Embed Size (px)
Citation preview

CHAPTER 1
THE STUDY OF COLLOCATIONS
1.0 Introduction
'Collocations' are usually described as "sequences of lexical items which
habitually co-occur [i.e. occur together]" (Cruse 1986:40). Examples of English
collocations are: ‘thick eyebrows’, 'sour milk', 'to collect stamps', 'to commit
suicide', 'to reject a proposal'.
The term collocation was first introduced by Firth, who considered that
meaning by collocation is lexical meaning "at the syntagmatic level" (Firth
1957:196). The syntagmatic and paradigmatic relations of lexical items can be
schematically represented by two axes: a horizontal and a vertical one. The
paradigmatic axis is the vertical axis and comprises sets of words that belong to
the same class and can be substituted for one another in a specific grammatical
and lexical context. The horizontal axis of language is the syntagmatic axis and
refers to a word's ability to combine with other words. Thus, in the sentence
'John ate the apple' the word 'apple' stands in paradigmatic relation with
'orange', 'sandwich', 'steak', 'chocolate', 'cake', etc., and in syntagmatic relation
with the word 'ate' and 'John'. Collocations represent lexical relations along the
syntagmatic axis.
114

Firth's attempt to describe the meaning of a word on the collocational
level was innovative in that it looked at the meaning relations between lexical
items, not from the old perspective of paradigmatic relations (e.g. synonyms,
antonyms) but from the level of syntagmatic relations. Syntagmatic relations
between sentence constituents had been widely used by structural linguists
(e.g. 'John ate the apple' is an 'Subject-Verb-Object' construction), but not in the
study of lexical meaning.
Up till now, studies on collocation have been insufficient in defining the
concept of collocation in a more rigorous way (Cowan 1989:1). Since the term
'collocation' was introduced by Firth to describe meaning at the syntagmatic
level, subsequent linguists and researchers have not often attempted to define
'collocation' in a more thorough and methodical way. Collocation is still
defined as the tendency of a lexical item to co-occur with one or more other
words (Halliday, McIntosh & Strevens 1964:33; Ridout & Waldo-Clarke 1970;
Backlund 1973, 1976; Seaton 1982; Crystal 1985:55; Cruse 1986:40; Zhang
1993:1).
Although the theoretical treatment of collocations has been inadequate,
the teaching of collocations to second language (L2) learners has gained
importance during the last decade. For a long time the emphasis in vocabulary
learning has been on accumulating and memorising lists of word definitions,
followed by gap filling exercises (Robinson 1989:276; Gitsaki 1992; for a review
of the development of vocabulary teaching see Carter and McCarthy 1988).
However, applied linguists realised that vocabulary skills involve more than
115

the ability to define a word. Suggestions were made for a new approach to
vocabulary teaching that would avoid the previous emphasis on words in
isolation and on word definitions. The new approach would include an
examination of the syntagmatic relations of collocation between lexical items, a
skill that is evident in the adult native speakers of a language (McCarthy
1984:14-16; Carter 1987:38; Sinclair 1991).
The shift of interest towards lexical learning is also evident in the
introduction of a new approach to L2 teaching. The Lexical Approach, as it is
outlined by Lewis (1993), regards language as grammaticalised lexis and places
the way words combine at the centre of its theoretical perspective (Hewitson &
Steele 1993). Lexis becomes the central organising principle of the syllabus, and
collocation assumes an important syllabus-generating role (Lewis 1993).
Raising the learners' understanding of the collocations of words is a
matter of first-rate importance (McCarthy 1984:21), since the task of learning
collocations can present both intralingual and interlingual problems.
'Collocation' as a term describing lexical relations is not well-defined, and
unfortunately joining words that are in principle semantically compatible does
not always produce acceptable collocations, e.g. 'many thanks' is an acceptable
collocation in English but *'several thanks' is not, in the same way that 'strong
tea' is well-formed but *'powerful tea' is not.
Further on, unlike paradigmatic relations between words which can be
the same for different languages, syntagmatic relations are more likely to differ
from language to language (Mitchell 1975:10). For example, English people
116

'draw conclusions' while the Greeks ‘bga;zoun sumpera;smata’ [take out
conclusions]; in English you have to 'wait for somebody' while in Greek
‘perime;neiß ka;poion’ [wait somebody]; in English you 'go on a diet' while in
Greek 'ka;neiß di;aita’ [do diet]; in English someone who drinks a lot is a
'heavy drinker' while in Greek he is a 'gero; poth;ri' [strong glass]; in English
you 'get in touch with someone', while in Greek you 'e;rcese se epafh; me
ka;poion' [come to touch with someone].
The purpose of this thesis is to study syntagmatic lexical relations within
a framework that will allow a more thorough treatment of the phenomenon of
'collocation', and to investigate the acquisition process of English collocations
by L2 learners as an attempt to describe the possible factors affecting the
development of English collocational knowledge.
1.1 The Importance of Collocations in L2 Learning
The importance of collocations for the development of L2 vocabulary
and communicative competence has been underscored by a number of linguists
and language teachers who recommend the teaching and learning of
collocations in the L2 classroom.
Collocation has been considered as a separate level of vocabulary
acquisition. Bolinger (1968) and (1976) argues that we learn and memorise
words in chunks and that most of our "manipulative grasp of words is by way
of collocations" (Bolinger 1976:8). The learning of language in segments of
collocation size, especially in children, is proved by the fact that "the collocate is
117

what the young child produces if you ask him a definition", e.g. a 'hole' is 'a
hole in the ground' (Cazden 1972:129, cited in Bolinger 1976:11). Bolinger
describes language learning as a continuum starting at the morpheme level
with word formation rules, moving to the word level and activating phrase
formation rules. The last stage before storage into memory is the level where
words enter into collocations. When learning a language people may or may
not store a morpheme as such, but they do store phrases. For example, the
phrase 'indelible ink' will be stored as a phrase, but few people will analyse the
word 'indelible' as having the morpheme 'in-' as a prefix (Bolinger 1968:106).
Among the early advocates for the importance of collocations in L2
learning and their inclusion in L2 teaching is Brown (1974), who suggests that
an increase of the students' knowledge of collocation will result in an
improvement of their oral and listening comprehension and their reading
speed. In an effort to make the advanced students achieve a better feel of what
is acceptable and what is appropriate, Brown outlines a number of exercises.
The combination of lexical items as a source of difficulty in vocabulary
acquisition has been noted by researchers like Korosadowicz-Struzynska (1980),
who claims that the learner's mastery of these troublesome combinations, rather
than her/his knowledge of single words, should be an indication of her/his
progress (Korosadowicz-Struzynska 1980:111). Korosadowicz-Struzynska
reports that students face intralingual and interlingual problems in the use of
collocations, and even advanced students who have considerable fluency of
expression in a foreign language make collocational errors. The teaching and
118

learning of collocations for production reasons is regarded as essential by
Korosadowicz-Struzynska, who also describes certain steps that should be
followed in order to promote the teaching of collocations from the initial stages
of foreign language learning. These include selection of the most essential
words on the basis of usefulness and frequency of occurrence, selection of the
most frequent collocations of these words, presentation of these collocations in
the most typical contexts, and contrasting any of the selected collocations with
the equivalent native-language collocations that could cause interference
problems for the learners.
The significant role that conventionalised language forms (idioms,
routine formulas and other forms such as collocations) play in the development
of foreign language learners' communicative competence is stressed by Yorio
(1980). One of the functions of conventionalised forms is that they "make
communication more orderly because they are regulatory in nature” (Yorio
1980:438). Realising that random selection on purely subjective grounds from
diverse conventionalised language forms is totally inadequate for the purposes
of foreign language teaching, Yorio describes a set of criteria for the selection of
specific forms to be taught: need, usefulness, productivity, currency, frequency,
and ease (Yorio 1980:439).
It has been claimed that prefabricated language chunks and routinized
formulas play an important role in acquiring and using language (Nattinger &
DeCarrico 1992:1; Nattinger 1980). Nattinger and DeCarrico have argued that a
common characteristic in acquiring a language is the progression from routine
119

to pattern to creative language use (Nattinger & DeCarrico 1992:116).
Therefore, it is suggested that the learning of prefabricated language patterns
should be promoted in the classroom.
The "apparent rulelessness" of collocations as one factor that interferes
with foreign language vocabulary learning has been noted by Laufer (1988).
Laufer reports that collocations constitute an essential aspect in the learners'
knowledge of vocabulary, and she acknowledges that problems can arise in the
learners' use of word combinations. She also suggests that collocations could
be found to provide help in many levels of vocabulary development and the
development of self-learning strategies such as guessing (Laufer 1988:16).
Realising the foreign language learner's difficulties in learning
vocabulary, Cowie (1978), (1981) stresses the importance of the compilation of
English dictionaries "in which collocation and examples play a separate but
complementary role" (Cowie 1978:131). Cowie points out that "meaning is not
the only determinant of the extent and semantic variety of collocating
words....The constraint may be situational" (Cowie 1978:134). For example, in
the collocation 'a tea/dinner service of 50 pieces' there is a restriction as to
which meals can combine with 'service' (tea, dinner, breakfast, ?luncheon) and
their combination is based on cultural factors, i.e. which of these meals it is
customary to serve, and whether it is conventional to have separate sets of
dishes and plates for each (Cowie 1978:134). As a result, special treatment of
the cultural factor of collocability in a learner's dictionary is proposed. He also
suggests the inclusion of 'free word-combinations' that could still cause
120

problems for the foreign language learners, as well as the inclusion of
grammatical rules that will indicate the correct grammatical treatment of the
included collocations (Cowie 1981:226,232).
The teaching of collocations in the classroom could help students
overcome problems of vocabulary, style and usage (Leed & Nakhimovsky
1979). Leed and Nakhimovsky suggest the utilisation of lexical functions, as
these are described by Mel'cuk and Zholkovsky (1988) (see Table 1), for the
construction of foreign language teaching materials, vocabulary exercises and
learners' dictionaries. Leed and Nakhimovsky argue that vocabulary exercises
should be based on the findings of a well-structured lexical analysis, in the
same way that pronunciation exercises are based on phonology (Leed &
Nakhimovsky 1979:111). The theory of lexical functions can provide the basis
for the generation of pedagogical exercises that are more consistent, diversified,
and elaborate, less arbitrary, and ultimately more effective. Such an approach
would help foreign language learners with problems of vocabulary, style and
usage, and give teachers a method to produce and carry out lexical exercises in
the classroom, as well as concentrate on the teaching of restricted collocations
such as 'heavy drinker', 'heavy smoker', 'deep trouble', etc., (Leed &
Nakhimovsky 1979:109).
Table 1. Examples of Lexical Functions Lexical Functions
Syn (to shoot) = to fire [synonym]
121

Sync (to shoot) = to machine-gun [narrower synonym]
Anti (victory) = defeat [antonym]
Oper1 (analysis) = to perform [be the subject of]
Oper2 (analysis) = to undergo [be the object of]
(Mel'cuk & Zholkovsky 1970:26; Mel'cuk 1981:39)
Teaching phrase-patterns and sentence patterns from the early stages of
L2 learning may help vocabulary expansion (Twaddell 1973; Korosadowicz-
Struzynska 1980). Twaddell argues that vocabulary expansion should take
place from the intermediate stages of L2 learning and onwards under the
condition that "the most habitual parts of language use" such as phrase-patterns
and sentence patterns will be "practised and established as early as possible"
(Twaddell 1973:63). After those habits have been adequately established, then
new vocabulary can be assimilated into the L2 patterns. Korosadowicz-
Struzynska also suggests that it is reasonable to teach collocations of words to
learners from the beginning rather than to arrange remedial courses afterwards,
when lexical errors have become fossilised (Korosadowicz-Struzynska
1980:116). She disagrees with Smith's view that "mastery of the utterance
should be the culmination of learning, not the beginning" (Smith 1971:42).
It has been argued that the teaching of collocations facilitates vocabulary
building for University-bound ESL students (Smith 1983). Smith (1983)
illustrates a type of exercise for the teaching of collocations that combines both
paradigmatic and syntagmatic relations between words. A number of
122

collocations that are primarily used in academic subjects are selected for
teaching, and the key words of these collocations are members of the same
semantic field (e.g. 'same', 'identical', 'equivalent', 'parallel', 'equal',
'homogeneous', 'similar') . According to Smith, this type of exercise could
prove to be useful in an ESP course.
A "carefully graded curriculum" should include word associations
according to Murphy (1983), who treats collocations and word associations as
synonymous. Murphy describes 11 steps that foreign language teachers could
follow in order to include collocations, word association, famous sayings and
catch phrases in their teaching program.
The study of fixed expressions in English has been suggested as a useful
starting point for a principled approach to vocabulary learning and teaching
(Alexander 1984:132). Alexander stresses the benefits in the learning process if
emphasis is placed "on the three C's of vocabulary learning: collocation,
context, and connotation" (Alexander 1984:128).
Contrastive analysis has been suggested as an approach to the teaching
of collocations. The main strategy of this approach is the compilation of lists of
collocations in the learner's L1 and their equivalents in the target language.
Newman (1988) conducted a contrastive analysis of Hebrew and English dress
and cooking verbs and their noun/object collocations. Newman suggests that
providing learners with words that are described in terms of meaning
components, derived from contrastive analysis and collocation restrictions, can
prove to be a useful device in the learners' disposal for making conscious
123

distinctions and avoiding lexical errors arising from negative L1 transfer
(Newman 1988:303). Therefore, the language learning process should be
complemented by frequent practice and immersion to cater for the acquisition
of idioms and rigidly restricted collocations, along with meaningful mnemonic
operations that will involve the "deliberate exercising of the learner's powers of
analysis and creativeness parallel to the characteristics of the transparent freer
end of the collocational range" (Newman 1988:304). A similar view is reported
by Bahns (1993). He argues that a contrastive analysis of the lexical collocations
in the students' L1 and the target language will reveal which collocations have
direct translational equivalents and therefore need not be taught, allowing
foreign language teaching to concentrate on items for which there is no
translational equivalence in the target language.
The studies reviewed above show the importance of teaching
collocations to ESL learners, and the necessity of the inclusion of collocations in
the second/foreign language curriculum, as this can prove to be beneficial for
the development of L2 vocabulary, communicative competence, and language
performance. Even though some criteria are offered in order to help teachers
decide which collocations to teach, these criteria are arbitrarily established, they
are not based on empirical research, and they are by no means conclusive. For
example, Brown (1974) recommends that 'normal' collocations should be taught
first because they form the basis for 'unusual' collocations (Brown 1974:3), but
she does not define the criteria that would help teachers distinguish 'normal'
from 'unusual' collocations. In addition, the proposed exercises do not seem to
124

have been constructed systematically; the choice of verbs and nouns to be
combined seems random, and no criteria are given as a means for establishing
the "usefulness" of the collocations provided by the exercises; and the teacher
has to rely on her/his own intuition about which of the collocations are more or
less useful.
Similarly, Laufer (1988) accepts the view that collocations constitute an
essential aspect in the learner’s knowledge of vocabulary, and she
acknowledges that problems can arise in the learner’s use of word
combinations, but she nevertheless concentrates on the paradigmatic lexical
relations, abandoning collocations to their 'rulelessness'. In addition, Laufer
does not explain how the problem of teaching, learning, and use of collocations
can be tackled, even though collocations could be found to provide help in
many levels of vocabulary development (Laufer 1988).
In Murphy's paper (1983) a number of exercises are outlined for the
teaching of collocations, but it is left to the teacher's personal judgement to
decide which collocations, word associations and phrases are more useful than
others and which ones should be taught first.
These are some of the problems presented by studies prescribing the
teaching of collocations. It is apparent that even though the importance of
collocations in L2 teaching and learning has been established, the treatment of
collocations has been inadequate. There are still decisions to be made as to
which collocations should be given priority in the classroom, how many
collocations per new word should be taught, how to practice collocations, at
125

which level the teaching of collocations should be attempted, how is the
acceptability of specific collocations to be established.
Finally, the large repertoire of terms employed by linguists and language
pedagogists to refer to word combinations includes 'combinations of lexical
items' (Korosadowicz-Struzynska 1980), 'conventionalised language forms'
(Yorio 1980), 'prefabricated language chunks and routinized formulas'
(Nattinger & DeCarrico 1992), 'phrase patterns and sentence patterns'
(Twaddell 1973), 'word associations' (Murphy 1983), 'fixed expressions'
(Alexander 1984)(see also Kennedy 1990). The variety of terms used
underscores the need for a more precise definition of 'collocation' and a method
for the systematic classification of individual collocations.
1.2 Collocations in L2 Acquisition Research
There have been a number of studies in L2 acquisition research that
investigated how the knowledge and use of collocations by students at different
levels of proficiency affect their communicative competence and language
performance, and so established the importance of collocations in L2 learning.
In her effort to identify the main factors in L2 acquisition for academic
achievement, Saville-Troike studied a group of nineteen non-English speaking
elementary school students who were subsequently taught and tested in
English. The longitudinal study revealed that the most usual verbal interaction
patterns consisted of the use of English routines such as 'don't do' and 'that's
mine' (Saville-Troike 1984:207) and that vocabulary knowledge in English is the
126

most important aspect of L2 competence for academic achievement (Saville-
Troike 1984:216). Students progressed from simply repeating after the teacher,
to nodding or shaking the head, to using single words, and finally to using
phrase and sentence patterns. These patterns and routines can be considered as
collocations since they are word combinations, and hence Saville-Troike's study
shows that collocations are essential for communicative interaction even from
the initial stages of L2 acquisition.
In an experiment carried out by Bahns and Eldaw (1993), a translation
and a cloze task were used to test German post-secondary learners' active
knowledge of 15 English verb-noun 'lexical collocations' (i.e. collocations that
included words belonging to open-class categories, and excluding words such
as prepositions, articles or conjunctions). The German collocations used in the
translation test were direct equivalents of the English collocations. In the cloze
test there were 15 sentences each sentence containing one verb-noun collocation
with the verb missing. The analysis of the data revealed that the subjects
produced more than twice as many errors in their translations of the nouns in
the noun-verb collocations as in their translation of general lexical words, while
in the cloze test nearly 52% of the responses were grammatically or
collocationally unacceptable to a native speaker of English. The results show
that for advanced ESL students collocations present a major problem in the
production of correct English. The results also indicate that the learners'
knowledge of collocations does not expand in parallel with their knowledge of
general vocabulary, since they could not identify the specific verb-noun
127

collocations, although they could use general lexical items. Also, the learners'
inability to paraphrase collocational phrases suggests that "a knowledge of
collocations is essential to full communicative mastery of English" (Bahns &
Eldaw 1993:109). Bahns and Eldaw suggest that the results of their study are
due to the fact that collocations are not taught explicitly in the classroom and
therefore learners do not pay any attention to learning them (p. 109).
Verb-noun collocations were also tested by Aghbar (1990) in a writing
task based on the assumption that the use of formulaic language should be
considered in assessing native and non-native English proficiency. Aghbar
defines formulaic language as language chunks that are used and learnt
together. He reports that "collocations are the less obvious examples of
formulaic language", possibly because they are not fixed in the same way that
idioms and proverbs are (Aghbar 1990:2). The writing test consisted of 50
sentences, appropriate for formal written contexts, with each sentence
containing one formulaic verb-noun expression. In each of these expressions
the verb was missing and the participants had to provide the verb most likely
to be used in a formal written context. The results showed that ESL students
did well where 'get' was the desirable word. However, they used 'get' even
when other more specific and more appropriate verbs were needed. For
example, 'This is an opportunity for you to _______ knowledge in your field of
study' could be filled with 'get' but also with other more appropriate verbs such
as 'acquire', 'accumulate', 'gain', 'demonstrate', 'display' etc. The reason for the
poor ESL performance in the test was the "lack of acquisition of those language
128

chunks that make discourse fluent and idiomatic" (Aghbar 1990:6). The results
also showed that the performance of American students was similar to that of
ESL students, thus proving that even the native undergraduates' knowledge of
the collocations used in formal written language was inadequate.
Similarly, 200 undergraduate third and fourth year Jordanian students
majoring in English performed poorly in a multiple choice test conducted by
Fayez-Hussein (1990), who aimed to assess the students' ability to collocate
words correctly in English. The multiple choice test consisted of 40 sentences,
with each sentence containing an incomplete collocation (i.e. idioms, fixed
expressions, restricted collocations). The collocations tested were mainly noun-
noun, adjective-noun, and verb-noun phrases. The students' performance on
the test (only 48.4% of the collocations were answered correctly) was found
unsatisfactory. Almost half of the incorrect responses were found to be due to
negative transfer from L1, e.g. in item 5 'By the weekend the death _________
had reached 95', 51% of the subjects chose 'death number' instead of 'death toll'.
Unfamiliarity with the structure of the particular idioms and fixed expressions
was another major factor for incorrect responses, e.g. in item 21 'The first
voyage of a new ship is referred to as a __________ voyage', 45.5% of the
subjects selected 'primary voyage' instead of 'maiden voyage'. Finally, the
students' tendency to use generic terms instead of specific ones accounted for
38.3% of incorrect responses, e.g. in item 29 'After the current repairs of the
city's water supply system, ________ water will be safe for drinking', 48.5% of
the subjects chose 'pipe water' instead of 'tap water'. Fayez-Hussein lists a
129

number of reasons for the students' inadequate knowledge of English
collocations: the neglect of lexicon in the teaching and learning of English as a
foreign language, the students' insufficient reading experience (which is
assumed to restrict their knowledge of vocabulary, synonyms, lexical
restrictions, etc.), the reduction and simplification that takes place in the
teaching of a foreign language (which can encourage students to use
oversimplified generalisations), and the subjects' overuse of guessing strategies
in answering the test items. The latter could have also been encouraged by the
format of the test, i.e. multiple choice test items.
The lack of emphasis which most syllabuses place on vocabulary has
been reported as the main reason for the frequency of learners' lexical errors
(e.g. collocational errors, over-use of a few general items) by Channell (1981). A
group of eight advanced students of English were asked to fill in a
'collocational grid' which had the adjectives 'handsome, pretty, charming,
lovely' as its vertical axis, and the nouns 'woman, man, child, dog, bird, flower,
weather, landscape, view, house, furniture, bed, picture, dress, present, voice'
as its horizontal axis. The test showed that the students failed to mark a large
number of acceptable collocations, even though they were very familiar with
the words involved in the test. Channell concludes that it is essential that
learners realise the potential of words they know and of the new words they
learn, and she recommends that syllabuses should take into account two things
about every new word the learner needs to learn: how it relates to other words
130

with similar meaning, and which other words it can be used with and in which
contexts (Channell 1981:116).
An analysis of the writing of four Arab college ESL students by Elkatib
(1984) showed unfamiliarity of collocation as well as overuse of a few general
lexical items to be among the eight main types of lexical errors that were
recorded. In a further analysis of the collocational errors, Elkatib observes that
the learners knew the basic meaning of the lexical item but they did not know
its collocative patterns, which resulted in the use of erroneous collocations such
as 'beautiful noise', 'shooting stones', 'I increased a hundred marks', 'do
progress'. Elkatib concludes that new words should be presented in company
with their most typical collocations in the form of example sentences or of
collocation grids like the ones proposed by Channell (1981). The importance of
such a practice derives from the fact that "students often fail to realise the
potential even of words they know well, because they use them only in a
limited number of collocations of which they are sure" (Elkatib 1984:50).
The analysis of frequent words and their collocations was used in order
to assess the writing proficiency of primary school students in Singapore
(Ghadessy 1989). Writing samples of grade three (8-9 years old) and grade six
(11-12 years old) students were analysed using the KWIC (key-word in context)
method. It was found that grade three students used content words (i.e. nouns,
verbs, adjectives and adverbs) more frequently than grade six students, who
showed a more frequent use of function words (i.e. articles, pronouns,
prepositions, etc.) (Ghadessy 1989:113). According to Ghadessy, the frequent
131

use of function words is indicative of a more advanced use of collocations,
grammatical patterns and cohesive devices on the part of grade 6 students
(Ghadessy 1989:114). Ghadessy reports that looking at the collocations students
use is a valid way of investigating what happens during their development
towards a full linguistic communicative competence, i.e. by looking at the
collocations of nouns, one can draw conclusions about the development of the
students' ability to use premodification and postmodification of nouns. For
example, in Ghadessy's study all students used premodification (e.g. ‘tall tree’,
‘tennis ball’, ‘shady tree’) more frequently than postmodification (e.g. ‘the tree
that...’, ‘’a tree near the place that...’, ‘the tree which...’), which appeared mainly
in the writings of grade six students. Therefore, it appears that
postmodification is a more complex skill that develops at later stages of L2
learning, and as such it may be used as an indicator of a more advanced level of
language acquisition.
The use of collocations in the writings of native and non-native college
freshmen was examined by Zhang (1993). Samples of written essays, as well as
a fifty-item blank filling test containing 21 types of collocation (11 grammatical
and 10 lexical ones), were analysed in order to examine any associations
between collocational knowledge (as this was measured by the blank filling
tests) and writing quality, on the one hand, and the use of collocations in the
students' essays and writing quality on the other. The results show that
collocational knowledge is a source of fluency in written communication, and
also that the quality of collocations in terms of variety and accuracy is
132

indicative of the quality of college freshmen writing. An interesting result in
Zhang's study is that the use of more grammatical collocations (e.g. SV to Inf)
and fewer lexical collocations (e.g. Verb Adverb) (see section 1.5. for definitions)
was found to be characteristic of the writing in native Good writers and non-
native Poor writers (Zhang 1993:168). Zhang considers this result indicative of
the development that takes place as non-native speakers develop from poor
writers to good writers to native-like writers. Even though Zhang did not test
subjects from different proficiency levels, he anticipates that learners at the
lower levels of English proficiency use more grammatical collocations, and
fewer lexical collocations in their writing, and whatever collocations they do
use are poor in variety and accuracy. As learners progress to intermediate
levels they produce a greater variety of collocations and fewer collocational
errors, but they are still dependent on the prefabricated routines they have
acquired, and thus they use more lexical collocations than grammatical ones.
At higher levels of English proficiency learners have a better knowledge of
grammatical collocations and they are able to use the analysed parts to create
new ones, resulting to fewer lexical collocations and more grammatical ones
(Zhang 1993:169). Zhang's study suggests that there is some kind of
development in collocational knowledge as L2 learners proceed from low
language proficiency to more advanced language proficiency.
In an investigation of possible ways of facilitating L2 vocabulary
learning, Cohen and Aphek (1981) concluded that intermediate level students
find tasks with contextualised words (average 77% correct) easier than tasks
133

involving lists of words, which in turn are easier for beginners (average 84%
correct) (Cohen & Aphek 1981:225). Thus, teaching words in their collocations
could be beneficial for intermediate level students but not for elementary
students.
Overall, the use of correct collocations in the reviewed studies was found
to be indicative of a higher level of language proficiency, and the lack of
collocational knowledge was found to impair language performance. Even
though the above studies pursued similar goals, i.e. to reveal that a limited
knowledge of collocations inhibits language performance and that the teaching
of collocations in L2 classroom is necessary, they present a number of
limitations. Some of the studies were limited to the examination of a small
number collocations, usually belonging to the same pattern (verb-noun
collocations in Bahns & Eldaw 1993; Aghbar 1990; adjective-noun collocations
in Channell 1981). The use of elicitation procedures differed from study to
study, making their results difficult to compare (translation and cloze test in
Bahns & Eldaw 1993; blank filling in Aghbar 1990; collocational grid in
Channell 1981; multiple choice test in Fayez-Houssein 1990; analysis of written
performance in Ghadessy 1989; Elkatib 1984; essay writing and blank filling in
Zhang 1993) (for a critique of the use of multiple choice tests and open-choice
tests in the investigation of collocational knowledge see Aghbar & Tang 1991).
Some studies contained only a small number of subjects (8 subjects in Channell
1981; four in Elkatib 1984; nineteen in Saville-Troike 1984; Cohen & Aphek
1981). There is no common theoretical framework for the study of collocations,
134

i.e. they are mainly descriptions of the problems that learners have with
collocations (word combinations, routinized patterns, phrase patterns, etc.).
With the exception of Zhang's (1993) study, where a number of collocational
patterns are identified and systematically tested, the rest of the studies lack
systematicity and methodology in the selection of the collocations they tested,
which were based mainly on native speaker intuitions. Due to these limitations
the study of the acquisition of collocations is still in need of systematic and
methodologically sound research, while a common framework for the study of
collocations is yet to be established.
The following section outlines the different approaches to the study of
collocations in an attempt to construct a theoretical framework as the basis of
the present study.
1.3 Approaches to the Study of Collocations
Since the 1960's there have been three main approaches to the study of
collocations, focusing on different aspects of the phenomenon of collocation. In
this study, these approaches are referred to as: the lexical composition
approach, the semantic approach, and the structural approach. The lexical
composition approach characterises collocation as a different level of lexical
meaning. The semantic approach attempts to predict the collocates of lexical
units by reference to their semantic features. The structural approach examines
collocations using grammatical patterns. Each approach is described in more
detail in the following sections.
135

1.3.1 The Lexical Composition Approach
The lexical composition approach in the study of collocations is based on
the assumption that words receive their meaning from the words they co-occur
with. Among those who perceived collocations as a lexical phenomenon
independent of grammar is Firth, who is also believed to be the 'father' of the
term "collocation". Collocation according to Firth is a "mode of meaning". Just
as the light of mixed wave-lengths disperses into a spectrum, "the lexical
meaning of any given word is achieved by multiple statements of meaning at
different levels", e.g. the orthographic level, phonological level, grammatical
level, and collocational level (Firth 1957:192). For example, the meaning of the
word 'peer' is described by Firth in the following way: at the orthographic level
the group of letters 'peer' is distinguished from the group of 'pier'. Next the
pronunciation is stated, then at the grammatical level we state whether 'peer' is
a noun or a verb, and by making such statements at the grammatical level we
make explicit a further component of meaning. Also, formal and etymological
meaning may be added, together with social indications of usage (Firth
1957:192). Finally, at the collocational level, one of the meanings of the word
'peer' is its collocation with 'school', as in 'school peers'. Firth highlights the
"general rule" that every word entering a new context is a new word. Firth also
distinguishes contextual meaning from meaning by collocation, and attempts a
classification of collocations into "general or usual collocations and more
restricted technical or personal collocations", though unfortunately without any
136

further elaboration (Firth 1957:195). Even though Firth does not enter into a
thorough exploration of a theory of collocations, he uses collocation in his book
as a technique for the stylistic criticism of literary works, e.g. personal or
'unusual' collocations can reflect personal idiosyncratic styles in the use of
language (for the use of collocations in the stylistic analysis of literature, see
Behre 1967).
Halliday (1966) and Sinclair (1966) took Firth's theory of meaning one
step forward and stressed the importance of lexical collocations, i.e. collocations
that consist of lexical items, in an integrated lexical theory. The so called Neo-
Firthians attempted the study of lexis as a distinct linguistic level. Sinclair saw
Grammar and Lexis as two 'interpenetrating ways' of looking at language form
(Sinclair 1966:411), and Halliday argued that lexical theory is complementary
to, but not part of, grammatical theory (Halliday 1966:148). Grammar organises
language as a system of choices and whatever patterns and/or items fail to
"resolve themselves into systems" are listed at the end of each grammatical
description (Sinclair 1966:411). 'Lexis', on the other hand, is devoted to the
study and description of individual lexical items and their collocational
tendencies that cannot be dealt with by grammar, since they are not a matter of
choice (one rather than another) but of likeliness of occurrence, i.e. "there are
virtually no impossible collocations, but some are more likely than others"
(Sinclair 1966:411), e.g. the collocation 'this lemon is sweet' could be considered
as unusual except in the context of somebody exclaiming over a child's painting
of still life (McIntosh 1961:329).
137

The Neo-Firthians also introduced a new set of linguistic terms related to
the study of collocations. They used the term Node to refer to a lexical item
whose collocations are being studied, Span to refer to the number of lexical
items on either side of the node that are considered to be relevant to the node,
and Collocates to refer to those items that are in the environment defined by the
span (Sinclair 1966:415). For example, when we study the collocational patterns
of 'tea', 'tea' is the node. If we decide to have a span of 3, that means we study
the 3 lexical items that occur before and after 'tea'. All the lexical items that are
within the span of the word 'tea' are considered to be its collocates.
To the extent to which words are specified by their collocational
environment, similarities of their collocational restrictions enables linguists to
group lexical items into "lexical sets", i.e. sets of words with similar
collocational restrictions. For example, the words 'bright', 'shine' and 'light' are
members of the same lexical set because they are frequent collocates of the
word 'moon' (Halliday 1966:156). Along the same lines, the lexical items
'bright', 'hot', 'shine', 'light', 'lie' and 'come out' are all members of the same
lexical set because they all collocate with the item 'sun' (Halliday 1966:158). The
criterion for a lexical item to enter a lexical set is its syntagmatic relation to a
specific lexical item (i.e. its collocation with a specific word) rather than its
paradigmatic relation to that lexical item. For example, lexical items like
'strong' and 'powerful' are considered members of the same lexical set because
they collocate with the lexical item 'argument', e.g. 'strong argument' and
'powerful argument'. As far as other collocates are concerned, e.g. 'car' and
138

'tea', the lexical items 'strong' and 'powerful' will enter different lexical sets, i.e.
'strong' will be a member of the lexical set defined by 'tea', and 'powerful' will
be a member of a lexical set defined by 'car' (Halliday 1966:152). Halliday is
also interested in the collocational patterns that lexical items enter. For
example, 'a strong argument' presents the same collocational pattern as 'the
strength of his argument' and 'he argued strongly'. Since 'strong', 'strength',
and 'strongly', are parts of the same collocational pattern, they are considered
as word-forms of the same lexical item (Halliday 1966:151). Halliday also
points out that lexical items need not have any formal relationship to one
another in order to collocate. For example 'strong' and 'argument' could be in
different sentences 'I wasn't convinced of his argument. He had some strong
points but they could all be met'.
What Halliday refers to as 'collocational pattern' McIntosh calls
'collocational range' in order to distinguish it from its grammatical equivalent,
i.e. 'pattern', which has to do with the structure of the sentences we produce,
while 'collocational range' has to do with the specific collocations we produce
in a series of particular instances (McIntosh 1961:337; McIntosh & Halliday
1966). McIntosh also argues that since collocations are the material out of
which sentences are made, collocational range should be taken into account
within the dictates of pattern when dealing with the text of actual sentences.
A theory of lexical meaning similar to the one outlined by Firth and the
Neo-Firthians is suggested by Anthony (1975). Even though Anthony was not
involved directly in the study of collocation, his proposed theory treats the
139

lexical word as an empty form capable of bonds to different kinds of meaning
(Anthony 1975:22). Each lexical word becomes a discourse word when it is
used in ordinary discourse, and the particular meaning which is in focus is
called its lexical meaning. For example, the lexical word 'pitch' can mean many
things, i.e. it is capable of bonds to different kinds of meaning (a throwing
action, a tar-like substance, something musical, etc.). The moment 'pitch' is
used communicatively in a group of other words and becomes a discourse
word, then a small portion of its repertory of meanings is in focus and this
becomes its lexical meaning, e.g. in the sentence 'pitch the ball to me', 'pitch'
receives the meaning of 'a throwing action'. Anthony also remarks that a word
that occurs in one grammatical construction differs in lexical meaning from the
same word in another construction. For example the use of 'mother' as a verb
has a different referential meaning from the use of 'mother' as a noun.
Collocation has also been identified by Halliday and Hasan as a form of
lexical cohesion, and it has been defined as the "cohesive effect" of pairs of
words such as 'bee...honey' and 'king...crown' which "depends not so much on
any systematic semantic relationship as on their tendency to share the same
lexical environment, to occur in COLLOCATION with one another" (Halliday
& Hasan 1976:286). However, 'collocational cohesion', as it is used by Halliday
and Hasan, is simply "a cover term" for textual cohesion, a kind of "semantic
interlace that provides texts with their texture- their non-structural cohesion or
lexical form" (Addison 1983:3), and leaves the "specific kinds of co-occurrence
which are variable and complex" to be dealt with by "a general semantic
140

description of the English language" (Halliday & Hasan 1976:287-288).
Halliday and Hasan's definition of collocation serves the task of textual
analysis, but it is restricted in lexically predictable collocational chains that
extend beyond the boundaries of a sentence. Furthermore, it does not pay
attention to idiosyncratic and unpredictable co-occurrences of words that are
not semantically or environmentally, in a physical sense, associated to each
other, e.g. there is nothing obvious in the meaning of 'tea' that explains why it
collocates with 'strong' but not with 'powerful'.
The main problem with lexical analysis has been identified as "the
circularity of the definition of the basic unit of description, the lexical item"
(Sinclair 1966:412). That is, every item is described in terms of its environment
which in its turn is defined in terms of the item. For example, one of the
meanings of 'night' is its collacability (i.e. ability to collocate) with 'dark', and of
'dark', its collocation with 'night' (Firth 1957:196). The above realisation makes
lexical statements look weaker and less precise than grammatical ones, which
are based on a well-defined and explicit framework.
One of the good points of the lexical composition approach is that it
drew attention to lexis and uncovered the insufficiency of grammatical analysis
to account for the 'patterns' a word enters in, in the Hallidayan sense, and the
collocatory idiosyncrasies of lexical items. The Neo-Firthians argue that
grammar alone cannot describe what the lexical item is, therefore the lexical
item "must be identified within Lexis, on the basis of collocation" (Halliday,
McIntosh & Strevens 1964:35).
141

Sinclair and Halliday do not underestimate the importance of
grammatical analysis; they rather highlight the significance of being able to
make valid statements about lexis that do not disregard but complement
grammar. However, the Neo-Firthians admit that they do not know "how far
collocational patterns are dependent on the structural relations into which the
items enter" (Halliday 1966:159), and therefore it is essential to examine
collocational patterns in their grammatical environments. In other words, the
advocates of the lexical composition approach recommend that collocational
patterns are best described and analysed through lexical analysis, but they do
admit that help from grammar is still needed.
1.3.2 The Semantic Approach
Collocation as a linguistic phenomenon associated with lexical semantics
was described as early as 2,300 years ago. Greek Stoic philosophers, according
to Robins (1967), rejected the equation of "one word, one meaning" and shed
light on an important aspect of the semantic structure of language: "word
meanings do not exist in isolation, and they may differ according to the
collocation in which they are used" (Robins 1967:21).
In parallel to the lexical composition approach, where linguists
recognised lexis as a level of analysis of language separate from grammar, in
the semantic approach linguists attempted to investigate collocations on the
basis of a semantic framework, also separate from grammar.
142

Chomsky was among the first to suggest the treatment of collocations by
semantics. Even though Chomsky did not examine collocations, he
distinguished between 'strict subcategorisation rules', i.e. rules that "analyze a
symbol in terms of its categorical context", and 'selectional rules', i.e. rules
which "analyze a symbol in terms of syntactic features of the frames in which it
appears" (Chomsky 1965:95). These rules assist the generation of grammatical
strings. The breaking of strict subcategorisation rules will result in strings such
as e.g. 'John found sad' and 'John became Bill to leave', while failure to observe
the selectional rules will give examples like 'Colorless green ideas sleep
furiously' (Chomsky 1965:149). He then finds that selectional rules play a
marginal role in the grammar and suggests that they should be dropped from
the syntax and be taken over by semantics.
The Neo-Firthians' approach to the study of collocations was found
inadequate by semanticists because it sorts lexical items into sets according to
their collocations, but it does not explain why there are lexical items that
collocate only with certain other lexical items. In the lexical composition
approach collocations and sets are studied as if the combinatorial processes of
language were arbitrary (Lehrer 1974:176).
Firth's theory of meaning was found to be insufficient for the study of
collocations (Lyons 1966). Lyons claims that Firth's definition of 'meaning' as a
"complex of contextual relations" is puzzling, and he criticises the apparent lack
of principles by means of which "lexical groups by association" can be
established and "lexical sets" can be defined (Lyons 1966:289-297). Overall,
143

Lyons proposes an abandonment of Firth's theory of meaning, in which the
statement of meaning by collocation was introduced, because it does not
coincide with well-established theories of meaning and language description
and furthermore there are other "more important meaning relations" which
must be accounted for in a theory of meaning (Lyons 1966:295). Even though
Lyons seems to agree that 'collocations' restricted to "syntagms (or collocations)
composed of a noun and a verb or a noun and an adjective" (Lyons 1977:261)
are worthy of study by the semanticist, he does not believe that a separate
collocational level has to be established. Lyons also proposes that collocations
should be studied only as part of the synchronic and diachronic analysis of
language. For the study of collocations Lyons proposes the notion of "lexical
fields" founded upon "the relations of sense holding between pairs of
syntagmatically connected lexemes" (Lyons 1977:261). However, he advises
against going to the extreme of "defining the meaning of a lexeme to be no
more than the set of its collocations" (Lyons 1977:265-268). He then proceeds to
describe the principles of a strong version of field-theory as if the vocabulary of
a language was a closed set of lexemes with each lexeme being a member of no
more than one field. However, the vocabulary of a language is an open system,
and lexemes do belong to different fields due to their different meanings.
Therefore, the study of vocabulary in a theory of lexical fields based on
syntagmatic relations presents problems. These problems led Lyons to suggest
that descriptive semantics can get along well without syntagmatic relations
(Lyons 1977:268). Thus, Lyons decides to deal with the 'more important'
144

paradigmatic relations of sense in his study of semantics, setting aside the
study of syntagmatic relations altogether.
Even though Lyons (1977) provided only a criticism of the Firthian
theory of meaning, there have been other semanticists who tried to put together
a theory of lexical meaning based on the semantic properties of lexical units.
This approach is the semantic approach to the study of collocations. According
to the semantic approach, the meaning of a lexical item is perceived as a
combination of the semantic properties of that item. It is the semantic
properties of a lexical item that determine its collocates.
Just as the Neo-Firthians tried to establish the lexis as different from
grammar, the semanticists also tried to establish a semantic theory that is
different from, but complementary to, grammar. Katz and Fodor (1963)
describe a semantic theory that would organise, systematise, and generalise
facts about meaning (Katz & Fodor 1963:170). They state that a semantic theory
of a language would "take over the explanation of the speaker's ability to
produce and understand new sentences at the point where grammar leaves off"
(Katz & Fodor 1963:172-173). They accept that one component of a semantic
theory of a language is a dictionary of that language, and they proceed to
describe the semantic markers for a few lexical entries of a model dictionary of
English. According to the semantic theory proposed by Katz and Fodor, each
entry for a lexical item in the dictionary must contain a selection restriction, i.e.
a condition for that particular lexical item to combine with others. For example,
the lexical item 'sleep' would require a subject with the feature [Animate], and
145

the lexical item 'break' would require as object something that is a [Physical
object] and [Rigid].
Due to the fact that under the semantic approach to the study of
collocations each lexical item will be defined by semantic markers based on its
meaning or meanings, Lehrer (1974) argues that the semantic approach is more
likely to explain why certain words can be found together. In his examination
of syntagmatic meaning relations between lexical units, Cruise describes
collocational restrictions as co-occurrence restrictions that are arbitrarily
established (Cruse 1986:279). For example, 'kick the bucket' can only be used
with human beings, although its propositional meaning is simply 'die' and not
'die in a characteristically human way'. Similarly, 'blond' refers to hair, but
describing a hairy animal or a fur coat as 'blond' would be unacceptable. Cruse
also distinguishes three kinds of collocational restrictions: systematic, semi-
systematic and idiosyncratic, according to whether, and if so to what degree,
the semantic properties of a lexical item set up an expectation of a certain
collocant. Lexical units that belong to the category of systematic collocational
restrictions are 'grill' and toast'. Both verbs denote the same process from the
point of view of the agent, but different patients: normally we 'grill' food that is
raw, while we 'toast' food that is already cooked. Semi-systematic are those
collocational restrictions that still behave as presuppositions of the lexical item
in question, but there can be certain exceptions to the general tendency. For
example, 'customers' obtain something material in exchange for money, while a
'client' receives a less tangible professional or technical service. So, butchers,
146

bakers, and grocers have 'customers', but solicitors and architects have 'clients'.
However, banks seem to have 'customers' rather than 'clients' (Cruse 1986:281).
Finally, for lexical items that present idiosyncratic collocational restrictions,
their collocational ranges can only be described by enumerating all their
acceptable collocants (Cruse 1986:281). For example, one can 'pay attention/a
visit' but not ?'pay a greeting or welcome'. Idiosyncratic collocational
preferences, such as 'flawless performance' but not *'unblemished
performance', do not give rise to presuppositions, according to the semantic
approach, and Cruse wonders whether "idiosyncratic restrictions are a matter
of semantics at all" (Cruse 1986:282). A close study of what collocational
restrictions can deliver to the sentence they are used in is totally justified, since
they are not 'logically' necessary. For example, 'die' and 'pass away' have the
same meaning, but 'pass away' refers to human beings, so the use of 'pass
away' in the sentence 'My grandfather passed away' adds semantic cohesion to
it; if it is used to describe the death of a pet animal then it anthropomorphises
the animal (Cruse 1986:280). Due to the difficulty of the syntagmatic relations,
Cruse (1986), like most lexical semanticists, finds that paradigmatic sense
relations are "a richer vein to mine than relations of the syntagmatic variety"
(Cruse 1986:86).
One of the weaknesses of the semantic approach - the view that co-
occurrence of words is the result of their semantic properties - is that there is a
large number of idiosyncratic co-occurrences or combinations that are
arbitrarily restricted (see Cruse's examples above). These constructions create
147

problems for the study of collocations under a theory of lexical fields, and
therefore they are left unexplained and marginal by semanticists. To return to
Halliday's example, since there is nothing in the meaning of 'tea' to explain why
it collocates with 'strong' but not with 'powerful', according to the semantic
approach, it will be listed as an idiom and as such it will be ignored in a study
of lexical semantics. Furthermore, as Lehrer (1974) points out, finding semantic
features for each lexical item that would account for all its collocates is an
extremely ambitious task (Lehrer 1974:178). Fillmore (1978) also points out the
difficulty of estimating the magnitude of collocational binding between lexical
items, while he acknowledges the fact that a semantic theory must not accept
the suggestion that all meanings must be described in the same terms.
An example of how the semantic approach to the study of collocations
can be best utilised was the compilation of a prototypical dictionary, the
Explanatory Combinatorial Dictionary (ECD), of any language. The ECD is
related to the Meaning-Text theory which defines language as "a specific
system of correspondences between an infinite set of meanings and an infinite
set of texts" (Mel'cuk 1988:167). As a core component of the Meaning-Text
Model, the ECD, according to Mel'chuk (1988):
"ensures the lexicalisation of the initial meaning (i.e., of semantic
representation), uniting bundles of configurations of semantic elements
into actual lexical units and supplying the enormous bulk of syntactic
and lexical co-occurrence information that accrues from the individual
lexical units of the language in question" (Mel'cuk 1988:167).
148

Each ECD entry is divided into three zones: a semantic zone, a syntactic
zone and a lexical co-occurrence zone. The latter comprises all the restricted
lexical co-occurrences of the entry lexeme. For this purpose, Mel'cuk and
Zholkovsky, the ECD initiators, devised the concept of Lexical Functions that
describe all the paradigmatic and syntagmatic relations that a lexeme can have
with other lexemes (Mel'cuk & Zholkovsky 1988:42). The above approach
resulted in a large number of standard basic lexical functions - some of which
had already been utilised in dictionaries for several decades (e.g. 'Syn' for
synonyms) and others were new (e.g. 'Instr' preposition meaning 'by means of',
and 'Propt' preposition meaning 'because of', 'as a result of') (see Table 1,
above). In the ECD version for French, Dictionnaire Explicatif et Combinatoire
du Francais Contemporain, there are 53 lexical functions listed, and these are
used together with the other semantic and syntactic information for the
description of 50 lexical items. Mel'cuk and Zholkovsky are considered
pioneers in their lexicographic principles and the heuristic criteria they used for
the compilation of the ECD. The fact that only 50 lexical items were described
in the French ECD underlines the extremely difficult task of listing all the
semantic features of lexical items in an effort to account to all its collocates.
Despite its limitations, the ECD could be used as "a central component of
automatic text synthesis and analysis", as a "format" for the development of
textbooks, pedagogically oriented dictionaries, and reference works, and also it
can contribute to language theory (Mel'cuk & Zholkovsky 1988:66-67).
149

