Embed Size (px)
Citation preview

Int. Fin. Markets, Inst. and Money 16 (2006) 318–344
Clustering and psychological barriersin exchange rates
Jason Mitchell a,∗, H.Y. Izan b,1
a University of Michigan Business School, 701 Tappan Street, Ann Arbor, MI 48109, USAb UWA Business School, M404 University of Western Australia, 35 Stirling Highway Crawley,
WA 6009, Australia
Received 11 March 2004; accepted 16 March 2005Available online 14 October 2005
Abstract
Contemporary press frequently attaches significance with specific numerical values in exchangerates. This research empirically tests for the presence of clustering and “psychological barriers”(transgressional effects) on various exchange rates involving the Australian dollar. Overall, we find awidespread clustering effect, which accordingly means there is partial information content in the actualnumbers of the exchange rates themselves. Furthermore, there is some, but not strong, evidence thatperceived “psychological barriers” do exist. Surprisingly, the location and form of both the clusteringand transgressional effects and hence the information content differ across different exchange ratesand in most instances, they are not in the expected direction.© 2005 Elsevier B.V. All rights reserved.
JEL classification: G10; G14; G15
Keywords: Clustering; Psychological barriers; Information content; Number preference
1. Introduction
“Psychological barriers” have attracted a great deal of interest over recent years. Individ-uals have a fascination and preoccupation with numbers in general life and this fascination
∗ Corresponding author. Tel.: +1 734 615 7536; fax: +1 734 764 3146.E-mail addresses: [email protected] (J. Mitchell), [email protected] (H.Y. Izan).
1 Tel: +61 8 6488 3567; fax: +61 8 6488 1072.
1042-4431/$ – see front matter © 2005 Elsevier B.V. All rights reserved.doi:10.1016/j.intfin.2005.03.003

J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344 319
pervades into financial markets. Such fascination manifests itself in the fixation withsymbolic, round or interesting numbers. For instance frequent mention is made in thecontemporary financial press of the phenomena of “support”, “resistance” and “psycholog-ical barriers”.1 The primary aim of this paper is twofold: to test for and document (i) anyclustering of observations and/or (ii) the existence of “psychological barriers” in Australiandollar (AUD) foreign exchange (FX) rates.
Donaldson and Kim (1993), Koedijk and Stork (1994) and Ley and Varian (1994)demonstrated the existence of price clustering in the last (trailing) digit of stock marketindices. They also tested for the so-called “psychological barriers” through the observationof unequal passing values of predetermined digits. De Grauwe and Decupere (1992) per-formed a similar analysis for various placed digits in the FX market for the USD/DEM,USD/JPY exchange rates and inverses. These studies all infer that clustering, or unequalobservations of various digits, implies that psychological barriers exist. This interpretationis misleading. There is some confusion in the above research of what constitutes a “psycho-logical barrier”, over the interpretation of the documented clustering as well as the variablesused to measure and identify “psychological barriers”.
On a superficial level, clustering contradicts the notion of rationality or efficient markets(Donaldson, 1990; Aitken et al., 1996) and is contrary to the tenet of uniform value in prices(Niederhoffer, 1965, 1966; De Grauwe and Decupere, 1992). Ample documentation of priceclustering is evident in various stock markets (see Aitken et al., 1996; Mitchell and Izan,2001 for an overview). The focus on the clustering phenomenon has been predominantly onequity markets (Osborne, 1962; Harris, 1991; Aitken et al., 1996; Hameed and Terry, 1998).It has been explored to only a limited degree in currency markets (Goodhart and Curcio,1991; De Grauwe and Decupere, 1992; Grossman et al., 1997 and more recently Sopranzettiand Datar, 2002). Clustering is further documented in derivatives, i.e., options and futuresmarkets and bonds (Gwilym et al., 1998a,b) as well as in commodity markets (Ball et al.,1985; Grossman et al., 1997), bank deposit rates (Kahn et al., 1999) initial public-offerauction bids (Kandel et al., 2001) and other price setting processes.2 This renewed interestin recent periods is in part driven by a need to understand this clustering phenomenon.
The focus on the FX market is motivated by a number of aspects. First, there is alack of comprehensive research work on clustering and psychological barriers in the FXarea. Second, clustering in the FX market is expected to be distinct from other financialmarkets due to the different characteristics, participants and the trading mechanism of theFX market. Goodhart and Curcio (1991) specifically examined clustering in the FX marketand then only for the final digit for the USD/DEM buy/sell exchange rate quotes. Morerecently Sopranzetti and Datar (2002) documented clustering in indicative quotes of theforeign exchange spot market for the DEM, GBP, FRF, ITL and SEK (Swedish Kroner)relative to the USD. Sopranzetti and Datar (2002) comment that price clustering in thespot exchange market may have significant consequences given the high volume of trading
1 An article “In search of inefficiency” in the Economist (5 September 1995, p. 85) cited De Grauwe andDecupere (1992) and Curcio and Goodhart (1992) papers and considered the issues of inefficiency arising frompsychological barriers.
2 Clustering has been documented in bid, offer and trade prices of equity markets, initial public offer prices,takeover bids and rights issues (Buckland, 1994).

320 J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344
and the proliferation of derivative contracts in the spot foreign exchange market. Third, thetheoretical and psychological irrelevance of numbers is much stronger in the FX marketthan in equity markets. Currency prices effectively represent a relative price in terms of atrade-off of one good for another. Unlike a share price, the exchange rate can always beexpressed in terms of an inverse and can be transformed by multiplying it by an arbitraryconstant (De Grauwe and Decupere, 1992).
There is to date no empirical investigation of clustering in the AUD FX market. Therelatively large turnover of the FX market compared to commodity and other financialmarkets, and the fact that trade takes place in relatively few currencies, add to the liquidityand uniqueness of the FX market (Krugman and Obstfeld, 1991).3 The Australian marketitself has approximately 45% of the AUD trade with 25% occurring in Asian markets.Hence the local Australian FX trade and market does not dominate the AUD. Trade in theAUD focuses predominantly on a select few currencies of which the relationship of theAUD to the USD is paramount. The focus on a single exchange rate – AUD/USD – makesthe currency and the market rather distinct, albeit not necessarily unique. This focus by themarket on the AUD/USD suggests that based on “informational equilibrium pricing theory”(Ball et al., 1985) other non-AUD/USD exchange rates may cluster to a greater extent asthe precision required for the AUD/USD will be greater and the market is more liquid.
The paper will proceed in the following manner. Section 2 looks at the theories of poten-tially why clustering may, or may not be expected in financial markets as well as evidencefrom financial markets on both clustering and psychological barriers. Data selection, vari-able identification and measurement are defined in Section 3. Section 4 documents and teststhe clustering and frequency of passing digits or transgression effects relative to benchmarkvalues obtained from simulated series. The final section presents the conclusion and impli-cations for further research.
2. Review of literature
2.1. Reasons for clustering and/or psychological barriers
If one makes the assumption that participants/traders in the market are well-informedprice setters, then activities, such as economically irrational price clustering and psycholog-ical barriers should not be observed. However, clustering and/or behavioural factors maynot be traded out of financial markets under a number of conditions which include domina-tion of a few traders/trades in the market, trading impediments that prevent the observanceof some values, a widespread number preference; and/or a bias in the decision makingenvironment.
Clustering can potentially arise from four diverse sources.4 First, the existing decimalplace-value system encourages individuals to think in groups of ten, or multiples thereof, and
3 The Bank for International Settlements (1992) survey estimated that net of double counting the global foreignexchange turnover was approximately USD 880 billion per day compared to USD 620 billion per day in 1989.The five most actively traded currencies as at 1992 in descending order were: USD, DEM, JPY, GBP and CHF.
4 A more comprehensive discussion of these aspects is given in Mitchell (2001).

J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344 321
encourages a numerousness concept, particularly through the adoption of the place-valuesystem and notation which leads to rounding (Mitchell, 2001). In the marketing literaturecognitive accessibility is the accepted reason for “even-ending” prices, which is the termconventionally used for round numbers ending in 0 or in some cases 5’s (see Tverskyand Kahneman, 1973; Fazio et al., 1982; Dehaene and Mehler, 1992). Consumers tend toidentify with and process round numbers so these are provided in retail prices and also inreal estate listing and transaction prices (Palmon et al., 2004). Coupled with this symbolism,mysticism and even cultural convention may dictate some form of basic number preference(Ziemba et al., 1986; Thaler, 1992).
Second, clustering can arise due to various behavioural explanations. For example,individuals use simple heuristics, such as anchoring to provide rough approximations indecisions rather than precise estimates (Yule, 1927; Tversky and Kahneman, 1974). Thereis also a tendency to simplify the information level when mentally processing numbers,which enables quicker and potentially more cost-effective decisions (Yule, 1927; Preece,1981). Investigation of numerical stimuli of digits confirms that rounding and fixed for-mats speed up numerical processing and comprehension and that individuals process evennumbers faster than odd digits (Hornik et al., 1994; Takayanagi et al., 1995).
Third, there may be rational economic explanations for clustering. The focal point liter-ature (Schelling, 1960; Sugden, 1995) suggest that individuals are not simply influenced bythe numerical attributes of a decision but tend to use number labels to identify strategies.People may select numbers that they believe others will recognise or which are readily dis-cernible to other parties to facilitate the decision-making process. In short, individuals usenumbers that they are familiar with, depending on the circumstances (Niederhoffer, 1965).In addition, clustering is influenced by what error is “acceptable” in decisions based on acost-benefit trade-off. Finally, in most cases individuals operate in a “sphere of haziness”(Loomes, 1988; Butler and Loomes, 1988) concerning the value of items and clusteringresults from attempts to overcome this uncertainty. The above economic explanations leadto the “informational equilibrium pricing” or price resolution/negotiation theory outlinedby Ball et al. (1985) and Harris (1991). Based on this theory, greater precision in prices(less clustering) occurs so as to trade-off the benefits of adopting a more precise price reso-lution and hence giving a more refined measure of value relative to the increase in costs ofacquiring that information and any costs associated with a reduction in the ability to traderapidly from increased negotiation.
Fourth, it is contentious and unlikely that clustering in a financial data series resultsfrom a natural order, or alternatively could be a product of the number progression or thenumber itself as ultimately this depends on the form of the particular series. The idea ofa general clustering phenomenon, such as propagated by Benford’s law, appears invalidespecially for financial data and markets (Mitchell, 2001). Mitchell (2001) argues thatany such relationships are (i) restricted to certain data series; (ii) depends on the placedigit and (iii) are influenced by the way in which the analysis is conducted and how theclustering is specified, e.g., whether it is relative to a floating or fixed digit place format.The above conclusion is contrary to De Grauwe and Decupere (1992), Ley (1996) andDe Ceuster et al. (1998) who suggest Benford’s law describes many data series, includingfinancial data, so that widespread clustering simply due to the form of the number itself ispossible.

