Embed Size (px)
Citation preview

Collocations in translated textissues, insights, implications
Silvia BernardiniUniversity of Bologna, [email protected]
Aston Corpus symposium23 May 2008

Talk outline
• Collocations– Corpus Linguistics– Corpus-Based Translation Studies
• Research questions, methodology, results– Fiction– Open source software
• Implications– Descriptive and applied
• Methodological follow up• Future work

Background: Collocations in CL
– “Phraseology-oriented” approaches• E.g. (Howarth 1996:47)
[Restricted collocations are] combinations in which one component is used in its literal meaning, while the other is used in a specialised sense. The specialised meaning of one element can be figurative, delexical or in some way technical and is an important determinant of limited collocability at the other. These combinations are, however, fully motivated.

• “Parameters” of collocation within phraseology approaches– Motivation/arbitrariness– Commutability– Non-literalness– Transparency– Unpredictability
Background: Collocations in CL

• “Frequency-oriented” approaches– “Automatisation” is the result of repetition– British school of linguistics (Firth)
• The statistical tendency of words to co-occur (Hunston 2002: 12)
• “Significant” collocation is regular collocation between items, such that they occur more often than their respective frequencies and the length of the text in which they occur would predict (Jones and Sinclair 1974:19)
Background: Collocations in CL

Searching for collocations in text
• “Keyword” method– Starting from a (set of) keyword(s) and looking
left and right• E.g. Sinclair 1998, Stubbs 2001, Danielsson 2001
• “Sequence” method– Selecting all sequences of N words (or lemmas,
or POS tags) that recur a certain number of times• E.g. Kjellmer 1994, Biber et al. 1999, Johansson 1993

Statistics
• MI, t-score, z-score, log-likelihood… – P. Baker (2006), McEnery et al (2006)
• Bare frequency – Krenn and Evert (2001)
• A mixture of both– MI * log fq
• Kilgarriff and Tugwell (2001)
– frequency-based cut-offs• Krenn (2000)

NN in ukWaC (bare fq, top 10)
175642 web site 81127 case study 70514 search engine 66693 application form 65198 credit card 60626 web page 56721 car park 48833 health care 47655 climate change 46643 email
address

Collocations in CBTSapplied perspectives
• Bahumaid (2006)– Arab university lecturers translating sentences
containing collocations (make a noise, domino effect) into English and into Arabic with any reference tools available
• Less than 50% “correct” answers even when translating into their L1
• Paraphrase most common strategy (40-48%)

• Hatim and Mason (1997:205)– Collocations should in general be neither less
unexpected (i.e. more banal) nor more unexpected (i.e. demanding greater processing effort) than in the ST
• Baker (1992: 56ff)– Engrossing effect of source text patterning – Tension between accuracy and naturalness– The use of established patterns of collocation […]
helps to distinguish between a smooth translation, one that reads like an original, and a clumsy translation which sounds ‘foreign’.
Collocations in CBTSapplied perspectives

Issues in descriptive CBTS
• Translation “norms” or “universals”
• Corpus research in TS should focus on the identification of “features which typically occur in translated text rather than original utterances and which are not the result of interference from specific linguistic systems”. (Baker 1993:243)
• E.g.: explicitation/explicitness, simplification, disambiguation, levelling out (homogeneity), preference for conventional grammar, avoidance of repetition, exaggeration of features of the target language, normalisation/sanitisation…

• Anecdotal evidence by Øverås (1998):ST: Arket i skrivemaskinen var like skinnende nyfødt blankt som da hun satte det inn i valsen for en time siden.(newborn blank) TT: The sheet of paper in her typewriter was as pristinely white as when she had inserted it over an hour ago.
• Confirms Toury’s (1995) hypothesis that translators often produce repertoremes in place of textemes, i.e. they “produce ready-made, cliché structures”.
Collocations in CBTSdescriptive perspectives

• Kenny (2001)– Normalisation/sanitisation in the translation of creative
lexical combinations• Danielsson (2001)
– Automatic identification of collocations (keyword-based) in ST corpus and analysis of renderings in TT corpus
• Dayrell (2007)– Range of collocations employed in original vs.
translated language (monolingual comparable comparison)
– 10 nouns with frequency >200 and their collocates in a span ±4, fq4, MI4
Collocations in CBTSdescriptive perspectives

Limits
• Kenny (2001)– Habitual collocations not covered; method not scalable
• Danielsson (2001)– Plagued by data-sparseness
• Only 2 units of meaning (of the ~12K identified in a large monolingual corpus) occur 5 times in a 800K word parallel corpus
• Dayrell (2007)– Main issue investigated is lexical repetitiveness at the
collocational level– Selective focus: collocations of frequent words only– No cross-check with source texts– Uncontrolled variable makes results difficult to interpret

An alternative approachResearch questions
– Are translated texts more/less collocational than original texts in the same language
• i.e., are their collocation types overall more/less frequently attested and/or significant?
– If so, is this a consequence of the translation process?
• i.e., can we identify shifts that could account for the observed overall differences?