Even though semanticists claimed that syntagmatic lexical relations
should be studied under the scope of semantics, they did not proceed any
further with the study of collocation and they did not make the phenomenon of
'collocation' any more explicit. Due to the irregularities and idiosyncrasies that
collocations present, semanticists, who followed a similar role to grammarians
(i.e. assigning semantic labels to sentence constituents and examining
generalisable tendencies and regularities), preferred to study the more regular
paradigmatic lexical relations, abandoning collocations to their rulelessness.
1.3.3 The Structural Approach
The structural approach consists of those linguists and researchers who
suggest that collocation is influenced by structure, and collocations occur in
patterns. Therefore, the structural approach recommends that the study of
collocations should include grammar.
The Neo-Firthians' view of separating lexical analysis from grammatical
analysis was criticised by Mitchell (1971), who argues for the "one-ness of
grammar, lexis and meaning" (Mitchell 1971:43). The interdependence of
grammar and lexicon is evident from the fact that 'lexical particularities' derive
their meaning not only from contextual extension of a lexical kind but also from
the generalised grammatical patterns in which they appear (Mitchell 1971:48).
For the study of collocations, Mitchell proposes that "collocations [which are 'of
roots' rather than 'of words'] are to be studied within grammatical matrices"
(Mitchell 1971:65). In a group of word forms like 'drinks', 'drinker' and
150

'drinking' Mitchell abstracts the common elements of each word form and
labels that as 'root', e.g. /drink, and the associations of different roots, e.g.
/drink- and /heav-, as 'collocations', e.g. 'heavy drinker', 'drink heavily'
(Mitchell 1971:51). Mitchell refers to the collocation 'heavy drinker' as an
exemplification of the colligation 'adjective + agentive noun' (Mitchell
1966:337). The relationship between 'collocation' and 'colligation' is one of
generality: 'colligations' are the generalised classes of associations and
'collocations' are their particular members (Mitchell 1971:53).
Mitchell's view that collocations are of roots rather than of words does
not hold for every combination of roots. For example, 'faint praise' is an
acceptable English collocation, but not all combinations of the two roots, /faint-
and /praise-, produce acceptable collocations: 'she was damned by faint praise'
is acceptable, but 'he praised her faintly' is not.
Matthews (1965) proposes another way of studying collocations within
grammar. He suggests enriching Chomsky's syntax with extra sets of rules that
will account for the selectional restrictions on lexical items. This approach
deals with the syntagmatic relations along a string of lexical items, a 'kernel
colligation' (p.38), rather than with individual collocational relations of pairs of
words, but Matthews realises that such a description of the language involves
double or triple the number of rules when compared to a description on the
lines of Chomsky's syntax (Matthews 1965). Matthews' theory suggested the
study of syntagmatic relations, and consequently of collocation, along the lines
of transformational grammar, but it was not developed any further.
151

The influence of grammar on collocation was also discussed by
Greenbaum (1970), (1974) who pointed out that certain instances of collocation
require syntactic information. For example 'much' collocates with 'prefer' when
it is in a pre-verb position as in 'I much prefer a dry wine', but it does not
collocate with 'prefer' in post-object position as in *'I prefer a dry wine much'
(Greenbaum 1974:82). Greenbaum suggests that the collacability of words (i.e.
their potential co-occurrence with other lexical items) should be "tied" to
syntax, and realises that there are certain lexical items that can occur only in
certain syntactic relationships, e.g. 'His sincerity frightens us' but not 'We
frighten his sincerity' (Greenbaum 1974:82). Without reference to syntax, the
notion of collacability becomes vacuous - virtually any two items can co-occur
at a given arbitrary distance. For example, 'sincerity' can collocate with
'frighten’, but the acceptability of the combinations they produce can only be
judged via syntax.
The notion of language blocks and lexicalised sentence stems was
introduced by Pawley and Syder (1983), who suggest that if a learner is going
to achieve a native-like control of a language, then along with the rules of a
generative grammar, she/he needs to "learn a means for knowing which of the
well-formed sentences are native-like -- a way of distinguishing those sentences
that are normal or unmarked from those that are unnatural or highly marked"
(Pawley & Syder 1983:194). Pawley and Syder propose a new way of
examining native-like selection and fluency. According to their approach,
learners memorise a language in blocks, and a big portion of a native speaker's
152

lexicon consists of "lexicalised sentence stems". For example, an expression of
apology like 'I'm sorry to keep you waiting' gives the sentence stem 'NP be-
TENSE sorry to keep-TENSE you waiting'; the constituents of this sentence are
its 'inflections' and any additional constituents (e.g. 'all this time') are its
'expansions' (Pawley & Syder 1983:210). According to Pawley and Syder
lexicalisation belongs to the domain of competence and a sentence stem can be
lexicalised if it is a standard expression of the meaning in question in a
particular community, or if it is an "arbitrary choice, in terms of linguistic
structure, for the role of standard expression". For example, 'it's twenty to six'
is a standard expression in English since it is a convention that one tells 'to
[Hour]' rather than 'preceding [Hour]' or 'before [Hour]', and 'I want to marry
you' is an arbitrarily established standard usage, compared to a less standard
paraphrase such as 'I wish to be wedded to you', which could be used in a
formal letter or a satirical speech (Pawley & Syder 1983:198). As with most of
the theories examined so far, Pawley and Syder do not define the notion of
lexicalised sentence stems any further, and they did not offer an explicit list of
sentence stems that could be used as a framework in the study of collocations.
The view that language consists of blocks or 'chunks' was also supported
by Nattinger and DeCarrico (1992), who proposed the compilation of a lexical
phrase dictionary for L2 learners. Nattinger and DeCarrico give the following
examples of lexical phrases for inclusion in the dictionary:
Conversational Maintenance (regularities of conversational interaction
that describe how conversations begin, continue and end). Summoning:
153

Excuse/pardon me (sustained intonation); Hey/hi/hello, (Name); How
are you (doing)? I didn't catch/get your name; Do you live around here?
Hello, I'm + NAME; Good morning/afternoon/evening, (how are you)
What's up? (Nattinger & DeCarrico 1993).
From the examples of lexical phrases, as these were presented by
Nattinger and DeCarrico, it appears that lexical phrases are not the same as
collocations or lexicalised sentence stems. Lexical phrases appear to be more
general than collocations and less systematic than lexicalised sentence stems.
Also, Nattinger and DeCarrico are not concerned with providing explanations
about why certain lexical phrases are put together, which would be more useful
for the study of collocations.
A set of criteria for examining whether a combination of words is a
collocation or not is outlined by Kjellmer (1984), who also suggests the study of
collocations in a grammatical framework. Kjellmer defines collocations as
"lexically determined and grammatically restricted sequences of words"
(Kjellmer 1984:163). According to this definition, only recurring sequences that
are grammatically well-formed can be considered as collocations. For example,
during a search of the Brown Corpus, Kjellmer found the following sequences:
'green ideas', 'try to', 'hall to'. From these strings, it is only 'hall to' and 'try to'
that recur, and from these two, only 'try to' that is grammatically well-formed.
Therefore, only 'try to' is a collocation (Kjellmer 1984:163). Kjellmer also tries to
establish a set of rules for assessing 'collocational distinctiveness'. According to
these, a sequence is highly distinctive when it appears frequently in many and
154

different categories of texts; it is long (minimum length is two words); and it is
structurally complex.
On the other hand, Renouf and Sinclair (1991) applied their theory of
studying collocations to 'frameworks' consisting of discontinuous sequences of
two words, whose grammatical well-formedness depends on what intervenes,
e.g. 'a + ? + of', 'too + ? + to' (Renouf & Sinclair 1991:128). They found out that
in some cases there seems to be a stronger collocational pull exerted by one of
the pair on some items rather than on others, e.g. in the framework 'too + ? +to',
'to' would be able to collocate with 'easy', 'hard', 'good' and 'proud' even in the
absence of 'too', e.g. ‘easy to do’, ‘good to do’, but not with 'much' or 'tired'
which require the presence of 'too', e.g. ‘too tired to dance’, ‘too full to eat’,
(Renouf & Sinclair 1991:133). Thus, Renouf and Sinclair demonstrated that the
collocations of grammatical words offer an appropriate basis for studying
collocations, since "co-occurrences in the language most commonly occur
among grammatical words" (Renouf & Sinclair 1991:128).
The importance of grammatical words for the study of collocations was
also confirmed by Jones and Sinclair (1974). Even though their study on
English lexical collocations was based on a relatively small corpus (147,000
running words), it yielded some interesting results concerning the study of
collocation: the influence of the node does not extend beyond span position
Node (N) + 4 (see also Berry-Rogghe 1973). Grammatical words are not
collocationally neutral (unlike Haskel 1971). Even though grammatical words
are weak at predicting their environment, they do show ability to predict word
155

classes at specific span positions, e.g. the collocates of the word 'the' in position
N-1 are mainly verbs and prepositions, while in position N+1 they are nouns
and adjectives. The significance of a collocation takes into account the overall
frequency of the two items concerned, the number of times they occur together,
and the length of the text. Collocations can appear to be 'text dependent'.
Verbs tend to collocate with grammatical items, e.g. 'put' and 'take' collocate
with a great number of prepositions to form phrasal verbs. Association
between lexical items is subject to grammatical influence, e.g. the adjective
'good' is preceded by adverbs and followed by nouns as significant collocates.
Significant collocations show a considerable amount of position dependence,
e.g. in a span of 4, significant collocations most frequently occur in the span
positions immediately next to the node, N-1 and N+1, while very little occurs at
the two extremes of the span, N-4 and N+4. Finally, collocation was found to
be an organising principle that influences the construction and interpretation of
utterances (Jones & Sinclair 1974:48; Leitner 1992).
The study of collocations in structural patterns was also suggested by
Aisenstadt (1979). Aisenstadt distinguishes collocability restrictions as part of
the wide field of collocability. Word combinations whose constituents are
restricted in their 'commutability', i.e. their ability to combine with other words,
are called restricted collocations (Aisenstadt 1979:71). Restricted collocations
are defined as combinations of two or more words used in one of their regular,
non-idiomatic meanings, following certain structural patterns (e.g.
V+(art)+(A)+N), and restricted in their commutability not only by grammatical
156

and semantic valency (e.g. in the restricted collocation 'shrug one's shoulders'
both components have a narrow semantic valency), but also by usage (e.g. we
can 'bear a grudge' but we cannot *'bear hatred/ scorn') (Aisenstadt 1979:71,
1981:54). Restricted collocations are different from free word-combinations.
For example 'carry' can enter a large number of free word-combinations when it
means 'to support the weight of something' like 'carry a
book/bag/chair/torch/table/etc.', but it may also enter a restricted collocation
pattern 'carry conviction', 'carry persuasion', 'carry weight' when it is used to
denote 'being convincing' or 'winning the argument' (Aisenstadt 1979:72).
Some of the structural patterns of restricted collocations in English listed by
Aisenstadt are given below in Table 2:
Table 2. Examples of structural patterns of restricted collocations in English
Pattern Example
V+(art)+(A)+N 'command devotion', 'give a loud laugh'
V+prep+(art)+(A)+N 'leap to a sudden conclusion', 'leap to a decision'
A+N 'cogent argument'
V+Adv 'take off', 'take away', 'sit down'
I(Intensifier)+A 'dead tired', 'dead drunk', 'stark naked'
Note: V = Verb, art = Article, A = Adjective, N = Noun, prep = Preposition,
Adv = Adverb, I = Intensifier
157

Aisenstadt also reports that restricted collocations have not yet been
studied yet adequately as a specific linguistic phenomenon, and therefore they
have not received a proper treatment in lexicography: some of them are listed
alongside free word combinations and others are listed in dictionaries of idioms
as idioms (Aisenstadt 1981:53). Aisenstadt concludes that a study of restricted
collocations is of great importance for applied linguistics, translators,
lexicographers, language teachers and students.
The structure-based studies make clear that collocational restrictions do
not apply only to lexical words (as the other two approaches assume) but also
to grammatical words. Furthermore, studies such as Jones and Sinclair (1974),
Renouf and Sinclair (1992), and Aisenstadt (1979) show that it is possible to
study collocations using structural patterns. Thus, there is no need for the
debate among linguists over whether collocations should be described using
lexical analysis, or semantic rules and/or grammar rules. It is possible that by
defining structurally and isolating a particular collocational pattern and
examining its frequency, variability and systematicity in a language corpus, the
notion of collocation could be enriched.
Benson, Benson and Ilson (1986a) compiled the BBI Combinatory
Dictionary of English, a dictionary of English collocations. The difference
between the BBI and the ECD, examined earlier on, is that the BBI includes
more lexical items and a less detailed grammatical and lexical treatment. The
BBI writers do not include in their dictionary "free combinations" that are
predictable and thus not needed, e.g. the collocation of the verb 'to destroy'
158

with a large number of nouns denoting physical objects like 'bridge', 'house',
'road' etc. (Benson 1985:66; Ilson 1985; Benson et al. 1986a). Fifteen different
types of "essential grammatical and lexical recurrent word combinations" are
defined and included in the BBI dictionary for "general use" (Benson et al.
1986a:7). The BBI distinguishes between grammatical and lexical collocations
in the following way: a grammatical collocation is a phrase that consists of a
dominant word (verb, noun, adjective) and a preposition or grammatical
structure such as an infinitive or clause. Lexical collocations normally do not
contain prepositions, infinitives, or clauses. Typical lexical collocations consist
of nouns, adjectives, verbs, and adverbs. Examples of grammatical and lexical
collocational patterns are given in Table 3.
Table 3. Examples of Grammatical and Lexical Collocations in the
BBI Combinatory Dictionary of English
Code Pattern Example
Grammatical Collocations:
(G4) preposition + noun in agony, at anchor
(G8) verb + to infinitive decide to come, offer to help
Lexical Collocations:
(L1) verb + noun make an impression
(L3) adjective + noun long hair
(L4) noun + verb dogs bark
(Benson et al. 1986)
159

The BBI contains seven types of lexical collocations, L1...L7, and eight
main types of grammatical collocations, G1...G8, with the eighth type consisting
of nineteen English verb patterns, e.g. SVO to O (e.g. ‘I gave the book to Mary’),
SVV-ing (e.g. ‘I started crying’), SV to inf (e.g. ‘I want to sleep’), etc. Altogether,
there are 33 patterns of grammatical and lexical collocations included in the
BBI.
One of the disadvantages of the BBI is that its writers do not explain how
they established that a word combination is recurrent enough to be included in
their dictionary. The recent advances in corpus analysis provide more accurate
examples of significant collocations for their inclusion in a dictionary (see
COLLINS COBUILD English Words in Use, forthcoming; cited in Bahns 1993;
also Collins COBUILD English Collocations on CD-ROM); for the advantages
of using corpus analysis in lexicography see also Sinclair (1985) and
Greenbaum (1984). The use of language corpora for the detection of collocative
semantic lexical relations in the compilation of dictionaries is also suggested by
Meijs (1992), Noel (1992), Sinclair (1992), (1993), and, for the making of a lexical
and phraseological grammar, Francis (1993).
Even though the BBI has methodological weaknesses, its major
contribution to the study of collocations is that it defines explicitly a number of
patterns and, unlike the previous studies on collocations, it actually organises
the collocations of a large number of words around those patterns, proving that
it is possible to use structural patterns in order to study collocations.
1.3.4 Summary of the Three Approaches
160

The three approaches to the study of collocations focus on different
aspects of the phenomenon of collocation. The lexical composition approach
regards lexical analysis as independent from grammar and considers lexis an
autonomous entity, choosing its own collocates which can be enumerated and
classified in lexical sets. The semantic approach tries to find semantic features
based on the meaning of lexical units that would enable the prediction of their
collocates. The structural approach tries to establish patterns of collocations
that include grammatical and lexical words alike.
The semantic and the lexical composition approaches are restricted to
the study of a small number of collocations (usually 'verb noun' and 'adjective
noun' collocations); they exclude grammatical words from their scope, and
eventually they achieved only limited results.
The structural approach, on the other hand, examines more patterns of
collocations, includes grammatical words in the study of collocations, and
provides a framework for the study of collocations that is feasible and
systematic (e.g. the collocational patterns included in the BBI).
1.4 Collocations and Idioms
Before proceeding to the description of the framework employed by the
present study on collocations, it is necessary to make reference to one of the
debates concerning the study of collocations: to what degree collocations are
similar to idioms.
161

Along the continuum with free combinations on one end and idioms on
the other, collocations seem to fall in the middle as they blend together the
semantic transparency of free combinations and the syntagmatic bonds of
idioms. An idiom is usually described as "a constituent or series of constituents
for which the semantic interpretation is not a compositional function of the
formatives of which it is composed" (Nagy 1978:296). Collocations, although
they are combinations of at least two words, exhibit a degree of syntactic
frozenness and resistance to lexical substitution; they are semantically
transparent; and hence they are not idioms. However, there are certain lexical
combinations that are semantically transparent, and therefore should be
classified as collocations, but which also show a certain degree of syntactic
frozenness and resistance to lexical substitution, just like idioms: for example,
'foot the bill', 'curry flavour', 'high explosive', 'highest confidence'. Such
expressions have been called 'bound collocations' (Cruse 1986:41), 'semi-
productive expressions’ (Nagy 1978:296), and 'partial idioms' (Palmer 1976:99).
There are linguists who do not distinguish between idioms and
collocations. For example, Wallace (1979) describes collocations as a class of
idioms, as stereotyped expressions that are easily decoded from the meaning of
their constituent elements. Wallace distinguishes two dimensions to the idiom:
the dimension of meaning (the semantic dimension) and the dimension of
grammatical context (the structural dimension) (Wallace 1979:63). Idioms,
according to the degree of their decodability, are classified as 'transparent', if
they are easily decoded, or 'opaque'. Idioms falling into the area of transparent
162

stereotypes are called 'restricted collocations', e.g. ‘Pleased to meet you’, ‘be
honest with’, ‘use up’.
The semantic approach to the study of collocations also considers lexical
co-occurrences that are arbitrarily restricted and so lacking a semantic
explanation. These are like idioms, i.e. linguistically non-productive, and as
such they should be left out of the study of lexical fields (Lehrer 1974:187).
By and large, semantic transparency appears to be the only criterion that
could make a difference in the process of classifying expressions as idioms or
collocations, while the importance of how clear-cut the distinction is between
collocations and idioms seems to vary among linguists, with some arguing that
"it is, of course, a matter of terminology whether collocations should be classed
separately from idioms or as a major sub-class" (Bolinger 1976:5).
This study examines collocations, i.e. word combinations, in terms of the
syntactic patterns in which they enter. Therefore, the degree of their semantic
transparency is, for the purposes of this study, overlooked.
1.5 A Framework for the Study of Collocations
For the investigation of the acquisition of collocations, this study adopts
a framework based on the structuralist approach. The framework comprises 37
patterns of collocation. 33 of these patterns are from the BBI, 2 patterns are
extensions of the BBI patterns, and 2 are adapted from Zhang (1993). The use of
structural patterns for the study of collocations has been employed in previous
studies (Zhang 1993; Bahns & Eldaw 1993; Biscup 1992). These patterns are
163

utilised in this study in order to operationalise the notion of collocation and to
examine the development of English collocational knowledge in L2 learners. In
order to avoid a confusion between structural/collocational patterns and
grammatical patterns, the patterns used in this study are, from now on, referred
to as 'types'. 'Type' with a capital 'T' is used for reference to individual
collocation types. For a complete list of the 37 types of collocation with
examples, see Table 4 below.
Table 4. Types of Collocation used in the study*
TYPE EXAMPLE
1. Noun Preposition argument about
2. Noun to Infinitive (it was a) pleasure to do it
3. Noun that-clause he took an oath that he would do ....
4. Preposition Noun in agony
5. Adjective Preposition angry at
6. Predicate Adjective to Infinitive she is ready to go
7. Adjective that-clause she was afraid that she would fail...
8. SVO to O/ SVOO he sent the book to his brother
9. SVO to O they described the book to her
10. SVO for O/ SVOO she bought a shirt for her husband
11. SV(O) Preposition O we export to many countries
12. SV to Infinitive they began to speak
13. SV Infinitive we must work
164

14. SV V-ing he kept talking
15. SVO to Infinitive she asked me to come
16. SVO Infinitive she heard them leave
17. SVO V-ing I caught them stealing apples
18. SV Possessive V-ing they love his clowning
19. SV(O) that-clause they admitted that they were wrong
20. SVO to be c we consider her to be well trained
21. SVOc she dyed her hair red
22. SVOO the teacher asked the pupil a question
23. SV(O) Adverbial he carried himself well
24. SV(O) wh-word he asked how to do it
25. S(it) VO to Infinitive it surprised me to learn of her decision
26. SVc he was a teacher
27. Verb Noun/Pronoun (creation) make an impression
28. Verb Noun (eradication) reject an appeal
29. Adjective Noun strong tea
30. Noun Verb bees buzz
31. Noun1 of Noun2 a piece of advice
32. Adverb Adjective deeply absorbed
33. Verb Adverb affect deeply
34. Noun Noun aptitude test
35. Miscellaneous in fact
36. Preposition Determiner Noun on the contrary
165

37. Phrasal Verb to pass on
Note: S: Subject, V: Verb, O: Object, c: complement
* Henceforth, ‘Preposition’ and ‘Prep’, ‘Adjective’ and ‘Adj’, ‘Noun’ and ‘N’,
‘Verb’ and ‘V’, ‘Infinitive’ and ‘Inf’, ‘creation’ and ‘creat’, ‘determiner’ and ‘det’
are used interchangeably depending on the availability of space in the tables.
See also table of abbreviations.
The categorisation of the above collocation types in lexical and
grammatical collocations by the BBI (see section 1.3.3.) was further refined by
Zhang (1993). According to Zhang, a lexical collocation is "a type of collocation
where one component recurrently co-occurs with one or more other
components as the only lexical choice or one of the few lexical choices in a
combination" (Zhang 1993:14). A grammatical collocation, on the other hand, is
"a type of collocation where one component recurrently co-occurs with one or
more other components as a grammatical category, rather than a particular
lexical item" (Zhang 1993:14). In other words, if a collocation is lexicalised, i.e.
if the combination of an open class word (verb, noun adjective, adverb) and a
preposition or another open class word is used as a single word, e.g. 'to do
one's homework', 'to depend on', 'strong in', then it is a lexical collocation. If
the collocation is a combination of an open class word (verb, adjective, noun,
adverb) and a clause, infinitive, gerund, or preposition, then it is a grammatical
collocation, e.g. 'enjoy + V-ing', 'want + to infinitive'. Zhang's definition of
lexical and grammatical collocations was found to be more appropriate than the
166

BBI's for pedagogical research, and this study considers the following types to
be lexical collocations (Types 27, 28, 29, 30, 31, 32, and 33 were also defined as
lexical collocations by the BBI):
Table 5. Types of Lexical Collocations used in the study
Type
1. Noun Prep
2. Adjective Prep
27. Verb Noun (creation)
28. Verb Noun (eradication)
29. Adjective Noun
30. Noun Verb
31. Noun1 of Noun2
32. Adverb Adjective
33. Verb Adverb
36. Prep Det Noun
37. Phrasal Verb
The use of syntactic structures to operationalise English collocations and
to examine the acquisition of an area of vocabulary, i.e. collocations, is
considered appropriate for this study for the following reasons:
i) English collocations have already been found to be influenced by structure
(see studies under the structuralist approach, above). Also, the classification of
167

English collocations in patterns/types enables a large scale investigation of
vocabulary acquisition, i.e. by using types of collocations a larger area of
vocabulary will be covered than by using a number of specific collocations.
ii) The use of syntactically defined structures will enable the description of the
development of collocational knowledge with respect to types of collocation
rather than to a limited number of specific collocations. If collocational
knowledge is affected by structure and does develop in terms of collocation
types, then the results of this investigation will be applicable for all the specific
collocations that belong to a particular collocation type. For example, if certain
conclusions can be drawn about how collocational knowledge develops with
respect to the 'SV inf' collocations, then the results will hold for all collocations
that belong to this type: 'I can sing', 'we must go', 'he might win', etc.
iii) The old debate in linguistics on the division between grammar/syntax and
vocabulary did not prove a constructive approach to the description of L2
acquisition. If vocabulary is not a mere listing of words in memory but
combinations of words carrying meaning and governed by syntactic rules, as
the studies reviewed in this chapter claim, then investigating the acquisition of
vocabulary in combination with syntactic structures will yield a more complete
picture of L2 vocabulary acquisition.
The investigation of the development of English collocations at different
proficiency levels was considered useful because previous studies have made
assumptions based on their results that learners at different levels of
proficiency use different types of collocation (Zhang 1993). The aim of the
168

present study will be to describe the development of collocational knowledge
in L2 learners at different proficiency levels and to investigate whether there
are any collocation types that are acquired before others. If different collocation
types are used by L2 learners at different levels of proficiency, could it be that
there are developmentally determined acquisition orders in the acquisition of
English collocations?
The following chapter reviews a number of studies on acquisition orders
and developmental sequences in L2 acquisition.
169

CHAPTER 2
SECOND LANGUAGE ACQUISITION AND THE DEVELOPMENT
OF COLLOCATIONAL KNOWLEDGE
2.0 Introduction
In the 1970's, research in L1 acquisition provided evidence of
developmental patterns and stages that characterise child language acquisition
(see Brown 1973). Along similar lines, studies in L2 acquisition investigated
how a L2 is acquired and whether it follows a similar developmental route.
Theories of L2 acquisition were formulated, deductively or inductively, and
research in the L2 classroom flourished. Longitudinal and cross-sectional
studies were conducted (for a critique see Miesel, Clahsen & Pienemann 1981;
Rosansky 1976) and the data were analysed to reveal "developmental
sequences" of L2 acquisition. These sequences were then compared to L1
developmental sequences and found to be either similar (Ravem 1968, 1970,
1974; Dato 1970; Milon 1974; Gillis & Weber 1976) or different (Wode 1976).
Among the studies investigating L2 development there is great variation
in the way language "development" is operationalised. Some studies describe
the various "stages" that the learner's interlanguage goes through before a
particular language structure is considered to be acquired, e.g. the five stages of
170

the acquisition of word order in German (Meisel et al. 1981). Such stages form
a "developmental sequence" that all learners seem to traverse regardless of their
native language or the learning context. Other studies describe "acquisition
orders" for certain language components, e.g. it has been shown that the
acquisition of a number of English morphemes follows such a predetermined
acquisition order (see Krashen 1977). Such orders have also been referred to as
"accuracy orders" because the criterion for a certain item to enter an order is its
accurate use by the L2 learner. Morpheme acquisition orders also support the
existence of developmental sequences in L2 acquisition. The most commonly
researched aspects of language for developmental sequences were the areas of
morphology (Dulay & Burt 1973, 1974; Bailey, Madden & Krashen 1974; Larsen-
Freeman 1975; Krashen, Sfelazza, Feldman & Fathman 1976; Mace-Matluck
1977; Fuller 1978; Fathman 1978; Makino, 1979; Lightbown 1983), word-order
and syntax (Huang 1970; Butterworth 1972; Ravem 1974; Wagner-Gough 1975;
Adams 1978; Cazden, Cancino, Rosansky & Schumann 1975; Gillis & Weber
1976; Meisel et al. 1981; Pienemann, Johnston & Brindley 1988).
This chapter reviews studies on developmental sequences pertaining to
different aspects of L2 acquisition and highlights the motivation for the present
study, i.e. the investigation of evidence of development in the acquisition of
English collocations.
2.1 Morphology
171

The Natural Order Hypothesis in Krashen's Monitor Theory suggests
that there is a natural order of acquisition of L2 rules. Some of them are early-
acquired and some are late-acquired. This order does not necessarily depend
on simplicity of form. It can also be influenced by classroom instruction
(Krashen 1985). Evidence for the Natural Order Hypothesis was provided by a
series of research studies investigating morpheme acquisition orders and
showing that grammatical morphemes elicited in free speech and with the use
of specifically designed instruments (e.g. the Bilingual Syntax Measure)
constitute a natural order of morpheme acquisition for performers (Houck,
Robertson & Krashen 1978; Krashen, Houck, Giunchi, Bode, Birnbaum & Strei
1977). Krashen's Natural Order for the acquisition of 9 English morphemes,
from the early acquired morphemes (top) to the late acquired ones (bottom), are
given below in Table 6:
Table 6. The acquisition of English morphemes
Morpheme
-ing
plural
copula
auxiliary
article
irregular past
regular past
172

3rd person singular
possessive 's
(Krashen 1977).
Dulay and Burt (1973), (1974) used the Bilingual Syntax Measure (BSM)
to elicit speech data from 250 Spanish- and Chinese- speaking children learning
English in the USA. They found statistically significantly related acquisition
orders for the two groups, but these were different from the order of
acquisition for English L1 obtained by Brown (1973) in his longitudinal study of
three children. Dulay and Burt's findings were also confirmed by Bailey et al.
(1974) in their study of 73 Spanish and non-Spanish ESL adults.
Acquisition orders that were L1-neutral were also found by Larsen-
Freeman (1975). She tested the acquisition of ten English morphemes by 24
adults from four different L1 backgrounds (Arabic, Spanish, Japanese, and
Farsi) using five different tasks: the BSM speaking task, a reading task, a
listening comprehension test, an imitating task, and a writing test. Larsen-
Freeman found that language background did not affect performance in
morpheme ordering in a significant way, i.e. there were significantly high
coefficients of concordance produced among the language groups on tasks
within the study, and also the BSM elicited a very similar order of morphemes
for learners from different L1 backgrounds. The BSM ordering from Larsen-
Freeman's study and the ordering obtained by Dulay and Burt (1974) correlated
highly at the .01 level of significance, rho = .87. Also the ordering elicited by
173

the imitating task correlated significantly with the ordering obtained in Dulay
and Burt (1974), rho = .60. However, the morpheme orderings that the other
three tasks produced had low correlations with Dulay and Burt's study, none of
them reaching statistical significance.
In an attempt to provide an explanation for the similar ordering obtained
by the BSM in both the Dulay and Burt (1974) and the Larsen-Freeman (1975)
studies, Larsen-Freeman suggested that input frequency could be one factor
influencing the order along with other factors (Larsen-Freeman 1975, 1976).
Also, other factors affecting morpheme acquisition by L2 learners are that the
learner supplies certain morphemes correctly because she/he is trying to match
the gestalt of the speech she/he hears, or that these certain morphemes occur in
speech patterns that she/he has memorised (Larsen-Freeman 1978:100).
Other morpheme studies involved learners from Indo-European and
non-Indo-European L1 backgrounds (Mace-Matluck 1977; Fuller 1978), in both
second and foreign language learning contexts (Fathman 1978; Makino 1979;
Lightbown 1983), and on different tasks (Krashen et al. 1976). Morpheme
studies for L2s other than English (e.g. Spanish in van Naersen 1980; Quiche
Mayan in Bye 1980; and a 'creoloid' (Singapore English) in Platt 1977) also
proved the existence of accuracy orders.
Evidence was also provided for strong similarities in the L2 acquisition
process for learners involved in different learning situations and with different
amounts of exposure (Makino 1979), and for the language acquisition processes
utilised by adults and children (Krashen et al. 1976).
174

An alternative to the morpheme order studies is reported by Wode,
Bahns, Bedey and Frank (1978). They describe the stages that German children
go through while acquiring one morpheme, i.e. plural in English. The data for
this study were from Wode's four children acquiring English naturalistically
(without classroom instruction) during a 6 month field trip to the U.S.A. There
are three stages described:
Stage 1: One form for both singular or plural intention
Stage 2: Two forms for each noun reflecting target singular and plural
Stage 3: Forms with plural target reflexes restricted to plural intention;
forms with singular target reflexes restricted to singular intention
(Wode et al. 1978:178-179).
Wode et al. argue that their approach of investigating morpheme order
and language acquisition as a developmental process can provide more insights
into the mechanisms of the process of language acquisition. However, their
approach was limited to the analysis of the acquisition of English plural
inflections, and it can only be used for the investigation of the acquisition of
morphemes that present a variety of allomorphs, like the English plural.
Although these results strongly suggest that common accuracy and
acquisition orders in morphemes are evident across L2 learners, there are
certain shortcomings in the morpheme studies. Research did not provide
enough empirical support for a theoretical explanation of the developmental
175

sequences (e.g. for a critique of Krashen's Monitor Theory see Gregg 1984).
Also, only a tiny portion of English grammar was studied, and the acquisition
orders obtained represented a linguistically heterogeneous group of bound and
free NP and VP morphemes. The methodology was also criticised for using a
limited number of elicitation methods (mainly the BSM for which claims have
been made that it is not a valid instrument for measuring the sequence of
morpheme acquisition; for a critique of the BSM see Porter 1977). However,
even though these orders are not rigidly invariable across studies, they are far
from being random (Krashen 1977; Larsen-Freeman & Long 1991).
2.2 Syntax
Empirical evidence for developmental sequences in the area of syntax is
also available. Studies identified developmental sequences for the acquisition
of ESL interrogatives (Huang 1970; Butterworth 1972; Ravem 1970, 1974; Young
1974; Wagner-Gough 1975; Adams 1978; Cazden, Cancino, Rosansky &
Schumann 1975; Gillis & Weber 1976; for a review see Larsen-Freeman & Long
1991). Four stages of interrogative formation in ESL were identified:
Stage 1. Rising intonation
e.g. He work today?
Stage 2. Uninverted Wh-word, with or without an auxiliary
e.g. What he (is) saying?
Stage 3. Overinversion
176

e.g. Do you know where is it?
Stage 4. Differentiation
e.g. Does she like where she lives?
(examples from Larsen-Freeman & Long 1991:93)
Four stages of acquisition were also identified for negation in ESL:
Stage 1: no + X
e.g. 'No book', 'No you playing here'
Stage 2: no/don't Verb
e.g. 'He don't have job'
Stage 3: auxiliary-negation
e.g. 'I can't play the guitar'
Stage 4: analysed don't
e.g. 'She doesn't drink alcohol'
(examples from Larsen-Freeman & Long 1991:94; for a review see
Schumann 1979).
Studies in German word order acquisition yielded a five stage model of
development in the acquisition of German L2 (Meisel et al. 1981). The
Multidimentional Model provided a theoretical basis for the observed
acquisition order and was further extended to ESL acquisition (Pienemann &
Johnston 1987). According to the model, invariant developmental stages in the
177

acquisition of certain morphological and syntactic elements in both German
and English can be predicted and explained in terms of "hierarchically ordered
speech processing constraints" (Pienemann, Johnston & Brindley 1988:217).
Based on the same data Pienemann (1984), (1985), and (1989) suggests that
formal input impedes rather than promotes language acquisition, therefore the
formal instruction of syntax can be abandoned (see also Dulay & Burt 1973).
For a review of the debate on whether instruction affects L2 acquisition see
Long (1983); for a critique of the Multidimensional Model see Hudson (1993).
The acquisition of relative clauses in ESL was also investigated and
found to follow a developmental route similar to that found in some L1
acquisition studies (Schumann 1980).
Apart from describing developmental stages for the acquisition of a
single syntactic structure, there have also been studies that investigated the
existence of acquisition orders of grammatical structures. Fathman (1977)
tested the usage of 20 grammatical structures by 500 non-native English-
speaking children learning English in public schools in the United States. She
found difficulty orders (or learning orders) that were similar for students
coming from different language backgrounds and ages. Fathman suggests that
the forms found to be used correctly early in the learning of L2 are those which
are needed for effective communication.
Difficulty orders were also found by Yamada and Matsuura (1982) in the
acquisition of English articles by Japanese students. Yamada and Matsuura
reported that the definite article was the easiest for both intermediate and
178

advanced students. The zero article was most difficult for the intermediate
students, while the indefinite article remained most difficult for the advanced
level students.
In a functional approach to linguistic universals in L2 acquisition
research, Keenan and Comrie (1977) constructed the Accessibility Hierarchy for
Relativisation. They argue that the degree of difficulty for relativising on a
particular noun phrase proceeds along an implicational order. For example,
sentences with NP in subject position are predicted to relativise easier than
sentences with NP in direct object position. Keenan and Comrie suggest that
the Accessibility Hierarchy could be considered as an acceptability ordering
within each language and used for the explanation of syntactic processes in
learners' interlanguage. A number of studies have used the Accessibility
Hierarchy for testing predictions concerning ease or difficulty of acquisition.
Gass (1979) and Gass and Ard (1980) tested relative clause formation in English
by learners from different L1 backgrounds. The results indicate that learners
followed the constraints of the Accessibility hierarchy in their English
regardless of their L1 background. All learners found it easier to relativise
sentences with NP in subject position than sentences with NP in direct object
position.
Markedness was also examined as a factor affecting L2 acquisition in the
Principles and Parameters approach (White 1989). Although there are a
number of definitions of markedness, most of them consider the structures
which are exceptions to linguistic generalisations, or which are of low
179

frequency across the world's languages, or which are very complex (White
1989:117). Markedness has been used to make predictions about L1 and L2
acquisition. It has been claimed that developmental sequences of language
structures based on the criterion of markedness can predict ease or difficulty of
acquisition of specific language structures. For example, it was shown that
learners acquire unmarked forms, i.e. the unmarked dative prepositional
phrase complement (e.g. Mary gave the book to John), before marked forms, i.e.
marked double noun phrase constructions (e.g. Mary gave John the book)
(Mazurkewich 1984). The limitations of the markedness theory in predicting
developmental sequences of L2 acquisition are reported by White (1987). In an
investigation of the value of markedness as a predictor of L1 transferability,
White (1987) concludes that even though markedness can affect acquisition, it is
not a clear predictor of what L2 learners will or will not transfer from L1.
The above studies provide evidence that there are stages of L2 learner
development which are sequenced in a predictable order and which can be
identified and described with a certain degree of accuracy. What is also evident
from the studies reviewed so far is that grammar (in the form of syntax, word-
order or morphology) has been the central issue in L2 acquisition research. In
contrast, phonology and vocabulary have not been investigated to the same
extent that grammar has (Tarone, Swain & Fathman, 1976). Other limitations
reported by Tarone et al. are the undeveloped methodology for data collection
and data analysis (the limitations of data collection instruments such as the
180

BSM have been noted by a number of researchers), and finally the limited
number of replicated studies in L2 acquisition.
The focus on form rather than function is another limitation in the
interlanguage studies (Long & Sato 1984). Long and Sato also argue that more
research is needed in "a broader array of morphosyntactic features, e.g.
complex syntactic structures, and for lexical choice" (Long & Sato 1984:279).
In the next sections of this chapter a representative selection of studies in
phonology and vocabulary acquisition are reviewed.
2.3 Phonology
In the limited research studies to-date, claims have been made that L2
phonology also follows certain patterns of development. For example, Tarone
(1976) found that L2 learners prefer to use open syllables (i.e. syllables that end
in a vowel) rather than closed syllables (i.e. syllables that end in a consonant) in
the early stages of L2 acquisition (Tarone 1976, 1978).
Also, Wode (1977) found that children acquire the L2 phonological
system in ordered developmental sequences. In his study of German children
acquiring ESL, he found that German children follow the same developmental
route for /r/ as the native, English-speaking children (Wode 1977: 213).
Similar findings were obtained in an analysis of the production of the English
syllable-final stops /b d g/ in Spanish, Polish and Mandarin learners by Flege
and Davidian (1985). The authors conclude that the observed developmental
processes are similar to those affecting child L1 speech production.
181

Markedness theory has also been applied to L2 phonology. Eckman
(1977) claimed that where there are differences between the phonemes of L1
and L2, those phonemes that are more 'marked' (e.g. word-final voicing
contrasts are more marked than medial or initial contrasts) will be more
difficult for the L2 learner.
In her review paper, Tarone (1978) reports that the following processes
have been utilised in shaping the development of L2 phonology:
i) negative transfer from L1
ii) first language acquisition processes
iii) overgeneralisation
iv) approximation
v) avoidance
(Tarone 1978:25, 1987:77).
These processes are similar to the general interlanguage strategies
employed by L2 learners (see Selinker 1972).
As yet there is no substantial evidence as to why some developmental
processes that occur in the acquisition of a L1 phonology are employed by the
L2 learner, and some others are not (Ioup & Weinberger 1987). What these
studies show, though, is that there are certain developmental processes that
learners follow in the acquisition of L2 phonology (for a review on the
acquisition of L2 speech see Leather & James 1991).
182

