Embed Size (px)
Citation preview

Chris Edmond, Virgiliu Midrigan, Daniel Yi Xu
Department of Economics
Working Paper Series
June 2014
Research Paper Number 1183
ISSN: 0819 2642
ISBN: 978 0 7340 4533 1
Department of Economics The University of Melbourne Parkville VIC 3010 www.economics.unimelb.edu.au
Competition, Markups, and the Gains from International Trade

Competition, Markups,and the Gains from International Trade⇤
Chris Edmond† Virgiliu Midrigan‡ Daniel Yi Xu§
First draft: July 2011. This draft: June 2014
Abstract
We study the pro-competitive gains from international trade in a quantitative model
with endogenously variable markups. We find that trade can significantly reduce
markup distortions if two conditions are satisfied: (i) there is extensive misallocation
and (ii) opening to trade exposes hitherto dominant producers to greater competitive
pressure. We measure the extent to which these two conditions are satisfied in Tai-
wanese producer-level data. Versions of our model consistent with the Taiwanese data
predict that opening up to trade strongly increases competition and reduces markup
distortions by up to one-third, thus significantly reducing productivity losses due to
misallocation.
Keywords: misallocation, markup dispersion, head-to-head competition.
JEL classifications: F1, O4.
⇤We thank our editor Penny Goldberg and four anonymous referees for valuable comments and suggestions.We have also benefited from discussions with Fernando Alvarez, Costas Arkolakis, Andrew Atkeson, ArielBurstein, Vasco Carvalho, Andrew Cassey, Arnaud Costinot, Jan De Loecker, Dave Donaldson, Ana CeciliaFieler, Oleg Itskhoki, Phil McCalman, Markus Poschke, Andres Rodrıguez-Clare, Barbara Spencer, IvanWerning, and from numerous conference and seminar participants. We also thank Andres Blanco, JiwoonKim and Fernando Leibovici for their excellent research assistance. We gratefully acknowledge support fromthe National Science Foundation, Grant SES-1156168.
†University of Melbourne, [email protected].‡New York University and NBER, [email protected].§Duke University and NBER, [email protected].

1 Introduction
Can international trade significantly reduce product market distortions? We study this ques-
tion in a quantitative trade model with endogenously variable markups. In such a model,
markup dispersion implies that resources are misallocated and that aggregate productivity is
low. By exposing producers to greater competition, international trade may reduce markup
dispersion thereby reducing misallocation and increasing aggregate productivity. Our goal is
to use producer-level data to quantify these pro-competitive e↵ects of trade on misallocation
and aggregate productivity.
We study these pro-competitive e↵ects in the model of Atkeson and Burstein (2008). In
this model, any given sector has a small number of producers who engage in oligopolistic
competition. The demand elasticity for any given producer is decreasing in its market share
and hence its markup is increasing in its market share. By reducing the market shares of
dominant producers, international trade can reduce markups and markup dispersion. The
Atkeson and Burstein (2008) model is particularly useful for us because it implies a linear
relationship between (inverse) producer-level markups and market shares, which in turn
makes the model straightforward to parameterize.
We find that trade can significantly reduce markup distortions if two conditions are satis-
fied: (i) there is extensive misallocation, and (ii) international trade does in fact put producers
under greater competitive pressure. The first condition is obvious — if there is no misalloca-
tion, there is no misallocation to reduce. The second condition is more subtle. Trade has to
increase the degree of e↵ective competition amongst producers prevailing within the market.
If both domestic and foreign producers have similar productivities within a given sector,
then opening to trade exposes them to genuine head-to-head competition that reduces market
power thereby reducing markups and markup dispersion. By contrast, if there are large cross-
country di↵erences in productivity within a given sector, then opening to trade may allow
producers from one country to substantially increase their market share in the other country,
thereby increasing markups and markup dispersion so that the pro-competitive ‘gains’ from
trade are negative.
We quantify the model using 7-digit Taiwanese manufacturing data. We use this data to
discipline two key determinants of the extent of misallocation: (i) the elasticity of substitution
across sectors, and (ii) the equilibrium distribution of producer market shares. The elasticity
of substitution across sectors plays a key role because it determines the extent to which
producers that face little competition in their own sector can raise markups. We pin down this
elasticity by requiring that our model fits the cross-sectional relationship between measures
of markups and market shares that we observe in the Taiwanese data. We pin down the
parameters of the producer-level productivity distribution and fixed costs of operating and
1

exporting by requiring that the model reproduces key moments of the distribution of market
shares within and across sectors in the Taiwanese data.
The Taiwanese data feature a large amount of dispersion and concentration in producer-
level market shares, as well as a strong relationship between market shares and markups.
Interpreted through the lens of the model, this implies a significant amount of misallocation
and hence the possibility of significant productivity gains from reduced markup distortions.
Given this misallocation, the model predicts large pro-competitive gains if, within a given
sector, domestic producers and foreign producers have relatively similar levels of productivity
so that increased trade in fact increases the degree of e↵ective competition amongst the
producers prevailing within the market. This feature of the model is largely determined
by the cross-country correlation in sectoral productivity draws. We choose the amount of
correlation in sectoral draws so that the model reproduces standard estimates of the elasticity
of trade flows with respect to changes in variable trade costs. As the amount of correlation
increases, there is less cross-country variation in the productivity with which producers within
a given sector operate. Consequently, small changes in trade costs have relatively larger
e↵ects on trade flows — in short, the trade elasticity is increasing in the amount of cross-
country correlation. To match standard estimates of the trade elasticity, the benchmark
model requires a relatively high 0.93 cross-country correlation in sectoral draws. This high
correlation also allows the model to reproduce the strong positive relationship between a
sector’s share of domestic sales and its share of imports that we observe in the data — i.e.,
reproduces the fact that sectors with relatively large, productive firms are also sectors with
relatively large import shares.
Given this high degree of correlation, opening to trade indeed reduces markup dispersion
and increases aggregate productivity. For the benchmark model, calibrated to Taiwan’s
import share, opening to trade reduces markup distortions by about one-fifth and increases
aggregate productivity by 12% relative to autarky. In short we find that, yes, opening to
trade can lead to a quantitatively significant reduction in misallocation. We also find that
these pro-competitive e↵ects are strongest near autarky — the pro-competitive e↵ects are
more important for an economy opening from autarky to a 10% import share than for an
economy increasing its openness from a 10% to 20% import share.
In the model, a given producer’s productivity has both a sector-specific component and
an idiosyncratic component, both drawn from Pareto distributions. In our benchmark model,
the sectoral draws are correlated across countries but the idiosyncratic draws are uncorrelated.
We also consider an extension of the model in which the idiosyncratic draws are also correlated
across producers in a given sector in di↵erent countries. This extension is motivated by the
observation that sectors with high concentration amongst domestic producers are also sectors
with high import penetration. While our benchmark model cannot reproduce this feature of
2

the data, our extension with correlated idiosyncratic draws can. This extension predicts an
even larger role for trade in reducing markup distortions because countries import more of
exactly those goods for which the domestic market is more distorted. In this version of the
model, trade eliminates about one-third of the productivity losses from misallocation.
We consider a large number of robustness checks on our benchmark model — including
allowing for heterogeneity in sector-level tari↵s, introducing labor market distortions, and
changing the mode of competition from Cournot to Bertrand, amongst others. Our main
findings are robust to these alternative specifications. We also study an extension of the model
in which we introduce capital and elastic labor supply and show that the pro-competitive
gains from trade are even larger. Finally, we study a version of the model with free-entry
and show that versions of the free-entry model that reproduce the salient features of the
Taiwanese data continue to predict significant pro-competitive gains from trade.
Markups, misallocation, and trade. Recent papers by Restuccia and Rogerson (2008),
Hsieh and Klenow (2009) and others show that misallocation of factors of production can
substantially reduce aggregate productivity. We focus on the role of markup variation as
a source of misallocation.1 We find that, by reducing markup dispersion, trade can play a
powerful role in reducing misallocation and can thereby increase aggregate productivity.
The possibility that opening an economy to trade may lead to welfare gains from increased
competition is, of course, one of the oldest ideas in economics. But standard quantitative
trade models, such as the perfect competition model of Eaton and Kortum (2002) or the
monopolistic competition models with constant markups of Melitz (2003) and Chaney (2008),
cannot capture this pro-competitive intuition.
Perhaps more surprisingly, existing trade models that do feature variable markups also
do not generally predict pro-competitive gains from trade. For example, the Bernard, Eaton,
Jensen and Kortum (2003, hereafter BEJK) model of Bertrand competition results in an
endogenous distribution of markups, that, due to specific functional form assumptions, is
exactly invariant to changes in trade costs and has exactly zero pro-competitive gains from
trade.2 Similarly, in the monopolistic competition models with non-CES demand3 studied by
Arkolakis, Costinot, Donaldson and Rodrıguez-Clare (2012b, hereafter ACDR), the markup
1Two closely related papers are Peters (2013), who considers endogenous markups, as we do, in a closedeconomy quality-ladder model of endogenous growth and Epifani and Gancia (2011) who consider an openeconomy model but with exogenous markup dispersion.
2An important contribution by De Blas and Russ (2010) extends BEJK to allow for a finite number ofproducers in a given sector so that, as in our model, the distribution of markups varies in response to changesin trade costs. Holmes, Hsu and Lee (2011) study the impact of trade on productivity and misallocationin this setting. Relative to these theoretical papers, as well as to Devereux and Lee (2001) and Melitz andOttaviano (2008), our main contribution is to quantify the pro-competitive gains from trade using micro data.
3Special cases of which include the non-CES demand systems used by Krugman (1979), Feenstra (2003),Melitz and Ottaviano (2008), and Zhelobodko, Kokovin, Parenti and Thisse (2012).
3

distribution is likewise invariant to changes in trade costs and there are in fact negative
pro-competitive ‘gains’ from trade.
The reason models with variable markups yield conflicting predictions regarding the pro-
competitive gains from trade is that, as emphasized by ACDR, what really matters for these
e↵ects is the joint distribution of markups and employment. The response of this joint distri-
bution to a reduction in trade costs depends on details of the parameterization of the model,
and in particular the amount of cross-country correlation in productivity draws. We show
that versions of our model with low correlation do indeed predict negative pro-competitive
gains. But such parameterizations also imply both (i) low aggregate trade elasticities, and
(ii) a weak or negative relationship between a sector’s share of domestic sales and its share
of imports — and thus are inconsistent with empirical evidence.
Empirical literature on markups and trade. There is a large empirical literature on
producer markups and trade, important early examples include Levinsohn (1993), Harrison
(1994), and Krishna and Mitra (1998). Tybout (2003) reviews this literature and concludes
that “in every country studied, relatively high sector-wide exposure to foreign competition
is associated with lower price-cost margins, and the e↵ect is concentrated in larger plants.”
More recently, Feenstra and Weinstein (2010) infer large markup reductions from observed
changes in US market shares from 1992–2005. De Loecker, Goldberg, Khandelwal and Pavc-
nik (2012) study the e↵ects of India’s tari↵ reductions on both final goods and inputs and
find that the net e↵ect was in fact to increase markups — because input tari↵s fell, so did
the costs of final goods producers. When they condition on the e↵ects of trade liberalization
through inputs, however, De Loecker et al. find that the markups of final goods producers
fall. In this sense, their results are consistent with our benchmark model.
There are important conceptual di↵erences between the e↵ects of trade in this literature
and pro-competitive gains that operate through reduced misallocation. Documenting changes
in the domestic markup distribution following a trade liberalization does not tell us whether
misallocation has gone down or not. Again, what matters for misallocation is the response
of the joint distribution of employment and markups of all producers, including exporters.
Trade flows and the gains from trade. Our focus on the gains from trade is related
to the work of Arkolakis, Costinot and Rodrıguez-Clare (2012a, hereafter ACR), who show
that the total gains from trade are identical in a large class of models and are summarized
by the aggregate trade elasticity. Interestingly, we find that the ACR formula provides an
accurate approximation in our setup with variable markups. This is only the case, however,
if we compute the trade elasticity as ACR do, namely as the responsiveness of trade flows
to changes in trade costs, and not as the responsiveness of trade flows to changes in relative
4

prices as is standard in the international macro literature. In our model, in contrast to
standard trade models, the trade cost elasticity is generally lower than the relative price
elasticity because variable markups imply incomplete pass-through from changes in trade
costs to changes in prices.
That said, while the total gains from trade in our model are well approximated by the ACR
formula, the decomposition of those gains into pro-competitive and other channels depends
quite sensitively on the micro details of producer-level productivity and competition. Our
model predicts, for example, that following a trade liberalization, an economy with very mild
markup distortions will receive gains primarily through standard trade channels whereas
an economy with extensive markup distortions may receive gains both through the pro-
competitive channel and through standard trade channels.
The remainder of the paper proceeds as follows. Section 2 presents the model. Section 3
gives an overview of the data and Section 4 explains how we use that data to quantify the
model. Section 5 presents our benchmark results on the gains from trade. Section 6 conducts
a number of robustness checks. Section 7 presents results for two more significant extensions
of our benchmark model, (i) trade between asymmetric countries, and (ii) free entry and an
endogenous number of competitors per sector. Section 8 concludes.
2 Model
Our world consists of two symmetric countries, Home and Foreign. In keeping with standard
assumptions in the trade literature, we assume a static environment with a single factor of
production, labor, that is in inelastic supply and immobile between countries. We focus on
describing the Home economy in detail. We indicate Foreign variables with an asterisk.
2.1 Final good producers
Perfectly competitive firms in each country produce a homogeneous final good for consump-
tion. These final good firms produce using inputs from a continuum of sectors
Y =
✓Z 1
0
y(s)✓�1✓ ds
◆ ✓✓�1
, (1)
where ✓ > 1 is the elasticity of substitution across sectors s 2 [0, 1]. Importantly, each
sector consists of a finite number of domestic and foreign intermediate producers. In sector
s, output is produced using n(s) 2 N domestic and n(s) imported intermediate inputs
y(s) =
0
@n(s)X
i=1
yHi
(s)��1� +
n(s)X
i=1
yFi
(s)��1�
1
A
���1
, (2)
5

where � > ✓ is the elasticity of substitution across goods i within a particular sector s 2 [0, 1].
In our benchmark model, the number of potential producers n(s) in sector s is exogenous
and the same in both countries. In Section 7 below we consider an extension of the benchmark
model with free entry that makes n(s) endogenous.4
2.2 Intermediate goods producers
Intermediate producer i in sector s produces output with labor
yi
(s) = ai
(s)li
(s) , (3)
where producer-level productivity ai
(s) is drawn from a distribution that we discuss in detail
in Section 4 below.
Trade costs. An intermediate producer sells output to final goods producers located in
both countries. Let yHi
(s) denote the amount sold by a Home intermediate producer to Home
final good producers and similarly let y⇤Hi
(s) denote the amount sold by a Home intermediate
producer to Foreign final good producers. The resource constraint for Home intermediate
producers is
yi
(s) = yHi
(s) + ⌧ y⇤Hi
(s) , (4)
where ⌧ � 1 is an iceberg trade cost, i.e., ⌧ y⇤Hi
(s) must be shipped for y⇤Hi
(s) to arrive abroad.
Foreign intermediate producers face symmetric trade costs. We let y⇤i
(s) denote their output
and note that the resource constraint facing Foreign intermediate producers is
y⇤i
(s) = ⌧ yFi
(s) + y⇤Fi
(s) , (5)
where y⇤Fi
(s) denotes the amount sold by a Foreign intermediate producer to Foreign final
good producers and yFi
(s) denotes the amount sold by a Foreign intermediate producer to
Home final good producers.
Demand for intermediate inputs. Final good producers buy intermediate goods from
Home producers at prices pHi
(s) and from Foreign producers at prices pFi
(s). Consumers buy
the final good at price P . The problem of a final good producer is to choose intermediate
inputs yHi
(s) and yFi
(s) to maximize profits:
PY �
Z 1
0
⇣ n(s)X
i=1
pHi
(s)yHi
(s) + ⌧
n(s)X
i=1
pFi
(s)yFi
(s)⌘ds , (6)
4In the Appendix we also report results for a version of our model where the numbers of Home and Foreignproducers per sector remain exogenous but are uncorrelated across countries.
6

subject to (1) and (2). The solution to this problem gives the demand functions:
yHi
(s) =
✓pHi
(s)
p(s)
◆��
✓p(s)
P
◆�✓
Y , (7)
and
yFi
(s) =
✓⌧pF
i
(s)
p(s)
◆��
✓p(s)
P
◆�✓
Y , (8)
where the aggregate and sectoral price indexes are
P =
✓Z 1
0
p(s)1�✓ ds
◆ 11�✓
, (9)
and
p(s) =
0
@n(s)X
i=1
�Hi
(s)pHi
(s)1�� + ⌧ 1��
n(s)X
i=1
�Fi
(s)pFi
(s)1��
1
A
11��
, (10)
and where �Hi
(s) 2 {0, 1} is an indicator function that equals one if a producer operates in
the Home market (its domestic market) and likewise �Fi
(s) 2 {0, 1} is an indicator function
that equals one if a Foreign producer operates in the Home market (its export market).
Market structure. An intermediate good producer faces the demand system given by
equations (7)-(10) and engages in Cournot competition within its sector.5 That is, each
individual firm chooses a given quantity yHi
(s) or y⇤Hi
(s) taking as given the quantity decisions
of its competitors in sector s. Due to constant returns, the problem of a firm in its domestic
market and its export market can be considered separately.
Fixed costs. A fixed cost fd
must be paid in order to operate in the domestic market and
a fixed cost fx
must be paid in order to export. Both of these are denominated in units of
domestic labor. A firm can choose to produce zero units of output for the domestic market
to avoid paying the fixed cost fd
. Similarly, a firm can choose to produce zero units of output
for the export market to avoid paying the fixed cost fx
.
Domestic market. Taking the wage W as given, the problem of a Home firm in its do-
mestic market can be written
⇡Hi
(s) := maxy
Hi (s) ,�H
i (s)
h⇣pHi
(s)�W
ai
(s)
⌘yHi
(s)�Wfd
i�Hi
(s) , (11)
5In Section 6 below we solve our model under the alternative assumption of Bertrand competition andfind similar results.
7

subject to the demand system above. The solution to this problem is characterized by a price
that is a markup over marginal cost
pHi
(s) ="Hi
(s)
"Hi
(s)� 1
W
ai
(s), (12)
where "Hi
(s) > 1 is the demand elasticity facing the firm in its domestic market. With
the nested CES demand system above and Cournot competition, it can be shown that this
demand elasticity is a weighted harmonic average of the underlying elasticities of substitution
✓ and �, specifically
"Hi
(s) =
✓!Hi
(s)1
✓+ (1� !H
i
(s))1
�
◆�1
, (13)
where !Hi
(s) 2 [0, 1] is the firm’s share of sectoral revenue in its domestic market
!Hi
(s) :=pHi
(s)yHi
(s)P
n(s)i=1 pH
i
(s)yHi
(s) + ⌧P
n(s)i=1 pF
i
(s)yFi
(s)=
✓pHi
(s)
p(s)
◆1��
. (14)
For short, we refer to !Hi
(s) as a Home firm’s domestic market share.
Export market. The problem of a Home firm in its export market is essentially identical
except that to export (operate abroad) it pays a fixed cost fx
rather than fd
so that its
problem is
⇡⇤Hi
(s) := maxy
⇤Hi (s) ,�⇤H
i (s)
h⇣p⇤Hi
(s)�W
ai
(s)
⌘y⇤Hi
(s)�Wfx
i�⇤Hi
(s) , (15)
subject to the demand system abroad. Prices are again a markup over marginal cost
p⇤Hi
(s) ="⇤Hi
(s)
"⇤Hi
(s)� 1
W
ai
(s), (16)
where "⇤Hi
(s) > 1 is the demand elasticity facing the firm in its export market
"⇤Hi
(s) =
✓!⇤Hi
(s)1
✓+ (1� !⇤H
i
(s))1
�
◆�1
, (17)
and where !⇤Hi
(s) 2 [0, 1] is the firm’s share of sectoral revenue in its export market
!⇤Hi
(s) :=⌧p⇤H
i
(s)y⇤Hi
(s)
⌧P
n(s)i=1 p⇤H
i
(s)y⇤Hi
(s) +P
n(s)i=1 p⇤F
i
(s)y⇤Fi
(s). (18)
For short, we refer to !⇤Hi
(s) as a Home firm’s export market share.
8

Market shares and demand elasticity. In general, each firm faces a di↵erent, endoge-
nously determined, demand elasticity. The demand elasticity is given by a weighted average
of the within-sector elasticity � and the across-sector elasticity ✓ < �. Firms with a small
market share within a sector (within a given country) compete mostly with other firms in
their own sector and so face a relatively high demand elasticity, closer to the within-sector �.
Firms with a large market share face relatively more competition from firms in other sectors
than they do from firms in their own sector and so face a relatively low demand elasticity,
closer to the across-sector ✓. The markup a firm charges is an increasing convex function of
its market share. An infinitesimal firm charges a markup of �/(� � 1), the smallest possible
in this model. At the other extreme, a pure monopolist charges a markup of ✓/(✓ � 1), the
largest possible in this model. Because of the convexity, a mean-preserving spread in market
shares will increase the average markup.
The extent of markup dispersion across firms depends both on the gap between ✓ and
� and on the extent of dispersion in market shares. In the special case where ✓ = �, the
demand elasticity is constant and independent of the dispersion in market shares and the
model collapses to a standard trade model with constant markups. But if ✓ is substantially
smaller than �, then even a modest change in market share dispersion can have a large e↵ect
on markup dispersion and hence a large e↵ect on aggregate productivity.
Notice also that a firm operating in both countries will generally have di↵erent market
shares in each country and consequently face di↵erent demand elasticities and charge di↵erent
markups in each country.
Market shares and markups. The formula (13) for a firm’s demand elasticity implies a
linear relationship between a firm’s inverse markup and its market share
1
µHi
(s)=� � 1
��
✓1
✓�
1
�
◆!Hi
(s) . (19)
where µHi
(s) := "Hi
(s)/("Hi
(s) � 1) denotes the firm’s gross markup from (12). Since ✓ < �,
the coe�cient on the market share !Hi
(s) is negative. Within a sector s, firms with relatively
high market shares have low demand elasticity and high markups. As discussed in Section 4
below, the strength of this relationship plays a key role in identifying plausible magnitudes
for the gap between the elasticity parameters ✓ and �.
Operating decisions. Each firm must pay a fixed cost fd
to operate in its domestic market
and a fixed cost fx
to operate in its export market. A Home firm operates in its domestic
market so long as ⇣pHi
(s)�W
ai
(s)
⌘yHi
(s) � Wfd
(20)
9

Similarly, a Home firm operates in its export market so long as⇣p⇤Hi
(s)�W
ai
(s)
⌘y⇤Hi
(s) � Wfx
(21)
There are multiple equilibria in any given sector. Di↵erent combinations of firms may choose
to operate, given that the others do not. As in Atkeson and Burstein (2008), within each
sector s we place firms in the order of their physical productivity ai
(s) and focus on equilibria
in which firms sequentially decide on whether to operate or not: the most productive decides
first (given that no other firm operates), the second most productive decides second (given
that no other less productive firm operates), and so on.6
2.3 Market clearing
In each country there is a representative consumer that inelastically supplies one unit of labor
and that consumes the final good. The labor market clearing condition is
Z 1
0
⇣ n(s)X
i=1
(lHi
(s) + fd
)�Hi
(s) +n(s)X
i=1
(l⇤Hi
(s) + fx
)�⇤Hi
(s)⌘ds = 1 , (22)
and the market clearing condition for the final good is simply C = Y .
2.4 Aggregate productivity and markups
Aggregation. The quantity of final output in each country can be written
Y = AL, (23)
where A is the endogenous level of aggregate productivity and L is the aggregate amount
of labor employed net of fixed costs. Using the firms’ optimality conditions and the market
clearing condition for labor, it is straightforward to show that aggregate productivity is a
quantity-weighted harmonic mean of firm productivities
A =
0
@Z 1
0
⇣ n(s)X
i=1
1
ai
(s)
yHi
(s)
Y+ ⌧
n(s)X
i=1
1
ai
(s)
y⇤Hi
(s)
Y
⌘ds
1
A�1
. (24)
Now denote the aggregate (economy-wide) markup by
µ :=P
W/A, (25)
6The exact ordering makes little di↵erence quantitatively when we calibrate the model to match thestrong concentration in the data. Productive firms always operate and unproductive ones never do, so theequilibrium multiplicity only a↵ects the operating decisions of marginal firms that have a negligible e↵ect onaggregates. Moreover, as we show in Section 6 below, our model’s implications for markup dispersion areessentially unchanged when we set f
d
= f
x
= 0 so that all firms operate and the equilibrium is unique.
10

that is, aggregate price divided by aggregate marginal cost. It is straightforward to show
that the aggregate markup is a revenue-weighted harmonic mean of firm markups
µ =
0
@Z 1
0
⇣ n(s)X
i=1
1
µHi
(s)
pHi
(s)yHi
(s)
PY+ ⌧
n(s)X
i=1
1
µ⇤Hi
(s)
p⇤Hi
(s)y⇤Hi
(s)
PY
⌘ds
1
A�1
, (26)
where µHi
(s) denotes a Home firm’s markup in its domestic market and µ⇤Hi
(s) denotes its
markup in its export market (implied by equations (12) and (16), respectively).
Misallocation and markup dispersion. In this model, dispersion in markups reduces
aggregate productivity, as in the work of Restuccia and Rogerson (2008) and Hsieh and
Klenow (2009). To understand this e↵ect, first notice that the expression (24) for aggregate
productivity can be written
A =
✓Z 1
0
⇣µ(s)µ
⌘�✓
a(s)✓�1 ds
◆ 1✓�1
, (27)
where µ(s) := p(s)/(W/a(s)) denotes the sector-level markup and where sector-level produc-
tivity is given by
a(s) =
0
@n(s)X
i=1
⇣µHi
(s)
µ(s)
⌘��
ai
(s)��1�Hi
(s) + ⌧ 1��
n(s)X
i=1
⇣µFi
(s)
µ(s)
⌘��
a⇤i
(s)��1�Fi
(s)
1
A
1��1
. (28)
First-best aggregate productivity. By contrast, the first-best level of aggregate pro-
ductivity (the best attainable by a planner, subject to the trade cost ⌧) associated with an
e�cient allocation of resources is
Ae�cient =
✓Z 1
0
a(s)✓�1 ds
◆ 1✓�1
, (29)
where sector-level productivity is
a(s) =
0
@n(s)X
i=1
ai
(s)��1�Hi
(s) + ⌧ 1��
n(s)X
i=1
a⇤i
(s)��1�Fi
(s)
1
A
1��1
, (30)
with operating decisions �Hi
(s),�Fi
(s) 2 {0, 1} as dictated by the solution to the planning
problem. If there is no markup dispersion (as occurs, for example, if ✓ = �), then aggregate
productivity from (27)-(28) is at its first-best level. But with markup dispersion, the most
productive producers employ a smaller share of the economy’s labor than e�ciency dictates,
since markups and productivity are positively correlated. Markup dispersion lowers aggregate
11

productivity relative to the first-best because it induces an ine�cient allocation of resources
across producers. If opening to trade reduces markup dispersion, then the losses due to
misallocation will be smaller and there will be pro-competitive gains from trade. If opening
to trade increases markup dispersion, then the losses due to misallocation will be larger and
the pro-competitive ‘gains’ will be negative, as they are in Arkolakis, Costinot, Donaldson
and Rodrıguez-Clare (2012b).
2.5 Trade elasticity
In standard trade models, and as emphasized by Arkolakis, Costinot and Rodrıguez-Clare
(2012a), the gains from trade are largely determined by the elasticity of trade flows with
respect to changes in trade costs. With constant markups, this elasticity with respect to
trade costs is the same as the elasticity with respect to changes in international relative
prices. But with variable markups, as in our model, these two concepts are not generally the
same.
Trade elasticity with respect to international relative prices. Suppose all foreign
prices uniformly change by a factor q (this may be because of changes in trade costs, or
productivity, or labor supply etc). We define the trade elasticity with respect to international
relative prices as
�relative prices :=d log 1��
�
d log q, (31)
where � denotes the aggregate share of spending on domestic goods,
� :=
R 1
0
Pn(s)i=1 pH
i
(s)yHi
(s) dsR 1
0
⇣Pn(s)i=1 pH
i
(s)yHi
(s) + ⌧P
n(s)i=1 pF
i
(s)yFi
(s)⌘ds
=
Z 1
0
�(s)!(s) ds , (32)
and where �(s) denotes the sector-level share of spending on domestically produced goods
and !(s) := (p(s)/P )1�✓ is that sector’s share of aggregate spending. Some algebra shows
that, in our model, the trade elasticity with respect to international relative prices is given
by a weighted average of the underlying elasticities of substitution � and ✓, specifically7
�relative prices = �
✓Z 1
0
�(s)
�
⇣1� �(s)
1� �
⌘!(s) ds
◆+ ✓
✓1�
Z 1
0
�(s)
�
⇣1� �(s)
1� �
⌘!(s) ds
◆� 1
7Our goal here is to obtain analytic results that aid in building intuition. To that end, in deriving (33)we abstract from the extensive margin and hold the set of producers in each country fixed. We relax thisassumption and determine the set of operating firms endogenously when we compute the trade elasticity inour model. It turns out that treating the set of producers as fixed is, quantitatively, a good approximationin our model. In particular, as we show in Section 6 below, the quantitative implications of our model arealmost identical when there are no fixed costs and all producers operate in both countries.
12

so that on collecting terms
�relative prices = (� � 1)� (� � ✓)Var[�(s)]
�(1� �), (33)
where Var[�(s)] is the variance across sectors of the share of spending on domestic goods and �
is the aggregate share, as defined in (32). For short, we refer to the term Var[�(s)]/�(1� �)
as our index of import share dispersion. Notice that this elasticity is generally less than
� � 1 and is decreasing in the index of import share dispersion. If there is no import share
dispersion, �(s) = � for all s, then Var[�(s)] = 0 and the elasticity is relatively high, equal
to � � 1. Intuitively, if all sectors have identical import shares then there is no across-sector
reallocation of expenditure and a uniform reduction in the relative price of foreign goods
symmetrically increases import shares within each sector, an e↵ect governed by �. At the
other extreme, if import shares are binary, �(s) 2 {0, 1}, then Var[�(s)] = �(1 � �) and
the elasticity is relatively low, equal to ✓� 1. Here there is only across-sector reallocation of
expenditure and a uniform reduction in the relative price of foreign goods induces reallocation
towards sectors with high import shares, an e↵ect governed by ✓.
The elasticity �relative prices is the trade elasticity as typically defined in the international
macro literature. We now contrast this with the trade elasticity with respect to trade costs.
Trade elasticity with respect to trade costs. We follow standard practice in the trade
literature and define the trade elasticity with respect to trade costs as
�trade costs :=d log 1��
�
d log ⌧, (34)
In a standard model, with constant markups, d log q = d log ⌧ so that �trade costs = �relative prices.
But in our model, with variable markups, there is incomplete pass-through : a 1% fall in trade
costs reduces the relative price of foreign goods by less than 1%.
To derive the trade elasticity with respect to trade costs in our model, begin by noting
that at the sector level the responsiveness of trade flows is given by
d log 1��(s)�(s)
d log ⌧= (� � 1)(1 + ✏(s)) ,
where
✏(s) :=n(s)X
i=1
pFi
(s)yFi
(s)
pF(s)yF(s)
⇣d log µFi
(s)
d log ⌧
⌘�
n(s)X
i=1
pHi
(s)yHi
(s)
pH(s)yH(s)
⇣d log µHi
(s)
d log ⌧
⌘,
denotes the elasticity with respect to trade costs of Foreign markups relative to Home
markups and where pF(s)yF(s) and pH(s)yH(s) denote spending on Foreign goods and spend-
ing on Home goods in sector s. In general, the relative markup elasticity ✏(s) is negative
13

