Embed Size (px)
Citation preview

COMPUTER ANIMATION AND VIRTUAL WORLDSComp. Anim. Virtual Worlds 2009; 20: 447–456Published online 20 June 2008 in Wiley InterScience(www.interscience.wiley.com) DOI: 10.1002/cav.227...........................................................................................Combined compression andsimplification of dynamic 3D meshes
By Libor Vasa∗ and Vaclav Skala..........................................................................
We present a new approach to dynamic mesh compression, which combines compressionwith simplification to achieve improved compression results, a natural support forincremental transmission and level of detail. The algorithm allows fast progressivetransmission of dynamic 3D content. Our scheme exploits both temporal and spatialcoherency of the input data, and is especially efficient for the case of highly detaileddynamic meshes. The algorithm can be seen as an ultimate extension of the clustering andlocal coordinate frame (LCF)-based approaches, where each vertex is expressed within itsown specific coordinate system. The presented results show that we have achieved bettercompression efficiency compared to the state of the art methods. Copyright © 2008 JohnWiley & Sons, Ltd.
Received: 7 August 2007; Revised: 28 February 2008; Accepted: 25 March 2008
KEY WORDS: dynamic mesh; compression; simplification; animation; PCA; prediction
Introduction
Compression of dynamic 3D meshes is one of theresearch areas of computer graphics which have receivedincreased attention in the last period. This is mainly dueto the fast development of capture and display hardwarewhich is likely to soon allow quick acquisition and high-quality display of truly 3D moving content.
It is important to realize that dynamic mesh processingis not a simple extension of the static case. On onehand, there are some new problems, which should beaddressed, such as avoiding temporal artifacts, while onthe other hand we have new opportunities to be exploitedduring the processing, namely the temporal coherency ofthe input data.
Dynamic mesh is a common term used for a series ofstatic triangular meshes that represent a developmentof some surface in time. Usually, two additionalassumptions are made about the dynamic mesh:
• every mesh in the series has the same connectivity, thatis, there is an one-to-one correspondence of verticesfrom frame to frame of the animation,
*Correspondence to: L. Vasa, Department of Computer Scienceand Engineering, Faculty of Applied Science, University of WestBohemia, Czech Republic. E-mail: [email protected]
• the animation represents some physical process, thatis, there are no sudden changes in the geometry of thesubsequent frames of the animation.
The task is to store the dynamic mesh using as few bitsas possible, while preserving the visual properties of theoriginal data.
There are generally two main classes of approaches tothis problem. First, there is a large class of compressionschemes. These approaches do not change the originaltopology of the mesh, and achieve size reduction bysophisticated encoding of the geometry of the mesh. Asecond class are the simplifications, which reduce thenumber of primitives in the data, thus achieving smallersize and faster processing.
Our approach, however, consists of both steps.Our primary goal is size reduction for incrementaltransmission of 3D meshes, and therefore we only usesimplification as a tool which allows better compressionrates and also adds some nice features to the algorithm.In our scheme, we use eigentrajectory-based PrincipalComponent Analysis (PCA) to describe the trajectories ofvertices. The decoder first receives the full connectivity,and subsequently decimates it according to decimationorder sent from the encoder.
Finally, the encoder incrementally sends the PCAcoefficients for the vertices needed by the decoder torefine the coarse version of the mesh. This allows us to
............................................................................................Copyright © 2008 John Wiley & Sons, Ltd.

L. VASA AND V. SKALA...........................................................................................
use neighborhood average predictor to predict the PCAcoefficients, and only transmit the residuals of very lowentropy.
The rest of the paper is structured as follows.Section “Related Work” gives a brief overview of theexisting approaches to dynamic mesh compression andsimplification. Section “Algorithm Description” specifiesour scheme, Section “Algorithm Details” clarifies somedetails, and Section “Evaluation” reports about thetesting we have performed to evaluate our approach.Finally, in Section “Conclusions and Future Work” wegive conclusions and sketch some concepts for futureresearch in the area.
Related Work
A first attempt to dynamic mesh compression has beenpublished in the paper by Lengyel,1 who suggested sub-dividing the mesh into clusters in which the movementcan be described by a single transformation matrix.
Ibarria and Rossignac2 later suggested the spatio-temporal prediction schemes ELP and Replica, whichwere used to predict the next vertex position duringa mesh traversal using the EdgeBreaker state machine.A similar approach has been used by Stefanoski andOstermann3 in their angle preserving predictor. Theposition of the new vertex is expressed in a localcoordinate system defined by a neighboring triangle.
A different approach has been proposed by Zhangand Owen,4 who suggested encoding the frame to framedifference vectors using an octree structure, exploitingthe fact that large portions of the mesh are moving in avery similar manner.
The octree-based approach has been improved byMueller et al.,5,6 who suggested selecting an appropriatepredictor for each cell, choosing from mean replacement,trilinear interpolation, and direct encoding.
Wavelet theory has been used for dynamic meshcompression in the work of Payan and Antonini,7
who suggested treating separate vertex trajectories assampled signal. However, their method did not use thespatial coherence present in the data.
