Embed Size (px)
Citation preview

XML Basics

Chapter 2 XML Basics Objectives
• Introduce XML concepts • Introduce the technologies for describing XML –
DTD and XML Schema• Discuss how to parse XML in Java using SAX,
DOM, and JAXP• Introduce two alternative APIs to SAX and DOM
– JDOM and dom4j• Introduce XSL Transformations and how to
process XSLT in Java• Give some step by step examples of parsing and
manipulating XML in Java

XML Overview
• eXtensible Markup Language (XML) is a language for defining markup languages
• HTML is an example of a well known markup language
• Tags in XML are defined by the author whereas tags in HTML are predefined by the W3C standard
• XML provides a portable (cross-platform) method for encapsulating and describing data
• An XML document is composed of elements consisting of opening and closing tags (<tag>data</tag>)

Example XML Document
<?xml version="1.0" encoding="iso-8859-1" ?>
<book>
<book-title>Paul Clifford</book-title>
<author>Edward George Bulwer-Lytton</author>
<year>1830</year>
<price>5.50</price>
<text>
<chapter>
<para>It was a dark and stormy night...</para>
</chapter>
</text>
</book>

XML Overview, cont.
• First line is document prolog: <?xml … ?>• Single root element, <book>, forms base of tree• Tag names describe the data, i.e., <price>• Additional info can be provided via attributes:
<price currency="usd" type="retail"> • Applications exchanging XML need a common
understanding of the semantic information provided by descriptive tag names and attributes
• Advanced example: XHTML is HTML restructured to conform to the rules of XML

XML Prolog
• Appears before the root of the XML document (e.g., <book>)
• May consist of an XML declaration and a Document Type Declaration (DTD) – discussed later
• XML declaration consists of the optional properties version, encoding, and standalone.
• Version describes the XML version used, encoding describes the character encoding used, and standalone provides a hint to the XML processor that no other files need to be loaded
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?>

XML Elements
• An XML element is an XML tag and the data it encapsulates (e.g., <price>5.50</price>)
• XML element names are case-sensitive must begin with a letter or underscore and may contain letters, numbers, hyphens, underscores, and periods (no spaces)
• Colons should only be used with namespace prefixes – discussed later
• Element contents must be character data in the encoding character set – no binary data
• All elements must be closed. Elements can be closed with a closing tag (e.g. <p>data</p>, or <p></p> - empty is OK) or can be self-closing (e.g., <p />).

XML Element Attributes
• The opening tag of an XML element may contain attributes (e.g., <price currency="usd" type="retail">)
• Attribute names must adhere to the same rules as element names.
• Attribute values are separated from the attribute name by an equal sign and must be enclosed in quotation marks, either the straight double quote (") or the apostrophe (').
• For every attribute there must be a value, even if the value is an empty string
• No duplicate attributes within a single element

XML Syntax
• Comments start with <!-- and end with -->, can not include a string of consecutive dashes (e.g., --), and may appear anywhere within the document because they are not XML elements.
• XML processing instructions begin with <? , immediately followed by a legal XML name called the target and end with ?> (e.g., <?php ?>). XML processors are designed to recognize certain targets and execute specific logic.
• Some characters in XML data must be replaced with their character entities because they otherwise interfere with a parser’s ability to recognize which parts of the document are elements and attributes and which parts are data. The five characters and their predefined character entities are: < (<), > (>), & (&), " ("), ' (')

XML Syntax, cont.
• Character entities represent a single character for which, possibly, no keyboard combination exists (such as à). They can be used only in text, not in element or attribute names. They can be numbered (e.g., à) or named (e.g., à). The number in numbered entities represents a code point in the Unicode set.
• Enclosing text and possibly markup in a CDATA section instructs the XML parser not to attempt to parse it. A CDATA section begins with the markup <![CDATA[ and ends with ]]>. A CDATA section may contain any characters except the CDATA ending sequence.

