Embed Size (px)
Citation preview

CAP6412AdvancedComputerVision
http://www.cs.ucf.edu/~bgong/CAP6412.html
Boqing GongFeb23,2016

Today
• Administrivia• Neuralnetworks&Backpropagation (IX)• Poseestimation,byAmar

Thisweek:Visionandlanguage
Tuesday(02/23)
SuhasNithyanandappa
[VQA-1] Antol,Stanislaw,AishwaryaAgrawal,Jiasen Lu,MargaretMitchell,Dhruv Batra,C.LawrenceZitnick,andDeviParikh.“VQA:VisualQuestionAnswering.”arXiv preprintarXiv:1505.00468(2015).& Secondary papers
Thursday(02/25)
NandakishorePuttashamachar
[VQA-2] Malinowski, Mateusz, and Mario Fritz. “A multi-world approachto question answering about real-world scenes based on uncertaininput.” In Advances in Neural Information Processing Systems, pp.1682-1690. 2014.& Secondary papers

Nextweek:Visionandlanguage
Tuesday(03/01)
Javier Lores
[RelationPhrases] Sadeghi,Fereshteh,SantoshK.Divvala,andAliFarhadi.“VisKE:VisualKnowledgeExtractionandQuestionAnsweringbyVisualVerificationofRelationPhrases.”InProceedingsoftheIEEEConferenceonComputerVisionandPatternRecognition,pp.1456-1464.2015.& Secondary papers
Thursday(03/03)
Aisha Urooji
[OCR in the wild] Jaderberg, Max, Karen Simonyan, Andrea Vedaldi, andAndrew Zisserman. "Reading text in the wild with convolutional neuralnetworks." International Journal of Computer Vision 116, no. 1 (2016):1-20.& Secondary papers

Project1:Dueon02/28
• Ifyouhavediscussedoption2withme• Sendmethemeetingminutes/slides--- gradingcriteria
• Ifyoutakeoption1• Intotal,>6,000validationimages• Test3imagesperclassofthevalidationset

Travelplan
• AtWashingtonDCon03/01,Tuesday• GuestlecturebyDr.Ulas Bagci

Today
• Administrivia• Neuralnetworks&Backpropagation (IX)• VQA-1,bySuhas

Recap
Data: (xi
, y
i
) 2 X ⇥ Y, i = 1, 2, · · · , nGoal: Find the labeling function c : X 7! Y, c(x) = y
Hypotheses: net(x;⇥)
Expected risk: R(⇥) = E(x,y)[net(x;⇥) 6= y]
Empirical risk: R̂(⇥) =1
n
nX
i=1
L(xi
, y
i
;⇥)

Recap2
Data: (xi
, y
i
) 2 X ⇥ Y, i = 1, 2, · · · , nGoal: Find the labeling function c : X 7! Y, c(x) = y
Hypotheses: net(x;⇥)
Expected risk: R(⇥) = E(x,y)[net(x;⇥) 6= y]
Empirical risk: R̂(⇥) =1
n
nX
i=1
L(xi
, y
i
;⇥)
Parameter estimation: ⇥̂ argmin⇥
R̂(⇥)
Optimization by stochastic gradient descent (SGD) :
w
t w
t�1 � ⌘rL(xi
, y
i
;⇥t�1)
⌘ : learning rate

Checkingforconvergence1
• Whathappened?• 1.Bugintheprogram• 2.Learningratetoohigh• 3.Whatifc(x)=yistotallyrandom?• 4.Noappropriatepre-processingoftheInputdataàdummygradients
R̂
iteration t

Checkingforconvergence2
• Whathappened?• Differentlearningrateà differentlocaloptimum&decreasingrate
• Whyoscillation:• 1.Skippedtheoptimumbecauseoflargelearningrate
• 2.Gradientofasingledatapointisnoisy
• 3.NotcomputingtherealR,insteadweapproximateit(seeP12)
R̂
iteration t

Checkingforconvergence3
• Turningdownthelearningrate!• Aftersomeiterations:
R̂
iteration t
⌘ =
const 1
t+ const 2

