punteros a estructuras y estructuras ligadas. Arboles binarios. Ejemplos de uso173
tero a la zona de memoria donde almacenar el nodo.
La nueva palabra se copia a una zona vacıa mediante strsave, el contadorse inicializa y los dos hijos toman el valor NULL. Esta parte de la rutina seejecuta al alcanzar un extremo del arbol para anadir un nuevo nodo.
freeprint imprime el arbol en orden simetrico; dado un nodo, se imprimeel subarbol izquierdo (todas las palabras menores que la del nodo), el propionodo, y luego el subarbol derecho (todas las palabras mayores).
treeprint(p) /*imprime el arbol recursivamente */
struct tnode *p;
{
if(p!= NULL)
{
treeprint(p->left);
printf("%4d %s\n", p->count, p->word);
treeprint(p->right);
}
}
Por ultimo una observacion practica: el arbol puede estar desequilibradoo no balanceado, si las palabras no aparecen aleatoriamente y el tiempode ejecucion puede, entonces, ser muy alto. En el peor de los casos, si laspalabras ya estan en orden, el programa realiza una busqueda lineal.
Antes de acabar con el ejemplo, vamos a realizar una pequena reflexionsobre administradores de memoria. Parece deseable que a lo largo de unprograma exista un unico administrador de memoria, aunque maneje dife-rentes tipos de objetos. Pero si un gestor acepta peticiones de apuntadoresa char y a struct tnode se plantean dos cuestiones. En primer lugar ¿comosatisfacer los requerimientos de casi todas las computadoras que imponenrestricciones de alineacion a diferentes tipos de objetos? (por ejemplo, losenteros a menudo suelen ubicarse en una direccion par). En segundo lugar,¿como se puede expresar el hecho de que alloc devuelva diferentes tipos deapuntadores?.
La declaracion del tipo en alloc puede ser un inconveniente para cualquierlenguaje que realice una comprobacion de tipos. En C, un procedimiento esdeclarar que alloc devuelva un apuntador a caracteres y forzarlo medianteuna declaracion encastrada “cast” al tipo deseado.
Si p se declara como
char *p;

174 9 · El lenguaje de programacion C (V)
(struct tnode *)p;
lo convierte en un puntero a la estructura tnode. De esta forma la rutinatalloc se escribe:

9.3 · Punteros a estructuras y estructuras ligadas. Arboles binarios. Ejemplos de uso175
struct tnode *talloc()
{
char *alloc();
return((struct tnode *)alloc(sizeof(struct tnode)));
}
Observar que devuelve un puntero a estructura, de la posicion dondepuede empezar a ser almacenada una estructura de ese tamano.

176 9 · El lenguaje de programacion C (V)

Capıtulo 10
Solucion de sistemas de ecuaciones
lineales
Un sistema de ecuaciones lineales con m ecuaciones y n incognitas (n ≤m)
a11x1+ · · · +a1nxn = b1· · · · · · · · · · · ·
am1x1+ · · · +amnxn = bm
puede escribirse con notacion matricial como Ax = b. Si b = 0 el sistemase dice homogeneo. Un sistema homogeneo siempre tiene la solucion trivialx = 0. Si rang(A) = r < n, el sistema Ax = 0 tiene (n − r) solucioneslinealmente independientes.
El sistema anterior puede escribirse de la forma
x1a·1 + · · · + xna·n = b
que expresa el vector b como una combinacion lineal de los vectores columnade A. Con esta representacion, se puede ver que la condicion para que unsistema lineal tenga solucion es que b ∈ R(A), donde R(A) es el subespaciogenerado por todas las columnas de A. Esto puede escribirse diciendo que
rang(A, b) = rang(A)
Si m = n = r, entonces R(A) = Rn y el sistema puede resolverse paracualquier b. En este caso la solucion es unica y se obtiene como x = A−1b.
Si sucede que rang(A) = r < n, entonces el sistema Ax = b tiene n − rsoluciones.
177