An alternative approachCorpus resources
• Literary and specialised texts English/Italian– Monolingual comparable corpora (MCC)
• Originals in Language A and comparable translations into Language A
– Parallel corpora• Originals in Language A and their translations into Language
B, usually combined with reference corpora
+ Reference corpora of English (BNC) and Italian (Repubblica)

• Literary texts – 8 English STs→ Italian TTs (samples)– 7 Italian STs→ English TTs (samples)– ~150K words per component
• Specialised texts– Open-source software documentation
• 10 English STs→ Italian TTs (full texts) • 6 Italian originals (full texts) (→ 1 English translation)
– ~250K words per component
An alternative approachCorpus resources

Fiction texts sampled
M. Atwood The handmaid’s tale
M. Atwood Cat’s eye
M. Cruz Smith
Gorky Park
C. Fowler Red bride
N. Gordimer My son’s story
G. Greene The tenth man
D. Leavitt A place I’ve never been
R. Rendell Kissing the gunner’s daughter
F. Camon La malattia chiamata uomo
G. Celati Narratori delle pianure
C. Comencini Le pagine strappate
Luther Blissett Q
D. Maraini Donna in guerra
G. Pontiggia Il giocatore invisibile
G. Tomasi di Lampedusa
Il gattopardo

OSS texts sampledS.Frampton Linux administration made easy)L.Wirzenius The Linux System Administrator’s GuideM.Cooper the Advanced Bash-Scripting GuideG.Beekmans Linux from scratchG. Short 3-button mouse HOWTOD.Jarvis 3D Graphics Modelling and Rendering mini HOWTOJ.Tranter Linux Amateur Radio AX.25 HOWTOE.Raymond The DocBook Demystification HOWTOP.Gortmaker Linux Ethernet HOWTOR.Russell Linux IPCHAINS HOWTO
A. Madesani IDE e SoundBlaster 32 creative – HOWTO
L. Pulici Adaptec AVA 1505 mini- HOWTO
G. Paolone LDR Linux Domande e Risposte
D. Medri Linux facile G. Giusti Programmare in
PHPD. Giacomini Appunti di informatica
libera

Extracting collocations
• Target sequences– Lexical collocations– Made of two words– Contiguous
• Pos-based extraction from study corpora• JN, NN, VN, V * N, N * * N (types)
– Collection of token frequencies from reference corpora (BNC and Repubblica)

Extracting collocations
• Calculate Mutual Information (MI)
• Rank sequences
• Take top– Arbitrary cut-off point: MI>2 and fq>1
• Calculate significance of difference btwn original and translated– Mann-Whitney significance tests

Mutual Information
MI compares the probability of observing x and y together (the joint probability) with the probabilities of observing x and y independently (chance). If there is a genuine association between x and y, then the joint probability P(x,y) will be much larger than chance […].
(Church & Hanks 1990:77)
p(xy) * NMI(x;y)= log2 ------------- p(x) * p(y)

Mann-Whitney-Wilcoxon ranks test
• Confidence with which we can reject the null hypothesis that two ranked sets of observations are taken from the same population
• Non-parametric, i.e. makes no assumptions about observations being normally distributed
• Used (and tested) by Kilgarriff (2001) in comparisons of the LOB and Brown corpora and of male and female speech in the BNC

