Embed Size (px)
DESCRIPTION
Exploiting Dynamic Resource Allocation forEfficient Parallel Data Processing in the Cloud
Citation preview

PARALLEL DATA PROCESSING IN THE CLOUD

• In recent years parallel data processing has emerged to be one of the
important applications for Infrastructure-as-a-Service (IaaS) clouds.
• Major Cloud computing companies have started to integrate frameworks for
parallel data processing in their product portfolio, making it easy for
customers to access these services and to deploy their programs.
• Examples are Google’s MapReduce ,Microsoft’s Dryad,or Yahoo!’s Map-
Reduce-merge
• The most modern framework used commonly is Nepheles framework.
• The main goal of our project is to decrease the overloads of the main cloud
and increase the performance of the cloud by using this Nephele’s
framework.
INTRODUCTION

• Today a growing number of companies have to process huge amounts of data
in a coefficient manner. Classic representatives for these companies are
operators of Internet search engines, like Google, Yahoo, or Microsoft.
• The vast amount of data they have to deal with every day has made
traditional database solutions prohibitively expensive.
• Cloud computing has emerged as a promising approach by using
frameworks.
• Current data processing frameworks like Google’s MapReduce or
Microsoft’s Dryad engine have been designed for cluster environments.
EXISTING SYSTEM

• The processing frameworks which are currently used have been
designed for static, homogeneous cluster setups and disregard the
particular nature of a cloud.
• The problem with these frameworks is that the resource allocation
when large jobs are submitted is not efficient as they take more time for
processing besides incurring more cost.
disadvantages of existing systems are:
• Expensive
• Complex
• Increases data base organization
• extra overload on cloud
• More time consuming for processing.
• problem providing in maintenance and hard to troubleshoot.

• The system as a whole is designed to overcome the major weaknesses of
Map/Reduce
• Here we use a new framework called Nephele
• Nephele is the first data processing framework to explicitly exploit the
dynamic resource allocation offered by today's IaaS clouds for both, task
scheduling and execution.
• Based on this new framework, we perform extended evaluations of
MapReduce-inspired processing cloud system.
• We present a parallel data processor centered around a programming model of
so called Parallelization Contracts (PACTs) and the scalable parallel execution
engine Nephele.
PROSOSED SYSTEM

• The PACT programming model is a generalization of the well-known
map/reduce programming model, extending it with further second-order
functions, as well as with Output Contracts that give guarantees about the
behavior of a function.
• Our definition of PACTs allows applying several types of optimizations on
the data flow during the transformation.
• Using this requirements in this paper we asigning the all job of the main
cloud to job manager,it divide the whole task and forward them to task
manager.
• We are adding some additional features in this project, that is We are
providing a facility that a user can access other user’s data if he has the right
to do.
• At the same time a message will be send to the users mobile.

• Task manager process the tasks and store in the cloud. Like this we can reduce
the work load and increase the performance of the cloud
• We can use this concept in big cloud like Amazon or IBM as their service
The advantages of proposed systems are as follows:
• Dynamic resource allocation
• Parallelism is implemented
• Designed to run data analysis jobs on a large amount of data
• Many Task Computing (MTC) has been developed
• Less expensive
• More effective
• More Faster
• Access to others data.
.

LITERATURE SURVEY
Title:
Map Reduce: Simplified Data Processing on Large Clusters
Author:
Jeffrey Dean and Sanjay Ghemawat
Description:
• Map Reduce is an approach that helps us perform cluster computing.
• MapReduce Is a programing model for processing large data sets wit
a parallel, distributed algorithm on a cluster
• MapReduce has four phases: map,combine,shuttle and sort,reduce.
.

"Map" step: The master node takes the input, divides it into smaller sub-
problems, and distributes them to worker nodes. A worker node may do this
again in turn, leading to a multi-level tree structure. The worker node processes
the smaller problem, and passes the answer back to its master node
"Reduce" step: The master node then collects the answers to all the sub-
problems and combines them in some way to form the output – the answer to
the problem it was originally trying to solve.
Map(k1,v1) → list(k2,v2)
Reduce(k2, list (v2)) → list(v3)
All values with same key are reduced together

• map() functions run in parallel, creating different intermediate values
from different input data sets
• reduce() functions also run in parallel, each working on a different output
key
• All values are processed independently
Implementations:
At Google: Index construction for Google Search Article clustering for Google News Statistical machine translationAt Yahoo!: “Web map” powering Yahoo! Search Spam detection for Yahoo! MailAt Facebook: Data mining Ad optimization

Advantages
• This approach has several advantages, namely:
• low initial cost, and ease of maintenance (through cheap replacement of faulty
machines).
• Fault-tolerant
• Automatic parallelization & distribution
• Provides status and monitoring tools
• Clean abstraction for programmers
• Simple and easy to use.
• Flexible.
• Independent of the storage.