A different class of approaches has been pioneeredby Alexa and Muller,8 who suggested using PCA inthe space of frames, expressing each frame as a linearcombination of eigenframes. However, this methodhad problems with rigid movement, which had tobe compensated for in a preprocessing step, where atransformation matrix for each frame has been foundusing the least squares approach.
The method has been subsequently improved by Karniand Gotsman,9 who suggested exploiting the temporalcoherence of the PCA coefficients by encoding them us-ing linear prediction coding (LPC), thus achieving lowerentropy of the encoded data. Another improvement hasbeen proposed by Sattler et al.,10 who suggested usingPCA in the space of trajectories, and finding clustersof vertices where PCA worked well (Clustered PCA).However, their randomly initialized iterative clusteringmethod reached very different clusterings in every run.
Another addition to the PCA-based method has beenproposed in 2007 by Amjoun,11 who suggested usingtrajectory-based analysis along with expressing eachtrajectory in a local coordinate frame (LCF) defined foreach cluster. Additionally, a bit allocation procedure isapplied, assigning more bits to cluster where more PCAcoefficients are needed to achieve desired precision.
A very efficient compression scheme for dynamicmeshes is the Coddyac algorithm by Vasa andSkala.12 This approach uses trajectory-based PCA to ex-ploit the temporal coherence of the data; however, in con-trast to the clustering prediction used by Sattler et al.,10
a more efficient local paralellogram predictor is used topredict the PCA coefficients associated with each vertex.
Mamou et al.13 have proposed an approach similar toPCA, called skinning-based compression. The mesh isfirst segmented to parts that move in an almost rigidfashion. Each cluster’s movement is expressed by atransformation matrix, and subsequently each vertex isassigned a vector of weights, that defines how to combinethe transforms of the neighboring clusters to obtain themovement of the vertex.
A resampling approach has been proposed by Bricenoet al.14 in their work on Geometry Videos. The idea is anextension of the previously proposed Geometry Images15
concept. The geometry of the object is unwrapped andprojected onto a square, which is regularly sampled.The resulting image is encoded using some off theshelf algorithm. The extension to videos solves theproblems of finding a single mapping of a movingcontent onto a square while minimizing the overalltension. Generally, the method is not easy to implementand suffers from some artifacts, especially for objectswith complex geometry.
A method on the borderline between compressionand simplification has been recently proposed byStefanoski et al.16 The approach utilizes a connectivity-driven simplification step, which uses a local spatio-temporal predictor where for each vertex a completeneighborhood is available at the decoder. Our methodutilizes simplification in a similar manner.
............................................................................................Copyright © 2008 John Wiley & Sons, Ltd. 448 Comp. Anim. Virtual Worlds 2009; 20: 447–456
DOI: 10.1002/cav

COMPRESSION AND SIMPLIFICATION OF DYNAMIC 3D MESHES...........................................................................................
Pure simplification of dynamic meshes has been ad-dressed by only a few papers so far. Mohr and Gleicher17
extend the quadric-based simplification static mesh sim-plification scheme by Garland.18 They suggest finding aglobal quadric for each vertex, and simplifying the globalconnectivity. Kircher and Garland19 propose using a mul-tiresolution representation of the first frame, and then tosend connectivity updates (swaps) with each followingframe. This way, they allow connectivity to change with-out need to send the whole connectivity with each frame.
None of the simplification methods so far proposedconsidered compression as the necessary following stepin dynamic 3D mesh processing.
Algorithm Description
Our scheme consists of following steps:
1. compute the PCA of the vertex trajectories,2. decimate the mesh,3. transmit the PCA coefficients for the non-decimated
vertices, using parallelogram predictor,4. transmit the PCA coefficients for decimated vertices,
using neighborhood average predictor.
We will now describe each step in detail.We have chosen the trajectory-based PCA as a core
algorithm because it allows efficient dimensionalityreduction. This first step allows us to express eachtrajectory as a combination of eigentrajectories, thusutilizing the temporal coherence.
We assume that the number of frames of a typicalmesh sequence will not change dramatically in the future,because the length of an animation is dictated by filmediting rules. On the other hand, we do expect thenumber of vertices to increase, as more detailed meshesare likely to be transmitted in the future. From thispoint of view, it is better to perform PCA in the spaceof trajectories, where the number of samples available(which is equal to the number of vertices) is a lot greaterthan the dimension of the space (which is equal to thetrajectory length). This also implies that the PCA itselfwill be performed with a relatively small correlationmatrix of size f × f where f stands for the numberof frames. Also, it can be expected that the PCA basis,which needs to be transmitted with the data, will beconsiderably smaller than in the case of eigenshapes.
After finding a basis of the space of trajectories,we express each trajectory as a linear combination ofthe eigentrajectories found. Usually about 80% of thecoefficients can be neglected without causing any majordistortion of the animation. From this point, we treat
the animation as a static mesh, where each vertex hasassociated a vector of reduced PCA coefficients.
The key observation for the following step is that thePCA coefficients of neighboring vertices are likely tobe similar. We can use any spatial predictor used forstatic meshes. Our suggestion is to use neighborhoodaverage (NA) predictor, which usually provides veryrobust estimation. The encoder at this point sorts allthe vertices according to the accuracy of their predictionby the NA predictor. This ordered set is then used as apriority queue for vertex removal.
