Embed Size (px)
Citation preview

The predominant method for large-scale population research analysis of whole-genomes has historically involved sequencing an individual genome using short-reads, and aligning to a consensus reference sequence. Shortcomings of this method include loss of haplotype knowledge, genetic phasing information, and structural variation. While short-read sequencing provides sufficient power to call single nucleotide variants (SNVs) across most of the consensus genome, a comprehensive analysis of the genome of each unique individual is not possible.
The 10x Genomics Chromium™ Genome Solution uses the power of Linked-Reads, a unique data type, to tag short reads from the same high molecular weight genomic DNA fragment with molecular barcodes, thus allowing the placement of short-read information in the context of the whole genome. This unique approach resolves genetic phasing and structural variation, and detects variants in previously inaccessible and complex regions of the genome.
PerkinElmer and 10x Genomics have created an efficient, automated workflow to maximize high molecular weight gDNA extraction, sample QC, and sample prep, providing Linked-Reads sequencing capabilities for a variety of sample types including saliva, DBS, and blood/plasma.
A collaborator in automating the 10x Genomics Chromium technology
For reseach use only. Not for use in diagnostic procedures.
PerkinElmer Linked-Reads Sequencing Solutions Include:
• chemagic™ 360 high molecular weight nucleic acid sample extraction technology
• Sciclone® NGS (Zephyr® NGS) automated sample prep workstations customized for 10x Genomics chip preparation and library preparation
• LabChip® GX Touch™ Nucleic Acid Analyzer automated capillary electrophoresis for gDNA analysis and QC
COMPLETE LONG READSEQUENCING WORKFLOWS

PerkinElmer and 10x Genomics® Long-Read Sequencing Workflow
The chemagic™ 360 nucleic acid extractor uses proprietary M-PVA magnetic beads in combination with the unique chemagen® Technology to isolate and purify nucleic acids from a variety of human samples such as blood, plasma, and saliva. The chemagen Technology features magnetizable rotating rods, combining the transfer and suspension of magnetic beads, to produce long and ultra-pure DNA fragments.
LabChip® GX Touch™ Nucleic Acid Analyzer microfluidics technology delivers rapid capillary electrophoresis analysis for DNA sample quality control, with fragment analysis in as few as 30 seconds per sample.
Normalization is required prior to 10X Genomics chip setup. Maintaining the integrity of the gDNA for long-range read quality and phasing is critical to this process. The Sciclone® NGS Workstation uses an intuitive normalization script optimized to eliminate gDNA degradation. A customized deck accommodates the chip fixture.
Powered by the GemCode™ Technology, the Chromium Controller massively partitions and molecularly barcodes ~1ng of DNA using microfluidics, producing sequencing-ready libraries with >1 million unique barcodes. After molecular barcoding, fragments are pooled and undergo standard library preparation. The barcoded DNA can then be bioinformaticaly stitched together to provide a new data type called Linked-Reads.
Post-recovery, after SPRI cleanup, library preparation is completed on the Sciclone® NGS workstation (Zephyr® NGS Workstation optional) using PerkinElmer / 10x Genomics protocols. The LabChip® GX Touch™ Nucleic Acid Analyzer platform quickly performs library QC.
Final libraries are quantified using qPCR and are compatible for sequencing on most Illumina® systems.
The Chromium Genome Solution includes Long Ranger™ Analayis Pipelines and Loupe™ Genome Browser, providing turn-key analysis pipelines and visualization tools utilizing Linked-Read data.
PerkinElmer offers a wide range of chemagic kits containing M-PVA magnetic beads to be used on the chemagic™ 360 instrument. The streamlined extraction workflow and optimized kit chemistry allow short extraction times (e.g. 25 min for 96 saliva samples) without compromising the yields or the quality of the DNA.
SEQUENCING

For a complete listing of our global offices, visit www.perkinelmer.com/ContactUs
Copyright ©2017-2018, PerkinElmer, Inc. All rights reserved. PerkinElmer® is a registered trademark of PerkinElmer, Inc. All other trademarks are the property of their respective owners.
AG021709_08_FL Printed in USA
PerkinElmer, Inc. 940 Winter Street Waltham, MA 02451 USA P: (800) 762-4000 or (+1) 203-925-4602www.perkinelmer.com
50000
40000
30000
20000
10000
0NA 12878 Control Saliva
DN
A S
ize,
bp
Sample ID
50 kb DNA Length from Saliva using chemagic™ Extraction
40000
30000
20000
10000
0
4e+06
3e+06
2e+06
1e+06
0e+00
Nu
mb
er o
f 50
bp
- 3
0 kb
Del
etio
ns
Nu
mb
er o
f SN
Ps C
alle
d
NA 12878 Control Saliva
Sample
NA 12878 Control Saliva
Sample
20000
10000
0
2500000
2000000
1500000
1000000
500000
0
Nu
mb
er o
f G
enes
Ph
ased
N50
Ph
ase
Blo
ck-L
eng
th
NA 12878 Control Saliva
Sample
NA 12878 Control Saliva
Sample
Reference
Sample with Deletion
Reference
Sample with Deletion
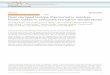
Figure 1. Unlock the Full Spectrum of Structural Variants: Most short-read methods struggle to call large structural variants, particularly balanced rearrangements such as inversions and translocations. With Linked-Reads, novel algorithms based on barcode-overlap and physical barcode-coverage facilitate the accurate and reliable detection of structural variants. Above, an example of a deletion and inversion that was called from the saliva sample which is visualized with Loupe™ Genome Browser.
Figure 2. Linked-Read analysis yielded contigs of an average of 50 kilobases in length.
Figure 3. Results from 10X Genomics linked-reads demonstrate similar phasing information between the extracted saliva from chemagen® and the control DNA, based on the number of genes.
Figure 4. Based on variant calling using SNPs and deletion blocks, the extracted saliva from chemagen® performed similarly to the control DNA, and exhibited significantly higher N50 phase blocking, associated with higher molecular weight DNA.
Homozygous Deletion
89 kb Inversion
Heterozygous Deletion
379 kb Inversion
Similar Variant Calling Performance from Saliva using chemagic™ Extraction Similar Phasing Performance from Saliva using chemagic™ Extraction
Number of 50 bp - 30 kb Deletions Number of Genes Phased (calculated) N50 Phase Block LengthNumber of SNPs
Magnitude of difference is consistent with difference in length (40 kb vs. 50 kb)