322 J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344
2.2. Previous empirical evidence
Reference to stock market price clustering originated as early as Gann (1930, pp. 63–64),who noted that “the popular trading prices are 25, 40, 50, 60, 75, 100”, and Wyckoff (1963,pp. 106–107), who concluded that “we think in round numbers and try to sell at roundnumbers”. For US stock market prices Osborne (1962), Niederhoffer (1966) and later Harris(1991) confirmed that clustering is a characteristic of closing day stock prices and/or orderswhere whole numbers were again more common than halves, which were more commonthan odd-quarters and odd-eighths. Harris suggested that, apart from forced constraints ofdiscreteness, clustering was due to voluntary behavioural or customary agreement of theterms of trade, as a means of lowering negotiation costs.
In a decimal context, we might naturally expect that a certain amount of clustering atround, and other, numbers in final digits of decimal stock prices. In Australia, Aitken et al.(1996) found analogous evidence for trade prices and the clustering was observed to followa pattern similar to US evidence. Furthermore, Buckland (1994) provided strong evidenceof clustering in Australian share market bid and ask orders similar to that of trade prices.More recent evidence by Grossman et al. (1997) used all inside quotes on the London StockExchange Automated Quotation System (SEAQ) and found that quotes ending in 0 and 5were the most frequent. Similarly, Hameed and Terry (1998) examined factors affectingprice clustering on the Stock Exchange of Singapore (SGX) revealing clustering across allprice ranges on the SGX.
Sopranzetti and Datar (2002) confirmed the existence of price clustering in the foreignexchange market. They argue that clustering in foreign exchange markets is especiallyproblematic (i) for valuing derivative securities that are written on spot exchange ratesand (ii) for those adopting hedge positions in foreign exchange as conventional models ofpricing do not allow for clustering. For indicative quotes of the DEM, JPY, GBP, FRF, ITLand the SEK relative to the USD they find that there is a tendency to cluster on zeros orfives as well as a tendency for exchange rates to cluster with increases in trading volumeand volatility. The clustering also differed in pervasiveness across the various exchangerates.
The literature also indicates that the two prime reasons for the clustering are the attractionand price resolution/negotiation arguments. For a more detailed exposition of these and otherhypotheses see Ball et al. (1985), Aitken et al. (1996) and Harris (1991). As an overview, theprice resolution/negotiation hypothesis is concerned primarily about uncertainty of valueand its impact on the price setting process. The hypothesis trades off the competing notionsthat in the price setting process, a coarser grid (more clustering) is a means of reducing thehigh negotiation and information costs but correspondingly, the coarser the grid, the higherlikely cost from a sub-optimal price and/or associated lost gains from trade. Generally, thehigher the value of the asset then the coarser the price grid as market participants are lessconcerned about fine partitions of value. We also expect that there is less clustering at thebottom end of the price range. Price grids are coarser where asset values are known lessprecisely, or when the market is more volatile in order to reduce high information costs.Similarly traders choose more salient numbers because they help them to transact morequickly—and they value immediacy. As a result they use a coarser price grid when a stockis traded more thinly.

J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344 323
The concept of “psychological barriers” in stock indices was first examined in Donaldson(1990) using index data from the US, Canada, UK and Japan.5 “Psychological barriers” instock market indices was confirmed. Traders seem hesitant to land on, or push, a popularlytracked index across a 00-digit resistance level, e.g., 2100, 2200, 2300, etc. In situationswhen a 00 “psychological barrier” was successfully broken, then the rate of change in stockprices was usually greater than one would expect in an efficient market. The documented dif-ference in movement observed around the 00-values was explained by irrational behaviour,or mass psychology.6
A subsequent study by Donaldson and Kim (1993) used a Monte Carlo simulation totest both the frequencies of observation and the returns conditional on passing the 00-digit barrier, for index levels with a multiple of 100. Their tests found barriers existed at 00values for the DJIA but not the Wiltshire Associates 5000 Index. However, Lalor and Easton(1997) replicated Donaldson and Kim (1993) and found that while there was a relativelylow frequency of daily closing prices of the DJIA in the two digits of 98, 99, 00, 01 and02 over the period 1952–1995, this result was not robust either over different sub-periodsor digit categories. They concluded that the clustering of prices within certain categories ofdigits was more indicative of “problems relating to small sample sizes and consequentialuneven price distributions, rather than being indicative of stable, barrier induced patternsin the long-run distribution of DJIA prices” (p. 24).
De Grauwe and Decupere (1992) undertook an extensive study of “psychological barri-ers” using daily quotations of the USD/DEM, and the USD/JPY exchange rates, togetherwith their inverse, over the sample period from 1 January 1980 to 12 December 1990. Obser-vations were classified in 100 classes, termed M-values, according to the various digits. Forunit “psychological barriers” the first two digits after the decimal point were utilised toconstruct 100 classes. In the case of the USD/DEM there were observations like, 1.00, 1.01,1.02, . . ., 1.10, and the “psychological barriers” are 1.00, 2.00, etc. Exchange rate observa-tions were categorised into one of the 100 classes depending on the first two digits after thedecimal point (00, 01, 02, . . ., 98, 99). These classes were referred to as unit M-values. Inthe case of “decimal” barriers, the authors classified all exchange rate observations into 100classes depending on the second and third digit after the decimal point decimal M-values. Inthe decimal case, “psychological barriers” occurred when the second and third digits afterthe decimal point were zeros, e.g., 1.100, 1.200, and 1.300.
Results for the USD/JPY indicated a barrier effect but for the USD/DEM the results wereambiguous. Evidence showed the existence of unequal distribution of the M-value obser-vations, denoted P(Mi), when a narrow neighbourhood was used, e.g., 09 ≥ M-value ≥ 90,but not with a wide neighbourhood, e.g., 25 ≥ M-value ≥ 75. No evidence of unequal fre-quencies was found for the decimal context regardless of the M-value specification.
5 The four indices used were the Dow Jones Industrial Average (DJIA), Toronto Stock Exchange CompositeIndex (TSE), London Financial Times Stock Exchange 100 Index (FTSE 100) and Tokyo’s Nikkei Index (Nikkei225) from 18/12/1986 to 18/5/1990. These four indices were chosen because they are the most widely reportedindex in each market. Therefore they are the most likely to be a source of “psychological barriers” for agentswhose buying and selling decisions are influenced by the value of the index reported on the television news.
6 Defenders of market efficiency claim that psychological barriers may not lead to exploitable profit opportunities.If this is the case, the existence of psychological barriers may not contradict market efficiency.

324 J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344
De Grauwe and Decupere (1992) performed a further test on whether the existence ofpsychological barriers tended to repulse the values of the exchange rate. The frequencieswith which the exchange rate passed through the various M-values, denoted T(Mi), werecomputed to test whether they are different when they are close to the 00-reference M-value.The USD/JPY unit and decimal results showed strong evidence of unequal T(Mi) but thiswas not the case for the USD/DEM. They also presented evidence on the inverted exchangerates, which demonstrated that for JPY/USD, rounded exchange rates tended to have dis-proportionate T(Mi). However, the direction was contrary to expectations, suggesting thatthe barriers are passed more often, i.e., they attract, not repel or reflect the exchange rate.Some discrepancies also existed as the DEM/USD T(Mi) results were contrary to the aboveresults for P(Mi). Overall, the results suggest some support for psychological barriers for theUSD/JPY exchange rate but the results differed across unit, decimal and inverse currencyspecifications.
One point that needs clarification is the necessary conditions for confirming a barrier.Donaldson (1990), Donaldson and Kim (1993), Koedijk and Stork (1994) and Ley andVarian (1994) as well as De Grauwe and Decupere (1992, p. 89) assumed that “the exis-tence of a psychological barrier implies we will observe significantly less daily closingprices in the neighbourhood of the psychological barriers.” Similarly, Donaldson and Kim(1993) and Cyree et al. (1999) identified different returns conditional on (passing) digitvalues as evidence of psychological barriers. The view put forward in this paper rejectsthis interpretation of “psychological” barriers by suggesting that the above literature simplydemonstrates clustering or unequal frequencies around or returns conditional on M-values(both unit and decimal). Clustering on its own does not provide prima facie evidence thatbarriers exist. De Grauwe and Decupere (1992) performed an additional test on whether theexistence of psychological barriers tended to repulse the exchange rate.7 This transgressionaleffect test is seen as strongly indicative, but not conclusive evidence that “psychological”barriers exist.
A second issue deserves special mention. Ley and Varian (1994) argued and demonstratedthat any finding of unequal frequencies of M-values, P(Mi), is potentially expected andshould not be perceived as indicative of clustering. This is because the index digits tendto cluster naturally based on their empirical distribution. A more rigorous formulation ofthe expectations would be necessary in order to determine whether clustering exists. Theequivalent point could also be stated for the T(Mi) and/or returns conditional on variousdigit values.8 The existence of unequal frequencies of P(Mi) and T(Mi) suggests a worldwhere agents allow their decisions to be influenced by the value of the last two digits of theexchange rate. To the extent that clustering or unequal passing M-values of digits is observed,i.e., a transgressional effect occurs then there are implications for investor decision-makingand for trading strategies (Curcio and Goodhart, 1992). In each instance, however, the effect
7 This was described by the exchange rate “hesitating” to move towards and “accelerating” away from a barrier.Thus, a test can be performed on whether the frequency with which the exchange passes through various M-valuesis less dense around the reference-00-M-value.
8 Ley and Varian (1994) found that some differences exist for mean returns conditional on the tens digit ordeciles, for the DJIA. However, using simulation analyses, i.e., random drawings from both normal density andempirical distribution of returns, they found that the observed maximum of the decile-conditioned returns was notsignificant when compared with the simulated distribution of the decile conditioned returns.