Disadvantages
• no high level language.
• reduce phase can’t start until map phase is completely finished.
• A single fixed dataflow.
• Low efficiency.
• Restrictive semantics
• Pipelining Map/Reduce stages possibly inefficient
• Missing common DBMS utilities and features
• Transactions, updates, integrity constraints, views, …
• Incompatible with DBMS tools
• Complex values, more serialization/deserialization overhead.
• More complex memory management. As value maps may grow too big, the
approach has potential for scalability bottleneck.

• Cluster computing itself can be defined as the use of large number of low end
machines to form a cluster, instead of a smaller number of high end machines
• although their purpose in the MapReduce framework is not the same as their
original forms. Furthermore, the key contribution of the MapReduce
framework are not the actual map and reduce functions,
• Provided each mapping operation is independent of the others, all maps can be
performed in parallel – though in practice it is limited by the number of
independent data sources and/or the number of CPUs near each source
• Google has now outgrown it, The main reason behind it is map reduce was
hindering their ability to provide near real time updates to their index. next
phase of operations cant start until you finish the first. If you want to build a
system that's based on series of map-reduces, there's a certain probability that
something will go wrong, and this gets larger as you increase the number of
operations

Title:
Dryad: Distributed Data-Parallel Programs from Sequential
Building Blocks
Author:
M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly.
Description:
• Dryad is Microsoft's alternative to MapReduce.
• Program specification isdone by building a Direct Acyclic Graph (DAG)
whose vertexes are operationsnand whose edges are data channels.
• An application written for Dryad is modeled as a directed acyclic
graph (DAG).
• The DAG defines the dataflow of the application, and the vertices of the
graph defines the operations that are to be performed on the data.

• Dryad is a general-purpose distributed execution engine forcoarse-grain data-parallel
applications
• 2 main components of Dryad is:
Job manager – coordinates jobs, constructs graph
Name server – exposes computers with network topology
• Dryad is what people see as “map reduce done right”.
• Dryad’s authors are claiming that they are able to to handle more general cases and
to keep a good performance Besides allowing several inputs/outputs sets , Dryad
allow runtime optimization such as aggregation .
• The approach offered by Dryad is pretty simple, you need to represent the flow of
execution of programs in the form of a graph .Job manager schedules vertices on
machines

Advantages
• Much more general than Map Reduce
• Greedy algorithm is used
• Vertices are deterministic, and graph is acyclic, so manager can easily restart
• Runtime manager can reschedule vertices for better locality
• Graphs manually constructed, Jobs executed on vertices,Edges represent data
channels
• More efficient communication,the ability to chain together multiple stages,and
express more complicated computation.
• DryadLINQ offers a higher-level computational model where complex
sequence of MapReduce steps can be easily expressed in a query language
similar to SQL.
• More control to developer than MapReduce
• Choose data transport mechanism (files, TCP pipes, shared memory FIFOs)

Disadvantages
• Can be used only in Cluster environments.
• Globally the cost of licensing both Windows servers (DryadLINQ was meant
for Windows servers) and DryadLINQ compared to Unix servers and Hadoop
(Free software developed by Apache) is a significantly higher.
• The lack of a real distributed file system. In short, in order to support large
inputs, Dryad need to create a graph for virtual nodes and the
communication is done via local write/distant read
• Graphs manually constructed
• Dryad is not a database engine; it does not include a query planner or optimizer
• No way of defining dynamic graphs.

Title:
Nephele/PACTs: A Programming Model and Execution Framework for Web-
Scale Analytical Processing
Author:
Dominic Odej Kao ,Battré Stephan Volker Markl, Ewen Fabian Hueske
Daniel Warneke
Description:
• A parallel data processor centered around a programming model of so
called Parallelization Contracts (PACTs) and the scalable parallel execution
engine Nephele .

• The PACT programming model is a generalization of the well-known
map/reduce programming model, extending it with further second-order
functions, as well as withOutput Contracts that give guarantees about the
behavior of a func- tion.
• We describe methods to transform a PACT program into a data flow for
Nephele, which executes its sequential building blocks in parallel and deals
with communication, synchronization and fault tolerance.
• The system as a whole is designed to be as generic as map/reduce systems,
while overcoming several of their major weaknesses:

• The paper describes the PACT programming model for the Nephele system.
The PACT programming model extends the concepts from map/reduce, but is
applicable to more complex operations.This paper provide the methods to
compile PACT programs to parallel data flows for the Nephele system, which
is a flexible execution engine for parallel data flows .
Programming Model
• The PACTs are second-order functions that define properties on the input and
output data of their associated first-order functions .
• The system utilizes these properties to parallelize the execution of the user
function(UF) and apply optimization rules.
• Here, the type of the second-order function is referred as the Input Contract.
The properties of the output data are described by an attached Output
Contract.

