Embed Size (px)
DESCRIPTION
Combating Outliers in map-reduce. Srikanth Kandula Ganesh Ananthanarayanan , Albert Greenberg, Ion Stoica , Yi Lu, Bikas Saha , Ed Harris . . . l og(size of cluster). 10 5. 10 4. mapreduce. 10 3. HPC, || databases. 10 2. e.g., the Internet, click logs, bio/genomic data. 10 1. - PowerPoint PPT Presentation
Citation preview

1
Combating Outliers in map-reduce
Srikanth Kandula
Ganesh Ananthanarayanan, Albert Greenberg, Ion Stoica, Yi Lu, Bikas Saha, Ed Harris

2
log(size of dataset)GB109
TB1012
PB1015
EB1018
log(size of cluster)
104
1
103
102
101
105
HPC,|| databases
mapreduce
map-reduce • decouples operations on data (user-code) from mechanisms to scale• is widely used
• Cosmos (based on SVC’s Dryad) + Scope @ Bing• MapReduce @ Google• Hadoop inside Yahoo! and on Amazon’s Cloud (AWS)
e.g., the Internet, click logs, bio/genomic data
3
Local write
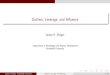
An Example
How it Works:
Goal Find frequent search queries to Bing
SELECT Query, COUNT(*) AS FreqFROM QueryTableHAVING Freq > X
What the user says:
Read Map Reduce
file block 0
job manager
task
task
tasktask
task
output block 0
output block 1
file block 1
file block 2
file block 3
assign work, get progress
4
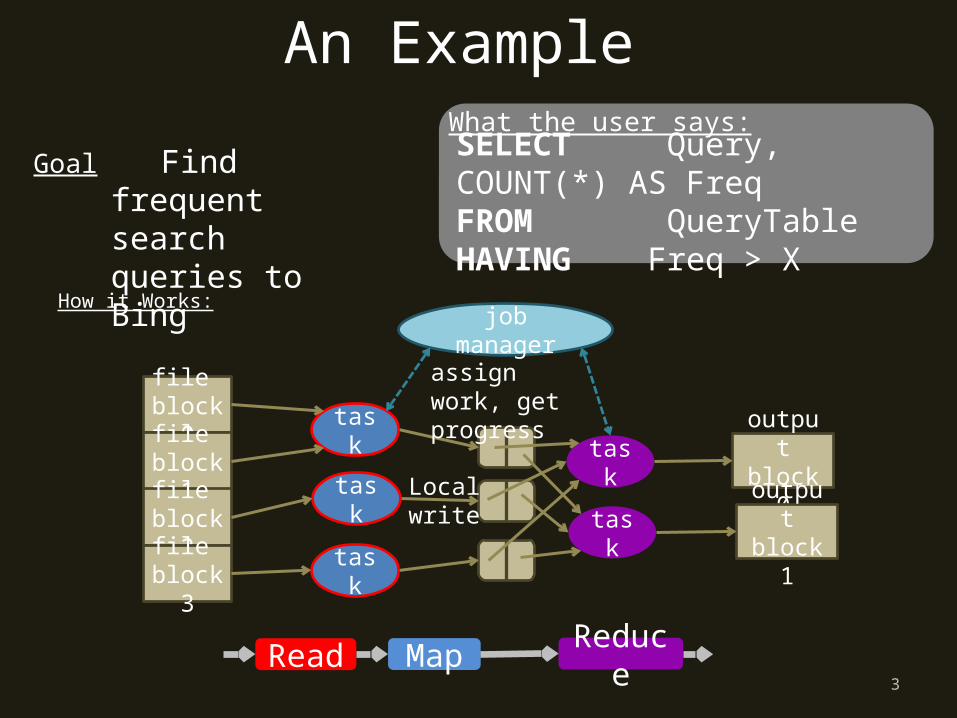
Outliers slow down map-reduce jobs
Map.Read 22K
Map.Move 15K
Map 13K
Reduce 51K
Barrier
File System
Goals• speeding up jobs improves productivity• predictability supports SLAs• … while using resources efficiently
We find that:

5
This talk…
Identify fundamental causes of outliers– concurrency leads to contention for resources– heterogeneity (e.g., disk loss rate)– map-reduce artifacts
Current schemes duplicate long-running tasks
Mantri: A cause-, resource-aware mitigation scheme• takes distinct actions based on cause• considers resource cost of actions
Results from a production deployment