— i.e., a reduction in trade costs tends to increase Foreign markups as their producers gain
market share and to decrease Home markups as their producers lose market share.
The aggregate trade elasticity with respect to trade costs can then be written
�trade costs = (� � ✓)
✓Z 1
0
�(s)
�
⇣1� �(s)
1� �
⌘(1 + ✏(s))!(s) ds
◆
+(✓ � 1)
✓Z 1
0
⇣1� �(s)
1� �
⌘(1 + ✏(s))!(s) ds
◆. (35)
Notice that in the special case where the relative markup elasticity is the same in each sector,
✏(s) = ✏ for all s, equation (35) reduces to
�trade costs =
✓(� � 1)� (� � ✓)
Var[�(s)]
�(1� �)
◆(1 + ✏)
and comparing this with (33) we see that, for this special case, �trade costs = �relative prices(1+✏).
In the further special case of � = ✓, so that markups are constant, then ✏ = 0 (there is
complete pass-through) so that the trade elasticity with respect to trade costs is the same as
with respect to relative prices and both trade elasticities equal ��1. With variable markups,
the trade elasticity is generally less than � � 1, both because the elasticity with respect to
relative prices is less than � � 1 and because the elasticity with respect to trade costs is less
than that with respect to relative prices.
3 Data
We now describe the data we use. First we give a brief description of the Taiwanese dataset.
We then highlight facts about producer concentration in this data that are crucial for our
model’s quantitative implications. Finally, we outline how we infer markups from this data.
3.1 Dataset
We use the Taiwan Annual Manufacturing Survey. This survey reports data for the universe
of establishments8 engaged in production activities. Our sample covers the years 2000 and
2002–2004. The year 2001 is missing because in that year a separate census was conducted.
Product classification. The dataset we use has two components. First, an establishment-
level component collects detailed information on operations, such as employment, expendi-
ture on labor, materials and energy, and total revenue. Second, a product-level component
8In the Taiwanese data, almost all firms are single-establishment. In our Appendix we show that usingfirm-level data rather than establishment-level data makes almost no di↵erence to our results. If anything,using establishments rather than firms understates the extent of concentration among producers, a key featurethat determines the gains from trade in our model.
14

reports information on revenues for each of the products produced at a given establishment.
Each product is categorized into a 7-digit Standard Industrial Classification created by the
Taiwanese Statistical Bureau. This classification at 7 digits is comparable to the detailed
5-digit SIC product definition collected for US manufacturing establishments as described
by Bernard, Redding and Schott (2010). Panel A of Table A1 in the Appendix gives an
example of this classification, while Panel B reports the distribution of 7-digit sectors within
4- and 2-digit industries. Most of the products are concentrated in the Chemical Materials,
Industrial Machinery, Computer/Electronics and Electrical Machinery industries.
Import shares. We supplement the survey with detailed import data at the harmonized
HS-6 product level. We obtain the import data from the WTO and then match HS-6 codes
with the 7-digit product codes used in the Annual Manufacturing Survey. This match gives
us disaggregated import penetration ratios for each product category.
3.2 Concentration facts
The amount of producer concentration in the Taiwanese manufacturing data is crucial for
our model’s quantitative implications.
Strong concentration within sectors. We measure a producer’s market share by their
share of domestic sales revenue within a given 7-digit sector. Panel A of Table 1 shows
that producers within a sector are highly concentrated. The top producer has a market
share of around 40 to 45%.9 The median inverse Herfhindhal (HH) measure of concentration
is about 3.9, much lower than 10 or so producers that operate in a typical sector. The
distribution of market shares is skewed to the right and extremely fat-tailed. The median
market share of a producer is just 0.5% while the average market share is 4%. The 95th
percentile accounts for only 19% of sales while the 99th percentile accounts for 59% of sales.
The overall pattern that emerges is consistently one of very strong concentration. Although
quite a few producers operate in any given sector, most of these producers are small and a
few large producers account for the bulk of the sector’s domestic sales.
Strong unconditional concentration. Panel A of Table 1 also reports statistics on the
distribution of sales revenue and the wage bill across sectors and across all producers. The
top 1% of sectors alone accounts for 26% of aggregate sales and 11% of the aggregate wage
bill. The top 5% of sectors accounts for fully half of all sales and a third of the wage bill. This
pattern is reproduced at the producer level. The top 1% of producers accounts for 41% of
sales and 24% of the wage bill, the top 5% of producers accounts for nearly two-thirds all sales
9We weight each sector by the sector’s share of aggregate sales.
15

and nearly a half of the wage bill. Again, the overall pattern is thus of strong concentration
both within and across sectors.
3.3 Inferring markups
In our model, as is standard in the trade literature, labor is the only factor of production and
a producer’s revenue productivity (which is observable) is its markup. But in comparing our
model’s implications for markups to the data, it is important to recognize that, in general,
revenue productivity di↵ers across producers not only because of markup di↵erences but also
because of di↵erences in the technology with which they operate. To control for this potential
source of heterogeneity, we use modern IO methods to purge our markup estimates of the
di↵erences in technology that surely exist across Taiwanese manufacturing industries.10
Controlling for heterogeneity in producer technology. To map our model into micro-
level production data, we relax the assumptions of a single factor of production and constant
returns to scale. In particular, we follow De Loecker and Warzynski (2012) and assume a
translog gross production function
log yi
= ↵l
log li
+↵k
log ki
+ ↵m
logmi
+ ↵ll
(log li
)2 + ↵kk
(log ki
)2 + ↵mm
(logmi
)2
+↵lk
(log li
log ki
) + ↵lm
(log li
logmi
) + ↵km
(log ki
logmi
) + log ai
where li
denotes labor, ki
denotes physical capital, mi
denotes material inputs and ai
is
physical productivity. We estimate this translog specification for each 2-digit Taiwanese
industry, giving us industry-specific coe�cient estimates. Let el,i
denote the elasticity of
output with respect to labor, that is
el,i
:=@ log y
i
@ log li
= ↵l
+ 2↵ll
log li
+ ↵lk
log ki
+ ↵lm
logmi
(36)
In a standard Cobb-Douglas specification, this elasticity is the constant ↵l
, but here
it varies across firms depending on their input use. Cost minimization then implies that
producer i setsWl
i
pi
yi
=el,i
µi
(37)
Thus variation in labor input cost shares across producers may be due to either variation in
markups µi
or to variation in output elasticities el,i
. Moreover, output elasticities may them-
selves vary both because of di↵erent levels of input use and because of di↵erent coe�cients
10More precisely, under the maintained assumptions of Hicks-neutral technology and constants returns toscale, our model’s implications for aggregate productivity in (27)-(28) depend only on the joint distributionof physical productivity a
i
and markups µ
i
and do not depend on the precise details of the producer-levelproduction technologies. But for this argument to hold, we must in fact be credibly measuring the producerlevel productivity and markups and to do that we do need to control for heterogeneity in technology. As itturns out, our estimated production functions are very close to constant returns.
16

(i.e., because producers are in di↵erent 2-digit industries). We now use data on labor input
cost shares and production function estimates of el,i
to back out markups µi
from (37).
Estimating the translog production function. As is well-known, a key di�culty in
estimating production functions is that input choices li
, ki
,mi
will generally be correlated
with true productivity ai
. We follow De Loecker and Warzynski (2012) and apply ‘control’
or ‘proxy function’ methods inspired by Olley and Pakes (1996), Levinsohn and Petrin (2003)
and Ackerberg, Caves and Frazer (2006) to deal with this simultaneity. We give the full details
of our implementation of this approach in the Appendix.
Estimation results. In Table 2, we report the median output elasticities and returns to
scale for each of 21 Taiwanese manufacturing industries along with the inter-quartile range of
output elasticities across producers within the same industry. Several points are worth noting:
First, there is modest variation in output elasticities either within or across industries. For
example, the 25th percentile of el,i
within industries is typically around 0.15 while the 75th
percentile is typically around 0.4 with the standard deviation of median el,i
across industries
being 0.04. Second, the median returns to scale within each industry is very close to 1 for
almost all industries. In addition, the variation in returns to scale across producers within
an industry is small, with the 25th percentile around 0.98 and the 75th percentile around
1.04. Third, the ranking of capital intensity across industries is intuitive, with Petroleum,
Chemical Material, Computer, Machinery Equipment the most capital intensive, and Wood,
Leather, Motor Vehicle Parts, Apparel the least.
Markup estimates. Given these estimates of cel,i
for each producer for each industry, we
recover ‘measured inverse markups’ d1/µi
from (37) as in De Loecker and Warzynski (2012).
Panel A of Table 3 reports summary statistics of the distribution of markups obtained in
this way. The estimated markups are highly dispersed, the 95th percentile markup is nearly
2.5 times the median markup and the 99th percentile markup is nearly 5 times the median.
We also report the sector-level counterparts of these markup statistics; in accordance with
the model, we measure sector-level markups as the revenue-weighted harmonic average of
producer markups within a given sector. The sector-level markups are similarly dispersed.
Our theoretical model motivates a simple linear relationship between inverse markups
and observed market shares, !i
, namely
d1/µi
= �µ
+ �!
!i
+ ⇠µ,i
(38)
One of the moments we will match in our model parameterization is the regression coe�cient
�!
. In keeping with our theoretical model, we assume that the measured inverse markups
17

are only systematically e↵ected by producer market shares such that any residual markup
variation, ⇠µ,i
, is orthogonal.11 Under this assumption, the regression coe�cient on market
shares is simply �!
= �(1✓
�
1�
). Given an estimate c�!
and a value for the within-sector
elasticity �, we can then calculate our estimate of the across-sector elasticity ✓. Panel B of
Table 3 reports the coe�cient c�!
we obtain from regressing the De Loecker and Warzynski
(2012) measured inverse markups d1/µi
on observed market shares !i
using samples of single-
product and multi-product producers. The market share coe�cient is in a tight range around
�0.66 to �0.69 across these regressions.
We also report moments for projected markups. These are moments of the inverse of
the fitted values from (38), i.e., moments of 1/(c�µ
+ c�!
!i
), which we normalize by setting
the intercept equal to its theoretical value, c�µ
= ��1�
(the markup level does not a↵ect
allocations in our benchmark model). These projected markups are less dispersed, the 95th
percentile sectoral markup is about 1.5 times the median and the 99th percentile is about
2.5 times the median. Since our model abstracts from any source of markup variation other
than market share variation, we view these projected markups as being the natural empirical
counterpart to the markups implied by our model. Moreover, since these projected markups
are less dispersed than the measured markups, this choice means that, if anything, we will
understate the amount of misallocation.
4 Quantifying the model
We now explain how we use the Taiwanese data to pin down the key parameters of our model.
4.1 Overview
In the model, the size of the gains from trade largely depends on two factors: (i) the extent
of misallocation, and (ii) the responsiveness of that misallocation to changes in trade costs.
In turn, these factors are largely determined by the joint distribution of productivity, both
within and across countries, and on the elasticity of substitution parameters ✓ and �. We
discipline our model along these dimensions as follows.
We choose a within-country distribution of productivities so that our model reproduces
the amount of concentration within and across sectors documented in the Taiwanese data.
We choose the gap between the elasticities ✓ and � so that our model reproduces the negative
correlation between inverse markups and market shares. Together these determine the extent
of misallocation in our benchmark economy. Given our within-country distribution of pro-
ductivities, the cross-country joint distribution of productivities in our model is pinned down
11We consider an example with non-orthogonal residuals in Section 6 below where we allow for labor marketdistortions that are correlated with producer productivity and hence with producer market shares.
18

by one remaining parameter, the cross-country correlation in productivities at the producer
level. We choose this correlation so that our model reproduces standard estimates of the
trade elasticity.
4.2 Productivity distribution
The distribution of producer-level productivities ai
(s) and a⇤i
(s) within sectors, across sectors,
and across countries plays a key role in our analysis. Within a given country, the distribution
of ai
(s) determines the pattern of concentration within and across sectors and thus crucially
shapes the extent of misallocation in the economy. Across countries, the correlation between
ai
(s) and a⇤i
(s) within a given sector determines the extent to which opening up to trade
exposes highly productive domestic firms to competition from similarly productive foreign
firms. If Home and Foreign productivities are strongly correlated within a sector, then open-
ing up to trade implies that highly productive firms face strong competition that reduces
their market share and hence reduces their markups. By contrast, if Home and Foreign pro-
ductivities are weakly correlated then trade does not much a↵ect the amount of competition
and so has little e↵ect on markups.
Within-country productivity distribution. We assume that across sectors the number
of producers n(s) 2 N is drawn IID Geometric with parameter ⇣ 2 (0, 1) so that Prob[n] =
(1 � ⇣)n�1⇣ and the average number of producers per sector is 1/⇣. We assume that an
individual producer’s productivity ai
(s) is the product of a sector-specific component and an
idiosyncratic component
ai
(s) = z(s)xi
(s) . (39)
We assume z(s) � 1 is independent of n(s) and across sectors is drawn IID Pareto with shape
parameter ⇠z
> 0. Within sector s, the n(s) draws of the idiosyncratic component xi
(s) � 1
are IID Pareto across producers with shape parameter ⇠x
> 0.
Cross-country productivity distribution. We assume that cross-country correlation in
productivity arises through correlation in sectoral productivities. In particular, let FZ
(z)
denote the Pareto distribution of sector-specific productivities within each country and let
HZ
(z, z⇤) denote the cross-country joint distribution of these sector-specific productivities.
We write this cross-country joint distribution as
HZ
(z, z⇤) = C(FZ
(z), FZ
(z⇤)) , (40)
where the copula C is the joint distribution of a pair of uniform random variables u, u⇤ on
[0, 1]. This formulation allows us to first specify the marginal distribution FZ
(z) so as to
19

match within-country productivity statistics and to then use the copula function to control
the pattern of dependence between z and z⇤.
Specifically, we assume that the marginal distributions are linked by a Gumbel copula, a
widely used functional form that allows for dependence even in the right tails of the distri-
bution
C(u, u⇤) = exp⇣� [(� log u)⇢ + (� log u⇤)⇢]1/⇢
⌘, ⇢ � 1 . (41)
The parameter ⇢ controls the pattern of dependence with higher values of ⇢ giving more
dependence. If ⇢ = 1, the copula reduces to C(u, u⇤) = uu⇤ so that the draws are independent.
If ⇢! 1 then, as is familiar from CES functions, the Copula approaches C(u, u⇤) = min[u, u⇤]
so that the draws are perfectly dependent. When working with heavy-tailed distributions
it is standard to summarize dependence using the robust correlation coe�cient known as
Kendall’s tau,12 which we denote by ⌧(⇢) to distinguish it from the trade cost. With the
Gumbel copula, this evaluates to ⌧(⇢) = 1 � 1/⇢. Notice that ⌧(1) = 0 (independence)
and ⌧(1) = 1 (perfect dependence). Once the within-country distribution FZ
(z) has been
specified, the single parameter ⌧(⇢) pins down the joint distribution HZ
(z, z⇤).
Finally, let FX
(x) denote the Pareto distribution of idiosyncratic productivities within
each sector and let HX
(x, x⇤) denote the associated joint distribution. For our benchmark
model we assume these are independent across countries so that HX
(x, x⇤) = FX
(x)FX
(x⇤).
4.3 Calibration
Elasticities of substitution. Following Atkeson and Burstein (2008), we directly assign
the value � = 10 to the within-sector elasticity of substitution.13 We choose the across-sector
elasticity of substitution ✓ so that our model reproduces the correlation between inverse
markups and market shares implied by the regression (19). In particular, we choose ✓ =
1.28 so that a regression of inverse markups on market shares gives a slope coe�cient of
�(1/✓ � 1/�) = �0.68, squarely in the range of such coe�cients we recover from the De
Loecker and Warzynski (2012) procedure outlined above.
Given these elasticities of substitution, we then simultaneously choose the remaining
parameters so that our model reproduces key features of the Taiwanese manufacturing data.
Panel A of Table 1 reports the moments we target and the counterparts for our benchmark
model. Panel B reports the parameter values that achieve this fit. We now briefly summarize
the key features of the data that pin down the various parameters.
12Defined by:
⌧(⇢) := 4
Z 1
0
Z 1
0C(u, u⇤) dC(u, u⇤),
which for the Gumbel copula in (41) evaluates to ⌧(⇢) = 1� 1/⇢.13We discuss the robustness of our results to alternative values for � in Section 6 below.
20

Number of producers, productivity, and fixed cost of operating. We choose the
parameters ⇣, ⇠z
, ⇠x
governing the within-country productivity distribution and the fixed cost
fd
of operating in the domestic market to match key concentration statistics in the Taiwanese
manufacturing data. Our model successfully reproduces the amount of concentration in the
data. Within a given sector, the largest producer accounts for an average 45% of that
sector’s domestic sales. The model also reproduces the heavy concentration in the tails of
the distribution of market shares with the 99th percentile share being 59% in both model
and data. Moreover, the model also produces a fat-tailed size distribution of sectors and a
fat-tailed size distribution of producers. The 99th percentile of sectors accounts for 24% of
domestic sales (26% in the data) while the 99th percentile of producers accounts for 37% of
domestic sales (41% in the data). The median number of producers per sector is a little too
high (16 in the model, 10 in the data) but the model reproduces well the dispersion in the
number of producers per sector (the 10th percentile is 3 producers in the model and 2 in the
data, the 90th percentile is 47 producers in the model and 52 in the data).
The within-country joint distribution of productivity ai
(s) = z(s)xi
(s) that generates this
concentration is likewise very fat-tailed. This mostly comes from the sectoral productivity
e↵ect, z(s), which has Pareto shape parameter ⇠z
= 0.56. By contrast, the idiosyncratic
productivity e↵ect, xi
(s), has relatively thin tails with Pareto shape parameter ⇠x
= 4.53.
The fixed cost to operate domestically is quite small, fd
= 0.004. This is about 0.16% of the
average domestic producer’s profits and 0.05% of their wage bill.
Trade costs. We choose the proportional trade cost ⌧ and the fixed cost of operating in
the export market fx
so that the model reproduces Taiwan’s aggregate import share of 0.38
and aggregate fraction of firms that export of 0.25. The model achieves this with a trade
cost of ⌧ = 1.128 (i.e., 1.128 units a good must be shipped for 1 unit to arrive) and a quite
large fixed cost of operating in the export market, fx
= 0.211. This is about 3.39% of the
average exporter’s profits and 1.02% of their wage bill.
Trade elasticity and import share dispersion statistics. Finally, we choose the copula
parameter ⌧(⇢) governing the degree of cross-country correlation in sectoral productivity so
that, jointly with all of our other parameters, our model produces realistic values for (i)
the trade elasticity, as well as (ii) the cross-sectional relationship between sector import
shares and sector domestic size,14 (iii) the amount of import share dispersion, and (iv) the
amount of intra-industry trade. We target a trade elasticity of 4, a fairly standard estimate
from aggregative data on trade flows — especially when one considers a two-country setting
14Specifically, the slope coe�cient in a regression of sector imports out of total imports on sector domesticsales out of total domestic sales.
21

like ours. For the other import share statistics we simply target their counterparts in the
Taiwanese data. Because the gains from trade depend crucially on the trade elasticity we
assign a much larger weight to this moment, ensuring we match it exactly, and thus we
slightly miss on the other statistics.
In the model, the trade elasticity is increasing in ⌧(⇢). This is because as the amount of
correlation increases, there is less cross-country variation in the productivity with which pro-
ducers within a given sector operate so that small changes in trade costs then have relatively
larger e↵ects on trade flows. To match a trade elasticity of 4 our model requires ⌧(⇢) = 0.93
so that there is a high degree of correlation in productivity draws across countries. We discuss
the sensitivity of our results to this value for ⌧(⇢) at length below.
4.4 Markup distribution
Table 4 reports moments of the distribution of markups µi
(s) in our benchmark model and
their counterparts in the data (these are the projected markups, implied by the fitted values
from (38), as discussed above). We compare these to an economy that is identical except
that we shut down international trade.
As shown in Panel A of Table 4, the benchmark model implies an average markup of 1.14,
a median markup of 1.12 (just above the minimum �/(��1) = 1.11) and a standard deviation
of log markups of 0.08. These are very close to their data counterparts. Moreover, as in the
data larger producers have considerably higher markups. The 95th percentile markup is 1.31
(compared to 1.20 in the data) and the 99th percentile markup is 1.67 (compared to 1.48
in the data) — though note that these are still a long way short of the ✓/(✓ � 1) = 4.57
markup a pure monopolist would charge in our model. Because large producers charge
higher markups, the aggregate markup, which is a revenue-weighted harmonic average of the
individual markups, is 1.31 — much higher than the simple average.
Let µ(s) = p(s)/(W/a(s)) denote the aggregate markup in sector s. This sector-level
markup µ(s) is likewise a revenue-weighted harmonic average of the producer-level markups
µi
(s) within that sector. Both in the model and in the data, these sector-level markups µ(s)
are larger and more dispersed than their producer-level counterparts µi
(s). In the model, the
median sectoral markup is 1.29 as opposed to 1.12 for producers while the 99th percentile
sectoral markup is 2.13 as opposed to 1.67 for producers. Thus, there are potentially large
gains from reduced dispersion in markups across sectors as well as from reduced markup
dispersion within sectors. Note however that the model fails to replicate the full extent of
the across-sector variation in markups, especially in the tails. The 99th percentile markup
in the data is 3.12, as opposed to 2.13 in the model. Since the actual dispersion in markups
across sectors is considerably larger than in the model, this suggests we will, if anything,
understate the true gains from reduced markup dispersion.
22

Now consider what happens when we shut down all international trade. The median
markup does not change, nor does the 75th percentile markup. Rather markups in the far
tails of the distribution rise: the 95th percentile markup increases from 1.31 to 1.35 and the
99th percentile markup increases from 1.67 to 1.76. Markup dispersion increases, with the
standard deviation of log markups rising from 0.08 in the benchmark to 0.10 under autarky,
with almost all of this increase in markup dispersion coming from a fanning out of the tails.
Even more significantly, the distribution of sector-level markups experiences a considerable
increase in dispersion, with the 95th percentile sectoral markup increasing from 1.80 to 2.25
and the 99th percentile markup increasing from 2.13 to 4.57 as some sectors become pure
monopolies. This increase in markup dispersion suggests there will be more misallocation
under autarky than in the benchmark economy.
Indeed, as shown in Panel B of Table 4, the benchmark economy implies aggregate pro-
ductivity 6.7% below the first-best level of productivity associated with the planning alloca-
tion. Under autarky, the economy is 8.5% below the first-best. In this sense, the extent of
misallocation is considerably worse under autarky.
5 Gains from trade
We now calculate the aggregate productivity gains from trade in our benchmark model. As
in Arkolakis, Costinot and Rodrıguez-Clare (2012a), we focus on the gains from trade due
to a permanent reduction in trade costs ⌧ .
Total gains from trade. We measure the gains from trade by the log percentage change in
aggregate productivity from one equilibrium to another (the percentage change in aggregate
consumption is very similar). As reported in Panel B of Table 4, for our benchmark economy
the total gains from trade are a 12.0% increase in aggregate productivity relative to autarky.
This is, of course, an extreme comparison. In Table 5 we report the gains from trade for
intermediate degrees of openness. In particular, holding all other parameters fixed, we change
the proportional trade cost ⌧ so as to induce import shares of 0 (autarky), 10%, 20%, 30%
and 38% (the Taiwan benchmark).
The model predicts a 3.1% increase in aggregate productivity moving from autarky to an
import share of 10%. Moving further to an import share of 20% adds another 2.8% so that
the cumulative gain moving from autarky to 20% is 3.1 + 2.8 = 5.9%. Continuing all the
way to Taiwan’s openness gives the 12.0% benchmark gains (relative to autarky) discussed
above. Local to the Taiwan benchmark, a 1% change in openness is associated with an
approximately 0.38% change in aggregate productivity. Put di↵erently, an increase in trade
costs resulting in a relatively modest 1% fall in the import share lowers Taiwanese aggregate
23

productivity by 0.38% relative to the benchmark.
Arkolakis, Costinot and Rodrıguez-Clare (2012a) show that, in a large class of models, the
gains from trade are summarized by the formula 1�
log(�/�0) where � is the trade elasticity
with respect to variable trade costs, as in (34) above, and where � and �0 denote the aggregate
share of spending on domestic goods before and after the change in trade costs. According
to this formula, moving from autarky to an import share of 10% with a trade elasticity of 4.2
(which is what our model implies for that degree of openness) gives gains of 14.2
log(1/0.9) =
0.025 or 2.5%. This is reasonably close to the 3.1% we find in our model. Similarly, according
to this formula, moving from autarky to Taiwan’s import share gives total gains of 11.8%,
remarkably close to the 12.0% we find in our model. In short, even though our model with
variable markups is not nested by the ACR setup, we find that their formula still provides a
good approximation to the total gains from trade in our setting.
Pro-competitive gains from trade. We now isolate the gains from trade that are at-
tributable to pro-competitive e↵ects. In our benchmark model, all pro-competitive e↵ects
operate through changes in misallocation (i.e., changes in markup dispersion). Thus the
most straightforward summary of the pro-competitive e↵ects of trade is the implied change
in misallocation. Under autarky, the economy is 8.5% below the first-best level of produc-
tivity. With a 10% import share, the economy is 7.3% below the first-best. So, as reported
in Table 5, with an import share of 10% misallocation relative to autarky is 7.3/8.5 = 0.86.
Opening further to an import share of 20% gives misallocation relative to autarky of 0.83.
Opening to Taiwan’s import share gives misallocation relative to autarky of 0.79, a reduction
in misallocation of some 21%. Notice that the extent of the reduction in misallocation, and
hence the strength of the pro-competitive e↵ects, is largest near autarky and then diminishes
in relative importance as the economy experiences increasing degrees of openness.
In Table 5 we also measure the pro-competitive gains from trade as the total gains from
trade less the log percentage change in first-best productivity. In a model with constant
markups, aggregate productivity equals first-best productivity (the equilibrium allocation is
e�cient) and hence there are zero pro-competitive gains. The pro-competitive gains will be
positive if increased trade reduces misallocation so that the increase in aggregate productivity
is larger than the increase in first-best productivity. The pro-competitive ‘gains’ will be
negative if increased trade increases misallocation. For our benchmark model, opening to
trade reduces misallocation so we see here that indeed aggregate productivity increases by
more than first-best productivity so that there are positive pro-competitive gains. Opening
from autarky to Taiwan’s import share gives pro-competitive gains of 1.8%.
Finally, while the trade elasticity changes with the degree of openness the changes are in
fact relatively modest, varying from 4.2 at an import share of 10% to 4 at the benchmark.
24

Domestic vs. import markups. As emphasized by Arkolakis, Costinot, Donaldson and
Rodrıguez-Clare (2012b), the overall sign of the pro-competitive e↵ect depends on markup
responses of producers both in their domestic market and in their export market. It can be the
case that a reduction in trade barriers leads to lower domestic markups (as Home producers
lose market share) combined with higher markups on imported goods (as Foreign producers
gain market share) such that overall markup dispersion increases and misallocation is worse
— in which case the pro-competitive ‘gains’ from trade would be negative. In short, looking
only at the markups of domestic producers may be misleading. As reported in Table 5, we
indeed see that markups on imported goods do increase as the economy opens to trade, the
revenue-weighted harmonic average of markups on imported goods increases by 15.8% as the
economy opens from autarky (where Foreign producers have infinitesimal market share) to
an import share of 10% while the corresponding average for domestic (Home) markups falls
by 1.4%. The latter fall receives much more weight in the economy-wide aggregate markup
so that overall the aggregate markup falls 1.6%. Notice that the fall in the aggregate markup
is larger than the fall in domestic markups alone. This is due to a compositional e↵ect.
In particular, although markups on imported goods are rising while domestic markups are
falling, the level of domestic markups is higher than the level of markups on imported goods.
As the economy opens, the aggregate markup falls both because the high domestic markups
of Home producers are falling and because a greater share of spending is on low-markup
imports from Foreign producers.
Role of cross-country correlation in productivity. To match an aggregate trade elas-
ticity of 4, our benchmark model requires a quite high degree of cross-country correlation in
sectoral productivity draws, ⌧(⇢) = 0.93. This degree of sectoral correlation implies, that,
following a reduction in trade barriers, there is a correspondingly high degree of head-to-head
competition between producers within any given sector. In Panel A of Table 6, we show the
sensitivity of our results to the extent of correlation in sectoral productivity. For each level
of ⌧(⇢) shown, we recalibrate our model to match our original targets except for the trade
elasticity and related import share dispersion statistics. As we reduce ⌧(⇢), the model trade
elasticity falls monotonically, reaching values of less than 1. Corresponding to these low trade
elasticities are extremely high total gains from trade. Mechanically, the trade elasticity falls
because the index of import share dispersion Var[�(s)]/�(1� �), i.e., the coe�cient on ✓ in
equation (33) above, rises as ⌧(⇢) falls. That is, an increasing proportion of sectors are either
completely dominated by domestic producers (with import shares close to 0) or completely
dominated by foreign producers (with import shares close to 1) so that the trade elasticity
depends more on the across-sector ✓ and less on the within-sector elasticity �.
When the correlation ⌧(⇢) is high, sectoral productivity draws are similar across countries
25

so that most trade is intra-industry. In this case, a given change in trade costs gives rise
to relatively large changes in trade flows. Panel A of Table 6 shows that the Grubel and
Lloyd (1971) index of intra-industry trade is monotonically decreasing in ⌧(⇢), falling from
0.5 for our benchmark model (meaning, 50% of trade is intra-industry) to less than 0.1 for
⌧(⇢) < 0.5. We also note that, in our benchmark model, there is a strong positive relationship
between a sector’s share of domestic sales and its share of imports. In particular, the slope
coe�cient in a regression of sector imports as a share of total imports on sector domestic
sales as a share of total domestic sales is about 0.77 — i.e., sectors with relatively large,
productive firms are also sectors with relatively large import shares, which is suggestive of
firms in these sectors facing a great deal of head-to-head competition. When we reduce ⌧(⇢)
we find this regression coe�cient falls, eventually becoming slightly negative, so that large
sectors no longer have large import shares, suggesting domestic producers no longer face as
much competition when ⌧(⇢) is low.
Importantly, when the correlation ⌧(⇢) is su�ciently low a reduction in trade costs actu-
ally increases misallocation so that, as in Arkolakis, Costinot, Donaldson and Rodrıguez-Clare
(2012b), the pro-competitive ‘gains’ from trade are negative. To understand this, begin with
an economy with high correlation, ⌧(⇢) = 0.9 (similar to our benchmark). As shown in Panel
B of Table 6, the 99th percentile of the domestic markup distribution falls from about 1.76
to 1.61, a fall of some 8.7%. Since markups near the median of the distribution change very
little, this also represents a substantial fall in markup dispersion across domestic producers.
Ultimately this fall in markups at the top of the distribution is a consequence of these do-
mestic producers losing substantial market share to foreign competition. By contrast, with
less correlation in draws, say ⌧(⇢) = 0.1, opening from autarky to trade reduces the 99th
percentile of domestic markups by only 2.3%. With less correlation, these dominant domes-
tic producers lose less market share and hence their markups fall by less than with high
correlation. Since markups near the median again change very little, this means there is a
smaller fall in markup dispersion across domestic producers. Indeed, with ⌧(⇢) = 0.1 the fall
in domestic markup dispersion is su�ciently small that it is dominated by the rise in markup
dispersion for imported goods so that, overall, misallocation is actually worse. In this case,
the increased misallocation subtracts about 0.5% from the total gains from trade (which are
nonetheless large here, because of the counterfactually low trade elasticity with ⌧(⇢) = 0.1).
In Panel A of Table 6, we also report the data counterparts of the index of import share
dispersion, the Grubel and Lloyd index, and the coe�cient of size on import shares. To
match these, our model requires ⌧(⇢) in the range 0.8 to 1.0 (depending on how much weight
is given to each measure) with the aggregate trade elasticity then being in the range 2.9 to
4.4. In short, to match the facts on import share dispersion and intra-industry trade, the
model requires a high degree of cross-country correlation in productivity draws.
26