Input Contract
• It define how the input data is organized into subsets that can be processed
independently and hence in a data parallel fashion by independent
instances of the UF.
Output Contract
• It denote some properties on the UF’s output data. Output Contracts are
attached to the second-order function by the programmer.
• They describe additional semantic infor- mation of the UFs, which is
exploited for optimization in order to generate e cient parallel data flowsffi .

Comparison between Map/Reduce and PACT programming
• PACT programming model add additional functions that fit many problems
which are not naturally expressible as a map or reduce function.
• In Map/Reduce systems like Hadoop , the programming model and the
execution model are tightly coupled – each job is executed with a static plan
that follows the steps map/combine/shu e/sort/reduce.ffl
• In contrast, PACT system separates the programming model and the
execution and uses a compiler to generate the execution plan from the
program. For several of the new PACTs multiple parallelization strategies are
available.
• Map/Reduce loses all semantic information from the application, except the
information that a function is either a map or a reduce.
• PACT model preserves more semantic information through both a larger set
of functions and through the annotations.
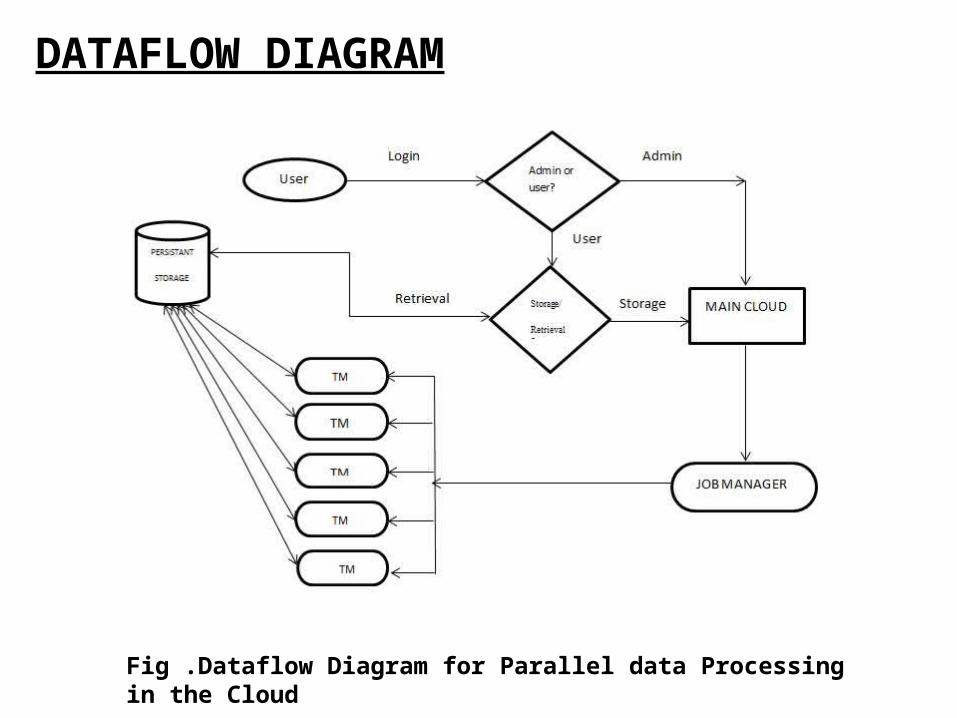
Fig .Dataflow Diagram for Parallel data Processing in the Cloud
DATAFLOW DIAGRAM

CONCLUSION
• In this paper we have discussed the challenges and opportunities for efficient
parallel data processing in cloud environments and presented Nephele, the
first data processing framework to exploit the dynamic resource provisioning
offered by today’s IaaS clouds.
• Cloud computing has emerged as a promising approach by using frameworks.
• The processing frameworks which are currently used have been designed for
static, homogeneous cluster setups and disregard the particular nature of a
cloud.
• The main goal of our project is to decrease the overloads of the main cloud
and increase the performance of the cloud.
• So we have implemented Nephele’s architecture

• The system as a whole is designed to overcome the major weaknesses of
Map/Reduce
• Nephele is the first data processing framework to explicitly exploit the
dynamic resource allocation offered by today's IaaS clouds for both, task
scheduling and execution.