178 10 · Solucion de sistemas de ecuaciones lineales
10.1. Metodos directos para la resolucion de sis-temas de ecuaciones lineales
Entenderemos como metodo directo aquel que necesita de un numerofinito de pasos para obtener la solucion, en este caso de un sistema de ecua-ciones lineales. Resultan mas eficientes para sistemas Ax = b en los que lamatriz A es densa (la mayorıa de sus elementos son no nulos). Sin embar-go, si la matriz es dispersa (una gran porcion de sus elementos son nulos)suelen ser mas apropiados los metodos iterativos. Dichos metodos propor-cionan una sucesion de soluciones aproximadas que converge a la verdaderasolucion cuando el numero de iteraciones tiende a infinito. En general, danbuenas soluciones con pocas operaciones elementales (no hay casi error deredondeo) y trabajan, principalmente con los elementos no nulos de la ma-triz, lo que permite que sean aplicados a sistemas de dimension mayor queun metodo directo.
La eleccion entre un metodo directo y un metodo iterativo depende nor-malmente del tamano del sistema y de la forma (densa o dispersa) de lamatriz A. En este capıtulo y en el siguiente, nos dedicaremos a comentaralgunos de los metodos directos mas habituales.
10.1.1. Sistemas triangulares
Los sistemas en los que la matriz A es triangular, son especialmentesencillos de resolver.
Consideremos por ejemplo un sistema triangular superior:
u11x1+ · · ·+ · · ·+ u1nxn = b1· · · · · · · · · · · · · · ·
un−1,n−1xn−1+ un−1,nxn = bn−1
unnxn = bn
Si uii �= 0, ∀i = 1, ..., n, entonces las incognitas pueden ser despejadas yobtenidas en el orden xn, xn−1, ..., x1.
xn =bnunn
xn−1 =bn−1 − un−1nxn
un−1,n−1
· · · · · ·

10.2 · Eliminacion gaussiana 179
x1 =b1 − u1nxn − · · · − u12x2
u11
sistema que puede ser escrito en forma compacta como:
xi =bi −∑n
k=i+1 uikxkuii
, i = n, n− 1, ..., 1
Como las incognitas se obtienen en orden decreciente, el algoritmo sedenomina de sustitucion hacia atras. Si el sistema fuese triangular inferior,la resolucion serıa similar. Suponiendo los coeficientes en la diagonal prin-cipal no nulos, lii �= 0, ∀i = 1, ..., n, las variables, en este caso se obtienensustituyendo hacia adelante, a partir de la expresion:
xi =bi −∑i−1
k=1 likxklii
, i = 1, 2, ..., n
De las expresiones anteriores, se deduce que la obtencion de las n incogni-tas necesita n divisiones. Ademas las sumas y multiplicaciones son
n∑i=1
(i− 1) =n(n− 1)
2≈ n2
2
Podemos decir entonces que la complejidad computacional, para la ob-tencion de las soluciones en un sistema lineal triangular es O(n
2
2 ).
10.2. Eliminacion gaussiana
Se trata del metodo mas importante de resolucion de sistemas de ecua-ciones lineales. La idea consiste en eliminar incognitas de forma sistematicahasta que el sistema tenga forma triangular, y entonces resolverlo. Conside-remos el sistema:
a11x1+ · · · +a1nxn = b1· · · · · · · · · · · ·
an1x1+ · · · +annxn = bn
o Ax = b, donde la matriz A = (aij) es no singular. En este caso el sistemaanterior tiene solucion unica.
Si a11 �= 0, podemos eliminar x1 de las (n−1) ultimas ecuaciones restandode la i-esima ecuacion la primera multiplicada por mi1 = ai1
a11, i = 2, ..., n

180 10 · Solucion de sistemas de ecuaciones lineales
Las n− 1 ultimas ecuaciones se pueden escribir despues de dicha opera-cion como:
a(2)22 x2+ · · · +a(2)
2n xn = b(2)2
· · · · · · · · · · · ·a
(2)n2 x2+ · · · +a(2)
nnxn = b(2)n
donde los coeficientes:
a(2)ij = aij −mi1a1j
b(2)i = bi −mi1b1
i = 2, ..., n
Este es un sistema de (n−1) ecuaciones con (n−1) incognitas. Si a(2)22 �= 0,
podemos eliminar de manera similar x2 de las n− 2 restantes ecuaciones.
Si llamamosmi2 = a(2)i2
a(2)22
, i = 3, ..., n, los coeficientes del sistema resultanteson:
a(3)ij = a
(2)ij −mi2a
(2)2j
b(3)i = b
(2)i −mi2b
(2)2
i = 3, ..., n
Los elementos a11, a(2)22 , a
(3)33 , ... se denominan elementos de pivotaje o
pivotes. Si todos ellos son no nulos, podemos continuar la eliminacion ydespues de (n− 1) pasos llegar a:
a(n)nn xn = b(n)
n
Si escribimos el sistema triangular resultante:
a(1)11 x1+ · · ·+ · · ·+ a
(1)1n xn = b
(1)1
a(2)22 x2+ · · ·+ a
(2)2n xn = b
(2)2
· · · · · · · · · · · · · · ·a
(n−1)n−1,n−1xn−1+ a
(n−1)n−1,nxn = b
(n−1)n−1
a(n)nn xn = b
(n)n
Senalar que el termino independiente b es transformado de la mismaforma que las columnas de A.
Ademas la descripcion de la eliminacion se simplifica si expresamos bcomo la ultima columna de A
a(k)i,n+1 = b
(k)i , i, k = 1, 2..., n

