Embed Size (px)
Citation preview

Compiling CUDA and Other Languages for GPUs Vinod Grover and Yuan Lin

Agenda
Vision
Compiler Architecture
Scenarios
SDK Components
Roadmap
Deep Dive
SDK Samples
Demos
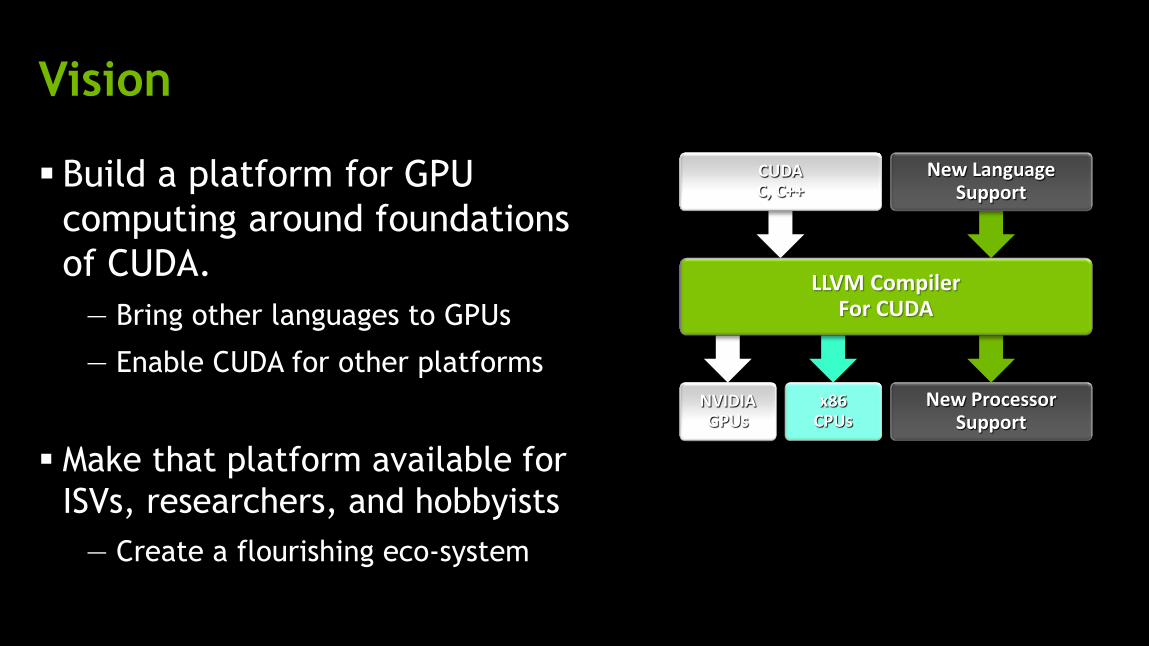
Vision
Build a platform for GPU
computing around foundations
of CUDA.
— Bring other languages to GPUs
— Enable CUDA for other platforms
Make that platform available for
ISVs, researchers, and hobbyists
— Create a flourishing eco-system
CUDA C, C++
LLVM Compiler For CUDA
NVIDIA GPUs
x86 CPUs
New Language Support
New Processor Support