Overfitting
• Training,validation,test• Whatshallwedo?• Earlystopping• Dataaugmentation• Regularization(Dropout)• Reducethenetworkcomplexity
• Whichplaceshouldwe(early)stop?• Theta_1
iteration t
Error
⇥1 ⇥2

Under-fitting
• Training,validation• Possible reasons
iteration t
Error

Recap
• Neuron• Twobasicneuralnetwork(NN)structures• ConvolutionalNN(CNN):aspecialfeedforward network• UsingNNtoapproximateconcepts(underlyinglabelingfunction)• TrainingaNN(howtodeterminetheweightsofneurons)?• Gradientdescent,stochasticgradientdescent(SGD)• Backpropagation (forefficientgradientcomputation)• Debuggingtricks:learningrate,momentum,earlystopping,dropout,weightdecay,etc.

Next:Recurrentneuralnetworks(RNN)
• Feed-forwardnetworks • Recurrentneuralnetworks
Imagecredit:http://mesin-belajar.blogspot.com/2016/01/a-brief-history-of-neural-nets-and-deep_84.html

WhyRNN?
• Feed-forwardnetworks• Modelstaticinput-outputconcept
• Notimeseries• Existsasingleforwarddirection
• CNN
• Recurrentneuralnetworks• Modeldynamicstatetransition
• Time&sequencedata• Existsfeedbackconnections
• LSTM

WhyRNN?(cont’d)
• Markovmodels• Modeldynamicstatetransition
• Time&sequencedata
• Markov(short-range)dependency• Moderatelysizedstates
• Recurrentneuralnetworks• Modeldynamicstatetransition
• Time&sequencedata
• Long-rangedependency• Exponentiallyexpressivestates

Next:Recurrentneuralnetworks(RNN)
• RNN• Vanishingandexplodinggradients• Longshort-termmemory(LSTM)• Bi-directionalRNN,GRU,Trainingalgorithms,Applications(tentative)

Today
• Administrivia• Neuralnetworks&Backpropagation (IX)• VQA-1,bySuhas

Uploadslidesbeforeorafterclass
• See“PaperPresentation”onUCFwebcourse
• Sharingyourslides• Refertotheoriginalssourcesofimages,figures,etc.inyourslides• ConvertthemtoaPDFfile• UploadthePDFfileto“PaperPresentation”afteryourpresentation

VQA: Visual Question Answering Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C.
Lawrence Zitnick, Devi Parikh; The IEEE International Conference on Computer Vision (ICCV), 2015
Presented by Suhas Nithyanandappa
February 23, 2016

Presentation Outline
• Motivation
• Problem Statement
• VQA Dataset Collection
• VQA Dataset Analysis
• VQA Baselines and Methods
• Results
• Related Work

Motivation
• Using word n-gram statistics to generate reasonable image captions isn’t Artificial Intelligence
• Current state of the art doesn’t capture the common sense reasoning present in the image
Image credits:(C) Dhruv Batra

Why is AI hard ?
Slide credits:(C) Dhruv Batra

(C) Dhruv Batra 5
Is it useful ? - VizWiz
Slide credits:(C) Dhruv Batra

Problem Statement
• In order to such common sense knowledge we need a big enough dataset
• Open-ended questions require a potentially vast set of AI capabilities to answer –
– fine-grained recognition
– object detection
– activity recognition
– knowledge base reasoning
• In order to building such a system we need blocks from various fields: CV, NLP and KR
• VQA – Good place to start

VQA Dataset Collection It is collect using Amazon Mechanical Turk service :
• >10,000 Turkers ~ >41,000 Human Hours ~ 4.7 Human Years ~ 20.61 Person-Job-Years!
Real Images
• 123,287 training and validation images and 81,434 test images from the newly-released Microsoft Common Objects in Context (MS COCO) dataset
• Images contain multiple objects and rich contextual information
• As they are visual complex, they are well-suited for VQA task
• Dataset contains five single-sentence captions for all images.
Image credits:(C) MS COCO

VQA Dataset Collection
Abstract Images
• In order to focus on reasoning, instead of the low-level vision tasks, a new abstract scenes dataset containing 50K scenes has been created
• The dataset contains 20 “paperdoll” human models : spanning genders, races, and ages with 8 different expressions
• The limbs are adjustable to allow for continuous pose variations.
• The clipart may be used to depict both indoor and outdoor scenes
• The set contains over 100 objects and 31 animals in various poses.
Image credits : Appendix of the paper

