Embed Size (px)
Citation preview

Clauselets: Leveraging Temporally Related Actions for Video Event Analysis
Hyungtae Lee Vlad I. Morariu Larry S. Davis∗
University of Maryland, College Park, MD, USAhtlee,morariu,[email protected]
Abstract
We propose clauselets, sets of concurrent actions andtheir temporal relationships, and explore their applicationto video event analysis. We train clauselets in two stages.We initially train first level clauselet detectors that finda limited set of actions in particular qualitative temporalconfigurations based on Allen’s interval relations. In thesecond stage, we apply the first level detectors to trainingvideos, and discriminatively learn temporal patterns be-tween activations that involve more actions over longer du-rations and lead to improved second level clauselet models.We demonstrate the utility of clauselets by applying themto the task of “in-the-wild” video event recognition on theTRECVID MED 11 dataset. Not only do clauselets achievestate-of-the-art results on this task, but qualitative resultssuggest that they may also lead to semantically meaningfuldescriptions of videos in terms of detected actions and theirtemporal relationships.
1. IntroductionWe are living in a world where it is easy to acquire videos
of events ranging from private picnics to public concerts,and to share them publicly via websites such as YouTube.The ability of smart-phones to create these videos and up-load them to the internet has led to an explosion of videodata, which in turn has led to interesting research directionsinvolving the analysis of “in-the-wild” videos. Recent ap-proaches to processing these types of videos use featuresthat range from low- to mid-level, some even using featuresthat directly correspond to words that describe portions ofthe videos [20]. While all of these approaches obtain com-petitive results on benchmark datasets, mid-level features
∗This work is supported by the Intelligence Advanced ResearchProjects Activity (IARPA) via the Department of Interior National Busi-ness Center contract number D11PC20071. The U.S. Government is au-thorized to reproduce and distribute reprints for Governmental purposesnot with standing any copyright annotation thereon. The views and con-clusions contained herein are those of the authors and should not be in-terpreted as necessarily representing the official policies or endorsements,either expressed or implied, of IARPA, DoI/NBC, or the U.S. Government.
low-level actions temporal relationslow-level actions temporal relationswalking kissing
marching
before meet
overlap
contain
startfinish
equal
kissing during dancingmarching . . .
marching
taking pictures
cut a cake and then hug
and then dance with a kiss
marchtake
pictures
Wedding ceremony
taking pictures
taking pictures
cutting cake. . .
dancing
kissing during dancing
cutting cake
hugging
1st level
clauselet
2nd level
clauselet
complex
event
video
ground
truth label
Figure 1. The illustration of our approach for describing the com-plex event video (wedding ceremony) with two level clauselets de-fined by relevant actions and temporal relationships. (e.g. cut acake and then hug and then dance with a kiss) Ground truth la-bels contain potentially concurrent actions in particular temporalrelationships. Given a video, 1st level clauselets search for rele-vant labels with the video. 2nd level clauselets group concurrentand consistent labels using coarse temporal relationships (wordscolored by red).
that can also describe the semantic content of a video aredesirable since they can be used to describe the video usinglanguage as well as to recognize events.
The detection of visual patterns that directly correspondto individual semantically meaningful actions is practicaleven in “in-the-wild” videos, as shown by recent works on

benchmark datasets. Izadinia and Shah [9] model the jointrelationship between two actions for recognizing high-levelevent. While pairs of actions capture more information thansingle actions alone, valuable information from higher orderinteractions remains unused. Ma et al. [15] introduce visualattributes that combine human actions with scenes, objects,and people for exploring mutual influence and mining extrainformation from them. Various approaches jointly modelmore than two local object or action detections. Bag-of-words (BOW) is a simple but still competitive video rep-resentation, which is formed by collecting local detectionsand generating a histogram by quantizing the feature space.Spatial-temporal pyramids collect local detections from dif-ferent spatial and temporal resolutions of a video. Vari-ous graphical structures to model relations of local detec-tions also exist. (e.g. HMMs [3], Dynamic Bayesian Net-works [24], prototype trees [11], AND-OR graphs [23],latent SVM [22], Sum-Product Network [4], and MarkovLogic Networks [16]). The key advantage of graphicalstructures is that they model the dependence of actions bylocal relationships while allowing for the joint optimizationof a global task-dependent objective function. Our goal isto design a mid-level representation that builds on previ-ous low- and mid-level representations, but which is ableto capture higher order relationships between actions oversmall spatio-temporal neighborhoods without the full useof graphical structures.