The removal of vertices is performed simultaneouslyat both encoder and decoder. Note that at this pointthe decoder has no information about the geometry atall, and therefore the retriangulation of the hole mustbe performed solely according to connectivity criteria.The only information the decoder receives is the indexof the vertex to be removed; however, this leaves somecontrol to the encoder—it knows how the decoder willretriangulate, and based on this knowledge it can avoidremoving such vertices where the retriangulation wouldintroduce geometrical problems—details on this will begiven in Section “Algorithm Details.”
The strategy of the encoder is the following:
1. set all vertices unlocked, evaluate the decimationcosts,
2. pick the best predicted vertex v from the head of thepriority queue,
3. if v is locked, remove v from queue and go to 2,4. simulate the retriangulation after removal of v, if it
violates geometrical criteria, then remove v from thequeue and go to 2,
5. lock the neighbors of v,6. mark the vertex v to be removed by the decoder at the
current level of simplification,7. if there are some vertices left, then go to 2,8. if further simplification is required, then go to 1.
The simplification process is repeated several times inorder to create multiple simplification levels of the mesh.After each step, all the vertices are unlocked (step 1),and the prediction accuracy (i.e., simplification cost) isreevaluated at each vertex, again allowing all the verticesto be removed in the following simplification step.
After this process, the encoder and decoder share asimplified connectivity, and every removed vertex can bepredicted from its neighbors (however, the decoder hasstill no information about the geometry of any vertex).
Note that there is some overhead associated withthe decimation. However, we do not need to send theexact order of vertices to be removed (which would
............................................................................................Copyright © 2008 John Wiley & Sons, Ltd. 449 Comp. Anim. Virtual Worlds 2009; 20: 447–456
DOI: 10.1002/cav

L. VASA AND V. SKALA...........................................................................................
take v · log2 v bits, v being the number of vertices), theonly information the decoder needs is at which level ofdecimation each vertex should be removed. To transmitthis information, we only need v · log2 s bits, where s isthe number of simplification levels, or even less than thatwhen entropy coding is used (simplification levels arenot distributed uniformly, most vertices will be removedat first level, less at second, etc.).
At this point, the encoder and decoder share a series ofincreasingly simplified versions of the mesh, where eachfiner one can be obtained by inverse vertex removal, thatis, we know where each vertex should be placed to reacha finer version of topology. In our experiments, we haveusually driven the algorithm to reduce the number ofvertices to less than one-fifth of their original number.
Now, we use another spatial predictor to finally passsome geometry information to the decoder. We traversethe coarsest mesh in EdgeBreaker20 fashion; however, wedo not need to send the CLERS string at all, as both sidesshare the connectivity of the coarsest level. The Edge-Breaker allows us to use the parallelogram predictor topredict the PCA coefficients at each vertex—the originalversion which predicted the spatial coordinates can beeasily extended to predict a general dimension vector cD
i :
Pred(cDi ) = cB
i + cCi − cA
i (1)
where cXi stands for PCA coefficient vectors at vertices
X = A, B, C, and D, where A, B, and C were alreadytransmitted, and D is a vertex found in a “new vertex”EdgeBreaker operation (see Figure 1).
Both encoder and decoder perform this prediction, andthe only information that is being sent with each vertex isa vector of quantized prediction residuals (except for theinitial three vertices, which need to be fully transmitted).This way, we transmit the complete geometry of thecoarsest version of the animation.
At this point, the decoder can start playing the anima-tion, while it is still receiving refinement information.The parallelogram predictor is now replaced by theNA predictor, and the decoder continuously refinesthe mesh by reversing the previous decimation. It isguaranteed, that for each vertex the decoder has all
A
B
C
D
Figure 1. Parallelogram prediction.
Compute PCA basis
Encoder
Decimate the mesh
Traverse the meshparalellogram
residuals
Send NA residuals
Send connectivityconnectivityinformation
Decoder
Receive connectivity
PCA basisvectors
decimationlevels
NA residuals
Decimate the mesh
Receive coarse geometry
Receive geometry refinements
Receive PCA basis
Figure 2. The data flow between the encoder and the decoder.
the neighbors available, and therefore it can computethe NA prediction. Again, the encoder only sends thequantized residuals. For a black scheme of both encoderand decoder see Figure 2.
Algorithm Details
There are two gaps in the scheme that are to be filled—theconditions for selecting the vertices for decimation, andthe criteria for retriangulation performed in the decoder.We are suggesting simple approaches for both tasks.
If we were creating only one decimation level, thenwe generally would not care about the geometryproperties of the created holes; however, when multiplesimplification levels are being created it is advisableto preserve a reasonable quality mesh. On the otherhand, the encoder cannot control the way the hole is
.
-2
-7
-3-5
-6-5
-4
-6
-4
Figure 3. An example of the hole retriangulation process.
............................................................................................Copyright © 2008 John Wiley & Sons, Ltd. 450 Comp. Anim. Virtual Worlds 2009; 20: 447–456
DOI: 10.1002/cav

COMPRESSION AND SIMPLIFICATION OF DYNAMIC 3D MESHES...........................................................................................
retriangulated by the decoder, as this would requireadditional information to be sent.