VQA Dataset Collection
Image credits : Appendix of the paper

VQA Dataset Collection
Questions
• Collecting interesting, diverse, and well-posed questions is a significant challenge.
• Many questions require low-level computer vision knowledge, such as “What color is the cat?” or “How many chairs are present in the scene?
• However, importance was given to collect questions that require common sense knowledge about the scene, such as “What sound does the pictured animal make?”
• Goal: Having wide variety of question types and difficulty, we may be able to measure the continual progress of both visual understanding and common sense reasoning
Image credits : Appendix of the paper
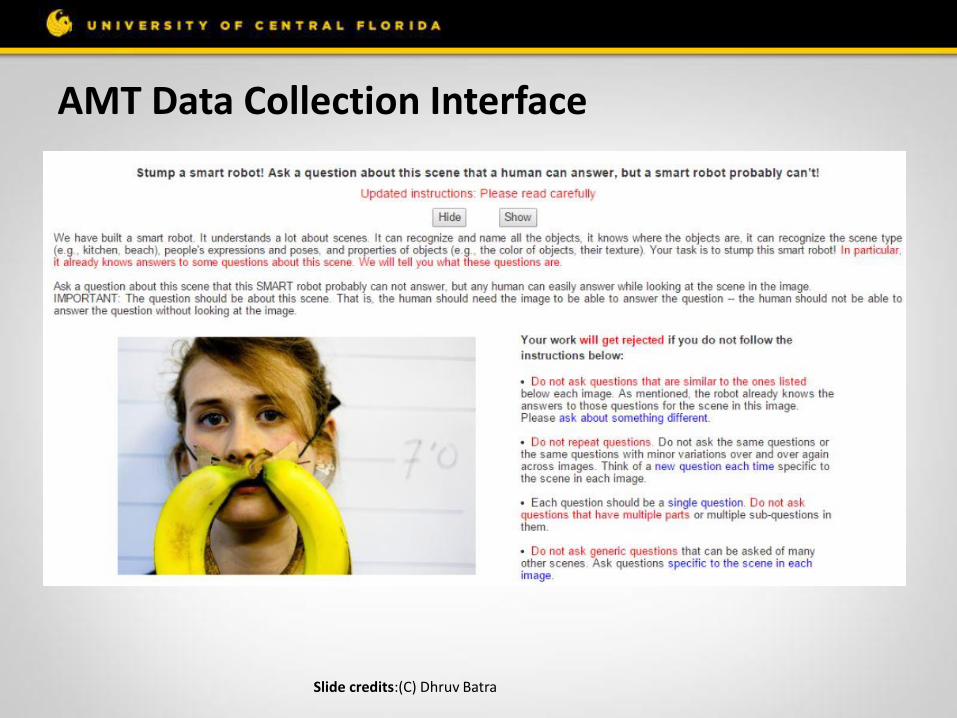
AMT Data Collection Interface
Slide credits:(C) Dhruv Batra

Slide credits:(C) Dhruv Batra

Slide credits:(C) Dhruv Batra

VQA Dataset Collection
Answers
• Open-ended questions result in a diverse set of possible answers.
• Human subjects may also disagree on the “correct” answer, e.g., some saying “yes” while others say “no”
• To handle these discrepancies, we gather 10 answers from unique workers
• Two types of questions: open-answer and multiple-choice.
• For the open-answer task – accuracy metric: an answer is deemed 100% accurate if at least 3 workers provided that exact answer
• Confidence level in answering – By taking in responses yes, no and maybe

AMT Interface for Answer Collection
(C) Dhruv Batra 15 Slide credits:(C) Dhruv Batra


