Embed Size (px)
Citation preview

���
Chapter XXIXHybrid Data Mining for Medical
ApplicationsSyed Zahid Hassan
Central Queensland University, Australia
Brijesh VermaCentral Queensland University, Australia
Copyright © 2009, IGI Global, distributing in print or electronic forms without written permission of IGI Global is prohibited.
AbstrAct
This chapter focuses on hybrid data mining algorithms and their use in medical applications. It reviews existing data mining algorithms and presents a novel hybrid data mining approach, which takes advantage of intelligent and statistical modeling of data mining algorithms to extract meaningful patterns from medical data repositories. Various hybrid combinations of data mining algorithms are formulated and tested on a benchmark medical database. The chapter includes the experimental results with existing and new hybrid approaches to demonstrate the superiority of hybrid data mining algorithms over standard algorithms.
INtrODUctION
In the last few decades, medical disciplines have become increasingly data-intensive. The advances in digital technology have led to an unprecedented growth in the size, complexity, and quantity of collected data, that is, medical reports and associated images. According to Damien McAullay (Damien, Graham, Jie, & Huidong, 2005), “there are 5.7 million hospitals admissions, 210 million doctor’s visits, and a similar number of prescribed medicines dispensed in Australia annually” (p. 381). All re-cords are captured electronically. There are billions of healthcare records transaction that occur world wide every year.
On the other hand, patient-centered medical ap-plications (e.g., electronic patient records, personal health record, electronic medical records, etc.) are also on the verge of becoming practical, further increasing data growth and leading to a data-rich but information-poor healthcare system. Thus, it has become crucial for data mining researchers to investigate and propose a novel approach that can appropriately utilize such valuable data to provide useful evidence as a basis for future medical prac-tice. The paramount important factor is to utilize the collected data that suit specific and useful purposes which leads to enable the discovery of new “knowledge’’ that provides insights to assists

���
Hybrid Data Mining for Medical Applications
healthcare analyst and policy makers to make stra-tegic decisions and predict future consequences by taking into account the actual outcomes of current operative values.
In addition, the world health organization (Gul-binat, 1997) identifies some possible needs for the discovery of knowledge from medical data reposi-tories; this includes, but is not limited to, medical diagnosis and prognosis, patient health planning and development, healthcare system monitoring and evaluation, health planning and resource al-location, hospital and health services management, epidemiological and clinical research, and disease prevention.
Lately, this abundance of healthcare data has resulted in a large number of concerted efforts to inductively discover “useful” knowledge from the collected data, and indeed interesting results have been reported by many researchers. How-ever, despite the noted efficacy of the knowledge discovery method—known as data mining (DM) algorithm—the challenge facing healthcare practi-tioners today is about data usability and impact, that is, the use of “appropriate” data mining algorithms with the right data to discover value-added “action-oriented” knowledge in terms of data-mediated decision-support services.
Notably, recent advances in data mining algo-rithms such as neural networks (NN), statistical modeling, evolutionary algorithms, and visualiza-tion tools have made it possible to transform any kind of raw data into high level knowledge. However, the main problem is that each method has its own approach to deal with data structure, shape, and validity. This limitation affects the performance of classification systems. Consequently, the need of a hybrid data mining approach is widely recognized by the data mining community (George, & Derek, 2004, p. 151). The number of hybrid data mining endeavours has been initiated all over the globe. The limitations associated with many existing hybrid approaches are: (1) most of the existing approaches either heavily dependant on intelligent methods or statistical methods, barely ensembled to take the
advantage of both computations, that is, intelligent and statistical; and most importantly (2), existing approaches generally do not utilize the data for “secondary purposes,” such as organisation plan-ning, decision making, forecasting, outcomes and trending, and so forth.
To this end, we argue that there is a need for a hybrid DM approach which is an effective combination of various DM techniques, in order to utilize the strengths of each individual technique and compensate for each other’s weaknesses. The aim of this chapter is to present current state-of-art data mining algorithms and their applications and propose a new hybrid data mining approach for clustering and classification of medical data. This chapter aims to further explore the data mining intel-ligent and statistical machine learning techniques, including supervised and unsupervised learning techniques as well as some effective conventional techniques and systems commonly used in the medical domain.
rEVIEW OF ExIstING DAtA MINING ALGOrItHMs
In this section we discuss the theoretical and technical aspects of data mining and machine learning techniques, data mining algorithms, hy-brid approaches, and their applications in medical domain.
Data Mining and Machine Learning
There is some confusion about the terms data mining and knowledge discovery in databases (KDD). Often these two terms are used interchangeably (Fayyad, Piatetsky-Shapiro, Smyth, & Uthurusamy, 1997, p. 154). The term KDD can be denoted to overall process of turning low-level data into high-level knowledge, whereas data mining can be defined as the extraction of useful patterns from the raw data.
The data mining step usually takes a small part of overall KDD process. More specifically, data

���
Hybrid Data Mining for Medical Applications
mining is not a single technique; it deploys various machine learning algorithms and any technique that can help to procure information out of the massive data is useful. Different algorithms serve different purposes; each algorithm offers its own advantages and disadvantages. However, the most commonly used methods for data mining are based on neural networks, decision trees, a-priori, regressions, k-means, Bayesian networks, and so forth.
Before analyzing which machine learning (ML) technique works best for which problem domain and situations, it is important to have a good un-derstanding of what machine learning is all about. ML is one of the disciplines of the AI research that deploys a variety of probability, statistical, and op-timizations tools to learn from past data/examples and use that prior learning to classify new data and identify new trends in data (Fayyad et al., 1997, p. 154). Beside heavily dependent on statistics, ML techniques also employ Boolean logic (AND, OR, NOT), absolute conditional (IF, THEN, ELSE), conditional probabilities (the probability of X given Y), and unconventional optimization strategies to model data or classify patterns. This provides ML with inference and decision making capabilities which cannot be achieved by using conventional statistical methods.
There are generally three types of machine learning techniques (Fayyad et al., 1997): 1) su-pervised learning, 2) unsupervised learning, and 3) reinforcement learning. In supervised learning, a ML algorithm is provided with a labeled set of training data/example. These labeled data assist the algorithm to map the input data with the desired out-put data. In unsupervised learning, a ML algorithm is provided with set of training data/example only (without classes) and leaves the algorithm to learn and discover the similar patterns. Reinforcement learning (RL) is learning from interaction with an environment, from the consequence of actions, rather than from explicit supervision.
ML algorithms have been incorporated in DM systems for knowledge discovery and decision-making purposes. The choice and success of any
particular algorithm is heavily dependent on the good understanding of the problem domain, quality of data sets, and the properly designed experiments. However, not all ML algorithms are created equal, some are better for certain kinds of problems while others are better for other kind of problems. Thus, it is always recommended to try more than one ML algorithm on any given training set. A com-mon problem associated with the failure of any ML algorithm is called “curse of dimensionality” (Fayyad et al., 1997), which occurs when too many variables and too few data sets are used to train the algorithm. A general rule is to reduce the number of variables (features) and increase the number of training samples. The sample-per-feature ratio should always exceed 5:1 (Fayyad et al., 1997). Over training is also an important issue as over trained algorithm tends to produce ambiguous classifica-tion (poor results).
Data Mining tasks
The overall data mining process can roughly be classified into five mains tasks (Fayyad, & Shapiro, 1996): clustering, classification, association, predic-tion, and visualization.
Given a set of data items, the clustering algo-rithms partition this set into a set of classes such that items with similar characteristics are grouped together. Clustering is best suited for finding groups of items that are similar in properties. For example, a doctor chain could mine patient diagnostic data to determine how often the patient has been smoking cigarettes and what treatment should be given to the patient.
Given a set of predefined classes, classifier algorithms determine to which of these classes a specific data item belongs to. For example, given classes of patients that correspond to medical treat-ment responses, the algorithms identify the form of treatment to which a new patient is most likely to respond.
Given a set of data items, the association algo-rithms identify relationships between attributes and