We rely on temporal relationships to capture the contextbetween actions and provide a richer description of a videothan each independent action alone. We define a clauselet asa conjunction of actions that are reliably detected in “in-the-wild” videos and their temporal relationships. We apply thisdefinition hierarchically at two levels of granularity, first todetect short sequences involving a limited number of actionlabels, and then to relate these detected sequences to eachother over larger time spans and more actions. Given a setof clauselets, we scan the test video, and use the detectedclauselet activations to vote for each clauselet’s dominantevent. We show our approach in figure 1. First, videos aresplit into clips which are annotated with one or more con-current actions per clip. Then, 1st level clauselets detectshort actions patterns (e.g. taking pictures, marches, kissingduring dancing etc.) that occur during an event (“weddingceremony” in the example). Finally, 2nd level clauseletsare formed modeling the temporal relationships between 1st
level clauselets and other 1st level clauselets that cooccurtemporally to create a richer and more discriminative de-scription of the video (e.g. cut a cake and then hug andthen dance with a kiss).
Our contributions are that we:
1. Introduce temporal relationships between actions andgroups of actions for richer video description (1st/2nd
level clauselet)
2. Propose a discriminative training process that automat-ically discovers action patterns and temporal relation-ships between them
As our experiments demonstrate, these contributions leadto improvements over state-of-the-art approaches to eventclassification.
In section 2, we discuss related works. In section 3 andsection 4, we describe details of 1st and 2nd level clause-lets and event recognition, respectively. In section 5, wepresent the experimental results that demonstrate the per-formance of our approach on “in-the-wild” videos from theTRECVID dataset [1]. We present our concluding remarksin section 6.
2. Related WorkWe divide recent related work into three groups: low-
level approaches that improve video features that captureshape and motion information, mid-level approaches thatmodel patterns in low-level features with varying degrees oftop-down supervision, and high-level approaches that applyhigh-level prior knowledge to low- and mid-level observa-tions.
Low-level representations are constructed from local fea-tures including SIFT [14], Dollar et al. [7], ISA [13],STIP [12] as well as global features including GIST [18].Low-level features alone yield competitive performance,however, they do not leverage task dependent informationand higher order relationships.
Mid-level representations add task-dependent informa-tion to extract more informative patterns from low-level fea-tures. Amer and Todorovic [4] train a sum-product net-work representing human activities by variable space-timearrangements of primitive actions. Jain et al. [10] intro-duce mid-level spatio-temporal patches that discriminatebetween primitive human actions, a semantic object. Songet al. [21] learn hidden spatio-temporal dynamics from ob-servations by CRFs with latent variables and, in the testphase, group observations that have similar semantic mean-ing in some latent space.
High-level modeling combines or organizes low- or mid-level detections based on a knowledge base (KB). Nevatiaet al. [17] define an event ontology that allows natural repre-sentation of complex spatio-temporal events common in thephysical world by a composition of simpler events. Brendelet al. [6] combine the probabilistic event logic (PEL) KBwith detections of primitive events for representing tempo-ral constraints among events. Morariu and Davis [16] usethe rules that agent must follow while performing activi-ties for multi-agent event recognition. We note that in high-level recognition task, the KB is generally used to reducefalse positives of low-level detections by providing spatial-temporal constraints.

Our proposed representation, the clauselet is a mid-leveldetector that bridges the gap between the low- and high-level task. Clauselets share many of the benefits of pose-lets [5] which are detectors trained to detect patches thatare tightly clustered in both appearance and pose space, forthe purpose of detecting people and their parts. However,in our case, clauselets are tightly clustered in temporal rela-tionships and video appearance, and our goal is to constructvisual event descriptions. Similar to poselets [5] we alsorescore clauselet activations by mutually consistent activa-tions, and find that this greatly improves performance.
3. ClauseletsMotivated by the intuition that the temporal relationships
between multiple concurrent actions are important for eventmodeling, we propose a mid-level representation involvingmultiple actions and their temporal relationships. We definea clauselet as a conjunction of reliably detected actions andtheir temporal relationships. We apply this intuition hier-archically at two levels of granularity, first to detect shortsequences involving a limited number of action labels (1st
level clauselets), and then to relate these detected sequencesto each other over larger time spans and more actions (2nd
level clauselets).
3.1. 1st level clauselets
3.1.1 Model
A 1st level clauselet models sequences containing one ortwo actions in particular temporal relationships. We use the7 base relations of Allen’s interval logic [2] as the 1st leveltemporal relationships: before, meet, overlap, start, con-tain, finish, and equal. Figure 2 (a) shows the definition ofthe 7 relations. In our experiments, meet is not used sinceit is too rigid to capture relations among actions annotatedat a relatively large granularity (10 seconds per clip in ourexperiments).
