Embed Size (px)
Citation preview

第 2 章.E-Views による OLS 推定
13
最小二乗法誤差の自乗和が最小になるような直線を見つける
100000
150000
200000
250000
300000
350000
400000
50000 75000 100000 125000 150000
変数A
変数
B
第 2 章.E-Views による OLS 推定
2-1.理想的な性質をもつ未知パラメータの推定量とは?
いま変数 Xと変数 Y の関係をもっとも
的確にあらわすように以下の式
・・・・・(1)
のパラメータ(α,β)を推定したい。
パラメータの推定方法には複数の候補
が考えられるが、そのうちのどの方法を
採用した場合に、もっとも望ましい性質
をもつパラメータ推定値が得られるだろ
うか。そもそも「望ましい性質」とはど
のように定義されるのだろうか
【パラメータ推定量の望ましい性質について検討するときの前提】
データの母集団は十分に大きい。ゆえに、母集団のデータを全て用いてパラメータ推
定を行うことは困難である。そこで、母集団から無作為にN個の標本を抽出し、その有
限標本を用いてパラメータを推定する。ここで「N 個の標本の無作為抽出」は何度でも
行えると想定する。このもとでは、たとえ同じ N個の標本セットであっても、第 1回目
の標本抽出時と第 S回目とでは、中身が一致しないことが自然である。
【具体的なイメージ】
日本の雇用者の給与(X)と消費額(Y)の関係を(1)式の定式化で推定する。
①母集団:約 6300 万人分の(X,Y)の組み合わせが存在
⇒ しかし、現実問題としてその全てを把握することは無理
②有限標本の無作為抽出:ランダムに調査票を郵送して 200 人分のデータを収集
(ここでは回収率 100%を仮定)
③複数回の標本抽出:50 機関が②の作業を同時に実施する。
⇒ 「200 人分の(X,Y)の標本」が 50 セット存在している状況
ttt xy εβα +⋅+=
変数Y
変数 X
【散布図】

第 2 章.E-Views による OLS 推定
14
1)6300 万人分のデータを全て使って(1)式の推定を行えば、αとβの「真の値」
を得ることが可能である。しかし、現実には母集団の完全な把握は困難
2)代替策として、50の研究機関が、各々の収集した 200 の標本を使って個別に
(1)式の推定を行う。このとき、
① 全ての標本を使っていない以上、個別の推計で得られる(α,β)の
推定値が「真の値」と同じになる保証はない。
② 各機関の標本セットの中身は原則として同じではない以上、50 組の
(α,β)の推定値がすべて同じになる保証はない。
◆ 望ましい推定量の尺度
ある方法で得られたパラメータ推定量が以下の性質をみたすとき、その推定量は「望
ましい性質」を有していると言える。
※ 上記具体例に対応させた場合
A)その方法で推計された 50 組の(α,β)の平均値が「真の値」と等しくなる。
→ 不偏性
B)その方法で推計された 50組の(α,β)の「真の値」からのばらつき具合を
みると、他のいかなる方法で推計した 50 組の(α,β)の「真の値」からの
ばらつき具合よりも小さくなっている。 → 有効性(最小分散(性))