���
Hybrid Data Mining for Medical Applications
items such that the presence of one pattern implies the presence of another pattern. These relations may be associations between attributes within the same data item (e.g., out of the patients who has heart problem, 90% also has cholesterol disease) or associations between different data items (e.g., every time a certain budget drops 5%, a certain other budget raises 13% between 6 and 12 months later). One may discover the set of symptoms often occurring together with certain kinds of diseases and this can lead to further study on the reason behinds them.
Given a data item and a predictive model, the prediction algorithms predict the value for a specific attribute of the data item. For example, patient billing information can be predicted by the length of the patient stay in the hospital and treatment provided to the patient or vice versa. Prediction can also be used to validate a discovered hypothesis.
The visualization model plays an important role in making the discovered knowledge understand-able by humans. The visualization techniques may range from simple scatter plots to histogram plots over parallel to two dimension coordinates. DM algorithm can be coupled with a visualization tool that aids users in understanding the discovered knowledge. These coupling of DM algorithms and visualization algorithms provides added value. For instance, the result of the neural network classifier can be displayed using a network visualizer. A simple decision tree model can be displayed and manipulated using a tree visualizer.
Intelligent (Neural Network-based) Data Mining Algorithms
The intelligent data mining algorithms based on neural networks, also known as symbolic machine learning techniques, provide a different approach of data analysis and knowledge discovery from pure statistical methods. These algorithms, which are different in computation and behaviors, have shown promising capabilities for analyzing quali-tative, symbolic, quantitative, and numeric data.
The most commonly used intelligent data mining algorithms are discussed below with their strengths and limitations.
Data Mining Using back Propagation Neural Network (bPNN)
Early development of neural networks gathered prominent attraction in the past decade (Maria-Luiza, Zaïane, & Coman, 2001, p. 94). Neural networks were originally designed to model the way the brain works with multiple neurons being interconnected to each other through multiple axon junctions. Neural networks use multiple layers (i.e., input, hidden, and output layers) to process their inputs and generate outputs. The inputs can be continuous/discrete, numerical/categorical values. The information learned by a neural network is stored in the form of a weight matrix (Аndreeva, Dimitrova, & Radeva, 2004, p. 148). The informa-tion stored inside the weights consists of real-valued numbers and therefore neural network computing can be classified as a symbolic type of processing. The various types of neural networks such as feed forward, multilayer perceptron, and so forth have been proposed. The neural networks based on back propagation algorithm are the most popular and widely used neural networks for their unique learn-ing capability (Michael, Patrick, Kamal, & David, 1994, p. 106). Back propagation neural networks are fully connected, layered, feed-forward models. Activations flow from the input layer through the hidden layer, then to the output layer.
The strength of back propagation neural net-works for data mining lies on its ability to perform a range of statistical (i.e., linear, logistic, and non-linear regression) and logical operations or infer-ences (i.e., AND, OR, XOR, NOT, IF-THEN) as part of the classification process. Other dominant strengths of NN include (Michael et al., 1994, p. 106): they are capable of handling a wide range of classification or pattern recognition problems and they represent compact knowledge in the form of weights and threshold values. They can also oper-

���
Hybrid Data Mining for Medical Applications
ate with noisy or missing data and can generalize quite well to similar unseen data.
The main challenge in using neural networks is its input-output mapping, that is, how the real-world input/output (for instance image, a physical charac-teristic, a list of medical problems, and a prognosis) can be mapped to a numeric vector. There are other common limitations (Michael et al., 1994, p. 106). They are considered as a “black-box” technology; the network structure can only be determined by experimentation which requires lengthy training times and may not necessarily reach to an optimal solution. The use of random weights initializations may lead to unwanted solutions. Neural network topology design is empirical, and that several at-tempts to develop an acceptable model may be necessary. NN have limited explanation facility which may prevent their use in certain applications. They are also difficult to understand as comprising of complex structure. Moreover, too many attributes can result in over fitting.
Some of the applications of BPNN with their performances in medical domain are listed in Chart 1.
Data Mining Using self Organization Map (sOM)
SOM is an unsupervised learning algorithm which includes such methods as self-organizing feature maps (SOFMs), hierarchical clustering, and k-means data mining algorithms to create clusters from raw, unlabeled, or unclassified data (Thiemjarus, Lo, Laerhoven, & Yang, 2004, p. 52). These clusters
can be used later to develop classification schemes or classifiers.
SOM is generally used to represent (visual-ize) high-dimensional unsupervised data (feature space) into low-dimensional data (feature space), yet preserving the graphical properties of the input patterns. In SOM, each input unit is connected to the each output (in a feed forward manner) through weight values. A SOM begins with a set of input units (neurons), random weights matrix, nearest neighborhood radius, output units, and map dimen-sion (width and heights). The patterns are presented to each input nodes and are calculated (generally using Euclidean distance) with the weighted values of the output unit. The output node whose weights vector closest to the input pattern is considered as the winner (Husin-Chuan, Ching-Hsue, & Jing-Rong, 2007, p. 499). When this node wins a competi-tion, all the output units who fall in the region of defined neighborhood radius are considered as the neighbors of the wining unit. The entire neighbors unit modifies their weight with respect to wining unit weights values to form a cluster. The process repeats for each input pattern for a large number of repetitions until the SOM is capable of associating output nodes with specific groups or patterns in the input data set.
There are major advantages of SOM (Sakthias-eelan, Cheah, & Selvakumar, 2005, p. 336). They are very simple in operation and easy to understand. They not only classify data accurately but are also easy to evaluate and analyze how good the maps are and how strong the similarities among the features. The basic limitation associated with SOM is getting
Reference Application Performance
BPNN (Maria-Luiza, Zaïane, & Coman, 2001)
Tumor Detection 81% Accuracy
BPNN (Аndreeva, Dimitrova, & Radeva, 2004)
Breast Cancer 97.89% Accuracy
BPNN (Michael, Patrick, Kamal, & David, 1994)
Breast Cancer 74% Accuracy
Chart 1. The performance of BPNN in medical domain