10.2 · Eliminacion gaussiana 181
Entonces las formulas se pueden resumir como sigue: La eliminacion serealiza en (n− 1) pasos, k = 1, ..., n− 1. En el paso k los elementos a(k)
ij coni, j > k, son transformados de acuerdo con:
mik =a
(k)ik
a(k)kk
,
a(k+1)ij = a
(k)ij −mika
(k)kj (10.1)
i = k + 1, ..., n j = k + 1, ..., n + 1
Por otra parte si tenemos distintos sistemas de ecuaciones con la mismamatriz A:
Ax1 = b1, Ax2 = b2, · · · , Axp = bp
dichos sistemas pueden ser tratados simultaneamente, adjuntando bj comola n+ j-esima columna de A. La unica diferencia con el algoritmo dado en(10.1), es que el ındice j toma los valores k + 1, ..., n, ..., n + p. Despues dela eliminacion tendremos p sistemas triangulares para resolver.

182 10 · Solucion de sistemas de ecuaciones lineales
Coste operativo
Vamos a calcular el numero de operaciones aritmeticas necesario parareducir mediante la eliminacion gaussiana, un sistema con p terminos inde-pendientes, a su forma triangular. De las ecuaciones (10.1) se sigue que enel paso k se realizan (n−k) divisiones y (n−k)(n−k+p) multiplicaciones ysumas. Si estamos interesados en ver el coste operativo para valores grandesde n, podemos eliminar el numero de divisiones, de manera que el numerototal de operaciones es aproximadamente:
n−1∑k=1
(n− k)(n − k + p) =n−1∑k=1
(n− k)2 + pn−1∑k=1
(n− k) =
=(n− 1)n(2n − 1)
6+ p
(n− 1)n2
=
=n2(n− 1)
3− n(n− 1)
6+p
2n(n− 1) =
=n2(n− 1)
3+ (3p − 1)
n(n − 1)6
≈ 13n3 +
(3p − 1)6
n2
donde cada operacion es en realidad, una suma y una multiplicacion. Si seseparan las sumas de las multiplicaciones el coste operativo varıa. Como elnumero de operaciones necesario para resolver un sistema triangular es n2
2 ,tenemos que cuando p = 1 y n suficientemente grande, el trabajo principaldel algoritmo recae en la reduccion del sistema a una forma triangular.
10.3. Estabilidad numerica y su mejora. Pivotado
total y parcial. Complejidad algorıtmica
Hemos visto que el algoritmo de eliminacion gaussiana es inoperativo sialgun elemento a
(k)kk = 0.
Vamos a ver como remodelar el metodo anterior para hacer el pro-cedimiento operativo. La idea es buscar en este caso otro elemento a
(k)ik ,
i = k + 1, ..., n, en la columna k que sea distinto de 0. Dicho elemento tie-ne que existir, puesto que en otro caso, las k primeras filas de A serıanlinealmente dependientes y recordemos que A es no singular. Sea a(k)
rk �= 0 elelemento buscado, entonces podemos intercambiar las filas k y r y procedercon la eliminacion. De esto se sigue que cualquier sistema no singular deecuaciones puede ser reducido a una forma triangular mediante la elimina-cion gaussiana combinada con un intercambio de filas.
Para asegurar la estabilidad numerica, a menudo es necesario realizar el

10.3 · Estabilidad numerica y su mejora. Pivotado total y parcial. Complejidad algorıtmica183
intercambio de filas incluso cuando el pivote no es exactamente 0, pero escercano a 0.
Ejemplo 10.1
x1+ x2+ x3 = 1x1+ 1,0001x2+ 2x3 = 2x1+ 2x2+ 2x3 = 1
El sistema triangular que resulta es:
x1+ x2+ x3 = 10,0001x2+ x3 = 1
9999x3 = 10000
Si realizamos las sustitucion hacia atras y permitimos tres decimales:
x3 = 1, x2 = 0, x1 = 0
mientras que si permitimos cuatro decimales:
x3 = 1,0001, x2 = −1,0001, x1 = 1
Si resolvemos el sistema con pivotaje, cambiando las filas 2 y 3, el sistematriangular que obtenemos es:
x1+ x2+ x3 = 1x1+ 2x2+ 2x3 = 1x1+ 1,0001x2+ 2x3 = 2
⇒x1+ x2+ x3 = 1
x2+ x3 = 00,9999x3 = 1
Resolviendo con tres decimales:
x3 = 1, x2 = −1, x1 = 1
y si permitimos cuatro decimales:
x3 = 1,0001, x2 = −1,0001, x1 = 1
De este modo para prevenir posibles errores, es necesario elegir el pivoteen el paso k, de una de las siguientes maneras:
Pivotaje parcial