J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344 325
needs to be evaluated against a more robust formulation of expectations. In this study, weuse simulation analysis as a way of formulating the expected frequencies, as an alternativeto the assumption of equal frequencies.
3. Data selection, variable definition and measurement
3.1. Data selection
Exchange rate data for the Deutsche Mark (DEM), French Franc (FFR), Italian Lira(ITL), British Pound Sterling (GBP), Swiss Franc (CHF), United States Dollar (USD),Japanese Yen (JPY), relative to the Australian Dollar (AUD) are used. The period coveredis from 1 January 1978 to 31 December 1992, except for the French Franc data whichcommenced as at 2 January 1981. This represents the full daily AUD trading history forthese currencies over that time period. The data are the FX rate quotes as at Sydney closingtime or close to it.9
One factor that may influence the clustering/barrier phenomena is the method by which anexchange rate is quoted. Unlike the US and most of the rest of the world, which employs thedirect method, Australia like the other Commonwealth countries adopts an indirect methodof quotation. The indirect method has the home currency (AUD) as the unit currency ofquotation rather than the foreign currency, and the Australian retail market quotes only theindirect rate. In the wholesale market, the focus of the market is again on the indirect rateeven though it displays the rate in terms of its demanded currency, i.e., either quote. Giventhe focus is on the indirect (AUD/FC) rate both in the retail and wholesale market as wellas the media it seems logical the potential for barriers would appear more pronounced inthe indirect rate. Thus, the AUD is in a rather special, albeit not unique position, in thisrespect. Apart from the other old Sterling block markets (GBP here) all quotes are, forthe most part, in the same form worldwide. Accordingly, the AUD/FC is adopted as theoriginal rate used in this study—termed the “original” rate and FC/AUD termed the “inverse”rate.
3.2. Variable definition and measurement
The i-M-values are defined as 100 classes of digits (i = 00–99) on which the exchangerate can land or be passed based on a two-digit representation. For convenience, the two-digit representations are all made relative to the decimal point of the exchange rate. Uniti-M-values are the first two digits after the decimal point. Accordingly, decimal i-M-valuesrefer to the second and third (second set of two) digits after the decimal point.
P(Mi) is then the relative frequency of the occurrence of the various i-M-values both unitand decimal and is calculated using the empirical exchange rate data. Clustering occurs
9 The data was obtained from Macquarie Bank and represents the full data set that was released to us. The quotesare indicative in that they are non-binding quotes offered by banks and disseminated over electronic networks suchas Reuters. Transaction data unlike quote data is not widely available for the FX market as no central marketclearing arrangement exists. Thus, FX transaction data only reflects individual participants in the market.

326 J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344
where there is a concentration of P(Mi), i.e., disproportionate P(Mi), across the i-M-values.A further relevant notion is when one of the 100 classes (i = 00–99) of M-values is passed asa result of a change in the exchange rate. This is determined as follows: when an exchangerate, e.g., AUD/DEM, moves from 4.2113 to 4.2154, it does not pass any M-values forthe unit specification as the observation 21 is repeated. However, it passes over the M-values 12, 13, 14 but not 15, for the decimal M-value specification. Thus, an additionalmeasure, the frequency of passing M-values, is calculated. The frequency of the pass-ing M-values, in a similar vein to observing the M-values, has both a unit and decimalspecification. Correspondingly, T(Mi) is the relative frequency of passing the various i-M-values, An unequal frequency of passing M-value effect, i.e., a transgressional effect,occurs where an excess of T(Mi), i.e., disproportionate T(Mi), is evident across the i-M-values.
The choice of M-values (digits) for examination and the calculation of P(Mi) and T(Mi)follows that of De Grauwe and Decupere (1992) and Koedijk and Stork (1994) and theapproach used to measure the frequency of passing M-values follows Donaldson (1990).10
Clustering and transgressional effects can be classified according to whether they are (i)simply general, (ii) located in various groups of M-values, (iii) have any discernible pattern,and/or (iv) are located proximate to the reference 00-M-values. A positional effect is definedwhen a clustering or transgressional effect is located in proximity to the reference digit, inthis case the 00-M-value.
3.3. Adjustment multiple mechanisms
Before the M-values can be tested, adjustment multiples need to be applied to the rawexchange rate data. This alters the selection of unit and decimal M-values that will be testedfor clustering and psychological barriers. The adjustments are applied for a number ofreasons.
First, the raw exchange specifications both for the original and inverse rates considerthe exchange number as a whole and have vastly different numerical or value ranges. Forinstance, a typical observation for the AUD/JPY is 271.51, relative to the correspondingAUD/USD rate of 0.7125 (see Table 1). The decimal place in each case is in the con-ventional position between the units and the tenths of unit digits. If we were to test theM-values selected relative to the decimal point in this initial, unadjusted or raw-M-valuesposition, then the digits tested would have vastly different relative digit magnitudes com-pared with the overall magnitude of the exchange number. This is termed the relative valueresolution of the digits. For example: the digit value which would be tested relative to totalnumber value for the typical observation for the AUD/JPY is (0.51/271.51) 0.002; for theAUD/DEM (0.37/2.37) 0.15 and for the AUD/USD (0.71/0.71) or 1. This vast differencein the relative value resolution of the digits tested may influence the tests for clustering andbarriers.
Second, the raw-M-values are not acceptable for testing, particularly against the expec-tation of a uniform distribution, as some M-values in the range 0–99 would simply not be
10 This is slightly different to De Grauwe and Decupere (1992) measure. For the number of data points employedin this research, the sensitivity of the T(Mi) metric to the different passing M-value measures is minimal.

J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344 327
observed. Examples of the latter are the AUD/GBP that has a range of 0.3571–0.7322 andthe AUD/USD, which has a range of 0.5851–1.1891 (see Table 1). A good portion of theraw-M-values is therefore not realisable for these exchange rates.11 Table 1 shows that forthe inverse rates, ITL/AUD and JPY/AUD, the issue is even more pronounced.
Third, the frequency of certain digits, in this case the M-values and passing M-values,may be influenced, in certain circumstances, by the distribution or range of the data mea-surements. Yule (1927) notes that when examining potential clustering, the range of the dataneeds to be large relative to the digit examined, before the expectation of a uniform distri-bution is considered reasonable. In the current context this is termed the relative tradingrange and is a comparison of the range of the overall exchange rate value with the mag-nitude represented by the digits. It is important to ensure that the overall observed tradingor data range of the exchange rate has a suitably high magnitude relative to the M-valuesselected.12
Fourth, the domain of the M-values, defined as the extent to which the exchange ratesvisit the region near a given M-value, is another issue to be resolved.13 The domain isan indication of the likelihood (expected frequency) of the various digits (M-values). Ifexchange rates are not often observed or occur in the region of the M-values then there isa lower expectation of the frequency of observations, P(Mi) or passing M-values, T(Mi).The domain or the extent to which the exchange rates move over or around the regionassociated with the various i-M-values thus affects the selection of the M-values.14 Thisdomain may not be equal or be vastly different across the various M-values, or may not existat all.
The raw exchange rate data, are initially multiplied by an adjustment multiple (factor of10) necessary to move the decimal place to one position after the first available digit. TheAUD/JPY, for instance, is initially adjusted by a multiple of 1/100 so that the exchange ratebecomes 2.7151 from its original 271.51. This allows the exchange rate to be stated in astandardised form.
The digits (M-values), relative to the initial adjusted decimal place are then examined tosee if they are acceptable for testing. The acceptability of the M-values is evaluated usingseveral criteria (see Table 1 footnote c—criteria (i)–(iv)). M-values have to meet thesecriteria or the exchange rate is further adjusted, i.e., the decimal place moved one furtherdigit to the right (×10) and hence a different set of (digits) M-values considered. This isrepeated until the criteria are satisfied and an appropriate set of M-values, suitable for testingis determined. In the AUD/JPY instance, the exchange rate is further multiplied by 10 sothat the exchange rate now becomes 27.151, the final adjusted exchange (see Table 1), fromthe 2.7151 initially adjusted value above.
11 This is akin to the example provided by Harris (1991) where no whole numbers (0’s) are observed as the wholenumbers are not close enough to the region of movement or trading associated with the digit(s).12 The relative trading range, i.e., the magnitude of the overall currency trading range relative to the magnitude
of the M-value digits, and the domain issue are both equally important for the expectations of P(Mi) and T(Mi).13 This is similar to Harris (1991). Analysis of the domain counters the serial dependence arising in the exchange
rates and consequently the M-values. The likelihood of the M-value being realised or passed depends on theproximity to the previous observed or passed M-value, i.e., the time series dependency.14 An alternative to the domain term is the notion of a trading or movement region of the exchange rate with
respect to the M-value, or the extent to which movement occurs within a region proximate to an M-value.