A video is split into n clips, t1, · · · , tn, and each clipt is represented by a standard set of features concatenatedinto a feature vector f(t) (see sec 5.1). A 1st level clauseletc model consists of k blocks bi for i = 1, . . . , k, each ofwhich must be matched to a video clip. Each block has anassociated weight vector wc,i which is used to score eachvalid configuration T = (T1, . . . , Tk) that matches everyblock bi to a clip index Ti ∈ {1, . . . , n} as follows:
Sc,T =
k∑i=1
wc,if(tTi). (1)
A configuration T is considered valid if it satisfies a setof temporal deformation rules, i.e., T ∈ {T1:k|T1 ∈{1, · · · , n}, Ti−1 ≤ Ti ≤ Ti−1 + 2, i = 2, · · · , k}. Thesetemporal deformations between blocks are similar to the
before(X, Y) X
YX takes place before Y
overlap(X, Y) X
YX overlaps with Y
start(X, Y) X
YX starts Y
contain(X, Y) X
YX contains Y
finish(X, Y) X
YX finishes Y
equal(X, Y) X
YX is equal to Y
meet(X, Y) X
YX meets Y
1st temporal
relationshipsIllustration Interpretation
(a)
T
F
T
F
F
T
F
T
a1
a2
b1 b2 b3 b4
T
F
T
T
T
T
F
T
a1
a2
T
F
T
T
T
T
T
F
a1
a2
T
T
T
T
T
T
T
T
a1
a2
D
F
T
T
D
T
F
T
a1
a2
F
T
D
T
T
T
D
F
a1
a2
before(a1, a2) overlap(a1, a2) start(a1, a2)
contain(a1, a2) equal(a1, a2)finish(a1, a2)
T T T Ta
c1 c2 c3 c4
T : ai is annotated during clip matched to block bj
F : ai is not annotated during clip matched to block bj
D : don`t care
1 label clauselet
2 label clauselet
b1 b2 b3 b4 b1 b2 b3 b4
b1 b2 b3 b4 b1 b2 b3 b4 b1 b2 b3 b4
(b)Figure 2. 1st level temporal relationships: (a) Allen’s intervallogic [2], (b) temporal templates used for searching positive ex-amples by matching to ground truth annotations; here we use 1st
level clauselets of length k=4 blocks (each block is matched to aclip).
spatial deformations of parts in a Deformable Part Model(DPM) [8], although we do not apply a deformation penaltyas long as a configuration is valid. Eq. 1 can be evaluatedusing a recursive matching process, where given an initialstarting clip T1 to which the first block of the clauselet c ismatched, the next block is matched to either T1, T1 + 1, orT1 + 2, and so on. This process allows the k blocks of aclauselet to span 1 to 2k − 1 clips. A configuration T ofclauselet c is called an activation if Sc,T ≥ λs, where λs isthe activation threshold.
3.1.2 Training
The training process requires a set of videos whose clipsare each annotated with a subset of zero, one, or moregroundtruth action labels from a large vocabulary. Because1st level clauselets are intended to detect an action or pair ofactions in particular temporal configurations, we define a setof temporal templates that are matched to groundtruth video
t1 t2 t3 t4 tn
. . .
{a2} {a4} {a2 ,a4}{a4} { }
clip
action labels
Input video
True if a4 is labeled in the clip t3
(don`t care a2 label)
according to b3 of template
D T D F
F T T T
a2
a4
b1 b2 b3 b4
Template of
start(a2, a4)T F F F ... T
F F T F ... F
F F T T ... F
F F F T ... F
b1
b2
b3
b4
t1 t2 t3 t4 tn
True if a2 is not labeled and
a4 is labeled in the clip t4
according to b4 of template
[t1 t3 t3 t4]
[t1 t3 t4 t4]
...
Configurations of
positive sample
Truth matrix – does bi match tj?