Alternative model: cross-country correlation in idiosyncratic draws. As a final
way to see the importance of head-to-head competition, we provide results for an alter-
native version of our model where there is correlation in both sectoral productivities z(s)
and in producer-specific idiosyncratic draws xi
(s). Specifically we assume HZ
(z, z⇤) =
C
Z
(FZ
(z), FZ
(z⇤)) and HX
(x, x⇤) = C
X
(FX
(x), FX
(x⇤)) both linked via a Gumbel copula
as in (41) but with distinct correlation coe�cients, ⌧z
(⇢) and ⌧x
(⇢). The benchmark model
is then the special case ⌧z
(⇢) = 0.93 and ⌧x
(⇢) = 0. We recalibrate this model targeting
the same moments as our benchmark model plus one new moment that helps identify ⌧x
(⇢).
In particular, we choose ⌧x
(⇢) so that our model reproduces the cross-sectional relationship
between sectoral import penetration and sectoral concentration amongst domestic producers
that we observe in the Taiwanese data. In the data, the slope coe�cient in a regression of sec-
tor import penetration on sector domestic HH indexes is 0.21 — i.e., sectors with high import
penetration are also sectors with relatively high concentration amongst domestic producers.15
To match this, we require a modest degree of cross-country correlation in idiosyncratic draws,
⌧x
(⇢) = 0.22. The required cross-country correlation in sectoral productivity is correspond-
ingly slightly lower, ⌧z
(⇢) = 0.90, down from the benchmark 0.93.
As reported in Panel B of Table 5, this alternative model implies very similar total gains
from trade, 11.7% versus the benchmark 12%, but because dominant producers face more
head-to-head competition there are now larger pro-competitive e↵ects. Opening from autarky
to Taiwan’s import share now reduces misallocation by almost one-third and the the pro-
competitive gains are 2.6%, up from the benchmark 1.8%. Here, trade plays a larger role in
reducing markup distortions because countries import more of exactly those goods for which
the domestic market is in fact more distorted.
Capital accumulation and elastic labor supply. In the benchmark model the only
gains are from changes in aggregate productivity and hence the only source of pro-competitive
gains is changes in markup dispersion. The aggregate markup falls 2.8% between autarky and
the Taiwan benchmark but this change in the aggregate markup has no welfare implications.
But with capital accumulation and/or elastic labor supply, the aggregate markup acts like
a distortionary wedge a↵ecting investment and labor supply decisions, and, because of this,
a reduction in the aggregate markup increases welfare beyond the increases associated with
a reduction in markup dispersion. In particular, suppose the representative consumer has
intertemporal preferencesP1
t=0 �tU(C
t
, Lt
) over aggregate consumption Ct
and labor Lt
and
that capital is accumulated according to Kt+1 = (1� �)K
t
+ It
. Suppose also that individual
producers have production function y = ak↵l1�↵. We solve this version of the model assuming
15For our benchmark model, the slope coe�cient of sector import penetration on sector domestic HHindexes is 0.08, low relative to the 0.21 in the data. See the Appendix for more details.
27

utility function U(C,L) = logC � L1+⌘/1 + ⌘, discount factor � = 0.96, depreciation rate
� = 0.1, output elasticity of capital ↵ = 1/3 and various elasticities of labor supply ⌘.
We start the economy in autarky and then compute the transition to a new steady-state
corresponding to the Taiwan benchmark. We measure the welfare gains as the consumption
compensating variation taking into account the dynamics of consumption and employment
during the transition to the new steady-state. For our benchmark experiment, TFP increases
by 12% of which 1.8% is due to pro-competitive e↵ects. As reported in Table 7, with capital
accumulation and a Frisch elasticity of 1, the welfare gains are 17.6% of which 3.3% is due
to pro-competitive e↵ects.
6 Robustness experiments
We now consider variations on our benchmark model, each designed to examine the sensitivity
of our results to parameter choices or other assumptions. For each robustness experiment
we recalibrate the trade cost ⌧ , export fixed cost fx
, and correlation parameter ⌧(⇢) so that
the Home country continues to have an aggregate import share of 0.38, fraction of exporters
0.25 and trade elasticity 4, as in our benchmark model. A summary of these robustness
experiments is given in Table 8. Further details and a full set of results for these experiments
are reported in the Appendix.
Heterogeneous labor market distortions. Our benchmark model focuses on the impor-
tance of product market distortions but ignores the role of labor market distortions. We now
show that this is not essential for our main results. We assume that there is a distribution of
producer-level labor market distortions that act like labor input taxes, putting a wedge be-
tween labor’s marginal product and its factor cost. Specifically, a producer with productivity
a also faces an input tax t(a) on its wage bill so that it pays (1+t(a))W for each unit of labor
hired. We assume t(a) = a⌧l1+a⌧l
and choose the parameter ⌧l
governing the sensitivity of the
labor distortion to producer productivity so that our model matches the spread between the
average producer labor share and the aggregate labor share that we observe in the data. In
the data, the average producer labor share is 1.35 times the aggregate labor share. Since the
latter is a weighted version of the former, this tells us that large producers tend to have low
measured labor shares. To match this, our model requires ⌧l
= 0.003, so indeed producers
with high productivities are also producers with relatively high labor distortions.16
These labor market distortions significantly reduce aggregate productivity relative to the
benchmark economy — the level of productivity turns out to be only about two-thirds that
16For our benchmark model the average labor share is also greater than the aggregate labor share, but thespread is 1.16, somewhat lower than the 1.35 in the data.
28

of the benchmark. In this sense, total misallocation is much larger in this economy. But
this is because there are now two sources of misallocation — labor market distortions and
markup distortions. The amount of misallocation due to markup distortions alone is roughly
the same as in the benchmark economy. To see this, notice that the level of productivity
associated with a planner who faces the same labor distortions but can otherwise reallocate
across producers is 6.4% higher than the equilibrium level of productivity, very close to the
corresponding 6.7% gap in the benchmark economy.
Given that there are similar amounts of misallocation due to markups, it is not then
surprising that the gains from trade turn out to be similar as well. The aggregate gains from
trade are 12.1% versus the benchmark 12% while the pro-competitive gains are about 1.8% in
both cases. Importantly, we find that allowing for labor market distortions does not change
the estimate of ✓ implied by equation (19) above. We continue to find that a regression of
inverse markups on market shares gives a coe�cient of about �0.68, which is consistent with
✓ = 1.28, just as in the benchmark. Essentially, this is because with ⌧l
= 0.003 there is in fact
only a weakly positive relationship between a producer’s productivity and their labor market
distortion and as a result the relationship between inverse markups and market shares is
mostly driven by the product market distortions, as in the benchmark model.
Heterogeneous tari↵s. In our benchmark model, the only barriers to trade are the phys-
ical trade costs ⌧ and fx
and these are the same for every producer in every sector. We
consider a version of our model where in addition to these trade costs there is a sector-
specific distortionary tari↵ that is levied on the value of imported goods. For simplicity we
assume the tari↵ revenues are rebated lump-sum to the representative consumer. We assume
the tari↵ rates are drawn from a Beta distribution on [0, 1] with parameters estimated by
maximum likelihood using the Taiwanese micro data. These estimates imply a mean tari↵
rate of 0.062 with cross-sectional standard deviation of 0.039. With a mean tari↵ of 0.062,
the trade cost required to match the aggregate import share is correspondingly lower, 1.067
down from the benchmark 1.128.
Perhaps surprisingly, we find the total gains from trade are somewhat larger than in the
benchmark, 14% as opposed to 12%, with the pro-competitive gains being similarly larger,
3.9% as opposed to 1.8% in the benchmark. One might expect that, for a given distribution
of tari↵s, a symmetric reduction in trade costs would make the cross-sectoral misallocation
due to tari↵s worse and thereby reduce the gains from trade (relative to an economy without
tari↵s). In this experiment, we find the opposite. This is due to a kind of ‘second best’
e↵ect — i.e., in the presence of two distortions, increasing one distortion does not necessarily
reduce welfare. In particular, the additional cross-sectoral misallocation due to tari↵s is more
than o↵set by strong reductions in within-sector market share dispersion.
29

Bertrand competition. In our benchmark model, firms engage in Cournot competition.
If we assume instead that firms engage in Bertrand competition, then the model changes in
only one respect. The demand elasticity facing producer i in sector s is no longer a harmonic
weighted average of ✓ and �, as in equation (13), but is now an arithmetic weighted average,
"i
(s) = !i
(s)✓+(1� !i
(s)) �. With this specification the results are similar to the benchmark.
The total gains from trade are 13.1%, up slightly from the benchmark 12%, and the pro-
competitive gains are 2%, likewise up slightly from the benchmark 1.8%. As shown in the
last two columns of Table 3, the Bertrand model implies somewhat lower markup dispersion
than the Cournot model. But it also implies a larger change in markup dispersion when
opening to trade and hence a larger reduction in misallocation. Opening from autarky to
Taiwan’s import share implies misallocation falls by one-half, up from the benchmark one-
fifth fall. Perhaps not surprisingly, the competitive pressure on dominant firms following a
trade liberalization is greater with Bertrand competition than with Cournot. Consequently,
the Bertrand model implies, if anything, larger pro-competitive e↵ects than the benchmark.
Sensitivity to �. In our benchmark model, we set the within-sector elasticity of substi-
tution to � = 10, following Atkeson and Burstein (2008). We assess the sensitivity of our
results to higher or lower values of � by recalibrating out model for � = 5 and � = 20. With
� = 5 we find that the model cannot produce a trade elasticity of 4, even setting ⌧(⇢) = 1
(perfect correlation) gives a low trade elasticity of 2.38. With this low trade elasticity, the
model implies much higher total gains from trade, 19% of aggregate productivity of which
2.3% are pro-competitive gains. With � = 20 we can match a trade elasticity of 4 with less
correlation, ⌧(⇢) = 0.85 than our benchmark. With less correlation, the pro-competitive
gains are smaller, about 0.8% as opposed to 1.8% in the benchmark, but still sizeable. As
discussed in the Appendix, compared to the benchmark model the � = 20 model also implies
a weaker relationship between sector size and import shares than we see in the data.
No fixed costs. To assess the role of the fixed costs fd
and fx
we compute results for
a version of our model with fd
= fx
= 0. In this specification, all firms operate in both
their domestic and export markets. Hence the equilibrium number of producers in a sector is
simply pinned down by the Geometric distribution for n(s). This version of the model yields
almost identical results to the benchmark. Shutting down these extensive margins makes
little di↵erence because the typical producer near the margin of operating or not is small and
has negligible impact on the aggregate outcomes.
Gaussian copula. Our benchmark model uses the Gumbel copula (41) to model cross-
country correlation in sectoral productivity draws. To examine the sensitivity of our results
30

to this functional form, we resolve our model using a Gaussian copula, namely
C(u, u⇤) = �2,⇢(��1(u),��1(u⇤)) (42)
where �(x) denotes the CDF of the standard Normal distribution and �2,⇢(x, x⇤) denotes
the standard bivariate Normal distribution with linear correlation coe�cient ⇢ 2 (�1, 1). To
compare results to the Gumbel case, we map the linear correlation coe�cient into our pre-
ferred Kendall correlation coe�cient, which for the Gaussian copula is ⌧(⇢) = 2 arcsin(⇢)/⇡.
To match a trade elasticity of 4 requires ⌧(⇢) = 0.97, up slightly from the benchmark 0.93
value. This version of the model also yields very similar results to the benchmark. Condi-
tional on choosing the amount of correlation to match the trade elasticity, the total gains
from trade are 11.5% with pro-competitive gains of 1.5%, both quite close to their benchmark
values. In short, our results are not sensitive to the assumed functional form of the copula.
7 Extensions
7.1 Asymmetric countries
Our benchmark model makes the stark simplifying assumption of trade between two sym-
metric countries. We now relax this and consider the gains from trade between countries that
di↵er in size and/or productivity. Specifically, we normalize the Home country labor force
to L = 1 and vary the Foreign labor force L⇤. Home producers continue to have production
function yi
(s) = ai
(s)li
(s), as in (3) above, and Foreign producers now have the production
function y⇤i
(s) = A⇤a⇤i
(s)l⇤i
(s) with productivity scale parameter A⇤. We again recalibrate key
parameters of the model so that for the Home country we reproduce the degree of openness
of the Taiwan benchmark — in particular, we choose the proportional trade cost ⌧ , export
fixed cost fx
, and correlation parameter ⌧(⇢) so that the Home country continues to have an
aggregate import share of 0.38, fraction of exporters 0.25 and trade elasticity 4.
Larger trading partner. The top panel of Table 9 shows the gains from trade when the
Foreign country has labor force L⇤ = 2 and L⇤ = 10 times as large as the Home country.
For the Home country, the total gains from trade are slightly smaller than under symme-
try. And when the Foreign country is larger, its total gains from trade are smaller than the
Home country gains. For example, when the Foreign country is 10 times as large as the
Home country, the Home gains are 11.1% (down from 12% in the symmetric benchmark)
whereas the Foreign gains are down to 1.8%. The Home country has much more to gain
from integration with a large trading partner than the Foreign country has to gain from in-
tegration with a small trading partner. The pro-competitive gains are also slightly lower for
both countries. When L⇤ = 10, the Home pro-competitive gains are 1.2% (down from 1.8%
31

in the symmetric benchmark) whereas the Foreign pro-competitive gains are down to 1.1%.
Interestingly, the pro-competitive gains account for a high share of the Foreign country’s
total gains, 1.1% out of 1.8%. In this calibration, the Foreign country is considerably less
open than the Home country, with an aggregate import share of 0.05 (as opposed to 0.38)
and a fraction of exporters of 0.06 (as opposed to 0.25). Despite the lower openness, we see
that Foreign consumers still gain considerably from exposing their producers to greater com-
petition (Home consumers gain even more), and that failing to account for pro-competitive
e↵ects can seriously understate the gains from integration, even for a large country.
More productive trading partner. The bottom panel of Table 9 shows the gains from
trade when the Foreign country has productivity scale A⇤ = 2 and A⇤ = 10 times that of the
Home country but has the same size, L⇤ = 1. Not surprisingly, for the Home country the total
gains from trade are considerably larger than under symmetry. For example, when A⇤ = 10,
the Home gains are 30.1% (up from 12% in the symmetric benchmark). But these very large
gains are almost entirely due to increases in the first-best level of productivity. The pro-
competitive gains are 1.2%, and hence relative to the symmetric benchmark are both smaller
in absolute terms and smaller as a share of the total gains. The more productive Foreign
country has smaller total gains (and so benefits less from trade than the less productive Home
country) and smaller pro-competitive gains.
The correlation in cross-country productivity required to reproduce a Home trade elas-
ticity of 4 is ⌧(⇢) = 0.55, considerably lower than the benchmark ⌧(⇢) = 0.93. With large
productivity di↵erences between countries, import shares are more responsive to changes in
trade costs than under symmetry. But because there is less correlation, there is also less
head-to-head competition and because of this the pro-competitive gains are smaller.
7.2 Free entry
In our benchmark model there is an exogenous number of firms in each sector, a subset of
which choose to pay the fixed cost fd
and operate. Some of the firms that do operate make
substantial economic profits and thus there is an incentive for other firms to try to enter. We
now relax the no-entry assumption and assume instead that there is free entry subject to a
sunk cost. In equilibrium, the expected profits simply compensate for this initial sunk cost.
To keep the analysis tractable, we assume that entry is not directed at a particular sector.
After paying its sunk cost, a firm learns the productivity with which it operates, as in Melitz
(2003), as well as the sector to which it is randomly assigned.17 We also assume that there
are no fixed costs of operating or exporting in any given period. Instead, we assume that a
17An unappealing implication of allowing directed entry is that the resulting model would predict lowdispersion in sectoral markups, in stark contrast to the very high dispersion in sectoral markups in the data.
32

firm’s productivity is drawn from a discrete distribution which includes a mass point at zero,
thus allowing the model to generate dispersion in the number of firms that operate.
Computational issues. Given the structure of our model, the expected profits of a po-
tential entrant (which, due to free entry, equals the sunk cost) are not equal to the average
profits across those firms that operate. One reason for this di↵erence is that a potential en-
trant recognizes the e↵ect its entry will have on its own profits and those of the incumbents.
An additional reason is that the measure of producers of di↵erent productivities in a given
sector is correlated with the profits a particular firm makes in that sector. Computing the
expected profits of a potential entrant is thus a computationally challenging task: we need to
integrate the distribution (across sectors) of the measures of firms (over their productivities)
— a finite, but high-dimensional object. In addition, a potential entrant must re-solve for
the distribution of markups that would arise if it enters. Given that the number of firms
that enter each sector is small, the law of large number fails, and the algorithm to compute
an equilibrium is involved. For this reason, we make a number of additional simplifying
assumptions relative to our benchmark model without entry. In particular, we use a coarse
productivity distribution and set the operating and exporting fixed costs to fd
= fx
= 0.
Setup. The productivity of a firm in sector s 2 [0, 1] is now given by a world component,
common to both countries, z(s), and a firm-specific component. In addition, we assume
a gap u(s) between the productivity with which firms produce for their domestic market
and that with which they produce for their export market. Specifically, let u(s) denote the
productivity gap for Home producers in sector s and let u⇤(s) denote the productivity gap
for Foreign producers in sector s. There is an unlimited number of potential entrants. To
enter, a firm pays a sunk cost fe
that allows it to draw (i) a sector s in which to operate,
and (ii) idiosyncratic productivity xi
(s) 2 {0, 1, x}. To summarize, a Home firm in sector
s with idiosyncratic productivity xi
(s) produces for its domestic market with overall pro-
ductivity aHi
(s) = z(s)u(s)xi
(s) and produces for its export market with overall productivity
a⇤Hi
(s) = z(s)xi
(s)/⌧ where ⌧ is the gross trade cost. Similarly, a Foreign firm in sector s with
idiosyncratic productivity x⇤i
(s) produces for its domestic market with overall labor produc-
tivity a⇤Fi
(s) = z(s)u⇤(s)x⇤i
(s) and produces for its export market with overall productivity
aFi
(s) = z(s)x⇤i
(s)/⌧ .
Cross-country correlation and head-to-head competition. In this version of the
model, the amount of head-to-head competition can now be varied flexibly by changing the
amount of dispersion in u(s) across sectors. Greater dispersion in u(s) reduces the amount
of head-to-head competition between Home and Foreign producers and thereby lowers the
33

aggregate trade elasticity.
Parameterization. The Taiwanese data feature a high degree of across-sector dispersion
in markups, in the number of producers, and in market concentration. We match this across-
sector dispersion by assuming that the probability that a firm draws idiosyncratic produc-
tivity xi
(s) 2 {0, 1, x} varies with s (but is the same across countries for a given sector).
In particular, we assume a non-parametric distribution Prob[xi
(s) | s] across sectors and cal-
ibrate this distribution to match the same set of moments we targeted for our benchmark
model (we have found that allowing for 9 types of sectors produces a good fit; in our Appendix
we also discuss results for a simpler model with a single sector type).
We assume that the gaps u(s) are drawn from a lognormal distribution with variance
�2u
and that the worldwide sectoral productivities z(s) are drawn from a Pareto distribution
with shape parameter ⇠z
.
Taiwan calibration revisited. We fix � = 10 and ✓ = 1.28, as in our benchmark model.
We calibrate the new parameters fe
, x, �u
, ⇠z
, the distribution Prob[xi
(s) | s] across sectors,
and the trade cost ⌧ targeting the same moments as in our benchmark model. The full set
of results for this calibration are reported in our Appendix.
Gains from trade with free entry. Panel A of Table 10 shows the gains from trade in
this economy. With free entry, 168 firms pay the sunk cost and enter any individual sector.
The economy is about 2% away from the first-best level of aggregate productivity. Thus,
although we target the same concentration moments and have the same elasticities ✓ and �
as in the benchmark model, with free entry there is less misallocation.
Aggregate productivity is 7.2% above its autarky level and opening to trade reduces
misallocation by just over one-third, from 3.2% to 2%. This reduction in misallocation
implies pro-competitive gains of 1.2%, somewhat lower than the benchmark pro-competitive
gains of 1.8%. Note that there are 187 firms attempting to enter under autarky, more than
in the open economy. For a given number of firms, expected profits are higher under autarky
and so more firms enter until the free-entry condition is satisfied. If we hold the number of
firms fixed at the autarky level of 187 but otherwise open the economy to trade, aggregate
productivity rises by 8.2%, larger than the 7.2% with free entry, and the pro-competitive
gains are correspondingly larger at 1.4% as opposed to 1.2%.
To summarize, even with free-entry there is a quantitatively significant reduction in mis-
allocation. Importantly, the somewhat weaker pro-competitive e↵ects reflect the alternative
calibration of the model which implies less initial misallocation, not the free entry itself. In
particular, the model predicts much less dispersion in sectoral markups — e.g., the ratio
34

of the 90th percentile to the median is 1.14 (compared to 1.31 in the data and 1.23 in the
benchmark), and the ratio of the 95th percentile to the median is 1.16 (1.56 in the data and
1.40 in the benchmark). We address this discrepancy between the model and the data next.
Collusion. Given this failure to match the dispersion of sectoral markups in the data, we
now consider a slight variation on the free-entry model designed to bridge the gap between
the model and the data along this dimension. We suppose that with probability all the
high-productivity firms (those with xi
(s) = x > 1) within a given sector are able to collude.18
These colluding firms choose a single price to maximize their group profits. Since their
collective market share is larger than their individual market shares, the price set by colluding
firms is higher than the price they would charge in isolation and hence their collective markup
is also correspondingly larger. Since this version of the model features more dispersion in
markups, it also features more misallocation.
Panel B of Table 10 shows results for this model with = 0.25. Even with free entry
this version of the model features productivity losses of 4.3% relative to the first-best. The
reason these productivity losses are greater is that now the dispersion in sectoral markups is
greater. For example, the ratio of the 90th percentile to the median is 1.22 (compared to 1.14
absent collusion) and the ratio of the 95th percentile to the median is 1.30 (compared to 1.16
absent collusion). Thus this version of the model produces sectoral dispersion in markups
more in line with our benchmark model and hence closer to the data.
Consequently, the model now predicts larger total gains from trade of 11.2%, of which 3.9%
are pro-competitive gains — i.e., the model with free-entry and collusion implies larger pro-
competitive gains than our benchmark model. With wide-spread collusion amongst domestic
producers, opening to foreign competition provides an import source of market discipline.
Notice also that the number of producers change very little (from 162 in autarky to 160 in
the open economy) despite the reduction in firm markups (the aggregate markup falls from
1.34 to 1.27). The reason the number of firms does not change much is an externality akin to
that in Blanchard and Kiyotaki (1987). Although an individual firm loses profits if its own
markup falls, it benefits when other firms reduce markups due to the increase in aggregate
output and the reduction in the aggregate price level. Overall, these two e↵ects on expected
profits roughly cancel each other out so that there is little e↵ect on the gains from trade.
In short, with free entry and collusion the model implies strong pro-competitive e↵ects.
In our Appendix we report results for a wide range of collusion probabilities and show that
the same basic pattern holds. For example, if the collusion probability is = 0.15 instead of
= 0.25 then the total gains from trade are 12.1% of which 3.8% are pro-competitive gains.
18Alternatively, this can be thought of as the result of mergers or acquisitions.
35

The results from the model with collusion reinforce our main message: the pro-competitive
gains from trade are larger when product market distortions are large to begin with.
8 Conclusions
We study the pro-competitive gains from international trade in a quantitative model with en-
dogenously variable markups. We find that trade can significantly reduce markup distortions
if two conditions are satisfied: (i) there must be large ine�ciencies associated with markups,
i.e., extensive misallocation, and (ii) trade must in fact expose producers to greater com-
petitive pressure. The second condition is satisfied if there is a high degree of cross-country
correlation in the productivity with which producers within a given sector operate.
We calibrate our model using Taiwanese producer-level data and find that these two
conditions are satisfied. The Taiwanese data is characterized by a large amount of dispersion
and concentration in producer market shares and a strong cross-sectional relationship between
producer market shares and markups, which implies extensive misallocation. Moreover to
match standard estimates of the trade elasticity, and at the same time match key facts on
import share dispersion, intra-industry trade and the cross-sectional relationship between
import penetration and domestic concentration, the model requires a high degree of cross-
country correlation in productivity. Consequently, the model implies that opening to trade
does in fact expose producers to considerably greater competitive pressure.
We find that opening to trade reduces misallocation by about one-fifth in our benchmark
model with Cournot competition, reduces misallocation by about one-third in our alternate
model that matches the correlation between domestic concentration and import penetration,
and reduces misallocation by about one-half in our model with Bertrand competition. In this
sense, we find that, indeed, trade can significantly reduce product market distortions.
We conclude by noting that, from a policy viewpoint, our model suggests that obtaining
large welfare gains from an improved allocation of resources may not require the detailed,
perhaps impractical, scheme of producer-specific subsidies and taxes that reduce the dis-
tortions associated with variable markups. Instead, simply opening an economy to trade
may provide an excellent practical alternative that substantially improves productivity and
welfare. Conversely, our model also predicts that countries which open up to trade after
having already implemented policies aimed at reducing markup distortions may benefit less
from trade than countries with large product market distortions. The former countries would
mostly receive the standard gains from trade, while the latter would also benefit from the
reduction in markup distortions.
36

References
Ackerberg, Daniel A., Kevin Caves, and Garth Frazer, “Structural Identification ofProduction Functions,” 2006. UCLA working paper.
Arkolakis, Costas, Arnaud Costinot, and Andres Rodrıguez-Clare, “New TradeModels, Same Old Gains?,” American Economic Review, February 2012, 102 (1), 94–130.
, , Dave Donaldson, and Andres Rodrıguez-Clare, “The Elusive Pro-CompetitiveE↵ects of Trade,” March 2012. MIT working paper.
Atkeson, Andrew and Ariel Burstein, “Pricing-to-Market, Trade Costs, and Interna-tional Relative Prices,” American Economic Review, 2008, 98 (5), 1998–2031.
Bernard, Andrew B., Jonathan Eaton, J. Bradford Jensen, and Samuel Kortum,“Plants and Productivity in International Trade,” American Economic Review, September2003, 93 (4), 1268–1290.
, Stephen J. Redding, and Peter Schott, “Multiple-Product Firms and ProductSwitching,” American Economic Review, March 2010, 100 (1), 70–97.
Blanchard, Olivier Jean and Nobuhiro Kiyotaki, “Monopolistic Competition and theE↵ects of Aggregate Demand,” American Economic Review, 1987, 77 (4), 647–666.
Chaney, Thomas, “Distorted Gravity: The Intensive and Extensive Margins of Interna-tional Trade,” American Economic Review, September 2008, 98 (4), 1707–1721.
De Blas, Beatriz and Katheryn Russ, “Teams of Rivals: Endogenous Markups in aRicardian World,” 2010. NBER Working Paper 16587.
De Loecker, Jan and Frederic Warzynski, “Markups and Firm-Level Export Status,”American Economic Review, October 2012, 102 (6), 2437–2471.
, Pinelopi K. Goldberg, Amit K. Khandelwal, and Nina Pavcnik, “Prices,Markups and Trade Reform,” 2012. Princeton University working paper.
Devereux, Michael B. and Khang Min Lee, “Dynamic Gains from International Tradewith Imperfect Competition and Market Power,” Review of Development Economics, 2001,5 (2), 239–255.
Eaton, Jonathan and Samuel Kortum, “Technology, Geography, and Trade,” Econo-metrica, September 2002, 70 (5), 1741–1779.
Epifani, Paolo and Gino Gancia, “Trade, Markup Heterogeneity, and Misallocations,”Journal of International Economics, January 2011, 83 (1), 1–13.
Feenstra, Robert C., “A Homothetic Utility Function for Monopolistic Competition Mod-els, Without Constant Price Elasticity,” Economics Letters, January 2003, 78 (1), 79–86.
37