���
Hybrid Data Mining for Medical Applications
the right data, that is, a value for each feature from the training set is required in order to generate a map. Sometimes this problem leads towards highly misclassified data; this problem is also referred as missing data.
Some of the applications of self-organizing map with their performances in medical domain are listed in Chart 2.
statistical Data Mining Algorithms
A number of statistical data mining algorithms has been developed and used in solving many real world data mining problems. These algorithms are used to examine quantitative data for the purposes of classification, clustering/association, hypothesis testing, trend analysis, and correlation between variables. These analysis techniques often rely on probabilistic assumptions and conditions, and complex mathematical functions. In the following subsections we provide an overview of some of the existing, yet advanced and widely used, data mining algorithms in detail.
support Vector Machine (sVM)
A SVM is somewhat a new emerging machine learning technique and received prominent attention in the recent years (Zheng & Kazunobu, 2006, p. 389). They use supervised learning techniques for the classification and regression problems. The SVM algorithm creates a hyperplane, which is a subset of the points of the two classes, which is referred to as a support vector. This hyperplane separates the
data into two classes with the maximum geometry margin, meaning that the distance between the hy-perplane and the closest data sample is maximized; this helps to minimize the empirical classification errors. SVMs can be used to perform nonlinear classification using what is called a nonlinear kernel. A nonlinear kernel is a mathematical function that transforms the data from a linear feature space to a nonlinear feature space. Like NNs, a SVM can be used in a wide range of pattern recognition and classification problems, spanning from handwriting analysis, speech and text recognition, and protein function prediction to medical diagnosis problem (Zheng, & Kazunobu, 2006, p. 389).
The benefits of a SVM include (Zheng, & Ka-zunobu, 2006, p. 389) the models’ nonlinear class boundaries, computational complexity reduced to quadratic optimization problem, over fitting is unlikely to occur, and easy to control complexity of decision rule and frequency of error. On the other hand, the major limitations associated with a SVM include: training is slow compared to Bayes clas-sifier and decision trees, it is difficult to determine optimal parameters when training data are not linearly separable, and the difficult to understand structure of an algorithm.
Some of the applications of support vector ma-chine with their performances in medical domain are listed below.
Decision trees (Dt)
Decision tree is a special form of tree structure (flow chart or graphical diagram) that is generated
Reference Application Performance
SOM (Thiemjarus, Lo, Laerhoven, & Yang, 2004)
Body Sensor Network 71-88% Accuracy
SOM (Husin-Chuan, Ching-Hsue, & Jing-Rong, 2007)
Cardiovascular Disease 98% Accuracy
SOM (Sakthiaseelan, Cheah, & Selvaku-mar, 2005)
Breast Cancer 98.89% Accuracy
Chart 2. The performance of SOM in medical domain

���
Hybrid Data Mining for Medical Applications
by a classifier system in order to evaluate associ-ated patterns (Lim, Loh, & Shih, 1997). The tree is structured in a way that represents sequence of problems or tasks. The solution associated to each problem is represented along the path down the tree, whereby the root of the tree determines the classification or prediction made by the clas-sifier. The tree can be used to represent all sorts of complex problems and patterns relation in the data sets. The decision trees can either be designed through consultation with experts or can automati-cally be generated by providing labeled data sets (Lim et al., 1997). A decision tree generally learns by randomly splitting the data into subsets based on a numerical or logical test. This process repeats in recursive manner until splitting stops and final classification is achieved.
The strengths of DTs are that they are simple to understand and interpret and require little data preparation (Lim et al., 1997). They can also deal with many kinds of data including numeric, nomi-nal (named), and categorical data. DT-generated models are easy to learn and can be validated us-ing various statistical tests. However, DTs do not generally perform as well as NN in more complex classification problems.
A disadvantage of this approach is that there will always be information loss, because a decision tree selects one specific attribute for partitioning at each stage with a single starting point. The decision tree can present one set of outcomes, but not more than one set, as there is a single starting point. Therefore, decision trees are suited for data sets where there is one clear attribute to start with. Small errors in a training data set can also lead to very complex decision trees.
The decision tree model can be designed by using various data mining analytical tools such as CHi-squared automatic interaction detector (CHAID), C4.5, ID3, and classification and regression trees (CART) (Lim et al., 1997). Bearing both classifica-tion and regression processing methods, CART is recognized as one of the most powerful approaches to design, test, and use advanced mathematically-
based decision trees. The hierarchical representation of CART models also enable users to understand and interact with tree-based finding easily. The main advantage of CART over other above-mentioned models is that it offers superior speed and ease-of-use and automatically provides insight into data and produces highly accurate, intelligible predictive models. The application for a CART algorithm in designing a healthcare predictive model is ranging from healthcare to nursing domain, such as CART used as a technique to recognize critical situations derived from specific laboratory results, quality, and safety issues of healthcare delivery and identifica-tion of nursing diagnosis.
Some of the applications of decision trees with their performances in medical domain are listed in Chart 3.
k-Means
k-Means is an unsupervised machine learning al-gorithm that partitions the data based on maximum interclass distance and minimum intraclass distance among the data/object (Abidi & Hoe, 2002, p. 50). More specifically, a k-means algorithm clusters the data based on attributes into k partitions, where k is a predefined number of clusters (Abidi & Hoe, 2002, p. 50). The algorithm starts by portioning (either randomly or heuristically) the input points into k initial sets and then calculates the mean point of each set. It constructs a new partition by associat-ing data-entities to one of the K clusters. Then the means are recalculated for the new clusters, for each data-record compares the distance-measure to each of the K cluster-centers and associates the record to the closest cluster. The algorithm is repeated until convergence is achieved, which is obtained when the mean points are no longer changed (Abidi & Hoe, 2002, p. 50).
A basic variation of the k-means algorithm are the “K-modes” algorithms (Derek, Alexey, Nadia, & Cunningham, 2004, p. 576), the choice of which variant should be used depends on the nature of data. If the distance function is defined based on

��0
Hybrid Data Mining for Medical Applications
continuous data, the k-means algorithm is sufficient whereas for nominal distance function, the k-mode is a better choice.
There are advantages of using k-means (Derek et al., 2004, p. 576). It is the fastest clustering al-gorithm and consumes the least memory and the algorithm can be run several times to achieve the best clustering.
The main drawback of the algorithm is that it requires predefined information regarding the number of clusters (i.e., k) to be found prior to start processing (Derek et al., 2004, p. 576). If the data are not naturally clustered or the data size is quite large, the classification accuracy is always a question.
Some of the applications of K-means with their performances in medical domain are listed in Chart 4.
K-Nearest Neighbor (k-NN)
The working of K-NN is quite similar as SOM as the input patterns are mapped into multidimen-sional output feature space (Zeng, Tu, Liu, Huang, Pianfetti, Roth, et al., 2007, p. 424). This output space is partitioned into regions with respect to class labels of the data patterns. When new data
are presented for prediction, the distance (usually uses Euclidean distance) between K and similar records in the data set is found and the most simi-lar neighbors are identified. The nearest neighbor method matches patterns between different samples of data with the given class. The class is identified as the nearest neighbor of k when it is predicted to be the class of the closest training sample (Zeng et al., 2007, p. 424).
In terms of strength, the algorithm is easy to implement, but it is computationally intensive, especially when the size of the training set grows. The main advantages of k-NN includes (Zeng et al., 2007, p. 424) fast classification of instances, it useful for nonlinear classification problems, it is robust with respect to irrelevant or novel attributes, it is tolerant of noisy instances or instances with missing attribute values, and it can be used for both regression and classification.
This method sometimes retains a small portion of the complete data sets to compare with the given class. This not only causes memory wastage but also sometimes leads to inaccuracies in the final result (Zeng et al., 2007, p. 424). The nearest neighbor ap-proach is also more suited to numeric values rather than non-numeric data. The accuracy of the k-NN algorithm is also subject to the dimension/scale
Reference Application Performance
SVM (Аndreeva, Dimitrova, & Radeva, 2004)
Breast Cancer 98.74% Accuracy
SVM (Аndreeva, Dimitrova, & Radeva, 2004)
Diabetics 76.34% Accuracy
SVM (Zheng, & Kazunobu, 2006) Brain Tumor 88-95% Accuracy
Chart 3. The performance of SVM in medical domain
Reference Application Performance
k-Means (Abidi & Hoe, 2002) Breast Cancer 96.1% Accuracy
k-Means (Derek et al, 2004) Diabetics 67.5 Accuracy
k-Means (Derek et al, 2004) Thyroid 79% Accuracy
Chart 4. The performance of k-Means in medical domain

