Embed Size (px)
Citation preview

calculation | consulting why deep learning works:
perspectives from theoretical chemistry
(TM)
c|c (TM)

calculation|consultingMMDS 2016
why deep learning works:perspectives from theoretical chemistry
(TM)

calculation | consulting why deep learning works
Who Are We?
c|c (TM)
Dr. Charles H. Martin, PhD University of Chicago, Chemical PhysicsNSF Fellow in Theoretical Chemistry
Over 10 years experience in applied Machine LearningDeveloped ML algos for Demand Media; the first $1B IPO since Google
Tech: Aardvark (now Google), eHow, GoDaddy, …Wall Street: BlackRockFortune 500: Big Pharma, Telecom, eBay
(TM)
3

Data Scientists are Different
c|c (TM)
theoretical physics machine learning specialist
(TM)
4
experimental physics data scientist
engineer software, browser tech, dev ops, …
not all techies are the same
calculation | consulting why deep learning works

c|c (TM)
Problem: How can SGD possibly work?Aren’t Neural Nets non-Convex ?!
(TM)
5calculation | consulting why deep learning works
can Spin Glass models suggest why ?
what other models are out there ?
expected observed ?

c|c (TM)
(TM)
6calculation | consulting why deep learning works
Outline
Random Energy Model (REM)
Temperature, regularization and the glass transition
extending REM: Spin Glass of Minimal Frustration
protein folding analogy: Funneled Energy Landscapes
example: Dark Knowledge
Recent work: Spin Glass models for Deep Nets

c|c (TM)
(TM)
7calculation | consulting why deep learning works
Warning
condensed matter theory is about qualitative analogies
we may seek a toy modela mean field theory
a phenomenological description

c|c (TM)
What problem is Deep Learning solving ?
(TM)
8calculation | consulting why deep learning works
minimize cross-entropyhttps://www.ics.uci.edu/~pjsados.pdf

c|c (TM)
Problem: What is a good theoretical model for deep networks ?
(TM)
9calculation | consulting why deep learning works
p-spherical spin glass
LeCun … 2015
L Hamiltonian (Energy function)X Gaussian random variablesw real valued (spins) , spherical constraintH >= 3 (p)
can be solved analytically, simulated easily

c|c (TM)
What is a spin glass ?
(TM)
10calculation | consulting why deep learning works
Frustration: constraints that can not be satisfied
J = X = weightsS = w = spins
Energetically: all spins should be paired

c|c (TM)
why p-spherical spin glass ?
(TM)
11calculation | consulting why deep learning works
crudely: deep networks (effectively) have no local minima !
local minima
k=1 critical points
floor / ground state
k = 2 critical points
k = 3 critical points
the critical points are ordered
saddle points

c|c (TM)
why p-spherical spin glass ?
(TM)
12calculation | consulting why deep learning works
crudely: deep networks (effectively) have no local minima !
http://cims.nyu.edu/~achoroma/NonFlash/Papers/PAPER_AMMGY.pdf
ap

c|c (TM)
(TM)
13calculation | consulting why deep learning works
any local minima will do; the ground state is a state of overtraining
good generalization
overtraining
Early Stopping: to avoid the ground state ?

c|c (TM)
(TM)
14calculation | consulting why deep learning works
it’s easy to find the ground state; it’s hard to generalize ?
Early Stopping: to avoid the ground state ?

c|c (TM)
Current Interpretation
(TM)
15calculation | consulting why deep learning works
•finding the ground state is easy (sic); generalizing is hard
•finding the ground state is irrelevant: any local minima will do
•the ground state is a state over training

c|c (TM)
recent p-spherical spin glass results
(TM)
16calculation | consulting why deep learning works
actually: recent results (2013) on the behavior (distribution of critical points, concentration of the means)
of an isotropic random function on a high dimensional manifold
require: the variables actually concentrate on their means the weights are drawn from isotropic random function
related to: old results TAP solutions (1977) # critical points ~ TAP complexity
avoid local minima? : increase Temperatureharder problem: low Temp behavior of spin glass

c|c (TM)
What problem is Deep Learning solving ?
(TM)
17calculation | consulting why deep learning works
minimize cross-entropy of output layer
entropic effects : not just min energy
more like min free energy (divergence)
Statistical Physics and Information Theory: Neri Merhav

c|c (TM)
(TM)
18calculation | consulting why deep learning works
https://web.stanford.edu/~montanar/RESEARCH/BOOK/partB.pdf
infinite limit of p-spherical spin glass
A related approach: Random Energy Model (REM)

c|c (TM)
Random Energy Model (REM)
(TM)
19calculation | consulting why deep learning works
ground state is governed by Extreme Value Statisticshttp://guava.physics.uiuc.edu/~nigel/courses/563/essays2000/pogorelov.pdf
http://scitation.aip.org/content/aip/journal/jcp/111/14/10.1063/1.479951
old result from protein folding theory