and David E. Weinstein, “Globalization, Markups, and the U.S. Price Level,” 2010.NBER Working Paper 15749.
Grubel, Herbert G. and Peter J. Lloyd, “The Empirical Measurement of Intra-IndustryTrade,” Economic Record, 1971, 47 (4), 494–517.
Harrison, Ann E., “Productivity, Imperfect Competition and Trade Reform: Theory andEvidence,” Journal of International Economics, February 1994, 36 (1), 53–73.
Holmes, Thomas J., Wen-Tai Hsu, and Sanghoon Lee, “Monopoly Distortions andthe Welfare Gains from Trade,” November 2011. FRB Minneapolis working paper.
Hsieh, Chang-Tai and Peter J. Klenow, “Misallocation and Manufacturing TFP inChina and India,” Quarterly Journal of Economics, November 2009, 124 (4), 1403–1448.
Krishna, Pravin and Devashish Mitra, “Trade Liberalization, Market Discipline, andProductivity Growth: New Evidence from India,” Journal of Development Economics,August 1998, 56 (2), 447–462.
Krugman, Paul R., “Increasing Returns, Monopolistic Competition, and InternationalTrade,” Journal of International Economics, November 1979, 9 (4), 469–479.
Levinsohn, James A., “Testing the Imports-as-Market-Discipline Hypothesis,” Journal ofInternational Economics, August 1993, 35 (1), 1–22.
Levinsohn, James and Amil Petrin, “Estimating Production Functions using Inputs toControl for Unobservables,” Review of Economic Studies, April 2003, 70 (2), 317–342.
Melitz, Marc J., “The Impact of Trade on Intra-Industry Reallocations and AggregateIndustry Productivity,” Econometrica, November 2003, 71 (6), 1695–1725.
and Giancarlo I.P. Ottaviano, “Market Size, Trade, and Productivity,” Review ofEconomic Studies, 2008, 75 (1), 295–316.
Olley, G. Steven and Ariel Pakes, “The Dynamics of Productivity in the Telecommuni-cations Equipment Industry.,” Econometrica, November 1996, 64 (6), 1263–1297.
Peters, Michael, “Heterogeneous Mark-Ups, Growth and Endogenous Misallocation,”September 2013. LSE working paper.
Restuccia, Diego and Richard Rogerson, “Policy Distortions and Aggregate Produc-tivity with Heterogeneous Establishments,” Review of Economic Dynamics, October 2008,11 (4), 707–720.
Tybout, James R., “Plant- and Firm-Level Evidence on “New” Trade Theories,” inE. Kwan Choi and James Harrigan, eds., Handbook of International Trade, Basil Blackwell.Oxford. 2003.
Zhelobodko, Evgeny, Sergey Kokovin, Mathieu Parenti, and Jacques-FrancoisThisse, “Monopolistic Competition: Beyond the Constant Elasticity of Substitution,”Econometrica, November 2012, 80 (6), 2765–2784.
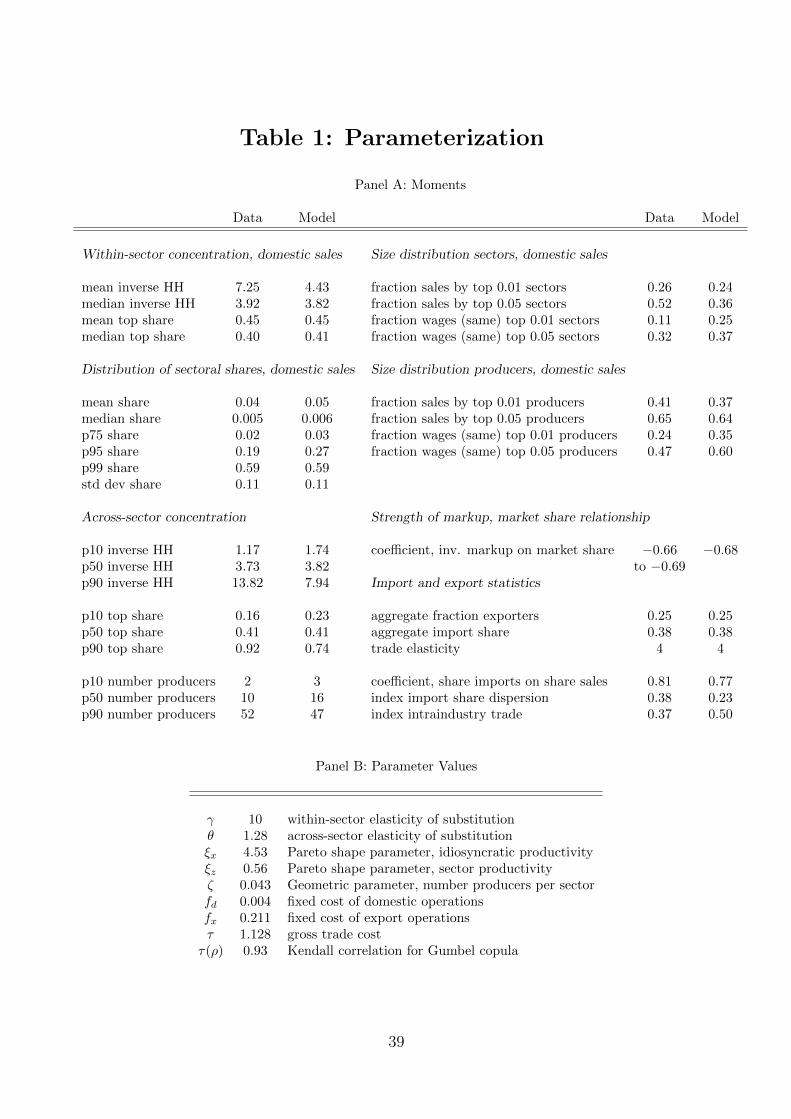
Table 1: Parameterization
Panel A: Moments
Data Model Data Model
Within-sector concentration, domestic sales Size distribution sectors, domestic sales
mean inverse HH 7.25 4.43 fraction sales by top 0.01 sectors 0.26 0.24median inverse HH 3.92 3.82 fraction sales by top 0.05 sectors 0.52 0.36mean top share 0.45 0.45 fraction wages (same) top 0.01 sectors 0.11 0.25median top share 0.40 0.41 fraction wages (same) top 0.05 sectors 0.32 0.37
Distribution of sectoral shares, domestic sales Size distribution producers, domestic sales
mean share 0.04 0.05 fraction sales by top 0.01 producers 0.41 0.37median share 0.005 0.006 fraction sales by top 0.05 producers 0.65 0.64p75 share 0.02 0.03 fraction wages (same) top 0.01 producers 0.24 0.35p95 share 0.19 0.27 fraction wages (same) top 0.05 producers 0.47 0.60p99 share 0.59 0.59std dev share 0.11 0.11
Across-sector concentration Strength of markup, market share relationship
p10 inverse HH 1.17 1.74 coe�cient, inv. markup on market share �0.66 �0.68p50 inverse HH 3.73 3.82 to �0.69p90 inverse HH 13.82 7.94 Import and export statistics
p10 top share 0.16 0.23 aggregate fraction exporters 0.25 0.25p50 top share 0.41 0.41 aggregate import share 0.38 0.38p90 top share 0.92 0.74 trade elasticity 4 4
p10 number producers 2 3 coe�cient, share imports on share sales 0.81 0.77p50 number producers 10 16 index import share dispersion 0.38 0.23p90 number producers 52 47 index intraindustry trade 0.37 0.50
Panel B: Parameter Values
� 10 within-sector elasticity of substitution✓ 1.28 across-sector elasticity of substitution⇠
x
4.53 Pareto shape parameter, idiosyncratic productivity⇠
z
0.56 Pareto shape parameter, sector productivity⇣ 0.043 Geometric parameter, number producers per sectorf
d
0.004 fixed cost of domestic operationsf
x
0.211 fixed cost of export operations⌧ 1.128 gross trade cost
⌧(⇢) 0.93 Kendall correlation for Gumbel copula
39
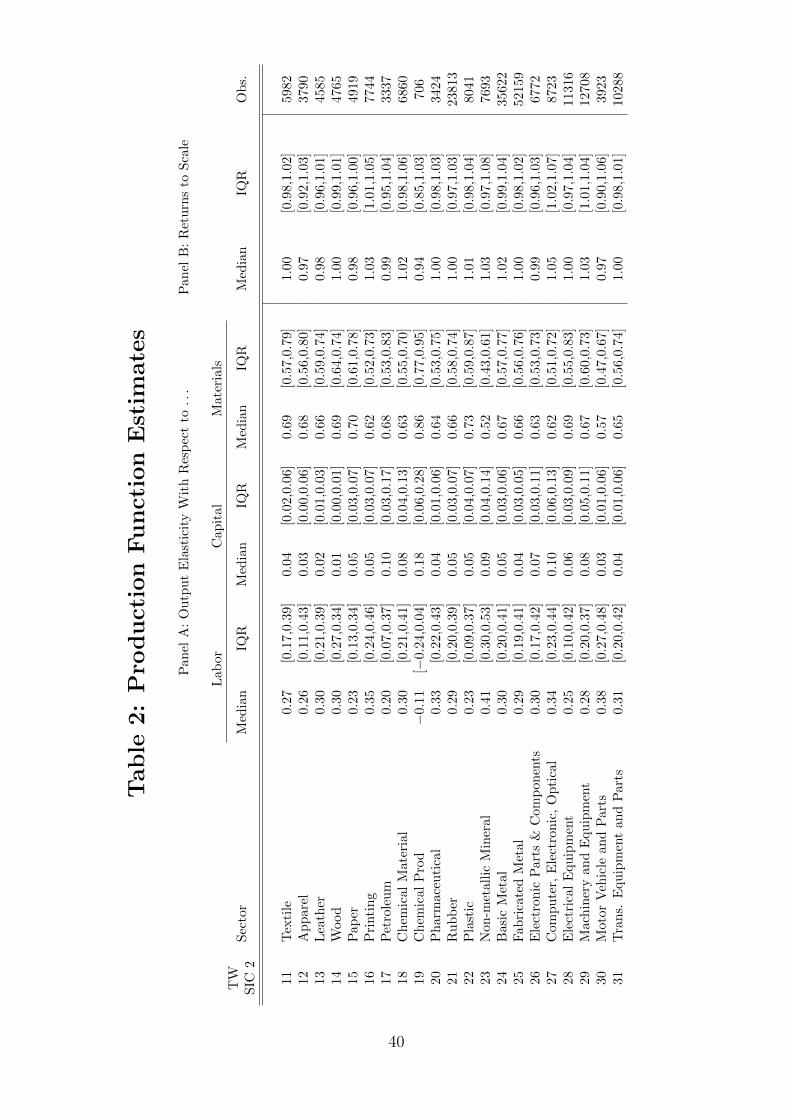
Table
2:Pro
ductionFunctionEstim
ates
Pan
elA:OutputElasticityW
ithRespectto
...
Pan
elB:Returnsto
Scale
Lab
orCap
ital
Materials
TW
SIC
2Sector
Median
IQR
Median
IQR
Median
IQR
Median
IQR
Obs.
11Textile
0.27
[0.17,0.39]
0.04
[0.02,0.06]
0.69
[0.57,0.79]
1.00
[0.98,1.02]
5982
12Apparel
0.26
[0.11,0.43]
0.03
[0.00,0.06]
0.68
[0.56,0.80]
0.97
[0.92,1.03]
3790
13Leather
0.30
[0.21,0.39]
0.02
[0.01,0.03]
0.66
[0.59,0.74]
0.98
[0.96,1.01]
4585
14Woo
d0.30
[0.27,0.34]
0.01
[0.00,0.01]
0.69
[0.64,0.74]
1.00
[0.99,1.01]
4765
15Pap
er0.23
[0.13,0.34]
0.05
[0.03,0.07]
0.70
[0.61,0.78]
0.98
[0.96,1.00]
4919
16Printing
0.35
[0.24,0.46]
0.05
[0.03,0.07]
0.62
[0.52,0.73]
1.03
[1.01,1.05]
7744
17Petroleum
0.20
[0.07,0.37]
0.10
[0.03,0.17]
0.68
[0.53,0.83]
0.99
[0.95,1.04]
3337
18Chem
ical
Material
0.30
[0.21,0.41]
0.08
[0.04,0.13]
0.63
[0.55,0.70]
1.02
[0.98,1.06]
6860
19Chem
ical
Prod
�0.11
[�0.24,0.04]
0.18
[0.06,0.28]
0.86
[0.77,0.95]
0.94
[0.85,1.03]
706
20Pharmaceutical
0.33
[0.22,0.43]
0.04
[0.01,0.06]
0.64
[0.53,0.75]
1.00
[0.98,1.03]
3424
21Rubber
0.29
[0.20,0.39]
0.05
[0.03,0.07]
0.66
[0.58,0.74]
1.00
[0.97,1.03]
23813
22Plastic
0.23
[0.09,0.37]
0.05
[0.04,0.07]
0.73
[0.59,0.87]
1.01
[0.98,1.04]
8041
23Non
-metallicMineral
0.41
[0.30,0.53]
0.09
[0.04,0.14]
0.52
[0.43,0.61]
1.03
[0.97,1.08]
7693
24Basic
Metal
0.30
[0.20,0.41]
0.05
[0.03,0.06]
0.67
[0.57,0.77]
1.02
[0.99,1.04]
35622
25Fab
ricatedMetal
0.29
[0.19,0.41]
0.04
[0.03,0.05]
0.66
[0.56,0.76]
1.00
[0.98,1.02]
52159
26Electronic
Parts
&Com
pon
ents
0.30
[0.17,0.42]
0.07
[0.03,0.11]
0.63
[0.53,0.73]
0.99
[0.96,1.03]
6772
27Com
puter,
Electronic,Optical
0.34
[0.23,0.44]
0.10
[0.06,0.13]
0.62
[0.51,0.72]
1.05
[1.02,1.07]
8723
28ElectricalEqu
ipment
0.25
[0.10,0.42]
0.06
[0.03,0.09]
0.69
[0.55,0.83]
1.00
[0.97,1.04]
11316
29Machineryan
dEqu
ipment
0.28
[0.20,0.37]
0.08
[0.05,0.11
]0.67
[0.60,0.73]
1.03
[1.01,1.04]
12708
30Motor
Vehicle
andParts
0.38
[0.27,0.48]
0.03
[0.01,0.06]
0.57
[0.47,0.67]
0.97
[0.90,1.06]
3923
31Trans.
Equ
ipmentan
dParts
0.31
[0.20,0.42]
0.04
[0.01,0.06]
0.65
[0.56,0.74]
1.00
[0.98,1.01]
10288
40
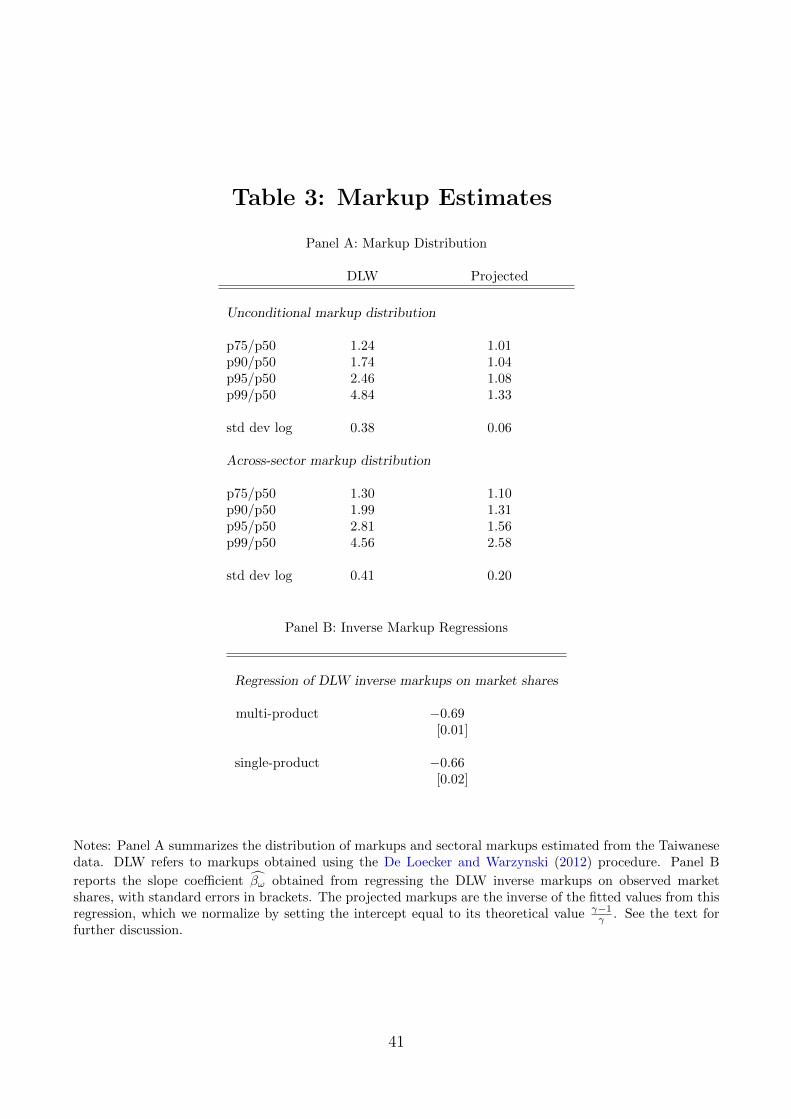
Table 3: Markup Estimates
Panel A: Markup Distribution
DLW Projected
Unconditional markup distribution
p75/p50 1.24 1.01p90/p50 1.74 1.04p95/p50 2.46 1.08p99/p50 4.84 1.33
std dev log 0.38 0.06
Across-sector markup distribution
p75/p50 1.30 1.10p90/p50 1.99 1.31p95/p50 2.81 1.56p99/p50 4.56 2.58
std dev log 0.41 0.20
Panel B: Inverse Markup Regressions
Regression of DLW inverse markups on market shares
multi-product �0.69[0.01]
single-product �0.66[0.02]
Notes: Panel A summarizes the distribution of markups and sectoral markups estimated from the Taiwanesedata. DLW refers to markups obtained using the De Loecker and Warzynski (2012) procedure. Panel B
reports the slope coe�cient c�
!
obtained from regressing the DLW inverse markups on observed marketshares, with standard errors in brackets. The projected markups are the inverse of the fitted values from thisregression, which we normalize by setting the intercept equal to its theoretical value ��1
�
. See the text forfurther discussion.
41
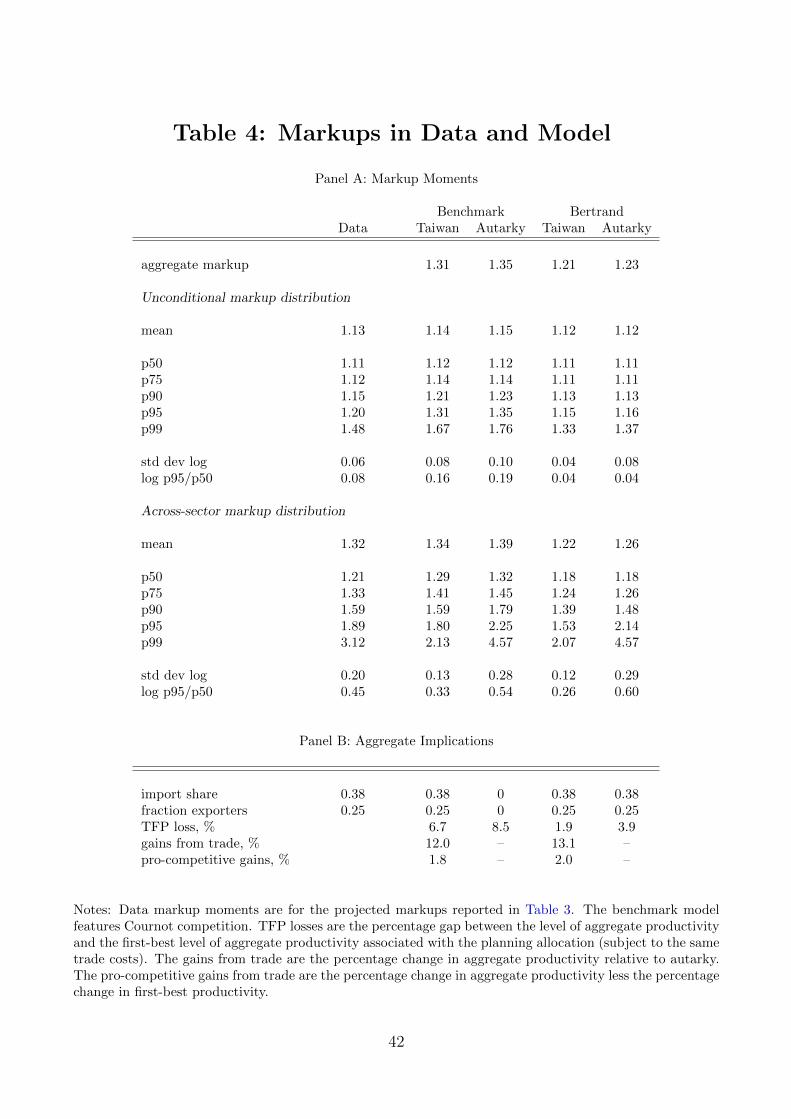
Table 4: Markups in Data and Model
Panel A: Markup Moments
Benchmark BertrandData Taiwan Autarky Taiwan Autarky
aggregate markup 1.31 1.35 1.21 1.23
Unconditional markup distribution
mean 1.13 1.14 1.15 1.12 1.12
p50 1.11 1.12 1.12 1.11 1.11p75 1.12 1.14 1.14 1.11 1.11p90 1.15 1.21 1.23 1.13 1.13p95 1.20 1.31 1.35 1.15 1.16p99 1.48 1.67 1.76 1.33 1.37
std dev log 0.06 0.08 0.10 0.04 0.08log p95/p50 0.08 0.16 0.19 0.04 0.04
Across-sector markup distribution
mean 1.32 1.34 1.39 1.22 1.26
p50 1.21 1.29 1.32 1.18 1.18p75 1.33 1.41 1.45 1.24 1.26p90 1.59 1.59 1.79 1.39 1.48p95 1.89 1.80 2.25 1.53 2.14p99 3.12 2.13 4.57 2.07 4.57
std dev log 0.20 0.13 0.28 0.12 0.29log p95/p50 0.45 0.33 0.54 0.26 0.60
Panel B: Aggregate Implications
import share 0.38 0.38 0 0.38 0.38fraction exporters 0.25 0.25 0 0.25 0.25TFP loss, % 6.7 8.5 1.9 3.9gains from trade, % 12.0 – 13.1 –pro-competitive gains, % 1.8 – 2.0 –
Notes: Data markup moments are for the projected markups reported in Table 3. The benchmark modelfeatures Cournot competition. TFP losses are the percentage gap between the level of aggregate productivityand the first-best level of aggregate productivity associated with the planning allocation (subject to the sametrade costs). The gains from trade are the percentage change in aggregate productivity relative to autarky.The pro-competitive gains from trade are the percentage change in aggregate productivity less the percentagechange in first-best productivity.
42
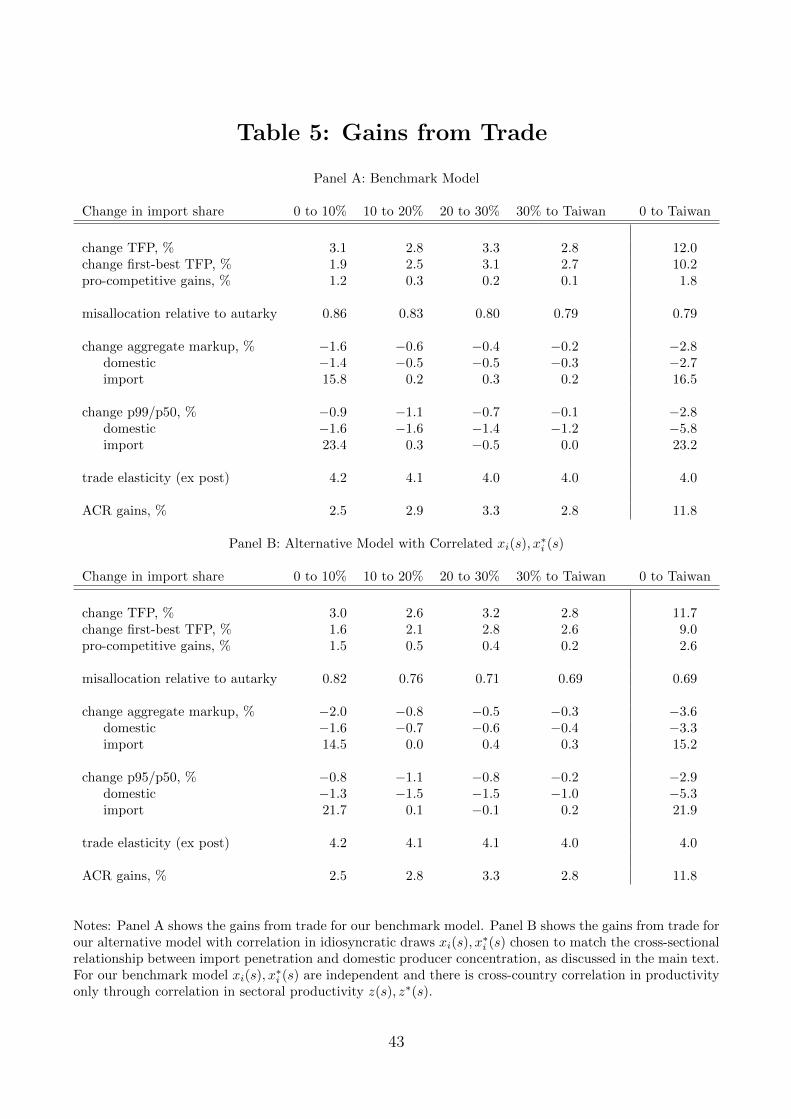
Table 5: Gains from Trade
Panel A: Benchmark Model
Change in import share 0 to 10% 10 to 20% 20 to 30% 30% to Taiwan 0 to Taiwan
change TFP, % 3.1 2.8 3.3 2.8 12.0change first-best TFP, % 1.9 2.5 3.1 2.7 10.2pro-competitive gains, % 1.2 0.3 0.2 0.1 1.8
misallocation relative to autarky 0.86 0.83 0.80 0.79 0.79
change aggregate markup, % �1.6 �0.6 �0.4 �0.2 �2.8domestic �1.4 �0.5 �0.5 �0.3 �2.7import 15.8 0.2 0.3 0.2 16.5
change p99/p50, % �0.9 �1.1 �0.7 �0.1 �2.8domestic �1.6 �1.6 �1.4 �1.2 �5.8import 23.4 0.3 �0.5 0.0 23.2
trade elasticity (ex post) 4.2 4.1 4.0 4.0 4.0
ACR gains, % 2.5 2.9 3.3 2.8 11.8
Panel B: Alternative Model with Correlated x
i
(s), x⇤
i
(s)
Change in import share 0 to 10% 10 to 20% 20 to 30% 30% to Taiwan 0 to Taiwan
change TFP, % 3.0 2.6 3.2 2.8 11.7change first-best TFP, % 1.6 2.1 2.8 2.6 9.0pro-competitive gains, % 1.5 0.5 0.4 0.2 2.6
misallocation relative to autarky 0.82 0.76 0.71 0.69 0.69
change aggregate markup, % �2.0 �0.8 �0.5 �0.3 �3.6domestic �1.6 �0.7 �0.6 �0.4 �3.3import 14.5 0.0 0.4 0.3 15.2
change p95/p50, % �0.8 �1.1 �0.8 �0.2 �2.9domestic �1.3 �1.5 �1.5 �1.0 �5.3import 21.7 0.1 �0.1 0.2 21.9
trade elasticity (ex post) 4.2 4.1 4.1 4.0 4.0
ACR gains, % 2.5 2.8 3.3 2.8 11.8
Notes: Panel A shows the gains from trade for our benchmark model. Panel B shows the gains from trade forour alternative model with correlation in idiosyncratic draws x
i
(s), x⇤
i
(s) chosen to match the cross-sectionalrelationship between import penetration and domestic producer concentration, as discussed in the main text.For our benchmark model x
i
(s), x⇤
i
(s) are independent and there is cross-country correlation in productivityonly through correlation in sectoral productivity z(s), z⇤(s).
43
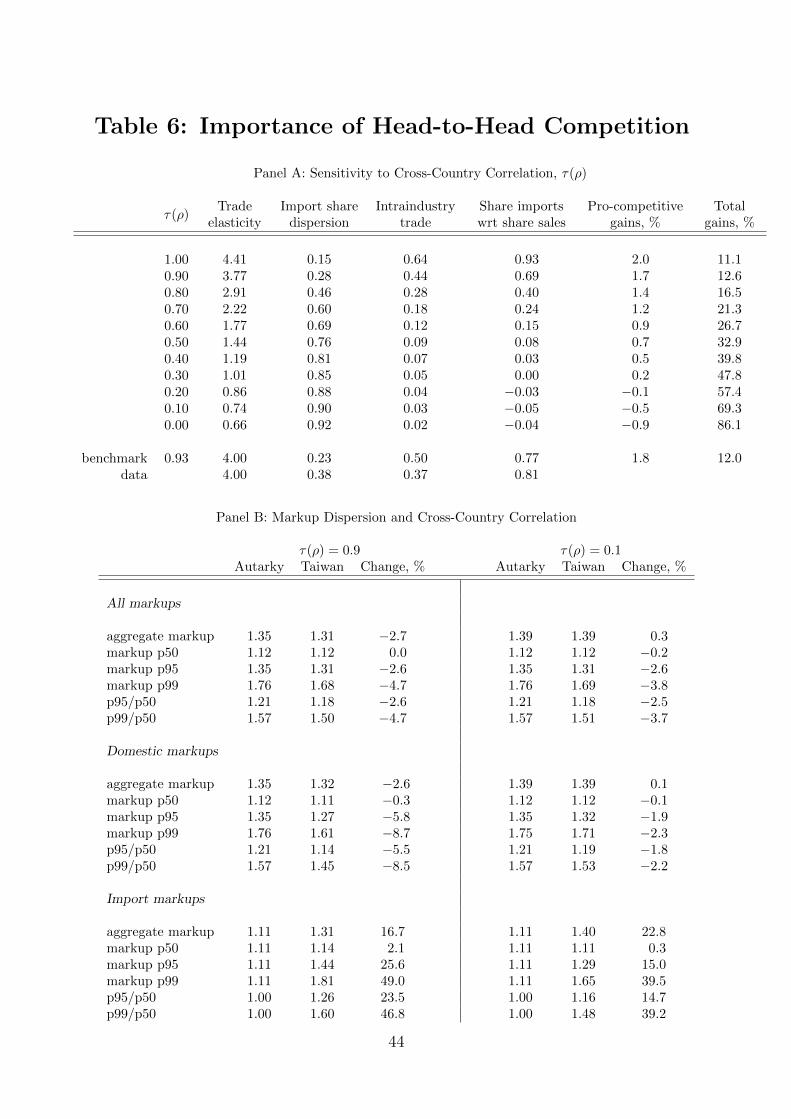
Table 6: Importance of Head-to-Head Competition
Panel A: Sensitivity to Cross-Country Correlation, ⌧(⇢)
⌧(⇢)Trade
elasticityImport sharedispersion
Intraindustrytrade
Share importswrt share sales
Pro-competitivegains, %
Totalgains, %
1.00 4.41 0.15 0.64 0.93 2.0 11.10.90 3.77 0.28 0.44 0.69 1.7 12.60.80 2.91 0.46 0.28 0.40 1.4 16.50.70 2.22 0.60 0.18 0.24 1.2 21.30.60 1.77 0.69 0.12 0.15 0.9 26.70.50 1.44 0.76 0.09 0.08 0.7 32.90.40 1.19 0.81 0.07 0.03 0.5 39.80.30 1.01 0.85 0.05 0.00 0.2 47.80.20 0.86 0.88 0.04 �0.03 �0.1 57.40.10 0.74 0.90 0.03 �0.05 �0.5 69.30.00 0.66 0.92 0.02 �0.04 �0.9 86.1
benchmark 0.93 4.00 0.23 0.50 0.77 1.8 12.0data 4.00 0.38 0.37 0.81
Panel B: Markup Dispersion and Cross-Country Correlation
⌧(⇢) = 0.9 ⌧(⇢) = 0.1Autarky Taiwan Change, % Autarky Taiwan Change, %
All markups
aggregate markup 1.35 1.31 �2.7 1.39 1.39 0.3markup p50 1.12 1.12 0.0 1.12 1.12 �0.2markup p95 1.35 1.31 �2.6 1.35 1.31 �2.6markup p99 1.76 1.68 �4.7 1.76 1.69 �3.8p95/p50 1.21 1.18 �2.6 1.21 1.18 �2.5p99/p50 1.57 1.50 �4.7 1.57 1.51 �3.7
Domestic markups
aggregate markup 1.35 1.32 �2.6 1.39 1.39 0.1markup p50 1.12 1.11 �0.3 1.12 1.12 �0.1markup p95 1.35 1.27 �5.8 1.35 1.32 �1.9markup p99 1.76 1.61 �8.7 1.75 1.71 �2.3p95/p50 1.21 1.14 �5.5 1.21 1.19 �1.8p99/p50 1.57 1.45 �8.5 1.57 1.53 �2.2
Import markups
aggregate markup 1.11 1.31 16.7 1.11 1.40 22.8markup p50 1.11 1.14 2.1 1.11 1.11 0.3markup p95 1.11 1.44 25.6 1.11 1.29 15.0markup p99 1.11 1.81 49.0 1.11 1.65 39.5p95/p50 1.00 1.26 23.5 1.00 1.16 14.7p99/p50 1.00 1.60 46.8 1.00 1.48 39.2
44
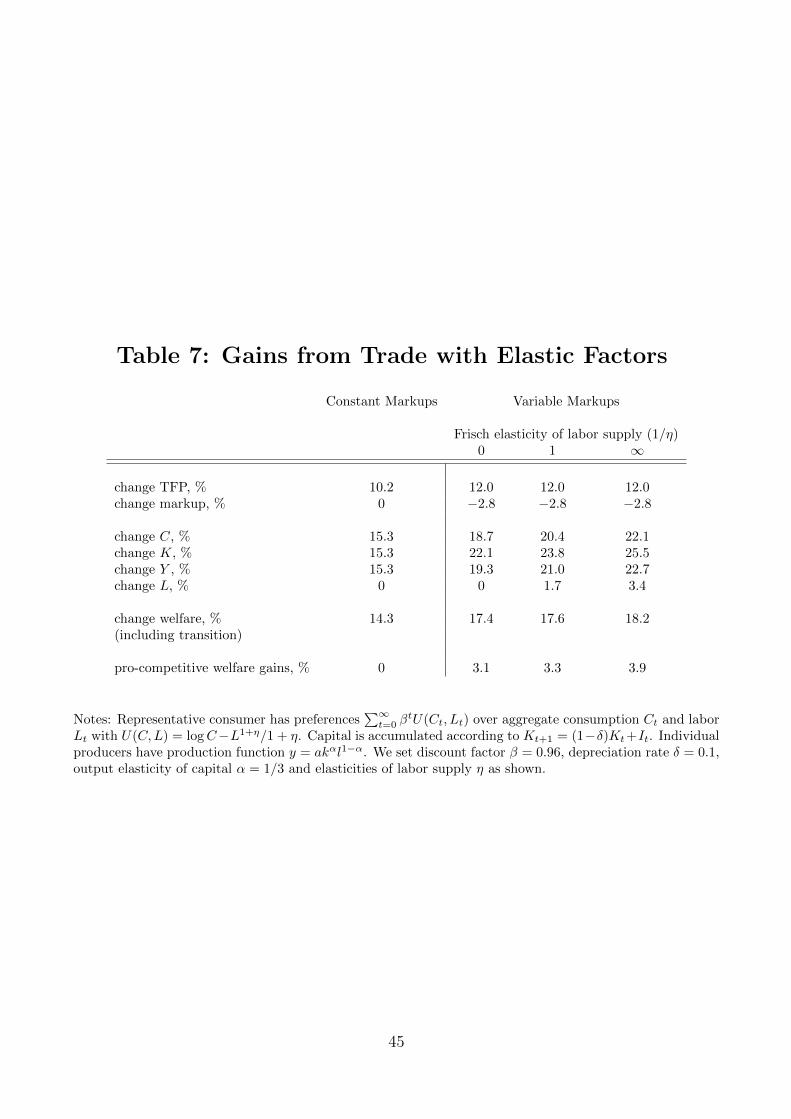
Table 7: Gains from Trade with Elastic Factors
Constant Markups Variable Markups
Frisch elasticity of labor supply (1/⌘)0 1 1
change TFP, % 10.2 12.0 12.0 12.0change markup, % 0 �2.8 �2.8 �2.8
change C, % 15.3 18.7 20.4 22.1change K, % 15.3 22.1 23.8 25.5change Y , % 15.3 19.3 21.0 22.7change L, % 0 0 1.7 3.4
change welfare, % 14.3 17.4 17.6 18.2(including transition)
pro-competitive welfare gains, % 0 3.1 3.3 3.9
Notes: Representative consumer has preferencesP
1
t=0 �t
U(Ct
, L
t
) over aggregate consumption C
t
and laborL
t
with U(C,L) = logC�L
1+⌘
/1 + ⌘. Capital is accumulated according to K
t+1 = (1��)Kt
+I
t
. Individualproducers have production function y = ak
↵
l
1�↵. We set discount factor � = 0.96, depreciation rate � = 0.1,output elasticity of capital ↵ = 1/3 and elasticities of labor supply ⌘ as shown.
45