Compiler Architecture
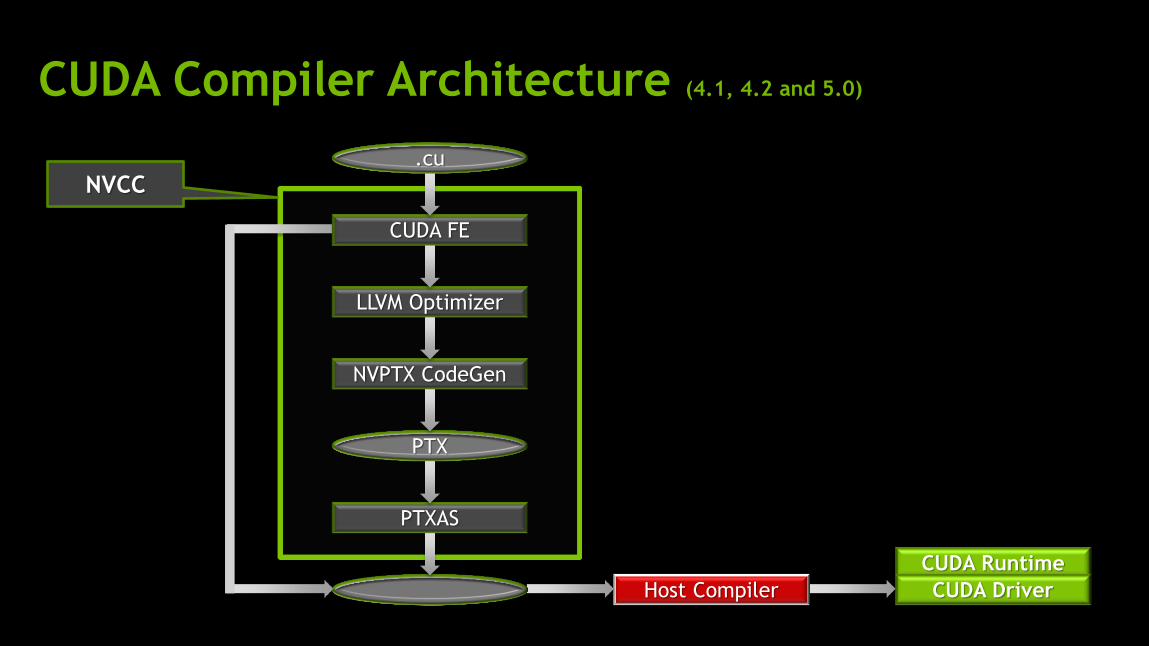
CUDA Runtime
CUDA Driver Host Compiler
CUDA Compiler Architecture (4.1, 4.2 and 5.0)
NVCC
PTXAS
PTX
NVPTX CodeGen
LLVM Optimizer
CUDA FE
.cu
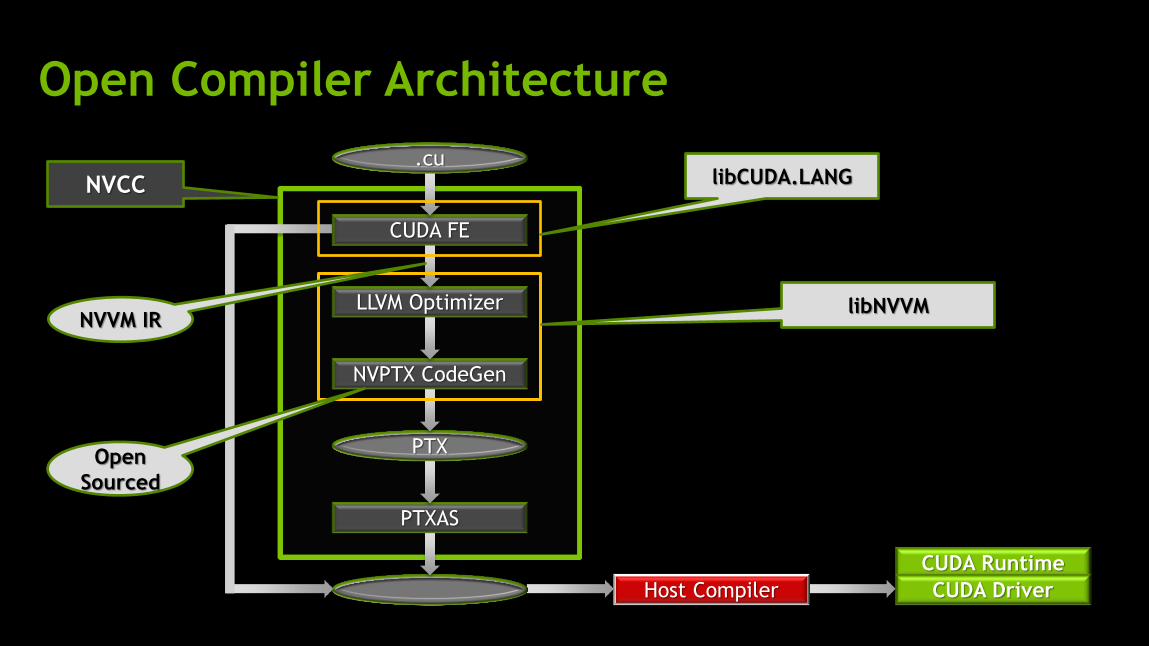
CUDA Runtime
CUDA Driver Host Compiler
Open Compiler Architecture
NVCC
PTXAS
PTX
NVPTX CodeGen
LLVM Optimizer
CUDA FE
.cu
Open
Sourced
NVVM IR libNVVM
libCUDA.LANG