2.4 Vocabulary
Until recently, lexical acquisition has been a "victim of discrimination"
(Levenston 1979:147). Traditionally, L2 acquisition research has meant
"grammar" research, in which the focus is on understanding the acquisition of
rules of structural development. Largely ignored was the fact that "using the
right word is the most important aspect of language use" (Politzer 1978:258),
and that lexis is "the major learning priority" in L2 acquisition (Jones 1994:441).
As a result, research in developmental sequences in ESL has been mainly
concerned with morphology and syntax. Lexical development has rarely been
researched (Meara 1978, 1980) even though it is evident that vocabulary is an
important aspect of L2 acquisition. It has been shown that lexical errors
outnumber grammatical ones by almost four to one (Meara 1984), and that a
poor knowledge of vocabulary has negative effects in the writing of L2 learners
(Linnarud 1986). Also, it was found that L2 learners vocabulary errors are
corrected more frequently by native speakers than errors in syntax (Chun, Day,
Chenoweth & Luppescu 1982).
2.4.1 Vocabulary as a Language Sub-skill
Interest in L2 vocabulary development has been expressed by two
sources: those linguists and language practitioners who saw vocabulary as a
component of one of the four major language skills, i.e. reading, and those who
183

saw vocabulary as an independent aspect of language development, equal in
importance and status to grammar.
L2 vocabulary development is viewed as a necessary subcomponent of
the development of reading skills because L2 learners need very well
developed vocabularies in order to read authentic selections (Dubin 1989).
However, according to Dubin, ESL learners do not have time to undertake
separate vocabulary building courses, and furthermore, teaching vocabulary
items which are not embedded in some meaningful context, such as a stretch of
text, does not seem to help learners, and therefore vocabulary should be taught
through unedited text.
Krashen's view on vocabulary acquisition is that vocabulary is acquired
in the same way that the rest of the language is acquired (Krashen 1989). In the
skill-building view, vocabulary learning "involves learning words one at a time,
by deliberate study" (Krashen 1989:440) and comprehensible input in the form
of reading and listening to stories is the way to successful vocabulary
development. Krashen concludes that explicit teaching of vocabulary is not so
effective and "in addition, many vocabulary teaching methods are at best
boring, and are at worst painful" (Krashen 1989:450). Thus, successful
vocabulary development can only occur through the development of reading
and listening skills.
Along the same lines Fox (1987) suggests an approach to vocabulary
development based on the assumption that "developing vocabulary and
reading skills takes time and extensive practice" (Fox 1987:310). According to
184

this approach, reading simplified texts followed by more complex ones results
in a gradual development of L2 vocabulary. Fox also expresses the need for
research on rates of acquiring receptive vocabulary.
Oral translation was also suggested as an adequate exercise to build
vocabulary (Heltai 1989) as it makes students devote attention to vocabulary,
and encourages them to extend their vocabulary into new areas, for example
synonymic sets, collocations and idioms (Heltai 1989:292). However, such an
approach can be made possible only under the condition that all the students
and the teacher share the same mother tongue. Other L2 vocabulary teaching
suggestions include the teaching of new words through a "meaningful learning
approach", i.e. teaching the etymology of a word, as opposed to other
techniques such as rote memorisation of words, especially with intermediate
and advanced L2 learners (Pierson 1989:57).
The above studies express an 'interest' in vocabulary acquisition mainly
due to fact that language practitioners realised that the development of reading
skills was impeded because of the lack of adequate vocabulary. The
suggestions given for vocabulary development are not the product of research
in the development of L2 vocabulary, but ways of circumventing the problem
of inadequate vocabulary in order to develop reading skills.
2.4.2 Vocabulary as a Language Skill
The first attempts to discover how L2 vocabulary is acquired led
researchers to investigate how vocabulary is stored and then retrieved by L2
185

learners. Evidence for a phonologically organised mental lexicon was provided
by Fay and Cutler (1977), Cutler and Fay (1982) through an investigation of
"malapropisms" (word substitution errors), e.g. 'we need a few laughs to break
up the monogamy' instead of 'monotony' (Fay & Cutler 1977:505). They conclude
that the mental dictionary lists its entries according to syllable structure and/or
stress pattern, and only within these categories according to sound (Fay &
Cutler 1977:511).
In investigating the problem of how new foreign words are stored in the
learner's mental lexicon, Meara (1978) tested the word associations of 76
English girls learning French in two London Comprehensive schools. The girls
were given a list of 100 French words and were asked to write down, beside
each one, the first French word that it made them think of (Meara 1978:194).
These associations were then compared with the word associations produced
by native French speakers. Meara concludes that the native speaker's mental
dictionary is organised mainly on semantic lines while in L2 learners this
semantic organisation seems to be much less well established (Meara 1978:208).
This lack of proper semantic organisation could be the source of difficulty that
foreign language learners experience in processing both written and spoken
foreign language material (Meara 1978:208). Meara finds it plausible that
learners follow a transition from a mental L2 lexicon organised on non-
semantic criteria to a more native-like one organised on semantic grounds.
Meara's claim that there are transitional stages in the lexicon has been criticised.
The results of his research have been described as "simply messy" and failing
186

to confirm the existence of developmental patterns (Sharwood-Smith 1984:238).
Despite the negative criticism, Sharwood-Smith suggests that the networks of
semantic associations that exist between words could be a viable avenue to
explore in the investigation of L2 vocabulary acquisition.
In a study of the acquisition of individual words, Meara and Ingle (1986)
tested the acquisition and retrieval of 35 low-frequency French nouns by
English-speaking learners. The nouns were presented and practised
phonetically. They found that the beginnings of L2 words were relatively
resistant to error, while subsequent consonants were more likely to be incorrect.
The results of Meara and Ingle's study are suggestive of how words are stored
and retrieved from mental lexicon, but they are limited in that they pertain to
words acquired phonetically. Furthermore, they concern individual lexical
items. In a more recent paper Meara (1992) draws attention to the examination
of vocabulary acquisition as a network of structures and associations.
Laufer's (1990a) study showed that in vocabulary acquisition learners
follow a similar developmental route according to the L1 acquisition = L2
acquisition hypothesis which predicts that L2 learners follow a similar
developmental route to that followed by a child learning the same language as
L1 (Laufer 1990a:290). Laufer compared adult EFL learners and English native
speaking children in order to examine the similarities and/or differences that
they experience in distinguishing between words of similar form (synforms),
e.g. 'considerate' and 'considerable', 'extend' and 'extent', 'simulate' and
'stimulate'. Laufer concludes that native speaking learners of English and
187

foreign learners of English share the same order of difficulty in the acquisition
of 'synforms', i.e. suffix synforms (e.g. considerable/considerate) created the
most difficult synformic distinctions, followed by the vocalic (e.g. cute/acute),
and then the prefix (e.g. superficial/artificial) and consonantal (e.g. price/prize)
(Laufer 1990a:281). Despite the interesting results, Laufer's study suffers from
certain shortcomings: she compared adult foreign learners of English and 12-
year-old native speakers of English without justifying why she expected
language development in these two groups to be comparable. Further on, the
multiple choice test she used for her research was poorly designed (e.g. the
fourth distractor of each item is almost always one that is definitely wrong - in
the 38 items tested, only one has (d) as the correct answer). Despite its
limitations Laufer's investigation suggests that in L2 vocabulary acquisition,
too, there are developmental sequences.
Palmberg (1987) also investigated patterns of vocabulary development in
Swedish ESL learners in Finland. Palmberg used 'spew' tests, which required
the students to write down as many words as they could think of that began
with a given letter (M or R). This was done for one minute per week for 17
weeks. Palmberg found that the words produced by his subjects consisted
mainly of textbook vocabulary. Results also show a steady increase in the
overall word-production capacity of the subjects over time (see also Palmberg
1988).
The acquisition of modal auxiliaries (i.e. can, could, may, and might) by
L2 learners was investigated by Gibbs (1990). She examined 75 Panjabi-
188

speaking pupils on their expression of English modal auxiliaries and found that
the acquisition of modal auxiliaries by the L2 learners follows an English L1
developmental pattern.
The acquisition of word formation processes was investigated by
Olshtain (1987). Word formation rules in Hebrew were tested using three tasks
(production, evaluation and interpretation) with a group of native speakers and
two groups of foreign speakers of Hebrew (advanced and intermediate levels).
In the production task, subjects were asked to coin new terms for concepts not
named in the conventional lexicon of Hebrew. In the evaluation task, subjects
were presented with five innovative forms representing word formation
devices in Hebrew and asked to judge which of these forms was the most
suitable name for a specified noun. In the interpretation task, subjects were
asked to supply the most likely meaning of an innovative blend. Olshtain's
results show that L2 learners acquire target word formation processes in a
gradual progression, with the advanced learners exhibiting productivity that is
very similar to native speaker's performance (Olshtain 1987:229). It was also
shown that at the advanced level the L1 influence in the application of L2 word
formation devices is marginal, while at the intermediate level students rely
mainly on word formation devices that were covered in their Hebrew course
(i.e. affixation devices). Olshtain's study strongly suggests a developmental
process in the acquisition of word-formation rules.
Giacobbe and Cammarota (1986) conducted an investigation of the
relationship between L1 and L2 in the construction of lexis during the first
189

phases of L2 acquisition. They collected their data by interviewing two Spanish
subjects acquiring French during the first months of their stay in France. They
concluded that there are two approaches to the construction of lexis, systematic
and non-systematic, depending on the learner's ability or inability to establish a
relationship between the L1 and L2. In the systematic approach, the learner
forms a General Lexeme Construction Hypothesis (GLCH) which is concretised
by a series of simple operations facilitating the transformation of L1 lexemes
into L2 lexemes. For example, Cacho, one of the subjects in the study,
suppressed the final vowel of Spanish lexemes, e.g. [kurs] instead of 'curso' and
[mism] instead of 'misma', in order to produce French lexemes, e.g. 'cours' and
'meme'. The GLCH is further complemented by parallel hypotheses
concerning other aspects of the lexemes such as stress. In the non-systematic
approach, the learner just memorises words that are frequently used in her/his
environment. Even though Giacobbe & Cammarota's study reveals that a
degree of systematicity can exist in the acquisition of L2 lexis, it has certain
shortcomings. First, their study was limited to the examination of only two
Spanish adults acquiring French without formal instruction. Second, the
similarity of the subjects' mother tongue and the L2 could have accentuated the
role of L1 in the construction of rules for the acquisition of lexis.
In the studies reviewed above, vocabulary acquisition has been equated
with the acquisition of individual words by L2 learners, even though it has
been suggested that an examination of vocabulary as a network of semantic
and structural associations would be worthwhile (Meara 1992). So far, results
190

suggest that in L2 vocabulary acquisition, too, there are certain patterns of
development. However, the scope of these studies has been mainly
exploratory, and there has not been a systematic framework of investigation of
patterns of vocabulary development. The rest of this chapter will focus on
studies exploring the acquisition of sequences of lexical items, i.e. lexical
phrases and collocations.
2.4.3 The Acquisition of Lexical Phrases
The studies considered so far dealt with the acquisition of individual
words. Other studies have also dealt with the acquisition of combinations of
two or more words.
The investigation of the early acquisition and use of prefabricated
patterns such as "can you", "where is", "how to" and others, revealed that in the
initial stages of L2 acquisition learners learn to use multiword phrases as if they
are individual lexical items (Hakuta 1974). Hakuta poses the question of
whether this rote memorisation of prefabricated patterns accelerates or
decelerates language development. Peters for one believes that 'chunks' play
an important role in L1 acquisition (Peters 1983).
Krashen and Scarcella (1978) have also identified the memorisation of
syntactic patterns, i.e. prefabricated routines, as part of the early stages of L2
acquisition. However they conclude that, when more learning has taken place,
"language development proceeds analytically, in the 'one word at a time'
fashion" (Krashen & Scarcella 1978:297). Krashen and Scarcella conclude that
191

prefabricated routines and patterns are useful for establishing social relations
and also for encouraging intake of target language. However, this intake is
insufficient for successful language acquisition and thus the teaching of
routines and patterns should be minor (Krashen & Scarcella 1978:298). Even
though Krashen and Scarcella provide an answer (negative) to Hakuta's
question, their conclusions are speculative since they have not been based on
empirical evidence.
Counter to Krashen and Scarcella's view of the usefulness of
prefabricated routines, Nattinger and DeCarrico (1992) have argued that
unanalysed chunks of language play an integral part in acquiring and using
language. Nattinger and DeCarrico identified the structural and functional
properties of lexical phrases (e.g. 'I'm sorry to hear that X' (expressing
sympathy), 'by the way' (topic shift), 'Could/Would you X ?' (request)
(DeCarrico & Nattinger, 1993)), and suggested ways for utilising lexical phrases
in language teaching. Nattinger and DeCarrico's lexical approach to language
learning draws attention to the systematic utilisation of lexical phrases in
language teaching, however, there is still little empirical evidence on the way
these 'lexico-grammatical units' are actually acquired by L2 learners;
furthermore their approach is limited - for the purposes of this study - by being
focused on the linguistic analysis of native adult language use (Weinert 1995).
Pienemann et al. (1988) also underscore the importance of lexical
phrases. The use of formulae in the oral production of English L2 learners was
classified as Stage 1 structure, i.e. low in processing complexity, and the
192

formulae were used as indicators of linguistic development by Pienemann et al.
(1988). However, these 'formulae' were left unexplained and the individuals
employed as 'assessors' of linguistic development had considerable difficulties
in identifying when a formula was used or not. It is possible that using an
umbrella term, i.e. 'formulae', to refer to word combinations memorised as
chunks, could create problems when this is used as an indicator of linguistic
development as different formulae can exhibit different levels of complexity
depending on factors such as the length of the collocational string, the
frequency of the lexical items in the formula, the formality of the formula, etc.
Thus, more refinement is needed in the description of formulae if it is going to
be used as an indicator of linguistic development.
The above studies suggest that the acquisition of formulae/lexical
phrases is characteristic of the initial stages of L2 acquisition, and that their
utilisation for language teaching would be of benefit to the learner. However,
their conclusions and suggestions are not based on empirical evidence, while
the use of the term 'formula' or 'lexical phrase' to describe any combination of
words that could be memorised as a whole is inappropriate and vague for a
detailed investigation and description of the acquisition process of such word
combinations. Still, we need to know much more about the role of formulaic
language in classroom L2 development (Weinert 1995).
2.4.4 The Acquisition of Collocations
193

Collocational development in L2 vocabulary acquisition has not been
investigated yet in terms of systematic patterns of acquisition, even though
there has been evidence for the existence of such sequences in the fields of
syntax and morphology and phonology, and also evidence that vocabulary
acquisition may also follow patterns of development.
There is already no doubt that collocations are an important part of L2
lexical development. It has been shown that collocational errors make up a
high percentage of all errors committed by L2 learners (Grucza & Jaruzelska
1978 cited in Biscup 1992); Marton 1977; Arabski 1979), and linguists have
acknowledged the importance of focusing on the relations that hold between
items in the lexical system in order to describe vocabulary development (White
1988; Meara 1992). It has also been suggested that collocations provide most of
the "initial lexical units", and thus their study is of great importance both for the
early stages of language acquisition and for the following years of vocabulary
development (Greenbaum 1974:89).
The need for research in collocations has long been identified (Levenston
1979), but it is only in recent years that empirical investigations have been
conducted. One reason for this lack of interest could be the shortage of suitable
research instruments designed specifically for testing hypotheses about lexical
acquisition processes (Levenston & Blum 1978:2). The recent research on
collocations has taken a number of forms.
Links between the acquisition and use of collocations and writing
proficiency were reported by Ghadessy (1989) (see Chapter 1). According to
194

Ghadessy, the use of function words indicates a more advanced use of
collocations, grammatical patterns and cohesive devices on the part of the older
students (Ghadessy 1989:114). Ghadessy's study demonstrates that the
examination of the collocations L2 learners use can be useful in an investigation
of what happens during the L2 learners' development towards a full linguistic
communicative competence.
A developmental process in the acquisition of collocations is also
suggested by Zhang (1993) in his study of the use of collocations in the writings
of native and non-native speakers of English (also see Chapter 1). One of the
results of the study is that poor non-native writers and good native writers use
more grammatical collocations and fewer lexical collocations. Even though
Zhang did not compare the acquisition of English collocations by L2 learners
from different proficiency levels, he assumes that the results of his study
indicate a certain development in the acquisition of collocations by L2 learners:
at the lower levels of English proficiency learners use more grammatical
collocations and fewer lexical collocations; when learners are at intermediate
levels they produce a greater variety of collocations but they still rely greatly on
the prefabricated routines they have acquired at early stages, and therefore use
more lexical collocations than grammatical ones; finally, when learners have
reached an advanced level of proficiency, they have a better knowledge of
grammatical collocations, which they are now able to break down into parts
and use to create new ones, thus resulting in a heavier use of grammatical
collocations. However, a developmental continuum like the one described by
195

Zhang would require empirical evidence from L2 learners at different
acquisition stages.
The acquisition of lexical collocations by advanced learners of English
from two different L1 backgrounds, Polish and German, was investigated by
Biskup (1992). Subjects were asked to supply the English translation
equivalents of lexical collocations in Polish and German respectively. German
learners were more prone to use descriptive answers and try alternative ways
of rendering the meaning of unfamiliar collocations, while the Polish students
would use a collocation only if they were sure it was the correct one. This
result is explained in the light of the different emphasis on EFL in Poland and
Germany. The Polish educational system insists on accuracy, so the Polish
learners would refrain from giving any answer at all unless they were certain
that it was the correct one. On the other hand, the Germans pay more attention
to communication and fluency and thus the German learners tried to use
alternative ways of expressing the meaning of collocations whose English
equivalents they did not know (Biskup 1992:88). Even though Biskup's study
does not concern the acquisition of collocations from a strictly linguistic point,
it suggests that by employing different approaches and taking into account
factors such as the focus of instruction, new and valuable insights in the field
vocabulary acquisition can be provided.
Aghbar and Tang (1991) devised an instrument to measure the
acquisition of collocations. The principle of the proposed scoring scheme is
based on the assumption that the acquisition and use of collocations evolves
196

along a continuum from the least semantic approximation to full mastery of
collocations that are idiomatic and appropriate, both semantically and by
register (Aghbar & Tang 1991:2). The scoring instrument was used to test
mastery of verb-noun collocations by 205 university level ESL students. The
collocations were collected using a blank filling test, and they were scored in
terms of their idiomaticity (idiomatic/non-idiomatic), semanticity
(semantic/marginally semantic/not semantic), and register (proper
register/not proper register). Results showed that the use of common verbs
such as 'take', 'get', 'find' were relatively easy for the low proficiency groups
and therefore do not discriminate between low and high proficiency in
collocations. It was also concluded that open-choice tests are more reflective of
the students' choice of collocations in their own natural communication, and
that low proficiency students are much more likely to choose an appropriate
answer in a multiple choice test.
The acquisition of low frequency (or rare) words and multi-word (or
complex) lexical units (e.g. noun phrases (a damp squib), adjectival/ adverbial/
prepositional phrases (at a pinch), predicates (to bite the bullet), and sayings
(the penny drops)) by advanced L2 learners was investigated by Arnaud and
Savignon (1994). A list of sixty rare words and sixty complex lexical units was
compiled in a multiple choice format (i.e. each item on the list was followed by
four choices, one of them being a paraphrase or a synonym of the item and the
other three distractors). The list was given to French advanced learners of
English, who were asked to complete the multiple choice test by choosing the
197

appropriate definition for each test item. Results show that native-like
performance was attained in the case of rare words but not in that of complex
lexical units (Arnaud & Savignon 1994). It is possible that because of lack of
awareness of the importance and nature of complex lexical units, learners did
not pay attention to them. Arnaud and Savignon conclude that even though
the acquisition of a large number of complex lexical units (such as collocations)
involves considerable difficulty, such an acquisition is necessary for the
advanced learner's receptive competence (Arnaud & Savignon 1994).
The acquisition of lexical collocations or "conventional syntagms" in
foreign language learning was also investigated by Marton (1977). Results
showed that recurrent exposure to conventional syntagms did not lead to their
remembering and recall by the learners. This could be due to the fact that
conventional syntagms are easily decodable and thus they do not cause any
difficulty in the process of recognition. Simple words or more idiomatic
expressions have a stronger impact on the learner's conscious mind as the
learner makes an effort to learn them, and thus they have a better chance of
being remembered. Marton suggests that intensive study of vocabulary and a
conscious effort in memorising and rehearsing of a great number of
conventional syntagms is the most effective way to learn how to handle target
language lexical collocations (Marton 1977:55). More recent studies have also
underscored the effects of practice in L2 acquisition (see Kirsner, Lalor & Hird
1993).
198

The above studies show that an investigation of how collocations are
acquired will be of potential benefit for illuminating some of the processes that
contribute to L2 vocabulary development and for L2 teaching.
2.4.5 Summary
The reviewed literature so far suggests that:
i) L2 vocabulary development only recently received systematic attention and
examination even though there have been studies suggesting the existence of
developmental patterns in the acquisition of L2 vocabulary.
ii) Given the emerging consensus that vocabulary knowledge is best viewed as
a network of associations, the acquisition of collocations is a valuable avenue to
explore since it represents structural and semantic relationships between lexical
items.
iii) Other language aspects have been found to exhibit developmental
processes and patterns. The acquisition of vocabulary, and in particular the
acquisition of collocations could be found to follow a developmental process of
some kind that can be described and analysed (Ellis 1994:113).
2.5 The Aims of the Present Study
The limited research in the development of L2 vocabulary, and the
availability of English collocations for a study of development, as these are
operationalised in this study (see Chapter 1), provided the rationale for this
199

study which aimed to investigate whether there are patterns in the
development of collocational knowledge in L2 learners.
Describing developmental 'stages' in the acquisition of collocations (i.e.
the stages that the learner goes through before the correct English collocations
are fully acquired) is not feasible in an investigation of vocabulary learning.
For example, in the investigation of the acquisition of English interrogatives
(Cazden et al. 1975) the end product (i.e. a well-formed interrogative
conforming to English grammar rules) was evident and the researchers had to
describe the stages learners go through in the acquisition of English
interrogatives. In vocabulary acquisition, however, and in particular in the
acquisition of collocations, the end product is not as obvious. For example,
when the learner uses 'bad milk', the end product cannot be confidently
determined. It is possible that the learner is trying to say 'sour milk', or even
that 'the milk is off'.
Due to the above limitation, this study aimed to explore 'patterns' or
'acquisition/difficulty/accuracy orders' rather than 'stages' of development in
the acquisition of collocations. Thus, development in the acquisition of
collocations is in the form of sequences or implicational steps of correctly used
English collocations by learners at different proficiency levels.
For the purposes of the present study, ESL learners from three different
proficiency levels were tested in their free and cued production of collocation
types as these are operationalised in the BBI and other studies on collocations
(see Biskup 1992; Zhang 1993). The proficiency level of the selected L2 learners
200

was based on the assumption that collocations are important for the early
stages of language acquisition and for the following years of vocabulary
development (Greenbaum 1974). Thus, the subjects in this study were at post-
beginner, intermediate, and post-intermediate levels of proficiency.
The correctly used collocations were sequenced to reveal implicational
orders from 'easy' or 'early acquired' collocation types to 'difficult' or 'late
acquired' types. In this way any systematic patterns of development in the
acquisition of collocations would emerge. As a result of the foregoing, there are
two hypotheses tested in this study:
i) There are stable patterns of development of collocational knowledge across
language proficiency levels.
ii) There are stable patterns of development of collocational knowledge
within language proficiency levels.
The next chapter describes the methodology of this study.
201

CHAPTER 3
METHODOLOGY FOR THE PRESENT STUDY
3.0 Introduction
This chapter specifies the methodology of the present study. It describes
the development of the testing materials, the data collection procedures, the
coding and scoring of the data, and the analyses to be performed in order to
test the two predictions:
1. There are stable patterns in the development of collocational
knowledge across language proficiency levels.
2. There are stable patterns in the development of collocational
knowledge within proficiency levels.
3.1 Analysis of the Teaching Materials
For the purposes of the present study an initial analysis and
classification of the collocations found in three textbooks, namely Task Way
202

English 1, 2 & 3, was performed. These textbooks are used in all the State
Junior High Schools in Greece for the teaching of English.
The Task Way English(TWE) series was designed by a five member
English Language Teaching (ELT) committee appointed by the Greek Ministry
of Education. All the members of the committee were Greek and their aim was
to design a series of textbooks for the teaching of English in the State Junior
High Schools that will meet the interests and needs of Greek students.
3.1.1 Curriculum Objectives
The objectives of the Junior High School ELT curriculum were reformed
under the task-based approach to foreign language learning adopted by the
authoring committee of the series. According to the committee, the new
objectives were "related to knowledge of language as a system and to language
as a means of communication" (Dendrinos 1988:2) and the TWE series was
designed to realise these objectives through role-play tasks, listening activities,
and emphasis on communicative competence.
3.1.2 Syllabus and Methodology
The syllabus for each of the three textbooks is graded in terms of both
grammar and the communicative functions of language: the contents page for
each book describes for each unit the title, the grammar points included, and
the language functions that are to be practised. The aim of the textbooks, as
203

outlined by the authoring team, is to develop the learners' communicative
competence and provide them with practice in using the target language. The
authors of the TWE series wanted to adopt a methodology that follows the
principles of "process-oriented learning" (Dendrinos 1988:5). Such a
methodology, the authors of the books claim, has made the grading of the
formal, semantic and pragmatic properties of language "far less important than
the sequencing of the learning tasks" (Dendrinos 1988:5).
3.1.3 Activities and Tasks
Each unit in the textbooks has a central theme, which is further divided
into several topics and issues leading to situations where the learner is invited
to participate by using her/his communicative skills. Before each task is
performed, the sociolinguistic context of the situation is given.
The team of authors designed the tasks, aiming to develop in learners
both receptive and productive skills and to encourage them to discover new
knowledge rather than impose it on them. They also wanted to offer the
students opportunities for metacognition and metacommunication (Dendrinos
1988:6). For example, learners are asked to look at the usage of different
grammar tenses in a comparative way, or they are informed about the roles of
certain grammatical structures, e.g. Passive Voice is used when we are
interested in the action rather than the agent (TWE3, p.57).
The last part of each unit in the three textbooks aims to help the learner
systematise the knowledge that she/he acquired throughout the unit. For
204

example, in TWE2, Unit 6, p. 84, an alphabetical list of more than eighty English
verbs with irregular past tense forms is presented in order to help learners
systematise their knowledge of irregular past tense verb forms. However, the
effectiveness of such tasks depends to a large extent on the way these are
presented to the learners, and the use that learners make of them.
The writers of the series did not design activities that could raise the
students' awareness of collocations in a systematic way. In TWE1, there is only
one activity that asks students to list nouns that could be accompanied by a
certain adjective, e.g. big: toe, finger, foot, hand, mouth, ear, eye. In TWE2,
there are no activities that would help learners acquire specific collocations.
Finally, in TWE3, there is one activity in which students are asked to make
adjective-noun and noun-noun compounds using specific words on a list, e.g.
'classified advertisement', 'natural resources', 'entertainment section'.
Instructors follow the curriculum closely and the TWE series textbooks
are the only textbooks used in the classroom. So the textbooks control the
learners lexical acquisition in the classroom.
3.1.4 The Use of L1
The learners' L1, Greek, is used in the textbooks in order to describe the
context of the tasks to the students, to tell them how to carry out the task, and
in some instances to give rules of language use. The use of Greek is much more
extensive in the first book, which is aimed at beginners.
205

3.1.5 The Vocabulary
The authors report that due to the communicative purposes of the
textbooks, "the vocabulary which appears in different discourse types has not
been chosen with any formal criteria in mind, while it has not been strictly
graded" (Dendrinos 1988:4).
For the purposes of this study, and in order to understand the linguistic
environment that the subjects of this study have been exposed to, the
vocabulary of the textbooks was analysed in terms of types of collocations. The
list of 37 types of collocation developed by the BBI was used (see Chapter 1).
The classification was performed manually by the researcher. Inter-rater
reliability of 90% was achieved with one other rater on a random 5% sample of
the total number of pages analysed, and it was considered to be sufficient. The
results were entered in a database using the Quattro Pro 3.0 software program.
Descriptive statistics were then calculated.
3.1.6 Descriptive Statistics for the TWE Series
There is a steady increase of the English collocations included in the
books (Figure 1). TWE1 contains 2,161 collocations, TWE2 contains 3,922
collocations, and TWE3 contains 5,901 collocations. Token-type ratios were
calculated for each book (see Table 7).
206
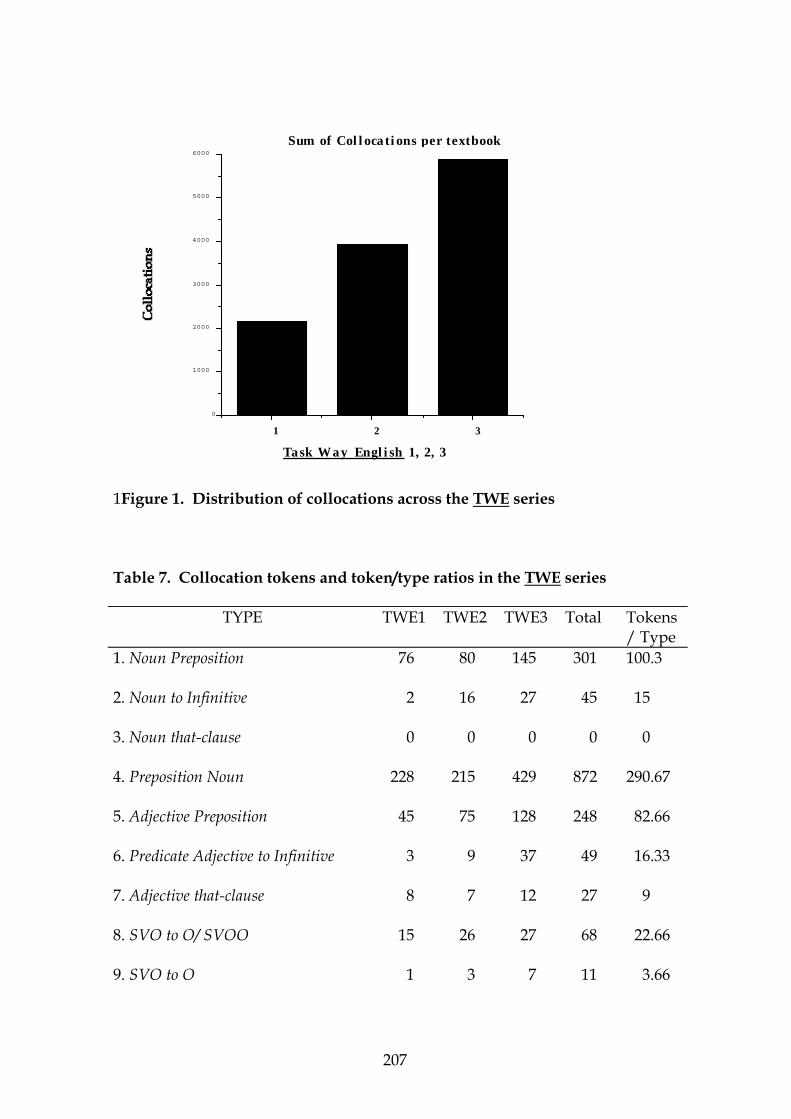
1 2 3
0
1000
2000
3000
4000
5000
6000
Sum of Col l oca ti ons per textbook
Task Way Engl i sh 1, 2, 3
1Figure 1. Distribution of collocations across the TWE series
Table 7. Collocation tokens and token/type ratios in the TWE series
TYPE TWE1 TWE2 TWE3 Total Tokens/ Type
1. Noun Preposition 76 80 145 301 100.3
2. Noun to Infinitive 2 16 27 45 15
3. Noun that-clause 0 0 0 0 0
4. Preposition Noun 228 215 429 872 290.67
5. Adjective Preposition 45 75 128 248 82.66
6. Predicate Adjective to Infinitive 3 9 37 49 16.33
7. Adjective that-clause 8 7 12 27 9
8. SVO to O/ SVOO 15 26 27 68 22.66
9. SVO to O 1 3 7 11 3.66
207
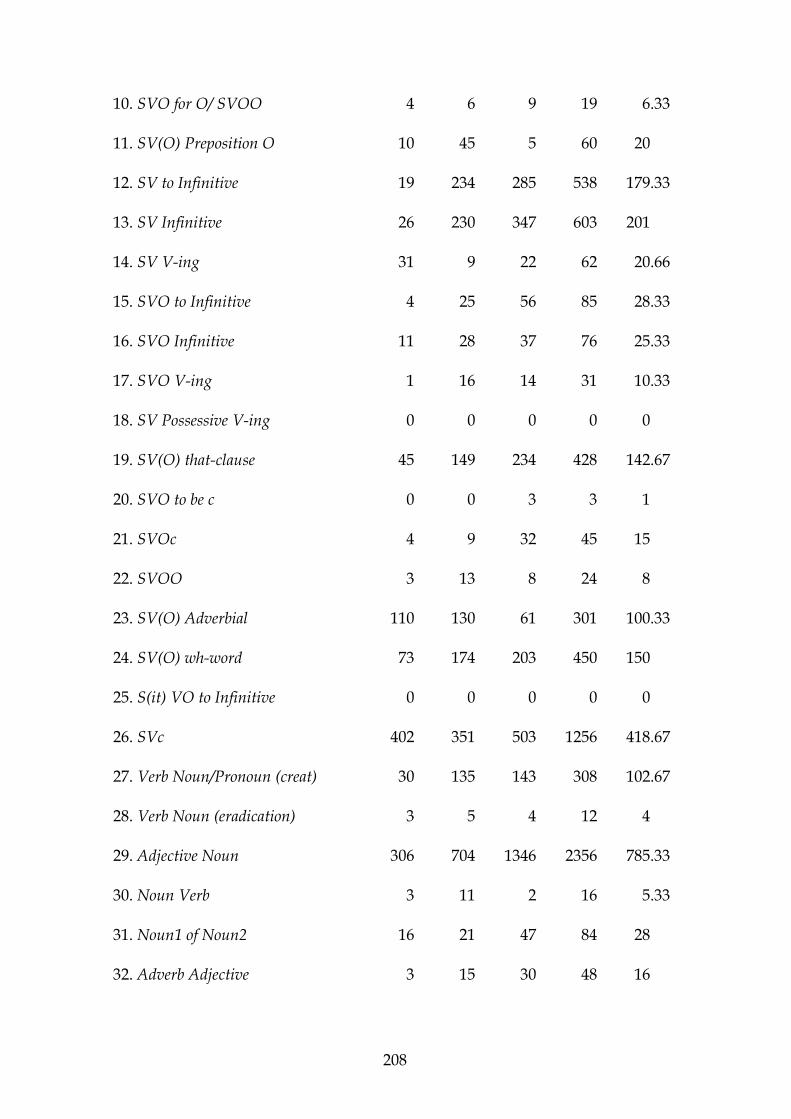
10. SVO for O/ SVOO 4 6 9 19 6.33
11. SV(O) Preposition O 10 45 5 60 20
12. SV to Infinitive 19 234 285 538 179.33
13. SV Infinitive 26 230 347 603 201
14. SV V-ing 31 9 22 62 20.66
15. SVO to Infinitive 4 25 56 85 28.33
16. SVO Infinitive 11 28 37 76 25.33
17. SVO V-ing 1 16 14 31 10.33
18. SV Possessive V-ing 0 0 0 0 0
19. SV(O) that-clause 45 149 234 428 142.67
20. SVO to be c 0 0 3 3 1
21. SVOc 4 9 32 45 15
22. SVOO 3 13 8 24 8
23. SV(O) Adverbial 110 130 61 301 100.33
24. SV(O) wh-word 73 174 203 450 150
25. S(it) VO to Infinitive 0 0 0 0 0
26. SVc 402 351 503 1256 418.67
27. Verb Noun/Pronoun (creat) 30 135 143 308 102.67
28. Verb Noun (eradication) 3 5 4 12 4
29. Adjective Noun 306 704 1346 2356 785.33
30. Noun Verb 3 11 2 16 5.33
31. Noun1 of Noun2 16 21 47 84 28
32. Adverb Adjective 3 15 30 48 16
208

33. Verb Adverb 58 173 146 377 125.67
34. Noun Noun 197 319 498 1014 338
36. Preposition Determiner Noun 240 345 454 1039 346.33
37. Phrasal Verb 184 344 600 1128 376
TOTAL OCCURRENCES 2,161 3,922 5,901 11,984 ------
As can be seen from Table 7, there were also collocation types for which
no instances of collocations were found in any of the books:
Type 18. SV Possessive V-ing
Type 25. S(it)VO to Infinitive
Type 3. Noun that-clause
These categories have not been included in the calculation of the means
and standard deviations for each textbook that appear below.
A look at the mean number of collocations found in each book confirms
this steady increase of collocations, see Table 8. The standard deviation was
also calculated for each book, see Table 8, and it was found that as the level of
English progresses in the TWE series the variability from the central point in
the distribution of scores becomes greater, that is, some types of English
collocations are represented by a large number of tokens, which gets even
larger in the third book of the series, while in other types the occurrences
remain consistently low. It also appears that the scores are much more spread
209

out in the second and third books than in the first one, which has generally low
levels of English collocations.
Table 8. Means and standard deviations per textbook
BOOK MEAN STD
TWE 1 61.5 97.01
TWE 2 111.1 150.1
TWE 3 167.8 261.9
As we can also see in Table 7 above, most of the collocation types have a
small number of tokens in all three books, a few have a medium sized number
of tokens, and only a couple have a high number of tokens. This indicates that
some types are represented more than others in the TWE series.
There is little recycling of collocations across the three books. For about
half of the collocation types there were no common collocations appearing in all
three books. The largest amount of recycled collocations across the three books
are under the following types:
Type 24. SV(O) wh-word (13 tokens appearing in all three books);
Type 37. Phrasal Verb (18 tokens appearing in all three books);
Type 36. Preposition Det Noun (11 tokens appearing in all three books); Type 4.
Preposition Noun (11 tokens appearing in all three books).
210

A closer look at these categories revealed the following:
i) Type 24. SV(O) wh-word - The collocations that belong to this category and
appear in all three books are instructions mainly for carrying out role-play tasks
- e.g. "ask if she has got a brother" (TWE1, Unit 5, p.66).
ii) Type 37. Phrasal Verb - Most of the recycled collocations in this category also
appear in task instructions - e.g. "try to fill in the 'What is Done By Whom'
table" (TWE3, Unit 3, p.47).
From the above, it appears that most of the recycled collocations are
mainly standard expressions used for giving instructions to the students about
the task they are asked to perform.
A close look at the textbook data shows that there is little recycling of the
collocations used in TWE1 and TWE2, and TWE1 and TWE3. TWE2 and TWE3
appear to be more compatible as they have 329 collocations in common.
However, an examination of these 329 collocations revealed that one third of
them (28%) belonged to the types used for task instructions (see above).
3.2 Subjects
Three groups of Greek students of English were involved in the present
study. They were all learners from the same Greek Junior High School and
were taught English via the TWE coursebooks. The first group consists of
students in the first year of Junior High School, the second one consists of
students in the second year of Junior High School, and the third group
comprises students in the third year of Junior High School.
211

The Junior High School that participated in the study used the TWE
series, and it was situated in an urban area, i.e. Veria which is the capital of the
prefecture of Imathia, to ensure that its students were mainly from the same
town rather than from the nearby villages. Permission was obtained from the
Principal of the Junior High School and the Department of Education for
Secondary Schools, as the research would engage the participating students for
one hour and forty minutes for the completion of the test.
There were 347 subjects participating in the study: 107 subjects for the
first group, 125 subjects for the second group, and 115 subjects for the third
group. All subjects were between 12 and 15 years of age. They were Greek
nationals who were native speakers of Greek, and they all had the same level of
formal education. These subjects had to be screened with regard to their
language proficiency and their production of collocations, and hence those
subjects that had not written an essay were not included in the study (see
3.5.2.). Ultimately, there were 275 subjects included in the study: 91 subjects for
Group 1, 94 subjects for Group 2, and 90 subjects in Group 3. The subjects'
mean age for each group was calculated: 12 years and 9 months for Group 1, 13
years and 8 months for Group 2, and 14 years and 7 months in Group 3 (see
Appendix A).
The study was conducted three teaching weeks before the end of the
school year in Greece. By this time students were in the final chapters of their
books and under revision in preparation for the annual exams which follow the
end of the school year.
212

3.3 Materials
The test instrument used for the data collection consisted of a
questionnaire eliciting background information about the subjects, and a
battery of three tests: an essay writing task eliciting free-production data, a
translation task, and a blank-filling task eliciting accuracy in the use of
collocations. The purpose and the contents of the materials are examined in
detail below.
3.3.1 Questionnaire
The first part of the test instrument was a questionnaire in Greek aiming
to elicit information about the students' background. There were 15 questions,
10 open ended and 5 closed ones, asking information such as the students' age,
sex, recent marks in English, how many languages they speak, whether they
had any additional exposure in English, when they started learning English,
how often they watch English movies with Greek subtitles or without subtitles,
how often they read English books and/or newspapers, how often they listen
to English songs, whether they speak English with their friends, and whether
they correspond with pen friends in English. The questionnaire was the same
for all three groups. See Appendix A for information on the subjects' gender
and age and Appendix B for the English translation of the questionnaire.
213

3.3.2 Composition
The first test in the battery of tests was a composition task measuring
free production of collocations. Students were asked to write an essay of
approximately 200 words on a given topic. There were different topics for the
three different groups and each topic had been covered in the textbook of the
particular group. The topic for each group was given in Greek (see Appendix C
for the topics in Greek and their English translations).
3.3.3 Translation
The second test consisted of an elicited translation task. The translation
test measured cued production of collocations. There were 10 sentences in
Greek for each group, and the subjects were asked to translate them into
English (see Appendix D for a word-by-word English translation of the Greek
sentences and their expected translations in English). Each sentence tested one
collocation. The collocations included in the translation test were selected from
the database of the collocations found in the students' textbooks, and each
collocation included in the test was different from its Greek equivalent, e.g.
'draw conclusions' is 'take out conclusions' in Greek.
The types of grammatical and lexical collocations tested in the elicited
translation task for each group are given below in Table 9.
Table 9. Collocation types included in the translation test.
214

TYPES Group1 Group2 Group3
1. Noun Preposition 2 2 2
5. Adjective Preposition 1 2 2
11. SV(O) Preposition O 2 2 1
13. SV Infinitive 1 0 1
14. SV V-ing 1 1 1
16. SVO Infinitive 1 1 1
23. SV(O) Adverbial 1 0 0
27. Verb Noun (creation) 1 2 2
TOTAL: 10 10 10
3.3.4 Blank-Filling
Finally a blank-filling test was also included. This test measured cued
production of collocations. There were a number of sentences in English (50
sentences for Group 1, 65 for Group 2, and 90 for Group 3), containing
collocations in context. Each sentence contained one collocation. In each
sentence, one part of the collocation was replaced by a blank and students were
asked to read the sentence and provide one suitable word for each blank. As
with the translation test, the collocations tested in the blank-filling test were
selected from those appearing in the students' textbooks, and they were
different from their Greek equivalents (see Appendix E for the sentences
215

included in the blank-filling tests with the intended collocations underlined and
the missing part bolded).
All parts of the tests were typed. There were instructions in Greek for
each part of the test.
The types of grammatical and lexical collocations tested in the elicited
translation and the blank-filling tasks for each group are given below in Table
10.
Table 10. Collocation types included in the blank-filling test.
TYPES Group1 Group2 Group3
1. Noun Preposition 1 5 3
4. Preposition Noun 3 6 7
5. Adjective Preposition 5 5 15
11. SV(O) Preposition O 12 14 27
23. SV(O) Adverbial 1 1 2
24. SV(O) wh-word 2 1 3
27. Verb Noun (creation) 6 10 11
28. Verb Noun (eradication) 0 0 2
29. Adjective Noun 1 0 2
30. Noun Verb 1 0 0
31. Noun1 of Noun2 3 1 0
33. Verb Adverb 1 3 1
34. Noun Noun 2 1 1
216

36. Preposition Determiner Noun 6 11 12
37. Phrasal Verb 6 7 4
TOTAL: 50 65 90
3.4 Data Collection Procedures
In the following sections, the procedures followed by the researcher for
the collection of data are reported.
3.4.1 Test Administration
The test was administered on three consecutive days: one day for each
group. All subjects for each group were tested on the same day. All the
subjects belonging in a particular group were tested together. During the data
collection, the researcher personally monitored the testing.
The subjects were told that their school had agreed to participate in a
research project undertaken by the Centre for Language Teaching and Research
of the University of Queensland. Their knowledge of English was to be
assessed using a test and the collective results of their performance would be
forwarded to their school after the completion of the project. A complementary
copy of the Macquarie Dictionary of Australian English would be donated to
the school library for student use as a reward for their participation to the
testing. Subjects were assured that the data would be treated confidentially
and would not affect their course marks.
217

After the tests were distributed to the subjects, they were asked to first
complete the questionnaire, then to write the essay, then to do the translation
task and finally to complete the blank-filling task. The researcher explained
what each test required the students to do. All test instructions were written
and spoken in Greek. The questionnaire and the topic for the essay were
written in Greek, while the translation and the blank-filling test were
introduced by instructions in Greek asking students to translate and fill in the
sentences respectively (see Appendix F for the exact wording of the
instructions).
Subjects were then asked to complete the tests. They were encouraged
to ask the researcher about anything in the test they might find difficult to
understand, or any unknown words. Even though the vocabulary used for the
test items came out of the students' textbooks, the researcher realised that the
students might not remember certain words under the pressure of time.
Therefore, any words unknown to the students were explained by the
researcher, with care taken that the particular words were not giving away the
answers to any of the test items. Such cases were limited only to subjects in
Group 1 because of their low level of English.
The subjects were allowed one hour and thirty minutes to complete the
test, and they were told that they should not leave any of the test items
unanswered.
218

Students finishing earlier than expected were asked to remain seated and
revise their tests, e.g. try to expand their composition. When the time was up
all of the subjects had finished and they were allowed to leave the room.
The same procedure was followed for each day of the testing, until all
three groups of subjects had been tested.
3.4.2 Debriefing
At the end of the last day of testing, the researcher had a meeting with
the two English teachers of the school during which she explained the purpose
of the testing and the research project. She also asked them to complete a
questionnaire about the use of the TWE coursebooks and the teaching of
collocations in the classroom (see Appendix G for the teachers’ questionnaire).
This information was to be used later in the data analysis and the discussion of
the results.
3.5 Coding Procedures
Each set of data from the three tests was coded and scored according to
the following criteria.
3.5.1 Free Composition
219

The data obtained from the free composition were treated as evidence of
both language proficiency and of collocational use. As language proficiency
data, the essays were analysed with respect to six different measurements:
holistic rating, target-like use of articles, lexical density, length of terminal
units, error-free terminal units, and sentence-nodes per terminal unit. The use
of each of the six measures is explained below.
i) Holistic Rating
The free compositions were scored on a holistic scale of 1-100 which is a
standardised and widely used scale compiled by Jacobs, Zinkgraf, Wormuth,
Hartfiel and Hughey (1981) (see Appendix H for a list of the criteria for
scoring). Each composition was assessed by two raters. The raters were native
speakers of English and experienced English teachers.
Each essay received two scores, one from each rater. In cases where the
two raters had more than ten points difference in their evaluation of a
particular essay, the essay in question was scored by a third rater. If the third
rater gave a score that was half way between the previous two scores, e.g. Rater
1 gave a 50, Rater 2 gave a 30, and Rater 3 gave a 40, then the third rater's score
was counted, and the previous two ignored. If the third rater gave a score that
was the same as or closer to one of the previous two scores, then the third score
and the closest other score were averaged and the estimated score was given to
the essay, e.g. Rater 1 gave a 50, Rater 2 gave a 30, Rater 3 gave also a 30, the
scores from Rater 2 and Rater 3 were averaged, while Rater 1 was ignored. If in
220

the previous case Rater 3 gave a 60, then Rater 1 and Rater 3 would be
averaged, and Rater 2 would be ignored. In 32 out of 275 essays (11.6%) where
a third rater was needed, the score from the third rater had no more than nine
points difference with at least one of the previous two scores. Finally, each
essay received a score on a scale 1-100 based on the average of the two ratings.
ii) Target-Like Use of Articles
The analysis of the Target-Like Use (TLU) of articles was performed by
the researcher. TLU is an accuracy measure. As in Pica (1983), the number of
accurately supplied articles (definite and indefinite) in obligatory contexts were
counted and divided by the overall number of obligatory contexts in the essay
(whether an article was provided in them or not) plus the number of
non-obligatory contexts with inappropriate articles multiplied by 100. The
TLU percentage score was recorded for each essay.
Inter-rater reliability was performed on a sub-set of the ratings randomly
sampled from the entire set of data. 5% of the data (i.e. 15 essays) was rated in
this way by two other raters and the inter-rater reliability was at 99%. The
raters were given a random selection of 15 essays, 5 essays from each sample,
and an instruction sheet, which reported what the measurement was and what
each rater was required to do (see Appendix I). The raters were given a short
training session by the researcher on the TLU analysis on two other essays.
After the raters had performed the measurement on the sample essays, the
researcher's and each rater's ratings were compared. In a total of 235 accurate
221

and inaccurate suppliance and omission of articles, there were two instances of
disagreement between the researcher and one of the raters in one of the essays.
In essay 13 from Group 1, there was an ungrammatical sentence, "He plays
basketball and sometimes he plays tennis or going with friends for jogging".
The researcher had considered the phrase "going with friends for jogging" as a
non-obligatory context for an article, provided that it was read as "going (for)
jogging with friends", while the rater had marked it as an obligatory context for
the use of an indefinite article, if it was read as "going with friends for a
jog(ging)". After the case was discussed, both the researcher and the rater
agreed that "going with friends for a jog" was closer to what the student had
written, and as such it was an obligatory context for an article. The second
instance was the phrase "she often climbs on the mountains" in the same essay.
Here the researcher had considered that the phrase did not need an article,
while the rater had marked it as correct, assuming that the student was
probably talking about a specific group of mountains. After discussion it was
agreed that the omission of the article was much more general and
consequently appropriate, especially since the student did not refer any further
to particular mountains in his essay. For the rest of the essays, there was total
agreement between the researcher and the raters.
iii) Lexical Density
A Lexical Density analysis (LD) was also performed by the researcher.
Lexical Density refers to the number of lexical, or 'open class', words divided by
222

the total number of words in each essay and multiplied by 100 (see Long 1991,
unpublished paper; Linnarud 1986). For this analysis a number of criteria were
defined: abbreviations such as 'etc.', 'e.g.' were not counted at all; proper names
were not counted as lexical words (in Group 1 the students were asked to
describe themselves and their family, so in each essay there was a considerable
number of Greek names that did not really contribute to the semantic richness
of the essay and so they were not considered to be lexical words, see also
Palmberg 1987:212); names of places in Greece were not counted as lexical
words (see above); numbers were not counted as lexical words; adverbs other
than those ending in -ly were not counted as lexical words; the verb 'do' was
not counted as a lexical word, even when it was used as a main verb; misspelt
words that could be easily recognised as English words either in writing or
when pronounced according to the Greek or English phonetic system were
counted (in this case it was assumed that the student knew the word and was
attempting to use it, see also Palmberg 1987:205); words written in Greek were
not counted at all.
Inter-rater reliability was also obtained for the LD analysis from two
other raters on 5% of the data, which randomly sampled (i.e. 15 essays), and
was at 98%. Each rater was given the same sample of essays that the TLU raters
were given and an instruction sheet (see Appendix J) and were asked to
underline the lexical words in each essay. A short training session was given
by the researcher on two other essays. After the raters performed the LD
analysis on the sample essays, the researcher's and each rater's ratings were
223

compared. There were three instances in which one of the raters had
underlined the verb "going" as a lexical word in phrases in which it was an
auxiliary, and as such it was a grammatical rather than a lexical word, e.g.
essay 37 Group 3 "we are going to do everything". In one case the adverb
"hard" was underlined as a lexical word even though it did not end in -ly.
Finally, words such as "other" and "everybody" were underlined by the raters
even though they were clearly grammatical words, while there were cases in
which the raters should have underlined words such as "think", "way", "worst",
"better", "use", "thanks" but they did not. Overall, there was agreement
between the researcher and the raters in the LD analysis in 1264 out of 1280
lexical words, and the inter-rater reliability was considered sufficient for the LD
measurement.
iv) Terminal-Units
The essays were also analysed with respect to the number of terminal
units (T-Units) they contained. All the main clauses plus any subordinate
clauses attached to or embedded in them were counted as T-Units (see Long
1991, unpublished paper; Hunt 1966). A T-Unit is a structural discourse unit
and it was used in this study in three different measures: length of T-Units,
Error-Free T-Units, and S-Nodes per T-Unit. Inter-rater reliability for the
number of T-Units was also obtained from two other raters on a randomly
sampled sub-set of the data (5% of the data), and was at 97%. Each of the raters
was given the same sample of essays and the T-Unit instructions (see Appendix
224