Slide credits:(C) Dhruv Batra

VQA Dataset Analysis
The dataset includes :
• MS COCO dataset : 614,163 questions and 7,984,119 answers for 204,721 images
• Abstract scenes dataset: 150,000 questions with 1,950,000 answers for 50, 000 images
Questions:
• We can cluster questions into different types based on the words that start the question
• Interestingly, the distribution of questions is quite similar for both real images and abstract scenes
• Length : We see that most questions range from four to ten words.
Answers:
• Many questions have yes or no answers
• Questions such as “What is. . . ” and “What type. . . ” have a rich diversity of responses
• Question types such as “What color. . . ” or “Which. . . ” have more specialized responses
• Length : The distribution of answers containing one, two, or three words, – 89.32%, 6.91%, and 2.74% for real images
– 90.51%, 5.89%, and 2.49% for abstract scenes
– This is in contrast with image captions that generically describe the entire image and hence tend to be longer

VQA Dataset Analysis Yes/ No and Number Answers
• Among these ‘yes/no’ questions, there is a bias towards “yes” – 58:83% and 55:86% of ‘yes/no’ answers are “yes” for real images and abstract scenes
Subject Confidence
• A majority of the answers were labelled as confident for both real images and abstract scenes
Inter Human Agreement
• Does the self-judgment of confidence correspond to the answer agreement between subjects?
Image credits:(C) Dhruv Batra

VQA Dataset Analysis Is the Image Necessary?
• Questions can sometimes be answered correctly using commonsense knowledge
• This issue by asking three subjects to answer the questions without seeing the image

VQA Dataset Analysis Captions vs. Questions
• Do generic image captions provide enough information to answer the questions?
• Answer : Statistically different from those mentioned in our questions + answers
• (Kolmogorov-Smirnov test, p < .001) for both real images and abstract scenes
Table credits:(C) Dhruv Batra

VQA Dataset Analysis Which Questions Require Common Sense?
• To capture required knowledge external to the image, three categories were formed
• Toddler (3-4), younger child (5-8), older child (9-12), teenager (13-17), adult (18+)
Statistics
• After data analysis it was observed that – For 47.43% of question 3 or more subjects voted ‘yes’ to common sense, (18:14%: 6 or more).
Image credits:(C) Dhruv Batra

Least “commonsense” questions
23 Slide credits:(C) Dhruv Batra

Most “commonsense” questions
24 Slide credits:(C) Dhruv Batra

VQA Baseline and Analysis To establish baselines, difficulty of the VQA dataset for the MS COCO images is explored
• If we randomly choose an answer from the top 1K answers of the VQA train/ validation dataset, the test-standard accuracy is 0.12%
• If we always select the most popular answer (“yes”), the accuracy is 29.72%
• Picking the most popular answer per question type does 36.18%
• Nearest neighbour approach does 40.61% on validation dataset

2-Channel VQA Model
Slide credits:(C) Dhruv Batra 26
Convolution Layer
+ Non-Linearity
Pooling Layer Convolution Layer
+ Non-Linearity
Pooling Layer Fully-Connected MLP
1k output
units
Embedding
Embedding (BoW)
“How many horses are in this image?”
what 0
where 0
how 1
is 0
could 0
are 0
…
are 1
…
horse 1
…
image 1
Beginning of
question words
Neural Network
Softmax
over top K answers
Image
Question

2-Channel VQA Model
27
Convolution Layer
+ Non-Linearity
Pooling Layer Convolution Layer
+ Non-Linearity
Pooling Layer Fully-Connected MLP
1k output
units
Embedding Neural Network
Softmax
over top K answers
Image
“How many horses are in this image?”
Embedding (LSTM) Question
Slide credits:(C) Dhruv Batra