Scenarios
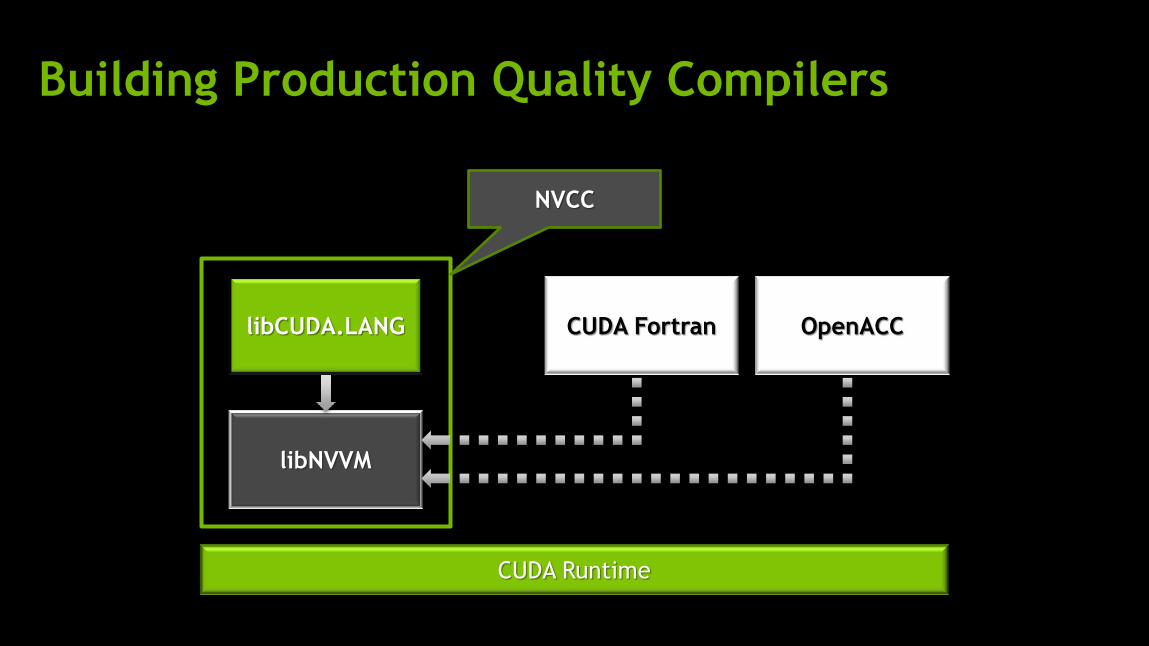
Building Production Quality Compilers
NVCC
CUDA Runtime
OpenACC CUDA Fortran
libNVVM
libCUDA.LANG
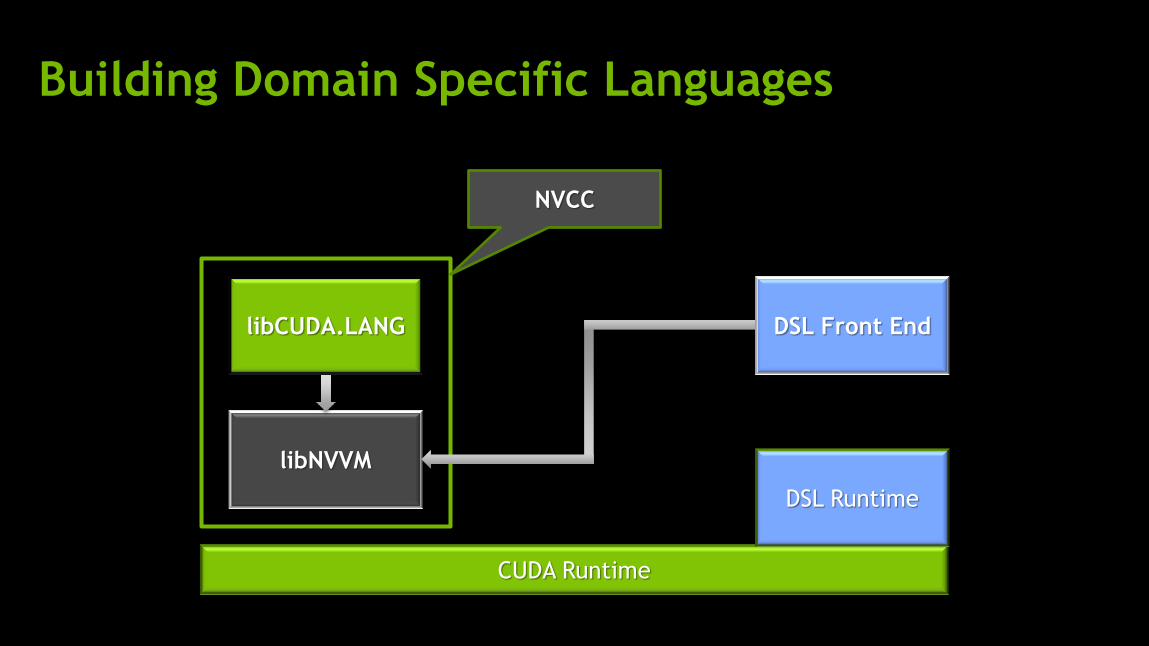
Building Domain Specific Languages
NVCC
CUDA Runtime
DSL Runtime
libNVVM
DSL Front End libCUDA.LANG
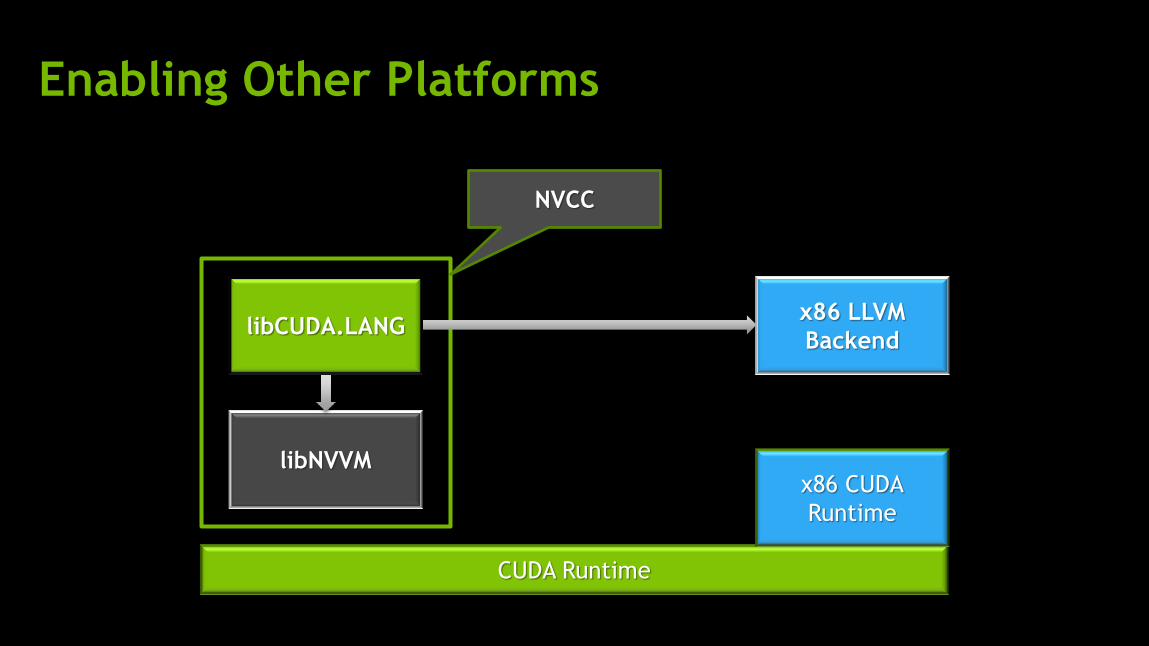
Enabling Other Platforms
NVCC
CUDA Runtime
x86 CUDA
Runtime
x86 LLVM
Backend
libNVVM
libCUDA.LANG
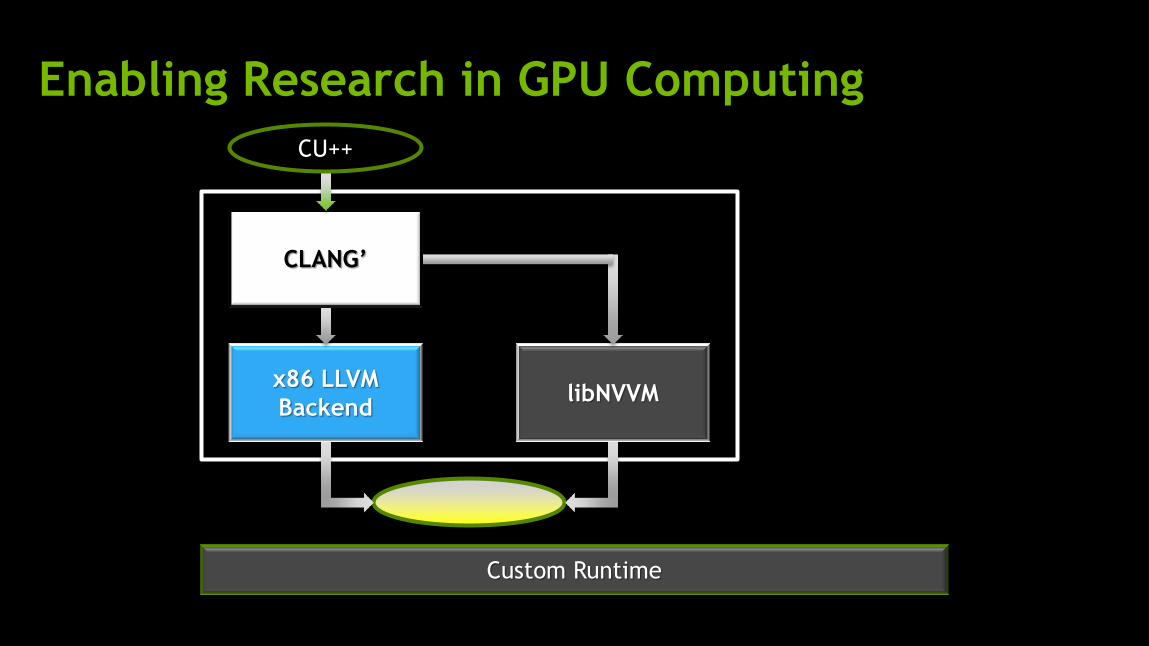
Enabling Research in GPU Computing
Custom Runtime
x86 LLVM
Backend libNVVM
CLANG’
CU++