K) and were asked to mark all the T-Units in each essay. A short training
session was given by the researcher on two other essays. After the
measurement, the number of T-Units marked by the raters and the researcher
were compared and the inter-rater reliability (97%) was considered sufficient
for the T-Units measurement.
v) Length of T-Units
After the T-Units per each essay were calculated, the average length for
the T-Units in each essay was estimated by dividing the total number of words
in each essay by the number of T-Units in that essay (see Larsen-Freeman 1978),
e.g. an essay with 186 words and 25 T-Units had 7.44 as the average length of a
T-Unit. This was a complexity measure.
vi) Error Free T-Units
The number of error-free T-Units per each essay was also calculated as
an accuracy measure. Only T-Units that were free from grammatical, syntactic,
lexical, spelling and punctuation errors were counted as Error-Free T-Units (see
Larsen-Freeman 1978). Inter-rater reliability on a randomly sampled sub-set of
the data (15 essays) was also obtained from two other raters, and was at 97%.
Each of the raters was given the same sample of essays and instructions for
counting the Error-Free T-Units in each essay (see Appendix K). A short
training session was given by the researcher on two other essays. After the
225

measurement, the number of Error-Free T-Units marked by the raters and the
researcher was compared, and the inter-rater reliability (97%) was considered
sufficient for the Error-Free T-Units measurement.
vii) S-Nodes per T-Unit
The essays were also analysed with respect to the number of sentence
nodes (S-Nodes) they contained. This was a measure of syntactic
accumulation. The number of underlying sentence nodes, indicated by tensed
and untensed verbs, was calculated for each essay and then the average
number of S-Nodes per T-Unit was estimated by dividing the number of S-
Nodes in each essay by the number of T-Units in that essay (see Long 1991,
unpublished paper). Inter-rater reliability on 5% of the data was also obtained
from two other raters, and was at 98%. Each of the raters was given the same
sample of essays and instructions for counting the S-Nodes in each essay (see
Appendix L). A short training session was given by the researcher on two
other essays. After the measurement, the number of S-Nodes marked by the
raters and the researcher were compared and the inter-rater reliability (98%)
was considered sufficient for the Error-Free T-Units measurement.
3.5.2 Use of Collocations in the Essays
The subjects' performance on the free composition task served not only
as a measurement of the subjects' writing proficiency in English (see above), but
226

also as a measurement of their free production of collocations. Test papers in
which no composition was given, either because of the particular subject's
inadequate level of English or because of lack of time, interest etc., were not
included in the study. Thus, there were 275 complete test papers: 91 complete
test papers in Group 1, 94 in Group 2, and 90 in Group 3.
The essays were then analysed with regard to the collocations they
contained. The students' production of the 37 different collocation types as
these are operationalised in this study (see Chapter 1) was recorded as
frequency data. Where the students provided a correct collocation they were
marked as having used a token of the particular type in which the collocation
belonged. Misspelt collocations were recorded as evidence of collocational use.
Each collocation found in the essays was checked against the collocations
included in the BBI. If the particular collocation was included in the BBI it was
recorded as correct evidence of use of the particular collocation type (see also
Zhang 1993). If it was not included in the BBI it was discarded. There were
13.1% of rejected collocations in all three groups. These collocations were
mainly Adjective Noun combinations with 'big' or 'good' as the adjective. Such
collocations are considered 'free combinations' by the BBI writers and they are
not listed in the BBI (Benson et al. 1986a:xxiv).
The quantity of collocations found in each essay for each of the 37 types
was also recorded as well as the percentage of the type-token ratio. Inter-rater
reliability of 90% was obtained for 5% of the data.
3.5.3 Translation
227

The data from the translation task were scored both as frequency data
and as accuracy data. As frequency data the answers in the translation test
were marked using a binary code: when students used the correct collocation
they received 1, and when they used the wrong collocation or they provided no
collocation at all, they received 0. As accuracy data, the mean accuracy of
response to each collocation type in the translation test was recorded. Spelling
mistakes were disregarded. For a list of the types of collocations tested in the
translation test see Table 9 above.
3.5.4 Blank-Filling
The data from the blank-filling test were also recorded both as frequency
data and as accuracy data. As frequency data, the same binary coding was
used as for the translation data. As accuracy data, the mean accuracy of
response to each of the collocation types included in the blank-filling test was
recorded. Spelling mistakes were disregarded. In the few cases where the
students provided a collocation that did not match with the target one, but
which belonged to the same collocation type, the collocation was recorded as
correct. For a list of the collocation types tested in the blank-filling test see
Table 10 above.
3.6 Analyses
228

In the following section, the analyses of the language proficiency
measures and the two hypotheses investigated by this study are outlined.
3.6.1 Language Proficiency Measures
Before testing the hypotheses it was necessary to perform a number of
language proficiency measures on the free production data in order to
determine that there are different levels of language proficiency in the groups.
The analyses performed included the following measurements: holistic rating,
target-like use of articles, lexical density, length of T-Units, error-free T-Units,
and S-Nodes per T-Unit. A six-way factorial MANOVA was calculated on the
scores obtained by the six different measures in order to determine whether the
three samples were different with respect to all six measures.
Following that, six one-way ANOVAs were then calculated for each of
the six measures.
3.6.2 Analyses for the Hypotheses
The analyses performed for testing the two hypotheses are described
below.
i) Analysis for Hypothesis 1
229

To address Hypothesis 1, that there are stable patterns of development in
the acquisition of collocations across proficiency levels, non-parametric
Kruskal-Wallis tests were performed on the data. Kruskal-Wallis is the non-
parametric equivalent of ANOVA. Due to the wide range of types of
collocations that were used in the analysis of the essay data, and the unequal
number of tokens for each of the types of collocations tested in the translation
and the blank-filling tests, the data were not expected to be normally
distributed and thus non-parametric statistics were considered suitable to
address the first hypothesis. Previous studies on collocations used non-
parametric statistics too (see Zhang 1993).
For the free production essay data that resulted from the analysis of the
students' essays, Kruskal-Wallis tests followed by Dunn's multiple comparison
procedures were performed on the mean tokens of each of the 37 collocation
types used by subjects in each group.
For the cued production translation data non-parametric Kruskal-Wallis
tests followed by Dunn's procedure were performed on the mean accuracy of
responses to each of the 6 types of collocations repeated across the three
groups.
For the cued production blank-filling data non-parametric Kruskal-
Wallis tests followed by Dunn's procedure were performed on the mean
accuracy of responses to each of the 11 types of collocations repeated across the
three groups.
230

Implicational scaling analysis for each of the three sets of data was also
performed in order to reveal any acquisition orders. The frequency data were
used for this analysis. For each implicational scale the Guttman's coefficients of
reproducibility and scalability were then calculated (Hatch & Lazaraton 1991:204)
in order to test the validity of the scales and the scalability of the items on the
scales.
ii) Analysis for Hypothesis 2
To address Hypothesis 2, that there are patterns of development in the
acquisition of collocations within proficiency levels, non-parametric Friedman
repeated measures tests were performed on each group for each set of data, i.e.
three Friedman tests per each set of data. Friedman repeated measures test is
the non-parametric equivalent for ANOVA repeated measures test. These tests
were followed by Nemenyi's multiple comparisons tests based on the Friedman
rank sums. The analysis for Hypothesis 2 also includes those collocation types
that were not repeated across groups.
For the free production essay data, separate repeated measures
Friedman tests were performed for each group on the tokens for each of the 37
types of collocation found in the students' essays, followed by Nemenyi's
multiple comparison procedures. Implicational scaling analyses using the
frequency data for each group were also performed and the Guttman's
coefficients of reproducibility and scalability were calculated.
231

For the cued production translation data, separate repeated measures
Friedman tests were performed for each group. There were 8 types of
collocation for Group 1, 6 types for Group 2, and 7 types for Group 3. These
tests were followed by Nemenyi's multiple comparisons procedures.
Implicational scaling analyses using the frequency data for each group were
also performed and the Guttman's coefficients of reproducibility and scalability
were calculated.
For the cued production blank-filling data, separate repeated measures
Friedman tests were performed for each group. There were 14 types of
collocation for Group 1, 12 types for Group 2, and 13 types for Group 3. These
tests were followed by Nemenyi's multiple comparisons procedures.
Implicational scaling analyses using the frequency data for each group were
also performed and the Guttman's coefficients of reproducibility and scalability
were calculated.
The following chapter presents the results of the analyses.
232

CHAPTER 4
ANALYSES AND RESULTS
4.0 Introduction
This chapter describes the results from the language proficiency
measures and the main analyses performed to address the two hypotheses
listed in 2.5. The presentation of the results is organised around the three sets
of data used to address each of the hypotheses: the free production essay data,
the elicited production translation data and the elicited production blank filling
data. In section 4.1 the results from the language proficiency measures
performed on the essay data are reported. The aim of these measures was to
screen the data and establish clear proficiency differences among the three
groups, using different measures of language proficiency on the essay data.
This initial screening of the data was considered necessary, since the
proficiency differences between groups are the major independent variable for
the present study.
In 4.2 the results of the main analyses of each set of data are described.
The analyses and results for Hypothesis 1 are first reported in 4.2.1. The aim of
these analyses was to examine evidence for developmental differences in the
knowledge of collocations, assessed both in terms of ability to use collocations
in the essay data, and in terms of accuracy of response to questions eliciting
collocations in the translation and blank filling data. These analyses involved
233

comparisons of collocation use and accuracy between groups using Kruskal-
Wallis tests. The Kruskal-Wallis one-way analysis of variance by ranks is a
non-parametric test for deciding whether a number of independent groups are
from different populations (Siegel & Castellan 1988:206). Evidence for
acquisition orders was then sought using implicational scaling of: i) the use of
collocations in essays across all groups, and ii) mean accuracy of response to
collocation types on the translation and blank filling tests across all groups. In
this way it was hoped to show what differences existed in the subjects'
knowledge of collocations across different proficiency levels, and how
knowledge of collocations developed. This evidence was used to address the
first hypothesis, which states that there are patterns in the development of
collocational knowledge across all groups.
Analyses and results for Hypotheses 2 are described in section 4.2.2
These analyses involved comparisons of collocation use and accuracy within
each group using Friedman Repeated Measures tests, which is a parallel non-
parametric test for repeated-measures ANOVA. Evidence for acquisition
orders within groups was then examined using implicational scaling of
collocation use and accuracy for each group. The aim of these analyses was to
show what developmental differences and sequences existed in the use of
collocations within groups. These results would reveal any group-specific
patterns in the development of collocational knowledge.
The results of all the analyses are summarised in 4.3 in relation to the
two hypotheses of the study.
4.1 Language Proficiency Results
234

In this section the results of the analyses performed to determine the
proficiency differences between the three groups are described.
4.1.1 Descriptive Statistics
Prior to performing the MANOVA for the six measurements on the free
production data, the data were examined with regard to the normality of their
distribution. The data for each group were tested for kurtosis and skewness.
The results are reported below.
4.1.1.1 Descriptive statistics for Group 1
The results of the descriptive analysis of the data for Group 1 show
normal distributions for the majority of the dependent variables: Holistic
Rating (Kurtosis: -.689, Skewness: -.162), Words per T-Unit (Kurtosis: -.183,
Skewness: .209), and Error-Free T-Units (Kurtosis: -.669, Skewness: .513). The
results of the analysis for the dependent variable Target-Like Use of Articles
also show no significant effects for kurtosis or skewness (Kurtosis: -1.099,
Skewness: -.229). Results of the analysis for the dependent variable Lexical
Density reveal a slightly peaked distribution (Kurtosis: 1.301, Skewness: -.54).
Finally, the results of the analysis for the dependent variable S-Nodes per T-
Unit show a distribution that is positively skewed and peaked (Kurtosis: 2.514,
Skewness: 1.51).
4.1.1.2 Descriptive Statistics for Group 2
The results of the analysis for the data in Group 2 reveal normal
distributions for the dependent variables: Holistic Rating (Kurtosis: .12,
Skewness: -.447), Target-Like Use of Articles (Kurtosis: .134, Skewness: -.747),
and S-Nodes per T-Unit (Kurtosis: .251, Skewness: .611). The data for Lexical
235

Density (Kurtosis: 7.005, Skewness: 1.94) and Error-Free T-Units (Kurtosis:
1.067, Skewness: 1.259) reveal distributions that are peaked and positively
skewed. Finally, the results of the analysis for the dependent variable Words
per T-Unit show a peaked distribution (Kurtosis: 3.312, Skewness: .891).
4.1.1.3 Descriptive Statistics for Group 3
The analysis of the data for Group 3 again reveal normal distributions
for the majority of the dependent variables: Holistic Rating (Kurtosis: -.855,
Skewness: -.3), Lexical Density (Kurtosis: .204, Skewness: .129), Words per T-
Unit (Kurtosis: -.042, Skewness: .354), and S-Nodes per T-Unit (Kurtosis: .394,
Skewness: .519). The results of the analysis for the dependent variable Target-
Like Use of Articles show a peaked and negatively skewed distribution
(Kurtosis: 2.986, Skewness: -1.815), while the results of the analysis for the
dependent variable Error-Free T-Units show a distribution that is peaked and
positively skewed (Kurtosis: 3.372, Skewness: 1.569).
Despite the fact that some variables in each group displayed slightly
peaked or skewed distributions, overall the distribution of the data from the
analyses of the language proficiency measures was found to be normal. For a
summary of the results on the frequency distributions of the language
proficiency measures see Table 11 below.
Table 11. Kurtosis* and skewness* for the language proficiency measures
Group 1 Group 2 Group 3
Measures Kurtosis Skewness Kurtosis Skewness Kurtosis Skewness
236
Hol. Rating -.689 -.162 .12 -.447 -.855 -.3
TLU -1.099 -.229 .134 -.747 2.986 -1.815
Lex. Density 1.301 -.54 7.005 1.94 .204 .129
Words per T -.183 .209 3.312 .891 -.042 .354
Error-Free T -.669 .513 1.067 1.259 3.372 1.569
S -nodes per T 2.514 1.51 .251 .611 .394 .519
* Values > +1 show distributions that are not normal.
4.1.2 Results of the MANOVA
A MANOVA was performed for the factor Group (three levels) and the
six dependent variables. The results of the MANOVA reveal a significant main
effect for Group (F(6, 268) = 69.363, p = .0001). Following this, six one-way
ANOVAs were performed on the data to examine which of the six language
proficiency measures show differences between the groups. The results of the
univariate ANOVAs for the six variables are reported below.
4.1.3 Holistic Rating
The results of the ANOVA for the holistic rating show no significant
difference between the groups (F(2, 272) = 1.148, p = .3188). As can be seen
from Table 12, the mean holistic rating for each group is similar.
Table 12. Means and standard deviations for the dependent variable:
Holistic Rating
GROUP COUNT MEAN STD. DEV.
237
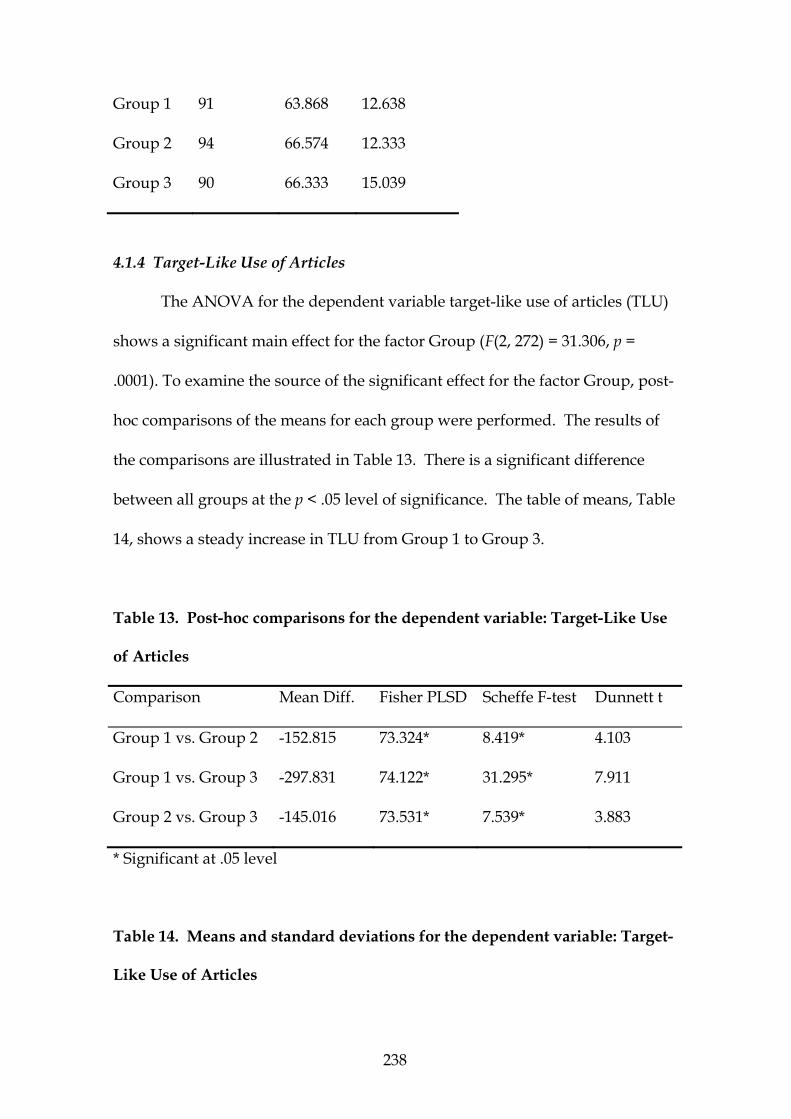
Group 1 91 63.868 12.638
Group 2 94 66.574 12.333
Group 3 90 66.333 15.039
4.1.4 Target-Like Use of Articles
The ANOVA for the dependent variable target-like use of articles (TLU)
shows a significant main effect for the factor Group (F(2, 272) = 31.306, p =
.0001). To examine the source of the significant effect for the factor Group, post-
hoc comparisons of the means for each group were performed. The results of
the comparisons are illustrated in Table 13. There is a significant difference
between all groups at the p < .05 level of significance. The table of means, Table
14, shows a steady increase in TLU from Group 1 to Group 3.
Table 13. Post-hoc comparisons for the dependent variable: Target-Like Use
of Articles
Comparison Mean Diff. Fisher PLSD Scheffe F-test Dunnett t
Group 1 vs. Group 2 -152.815 73.324* 8.419* 4.103
Group 1 vs. Group 3 -297.831 74.122* 31.295* 7.911
Group 2 vs. Group 3 -145.016 73.531* 7.539* 3.883
* Significant at .05 level
Table 14. Means and standard deviations for the dependent variable: Target-
Like Use of Articles
238
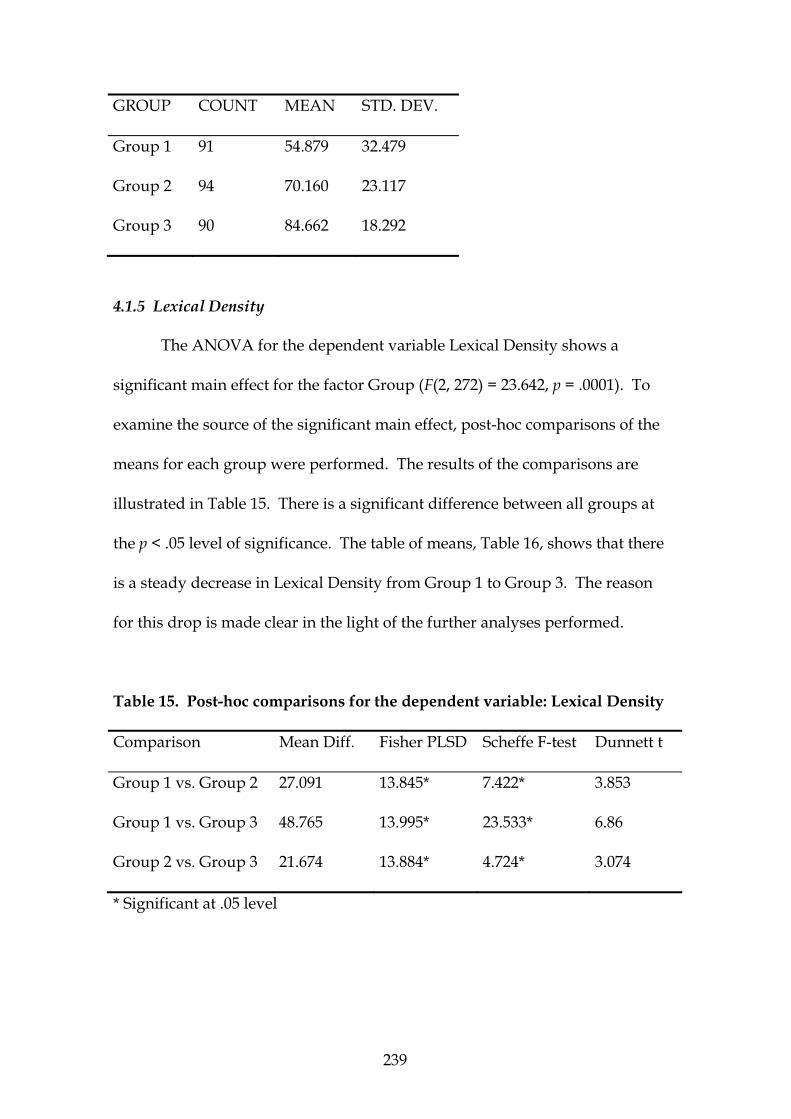
GROUP COUNT MEAN STD. DEV.
Group 1 91 54.879 32.479
Group 2 94 70.160 23.117
Group 3 90 84.662 18.292
4.1.5 Lexical Density
The ANOVA for the dependent variable Lexical Density shows a
significant main effect for the factor Group (F(2, 272) = 23.642, p = .0001). To
examine the source of the significant main effect, post-hoc comparisons of the
means for each group were performed. The results of the comparisons are
illustrated in Table 15. There is a significant difference between all groups at
the p < .05 level of significance. The table of means, Table 16, shows that there
is a steady decrease in Lexical Density from Group 1 to Group 3. The reason
for this drop is made clear in the light of the further analyses performed.
Table 15. Post-hoc comparisons for the dependent variable: Lexical Density
Comparison Mean Diff. Fisher PLSD Scheffe F-test Dunnett t
Group 1 vs. Group 2 27.091 13.845* 7.422* 3.853
Group 1 vs. Group 3 48.765 13.995* 23.533* 6.86
Group 2 vs. Group 3 21.674 13.884* 4.724* 3.074
* Significant at .05 level
239
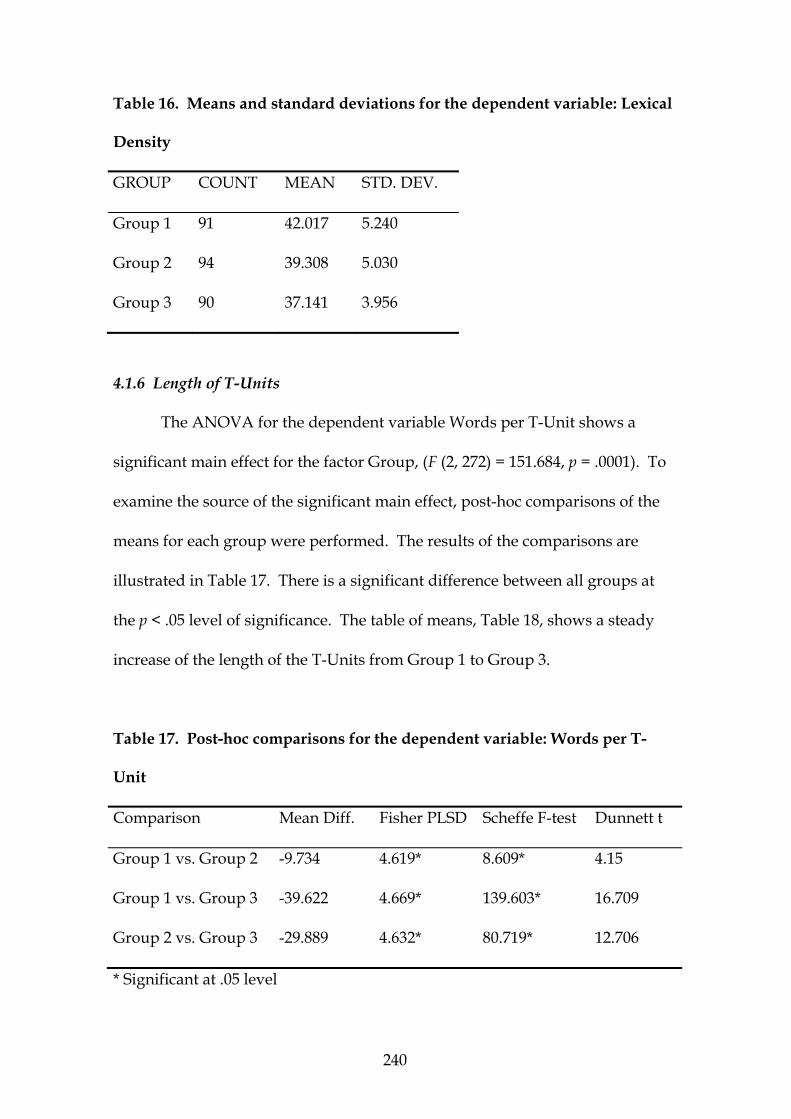
Table 16. Means and standard deviations for the dependent variable: Lexical
Density
GROUP COUNT MEAN STD. DEV.
Group 1 91 42.017 5.240
Group 2 94 39.308 5.030
Group 3 90 37.141 3.956
4.1.6 Length of T-Units
The ANOVA for the dependent variable Words per T-Unit shows a
significant main effect for the factor Group, (F (2, 272) = 151.684, p = .0001). To
examine the source of the significant main effect, post-hoc comparisons of the
means for each group were performed. The results of the comparisons are
illustrated in Table 17. There is a significant difference between all groups at
the p < .05 level of significance. The table of means, Table 18, shows a steady
increase of the length of the T-Units from Group 1 to Group 3.
Table 17. Post-hoc comparisons for the dependent variable: Words per T-
Unit
Comparison Mean Diff. Fisher PLSD Scheffe F-test Dunnett t
Group 1 vs. Group 2 -9.734 4.619* 8.609* 4.15
Group 1 vs. Group 3 -39.622 4.669* 139.603* 16.709
Group 2 vs. Group 3 -29.889 4.632* 80.719* 12.706
* Significant at .05 level
240

Table 18. Means and standard deviations for the dependent variable: Words
per T-Unit
GROUP COUNT MEAN STD. DEV.
Group 1 91 6.801 1.070
Group 2 94 7.774 1.339
Group 3 90 10.763 2.177
4.1.7 Error-Free T-Units
The ANOVA for the dependent variable Error-Free T-Units shows a
significant main effect for the factor Group, (F(2, 272) = 9.031, p = .0002). To
examine the source of the significant effect for the factor Group, post-hoc
comparisons of the means for each group were performed. The results of the
comparisons are illustrated in Table 19. There is a significant difference
between Group 3 and Group 1, and between Group 3 and Group 2, at the p <
.05 level of significance. The highest proficiency group had the smallest
number of Error-Free T-Units, see Table 20.
Table 19. Post-hoc comparisons for the dependent variable: Error-Free T-
Units
Comparison Mean Diff. Fisher PLSD Scheffe F-test Dunnett t
Group 1 vs. Group 2 -.095 2.09 .004 .09
Group 1 vs. Group 3 3.892 2.112* 6.581* 3.628
241
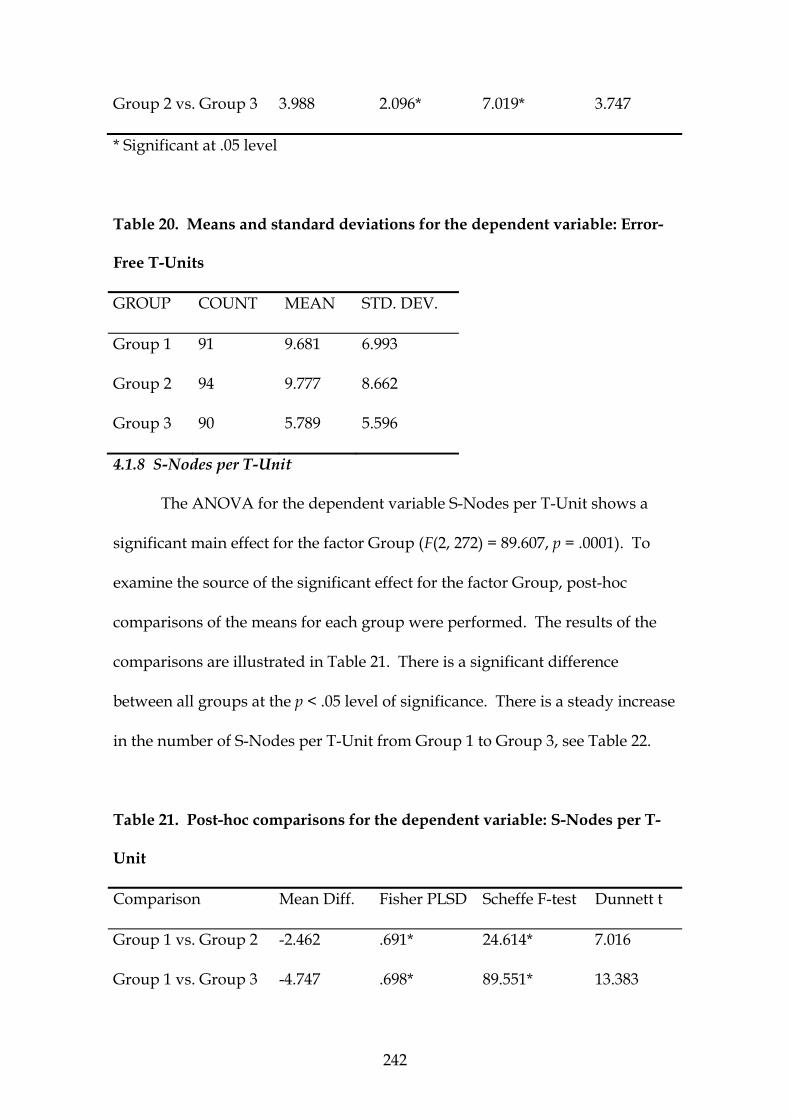
Group 2 vs. Group 3 3.988 2.096* 7.019* 3.747
* Significant at .05 level
Table 20. Means and standard deviations for the dependent variable: Error-
Free T-Units
GROUP COUNT MEAN STD. DEV.
Group 1 91 9.681 6.993
Group 2 94 9.777 8.662
Group 3 90 5.789 5.596
4.1.8 S-Nodes per T-Unit
The ANOVA for the dependent variable S-Nodes per T-Unit shows a
significant main effect for the factor Group (F(2, 272) = 89.607, p = .0001). To
examine the source of the significant effect for the factor Group, post-hoc
comparisons of the means for each group were performed. The results of the
comparisons are illustrated in Table 21. There is a significant difference
between all groups at the p < .05 level of significance. There is a steady increase
in the number of S-Nodes per T-Unit from Group 1 to Group 3, see Table 22.
Table 21. Post-hoc comparisons for the dependent variable: S-Nodes per T-
Unit
Comparison Mean Diff. Fisher PLSD Scheffe F-test Dunnett t
Group 1 vs. Group 2 -2.462 .691* 24.614* 7.016
Group 1 vs. Group 3 -4.747 .698* 89.551* 13.383
242

Group 2 vs. Group 3 -2.285 .693* 21.085* 6.494
* Significant at .05 level
Table 22. Means and standard deviations for the dependent variable: S-
Nodes per T-Unit
GROUP COUNT MEAN STD. DEV.
Group 1 91 1.119 .144
Group 2 94 1.366 .229
Group 3 90 1.594 .312
4.1.9 Summary of the Results for the Language Proficiency Analyses
The results of the analyses for the language proficiency measures show
an overall significant main effect for the factor Group. No difference was found
between the three groups in the holistic rating of the essays, even though the
three groups represent three different levels of language proficiency. This
could be due to the nature of the holistic rating since it takes into account not
just the use of language, but also the structure of the essay, its organisation, the
expression of ideas, the explanations and arguments provided by the writer,
etc. Therefore the ratings based on the holistic scale may obscure differences
among subjects that are attributable to language proficiency, which is of most
interest to this study. However, this lack of significant differences between
groups using this measure is counter-balanced by the fact that reliable
differences were found using the other measures, and these are in line with the
243

claim that the different groups are composed of subjects at different levels of
proficiency, and possibly different stages of development.
As can be seen from Table 16, there is a significant drop in Lexical
Density for subjects in Groups 2 and 3 compared with subjects in Group 1, and
for subjects in Group 3 compared with subjects in Group 2. To this extent,
increases in proficiency appeared to be related to increases in the number of
grammatical words used in the essays (as the TLU analysis showed). As a
result, lower-level students were grammatically less accurate in their essays (as
the results from the TLU analysis show), and thus the omission of grammatical
words (e.g. articles) contributed to a higher percentage score for Lexical
Density. In Group 3 where the students are grammatically more accurate, as
the TLU analysis showed, the lexical density is lower. These results are also
consistent with the findings of recent research which showed that subjects of
lower proficiency levels use more content words, while those of higher
proficiency levels use more function words , e.g. pronouns, articles, and
prepositions (Ghadessy 1989).
The results for the dependent variable Words per T-Unit also reflect
different proficiency groupings (see Table 18). The higher the level of
proficiency, the more subordination and embedding the student uses in the
construction of sentences, and thus the longer the sentences they produce. This
finding, it must be noted, is in partial agreement with the finding reported by
Larsen-Freeman and Strom (1977), who found that the mean length of the T-
Units in the writings of the subjects in their study increased steadily with
244

proficiency level, but the statistical analysis performed on their data did not
yield significant differences. Larsen-Freeman and Strom conclude that length
of T-Units is still "a viable contender on which to base an index of
development" (Larsen-Freeman & Strom 1977:132).
The results for the dependent variable Error-Free T-Units do show
significant differences between the three groups (see Table 19). Although these
differences support the claim that the three different groups reflect different
proficiency groupings, the direction of the difference is in contrast to the
findings of previous research. In line with Larsen-Freeman's findings (1978) it
was expected that more proficient subjects would use more Error-Free T-Units
than less proficient subjects. However, the present findings show that subjects
in Group 1 use significantly more Error-Free T-Units than subjects in Group 2,
and these subjects in turn use significantly more Error-Free T-Units than
subjects in Group 3. The present results could be due to the fact that subjects in
this study are simply trying harder to produce more complex syntax than less
proficient subjects. It is certainly true that subjects in the present study are not
at a sufficiently advanced level to make no mistakes in their writing, since the
subjects in Group 3, who have had the longest period of instruction in English,
and who are older by one and two years on average than subjects in the other
groups, are only at a post-intermediate level. In Larsen-Freeman's study
subjects were from a larger range of proficiency levels (5 groups), from subjects
that were of very low proficiency and needed a great deal of ESL instruction
(Group 1) to subjects that were advanced enough not to need any more ESL
245

instruction (Group 5). Even though Larsen-Freeman does not report the post-
hoc comparisons for the Error-Free T-Units measure, it is apparent from the
percentages reported in her paper that it is at the advanced level that subjects
singificantly use more Error-Free T-Units, e.g. there is a 15% increase in the
amount of Error-Free T-Units used by the advanced learners in group 5 (see
Table 23).
Table 23. Percentage of Error-Free T-Units in Larsen-Freeman (1978)
Group Number %EFT
1 37 11.4
2 39 18.5
3 45 22.1
4 56 34.3
5 35 49.6
(Adapted from Larsen-Freeman 1978:445)
In line with the above interpretation, that more proficient subjects in
Group 3 try harder to produce more complex syntax and so make greater
numbers of errors, it was shown that Group 3 students write longer T-Units
than subjects in the other groups. They should therefore have a higher chance
factor of making mistakes than subjects in the other two groups. The shorter
the T-units, the less chance subjects have of making spelling, punctuation,
grammatical, or syntactic mistakes.
246

Also in line with this argument are the results for the dependent variable
S-Nodes per T-Unit. The higher the level of the students’ proficiency, the more
syntactically complex sentences they produce in writing (see Bardovi-Harlig
1992a). In summary, the higher the level students belong to, the more accurate
they are in the use of articles, and the more syntactically complex and longer
sentences they produce, while their lexical density decreases and their chance
of making an error increases.
4.2 Results of the Main Analyses
In this section the results of the analyses performed to address each of
the two hypotheses are described.
4.2.1 Hypothesis 1: There are patterns of development in collocational
knowledge across proficiency levels
To address Hypothesis 1, the three sets of data were analysed separately:
i) For the free production data, tokens of the correct use of the thirty-seven
types of collocation were recorded. Lack of, or incorrect use of, a particular
type were scored as 0. The data were entered as the sum of tokens of correct
usage of each collocation type by each subject.
ii) For the translation data, the mean accuracy of response to each of the six
types of collocation repeated across groups was calculated.
iii) For the blank filling data, the mean accuracy of response to each of the
eleven types of collocation repeated across groups was calculated.
247

The data for these analyses were examined and were not found to be
normally distributed. This is due, in the case of the elicited production
measures, to the fact that means for accurate responses to some types were
calculated on the basis of a small number of responses to tokens, thus
restricting the possible range of scores on these types. In the case of the essay
data the mean use of many types of collocation did not follow the normal
pattern of distribution within and across groups. This justifies the use of non-
parametric Kruskal-Wallis tests, followed by Dunn's multiple comparisons
procedures to address the first hypothesis regarding between-group differences
in accuracy and use of collocations.
4.2.1.1 Essay Data (All Groups)
The sum of tokens for each of the 37 types of collocation were calculated
for each essay. Kruskal-Wallis tests were performed to identify significant
between-group differences with respect to each collocation type. The results of
the Kruskal-Wallis tests of the mean tokens of each of the 37 collocation types
used by subjects in each group, corrected for ties, together with the results of
the post-hoc Dunn's multiple comparisons procedures, are reported below.
These are summarised in Table 24. Collocation types that did not show
significant differences across all groups, or which did not contain any tokens
for one or two of the groups, are not included in the table.
Table 24. Summary of the results of the Kruskal-Wallis tests and post-hoc
analyses for the essay data
Dunn’s Procedure: Mean Rank Differences
248
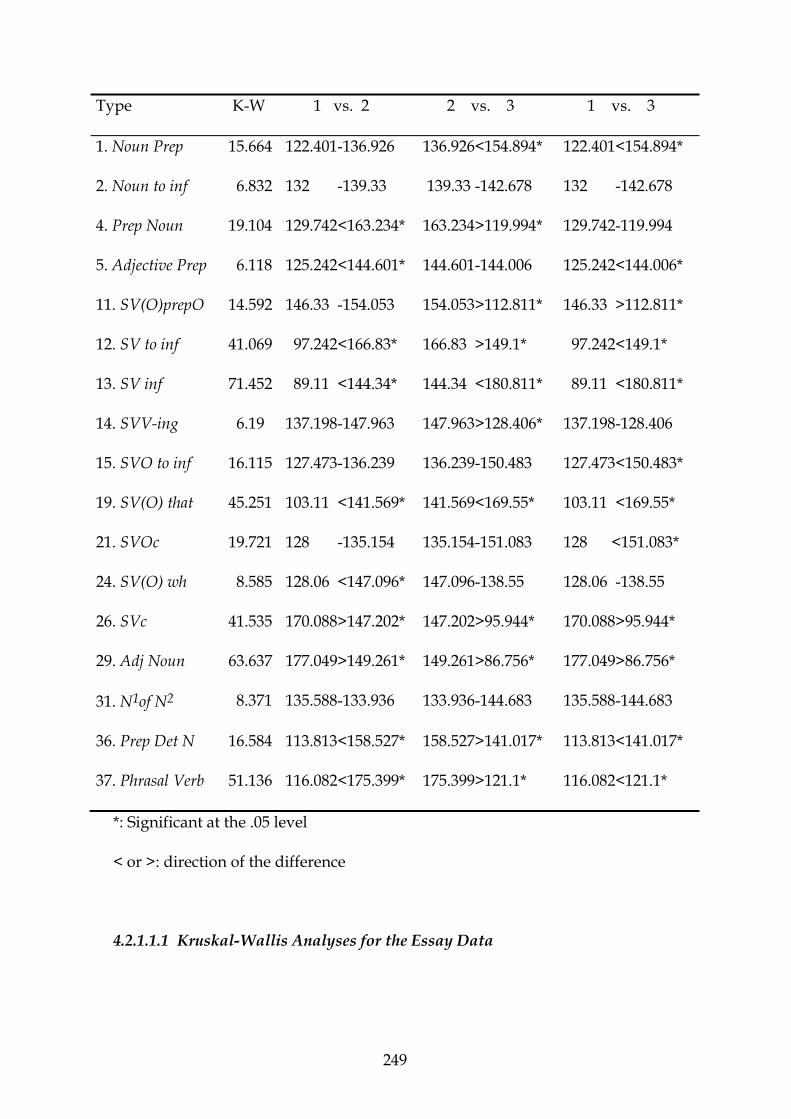
Type K-W 1 vs. 2 2 vs. 3 1 vs. 3
1. Noun Prep 15.664 122.401-136.926 136.926<154.894* 122.401<154.894*
2. Noun to inf 6.832 132 -139.33 139.33 -142.678 132 -142.678
4. Prep Noun 19.104 129.742<163.234* 163.234>119.994* 129.742-119.994
5. Adjective Prep 6.118 125.242<144.601* 144.601-144.006 125.242<144.006*
11. SV(O)prepO 14.592 146.33 -154.053 154.053>112.811* 146.33 >112.811*
12. SV to inf 41.069 97.242<166.83* 166.83 >149.1* 97.242<149.1*
13. SV inf 71.452 89.11 <144.34* 144.34 <180.811* 89.11 <180.811*
14. SVV-ing 6.19 137.198-147.963 147.963>128.406* 137.198-128.406
15. SVO to inf 16.115 127.473-136.239 136.239-150.483 127.473<150.483*
19. SV(O) that 45.251 103.11 <141.569* 141.569<169.55* 103.11 <169.55*
21. SVOc 19.721 128 -135.154 135.154-151.083 128 <151.083*
24. SV(O) wh 8.585 128.06 <147.096* 147.096-138.55 128.06 -138.55
26. SVc 41.535 170.088>147.202* 147.202>95.944* 170.088>95.944*
29. Adj Noun 63.637 177.049>149.261* 149.261>86.756* 177.049>86.756*
31. N1of N2 8.371 135.588-133.936 133.936-144.683 135.588-144.683
36. Prep Det N 16.584 113.813<158.527* 158.527>141.017* 113.813<141.017*
37. Phrasal Verb 51.136 116.082<175.399* 175.399>121.1* 116.082<121.1*
*: Significant at the .05 level
< or >: direction of the difference
4.2.1.1.1 Kruskal-Wallis Analyses for the Essay Data
249

Type 1. Noun Preposition - Results of the Kruskal-Wallis test for
numbers of tokens of Noun Preposition collocations used in the subjects' essays
show a significant main effect for the factor Group (Kruskal-Wallis c2 (2, N =
275) = 15.664, p = .0004). The table of means, Table 25, shows that the mean
number of tokens used per group increases across groups. The results of the
post-hoc Dunn's multiple comparisons procedure show significant differences
at the p < .05 level between numbers of tokens of this type used in Groups 1
and 3, and in Groups 2 and 3, but not in Groups 1 and 2 (see Table 24).
Type 2. Noun to Infinitive - Results of the Kruskal-Wallis test for
numbers of tokens of Noun to Infinitive collocations used in the subjects' essays
show the difference between groups to be significant (Kruskal-Wallis c2 (2, N =
275) = 6.832, p = .0328). However, the results of the Dunn's multiple
comparisons procedure show no significant difference between any pairs of
groups at the p < .05 level, even though the mean number of tokens used per
group increases across groups and the difference between Group 1 and Group
2 is approaching significance (see Table 24).
Type 4. Preposition Noun - Results of the Kruskal-Wallis test for
numbers of tokens of Preposition Noun collocations used in the subjects' essays
show a significant main effect for the factor Group (Kruskal-Wallis c2 (2, N =
275) = 19.104, p = .0001). The table of means, Table 25, shows that subjects in
Group 2 used more collocations of this type in their essays that subjects in
250

Group 1, and subjects in Group 1 used more collocations of this type than
subjects in Group 3. The results of the post-hoc Dunn's multiple comparisons
procedure show significant differences in numbers of tokens of this type used
between Groups 1 and 2, and between Groups 2 and 3, but not between Groups
1 and 3 (see Table 2.5).
Type 5. Adjective Preposition - Results of the Kruskal-Wallis test for
numbers of tokens of Adjective Preposition collocations used in the subjects'
essays show a significant main effect for the factor Group (Kruskal-Wallis c2 (2,
N = 275) = 6.118, p = .0469). The table of means, Table 25, shows that the mean
number of tokens used by subjects in Group 2 is equal to the mean number of
tokens of this type used by subjects in Group 3, while subjects in Group 1
produced considerably less tokens on this type than subjects in Groups 2 and 3.
The results of the post-hoc Dunn's multiple comparisons procedure show
significant differences in numbers of tokens of this type used between Groups 1
and 3, and between Groups 1 and 2, but not between Groups 2 and 3 (see Table
24).
Type 11. SV(O) Preposition O - Results of the Kruskal-Wallis test for
numbers of tokens of SV(O) Preposition O collocations used in the subjects'
essays show a significant main effect for the factor Group (Kruskal-Wallis c2 (2,
N = 275) = 14.592, p = .0007). The table of means, Table 25, shows that subjects
in Group 2 produced more tokens of this type of collocation than subjects in
251

Group 1, who used more tokens of this type of collocation than subjects in
Group 3. The results of the post-hoc Dunn's multiple comparisons procedure
show significant differences in numbers of tokens of this type used between
Groups 1 and 3, and between Groups 2 and 3, but not between Groups 1 and 2
(see Table 24).
Type 12. SV to Infinitive - Results of the Kruskal-Wallis test for numbers
of tokens of SV to Infinitive collocations used in the subjects' essays show a
significant main effect for the factor Group (Kruskal-Wallis c2 (2, N = 275) =
41.069, p = .0001). The table of means, Table 25, shows that subjects in Group 2
produced more tokens of this type of collocation than subjects in Group 3, who
used more tokens of this type of collocation than subjects in Group 1. The
results of the post-hoc Dunn's multiple comparisons procedure show
significant differences in numbers of tokens of this type used across all groups
(see Table 24).
Type 13. SV Infinitive - Results of the Kruskal-Wallis test for numbers of
tokens of SV Infinitive collocations used in the subjects' essays show a
significant main effect for the factor Group (Kruskal-Wallis c2 (2, N = 275) =
71.452, p = .0001). The table of means, Table 25, shows that the mean number of
tokens used per group increases across groups. The results of the post-hoc
Dunn's multiple comparisons procedure show significant differences in
numbers of tokens of this type used across all groups (see Table 24).
252

Type 14. SVV-ing - Results of the Kruskal-Wallis test for numbers of
tokens of SVV-ing collocations used in the subjects' essays show a significant
main effect for the factor Group (Kruskal-Wallis c2 (2, N = 275) = 6.19, p =
.0453). The table of means, Table 25, shows that subjects in Group 2 produced
more tokens of this type of collocation than subjects in Group 1, who used more
tokens of this type of collocation than subjects in Group 3. The results of the
post-hoc Dunn's multiple comparisons procedure show significant differences
in numbers of tokens of this type used only between Groups 2 and 3, but not
between Groups 1 and 2, or between Groups 1 and 3 (see Table 24).
Type 15. SVO to Infinitive - Results of the Kruskal-Wallis test for
numbers of tokens of SVO to Infinitive collocations used in the subjects' essays
show a significant main effect for the factor Group (Kruskal-Wallis c2 (2, N =
275) = 16.115, p = .0003). The table of means, Table 25, shows that the mean
number of tokens used increases across groups. The results of the post-hoc
Dunn's multiple comparisons procedure show significant differences in
numbers of tokens of this type only between Groups 1 and 3, but not between
Groups 1 and 2, or between Groups 2 and 3 (see Table 24).
Type 19. SV(O) that-clause - Results of the Kruskal-Wallis test for
numbers of tokens of SV(O) that-clause collocations used in the subjects' essays
show a significant main effect for the factor Group (Kruskal-Wallis c2 (2, N =
275) = 45.251, p = .0001). The table of means, Table 25, shows that the mean
253

number of tokens used per group increases across groups. The results of the
post-hoc Dunn's multiple comparisons procedure show significant differences
in numbers of tokens of this type used between all groups (see Table 24).
Type 21. SVOc - Results of the Kruskal-Wallis test for numbers of tokens
of SVOc collocations used in the subjects' essays show a significant main effect
for the factor Group (Kruskal-Wallis c2 (2, N = 275) = 19.721, p = .0001). The
tables of means, Table 25, shows that the mean number of tokens used per
group increases across groups. The results of the post-hoc Dunn's multiple
comparisons procedure show significant differences in numbers of tokens of
this type used only between Groups 1 and 3, but not between Groups 1 and 2,
or between Groups 2 and 3 (see Table 24).
Type 24. SV(O) wh-word - Results of the Kruskal-Wallis test for
numbers of tokens of SV (O) wh-word collocations used in the subjects' essays
show a significant main effect for the factor Group (Kruskal-Wallis c2 (2, N =
275) = 8.585, p = .0137). The table of means, Table 25, shows that subjects in
Group 2 produced more tokens of this type of collocation than subjects in
Group 3, who used more tokens of this type of collocation than subjects in
Group 1. The results of the post-hoc Dunn's multiple comparisons procedure
show significant differences in numbers of tokens of this type used only
between Groups 1 and 2, but not between Groups 2 and 3, or Groups 1 and 3
(see Table 24).
254