Well Formed XML Documents
• A well formed XML document conforms to the syntax rules of XML
• Unlike HTML parsers, XML parsers must report errors and may not replace missing quotes, close unclosed tags, or silently rearrange overlapping tags based on an assumption about the intended meaning.
• Some commonly abused XML syntax rules are: 1) Element and attribute names must be legal XML names; 2) Characters < and & must be escaped as character entities when used in text; 3) Every element must be closed; 4) Attributes must have values and values must be delimited with quotation marks; 5) Every element except the root element must be the child of exactly one element; 6) Comments must be properly formed, in particular, a comment may not contain the string “--”

Namespaces
• Use XML Namespaces to prevent name collisions among element and attribute names, which can be caused by designers choosing their own element names that conflict with imported elements defined in other XML documents.
• Namespaces are declared by adding an xmlns attribute to an element where the value of the xmlns attribute is a unique URI (not necessarily a valid URL).
• The element with the xmlns attribute and all of it’s children (nested elements) inherit the namespace; others that are not nested are not affected.
• xmlns can also be used repeatedly with different qualifiers, e.g., <html xmlns:xhtml="…" xmlns:furniture="…">. Then use the prefix to associate a namespace with a specific element (qualify): <furniture:table>

Namespaces, cont.
• A default namespace can be defined by using an unqualified xmlns on the root element of the XML document, e.g., <html xmlns="...">. Unqualified elements and attributes (names without prefixes) fall under the default namespace.
• Valid XML requires the root element of an XML document to be qualified, but other elements need not be. Best practice is to make sure that all of the elements in an XML document are qualified, either by the default namespace or explicitly by a prefix.
• Support for namespaces has to be built into the application that processes the XML. It is up to the application processing the XML to recognize namespaces, map the namespace URI to the identifying prefix, and process elements correctly depending upon their namespace.

Validating XML Documents
• A well formed document conforms to the syntax rules of XML, but it is not necessarily valid in the context of a particular application. For instance, a well formed XML document describing an invoice is probably not valid in the context of an application dealing with a catalog of books.
• If no formal document model is defined for an XML document, the document must still be well formed, but there are no limits on the element names used, the structure or contents of the elements, or the use of attributes. For complex documents or documents that will be used across organizational boundaries, a more formal definition of validity is needed.
• Two popular solutions are Document Type Definition (DTD) and XML Schema

Document Type Definition (DTD)
• A formal, machine-readable specification that defines the structure of an XML document and provides some information about the required content
• DTDs Provides syntax for declaring elements, attribute lists, entities, and notations
• DTD element declarations begin with the opening delimiter sequence <!, followed by one of the four keywords ELEMENT, ATTLIST, ENTITY, or NOTATION, then a case sensitive element name, a content description, and end with >, e.g.,
<!ELEMENT element_name content_description>
• A DTD is a sequence of these declarations enclosed in a DOCTYPE declaration or stored separately and referred to from a DOCTYPE

DTD in XML Prolog (Internal Subset)
<?xml version="1.0" encoding="iso-8859-1"?><!DOCTYPE memo [ <!ELEMENT memo (from, to, date, body)> <!ELEMENT from (#PCDATA)> <!ELEMENT to (#PCDATA)> <!ELEMENT date (#PCDATA)> <!ELEMENT body (#PCDATA)>]><memo> <from>Boss</from> <to>Troops</to> <date>15 April 1951</date> <body>The buck stops here.</body></memo> • Parentheses are grouping operators and commas are and operators • #PCDATA means parsed character data

External Subset DTD
• An external subset DTD is specified in the DOCTYPE declaration using the SYSTEM keyword
• The DTD definition is stored in its own file, and the XML document looks like the following:
<?xml version="1.0" encoding="iso-8859-1" ?><!DOCTYPE memo SYSTEM
"http://webdev.spsu.edu/~bbrown/memo.dtd" ><memo> <from>Boss</from> <to>Troops</to> <date>15 April 1951</date> <body>The buck stops here.</body>
</memo>

Document Type Definition (DTD), cont.
• DTDs can be declared as PUBLIC rather than SYSTEM where a unique name is specified as the URI and a URI is supplied following the DTD unique name (typical practice)
• Both external subset and internal subset DTDs may be used in the same document
• Operators and keywords available for declaring content descriptions:, (comma) ordered list (and operator)| or operator( ) content grouping? preceding item may occur zero or one time+ preceding item may occur one or more times* preceding item may occur zero or more times#PCDATA parsed character dataEMPTY element may not contain contentANY element may contain any content