6
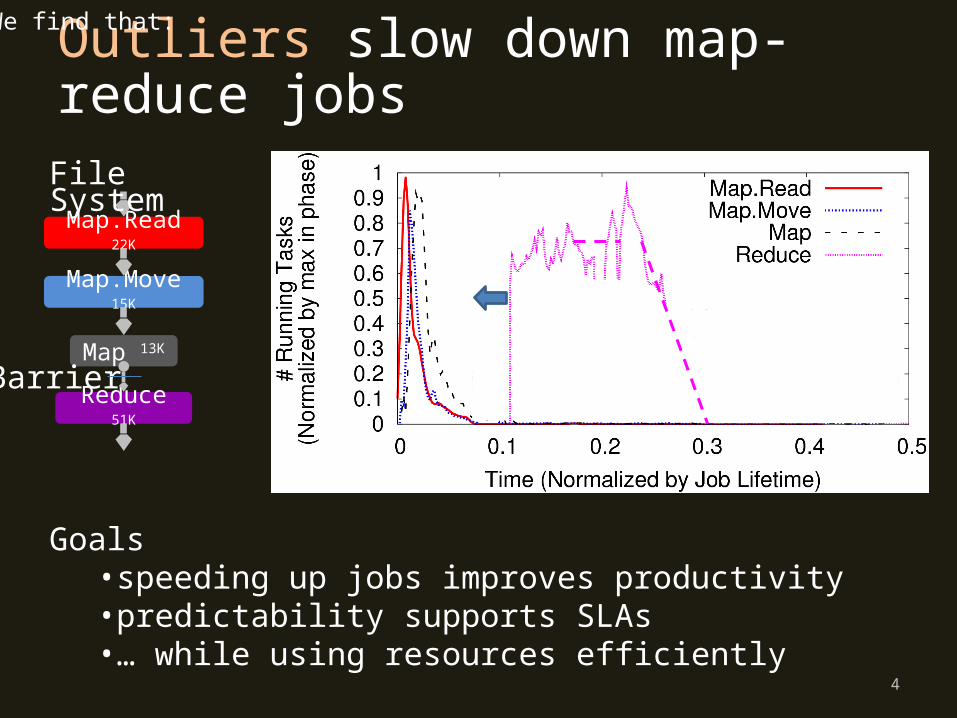
stragglers = Tasks that take 1.5 times the median task in that phaserecomputes = Tasks that are re-run because their output was lost
•The median phase has 10% stragglers and no recomputes
•10% of the stragglers take >10X longer
•The median phase has 10% stragglers and no recomputes
•10% of the stragglers take >10X longer
Why bother? Frequency of Outliers
straggler straggler
Outlier
7
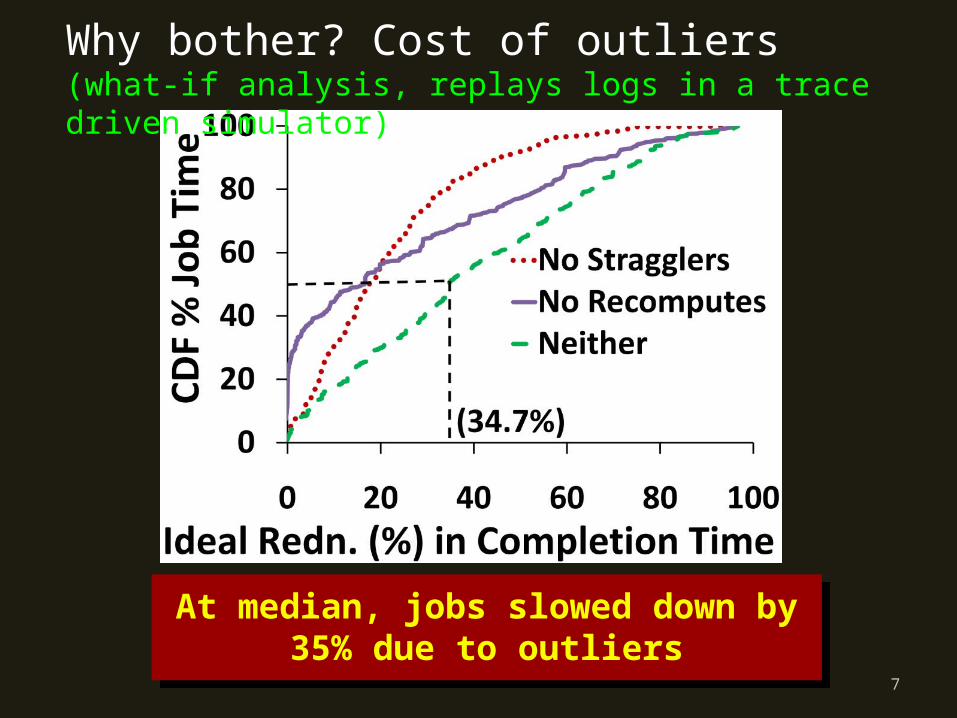
Why bother? Cost of outliers(what-if analysis, replays logs in a trace driven simulator)
At median, jobs slowed down by 35% due to outliers
At median, jobs slowed down by 35% due to outliers
8
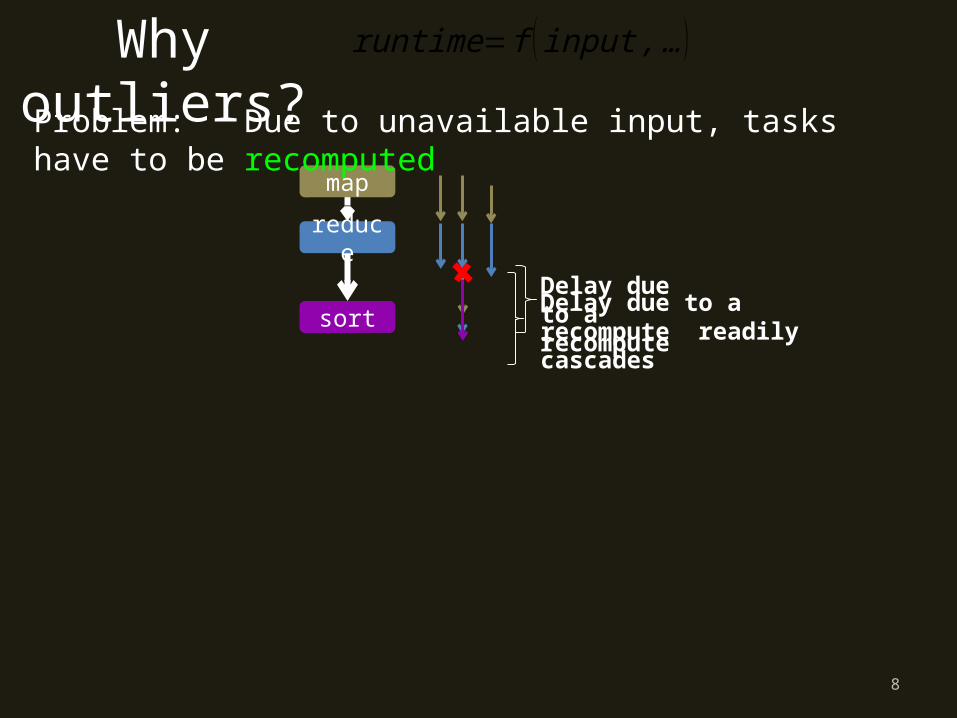
Delay due to a recompute readily cascades
runtime=f (input ,…)Why outliers?
reduce
sortDelay due to a recompute
map
Problem: Due to unavailable input, tasks have to be recomputed
9
runtime=f (input ,…)Why outliers?