Compiler SDK Components
Open source NVPTX backend
NVVM IR specification
libNVVM
libCUDA.LANG

Enabling open source GPU compilers
Contribute NVPTX code generator sources back to LLVM trunk
Sources available directly from LLVM!
— Standard LLVM license
Invite community to:
Use it!
Contribute improvements to it!

NVVM IR
An intermediate representation based on LLVM and targeted for
GPU computing
IR Specification describes:
— Address spaces
— Kernels and device functions
— Intrinsics
— … more

libNVVM
A binary component library for Windows, Linux and MacOS
targeting PTX 3.1
— Fermi, Kepler and later architectures
— 32-bit and 64-bit hosts
— NVVM IR verifier
API document
Sample applications

libCUDA.LANG
A binary library that takes CUDA source program and generates
NVVM IR and host C++ program for supported platforms
— API document
Sample applications

Roadmap

Availability
Open source NVPTX backend
— May 2012
NVVM IR spec, libNVVM, samples
— Preview release (May 2012)
http://developer.nvidia.com/cuda-llvm-compiler
— Production release (Next release after CUDA 5.0)
libCUDA.LANG
— To be announced

Deep Dive

Deep Dive
NVVM IR
libNVVM
SDK Samples

NVVM IR
Designed to represent GPU kernel functions and device functions
— Represents the code executed by each CUDA thread
NVVM IR Specification 1.0

NVVM IR and LLVM IR
NVVM IR
— Based on LLVM IR
— With a set of rules and intrinsics
No new types. No new operators. No new reserved words.
An NVVM IR program can work with any standard LLVM IR tool
llvm-as llvm-link llvm-extract
llvm-dis llvm-ar …
An NVVM IR program can be built with the standard LLVM
distribution.
svn co http://llvm.org/svn/llvm-project/llvm/branches/release_30 llvm

NVVM IR

NVVM IR: Address Spaces

NVVM IR: Address Spaces
CUDA C/C++
— Address space is a storage qualifier.
— A pointers is generic pointer, which can point
to any address space.
__global__ int g;
__shared__ int s;
__constant__ int c;
void foo(int a) {
int l;
int *p ;
switch (a) {
case 1: p = &g; …
case 2: p = &s; …
case 3: p = &c; …
case 4: p = &l; …
}
…
}

NVVM IR: Address Spaces
CUDA C/C++
— Address space is a storage qualifier.
— A pointers is generic pointer, which can point
to any address space.
OpenCL C
— Address space is part of the type system.
— A pointer type must be qualified with an
address space.
global int g;
constant int c;
foo(local int *ps) {
int l;
int *p ;
p = l;
global int *pg = &g;
constant int *pc = &c;
…
}

NVVM IR: Address Spaces
CUDA C/C++
— Address space is a storage qualifier.
— A pointers is generic pointer, which can point
to any address space.
OpenCL C
— Address space is part of the type system.
— A pointer type must be qualified with an
address space.
NVVM IR
— Support both in the same program.