���
Hybrid Data Mining for Medical Applications
of the features and noisy or irrelevant features. Other limitations include (Zizhen & Walter, 2006, p. 11): it is slower to update a concept description neighbor and it makes the wrong assumption that instances with similar attributes will have similar classifications and attributes and will be equally relevant and too computationally complex as the number of attributes increases.
Some of the applications of k-NN with their performances in medical domain are listed in Chart 5.
Naive bayes
The naive bayes (NB) is a probabilistic classifier (Langley, Iba, & Thompson, 1992, p. 223). The Bayes classifier greatly simplifies learning by as-suming that features are independent to a given class. Although, independence is generally a poor assumption which often has no bearing in realities, hence, it is deliberately naive. However, in practice, naive Bayes often competes well with more sophis-ticated classifiers.
Bayes classifiers are based on probability mod-els which can be derived by using Bayes theorem, maximum like hood method (for parameters estima-tions), or Bayesian inference (Langley et al., 1992, p. 223). In a supervised learning environment and depending on the nature of its probability model, a Bayes classifier can be trained very efficiently. Naive Bayes reaches its best performance in two opposite cases: completely independent features and functionally dependent features. Naive Bayes has its worst performance between these extremes. The
accuracy of naive Bayes is not directly correlated with the degree of feature dependencies measured as the class conditional mutual information between the features. Instead, a better predictor of naive Bayes accuracy is the amount of information about the class that is lost because of the independence assumption (Langley et al., 1992, p. 223).
There are some main advantages of the naive Bayes classifiers (Langley et al., 1992, p. 223). Their foundation is based on statistical modeling. They are easy to understand and are efficient training algorithms. The order of training instances has no effect on training which make them useful across multiple domains. In terms of limitations (Langley et al., 1992, p. 223), NB assumptions that are at-tributes are statistically independent and numeric attributes are distributed normally. In NB, redun-dant attributes and class frequencies can mislead classification and affect accuracy
Some of the applications of naive bayes with their performances in medical domain are listed Chart 6.
Hybrid Data Mining systems
Various hybrid approaches have been proposed, implemented, and tested for different application domains (Dounias, 2003). Neural network and fuzzy logic-based hybrid models have been widely reported in the literature (Dounias, 2003). The model presented by Clarke and Wei (1998, p. 3384) focuses on an integration of the merits of neural and fuzzy approaches to build intelligent decision-making systems. It has the benefits of both “neural networks” like massive parallelism, robustness, and learning
Reference Application Performance
K-NN (Zeng et al, 2007) Predicting Protein Structure 75.53% Accuracy
K-NN(Zizhen, et al, 2006) Gene Function Prediction 52% Accuracy
K-NN (Rajkumar, Ognen, & Dong, 2005)
Audio-Video Emotion Recognition 95.57% Accuracy
Chart 5. The performance of K-NN in medical domain