c|c (TM)
REM: What is Temperature ?
(TM)
20calculation | consulting why deep learning works
We can use statistical mechanics to analyze known algorithms
I don’t mean in the traditional sense of algorithmic analysis
take Ej as the objective = loss function + regularizer
study Z: form a mean field theory;take limits N -> inf, T -> 0

c|c (TM)
REM: What is Temperature ?
(TM)
21calculation | consulting why deep learning works
let E(T) by the effective energy
E(T) = E/T ~ sum of weights*activations
as T -> 0, E(T) effective energies diverge; weights explode
Temperature is a proxy for weight constraints
T sets the Energy Scale

c|c (TM)
Temperature: as Weight Constraints
(TM)
22calculation | consulting why deep learning works
•traditional weight regularization
•max norm constraints (i.e. w/dropout)
•batch norm regularization (2015)
we avoid situations when the weights explode
in deep networks, we temper the weightsand the distribution of the activations (i.e local entropy)

c|c (TM)
REM: a toy model for real Glasses
(TM)
23calculation | consulting why deep learning works
but it is believed that entropy collapse ‘drives’ the glass transition
the glass transition is not well understood

c|c (TM)
what is a real (structural) Glass ?
(TM)
24calculation | consulting why deep learning works
Sand + Fire = Glass