Document Type Definition (DTD), cont.
• Attributes are declared with an <!ATTLIST > declaration, which contains the element name for which the attributes are being declared followed by a list of attribute declarations. Each declaration includes the attribute name, a data type specification, and a default definition that tells whether the attribute is required and if not, what action the parser should take. Example:
<!ELEMENT memo (from, to, date, body)><!ATTLIST memo date CDATA #REQUIRED priority
(high | medium | low) "medium"> • In this example, the date attribute is required (#REQUIRED)
and is of type CDATA (character data). The priority attribute is an enumerated type. The values for the enumeration must be legal XML names, enclosed in parentheses, and separated by | operators. The quoted string "medium" in the example makes the priority attribute optional with a default value of medium.

Document Type Definition (DTD), cont.
• Data type definitions and their meanings:CDATA - Character data(enumerated list) - List of permitted valuesID - Unique legal XML nameIDREF, IDREFS - Element ID or list of IDsNMTOKEN, NMTOKENS - One or list of name tokensENTITY, ENTITIES - One or list of unparsed entitiesNOTATION - Previously declared notation name
• Attribute default definitions and their meanings:#REQUIRED - Required to be present#IMPLIED - Optional(quoted string) - Optional and defaults to given value#FIXED (quoted string) - Always the given value
• Entities can also be defined. For example, this declaration will cause &boss; to be replaced by “Harry S Truman”:
<!ENTITY boss "Harry S Truman" >

XML Schema
• Created to solve DTD shortcomings.• DTDs have a very week typing system that can
only restrict XML elements to contain no data, other XML elements, or text data
• DTDs do not support data types like integers, decimals, booleans, dates, or enumerations
• DTDs do not allow one to specify that the data appear in a specific format.
• DTDs do not support namespaces• DTDs use a different syntax than the XML
documents they describe• An XML schema is an XML document that
conforms to the XML Schema specification

XML Schema, cont.
• Binding an XML schema to an XML document is done via attributes in the root XML element.
• xmlns:xsi attribute declares the XML Schema namespace• xsi:schemaLocation attribute declares the location of the
XML schema document being used• xmlns attribute declares the default namespace being used,
which is defined in the schema document
<?xml version="1.0" encoding="iso-8859-1" ?><memo xmlns="http://webdev.spsu.edu/memo" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://webdev.spsu.edu/memo.xsd"> <from>Boss</from> <to>Troops</to> <date>15 April 1951</date> <body>The buck stops here.</body></memo>

XML Schema, cont.
• The XML schema definition defines the XML elements and attributes including their structure and the data types they support.
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:mmo="http://webdev.spsu.edu/memo" targetNamespace="http://webdev.spsu.edu/memo" elementFormDefault="qualified"> <xsd:element name="memo"> <xsd:complexType>… <xsd:attribute name="date" type="xsd:date“ use="required" />… </xsd:complexType> </xsd:element>… <xsd:simpleType name="priorityValues">… </xsd:simpleType></xsd:schema>

XML Schema, cont.
• The root XML element for the XML schema definition is <xsd:schema>.
• The xmlns attribute of the schema definition binds the namespace prefix xsd to the version of XML Schema being used, in this case http://www.w3.org/2001/XMLSchema.
• The targetNamespace for the XML schema is the namespace for the elements and attributes defined by the schema definition. When this schema is referenced by another XML document, the targetNamespace will be used to qualify the elements defined by this schema.
• The elementFormDefault attribute set to "qualified" indicates that nested elements in the XML document instance must be namespace qualified; default is unqualified.

XML Schema, cont.
• XML elements are defined using the <xsd:element> tag and XML element attributes are defined using the <xsd:attribute> tag.
• The name and type attributes are used to define the element/attribute name and data type, respectively.
• Elements can be defined as either complexType or simpleType, attributes can only be simpleType. Simple types can have neither attributes nor child elements. Complex types can have either.
• XML Schema defines many built-in atomic types including strings, numbers, dates, and times.
• The built-in atomic types can be further constrained by a derived simple type specifying facets using the <restriction> element, e.g., minLength and maxLength.