���
Hybrid Data Mining for Medical Applications
in data-rich environments, and “fuzzy logic,” which deals with the modeling of imprecise and qualitative knowledge in natural/linguistic terms as well as the transmission of uncertainty. This hybrid approach has shown a high rate of success when applied in various complex domains of medical applications. For example, Clark and Wei (1998, p. 3384) present a neural fuzzy approach to measure radiotracers in vivo. In this application, fuzzy logic is the core part of the system, which deals with the modeling of imprecise knowledge (image degradation) due to the photon scattering through the collimated gamma rays.
The neural networks and evolutionary algorithms (NN-EA) hybrid approach has also received prominent attention in the medical domain (Dou-nias, 2003). In general, EA is used to determine the NN weights and architecture. In most cases NN are tuned (not generated) by the EA, but there are also appreciation when NN are tuned as well as generated by EA. Hussein and Abbas (2002, p. 265), present an EA-NN hybrid approach to diagnose breast cancer, both benign and malignant. The other hybrid combination, fuzzy logic and genetic algorithms (FL-GA) has also been deployed successfully in various control engineering applications and complex optimisation problems. GA is used for solving fuzzy logical equations in medical diagnostic expert systems (Hussein & Ab-bas, 2002, p. 265).
The another interesting hybrid combination examined in the literature is a decision trees and fuzzy logic (DT-FL) combination, where fuzzy logic is used to model uncertainty and missing decision attributes before these attributes are subjected
to decision trees for classification and diagnosis tasks (Jzau-Sheng, Kuo-Sheng, & Chi-Wu, 1996, p. 314). With regards to medical applications, this approach showed some great accuracy in diagnosing coronary stenosis and segmentation of multispectral magnetic resonance images (MRI) (Jzau-Sheng et al., 1996, p. 314). Some authors have also proposed the combination of decision trees and evolutionary algorithms (DT-EA). In this hybrid approach, decision trees are generally used to extract relevant features from large datasets whereas EA algorithms are used to generalize the data (Jzau-Sheng et al., 1996, p. 314). This approach overcomes the limitation of the EA which requires more time to process complex tasks. Pabitra and Sushmita (2001, p. 67) combine an evolutionary modular multilayer perceptron (MLP) with the ID3 decision tree algorithm for the staging of cervical cancer.
The hybridization of fuzzy decision tree (FDT) and neural network has also been investigated (Tsang, Wang, & Yeung, 2000, p. 601). With the induction of fuzzy decision trees, they happened to perform well and generate comprehensive results, but learning accuracy was not very good. A new hybrid methodology with neural networks-based FDT weights training was proposed by Tsang et al. (2000, p. 601), which lead to the development of hybrid intelligent systems with higher learning ac-curacy. This approach has been successfully tested on various databases and interesting results have been reported (Tsang et al., 2000, p. 601).
Chart 7 lists of some of the proposed hybrid approaches and their performances in medical diagnosis.
Reference Application Performance
Naive Bayes (Аndreeva et al., 2004) Breast Cancer 97.05% Accuracy
Simple naive bayes (Аndreeva et al., 2004)
Diabetics 79.95% Accuracy
Bayesian (Michael et al., 1994) Breast Cancer 84% Accuracy
Chart 6. The performance of Naive Bayes in medical domain
���
Hybrid Data Mining for Medical Applications
PrOPOsED HybrID DAtA MINING APPrOAcH
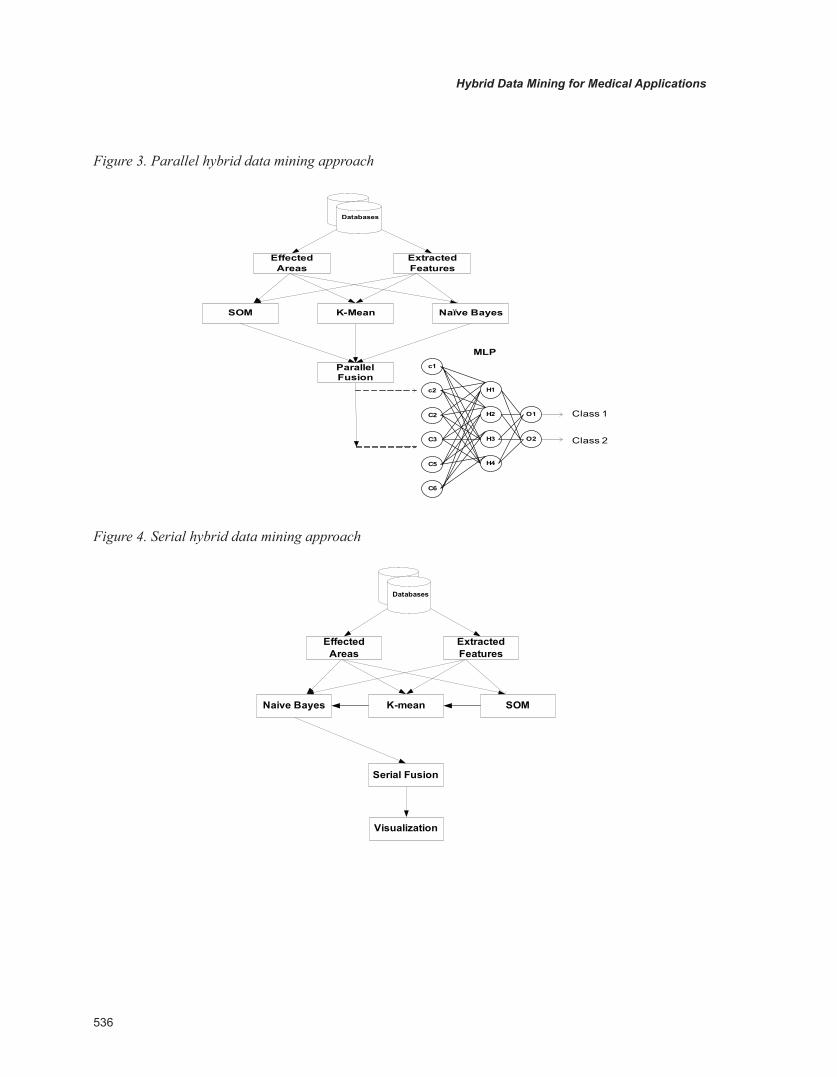
In this section, we present the architectural and functional overview of our proposed hybrid data mining methodology, as depicted in Figures 1 and 2. The proposed approach formulates a methodology whereby a number of data mining algorithms can be fused together to provide data mining decision-making services to healthcare practitioners. The concept of combining various clustering algorithms is an attempt to enhance the performance of learn-ing classifiers.
Functionally, we implement a computer process comprising of two functionally distinct layers. Each layer comprises a number of modules; each module is responsible to perform certain tasks. Figure 1 shows the functional architecture and the work-flow of the proposed methodology. The following sections explain the basic steps/phases involved in formulating the proposed approach.
step 1: Procurement and transformation of a Patient-centered Data from Medical repositories
We emphasized on the “context of data” stored in medical repositories. The word context can
be defined as the extract definition of a concept and its parameters associated with it, such as measure value, the unit value, and the precision of measure. More specifically, this phase is responsible for (i) procurement of patient-centered data from distributed repositories, (ii) cleansing and transformation of legacy data into XML-based structured database, and (iii) creation of medical data warehouses:
i. This step involves the procurement of health data from multiple distributed data repositories such as electronic medical record (EMR), electronic patient record (EPR), and patient health record (PHR).
ii. The procured health record are next cleansed by way of removing undesirable information and transformed into a XML-structured database (intermediate database).
iii. Finally a data warehouse is created. The main reason for the creation of these data warehouses is that they are useful for quality improvement and decision making. Most importantly, it is also easier to query a data warehouse compare to electronic medical records because of its complex structure. The creation of these data warehouses is heavily dependant on the understanding of what constitutes medical
Reference Application Performance
Neural-Fuzzy Combination (Wang, Palade, & Xu, 2006)
Leukemia Cancer 95.85 % Accuracy
Neural-Fuzzy Combination (Wang et al., 2006)
Lymphomia Cancer 95.65 % Accuracy
Neural Network Combination-Evolution-ary Algorithm (Xin & Yong, 1996)
Diabetics 76.80 % Accuracy
Neural Network-Evolutionary Algorithm Combination (Xin & Yong, 1996)
Heart Disease 84.60 % Accuracy
Evolutionary Algorithm-Fuzzy Logic Combination (Xin & Yong, 1996)
Breast Cancer 94 % Accuracy
Decision Tree-Evolutionary Algorithm (Spela, Peter, Vili, Milan, Matej, & Milojka, 2000)
Metabolic Acidosis Classification 83.33 % Accuracy
Chart 7. The performance of hybrid data mining in medical domain

���
Hybrid Data Mining for Medical Applications
data repositories. The features stored in EMR can be basic (e.g., text-based display of lab results) to a very advanced (e.g., dynamic graphs of lab trends). Different EMRs have different functionality domains and features. The main concern here is to identify what EMR features will be used in our domain to enable knowledge discovery.
When the data are preprocessed, they are fed into a data mining inductive learning unit, which is comprised of sets of machine learning algorithms (both intelligent and statistical), as shown in Figure 1. To elaborate it further, Figure 2 provides the detail overview and workflow of a data mining inductive learning unit.
step2: Designing of a DM Inductive Learning Unit (ILU)
The proposed inductive learning unit deploys the variety of clustering algorithms, which varies in their methods of search and representation to ensure diversity in the errors of the learned models. The entire amount of medical data (i.e., data, text, and images features) is introduced to each clustering algorithm in the ILU. The soft clusters produced
by each algorithm are recorded, combined, and fused into MLP in both serial and parallel fashion, as depicted in Figures 3 and 4. The parallel fusion incorporates a multilayer perceptron for learning of soft clusters and classification into appropriate classes, as demonstrated in Figure 3. In the serial approach, we first monitor the individual classifier performance and then train each classifier with the classified patterns of other classifiers and note its affect on overall system performance. The deployed algorithms vary in their methods of search and representation, which ensures diversity in the errors of the learned models. More specifically, the two types of hybrid combinations are investigated in this chapter, that is, parallel hybrid data mining and serial hybrid data mining, whereby each hybrid combination consists of four parts: 1) input data, 2) hybrid clustering, 3) fusion of clusters, and 4) data visualization.
Input Data
The input data contain raw data as well as extracted features which are used as an input to the data mining algorithms. The input data are normalized between 0-1.
Figure 1. Demonstrates the functional overview of proposed methodology
Dat
a P
rocu
rem
ent a
nd
Tran
sfor
mat
ion
Dat
a M
inin
g In
fere
nce
Eng
ine
PHrDatabase
EMrDatabase
sQL
serv
er
EPrDatabase
Data Procurement and transformation
Db
xML
Data Dictionary
DtD
Data to xML conversion
xML Parser Db3
Db2
Db1
sructured Intermediate Database
Inductive Learning UnitData Mining repot Generation Data Warehouses
Re g u ra lity Re p o rtTre n d A n a lys is
P a tie n t D ia g n o sis a n d P ro g n o sis Re su lts D e cisio n
tre e
N e u ra l N e tw o rk
K-me a n T R EEN ET
SOF M SOMC AR T
K-N e ig h b o u r
Data Mining clustering Methods
Preprocessing Verification synthesis retrieval
Data collection and Preprocessing
tExt_Data Warehouse
IMAGE_Data Warehouse
NUM_DataWarehouse
P a tie n t H is to ry