Type 26. SVc - Results of the Kruskal-Wallis test for numbers of tokens
of SVc collocations used in the subjects' essays shows a significant main effect
for the factor Group (Kruskal-Wallis c2 (2, N = 275) = 41.535, p = .0001). The
table of means, Table 25, shows that the mean number of tokens of this type of
collocation decreases as the proficiency level of the subjects increases. The
results of the post-hoc Dunn's multiple comparisons procedure show
significant differences in numbers of tokens of this type of collocation between
all groups (see Table 24).
Type 29. Adjective Noun - Results of the Kruskal-Wallis test for numbers
of tokens of Adjective Noun collocations used in the subjects' essays show a
significant main effect for the factor Group (Kruskal-Wallis c2 (2, N = 275) =
63.637, p = .0001). The table of means, Table 25, shows that the mean number of
tokens of this type of collocation decreases as the proficiency level of the
subjects increases. The results of the post-hoc Dunn's multiple comparisons
procedure show significant differences in numbers of tokens of this type of
collocation across all groups (see Table 25).
Type 30. Noun Verb - Results of the Kruskal-Wallis test for numbers of
tokens of Noun Verb collocations used in the subjects' essays show a significant
main effect for the factor Group (Kruskal-Wallis c2 (2, N = 275) = 6.212, p =
255

.0448), though the Dunn's multiple comparisons procedure revealed no
significant between-group differences (see Table 24).
Type 31. Noun1 of Noun2 - Results of the Kruskal-Wallis test for numbers
of tokens of Noun1 of Noun2 collocations used in the subjects' essays show the
difference between groups to be significant (Kruskal-Wallis c2 (2, N = 275) =
8.371, p = .0152). However, the results of the Dunn's multiple comparisonss
procedure show no significant differences between any of the groups at the p <
.05 level (see Table 24).
Type 36. Preposition Determiner Noun - Results of the Kruskal-Wallis
test for numbers of tokens of Preposition Determiner Noun collocations used in
the subjects' essays show a significant main effect for the factor Group
(Kruskal-Wallis c2 (2, N = 275) = 16.584, p = .0003). The table of means, Table
25, shows that subjects in Group 2 produced more tokens of this type of
collocation than subjects in Group 3, who used more tokens of this type of
collocation than subjects in Group 1. The results of the post-hoc Dunn's
multiple comparisons procedure show significant differences between all
groups (see Table 24).
Type 37. Phrasal Verb - Results of the Kruskal-Wallis test for numbers of
tokens of Phrasal Verb collocations used in the subjects' essays show a
significant main effect for the factor Group (Kruskal-Wallis c2 (2, N = 275) =
256
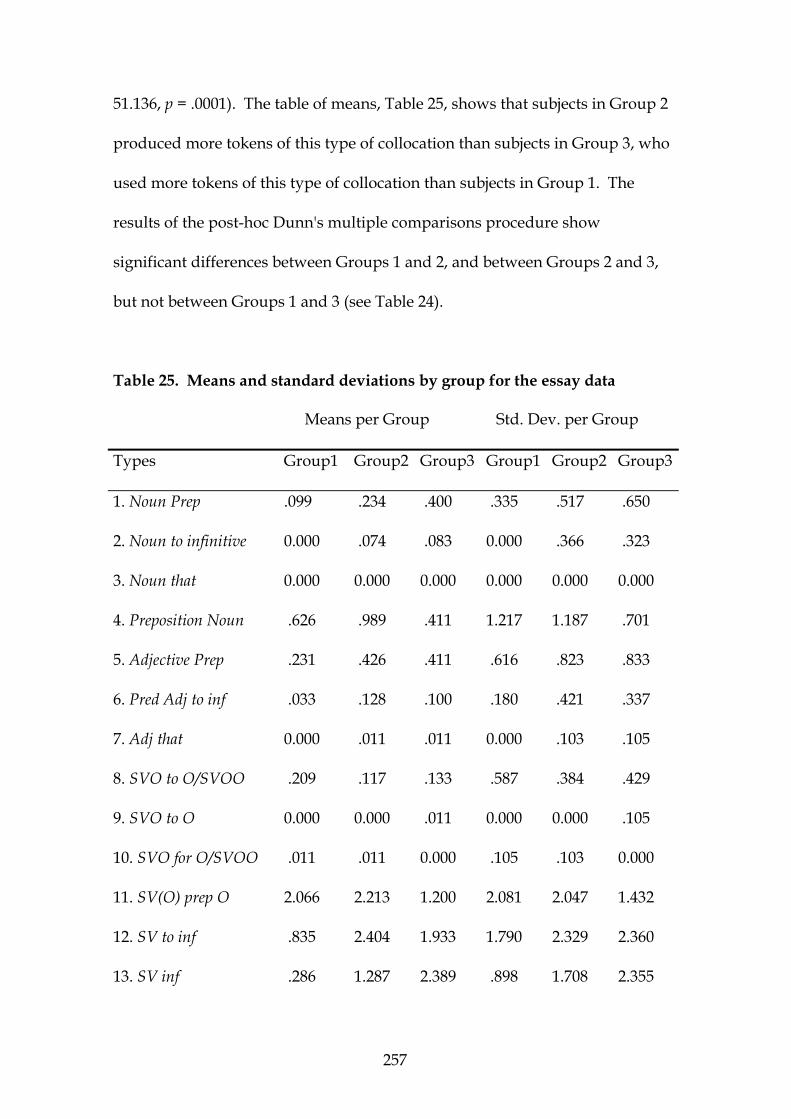
51.136, p = .0001). The table of means, Table 25, shows that subjects in Group 2
produced more tokens of this type of collocation than subjects in Group 3, who
used more tokens of this type of collocation than subjects in Group 1. The
results of the post-hoc Dunn's multiple comparisons procedure show
significant differences between Groups 1 and 2, and between Groups 2 and 3,
but not between Groups 1 and 3 (see Table 24).
Table 25. Means and standard deviations by group for the essay data
Means per Group Std. Dev. per Group
Types Group1 Group2 Group3 Group1 Group2 Group3
1. Noun Prep .099 .234 .400 .335 .517 .650
2. Noun to infinitive 0.000 .074 .083 0.000 .366 .323
3. Noun that 0.000 0.000 0.000 0.000 0.000 0.000
4. Preposition Noun .626 .989 .411 1.217 1.187 .701
5. Adjective Prep .231 .426 .411 .616 .823 .833
6. Pred Adj to inf .033 .128 .100 .180 .421 .337
7. Adj that 0.000 .011 .011 0.000 .103 .105
8. SVO to O/SVOO .209 .117 .133 .587 .384 .429
9. SVO to O 0.000 0.000 .011 0.000 0.000 .105
10. SVO for O/SVOO .011 .011 0.000 .105 .103 0.000
11. SV(O) prep O 2.066 2.213 1.200 2.081 2.047 1.432
12. SV to inf .835 2.404 1.933 1.790 2.329 2.360
13. SV inf .286 1.287 2.389 .898 1.708 2.355
257
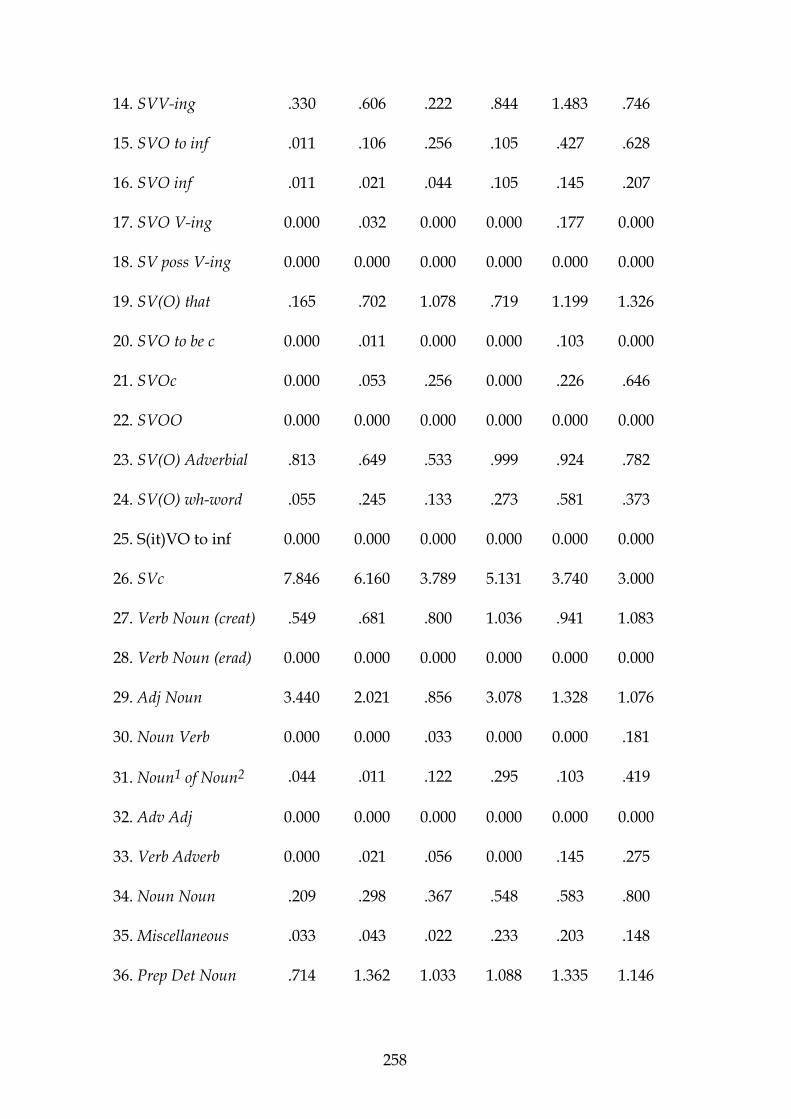
14. SVV-ing .330 .606 .222 .844 1.483 .746
15. SVO to inf .011 .106 .256 .105 .427 .628
16. SVO inf .011 .021 .044 .105 .145 .207
17. SVO V-ing 0.000 .032 0.000 0.000 .177 0.000
18. SV poss V-ing 0.000 0.000 0.000 0.000 0.000 0.000
19. SV(O) that .165 .702 1.078 .719 1.199 1.326
20. SVO to be c 0.000 .011 0.000 0.000 .103 0.000
21. SVOc 0.000 .053 .256 0.000 .226 .646
22. SVOO 0.000 0.000 0.000 0.000 0.000 0.000
23. SV(O) Adverbial .813 .649 .533 .999 .924 .782
24. SV(O) wh-word .055 .245 .133 .273 .581 .373
25. S(it)VO to inf 0.000 0.000 0.000 0.000 0.000 0.000
26. SVc 7.846 6.160 3.789 5.131 3.740 3.000
27. Verb Noun (creat) .549 .681 .800 1.036 .941 1.083
28. Verb Noun (erad) 0.000 0.000 0.000 0.000 0.000 0.000
29. Adj Noun 3.440 2.021 .856 3.078 1.328 1.076
30. Noun Verb 0.000 0.000 .033 0.000 0.000 .181
31. Noun1 of Noun2 .044 .011 .122 .295 .103 .419
32. Adv Adj 0.000 0.000 0.000 0.000 0.000 0.000
33. Verb Adverb 0.000 .021 .056 0.000 .145 .275
34. Noun Noun .209 .298 .367 .548 .583 .800
35. Miscellaneous .033 .043 .022 .233 .203 .148
36. Prep Det Noun .714 1.362 1.033 1.088 1.335 1.146
258
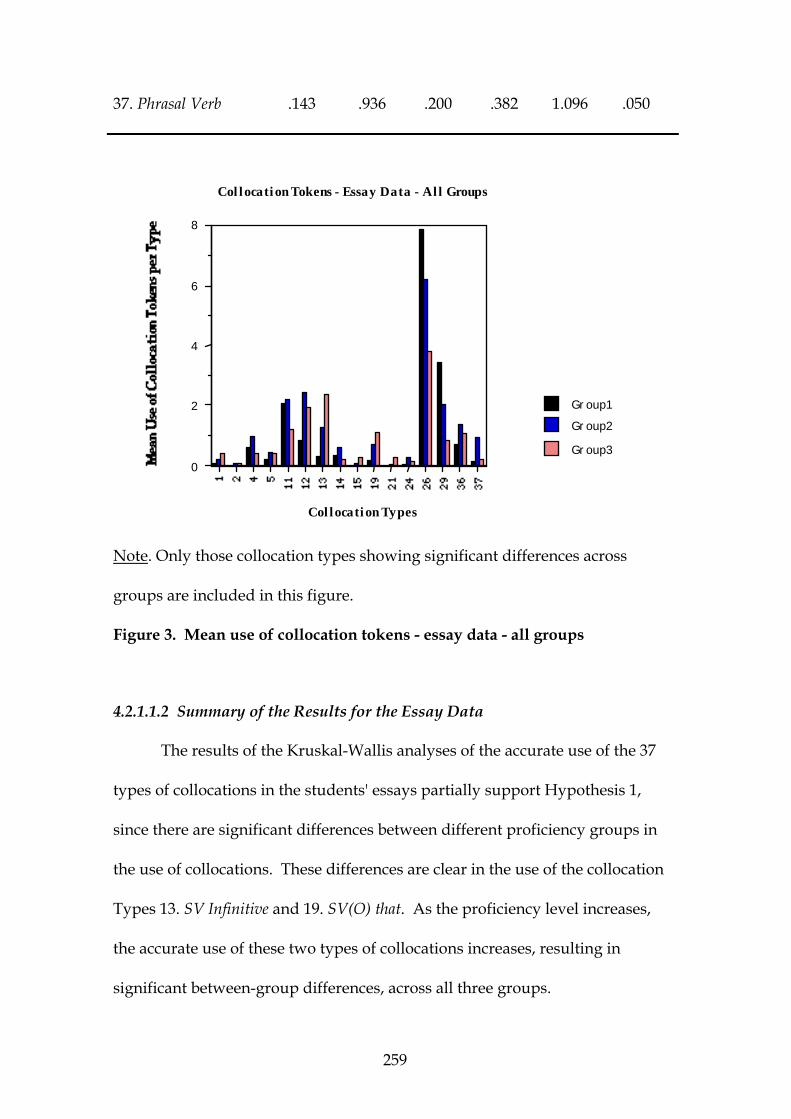
37. Phrasal Verb .143 .936 .200 .382 1.096 .050
0
2
4
6
8
Gr oup1
Gr oup2
Gr oup3
Col location Tokens - Essay Data - Al l Groups
Col location Types
Note. Only those collocation types showing significant differences across
groups are included in this figure.
Figure 3. Mean use of collocation tokens - essay data - all groups
4.2.1.1.2 Summary of the Results for the Essay Data
The results of the Kruskal-Wallis analyses of the accurate use of the 37
types of collocations in the students' essays partially support Hypothesis 1,
since there are significant differences between different proficiency groups in
the use of collocations. These differences are clear in the use of the collocation
Types 13. SV Infinitive and 19. SV(O) that. As the proficiency level increases,
the accurate use of these two types of collocations increases, resulting in
significant between-group differences, across all three groups.
259

Type 1. Noun Preposition collocations are also positively related to
proficiency, since Group 3 subjects use significantly more tokens of this type of
collocation than subjects in the other two groups.
The results also show that the direction of the between-group differences
is not always the expected one. With respect to the collocation Types 26. SVc
and 29. Adjective Noun, proficiency is negatively correlated with accurate use of
these two types across groups: the less proficient students use significantly
more tokens of these two types of collocation than the more proficient students.
There are also collocation Types, 4. Preposition Noun, 12. SV to Infinitive, 36.
Prep Det Noun, and 37. Phrasal Verb, for which Group 2 subjects use
significantly more tokens than either Group 1 or Group 3 subjects. For Type 5.
Adjective Preposition, Group 2 and Group 3 subjects use significantly more
collocations than subjects in Group 1, while for Type 11. SV(O) Preposition O
Group 1 and 2 subjects are significantly better users than Group 3 subjects.
There is also a number of collocation types that did not receive any tokens of
accurate use by any of the groups (3. Noun that, 18. SV possessive V-ing, 22.
SVOO, 25. S(it)VO to inf, 28. Verb Noun (eradication), and 32. Adverb Adjective).
The results of the analysis for this set of data, summarised below in
Table 26, suggest that there are indeed proficiency-related differences in the
accurate use of collocations, and that there are specific types of collocation that
are used in the early stages of proficiency, and others that are used in the later
stages of development.
Table 26. Collocational use distinguishing proficiency levels
260

Group 1 Group 2 Group 3
Collocation Types Collocation Types Collocation Types
26. SV c** 4. Prep Noun** 1. Noun Prep**
29. Adjective Noun** 12. SV to Inf** 13. SV Inf**
11. SV(O) Prep O* 36. Prep Det Noun** 19. SV(O) that**
37. Phrasal Verb** 5. Adjective Prep*
5. Adjective Prep*
11. SV(O) Prep O*
**: Significantly more occurences than the other two groups
*: Significantly more occurences than one other group
4.2.1.1.3 Implicational Scaling for the Essay Data (All Groups)
For the implicational scaling analysis the Guttman procedure was used.
When the Guttman analysis reveals that a particular scale is consistently
interpretable, that is if one item on the scale is statistically consistently more
difficult than another, which is in turn harder than another, then the scale
attains a certain predictive power (Davidson 1987). The coefficient of
reproducibility, which shows how accurately a subject's performance can be
predicted from that person's position in the matrix, and the coefficient of
scalability, which is a single statistic detailing the strength of the items as an
ordered scale and indicating whether a given set of features is truly scalable
and unidimensional, were calculated. The higher the value of the coefficient of
scalability, the more "implicational" the scale (Davidson 1987).
261

Each subject was coded as having used (1), or not used (0), each of the 37
types of collocation in their essays. The two axes of the matrix for the
implicational scaling consisted of the 37 items ranked from most commonly
used by all subjects to least commonly used, and the 275 subjects ranked in
order of their frequency of use of all types of collocations, from subjects using
the most types to subjects using the fewest types. This matrix is summarised
for the first 17 types, mean >.1, in Figure 4 below. The coefficient of
reproducibility for this analysis was .90. The coefficient of scalability was .33.
While the coefficient of reproducibility is at the level necessary for this
implicational scale to be considered valid (see Andersen 1978), the coefficient of
scalability is below the recommended level of .6 (Hatch & Lazaraton 1991:212).
This suggests that while the implicational scale for the essay data is valid, the
variance in terms of numbers of errors, and the fact that most subjects did not
use the majority of the scaled collocations, resulted in the low coefficient of
scalability.
262

0
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
Note. Only those types with a mean > .1 are included in this figure.
Figure 4. Mean use of collocation tokens per type in the essay data.
4.2.1.2 Translation Data (All Groups)
The data set used in these analyses consisted of the mean accuracy of
response to each of the six types of collocation repeated across groups in the
translation test. As with the essay data reported above, the procedure followed
in analysing the translation data was to perform Kruskal-Wallis tests of the
differences between groups for each collocation type separately. Subsequently,
where significant group effects were identified, post-hoc Dunn's multiple
comparisons procedures were calculated in order to identify the source of the
significant contrasts between groups. The results of the Kruskal-Wallis tests,
together with the results of post-hoc Dunn's multiple comparisons procedures,
are reported below. These are summarised in Table 27. Type 16. SVO Infinitive
263
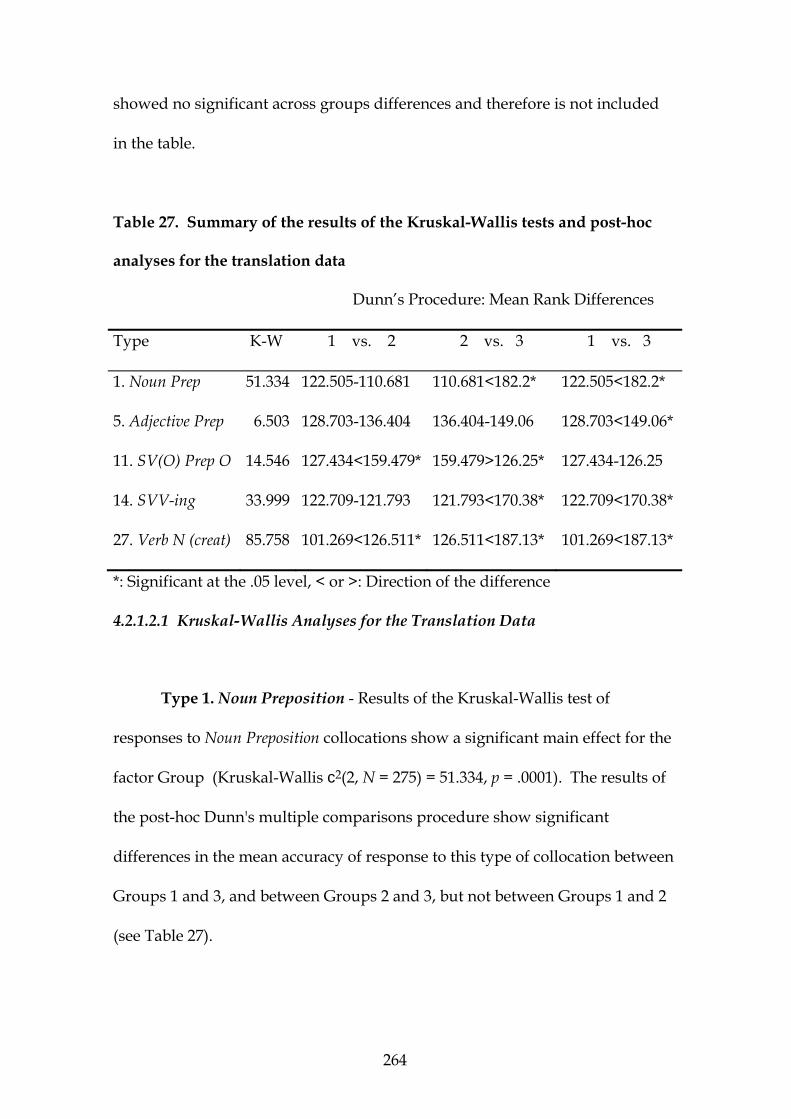
showed no significant across groups differences and therefore is not included
in the table.
Table 27. Summary of the results of the Kruskal-Wallis tests and post-hoc
analyses for the translation data
Dunn’s Procedure: Mean Rank Differences
Type K-W 1 vs. 2 2 vs. 3 1 vs. 3
1. Noun Prep 51.334 122.505-110.681 110.681<182.2* 122.505<182.2*
5. Adjective Prep 6.503 128.703-136.404 136.404-149.06 128.703<149.06*
11. SV(O) Prep O 14.546 127.434<159.479* 159.479>126.25* 127.434-126.25
14. SVV-ing 33.999 122.709-121.793 121.793<170.38* 122.709<170.38*
27. Verb N (creat) 85.758 101.269<126.511* 126.511<187.13* 101.269<187.13*
*: Significant at the .05 level, < or >: Direction of the difference
4.2.1.2.1 Kruskal-Wallis Analyses for the Translation Data
Type 1. Noun Preposition - Results of the Kruskal-Wallis test of
responses to Noun Preposition collocations show a significant main effect for the
factor Group (Kruskal-Wallis c2(2, N = 275) = 51.334, p = .0001). The results of
the post-hoc Dunn's multiple comparisons procedure show significant
differences in the mean accuracy of response to this type of collocation between
Groups 1 and 3, and between Groups 2 and 3, but not between Groups 1 and 2
(see Table 27).
264

Type 5. Adjective Preposition - Results of the Kruskal-Wallis test of
responses to Adjective Preposition collocations show a significant main effect for
the factor Group (Kruskal-Wallis c2 (2, N = 275) = 6.503, p = .0387). The table of
means, Table 28, shows that the mean accuracy of response to Adjective
Preposition collocations increases across groups. The results of the post-hoc
Dunn's multiple comparisons procedure show significant differences in the
mean accuracy of response to this type of collocation only between Groups 1
and 3, but not between Groups 2 and 3, or between Groups 1 and 2 (see Table
27).
Type 11. SV(O) Preposition O - Results of the Kruskal-Wallis test of
responses to SV(O) Preposition O collocations show a significant main effect for
the factor Group (Kruskal-Wallis c2 (2, N = 275) = 14.546, p = .0007). The results
of the post-hoc Dunn's multiple comparisons procedure show significant
differences in the mean accuracy of response to this type of collocation between
Groups 1 and 2, and between Groups 2 and 3, but not between Groups 1 and 3
(see Table 27).
Type 14. SVV-ing - Results of the Kruskal-Wallis test of responses to
SVV-ing collocations show a significant main effect for the factor Group
(Kruskal-Wallis c2 (2, N = 275) = 33.999, p = .0001). The results of the post-hoc
Dunn's multiple comparisons procedure show significant differences in the
265

mean accuracy of response to this type of collocation between Groups 1 and 3,
and between Groups 2 and 3, but not between Groups 1 and 2 (see Table 27).
Type 27. Verb Noun (creation) - Results of the Kruskal-Wallis test of
responses to Verb Noun (creation) collocations show a significant main effect for
the factor Group (Kruskal-Wallis c2 (2, N = 275) = 85.758, p = .0001). The table
of means, Table 28, shows that the mean accuracy of responses to Verb Noun
collocations increases across groups. The results of the post-hoc Dunn's
multiple comparisons procedure show significant differences in the mean
accuracy of response to this type of collocation across all groups (see Table 27).
Table 28. Means and standard deviations by group for the translation data
Means per Group Std. Dev. per Group
Types Group1 Group2 Group3 Group1 Group2 Group3
1. Noun Prep 23.077 18.085 57.222 29.162 29.193 4.368
5. Adjective Prep 10.989 10.106 20.000 31.449 21.477 35.790
11. SV(O) Prep O 19.231 40.957 23.333 30.523 44.579 42.532
14. SVV-ing 20.879 20.213 55.556 40.870 40.374 49.969
16. SVO Inf 25.275 23.404 36.667 43.699 42.567 48.459
27. Verb Noun (creat) 3.297 11.702 37.222 17.954 21.283 29.567
266
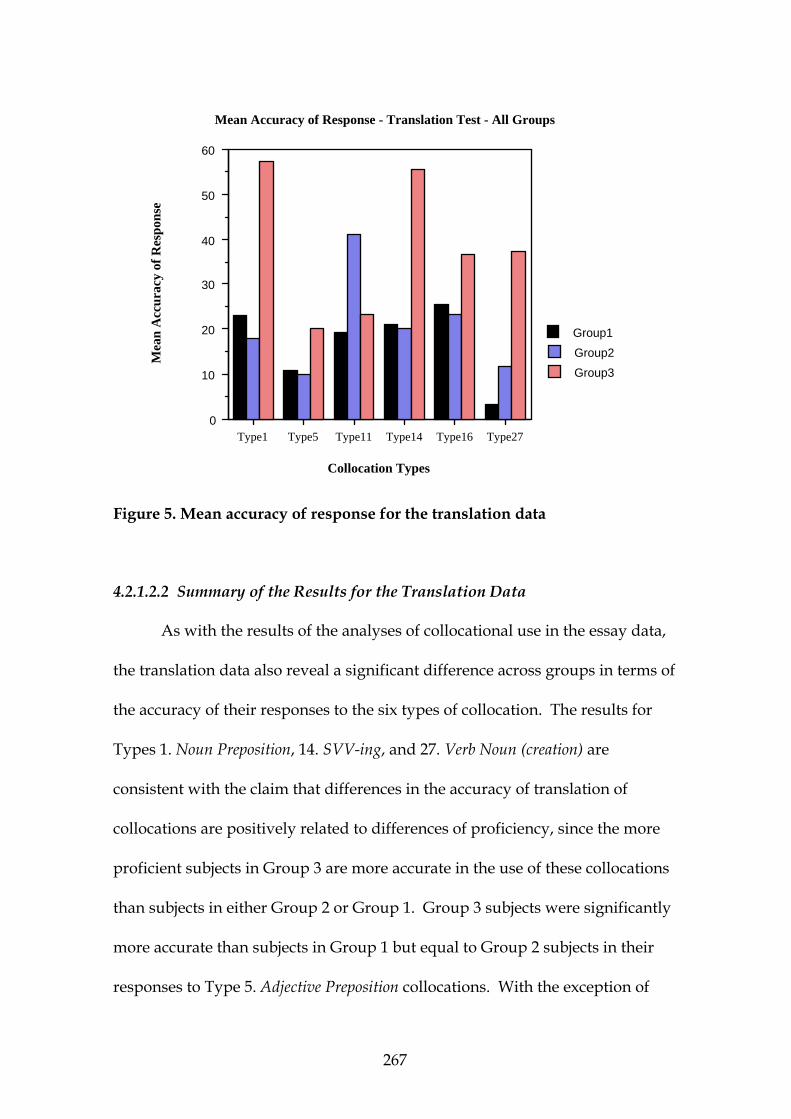
Type1 Type5 Type11 Type14 Type16 Type270
10
20
30
40
50
60
Group1
Group2
Group3
Mean Accuracy of Response - Translation Test - All Groups
Collocation Types
Mea
n A
ccur
acy
of R
espo
nse
Figure 5. Mean accuracy of response for the translation data
4.2.1.2.2 Summary of the Results for the Translation Data
As with the results of the analyses of collocational use in the essay data,
the translation data also reveal a significant difference across groups in terms of
the accuracy of their responses to the six types of collocation. The results for
Types 1. Noun Preposition, 14. SVV-ing, and 27. Verb Noun (creation) are
consistent with the claim that differences in the accuracy of translation of
collocations are positively related to differences of proficiency, since the more
proficient subjects in Group 3 are more accurate in the use of these collocations
than subjects in either Group 2 or Group 1. Group 3 subjects were significantly
more accurate than subjects in Group 1 but equal to Group 2 subjects in their
responses to Type 5. Adjective Preposition collocations. With the exception of
267

Type 11. SV(O) Preposition O collocations, in which Group 2 subjects were
better than either Group 1 or Group 3 subjects, the differences across all groups
are in the predicted direction (see Table 29).
Table 29. Translation accuracy distinguishing proficiency levels
Group 1 Group 2 Group 3
Collocation Types Collocation Types Collocation Types
11. SV(O) Prep O** 1. Noun Prep**
5. Adjective Prep* 14. SVV-ing**
27. Verb Noun (creat)**
5. Adjective Prep*
**: Significantly more accurate than the other two groups
*: Significantly more accurate than one other group
4.2.1.2.3 Implicational Scaling for the Translation Data (All Groups)
For the implicational scaling analysis, following the Guttman procedure,
each subject was coded as having translated accurately (1), or not (0), each of
the 6 types of collocations in the translation test. A criterion of 80% accuracy
was used for the coding of the data (see also Andersen 1978; Anderson 1978).
That is, if a subject was 80 to 100% accurate in translating the particular
collocation type, she/he was coded as 1. Accuracy less than 80% was coded as
0. As with the essay data, the two axes of the matrix for the implicational
scaling consisted of the six items ranked from the most accurately translated by
268
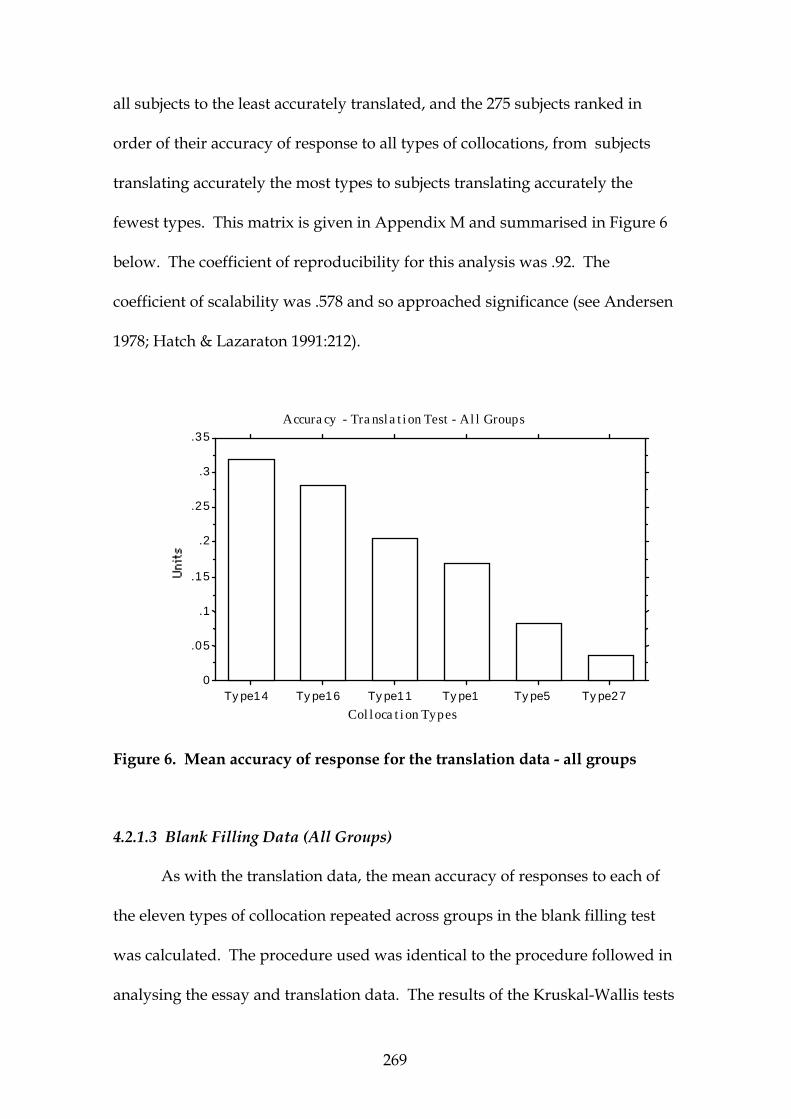
all subjects to the least accurately translated, and the 275 subjects ranked in
order of their accuracy of response to all types of collocations, from subjects
translating accurately the most types to subjects translating accurately the
fewest types. This matrix is given in Appendix M and summarised in Figure 6
below. The coefficient of reproducibility for this analysis was .92. The
coefficient of scalability was .578 and so approached significance (see Andersen
1978; Hatch & Lazaraton 1991:212).
0
.05
.1
.15
.2
.25
.3
.35
Ty pe14 Ty pe16 Ty pe11 Ty pe1 Ty pe5 Ty pe27Col loca t i on Types
Accura cy - Tra nsl a t i on Test - Al l Groups
Figure 6. Mean accuracy of response for the translation data - all groups
4.2.1.3 Blank Filling Data (All Groups)
As with the translation data, the mean accuracy of responses to each of
the eleven types of collocation repeated across groups in the blank filling test
was calculated. The procedure used was identical to the procedure followed in
analysing the essay and translation data. The results of the Kruskal-Wallis tests
269
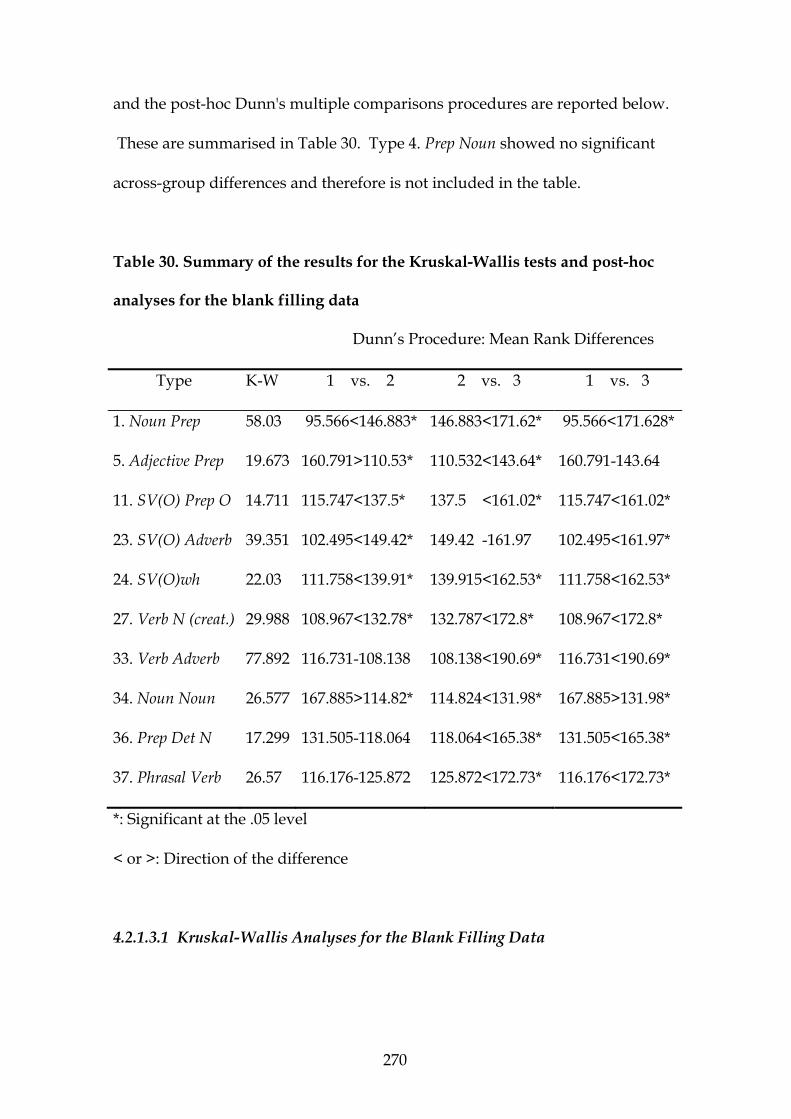
and the post-hoc Dunn's multiple comparisons procedures are reported below.
These are summarised in Table 30. Type 4. Prep Noun showed no significant
across-group differences and therefore is not included in the table.
Table 30. Summary of the results for the Kruskal-Wallis tests and post-hoc
analyses for the blank filling data
Dunn’s Procedure: Mean Rank Differences
Type K-W 1 vs. 2 2 vs. 3 1 vs. 3
1. Noun Prep 58.03 95.566<146.883* 146.883<171.62* 95.566<171.628*
5. Adjective Prep 19.673 160.791>110.53* 110.532<143.64* 160.791-143.64
11. SV(O) Prep O 14.711 115.747<137.5* 137.5 <161.02* 115.747<161.02*
23. SV(O) Adverb 39.351 102.495<149.42* 149.42 -161.97 102.495<161.97*
24. SV(O)wh 22.03 111.758<139.91* 139.915<162.53* 111.758<162.53*
27. Verb N (creat.) 29.988 108.967<132.78* 132.787<172.8* 108.967<172.8*
33. Verb Adverb 77.892 116.731-108.138 108.138<190.69* 116.731<190.69*
34. Noun Noun 26.577 167.885>114.82* 114.824<131.98* 167.885>131.98*
36. Prep Det N 17.299 131.505-118.064 118.064<165.38* 131.505<165.38*
37. Phrasal Verb 26.57 116.176-125.872 125.872<172.73* 116.176<172.73*
*: Significant at the .05 level
< or >: Direction of the difference
4.2.1.3.1 Kruskal-Wallis Analyses for the Blank Filling Data
270

Type 1. Noun Preposition - Results of the Kruskal-Wallis test of
responses to Noun Preposition collocations show a significant main effect for the
factor Group (Kruskal-Wallis c2 (2, N = 275) = 58.03, p = .0001). The mean
accuracy of responses to Noun Preposition collocations increases across groups
(see Table 31). The results of the post-hoc Dunn's multiple comparisons
procedure show significant differences in the mean accuracy of response to this
type of collocation between all groups (see Table 30).
Type 5. Adjective Preposition - Results of the Kruskal-Wallis test of
responses to Adjective Preposition collocations show a significant difference
between conditions (Kruskal-Wallis c2 (2, N = 275) = 19.673, p = .0001). The
results of the post-hoc Dunn's multiple comparisons procedure show
significant differences in the mean accuracy of response to this type of
collocation between Groups 1 and 2, and between Groups 2 and 3, but not
between Groups 1 and 3 (see Table 30).
Type 11. SV(O) Preposition O - Results of the Kruskal-Wallis test of
responses to SV(O) Preposition O collocations show a significant main effect for
the factor Group (Kruskal-Wallis c2 (2, N = 275) = 14.711, p = .0006). The mean
accuracy of responses to SV(O) Preposition O collocations increases across
groups (see Table 31). The results of the post-hoc Dunn's multiple comparisons
procedure show significant differences in the mean accuracy of response to this
type of collocation between all groups (see Table 30).
271

Type 23. SV(O) Adverbial - Results of the Kruskal-Wallis test of
responses to SV(O) Adverbial collocations show a significant main effect for the
factor Group (Kruskal-Wallis c2 (2, N = 275) = 39.351, p = .0001). The mean
accuracy of responses to SV(O) Adverbial collocations increases across groups
(see Table 31). The results of the post-hoc Dunn's multiple comparisons
procedure show significant differences in the mean accuracy of response to this
type of collocation between Groups 1 and 2, and between Groups 1 and 3, but
not between Groups 2 and 3 (see Table 30).
Type 24. SV(O) wh-word - Results of the Kruskal-Wallis test of
responses to SV(O) wh-word collocations show a significant main effect for the
factor Group (Kruskal-Wallis c2 (2, N = 275) = 22.03, p = .0001). The mean
accuracy of responses to SV(O) wh-word collocations increases across groups
(see Table 31). The results of the post-hoc Dunn's multiple comparisons
procedure show significant differences in the mean accuracy of response to this
type of collocation between all groups (see Table 30).
Type 27. Verb Noun (creation) - Results of the Kruskal-Wallis test of
responses to Verb Noun (creation) collocations show a significant main effect for
the factor Group (Kruskal-Wallis c2 (2, N = 275) = 29.988, p = .0001). The mean
accuracy of responses to Verb Noun (creation) collocations increases across
groups (see Table 31). The results of the post-hoc Dunn's multiple comparisons
272

procedure show significant differences in the mean accuracy of response to this
type of collocation between all groups (see Table 30).
Type 33. Verb Adverb - Results of the Kruskal-Wallis test of responses to
Verb Adverb collocations show a significant main effect for the factor Group
(Kruskal-Wallis c2 (2, N = 275) = 77.892, p = .0001). The results of the post-hoc
Dunn's multiple comparisons procedure show significant differences in the
mean accuracy of response to this type of collocation between Groups 1 and 3,
and between Groups 2 and 3, but not between Groups 1 and 2 (see Table 30).
Type 34. Noun Noun - Results of the Kruskal-Wallis test of responses to
Noun Noun collocations show a significant main effect for the factor Group
(Kruskal-Wallis c2 (2, N = 275) = 26.577, p = .0001). The results of the post-hoc
Dunn's multiple comparisons procedure show significant differences in the
mean accuracy of response to this type of collocation between all groups (see
Table 30).
Type 36. Preposition Determiner Noun - Results of the Kruskal-Wallis
test of responses to Preposition Determiner Noun collocations show a significant
main effect for the factor Group (Kruskal-Wallis c2 (2, N = 275) = 17.299, p =
.0002). The results of the post-hoc Dunn's multiple comparisons procedure
show significant differences in the mean accuracy of response to this type of
273
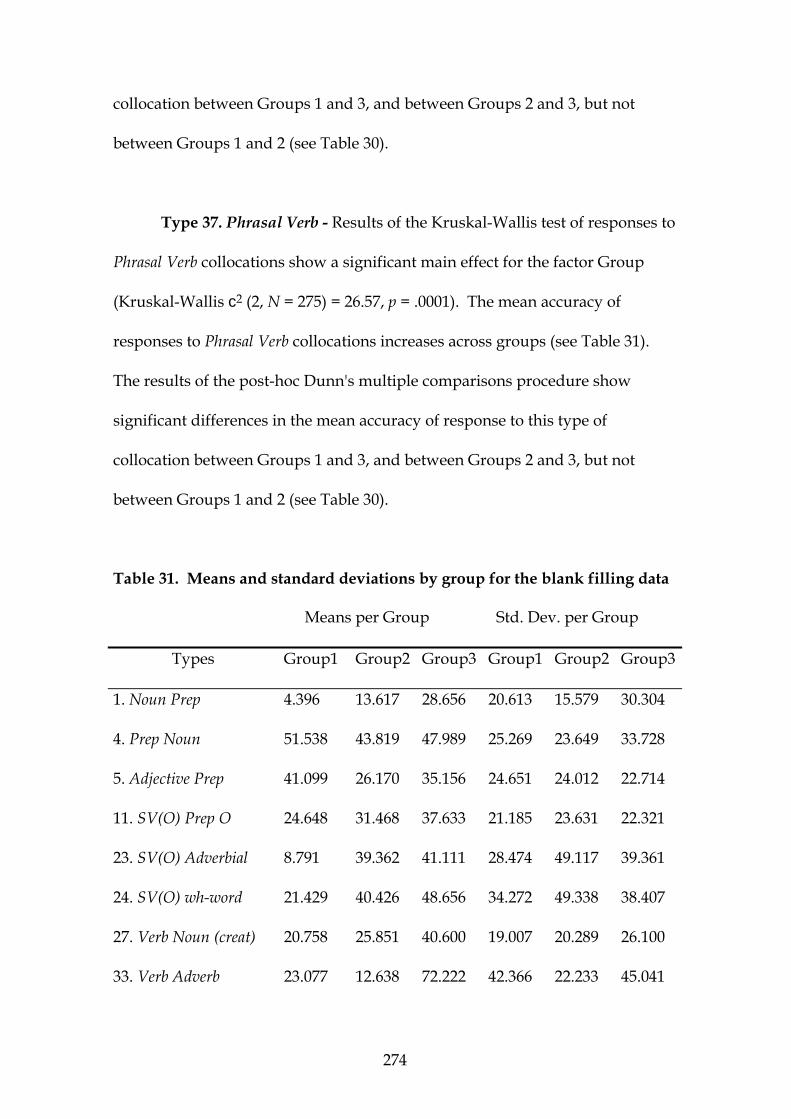
collocation between Groups 1 and 3, and between Groups 2 and 3, but not
between Groups 1 and 2 (see Table 30).
Type 37. Phrasal Verb - Results of the Kruskal-Wallis test of responses to
Phrasal Verb collocations show a significant main effect for the factor Group
(Kruskal-Wallis c2 (2, N = 275) = 26.57, p = .0001). The mean accuracy of
responses to Phrasal Verb collocations increases across groups (see Table 31).
The results of the post-hoc Dunn's multiple comparisons procedure show
significant differences in the mean accuracy of response to this type of
collocation between Groups 1 and 3, and between Groups 2 and 3, but not
between Groups 1 and 2 (see Table 30).
Table 31. Means and standard deviations by group for the blank filling data
Means per Group Std. Dev. per Group
Types Group1 Group2 Group3 Group1 Group2 Group3
1. Noun Prep 4.396 13.617 28.656 20.613 15.579 30.304
4. Prep Noun 51.538 43.819 47.989 25.269 23.649 33.728
5. Adjective Prep 41.099 26.170 35.156 24.651 24.012 22.714
11. SV(O) Prep O 24.648 31.468 37.633 21.185 23.631 22.321
23. SV(O) Adverbial 8.791 39.362 41.111 28.474 49.117 39.361
24. SV(O) wh-word 21.429 40.426 48.656 34.272 49.338 38.407
27. Verb Noun (creat) 20.758 25.851 40.600 19.007 20.289 26.100
33. Verb Adverb 23.077 12.638 72.222 42.366 22.233 45.041
274
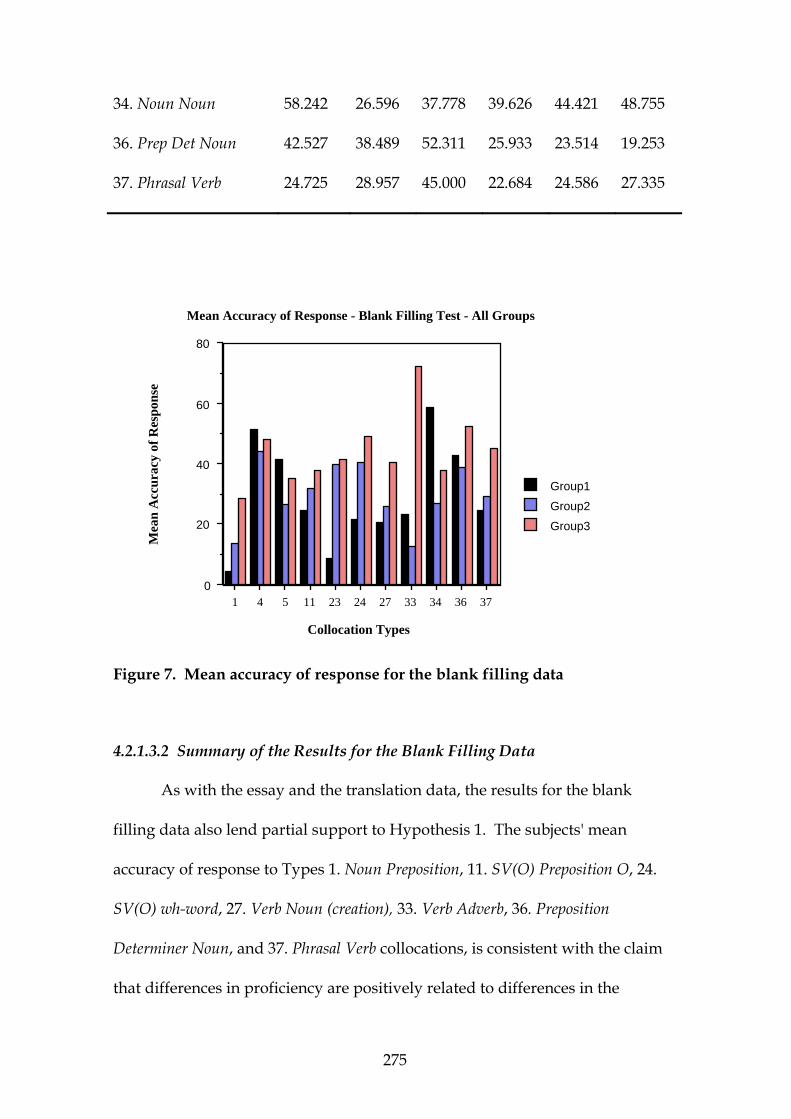
34. Noun Noun 58.242 26.596 37.778 39.626 44.421 48.755
36. Prep Det Noun 42.527 38.489 52.311 25.933 23.514 19.253
37. Phrasal Verb 24.725 28.957 45.000 22.684 24.586 27.335
1 4 5 11 23 24 27 33 34 36 370
20
40
60
80
Group1
Group2
Group3
Mean Accuracy of Response - Blank Filling Test - All Groups
Collocation Types
Mea
n A
ccur
acy
of R
espo
nse
Figure 7. Mean accuracy of response for the blank filling data
4.2.1.3.2 Summary of the Results for the Blank Filling Data
As with the essay and the translation data, the results for the blank
filling data also lend partial support to Hypothesis 1. The subjects' mean
accuracy of response to Types 1. Noun Preposition, 11. SV(O) Preposition O, 24.
SV(O) wh-word, 27. Verb Noun (creation), 33. Verb Adverb, 36. Preposition
Determiner Noun, and 37. Phrasal Verb collocations, is consistent with the claim
that differences in proficiency are positively related to differences in the
275

accuracy of collocation use, since the more proficient subjects in Group 3 are
more accurate in the use of these collocations than subjects in Group 2 and
Group 1. Responses to Type 23. SV(O) Adverbial collocations partially confirm
Hypothesis 1, since Groups 2 and 3 are more accurate than Group 1. With
respect to accuracy of responses to Type 5. Adjective Preposition collocations,
Groups 1 and 3 are significantly better than Group 2. The results for Type 34.
Noun Noun collocations are the only exception to the general direction of the
blank filling data, since Group 1 students are significantly more accurate than
students in Groups 2 and 3.
Overall, the results for the blank filling data are in the predicted
direction, that is, accuracy of response to collocational types increases with
proficiency (see Table 32).
Table 32. Blank filling accuracy distinguishing proficiency levels
Group 1 Group 2 Group 3
Collocation Types Collocation Types Collocation Types
34. Noun Noun** 23. SV(O) Adverbial* 1. Noun Prep**
5. Adjective Prep* 11. SV(O) Prep O**
24. SV(O) wh-word**
27. Verb Noun (creat) **
33. Verb Adverb**
36. Prep Det Noun**
37. Phrasal Verb**
276