XML Schema, cont.
• Example complexType and simpleType:
<xsd:complexType name="nameStructure"> <xsd:sequence> <xsd:element name="surname" type="xsd:string" minOccurs="1" maxOccurs="1" /> <xsd:element name="forename" type="xsd:string" minOccurs="0" maxOccurs="unbounded" /> </xsd:sequence> </xsd:complexType> <xsd:simpleType name="priorityValues"> <xsd:restriction base="xsd:string"> <xsd:enumeration value="high"/> <xsd:enumeration value="medium"/> <xsd:enumeration value="low"/> </xsd:restriction> </xsd:simpleType>

Parsing XML
• XML parsers are software programs that know how to read and manipulate XML documents.
• The most popular XML parser APIs today are the Simple API for XML (SAX) and the Document Object Model (DOM).
• DOM caches the parsed XML in memory, SAX does not.• SAX sends events to registered listeners when it
encounters data while parsing an XML document, but does not store the parsed data in memory. Listeners must cache data if they want to keep it around.
• DOM parses the entire XML document into memory as a hierarchical object model – a tree structure of objects called nodes.
• SAX parsers tend to consume less memory and be faster than DOM parsers. However, DOM provides the benefit of being able to randomly access the parsed document.

Simple API for XML (SAX)
• SAX is an event-driven model where you provide objects with callback methods (sometimes called listeners) that the parser invokes as it reads data from an XML document. Access to the XML data is provided by a SAX parser in a serial fashion. Meaning once a piece of data is read and provided to a callback method, that data is not read again.
• SAX interfaces with callback methods that have to be implemented by the developer:
org.xml.sax.ContentHandler – The primary listener that you will implement for most all applications that use SAX. Called by the parser to notify the listener that data (content) was encountered.
org.xml.sax.ErrorHandler – Called when an error is encountered. SAX parsers do not throw exceptions.
org.xml.sax.DTDHandler – Provides information about a DTD being used
org.xml.sax.EntityResolver – Used to get external data defined by an external entity
• org.xml.sax.helpers.DefaultHandler implements the methods of all four interfaces so one only has to extend this class

SAX Example
import org.xml.sax.*; import java.io.*;public class SAXTest { public static void main(String[] args) throws Exception { String xhtmlFileName = args[0]; String contentHandlerClass = args[1]; ContentHandler contentHandler = (ContentHandler) Class.forName(contentHandlerClass).newInstance(); XMLReader reader = XMLReaderFactory.createXMLReader(); reader.setContentHandler(contentHandler); reader.setFeature( "http://xml.org/sax/features/namespace-prefixes", true); reader.setFeature( "http://xml.org/sax/features/validation", true); reader.setFeature( "http://apache.org/xml/features/validation/schema", true); reader.setProperty( "http://apache.org/xml/properties/schema/external-schemaLocation", "http://www.w3.org/2002/08/xhtml/xhtml1-strict.xsd"); String uri = "file:" + new File(xhtmlFileName).getAbsolutePath(); InputSource input = new InputSource(uri); reader.parse(input); }}