���
Hybrid Data Mining for Medical Applications
Data Mining Algorithms
Three data mining algorithms, that is, SOM, k-means, and naive Bayes have been combined in conjunction with multilayer perceptron. SOM is self-organizing, map-based on Kohonen neural network. SOM consisted of 16 neurons partitioned in a single layer in a 2-D grid of 4x4 neurons. We construed and assigned the random reference input vectors (neuron weights) to each partition. For each input, the Euclidean distance between the input and each neuron was calculated.
The reference vector with minimum distance is identified. After the most similar case is determined, all the neighbourhood neurons, connected with the same link, adjust their weights with respect to the reference vector to form a group in two dimensional grids. The whole process is repeated several times, decreasing the amount of learning rate to increase the
reference vector, until the convergence is achieved. The SOM visualization offers the clear partition of data into discernable clusters.
In the k-means algorithm, we randomly partitioned the input data into k-cluster centers along with its all closest features. With each input feature, it calculates the mean point of each feature and constructs a new partition by associating data-entities to one of the k clusters. Cluster features are moved iteratively between k-clusters and intra and intercluster similarity. Distances are measured at each move. Features remained in the same cluster if they were closer to it, or they otherwise moved into a new cluster. The centers for each cluster are recalculated after every move. The convergence achieved when moving the object increases intracluster distances and decreases intercluster dissimilarity.
Figure 2. Work flow of data mining inductive learning unit
Numeric Data Image data
(Medical Images e.g x-rays)
text Data(Medical reports)
Data Mining cluster Method N
Data Mining cluster Method 2 Data Mining
cluster Method 1
c! c4c3c2 c5 c6 c7 c8 C-n
clustered Decisions Fusion
DAtA
DM INFErENcEs
FUsION
New Medical records(Data, text and Images) Visualised Data
(Graphs, charts, and tables etc.)
Electronic Medical record
���
Hybrid Data Mining for Medical Applications
Figure 3. Parallel hybrid data mining approach
Figure 4. Serial hybrid data mining approach
Databases
Effected Areas
Extracted Features
sOM K-Mean Naïve bayes
Parallel Fusion
c1
c3
c2
c2
c5
c6
H1
H4
H3
H2
O2
O1 Class �
Class �
MLP
Databases
Effected Areas
Extracted Features
Naive bayes K-mean sOM
serial Fusion
Visualization

���
Hybrid Data Mining for Medical Applications
Naive Bayes clustering is based on probability distribution. It accepts raw data or features as input and creates soft clusters which are later combined with the results generated by other data mining algorithms and passed into the fusion module.
Data Fusion
The workings of a data fusion model can be un-derstood by its fusion hypothesis, which assumes that the more similar data a cluster contains, the more reliable the cluster is for decision making. The outputs of data mining algorithms are combined using serial fusion and parallel fusion. The paral-lel fusion is based on a MLP as shown in Figure 3. A simple majority voting method is also used and compared with MLP.
step 3: Data Visualization
This process involves the designing of a data mining visualization model, coupled with all data mining methods to generate the knowledge, which is derived by the data mining inference engine, in the form of charts, graphs, and maps. These coupling of DM algorithms and visualization algorithms provide added value. The visualization techniques may range from simple scatter plots to histogram plots over parallel to two dimensions coordinates.
IMPLEMENtAtION AND ExPErIMENtAL rEsULts
The proposed data mining approach has been implemented in order to evaluate the performance and accuracy. The experiments were conducted on a benchmark dataset. The dataset and experimental results are described below.
benchmark Database
The dataset of digital mammograms is used in this chapter and it is adopted from digital database for
screening mammography (DDSM) established by University of South Florida. The main reason to choose DDSM for the experiment purposes is that it is a benchmark dataset so the final results can be compared with published results by other researchers. The DDSM database contains approximately 2,500 case studies, whereby each study includes two images of each breast, along with some associated patient information (ie., age at time of study, breast density rating, subtlety rating for abnormalities, and keyword description of abnormalities) and image information (e.g., scanner, spatial resolution, etc.). The database contains a mixture of normal, benign, benign without call-back, and cancer volumes selected and digitized. Images containing suspicious areas have associated pixel-level information about the locations and types of suspicious regions.
The data set consists of six features (measurements) from 200 mammograms cases: 100 benign and 100 malignant. The features include patients’ age, density, shape, margin, assessment rank, and subtlety.
results and Discussion
The experimental results are presented below in Tables 1 and 2. From the comparative results shown in Table 1, it is observed that the proposed hybrid approach, a combination of statistical and intelligent techniques, provides better results than the stand alone individual technique. It is also noticed that the proposed approach outperforms all individual approaches in all main output categories (see Table 1), that is, classification accuracy, misclassifica-tion accuracy, and error rates. Out of the total of 100 digital mammogram cases of the test dataset, SOM made 12% misclassifications, k-means made 16% misclassifications, naive Bayes misclassified 10% cases, and proposed approach made 7.6923% misclassifications. This corresponds to classifica-tion accuracies achieved by SOM, K-means, naive Bayes, and the proposed approach, which are, 88%, 84%, 90% and 92.3%, respectively.