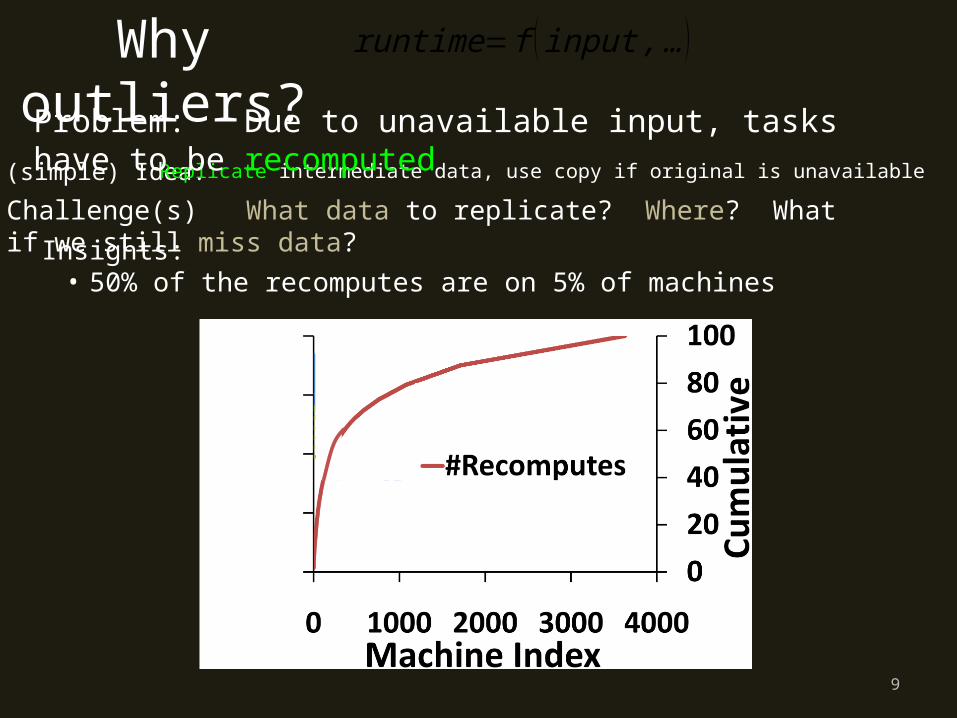
(simple) Idea: Replicate intermediate data, use copy if original is unavailable
Challenge(s) What data to replicate? Where? What if we still miss data?Insights:
• 50% of the recomputes are on 5% of machines
Problem: Due to unavailable input, tasks have to be recomputed

10
Why outliers?
t = predicted runtime of taskr = predicted probability of recompute at machine
trep = cost to copy data over within rack
M1
M2
tredo = r2(t2
+t1redo)
Mantri preferentially acts on the more costly recomputesMantri preferentially acts on the more costly recomputes
(simple) Idea: Replicate intermediate data, use copy if original is unavailable
Challenge(s) What data to replicate? Where? What if we still miss data?
Problem: Due to unavailable input, tasks have to be recomputed
runtime=f (input ,…)
Insights: • 50% of the recomputes are on 5% of machines• cost to recompute vs. cost to replicate

11
runtime=f (input , network ,…)Why outliers?
Reduce taskMap output
uneven placement is typical in production• reduce tasks are placed at first available slot
Problem: Tasks reading input over the network experience variable congestion
12
Why outliers?
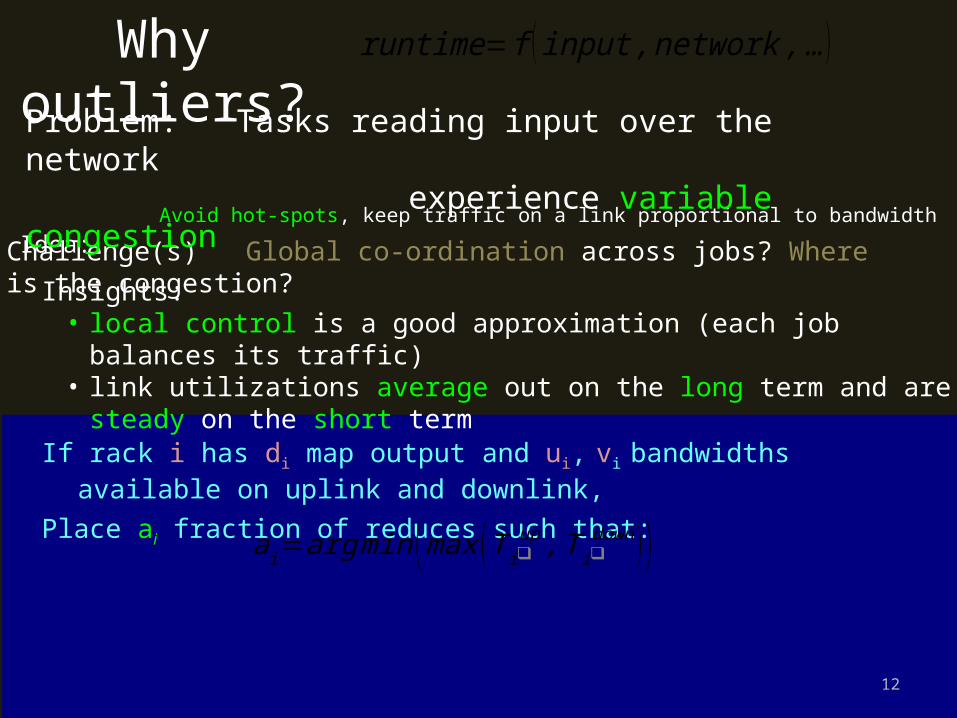
Idea: Avoid hot-spots, keep traffic on a link proportional to bandwidth
If rack i has di map output and ui, vi bandwidths available on uplink and downlink,
Place ai fraction of reduces such that:
a i=argmin (max (T i❑up ,T i❑down ) )
Challenge(s) Global co-ordination across jobs? Where is the congestion?Insights:
• local control is a good approximation (each job balances its traffic)• link utilizations average out on the long term and are steady on the short term
runtime=f (input , network ,…)
Problem: Tasks reading input over the network experience variable congestion

13
runtime=f (input , network ,machine ,…)
Persistently slow machines rarely cause outliers
Cluster Software (Autopilot) quarantines persistently faulty machines
Why outliers?