184 10 · Solucion de sistemas de ecuaciones lineales
Elegir r como el menor entero para el que|a(k)rk | = max |a(k)
ik |, k ≤ i ≤ nk = 1, ..., n − 1 e intercambiar filas k y r
a(k+1)ij =
a(k)ij
{i = 1, ..., k, ∀ji = k + 1, ..., n, j = 1, ..., k − 1
0 i = k + 1, ..., n, j = k
a(k)ij −mika
(k)kj j = k + 1, ..., n + 1
donde mik =a(k)ik
a(k)kk
, i = k + 1, ..., n

10.3 · Estabilidad numerica y su mejora. Pivotado total y parcial. Complejidad algorıtmica185
Pivotaje total
Elegir r y s como los menores enteros para los que|a(k)rs | = max |a(k)
ij |, k ≤ i, j ≤ n
k = 1, ..., n − 1 e intercambiar filas k y r y las columnas k y s
a(k+1)ij =
a(k)ij
{i = 1, ..., k, ∀ji = k + 1, ..., n, j = 1, ..., k − 1
0 i = k + 1, ..., n, j = k
a(k)ij −mika
(k)kj j = k + 1, ..., n + 1
donde mik =a(k)ik
a(k)kk
, i = k + 1, ..., n
En cuanto al coste operativo, hemos visto que en el metodo de elimina-cion gaussiana sin pivotaje para un sistema de ecuaciones, necesita en tornoa n3
3 operaciones.
En el caso de pivotaje parcial, en cada paso k hay que anadir un nuevotipo de operacion: busqueda del maximo de (n− k + 1) valores.
Una forma de determinar el maximo de r elementos (v1, ..., vr) es:
Comparar v1 con v2: obtenemos max{v1, v2}.Comparar max{v1, v2} con v3: obtenemos max{v1, v2, v3}.· · · · · ·Comparar max{v1, ..., vr−1} con vr: obtenemos max{v1, ..., vr}.
El numero de comparaciones necesarias es r−1. De manera que el numerototal de operaciones es aproximadamente:
n3
3+n−1∑k=1
(n− k) ≈ n3
3+n2
2
En el caso del pivotaje total, en cada paso k hay que realizar la busquedadel maximo de (n − k + 1)2 elementos, de manera que el numero total deoperaciones es:
n3
3+n−1∑k=1
[(n− k + 1)2 − 1] =
n3
3+ [n2 + (n− 1)2 + ...+ 22]− (n − 1) =
≈ n3
3+n3
3=
2n3
3es decir el numero de operaciones se duplica.

186 10 · Solucion de sistemas de ecuaciones lineales
10.4. La variante de Gauss-Jordan
Se trata de un metodo tan eficiente como la eliminacion gaussiana y mascaro en cuanto a coste operativo. Se eliminan incognitas transformando elsistema en diagonal. Dado el sistema Ax = b, A no singular, existe una unicasolucion.
a11x1+ · · · +a1nxn = b1· · · · · · · · · · · ·
an1x1+ · · · +annxn = bn
Si a11 �= 0, podemos eliminar x1 de las (n − 1) restantes ecuacionesrestando de la i-esima ecuacion la primera multiplicada por mi1 = ai1
a11,
i = 2, ..., n. De manera que el sistema resultante es:
a11x1+ a12x2+ · · · +a1nxn = b1
a(2)22 x2+ · · · +a(2)
2n xn = b(2)2
· · · · · · · · · · · ·a
(2)n2 x2+ · · · +a(2)
nnxn = b(2)n
Si a(2)22 �= 0, eliminamos x2 de las (n− 1) restantes ecuaciones.
-. Para eliminarla de la primera ecuacion, restamos de dicha ecuacion lasegunda multiplicada por:
m12 =a12
a(2)22
-. Para eliminarla de las (n − 2) ultimas, restamos de cada ecuacion lasegunda multiplicada por:
mi2 =a
(2)i2
a(2)22
, i = 3, 4, ..., n
De nuevo a los elementos a11, a(2)22 , ..., a
(n)nn se les denomina pivotes. Si
todos ellos son no nulos, se realiza la eliminacion, llegando despues de npasos al sistema:
a(n+1)11 x1 = b
(n+1)1
a(n+1)22 x2 = b
(n+1)2
· · · · · · · · · · · · · · ·a
(n+1)nn xn = b
(n+1)n