c|c (TM)
what is a real (structural) Glass ?
(TM)
25calculation | consulting why deep learning works
all liquids can be made into glassesif we cool then fast enough
the glass transition is not a normal phase transitionnot the melting point
arrangement of atoms is amorphous; not completely random
different cooling rates produce different glassy states
universal phenomena; not universal physicsmolecular details affect the thermodynamics
c|c (TM)
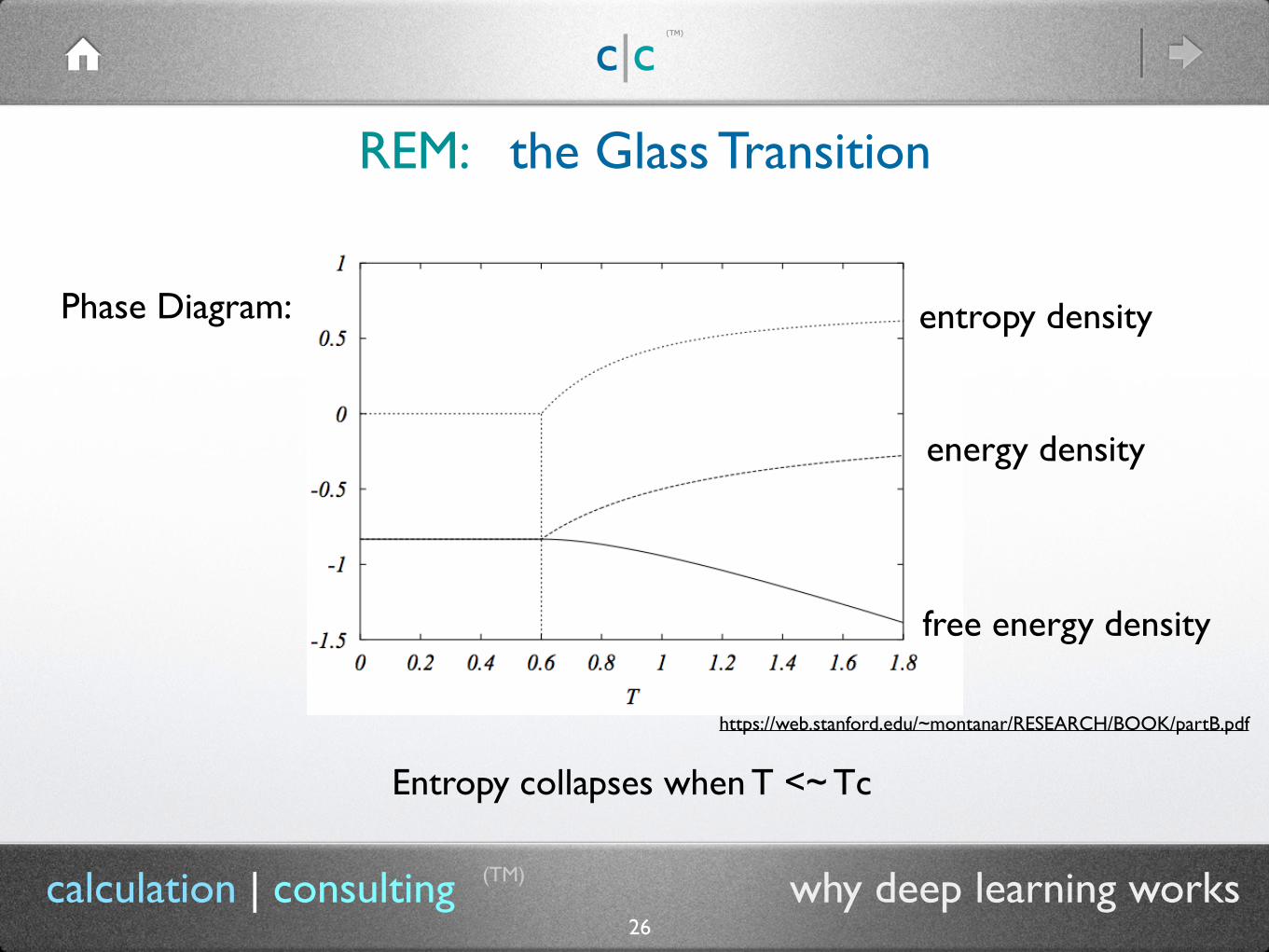