Rankings (top 10) for JN (eng)
Original fiction corpus
MI collocation fq (BNC)7,0621 Shredded Wheat 96,4372 open-toed sandals 55,9465 beta carotene 55,7365 Milky Way 805,5479 barbed wire 1935,4172 floppy disks 635,3891 eternal damnation 145,3798 cursive script 185,3046 pearl necklace 145,2500 herbal teas 7
Translated fiction corpus
MI collocation fq (BNC)6,2687 wall-to-wall carpeting 66,1698 vous plait 105,6773 pistachio nuts 105,3305 boric acid 55,2218 submachine gun 95,2170 Venetian blinds 165,2060 Neapolitan dialect 45,1170 nasal twang 25,0816 westering sun 45,0775 hard-boiled eggs 30
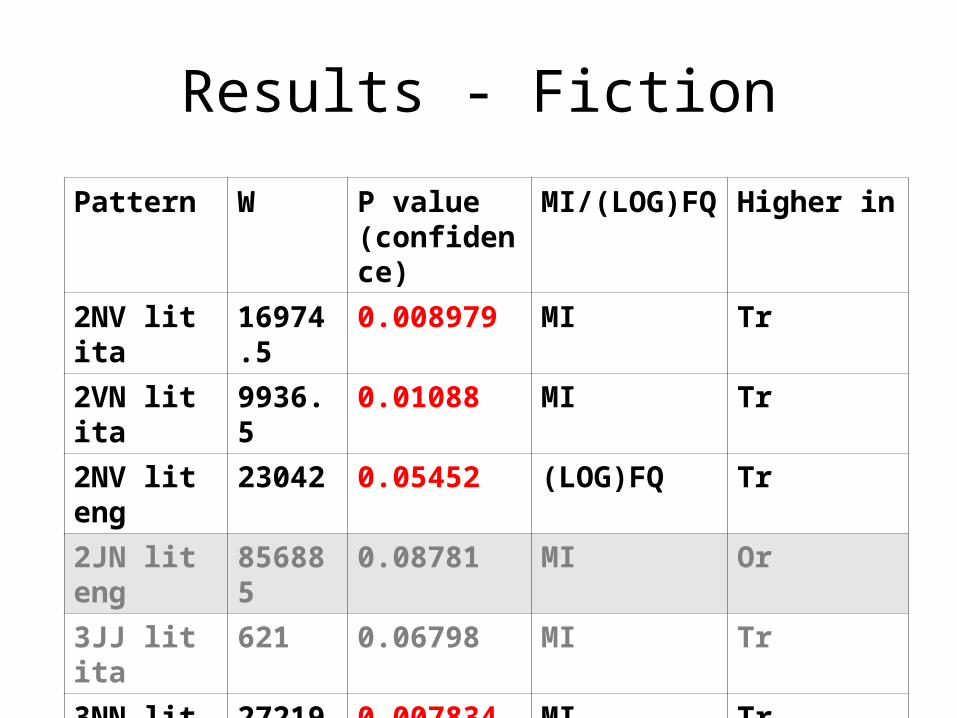
Results - Fiction
Pattern W P value (confidence)
MI/(LOG)FQ Higher in
2NV lit ita 16974.5 0.008979 MI Tr
2VN lit ita 9936.5 0.01088 MI Tr
2NV lit eng 23042 0.05452 (LOG)FQ Tr
2JN lit eng 856885 0.08781 MI Or
3JJ lit ita 621 0.06798 MI Tr
3NN lit ita 272195 0.007834 MI Tr
3NN lit eng 42888 0.06323 (LOG)FQ Tr
4NN lit ita 3009.5 0.07768 (LOG)FQ Tr

Results - OSSPattern W p value
(confidence)MI/(LOG) FQ Higher in
2JN ita w=122618 p=0.002261 MI Or
3NN ita w=21683w=22066.5
p=0.02607p=0.01029
MI(LOG)FQ
OrOr
2NJ ita w=78109.5 p=0.001134 MI Or
2NN eng w =19142.5 p=0.005172 (LOG)FQ Tr
2RJ eng w=7609 p=0.06921 MI Or
2RV eng w=10458 p=0.04767 MI Or
2VR eng w=2907 p=0.01517 (LOG)FQ Or
3VN eng w=11904 p=0.05694 MI Or
3NN eng w=1910.5 p=0.0429 (LOG)FQ Or
4VN eng w=1027 p=0.06974 (LOG)FQ Or

Summing up
• Translated fiction texts (Italian and English) tend to be (overall) richer in salient collocations than original texts in the same language
• Italian (and English) open source software manuals however show the opposite trend…

Implications for descriptive TS
• Norm/law-governed (rather than universal) trends (Toury 1995)
– Law of interference • Stronger in OSS translation
– Law of growing standardization • Stronger in fiction translation

Implications for applied TS
• Parallel comparison (not discussed here) highlights strategies displayed by professional translators at the collocational level
• Starting point for awareness-raising and revision exercises focusing on:– Normalization– Rise in formality– Explicitation

Methodological follow up
• Crucial role played by reference corpora
• What happens if we repeat the calculations with MI data from different reference corpora?

Adjective-Noun (Italian OSS texts)
• Repubblica (fq>1 and MI>2)
• itWaC (fq>10 and MI>1)
Pattern W p value (confidence) MI/(LOG) FQ
2JN ita w=122618 p=0.002261 MI
Pattern W p value (confidence) MI/(LOG) FQ
2JN ita W = 147350 p= 0.675 MI

Noun – prep|conj - Noun (Italian fiction texts)
• Repubblica (fq>1 and MI>2)
• itWaC (fq>10 and MI>1)
Pattern W p value (confidence) MI/(LOG) FQ
3N prep|conj N ita w= 272195 p= 0.007834 MI
Pattern W p value (confidence) MI/(LOG) FQ
3N prep|conj N ita w=320480 p=0.001959 MI

Further work
– Bottom-up search for regularities• Other genres?
– Source-oriented approach• Starting from ST collocations
– Collocation extraction and reference corpora• Evaluation of method
– Search for creative exploitation of collocations• Can it be automatised?

Thank you
Silvia Bernardini
University of Bologna, [email protected]
Aston Corpus symposium23 May 2008