328 J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344
Table 1Adjustments to raw foreign exchange rate data
Exchangerate quotea
Typicalunadjustedobservationb
Adjustmentmultiplec
Typicaladjustedexchange
Adjustedtrading ranged
Unit barrier testede
Original rateAUD/CHF 2.2236 10 22.236 8.794–25.054 [2.300; 2.400; . . .]AUD/DEM 2.3721 10 23.721 9.962–29.209 [2.30; 2.40; . . .]AUD/FRF 5.4052 1 5.405 3.391–8.171 [5.00; 6.00; . . .]AUD/GBP 0.5869 10 5.869 3.571–7.322 [0.400; 0.500; . . .]AUD/ITL 989.80 1/100 9.898 7.608–16.486 [800; 900; . . .]AUD/JPY 271.51 1/10 27.151 8.437–27.745 [270.00; 260.00; . . .]AUD/USD 0.7125 10 7.125 5.851–11.891 [0.500; 0.600; . . .]
Inverse rateCHF/AUD 0.4497 10 4.497 3.991–11.371 [0.400; 0.500; . . .]DEM/AUD 0.4215 10 4.215 3.423–10.038 [0.400; 0.500; . . .]FRF/AUD 0.1850 100 18.500 12.238–29.489 [0.1400; 0.1500; . . .]GBP/AUD 1.7039 10 17.039 13.657–28.002 [1.500; 1.600; . . .]ITL/AUD 0.001010 10000 10.103 6.065–13.142 [0.0009, 0.0010; . . .]JPY/AUD 0.003683 1000 3.683 3.604–11.853 [0.003, 0.004; . . .]USD/AUD 1.4035 10 14.035 8.409–17.091 [0.400; 0.500; . . .]
a Exchange rate quote—including original/indirect quotes and inverse representations.b Typical observation represents an example of the unadjusted (raw) foreign exchange quotation.c Adjustment multiple represents an adjustment mechanism to the (raw) unadjusted exchange quotation. Adjust-
ments are made if the raw-M-values do not satisfy one of the designated criteria. Criteria for adjustment are asfollows: (i) 00-M-value barrier-of-interest and all other M-values can be realised within the trading range of thedata. Operational dictum for this criterion is that all M-values have at least one realisation point. (ii) Identifiableregions, namely 00-M-value and proximate M-values (85–15) as well as decile representations and sequences ofM-values, are examined to ensure a sufficiently reasonable likelihood of realisation exists, i.e., the extent to whichexchange rates are likely to visit the region proximate to the M-values. Two operational dicta are used: (a) exchangerates are required to have at least an average frequency of 0.75% of M-values for the identified regions; and (b) thefrequency of the passing M-values is required to be at least 0.75% on average for the same identified regions. (iii)Graphic representations of the data suggest that the exchange rates have a sufficient history of “gravitation” aroundor through the M-values proximate to the area-of-significance (00-M-values) and the other identifiable regions.(iv) M-values, post the adjustment multiples, are required to mirror the heuristic of the market in terms of a focuson what is considered the appropriate barrier. Unit specifications are thus: 50, 60, etc., USD cents or equivalentGBP pence; 3.10, 3.20, . . ., 5.10, CHF or DEM; 3.00, 4.00, . . ., 5.00, FRF; hundreds (100, 200) of ITL; and tens(70, 80, 90) of JPY to the AUD. Decimal specifications are naturally of a finer nature (see (e)).
d Trading range: the value range within which the exchange rate fluctuates as a result of the sample underconsideration. All expressed in terms of the exchange rates after adjustment.
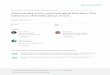
e All testable barrier representations are expressed in terms of the original exchange value for convenience.Unit barriers are 00-M-values for the first and second digits after the decimal point and are depicted by the solidhorizontal gridlines in Fig. 1 for the AUD/USD. Decimal barriers are 00-M-values relative to second and thirdnumbers after the decimal point and are depicted by dotted horizontal gridlines in Fig. 1.
Table 1 documents the final adjustment multiples used to transform the raw exchangerates. AUD/DEM, AUD/CHF, AUD/GBP and AUD/USD, are all adjusted by a multiple of10 relative to the raw exchange rate. The AUD/FRF is not adjusted. The AUD/JPY, i.e.,271.51 and AUD/ITL, i.e., 989.80 are, respectively, divided by 10 and 100. For the inverses,

J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344 329
Fig. 1. Exchange rate—AUD/USD.
the JPY/AUD i.e., 0.003683 is multiplied by 1000, ITL/AUD (0.0010103) by 10,000 andthe remaining inverses all by 10.15 The various adjustment multiples, typical unadjustedand adjusted observations, and examples of the barriers tested are all provided in Table 1for all the original and inverse exchange rate specifications. Fig. 1 notes the unit/decimalbarriers (first and second/second and third digits) tested and are depicted by solid/dottedhorizontal gridlines for the AUD/USD exchange rate.
4. Simulation analysis and test results
4.1. Rationale for simulation analysis
Previous literature has mainly evaluated clustering or transgressional effects against thesimple expectation that the M-values are uniformly distributed. This benchmark may notbe valid for the reasons articulated below.
First and foremost, the distribution of the data may affect the expectation in relationto the frequencies of digits. Ley and Varian (1994) provided an intuitive example. If thedistribution of an observed variable is considered to be standard normal, then as the densityfunction is monotonically decreasing the most likely digit in any position is firstly 0, then1, up to 9. The implication is that the underlying distribution of the exchange rate datahas an impact on the frequency of any individual digits. This influence will also naturallyimpact on any two-digit representations, such as the unit and decimal M-values used here.The distribution of the data therefore may also influence the distribution of P(Mi) andT(Mi).
15 Results of tests will be sensitive to the digit(s) selected and consequently to the procedures adopted for theirselection. Considerable effort is thus made to ensure the digits selected for testing are appropriate.

330 J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344
Second, Ley and Varian (1994) provided evidence that the expectation of equal frequencyof digits is perhaps misplaced for stock market indices. Simulated index levels with similarcharacteristics were compared with the Dow Jones Industrial Average (DJIA) index series.The frequency of observed digits was then computed based on the simulated series andfound to be non-uniform. Ley and Varian (1994), however, did not investigate whetherthe respective frequencies of the digits from the simulated series were equivalent to thefrequencies of the observed series.
Third, Harris (1991) initially raised the issue of the domain region associated with finan-cial series and the impact this has for measuring the extent of clustering.16 Another conjointfactor is that financial series are time dependent. Observed digits (M-values) depend onprevious digits (M-values) and are thus not equally likely. An expectation of uniformity inrelation to observable M-values will only be appropriate when all the M-values are poten-tially equally realisable for each data point. This is clearly not possible based on the currenttrading region for the exchange rates. However, the above represents a sufficient condition;a necessary condition is simply that the domain of the M-values is approximately equal overthe sample.17
Fourth and finally, Connolly (1989), following the work of Zellner and Siow (1980),raised three issues concerning inference drawn from financial series data. First, the largesample size can distort the interpretation of classical test statistics, as the significancelevel of classical tests (e.g., t- and F-statistics) is frequently overstated. Second, the non-Gaussian error problem and third, persistent and time-varying volatility (heteroskedasticity)in financial market data are additional issues. The first issue is overcome by the use ofnon-parametric (mean-rank) statistics and all the issues are further countered through thesimulation analysis, as described above. The simulations capture the large sample property,non-normality and time-series dependent volatility within the shape and characteristics ofthe simulated series. The frequencies of the observations and the passing values obtainedfrom the simulated series are then used as the expectation against which the observedexchange rate results are compared.
4.2. Models and method of simulation analysis
To generate robust expectations (“normalised or control measures”) of P(Mi) and T(Mi)using a simulation approach requires us to develop model(s) of the underlying exchangerate. We adopt the following stages in the simulation exercise: (i) in each case 200 seriesof 3500 observations for each exchange rate (st) (3663 observations is the longest sampledata series) are generated using a number of model specifications; (ii) for each of the 200simulated series the simulated frequencies of the P(Mi) and T(Mi) metrics are derived foreach of the M-values; and (iii) the Observed (empirical) frequencies for the metrics are then
16 The expectation is that the final digits of prices are uniformly distributed as the fractional portions of underlyingvalue are uniform and the market is efficient (Niederhoffer, 1965, 1966; Niederhoffer and Osborne, 1966).17 The exchange rates were adjusted in Section 3 to alleviate obvious problems of trading range which may
influence the expectation of unequal P(Mi) and T(Mi) across M-values. It was noted these adjustments were onlya first-pass attempt at controlling for these problems. They could still remain mainly as a result of the distributionof the overall exchange rate series and the impact of this upon the distribution of the M-values (digits).

J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344 331
compared to the average of the simulated (control) frequencies for the corresponding P(Mi)and T(Mi) metrics, matched by the appropriate ith M-value.18
We developed four separate models of the underlying exchange rate. The first and sim-plest model is one of a geometric random walk with a drift component, similar to that ofLey and Varian (1994). In each case, the model parameters (mean, standard deviation andstarting values) are estimated from the sample values. This allows the exchange rate levels(st) to be derived from the random deviations around the drift expectation for the returns.19
The second is based on a randomised empirical trading returns or quasi-bootstrap approach.The empirical distribution is used as an alternative to counter the problem of the leptokurtic(fat-tailed) nature of the distribution of exchange rate changes that may influence the results.This approach is similar to Donaldson and Kim (1993). The empirical returns are randomlyreordered and a new sequence of exchange rate levels produced using the sample startingvalue (s0) and the exchange rate levels (st) implied by the reordered return series.
The third model is perhaps the most rigorous model specification from an empirical andtheoretical sense, namely a GARCH (1, 1) model. It was chosen partly for a parsimoniousrepresentation and the higher-order dependence process i.e., GARCH (2, 2) did not pro-vide a more appropriate model. The model is similar to Akgiray (1989), and is estimatedassuming (i) normality of the conditional distribution and (ii) the conditional distribution ofthe errors (ε) are t-distributed with (υ) degrees of freedom estimated from the data (Engleand Bollerslev, 1986). The parameter estimates for the GARCH (1, 1) model are given inTable 2.20
Finally, a structural change random walk incorporating time-varying parameters is usedas a fourth model. The sample is divided into three periods: (1) the pre-deregulationsub-period (pre 12 December 1983), (2) the post-deregulation sub-period (post 12 Decem-ber 1983 until December 1989) and (3) the stable 90s sub-period (January 1990 untilDecember 1992). These sub-sections correspond approximately to three readily identifi-able structurally different sub-periods.21 In order to accommodate the structural changes,this simulation approach uses three different means and variances for the three sub-periods.It uses the first sub-period mean and variance to estimate the first period (1400) exchangerate returns and rates, then the second sub-period mean and variance for the next period(1400) returns and finally the third sub-period mean and variance for the remaining period
18 A robustness check is performed to examine whether the above proportion is sensitive to the number (200) ofsimulation replications used. For the AUD/USD, the P(Mi) and T(Mi) frequencies are calculated for the variousspecifications of the M-values based on the following number of simulated runs: 400, 600, 800 and 1000 replica-tions. The average results are almost identical. Correlations between the values achieved for the 200 relative tothe 1000 replications for the various M-values are in no case below 0.99.19 For an overview and formal representation of this model the interested reader is referred to Ley and Varian
(1994).20 Only the results of the t-distribution estimation are given in Table 2. Results using the normal distribution
are similar with the GARCH coefficients having an equivalent magnitude with the exception of the interceptcoefficients (φ0 and α0), which are lower. This is similar to the results of Pagan (1996).21 Structural change in exchange rates over the various sub-periods arises for a number of reasons—economic
market forces, regulation and the changing of the financial market structure. It is well documented that substantialvolatility in exchange rates existed for the post-December 1983 deregulation sub-period and continued until 1989.Examination of the exchange rate series as well as their return and volatility plots provides anecdotal evidencethat the exchange rate series are different over these three distinct sub-periods of the sample.