REM: the Glass Transition
(TM)
26calculation | consulting why deep learning works
Entropy collapses when T <~ Tc
Phase Diagram: entropy density
energy density
free energy density
https://web.stanford.edu/~montanar/RESEARCH/BOOK/partB.pdf
c|c (TM)
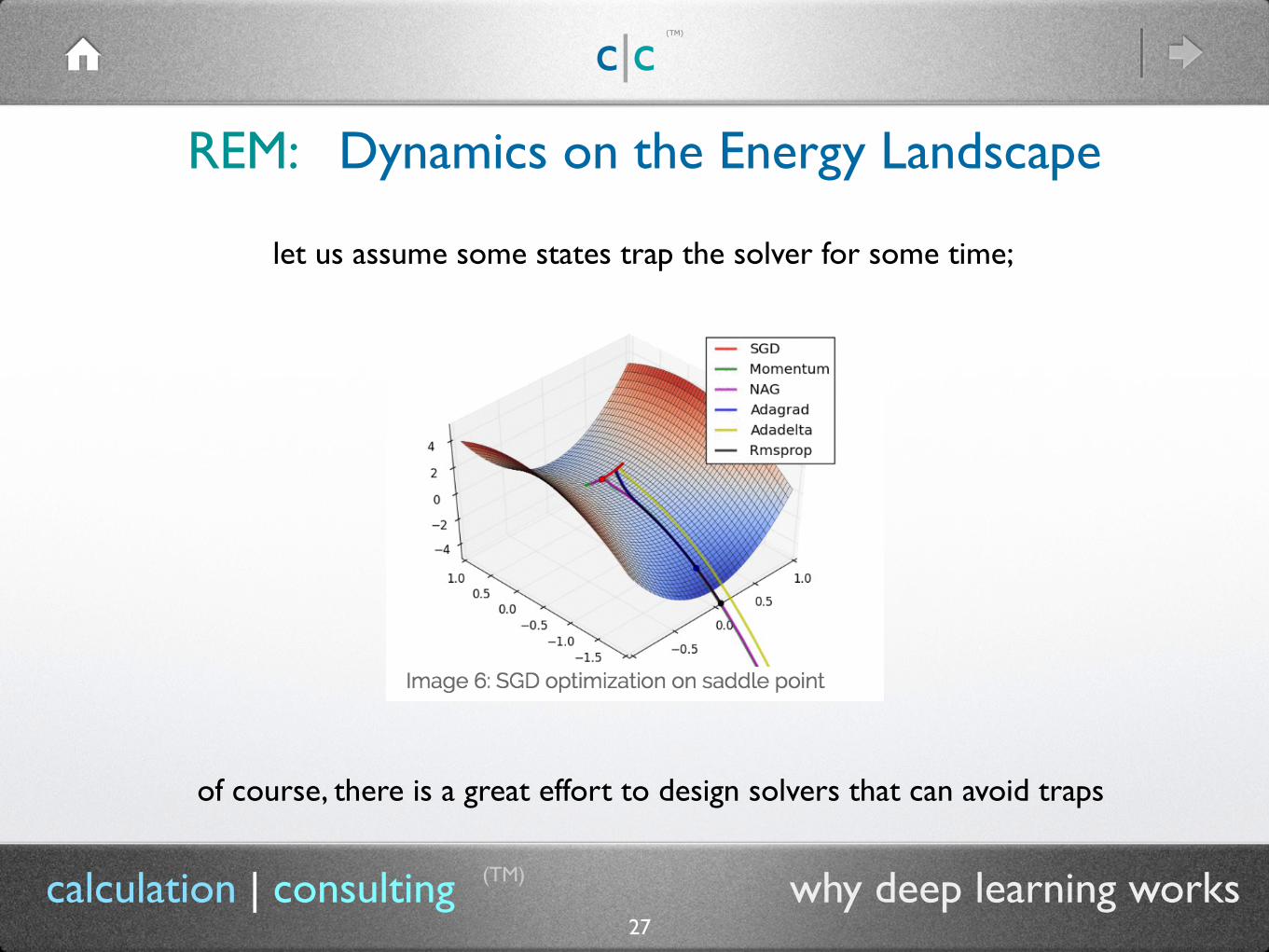
REM: Dynamics on the Energy Landscape
(TM)
27calculation | consulting why deep learning works
let us assume some states trap the solver for some time;
of course, there is a great effort to design solvers that can avoid traps