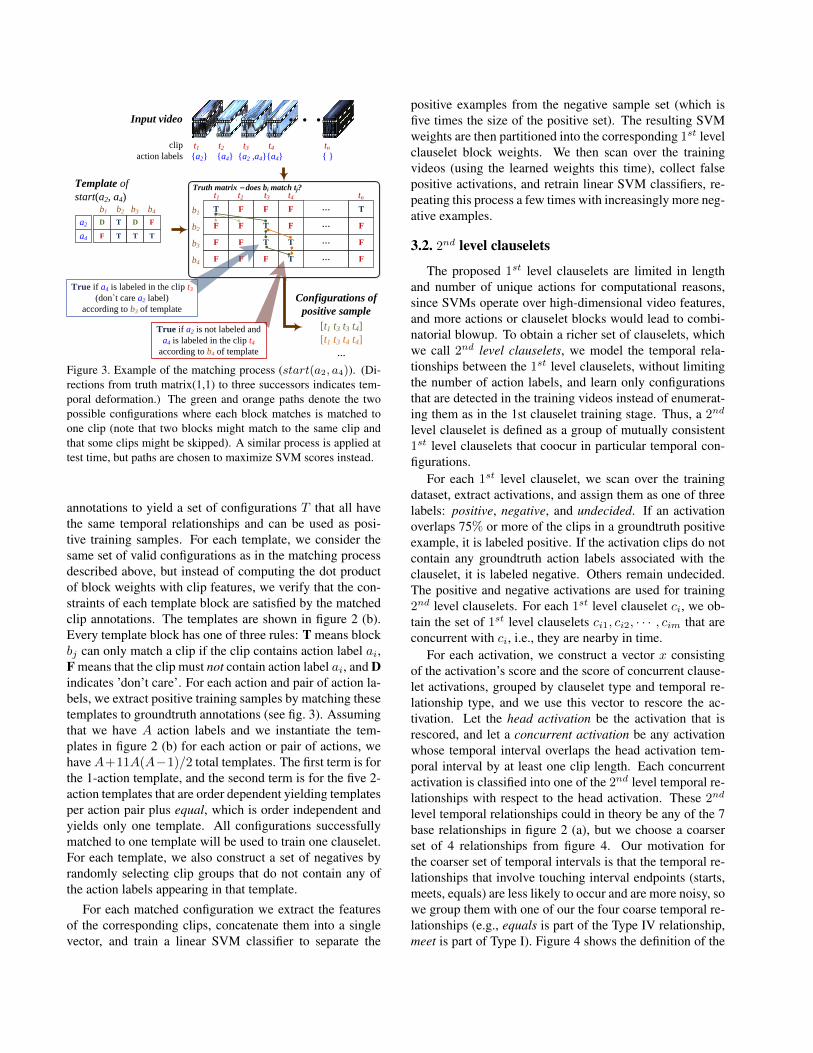
Figure 3. Example of the matching process (start(a2, a4)). (Di-rections from truth matrix(1,1) to three successors indicates tem-poral deformation.) The green and orange paths denote the twopossible configurations where each block matches is matched toone clip (note that two blocks might match to the same clip andthat some clips might be skipped). A similar process is applied attest time, but paths are chosen to maximize SVM scores instead.
annotations to yield a set of configurations T that all havethe same temporal relationships and can be used as posi-tive training samples. For each template, we consider thesame set of valid configurations as in the matching processdescribed above, but instead of computing the dot productof block weights with clip features, we verify that the con-straints of each template block are satisfied by the matchedclip annotations. The templates are shown in figure 2 (b).Every template block has one of three rules: T means blockbj can only match a clip if the clip contains action label ai,F means that the clip must not contain action label ai, and Dindicates ’don’t care’. For each action and pair of action la-bels, we extract positive training samples by matching thesetemplates to groundtruth annotations (see fig. 3). Assumingthat we have A action labels and we instantiate the tem-plates in figure 2 (b) for each action or pair of actions, wehaveA+11A(A−1)/2 total templates. The first term is forthe 1-action template, and the second term is for the five 2-action templates that are order dependent yielding templatesper action pair plus equal, which is order independent andyields only one template. All configurations successfullymatched to one template will be used to train one clauselet.For each template, we also construct a set of negatives byrandomly selecting clip groups that do not contain any ofthe action labels appearing in that template.
For each matched configuration we extract the featuresof the corresponding clips, concatenate them into a singlevector, and train a linear SVM classifier to separate the
positive examples from the negative sample set (which isfive times the size of the positive set). The resulting SVMweights are then partitioned into the corresponding 1st levelclauselet block weights. We then scan over the trainingvideos (using the learned weights this time), collect falsepositive activations, and retrain linear SVM classifiers, re-peating this process a few times with increasingly more neg-ative examples.
3.2. 2nd level clauselets
The proposed 1st level clauselets are limited in lengthand number of unique actions for computational reasons,since SVMs operate over high-dimensional video features,and more actions or clauselet blocks would lead to combi-natorial blowup. To obtain a richer set of clauselets, whichwe call 2nd level clauselets, we model the temporal rela-tionships between the 1st level clauselets, without limitingthe number of action labels, and learn only configurationsthat are detected in the training videos instead of enumerat-ing them as in the 1st clauselet training stage. Thus, a 2nd
level clauselet is defined as a group of mutually consistent1st level clauselets that coocur in particular temporal con-figurations.