SAX ContentHandler Implementation
import org.xml.sax.*;public class ContentHandlerExample extends DefaultHandler { StringBuffer buffer = new StringBuffer(); boolean foundTag = false; boolean processTag = false; public void startElement(String uri, String localName, String qName, Attributes atts) throws SAXException { System.out.println(“startElement() called for tag: ” + localName); if (!foundTag && localName.equals(“p”)) { foundTag = true; processTag = true; } } public void characters(char[] chars, int start, int length) throws SAXException { System.out.println(“characters() called”); if (processTag) { buffer.append(chars, start, length); } } public void endElement(String uri, String localName, String qName) throws SAXException { System.out.println(“endElement() called for tag: ” + localName); if (processTag) { processTag = false; System.out.println(“Content of first paragraph: ” + buffer.toString()); } }}
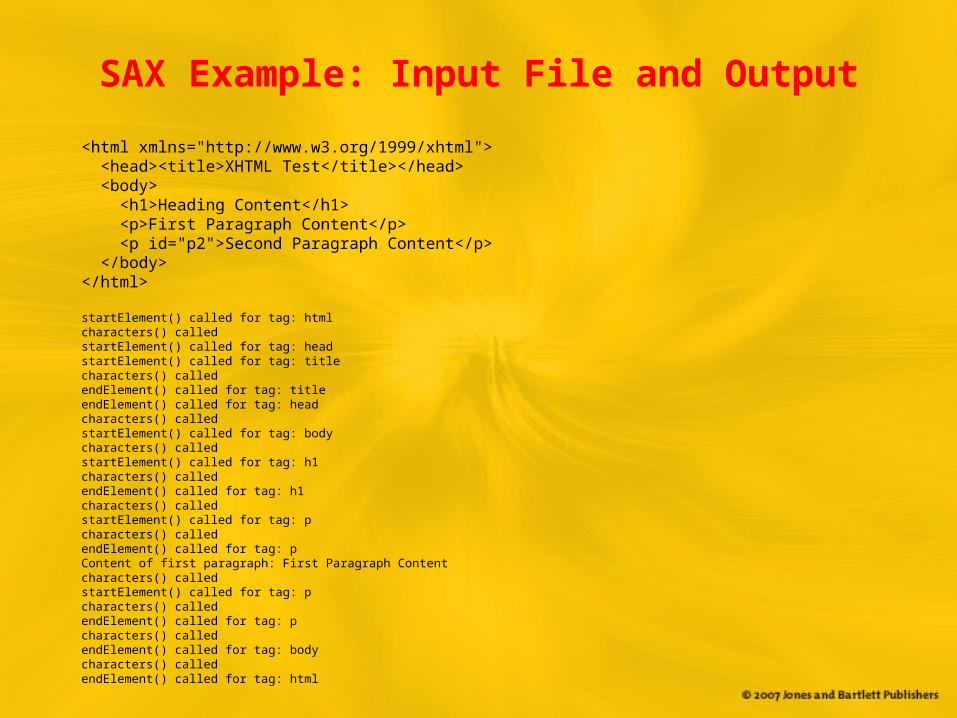
SAX Example: Input File and Output
<html xmlns="http://www.w3.org/1999/xhtml"> <head><title>XHTML Test</title></head> <body> <h1>Heading Content</h1> <p>First Paragraph Content</p> <p id="p2">Second Paragraph Content</p> </body></html>
startElement() called for tag: htmlcharacters() calledstartElement() called for tag: headstartElement() called for tag: titlecharacters() calledendElement() called for tag: titleendElement() called for tag: headcharacters() calledstartElement() called for tag: bodycharacters() calledstartElement() called for tag: h1characters() calledendElement() called for tag: h1characters() calledstartElement() called for tag: pcharacters() calledendElement() called for tag: pContent of first paragraph: First Paragraph Contentcharacters() calledstartElement() called for tag: pcharacters() calledendElement() called for tag: pcharacters() calledendElement() called for tag: bodycharacters() calledendElement() called for tag: html