23. SV(O) Adverbial*
5. Adjective Prep*
**: Significantly more accurate than the other two groups
*: Significantly more accurate than one other group
4.2.1.3.3 Implicational Scaling for the Blank Filling Data (All Groups)
For the implicational scaling analysis the Guttman procedure was used.
Each subject was coded as having answered accurately (1), or not (0), each of
the 11 types of collocations repeated across groups in the blank filling test. As
with the translation data, an 80% accuracy criterion was used for the coding of
the data, i.e. accuracy less than 80% was coded as 0, accuracy 80 to 100% was
coded as 1. The two axes of the matrix for the implicational scaling consisted of
the eleven types ranked from most accurately answered by all subjects to the
least accurately answered, and the 275 subjects ranked in order of their
accuracy of response to all types of collocations, from types most accurately
answered to types least accurately answered. This matrix is summarised in
Figure 8 below. The coefficient of reproducibility for this analysis was .91. The
coefficient of scalability was .4. As with the essay data, even though the
coefficient of reproducility for the blank filling data is at the level necessary for
this implicational scale to be considered valid, the coefficient of scalability is
below the recommended level of .6 (see Andersen 1978; Hatch & Lazaraton
1991:212).
277
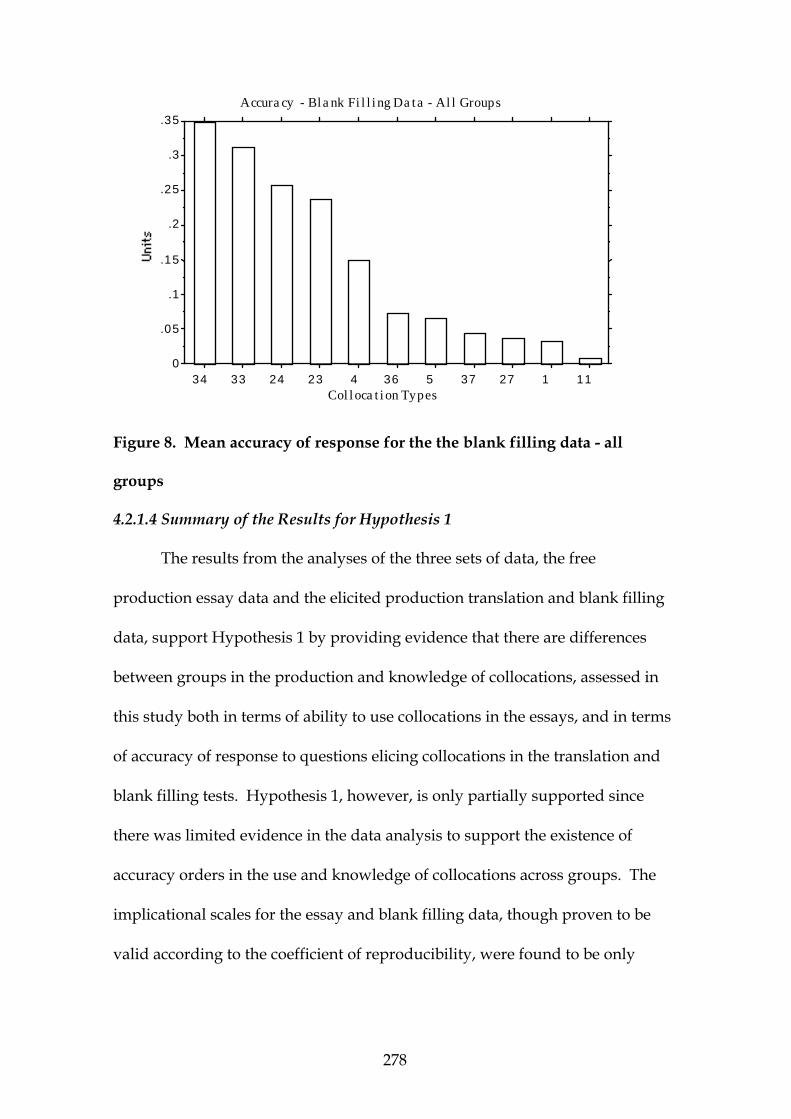
0
.05
.1
.15
.2
.25
.3
.35
34 33 24 23 4 36 5 37 27 1 11 Col loca t i on Types
Accura cy - Bl a nk Fi l l i ng Da t a - Al l Groups
Figure 8. Mean accuracy of response for the the blank filling data - all
groups
4.2.1.4 Summary of the Results for Hypothesis 1
The results from the analyses of the three sets of data, the free
production essay data and the elicited production translation and blank filling
data, support Hypothesis 1 by providing evidence that there are differences
between groups in the production and knowledge of collocations, assessed in
this study both in terms of ability to use collocations in the essays, and in terms
of accuracy of response to questions elicing collocations in the translation and
blank filling tests. Hypothesis 1, however, is only partially supported since
there was limited evidence in the data analysis to support the existence of
accuracy orders in the use and knowledge of collocations across groups. The
implicational scales for the essay and blank filling data, though proven to be
valid according to the coefficient of reproducibility, were found to be only
278

marginally scalable. The implicational scaling for the translation data
approached statistical significance and revealed a valid accuracy order.
4.2.2 Hypothesis 2: There are patterns in the development of collocational
knowledge within proficiency groups
To address Hypothesis 2 and examine the extent of the within-group
differences in the use and knowledge of collocations, non-parametric Friedman
repeated measures tests were used, followed by post-hoc Nemenyi's multiple
comparisons procedures. Implicational scaling for each of the three groups in
each of the three sets of data was then performed. Results of the analyses are
reported below.
4.2.2.1 Essay Data
As for the analyses in Hypothesis 1, the tokens of accurate use of the 37
types of collocation by each subject in each group were used as data for these
analyses.
4.2.2.1.1 Friedman test for the Essay Data - Group 1
The results of the Friedman test for Group 1 show a significant
difference in the use of the 37 types of collocation in the students' essays
(Friedman c2 (36, N = 37) = 1699.221, p = .0001). Nemenyi's multiple
comparisons tests based on the Friedman rank sums were performed on the
data. The results of these tests are summarised below in Table 33. The results
of the post-hoc analysis show a clustering of certain collocations. Types 11.
279

280
SV(O) Prep O, 26. SVc, and 29. Adjective Noun are used significantly more than
almost all the other types of collocation.
4.2.2.1.2 Friedman Test for the Essay Data - Group 2
The results of the Friedman test for Group 2 show a significant difference
in the use of the 37 types of collocation in the students' essays (Friedman c2 (36,
N = 37) = 1823.796, p = .0001). Nemenyi's multiple comparisons tests based on
the Friedman rank sums were performed on the data. The results of these tests
are summarised below in Table 4.24. The results show types 11. SV(O) Prep O,
12. SV to Inf, 26. SVc, 29. Adjective Noun, and 36. Prep Det Noun to be used
significanlty more than all the other types.
4.2.2.1.3 Friedman Test for Group 3 - Essay Data
The results of the Friedman test for Group 3 show a significant
difference in the use of the 37 types of collocation in the students' essays
(Friedman c2 (36, N = 37) = 1401.246, p = .0001). Nemenyi's multiple
comparisons tests based on the Friedman rank sums were performed on the
data. The results of these tests are summarised below in Table 35. The results
show that types 12. SV to Inf, 13. SV Inf, and 26. SVc are used significantly more
than all other types.
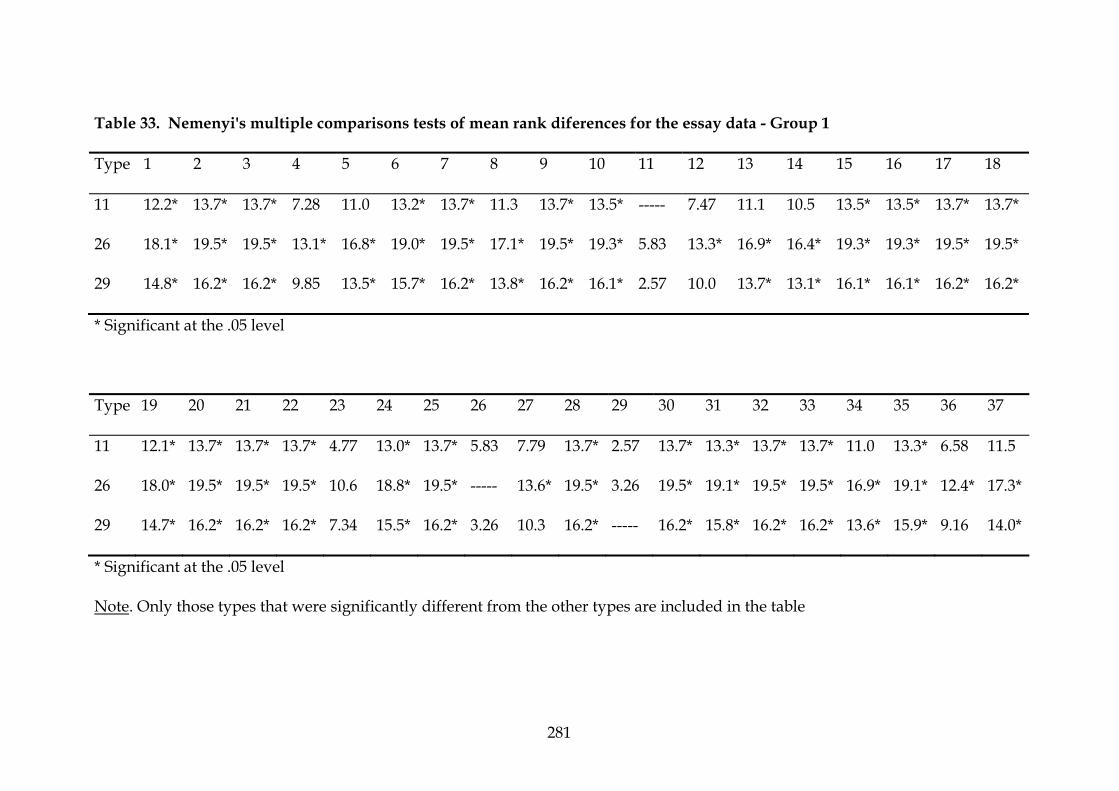
Table 33. Nemenyi's multiple comparisons tests of mean rank diferences for the essay data - Group 1
Type 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
11 12.2* 13.7* 13.7* 7.28 11.0 13.2* 13.7* 11.3 13.7* 13.5* ----- 7.47 11.1 10.5 13.5* 13.5* 13.7* 13.7*
26 18.1* 19.5* 19.5* 13.1* 16.8* 19.0* 19.5* 17.1* 19.5* 19.3* 5.83 13.3* 16.9* 16.4* 19.3* 19.3* 19.5* 19.5*
29 14.8* 16.2* 16.2* 9.85 13.5* 15.7* 16.2* 13.8* 16.2* 16.1* 2.57 10.0 13.7* 13.1* 16.1* 16.1* 16.2* 16.2*
* Significant at the .05 level
Type 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
11 12.1* 13.7* 13.7* 13.7* 4.77 13.0* 13.7* 5.83 7.79 13.7* 2.57 13.7* 13.3* 13.7* 13.7* 11.0 13.3* 6.58 11.5
26 18.0* 19.5* 19.5* 19.5* 10.6 18.8* 19.5* ----- 13.6* 19.5* 3.26 19.5* 19.1* 19.5* 19.5* 16.9* 19.1* 12.4* 17.3*
29 14.7* 16.2* 16.2* 16.2* 7.34 15.5* 16.2* 3.26 10.3 16.2* ----- 16.2* 15.8* 16.2* 16.2* 13.6* 15.9* 9.16 14.0*
* Significant at the .05 level
Note. Only those types that were significantly different from the other types are included in the table
281
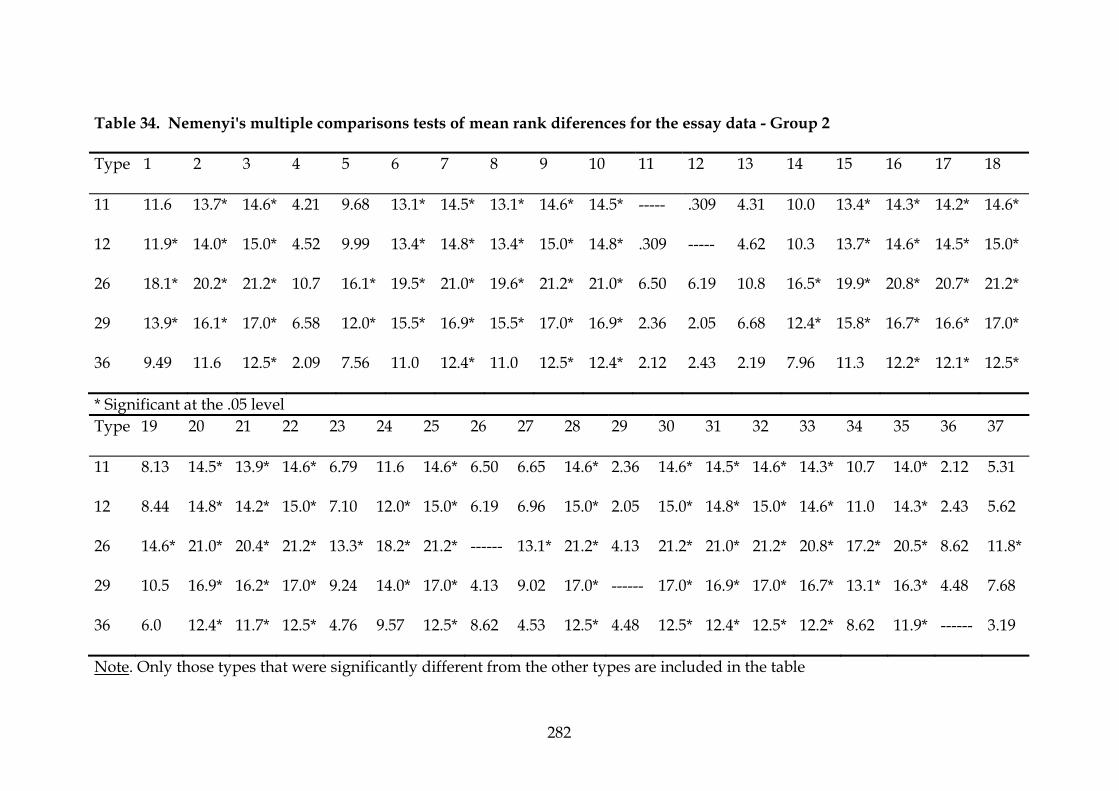
Table 34. Nemenyi's multiple comparisons tests of mean rank diferences for the essay data - Group 2
Type 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
11 11.6 13.7* 14.6* 4.21 9.68 13.1* 14.5* 13.1* 14.6* 14.5* ----- .309 4.31 10.0 13.4* 14.3* 14.2* 14.6*
12 11.9* 14.0* 15.0* 4.52 9.99 13.4* 14.8* 13.4* 15.0* 14.8* .309 ----- 4.62 10.3 13.7* 14.6* 14.5* 15.0*
26 18.1* 20.2* 21.2* 10.7 16.1* 19.5* 21.0* 19.6* 21.2* 21.0* 6.50 6.19 10.8 16.5* 19.9* 20.8* 20.7* 21.2*
29 13.9* 16.1* 17.0* 6.58 12.0* 15.5* 16.9* 15.5* 17.0* 16.9* 2.36 2.05 6.68 12.4* 15.8* 16.7* 16.6* 17.0*
36 9.49 11.6 12.5* 2.09 7.56 11.0 12.4* 11.0 12.5* 12.4* 2.12 2.43 2.19 7.96 11.3 12.2* 12.1* 12.5*
* Significant at the .05 level Type 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
11 8.13 14.5* 13.9* 14.6* 6.79 11.6 14.6* 6.50 6.65 14.6* 2.36 14.6* 14.5* 14.6* 14.3* 10.7 14.0* 2.12 5.31
12 8.44 14.8* 14.2* 15.0* 7.10 12.0* 15.0* 6.19 6.96 15.0* 2.05 15.0* 14.8* 15.0* 14.6* 11.0 14.3* 2.43 5.62
26 14.6* 21.0* 20.4* 21.2* 13.3* 18.2* 21.2* ------ 13.1* 21.2* 4.13 21.2* 21.0* 21.2* 20.8* 17.2* 20.5* 8.62 11.8*
29 10.5 16.9* 16.2* 17.0* 9.24 14.0* 17.0* 4.13 9.02 17.0* ------ 17.0* 16.9* 17.0* 16.7* 13.1* 16.3* 4.48 7.68
36 6.0 12.4* 11.7* 12.5* 4.76 9.57 12.5* 8.62 4.53 12.5* 4.48 12.5* 12.4* 12.5* 12.2* 8.62 11.9* ------ 3.19
Note. Only those types that were significantly different from the other types are included in the table
282
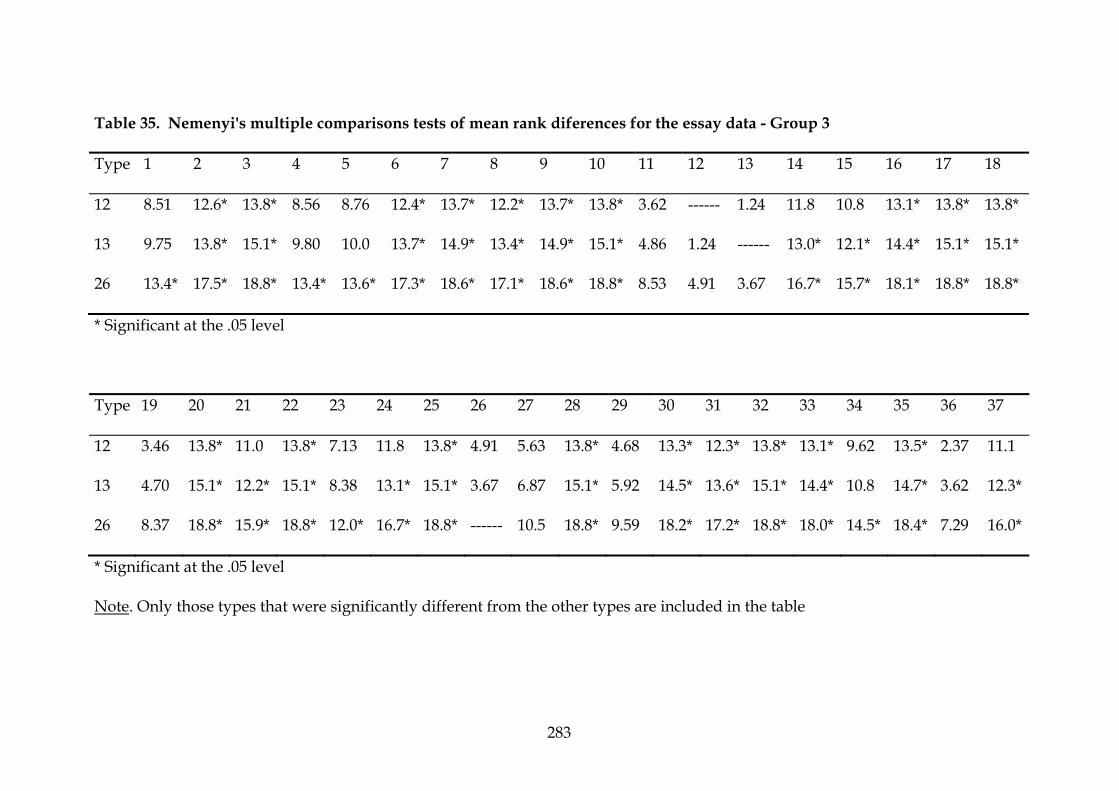
283
Table 35. Nemenyi's multiple comparisons tests of mean rank diferences for the essay data - Group 3
Type 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
12 8.51 12.6* 13.8* 8.56 8.76 12.4* 13.7* 12.2* 13.7* 13.8* 3.62 ------ 1.24 11.8 10.8 13.1* 13.8* 13.8*
13 9.75 13.8* 15.1* 9.80 10.0 13.7* 14.9* 13.4* 14.9* 15.1* 4.86 1.24 ------ 13.0* 12.1* 14.4* 15.1* 15.1*
26 13.4* 17.5* 18.8* 13.4* 13.6* 17.3* 18.6* 17.1* 18.6* 18.8* 8.53 4.91 3.67 16.7* 15.7* 18.1* 18.8* 18.8*
* Significant at the .05 level
Type 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
12 3.46 13.8* 11.0 13.8* 7.13 11.8 13.8* 4.91 5.63 13.8* 4.68 13.3* 12.3* 13.8* 13.1* 9.62 13.5* 2.37 11.1
13 4.70 15.1* 12.2* 15.1* 8.38 13.1* 15.1* 3.67 6.87 15.1* 5.92 14.5* 13.6* 15.1* 14.4* 10.8 14.7* 3.62 12.3*
26 8.37 18.8* 15.9* 18.8* 12.0* 16.7* 18.8* ------ 10.5 18.8* 9.59 18.2* 17.2* 18.8* 18.0* 14.5* 18.4* 7.29 16.0*
* Significant at the .05 level
Note. Only those types that were significantly different from the other types are included in the table

4.2.2.1.4 Implicational Scaling for the Essay Data by Groups
The implicational scaling was done by coding each subject as having
used (1), or not used (0), each of the 37 types of collocations in their essays. The
two axes of the matrix for the implicational scaling consisted of the 37
collocation types, ranked from most commonly used to least commonly used,
and the subjects in each group ranked in order of their use of types of
collocations, from subjects using the most types to subjects using the fewest.
This matrix is summarised in Figures 9, 10, and 11 below.
For Group 1, the coefficient of reproducibility was .94, which is
considered to be valid (see Andersen 1978). The coefficient of scalability was
.40. While the coefficient of reproducibility is at the level necessary for this
implicational scale to be considered valid, the coefficient of scalability is below
the recommended level of .6 (see Hatch & Lazaraton 1991:212). This suggests
that while the implicational scale for Group 1 is valid, the fact that most
subjects did not use the majority of the 37 scaled collocation types resulted in
the low coefficient of scalability. The implicational scale shows that the first
three collocation types are those that were found to be used significantly more
than all the other types in the post-hoc analyses (see Table 33).
For Group 2, the coefficient of reproducibility was .90, which is
considered to be valid (see Andersen 1978). The coefficient of scalability was
.33, below the recommended level of .6 (see Hatch & Lazaraton 1991:212). The
implicational scale shows that the first five items are those types that were
found to be used significantly more than all the other types in the post-hoc
analyses (see Table 34).
284
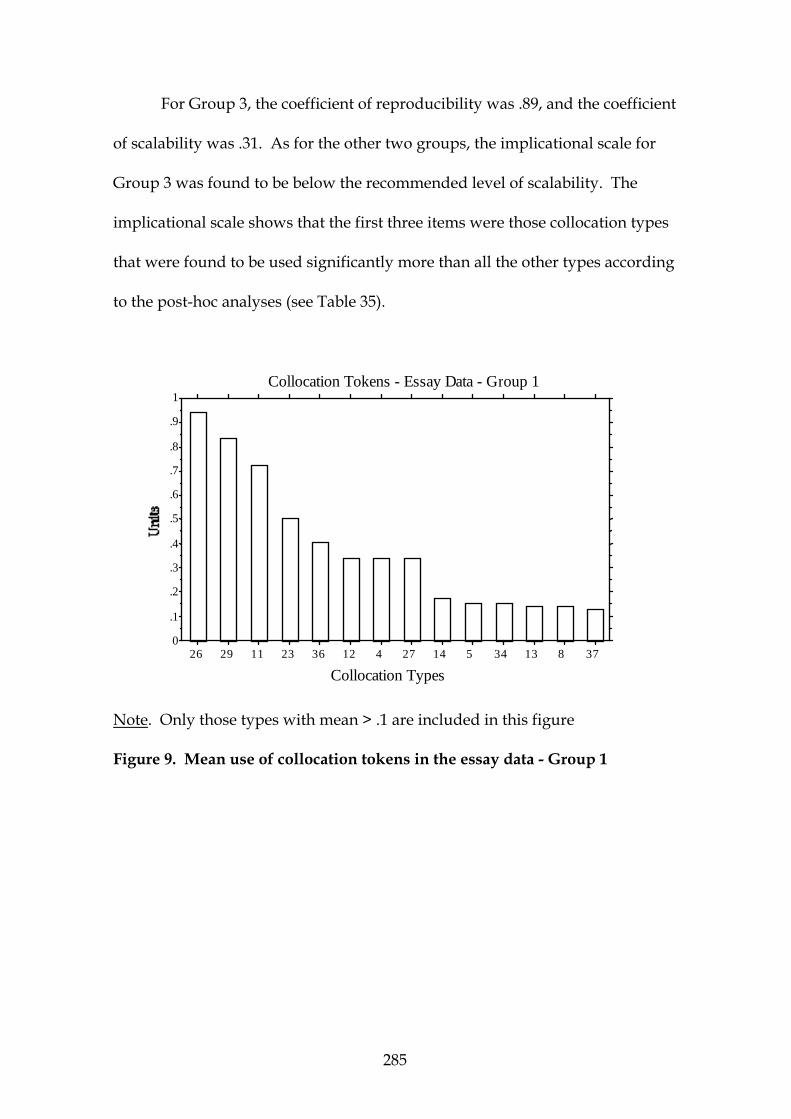
For Group 3, the coefficient of reproducibility was .89, and the coefficient
of scalability was .31. As for the other two groups, the implicational scale for
Group 3 was found to be below the recommended level of scalability. The
implicational scale shows that the first three items were those collocation types
that were found to be used significantly more than all the other types according
to the post-hoc analyses (see Table 35).
0
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
26 29 11 23 36 12 4 27 14 5 34 13 8 37
Collocation Tokens - Essay Data - Group 1
Collocation Types
Note. Only those types with mean > .1 are included in this figure
Figure 9. Mean use of collocation tokens in the essay data - Group 1
285
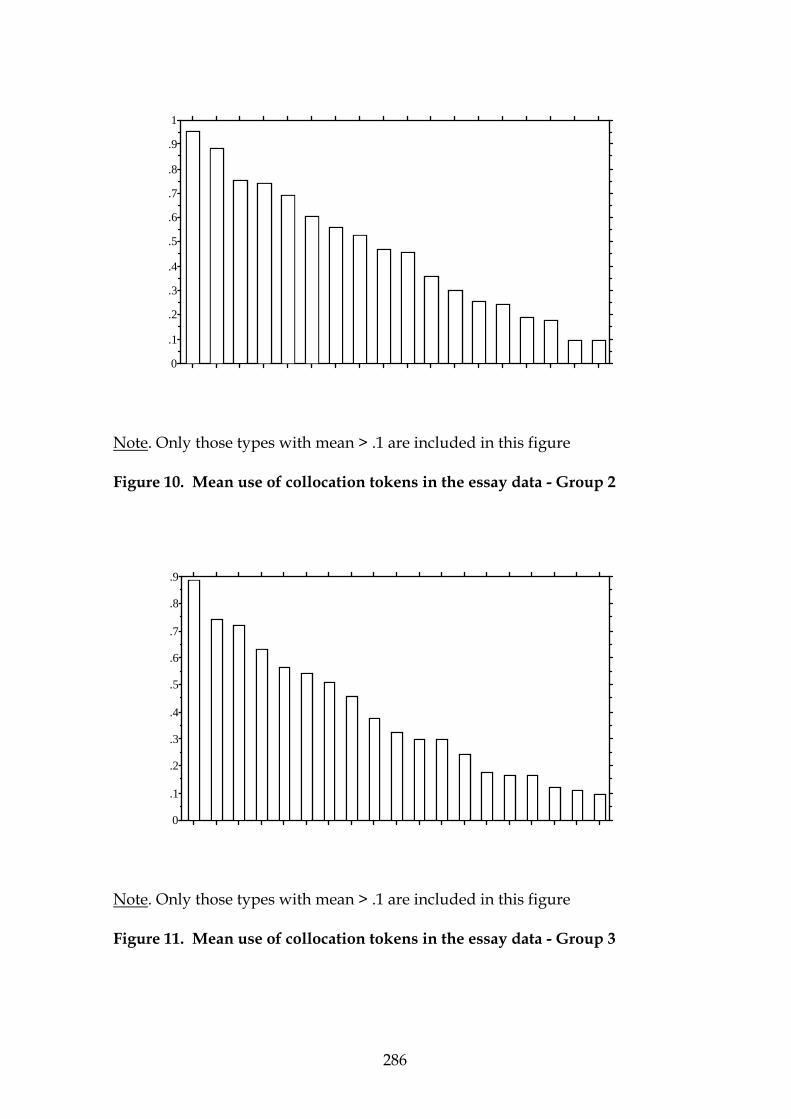
0
.1
.2
.3
.4
.5
.6
.7
.8
.9
1
Note. Only those types with mean > .1 are included in this figure
Figure 10. Mean use of collocation tokens in the essay data - Group 2
0
.1
.2
.3
.4
.5
.6
.7
.8
.9
Note. Only those types with mean > .1 are included in this figure
Figure 11. Mean use of collocation tokens in the essay data - Group 3
286

4.2.2.1.5 Summary of the Results for the Essay Data
The results of the Friedman repeated measures for the essay data
support Hypothesis 2 that there are group-specific patterns in the development
of collocational knowledge. For Group 1, Types 26. SVc, 29. Adjective Noun, and
11. SV(O) Prep O were used significantly more than the other types of
collocation. For Group 2, Types 26. SVc, 29. Adjective Noun, 12. SV to Inf, and
11. SV(O) Prep O were used significantly more than the other types. For Group
3, Types 26. SVc, 13. SV Inf, and 12 SV to Inf were used significantly more than
the other types. These results suggest that for each group there are certain
types that are used more than others, indicating that subjects in each group
prefer to use, and are more accurate in using, specific types of collocation.
These results also indicate the existence of group-specific patterns in the
acquisition of collocation, as was predicted by Hypothesis 2.
4.2.2.1.6 Further Analyses on the Essay Data
Due to the lack of statistical significance of the accuracy orders obtained
from the implicational scaling analyses for the essay data, further analyses were
performed to investigate the correlation of the accuracy orders for the three
groups. Spearman’s Rho Correlation Coefficient was calculated for the
accuracy orders by Groups 1 and 2, Groups 2 and 3, and Groups 1 and 3. Only
those types with a mean greater than .1 were included in the analyses. The
correlation for Groups 1 and 2 was rs = .832, p = .0004; for Groups 2 and 3 rs =
.766, p = .0011; and for Groups 1 and 3 rs = .552, p = .019. The significance of
these results are discussed in the next chapter.
287
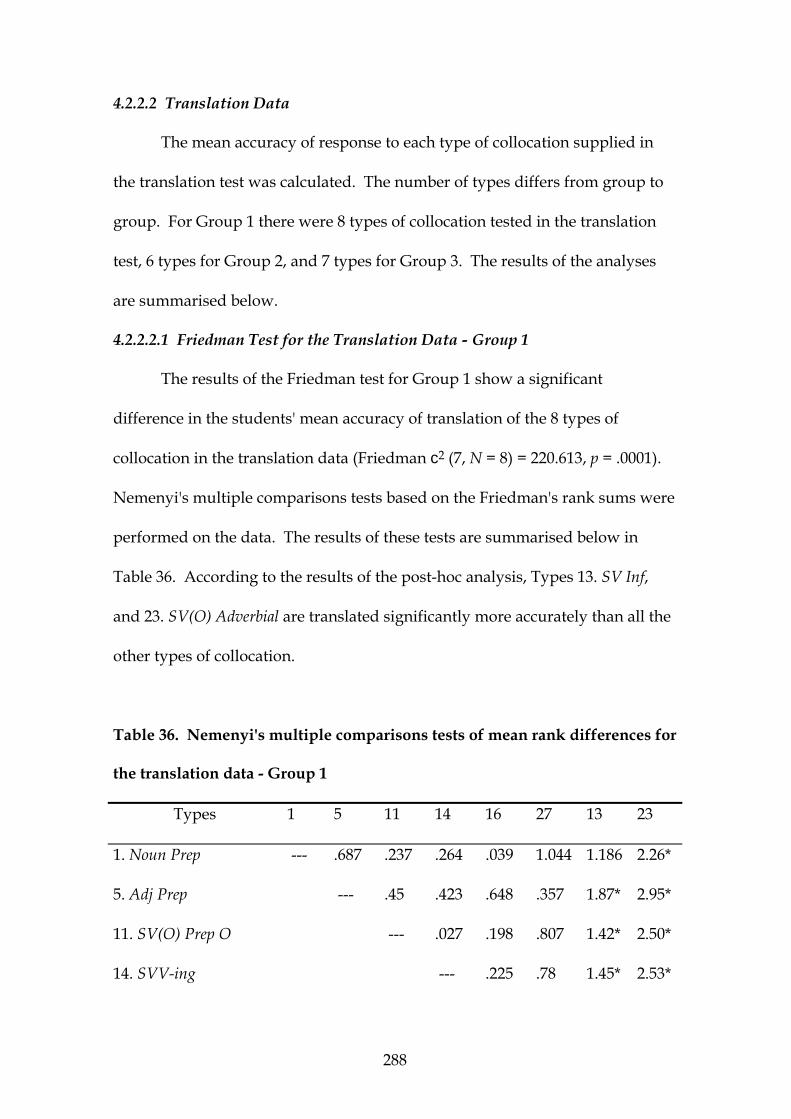
4.2.2.2 Translation Data
The mean accuracy of response to each type of collocation supplied in
the translation test was calculated. The number of types differs from group to
group. For Group 1 there were 8 types of collocation tested in the translation
test, 6 types for Group 2, and 7 types for Group 3. The results of the analyses
are summarised below.
4.2.2.2.1 Friedman Test for the Translation Data - Group 1
The results of the Friedman test for Group 1 show a significant
difference in the students' mean accuracy of translation of the 8 types of
collocation in the translation data (Friedman c2 (7, N = 8) = 220.613, p = .0001).
Nemenyi's multiple comparisons tests based on the Friedman's rank sums were
performed on the data. The results of these tests are summarised below in
Table 36. According to the results of the post-hoc analysis, Types 13. SV Inf,
and 23. SV(O) Adverbial are translated significantly more accurately than all the
other types of collocation.
Table 36. Nemenyi's multiple comparisons tests of mean rank differences for
the translation data - Group 1
Types 1 5 11 14 16 27 13 23
1. Noun Prep --- .687 .237 .264 .039 1.044 1.186 2.26*
5. Adj Prep --- .45 .423 .648 .357 1.87* 2.95*
11. SV(O) Prep O --- .027 .198 .807 1.42* 2.50*
14. SVV-ing --- .225 .78 1.45* 2.53*
288

16. SVO Inf --- 1.005 1.225 2.30*
27. Verb Noun(creat) --- 2.23* 3.31*
13. SV Inf --- 1.083
23. SV(O) Adverb ---
*: Significant at the .05 level
4.2.2.2.2 Friedman Test for the Translation Data - Group 2
The results of the Friedman test for Group 2 show a significant
difference in the students' mean accuracy of translation of the 6 types of
collocation in the translation data (Friedman c2 (5, N = 6) = 74.279, p = .0001).
Nemenyi's multiple comparisons tests based on Friedman's rank sums were
performed on the data. The results of these tests are summarised below in
Table 37. According to the results of the post-hoc analysis, only Type 11. SV(O)
Prep O is significantly more accurately translated than all the other types.
Table 37. Nemenyi's multiple comparisons tests of mean rank differences for
the translation data - Group 2
Types 1 5 11 14 16 27
1. Noun Prep --- .346 .931* .037 .154 .298
5. Adj Prep --- 1.27* .383 .5 .048
11. SV(O) Prep O --- .894 .777 1.22*
14. SVV-ing --- .117 .335
16. SVO Inf --- .452
289

27. Verb Noun(creat) ---
*: Significant at the .05 level
4.2.2.2.3 Friedman Test for the Translation Data - Group 3
The results of the Friedman test for Group 3 show a significant
difference in the students' mean accuracy of translation of the 7 types of
collocation in the translation data (Friedman c2 (6, N = 7) = 134.62, p = .0001).
Nemenyi's multiple comparisons tests based on the Friedman rank sums were
performed on the data. The results of these tests are summarised below in
Table 38. According to the post-hoc analysis, Types 13. SV Inf, 14. SVV-ing, and
1. Noun Prep were found to be significantly more accurately translated than all
the other types of collocation.
Table 38. Nemenyi's multiple comparisons tests of mean rank differences for
the translation data- Group 3
Types 1 5 11 14 16 27 13
1. Noun Prep --- 1.52* 1.33* .056 .8 .789 .972
5. Adj Prep --- .189 1.47* .728 .739 2.5*
11. SV(O) Prep O --- 1.28* .539 .55 2.31*
14. SVV-ing --- .744 .733 1.028
16. SVO Inf --- .011 1.77*
27. Verb Noun(creat) --- 1.76*
13. SV Inf ---
*: Significant at the .05 level
290

4.2.2.2.4 Implicational Scaling for the Translation Data by Groups
As for the implicational scaling analysis of the translation data in the
first hypothesis, each subject was coded as having translated accurately (1), or
not (0), each of the types of collocations in the translation test according to the
80% accuracy criterion. The two axes of the matrix for the implicational scaling
consisted of the collocation types ranked from most accurately translated by all
subjects in each group to least accurately translated, and the subjects in each
group ranked in order of their accuracy of translation of all types of
collocations, from subjects translating accurately the most types to subjects
translating accurately the fewest. The matrix for each group is given in
Appendix N and summarised in Figures 12, 13, and 14 below.
For Group 1, the coefficient of reproducibility was .936, and the
coefficient of scalability was .632. The implicational scale for this set of data
was found to be significant and the items on the scale are scalable (see
Andersen, 1978; Hatch & Lazaraton 1991:212). The implicational scale (Figure
12) also shows that the first two items on the scale are the two types of
collocation that were found to be tranlated significantly more accurately than
all the other types in the post-hoc analyses (see Table 36).
For Group 2, the coefficient of reproducibility was .97 and the coefficient
of scalability was .78. As for Group 1, the implicational scale for this set of data
was found to be significant and the items on the scale scalable. The
implicational scale (Figure 13) also shows that the first item on the scale is Type
291
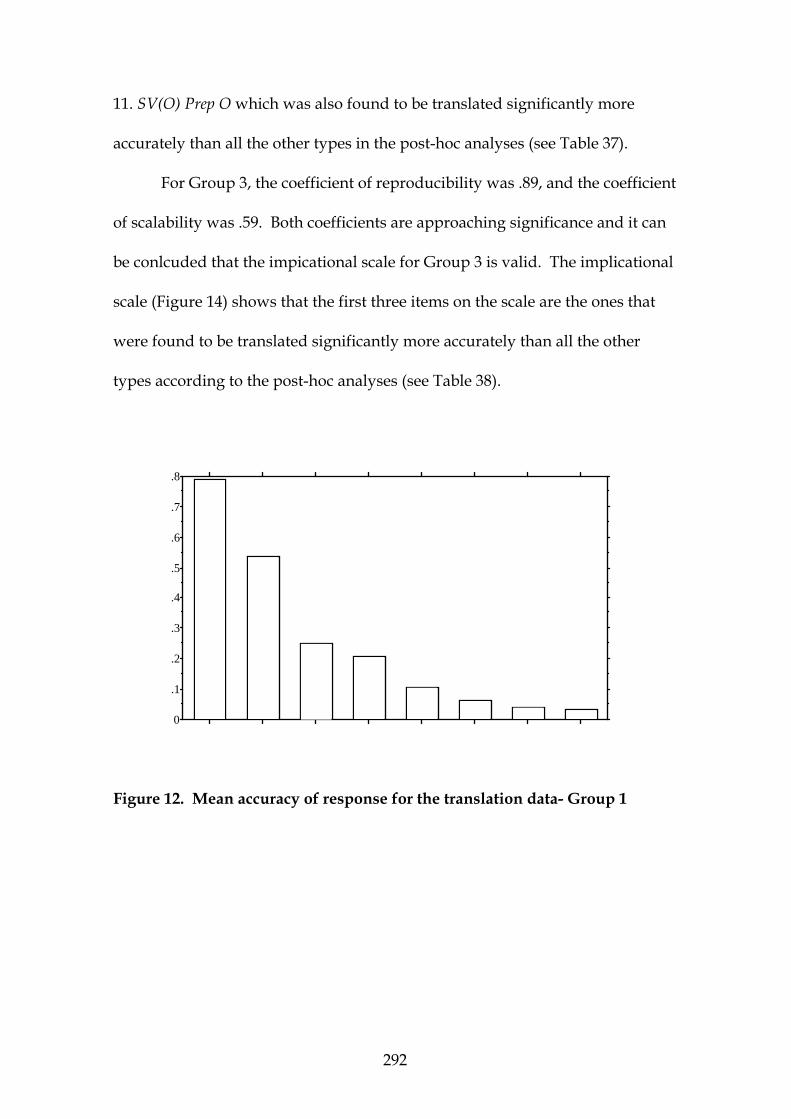
11. SV(O) Prep O which was also found to be translated significantly more
accurately than all the other types in the post-hoc analyses (see Table 37).
For Group 3, the coefficient of reproducibility was .89, and the coefficient
of scalability was .59. Both coefficients are approaching significance and it can
be conlcuded that the impicational scale for Group 3 is valid. The implicational
scale (Figure 14) shows that the first three items on the scale are the ones that
were found to be translated significantly more accurately than all the other
types according to the post-hoc analyses (see Table 38).
0
.1
.2
.3
.4
.5
.6
.7
.8
Figure 12. Mean accuracy of response for the translation data- Group 1
292
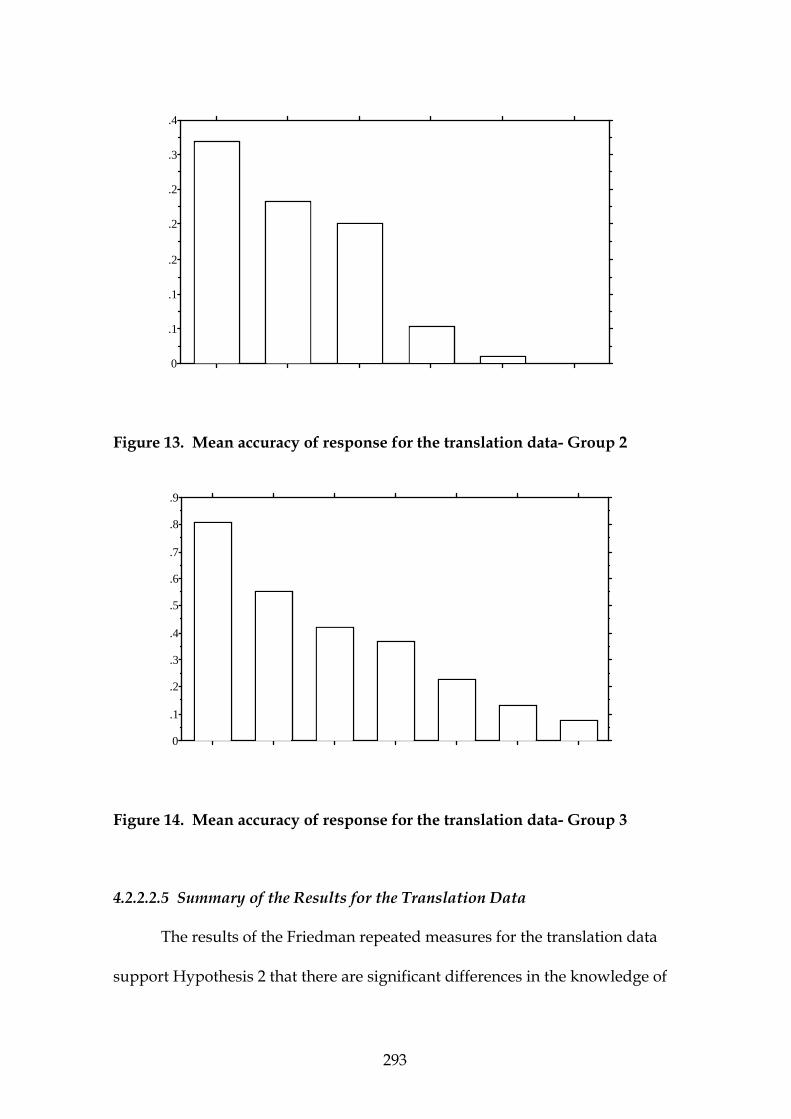
0
.1
.1
.2
.2
.2
.3
.4
Figure 13. Mean accuracy of response for the translation data- Group 2
0
.1
.2
.3
.4
.5
.6
.7
.8
.9
Figure 14. Mean accuracy of response for the translation data- Group 3
4.2.2.2.5 Summary of the Results for the Translation Data
The results of the Friedman repeated measures for the translation data
support Hypothesis 2 that there are significant differences in the knowledge of
293

collocations within proficiency groups. For Group 1, Types 23. SV(O) Adverbial,
and 13. SV Inf were translated significantly more accurately than the other
types of collocation. For Group 2, only Type 11. SV(O) Prep O was translated
significantly more accurately than the other types. For Group 3, Types 13. SV
Inf, 14. SVV-ing, and 1. Noun Prep were translated significantly more accurately
than the other types. These results suggest that for each group certain
collocation types are easier to translate than others.
4.2.2.3 Blank Filling Data
As for the translation data, for the within-group analyses of the blank
filling data the mean accuracy of responses to each type of collocation included
in the blank filling test for each group was calculated. Thus, the number of
types differs from group to group. For Group 1 there were 14 types of
collocation included in the blank filling test, for Group 2 there were 12 types,
and for Group 3 there were 13 types (see Table 10, Chapter 3). The results of
the analyses are summarised below.
4.2.2.3.1 Friedman Test for the Blank Filling Data - Group 1
The results of the Friedman test for the blank filling data for Group 1
show a significant difference in the students' mean accuracy of response to the
14 types of collocation in the blank filling data (Friedman c2 (13, N = 14) =
541.595, p = .0001). Nemenyi's multiple comparisons tests based on the
Friedman's rank sums were performed on the data. The results of these tests
are summarised below in Table 39. According to the results, the significant
differences are spread among many different pairs of collocation types. Thus,
the clustering of only a limited number of types that are significantly different
294