For each 1st level clauselet, we scan over the trainingdataset, extract activations, and assign them as one of threelabels: positive, negative, and undecided. If an activationoverlaps 75% or more of the clips in a groundtruth positiveexample, it is labeled positive. If the activation clips do notcontain any groundtruth action labels associated with theclauselet, it is labeled negative. Others remain undecided.The positive and negative activations are used for training2nd level clauselets. For each 1st level clauselet ci, we ob-tain the set of 1st level clauselets ci1, ci2, · · · , cim that areconcurrent with ci, i.e., they are nearby in time.
For each activation, we construct a vector x consistingof the activation’s score and the score of concurrent clause-let activations, grouped by clauselet type and temporal re-lationship type, and we use this vector to rescore the ac-tivation. Let the head activation be the activation that isrescored, and let a concurrent activation be any activationwhose temporal interval overlaps the head activation tem-poral interval by at least one clip length. Each concurrentactivation is classified into one of the 2nd level temporal re-lationships with respect to the head activation. These 2nd
level temporal relationships could in theory be any of the 7base relationships in figure 2 (a), but we choose a coarserset of 4 relationships from figure 4. Our motivation forthe coarser set of temporal intervals is that the temporal re-lationships that involve touching interval endpoints (starts,meets, equals) are less likely to occur and are more noisy, sowe group them with one of our the four coarse temporal re-lationships (e.g., equals is part of the Type IV relationship,meet is part of Type I). Figure 4 shows the definition of the

si ei
si ei
si ei
si ei
Type I
Type II
Type III
Type IV
2nd
temporal
relations
True
False
True
False
False
True
True
False
Before start index
si < s
After end index
ei > es e
Figure 4. Definition and illustration of 2nd temporal relationships
4 types of 2nd level temporal relationships. The vector xis constructed by placing the head activation score as thefirst feature, and then for each clauselet and each 2nd leveltemporal relation, we add a feature equal to the maximumscore of each activation of that clauselet (i.e., we use max-pooling if there are multiple activations of the same clause-let and temporal relation type). The total vector length is4n+ 1, where 4 corresponds to the number of temporal re-lationships, n is a total number of trained clauselet models,and the 1 corresponds to the head activation. This activa-tion vector is treated as a feature vector for rescoring thehead activation.
The rescoring function is defined as
fws,S(x) = wTs Sx, (2)
where x ∈ R4n+1 is the input activation vector, S ∈Rm×(4n+1),m ≤ 4n + 1 is a subset matrix which selectsm of the 4n + 1 scores in x and is formed by selecting theappropriate rows of the identity matrix I4n+1. The weightvector ws ∈ Rm is a vector that determines how the scoresof selected activations are combined linearly to rescore thehead activation. S and ws are optimized by minimizing theobjective function below:
LD(ws, S) =1
2wT
s ws + C
n∑i=1
max(0, 1− yifws,S(xi)).
(3)The objective function is the same to that of linear SVMmodel except for the score function in the hinge loss. Weuse a coordinate descent approach to minimize the objectivefunction as
1. Weight learning: optimize LD(ws, S) over ws bylearning linear SVM weights with subset of activationvector Sx
2. Subset selection: optimize LD(ws, S) over S by se-lecting subset of features to minimize the hinge loss ofLD(ws, S).
The subset matrix S selects from among the concurrent ac-tivations only those that are mutually consistent (i.e. thosethat add to the score of the head activation), and the weightvector ws decides how much weight each mutually consis-tent activation adds to the score of the head activation.
4. Event RecognitionWe expect that clauselets will serve as useful building
blocks for complex high-level reasoning (e.g., in probabilis-tic logical frameworks such as [2, 3]). However, to bestisolate their contribution and demonstrate their utility, weemploy a simple voting strategy where each clauselet ac-tivation votes for its predominant event class. Not all 1st
level clauselet templates lead to a trained clauselet model,because of insufficient training examples. Also, not all ofthe clauselet models that are trained cast a vote for an event,because they are not sufficiently predictive of a set of events.For this purpose, we find clauselets that achieve high recalland precision, defined as follows:
• precision(e, c): ratio of all activations of clauselet cthat occur during events of class e
• recall(e, c): ratio of all instances of event class e con-taining at least one activation of clauselet c
A precision threshold is used to choose clauselets domi-nant in a certain event while a recall threshold is used toavoid overfitting to a few positive samples during training.Table 1 shows the number of clauselets used or discarded invoting according to the precision criterion. To avoid multi-ple votes by activations of the same type that are temporallyclose, we use non-maximum suppression, removing activa-tions if they overlap temporally more than 50% with one ormore activations with higher score. While not all 1st levelclauselets that are trained cast a vote for event recognition,all successfully trained 1st level clauselets are used for con-text rescoring in 2nd level clauselets.