Table
8:RobustnessExperim
ents
Benchmark
Lab
orwedges
Tari↵s
Bertran
dLow
�High�
Nofixcosts
Gau
ss.copula
trad
eelasticity
4.00
4.00
4.00
4.00
2.38
4.00
4.00
4.00
importshare
0.38
0.38
0.38
0.38
0.38
0.38
0.38
0.38
fraction
exporters
0.25
0.25
0.25
0.25
0.25
0.25
10.25
TFP
loss
autarky,
%8.5
8.2
8.5
3.9
9.1
9.0
8.5
8.6
TFP
loss
Taiwan
,%
6.7
6.4
6.7
1.9
6.8
8.2
6.7
7.1
gainsfrom
trad
e,%
12.0
12.1
14.0
13.1
19.0
11.1
11.5
11.5
pro-com
petitivegains,
%1.8
1.8
3.9
2.0
2.3
0.8
1.8
1.5
Keyparameters
⌧(⇢)
0.93
0.91
0.92
0.90
1.00
0.85
0.93
0.97
⌧1.128
1.128
1.067
1.132
1.21
41.137
1.137
1.129
f
x
0.211
0.243
0.199
0.109
0.71
00.018
00.195
Additionalmoments
average/aggregatelabor
share
1.16
1.35
1.16
1.08
1.20
1.17
1.18
1.17
meantari↵
0.062
stddev
tari↵
0.039
46
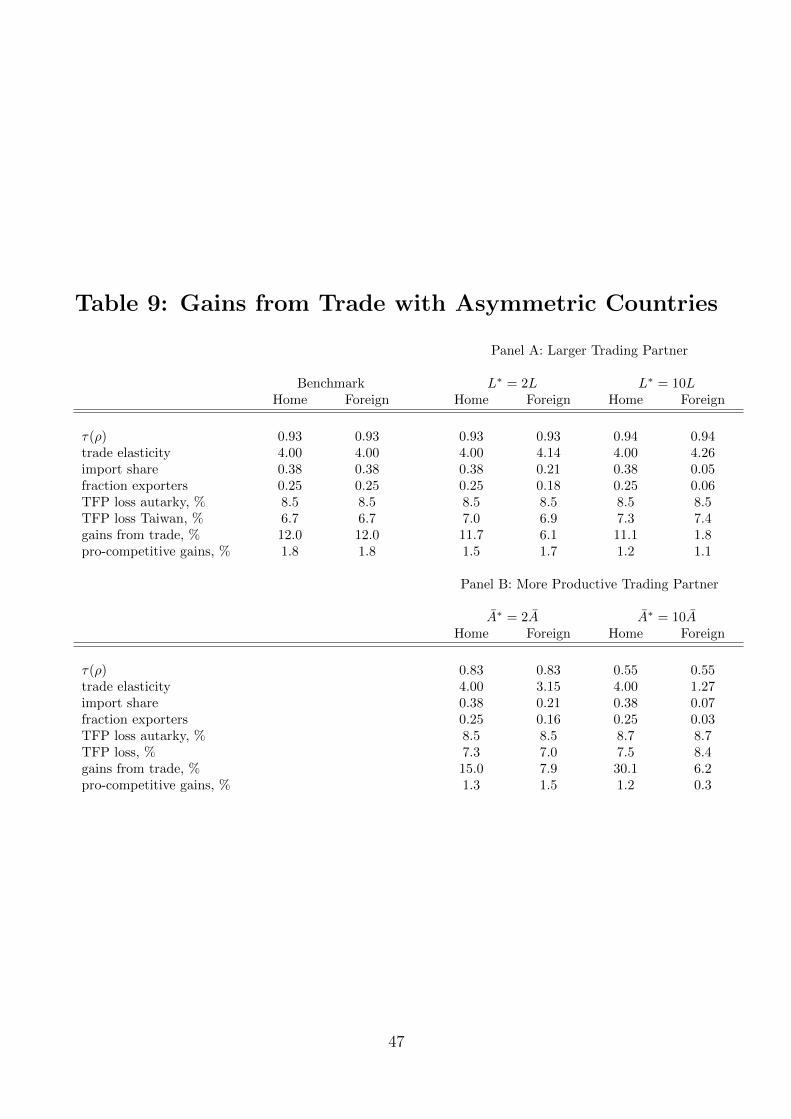
Table 9: Gains from Trade with Asymmetric Countries
Panel A: Larger Trading Partner
Benchmark L
⇤ = 2L L
⇤ = 10LHome Foreign Home Foreign Home Foreign
⌧(⇢) 0.93 0.93 0.93 0.93 0.94 0.94trade elasticity 4.00 4.00 4.00 4.14 4.00 4.26import share 0.38 0.38 0.38 0.21 0.38 0.05fraction exporters 0.25 0.25 0.25 0.18 0.25 0.06TFP loss autarky, % 8.5 8.5 8.5 8.5 8.5 8.5TFP loss Taiwan, % 6.7 6.7 7.0 6.9 7.3 7.4gains from trade, % 12.0 12.0 11.7 6.1 11.1 1.8pro-competitive gains, % 1.8 1.8 1.5 1.7 1.2 1.1
Panel B: More Productive Trading Partner
A
⇤ = 2A A
⇤ = 10AHome Foreign Home Foreign
⌧(⇢) 0.83 0.83 0.55 0.55trade elasticity 4.00 3.15 4.00 1.27import share 0.38 0.21 0.38 0.07fraction exporters 0.25 0.16 0.25 0.03TFP loss autarky, % 8.5 8.5 8.7 8.7TFP loss, % 7.3 7.0 7.5 8.4gains from trade, % 15.0 7.9 30.1 6.2pro-competitive gains, % 1.3 1.5 1.2 0.3
47
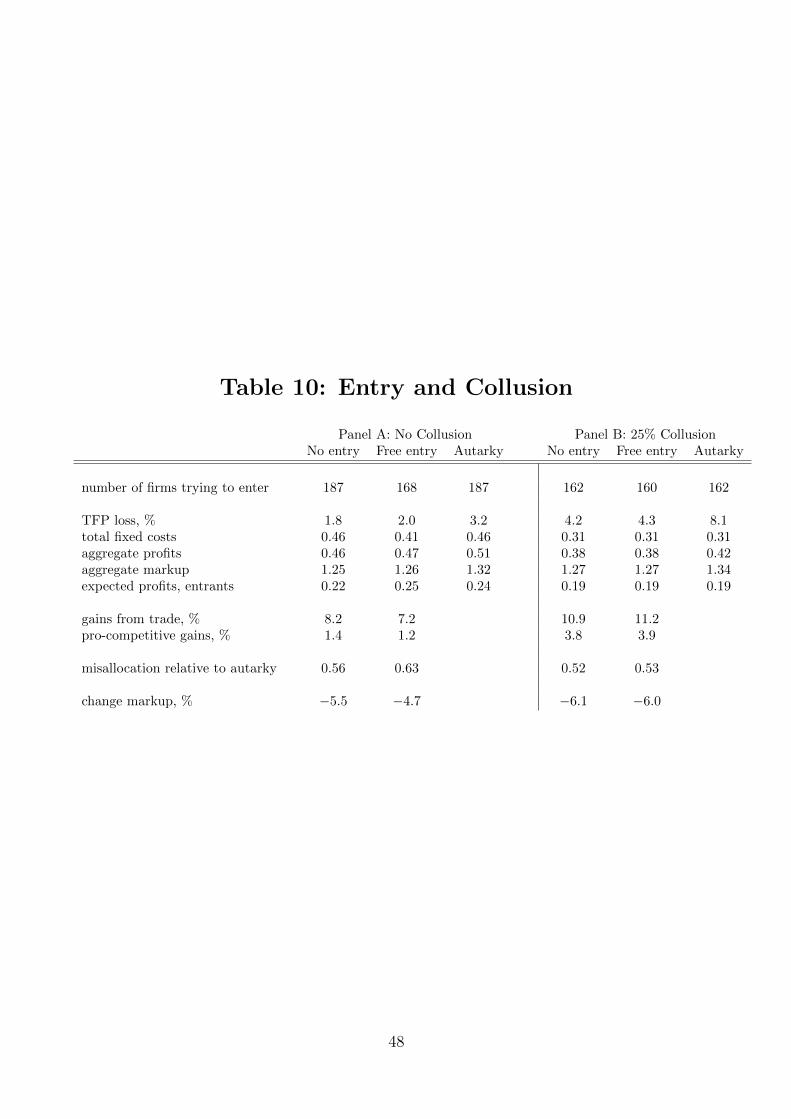
Table 10: Entry and Collusion
Panel A: No Collusion Panel B: 25% CollusionNo entry Free entry Autarky No entry Free entry Autarky
number of firms trying to enter 187 168 187 162 160 162
TFP loss, % 1.8 2.0 3.2 4.2 4.3 8.1total fixed costs 0.46 0.41 0.46 0.31 0.31 0.31aggregate profits 0.46 0.47 0.51 0.38 0.38 0.42aggregate markup 1.25 1.26 1.32 1.27 1.27 1.34expected profits, entrants 0.22 0.25 0.24 0.19 0.19 0.19
gains from trade, % 8.2 7.2 10.9 11.2pro-competitive gains, % 1.4 1.2 3.8 3.9
misallocation relative to autarky 0.56 0.63 0.52 0.53
change markup, % �5.5 �4.7 �6.1 �6.0
48

Competition, Markups,
and the Gains from International Trade:
Appendix, Not for Publication
Chris Edmond
⇤Virgiliu Midrigan
†Daniel Yi Xu
‡
June 2014
Contents
A Data 2
A.1 Data description and product classification . . . . . . . . . . . . . . . . . . . . . . . 2
A.2 Firm-level moments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
A.3 Markup estimation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
A.4 Nonparametric productivity distribution . . . . . . . . . . . . . . . . . . . . . . . . . 5
B Robustness experiments and sensitivity analysis 7
B.1 Correlated xi
(s), x⇤i
(s) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
B.2 Labor wedges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
B.3 Heterogeneous tari↵s . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
B.4 Bertrand competition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
B.5 Sensitivity to � . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
B.6 No fixed costs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
B.7 Gaussian copula . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
B.8 Uncorrelated n(s), n⇤(s) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
B.9 5-digit sectors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
B.10 Fixed N competitors per sector . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
C Extensions 12
C.1 Capital accumulation and elastic labor supply . . . . . . . . . . . . . . . . . . . . . . 12
C.2 Asymmetric countries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
C.3 Free entry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
⇤University of Melbourne, [email protected].
†New York University and NBER, [email protected].
‡Duke University and NBER, [email protected].
1

This appendix is organized as follows. In Appendix A we provide more details on our data, our
procedure of inferring markups, and alternative methods for inferring producer-level productivity.
In Appendix B we provide further details of the robustness experiments mentioned in the main
text as well as related sensitivity analysis. In Appendix C we provide further details on three more
substantial extensions of our benchmark model, namely: (i) a dynamic model with endogenous
capital accumulation and labor supply, (ii) asymmetric countries that di↵er in size and/or economy-
wide productivity, and (iii) a free-entry model with an endogenous number of competitors per sector.
A Data
A.1 Data description and product classification
We use the Taiwan Annual Manufacturing Survey. Our sample covers the years 2000 and 2002–2004.
The year 2001 is missing because in that year a separate census was conducted. The dataset we use
has two components. First, an establishment-level component collects detailed information on oper-
ations, such as employment, expenditure on labor, materials and energy, and total revenue. Second,
a product-level component reports information on revenues for each of the products produced at a
given establishment. Each product is categorized into a 7-digit Standard Industrial Classification
created by the Taiwanese Statistical Bureau. This classification at 7 digits is comparable to the
detailed 5-digit SIC product definition collected for US manufacturing establishments as described
by Bernard, Redding and Schott (2010). Panel A of Table A1 gives an example of this classification
while Panel B reports the distribution of 7-digit sectors within 4- and 2-digit industries. Most of the
products are concentrated in the Chemical Materials, Industrial Machinery, Computer/Electronics
and Electrical Machinery industries.
A.2 Firm-level moments
The Taiwanese manufacturing sector is dominated by single-establishment (single-plant) firms. In
our data, 98% of firms are single-plant firms and these firms account for 92% of total manufacturing
sales. Consequently, whether we choose firms or plants as our unit of analysis makes little di↵erence
for our analysis. As reported in Table A2, our key micro and sectoral concentration moments are
very similar whether we use firms or plants. We use plant-level data for our benchmark model
because it is the natural unit of analysis at which to measure a producer’s production technology.
A.3 Markup estimation
In our model, as is standard in the trade literature, labor is the only factor of production and
a producer’s revenue productivity is its markup. But in comparing our model’s implications for
markups to the data, it is important to recognize that, in general, revenue productivity di↵ers across
producers not only because of markup di↵erences but also because of di↵erences in the technology
with which they operate. To control for this heterogeneity, we use modern IO methods to purge our
2

markup estimates of the di↵erences in technology that surely exist across Taiwanese manufacturing
industries.
Controlling for heterogeneity in producer technology. To map our model into micro-level
production data, we relax the assumptions of a single factor of production and constant returns
to scale. In particular, we follow De Loecker and Warzynski (2012) and assume a translog gross
production function
log yi
= ↵l
log li
+↵k
log ki
+ ↵m
logmi
+ ↵ll
(log li
)2 + ↵kk
(log ki
)2 + ↵mm
(logmi
)2
+↵lk
(log li
log ki
) + ↵lm
(log li
logmi
) + ↵km
(log ki
logmi
) + log ai
,
where li
denotes labor, ki
denotes physical capital, mi
denotes material inputs and ai
is physical
productivity. The translog specification serves as an approximation to any twice continuously
di↵erentiable production function in these inputs and allows the elasticity of output with respect
to any variable input, say labor, to di↵er across firms within the same sector.
We estimate this translog specification for each 2-digit Taiwanese industry, giving us industry-
specific coe�cient estimates. Let el,i
denote the elasticity of output with respect to labor
el,i
:=@ log y
i
@ log li
= ↵l
+ 2↵ll
log li
+ ↵lk
log ki
+ ↵lm
logmi
. (1)
Cost minimization then implies that producer i sets
Wli
pi
yi
=el,i
µi
. (2)
Thus variation in labor input cost shares across producers may be due to either variation in markups
µi
or to variation in output elasticities el,i
. We use data on labor input cost shares and production
function estimates of el,i
to back out markups µi
from (2).
Controlling for simultaneity. As is well-known, a key di�culty in estimating production func-
tions is that input choices li
, ki
,mi
will generally be correlated with true productivity ai
. We follow
De Loecker and Warzynski (2012) and apply ‘control’ or ‘proxy function’ methods inspired by Olley
and Pakes (1996), Levinsohn and Petrin (2003) and Ackerberg, Caves and Frazer (2006) to deal
with this simultaneity.
More specifically, we write the measurement equation for the translog production function as
log ydit
= ↵l
log lit
+↵k
log kit
+ ↵m
logmit
+ ↵ll
(log lit
)2 + ↵kk
(log kit
)2 + ↵mm
(logmit
)2
+↵lk
(log lit
log kit
) + ↵lm
(log lit
logmit
) + ↵km
(log kit
logmit
)
+ log ait
+ ✏it
,
where ydit
is output in the data and where ✏it
is IID noise.
Our approach to estimating the production function closely follows the procedure in Ackerberg,
Caves and Frazer (2006) (and in particular we follow their timing assumptions that rationalize a
mapping from a firm’s capital kit
, labor lit
and productivity ait
to its demand for materials). To be
specific, we:
3

1. Write the so-called control function as
mit
= f(kit
, lit
, ait
) ,
where, as is standard in the literature, we assume that this function can be inverted to uniquely
determine a level of productivity associated with a given configuration of observed inputs, so
that we can write
log ait
= g(kit
, lit
,mit
) .
We can then write the conditional mean of measured log output as
h(kit
, lit
,mit
) = ↵l
log lit
+↵k
log kit
+ ↵m
logmit
+ ↵ll
(log lit
)2 + ↵kk
(log kit
)2 + ↵mm
(logmit
)2
+↵lk
(log lit
log kit
) + ↵lm
(log lit
logmit
) + ↵km
(log kit
logmit
)
+ g(kit
, lit
,mit
) ,
so that log output in the data is simply
log ydit
= h(kit
, lit
,mit
) + ✏it
,
and we can estimate the conditional mean function h(·) by high-order polynomials. Given
the nonparametric function g(·) on the right-hand-side of the conditional mean, no structural
parameters of production function can be identified at this stage. The purpose of this repre-
sentation is to isolate the measurement/transitory shock component ✏it
which is orthogonal
to all inputs at time t.
2. Let ↵ := (↵l
,↵k
,↵m
,↵ll
,↵kk
,↵mm
,↵lk
,↵lm
,↵km
) denote the parameters of the production
function and let bhit
(↵) := bh(kit
, lit
,mit
,↵) denote the fitted values for some candidate param-
eter vector ↵. This implies an estimate of log productivity
bait
(↵) = bhit
(↵)� ↵l
log lit
�↵k
log kit
� ↵m
logmit
� ↵ll
(log lit
)2 � ↵kk
(log kit
)2 � ↵mm
(logmit
)2
�↵lk
(log lit
log kit
)� ↵lm
(log lit
logmit
)� ↵km
(log kit
logmit
) ,
Estimating the parameters ↵ then depends on specific parametric assumptions about the
data generating process for ait
and in particular on how it evolves over time. As in standard
literature, we assume that log productivity follows a flexible AR(1) process
bait
(↵) = �(bait�1(↵)) + ⇣a
it
(↵) ,
where �(·) is a second-order polynomial.
3. Use GMM to estimate the parameter vector ↵. As in the dynamic panel literature, we exploit
the sequential exogeneity condition that ⇣ait
(↵) is uncorrelated with a vector of lagged input
variables, specifically
z
it
:=hlog l
it�1 , log kit , logmit�1,
(log lit�1)
2 , (log kit
)2 , (logmit�1)
2,
(log lit�1 log kit) , (log lit�1 logmit�1) , (log kit logmit�1)
i.
4

Note that, as is standard in this literature, capital enters without a lag since it is assumed to
be pre-determined.
With estimates of the production function parameters b↵ in hand, we then use data on inputs
kit
, lit
,mit
to calculate estimated output elasticities for each input bel,i
, bek,i
, bem,i
, as in (1), and then
use the optimality condition (2) to recover estimated ‘inverse markups’ d1/µi
. We report our results
for bel,i
, bek,i
, bem,i
in Table 2 in the main text and our results for d1/µi
in Table 3 in the main text.
A.4 Nonparametric productivity distribution
We now show how to use our model to recover the exact nonparametric distribution of producer-level
productivity ai
(s) given data on producer market shares !i
(s). This procedure uses the structure
of the model, but makes no parametric assumptions about the distribution of productivity.
The main idea is fairly intuitive: we simply back out for each producer and sector the produc-
tivity draws that are needed to rationalize that producer’s and sector’s relative size. To do this,
begin by recalling that for producer i in sector s the inverse markup is given by
1
µHi
(s)=
� � 1
��✓1
✓� 1
�
◆!Hi
(s) , (3)
and that we can write the market share !Hi
(s) as
!Hi
(s) =pHi
(s)1��
Pi
pHi
(s)1�� + ⌧1��
Pi
pFi
(s)1��
,
or
!Hi
(s) =pHi
(s)1��
Pi
pHi
(s)1��
⇥P
i
pHi
(s)1��
Pi
pHi
(s)1�� + ⌧1��
Pi
pFi
(s)1��
,
or
!Hi
(s) = !Hi
(s)⇥ (1� !F(s)) , (4)
where !Hi
(s) is producer i’s share of sales among only domestic firms in sector s and 1 � !F(s) is
the share of spending on domestic firms in that sector. Both of these terms come directly from the
data. The first term can be written
!Hi
(s) =
�µHi
(s)/ai
(s)�1��
Pi
�µHi
(s)/ai
(s)�1��
(5)
where we simply use the definition of the markup to write pHi
(s) = µHi
(s)W/ai
(s). Thus, given
parameter values � and ✓, we can use an iterative procedure to recover the ai
(s) of domestic
producers that exactly rationalizes the observed market share data !Hi
(s) and 1 � !F(s). The
iterations are as follows:
1. Given data on !Hi
(s) and !F(s) we construct !Hi
(s) from (4) and calculate µHi
(s) from (3).
Now set ai
(s) = z(s)xi
(s) and impose the normalization mini
[xi
(s)] = 1 for each s (we can
always multiply the numerator and denominator on the right-hand-side of (5) by a sector-
specific constant).
5

2. Guess productivities a0i
(s). Then update the guess a0i
(s) ! a1i
(s) by iterating on the mapping
ak+1i
(s) =
1
!Hi
(s)
µHi
(s)1��
Pi
�µHi
(s)/aki
(s)�1��
! 11��
, k = 0, 1, . . .
and iterate on this until convergence.
To further compute z(s), we repeat this argument at the sectoral level. Specifically, we use
!Hi
(s) =
✓pHi
(s)
p(s)
◆1��
,
thus
p(s) =
X
i
✓µHi
(s)
xi
(s)z(s)
◆1��
! 11��
=:⌅H(s)
z(s),
where we have already recovered ⌅H(s) in the previous within-sector iteration, that is
⌅H(s) =
X
i
✓µHi
(s)
xi
(s)
◆1��
! 11��
.
Finally, note that the sectoral share !(s) = (p(s)/P )1�✓, thus we can again use an iterative proce-
dure to find z(s) using observed data of sectoral expenditure shares
!(s) =(⌅H(s)/z(s))1�✓
R 10 (⌅
H(s)/z(s))1�✓ ds.
Since we are primarily interested in the tail properties of the recovered nonparametric produc-
tivity distribution, we calculate standard measures of the tail exponent of the recovered distribution
and compare this summary statistic to its counterpart in our benchmark model, i.e., our original
Pareto shape parameter.
Specifically, to estimate the tail exponent implied by the recovered distribution we follow Gabaix
and Ibragimov (2011) and run a log-rank regression. The basic idea is that for any power law
distributed randomly distributed data, we have
log(r � r) = constant� ⇠x
logX(r) + noise
where r is the ranking of observation X(r). The slope coe�cient b⇠x
then corresponds to the Pareto
shape parameter. Gabaix and Ibragimov suggest using the correction r = 1/2 to reduce small-
sample bias, but our results are almost identical when we use r = 0. Our estimate implies a shape
parameter ⇠x
= 3.46 with a standard error 0.02.
We apply the same regression to sectoral productivity1 Z(r), and find an estimate b⇠z
= 0.27
with a standard error 0.01. Both cases indicate that, if anything, the nonparametric productivity
distribution is fatter tailed than our benchmark Pareto distribution (which has ⇠x
= 4.53 and
⇠z
= 0.56). Our benchmark results are thus conservative in the sense that, if anything, we somewhat
understate the amount of misallocation in the data.1We leave out the bottom 25% of sectoral observations, these look more lognormal and our interest here is in the
right tail of the distribution. We find
b⇠z = 0.14 if we include all sectoral observations.
6

B Robustness experiments and sensitivity analysis
Here we provide further details of the robustness experiments reported in the main text along with
related sensitivity analysis. Unless stated otherwise, for each experiment we recalibrate the trade
cost ⌧ , export fixed cost fx
, and correlation parameter ⌧(⇢) so that the Home country continues to
have an aggregate import share of 0.38, fraction of exporters 0.25 and trade elasticity 4, as in our
benchmark model. The full set of parameters used for each experiment are reported in Table A3.
The target moments and the moments implied by each model are reported in Table A4. The gains
from trade and statistics on markup dispersion for each model are reported in Table A5.
B.1 Correlated x
i
(s), x
⇤i
(s)
For this experiment (which we refer to in the main text as the alternative model), we allow for
cross-country correlation in both sectoral productivity draws and in idiosyncratic producer-level
productivity draws. Specifically, we assume the cross-country joint distribution of sectoral pro-
ductivity HZ
(z, z⇤) = CZ
(FZ
(z), FZ
(z⇤)) and the cross-country joint distribution of idiosyncratic
productivity HX
(x, x⇤) = CX
(FX
(x), FX
(x⇤)) are both linked via a Gumbel copula but with distinct
correlation coe�cients, ⌧z
(⇢) and ⌧x
(⇢). As in the benchmark model, we choose the sectoral correla-
tion ⌧z
(⇢) so that the model implies a trade elasticity of 4. We choose the cross-country correlation
in idiosyncratic draws ⌧x
(⇢) so that the model reproduces the cross-sectional relationship between
domestic producer concentration and import penetration that we see in the data, i.e., that sectors
with high import penetration are also sectors with relatively high concentration amongst domestic
producers. As shown in the last row of Table A4, our benchmark model implies a mild association,
the slope coe�cient in a regression of sector import penetration on sector domestic HH indexes is
0.08, low relative to the 0.21 in the data. To match this regression coe�cient, the alternative model
needs a modest amount of cross-country correlation in in idiosyncratic draws, ⌧x
(⇢) = 0.22 (with
a correspondingly slightly lower correlation in sectoral draws, ⌧z
(⇢) = 0.90). This version of the
model otherwise fits the data about as well as the benchmark model. As shown in Table A5, it
implies slightly larger pro-competitive gains from trade.
B.2 Labor wedges
For this experiment we assume there is a distribution of producer-level labor market distortions
that act like labor input taxes, putting a wedge between labor’s marginal product and its factor
cost. Specifically, we assume a producer with productivity a faces an input tax
t(a) :=a⌧
l
1 + a⌧l
,
and pays (1 + t(a))W for each unit of labor hired. The price a Home producer with productivity
ai
(s) sets in its domestic market is then
pHi
(s) =⇣ "H
i
(s)
"Hi
(s)� 1
⌘ 1 + t(ai
(s))
ai
(s)W , (6)
7
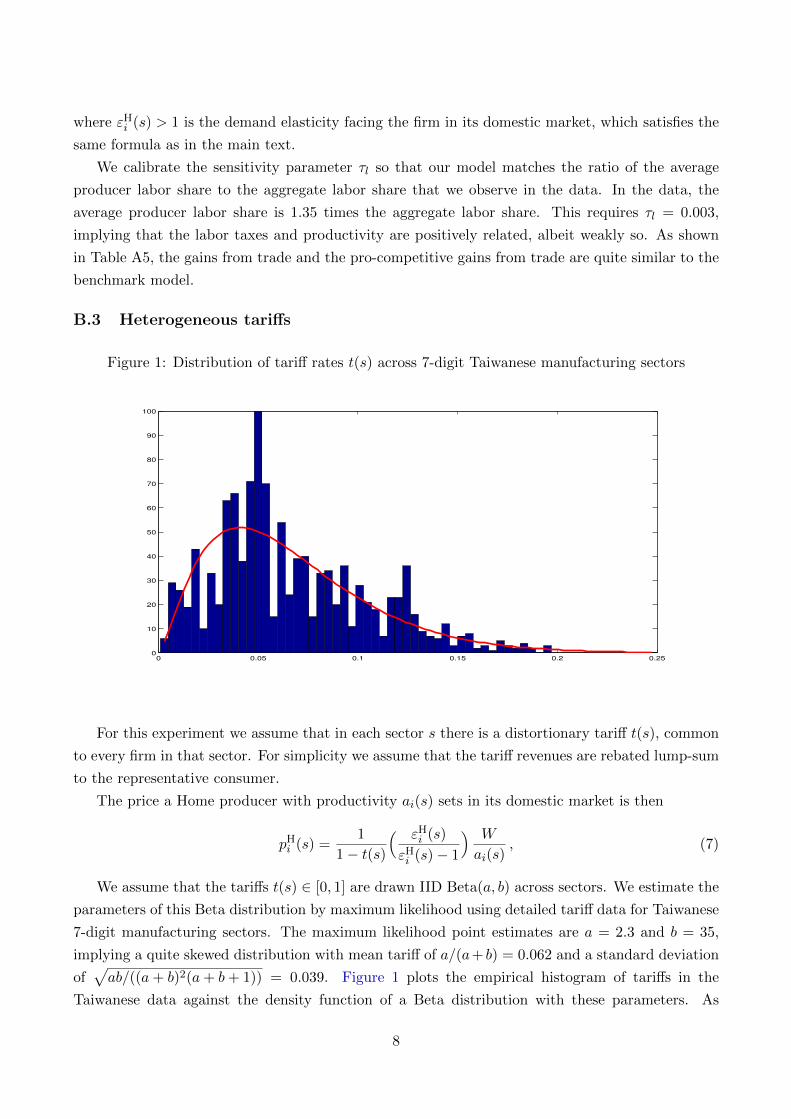
where "Hi
(s) > 1 is the demand elasticity facing the firm in its domestic market, which satisfies the
same formula as in the main text.
We calibrate the sensitivity parameter ⌧l
so that our model matches the ratio of the average
producer labor share to the aggregate labor share that we observe in the data. In the data, the
average producer labor share is 1.35 times the aggregate labor share. This requires ⌧l
= 0.003,
implying that the labor taxes and productivity are positively related, albeit weakly so. As shown
in Table A5, the gains from trade and the pro-competitive gains from trade are quite similar to the
benchmark model.
B.3 Heterogeneous tari↵s
Figure 1: Distribution of tari↵ rates t(s) across 7-digit Taiwanese manufacturing sectors
0 0.05 0.1 0.15 0.2 0.250
10
20
30
40
50
60
70
80
90
100
For this experiment we assume that in each sector s there is a distortionary tari↵ t(s), common
to every firm in that sector. For simplicity we assume that the tari↵ revenues are rebated lump-sum
to the representative consumer.
The price a Home producer with productivity ai
(s) sets in its domestic market is then
pHi
(s) =1
1� t(s)
⇣ "Hi
(s)
"Hi
(s)� 1
⌘ W
ai
(s), (7)
We assume that the tari↵s t(s) 2 [0, 1] are drawn IID Beta(a, b) across sectors. We estimate the
parameters of this Beta distribution by maximum likelihood using detailed tari↵ data for Taiwanese
7-digit manufacturing sectors. The maximum likelihood point estimates are a = 2.3 and b = 35,
implying a quite skewed distribution with mean tari↵ of a/(a+ b) = 0.062 and a standard deviation
ofp
ab/((a+ b)2(a+ b+ 1)) = 0.039. Figure 1 plots the empirical histogram of tari↵s in the
Taiwanese data against the density function of a Beta distribution with these parameters. As
8