The retriangulation process must be driven byconnectivity only, as this is the only information availableat the decoder. Although there are more advancedmethods for this task, we have chosen a simple “earcutting” algorithm21 for triangulation of a simple hole.The decoder, however, has no information about theconvexity/concavity of the hole border, and therefore itsimply considers any vertex to be a candidate ear tip.
The only criterion the decoder uses for selecting an eartip is the regularity of degrees of the vertices. It is knownthat the expected degree of a vertex is six, and good-shaped meshes have very regular distribution of vertexdegrees. Cutting an ear does not increase the ear tipdegree, while it increases the degree of the two verticesnext to the tip by one. Therefore, we select the candidatetip where the following expression is maximal:
δ(tip) − δ(tipleft) − δ(tipright) (2)
where δ(x) stands for the degree of vertex x. The tip iscut, and the remaining hole is again searched for bestcandidate tip, until it is fully retriangulated. Ambiguoussituations are solved by selecting a candidate tip vertexwith lowest index, so that both encoder and decoder havethe same retriangulation. For an example of a completeretriangulation of a hole see Figure 3.
There is, however, no guarantee that the retriangu-lation is geometrically correct. Therefore, we performthe retriangulation at the encoder as well and check forgeometry correctness. If it is not preserved, then thevertex is not decimated. We only evaluate the criteriafor the first frame, as it is likely that if geometry isnot compromised in the first frame then it will not bechanged in the following frames either. Note here thatsimplification is only a tool for compression, and we donot aim for perfect simplified version of the model, noris geometry preservation of essential importance for us.
First, we check for normal flips. We compute anaverage normal of the hole by averaging the normalsof all removed triangles. If any of the normals of thenew triangles is oriented opposite to the original normal(we use scalar multiplication), then the decimation is notperformed.
Second, we check for “sharp” triangles. We check allthe corner angles of the new triangles, and if any angle islower than some threshold (0.05 rad in our experiments,i.e., cca 1.4◦) then the decimation of the vertex is alsocanceled.
Finally, we do not consider decimation of all thevertices. We only use the first 80% of the priority queue,
the rest is considered to be too badly predicted by the NApredictor. The exact value of this threshold has only lowsignificance, setting it too low results in higher numberof simplification levels, while setting it too high (above95%) results in higher values of prediction residuals.
Evaluation
We have implemented our algorithm and compared itto competing approaches. We have used several datasetsof varying properties and density. We have performedtesting with the chicken sequence; however, we note thatthe nature of this sequence is not ideal for our approach,as it is a low-poly model (3030 vertices, 400 frames)where the simplification does not provide so substantialimprovement as it does in the case of highly detaileddense mesh sequences.
We have used high precision datasets which describehuman movement. We have used the dance sequence(7000 vertices, 200 frames), the human jump sequence22,23
(15 700 vertices, we have chosen a subset of 200 frames)and a walk sequence (36 000 vertices, 187 frames)generated by the animation software SmithMicro Poser(http://graphics.smithmicro.com/go/poser).
For the human motion sequences, it can be arguedthat a skinning approach, where a bone system is sentwith the model in some basic pose, can achieve bettercompression ratios. However, aside from the fact that forsome of the sequences a bone system is not known, wehave also tested our approach on a sequence of fallingcloth (10 000 vertices, 200 frames), where a bone systemcan be applied only with some difficulties,24 and eventhen it produces quite high number of bones, higher thanthe number of eigentrajectories.
Unfortunately, there is no public implementation of thestate of the art methods for dynamic mesh compression,and therefore we could only compare our results withthe results that are claimed by the authors of thecorresponding papers. This also restricts the choice ofquality measures to the approaches used in given papers,which are usually based on MSE computation or per-frame Hausdorff distance evaluation. There are somerecent efforts to create a better human-vision-basedmetric for dynamic mesh processing;25 however, the areais still waiting for some standard metric which would befollowed by the researchers.