C)ここでは 200 としている有限標本のサイズを大きくしていくにつれ、その方
法で推計された(α,β)の推定値は「真の値」と高い確率で一致する。
→ 一致性
【整理】望ましい線形推定量(Linear Estimator) が満たしているべき条件
① 不偏性(Unbiased Estimator) :
② 有効性(Best Estimator) : :あらゆる線形推定量
③ 一致性(Consistent Estimator): plim
※「線形」推定量の定義については省略するが、本書のレベルでは普通に「推定量」と考えてさしつかえない。
*β
ββ =][ *E
]~[][ * ββ VarVar ≤ β~
ββ =*
n→∞

第 2 章.E-Views による OLS 推定
15
最小二乗法誤差の自乗和が最小になるような直線を見つける
100000
150000
200000
250000
300000
350000
400000
50000 75000 100000 125000 150000
変数A
変数
B
2-2.最小二乗法による未知パラメータ推定
[最小二乗法(Ordinary Least Squares)]
いま変数 X と変数 Y の関係をもっとも的
確にあらわすように以下の式
・・・・・(1)
のパラメータ(α,β)を推定したい。
このとき、右図のように、プロットされ
た1つ1つの点と想定する直線上の(同じ
X 座標をもつ)点の差の二乗和が最小にな
るようにα,βの推定値を導出する。
[ ]∑=
⋅+−=T
ttt xyQ
1
2)ˆˆ(min βα
以下に示す「古典的標準線形回帰モデルの諸仮定」が満たされている場合、この OLS 推定値は、
不偏性と有効性を満たし(=最小分散線形不偏推定量:Best Linear Unbiased Estimator)、加
えて一致性も満たす。 (OLS 推定量の具体的な導出手順は章末補論の 2a-Ⅰ節を参照のこと)
【古典的標準線形回帰モデルの諸仮定】
① 推計モデルの誤差項の平均は 0 である。
② 推計モデルの誤差項は自己相関していない。
③ 推計モデルの誤差項は均一分散σ2をもつ。
④ 説明変数行列は非確率変数である。もしくは、各説明変数は誤差項とは無相関である。
⑤ モデルの誤差項は正規分布する。
※⑤は OLS 推定量が BLUE であるために直接的に必要な条件ではないが、得られた推定量に対して様々
な仮説検定を行うことを正当化するうえで必要。
注)正規分布の詳細については、章末補論の 2a-Ⅲ-1 節を参照のこと
変数 X
変数Y
ttt xy εβα +⋅+=
【残差の二乗和を最小化】
第 2 章.E-Views による OLS 推定
16
図 2-1.誤差項の系列相関の有無
①自己相関のない誤差項 ②正の(1 階の)自己相関をもつ誤差項 ③負の(1 階の)自己相関
をもつ誤差項
図 2-2.誤差項の不均一分散
①均一分散のイメージ ②不均一分散のイメージ
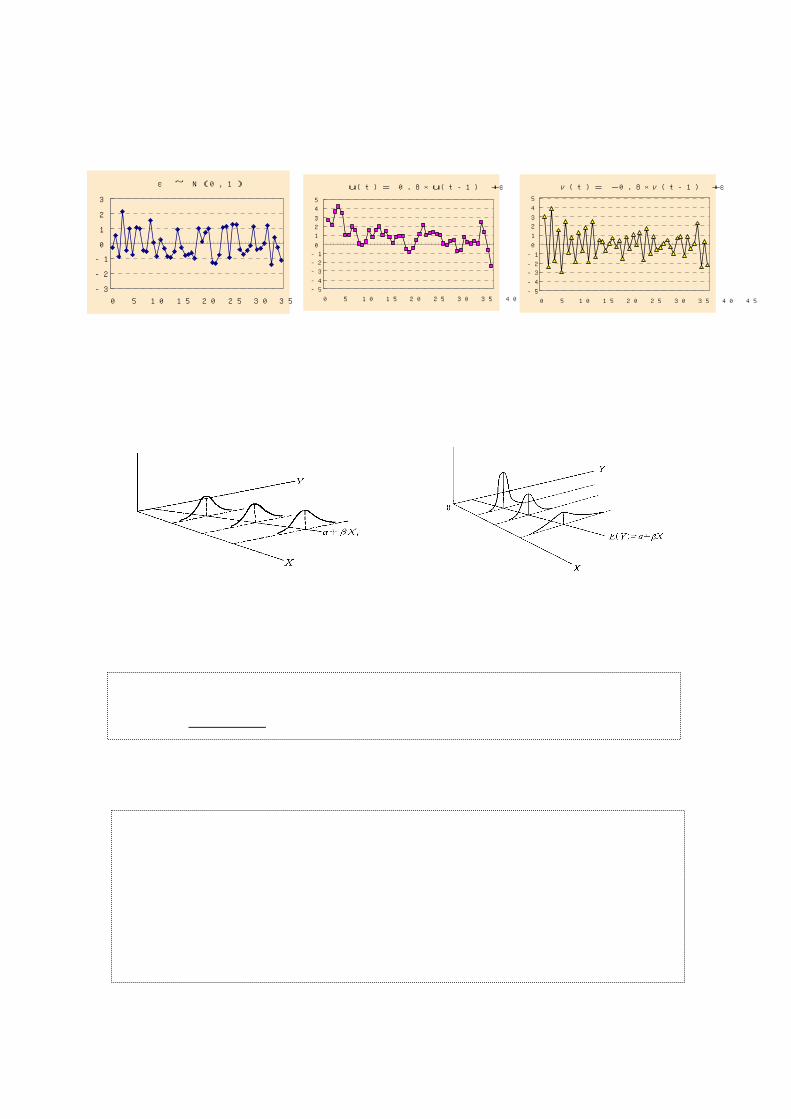
◆ 古典的標準線形回帰モデルの諸仮定を満たす誤差項:White Noise
誤差項が「期待値(平均)ゼロ、均一分散、自己相関なし」の性質をみたすとき、その
誤差項は“White Noise"といわれる。
◆ 再確認:古典的標準線形回帰モデルの仮定が成立するもとで OLS 推定量の性質