295
to all other types, evident in the results of the post-hoc analyses for the
translation and essay data, is not found in the post-hoc analyses for the blank
filling data for Group 1.
4.2.2.3.2 Friedman Test for the Blank Filling Data - Group 2
The results of the Friedman test for the blank filling data for Group 2
show a significant difference in the students' mean accuracy of response to the
12 types of collocation in the blank filling data (Friedman c2 (11, N = 12) =
202.339, p = .0001). Nemenyi's multiple comparisons tests based on the
Friedman's rank sums were performed on the data. The results of these tests
are summarised below in Table 40. According to the results of the post-hoc
analysis, Type 4. Prep Noun with the highest mean rank (i.e. most accurately
answered) and Type 33. Verb Adverb with the lowest mean rank (i.e. least
accurately answered) are the ones that show significant differences to most of
the other collocation types.
4.2.2.3.3 Friedman Test for the Blank Filling Data - Group 3
The results of the Friedman test for the blank filling data for Group 3
show a significant difference in the students' mean accuracy of response to the
13 types of collocation in the blank filling data (Friedman c2 (12, N = 13) =
191.452, p = .0001). Nemenyi's multiple comparisons tests based on Friedman's
rank sums were performed on the data. The results of these tests are
summarised below in Table 41. According to the results, Type 33. Verb Adverb
with the highest mean rank (i.e. most accurately answered), and Type 28. Verb
Noun (eradication) with the lowest mean rank (i.e. least accurately answered),
are significantly different to all the other types of collocation.
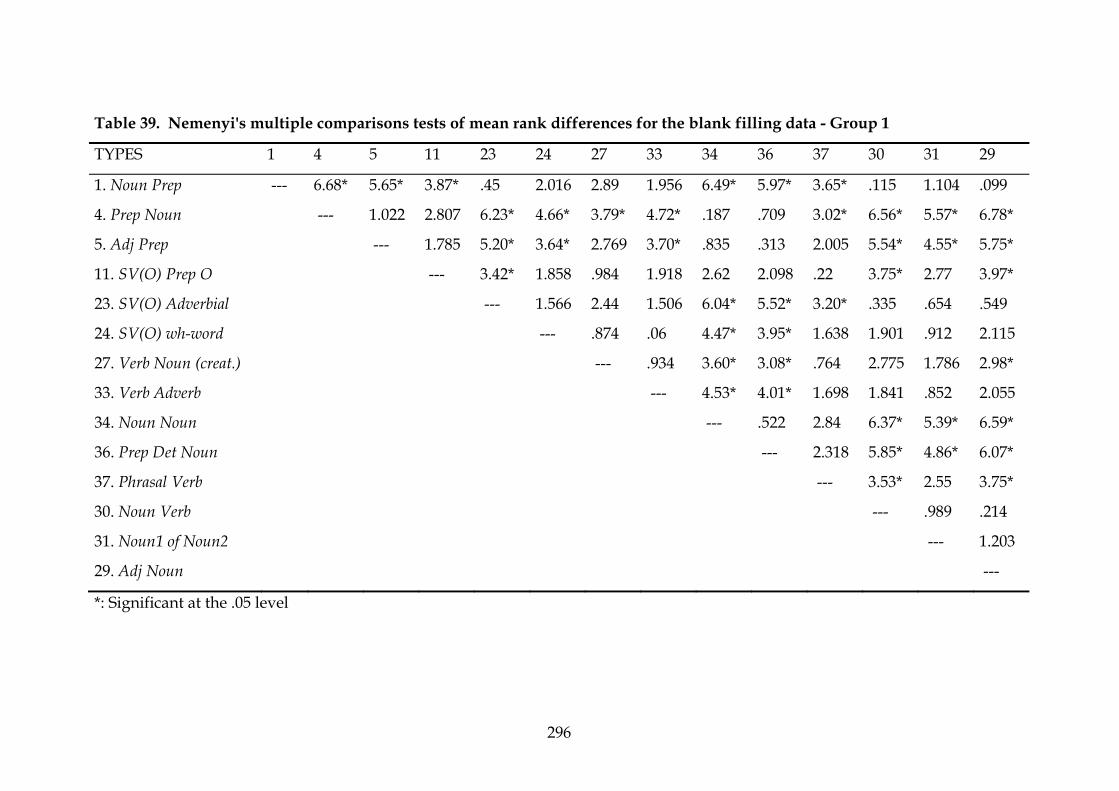
Table 39. Nemenyi's multiple comparisons tests of mean rank differences for the blank filling data - Group 1
TYPES 1 4 5 11 23 24 27 33 34 36 37 30 31 29
1. Noun Prep --- 6.68* 5.65* 3.87* .45 2.016 2.89 1.956 6.49* 5.97* 3.65* .115 1.104 .099
4. Prep Noun --- 1.022 2.807 6.23* 4.66* 3.79* 4.72* .187 .709 3.02* 6.56* 5.57* 6.78*
5. Adj Prep --- 1.785 5.20* 3.64* 2.769 3.70* .835 .313 2.005 5.54* 4.55* 5.75*
11. SV(O) Prep O --- 3.42* 1.858 .984 1.918 2.62 2.098 .22 3.75* 2.77 3.97*
23. SV(O) Adverbial --- 1.566 2.44 1.506 6.04* 5.52* 3.20* .335 .654 .549
24. SV(O) wh-word --- .874 .06 4.47* 3.95* 1.638 1.901 .912 2.115
27. Verb Noun (creat.) --- .934 3.60* 3.08* .764 2.775 1.786 2.98*
33. Verb Adverb --- 4.53* 4.01* 1.698 1.841 .852 2.055
34. Noun Noun --- .522 2.84 6.37* 5.39* 6.59*
36. Prep Det Noun --- 2.318 5.85* 4.86* 6.07*
37. Phrasal Verb --- 3.53* 2.55 3.75*
30. Noun Verb --- .989 .214
31. Noun1 of Noun2 --- 1.203
29. Adj Noun ---
*: Significant at the .05 level
296
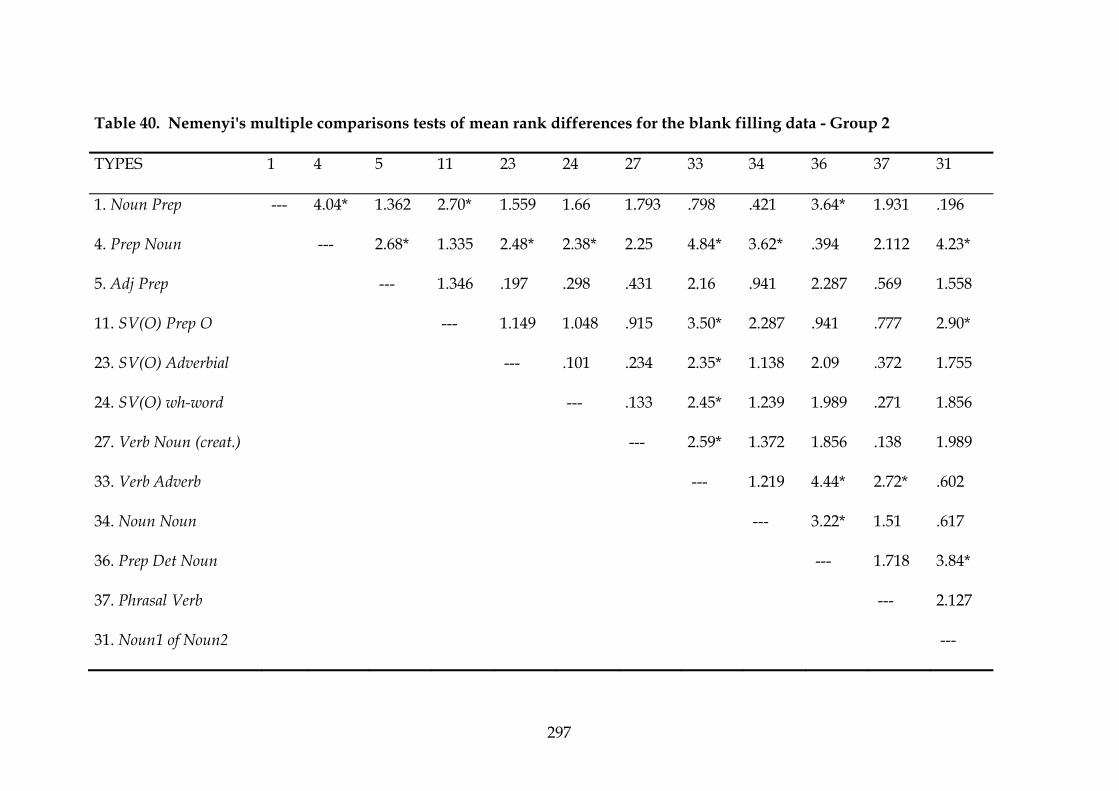
Table 40. Nemenyi's multiple comparisons tests of mean rank differences for the blank filling data - Group 2
TYPES 1 4 5 11 23 24 27 33 34 36 37 31
1. Noun Prep --- 4.04* 1.362 2.70* 1.559 1.66 1.793 .798 .421 3.64* 1.931 .196
4. Prep Noun --- 2.68* 1.335 2.48* 2.38* 2.25 4.84* 3.62* .394 2.112 4.23*
5. Adj Prep --- 1.346 .197 .298 .431 2.16 .941 2.287 .569 1.558
11. SV(O) Prep O --- 1.149 1.048 .915 3.50* 2.287 .941 .777 2.90*
23. SV(O) Adverbial --- .101 .234 2.35* 1.138 2.09 .372 1.755
24. SV(O) wh-word --- .133 2.45* 1.239 1.989 .271 1.856
27. Verb Noun (creat.) --- 2.59* 1.372 1.856 .138 1.989
33. Verb Adverb --- 1.219 4.44* 2.72* .602
34. Noun Noun --- 3.22* 1.51 .617
36. Prep Det Noun --- 1.718 3.84*
37. Phrasal Verb --- 2.127
31. Noun1 of Noun2 ---
297
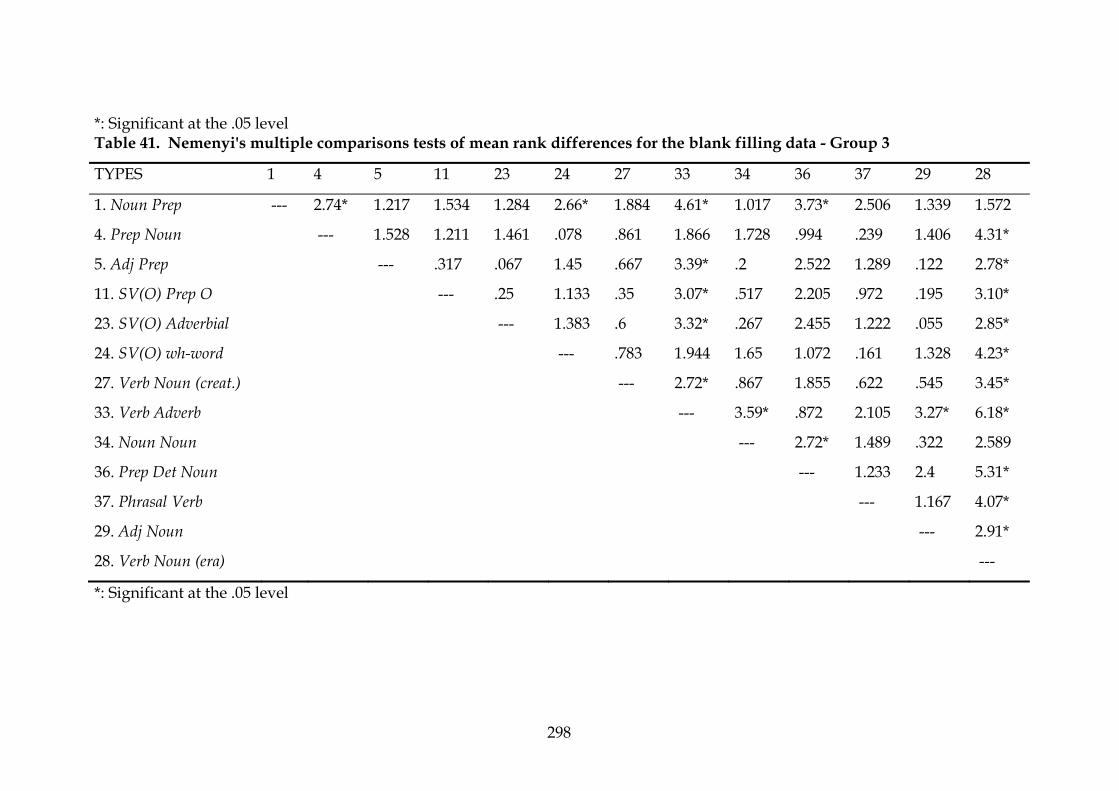
298
*: Significant at the .05 level Table 41. Nemenyi's multiple comparisons tests of mean rank differences for the blank filling data - Group 3
TYPES 1 4 5 11 23 24 27 33 34 36 37 29 28
1. Noun Prep --- 2.74* 1.217 1.534 1.284 2.66* 1.884 4.61* 1.017 3.73* 2.506 1.339 1.572
4. Prep Noun --- 1.528 1.211 1.461 .078 .861 1.866 1.728 .994 .239 1.406 4.31*
5. Adj Prep --- .317 .067 1.45 .667 3.39* .2 2.522 1.289 .122 2.78*
11. SV(O) Prep O --- .25 1.133 .35 3.07* .517 2.205 .972 .195 3.10*
23. SV(O) Adverbial --- 1.383 .6 3.32* .267 2.455 1.222 .055 2.85*
24. SV(O) wh-word --- .783 1.944 1.65 1.072 .161 1.328 4.23*
27. Verb Noun (creat.) --- 2.72* .867 1.855 .622 .545 3.45*
33. Verb Adverb --- 3.59* .872 2.105 3.27* 6.18*
34. Noun Noun --- 2.72* 1.489 .322 2.589
36. Prep Det Noun --- 1.233 2.4 5.31*
37. Phrasal Verb --- 1.167 4.07*
29. Adj Noun --- 2.91*
28. Verb Noun (era) ---
*: Significant at the .05 level

4.2.2.3.4 Implicational Scaling for the Blank Filling Data by Groups
A matrix was compiled for each group, consisting of the types of collocation
included in the blank filling test, ranked from most accurately answered by all
subjects in each group to least accurately answered, and the subjects in each group
ranked in order of their accuracy of response to all types of collocations, from
subjects responding accurately to the most types to subjects responding accurately
to the fewest types. As with the translation data, the 80% accuracy criterion was
used. These matrices are given in Appendix O and summarised in Figures 15, 16,
and 17 below.
For Group 1, the coefficient of reproducibility was .95, and the coefficient of
scalability was .5. Even though the coefficient of reproducibility for the blank
filling data for Group 1 is at the level necessary for this implicational scale to be
considered valid, the coefficient of scalability is below the recommended level of .6
(see Andersen 1978; Hatch & Lazaraton 1991:212).
For Group 2, the coefficient of reproducibility was .95, and the coefficient of
scalability was .61. The implicational scale for this set of data was found to be
significant and the items on the scale scalable.
For Group 3, the coefficient of reproducibility was .928, and the coefficient
of scalability was .68. The implicational scale for Group 3 was found to be
significant and the items on the scale scalable.
1
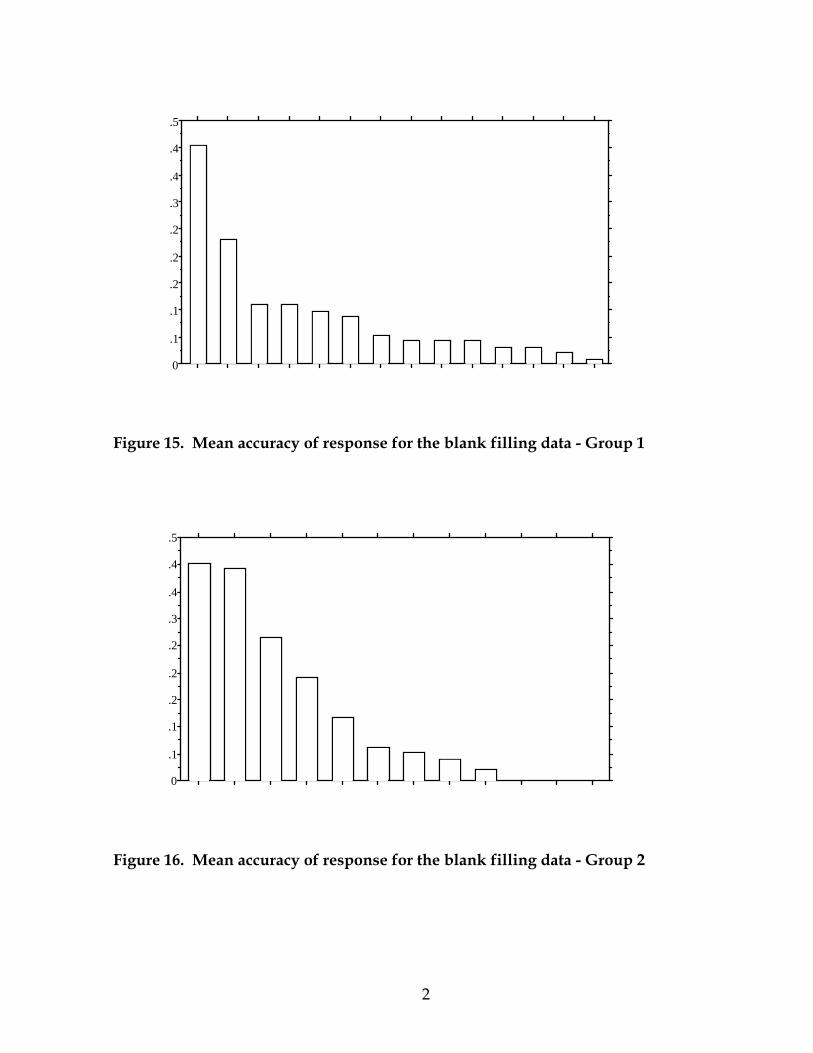
0
.1
.1
.2
.2
.2
.3
.4
.4
.5
Figure 15. Mean accuracy of response for the blank filling data - Group 1
0
.1
.1
.2
.2
.2
.3
.4
.4
.5
Figure 16. Mean accuracy of response for the blank filling data - Group 2
2
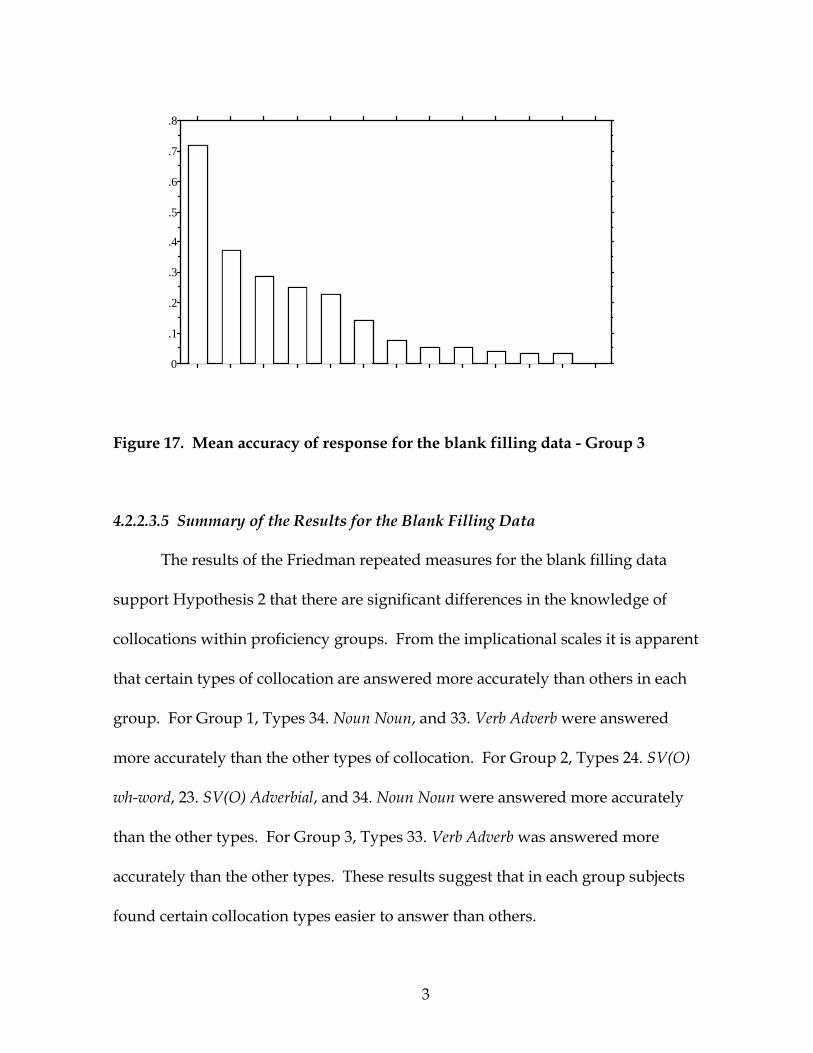
0
.1
.2
.3
.4
.5
.6
.7
.8
Figure 17. Mean accuracy of response for the blank filling data - Group 3
4.2.2.3.5 Summary of the Results for the Blank Filling Data
The results of the Friedman repeated measures for the blank filling data
support Hypothesis 2 that there are significant differences in the knowledge of
collocations within proficiency groups. From the implicational scales it is apparent
that certain types of collocation are answered more accurately than others in each
group. For Group 1, Types 34. Noun Noun, and 33. Verb Adverb were answered
more accurately than the other types of collocation. For Group 2, Types 24. SV(O)
wh-word, 23. SV(O) Adverbial, and 34. Noun Noun were answered more accurately
than the other types. For Group 3, Types 33. Verb Adverb was answered more
accurately than the other types. These results suggest that in each group subjects
found certain collocation types easier to answer than others.
3

4.2.2.4 Summary of the Results for Hypothesis 2
The results from the analyses of the three sets of data, the essay data, the
translation data and the blank filling data, support Hypothesis 2 by providing
evidence that there are within-group differences in the use and knowledge of
collocation types, assessed in this study both in terms of ability to produce
collocations in the essays, and in terms of accuracy of response to questions
eliciting collocations in the translation and blank filling tests. The statistical
significance for the implicational analyses of the translation and the blank filling
data strongly suggests that there are group-specific patterns in the acquisition of
collocations; that certain collocation types are easier than others to acquire; and
that they do form an accuracy order.
The next chapter discusses the significance of the results for the two
hypotheses.
4

CHAPTER 5
DISCUSSION OF THE FINDINGS
5.0 Introduction
This study investigated the acquisition of English collocations by ESL
subjects at three proficiency levels - post-beginners, intermediate, and post-
intermediate - in an attempt to describe the development of English collocational
knowledge in L2 learners. The acquisition of English collocations was measured
both as free production of collocations (accuracy of use in the students' essays) and
cued production of collocations (accuracy of response in the translation and blank-
filling tests). Evidence for the development of collocational knowledge was sought
in comparing the production and knowledge of collocation types across and within
the different proficiency groups. An implicational scaling analysis was also
performed on the data in an attempt to find evidence for accuracy orders in the
acquisition of English collocations. The findings are summarised and discussed in
the following sections. In section 5.1. the free production results are discussed; in
5.2. the cued production results are considered; a summary of the findings is then
presented in 5.3.; the factors affecting the development of collocational knowledge
5

are discussed in 5.4.; and finally a summary of the discussion is given in 5.5. The
pedagogical implications of this study are given in 5.6.
5.1 Free Production of Collocations
The accurate use of collocations in the subjects' essays was used as evidence
for the acquisition of collocations. There were significant differences in the
production of a number of collocation types between and within the three
proficiency groups.
5.1.1 Between-Group Differences
Subjects used significantly more Type 13. SV Inf and 19. SV(O) that
collocations as their level of proficiency increased (see Table 24). There were also a
number of collocations which were used significantly more by subjects in the
highest level group. For example, Type 1. Noun Prep, 5. Adjective Prep, 15. SVO to
Inf, and 21. SVOc collocations were used significantly more by subjects in Group 3.
Types 1 and 5 are lexical collocations, and Types 13, 19, 15 and 21 are grammatical
collocations that are syntactically more demanding than the simple grammatical
collocations SV to Inf and SVc.
The analysis of the collocations in the subjects' textbooks revealed that the
use of Type 13. SV Inf, 19. SV(O) that, 1. Noun Prep, 5. Adjective Prep, 15. SVO to Inf,
6

and 21. SVOc collocations in the textbooks also increases as the level of difficulty of
the language increases from TWE1 to TWE3. It is possible that the subjects'
exposure to larger amounts of collocations of these collocations as their level of
proficiency increased has influenced the production of these types in their essays.
That is, the more the subjects were exposed to a particular collocation type, the
more they used it. This is also reflected in the fact that the order of frequency of
the 37 collocation types in each of the three textbooks correlated significantly with
the frequency of use of the 37 types of collocation in the students' essays, i.e. the
order of frequency of use for each group correlated significantly with the order of
frequency of the 37 types of collocation in the textbook for that particular group.
Types 26. SVc and 29. Adjective Noun were used significantly more by
subjects at the lower proficiency levels. This could be due to the fact that these two
types of collocation are more frequent in everyday speech and syntactically simple
(e.g. Type 26. SVc includes constructions such as 'I am a student', 'I am bad', 'She
became a teacher'; Type 29. Adjective Noun includes collocations such as 'long hair',
'good student', 'beautiful girl'). Another explanation for the extensive use of these
collocation types by Group 1 subjects is that students in this group used fewer
collocation types overall, with more tokens used for each type. As the level of
proficiency increased, the number of collocation types used in the essays also
increased. The analysis of the collocations in the essays showed that subjects in the
lowest proficiency level, Group 1, used only 23 out of the 37 collocation types
investigated in this study, while subjects in the higher proficiency levels, Groups 2
7

and 3, used 29 and 28 of the 37 types respectively. Group 1 used fewer collocation
types and a greater number of tokens for some types (e.g. 26. SVc and 29. Adjective
Noun). Similar results were reported by Zhang (1993), who found that the more
proficient L2 learners used significantly more collocation types than the less
proficient L2 learners (Zhang 1993:147).
Another factor that could have influenced the subjects' performance with
regard to the use of SVc and Adjective Noun collocations is the topic of the essay.
Group 1 subjects had to describe themselves and their family in the essay, a topic
that may have prompted the use of more Adjective Noun and SVc phrases. Group 2
subjects had to describe themselves and their plans for the future, and Group 3
students had to describe and discuss pollution problems in their home town. The
essay topics for Groups 2 and 3 were thus not as purely descriptive as for Group 1.
Type 11. SV(O) Prep O collocations were also more frequent in the Group 1
and 2 essays. The textbook analysis also shows that TWE3, the textbook for Group
3 (post-intermediate students), contains the least number of collocations of this
type when compared to the other two textbooks, i.e. the students' production of
collocations may mirror their exposure to these collocations in their current
textbook, and not necessarily the incremental growth of collocations from TWE1 to
TWE3.
There were also collocation types which were used significantly more by
Group 2 than by Group 1, but they were used less frequently by Group 3. These
types are: 12. SV to Inf, 36. Prep Det Noun, 37. Phrasal Verb, 4. Prep Noun, 14. SVV-
8

ing, and 24. SV(O) wh-word. Such a phenomenon has been described in previous
studies as 'backsliding' (Lightbown 1985a). According to Lightbown, L2
acquisition is not linear and cumulative, but is characterised by backsliding and
loss of forms that appeared to be previously mastered. In this study, Group 3
subjects are able to use the above collocation types, but they seem to rely less on
the use of these types than subjects in the lower proficiency levels. Backsliding has
been reported in previous developmental studies too (see Hyltenstam 1977;
Andersen 1978).
There were also collocation types which were not used at all. These are: 3.
Noun that, 18. SV possessive V-ing, 22. SVOO, 25. S(it)VO to Inf, 28. Verb Noun
(eradication), and 32. Adverb Adjective. The majority of these types are structurally
demanding and infrequent in everyday English. According to the BBI, examples of
these types are: 'We reached an agreement that she would represent us in court',
or 'it was his desire that his estate be divided equally' (Type 3. Noun that); 'They
love his clowning', or 'This fact justifies Bob's coming late' (Type 18. SV Possessive
V-ing); 'It surprised me to learn of her decision' (Type 25. S(it)VO to Inf). Type 22.
SVOO collocations consist of a transitive verb and two objects, neither of which can
be used in the prepositional phrase with to or for, e.g. 'God will forgive them their
sins', or 'we bet her ten pounds'. Previous research has also shown that SV
Possessive V-ing constructions are acquired late (Anderson 1978:97). Also, SVOO
constructions were found to be acquired after the more unmarked SVO to O
constructions (Mazurkewich 1984). What the above collocation types appear to
9

have in common is a greater degree of complexity. Studies in L1 acquisition have
shown that grammatical complexity is a determinant of acquisition orders (see
Brown 1973). Given that collocations in this study are operationalised in terms of
structurally determined patterns, grammatical complexity could be a factor
affecting the pattern of results obtained in this study. Zhang's (1993) study also
defined collocations in structural terms, and he found that the L2 learners in the
study avoided, and were unable to produce, the more structurally demanding
collocations when compared with native speakers (Zhang 1993:126). These
collocation types are also structurally different from their equivalent collocations in
Greek, e.g. Noun that collocations are Noun to [Passive Voice] Infinitive. Laufer and
Eliasson (1993) have also reported that L1-L2 difference was the best predictor of
avoidance in their investigation of the use of phrasal verbs by Swedish and
Hebrew ESL learners.
Finally, the absence of Type 28. Verb Noun (eradication) and 32. Adverb
Adjective collocations could be due to the fact that these types are relatively fixed
(not free combinations) and therefore difficult to acquire. For example, some Type
28. Verb Noun (eradication) collocations in the BBI are 'to reject an appeal', 'to
reverse a decision', 'to rescind a tax'. The authors of the BBI suggest that
collocations of this type are arbitrary and unpredictable, i.e. no predictions can be
made as to why certain verbs combine with certain nouns, therefore L2 learners
have difficulties acquiring them as they cannot tell why 'make an estimate' is
acceptable but *'make an estimation' is not (Benson et al. 1986b:258). For Type 32.
10

Adverb Adjective collocations the BBI includes 'deeply absorbed', 'strictly accurate',
'sound asleep'. Previous research has also revealed that adverbs, in particular, are
difficult for the L2 learner to use appropriately because they typically collocate
with specific words, i.e. they are fixed (Linnarud 1986:105). With respect to Types
3, 18, 22, 25, 28, and 32, it is possible that the subjects in this study have not yet
reached a proficiency level advanced enough to use such complex, infrequent,
and/or fixed collocations. Also, the analysis of the TWE series showed that Types
3. Noun that, 18. SV Possessive V-ing, and 25. S(it)VO to Inf do not appear in the
subjects' textbooks, i.e. no tokens of those collocation types were found in any of
the three textbooks. Furthermore, only a limited number of Type 22. SVOO, 28.
Verb Noun (eradication), and 32. Adverb Adjective collocations were found in the
textbooks (see Table 7, Chapter 3). It appears that lack of exposure to specific
collocation types or the low frequency of these collocation types in the subjects'
textbooks have also contributed to the avoidance of these types by the subjects.
Collocational development across groups was examined by implicational
scaling analysis of acquisition orders. The implicational scale for the essay data
was found to have a significant coefficient of reproducibility which means that a
subject's performance can be predicted with a high degree of accuracy from that
subject's position on the scale. Although previous studies using implicational
scaling analysis considered a high coefficient of reproducibility as adequate
evidence for the presence of an implicational scale (see Andersen 1978; Hyltenstam
11

1977), in this study the coefficient of scalability was also calculated, to provide
additional evidence as to the strength of the collocation types as an ordered scale.
The essay data were found to have a low coefficient of scalability (Cscalability =
.33). It is possible that the large number of items on the scale for this data could
have reduced the strength of the scale. Also, the backsliding learning patterns
which occurred for some collocation types will influence the scalability of the data
(Hatch & Lazaraton 1991:216). Even though the statistical validity of the essay
scale does not reach statistical significance, the relative magnitude of the predictive
power of the scale cannot be determined, due to the lack of other implicational
analysis studies in the acquisition of collocations. According to Davidson (1987)
"the magnitude of a coefficient of scalability should rightly be judged against
similar findings in the field" (p. 25). Since there are no other studies similar to this
one, it is possible that even scalability of .33 is valid enough as a predictor for the
order of acquisition of collocation types (Davidson 1987:26). However, only future
research and implicational analysis on collocations can verify this.
5.1.2 Within-Group Differences
Differences in the use of collocations were also sought in the writing
performance of each group of subjects. The following types were used most
frequently in each of the three groups.
12

Table 42. Collocation types used most frequently in the students' essays
Group 1 Group 2 Group 3
26. SVc 26. SVc 26. SVc
29. Adjective Noun 29. Adjective Noun 13. SV Inf
11. SV(O) Prep O 12. SV to Inf 12. SV to Inf
11. SV(O) Prep O
36. Prep Det Noun
It appears that Type 26. SVc collocations were used significantly more than
the other types in all three groups. Given that Type 26. SVc constructions are basic
and frequent in everyday speech, e.g. 'I am a student', 'I am happy, 'She became a
teacher', it is not surprising that subjects in all levels of proficiency used
collocations of this type more than any other type. Zhang's (1993) study also
showed that more SVc collocations were used by all learners, more and less
proficient, in their essays (Zhang 1993:125). These results are also in line with
previous research in the sequence of acquisition of grammatical structures by
Fathman (1977). She found that structures that needed to be produced correctly for
effective communication, such as SVc constructions, were learned early. Also,
according to Pienemann's Processability Model, copula sentences such as 'I am a
student' belong to Stage 1 (basic sentence structures and basic categories) of second
language acquisition (Pienemann 1996). Evidence from Japanese as a second
13

language have also shown copula sentences to be a Stage 1 structure (Huter 1996).
This collocation type may then be considered a 'core' type in the acquisition of
collocations.
Groups 1 and 2 also used Type 29. Adjective Noun and 11. SV(O) Prep O
collocations significantly more than the other types. As already mentioned above,
it is possible that the topic of the essay for these two groups (see Appendix B)
could have influenced the frequency of use of Type 29. Adjective Noun collocations.
As far as Type 11. SV(O) Prep O collocations are concerned, TWE1 and TWE2
contain more collocations of this type than TWE3.
The implicational scaling for the essay data between groups (see Figure 3)
shows that Types 26, 29 and 11 are also the first three items on the implicational
scale for all groups. Since, Group 1 is the lowest proficiency group investigated by
this study, it is understandable that the subjects in this group use the easiest
collocation types more than the others. Therefore, it can be concluded that Types
26, 29 and 11 are early acquired collocation types, as their use was measured in the
writing performance of L2 learners in this study.
Types 12. SV to Inf and 13. SV Inf are also used more than the others by
higher level students, Groups 2 and 3. Both these types are still among the first six
items on the implicational scale of the essay data for all groups (see Figure 3), i.e.
they are among the most frequently used types of collocation, but their use
increases significantly in Groups 2 and 3. Zhang (1993) also reports that these two
types of collocation were used frequently by the L2 learners in his study (Zhang
14

1993:126). The textbook analysis reveals a few tokens of these two types in TWE1
(19 tokens for Type 12, and 26 tokens for Type 13) and a considerable increase in
TWE2 and TWE3 (TWE2: 234 tokens for Type 12, and 230 tokens for Type 13;
TWE3: 285 tokens for Type 12, and 347 tokens for Type 13). From a linguistic point
of view, the fact that Type 13. SV Inf collocations are acquired later than Type 12.
SV to Inf collocations could be due to the cumulative grammatical complexity,
introduced by Brown (1973). The cumulative grammatical complexity assumes
that a construction y is more complex than a construction x only if y involves all the
transformations involved in x plus one or more others (Brown 1973:377). In this
respect, the cumulative grammatical complexity is different from the theory of
derivational syntactic complexity which assumes that all transformations involve a
constant increment of complexity (see Brown & Hanlon 1970). Derivational
syntactic complexity proved inadequate for providing an explanation of language
acquisition (see Smith 1988), and Brown claims that the cumulative number of
transformations is a better index of complexity (Brown 1973:377; for other
approaches to assessing lexico-syntactic complexity see Frazier 1988; Crain &
Shankweiler 1988; Cheung & Kemper 1992; Hulstijn & deGraaff 1994; Hulstijn
1995). In the present data, Type 13. SV Inf requires all the rules that constructions
that contain infinitives do, plus one more, i.e. to-deletion. Type 13. SV Inf
collocations are thus more difficult and hence are acquired later. Furthermore,
Type 13. SV Inf represents collocations that contain modal auxiliaries, e.g. 'can,
could, should, would, may + Inf'. Modal auxiliaries constitute a closed class of
15

verbs with limited distributions and have distinct features when compared to
regular verbs, e.g. they require to-deletion before their combination with an
infinitive, they take no third-person inflection, they have abnormal time reference,
and they can only occur as the first element of the verb phrase (see Quirk,
Greenbaum, Leech & Svartvik 1985; Steele 1981; on the learnability of English
auxiliaries in L1 acquisition see Pinker 1984). From a developmental point of view,
the correct use of Type 13 collocations mainly by Group 3 subjects indicates that
accurate use of modal auxiliaries develops later in L2 learners and thus Type 13
collocations are developmentally 'difficult'. From a learnability point of view,
Type 13 collocations are different from their equivalent collocations in Greek
which do not require to-deletion, e.g. ‘mporei;s na ywni;seis edw;’[you can to shop
here] is SV[Modal Auxiliary] to Inf. Due to the L1-L2 difference, Type 13
collocations can be considered more difficult than Type 12 collocations. Similar
results regarding the use of modal auxiliaries are also reported by Anderson
(1978). In Ravem (1974) too, it was reported that the acquisition of a full range of
auxiliary morphemes (which included Modals) and their distribution develops late
(Ravem 1974:148).
The implicational scales for the essay data by group have coefficients of
scalability below the recommended level of statistical significance. As with the
implicational scale for the essay data (all groups), the large number of items on the
scale could be responsible for the low scalability. Despite the low coefficients of
scalability, the three scales reveal orders of difficulty similar to the patterns of
16

acquisition, as measured by the Friedman repeated measures analyses. The scale
for Group 1 has Types 26, 29 and 11 as the first three items on the scale. The scale
for Group 2 has Types 26, 29, 12, 11 and 36 as the first five items on the scale.
Finally, the scale for Group 3 has Types 26, 13, 12, and 36 as the first four items on
the scale. The results from the implicational scaling analysis, although not
reaching statistical significance, exhibit a pattern that supports the view that
certain orders exist in the acquisition of collocations, as measured by the writing
performance of L2 learners. These orders appeared to be influenced by exposure,
as the subjects' textbook analysis shows, and/or the complexity, arbitrariness, and
predictability of specific collocation types (see above). The correlation of the three
implicational orders (see also Fathman 1977; Pica 1983) showed that the orders for
subjects in Groups 1 and 2 were highly correlated (rs = .832); the orders for Groups
2 and 3 were also highly correlated (rs = .766); and the orders for Groups 1 and 3
revealed the lowest correlation (rs = .552). These results show a gradual
development of collocational knowledge across the three Groups in the study.
Since the subjects in each Group for this study were only one year apart, the
development of collocational knowledge had progressed to a different stage after
only two years of instruction (exposure to collocations via the TWE textbooks) and
maturation (during the period between 12-15 years of age) had taken place. Thus,
even though the implicational scales for the essay data lack statistical significance,
they can still be used as indicators of the development of English collocational
knowledge in L2 learners.
17

5.2 Cued Production of Collocations
Knowledge of collocations was also measured as accuracy of response to the
translation and blank-filling tests. Between- and within-group differences in the
accuracy of responses were used as evidence of the development of collocational
knowledge in the three proficiency levels.
5.2.1 Translation Data
Subjects were tested on their ability to translate correctly sentences from
their L1 into English. Each sentence contained an English collocation that was
different from its equivalent in the learners' L1. The significant results for this set
of data are discussed below.
5.2.1.1 Between-Group Differences
The students in Group 3 performed with the greatest accuracy in the
translation test. The results showed that Type 1. Noun Prep, 5. Adjective Prep, 14.
SVV-ing, and 27. Verb Noun (creation) collocations were translated significantly
more accurately by higher proficiency subjects.
18

The results for Type 1. Noun Prep reflect to some extent the treatment of this
collocation type in the subjects' textbooks: 76 tokens in TWE1, 80 tokens in TWE2
and 145 tokens in TWE3. The use of Type 27. Verb Noun (creation) collocations also
increases in the textbooks in a pattern similar to the one found in the results of the
translation test, i.e. as level increases the number of collocations found in the
textbooks increases. The results for Type 5. Adjective Prep collocations show a
significant difference in accuracy only between Group 1 and Group 3, with the
highest proficiency subjects, Group 3, were more accurate than the others. A
similar pattern is also found in the students' textbooks. Although Type 14. SVV-
ing collocations appear more in TWE1, students were able to translate them with
significantly more accuracy after their level increased. Finally, Type 11. SV(O) Prep
O collocations were translated most accurately by subjects in Group 2.
Collocations of this type were also found more in TWE2 than in the other two
textbooks.
Implicational scaling analysis was also used for the between-group
differences. The coefficient of reproducibility was found to be significant, which
confirmed the predictive power of the scale. The coefficient of scalability for the
translation data approached significance (Cscalability = .57). The smaller number of
collocation types included in the translation test could have contributed to the high
coefficient of scalability. This result also indicates that a small number of items
and a translation test are more likely to yield strong enough differences in
19

performance for a set of collocation types to be truly scalable, i.e. implicationally
ordered.
Considering the implicational scale for the translation data, the following
order of accuracy was found after the 80% criterion of acquisition was applied to
the data (types at the top of the order were more accurately translated than types at
the bottom):
Table 43. Accuracy order for the collocation types included in the translation
test - All Groups
Type
14. SVV-ing
16. SVO Inf
11. SV(O) Prep O
1. Noun Prep
5. Adjective Prep
27. Verb Noun (creation)
The results from the implicational analysis indicate that students were more
accurate in translating grammatical collocations (Types 14, 16, and 11) than lexical
collocations (Types 1, 5, and 27). Type 14. SVV-ing was easier to translate than
Type 16. SVO Inf. Similar results were reported by Anderson (1978), who found
20

that gerund SVV-ing constructions were acquired earlier than SVO Inf
constructions that required to-deletion (Anderson 1978:97).
The most accurately translated lexical collocation type on the scale, Type 1.
Noun Prep, included collocations such as 'things about', 'flight to', 'plans about',
'champion in', 'success in', 'pain in [the stomach]'. Students found these lexical
collocations easier to translate than Type 5. Adjective Prep collocations. The
following Type 5 collocations were included in the translation test: 'afraid of',
'interested in', 'bored with', 'married to'. Type 1 occurred more frequently than
Type 5 in the TWE series, i.e. the type-token ratio for Type 1 in the TWE series was
100.3, while for Type 5 it was 82.6. Also, all of the Type 1 collocations included in
the translation test have a similar structure in Greek, i.e. a noun followed by a
preposition. Some Type 5 collocations, on the other hand, e.g. 'afraid of' and 'bored
with', have a different structure in Greek, i.e. Verb Det Noun ’foba;mai ta fi;dia’
[afraid-[Middle Voice Verb] the snakes], ’barie;mai to scolei;o’ [bored-[Middle
Voice Verb] the school]. The L1-L2 difference with regard to the English Adjective
Prep collocations could be one factor responsible for the subjects' low accuracy in
the translation of Type 5. Adjective Prep collocations. It has also been reported that
Adjective Prep collocations are more fixed (i.e. consistently used with a preposition,
e.g. 'fond of', 'afraid of', 'deaf to' (Benson et al. 1986a:xii)) and difficult for low
proficiency students, and as such they are indicative of a higher level of
proficiency. Zhang (1993) also reports that in his investigation of English
21

collocational knowledge by L2 learners and native speakers, collocations such as
Adjective Prep were used considerably more by native writers than L2 learners.
Type 27, the most difficult collocation type on the scale, included lexical
collocations that are fairly fixed in English, e.g. 'draw conclusions', 'face problems',
and different from their equivalent collocations in Greek, e.g. 'bga;zw
sumpera;smata' [take out conclusions], 'antimetwpi;zw problh;mata' [confront
problems]. The arbitrary nature of Verb Noun (creation) collocations has also been
reported by the writers of the BBI (Benson et al. 1986b). The arbitrariness and
unpredictability of these collocations makes non-native speakers unable to cope
with them. It is not surprising, then, that such collocations were difficult for the
subjects of this study. Also, an examination of the translations supplied by the
students showed considerable influence from Greek. It is possible that the nature
of the test, i.e. translation, could have increased L1 influence. L1 interference has
been also reported in past studies on collocations involving a translation test
(Marton 1977:46).
The acquisition order for the translation data approached statistical
significance: that is, students who correctly translated Type 27. Verb Noun (creation)
collocations, the last and most difficult to translate type on the scale, also translated
correctly the rest of the collocation types included in the translation test.
Overall, results show a very low accuracy in the translation test, i.e. only 88
out of 275 subjects, about 33%, were 80% or more accurate in the translation of
Type 14. SVV-ing collocations, which was the most accurately translated type on
22

the scale. Hence, translation proved to be a difficult test for the subjects. Previous
research involving advanced L2 learners, i.e. fifth year Polish students majoring in
English, in a translation test, Polish to English, showed that even advanced
students did not have most of the collocations which were tested in their
productive repertoires (Marton 1977:45).
5.2.1.2 Within-Group Differences
The results for the translation data revealed significant within-group
differences in the translation responses.
Group 1
For Group 1, Types 23. SV(O) Adverbial and 13. SV Inf were translated more
accurately than all the other types. The implicational scaling analysis also confirms
that subjects were 80% or more accurate in translating Types 23 and 13 than the
other types. The coefficient of reproducibility and the coefficient of scalability
were both found to be statistically significant for this analysis, which suggests that
the accuracy order for the translation data for Group 1 has validity and predictive
power. The order is the following (at the top are those types that were the easiest
to translate, while at the bottom are those types that were the most difficult to
translate):
23