332J.M
itchell,H.Y.Izan
/Int.Fin.M
arkets,Inst.andM
oney16
(2006)318–344
Table 2AR(1)–GARCH(1, 1) model of exchange rate returns
Exchange rate AUD/CHF AUD/DEM AUD/FRF AUD/GBP AUD/ITL AUD/JPY AUD/USD
AR (1) of returnsφ0 0.016 0.006 0.014 0.015 0.021 0.025 −0.004t-value–φ0 1.132 (0.258) 0.472 (0.637) 1.037 (0.300) 1.138 (0.255) 1.625 (0.104) 1.986 (0.047) −0.556 (0.578)φ1 −0.052 −0.058 −0.065 −0.045 −0.060 −0.108 −0.044t-value–φ1 −2.676 (0.007) −2.991 (0.003) −3.361 (0.001) −2.375 (0.018) −3.107 (0.002) −5.620 (<0.001) −2.241 (0.025)
GARCH (1, 1) of conditional variance of return equation errorα0 0.057 0.060 0.071 0.032 0.054 0.080 0.009t-value–α0 4.229 (<0.001) 4.174 (<0.001) 4.477 (<0.001) 3.352 (0.001) 4.385 (<0.001) 4.425 (<0.001) 4.160 (<0.001)α1 0.109 0.124 0.138 0.096 0.136 0.162 0.224t-value–α1 6.120 (<0.001) 5.985 (<0.001) 6.075 (<0.001) 5.396 (<0.001) 6.093 (<0.001) 6.006 (<0.001) 7.233 (<0.001)β1 0.827 0.803 0.779 0.865 0.795 0.736 0.793t-value–β1 30.498 (<0.001) 25.115 (<0.001) 23.387 (<0.001) 34.441 (<0.001) 25.669 (<0.001) 17.823 (<0.001) 34.686 (<0.001)υ 6.099 5.695 5.105 5.251 5.199 4.764 4.247t-value–υ 9.065 (<0.001) 9.782 (<0.001) 10.839 (<0.001) 10.299 (<0.001) 10.659 (<0.001) 11.179 (<0.001) 12.543 (<0.001)R̄2 −0.0022 −0.0021 −0.0004 −0.0022 −0.0032 −0.0084 0.0020F-stat N/A N/A N/A N/A N/A N/A N/AL-L −3691.4 −3528.9 −3536.5 −3491.2 −3.367.8 −3318.3 −2241.3
R̄2—R-bar-squared; F-stat—regression F-statistic; L-L—Log-likelihood. Figures in parentheses denote probability-values for corresponding test statistic. The model isAR(1)–GARCH(1, 1) estimated assuming the conditional distribution of the errors (ε) are t-distributed with (υ) degrees of freedom (Engle and Bollerslev, 1986). Themodel is similar to Akgiray (1989) and uses the general GARCH approach introduced by Bollerslev (1986). The model is conditional on the information set It−1; Rt
is drawn from the distribution f(µt, σ2t ) with conditional mean (µt) and conditional variance (σ2
t ); µt = φ0 + φ1Rt−1; ε = Rt − φ0 − φ1Rt−1 and σ2t = α0 + β1σ
2t−1 + α1ε
2t .
Estimation is done using maximisation of the likelihood function. t-statistics for the GARCH coefficients are based on asymptotic standard errors. Model is estimatedusing (%) returns, to convert to return format multiply by 10−2 and 10−4 for the returns and variances, respectively.

J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344 333
(700) returns. The expected P(Mi) and T(Mi) are then calculated from the reconstructedsimulated exchange rate series, as previously, for comparison to the observed P(Mi) andT(Mi).
4.3. Results of simulation analysis
The results are not sensitive to the use of the various models so we concentrate on thefirst and simplest model, the geometric random walk with drift. Initially, the results oftests of the frequencies of the observations (Table 3) and passing M-values (Table 4) ofthe simulated data relative to that of a uniform distribution are examined. This is done (i)across all M-values—χ2SU (99); (ii) across the specific adjacent decile grouping—χ2SD(9) where the M-values are split into adjacent decile categories, namely 00–9, 10–19, . . .,90–99; and (iii) for a random decile grouping—χ2SR (9) where the M-values are randomlyassigned into ten groups.
For the unit specification, the simulated observations of M-values, P(Mi), in Table 3 donot conform to a uniform distribution as reflected in the χ2SU (99) tests. Notable exceptionsto this finding are the AUD/CHF, FRF/AUD, GBP/AUD, ITL/AUD and USD/AUD. Further,these same exchange rates except for the AUD/CHF do not have a significant deviation fromthe expectation of a uniform distribution of M-values for the designated decile, and randomdecile groups. The degree of non-conformity of the simulated observations to a uniformdistribution within groups is somewhat dependent on how the grouping is specified. Randomgrouping—�2SR (9) tests do not display the same degree of deviation from the uniformdistribution as the other adjacent decile—χ2SD (9) tests do. In fact, for the unit specificationthe random grouping tests for the AUD/CHF, AUD/ITL, and DEM/AUD, are not significanteven though the decile groupings are. Regardless, the decimal specification clustering testsare not significant either for the general or group M-values, for the original exchange or forthe inverse specification.
Transgressional effect tests in Table 4 for the unit specification in the simulated exchangerate data display clear results. The chi-squared tests for T(Mi) show significant deviationsfrom uniformity in all cases. The simulated decimal M-values (see lower half of Table 4)display significant transgressional effects or disproportionate T(Mi) in contrast to the non-significant results in relation to the simulated P(Mi) noted above. This effect occurs notonly in the T(Mi) across all M-values but also for the decile and random groupings.
In summary, apart from the decimal M-value specification and the FRF/AUD, GBP/AUD,ITL/AUD and USD/AUD for the unit specification for P(Mi), the overriding conclusion isthat the observations of the M-values from the simulated series are not uniformly distributed.The difference of the simulated T(Mi) relative to a uniform distribution is supported for allspecifications (Table 4). These findings suggest that the initial benchmark of a uniformdistribution as tested in studies by De Grauwe and Decupere (1992) and Koedijk and Stork(1994) is questionable.22 That said, for finer partitions of value – decimal specification – it
22 Tests of clustering and transgressional effects relative to the naı̈ve expectation of a uniform distribution werealso carried out but not included due to space considerations. Overall the tests revealed more extensive departuresand hence tended to confirm the effect more often than they should. The interested reader is referred to Mitchell(1998) for details.

334J.M
itchell,H.Y.Izan
/Int.Fin.M
arkets,Inst.andM
oney16
(2006)318–344
Table 3Tests of P(Mi) and clustering relative to simulated data
Panel A—original exchange specification
AUD/CHF AUD/DEM AUD/FRF AUD/GBP AUD/ITL AUD/JPY AUD/USD
Unit M-value Tests of uniform distribution of simulated P(Mi) across M-valuesχ2SU (99) 116.57 (0.110) 124.64 (0.042) 649.64 (<0.001) 430.26 (<0.001) 180.37 (<0.001) 164.07 (<0.001) 146.06 (0.001)χ2SD (9) 42.67 (<0.001) 13.24 (0.152) 547.08 (<0.001) 320.84 (<0.001) 62.13 (<0.001) 47.60 (<0.001) 46.16 (<0.001)χ2SR (9) 6.48 (0.691) 9.51 (0.392) 48.82 (<0.001) 49.41 (<0.001) 13.77 (0.131) 13.03 (0.161) 28.87 (0.001)
Tests of observed relative to simulated P(Mi) across M-valuesχ2SO (99) 123.99 (0.051) 120.04 (0.074) 183.41 (<0.001) 424.28 (<0.001) 195.31 (<0.001) 160.87 (<0.001) 217.05 (<0.001)χ2P (30) 32.42 (0.348) 49.04 (0.016) 66.80 (<0.001) 315.33 (<0.001) 34.88 (0.247) 39.52 (0.115) 54.87 (0.004)
Decimal M-value Tests of uniform distribution of simulated P(Mi) across M-valuesχ2SU (99) 91.83 (0.683) 89.83 (0.734) 105.89 (0.299) 97.42 (0.526) 114.93 (0.131) 73.50 (0.974) 111.59 (0.182)χ2SD (9) 8.65 (0.470) 7.28 (0.608) 7.52 (0.583) 13.70 (0.133) 18.15 (0.033) 7.30 (0.606) 8.18 (0.516)χ2SR (9) 18.32 (0.032) 7.22 (0.614) 4.39 (0.884) 23.65 (0.005) 4.43 (0.881) 6.89 (0.648) 12.58 (0.182)
Tests of observed relative to simulated P(Mi) across M-valuesχ2SO (99) 110.62 (0.290) 91.91 (0.707) 109.67 (0.238) 125.78 (0.036) 103.84 (0.350) 104.93 (0.323) 190.71 (<0.001)χ2P (30) 26.44 (0.652) 17.923 (0.960) 40.837 (0.090) 37.75 (0.156) 28.35 (0.552) 25.49 (0.701) 38.95 (0.127)