NVVM IR: Address Spaces
Define address space numbers
Allow generic pointers and specific pointers
Provide intrinsics to perform conversions between generic pointers
and specific pointers

NVVM IR: GPU Program Properties
Properties:
— Maximum/minimum expected CTA size from any launch
— Minimum number of CTAs on an SM
— Kernel function vs. device function
— Texture/surface variables
— more
Use Named Metadata

NVVM IR: Intrinsics
Atomic operations
Barriers
Address space conversions
Special registers read
Texture/surface access
more

NVVM IR: NVVM ABI for PTX
Allow interoperability of PTX codes generated by different NVVM compilers
How NVVM linkage types are mapped
to PTX linkage types
How NVVM data types are mapped to PTX data types
How function calls are lowered to PTX
calls

libNVVM Library
libNVVM : An optimizing compiler library
NVVM IR -> PTX
• sign extension elimination
• Inline asm (PTX) support
• Tuning of existing optimizations
• New phi elimination
• Address space access optimization
• Thread convergence analyses
• Re-materialization
• Load / store coalescing
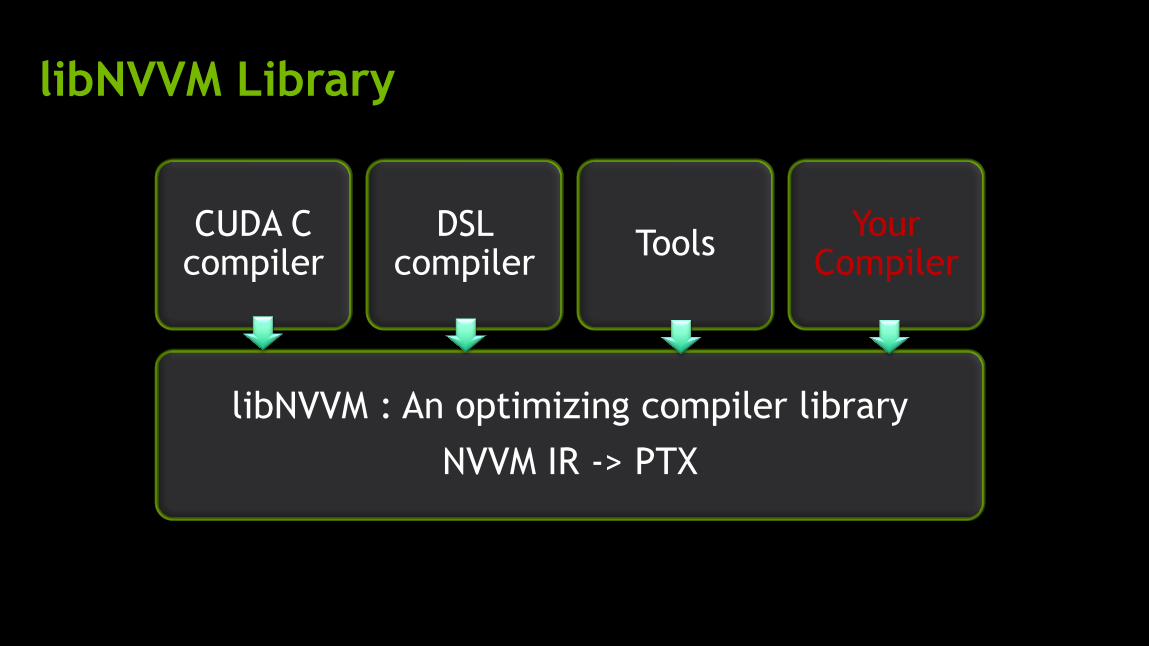
libNVVM Library
libNVVM : An optimizing compiler library
NVVM IR -> PTX
CUDA C compiler
DSL compiler
Tools Your
Compiler

libNVVM APIs
Start and shutdown
Create a compilation unit
— Add NVVM IR modules to a compilation unit.
— Support NVVM IR level linking
Verify the input IR
Compile to PTX
Get result
— Get back PTX string
— Get back message log

Samples

SDK Sample 1: Simple
Read in an NVVM IR
program in LL or BC
format from disk
Generate PTX
Execute the PTX on
GPU
// Read in fread (source, size, 1, fh);
// Compile nvvmInit (); nvvmCreateCU (&cu); nvvmCUAddModule (cu, source, size); nvvmCompileCU (cu, num_options, options); nvvmGetCompiledResultSize (cu, &ptxsize); nvvmGetCompiledResult (cu, ptx); nvvmDestroyCU (&cu); nvvmFini ();
// Execute ... cuModuleLoadDataEx (phModule, ptx, 0, 0, 0); cuModuleGetFunction (phKernel, *phModule, "simple"); cuLaunchGrid (hKernel, nBlocks, 1))

SDK Sample 1: Simple
libNVVM
NVVM IR -> PTX
PTX JIT and Execution on GPU
IR from
file

SDK Sample 2: ptxGen
Read in a list of NVVM IR programs in LL or BC format from disk
Perform IR level linking
Generate PTX, or verify the IR against NVVM IR spec
for (i=0; i<num_files; i++) nvvmCUAddModule (cu, source[i], size[i]);
nvvmCompileCU (cu, 1, “-target=nvptx”); nvvmCompileCU (cu, 1, “-target=verify”);

SDK Sample 2: ptxGen
libNVVM
NVVM IR -> PTX
IR level linking
IR Verifier
IR from
file

SDK Sample 3: Kaleidoscope
Based on the “Kaleidoscope” example in LLVM tutorial
An interpreter for a simple language
— build expressions using primitive operators and user defined functions
Can evaluate a function on a GPU over a sequence of arguments
Uses LLVM IR builder
— Statically linked with stock llvm 3.0 libLLVMCore.a and libLLVMBitWriter.a
Dynamically linked with libnvvm.so and libcuda.so.