1 label 1 label 2 label 2 label(used (not used (used (not usedin voting) in voting) in voting) in voting)
# of clets 87 6 372 17
Table 1. Number of 1st level clauselets
5. Experiments5.1. Dataset and parameter setting
We evaluate clauselet based voting event recognition onthe TRECVID MED 11 dataset [1] containing 15 complexevents. Each event category contains at least 111 videoswhose duration varies from several seconds to longer than10 minutes. Following [9], we split every video into 10second clips and annotate 123 action labels in each clip.We represent each clip by the 6 features used in [9]: ISA(Independent Subspace Analysis) [13], STIP [12], Dollar etal. [7], GIST [18], SIFT [14], and MFCC (Mel-FrequencyCepstral Coefficient) [19]. For all features, histogram-basedclip representations are generated via bag-of-visual words(BOVW).
We also follow the evaluation setting of [9] that ran-domly splits the dataset into training and test set by a ratioof 0.7. We re-split the training dataset into two sets with aratio of 0.7 for training 1st level and 2nd level clauselets,respectively.
We compute precision and recall of the trained clause-lets, and then empirically set their thresholds to 0.5 and 0.1,respectively, to ensure enough clauselets are trained andselected for voting. We also set the number of clauseletblocks to 4 in order to limit computational complexity andto extract sufficiently many positive examples for training(templates become more specific and rare as the number ofblocks increases). We set λs to -0.5 to detect sufficient truepositives.
5.2. Detection performance
We evaluate our detection performance and compare 1st
and 2nd level clauselets while evaluating the boost obtainedby adding 2-label clauselets to 1-label clauselets. Based onprecision and recall, 93 action alone (out of 123) and 359pairs of actions and their particular temporal relationships(out of 82533) are selected as 1-label and 2-label clauseletsfor the evaluation, respectively. The distribution of tempo-ral relationships used in 2-label clauselets is given in table 2.Before is understandably dominant but number of other re-lationships seems to be large enough to be useful for de-scribing video.
Temporalbefore overlap start contain finish equalrelations
# 180 25 57 34 61 32
Table 2. Number of interval relations
Table 3 compares the detection performance of 1st and2nd level clauselets (note that we are evaluating the abilityof the clauselet detector to find the intended action pattern,not to perform event recognition). To confirm the utilityof mutually consistent subset selection and temporal rela-tionship binning 2nd level clauselets, we evaluate 2nd levelclauselets in three ways: (i) rescoring by collecting all con-current activations and without differentiating them basedon temporal relationships (second row in table 3), (ii) ap-plying the feature selection scheme to group concurrent andconsistent activations, ignoring irrelevant activations (thirdrow in table 3), and (iii) our proposed approach of applyingboth feature selection and coarse temporal relationships inrescoring (last row in table 3).
Our experiments confirm two things based on table 3.First, 2 label 1st level clauselets are more accurate detec-tors than 1 label 1st level clauselet (i.e., they are more ef-fective at finding the corresponding ground truth patterns ofaction labels). This is consistent with the trend in computervision where detectors of more complex pattern tend to
1 label 1&2 label
1st level clauselet 0.1497 0.16132nd level clauselet
0.1637 0.1906w/o selection matrix S & tempo. relation2nd level clauselet
0.1638 0.1913w/o temporal relationships2nd level clauselet 0.1703 0.1915
Table 3. Comparison of detection performance of 1st and 2nd levelclauselets. We report the Average Precision (AP) of all clauselets,evaluated against the ground truth action patterns that the clause-lets are intended to detect.
1 label 1&2 label
1st level clauselet 0.3893 0.46512nd level clauselet
0.4016 0.6596w/o selection matrix S & tempo. relation2nd level clauselet
0.4068 0.6641w/o selection matrix S
2nd level clauselet 0.4371 0.6730
Table 4. Mean of average precision (mAP) on the event recognitiontask, obtained via the our proposed voting scheme.
have fewer false positives. Second, exploiting consistencyamong concurrent activations and selecting subset featuresto maximize the discriminability seems to increase the de-tection performance of the clauselets. We note that 2nd levelclauselets provide the more descriptive analysis with com-parable detection performance, since multiple actions arerelated to each other temporally.