J.Mitchell,H
.Y.Izan/Int.F
in.Markets,Inst.and
Money
16(2006)
318–344335
Table 3 (Continued )
Panel B—inverse exchange specification
CHF/AUD DEM/AUD FRF/AUD GBP/AUD ITL/AUD JPY/AUD USD/AUD
Unit M-value Tests of uniform distribution of simulated P(Mi) across M-valuesχ2SU (99) 410.66 (<0.001) 154.95 (<0.001) 90.19 (0.725) 81.83 (0.894) 115.01 (0.130) 833.50 (<0.001) 102.79 (0.377)χ2SD (9) 270.93 (<0.001) 46.31 (<0.001) 9.90 (0.359) 10.98 (0.277) 10.30 (0.327) 712.42 (<0.001) 5.82 (0.758)χ2SR (9) 25.48 (0.002) 15.56 (0.077) 6.29 (0.711) 15.54 (0.077) 11.54 (0.240) 172.98 (<0.001) 4.99 (0.835)
Tests of observed relative to simulated P(Mi) across M-valuesχ2SO (99) 172.96 (<0.001) 376.57 (<0.001) 115.94 (0.117) 117.18 (0.103) 265.70 (<0.001) 383.48 (<0.001) 260.31 (<0.001)χ2P (30) 59.14 (0.001) 110.17 (<0.001) 31.31 (0.400) 33.89 (0.285) 60.80 (0.001) 126.26 (<0.001) 67.994 (<0.001)
Decimal M-value Tests of uniform distribution of simulated P(Mi) across M-valuesχ2SU (99) 98.50 (0.495) 112.64 (0.165) 119.41 (0.080) 81.78 (0.896) 140.79 (0.004) 104.63 (0.330) 102.79 (0.377)χ2SD (9) 8.58 (0.477) 13.53 (0.140) 7.07 (0.630) 4.21 (0.897) 4.58 (0.869) 14.81 (0.096) 5.82 (0.758)χ2SR (9) 5.89 (0.751) 6.93 (0.644) 12.08 (0.209) 3.42 (0.945) 9.82 (0.366) 10.54 (0.309) 4.99 (0.835)
Tests of observed relative to simulated P(Mi) across M-valuesχ2SO (99) 130.67 (0.018) 97.80 (0.515) 112.86 (0.161) 107.21 (0.269) 98.77 (0.488) 94.78 (0.601) 145.06 (0.002)χ2P (30) 37.28 (0.169) 30.78 (0.426) 21.07 (0.888) 38.87 (0.129) 20.61 (0.900) 30.26 (0.453) 38.45 (0.138)
Chi-squared test (degrees-of-freedom) of average of simulated (control) frequencies: χ2SU—across all M-values, χ2SD—decile, and χ2SR—random decile grouping.Chi-squared test for differences between observed and simulated frequencies: χ2SO (99)—across all M-values. χ2P (30)—across the positional specification of the 85-15M-values. The observed frequencies are tested relative to the frequencies of simulated distribution, which are used as the expected or control. Figures in parentheses areprobability-values for the corresponding test statistic.

336J.M
itchell,H.Y.Izan
/Int.Fin.M
arkets,Inst.andM
oney16
(2006)318–344
Table 4Tests of T(Mi) and transgressional effects relative to simulated data
Panel A—original exchange specification
AUD/CHF AUD/DEM AUD/FRF AUD/GBP AUD/ITL AUD/JPY AUD/USD
Unit M-value Tests of uniform distribution of simulated T(Mi) across M-valuesχ2SU (99) 10518.6 (<0.001) 11864.6 (<0.001) 1210.1 (<0.001) 612.5 (<0.001) 9960.9 (<0.001) 11088.7 (<0.001) 5367.5 (<0.001)χ2SD (9) 9266.2 (<0.001) 10587.8 (<0.001) 1046.7 (<0.001) 367.5 (<0.001) 7326.7 (<0.001) 9776.2 (<0.001) 3119.9 (<0.001)χ2SR (9) 715.2 (<0.001) 809.9 (<0.001) 98.3 (<0.001) 68.36 (<0.001) 701.8 (<0.001) 694.1 (<0.001) 420.0 (<0.001)
Tests of observed relative to simulated T(Mi) across M-valuesχ2SO (99) 98.90 (0.484) 64.56 (0.997) 170.49 (<0.001) 254.45 (<0.001) 127.49 (0.028) 63.72 (0.998) 255.60 (<0.001)χ2P (30) 19.62 (0.926) 16.50 (0.978) 58.96 (0.001) 159.99 (<0.001) 12.55 (0.998) 15.87 (0.984) 70.91 (<0.001)
Decimal M-value Tests of uniform distribution of simulated T(Mi) across M-valuesχ2SU (99) 8441.1 (<0.001) 8292.8 (<0.001) 18380.5 (<0.001) 18950.4 (<0.001) 13082.5 (<0.001) 8820.6 (<0.001) 18572.0 (<0.001)χ2SD (9) 8020.2 (<0.001) 7898.9 (<0.001) 17379.1 (<0.001) 17974.1 (<0.001) 12428.6 (<0.001) 8408.9 (<0.001) 17680.8 (<0.001)χ2SR (9) 560.7 (<0.001) 579.1 (<0.001) 1249.5 (<0.001) 1276.9 (<0.001) 891.8 (<0.001) 607.8 (<0.001) 1244.2 (<0.001)
Tests of observed relative to simulated T(Mi) across M-valuesχ2SO (99) 11.09 (>0.999) 21.99 (>0.999) 18.68 (>0.999) 50.81 (>0.999) 42.02 (>0.999) 22.53 (>0.999) 26.68 (>0.999)χ2P (30) 3.27 (>0.999) 8.08 (>0.999) 3.64 (>0.999) 9.41 (>0.999) 10.85 (0.999) 7.79 (>0.999) 9.16 (>0.999)

J.Mitchell,H
.Y.Izan/Int.F
in.Markets,Inst.and
Money
16(2006)
318–344337
Table 4 (Continued )
Panel B—inverse exchange specification
CHF/AUD DEM/AUD FRF/AUD GBP/AUD ITL/AUD JPY/AUD USD/AUD
Unit M-value Tests of uniform distribution of simulated T(Mi) across M-valuesχ2SU (99) 4312.8 (<0.001) 1997.9 (<0.001) 20265.3 (<0.001) 15265.6 (<0.001) 11070.8 (<0.001) 2919.6 (<0.001) 8129.6 (<0.001)χ2SD (9) 3691.2 (<0.001) 1512.2 (<0.001) 18886.4 (<0.001) 14033.7 (<0.001) 8177.73 (<0.001) 2366.0 (<0.001) 5663.2 (<0.001)χ2SR (9) 309.8 (<0.001) 164.38 (<0.001) 1383.5 (<0.001) 997.6 (<0.001) 812.5 (<0.001) 277.1 (<0.001) 635.34 (<0.001)
Tests of observed relative to simulated T(Mi) across M-valuesχ2SO (99) 37.95 (>0.999) 328.64 (<0.001) 37.69 (>0.999) 58.16 (>0.999) 65.92 (0.996) 99.42 (0.469) 348.92 (<0.001)χ2P (30) 14.90 (0.990) 116.39 (<0.001) 10.95 (0.999) 20.52 (0.902) 21.50 (0.872) 37.02 (0.177) 144.88 (<0.001)
Decimal M-value Tests of uniform distribution of simulated T(Mi) across M-valuesχ2SU (99) 15223.5 (<0.001) 16546.9 (<0.001) 6334.8 (<0.001) 7238.2 (<0.001) 11903.4 (<0.001) 16311.0 (<0.001) 15149.7 (<0.001)χ2SD (9) 14512.9 (<0.001) 15667.0 (<0.001) 6018.4 (<0.001) 6888.0 (<0.001) 11304.3 (<0.001) 15486.9 (<0.001) 14407.1 (<0.001)χ2SR (9) 1014.4 (<0.001) 1100.5 (<0.001) 455.4 (<0.001) 485.3 (<0.001) 839.2 (<0.001) 1114.1 (<0.001) 1067.1 (<0.001)
Tests of observed relative to simulated T(Mi) across M-valuesχ2SO (99) 19.51 (>0.999) 17.31 (>0.999) 4.46 (>0.999) 18.84 (>0.999) 11.40 (>0.999) 42.98 (>0.999) 42.43 (>0.999)χ2P (30) 5.63 (>0.999) 1.94 (>0.999) 1.14 (>0.999) 6.40 (>0.999) 2.32 (>0.999) 7.97 (>0.999) 12.05 (0.999)
Chi-squared test (degrees-of-freedom) of average of simulated (control) frequencies: χ2SU—across all M-values, χ2SD—decile, and χ2SR—random decile grouping.Chi-squared test for differences between observed and simulated frequencies: χ2SO (99)—across all M-values. χ2P (30)—across the positional specification of the 85–15M-values. The observed frequencies are tested relative to the frequencies of simulated distribution, which are used as the expected or control. Figures in parentheses areprobability-values for the corresponding test statistic.

338 J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344
Fig. 2. (a) Comparison of observed and simulated P(M) for unit M-value specification—AUD/USD. (b) Compar-ison of observed and simulated P(M) for decimal M-value specification—AUD/USD. (c) Comparison of observedand simulated T(M) for unit M-value specification—AUD/USD. (d). Comparison of observed and simulated T(M)for decimal M-value specification—AUD/USD.
seems that the uniform distribution is acceptable when examining the frequency of M-valuesor digits.
Results of tests based on the simulated frequencies as benchmarks are further providedin Tables 3 and 4. Chi-squared tests for differences between observed and simulated P(Mi)and T(Mi) are computed across all M-values, denoted χ2SO (99); and across the positionalspecification of the 85–15 M-values, denoted χ2SOP (30). For each of the above tests, theexpected frequencies are determined by obtaining the proportion of the simulated relativefrequencies for each ith-M-value, multiplied by the total of the observed frequencies asdetermined by the empirical results.23 The observed P(Mi) and T(Mi) are compared with thesimulated P(Mi) and T(Mi) and the results for the AUD/USD are illustrated in Fig. 2(a)–(d).24
The FX unit specifications display a general clustering effect (see Table 3, Panel A)that in some instances is evident as a positional effect for the AUD/DEM, AUD/FRF,AUD/GBP and AUD/USD. The results for the inverse rates are similar to the originalexchange specification (see Table 3, Panel B) with the positional clustering evident forCHF/AUD, DEM/AUD, ITL/AUD, JPY/AUD and USD/AUD. For the decimal specifica-tion the clustering results are unambiguous—no general or specific positional effects exist(see lower half of Table 3). Somewhat surprisingly, the unit specification results are similar,but not identical to those obtained using the uniform benchmark (not reported). Signifi-cant transgressional effects occur for some exchange rates (see Table 4). Again, in select
23 This ensures that the simulated frequencies are expressed on the same relative basis as the observed frequencies.The chi-squared test requires the actual frequency not the relative frequency for testing.24 As the other exchange rates and the inverses display similar characteristics, only the original AUD/USD
specification FX figures are provided in Fig. 2.