Document Object Model (DOM)
• After parsing an XML document, DOM parsers generate a Document object, which represents an entire XML document instance containing references to all of the other objects generated by the DOM parser. XML elements are parsed into Element objects, XML attributes into Attr objects, text into Text objects, and so on. The common supertype for all of the XML artifacts is the Node type.
Comment
Node
Document ElementCharacterData
Text
Attr
DOM 2 Interface
DOM 2 Class
java.lang Class
DocumentFragment
EntityReference
Entity
DocumentType
Notation
CDATASection DOMImplementationNodeList NamedNodeMap
ProcessingInstruction
DOMException
RuntimeException
package org.w3c.dom
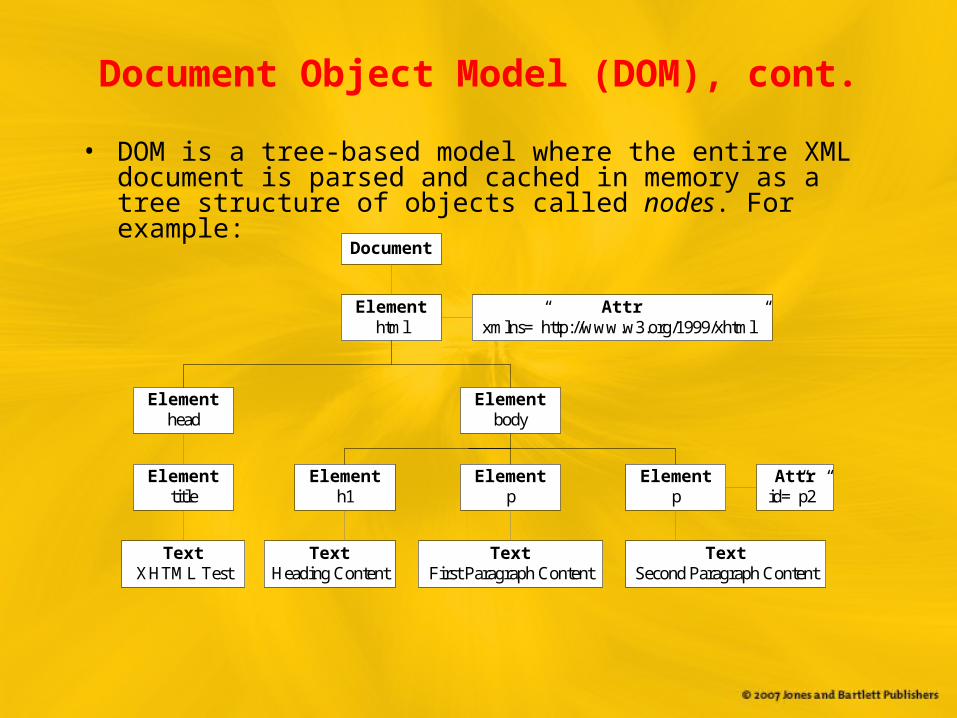
Document Object Model (DOM), cont.
• DOM is a tree-based model where the entire XML document is parsed and cached in memory as a tree structure of objects called nodes. For example:
Document
Elementhtml
Elementhead
Elementtitle
Elementbody
Elementp
Elementp
Elementh1
TextXHTML Test
TextHeading Content
TextFirst Paragraph Content
TextSecond Paragraph Content
Attrxmlns=”http://www.w3.org/1999/xhtml”
Attrid=”p2”

DOM Node Methods
• Methods to obtain/set type-specific information:getNodeType(), getNodeName(), getNodeValue(),
setNodeValue()• Methods to obtain/set the XML namespace information:getLocalName(), getNamespaceURI(), getPrefix(),
setPrefix()• Methods to reference the attributes:hasAttributes(), getAttributes()• Methods to get references to the Node’s parent, siblings, and children.getParentNode(), hasChildNodes(), getFirstChild(),
getLastChild(), getChildNodes(), getPreviousSibling(), getNextSibling()
• Methods to add or remove children:appendChild(), replaceChild(), removeChild(),
insertBefore()• If you call getFirstChild() on the Document, you will get a
reference to the top level XML element of the document, which is Element html in the previous example. If you call getFirstChild() on that Node (Element html), you will get a reference to Element head.

DOM Example
import java.io.IOException; import org.w3c.dom.*;import org.xml.sax.SAXException; import org.apache.xerces.parsers.DOMParser;public class DOMTest { public static void main(String[] args) throws Exception { String xhtmlFileName = args[0]; DOMParser parser = new DOMParser(); parser.parse(xhtmlFileName); Document document = parser.getDocument(); Node rootNode = document.getFirstChild(); Element htmlElement = (Element) rootNode; NodeList childNodes = htmlElement.getChildNodes(); Element bodyElement = null; for (int i = 0; i < childNodes.getLength(); i++) { if (childNodes.item(i).getNodeName().equals("body")) { bodyElement = (Element) childNodes.item(i); break; } } childNodes = bodyElement.getChildNodes(); Element secondParagraphElement = null; int count = 0; for (int i = 0; i < childNodes.getLength(); i++) { if (childNodes.item(i).getNodeName().equals("p") && (++count == 2)) { secondParagraphElement = (Element) childNodes.item(i); } } Text secondParagraphContent = (Text) secondParagraphElement.getFirstChild(); System.out.println(secondParagraphContent.getNodeValue()); }}