reported in Table A5, both the total gains from trade and the pro-competitive gains are somewhat
larger than in the benchmark.
B.4 Bertrand competition
For this experiment we re-solve the model under the assumption that producers compete by simulta-
neously choosing prices (Bertrand) rather than simultaneously choosing quantities (Cournot). This
changes the model set-up in only one way. The demand elasticity facing producer i in sector s is no
longer a harmonic weighted average, of ✓ and � but is instead a simple arithmetic weighted average,
"i
(s) = !i
(s)✓ + (1� !i
(s)) �. With this specification the results are similar to the benchmark.
The Bertrand model implies somewhat lower markup dispersion than the Cournot model but also
implies a larger change in markup dispersion when opening to trade — and hence a larger reduction
in misallocation.
One problem with the Bertrand model is that it implies a negative correlation between do-
mestic sectoral concentration and domestic import penetration, i.e., in the Bertrand model highly
concentrated sectors tend to have low import penetration, the opposite of what we see in the data.
B.5 Sensitivity to �
In our benchmark model, we set the within-sector elasticity of substitution to � = 10. For this
robustness exercise we consider � = 5 and � = 20. For each case we reset the across-sector elasticity
✓ so that a regression of inverse markups on market share continues to have a slope of �0.68, as in
the benchmark, i.e., for each � we set ✓ = (1/� + 0.68)�1, giving a lower ✓ = 1.13 when � = 5 and
a higher ✓ = 1.37 when � = 20.
With � = 5 we find that the model cannot produce a trade elasticity of 4, even setting ⌧(⇢) =
0.999 (e↵ectively perfect correlation) gives a low trade elasticity of 2.38. In addition, as shown in
the last few rows of Table A4, the � = 5 version of the model has a number of problems replicating
the facts on intra-industry trade and import share dispersion, it implies: (i) too much intra-industry
trade, (ii) too little dispersion in import shares, (iii) too strong an association between sector import
shares and size, and (iv) a negative correlation between sector concentration and import penetration.
With � = 20, we can match a trade elasticity of 4 with correlation ⌧(⇢) = 0.85, somewhat lower
than our benchmark. As shown in Table A4, the � = 20 version of the model also has problems
replicating the facts on intra-industry trade and import share dispersion, but, roughly speaking, it
gets them the opposite way round to the � = 5 version. Specifically, the � = 20 version implies
(i) too little intra-industry trade, (ii) slightly too much dispersion in import shares, (iii) too weak
an association between sector import shares and size, and (iv) too strong an association between
sector concentration and import penetration.
In short, very low values like � = 5 and very high values like � = 20 are at odds with the data.
To narrow in on an estimate of �, we conducted a grid search and varied the value of � over the
range 5 to 20 and re-estimated the entire model for each such �. When we did so, we found that
the value of the objective function (squared deviation between the moments in the model and the
9

data) is minimized at a value of � between about 8 and 12. The objective is, however, extremely
flat in this region so there is not much information in our data that would allow us to narrow in
any further.
Given this, we decided to simply set � = 10, a standard number in the macro literature. Our
results on the gains from trade are in any case very robust to perturbations of � in the range 8-12.
B.6 No fixed costs
For this experiment, we solve our model assuming that fixed costs are zero, fd
= fx
= 0. In this
version of the model, all producers operate in both markets. Thus the number of domestic producers
in each country in sector s is just given by the Geometric draw n(s) for that sector.
As shown in Table A5, this version of the model yields almost identical gains from trade as
the benchmark. Shutting down these extensive margins makes little di↵erence because the typical
firm near the margin of operating or not is very small and has negligible impact on the aggregate
outcomes.
B.7 Gaussian copula
For this experiment we resolve the model using a Gaussian copula to model the cross-country
correlation in sectoral productivity draws, specifically
C(u, u⇤) = �2,⇢(��1(u),��1(u⇤)) (8)
where �(x) denotes the CDF of the standard Normal distribution and �2,⇢(x, x⇤) denotes the
standard bivariate Normal distribution with linear correlation coe�cient ⇢ 2 (�1, 1). To compare
results to the benchmark Gumbel copula, we map the linear correlation coe�cient into our preferred
Kendall correlation coe�cient, which for the Gaussian copula is ⌧(⇢) = 2 arcsin(⇢)/⇡. To match
a trade elasticity of 4 requires ⌧(⇢) = 0.97, up slightly from the benchmark. As shown in Table
A5, this version of the model yields very similar results to our benchmark model. In this sense,
the functional form of the copula per se does not seem to matter much for our results, instead, as
discussed at length in the main text, it is the amount of correlation ⌧(⇢) in cross-country productivity
draws that matters.
B.8 Uncorrelated n(s), n
⇤(s)
For this experiment, for each sector s we independently draw n(s) producers for the Home country
and n⇤(s) producers for the Foreign country (each drawn from the same Geometric marginal distri-
bution as in the benchmark model). With independent draws for n(s), n⇤(s) we find that the model
cannot produce a trade elasticity of 4, even setting ⌧(⇢) = 0.999 (e↵ectively perfect correlation)
gives a trade elasticity of 2.47. As a consequence of this low trade elasticity, this version of the
model implies very large total gains from trade.
As shown in the last few rows of Table A4, with independent draws for n(s), n⇤(s) the model
also implies that there there is no relationship between a sector’s import share and its size, an
10

implication which is clearly at odds with the data, and moreover the model also implies too strong
an association between sector concentration and import penetration.
B.9 5-digit sectors
For this last robustness experiment, we recalibrate our model to 5-digit rather than 7-digit data.
The second-last column of Table A4 reports the 5-digit counterparts of our usual 7-digit moments in
the Taiwanese data while the last column of Table A4 reports the model moments when calibrated
to this 5-digit data.
At this higher level of aggregation there is less concentration in sectoral shares than there is
at the 7-digit level and hence there is less measured misallocation. The productivity losses due to
markups are 5.8%, down from the 6.7% for our benchmark model calibrated to 7-digit data. The
total gains from trade remain about 12%, as in the benchmark, but since there is less measured
misallocation, the pro-competitive e↵ects are weaker, contributing 0.3% down from our benchmark.
Thus, consistent with our earlier results, we see that the pro-competitive gains from trade are
smaller when product market distortions are small.
To maintain comparability with our other results, for this experiment we have kept the across-
sector elasticity fixed at ✓ = 1.28, which is arguably quite high for 5-digit data.2 With a lower value
for ✓ (e.g., with Cobb-Douglas ✓ = 1) measured misallocation is higher and the pro-competitive
gains from trade are correspondingly higher also.
B.10 Fixed N competitors per sector
To further highlight the role of cross-country correlation in sectoral productivity draws, we have
solved a simplified version of our model with the following structure: a fixed number of producers N
per sector (the same in both countries), no fixed costs of operating (so all N producers operate), and
either perfectly dependent cross-country draws, ⌧(⇢) = 1, or perfectly independent cross-country
draws, ⌧(⇢) = 0. We compare autarky to free trade — i.e., no net trade costs, ⌧ = 1, and no fixed
costs of exporting, fx
= 0.
Panel A of Table A6 shows results for the case of no idiosyncratic productivity draws, xi
(s) = 1
for all i, s. Consider the case N = 1, so that under autarky there is a single monopolist in each
sector. In this case there is no misallocation in autarky (there is neither within-sector nor across-
sector markup dispersion). Now with free trade there are two producers in each sector (in this
sense, it is as if the country size doubles). The e↵ects on misallocation crucially depend on the
cross-country correlation in sectoral productivity. If sectoral productivity draws are independent
across countries, then typically one producer gains market share at the expense of the other, and,
crucially, this pattern varies across sectors depending on the particular pairs of productivity draws.
This creates markup dispersion and hence with free trade there is misallocation whereas there was
no misallocation in autarky. Thus the gains from trade will be less than if markups were constant
(i.e., aggregate productivity increases by less than first-best productivity). By contrast, if sectoral
2A 5-digit sector in Taiwan best corresponds to a 4-digit sector in the US.
11

productivity draws are perfectly correlated across countries, then the two producers (who have equal
productivity) split the market between them and this happens exactly the same way in each sector,
hence in this case trade does not lead to misallocation. Put di↵erently, having ⌧(⇢) = 1 perfectly
mitigates the increase in misallocation that would otherwise happen.
Notice that the extent of markup dispersion and hence misallocation created when sectoral
productivity draws are independent is decreasing in N — and steeply decreasing in N at that.
With independent draws and N = 1, free trade creates productivity losses of 13.2% relative to the
first-best, with N = 2 the losses are much smaller, 0.8% and with N = 10 the losses are down to
0.02%.
Panel B of Table A6 shows the same exercise but now with idiosyncratic productivity draws, as
in the benchmark model. We again see that for low N opening to trade creates misallocation and
that this misallocation is mitigated by correlated sectoral productivity draws. By the time we get
to N = 10 (which is similar to our benchmark model, which has a median of about 10 producers
per sector per country), opening to free trade reduces misallocation if sectoral draws are correlated.
C Extensions
Our benchmark model makes several stark simplifying assumptions: (i) labor is the only factor of
production and is in inelastic supply, (ii) the two countries Home and Foreign are symmetric at the
aggregate level, and (iii) there is an exogenous number of competitors per sector. Here we provide
further details on extensions of our benchmark model that relax these assumptions. Since the main
text already discusses the results from these extensions at some length, here we focus on recording
additional details that were omitted from the main text to save space.
C.1 Capital accumulation and elastic labor supply
In the benchmark model, the only source of pro-competitive gains from trade is changes in markup
dispersion. Changes in the level of the aggregate markup µ have no welfare implications. But with
capital accumulation and/or elastic labor supply, the aggregate markup µ acts like a distortionary
wedge a↵ecting investment and labor supply decisions, and, because of this, a reduction in the
aggregate markup increases welfare beyond the increases associated with a reduction in markup
dispersion.
Setup. To illustrate this, we solve a simple dynamic extension of our benchmark model. Specif-
ically, we suppose the representative consumer has intertemporal preferencesP1
t=0 �tU(C
t
, Lt
)
over aggregate consumption Ct
and labor Lt
, that capital is accumulated according to Kt+1 =
(1 � �)Kt
+ It
, and that individual producers have production function y = ak↵l1�↵. We then
have a standard two-country representative consumer economy with aggregate production function
Yt
= At
K↵
t
L1�↵
t
where At
is aggregate productivity (TFP) as in the main text and where Lt
is
aggregate employment net of fixed costs.
12

Aggregate markup distortions. Using the representative consumer’s optimality conditions for
capital accumulation and labor supply and the firms’ optimal input demands gives the equilibrium
conditions
Uc,t
= �Uc,t+1
⇣ 1
µt+1
↵Yt+1
Kt+1
+ 1� �⌘, (9)
and
�Ul,t
Uc,t
=W
t
Pt
=1
µt
(1� ↵)Yt
Lt
, (10)
where µt
is the aggregate markup as in the main text. High aggregate markups thus act like
distortionary capital and labor income taxes and reduce output relative to its e�cient level.
Parameterization. To quantify the additional welfare e↵ects of changes in the aggregate markup,
we solve this version of the model assuming utility function U(C,L) = logC � L
1+⌘
1+⌘
and assuming
discount factor � = 0.96, depreciation rate � = 0.1 and output elasticity of capital ↵ = 1/3. We
report results for various elasticities of labor supply ⌘. We start the economy in autarky and then
compute the transition to a new steady-state corresponding to the Taiwan benchmark. We measure
the welfare gains as the consumption compensating variation taking into account the dynamics of
consumption and employment during the transition to the new steady-state.
Results. The first column of Table A7 shows what happens in a standard model with constant
markups if TFP increases by 10.2%, i.e., the benchmark increase in first-best TFP. Physical capital,
output, and consumption all increase by 15.3%, i.e., by 1/(1� ↵) = 1.5 times the increase in TFP.
Aggregate labor does not change because utility is log in consumption so that the income and
substitution e↵ects implied by the change in TFP exactly cancel out. The measured welfare gain is
slightly less than the long-run increase in aggregate consumption because we take the transitional
dynamics into account.
The next column shows the corresponding results in our model with variable markups but where
we hold the aggregate markup unchanged. Thus TFP increases by 12% because in addition to the
first-best 10.2% there are now pro-competitive gains of 1.8%. Aggregate labor is again constant
because of log utility and because the aggregate markup is held fixed. Thus the additional gains
here are entirely because capital accumulation magnifies the TFP gains.
The remaining columns show results when we also allow the aggregate markup to change, falling
by 2.8% from autarky to the new steady-state. We report results for various choices of the Frisch
elasticity of labor supply 1/⌘. If labor supply is inelastic, so the fall in the aggregate markup a↵ects
capital accumulation alone, welfare increases by 17.4%. This gain is larger than the 16.3% we had
when only TFP changes and the additional gain of 1.1% is entirely due to the e↵ect of the change in
the aggregate markup and hence this extra 1.1% is entirely due to pro-competitive e↵ects, making
for a total pro-competitive gain of some 3%. Elastic labor supply magnifies these gains yet further.
With a Frisch elasticity of 1, the pro-competitive gains rise to 3.3% (as shown in Table A7, the size
of the pro-competitive gains are not sensitive to a Frisch elasticity in the range 0.5 to 2). In short,
13

we see that with elastic factor supply the relative importance of the pro-competitive e↵ects is larger
than in our benchmark model.
C.2 Asymmetric countries
Our benchmark model assumes trade between two symmetric countries. We now relax this and
consider trade between countries that di↵er in size and/or productivity.
Setup. Let L,L⇤ denote Home and Foreign labor forces and let A, A⇤ denote Home and Foreign
economy-wide productivity — that is, Home producers now have technology yi
(s) = Aai
(s)li
(s)
and Foreign producers have y⇤i
(s) = A⇤a⇤i
(s)l⇤i
(s). We normalize L = 1 and A = 1 and consider
various L⇤ and A⇤.
In our benchmark model, aggregate symmetry implied that the wage in each country was the
same so that by choosing the Home wage as numeraire we simply had W = W ⇤ = 1 along with
symmetric price levels P = P ⇤ and symmetric productivities A = A⇤ so that the real wage in both
countries was 1/P and the aggregate (economy-wide) markup in both countries was µ = PA.
We continue to choose the Home country wage as numeraire, W = 1, but with asymmetric
countries now have to solve for the Foreign wage W ⇤ in equilibrium. Intuitively, W ⇤ has to adjust to
ensure that trade between the two countries is balanced. With asymmetric countries, the equilibrium
price levels P, P ⇤ and aggregate productivities A,A⇤ likewise di↵er across countries. We then have
Home real wage 1/P and aggregate markup µ = PA and Foreign real wage W ⇤/P ⇤ and aggregate
markup µ⇤ = P ⇤A⇤/W ⇤.
Parameterization. We consider L⇤ = 2 and L⇤ = 10 times as large as Home, holding economy-
wide productivity the same in both countries, and then consider A⇤ = 2 and A⇤ = 10 times as great
as Home productivity, now holding the labor force the same in both countries. For each of these
four experiments, we recalibrate the model so that, for the Home country, we reproduce the degree
of openness of the Taiwan benchmark — in particular, we choose the proportional trade cost ⌧ ,
export fixed cost fx
, and correlation parameter ⌧(⇢) so that the Home country continues to have an
aggregate import share of 0.38, fraction of exporters 0.25 and trade elasticity 4. Table A8 reports the
full set of parameters used for each experiment, Table A9 reports the target moments and their model
counterparts for both Home and Foreign countries for each experiment, and Table A10 reports the
gains from trade and statistics on markup dispersion for both Home and Foreign countries for each
experiment. In addition to our usual aggregate statistics, in Table A10 we also report the relative
real wage expressed as the real wage of Foreign to Home, that is (W ⇤/P ⇤)/(W/P ) = (A⇤/A)/(µ⇤/µ).
C.3 Free entry
We now discuss in somewhat greater detail a version of our model with free entry and an endogenous
number of competitors per sector. We assume that entry is not directed at a particular sector: after
paying a sunk entry cost, a firm learns the productivity with which it operates, as in Melitz (2003),
14

as well as the sector to which it is assigned. We also assume that there are no fixed costs of operating
or exporting in any given period. Instead, we assume that a firm’s productivity is drawn from a
discrete distribution which includes a mass point at zero.
Setup. The productivity of a firm in sector s 2 [0, 1] is given by a world component, common to
both countries, z(s), and a firm-specific component. In addition, we assume a gap, u(s), between
the productivity with which a firm produces for its domestic market and that with which it produces
in its export market. Greater dispersion in u(s) reduces the amount of head-to-head competition
between Home and Foreign producers, lowers the aggregate trade elasticity, and thus has the same
role as reducing the correlation between sectoral productivity draws in our benchmark model.
Specifically, let u(s) denote the productivity gap of Home producers in sector s and u⇤(s) denote
the productivity gap of Foreign producers in sector s. There is an unlimited number of potential
entrants. To enter, a firm pays a sunk cost fe
that allows it to draw (i) a sector s in which to operate
and (ii) idiosyncratic productivity xi
(s) 2 {0, 1, x}. A Home firm in sector s with idiosyncratic
productivity xi
(s) produces for its domestic market with overall productivity aHi
(s) = z(s)u(s)xi
(s)
and produces for its export market with overall productivity a⇤Hi
(s) = z(s)xi
(s)/⌧ where ⌧ is the
gross trade cost. Similarly, a Foreign firm in sector s with idiosyncratic productivity x⇤i
(s) produces
for its domestic market with overall labor productivity a⇤Fi
(s) = z(s)u⇤(s)x⇤i
(s) and produces for
its export market with overall productivity aFi
(s) = z(s)x⇤i
(s)/⌧ .
Sector types. Sectors di↵er in the probability that any individual entrant assigned to that sector
draws a particular productivity xi
(s). To simplify computations, we assume a finite number of
sector types k = 1, ...,K. A sector type is a pair ⌦1(k),⌦2(k) where ⌦1 denotes the probability
that an entrant is successful, i.e., that it draws xi
(s) > 0, and ⌦2 denotes the probability that a
successful entrant draws high productivity xi
(s) = x. We write ⌫(k) for the measure of sectors of
type k withP
k
⌫(k) = 1.
The special case of a single sector type, K = 1, is of particular significance since it implies that
there is no cross-country correlation in productivities — in this case the probability that a successful
entrant gets a high productivity draw x is the same in all sectors and such draws are IID across
producers. In the more general case with heterogeneous sector types, K > 1, there is cross-country
correlation in productivities since the sector type k is the same for both countries so that producers
in a sector with high ⌦2(k) have a common high probability of drawing x, irrespective of which
country they are located in. We think of these sectoral di↵erences as being primarily technological
in nature and thus invariant across countries.
Timing. The timing of entry is as follows:
1. An entrant draws a sector and thus implicitly a type k 2 {1, ...,K}. The type k determines
both the probability of any individual entrant drawing a particular productivity realization
as well as the distribution of other competitors it will face.
15

2. The entrant draws a random variable that determines whether it is successful (with probability
⌦1(k)) and can thus begin operating, or whether it exits (with probability 1� ⌦1(k)).
3. Successful entrants then draw their productivity type. With probability ⌦2(k) a successful
entrant becomes a high-productivity producer (with xi
(s) = x), while with probability 1 �⌦2(k) they become a low-productivity producer (with x
i
(s) = 1).
Now let N be the measure of producers that actually enter. Recall that we assume entrants are
uniformly distributed across sectors. Then since the total measure of sectors is 1, the number of
successful entrants who produce in a sector of type k is a Binomial random variable with a success
probability ⌦1(k) and N trials. For each sector s 2 [0, 1], let k(s) denote that sector’s type and
let n(s) denote the resulting number of producers. Likewise let n1(s) and n2(s) denote the number
of low-productivity producers (xi
(s) = 1) and high-productivity producers (xi
(s) = x). Given the
realization of n(s), n2(s) is a Binomial random variable with a success probability of ⌦2(k(s)) and
n(s) trials. Finally, let n⇤1(s) and n⇤
2(s) denote the number of Foreign producers of each type that
produce in sector s
To summarize, any individual sector s is characterized by (i) the number of competitors of
each productivity type, n1(s), n2(s), n⇤1(s), n
⇤2(s), (ii) the common productivity component of all
producers (both Home and Foreign) operating in that sector, z(s), (iii) the productivity advantage
of Home producers relative to importers in the Home market, u(s), and (iv) the productivity
advantage of Foreign producers relative to Home exporters in the Foreign market, u⇤(s).
Production and pricing. The rest of the model is essentially identical to the benchmark model
in the main text. For example, the final good is a CES aggregate of sector inputs
Y =
✓Z 1
0y(s)
✓�1✓ ds
◆ ✓✓�1
,
while sector output is a CES aggregate of the production of the various types of producers in each
sector, which we now write
y(s) =⇣n1(s)y
H1 (s)
��1� + n2(s)y
H2 (s)
��1� + n⇤
1(s)yF1 (s)
��1� + n⇤
2(s)yF2 (s)
��1�
⌘ ���1
,
where � is, as earlier, the elasticity of substitution within a sector and ✓ is the elasticity of sub-
stitution across sectors. Since there are no fixed costs of exporting or selling domestically, all n(s)
producers operate in sector s.
As in the benchmark model, the markup a firm charges is a function of the number of competitors
of each productivity it competes with. For example, in its domestic market a Home firm with
idiosyncratic productivity xi
(s) in sector s has markup
µHi
(s) ="Hi
(s)
"Hi
(s)� 1,
16

where
"Hi
(s) =
✓!Hi
(s)1
✓+�1� !H
i
(s)� 1�
◆�1
,
and where !Hi
(s) denotes their market share in their domestic market
!Hi
(s) =
0
@µ
Hi (s)
z(s)xi(s)u(s)
p(s)
1
A1��
.
Similarly, a Home firm with idiosyncratic productivity xi
(s) in sector s has export market share
!⇤Hi
(s) =
0
@µ
⇤Hi (s)
z(s)xi(s)
p⇤(s)
1
A1��
.
Given the markups, the Home price of the sector s composite satisfies
p(s)1�� = n1(s)µH1 (s)
1�� (z(s)u(s))��1 + n2(s)µH2 (s)
1�� (z(s)u(s)x)��1
+ ⌧1��n⇤1(s)µ
F1 (s)
1��z(s)��1 + ⌧1��n⇤2(s)µ
F2 (s)
1�� (z(s)x)��1 ,
and the Foreign price of the sector s composite satisfies
p⇤(s)1�� = ⌧1��n1(s)µ⇤H1 (s)1��z(s)��1 + ⌧1��n2(s)µ
⇤H2 (s)1�� (z(s)x)��1
+ n⇤1(s)µ
⇤F1 (s)1�� (z(s)u⇤(s))��1 + n⇤
2(s)µ⇤F2 (s)1�� (z(s)u⇤(s)x)��1 .
Expected profits of a potential entrant. We now compute the expected profits of a firm that
contemplates entry. Such a firm has an equal probability of entering any one of the sectors. Recall
that sectors di↵er in
� = (⌦1,⌦2, u, u⇤, z, n1, n2, n
⇤1, n
⇤2) ,
where z, u, u⇤ are all independent random variables. Let F (�) denote the distribution of producers
over � and let ⇡1(�),⇡2(�) denote respectively the profits of an entrant with idiosyncratic produc-
tivity x = 1 and x = x in sector �. Since a potential entrant is equally likely to enter any sector,
its expected profits are
⇡e
=
Z⌦1(�)
h(1� ⌦2(�))⇡1(�1(�)) + ⌦2(�)⇡2(�2(�))�Wf
e
(�)idF (�) ,
where �1(�) is equal to � except that n1 is replaced by n1+1 and �2(�) is equal to � except that n2
is replaced by n2 + 1 — i.e., a potential entrant recognizes that its entry, if successful, will change
the number of producers and thus alter the industry equilibrium by changing the price p(s) and
p⇤(s) of that sector’s composite in both countries.
This expression says that the expected profits conditional on entering a sector � are given by
⌦1(�), the probability of successful entry into that sector, times the expected profits conditional on
entry, which in turn depend on the probability of getting the higher productivity draw, ⌦2(�). This
expression also reveals why we simplify the productivity distribution for this free-entry version of the
model: the distribution F (�) is a high-dimensional object which we can only integrate accurately
when we use the simpler productivity distribution assumed here.
17

Free entry condition. Expected profits ⇡e
are implicitly a function of N , the measure of entrants
— since N characterizes the Binomial distribution of the number of producers of each type in a
given sector — as well as the trade cost ⌧ , which determines how much the producer is making from
its export sales as well as how much competition it faces from Foreign producers. We pin down the
measure of entrants N in equilibrium by setting
⇡e
(N, ⌧) = 0 ,
for any given level of the trade cost ⌧ .
Notice here that we implicitly allow the fixed cost of entering, to vary with the sector to which a
producer is assigned. More specifically, we assume that the fixed cost is proportional to the sector’s
productivity, fe
(s) = fe
⇥ z(s)✓�1 for some constant fe
> 0. Sectoral profits are homogeneous of
degree 1 in z(s)✓�1 so this assumption simply implies that the fixed cost scales up with the profits
of the sector to which the entrant is assigned.
Model with collusion: setup. We also report results based on a model in which all high-
productivity producers from a given country and sector are able to collude and maximize joint
profits. We assume that producers in a fraction of sectors collude, while the rest face the same
problem as that described above.
Consider the problem of the colluding Home producers selling in Home. They choose their price
to maximize joint profits
n2(s)hpH2 (s)y
H2 (s)�WlH2 (s)
i,
taking as given the inverse demand curve
pH2 (s) =
✓yH2 (s)
y(s)
◆� 1�✓y(s)
Y
◆� 1✓
P ,
and recognizing that
y(s) =⇣n1(s)y
H1 (s)
��1� + n2(s)y
H2 (s)
��1� + n⇤
1(s)yF1 (s)
��1� + n⇤
2(s)yF2 (s)
��1�
⌘ ���1
.
The optimal markup is now given by
1
µH2 (s)
=� � 1
��✓1
✓� 1
�
◆n2(s)!
H2 (s) ,
and now reflects the overall sectoral share n2(s)!H2 (s) of the colluding producers, not each individual
producer’s share in isolation.
Parameterization. We continue to set � = 10 and ✓ = 1.28 as in our benchmark model to allow
comparability of results. We again choose the trade cost, ⌧ , to match Taiwan’s import share of
0.38. We assume the productivity gaps u(s), u⇤(s) are IID logormal with variance �2u
and choose
the dispersion to match a trade elasticity of 4.
18

We consider two variants of the model, (i) with a single sector type K = 1 (and hence two
probabilities ⌦1,⌦2) and (ii) with heterogeneous sector types, that, as we will see, does a better job
of matching the dispersion in concentration we see in the data. For the latter we have found that
allowing for 3 values for ⌦1(k) and another 3 values for ⌦2(k) works reasonably. In this case, we
have to determine these 6 values plus 8 = 32 � 1 values for the measures ⌫(k) of each sector type.
For both variants, we choose the entry cost fe
, the productivity advantage of type 2 producers x,
and the distribution of ⌦1(k),⌦2(k) across sectors targeting the same set of concentration moments
we targeted for the benchmark model. Finally, we choose the dispersion of sectoral productivity
z(s) to match the amount of concentration in output and employment across sectors. Specifically,
we assume a Pareto distribution of z(s) and choose the shape parameter to match the fraction of
value added (employment) accounted for by the top 1% and 5% of sectors.
Table A11 reports the full set of parameters used for each free-entry experiment, Table A12
reports the target moments and their model counterparts, and Table A13 reports the gains from
trade and statistics on markup dispersion for each free-entry experiment.
Single sector type: results. With a single sector type, K = 1, the free-entry model implies
total gains of 6.4% of which 1.5% is due to pro-competitive e↵ects. The free-entry model implies
less misallocation in autarky than in the benchmark model but also implies a greater reduction
in misallocation when the economy opens to trade. Misallocation relative to autarky falls by just
under a half. As shown in Table A12, this version of the model is not able to reproduce the amount
of dispersion in concentration that we see in the data. Consequently, as shown in Table A13, this
version of the model also implies very little dispersion in sectoral markups as compared to the data.
Heterogeneous sector types: results. By allowing sectoral di↵erences in the probability of a
successful entrant drawing the high-productivity x, the model produces more dispersion in concen-
tration and hence more dispersion in sectoral markups. We have found that, as shown in Table A12,
with nine sector types the model does a considerably better job at matching the facts on dispersion
in sectoral concentration. This version of the model implies total gains of 7.2% of which 1.2% is due
to pro-competitive e↵ects. Nonetheless, this version of the model still produces too little dispersion
in sectoral markups. For example, the ratio of the 95th percentile of markups to that of the median
is equal to only 1.16 in the model, much lower than the 1.56 in the data.
To better match the dispersion in sectoral markups, we turn to the extension with collusion out-
lined above. With collusion the model produces considerably more dispersion in sectoral markups.
For example, when 25% of sectors collude, the ratio of the 95th to the median markup increases
from 1.16 to 1.30, still smaller than in the data but now almost double the dispersion of the nine
sector model without collusion. With 25% collusion, the model implies total gains of 11.2% of which
3.9% is due to pro-competitive e↵ects. Thus this version of the model implies total gains about the
same as the benchmark but gives a much larger share to the pro-competitive e↵ect. In short, we
again see that the pro-competitive gains from trade are large when product market distortions are
large to begin with.
19