���
Hybrid Data Mining for Medical Applications
The experiments were also performed to com-pare the accuracies of algorithms by considering individual classes, both benign and malignant. For each class, the receiver operating characteristic (ROC) analysis attributes, such as true positive (TP) rate, false positive (FP) rate, and F-measure, are measured with particular algorithm as shown in Table 2. It is noticeable that the attributes frequency measures for both benign and malignant are quite high with the proposed hybrid approach.
We created a confusion matrix to evaluate individual classifier performance by displaying the correct and incorrect pattern classifications. Typical confusion matrix can be represented as:
Confusion Matrixa b <-------- Classified as x1 x2 | a = Malignant
y1 y2 | b = Benign
Where row x1 and x2 represents the actual patterns and column x1 and y1 represents the classified patterns for class a (malignant). The difference between the actual patterns and the classified pat-terns can be used to determine the performance of a classifier. To explicate it further, we draw the confusion matrix for each classifier to evaluate how many patterns in a given class are classified correctly/incorrectly. Note the 200 mammogram
cases were used, 200 cases for training purposes and 100 for testing purposes.
SOM Confusion Matrixa b <-------- Classified as 48 2 | a = Malignant
10 40 | b = Benign
This SOM classifier successfully classified 88 cases out of 100 cases presented. The row values (48, 2) are the actual cases for the class malignant, and row values (10, 40) represent the actual class benign. However, the classified outputs are rep-resented by column a (48, 10) and column b (2, 40). The comparison of these rows and columns, between actual pattern and classified patterns, can provide interesting insights. For instance, for the malignant class accuracy, we notice that the original malignant patterns were (48, 2) and the classifier indicates (48, 10). Thus, it classified 48% cases correctly as a malignant class and misclas-sified 2 cases. It is also noticeable that those two patients will be cleared when they were supposed to be treated like a cancer patients. Similarly, for the benign class accuracy, the actual cases are (10, 40) whereas the classifier indicates (2, 40). The 40% cases were classified correctly as a class benign and 10% cases were misclassified. In this scenario, those 10 patients who are not the victim of cancers will
Table 1. Results showing the improvement in classification accuracies
Algorithms Classification Error [%] Root Mean Square Error
Classification Accuracy [%]
SOM 12 0.2777 88
k-Means 16 0.2433 84
Naive Bayes 10 0.3022 90
Proposed Parallel Hybrid Approach
7.6 0.2572 92.3

���
Hybrid Data Mining for Medical Applications
be treated like a cancer patient despite it being the opposite scenario. However, the overall outcome is much more favourable: 48% classified correctly as a malignant class and 40% classified correctly as a benign class.
k-Means Confusion Matrixa b <-------- Classified as 38 11 | a = Malignant
5 46 | b = Benign
By applying the above-mentioned confusion matrix method on the k-means classifiers, the 38% cases that were classified correctly as a class malignant (11 cases were misclassified) and 46% cases that were classified correctly as a class benign (misclas-sified 5 cases) overall achieved 84% classification accuracy.
Naive Bayes Confusion Matrixa b <-------- Classified as 43 7 | a = Malignant
3 47 | b = Benign
The naive bayes classified 43% and 47% cases correctly as a class malignant and benign, respectively, with the ratio of 2 misclassified cases of a class malignant and 3 cases for a class benign, an overall computed 90% accuracy.
From the decision-making perspective, it is also noticeable that by fusing the outputs of all data mining algorithms, based on a simple voting method, we can get the final clusters which are more accurately classified. In this voting approach, the winner cluster is the one with the most votes from the classifiers. The experiments show that the proposed hybrid data mining approach is useful for the analysis of digital mammography data for the cancer diagnosis.
clustered Visualization
Figures 5(a) and 5(b); demonstrate the visualization of the SOM of mammography data.
From the above Figure 5(a), the U-matrix, which shows the overall clustering structure of the SOM, is shown along with all six component planes. The clear separation of two classes, benign and malignant, cannot really be accessed by what U-matrix shows, but from the labels it seems that they correspond to two different parts of the cluster.
Table 2. Detailed accuracy by classes
Classes TP Rate FP Rate F-Measure
Individual Algorithms Benign(SOM)
0.8 0.04 0.87
Malignant(SOM)
0.96 0.2 0.889
Benign(Naïve Bayes)
0.94 0.14 0.904
Malignant(Naïve Bayes)
0.86 0.06 0.896
Proposed Parallel Hybrid Approach Benign 0.885 0.038 0.923
Malignant 0.962 0.115 0.926
TP = true positive rate; FP = false positive rate; F-Measure= frequency measure over class accuracy

��0
Hybrid Data Mining for Medical Applications
By looking at the labels, it is easy to interpret that the first two rows of the SOM form a very clear cluster; it is immediately seen that this corresponds to the benign class. The other class, malignant, forms the other clear clusters which can be seen in last two rows. The rest of the middle layers are the combination of both clusters. The empty cluster indicates some missing information in the sample data. From the component planes in Figure 5(b), it can be seen that the patient age, assessment rank, and subtlety features are very closely related to each other. Also some correlation exists between them and feature shape, margin, and density.
The variation in the colors of map units shows the similarities between the data vector. The grid scale used to measure these similarities is the normalized values of the variables used to represent one feature.
sIGNIFIcANcE AND FUtUrE trENDs
With the need for advance decision-support systems in the medical domain, this research on hybrid data mining system will set the new directions. The healthcare community is being overwhelmed with an influx of data that are stored in distributed
repositories. Accessing data and extracting meaningful information requires a system with powerful analytical tools rather than traditional information retrieval methods.
In this chapter, we introduced a new hybrid approach, that is, clusters of various data mining algorithms that form the predictive model to generate effective knowledge which can assist healthcare practitioners to make future decisions about the patient treatments and organization policies. For instance, outcome measurement—a data mining technique to search previously unknown valuable information from distributed databases—can help healthcare parishioners by showing statistically—in the form of graph, charts, tables, and so forth—which treatments have been most effective to the patient.
The procurement of data mining-specific knowledge (i.e., features extracted from data, text, and images) from routinely collected information will enhance the practicability of data mining systems in real-life applications, in particular for healthcare applications where a large corpus of medical data is routinely collected for clinical tasks. Thus, it is argued that the research on hybrid data mining system is very effective and significant. This research will impact both the fields of health informatics and data mining.
Figure 5(a). Data clustering based on similarities

���
Hybrid Data Mining for Medical Applications
cONcLUsION
In this chapter, we presented a critical review of existing intelligent (neural network-based) and statistical-based data mining algorithms. The ad-vantages and disadvantages of each algorithm and comparative performances have been substantiated. We also proposed a novel hybrid data mining ap-proach, an approach that combines intelligent and statistical data mining algorithms such as SOM, k-means, and naive Bayes in conjunction with a serial fusion and a multilayer perceptron-based parallel fusion. The approach was implemented and tested on a DDSM benchmark database. The proposed hybrid approach achieved over 92% classification accuracy on a test set, which is very promising. The proposed approach is also able to visualize the data which helps in interpretation of the results.
rEFErENcEs
Abidi, S. S. R., & Hoe, K. M. (2002). Symbolic exposition of medical data-sets: A data mining workbench to inductively derive data-defining
symbolic rules. In Proceeding of the 15th IEEE Symposium on Computer Based Medical Systems (CBMS 2002) (Vol. 7, pp. 50-55).
Аndreeva, P., Dimitrova, M., & Radeva, P. (2004). Data mining learning models and algorithms for medical applications. Paper presented at the 18th International Conference on Systems for Automa-tion of Engineering and Research (SAER-2004) (Vol. 24, pp. 148-152).
Clarke, L. P., & Wei, Q. (1998). Fuzzy-logic adap-tive neural networks for nuclear medicine image restorations. In Proceedings of the 20th Annual International Conference of the IEEE Engineer-ing in Medicine and Biology Society. Biomedical Engineering Towards the Year 2000 and Beyond, IEEE, Piscataway NJ (Vol. 20, pp. 3384-3390).
Damien, M., Graham, J. W., Jie, C., & Huidong, J. (2005). A delivery framework for health data mining and analytics. In Proceedings of the Twenty-eighth Australasian Conference on Computer Science 38 (pp. 381-387).
Derek, G., Alexey, T., Nadia, B., & Cunningham, P. (2004). Ensemble clustering in medical diagnos-
Figure 5(b). Visualizing individual feature strength