Table 44. Accuracy order for the collocation types included in the translation
test - Group 1
Type
23. SV(O) Adverbial
13. SV Inf
16. SVO Inf
14. SVV-ing
5. Adjective Prep
11. SV(O) Prep O
1. Noun Prep
27. Verb Noun (creation)
The above accuracy order shows the following.
i) SV Inf collocations are easier to translate than SVO Inf collocations, which in
turn are easier to translate than SVV-ing collocations.
24

ii) Collocations containing a preposition, i.e. Adjective Prep, SV(O) Prep O, and
Noun Prep, are more difficult to translate than collocations containing an infinitive,
i.e. SV Inf, and SVO Inf. Prepositions are also more likely to cause interference
from the subjects' L1 than infinitives. Greek has a number of prepositions that do
not always coincide with the English prepositions, i.e. 'pain in the stomach' is
‘po;nos sto stoma;ci’ [pain to the stomach], 'things about other countries' is
'pra;gmata gia a;lles cw;res’ [things for other countries]. On the other hand,
infinitives in Greek are like their English equivalents. Prepositional phrases and
phrasal verbs have also been reported as constructions that exhibit arbitrary lexical
restrictions (Allerton 1984), and as such they are difficult to acquire.
iii) Verb Noun (creation) lexical collocations are the most difficult to translate, a
result that was also evident from the between-group analysis of the translation
data.
Group 2
The results for Group 2 show that only Type 11. SV(O) Prep O collocations
were translated significantly more accurately than the other collocation types. The
implicational scaling analysis for this set of data, which was also found to be
statistically significant, shows the accuracy order given in Table 45:
25

Table 45. Accuracy order for the collocation types included in the translation
test - Group 2
Type
11. SV(O) Prep O
16. SVO Inf
14. SVV-ing
1. Noun Prep
5. Adjective Prep
27. Verb Noun (creation)
The above accuracy order shows that:
i) Grammatical collocations are easier to translate than lexical collocations.
ii) As with the accuracy order for Group 1, collocations that contain a preposition,
i.e. Noun Prep and Adjective Prep, are more difficult to translate than collocations
that contain an infinitive.
iii) Verb Noun (creation) lexical collocations are also the most difficult to translate
for Group 2.
Comparing the accuracy orders for Groups 1 and 2, it appears that they are
similar with respect to most types. The only exception is Type 11. SV(O) Prep O.
Subjects in Group 2 found collocations of this type easier to translate than the
subjects in Group 1. That is, subjects that received an additional year of instruction
26

were more accurate in translating Type 11. SV(O) Prep O collocations. Group 2
subjects also received more exposure to Type 11 collocations through their
textbooks than Group 1 students, i.e. Type 11 collocations were found more
frequently in TWE2 than in TWE1.
Group 3
The results for the translation data for Group 3 show Types 13. SV Inf, 14.
SVV-ing and 1. Noun Prep, to be translated more accurately than the other types.
The implicational scaling analysis approached statistical significance (Cscalability =
.59). The following accuracy order was obtained:
Table 46. Accuracy order for the collocation types included in the translation
test - Group 3
Type
13. SV Inf
14. SVV-ing
1. Noun Prep
16. SVO Inf
11. SV(O) Prep O
27

5. Adjective Prep
27. Verb Noun (creation)
The above accuracy order shows that:
i) SV Inf collocations are easier to translate than SVO Inf collocations.
ii) With the exception of Noun Prep collocations, collocation types that contain a
preposition are more difficult to translate than collocation types that contain an
infinitive.
iii) Verb Noun (creation) collocations are the most difficult to translate for Group 3.
Even for the subjects in the highest proficiency level, Verb Noun (creation)
collocations are the most difficult to translate with accuracy. The same applies for
structures that are grammatically more complex, e.g. SVO Inf versus SV Inf (see
above). According to the cumulative grammatical complexity (Brown 1973), SVO
Inf structures are more complex than SV Inf structures since they require the
insertion of an Object, and as such they are more difficult to acquire. Also, recent
research in L2 acquisition has shown that the greater number of units and
morphemes in some structures obscure their perceptual 'salience' making them
harder to 'notice' and therefore to produce accurately (Bardovi-Harlig 1987;
Robinson 1995; Schmidt 1990, 1995). SVO Inf collocations contain all the units of
SV Inf constructions plus one more, i.e. Object, and as such they are less salient and
harder to produce accurately. The above result is also consistent with previous
studies on the acquisition of grammatical structures (see Anderson 1978).
28

The subjects' accuracy improves significantly in the translation of Type 1.
Noun Prep collocations, i.e. as the students' level increased, their ability to translate
lexical collocations also improved. This result is in line with Zhang's (1993) study,
in which he found that the high proficiency L2 students had a better command of
English lexical collocations than the low proficiency L2 students (Zhang 1993:148).
Comparing the three accuracy orders for the translation data, we can
conclude the following.
i) Verb Noun (creation) collocations are difficult for all three proficiency groups.
This was also evident from the between-group analysis. Collocations of this type
also appeared infrequently in the students' essays with no significant between-
group differences. As mentioned above, collocations of this type are fixed, e.g. 'to
face problems', 'to draw conclusions', and subjects at all three levels exhibit a
general weakness in the free production (essay data) and cued production
(translation data) of Verb Noun (creation) collocations. Zhang (1993) also found the
use of such collocations to be "weak areas" for L2 learners (Zhang 1993:106).
ii) Grammatical collocations, e.g. SV Inf, SVO Inf, SVV-ing, are easier to translate
than lexical collocations, e.g. Noun Prep, Adjective Prep, Verb Noun (creation).
However, as subjects become more proficient, their accuracy in lexical collocations
improves, i.e. Group 3 subjects become more accurate in translating Noun Prep
collocations than students in Groups 1 and 2. This is also consistent with Zhang's
results.
29

iii) Collocations that contain prepositions are harder to translate than collocations
that contain infinitives. Zhang reports that "knowing prepositions and being able
to use them in idiomatic combinations with other words are part of native fluency"
(Zhang 1993:135). In his study, too, L2 learners showed a weakness in knowledge
and ability to use collocations that contained prepositions.
5.2.2 Blank-Filling Data
Cued production of collocations was also measured in a blank-filling test.
Each sentence contained an English collocation with one part missing. Subjects
were required to provide the missing part of each collocation. The collocations
included in the blank-filling test could not be translated directly into the learners'
L1, Greek. The results for this set of data are discussed below.
5.2.2.1 Between-Group Differences
The results in the blank-filling data revealed that for Type 1. Noun Prep, 11.
SV(O) Prep O, 23. SV(O) Adverbial, 24. SV(O) wh-word, 27. Verb Noun (creation), 33.
Verb Adverb, 36. Prep Det Noun, and 37. Phrasal Verb collocations, subjects were
30

significantly more accurate in supplying the correct collocation as their level of
proficiency increased.
The textbook analysis (see Chapter 3) also showed that all but two of the
above collocation types exhibit a similar pattern of increase across the three
textbooks. For example, tokens for Types 1. Noun Prep, 24. SV(O) wh-word, 27. Verb
Noun (creation), 33. Verb Adverb, 36. Prep Det Noun, and 37. Phrasal Verb increase as
the level of language proficiency increases from TWE1 to TWE3. The students'
exposure to these collocation types could have influenced their performance to the
blank-filling test, i.e. the more frequently students were exposed to a particular
type of collocation, the more accurate they became in their knowledge of
collocations of this type.
The subjects' performance on two collocation types showed a U-shaped
pattern of acquisition. For Types 5. Adjective Prep and 34. Noun Noun, subjects in
Group 1 were more accurate than subjects in Group 2, who were also less accurate
than subjects in Group 3. A look at the specific collocations shows that the level of
difficulty increases with proficiency. For example, Type 34. Noun Noun
collocations for Group 1 were 'post office' and 'phone number', for Group 2 'traffic
lights', and for Group 3 'curriculum vitae'. Group 3 subjects were more accurate in
responding to the 'curriculum vitae' collocation than subjects in Group 2 were with
the 'traffic lights' collocation, even though 'curriculum vitae' is less frequent than
'traffic lights' in everyday speech. The analysis of the textbooks shows that 'traffic
lights' appears twice in TWE2, while 'curriculum vitae' appears only in TWE3, four
31

times. Again, the amount of exposure to a specific collocation appears to influence
performance.
Performance on the Adjective Prep collocations also increased as the level of
proficiency increased. For example, some of the Adjective Prep collocations for
Group 3 were: 'competent in', 'fond of', successful in', 'married to', 'unsure about',
'similar to', 'slow in', 'capable of', 'regardless of'. Group 2 subjects were tested on
the following Type 5 collocations: 'full of', 'sympathetic to', 'engaged to', 'upset
about'. Despite the fact that Group 3 students were faced with a larger number of
Type 5 collocations compared to Group 2 students, they were more accurate in
supplying the correct collocations. Both Noun Noun and Adjective Prep collocations
are lexical collocations. It appears that students at the initial stages of ESL learn
specific lexical collocations, possibly as unanalysed chunks, and hence they are
relatively accurate with respect to selected lexical collocations. As their proficiency
increases and their grammatical knowledge develops, their relative accuracy in
lexical collocations declines and they become better in grammatical collocations (in
the translation test too, intermediate level students were better in SV(O) Prep O
collocations). At the post-intermediate level, the subjects' overall accuracy
increases, and they once again become more accurate in lexical collocations. Such a
U-shaped development in L2 learners has been reported in previous linguistic
studies too (see McLaughlin 1987, 1990; Lightbown et al. 1980).
32

Overall, accuracy improves in the same fashion as in the essay and
translating tasks. Subjects in Group 3 performed the best and subjects in Group 1
performed the worst.
The implicational analysis for the blank-filling data had a low coefficient of
scalability (Cscalability = .33), and thus there is little evidence of a stable acquisition
order. Again, the U-shaped learning patterns probably contributed to the low
scalability of the blank-filling data (see Hatch & Lazaraton 1991:216).
5.2.2.2 Within-Group Differences
These were the significant differences in the accuracy of the subjects'
responses to specific collocation types within each group.
Group 1
After the 80% accuracy criterion was applied to the data for the
implicational scaling analysis, the following accuracy order was revealed here):
Table 47. Accuracy order for the collocation types included in the blank-filling
test - Group 1
Type
34. Noun Noun
33

33. Verb Adverb
24. SV(O) wh-word
36. Prep Det Noun
5. Adjective Prep
23. SV(O) Adverbial
30. Noun Verb
1. Noun Prep
4. Prep Noun
37. Phrasal Verb
29. Adjective Noun
31. Noun1 of Noun2
11. SV(O) Prep O
27. Verb Noun (creation)
The non-significant accuracy order shows that subjects in Group 1 were
more accurate in lexical collocations, i.e. Noun Noun, Verb Adverb, Prep Det Noun,
Adjective Prep, than in grammatical collocations that were more difficult to produce
(longer collocational strings), e.g. SV(O) wh-word, SV(O) Adverbial, SV(O) Prep O.
Group 2
34

After the 80% accuracy criterion was applied to the data for the
implicational scaling analysis, the following accuracy order was obtained for
Group 2 subjects:
Table 48. Accuracy order for the collocation types included in the blank-filling
test - Group 2
Type
24. SV(O) wh-word
23. SV(O) Adverbial
34. Noun Noun
31. Noun1 of Noun2
4. Prep Noun
5. Adjective Prep
36. Prep Det Noun
37. Phrasal Verb
27. Verb Noun (creation)
11. SV(O) Prep O
33. Verb Adverb
1. Noun Prep
The accuracy order for Group 2 is statistically significant and reveals that as
the level of proficiency increases, subjects become more accurate in their responses
35

to grammatical collocations that were initially difficult to produce (see scale for
Group 1 subjects), i.e. SV(O) wh-word, SV(O) Adverbial.
With regard to SV(O) wh-word collocations, the subjects' accuracy could be
due to the systematic appearance of this type of collocation in their textbook,
TWE2. SV(O) wh-word collocations are mainly used in the TWE series to give
instructions for the various tasks in the textbooks, e.g. "ask what the area code for
Liverpool is" (TWE2:56), "find out why Sam went back to his home town"
(TWE2:100). TWE1, because it was designed for beginner levels, gives task
instructions in Greek. It is in TWE2 that instructions are given in English and a
large amount of SV(O) wh-word collocations are included in the textbook. Hence,
the subjects in Group 2 had more exposure to SV(O) wh-word collocations
compared with Group 1 students.
Group 3
After the 80% accuracy criterion was applied on the data for the
implicational scaling analysis, the following accuracy order was evident for
subjects in Group 3:
Table 49. Accuracy order for the collocation types included in the blank-filling
test - Group 3
Type
36

33. Verb Adverb
34. Noun Noun
4. Prep Noun
24. SV(O) wh-word
23. SV(O) Adverbial
29. Adjective Noun
27. Verb Noun (creation)
1. Noun Prep
36. Prep Det Noun
37. Phrasal Verb
28. Verb Noun (eradication)
5. Adjective Prep
11. SV(O) Prep O
The above accuracy order for Group 3 was statistically significant. It shows
that subjects in the highest proficiency level were accurate in both lexical and
grammatical collocations.
Overall, as with the translation data, the subjects were less accurate in their
responses to the blank-filling test, i.e. 45 subjects out of 275, about 16%, were
accurate in their responses to Type 34, the type with the most accurate answers.
Comparing the results from the three scales, the following conclusions can
be drawn.
37

i) Type 11. SV(O) Prep O and 27. Verb Noun (creation) collocations were among the
most difficult collocation types (see also the results for the translation data). Also,
the subjects' responses to Type 28. Verb Noun (eradication) collocations were no
more accurate than their responses to Type 27. Verb Noun (creation) collocations
(see implicational scale for Group 3). It appears that Verb Noun collocations are
difficult to acquire, irrespective of whether or not they denote creation or eradication
(see Benson et al. 1986a).
ii) Subjects in Groups 1 and 2 achieved similar levels of accuracy, while subjects in
Group 3 were clearly more accurate in the blank-filling test, despite the fact that
their test contained more items. Undoubtedly, students at the most proficient level
for this study had a more advanced level of collocational knowledge.
iii) The greatest difference in the three acquisition orders was with respect to Type
33. Verb Adverb collocations. Subjects in Groups 1 and 3 were accurate in their
responses to this type of collocation, with Group 3 subjects significantly more
accurate than Group 1 subjects, while subjects in Group 2 were not at all accurate
on this collocation type. An examination of the specific collocations tested showed
that Groups 1 and 3 were tested only on the collocation 'work hard', while subjects
in Group 2 were tested on 'work hard', 'brake hard', and 'think highly'. In terms of
idiomaticity, 'think highly' is more idiomatic than the other two Verb Adverb
collocations. The idiomaticity of the collocation 'think highly' can be determined in
terms of its level of abstraction and literalness (i.e. the likelihood of its literal
meaning): 'think highly' is a more abstract collocation compared to the 'work hard'
38

and 'brake hard', which represent physical actions; also 'think highly' is of low
literalness (i.e. of unlikely literal meaning), while 'work hard' and 'brake hard' are
collocations with high literalness (see Cronk & Schweigert 1992). The collocation
'think highly' appeared to be especially difficult for subjects in Group 2, and even if
they answered the other two collocations correctly they still would not be able to
score more than 66% accuracy on this type of collocation (less than the 80%
accuracy criterion).
iv) As the level of proficiency increased, the students' performance on Prep Noun
collocations also increased. Despite the fact that subjects in Group 3 had more than
double the number of Prep Noun collocations in their version of the blank-filling
test than subjects in Group 1, they were far more accurate in their responses to this
type of collocation. On the other hand, Noun Prep collocations were difficult for all
three groups. The two types of collocation consist of the same parts of speech (a
noun and a preposition) but in a different order. When the preposition precedes
the noun, collocations are easier for L2 learners. When the preposition comes after
the noun, collocations become more difficult. A look at some of the Prep Noun
collocations included in the test shows that these collocations are fairly fixed,
frequent and regular (i.e. rule-governed), e.g. 'on Sundays' [on + day of the week],
'at 7:06' [at + time], 'in favour', 'in danger'. Noun Prep collocations are also fixed but
less regular, more unpredictable (i.e. no rules can be generated for them) and
associative, e.g. 'skills in', 'attitude towards', 'accusations against', 'degree in'. It is
possible that the order in which the parts of a collocation combine, rather than the
39

class they belong to (e.g. noun, verb, preposition, etc.), influences the degree of
difficulty and consequently the acquisition of a collocation.
v) SV(O) Adverbial and SV(O) wh-word collocations were relatively easy for all
groups, with SV(O) Adverbial collocations slightly more difficult than SV(O) wh-
word collocations. Both these types have occurred frequently in the TWE series,
with SV(O) wh-word collocations more frequent than SV(O) Adverbial collocations.
vi) As students became more proficient their accuracy on Adjective Noun lexical
collocations also improved. The Adjective Noun collocations for this test were fixed
and formal, e.g. 'sore throat', 'marine life', 'heavy drinker'. The subjects' knowledge
of fixed collocations therefore improved significantly with proficiency.
5.3 Summary of the Findings
As far as the free production of collocations is concerned, the following
conclusions can be drawn:
i) Type 26. SVc collocations are 'core' collocations, as they were the most frequently
used by students at all proficiency levels.
ii) Type 26. SVc and 29. Adjective Noun collocations are early acquired ones as their
use by subjects in this study revealed.
iii) Types 3. Noun that, 18. SV Possessive V-ing, 22. SVOO, 25. S(it)VO to Inf, 28. Verb
Noun (eradication), and 32. Adverb Adjective were avoided by subjects in all groups.
40

These types represent collocations that are structurally demanding, infrequent,
and/or fixed.
iv) The use of Type 12. SV to Inf, 13. SV Inf, 15. SVO to Inf, 21. SVOc, 1. Noun Prep,
and 5. Adjective Prep collocations indicates a higher level of proficiency and
development of collocational knowledge, as they were used mainly by subjects in
Group 3, the highest proficiency level.
v) The development of collocational knowledge occurs gradually, and collocational
use develops significantly after two years of instruction, exposure and maturation
has taken place (see correlations of the acquisition orders for the three Groups).
As far as the learners' cued production of collocations is concerned, the
following conclusions can be drawn.
i) Grammatical collocations are easier to translate than lexical collocations.
Accuracy in translating lexical collocations, Types 1,5, and 27, increased as
language proficiency increased.
ii) Grammatically more complex types were more difficult, e.g. Type 16. SVO inf
collocations were more difficult to translate with accuracy than Type 13. SV Inf
collocations.
iii) Collocations containing a preposition were more difficult to translate than
collocations containing an infinitive, as prepositions appeared to be more likely to
cause L1 interference for the subjects in this study, and their combination with
other words produced relatively fixed and difficult collocations.
41

iv) Type 27. Verb Noun (creation) lexical collocations were the most difficult to
translate with accuracy for all subjects. Verb Noun collocations in the blank-filling
test were also difficult for all subjects and they were also infrequent in the students'
essays.
5.4 Factors Affecting the Development of Collocational Knowledge
In previous developmental studies, frequency in the input has been
considered a determinant of the sequence of acquisition of morphemes (Larsen-
Freeman 1976a, 1976b). In this study too, frequency of input seemed to affect the
development of collocational knowledge. The results from the translation and the
blank-filling tests suggest that the more frequently students are exposed to a
particular collocation type, the more likely they are to know it. There is also
evidence that the amount of exposure to a particular collocation via textbooks can
influence the acquisition of that particular collocation, irrespective of how
frequently that particular collocation occurs in everyday speech, e.g. 'curriculum
vitae'. The results of the essay data strongly suggest that the production of English
collocations by the subjects in the present study was influenced by the frequency of
occurrence of English collocations in their textbooks. Greater frequency could
have made certain collocations more salient and noticeable, supporting the
argument that 'noticing' the form of input leads to learning (Doughty 1991;
Robinson 1995; Schmidt 1990, 1995). Palmberg (1987), (1988) also found that the
42

vocabulary L2 learners produced consisted mainly of textbook vocabulary.
Instruction has been found to influence the rate of acquisition in other studies too
(Olshtain 1987; Doughty 1991). However, given the fact that the subjects in this
study were tested on collocations already taught to them, their overall low
accuracy in both the translation and the blank-filling tests suggests that mere
exposure to collocations is not enough to facilitate recall. This conclusion is also in
line with past research (Marton 1977:47; Bardovi-Harlig 1992b:272).
Complexity was also considered as another factor influencing the
development of collocational knowledge in ESL learners. With regard to
grammatical collocations, for specific pairs of collocational structures, the type that
was grammatically more complex was also more difficult for L2 learners. For
example, learners were more accurate in SV Inf collocations than in SVO Inf
collocations, and their use of SV Inf collocations increased later than the use of SV
to Inf collocations. Also, grammatically complex and infrequent collocation types
were avoided by the L2 learners in this study, e.g. students showed no evidence of
acquisition of SV Possessive V-ing collocations. With regard to lexical collocations,
'complexity' in terms of arbitrariness, unpredictability and idiomaticity seemed to
influence their acquisition by L2 learners, e.g. subjects were less accurate with fixed
(not free), arbitrary, and unpredictable Verb Noun lexical collocations. Idiomaticity
and arbitrariness have been previously found to affect the acquisition of individual
words too (for a review see Laufer 1990b). Also, in this study, those collocation
types, grammatical and lexical, that were early acquired, i.e. SVc and Adjective
43

Noun, represent collocations that are structurally 'salient' and need to be produced
correctly for effective communication due to their high frequency in every day
speech. Similar results with respect to these two structures were reported by
Fathman (1977) in her study of the acquisition of grammatical structures.
Also, there has been suggestive evidence that the order in which the parts of
a certain collocation type combine can influence the degree of regularity of the
collocations represented by that particular type. This has also been found to affect
the degree of difficulty of acquisition for that particular type. For example, Prep
Noun collocations, 'on Sundays', 'at 7:06', have been found to be more regular (i.e.
rule-governed) and hence easier to acquire than Noun Prep collocations, e.g. 'degree
in', 'attitude towards', 'skills in', which are unpredictable (i.e. associative).
There is also evidence that the degree of L1-L2 difference influences the
salience and consequently the acquisition of certain collocation types. For
example, collocation types that were structurally different from the subjects' L1
were more difficult to translate, e.g. Type 5. Adjective Prep collocations that were
'Verb Determiner Noun' collocations in Greek were more difficult to translate, e.g.
the Greek equivalent of 'I am bored with school' is ‘Barie;mai to scolei;o’
[bore[Middle Voice Verb] the school].
Finally, for a number of collocation types, knowledge develops as overall
language proficiency increases, i.e. the subjects' accuracy and production of
collocations was influenced by their overall language proficiency, and the most
proficient students performed with greater accuracy in the translation and the
44
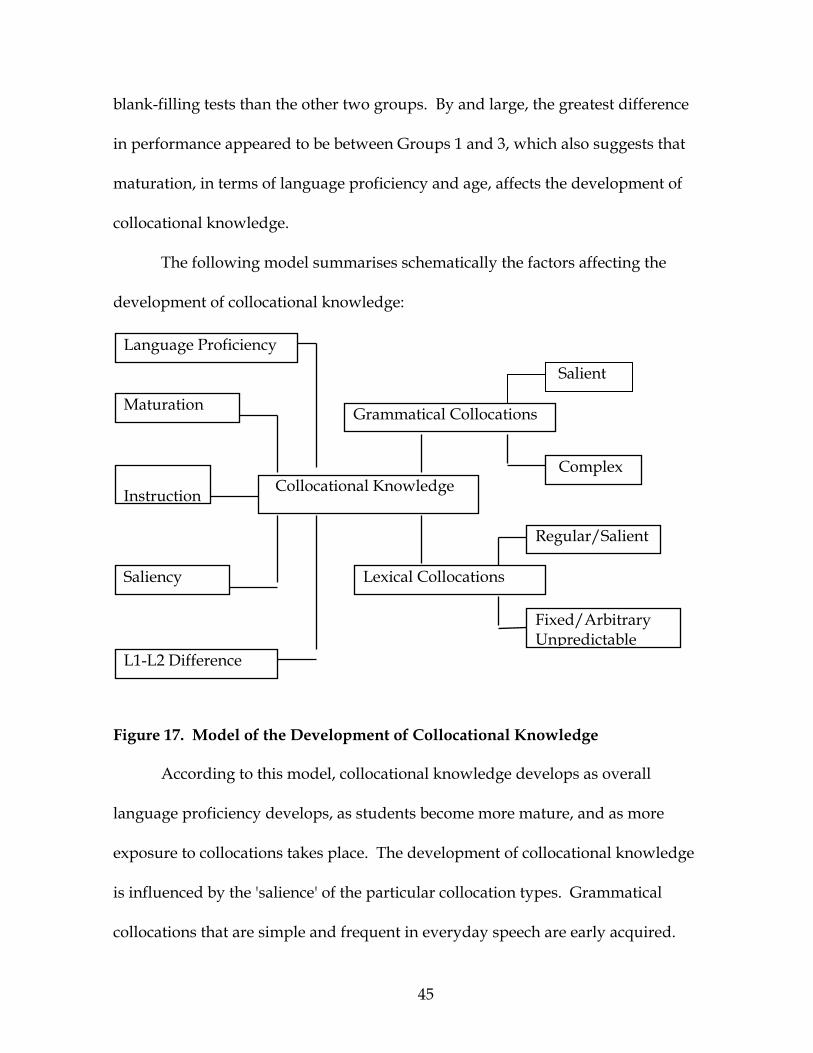
blank-filling tests than the other two groups. By and large, the greatest difference
in performance appeared to be between Groups 1 and 3, which also suggests that
maturation, in terms of language proficiency and age, affects the development of
collocational knowledge.
The following model summarises schematically the factors affecting the
development of collocational knowledge:
Language Proficiency
Maturation
Instruction
Saliency
L1-L2 Difference
Fixed/Arbitrary Unpredictable
Lexical Collocations
Regular/Salient
Collocational Knowledge Complex
Grammatical Collocations
Salient
Figure 17. Model of the Development of Collocational Knowledge
According to this model, collocational knowledge develops as overall
language proficiency develops, as students become more mature, and as more
exposure to collocations takes place. The development of collocational knowledge
is influenced by the 'salience' of the particular collocation types. Grammatical
collocations that are simple and frequent in everyday speech are early acquired.
45

The more complex structures are acquired later. Lexical collocations are more
difficult to acquire than the simple grammatical collocations. They are
syntactically simple (e.g. Noun Verb, Verb Noun, Noun Prep, Prep Noun, Verb
Adverb), but their acquisition is affected by other factors of 'semantic complexity',
e.g. arbitrariness, predictability and idiomaticity, i.e. the more fixed and idiomatic
they are, the more difficult they are to acquire.
Also, based on these results, a continuum of collocational knowledge and
language proficiency can be described. Beginning students (Group 1) are able to
produce simple grammatical collocations, they are more accurate on lexical
collocations than complex grammatical collocations, but their overall accuracy is
low. This can be interpreted as evidence that these students use lexical collocations
as unanalysed blocks of language that they have memorised, and because their
grammatical competence is not yet well-developed, they are less accurate with the
more structurally demanding grammatical collocations. The fact that they can
memorise lexical collocations more than grammatical ones could be due to the
saliency of lexical collocations in terms of length of the collocational strings, i.e.
most of the lexical collocation types consist of two words (Verb Adverb, Adjective
Noun, Noun Prep, Adjective Prep) so they are easier to remember. Grammatical
collocations, on the other hand, are longer and as such harder to memorise.
At the intermediate level (Group 2), students become more accurate with
the more complex grammatical collocations as their grammatical competence
46

increases, but their accuracy on lexical collocations and their overall accuracy do
not improve.
As students reach a higher level of proficiency, post-intermediate (Group 3),
their overall accuracy in collocations (both lexical and grammatical) increases
considerably, and they once again show greater accuracy on lexical collocations,
indicating a richer vocabulary. Previous research has also shown that more
advanced learners have more lexical and syntactic tools when they approach a
language learning task (Ferris 1991, 1994).
A similar step-by-step model of L1 acquisition is described by Berman
(1986). According to Berman's model, children in acquiring their L1 go through
three main phases:
(a) a PREGRAMMATICAL phase... where children's knowledge is largely
item-bound...; (b) the phase of GRAMMAR ACQUISITION..., where rules
are applied productively across items in terms of linguistic structure, and
items are interrelated within more general systems, categories and
paradigms; and (c) a final phase of APPROPRIATE USAGE where the
repertoire of forms and rules acquired previously are deployed with
increasing skill.
(Berman 1986:193).
The beginners' stage is similar to Berman's pregrammatical phase: they learn
collocations as lexicalised items. At the intermediate level, learners are at the
phase of grammar acquisition: they apply rules productively, increasing their
47

knowledge of grammatical collocations. At the post-intermediate level, students
are approaching Berman's final phase of appropriate usage: their overall
knowledge of collocations increases for both grammatical and lexical collocations.
Since collocations are one of the key building blocks of language, it is not
surprising that their acquisition proceeds to a pattern similar to L1 acquisition.
Pienemann's Processability Model also provides a framework for
understanding the development of collocational knowledge. The first stage of
Pienemann's model consists of basic sentence structures and basic categories
(Pienemann 1996). This stage coincides with the initial stage of collocational
knowledge: learners acquire simple grammatical collocations and relatively free
lexical collocations that are basic and frequent in everyday speech. The second
stage of Pienemann's model contains extensions of the noun phrase, verb phrase,
and sentence. This is the stage where students become able to apply grammatical
rules productively and have a better understanding of the constituents of the
sentence resulting to the use of more complex collocational strings. Stage 3 of the
Processability model is characterised by the use of new categories which are filled
with lexical items. The third stage of collocational knowledge is also characterised
by a better command of both lexical and grammatical and a preference for lexical
collocations signifying a richer vocabulary. The roughly parallel stages between
Pienemann's Processability model and the model of the development of
collocational knowledge described in this study underscore the existence of a
48

stage-by-stage development of collocational knowledge and its significance for the
overall development of L2 proficiency.
5.5 Summary of the Discussion
With regard to the main questions in this study - is there development of
collocational knowledge in L2 learners as their overall language proficiency
develops; and are there any differences in development between and within
proficiency levels? - the answer is affirmative. There is significant development of
collocational knowledge as overall language proficiency develops. Evidence has
been provided by both production (essay data) and knowledge of collocations
(translation and blank-filling data). The development of collocational knowledge
has been defined in the differences in the use and knowledge of collocations
between and within three different proficiency levels: post-beginners,
intermediate, and post-intermediate.
This study also explored what possible factors can account for the
acquisition of English collocations by L2 learners, and whether there are
identifiable patterns of acquisition of that part of vocabulary previously described
as 'ruleless'. As with most of the developmental studies, the main emphasis has
been on describing the emerging patterns of acquisition of English collocations.
The large number of structures examined by this study has led to the emergence of
a number of different patterns of acquisition. Where possible, explanations
49

pertaining to theories of second language acquisition have been provided with
regard to specific patterns of acquisition. The present study has shown that an
overall explanation of lexical acquisition may require a modular theory of
language acquisition with different modules on the grammatical complexity,
learnability, processability, and developmental order of the different collocational
structures.
The ultimate aim of this study has been to shed light on the acquisition of
collocations, which are considered an important aspect of L2 acquisition.
In the next section, some pedagogical implications of the results of the
present study are given. It is hoped that the data can also provide language
instructors with an anchor point in the teaching of English collocations.
5.6 Pedagogical Implications
The main goal of this study has been to investigate the acquisition of L2
collocations. L2 learners have been tested on how their collocational knowledge
develops. Overall, results show that students from the three proficiency levels
tested were not very accurate in either the translation or the blank-filling tests.
This is indicative of the L2 learners' general weakness in producing acceptable
collocations noted by other researchers, and of the need to provide L2 learners
with help for the improvement of their collocational knowledge.
50

The subjects in this study did not receive explicit teaching on collocations.
The teachers' questionnaire (see Appendix F) showed that the teachers did not
emphasise either the importance of collocations to their students, or the use of
other resources in learning collocations. The teachers also agreed that the
treatment of vocabulary in TWE is inadequate. The results of this project reveal
certain weaknesses and needs on the part of L2 learners, and ways to utilise these
results in L2 classrooms are suggested below.
The results provide useful information as to how collocational knowledge
develops in L2 learners. Such information can be used for improving the treatment
of collocations in ESL syllabuses. The knowledge of which collocation types are
acquired early in L2 learning, and which are acquired later, can help syllabus
designers order the presentation of collocations to promote a step-by-step
development of collocational knowledge.
Specific collocational problems for L2 learners have also been identified.
Students from all the proficiency levels had difficulties with lexical collocations
that are fairly fixed and arbitrary (not predictable) in English, e.g. Verb Noun
collocations such as ’draw conclusions’, ’earn a living’, ’take shorthand’, ’call a
penalty’. Such lexical combinations require specific collocational knowledge and
native-like ability. L2 learners have no means of telling which words collocate
with which unless they are specifically taught about such collocations.
The findings can also be used as a guide to help teachers decide how to
handle the teaching of collocations in their classroom, e.g. teaching early acquired
51

types before late acquired types, or more regular and frequently used collocations
before more fixed and idiomatic ones. Also, by analysing teaching materials (e.g.
readings) with respect to which collocation types they contain, teachers can assess
the different teaching materials to be used with the different proficiency levels.
Making teachers aware of the importance of collocations is not enough.
Students also need to become aware of collocations and develop strategies for their
acquisition. By raising the students' awareness of the existence of collocations and
their usefulness in L2 learning, teachers can help students take note of the
collocations they come across and make more effective use of them. Students
should become aware that words do not occur in isolation, but in combination with
other words. Increased awareness of and attempt to use communicatively
redundant grammatical structures may also lead to faster rates of acquisition and
possibly higher levels of L2 attainment (Long 1988:120).
The present study also showed that the L1 can influence the learners'
knowledge of collocations, especially lexical collocations, that are different from
their equivalent collocations in the learners' L1. For example, Adjective Preposition
collocations, such as ’afraid of [snakes]’, are Verb Det Noun collocations in Greek,
‘foba;mai ta fi;dia’ [afraid-[Middle Voice Verb] the snakes]. As a result, the Greek
learners in this study often translated the Adjective Preposition collocations leaving
out the preposition. Also, in coping with arbitrary Verb Noun collocations, such as
’draw conclusions’, ’take an examination’, 'earn a living', subjects seemed to use
their knowledge of Greek, e.g. *’take out conclusions’ ‘bga;zw sumpera;smata’
52

[take out conclusions], *’give an examination’ ‘di;nw exeta;seis’ [give
examinations], *’take out a living’ ‘bga;zw to ywmi; mou’ [take out my bread].
Such differences between the L1 and the L2 should be pointed out to the L2
learners, and L2 learners should be encouraged to practise and use such
collocations in order to sound more idiomatic in the target language.
The accuracy orders reported here may also be relevant as a starting point
for an index of L2 development (see Larsen-Freeman 1978b, 1978c). That is, the
students' language proficiency can be determined according to which collocation
types they have acquired. Such an index of development can also be used for
designing language testing materials, and for the placement of students in a
suitable proficiency level.
53

CHAPTER 6
CONCLUSIONS
6.1 Summary and Conclusions
This study has investigated the development of English collocational
knowledge in three different proficiency levels - post-beginners, intermediate and
post-intermediate - of 275 Greek learners of ESL. Three tests measuring the
learners’ knowledge of collocations were used: essay writing, a translation test and
a blank-filling test. The essay writing measured free production of collocations,
and the translation and blank-filling tests were measures of cued production.
Evidence was sought for the development of collocational knowledge between and
within the three proficiency groups. Results revealed that there are specific
patterns of development across and within the three different groups.
Collocational knowledge increased steadily as the overall language proficiency
increased, and the development of collocational knowledge was found to be
influenced by the frequency of the input, the L1-L2 difference, the overall language
proficiency, and the 'saliency' of the collocation types. Grammatical and lexical
collocations that were simple and frequent in everyday use of English were
acquired early and the more complex grammatical collocations were acquired
54

later. Lexical collocations that were idiomatic, fixed and/or unpredictable were
more difficult than those that were less arbitrary and more rule-bound. Finally, the
development of collocational knowledge in terms of the three proficiency levels
can be described as follows: Post-beginner students have already acquired the
simple and frequent grammatical collocations, e.g. SVc, they use few types of
collocation and a large number of tokens for some of them, they are more accurate
with regard to lexical collocations than complex grammatical collocations, but their
overall accuracy is very low. At the intermediate level, students use more
collocation types and they use both simple and complex grammatical collocations,
but their overall accuracy does not improve. At the post-intermediate level,
students become more accurate with respect to grammatical, both simple and
complex, and lexical collocations, and their collocational knowledge is significantly
advanced.
From a theoretical point of view, the present study developed a
classification of the various studies on collocations in three major approaches:
lexical composition, the semantic and the structural approach. Each approach has
been critically reviewed to reveal its strengths and weaknesses for the study of
collocations.
The systematic use of a classification system for classifying collocations
makes the replication of this study possible. If this classification system is used in
future studies on collocations, it will enable a comparison of the results, and
support a systematic contribution to how collocational ability develops.
55

The empirical contribution of this study lies in the use of the different
elicitation instruments and the analyses of the data. The detailed description of the
construction of the battery of tests used for the collection of data (Chapter 3), as
well as their strengths and weakness (see next section) can be used as a guide for
designing future studies on collocations and developing more sensitive and
effective elicitation instruments.
The analysis performed on the data is an improvement over analyses in
other developmental studies, i.e. studies on the order of acquisition of morphemes.
It shows not only the order of acquisition of collocational types, but also the
strength of the relationship of the items on the implicational order.
From a pedagogical point of view, this study provides a picture of how
English collocational knowledge develops in ESL learners. Knowing how
collocations are acquired is fundamental for devising ways of teaching them and
strategies for learning them.
It was the aim of this study to investigate the development of collocational
knowledge in L2 acquisition, and to provide a starting point towards unravelling
the acquisition process of English collocations. A model for the development of
collocational knowledge has been suggested, and the possible factors affecting the
various stages of collocational knowledge have been examined. Hopefully, the
study of collocations will continue in the future. Further studies should reveal a
more detailed picture of the development of collocational knowledge in L2
learners, with important implications for L2 theory and instruction.
56

6.2 Directions for Further Research
This study used syntactic structures in defining and operationalising
collocational knowledge, which is traditionally considered an area of lexical
acquisition. The results suggest that defining collocational types syntactically is a
valid approach in the examination of collocational development, especially with
grammatical collocations. The description of the acquisition of lexical collocations,
however, requires further refinement using semantic information. As it has
already been mentioned in the discussion of the results (Chapter 5), lexical
collocations are syntactically simple, i.e. they are usually combinations of two
words such as Verb Noun, Adjective Prep, Noun Prep, Verb Adverb, but their
acquisition is influenced by other factors. For example, lexical collocations that
belonged to the same collocation type were found to vary in difficulty, e.g. subjects
had more difficulties with the collocation ’think highly’ than with ’work hard’ even
though both collocations belonged to the same collocation type, Verb Adverb.
’Think highly’ is more idiomatic than ’work hard’ and as such it was more difficult
for the ESL learners in this study. Future researchers should be aware that the
acquisition of syntactic forms is a necessary but not sufficient condition for the
development of collocational knowledge, especially with regard to lexical
collocations.
57

The translation test revealed strong differences in the development of
collocational knowledge between and within proficiency levels. One of the
advantages of translation, as opposed to a blank-filling test, is that it enables the
testing of grammatical collocations as well as lexical ones. However, translation
has proved to be difficult for both beginning and more advanced L2 learners.
Furthermore, there is evidence that it promotes L1 interference in the students'
production. Future research on collocations should take the above limitations into
account before deciding on the use of a translation test.
The blank-filling test for this study contained more lexical than grammatical
collocations, mainly because grammatical collocations are more difficult to test in a
blank-filling test. For example, testing SVO to O collocations in a blank-filling test
creates the problem of where to put the blank space without making the
collocation too general or too obvious. Even though the blank-filling test showed
that most of the differences in accuracy reflect language proficiency, the accuracy
orders were weak. This could be due to the fact that the majority of the test items
tested lexical collocations. Lexical collocations, as already discussed above, are
influenced by semantic factors as well as syntactic ones. Therefore, the students'
performance on the blank-filling test was not consistent enough to produce a
reliable accuracy order, as the students' accuracy of responses reflected not only
their knowledge of the particular collocational type, but also which particular
words were required for the particular lexical collocations. Research on
collocations is in need of a reliable instrument to elicit information on a wider
58

range of collocational knowledge. For example, future research might examine the
development of collocational knowledge in a two-fold way, i.e. development with
respect to lexical collocations, controlling collocations for formality, frequency of
occurrence and idiomaticity, and development with respect to grammatical
collocations, controlling for grammatical complexity.
Although the present study did not set out to determine the extent to which
syllabuses influence the acquisition and the rate of acquisition of collocations, it
has provided evidence that the frequency of occurrence of collocations in L2
textbooks influences their acquisition (see Long 1988). That is, the more students
were exposed to a particular collocation type, the more they used it accurately.
Future research can test this result by controlling for number of exposures to given
collocations in an experimental condition. One question of interest is how much
exposure to collocations accounts for acquisition orders. This would help identify
the optimal instruction conditions leading to the acquisition of collocations (see
also Chaudron 1988; Sheen 1994). Also, it will be useful to determine whether
instruction can change the order of acquisition, i.e. whether emphasis of exposure
on some types of collocation will produce a change in the acquisition orders
obtained in this study, or whether classroom instruction affects only the rate of
acquisition but not the order of acquisition of collocations (see also Ellis 1989).
Long (1988) also underscores the need for research on collocational ability
achievable with and without instruction.
59

In this study, essay writing revealed a number of interesting results with
respect to the use of collocations. Subjects were controlled with respect to
variables such as age, formal education, English proficiency, first language
background, and knowledge of vocabulary. Unlike previous studies on
collocations, subjects in the present study were tested on their knowledge of
collocations already taught to them. The collocations included in the translation
and the blank-filling tests were taken from the subjects' textbooks. This ensured
that the subjects were tested on knowledge of collocations already presented to
them. The topics of the essays were also chosen with the subjects' textbooks in
mind. This ensured that subjects from all proficiency levels could perform
successfully in the essay composition and produce those collocations that they had
acquired and felt comfortable with using. However, the use of specific topics has
been shown to promote the use of specific collocation types, such as a large
number of SVc and Adjective Noun constructions in the essays by subjects in Group
1. Future research could investigate the performance of different proficiency levels
in essay writing, using the same topic for all proficiency levels. In this way, any
influences of the essay topic on the use of collocations would be equal for all levels.
The present study has concentrated on accuracy in the use and knowledge
of collocations. The analysis of collocational errors was not part of this study.
However, future research could investigate the misuse of collocations by L2
learners, the possible causes leading to collocational errors, and ways to remedy
them. The use of a corpus-based dictionary could also provide future researchers
60

with information as to whether collocational misuse is greater with infrequent
collocations or not. Note that the BBI does not provide frequency information.
Further research is also needed on how collocational knowledge develops in
native speakers of English. Such information can be used to compare the routes of
development by L2 learners and native speakers in the acquisition of English
collocations. Also, research in the development of collocational knowledge by
learners from different L1 backgrounds would reveal whether the accuracy orders
found in this study are L1-neutral. A comparison of the collocational errors would
yield important information about the extent of the influence of L1 in the
development of collocational knowledge in L2 learners.
The classification system used in this study has proved to be useful for a
systematic categorisation of the collocations found in the students' essays. Some
types, though, need some fine-tuning. For example, Type 15. SVO to Infinitive , as
it is used in the BBI, implies that the object of the main verb is the subject of the
infinitive, e.g. 'she told him to leave'. There can be cases, though, in which the
subject of the main verb is also the subject of the infinitive, e.g. 'she used the knife
to cut the bread'. In the present study both examples would be classified under the
same type. However, future research could use a different type of collocation for
the second example, e.g. 'SVO to Inf O' or 'SVO to Inf NP' (NP = Noun Phrase).
Such fine-tuning may yield more sensitive differences in collocational performance
among learners from different language proficiency levels.
61

62
Studies on collocations to date have concentrated on written data. It would
be interesting also to investigate L2 learners' use of collocations in oral production.
By using the classification system employed by the present study, L2 learners' oral
production data could be analysed in a similar way to reveal acquisition orders
and development of collocational knowledge. These orders could then be
compared with the ones found in this study and reveal helpful information as to
whether collocational knowledge in L2 writing and speech develop in similar or
different ways.
The above are selected directions for future research on collocations. The
development of collocational knowledge in L2 learners is far from being
exhaustively described. More work is needed in the area of lexical acquisition both
for theoretical and pedagogical reasons as it has proved to be a profitable avenue
for inquiry in the study of L2 acquisition.





