14
Solution:
Ignoring these is better than the state-of-the-art! (duplicating)
In an ideal world, we could divide work evenly…
Problem: About 25% of outliers occur due to more dataToProcess
runtime=f (input , network ,machine ,dataToProcess ,… )Why outliers?
We schedule tasks in descending order of dataToProcess
Theorem [due to Graham, 1969] Doing so is no more than 33% worse than the optimal
We schedule tasks in descending order of dataToProcess
Theorem [due to Graham, 1969] Doing so is no more than 33% worse than the optimal
15
runtime=f (input , network ,machine ,dataToProcess ,… )Why outliers?
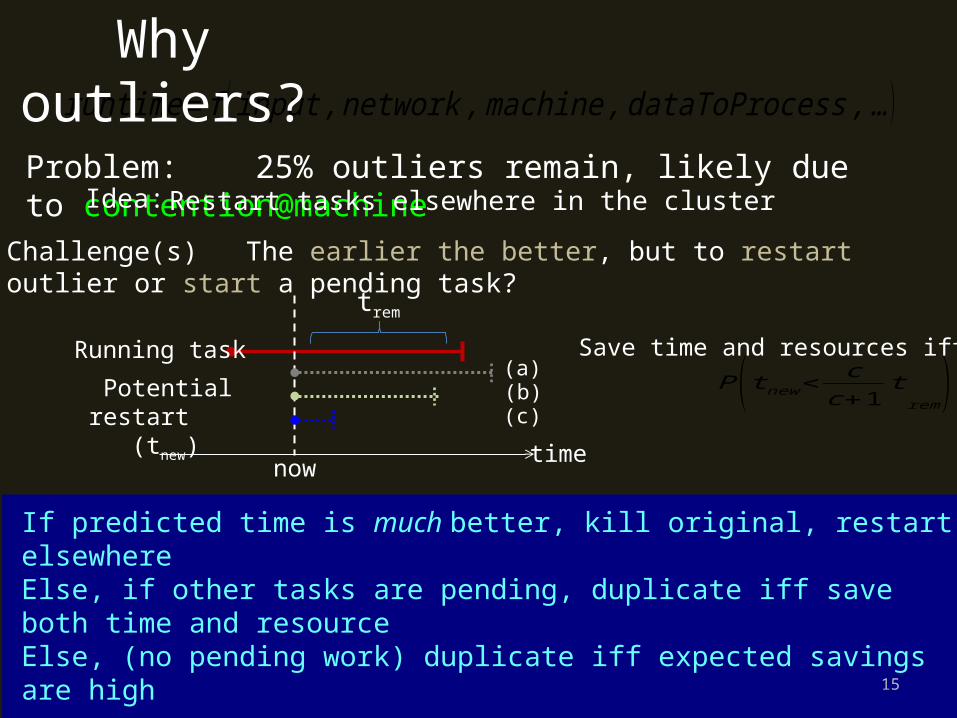
Problem: 25% outliers remain, likely due to contention@machineIdea: Restart tasks elsewhere in the cluster
Challenge(s) The earlier the better, but to restart outlier or start a pending task?