We have used two different error measures to compareour results with competing algorithms. First, we haveused the measure proposed by Karni and Gotsman,9
denoted KG-error. In this approach, an animation is
............................................................................................Copyright © 2008 John Wiley & Sons, Ltd. 451 Comp. Anim. Virtual Worlds 2009; 20: 447–456
DOI: 10.1002/cav
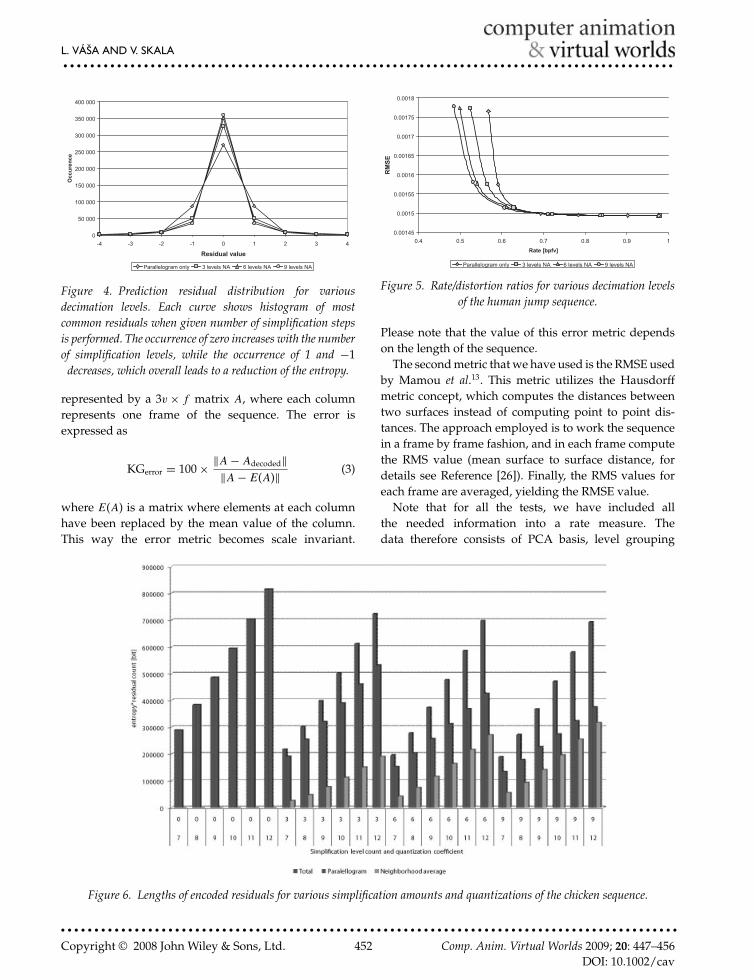
L. VASA AND V. SKALA...........................................................................................
0
50 000
100 000
150 000
200 000
250 000
300 000
350 000
400 000
-4 -3 -2 -1 0 1 2 3 4
Residual value
Occu
ren
ce
Parallelogram only 3 levels NA 6 levels NA 9 levels NA
Figure 4. Prediction residual distribution for variousdecimation levels. Each curve shows histogram of mostcommon residuals when given number of simplification stepsis performed. The occurrence of zero increases with the numberof simplification levels, while the occurrence of 1 and −1
decreases, which overall leads to a reduction of the entropy.
represented by a 3v × f matrix A, where each columnrepresents one frame of the sequence. The error isexpressed as
KGerror = 100 × ‖A − Adecoded‖‖A − E(A)‖ (3)
where E(A) is a matrix where elements at each columnhave been replaced by the mean value of the column.This way the error metric becomes scale invariant.
0.00145
0.0015
0.00155
0.0016
0.00165
0.0017
0.00175
0.0018
0.4 0.5 0.6 0.7 0.8 0.9 1
Rate [bpfv]
RM
SE
Parallelogram only 3 levels NA 6 levels NA 9 levels NA
Figure 5. Rate/distortion ratios for various decimation levelsof the human jump sequence.
Please note that the value of this error metric dependson the length of the sequence.
The second metric that we have used is the RMSE usedby Mamou et al.13. This metric utilizes the Hausdorffmetric concept, which computes the distances betweentwo surfaces instead of computing point to point dis-tances. The approach employed is to work the sequencein a frame by frame fashion, and in each frame computethe RMS value (mean surface to surface distance, fordetails see Reference [26]). Finally, the RMS values foreach frame are averaged, yielding the RMSE value.
Note that for all the tests, we have included allthe needed information into a rate measure. Thedata therefore consists of PCA basis, level grouping
Figure 6. Lengths of encoded residuals for various simplification amounts and quantizations of the chicken sequence.
............................................................................................Copyright © 2008 John Wiley & Sons, Ltd. 452 Comp. Anim. Virtual Worlds 2009; 20: 447–456
DOI: 10.1002/cav
COMPRESSION AND SIMPLIFICATION OF DYNAMIC 3D MESHES...........................................................................................
information, parallelogram prediction residuals, andNA prediction residuals, and the rate is computed as
r = connectivity + basis + grouping + PP + NAfv
(4)
where f is the number of frames and v is the number ofvertices.
First, we have investigated the influence of thesimplification level on the prediction performance.Figure 4 shows the dependency of residual distributionon the decimation level of the human jump sequence.It can be seen that the entropy drops when the mesh ismore decimated, as more residuals become zero. Figure 5shows the dependency of achieved rate/distortion ratioon used decimation level. It can be seen that usingmore NA-predicted vertices leads to better performance.However, for the precise quantizations (right side ofthe graph), the parallelogram predictor version provideslower rate with equal distortion. This is caused by thefact that the parallelogram predictor does not require thegrouping information.
The effect of the simplification step is illustrated byFigure 6, where we show the theoretical amount of dataneeded to transmit the sequence for various numbers ofsimplification levels and various bitrates. The height ofeach column is computed as the number of residualsencoded multiplied by the entropy of the residuals.Generally, the entropy of the paralellogram residualsincreases; however, the number of these is lower, and theentropy of the NA residuals (whose number increaseswith the number of levels) is substantially lower.