References
Ackerberg, Daniel A., Kevin Caves, and Garth Frazer, “Structural Identification of Pro-
duction Functions,” 2006. UCLA working paper.
Bernard, Andrew B., Stephen J. Redding, and Peter Schott, “Multiple-Product Firms and
Product Switching,” American Economic Review, March 2010, 100 (1), 70–97.
De Loecker, Jan and Frederic Warzynski, “Markups and Firm-Level Export Status,” Ameri-
can Economic Review, October 2012, 102 (6), 2437–2471.
Gabaix, Xavier and Rustam Ibragimov, “Rank �1/2: A Simple Way to Improve the OLS
Estimation of Tail Exponents,” Journal of Business and Economic Statistics, 2011, 29 (1), 24–
39.
Levinsohn, James and Amil Petrin, “Estimating Production Functions using Inputs to Control
for Unobservables,” Review of Economic Studies, April 2003, 70 (2), 317–342.
Melitz, Marc J., “The Impact of Trade on Intra-Industry Reallocations and Aggregate Industry
Productivity,” Econometrica, November 2003, 71 (6), 1695–1725.
Olley, G. Steven and Ariel Pakes, “The Dynamics of Productivity in the Telecommunications
Equipment Industry.,” Econometrica, November 1996, 64 (6), 1263–1297.
20
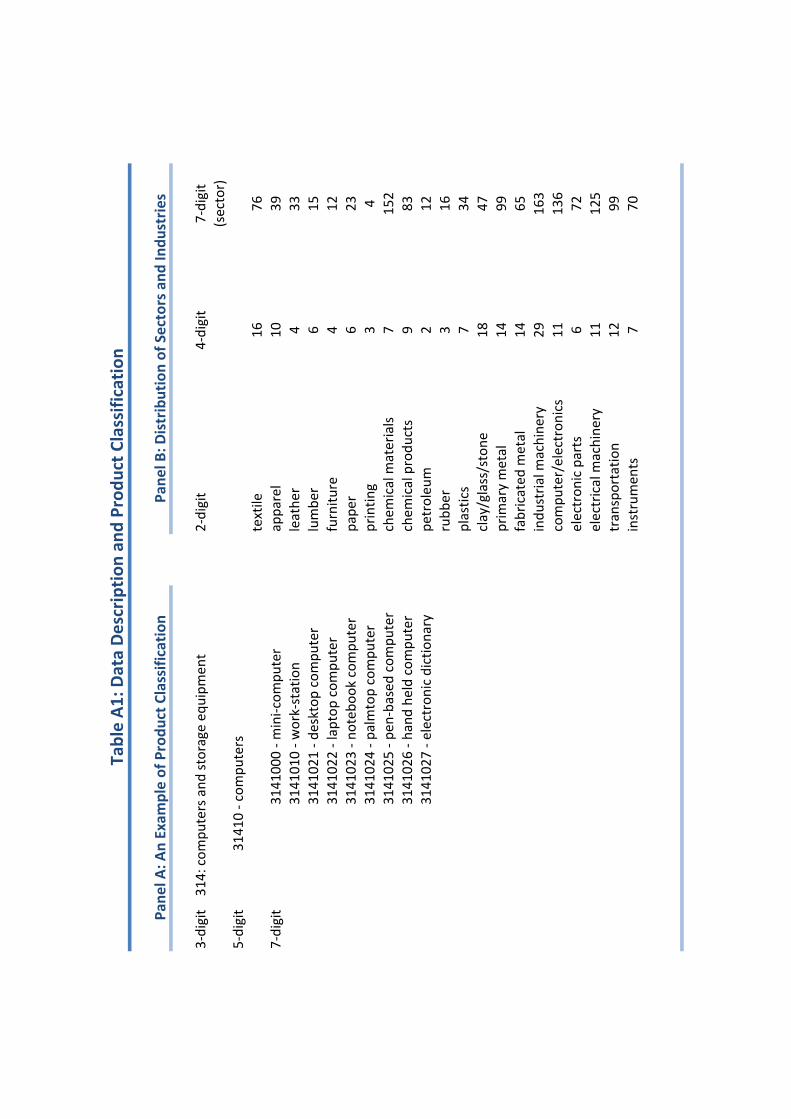
3"digit
314:*com
puters*and
*storage*eq
uipm
ent
2"digit
4"digit
7"digit
(sector)
5"digit
31410*"*com
puters
textile
1676
7"digit
3141000*"*m
ini"com
puter
apparel
1039
3141010*"*w
ork"station
leathe
r4
333141021*"*d
esktop
*com
puter
lumbe
r6
153141022*"*laptop*compu
ter
furnitu
re4
123141023*"*n
oteb
ook*compu
ter
pape
r6
233141024*"*p
almtop*compu
ter
printin
g3
43141025*"*p
en"based
*com
puter
chem
ical*m
aterials
7152
3141026*"*h
and*he
ld*com
puter
chem
ical*produ
cts
983
3141027*"*e
lectronic*dictionary
petroleu
m2
12rubb
er3
16plastics
734
clay/glass/stone
1847
prim
ary*metal
1499
fabricated
*metal
1465
indu
stria
l*machine
ry29
163
compu
ter/electron
ics
11136
electron
ic*parts
672
electrical*m
achine
ry11
125
transportatio
n12
99instrumen
ts7
70
Table&A1
:&Data&De
scrip
tion&an
d&Prod
uct&C
lassificatio
n
Pane
l&B:&D
istribution&of&Sectors&and
&Indu
strie
sPa
nel&A
:&An&Exam
ple&of&Produ
ct&Classificatio
n
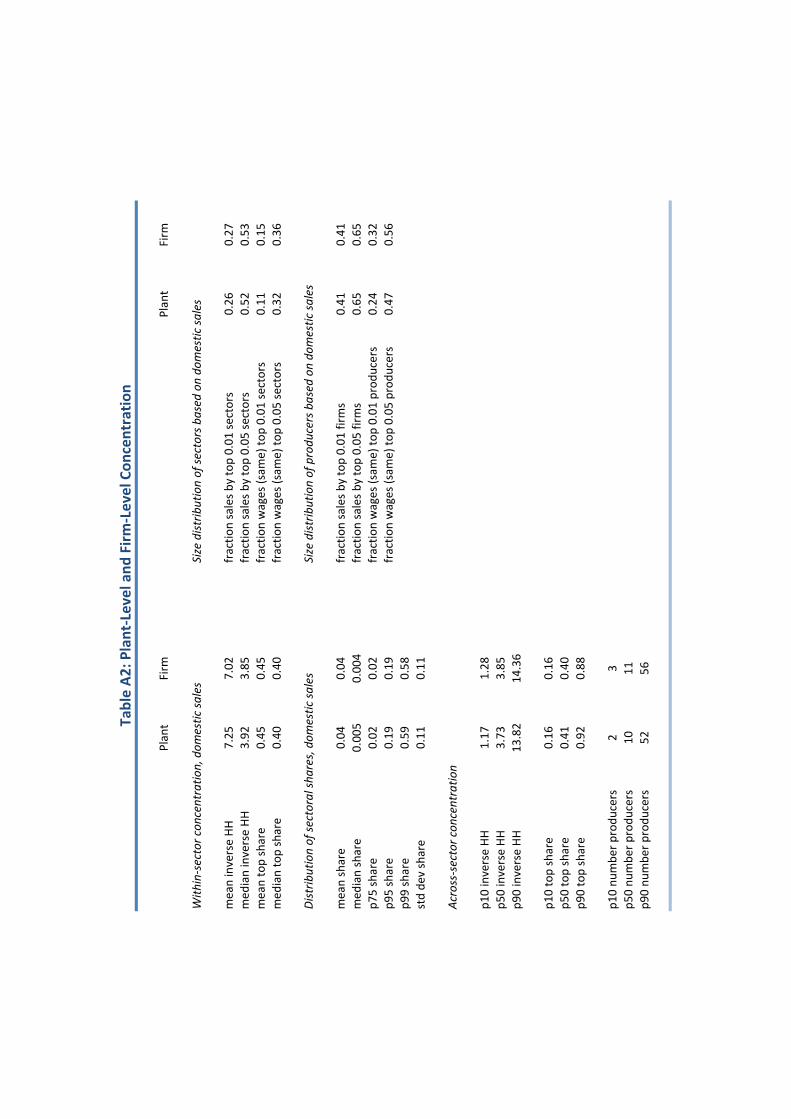
Plant
Firm
Plant
Firm
With
in§or,con
centratio
n,,dom
estic,sa
les
Size,distrib
ution,of,se
ctors,b
ased,on,do
mestic,sa
les
mean+inverse+HH
7.25
7.02
fractio
n+sales+b
y+top+0.01+se
ctors
0.26
0.27
med
ian+inverse+HH
3.92
3.85
fractio
n+sales+b
y+top+0.05+se
ctors
0.52
0.53
mean+top+share
0.45
0.45
fractio
n+wages+(sam
e)+to
p+0.01+se
ctors
0.11
0.15
med
ian+top+share
0.40
0.40
fractio
n+wages+(sam
e)+to
p+0.05+se
ctors
0.32
0.36
Distrib
ution,of,se
ctoral,sh
ares,,dom
estic,sa
les
Size,distrib
ution,of,produ
cers,based,on,do
mestic,sa
les
mean+share
0.04
0.04
fractio
n+sales+b
y+top+0.01+firm
s0.41
0.41
med
ian+share
0.005
0.004
fractio
n+sales+b
y+top+0.05+firm
s0.65
0.65
p75+share
0.02
0.02
fractio
n+wages+(sam
e)+to
p+0.01+produ
cers
0.24
0.32
p95+share
0.19
0.19
fractio
n+wages+(sam
e)+to
p+0.05+produ
cers
0.47
0.56
p99+share
0.59
0.58
std+de
v+share
0.11
0.11
Across§or,con
centratio
n
p10+inverse+HH
1.17
1.28
p50+inverse+HH
3.73
3.85
p90+inverse+HH
13.82
14.36
p10+top+share
0.16
0.16
p50+top+share
0.41
0.40
p90+top+share
0.92
0.88
p10+nu
mbe
r+produ
cers
23
p50+nu
mbe
r+produ
cers
1011
p90+nu
mbe
r+produ
cers
5256
Table&A2
:&Plant-Level&and
&Firm
-Level&Con
centratio
n

Benchm
ark
Alternative
Labo
r2wed
ges
Tariffs
Bertrand
Low2γ
High2γ
No2fix
2costs
Gauss.2cop
ula
n(s),n*(s)
5Edigit
Main%pa
rameters
γwithin§or,elasticity,of,sub
stitution
1010
1010
105
2010
1010
10θ
across§or,elasticity,of,sub
stitution
1.28
1.28
1.28
1.28
1.28
1.13
1.37
1.28
1.28
1.28
1.28
ξ_x
pareto,shape
,param
eter,,idiosyncratic,produ
ctivity
4.53
4.53
4.53
4.53
4.53
2.70
5.65
4.53
4.53
4.53
5.60
ξ_z
pareto,shape
,param
eter,,sector,prod
uctivity
0.56
0.56
0.56
0.56
0.56
0.25
0.74
0.56
0.56
0.56
0.56
ζgeom
etric,parameter,,num
ber,prod
ucers,pe
r,sector
0.043
0.043
0.043
0.043
0.043
0.04
40.03
20.043
0.043
0.043
0.020
f_d
fixed
,cost,of,dom
estic,op
erations
0.0043
0.0043
0.0043
0.0043
0.0043
0.01
850.0035
00.0043
0.0043
1e&7
f_x
fixed
,cost,of,export,op
erations
0.211
0.211
0.243
0.199
0.109
0.71
00.01
80
0.195
0.050
0.049
τtrade,cost
1.128
1.129
1.128
1.067
1.132
1.21
41.13
71.137
1.129
1.223
1.130
τ ( ρ
)kend
all's,tau,fo
r,sectoral,draws,
0.93
0.90
0.91
0.92
0.90
1.00
0.85
0.93
0.97
1.00
0.91
Additio
nal%param
eters%/%m
oments
kend
all's,tau,fo
r,idiosyncratic,draw
s0
0.22
00
00
00
00
0sensitivity,of,labo
r,wed
ge,to,prod
uctivity
00
0.003
00
00
00
00
mean,tariff
00
00.062
00
00
00
0std,de
v,tariffs
00
00.039
00
00
00
0
Table2A3
:2Param
eters2for2Rob
ustness2E
xperim
ents
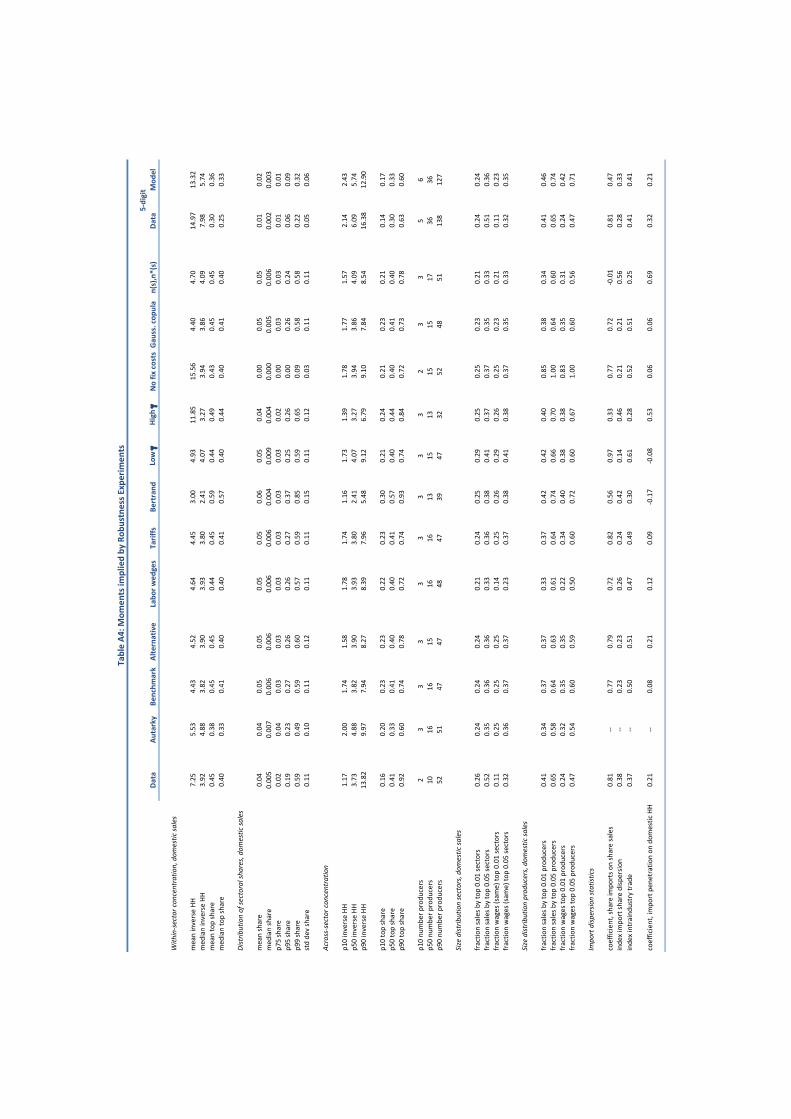
Data
Autarky
Benchmark
Alternative
Labor5wedges
Tariffs
Bertrand
Low5γ
High5γ
No5fix5costsGauss.5copula
n(s),n*(s)
Data
Model
With
in§or,con
centratio
n,,dom
estic,sa
les
mean%inverse%HH
7.25
5.53
4.43
4.52
4.64
4.45
3.00
4.93
11.85
15.56
4.40
4.70
14.97
13.32
med
ian%inverse%HH
3.92
4.88
3.82
3.90
3.93
3.80
2.41
4.07
3.27
3.94
3.86
4.09
7.98
5.74
mean%top%share
0.45
0.38
0.45
0.45
0.44
0.45
0.59
0.44
0.49
0.43
0.45
0.45
0.30
0.36
med
ian%top%share
0.40
0.33
0.41
0.40
0.40
0.41
0.57
0.40
0.44
0.40
0.41
0.40
0.25
0.33
Distrib
ution,of,se
ctoral,sh
ares,,dom
estic,sa
les
mean%share
0.04
0.04
0.05
0.05
0.05
0.05
0.06
0.05
0.04
0.00
0.05
0.05
0.01
0.02
med
ian%share
0.005
0.007
0.006
0.006
0.006
0.006
0.004
0.009
0.004
0.000
0.005
0.006
0.002
0.003
p75%share
0.02
0.04
0.03
0.03
0.03
0.03
0.03
0.03
0.02
0.00
0.03
0.03
0.01
0.01
p95%share
0.19
0.23
0.27
0.26
0.26
0.27
0.37
0.25
0.26
0.00
0.26
0.24
0.06
0.09
p99%share
0.59
0.49
0.59
0.60
0.57
0.59
0.85
0.59
0.65
0.09
0.58
0.58
0.22
0.32
std%de
v%share
0.11
0.10
0.11
0.12
0.11
0.11
0.15
0.11
0.12
0.03
0.11
0.11
0.05
0.06
Across§or,con
centratio
n
p10%inverse%HH
1.17
2.00
1.74
1.58
1.78
1.74
1.16
1.73
1.39
1.78
1.77
1.57
2.14
2.43
p50%inverse%HH
3.73
4.88
3.82
3.90
3.93
3.80
2.41
4.07
3.27
3.94
3.86
4.09
6.09
5.74
p90%inverse%HH
13.82
9.97
7.94
8.27
8.39
7.96
5.48
9.12
6.79
9.10
7.84
8.54
16.38
12.90
p10%top%share
0.16
0.20
0.23
0.23
0.22
0.23
0.30
0.21
0.24
0.21
0.23
0.21
0.14
0.17
p50%top%share
0.41
0.33
0.41
0.40
0.40
0.41
0.57
0.40
0.44
0.40
0.41
0.40
0.30
0.33
p90%top%share
0.92
0.60
0.74
0.78
0.72
0.74
0.93
0.74
0.84
0.72
0.73
0.78
0.63
0.60
p10%nu
mbe
r%produ
cers
23
33
33
33
32
33
56
p50%nu
mbe
r%produ
cers
1016
1615
1616
1315
1315
1517
3636
p90%nu
mbe
r%produ
cers
5251
4747
4847
3947
3252
4851
138
127
Size,distrib
ution,sectors,,do
mestic,sa
les
fractio
n%sales%b
y%top%0.01%se
ctors
0.26
0.24
0.24
0.24
0.21
0.24
0.25
0.29
0.25
0.25
0.23
0.21
0.24
0.24
fractio
n%sales%b
y%top%0.05%se
ctors
0.52
0.35
0.36
0.36
0.33
0.36
0.38
0.41
0.37
0.37
0.35
0.33
0.51
0.36
fractio
n%wages%(sam
e)%to
p%0.01%se
ctors
0.11
0.25
0.25
0.25
0.14
0.25
0.26
0.29
0.26
0.25
0.23
0.21
0.11
0.23
fractio
n%wages%(sam
e)%to
p%0.05%se
ctors
0.32
0.36
0.37
0.37
0.23
0.37
0.38
0.41
0.38
0.37
0.35
0.33
0.32
0.35
Size,distrib
ution,prod
ucers,,do
mestic,sa
les
fractio
n%sales%b
y%top%0.01%produ
cers
0.41
0.34
0.37
0.37
0.33
0.37
0.42
0.42
0.40
0.85
0.38
0.34
0.41
0.46
fractio
n%sales%b
y%top%0.05%produ
cers
0.65
0.58
0.64
0.63
0.61
0.64
0.74
0.66
0.70
1.00
0.64
0.60
0.65
0.74
fractio
n%wages%to
p%0.01%produ
cers
0.24
0.32
0.35
0.35
0.22
0.34
0.40
0.38
0.38
0.83
0.35
0.31
0.24
0.42
fractio
n%wages%to
p%0.05%produ
cers
0.47
0.54
0.60
0.59
0.50
0.60
0.72
0.60
0.67
1.00
0.60
0.56
0.47
0.71
Impo
rt,disp
ersio
n,statistics
coefficient,%share%im
ports%o
n%share%sales
0.81
FF0.77
0.79
0.72
0.82
0.56
0.97
0.33
0.77
0.72
F0.01
0.81
0.47
inde
x%im
port%sh
are%dispersio
n0.38
FF0.23
0.23
0.26
0.24
0.42
0.14
0.46
0.21
0.21
0.56
0.28
0.33
inde
x%intraind
ustry%trade
0.37
FF0.50
0.51
0.47
0.49
0.30
0.61
0.28
0.52
0.51
0.25
0.41
0.41
coefficient,%impo
rt%pen
etratio
n%on
%dom
estic%HH
0.21
FF0.08
0.21
0.12
0.09
F0.17
F0.08
0.53
0.06
0.06
0.69
0.32
0.21
5Hdigit
Table5A4:5Moments5implied5by5Robustness5Experiments
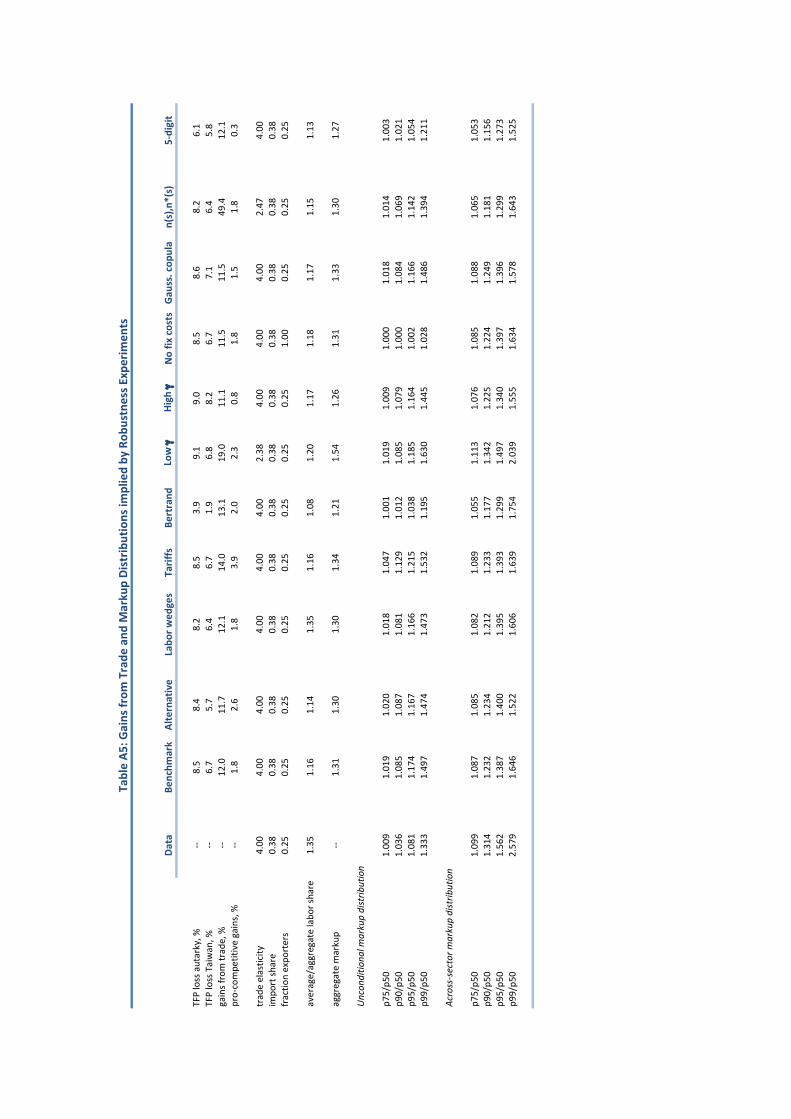
Data
Benchm
ark
Alternative
Labo
r3wed
ges
Tariffs
Bertrand
Low3γ
High3γ
No3fix
3costs
Gauss.3cop
ula
n(s),n*(s)
5Fdigit
TFP$loss$autarky,$%
008.5
8.4
8.2
8.5
3.9
9.1
9.0
8.5
8.6
8.2
6.1
TFP$loss$Taiwan,$%
006.7
5.7
6.4
6.7
1.9
6.8
8.2
6.7
7.1
6.4
5.8
gains$from$trade,$%
0012.0
11.7
12.1
14.0
13.1
19.0
11.1
11.5
11.5
49.4
12.1
pro0compe
titive$gains,$%
001.8
2.6
1.8
3.9
2.0
2.3
0.8
1.8
1.5
1.8
0.3
trade$elasticity
4.00
4.00
4.00
4.00
4.00
4.00
2.38
4.00
4.00
4.00
2.47
4.00
impo
rt$sh
are
0.38
0.38
0.38
0.38
0.38
0.38
0.38
0.38
0.38
0.38
0.38
0.38
fractio
n$expo
rters
0.25
0.25
0.25
0.25
0.25
0.25
0.25
0.25
1.00
0.25
0.25
0.25
average/aggregate$labo
r$share
1.35
1.16
1.14
1.35
1.16
1.08
1.20
1.17
1.18
1.17
1.15
1.13
aggregate$markup
001.31
1.30
1.30
1.34
1.21
1.54
1.26
1.31
1.33
1.30
1.27
Uncond
ition
al*m
arkup*distrib
ution
p75/p5
01.009
1.019
1.020
1.018
1.047
1.001
1.019
1.009
1.000
1.018
1.014
1.003
p90/p5
01.036
1.085
1.087
1.081
1.129
1.012
1.085
1.079
1.000
1.084
1.069
1.021
p95/p5
01.081
1.174
1.167
1.166
1.215
1.038
1.185
1.164
1.002
1.166
1.142
1.054
p99/p5
01.333
1.497
1.474
1.473
1.532
1.195
1.630
1.445
1.028
1.486
1.394
1.211
Across3sector*m
arkup*distrib
ution
p75/p5
01.099
1.087
1.085
1.082
1.089
1.055
1.113
1.076
1.085
1.088
1.065
1.053
p90/p5
01.314
1.232
1.234
1.212
1.233
1.177
1.342
1.225
1.224
1.249
1.181
1.156
p95/p5
01.562
1.387
1.400
1.395
1.393
1.299
1.497
1.340
1.397
1.396
1.299
1.273
p99/p5
02.579
1.646
1.522
1.606
1.639
1.754
2.039
1.555
1.634
1.578
1.643
1.525
Table3A5
:3Gains3from
3Trade
3and
3Marku
p3Distrib
utions3im
plied3by3Rob
ustness3E
xperim
ents
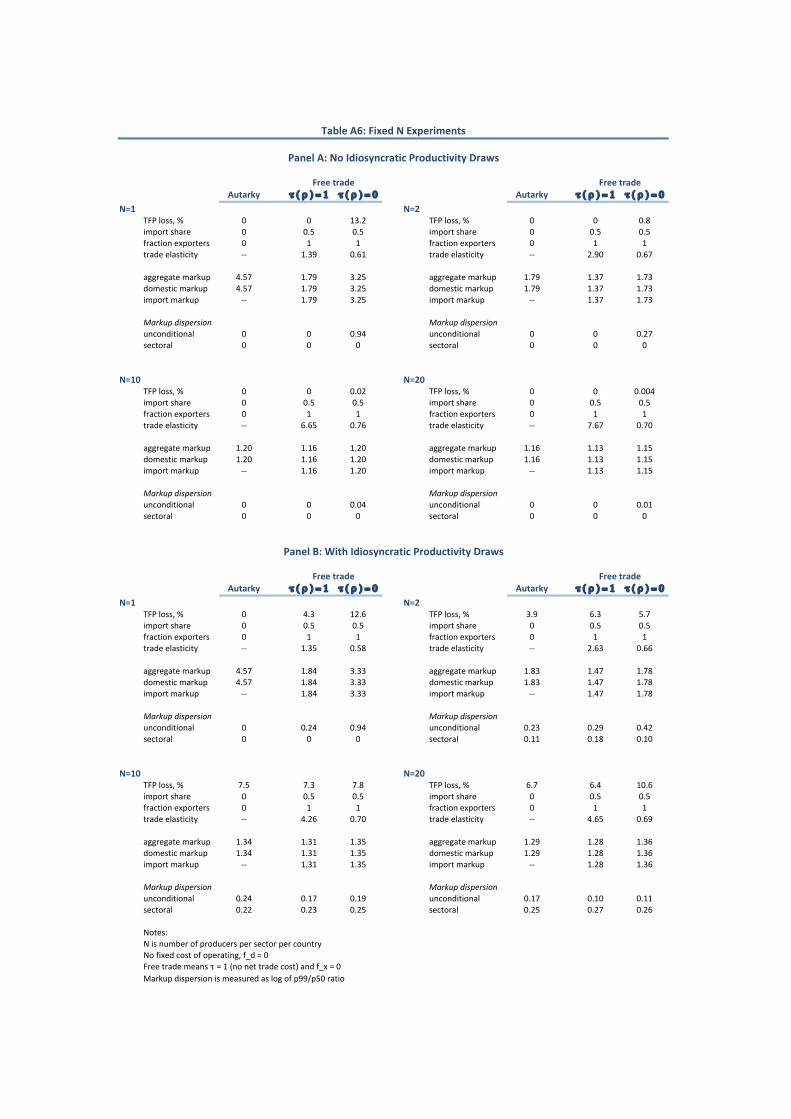
Autarky τ ( ρ ) = 1 τ ( ρ ) = 0 Autarky τ ( ρ ) = 1 τ ( ρ ) = 0
N=1 N=2TFP$loss,$% 0 0 13.2 TFP$loss,$% 0 0 0.8import$share 0 0.5 0.5 import$share 0 0.5 0.5fraction$exporters 0 1 1 fraction$exporters 0 1 1trade$elasticity ?? 1.39 0.61 trade$elasticity ?? 2.90 0.67
aggregate$markup 4.57 1.79 3.25 aggregate$markup 1.79 1.37 1.73domestic$markup 4.57 1.79 3.25 domestic$markup 1.79 1.37 1.73import$markup ?? 1.79 3.25 import$markup ?? 1.37 1.73
Markup'dispersion Markup'dispersionunconditional 0 0 0.94 unconditional 0 0 0.27sectoral 0 0 0 sectoral 0 0 0
N=10 N=20TFP$loss,$% 0 0 0.02 TFP$loss,$% 0 0 0.004import$share 0 0.5 0.5 import$share 0 0.5 0.5fraction$exporters 0 1 1 fraction$exporters 0 1 1trade$elasticity ?? 6.65 0.76 trade$elasticity ?? 7.67 0.70
aggregate$markup 1.20 1.16 1.20 aggregate$markup 1.16 1.13 1.15domestic$markup 1.20 1.16 1.20 domestic$markup 1.16 1.13 1.15import$markup ?? 1.16 1.20 import$markup ?? 1.13 1.15
Markup'dispersion Markup'dispersionunconditional 0 0 0.04 unconditional 0 0 0.01sectoral 0 0 0 sectoral 0 0 0
Autarky τ ( ρ ) = 1 τ ( ρ ) = 0 Autarky τ ( ρ ) = 1 τ ( ρ ) = 0
N=1 N=2TFP$loss,$% 0 4.3 12.6 TFP$loss,$% 3.9 6.3 5.7import$share 0 0.5 0.5 import$share 0 0.5 0.5fraction$exporters 0 1 1 fraction$exporters 0 1 1trade$elasticity ?? 1.35 0.58 trade$elasticity ?? 2.63 0.66
aggregate$markup 4.57 1.84 3.33 aggregate$markup 1.83 1.47 1.78domestic$markup 4.57 1.84 3.33 domestic$markup 1.83 1.47 1.78import$markup ?? 1.84 3.33 import$markup ?? 1.47 1.78
Markup'dispersion Markup'dispersionunconditional 0 0.24 0.94 unconditional 0.23 0.29 0.42sectoral 0 0 0 sectoral 0.11 0.18 0.10
N=10 N=20TFP$loss,$% 7.5 7.3 7.8 TFP$loss,$% 6.7 6.4 10.6import$share 0 0.5 0.5 import$share 0 0.5 0.5fraction$exporters 0 1 1 fraction$exporters 0 1 1trade$elasticity ?? 4.26 0.70 trade$elasticity ?? 4.65 0.69
aggregate$markup 1.34 1.31 1.35 aggregate$markup 1.29 1.28 1.36domestic$markup 1.34 1.31 1.35 domestic$markup 1.29 1.28 1.36import$markup ?? 1.31 1.35 import$markup ?? 1.28 1.36
Markup'dispersion Markup'dispersionunconditional 0.24 0.17 0.19 unconditional 0.17 0.10 0.11sectoral 0.22 0.23 0.25 sectoral 0.25 0.27 0.26
Notes:N$is$number$of$producers$per$sector$per$countryNo$fixed$cost$of$operating,$f_d$=$0Free$trade$means τ =$1$(no$net$trade$cost)$and$f_x$=$0Markup$dispersion$is$measured$as$log$of$p99/p50$ratio
Free/trade Free/trade
Table/A6:/Fixed/N/Experiments
Panel/A:/No/Idiosyncratic/Productivity/Draws
Panel/B:/With/Idiosyncratic/Productivity/Draws
Free/trade Free/trade
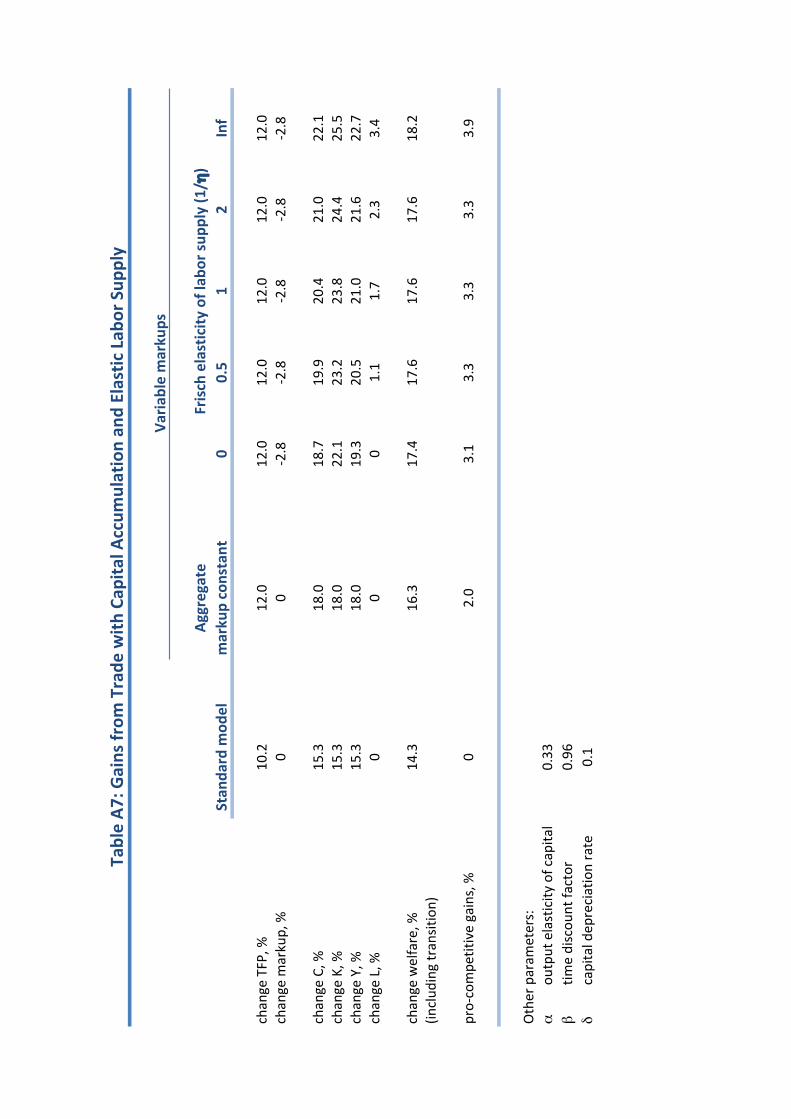
Aggregate
Stan
dard*m
odel
marku
p*constant
00.5
12
Inf
change'TFP,'%
10.2
12.0
12.0
12.0
12.0
12.0
12.0
change'm
arkup,'%
00
62.8
62.8
62.8
62.8
62.8
change'C,'%
15.3
18.0
18.7
19.9
20.4
21.0
22.1
change'K,'%
15.3
18.0
22.1
23.2
23.8
24.4
25.5
change'Y,'%
15.3
18.0
19.3
20.5
21.0
21.6
22.7
change'L,'%
00
01.1
1.7
2.3
3.4
change'welfare,'%
14.3
16.3
17.4
17.6
17.6
17.6
18.2
(includ
ing'transitio
n)
pro6compe
titive'gains,'%
02.0
3.1
3.3
3.3
3.3
3.9
Other'param
eters:
αou
tput'elasticity
'of'capita
l0.33
βtim
e'discou
nt'factor
0.96
δcapital'dep
reciation'rate
0.1
Frisch*elasticity
*of*lab
or*su
pply*(1
/η)
Varia
ble*marku
ps
Table*A7
:*Gains*from
*Trade
*with
*Cap
ital*A
ccum
ulation*an
d*Elastic*Lab
or*Sup
ply