(a)(b)(c)
Running task
Potential restart (tnew)
nowtime
trem
If predicted time is much better, kill original, restart elsewhereElse, if other tasks are pending, duplicate iff save both time and resourceElse, (no pending work) duplicate iff expected savings are high
Continuously, observe and kill wasteful copies
If predicted time is much better, kill original, restart elsewhereElse, if other tasks are pending, duplicate iff save both time and resourceElse, (no pending work) duplicate iff expected savings are high
Continuously, observe and kill wasteful copies
P( t new< cc+1
trem
)Save time and resources iff

16
Summary
runtime=f (input , network ,machine ,dataToProcess ,… )
a) preferentially replicate costly-to-recompute tasksb) each job locally avoids network hot-spotsc) quarantine persistently faulty machinesd) schedule in descending order of data sizee) restart or duplicate tasks, cognoscent of resource cost. Prune.
(a) (b) (c) (d) (e)
Theme: Cause-, Resource- aware action
Explicit attempt to decouple solutions, partial success
Theme: Cause-, Resource- aware action
Explicit attempt to decouple solutions, partial success

17
Results
Deployed in production cosmos clusters• Prototype Jan’10 baking on pre-prod. clusters release May’10
Trace driven simulations• thousands of jobs• mimic workflow, task runtime, data skew, failure prob.• compare with existing schemes and idealized oracles
18
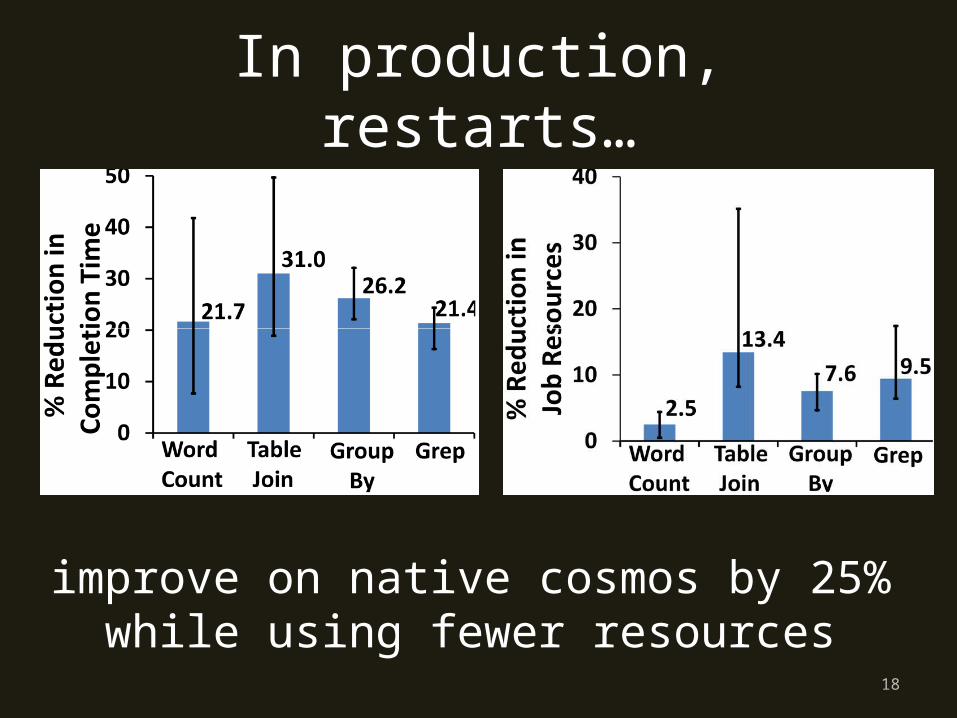
In production, restarts…
improve on native cosmos by 25% while using fewer resources
19
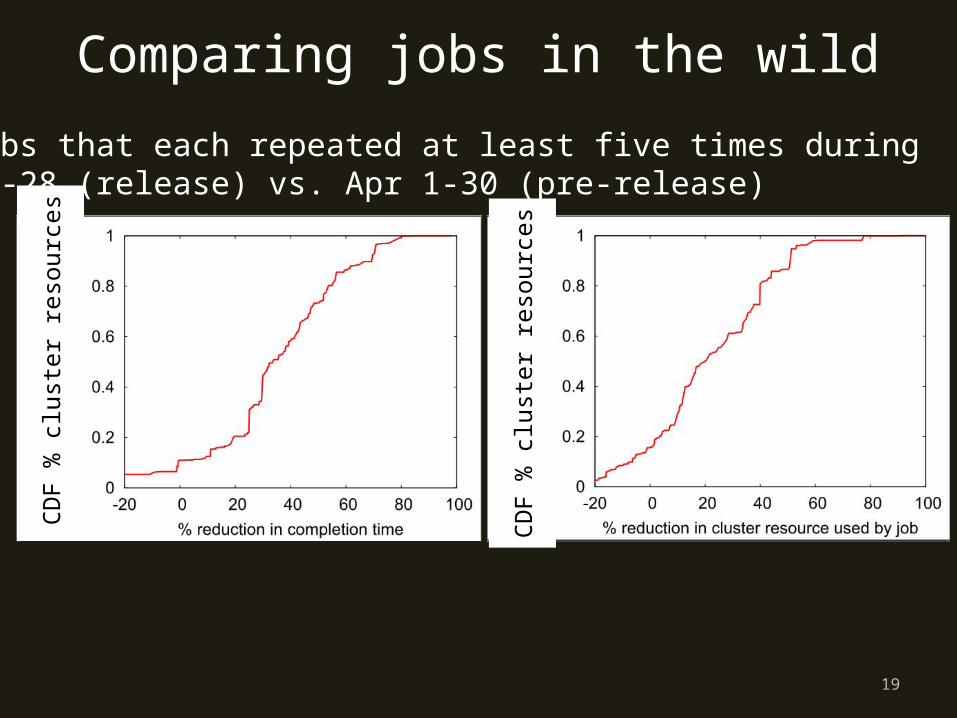