10.4 · La variante de Gauss-Jordan 187
que puede resolverse:
xk =b(n+1)k
a(n+1)kk
, k = 1, ..., n
Es decir, la eliminacion se realiza en n pasos, k = 1, ..., n. Si A(1) = A yb(1) = b.
A(1) = A, b(1) = b
k = 1, ..., n a(k+1)ij =
a(k)ij
{j = 1, ..., k − 1, ∀ij = k, ..., n, i = k
0 j = k, i �= k
a(k)ij −mika
(k)kj j = k + 1, ..., n, i �= k
donde mik =a(k)ik
a(k)kk
b(k+1)i =
{b(k)i i = k
b(k)i −mikb
(k)k i �= k
En cuanto al pivotaje, tanto el parcial como el total se realizan de manerasimilar al realizado en la eliminacion gaussiana. El pivote se busca entre loselementos de la columna posteriores al elemento considerado, no entre losanteriores.
Coste operativo
En cada paso k:
-. Divisiones: 1 por cada fila para calcular el multiplicador mik, i �= k.(n− 1) filas.
-. Multiplicaciones y sumas (contadas como un sola operacion): 1 porcada uno de los (n−k+1) elementos de cada fila y hay (n−1) filas. Ademas1 por cada termino independiente y hay (n− 1).
En total:
n∑k=1
[1 + (n− k + 1) + 1](n − 1) =
= (n− 1)n∑k=1
[2 + (n− k + 1)] =
= (n− 1)[2n +n∑k=1
(n− k + 1) =

188 10 · Solucion de sistemas de ecuaciones lineales
= 2n(n− 1) + (n− 1)n(n+ 1)
2≈ n3
2
Faltarıan las n divisiones necesarias para resolver el sistema diagonal.
Observacion:
Eliminacion gaussiana: n3
3 + n2
2 ¡n3
2 + n en la variante de Gauss-Jordan.

Capıtulo 11
Solucion de sistemas de ecuaciones
lineales sin inversion de la matriz de
coeficientes
11.1. La descomposicion LU
Hemos visto que el metodo de eliminacion gaussiana permite tratar va-rios sistemas con distintos terminos independientes. Sin embargo en muchasocasiones, todos los terminos independientes no se conocen al principio. Po-demos querer resolver por ejemplo:
Ax1 = b1, Ax2 = b2, donde b2 es funcion de x1
Parece entonces que habrıa que repetir el proceso de eliminacion desdeel principio, con un coste considerable en cuanto al numero de operaciones.Veremos como evitar esto.
Supongamos que tenemos una descomposicion de A en el producto deuna matriz triangular inferior y otra triangular superior. A = LU .
Entonces el sistema Ax = b ⇔ LUx = b, que se puede descomponer endos sistemas triangulares:
Ux = y, Ly = b
De manera que si conocieramos L y U podrıamos resolver Ax = b, con21
2n2 = n2 operaciones.
Teorema 11.1 Sea A una matriz nxn, y denotemos por Ak la matrizde orden kxk formada por la interseccion de las k primeras filas y columnas
189

19011 · Solucion de sistemas de ecuaciones lineales sin inversion de la matriz de coeficientes
de A. Si det(Ak) �= 0, k = 1, ..., n − 1, entonces existe una unica matriztriangular inferior L = (lij) con lii = 1, i = 1, ..., n y una unica matriztriangular superior U = (uij), tal que LU = A.