Java API for XML Processing (JAXP)
• API that provides an abstraction layer to XML parser implementations (specifically implementations of DOM and SAX), and applications that process Extensible Stylesheet Language Transformations (XSLT)
• JAXP is is a layer above the parser APIs that makes it easier to perform some vendor-specific tasks in a vendor-neutral fashion. JAXP employs the Abstract Factory design pattern to provide a plugability layer, which allows you to plug in an implementation of DOM or SAX, or an application that processes XSLT
• The primary classes of the JAXP plugability layer are javax.xml.parsers.DocumentBuilderFactory, javax.xml.parsers.SAXParserFactory, and javax.xml.transform.TransformerFactory.
• Classes are abstract so you must ask the specific factory to create an instance of itself, and then use that instance to create a javax.xml.parsers.DocumentBuilder, javax.xml.parsers.SAXParser, or javax.xml.transform.Transformer, respectively.
• DocumentBuilder abstracts the underlying DOM parser implementation, SAXParser the SAX parser implementation, and Transformer the underlying XSLT processor. DocumentBuilder, SAXParser, and Transformer are also abstract classes, so instances of them can only be obtained through their respective factory.

JAXP Example
import java.io.*;import javax.xml.*;import org.w3c.dom.Document;import org.xml.sax.SAXException;import javawebbook.sax.ContentHandlerExample;public class JAXPTest { public static void main(String[] args) throws Exception { File xmlFile = new File(args[0]); File xslFile = new File(args[1]); File xsltResultFile = new File(args[2]); DocumentBuilderFactory docBuilderFactory=DocumentBuilderFactory.newInstance(); docBuilderFactory.setNamespaceAware(true); docBuilderFactory.setValidating(true); DocumentBuilder docBuilder = docBuilderFactory.newDocumentBuilder(); Document doc = docBuilder.parse(xmlFile); SAXParserFactory saxParserFactory = SAXParserFactory.newInstance(); saxParserFactory.setNamespaceAware(true); saxParserFactory.setValidating(true); SAXParser saxParser = saxParserFactory.newSAXParser(); saxParser.parse(xmlFile, new ContentHandlerExample()); TransformerFactory transformerFactory = TransformerFactory.newInstance(); Source xslSource = new StreamSource(xslFile); Transformer transformer = transformerFactory.newTransformer(xslSource); Source xmlSource = new StreamSource(xmlFile); Result xsltResult = new StreamResult(xsltResultFile); transformer.transform(xmlSource, xsltResult); }}

JDOM and dom4j
• DOM is useful but can be awkward to use because it was designed to be independent of any programming language.
• Implementations that take advantage of the strengths of Java can be easier to use. Examples are JDOM (http://jdom.org) and dom4j (http://dom4j.org).
• Both JDOM and dom4j are open source and can be used with JAXP• Both APIs take advantage of built-in Java classes, provide an object
model to represent an XML tree, are intuitive and easy to use, integrate well with SAX and DOM, support XPath, and are more efficient than DOM.
• JDOM is built on concrete classes and dom4j on interfaces.• dom4j is more flexible, yet more complex.• dom4j additional features over JDOM like event-based processing for
handling very large documents or streamed documents.• dom4j also aims to be a more complete solution than JDOM, whose
goal is to solve only about 80% of the Java/XML problems.

Transforming XML Using XSLT
• Extensible Stylesheet Language Transformations (XSLT) are part of the XML Stylesheet Language (XSL).
• An XSLT stylesheet, which is simply and XML document, contains instructions on how an XML document should be transformed by an XSLT processor. XSLT is a full programming language, expressed as XML, designed specifically for reformatting XML documents. There are more than 50 XSLT elements and more than 200 attributes.
• XSL Transformations provide a way to translate the semantic descriptions of an XML document to presentational descriptions, e.g., translate XML to HTML.
• XSL Transformations allow XML data to be reordered, permit the display of attributes, and allow elements to be displayed in an order other than that in which they are given in the XML document. XSL Transformations can also add static data to the output, such as XHTML tags and CSS style specifications.