The rate/distortion curve for the walk sequence isshown in Figure 7. The rate/distortion curve for the
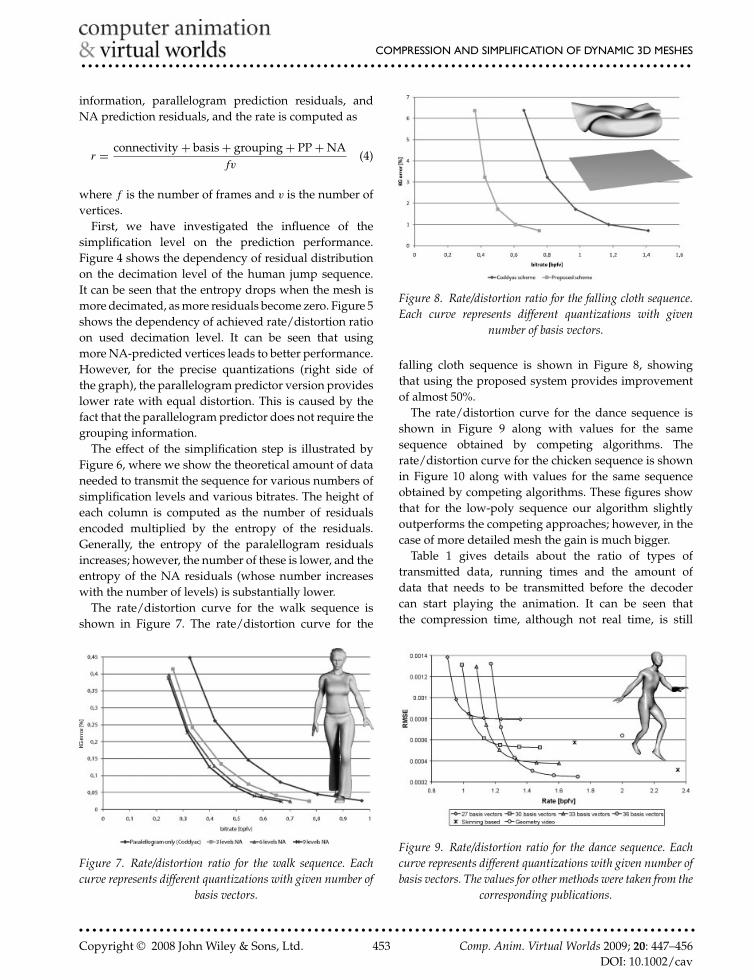
Figure 7. Rate/distortion ratio for the walk sequence. Eachcurve represents different quantizations with given number of
basis vectors.
Figure 8. Rate/distortion ratio for the falling cloth sequence.Each curve represents different quantizations with given
number of basis vectors.
falling cloth sequence is shown in Figure 8, showingthat using the proposed system provides improvementof almost 50%.
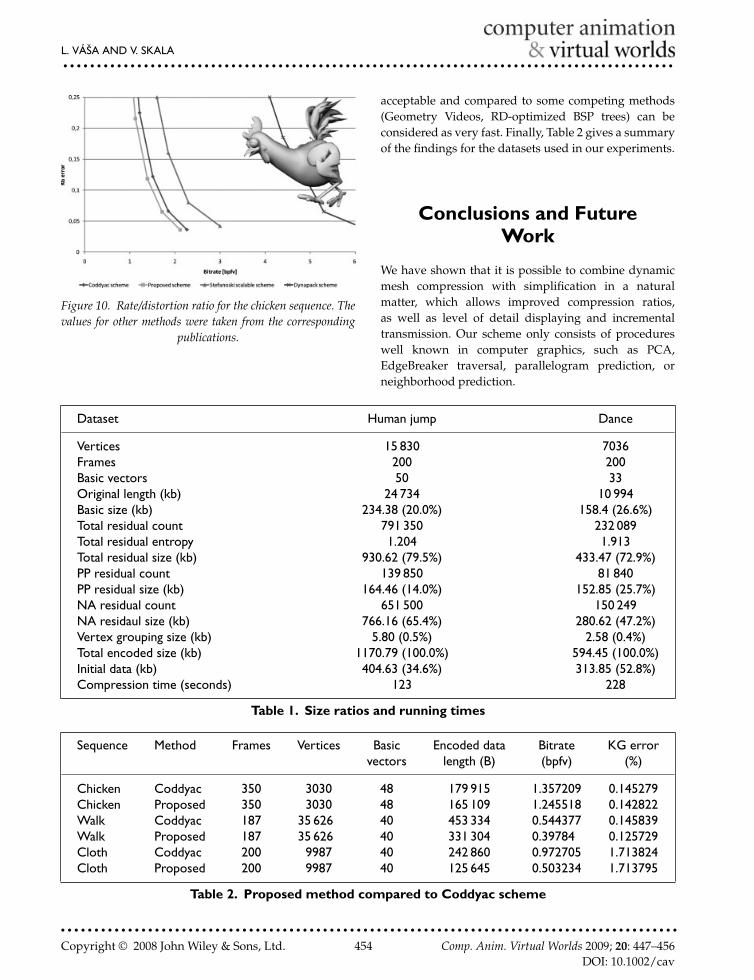
The rate/distortion curve for the dance sequence isshown in Figure 9 along with values for the samesequence obtained by competing algorithms. Therate/distortion curve for the chicken sequence is shownin Figure 10 along with values for the same sequenceobtained by competing algorithms. These figures showthat for the low-poly sequence our algorithm slightlyoutperforms the competing approaches; however, in thecase of more detailed mesh the gain is much bigger.