5.3. Performance in recognizing complex events
We evaluate the voting based event recognition perfor-mance of our model and also compare the proposed clause-lets against our baseline including 1st level clauselets and2nd level clauselets, excluding various components of ourproposed approach such as coarse temporal relationshipsand feature selection, in order to evaluate the impact ofeach of the components of our approach. Table 4 showsevent recognition performances of our models. Votes byrelevant clauselet activations to a particular event are usedto compute a mean of average precision (mAP) of theevent. Table 4 shows that recognition performance is di-rectly related to clauselet detection performance. We notethat the rescoring scheme alone achieves state-of-the-artperformance (0.6639). By additionally including our pro-posed mutually consistent clauselet selection and temporalrelationships we are able to obtain a richer description ofthe video employing various temporal relationships as wellas outperform the state-of-the-art on the event recognitiontask.
We also compare the recognition performance of ourproposed approach against that of the state-of-the-art ineach event category. Table 5 compares the performance of

Event [9] [20] clauselets
Boarding trick 0.7570 0.8402 0.9133Feeding animal 0.5650 0.4595 0.5472Landing fish 0.7220 0.6593 0.4902Wedding ceremony 0.6750 0.7871 0.5696Woodworking project 0.6530 0.3568 0.5241Birthday party 0.7820 0.9008 0.9005Changing tire 0.4770 0.5012 0.6901Flash mob 0.9190 0.9240 0.8392Vehicle unstuck 0.6910 0.6173 0.9019Grooming animal 0.5100 0.5415 0.6464Making sandwich 0.4190 0.5704 0.6978Parade 0.7240 0.7335 0.5469Parkour 0.6640 0.6144 0.5543Repairing appliance 0.7820 0.7840 0.7329Sewing project 0.5750 0.6688 0.5402
mean 0.6610 0.6639 0.6730
Table 5. Comparison of clauselets against two baselines.
our approach against two baselines: [9] and [20].Figure 5 shows examples of 1st and 2nd level clause-
let activations in some events for a qualitative evaluation.In this figure, we manually describe the video using theautomatically obtained clauselet activations to show thatclauselets are also useful for video event description as wellas for event recognition. Note that false positives of 1st
level clauselet activations (e.g. taking pictures in an eventwoodworking project.) are removed by the 2nd levelclauselet.
6. Conclusion
We proposed a new mid-level representation, a clause-let, that consists of a group of actions and their temporalrelationships. We presented a training process that initiallytrains first level clauselets in a top-down fashion, and thenlearns more discriminative 2nd level clauselets models us-ing 1st level activations that are consistent with each modeland occur in particular temporal configurations. We haveshown that the 2nd level clauselets improve over the 1st
level clauselets, that they benefit from the automatic selec-tion of which clauselets are “mutually consistent” (i.e., areassigned a non-zero weight in the model), that temporal re-lationships are important for both levels, and that our finalmodel outperforms state-of-the-art recognition techniqueson “in-the-wild” data when used in a simple voting scheme.Qualitative results show that clauselets are not only usefulfor event recognition, but the detected first and second levelclauselets provide semantically meaningful descriptions ofthe video in terms of which actions occurred when with re-spect to each other.
References[1] Trecvid multimedia event detection track, 2011.[2] J. F. Allen and G. Ferguson. Actions and events in interval
temporal logic. Jour. of Logic and Computation, 1994.[3] M. Amer and S. Todorvic. A chains model for localizing
group activities in videos. In ICCV, 2011.[4] M. R. Amer and S. Todorovic. Sub-product networs for mod-
eling activities with stochastic structure. In CVPR, 2012.[5] L. Bourdev, S. Maji, T. Brox, and J. Malik. Detecting peo-
ple using mutually consistent poselet activations. In ECCV,2010.
[6] W. Brendel, A. Fern, and S. Todorovic. Probabilistic eventlogic for interval-based event recognition. In CVPR, 2011.
[7] P. Dollar, V. Raboud, G. Cotterell, and S. Belongie. Behav-ior recognition via sparse spatio-temporal features. In IEEEInternational Workshop on VS-PETS, 2005.
[8] P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ra-manan. Object detection with discriminatively trained partbased models. PAMI, 32(9), 2010.
[9] H. Izadinia and M. Shah. Recognizing complex events usinglarge margin joint low-level event model. In ECCV, 2012.
[10] A. Jain, A. Gupta, M. Rodriquez, and L. S. Davis. Represent-ing videos using mid-level discriminative patches. In CVPR,2013.