11.1 · La descomposicion LU 191
Demostracion:
Por induccion sobre n. Para n = 1, la descomposicion a11 = 1u11 esunica. Supongamos que el resultado es cierto para n = k − 1 y lo vamos aprobar para n = k.
Descomponemos Ak, Lk y Uk de la siguiente forma:
Ak =
(Ak−1 bcT akk
), Lk =
(Lk−1 0lT 1
), Uk =
(Uk−1 u0 ukk
)
donde b, c, l y u son vectores columna con n−1 componentes: si formaramosel producto LkUk y lo identificamos con Ak:
Lk−1Uk−1 = Ak−1, Lk−1u = b
lTUk−1 = cT , lTu+ ukk = akk
Por hipotesis de induccion, Lk−1 y Uk−1 estan determinadas de maneraunica y como det(Ak) = det(Lk)det(Uk) �= 0, son no singulares.
Se sigue que u y l quedan unicamente determinadas por los sistemastriangulares: Lk−1u = b, lTUk−1 = cT , sı y solo si UT
k−1l = c. Finalmenteukk = akk − lTu. Entonces Lk y Uk estan unicamente determinadas, lo cualconcluye la demostracion. •
Ejemplo 1: Si para algun k, det(Ak) = 0, puede no existir la descom-posicion LU de A. Por ejemplo si
A =
(0 11 1
)
y suponemos que A = LU , donde
LU =
(l11 0l21 l22
)(u11 u12
0 u22
)=
(l11u11 l11u12
l21u11 l21u12 + l22u22
)=
(0 11 1
)
Entonces forzosamente l11 = 0 o u11 = 0, pero entonces la primera filade L o la primera columna de U son 0, por lo tanto A �= LU .
Sin embargo si las filas de A se intercambian, entonces la matriz se con-vierte en triangular (superior), y la descomposicion LU existe trivialmente.En efecto, para cualquier matriz no singular A, las filas pueden ser reor-denadas, de manera que exista una transformacion LU . Esto se sigue dela equivalencia entre la eliminacion gaussiana y la descomposicion LU queveremos ahora.

19211 · Solucion de sistemas de ecuaciones lineales sin inversion de la matriz de coeficientes
Supongamos primero que la matriz A es tal que la eliminacion gaussianapuede ser llevada a cabo sin intercambio de filas ni columnas. Podemospensar en la eliminacion como en la generacion de una sucesion de matrices,A = A(1), A(2), ..., A(n), donde A(k) = (a(k)
ij ) es la matriz que se obtiene antesde realizar la eliminacion de los coeficientes correspondientes a la variablexk:
a(1)11 a
(1)12 · · · a
(1)1k · · · a
(1)1n
a(2)22 · · · a
(2)2k · · · a
(2)2n
· · · · · · · · · · · · · · · · · ·a
(k)kk · · · a
(k)kn
· · · · · · · · · · · · · · · · · ·a
(k)nk · · · a
(k)nn
Consideremos ahora un cierto elemento aij de A durante la eliminacion.Si aij esta en la diagonal principal o sobre esta (es decir i ≤ j), entonces:
a(n)ij = ... = a
(i+1)ij = a
(i)ij , i ≤ j
Si aij esta bajo la diagonal principal, (i > j), entonces:
a(n)ij = ... = a
(j+1)ij = 0, i > j
Ademas los elementos aij son transformados en cada iteracion k =1, ..., r, donde r = mın(i− 1, j), de manera que
a(k+1)ij = a
(k)ij −mika
(k)kj
Si sumamos estas ecuaciones para k = 1, ..., r, obtenemos:r∑
k=1
a(k+1)ij =
r∑k=1
a(k)ij −
r∑k=1
mika(k)kj ⇔
r∑k=1
a(k+1)ij −
r∑k=1
a(k)ij = −
r∑k=1
mika(k)kj ⇔
a(r+1)ij − a
(1)ij = −
r∑k=1
mika(k)kj
expresion que puede ser escrita: (a(1)ij = aij)
aij =
a
(i)ij +
∑i−1k=1mika
(k)kj , si i ≤ j, (r = i− 1)
0 +∑jk=1mika
(k)kj , si i > j, (r = j)

11.1 · La descomposicion LU 193
o, si definimos mii = 1, i = 1, ..., n:
aij =p∑
k=1
mika(k)kj , p = mın{i, j}
Sin embargo, estas ecuaciones son equivalentes a la ecuacion A = LU ,donde los elementos no nulos de L y U son:
(L)ik = mik, i ≥ k
(U)kj = a(k)kj , j ≥ k
Concluımos entonces que los elementos de L, son los multiplicadorescalculados en la eliminacion gaussiana y la matriz U , la descomposicionfinal de A obtenida mediante eliminacion gaussiana.
Entonces para obtener la matriz L, debemos guardar los multiplicadores,
mik =a(k)ik
a(k)kk
, en los lugares correspondientes a los elementos a(k)ik . Ademas los
elementos de la diagonal de L no necesitan ser almacenados.
Graficamente;
A =
a11 · · · · · · a1n
· · · · · · · · · · · ·· · · · · · · · · · · ·an1 · · · · · · ann
⇒
u11 · · · · · · u1n
m21 u22 · · · u2n
· · · · · · · · · · · ·mn1 · · · mnn−1 unn
= LU
Ademas, como detL = 1, detA = a(1)11 · · · a(n)
nn . En general:
det(Lk) = 1 ⇒ det(Ak) = a(1)11 · · · a(k)
kk , k = 1, ..., n
Entonces, la eliminacion gaussiana puede ser realizada sin intercambio defilas o columnas, sı y solo si det(Ak) �= 0, k = 1, ..., n− 1, que es la condicionpara la descomposicion unica en el Teorema 11.1.
Nota: Sabemos que la eliminacion gaussiana puede resultar ines-table sin pivotaje parcial, de manera que es usual el intercambiode filas durante la eliminacion. Es importante senalar que en este