c|c (TM)
Energy Landscapes: and Protein Folding
(TM)
28calculation | consulting why deep learning works
let us assume some states trap the solver in state E(j) for a short time
and the transitions E(j) -> E(j-1) are governed by finite, reversible transitions (i.e. SGD oscillates back and forth for a while)
classic result(s): for T near the glass Temp (Tc) the traversal times are slower than exponential !
in a physical system, like a protein or polymer, it would take longer than the known lifetime of the universe to find the ground (folded) state

c|c (TM)
Protein Folding: the Levinthal Paradox
(TM)
29calculation | consulting why deep learning works
folding could take longer than the known lifetime of the universe ?

c|c (TM)
(TM)
30calculation | consulting why deep learning works
http://arxiv.org/pdf/cond-mat/9904060v2.pdf
Old analogy between Protein folding and Hopfield Associative Memories
Natural pattern recognition could
• use a mechanism with a glass Temp (Tc) that is as low as possible
• avoid the glass transition entirely, via energetics
Nature (i.e. folding) can not operate this way !
Protein Folding: around the Levinthal Paradox

c|c (TM)
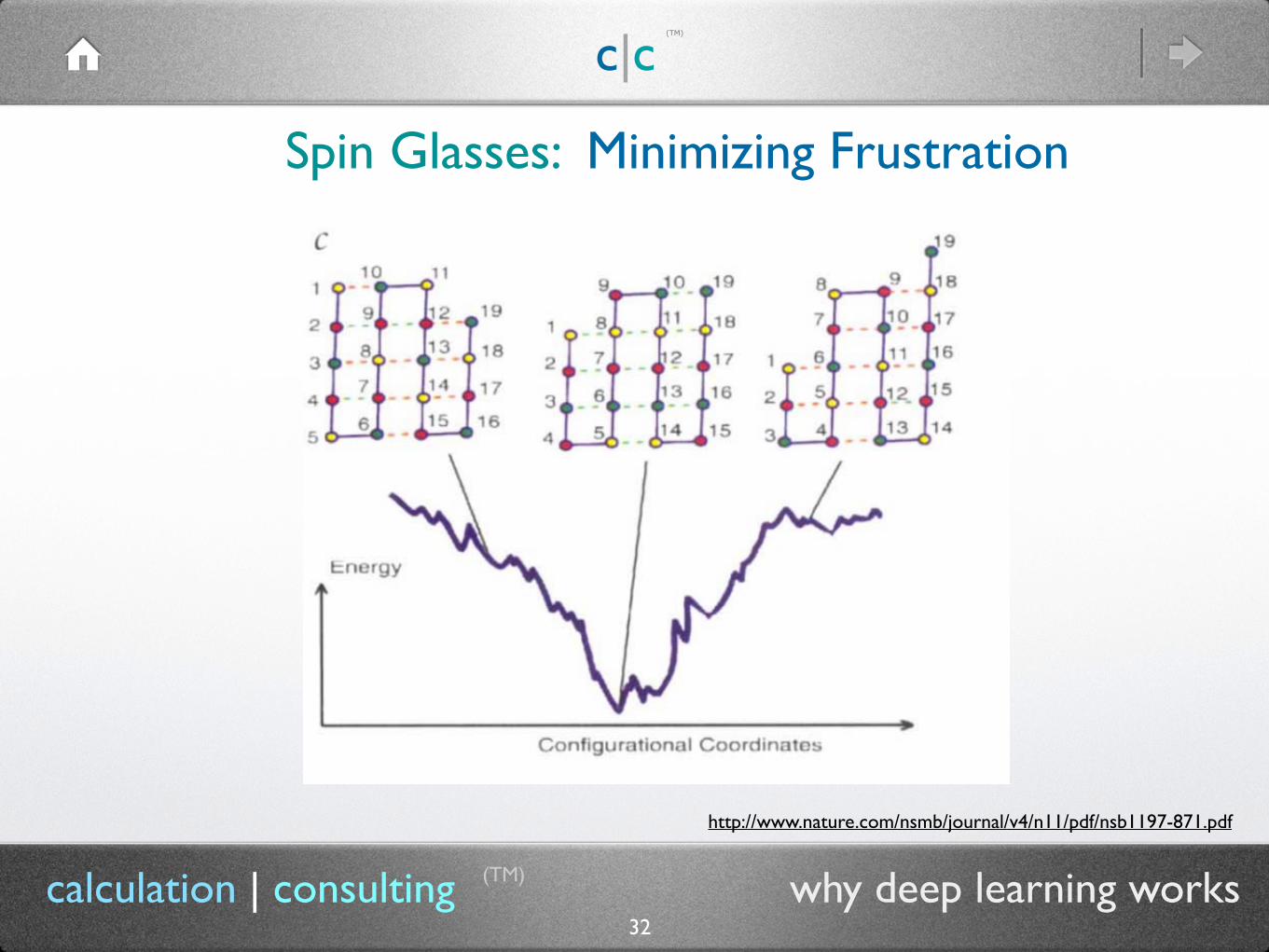
Spin Glasses: Minimizing Frustration
(TM)
31calculation | consulting why deep learning works
http://www.nature.com/nsmb/journal/v4/n11/pdf/nsb1197-871.pdf
c|c (TM)
Spin Glasses: Minimizing Frustration
(TM)
32calculation | consulting why deep learning works
http://www.nature.com/nsmb/journal/v4/n11/pdf/nsb1197-871.pdf