SDK Sample 3: Kaleidoscope
ready> def foo(x)
ready> 4*x;
ready> eval foo 1 2 3 4;
ready> Evaluating foo on a gpu:
Using CUDA Device [0]: GeForce GTX 480
4.000000 8.000000 12.000000 16.000000
ready> def bar(a b)
ready> foo(a)+b;
ready> eval bar 1 2 3 4 ;
ready> Evaluating bar on a gpu:
Using CUDA Device [0]: GeForce GTX 480
6.000000 16.000000

SDK Sample 3: Kaleidoscope
libNVVM
NVVM IR -> PTX
PTX JIT and Execution on GPU
LLVM IR Builder
interpreter

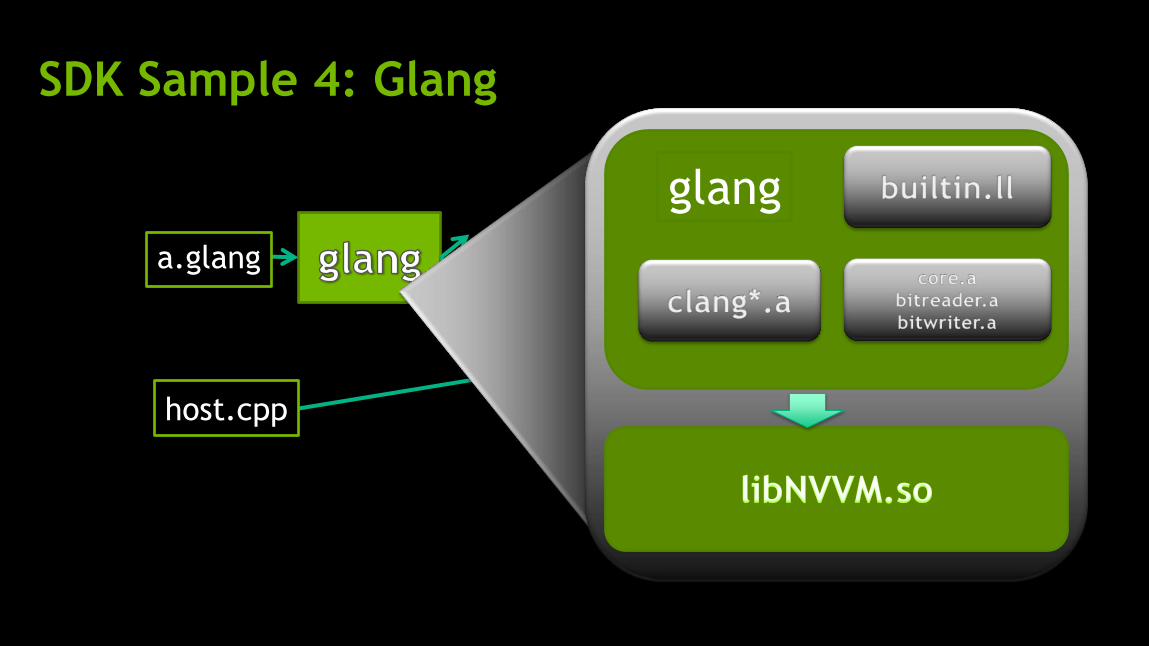
SDK Sample 4: Glang
A prototype compiler based on Clang
Compile a subset of C++ programs to execute on GPUs
Has its own set of builtin functions
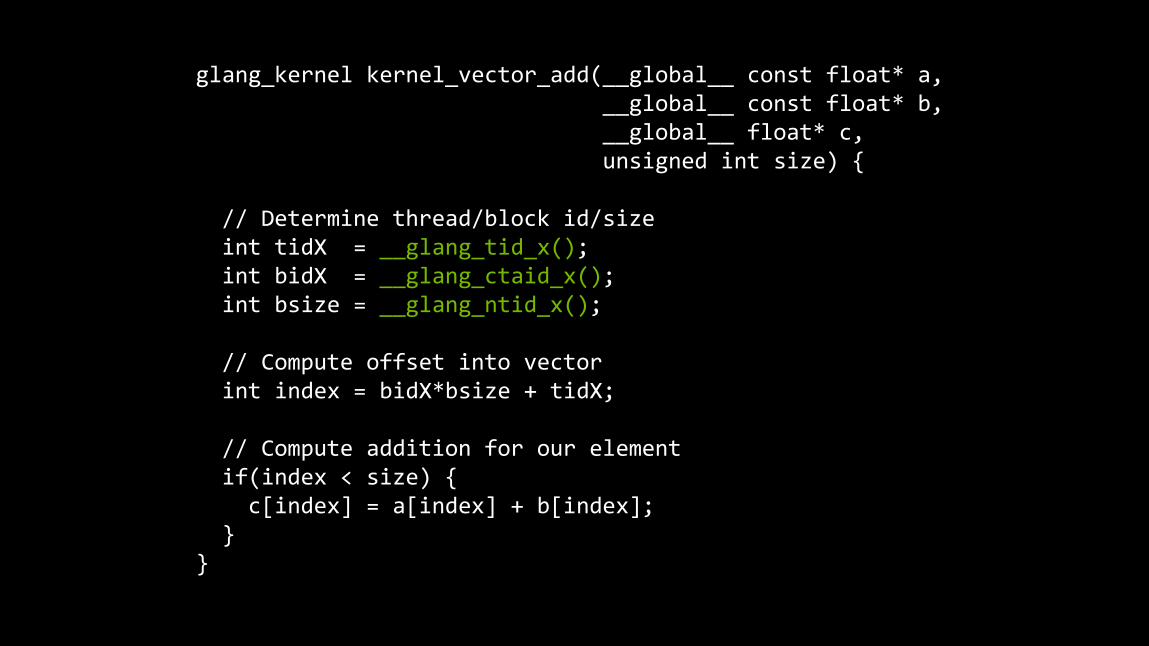
glang_kernel kernel_vector_add(__global__ const float* a, __global__ const float* b, __global__ float* c, unsigned int size) { // Determine thread/block id/size int tidX = __glang_tid_x(); int bidX = __glang_ctaid_x(); int bsize = __glang_ntid_x(); // Compute offset into vector int index = bidX*bsize + tidX; // Compute addition for our element if(index < size) { c[index] = a[index] + b[index]; } }