XSLT, cont.
• Writing an XSLT stylesheet simply involves writing templates for those elements that are to be a part of the output. The XSLT processor traverses the supplied XML document tree looking for elements that match these templates. Templates may include XML element and attribute contents, other markup, such as XHTML tags, and other literal and computed values. For example:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="memo"> <xsl:apply-templates select="to/name" /> </xsl:template> <xsl:template match="name"> <xsl:for-each select="forename"> <xsl:value-of select="."/><xsl:text> <xsl:text> </xsl:for-each> <xsl:value-of select="surname" /> <br /> </xsl:template></xsl:stylesheet>

XSLT, cont.
• An XSLT processor that was supplied this XSLT stylesheet and a valid XML document would, for each <memo><to><name> element combination it encountered, iterate over the nested <forename> elements outputting the value of each <forename> element followed by a space, then the value of the <surname> element followed by the markup <br />.
• <xsl:template match="memo"> matches a <memo> element as the root of the XML document. It specifies <xsl:apply-templates select="to/name">, which means apply any <xsl:template> tags that match a <name> element, which is nested within a <to> element.
• <xsl:template match="name"> matches the <name> element, within which <xsl:for-each select="forename"> iterates over any <forename> elements using <xsl:value-of select="."/> to output the <forename> element value and <xsl:text> to output a space. Without <xsl:text> the XSLT processor would remove the whitespace.

XSLT, cont.
• <xsl:value-of select="surname" /> then outputs the value of a matched <surname> tag nested within a <name> tag. An <xsl:value-of > element can be used for computation, but is most often used to select elements or attributes of the input document for writing to output. The select attribute of <xsl:value-of > is an XPath expression that determines what value from the input document is to be written to the output.
• The <br /> tag is simply XHTML markup; it is not in the xsl namespace, so it will be copied to the output just like any other text.
• The default behavior of XSLT is to copy the element values and whitespace outside of elements to the output document. A template at the outermost level can be used to specify which inner elements are to be used, and in what order.

XPath
• XPath expressions look a lot like directory path expressions for operating systems; both describe a path through a tree structure. Absolute paths begin with a / and start at the root element of the document. The XSLT processor traverses the input document in preorder fashion and keeps track of its current position. The current position is called the context node, and it is referred to with a period. Relative path specifications are relative to the context node and do not begin with a slash. Possible XPath specifications and their meanings:/ – The root of the document.. – Contents of the current context node.to/text() – Contents of the text node of the <to> element/memo/to/name – <name> elements that are a child element of /memo/to.//surname – All <surname> elements, even if at different levels./memo/to/name[1] – First <name> child element of /memo/to./memo/to/name[last()] – Last <name> child element of /memo/to.@date – Contents of the date attribute of the current context element./memo@date – Contents of the date attribute of the <memo> element.
• XPath also includes functions and operators, which were’nt discussed.


![Synthesis of Novel Electrically Conducting Polymers: Potential ... · PPh3 + Br(CH2). CO2Me ..... > [Ph3P--CH2(CH2). i CO2Me]*Br* [phaP--CH2(CH2)n__CO2Mel*Br -Z--BuL>_phaP=CH (C H2)n_i](https://img.pdfslide.us/doc/110x75/5ebc39ab077be8135d1c1d2a/synthesis-of-novel-electrically-conducting-polymers-potential-pph3-brch2.jpg)






![blog. · Web viewANSWER: B ANSWER: C [CI`(H2O)4C1(NO2)]CI COON HOOC-CH2\N_CCH~_CH___N/H Ml ` | ` \' ' CH2 CH2 -COOH HOOC' HOOC`.."CHZ CH2"COOH \ I /N-CH2-CH2-N\ HOOC""CH2 CH2-COOH](https://img.pdfslide.us/doc/110x75/5ab561c67f8b9a0f058cbd1a/blog-viewanswer-b-answer-c-cih2o4c1no2ci-coon-hooc-ch2ncchchnh.jpg)



