J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344 339
instances, this transgressional effect is also evident as a positional effect for the AUD/FRF,AUD/GBP and AUD/USD and the DEM/AUD and USD/AUD. For the decimal case, neitherthe original nor the inverse rates indicate any general or positional transgressional effect(see Table 4).25
Overall, tests based on the simulation benchmarks show that the clustering effect orunequal P(Mi) for the unit specification is supported, but only for select exchange rates.There is no guarantee that significance or a particular shape of the general clustering acrossall i-M-values will lead to a significant positional clustering effect around the 85–15 M-values, and more importantly that the concentration of observations is in the appropriate formand direction. This would be evidenced by a hump shape when the P(Mi) are plotted relativeto the 00–99 M-values in sequential order (see Fig. 2(a) and (b)). Ultimately, for the unitspecification only the AUD/USD, see Fig. 2(a) (with perhaps AUD/JPY) and ITL/AUD, dis-play the appropriate directional positional clustering. The AUD/CHF and the FRF/AUD donot have significant directional clustering (see Table 3) and are different to results using testsbenchmarked against the uniform distribution. The decimal specification results are clear inthat no positional clustering exists regardless of whether this is measured against a uniformor simulation benchmark (see Table 3 and Fig. 2(b) for an illustration using the AUD/USD).
Based on these results, the assumption of a uniform distribution for the frequency ofthe passing M-values as the benchmark is not appropriate. For the unit specification thesimulation expectation of T(Mi) is hump-shaped (Fig. 2(c)) although it is not often pro-nounced. For the decimal specifications, the simulation expectation of T(Mi) is in all casesa pronounced hump or umbrella-shape (see Fig. 2(d)). This nullifies the significance andchanges the direction of the test results for T(Mi) computed using the simulated benchmarkwhen compared to the tests using the uniform distribution benchmark. Only AUD/FRF,AUD/GBP, AUD/USD, DEM/AUD and USD/AUD for the unit specification exhibit any(positional) transgressional effect. Several of the unit and decimal specifications exhibiteda significant appropriate directional transgressional result when the benchmark was theuniform distribution, but not when the simulated benchmark is used. All decimal exchangerates display the correct directional transgressional using the simulated benchmark but it isnot significant. This result is encapsulated in Fig. 2(d) as the benchmark simulated T(Mi) aremuch closer to the observed T(Mi) than the equal frequencies under the uniform distribution.
With the exception of the decimal transgressional effects, there does not appear to be anyconsistency in the clustering and transgressional effects for the various specifications acrossthe exchange rates. Neither do the effects appear consistent in one exchange rate nor doone exchange rate or inverse exhibit all effects consistently more than another. The effectsare thus only evident on a case-by-case basis. The focus on the AUD/USD by the financial
25 The tests above are based on a comparison of the observed metric to the average of the simulations or thecontrol metrics. Information may be lost in the averaging process or the average may fail to highlight the extremenature of the difference across repeated simulations. An alternative measure is to compare the degree of significantdifferences of the observed metric relative to the distribution of the simulated metric rather than the averageobtained from the simulated series. This can be represented as the proportion of the number of times the observedfrequencies are greater than the simulated frequencies or O#/(O# + S#). Here, O# is the number of times the observedfrequencies are greater than the simulated frequencies and Ss is the number of times the observed frequencies areless than the simulated frequencies. Results using the distribution of the simulated metric are equivalent to thoseusing the average.

340 J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344
market and press may be an important factor as the clustering appears more pronounced inthe AUD/USD.
4.4. Implications of the results
A number of implications arise from the results found in this study. First, the market andfinancial press references to “barriers”, “support” and “resistance” levels or zones regardlessof whether they are psychologically induced, or otherwise, seem somewhat misplaced in sofar as it relates to 00-reference digits. To the extent that they occur in exchange rates, theyare not necessarily located in a specific 00-digit location.
Second, a large majority of the exchange rates do not have a reduced number of obser-vations or relative frequency of passing M-values associated with the 85–15 M-value digitregion i.e., the positional effect is positive (more observations) in that region which contrastswith the expectation of lower frequencies based on the simulated models. Clustering andtransgressional effects exist and are widespread, but they are more often than not located inother (non-85–15) M-values digits. Furthermore, they are not necessarily in the expecteddirection. As a result, the anecdotal evidence presented earlier of less concentration around00-digits is only confirmed for a few of the exchange rates and then only in a select numberof instances. In short, the effects are there, but not necessarily in the postulated location.
Third, evidence of general clustering and transgressional effects exists in AUD exchangerates. However, such effects do not have a consistent form, shape or location with respectto the M-values. It is notable that for some rates, the positional effects are opposite to theexpected direction. The expected direction across all i-M-values was postulated as a humpform when compared over the 00–99 M-values, which means the positional effect has a lowerfrequency for the 85–15 M-values. In several instances the observed shape is a bowl-shape,similar and even more pronounced than that illustrated in Fig. 2(c), and completely oppositeto that postulated. In other cases, the effect is an oscillatory wave form (see Fig. 2(a) and (b)).The implication for trading strategies is that an examination of the exchange rates needs tobe made on a case-by-case basis. It is not sufficient to assume that any information structureimplied by clustering and transgressional effects is consistent across exchange rates.
Fourth, the haphazard findings across the various exchange rates suggest an economicrather than a general behavioural, social or cultural explanation. The widespread type ofnumber preference exhibited by individuals in other non-financial contexts – superstition,measuring, recording or consumer markets – is not evident in the FX at least as it relates to 00-digits as a reference point. Similarly, ingrained social or broad-based cultural conventionsor a behavioural by-product of the decimal number system itself are also not evident.26
Furthermore, behavioural explanations, such as reducing computational time and ease ofmental processing do not fit the findings. Only if the effects were widespread and consistentacross exchange rates would these explanations be tenable. Based on the “information
26 One may argue that the effect of the T(Mi) especially the decimal specification is sufficiently widespread toconstitute a barrier to passing 00-M-values. This would lend support to the idea of a general behavioural factor ornumerousness concept occurring as a by-product of the decimal number system. However, as noted the effect haspartly a statistical explanation as the same type of effect occurs in artificially generated simulated series with theequivalent statistical characteristics.

J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344 341
equilibrium pricing” theory clustering would be less pervasive in the AUD/USD exchangequote. This is not the case; while differences in clustering are certainly evident across theexchange rates the extent and positioning of the clustering is not of any lesser magnitudefor the AUD/USD.
The fifth implication concerns the hump-shape form that occurs in some of the observedP(Mi) and especially the T(Mi). Pesenti (1990) and Bertola and Caballero (1992) suggestedthe possibility that FX rates exhibit some aspects of a perforate barrier or zone that has asupport or resistance level that can be crossed only with some difficulty.27 The argument isthat, after the zone is crossed, the amount of time the asset price or exchange rate spendsclose to those barriers is less than the time it spends away. We document that this hump-shaped distribution is in part a product of the exchange rate itself, as all the simulatedP(Mi) and T(Mi) produce this same shape for the decimal specifications. These simulatedexchange series were not constructed with a capacity to identify or resist passing throughtarget zones.
5. Conclusion
There are numerous potential reasons why either clustering and transgressional effects,or barriers, may occur in exchange rates. Those stem from a wide variety of sources, somepragmatic, others arguably not. The view of this research was that prima facie evidenceof FX rate clustering is neither a necessary nor a sufficient condition to conclude evidenceof a psychological barrier. This argument is an offshoot of Harris’ work in that clusteringin financial markets may have an economic interpretation mainly related to the optimalprice resolution depending on how well the underlying asset value is known. It is alsopossible that clustering mainly through stop or limit orders (Niederhoffer, 1965, 1966) atround number focal points (Schelling, 1960; Sugden, 1995) may combine with technicalanalysis procedures, such as support/resistance levels to induce a psychological barrier (seeTschoegl, 1988). Tschoegl (1988) further notes that traders will be hesitant to cross thesebarrier levels and once crossed, different trading behaviour will be observed as the ordersare executed. Hence, an alternative test to that of clustering based on the unequal frequencyof passing M-values, or T(Mi), is necessary to determine whether a barrier occurs or not.
Empirical tests were conducted for clustering and transgressional effect in relation toexchange rates involving the Australian dollar. In contrast to previous studies, the appropri-ateness of the assumption of testing against a uniform distribution of digits was evaluatedusing a simulation analysis that generated an expected frequency of and passing of M-valuesor digits. The findings using the simulated rather than the uniform distribution as a bench-mark reveal that both clustering and transgressional effects remain, but were markedly lesspronounced and in the majority of instances were no longer significant and no longer hadthe expected position and shape. One can thus infer that some degree of dependent struc-ture or information content, both in the frequencies of occurrence and the frequencies of
27 This followed work by Krugman (1991) and Flood and Garber (1991) who looked at imperforate barriers orzones in which the asset price, e.g., an exchange rate, could not take on values outside the target zone. The barriersconsidered here are clearly perforate (see Donaldson and Kim, 1993).

342 J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344
the passing of digits is associated with identifiable digits or M-values. However, differenttypes of clustering and transgressional effects were located in various unit and decimal digitspecifications.
The finding that the pattern of T(Mi) differs across the various exchange rates is consistentwith the view that focal points may exist for, but differ between, the exchange rates. Thesefocal points are not consistent across time and do not necessarily exist solely for 00-digits.In fact, these focal points may be linked with the “support”, “resistance” and “psychologicalbarriers” through technical analysis which may influence the FX trading dynamics partic-ularly through stop (Tschoegl, 1988) and/or limit orders (Niederhoffer, 1965). Similarly,positive feedback trading may exacerbate these price moves as some market participantsbuy when prices are rising or sell when prices are reducing particularly at crucial focalpoints (DeLong et al., 1990).
Overall, the results of the current study are consistent with the notion that barriers dependnot only on the number themselves or any properties it may have such (such as a beinga round number focal point) but also on the existing exchange value and the distancebetween these numbers. The dynamics of the exchange rate setting process is importantand appears to shift over time and across exchange rates. Quite simply, the same numbermay be a psychological barrier at one point but not at another. This fits in well with thetechnical analysis explanation of support/resistance levels and the potential of stop ordersand positive feedback trading behaviour at these points. Clearly, trading strategies basedon the support/resistance levels in the digits presents themselves. However, this is left asan avenue for future research as the prime focus here was simply to isolate and documentthe effects. Market efficiency implications would naturally hinge on the outcome of anyobservable profits from the trading strategies developed.
Acknowledgments
The authors would like to acknowledge the helpful comments of Philip Brown, StephenEaston, Robert Faff, Robert Webb, and seminar participants at The University of WesternAustralia on earlier versions this work. Paul Lloyd deserves special thanks for developing thesimulation programs and Rhys Hollow provided additional valuable computer assistance.Appreciation is extended to Macquarie Bank for providing the foreign exchange data andJason Mitchell acknowledges funding support for this project from a Faculties IndividualResearch Grant at the University of Western Australia.
References
Aitken, M., Brown, P., Buckland, C., Izan, H.Y., Walter, T., 1996. Price clustering on the Australian Stock Exchange.Pacific Basin Finance Journal 4 (2&3), 297–314.
Akgiray, V., 1989. Conditional heteroskedasticity in time series of stock returns: evidence and forecasts. Journalof Business 62 (1), 55–80.
Ball, C.A., Torous, W.A., Tschoegl, A.E., 1985. The degree of price resolution: the case of the gold market. Journalof Futures Markets 5 (1), 29–43.
Bank for International Settlements, 1992. Central bank survey of foreign exchange market activity. Bank forInternational Settlements, April 1992.