SDK Samples
libNVVM
NVVM IR -> PTX
IR level linking
User builtin functions
PTX JIT and Execution on GPU
clang

SDK Sample 5: Rg
R is a language and environment for statistical computing and
graphics – www.r-project.org
Dynamically compile R code and execute it on a GPU
— Supports a useful subset of R
An example of how to accelerate a DSL using libNVVM

SDK Sample 5: Rg
> v1 = c (1, 2, 3, 4)
> dv1 = rg.dv (c (1, 2, 3, 4))
> dv2 = rg.dv (c (10, 20, 30, 40))
> dv3 = rg.gapply (function(x, y) {x+y;}, dv1, dv2)
> as.double (dv3)
[1] 11 22 33 44
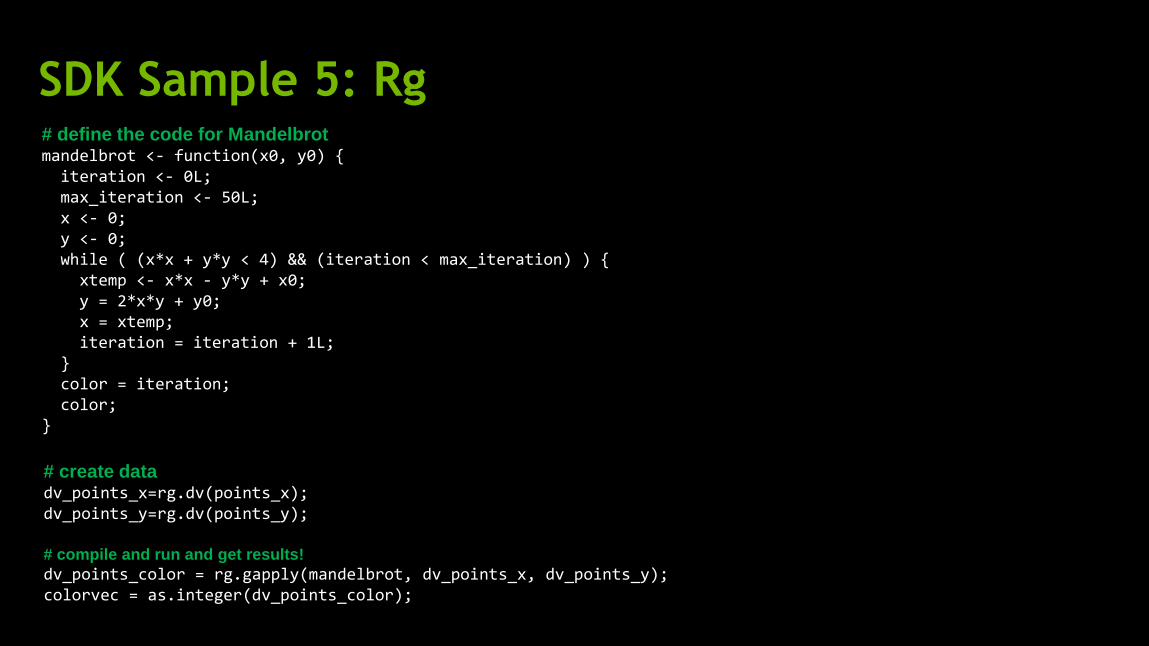
SDK Sample 5: Rg # define the code for Mandelbrot mandelbrot <- function(x0, y0) { iteration <- 0L; max_iteration <- 50L; x <- 0; y <- 0; while ( (x*x + y*y < 4) && (iteration < max_iteration) ) { xtemp <- x*x - y*y + x0; y = 2*x*y + y0; x = xtemp; iteration = iteration + 1L; } color = iteration; color; }
# create data dv_points_x=rg.dv(points_x); dv_points_y=rg.dv(points_y); # compile and run and get results!
dv_points_color = rg.gapply(mandelbrot, dv_points_x, dv_points_y); colorvec = as.integer(dv_points_color);

Demo

SDK Sample 5: Rg
libNVVM
NVVM IR -> PTX
PTX JIT and Execution on GPU
LLVM IR Builder
R

SDK Samples
libNVVM
NVVM IR -> PTX
IR level linking
IR Verifier
User builtin functions
PTX JIT and Execution on GPU
IR from
file LLVM IR Builder clang
intepreter R

How to get it?
http://developer.nvidia.com/cuda-llvm-compiler
Open to all NVIDIA registered developers
Available with CUDA 5.0 Preview Release
File bugs and post questions to NVIDIA forum
— Tag ‘NVVM’