19411 · Solucion de sistemas de ecuaciones lineales sin inversion de la matriz de coeficientes
caso, despues de los correspondientes intercambios obtendremosuna descomposicion LU = A′, donde A′ es la matriz que resul-tarıa si los intercambios realizados en la eliminacion, se realizanen el mismo orden en la matriz A.
11.2. Escenas compactas en la eliminacion gaus-
siana: metodos de Doolittle, Crout y Cho-leski
Cuando resolvemos un sistema de ecuaciones lineales mediante elimina-cion gaussiana tenemos que obtener aproximadamente n3
3 resultados inter-medios, uno para cada operacion. Incluso para valores pequenos de n estoresulta bastante tedioso, y en ocasiones da lugar a errores. Sin embargo,es posible ordenar los calculos de manera que los elementos de L y U seobtengan directamente. Como en la eliminacion gaussiana, en el paso k sedeterminan los elementos de la fila k-esima de U y de la columna k-esimade L, pero en el metodo compacto, los elementos aij , i, j > k estan todavıasin intercambiar. La ecuacion matricial A = LU es equivalente a
aij =r∑p=1
mipupj, r = mın(i, j), mip = lip
Esto puede suponer unas n2 operaciones para las n(n+1) incognitas enL y U . Para el k-esimo paso utilizamos las siguientes ecuaciones:
akj =k∑p=1
mkpupj, j ≥ k,
aik =k∑p=1
mipupk, i > k,
Si hacemos mkk = 1, entonces los elementos
ukk, ukk+1, ..., ukn, y mk+1k, ...,mnk
pueden ser obtenidos en este orden de las expresiones:
ukj = akj −k−1∑p=1
mkpupj, j ≥ k
mik =aik −
∑k−1p=1 mipupk
ukk, i > k

11.2 · Escenas compactas en la eliminacion gaussiana: metodos de Doolittle, Crout y Choleski195
Este se denomina metodo de Doolittle y da como resultado los mismosfactores L, U que la eliminacion gaussiana. El metodo es incluso numeri-camente equivalente a la eliminacion gaussiana, aunque para ordenadoresdonde las sumas y los productos pueden ser acumuladas en doble precision,este metodo presenta ventajas computacionales sobre el metodo de elimina-cion gaussiana.
Si en lugar de normalizar de manera quemkk = 1, lo hacemos de maneraque los elementos de la diagonal principal de U cumplan ukk = 1, k = 1, ..., n,se obtiene el metodo de Crout. En este caso, las ecuaciones para el paso kson:
mik = aik −k−1∑p=1
mipupk, i = k, k + 1, ..., n
ukj =akj −
∑k−1p=1 mkpupj
mkk, j = k + 1, ..., n
En ambos casos hemos supuesto que no ha habido intercambio de filas(pivotaje). Sin embargo es esencial pensar en ambos metodos como candi-datos a ser combinados con estrategias de pivotaje (al menos parcial). Masdifıcil resulta, sin embargo, realizar pivotaje total en cualquiera de los doscasos.
Caso de matrices simetricas definidas positivas
Sea A = (aij) una matriz simetrica i.e. aij = aji, 1 ≤ i, j ≤ n. Proba-remos que si la eliminacion gaussiana se realiza, sin intercambio de filas nicolumnas (pivotaje), entonces:
a(k)ij = a
(k)ji , k ≤ i, j ≤ n
es decir, los elementos transformados forman matrices simetricas de orden(n+ 1− k), k = 2, ..., n. Esta afirmacion se puede probar por induccion. Escierta para k = 1. En el paso k, los elementos son transformados de acuerdocon:
a(k+1)ij = a
(k)ij −mika
(k)kj = a
(k)ij − a
(k)ik
a(k)kk
a(k)kj
Si la hipotesis de simetrıa es cierta para algun k: (a(k)ij = a
(k)ji )
a(k+1)ij = a
(k+1)ji = a
(k)ji −mjka
(k)ki = a
(k)ji − a
(k)jk
a(k)kk
a(k)ki