[11] Z. Jiang, Z. Lin, and L. S. Davis. Recognizing humanactions by learning and matching shape-motion prototypetrees. PAMI, 34(3), 2012.
[12] I. Laptev. On space time interest points. IJCV, 2005.[13] Q. Le, W. Zou, S. Yeung, and A. Ng. Learning hierarchical
invariant spatio-temporal features for action recognition withindependent subspace analysis. In CVPR, 2011.
[14] D. Lowe. Distinctive image featrues from scale-invariantkeypoints. IJCV, 60(2), 2004.
[15] Z. Ma, Y. Yang, Z. Xu, S. Yan, N. Sebe, and A. G. Haupt-mann. Complex event detection via multi-source video at-tributes. In CVPR, 2013.
[16] V. I. Morariu and L. S. Davis. Multi-agent event recognitionin structured scenarios. In CVPR, 2011.
[17] R. Nevatia, T. Zhao, and S. Hongeng. Hierarchical language-based representation of events in video streams. In CVPR,2003.
[18] A. Oliva and A. Torralba. Modeling the shape of the scene:A holistic representation of the spatial envelope. IJCV, 42,2001.
[19] L. Rabiner and B. Juang. Fundamentals of Speech Recogni-tion. Prentice Hall, 1993.
[20] V. Ramanathan, P. Liang, and L. Fei-Fei. Video event un-derstanding using natural language descriptions. In ICCV,2013.
[21] Y. Song, L.-P. Morency, and R. Davis. Action recognition byhierarchical sequence summarization. In CVPR, 2013.
[22] K. Tang, L. Fei-Fei, and D. Koller. Learning latent temporalstructure for complex event detection. In CVPR, 2012.
[23] K. Tang, B. Yao, L. Fei-Fei, and D. Koller. Combining theright features for complex event recognition. In ICCV, 2013.
[24] Z. Zeng and Q. Ji. Knowledge based activity recognitionwith dynamic bayesian network. In ECCV, 2010.

Dancing in unison. Performing play. Clapping. Lurching a pole. Reeling in is before holding objects.
Playing instrument. Yelling starts clapping. Dancing in unison is before clapping.
Dancing in unison (head clauselet) Performing play. (type II)
Yelling starts clapping. (type II) Dancing in unison is before clapping. (type II)
People dance in unison and then perform a play. Spectators yell and clap after watching their dance and performance.
Marching. Squatting down. Flipping the board. Singing in unison. Marching contains playing instrument.
Dancing in unison equals marching. Fitting bolts. Marching equals playing instrument.
Marching (head clauselet) Marching. (type II) Squatting down. (type II)
Marching contains playing instrument. (type II) Dancing in unison equals marching. (type I)
People dance in unison and march. Then they play instruments during marching. Someone squats down.
Cutting wood. Taking pictures. Speaking. Shaping wood. Smoothing/sanding wood. Hammering.
Speaking is before shaping wood. Speaking equals holding objects.
Cutting wood (head clauselet) Speaking. (type III) Shaping wood. (type I) Shaping wood. (type II) Shaping wood. (type III)
Cutting wood. (type I) Cutting wood. (type II) Cutting wood. (type III)
Person cut and shape wood. Then speaking what he is doing.
Speaking. Speaking contains unscrewing parts. Speaking is before holding objects. Speaking overlaps pointing to the object.
Speaking start pointing to the object. Unscrewing parts finishes speaking. Speaking starts unscrewing parts.
Speaking is before holding objects. (head clauselet) Speaking overlaps pointing to the object. (type IV)
Speaking start pointing to the object. (type II) Unscrewing parts finishes speaking. (type II)
Person speaks while pointing to an object and then holds the object. After speaking, he unscrews parts from the obejct.
1st level
clauselet
2nd level
clauselet
Description
Flash mob
1st level
clauselet
2nd level
clauselet
Description
Parade
1st level
clauselet
2nd level
clauselet
Description
Woodworking
project
Repairing
appliance
1st level
clauselet
2nd level
clauselet
Description
Figure 5. Example activations of 1st and 2nd clauselets automatically detected for some events in TRECVID MED11 dataset. Videodescriptions are manually written to emphasize the utility of clauselets for the description task (few additional words/phrases need to beadded to form sentences from the detected clauselets). Bold activations in a list of 1st level clauselet activations are used to rescore thehead clauselet of each 2nd level clauselet. In a list of 2nd clauselet activations, a temporal relationship type of each concurrent activationtoward head clauselet is depicted beside the activation. In the parade event, gray words denote the wrong description due to a falsepositive 2nd level clauselet.





