J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344 343
Bertola, G., Caballero, R., 1992. Target zones and realignment. American Economic Review 82 (3), 520–536.Bollerslev, T., 1986. Generalised autoregressive conditional heteroskedasticity. Journal of Econometrics 31 (3),
307–327.Buckland, C., 1994. An investigation of the prevalence of price clustering on the Australian Stock Exchange,
Unpublished BCom Honours Dissertation, Department of Accounting and Finance, University of WesternAustralia.
Butler, D., Loomes, G., 1988. Decision difficulty and imprecise preferences. Acta Psychologica 68 (1–3), 183–196.Connolly, R.A., 1989. An examination of the robustness of the weekend effect. Journal of Financial and Quantitative
Analysis 24 (2), 133–170.Curcio, R., Goodhart, C.A.E., 1992. When support/resistance levels are broken, can profits be made? evidence
from the foreign exchange market. Discussion Paper No. 142, London School of Economics Financial MarketsGroup.
Cyree, K.B., Domain, D.L., Louton, D.A., Yobaccio, E.J., 1999. Evidence of psychological barriers in the condi-tional moments of major world stock indices. Review of Financial Economics 8 (1), 73–91.
De Ceuster, M.J.K., Dhaene, G., Schatteman, T., 1998. On the hypothesis of psychological barriers in stock marketsand Benford’s Law. Journal of Empirical Finance 5 (4), 263–279.
De Grauwe, P., Decupere, D., 1992. Psychological barriers in the foreign exchange market. Journal of Internationaland Comparative Economics 1, 87–101.
Dehaene, S., Mehler, J., 1992. Cross-linguistic regularities in the frequency of number words. Cognition 43 (1),1–29.
DeLong, J.B., Shleifer, A., Summers, L.H., Waldman, R.J., 1990. Positive feedback investment strategies anddestabilising rational speculation. Journal of Finance 45 (2), 379–396.
Donaldson, R.G., 1990. International evidence on psychological barriers in asset prices and the efficient markethypothesis, Financial Research Centre Memorandum No. 116, Woodrow Wilson School, Princeton University.
Donaldson, R.G., Kim, H.Y., 1993. Price barriers in the Dow Jones Industrial Average. Journal of Financial andQuantitative Analysis 28 (3), 313–330.
Engle, R.F., Bollerslev, T., 1986. Modelling the persistence of conditional variances. Econometric Reviews 5 (1),1–50.
Fazio, R.H., Chen, J.M., McDonel, E.C., Sherman, S.J., 1982. Attitude accessibility, attitude behavior consistency,and the strength of the object evaluation association. Journal of Experimental Social Psychology 18 (4),339–357.
Flood, R.P., Garber, P.M., 1991. The linkage between speculative attack and target zone models of exchange rates.Quarterly Journal of Economics 106 (4), 1367–1372.
Gann, W.D., 1930. Truth of the stock tape and Wall Street stock selector. Financial Guardian Publishing Co, NewYork.
Goodhart, C.A.E., Curcio, R., 1991. The clustering of bid/ask prices and the spread in the foreign exchange market.Discussion Paper No. 110, London School of Economics Financial Markets Group.
Grossman, S.J., Miller, M.H., Cone, K.R., Fischel, D.R., Ross, D.J., 1997. Clustering and competition. Journal ofLaw and Economics 40 (1), 23–60.
Gwilym, O.A., Claire, A., Thomas, S., 1998a. Extreme price clustering in the London equity index futures andoptions market. Journal of Banking and Finance 22 (9), 1193–1206.
Gwilym, O.A., Claire, A., Thomas, S., 1998b. Price clustering and bid-ask spreads in international bond futures.Journal of International Financial Markets Institutions and Money 8 (3/4), 377–391.
Hameed, A., Terry, E., 1998. The effect of tick size on price clustering and trading volume. Journal of BusinessFinance and Accounting 25 (7&8), 849–867.
Harris, L., 1991. Stock price clustering and discreteness. The Review of Financial Studies 4 (3), 389–415.Hornik, J., Cherian, J., Zakay, D., 1994. The influence of prototypic values on the validity of studies using time
estimates. Journal of the Market Research Society 36 (2), 145–147.Kahn, C., Pennacchi, B., Sopranzetti, B., 1999. Bank deposit rate clustering: theory and empirical evidence. Journal
of Finance 54 (6), 2185–2214.Kandel, S., Sarig, O., Wohl, A., 2001. Do investors prefer round stock prices? Evidence from Israeli IPO auctions.
Journal of Banking and Finance 25 (8), 1543–1551.Koedijk, K.G., Stork, P.A., 1994. Should we care? Psychological barriers in stock markets. Economics Letters 44
(4), 427–432.

344 J. Mitchell, H.Y. Izan / Int. Fin. Markets, Inst. and Money 16 (2006) 318–344
Krugman, P.R., 1991. Target zones and exchange rate dynamics. Quarterly Journal of Economics 106 (3), 669–682.Krugman, P.R., Obstfeld, M., 1991. International Economics Theory and Policy, second ed. Harper Collins, New
York.Lalor, P.A., Easton, S.A., 1997. An empirical evaluation of the psychological barriers hypothesis of security
pricing. Working Paper Department of Accounting and Finance, University of Newcastle.Ley, E., 1996. On the peculiar distribution of the U.S. stock indexes’ digits. The American Statistician 50 (4),
311–313.Ley, E., Varian, H.L., 1994. Are there psychological barriers in the Dow-Jones Index? Applied Financial Economics
4 (3), 217–224.Loomes, G., 1988. Different experimental procedures for obtaining valuations of risky actions: Implications for
utility theory. Theory and Decision 25 (1), 1–23.Mitchell, J.D., 1998. Clustering and psychological barriers in Australian dollar exchange rates. Ph.D. thesis,
University of Western Australia.Mitchell, J.D., 2001. Clustering and psychological barriers: the importance of numbers. Journal of Futures Markets
21 (5), 395–428.Mitchell, J.D., Izan, H.Y., 2001. Behavioural and psychological factors in financial markets. Accounting Research
Journal 14 (2), 149–171.Niederhoffer, V., 1965. Clustering of stock prices. Operations Research 13 (2), 258–265.Niederhoffer, V., 1966. A new look at clustering of stock prices. Journal of Business 39 (2), 309–313.Niederhoffer, V., Osborne, M., 1966. Market making and reversals on the stock exchange. Journal of the American
Statistical Association 61 (316), 897–916.Osborne, M.F., 1962. Periodic structure in the Brownian motion of stock prices. Operations Research 10 (3),
345–379.Pagan, A., 1996. The econometrics of financial markets. Journal of Empirical Finance 3 (1), 15–102.Palmon, O., Smith, B.A., Sopranzetti, B.J., 2004. Clustering in real estate prices: determinants and consequences.
The Journal of Real Estate Research 26 (2), 115–136.Pesenti, P., 1990. Perforate and imperforate currency bands. Unpublished Yale University Manuscript, Yale Uni-
versity.Preece, D.A., 1981. Distribution of the final digits in data. The Statistician 30 (1), 31–60.Schelling, T.C., 1960. The Strategy of Conflict. Harvard University Press, Cambridge Massachusetts.Sopranzetti, B.J., Datar, V., 2002. Price clustering in the foreign exchange spot markets. Journal of Financial
Markets 5 (4), 411–417.Sugden, R., 1995. A theory of focal points. The Economic Journal 105 (530), 533–550.Takayanagi, S., Cliff, N., Fidler, P., 1995. Redundant leading and following zeros in comparative numerical
judgement. Perceptual and Motor Skills 80 (3PtI), 819–829.Thaler, R., 1992. The winners’ curse: paradoxes and anomalies of recent life. In: A Russell Sage Foundation Book.
Maxwell Macmillan International, New York.Tschoegl, A.E., 1988. The source and consequences of stop orders: a conjecture. Managerial and Decision Eco-
nomics 9 (1), 83–85.Tversky, A., Kahneman, D., 1973. Availability: a heuristic for judging frequency and probability. Cognitive
Psychology 5 (2), 207–232.Tversky, A., Kahneman, D., 1974. Judgement under uncertainty: heuristics and biases. Science 185 (4157),
1124–1131.Wyckoff, P., 1963. The Psychology of Stock Market Timing. Prentice Hall Inc., Englewood Cliffs, NJ.Yule, G.U., 1927. On reading a scale. Journal of the Royal Statistical Society 90 (3), 570–579.Zellner, A., Siow, A., 1980. Posterior odds ratios for selected regression hypotheses. In: Bernardo, J.M., DeGroot,
M.H., Lindley, D.V., Smith, A.F.M. (Eds.), Bayesian Statistics: Proceeds of the First International Meeting.Valencia (Spain), 28 May to 2 June 1979. University Press, Valencia, Spain, pp. 585–603.
Ziemba, W.T., Brumelle, S.L., Gautier, A., Schwartz, S.L., 1986. Dr. Z’s 6/49 Lotto Guidebook. Dr. Z InvestmentsInc., Vancouver and Los Angeles.