c|c (TM)
Spin Glasses: vs Disordered FerroMagnets
(TM)
33calculation | consulting why deep learning works
http://arxiv.org/pdf/cond-mat/9904060v2.pdf
c|c (TM)
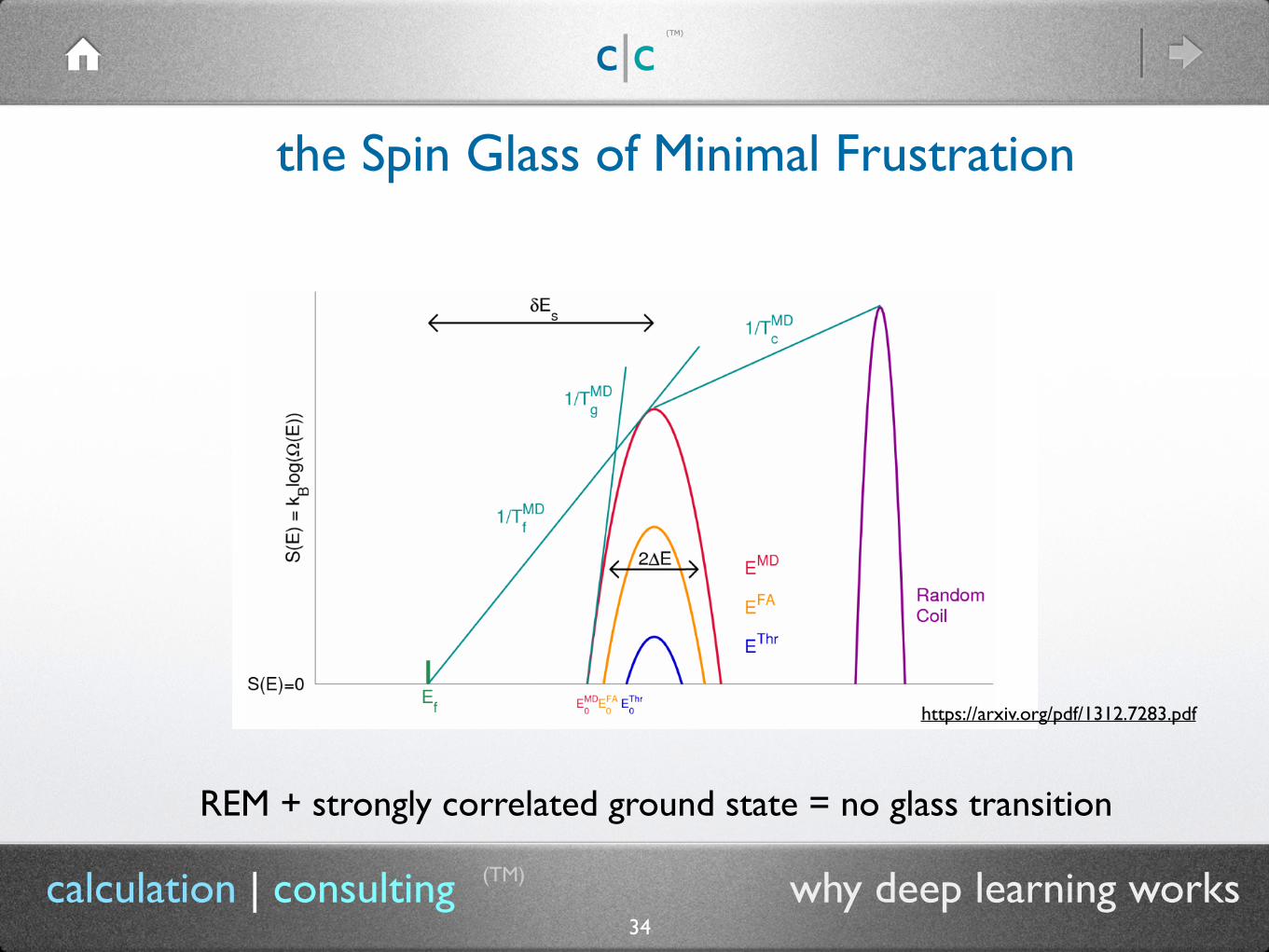
the Spin Glass of Minimal Frustration
(TM)
34calculation | consulting why deep learning works
REM + strongly correlated ground state = no glass transition
https://arxiv.org/pdf/1312.7283.pdf
c|c (TM)