1)OLS 推定量は、未知パラメータの最小分散線形不偏推定量(BLUE)となる。
( Cf. BLUE:Best Linear Unbiased Estimator )
2)OLS 推定量は一致性をもつ
3)OLS 推定量は「同時正規分布」に従う ⇒ 様々な仮説検定の実施が正当化される
※ この証明には⑤の仮定を使う
ε ~ N(0,1)
-3
-2
-1
0
1
2
3
0 5 10 15 20 25 30 35 40 45
u(t)= 0.8×u(t-1) +ε
-5
-4
-3
-2
-1
0
1
2
3
4
5
0 5 10 15 20 25 30 35 40 45
ν(t)= -0.8×ν(t-1) +ε
-5
-4
-3
-2
-1
0
1
2
3
4
5
0 5 10 15 20 25 30 35 40 45
確率密度確率密度

第 2 章.E-Views による OLS 推定
17
◆古典的標準線形回帰モデルの諸仮定が成立しないもとで OLS 推定を実施した場合の問題点
1)モデルの誤差項が自己相関しているケース or 不均一分散しているケース
→ OLS 推定量の不偏性は維持されるが、もはや最小分散推定量ではない。
→ 対処法:Beach and MacKinnon(1978)による最尤法、一般化最小二乗法など
→ 第 3 章で検討
2)モデルの説明変数と誤差項が相関しているケース
→ OLS 推定量は「不偏性」も「一致性」も満たさず、「最小分散」推定量でもない。
→ 対処法:操作変数法など
→ 第 5 章で検討
[ポイント]
自分が推計したパラメータが BLUE であることが望ましい。その確信を得るためには、
仮定①~④が満たされていることを確認する必要がある。特に、②自己相関と③不均一
分散は事前に満たされているか否かわからないので、事後的に検定することが不可欠。
2-3.E-Views による OLS 推定
Q2-1 (保存 Workfile 名:“Q2-1.wf1”)
配布された“Q2-1 製造業生産関数.xls”のデータを用い、1978 年~2000 年(暦年)に
おける製造業のコブ=ダグラス型生産関数を推定せよ。具体的な作業は以下に従うこと。
2-3-1.推計式の構築
① 生産関数の一般型:
),,,( ,3,2,1 Lttttt XXXFAY ⋅= (2-1) Y:産出量 Xi:生産要素 A:技術
② 生産要素の決定: ここでは「前期末の民間資本」と「労働」のみとする。
),( 1 tttt LKFAY −⋅= (2-2) Y:産出量 K:民間資本 L:労働
③ 生産関数の特定化: ここでは単純なコブ=ダグラス型を採用
( ) γβαtt
Timet LKeAY ⋅⋅⋅= −
⋅1
~ (2-3) Time:トレンド項

第 2 章.E-Views による OLS 推定
18
④ 推計可能なかたちに定式化: ここでは対数線形を採用する。
tttTime
t LKeAY εγβα +⋅+⋅+⋅+= − logloglog~loglog 1
ttt LaKaTimeaa ε+⋅+⋅+⋅+= − loglog 31210 (2-4)
2-3-2.推計の手順(第 1章の復習)
1)(2-4)式の推計に必要となる製造業のデータを確認
Y:実質 経済活動別国内総生産