Benchm
ark
L*=2L
L*=10L
Abar*=2A
bar
Abar*=10Ab
ar
γwith
in§or,e
lasticity
,of,sub
stitu
tion
1010
1010
10θ
across§or,e
lasticity
,of,sub
stitu
tion
1.28
1.28
1.28
1.28
1.28
ξ_x
pareto,sh
ape,parameter,,idiosyncratic,produ
ctivity
4.53
4.53
4.53
4.53
4.53
ξ_z
pareto,sh
ape,parameter,,sector,p
rodu
ctivity
0.56
0.56
0.56
0.56
0.56
ζgeom
etric,param
eter,,num
ber,p
rodu
cers,per,se
ctor
0.043
0.043
0.043
0.043
0.043
f_d
fixed
,cost,o
f,dom
estic,ope
ratio
ns0.0043
0.0043
0.0043
0.0043
0.0043
f_x
fixed
,cost,o
f,export,o
peratio
ns0.211
0.211
0.211
0.231
0.350
τtrade,cost
1.128
1.245
1.510
1.322
2.624
τ ( ρ
)kend
all's,ta
u,for,g
umbe
l,cop
ula,
0.93
0.93
0.94
0.83
0.55
Table4A8
:4Param
eters4for4Asymmetric
4Cou
ntrie
s4Experim
ents
Larger4trad
ing4pa
rtne
rMore4prod
uctiv
e4trad
ing4pa
rtne
r
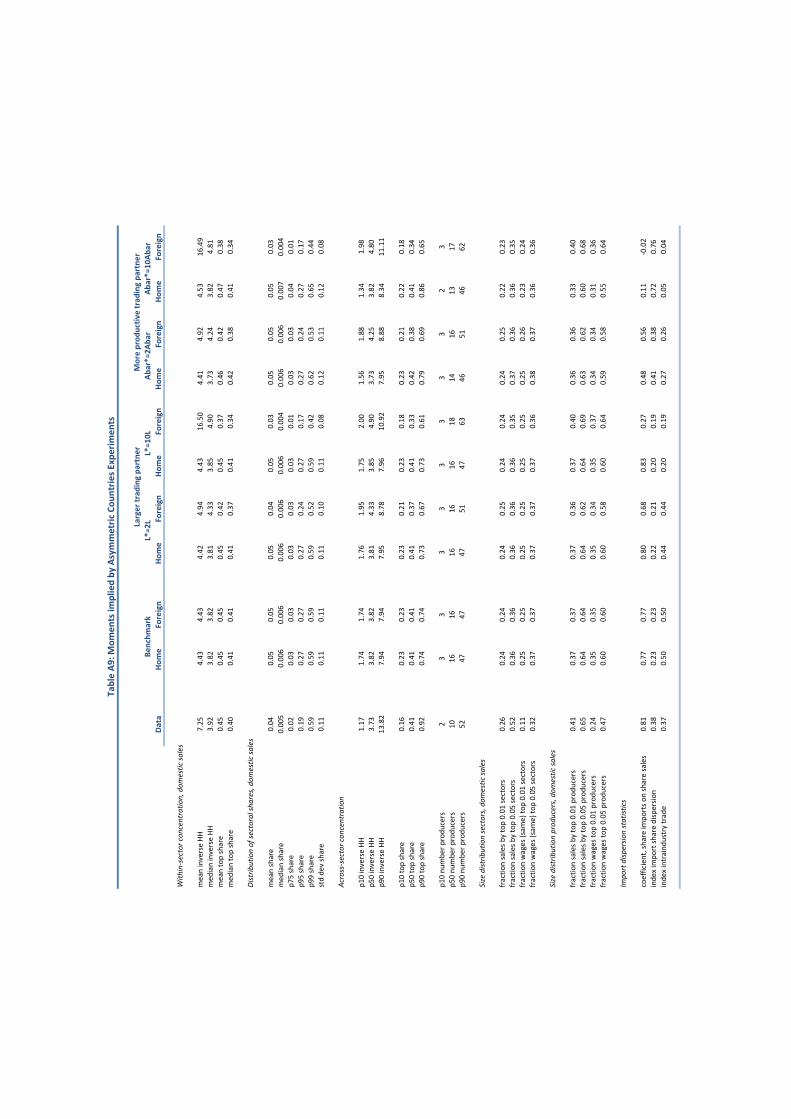
Data
Home(
Foreign
Home(
Foreign
Home(
Foreign
Home(
Foreign
Home(
Foreign
With
in§or,con
centratio
n,,dom
estic,sa
les
mean%inverse%HH
7.25
4.43
4.43
4.42
4.94
4.43
16.50
4.41
4.92
4.53
16.49
med
ian%inverse%HH
3.92
3.82
3.82
3.81
4.33
3.85
4.90
3.73
4.24
3.82
4.81
mean%top%share
0.45
0.45
0.45
0.45
0.42
0.45
0.37
0.46
0.42
0.47
0.38
med
ian%top%share
0.40
0.41
0.41
0.41
0.37
0.41
0.34
0.42
0.38
0.41
0.34
Distrib
ution,of,se
ctoral,sh
ares,,dom
estic,sa
les
mean%share
0.04
0.05
0.05
0.05
0.04
0.05
0.03
0.05
0.05
0.05
0.03
med
ian%share
0.005
0.006
0.006
0.006
0.006
0.006
0.004
0.006
0.006
0.007
0.004
p75%share
0.02
0.03
0.03
0.03
0.03
0.03
0.01
0.03
0.03
0.04
0.01
p95%share
0.19
0.27
0.27
0.27
0.24
0.27
0.17
0.27
0.24
0.27
0.17
p99%share
0.59
0.59
0.59
0.59
0.52
0.59
0.42
0.62
0.53
0.65
0.44
std%de
v%share
0.11
0.11
0.11
0.11
0.10
0.11
0.08
0.12
0.11
0.12
0.08
Across§or,con
centratio
n
p10%inverse%HH
1.17
1.74
1.74
1.76
1.95
1.75
2.00
1.56
1.88
1.34
1.98
p50%inverse%HH
3.73
3.82
3.82
3.81
4.33
3.85
4.90
3.73
4.25
3.82
4.80
p90%inverse%HH
13.82
7.94
7.94
7.95
8.78
7.96
10.92
7.95
8.88
8.34
11.11
p10%top%share
0.16
0.23
0.23
0.23
0.21
0.23
0.18
0.23
0.21
0.22
0.18
p50%top%share
0.41
0.41
0.41
0.41
0.37
0.41
0.33
0.42
0.38
0.41
0.34
p90%top%share
0.92
0.74
0.74
0.73
0.67
0.73
0.61
0.79
0.69
0.86
0.65
p10%nu
mbe
r%produ
cers
23
33
33
33
32
3p5
0%nu
mbe
r%produ
cers
1016
1616
1616
1814
1613
17p9
0%nu
mbe
r%produ
cers
5247
4747
5147
6346
5146
62
Size,distrib
ution,sectors,,do
mestic,sa
les
fractio
n%sales%b
y%top%0.01%se
ctors
0.26
0.24
0.24
0.24
0.25
0.24
0.24
0.24
0.25
0.22
0.23
fractio
n%sales%b
y%top%0.05%se
ctors
0.52
0.36
0.36
0.36
0.36
0.36
0.35
0.37
0.36
0.36
0.35
fractio
n%wages%(sam
e)%to
p%0.01%se
ctors
0.11
0.25
0.25
0.25
0.25
0.25
0.25
0.25
0.26
0.23
0.24
fractio
n%wages%(sam
e)%to
p%0.05%se
ctors
0.32
0.37
0.37
0.37
0.37
0.37
0.36
0.38
0.37
0.36
0.36
Size,distrib
ution,prod
ucers,,do
mestic,sa
les
fractio
n%sales%b
y%top%0.01%produ
cers
0.41
0.37
0.37
0.37
0.36
0.37
0.40
0.36
0.36
0.33
0.40
fractio
n%sales%b
y%top%0.05%produ
cers
0.65
0.64
0.64
0.64
0.62
0.64
0.69
0.63
0.62
0.60
0.68
fractio
n%wages%to
p%0.01%produ
cers
0.24
0.35
0.35
0.35
0.34
0.35
0.37
0.34
0.34
0.31
0.36
fractio
n%wages%to
p%0.05%produ
cers
0.47
0.60
0.60
0.60
0.58
0.60
0.64
0.59
0.58
0.55
0.64
Impo
rt,disp
ersio
n,statistics
coefficient,%share%im
ports%o
n%share%sales
0.81
0.77
0.77
0.80
0.68
0.83
0.27
0.48
0.56
0.11
F0.02
inde
x%im
port%sh
are%dispersio
n0.38
0.23
0.23
0.22
0.21
0.20
0.19
0.41
0.38
0.72
0.76
inde
x%intraind
ustry%trade
0.37
0.50
0.50
0.44
0.44
0.20
0.19
0.27
0.26
0.05
0.04
Larger(trad
ing(pa
rtne
rMore(prod
uctiv
e(trad
ing(pa
rtne
r
Table(A9
:(Mom
ents(im
plied(by(Asymmetric
(Cou
ntrie
s(Experim
ents
Benchm
ark
L*=2L
L*=10L
Abar*=2A
bar
Abar*=10Ab
ar
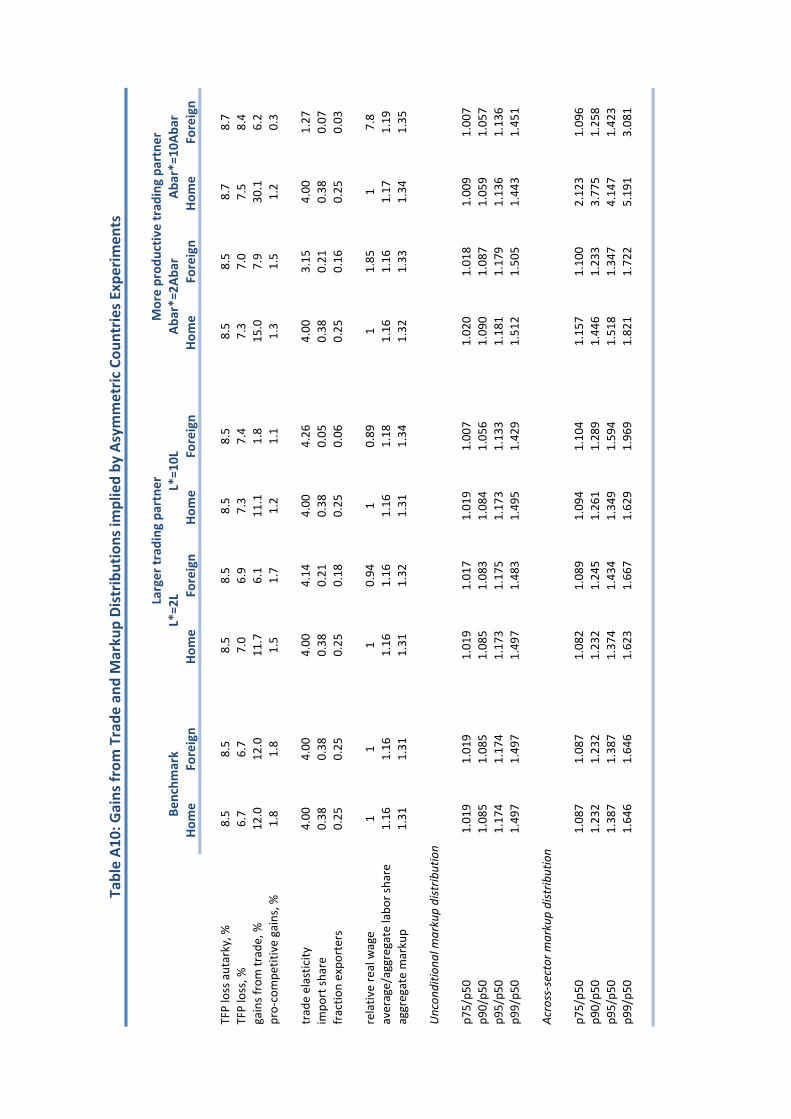
Home%
Foreign
Home%
Foreign
Home%
Foreign
Home%
Foreign
Home%
Foreign
TFP$loss$autarky,$%
8.5
8.5
8.5
8.5
8.5
8.5
8.5
8.5
8.7
8.7
TFP$loss,$%
6.7
6.7
7.0
6.9
7.3
7.4
7.3
7.0
7.5
8.4
gains$from$trade,$%
12.0
12.0
11.7
6.1
11.1
1.8
15.0
7.9
30.1
6.2
proCcompe
titive$gains,$%
1.8
1.8
1.5
1.7
1.2
1.1
1.3
1.5
1.2
0.3
trade$elasticity
4.00
4.00
4.00
4.14
4.00
4.26
4.00
3.15
4.00
1.27
impo
rt$sh
are
0.38
0.38
0.38
0.21
0.38
0.05
0.38
0.21
0.38
0.07
fractio
n$expo
rters
0.25
0.25
0.25
0.18
0.25
0.06
0.25
0.16
0.25
0.03
relativ
e$real$wage
11
10.94
10.89
11.85
17.8
average/aggregate$labo
r$share
1.16
1.16
1.16
1.16
1.16
1.18
1.16
1.16
1.17
1.19
aggregate$markup
1.31
1.31
1.31
1.32
1.31
1.34
1.32
1.33
1.34
1.35
Uncond
ition
al*m
arkup*distrib
ution
p75/p5
01.019
1.019
1.019
1.017
1.019
1.007
1.020
1.018
1.009
1.007
p90/p5
01.085
1.085
1.085
1.083
1.084
1.056
1.090
1.087
1.059
1.057
p95/p5
01.174
1.174
1.173
1.175
1.173
1.133
1.181
1.179
1.136
1.136
p99/p5
01.497
1.497
1.497
1.483
1.495
1.429
1.512
1.505
1.443
1.451
Across3sector*m
arkup*distrib
ution
p75/p5
01.087
1.087
1.082
1.089
1.094
1.104
1.157
1.100
2.123
1.096
p90/p5
01.232
1.232
1.232
1.245
1.261
1.289
1.446
1.233
3.775
1.258
p95/p5
01.387
1.387
1.374
1.434
1.349
1.594
1.518
1.347
4.147
1.423
p99/p5
01.646
1.646
1.623
1.667
1.629
1.969
1.821
1.722
5.191
3.081
Table%A1
0:%Gains%from
%Trade
%and
%Marku
p%Distrib
utions%im
plied%by%Asymmetric
%Cou
ntrie
s%Experim
ents
Larger%trad
ing%pa
rtne
rMore%prod
uctiv
e%trad
ing%pa
rtne
rBe
nchm
ark
L*=2L
L*=10L
Abar*=2A
bar
Abar*=10Ab
ar
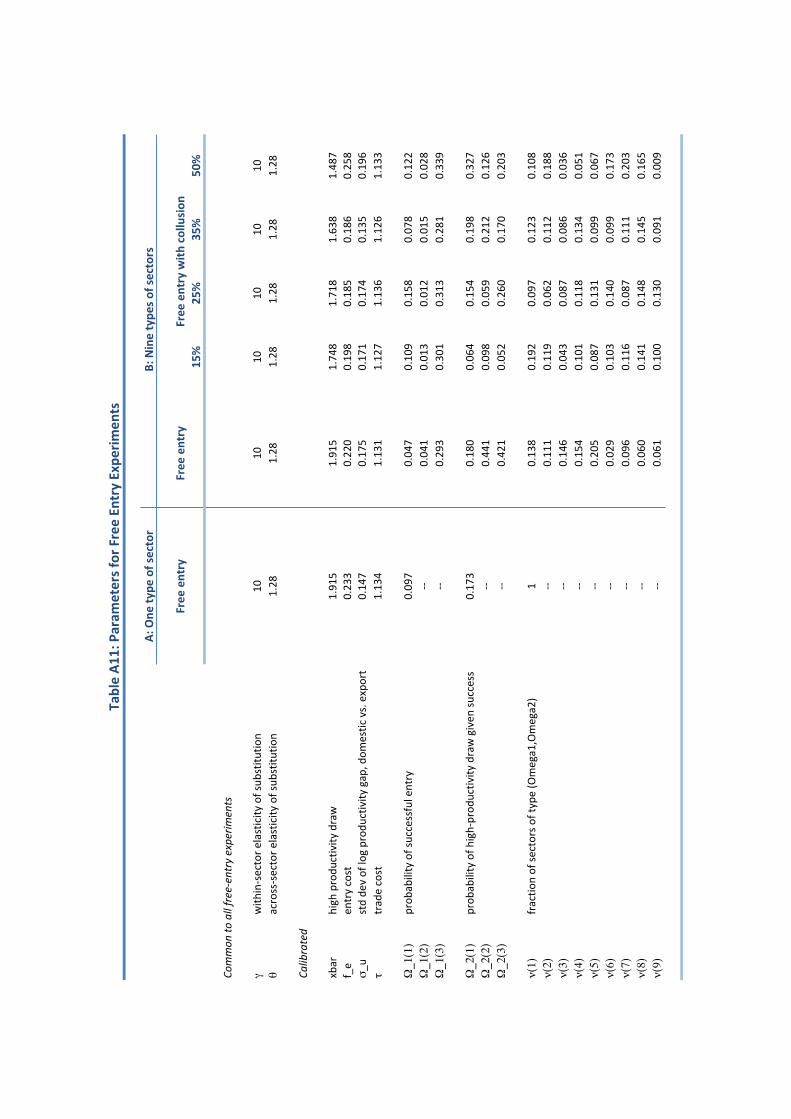
A:#One
#type
#of#sector
Free#entry
Free#entry
15%
25%
35%
50%
Common
%to%all%free,entry%experim
ents
γwith
in§or,e
lasticity
,of,sub
stitu
tion
1010
1010
1010
θacross§or,e
lasticity
,of,sub
stitu
tion
1.28
1.28
1.28
1.28
1.28
1.28
Calibrated
xbar
high,produ
ctivity
,draw
1.915
1.915
1.748
1.718
1.638
1.487
f_e
entry,cost
0.233
0.220
0.198
0.185
0.186
0.258
σ_u
std,de
v,of,log,prod
uctiv
ity,gap,,dom
estic,vs.,export
0.147
0.175
0.171
0.174
0.135
0.196
τtrade,cost
1.134
1.131
1.127
1.136
1.126
1.133
Ω_1(1)
prob
ability,of,successful,entry
0.097
0.047
0.109
0.158
0.078
0.122
Ω_1(2)
&&0.041
0.013
0.012
0.015
0.028
Ω_1(3)
&&0.293
0.301
0.313
0.281
0.339
Ω_2(1)
prob
ability,of,h
igh&prod
uctiv
ity,draw,given
,success
0.173
0.180
0.064
0.154
0.198
0.327
Ω_2(2)
&&0.441
0.098
0.059
0.212
0.126
Ω_2(3)
&&0.421
0.052
0.260
0.170
0.203
ν(1)
fractio
n,of,se
ctors,o
f,type,(Omega1,Omega2)
10.138
0.192
0.097
0.123
0.108
ν(2)
&&0.111
0.119
0.062
0.112
0.188
ν(3)
&&0.146
0.043
0.087
0.086
0.036
ν(4)
&&0.154
0.101
0.118
0.134
0.051
ν(5)
&&0.205
0.087
0.131
0.099
0.067
ν(6)
&&0.029
0.103
0.140
0.099
0.173
ν(7)
&&0.096
0.116
0.087
0.111
0.203
ν(8)
&&0.060
0.141
0.148
0.145
0.165
ν(9)
&&0.061
0.100
0.130
0.091
0.009
Free#entry#with
#collusion
B:#Nine#type
s#of#sectors
Table#A1
1:#Param
eters#for#Free#En
try#Expe
rimen
ts
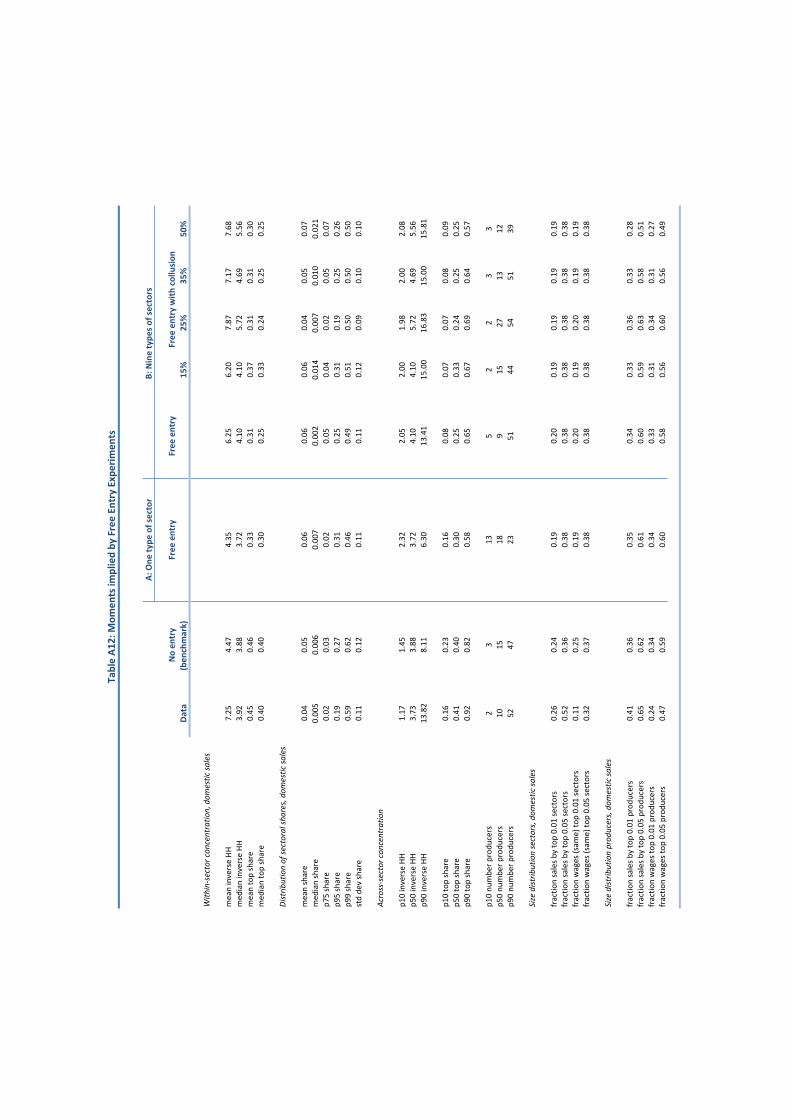
A:#One
#type
#of#sector
No#en
try
Free#entry
Free#entry
Data
(ben
chmark)
15%
25%
35%
50%
With
in§or,con
centratio
n,,dom
estic,sa
les
mean%inverse%HH
7.25
4.47
4.35
6.25
6.20
7.87
7.17
7.68
med
ian%inverse%HH
3.92
3.88
3.72
4.10
4.10
5.72
4.69
5.56
mean%top%share
0.45
0.46
0.33
0.31
0.37
0.31
0.31
0.30
med
ian%top%share
0.40
0.40
0.30
0.25
0.33
0.24
0.25
0.25
Distrib
ution,of,se
ctoral,sh
ares,,dom
estic,sa
les
mean%share
0.04
0.05
0.06
0.06
0.06
0.04
0.05
0.07
med
ian%share
0.005
0.006
0.007
0.002
0.014
0.007
0.010
0.021
p75%share
0.02
0.03
0.02
0.05
0.04
0.02
0.05
0.07
p95%share
0.19
0.27
0.31
0.25
0.31
0.19
0.25
0.26
p99%share
0.59
0.62
0.46
0.49
0.51
0.50
0.50
0.50
std%de
v%share
0.11
0.12
0.11
0.11
0.12
0.09
0.10
0.10
Across§or,con
centratio
n
p10%inverse%HH
1.17
1.45
2.32
2.05
2.00
1.98
2.00
2.08
p50%inverse%HH
3.73
3.88
3.72
4.10
4.10
5.72
4.69
5.56
p90%inverse%HH
13.82
8.11
6.30
13.41
15.00
16.83
15.00
15.81
p10%top%share
0.16
0.23
0.16
0.08
0.07
0.07
0.08
0.09
p50%top%share
0.41
0.40
0.30
0.25
0.33
0.24
0.25
0.25
p90%top%share
0.92
0.82
0.58
0.65
0.67
0.69
0.64
0.57
p10%nu
mbe
r%produ
cers
23
135
22
33
p50%nu
mbe
r%produ
cers
1015
189
1527
1312
p90%nu
mbe
r%produ
cers
5247
2351
4454
5139
Size,distrib
ution,sectors,,do
mestic,sa
les
fractio
n%sales%b
y%top%0.01%se
ctors
0.26
0.24
0.19
0.20
0.19
0.19
0.19
0.19
fractio
n%sales%b
y%top%0.05%se
ctors
0.52
0.36
0.38
0.38
0.38
0.38
0.38
0.38
fractio
n%wages%(sam
e)%to
p%0.01%se
ctors
0.11
0.25
0.19
0.20
0.19
0.20
0.19
0.19
fractio
n%wages%(sam
e)%to
p%0.05%se
ctors
0.32
0.37
0.38
0.38
0.38
0.38
0.38
0.38
Size,distrib
ution,prod
ucers,,do
mestic,sa
les
fractio
n%sales%b
y%top%0.01%produ
cers
0.41
0.36
0.35
0.34
0.33
0.36
0.33
0.28
fractio
n%sales%b
y%top%0.05%produ
cers
0.65
0.62
0.61
0.60
0.59
0.63
0.58
0.51
fractio
n%wages%to
p%0.01%produ
cers
0.24
0.34
0.34
0.33
0.31
0.34
0.31
0.27
fractio
n%wages%to
p%0.05%produ
cers
0.47
0.59
0.60
0.58
0.56
0.60
0.56
0.49
Free#entry#with
#collusion
B:#Nine#type
s#of#sectors
Table#A1
2:#M
omen
ts#im
plied#by#Free#En
try#Expe
rimen
ts
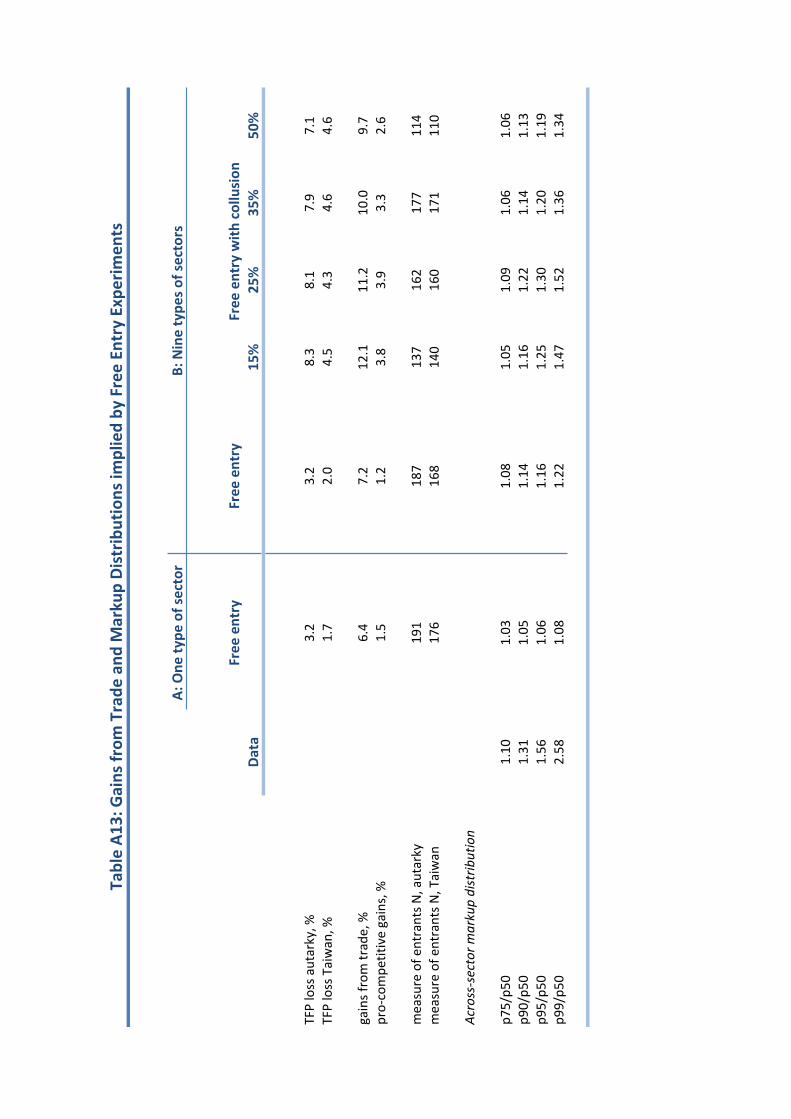
A:#One
#type
#of#sector
Free#entry
Free#entry
Data
15%
25%
35%
50%
TFP$loss$autarky,$%
3.2
3.2
8.3
8.1
7.9
7.1
TFP$loss$Taiwan,$%
1.7
2.0
4.5
4.3
4.6
4.6
gains$from$trade,$%
6.4
7.2
12.1
11.2
10.0
9.7
proDcompe
titive$gains,$%
1.5
1.2
3.8
3.9
3.3
2.6
measure$of$e
ntrants$N
,$autarky
191
187
137
162
177
114
measure$of$e
ntrants$N
,$Taiwan
176
168
140
160
171
110
Across§or)m
arkup)distrib
ution
p75/p5
01.10
1.03
1.08
1.05
1.09
1.06
1.06
p90/p5
01.31
1.05
1.14
1.16
1.22
1.14
1.13
p95/p5
01.56
1.06
1.16
1.25
1.30
1.20
1.19
p99/p5
02.58
1.08
1.22
1.47
1.52
1.36
1.34
Free#entry#with
#collusion
B:#Nine#type
s#of#sectors
Table#A1
3:#Gains#from
#Trade
#and
#Marku
p#Distrib
utions#im
plied#by#Free#En
try#Expe
rimen
ts








![Inventories, Markups, and Real Rigidities in Menu Cost Models · 2019-10-31 · [11:50 10/8/2012 rds028.tex] RESTUD:The Review of Economic Studies Page: 3 1–28 KRYVTSOV & MIDRIGAN](https://img.pdfslide.us/doc/110x75/5f379429e388b1744c0e5255/inventories-markups-and-real-rigidities-in-menu-cost-2019-10-31-1150-1082012.jpg)