Comparing jobs in the wild340 jobs that each repeated at least five times during May 25-28 (release) vs. Apr 1-30 (pre-release)
CDF
% c
lust
er re
sour
ces
CDF
% c
lust
er re
sour
ces
20
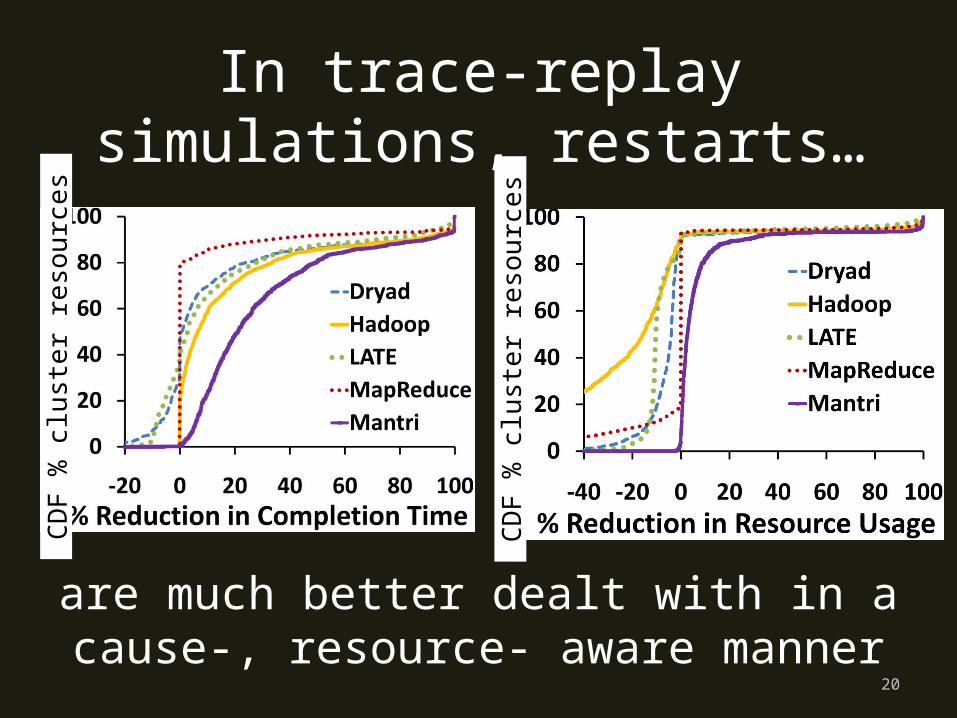
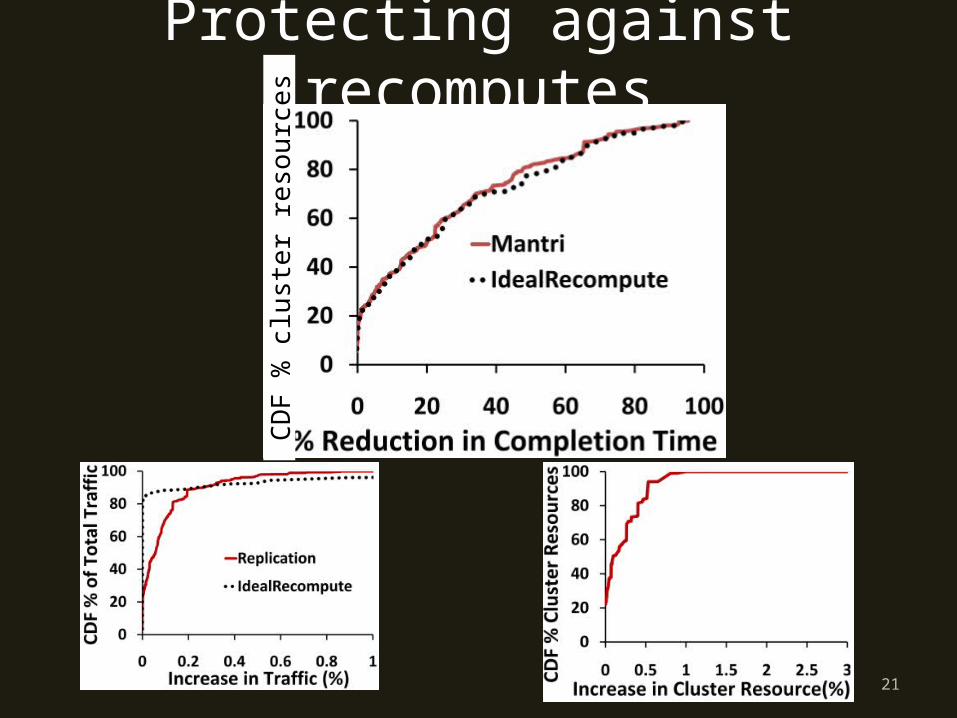
In trace-replay simulations, restarts…
are much better dealt with in a cause-, resource- aware manner
CDF
% c
lust
er re
sour
ces
CDF
% c
lust
er re
sour
ces
21
Protecting against recomputes
CDF
% c
lust
er re
sour
ces

22
Outliers in map-reduce clusters
• are a significant problem• happen due to many causes
– interplay between storage, network and map-reduce• cause-, resource- aware mitigation improves on
prior art

23
Back-up
24
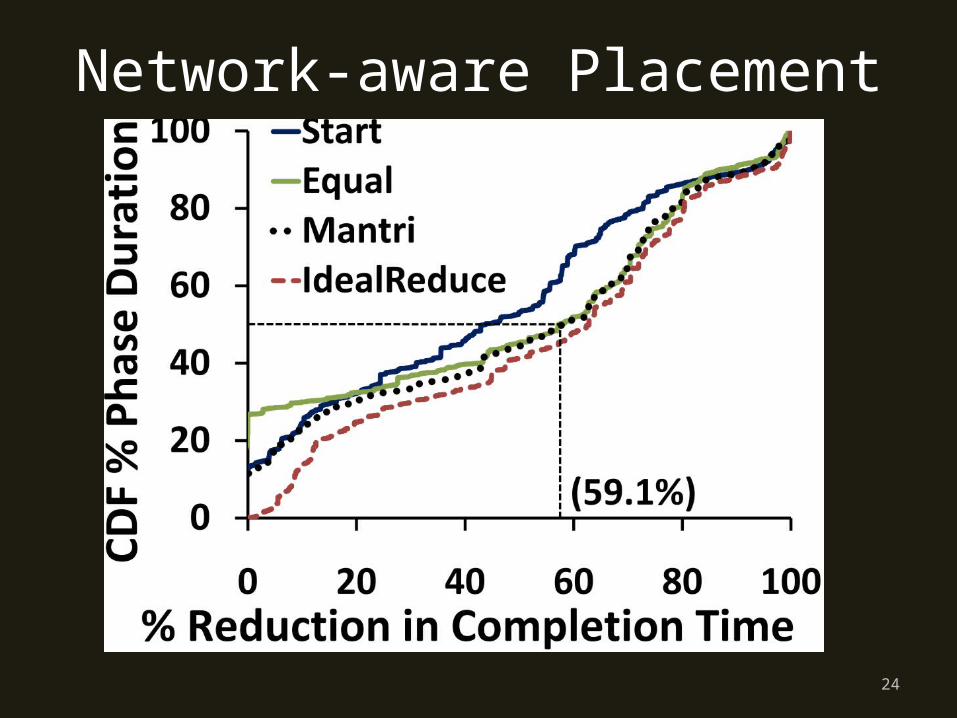
Network-aware Placement