K:実質 実稼働民間資本ストック = 実質民間資本ストック(KP) × 稼働率指数(ORI)
L:労働 = 就業者数(MAN)× 実労働時間指数(HOUR)
2)第 1章の資料を参照してデータを E-Views に読み込む。
3)推計式の確認
ttt MHLaKaTimeaaY log95log95log 31210 ⋅+⋅+⋅+= − (2-5)
Where ttt ORIKPK ×= 9595 , ttt AHWELFMHL ×=
Y95 :実質 経済活動別 GDP(製造業) K95:実質 実稼動民間資本ストック(製造業)
KP95:実質 民間資本ストック(製造業) ORI:稼働率指数(製造工業)
MHL :労働需要(製造業) ELF:就業者(製造業)
AHW:実労働時間指数(製造業) Time:タイムトレンド項
4)推計に必要なデータ加工を行う
⇒ LY = LOG(Y95), LK = LOG( KP95 * ORI ), LH = LOG( ELF * AHW )
◎タイムトレンド項のつくりかた ※ このケースでは 1978 年
Genr ボタンを押し、ボックスに“TIME = @TREND(開始時期※)”を入力
5)最終的な推計式
tttt LHaLKaTimeaaLY ε+⋅+⋅+⋅+= − 31210 (2-6)
6)第 1章の資料を参照しつつ、 (2-6)式 を推定する。 ⇒ 推計結果を“EQ01”として保存
2-3-3.数式の直接記述による推計方法
これまでは、推計に用いる説明変数と被説明変数を順番に選択して推計する方法を示してき

第 2 章.E-Views による OLS 推定
19
たが、これとは別に Estimate Equation ボックスに直接的に推計式を記述する方法もある。
⇒ E-Views 全体のメニュー(注:Workfile のメニューではない)から
⇒“Quick” ⇒ “Estimate Equation” ⇒ ボックスに以下を入力
LOG(Y95) = C(1) + C(2)*TIME + C(3)*log(KP95(-1)*ORI(-1)) + C(4)*log(ELF * AHW)
⇒ 同様の推定結果を得ることができる。
① E-Views では「C(数字)」という形式で未知パラメータを定義する。
② 逆に、第 1 章で示した簡便な方法で推計した場合、E-Views は推計されたパラメータ
に対して自動的に C(1)、C(2)・・・と名前をつけていく。各説明変数と C(・)との番
号対応については、推計結果の出力後に「View → Representation」とれば確認できる。
③ 後の実習では、この機能を応用して係数制約の検定を行う。
2-4.OLS の推計結果の見方
前節(2-6)式の推計結果は以下のようになる
表 A.E-Views で OLS を実施したときの出力結果
Dependent Variable: LY Method: Least Squares Date: 12/03/04 Time: 20:14 Sample(adjusted): 1979 2000 Included observations: 22 after adjusting endpoints
Variable Coefficient Std. Error t-Statistic Prob.