the Spin Glass of Minimal Frustration
(TM)
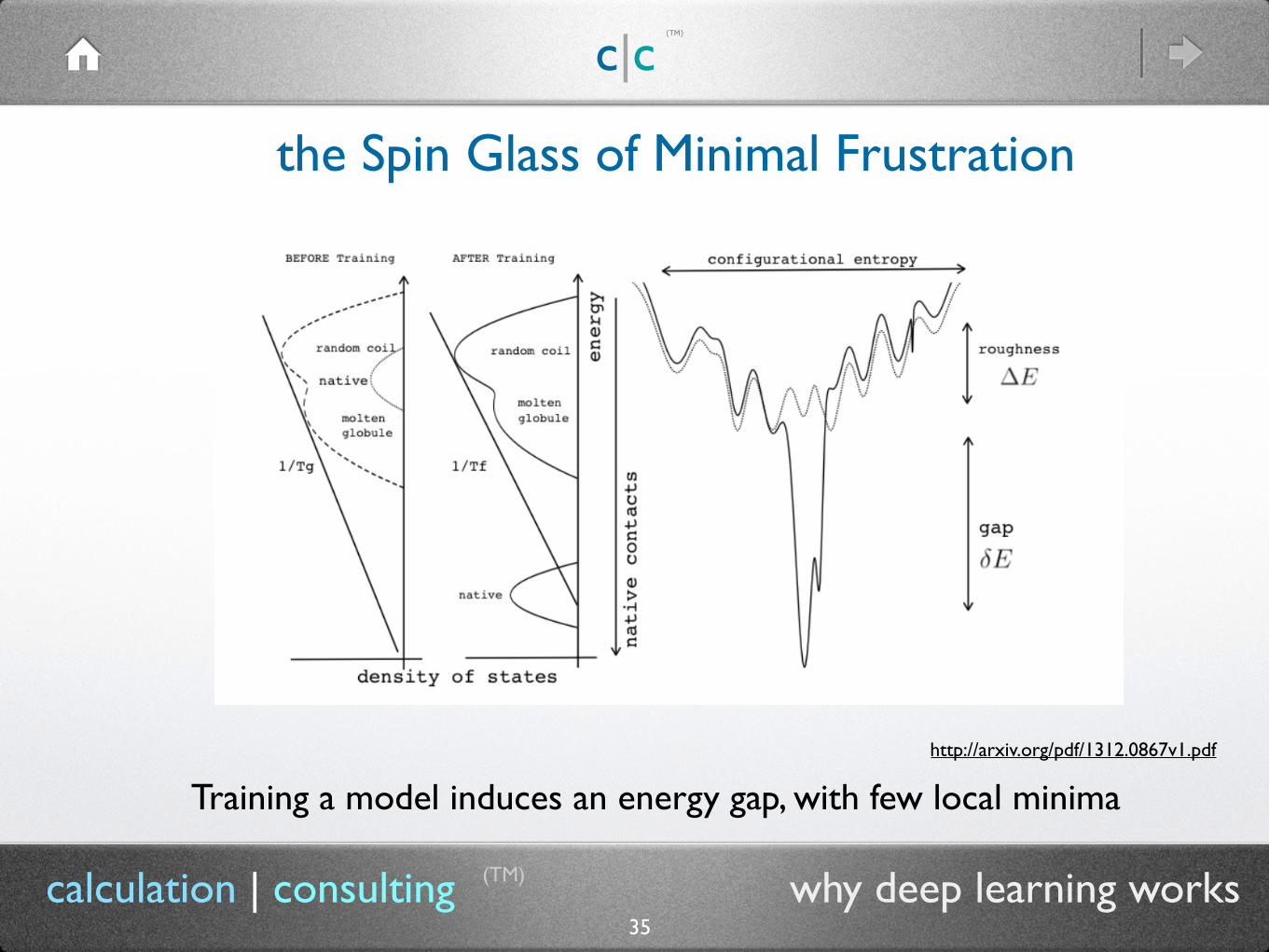
35calculation | consulting why deep learning works
Training a model induces an energy gap, with few local minimahttp://arxiv.org/pdf/1312.0867v1.pdf
c|c (TM)
Energy Funnels: Entropy vs Energy
(TM)
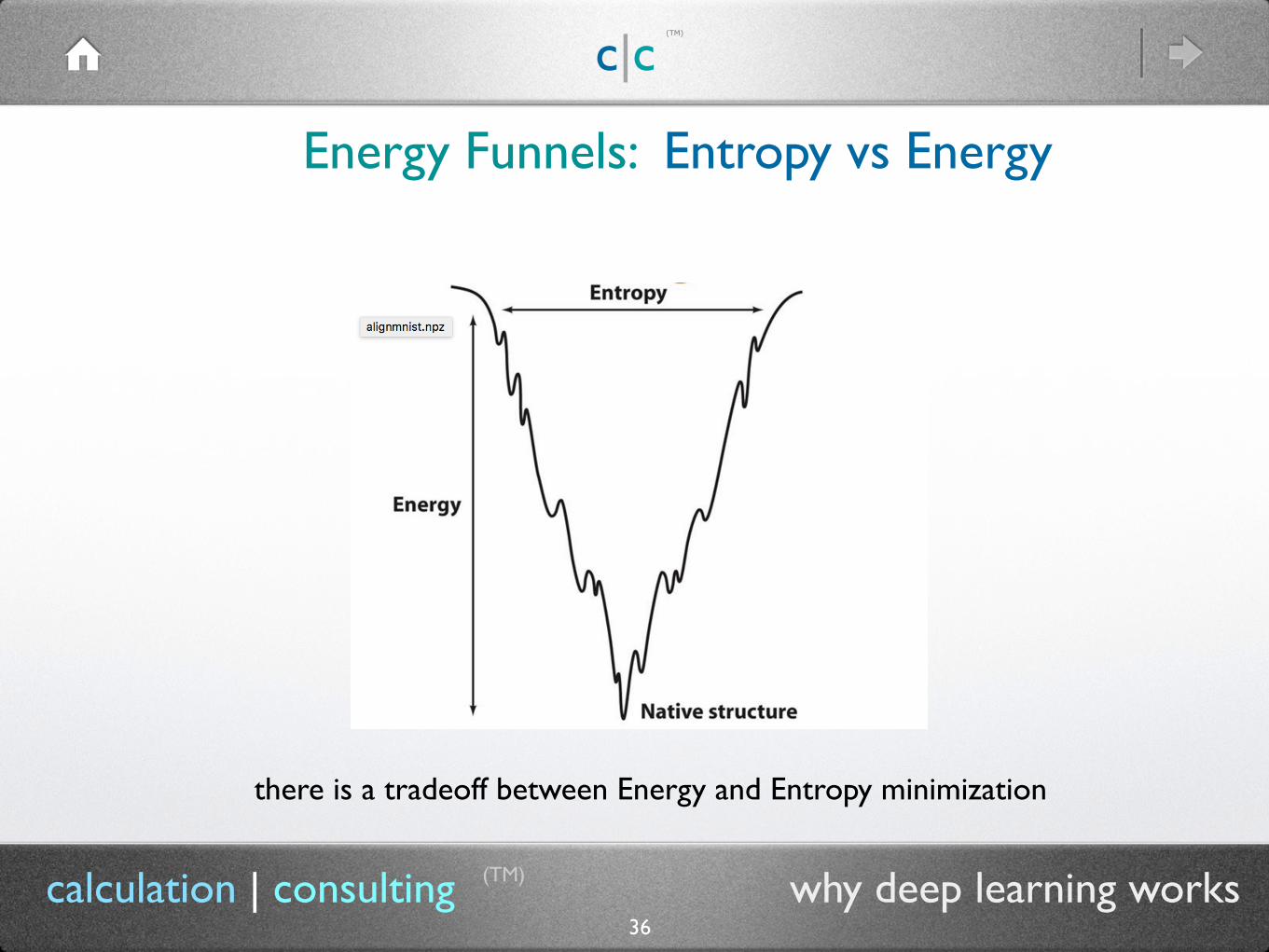
36calculation | consulting why deep learning works
there is a tradeoff between Energy and Entropy minimization