VQA Baseline and Analysis
Results
Slide credits:(C) Dhruv Batra
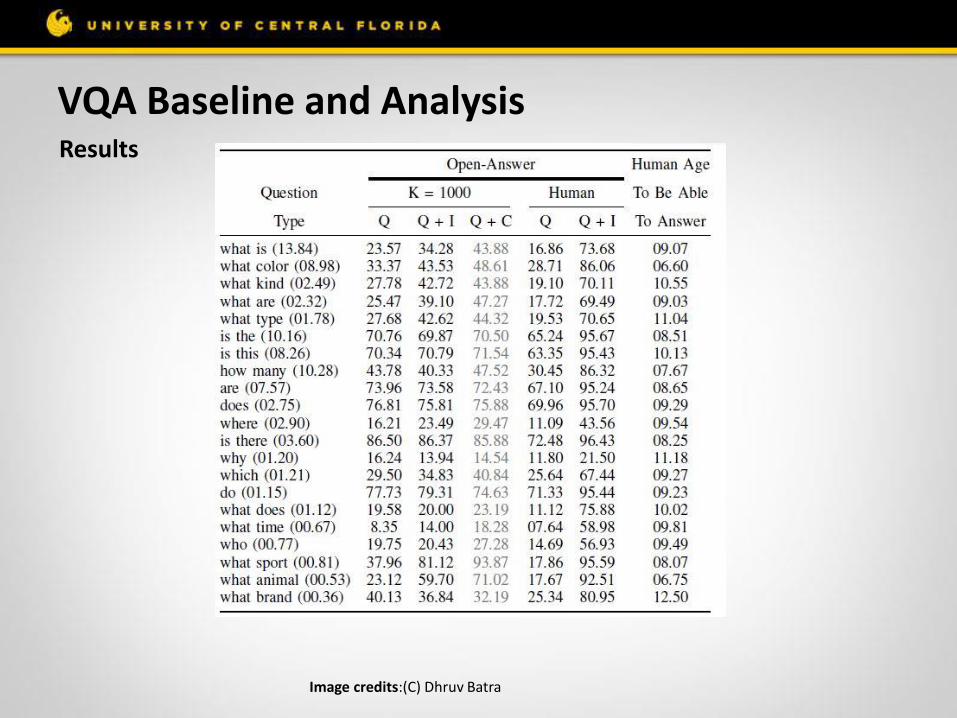
VQA Baseline and Analysis Results
Image credits:(C) Dhruv Batra

Future Work • Training on task-specific datasets may help enable practical
VQA applications.
• Creation of Video datasets performing basic actions might help in capturing commonsense

Are You Talking to a Machine? Dataset and Methods for Multilingual Image
Question Answering Haoyuan Gao, Junhua Mao, Jie Zhou, Zhiheng Huang, Lei Wang, Wei Xu
Related Work:

Introduction • It contains over 150,000 images and 310,000 freestyle
Chinese question-answer pairs and their English translations.
• The quality of the generated answers of our mQA model on this dataset is evaluated by human judges through a Turing Test
• They will also provide a score (i.e. 0, 1, 2, the larger the better) indicating the quality of the answer

Model
Image credits: Paper -Are You Talking to a Machine? Dataset and Methods for Multilingual Image Question Answering

Fusing:
The activation of the fusing layer f(t) for the (t)th word in the answer can be
calculated as follows:
• where “+” denotes element-wise addition
• rQ stands for the activation of the LSTM(Q) memory cells of the last word in the
question
• I denotes the image representation
• Ra(t) and Wa(t) denotes the activation of the LSTM(A) memory cells and the
word embedding of the t th word in the answer respectively
• Vrq, Vi, Vra and Vw are the weight matrices that need to be learned
• g(.) is an element-wise non-linear function
Image credits: Paper -Are You Talking to a Machine? Dataset and Methods for Multilingual Image Question Answering

Results
Table credits: Paper -Are You Talking to a Machine? Dataset and Methods for Multilingual Image Question Answering








![CAP 6412 Advanced Computer Vision - CS Departmentbgong/CAP6412/lec1.pdfEmail --- the best way to reach me • Put [CAP6412] in subject line • Summarize message in subject line •](https://img.pdfslide.us/doc/110x75/5f0cd1657e708231d43747fa/cap-6412-advanced-computer-vision-cs-bgongcap6412lec1pdf-email-the-best.jpg)



![CAP 6412 Advanced Computer Vision - CS Departmentbgong/CAP6412/lec17.pdf · Next week: DAG-CNN & Transferability Tuesday (03/22) NiladriBasuBal [DAG-CNN]Yang, Songfan, and Deva Ramanan."Multi-scale](https://img.pdfslide.us/doc/110x75/5ed6ea40ff4a11075f77097e/cap-6412-advanced-computer-vision-cs-bgongcap6412lec17pdf-next-week-dag-cnn.jpg)
