C -3.473873 1.274539 -2.725591 0.0139TIME 0.023543 0.006668 3.530861 0.0024LK(-1) 0.232611 0.128694 1.807477 0.0874LH 0.901654 0.164489 5.481533 0.0000
R-squared 0.988829 Mean dependent var 11.49307Adjusted R-squared 0.986967 S.D. dependent var 0.208545S.E. of regression 0.023808 Akaike info criterion -4.474630Sum squared resid 0.010203 Schwarz criterion -4.276259Log likelihood 53.22093 F-statistic 531.0988Durbin-Watson stat 1.363014 Prob(F-statistic) 0.000000

第 2 章.E-Views による OLS 推定
20
2-4-1.係数推定値の統計的な有意性の判断:仮説検定
以下では、推計結果の解釈の仕方を中心に説明する。仮説検定の統計学的な背景に関しての詳
細は章末補論の 2a-Ⅱ節を参照されたい。
1)推計の前提(2-1 節の再確認)
推計に用いられるデータセットは「母集団」ではなく、母集団から無作為に取り出した
N個の「標本」にすぎない。
2)検定の必要性
「母集団」を用いて推計したとき、第 j番目の説明変数の真の係数(αj)がゼロである
としよう。しかし、母集団の全てのデータを推計に用いるのはほぼ不可能なため、実際に
は無作為に抽出された N 個の「標本」を用いてモデルを推計することになる。標本抽出が
無作為である以上、偶然にも第 j 番目の説明変数の係数推定値(aj)が非ゼロのa-
j となる
こともありえる。だが、このとき真の係数を非ゼロとみなすのは明らかに誤っている。
こうした誤った判断を回避するため、推計を行ったときには「(真の値はゼロなのに)
自分が用いた標本で推計されたパラメータがたまたま非ゼロになっている」ことがないか
どうかを必ず確認(=検定)しなければならない。
3)時系列データと「母集団」・「標本」
実習問題 Q2-1 のように、時系列データを用いて日本のマクロ生産関数を推定するケー
スについて考えよう。ここで、1978 年~2000 年の日本の GDP や資本ストックのマクロ系
列は一意である。よって、これを「無作為抽出された標本」と解釈することには違和感が
あるかもしれない。
しかし、統計理論に則れば、我々が知りたいと思っているのは、(特定の期間だけでな
く)過去から未来にかけて普遍的に成立する生産要素と産出量の相関関係である。 そし
て、その普遍的な相関関係を知る手がかりとして、たまたま 1978 年~2000 年の 23 個の標
本を使って推計しているに過ぎない。(実際には、①統計が十分に過去まで整備されてい
ない、②「将来」はまだ実現していないので当然ながらデータもない、という理由から母
集団を把握することはできない。) ゆえに、時系列データを用いて推計をした場合にも係
数推定値に関する仮説検定は必要である。

第 2 章.E-Views による OLS 推定
21
2-4-2.個別の係数の有意性の検定:t検定
推計結果の各項目を以下のように定義する。
aj :第 j番目の説明変数の係数推定値(表 A中の“Estimated Coefficient”)
sA j :第 j番目の説明変数の係数推定値の標準偏差(表 A中の“Standard Error”)
n :標本数(表 A中の“Included Observations”)
k :説明変数の数(含 定数項)
このとき「係数(αj)がゼロに等しい(=説明変数として無意味である)」という帰無仮説が
正しければ、tj=aj/sA j が自由度(n-k)の Student の t 分布に従うことが知られている。
(Student の t分布については章末補論の 2a-Ⅲ-3節、2a-Ⅳ節を参照のこと)
① 実習例における自由度 → n-k = 22 - 4 =18
② 実習例における各係数推定値のt値 → 表 A 中の“t-Statistic”
③ 帰無仮説αj=0 が棄却される確率 → 表 A 中の“P-Value”
※検定の有意水準
確率値(P-Value) が 0.01(0.05)以下の場合、「帰無仮説は有意水準 1%(5%)で統計的に
棄却される」という。t検定のように帰無仮説が棄却されるほうが分析者にとって望ましいケ
ースでは、少なくとも有意水準 5%(最悪でも 10%)以下で帰無仮説が棄却されることが望ま