Back up slides
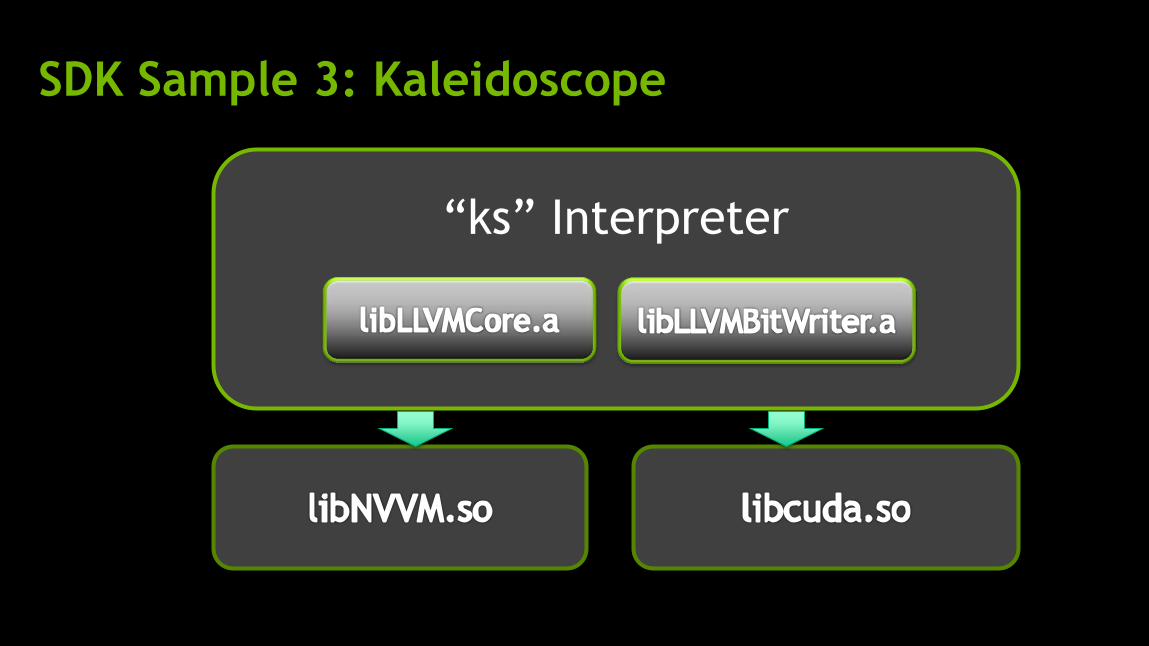
SDK Sample 3: Kaleidoscope
“ks” Interpreter
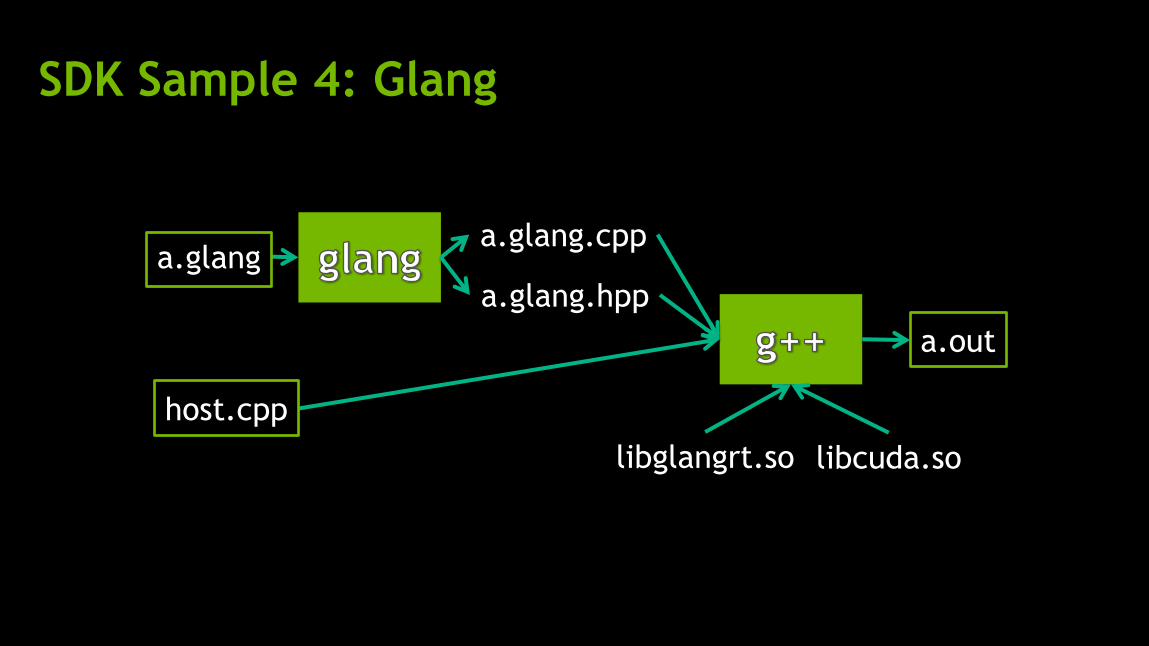
SDK Sample 4: Glang
a.glang.cpp
a.glang.hpp
libglangrt.so libcuda.so
a.glang
host.cpp
a.out
SDK Sample 4: Glang
a.glang a.glang.cpp
a.glang.hpp
host.cpp
libglangrt.so libcuda.so
a.out
glang

SDK Sample 5: Rg (Overview)
Create R objects as proxies for GPU vector data
— Rg runtime handles data creation and transfers to and from the GPU
Write scalar R functions
Use rg.gapply to map the scalar function to the vector data
— Dynamically create code for the scalar function.
— Generated code is specialized to the runtime type of the respective vector
elements
— Launch the generated code on the GPU and create an R object which is a
proxy for the result.

SDK Sample 5: RG (Compiler)
rg.gapply(f, v1, v2, …, vn) –
— compiles f and launches the generated code on vector arguments v1, …, vn
already resident on the GPU.
v1, …, vn are atomic vectors of element types t1, …, tn
discovered at runtime.
Creates a type specialized LLVM IR for f with signature f: t1 x … x
tn -> T where T is the inferred type of the body of f




