c|c (TM)
Energy Landscape Theory of Protein Folding
(TM)
37calculation | consulting why deep learning works
there is a tradeoff between Energy and Entropy minimization

c|c (TM)
(TM)
38calculation | consulting why deep learning works
Avoids the glass transition by having more favorable energetics
Levinthal paradoxglassy surfacevanishing gradients
Energy Landscape Theory of Protein Folding
funneled landscaperugged convexityenergy / entropy tradeoff

c|c (TM)
Dark Knowledge: an Energy Funnel ?
(TM)
39calculation | consulting why deep learning works
784 -> 800 -> 800 -> 10 MLP on MNIST
Distilled
10,000 test cases, 10 classes
99 errors
same entropy (capacity); better loss function
fit to ensemble soft-max probabilities
146 errors
784 -> 800 -> 800 -> 10
c|c (TM)
Adversarial Deep Nets: an Energy Funnel ?
(TM)
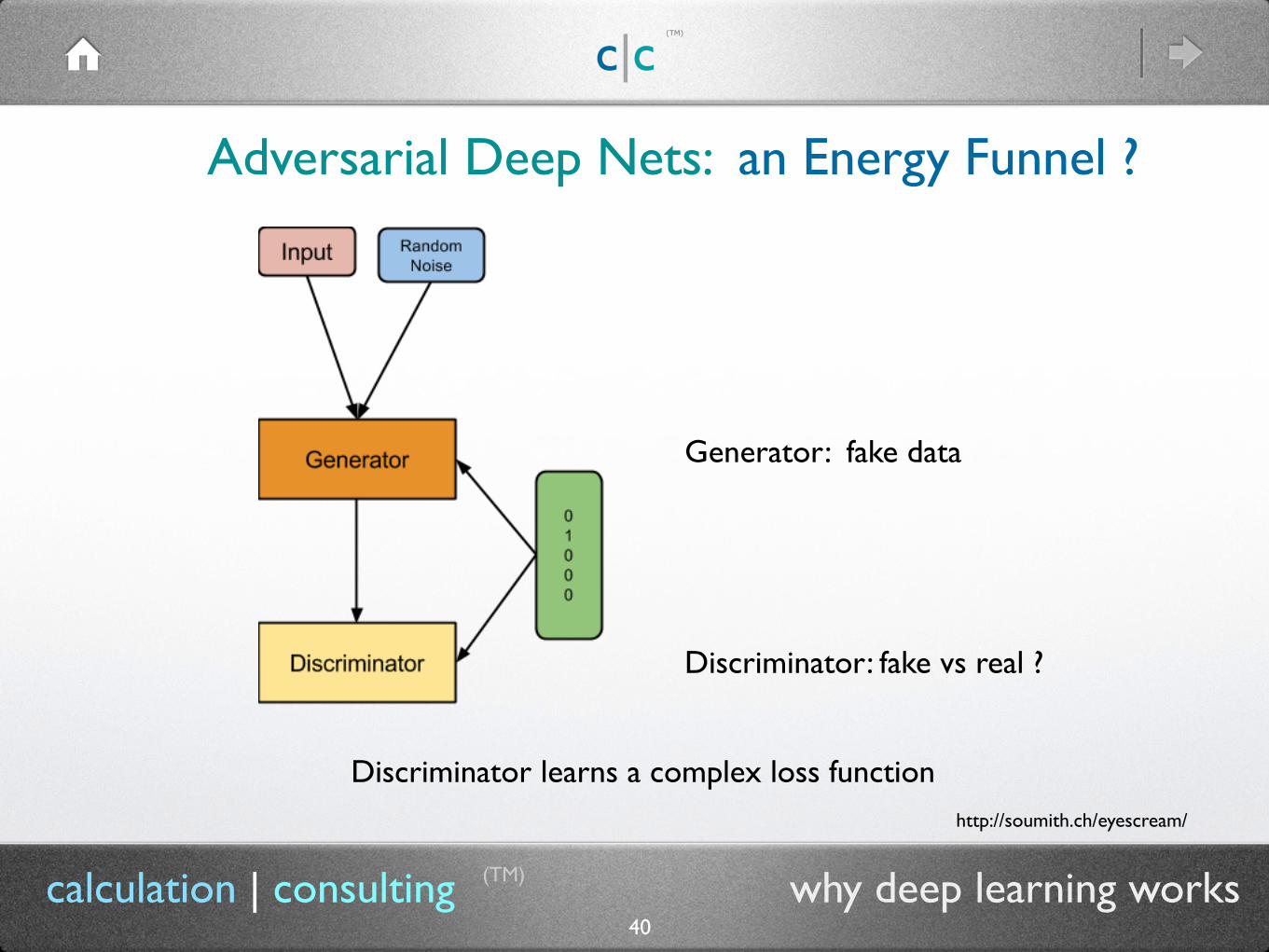
40calculation | consulting why deep learning works
Discriminator learns a complex loss function
Generator: fake data
Discriminator: fake vs real ?
http://soumith.ch/eyescream/

c|c (TM)
(TM)
41calculation | consulting why deep learning works
Summary
Random Energy Model (REM): simpler theoretical model
Glass Transition: temperature ~ weight constraints
extending REM: Spin Glass of Minimal Frustration
possible examples: Dark Knowledge
Funneled Energy Landscapes
Adversarial Deep Nets













![Colored Point Cloud Registration Revisited Supplementary ...redwood-data.org/indoor_lidar_rgbd/supp.pdf · ing Poisson surface reconstruction [3]. The renderings thus exhibit meshing](https://img.pdfslide.us/doc/110x75/6066904f8446635cbe03bcd3/colored-point-cloud-registration-revisited-supplementary-redwood-dataorgindoorlidarrgbdsupppdf.jpg)
