���
Hybrid Data Mining for Medical Applications
tics. In Proceedings of the 17th IEEE Symposium on Computer-Based Medical Systems (Vol. 2, pp. 576-580).
Dounias, G. (2003). Hybrid and adaptive computa-tional intelligence in medicine and bio-informatics. ISBN 960-7475-23-2.
Fayyad, U., Piatetsky-Shapiro, G., Smyth, P., & Uthurusamy, R., E. (1997). Advances in knowledge discovery and data mining (pp. 154-164). Cam-bridge, MA: MIT Press.
Fayyad, U. M., & Shapiro, P. (1996). Advances in knowledge discovery and data mining (pp. 101-110). CA: AAAI Press.
George, D., & Derek, A. (2004). Linkens: Adap-tive systems and hybrid computational intelligence in medicine. Artificial Intelligence in Medicine, 32,151-155.
Gulbinat, W. (1997). What is the role of WHO as an intergovernmental Organisation in the Coordi-nation of Telematics in Healthcare? World Health Organisation. Geneva, Switzerland. Retrieved April 8, 2008, from at http://www.hon.ch/libraray/papers/gulbinat.html
Husin-Chuan, C., Ching-Hsue, & Jing-Rong, C. (2007). Extracting drug utilization knowledge using self-organizing map and rough set theory. Expert Systems with Applications: An International Journal, 33, 499-508.
Hussein, A. (2002). An evolutionary artificial neu-ral networks approach for breast cancer diagnosis. Artificial Intelligence in Medicine, 25, 265-28.
Jzau-Sheng, L., Kuo-Sheng, C., & Chi-Wu, M. (1996). Segmentation of multispectral magnetic resonance image using penalized fuzzy competitive learning. Neural Computational and Biomedical Resources, 29, 314-326.
Langley, P., Iba, W., & Thompson, K. (1992). An analysis of baysian classifiers. In W. Swartout (Ed.), Proceeding of the Tenth National Conference on Artificial Intelligence (Vol. 6, pp. 223-228).
Lim, T. S., Loh, W. Y., & Shih, Y. S. (1997). An empirical comparison of decision trees and other classification methods (Tech. Rep. 979). Madison, WI.
Maria-Luiza, A., Zaïane, O. R., & Coman, A. (2001). Application of data mining techniques for medical image classification. In Proceeding of Second In-ternational Workshop on Multimedia Data Mining (MDM/KDD’2001,) in conjunction with the Seventh ACM SIGKDD (Vol. 2, pp. 94-101).
Michael, J. P., Patrick, M., Kamal, A., & David, S. (1994). Trading off coverage for accuracy in forecasts: Applications to clinical data analysis. Paper presented at the AAAI Symposium on AI in Medicine (Vol. 2, pp. 106-110).
Pabitra, M., & Sushmita, M. (2001). Evolutionary modular MLP with rough sets and id3 algorithm for staging of cervical cancer. Neural Computation and Application, 10, 67-76.
Rajkumar, B., Ognen, D., & Dong, X. (2005). Profiles and fuzzy k-nearest neighbor algorithm for protein secondary structure prediction. In Proceedings of 3rd Asia-Pacific Bioinformatics Conference (APBC 2005) (pp. 85-94).
Sakthiaseelan, K., Cheah, Y., & Selvakumar, M. (2005). A knowledge discovery pipeline for medi-cal decision support using clustering ensemble and neural network ensemble. International Associa-tion for Development of the Information Society (IADIS), 9, 336-343.
Spela, H. B., Peter, K., Vili, P., Milan, Z., Matej, S., & Milojka, M. S. (2000). The art of building decision trees. Journal of Medical Systems, 24, 43-52.
Thiemjarus, S., Lo, B. P. L., Laerhoven, K. V., & Yang, G. Z. (2004). Feature selection for wireless sensor networks. In Proceeding of the 1st Inter-national Workshop on Wearable and Implantable Body Sensor Networks (Vol. 5, pp. 52-57).
Tsang, X. Z., Wang, D. S., & Yeung, D. S. (2000). Improving learning-accuracy of fuzzy decision trees

���
Hybrid Data Mining for Medical Applications
by hybrid neural networks. In IEEE Transactions on Fuzzy Systems, 8, 601-614.
Wang, Z., Palade, V., & Xu, Y. (2006). Neuro-Fuzzy ensemble approach for microarray cancer gene expression data analysis. In Proceedings of the Second International Symposium on Evolving Fuzzy System (EFS’06), IEEE Computational Intelligence Society, Lancaster, UK (pp. 82-86).
Xin, Y., & Yong, L. (1996). Evolutionary artificial neural networks that learn and generalise well. In Proceedings of the IEEE International Conference on Neural Networks (ICNN’96), On Plenary Panel and Special Sessions (pp. 25-29).
Zeng, Z., Tu, J., Liu, M., Huang, T. S., Pianfetti, B., Roth, D., et al. (2007). Audio-visual affect recognition. IEEE Transactions on Multimedia, 9, 424-428.
Zheng, J., & Kazunobu, Y. (2006). Support vector machine-based feature selection for classification of liver fibrosis grade in chronic hepatitis C. Journal of Medical Systems, 30, 389-394.
Zizhen, Y., & Walter, L. R. (2006). A regression-based k nearest neighbor algorithm for gene func-tion prediction from heterogeneous data. BMC Bioinformatics, 7, 11-15.
KEy tErMs
Data Mining: The process of extracting useful patterns from massive amount of data.
Electronic Medical Records: A database con-sists of a patient’s examination and treatment records in the form of data, text, and images. This includes patient’s demographical and medical records and complaints, the physician’s physical findings, the results of diagnostic tests and procedures, and medications and therapeutic procedures.
Hybrid Data Mining: It can be defined as any effective combination of two or more machine learning methods (algorithms) that performs in a superior or competitive way to a simple individual machine learning method.
Machine Learning (ML): ML is one of the disciplines of the AI research that deploys a variety of probability, statistical, and optimizations tools to learn from past data/examples and use that prior learning to classify new data and identify new trends in data.
Neural Networks: Neural networks were originally designed to model the way a brain works, with multiple neurons being interconnected to each other through multiple axon junctions. Neural net-works use multiple layers (i.e., input, hidden, and output layers) to process their inputs and generate outputs.
Supervised Learning: A machine learning algorithm is provided with a labeled set of training data/example to learn the object. This labeled data assist the algorithm to map the input data with the desired output data.
Unsupervised Learning: A machine learning algorithm is provided with a set of training data/example only (without labeled) and leaves the algo-rithm to learn and discover the similar patterns.