Embed Size (px)
DESCRIPTION
Chap. 6 Problem 2. - PowerPoint PPT Presentation
Citation preview

Chap. 6 Problem 2
Protein coding genes are grouped into the classes known as solitary (single) genes, and duplicated or diverged genes in gene families (Table 6.1). In humans, roughly equal numbers of protein-coding genes fall into these two categories. Examples of gene and protein families are the ß-globin and tubulin families. Gene families consist of duplicated genes that encode proteins with similar but non-identical sequences. Pseudogenes are rare non-functional DNA sequences derived from gene duplication or reverse transcription and integration of cDNA sequences made from mRNA. Through sequence drift, they have become nonfunctional. Tandemly repeated genes (e.g., rRNAs) were derived by gene duplication but show minimal sequence drift. They commonly are present in head-to-tail arrays in the genome.

Chap. 6 Problem 3
Satellite DNA is classified into 3 categories based on length. Satellite DNA consists of 14-500 bp sequence units that tandemly repeat over 20-100 kb lengths of genomic DNA. Minisatellite DNA consists of 15-100 bp sequence units that tandemly repeat over 1-5 kb stretches of DNA. Microsatellite DNA consists of 1-13 bp units that can repeat up to 150 times. Although the sequences of satellite DNA are highly conserved, the number of tandem copies at each locus is highly variable between individuals. This originates due to unequal crossing over during formation of gametes in meiosis (Upper figure). DNA fingerprinting is a method for identifying individuals based on variations in minisatellite DNA (Fig. 6.7). In the method, minisatellite DNA is amplified by PCR using unique primers flanking repeat regions, and the collection of fragments is run on a gel. Due to the variation in the number of repeats at different loci, different individuals can be readily distinguished.

Chap. 6 Problem 6
Mobile DNA is grouped into two classes, DNA transposons and retrotransposons (see Fig. 6.8). DNA transposons move directly as DNA via a "cut-and-paste" mechanism. Retrotransposons move via an RNA intermediate and a "copy-and-paste" mechanism, wherein the original copy of the transposon is preserved. Insertion of mobile DNA can directly cause mutations that influence genome evolution. In addition, mobile DNA plays an important role in gene evolution via promoting exon shuffling. Exons can be shuffled by unequal crossing over between mobile DNA elements such as the Alu sequence (Fig. 6.18, top), DNA transposon transposition (Fig. 6.19a, middle), or LINE element transposition (Fig. 6.19b, bottom).

Chap. 6 Problem 8
Paralogous genes are derived from gene duplications and have diverged to perform different functions in a given organism. Orthologous genes typically perform the same function in different organisms, and have diverged in sequence due to mutations associated with speciation (Fig. 6.26b).The complexity of an organism is not simply related to the size of its genome. Due to alternative splicing of mRNA transcripts, many more proteins can be encoded than there are genes. A small increase in gene number results in a much larger increase in protein number, and associated complexity.

Chap. 6 Problem 9
Nucleosomes consist of 147 bp of DNA wrapped in almost two turns around the outside of an octamer of histone proteins (Fig. 6.29). The octamer has a stoichiometry of H2A2H2B2H32H42. Histones have a large number of basic amino acids and bind to DNA mostly by salt-bridge interactions to phosphates in the DNA backbone. Another histone, H1, binds to the linker DNA between nucleosomes. Linker DNA is 15-55 bp in length depending upon the organism. In 30-nm fibers, nucleosomes bind to one another in a spiral arrangement wherein ~6 nucleosomes occur per turn (Fig. 6.30). Histone H1 molecules help mediate interactions between individual nucleosomes. Interactions between nucleosomes in 30-nm fibers also are modulated by post-translational modification of the tails of histones in the octamers (H3 & H4 in particular).

Chap. 6 Problem 11
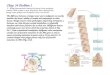
Eukaryotic chromosomes consist of long linear DNA molecules in which the DNA is wrapped around histones to form chromatin. The DNA occurs in a highly condensed state in metaphase chromosomes and in a less condensed form in interphase chromosomes. In both types of chromosomes, loops composed of chromatin fibers project out from a scaffold composed of non-histone proteins (Fig. 6.35). In interphase chromosomes, regions of the loops containing non-expressed genes are thought to retain a condensed 30-nm chromatin fiber structure. Regions containing expressed genes adopt the more extended beads-on-a-string packing. 30-nm fibers attach to the scaffold at scaffold-associated regions (SARs) and matrix attachment regions (MARs). Protein-coding genes are not located in regions with SARs and MARs because the DNA in these areas is highly condensed.

Chap. 6 Problem 15
Replication origins are DNA sequences at which DNA synthesis initiates in S phase of the cell cycle. In M phase, condensed metaphase chromosomes formed after DNA replication are observed. They contain two sister chromatids joined at a structure called the centromere (Fig. 6.39). Centromeres are required for chromatid separation in mitosis and are the sites where mitotic spindle fibers attach. The ends of chromatids are called telomeres. Telomeres are important in preventing chromosome shortening during replication. A special mechanism is needed for the replication of DNA within the 3' ends of DNA strands at chromosome ends. Otherwise, chromosomes become shortened with each round of replication, resulting eventually in deletion of essential genes. a) If a chromosome lacked replication origins, it could not duplicate during S phase of the cell cycle. b) If a chromosome lacked a centromere, the chromosome could be replicated, but the two sister chromatids of a metaphase chromosome may not segregate equally to the two daughter cells during cell division.