19611 · Solucion de sistemas de ecuaciones lineales sin inversion de la matriz de coeficientes
y se obtiene el resultado.
Hemos visto entonces, que si la eliminacion gaussiana se realiza sin pi-votaje, en una matriz simetrica, tenemos que computar unicamente los ele-mentos de A(k), que estan en la diagonal principal o sobre ella. Esto significaque el numero de operaciones realizado es aproximadamente n3
6 y se ahorraaproximadamente la mitad del espacio en memoria.
Sin embargo, no es siempre posible realizar eliminacion gaussiana sinpivotaje sobre matrices simetricas. La simetrıa se preserva si elegimos cual-quier elemento de la diagonal principal como pivote y completamos el pivo-taje, pero como muestra la matriz(
0 11 ε
), |ε| << 1
a veces esto no resulta estable. Por otro lado, el intercambio de filas destruyela simetrıa, lo cual se ve en el mismo ejemplo. De manera que la eliminaciongaussiana anterior no se puede utilizar para cualquier matriz simetrica.
Para matrices simetricas definidas positivas, la eliminacion gaussiana sinpivotaje es siempre estable. Una forma de determinar si una matriz es defini-da positiva es utilizar el siguiente criterio que enunciamos sin demostracion.
Teorema 11.2(Criterio de Sylvester) Una matriz simetrica de ordennxn es definida positiva sı y solo si det(Ak) > 0, k = 1, ...n, donde Ak es lamatriz kxk formada por las k primeras filas y columnas de A.
Es decir, todos los pivotes de A son positivos sı y solo si A es definidapositiva y la eliminacion gaussiana esta bien definida.

11.2 · Escenas compactas en la eliminacion gaussiana: metodos de Doolittle, Crout y Choleski197
Teorema 11.3 Para una matriz simetrica definida positiva A:
|aij|2 ≤ aiiajj
y por lo tanto los mayores elementos de A estan en la diagonal.
Demostracion:
Si la misma permutacion se aplica a las filas y columnas de A, la ma-triz resultante es simetrica y definida positiva. Para k = 2 y una ciertapermutacion, el Terorema 11.2, da
0 < det
(aii aijaji ajj
)= aiiajj − (aij)2
de donde se obtiene el resultado. •
Teorema 11.4 Sea A una matriz simetrica y definida positiva. Entoncesexiste una unica matriz triangular superior R con elementos positivos en ladiagonal principal tal que A = RTR.
Demostracion:
Del Teorema 11.1, tenemos que A = LU , donde u11 = a11 > 0 y
ukk =det(Ak)det(Ak−1)
> 0, k = 2, ..., n
Si introducimos la matriz diagonal D = diag(u11, ..., unn), podemos es-cribir:
A = LU = LDD−1U = LDU ′, U ′ = D−1U
donde L y U ′ son matrices triangulares con unos en la diagonal principal yestan unicamente determinadas.
Como A es simetrica:
A = AT = (U ′)TDLT o LT = U ′ = D−1U
Ahora, si hacemos R = D− 12U , donde D− 1
2 tiene elementos positivos en
su diagonal (u− 1
2kk ), obtenemos:
RTR = UTD− 12D− 1
2U = UTD−1U = LU = A

19811 · Solucion de sistemas de ecuaciones lineales sin inversion de la matriz de coeficientes
Por lo tanto, podemos afirmar que la eliminacion gaussiana sin pivotajees siempre posible y estable en matrices simetricas definidas positivas yademas es posible elegir los elementos de la diagonal de L reales y de maneraque U = LT . •
Ası, la eliminacion compacta en este caso particular, nos darıa expresio-nes en las que ukk = mkk y upk = mkp,
ukk = mkk = (akk −k−1∑p=1
m2kp)
12
uki = mik =aik −
∑k−1p=1 mipmkp
mkk, i = k + 1, ..., n
Este metodo se denomina metodo de Choleski o de la raız cuadrada. Encuanto a coste operativo:
Son necesarias del orden de n2
2 operaciones hasta obtener la descompo-sicion LLT , +n raıces cuadradas, (1 raız cuadrada ≈ 6 operaciones). Luegon2
2 + 6n operaciones.
LLTx = b
LTx = y → sistema triangular inferior (n2
2 operaciones).
Ly = b → sistema triangular superior (n2
2 operaciones).
Total: n2
2 + n2
2 + n2
2 + 6n = 3n2
2 (+6n de las raıces cuadradas).












![12375368[1]ultimos dias de la atlantida](https://img.pdfslide.us/doc/110x75/556343b1d8b42a6f7b8b46e2/123753681ultimos-dias-de-la-atlantida.jpg)