Table 1 gives details about the ratio of types oftransmitted data, running times and the amount ofdata that needs to be transmitted before the decodercan start playing the animation. It can be seen thatthe compression time, although not real time, is still
Figure 9. Rate/distortion ratio for the dance sequence. Eachcurve represents different quantizations with given number ofbasis vectors. The values for other methods were taken from the
corresponding publications.
............................................................................................Copyright © 2008 John Wiley & Sons, Ltd. 453 Comp. Anim. Virtual Worlds 2009; 20: 447–456
DOI: 10.1002/cav
L. VASA AND V. SKALA...........................................................................................
Figure 10. Rate/distortion ratio for the chicken sequence. Thevalues for other methods were taken from the corresponding
publications.
acceptable and compared to some competing methods(Geometry Videos, RD-optimized BSP trees) can beconsidered as very fast. Finally, Table 2 gives a summaryof the findings for the datasets used in our experiments.
Conclusions and FutureWork
We have shown that it is possible to combine dynamicmesh compression with simplification in a naturalmatter, which allows improved compression ratios,as well as level of detail displaying and incrementaltransmission. Our scheme only consists of procedureswell known in computer graphics, such as PCA,EdgeBreaker traversal, parallelogram prediction, orneighborhood prediction.
Dataset Human jump Dance
Vertices 15 830 7036Frames 200 200Basic vectors 50 33Original length (kb) 24 734 10 994Basic size (kb) 234.38 (20.0%) 158.4 (26.6%)Total residual count 791 350 232 089Total residual entropy 1.204 1.913Total residual size (kb) 930.62 (79.5%) 433.47 (72.9%)PP residual count 139 850 81 840PP residual size (kb) 164.46 (14.0%) 152.85 (25.7%)NA residual count 651 500 150 249NA residaul size (kb) 766.16 (65.4%) 280.62 (47.2%)Vertex grouping size (kb) 5.80 (0.5%) 2.58 (0.4%)Total encoded size (kb) 1170.79 (100.0%) 594.45 (100.0%)Initial data (kb) 404.63 (34.6%) 313.85 (52.8%)Compression time (seconds) 123 228
Table 1. Size ratios and running times
Sequence Method Frames Vertices Basic Encoded data Bitrate KG errorvectors length (B) (bpfv) (%)
Chicken Coddyac 350 3030 48 179 915 1.357209 0.145279Chicken Proposed 350 3030 48 165 109 1.245518 0.142822Walk Coddyac 187 35 626 40 453 334 0.544377 0.145839Walk Proposed 187 35 626 40 331 304 0.39784 0.125729Cloth Coddyac 200 9987 40 242 860 0.972705 1.713824Cloth Proposed 200 9987 40 125 645 0.503234 1.713795
Table 2. Proposed method compared to Coddyac scheme
............................................................................................Copyright © 2008 John Wiley & Sons, Ltd. 454 Comp. Anim. Virtual Worlds 2009; 20: 447–456
DOI: 10.1002/cav

COMPRESSION AND SIMPLIFICATION OF DYNAMIC 3D MESHES...........................................................................................
Our approach can be seen as an ultimate extensionof the LCF-based method, which is based on the factthat vertex coordinates are better compressed whenexpressed in dependency on some other vertices in thevicinity. Our algorithm expresses most of the verticesbased on their immediate neighborhood, thus achievingbetter results and removing the need to create any vertexclustering.
The method is well suited for sequences of highlydetailed geometry with hundreds of frames. It isprobably not the best possible choice for low-poly meshesor extremely long lasting animations; however, dividinga long animation into shorter frame series should fix theproblem quite easily.
In the future, the method can be enhanced by replacingsome of the trivially solved parts with more rigoroussolutions. Especially the retriangulation of holes canbe performed using other approaches known in theliterature.
We would also like to test our approach along withcompeting algorithms using different error measures. Wesee current quality measures as despicably insufficient,and we will focus our research on finding measuresthat better model human spatio-temporal perception ofmoving 3D content.
Our implementation of the presented algorithm is pub-licly available at http:\\herakles.zcu.cz\∼lvasa\compression in the form of modules for the ModularVisualization Environment. Any comments or compar-isons with other compression methods are welcome.
ACKNOWLEDGEMENTS
This work has been supported by EU within FP6 underGrant 511568 with the acronym 3DTV and by the Ministry ofEducation, Youth and Sports of the Czech Republic under theresearch program LC-06008 (Center for Computer Graphics).The chicken character was created by Andrew Glassner, TomMcClure, Scott Benza, and Mark Van Langeveld. This shortsequence of connectivity and vertex position data is distributedsolely for the purpose of comparison of geometry compressiontechniques.
References
1. Lengyel JE. Compression of time-dependent geometry. InSI3D’99: Proceedings of the 1999 Symposium on Interactive 3DGraphics, New York, NY, USA, ACM Press, 1999; 89–95.
2. Ibarria L, Rossignac J. Dynapack: space-time compressionof the 3d animations of triangle meshes with fixed
connectivity. In SCA’03: Proceedings of the 2003 ACMSIGGRAPH/Eurographics Symposium on Computer Animation,Aire-la-Ville, Switzerland, Switzerland, Eurographics Asso-ciation, 2003; 126–135.
3. Stefanoski N, Ostermann J. Connectivity-guided predictivecompression of dynamic 3d meshes. In Proceedings ofICIP’06—IEEE International Conference on Image Processing,number 0, October 2006.
4. Zhang J, Owen CB. Octree-based animated geometrycompression. In DCC ‘04: Proceeding of the Conference on DataCompression, Washington, DC, USA, IEEE Computer Society,2004; 508–517.
5. Muller K, Smolic A, Kautzner M, Eisert P, Wiegand T. Rate-distortion-optimized predictive compression of dynamic 3Dmesh sequences. SP:IC 2006; 21(9): 812–828.
6. Muller K, Smolic A, Kautzner M, Eisert P, Wiegand T.Predictive compression of dynamic 3D meshes. In ICIP05,pages I: 621–624, 2005.
7. Payan F, Antonini M. Wavelet-based compression of 3dmesh sequences. In Proceedings of IEEE ACIDCA-ICMI’2005,Tozeur, Tunisia, November 2005.
8. Alexa M, Muller W. Representing animations by principalcomponents. Computer Graphics Forum 2000; 19(3): 411–418.
9. Karni Z, Gotsman C. Compression of soft-body animationsequences. Computers & Graphics 2004; 28(1): 25–34.
10. Sattler M, Sarlette R, Klein R. Simple and efficientcompression of animation sequences. In SCA’05: Pro-ceedings of the 2005 ACM SIGGRAPH/Eurographics Sym-posium on Computer Animation, ACM Press, 2005; 209–217.
11. Amjoun R. Efficient compression of 3D dynamic meshsequences. Journal of WSCG 2007; 15: 99–106.
12. Vasa L, Skala V. Coddyac: connectivity driven dynamicmesh compression. In 3DTV-CON, The True Vision—Capture,Transmission and Display of 3D Video, 2007.
13. Mamou K, Zaharia T, Preteux F. A skinning approach fordynamic 3d mesh compression: Research articles. ComputerAnimation & Virtual Worlds 2006; 17(3–4): 337–346.
14. Briceno H, Sander P, McMillan L, Gortler S, HoppeH. Geometry videos: a new representation for 3Danimations. In ACM Symposium on Computer Animation 2003,Eurographics Association, 2003; 136–146.
15. Gu X, Gortler SJ, Hoppe H. Geometry images. In Proceedingsof the 29th Annual Conference on Computer Graphics andInteractive Techniques, ACM Press, 2002; 355–361.
16. Stefanoski N, Liu X, Klie P, Ostermann J. Scalable linearpredictive coding of time-consistent 3D mesh sequences.In 3DTV-CON, The True Vision—Capture, Transmission andDisplay of 3D Video, May 2007.
17. Mohr A, Gleicher M. Deformation sensitive decimation.Technical report, University of Wisconsin Graphics Group,2003.
18. Garland M. Quadric-based polygonal surface simplifica-tion, 1998.
19. Kircher S, Garland M. Progressive multiresolution meshesfor deforming surfaces. In SCA’05: Proceedings of the2005 ACM SIGGRAPH/Eurographics Symposium on ComputerAnimation, ACM Press, 2005; 191–200.
20. Rossignac J. Edgebreaker: connectivity compression fortriangle meshes. IEEE Transactions on Visualization andComputer Graphics 1999; 5(1): 47–61.
............................................................................................Copyright © 2008 John Wiley & Sons, Ltd. 455 Comp. Anim. Virtual Worlds 2009; 20: 447–456
DOI: 10.1002/cav

L. VASA AND V. SKALA...........................................................................................
21. Meisters GH. Polygons have ears. American MathematicalMonthly, June 1975; 548–551.
22. Anuar N, Guskov I. Extracting animated meshes withadaptive motion estimation. In VMV, 2004; 63–71.
23. Sand P, McMillan L, Popovic J. Continuous capture ofskin deformation. In SIGGRAPH’03: ACM SIGGRAPH 2003Papers, New York, NY, USA, ACM Press, 2003; 578–586.
24. Kavan L, Collins S, Zara J, O’Sullivan C. Skinning withdual quaternions. In 2007 ACM SIGGRAPH Symposium on
Interactive 3D Graphics and Games, ACM Press, April/May2007; 39–46.
25. Vasa L, Skala V. A spatio-temporal metric for dynamic meshcomparison. In AMDO Lecture Notes on Computer Graphics,number 4096. Springer-Verlag: Berlin, Heidelberg, 2006; 29–37.
26. Cignoni P, Rocchini C, Scopigno R. Metro: measuring erroron simplified surfaces. Computer Graphics Forum 1998; 17(2):167–174.
............................................................................................Copyright © 2008 John Wiley & Sons, Ltd. 456 Comp. Anim. Virtual Worlds 2009; 20: 447–456
DOI: 10.1002/cav





