しい。 つまり、分析者に都合のよい結論が得られにくいように、「棄却」を結論づける閾値を
厳しめに設定して自身を律する。
有意水準の設定に関する議論を厳密に行うためには、仮説検定に伴う「第Ⅰ種の過誤」と「第
Ⅱ種の過誤」を理解せねばならない。詳細については章末補論の 2a-Ⅱ節を参照されたい。
2-4-3.全ての係数がゼロと有意に異ならないかの検定:F検定
t 検定は、単一の係数(例:αj =0)に関する仮説の検定を行うものであった。これとは別に
複数の仮説が同時に成立しているか否かを検定したいときもある(複合仮説の検定)。
実習問題 Q2-1 の推定式
tttt LHaLKaTimeaaLY ε+⋅+⋅+⋅+= − 31210 (2-6:再掲)
における複合仮説の例として、以下のようなものが考えられる。

第 2 章.E-Views による OLS 推定
22
)()1()(
0
01
knSkSS
−−−
)()(
0
01
knSrSS
−−
1)定数項を除く全ての説明変数の係数がゼロ
a1=0 , a2=0 and a3=0(または a1= a2= a3=0 ) → 制約の数(r)=3
2)定数項を除く全ての説明変数の係数が等しい。
a1=a3 and a2=a3(または a1= a2= a3 ) → 制約の数(r)=2
3)技術進歩なし かつ 資本と労働の 1次同次
a1=0 and a2+a3=1 → 制約の数(r)=2
このもとで、上記各ケースのように複数の係数制約が同時に成立するという帰無仮説が正
しいとき、以下の Fは自由度(r,n-k)の F分布に従うことが知られている。
F0 = ~ F(r,n-k) 〈2-7〉
k :説明変数の数(含:定数項) n :標本数
r :制約の数
S1 :制約を課した回帰での残差の平方和 S0 :制約を課さない回帰での残差の平方和
なお、F 分布は 0 を左端とする非対称分布となる。(F 分布の詳細は章末補論の 2a-Ⅲ-4 節、
2a-Ⅴ節を参照のこと)
E-Views の OLS 推定では、「定数項を除く全ての説明変数の係数がゼロ(=自分の変数選択
が無意味)」という帰無仮説が正しいか否かの F検定の結果がデフォルトで表示される。この
とき算出される F値は、
F1 = ※ 制約の数(r) = 説明変数(含:定数項)の数(k) - 1(定数項)
k :説明変数の数(含 定数項)
n :標本数
S0 :もとのモデルを回帰したときの残差の平方和
S1 :定数項だけで回帰したときの残差平方和
※ 実習問題 Q2-1 のケース
・対応する F分布の自由度 → (3,18) ※ n=22, k=4
・F 値(表 A中の“F-Statistic”) → 531.0988
・P 値(表 A中の“Prob(F-statistic)”) → 0.000000

第 2 章.E-Views による OLS 推定
23
この検定も、帰無仮説が棄却されるほうが分析者にとって都合が良い。よって、少なくと
も有意水準 5%以下で帰無仮説が棄却されることが望ましい。上のケースでは、F値は非常に
大きく、有意確率は限りなくゼロに近いので、帰無仮説は強く棄却される。
【注意】
①この検定の対立仮説は「少なくとも1つの係数がゼロではない」である。したがって、帰無
仮説が棄却されたからといって、全ての係数が非ゼロであることを意味するわけではない。
②例えば、複合仮説の具体例 3)に示されるように、分析者が「a1=0 and a2+a3=1」の成立
を信じているとしよう。この場合には、帰無仮説は棄却されないほうがよい。一般に、P値
が 10%より大きくなれば帰無仮説は棄却されないとみなす。このとき「有意水準 10%で帰
無仮説が棄却されない」という。
2-4-4.推計式全体としてのあてはまりの良さを判断する指標:決定係数
1)決定係数
いま、推計しようとしているモデルを以下のように定数項付きで定式化する。
ttt XY εβα ++= 〈2-8〉 ε:誤差
OLS 推計によって得られたパラメータをそれぞれa、bとすると、
ttt ebXaY ++= 〈2-9〉 e:残差(=誤差の推計値)
このとき推定値は以下のように表される。
tt bXaY +=ˆ 〈2-10〉
である。さて、被説明変数の各サンプルについて標本平均からの偏差をとり、その二乗を全標
本について合計したものを「全変動」と定義する。すなわち、
{ } { }222 )()()( ∑∑∑ +−+=−++=− ttttt eYbXaYebXaYY
{ }∑ ⋅−+++−+= tttt eYbXaeYbXa )(2)( 22
{ }∑ ⋅−+++−= tttt eYbXaeYY )(2)ˆ( 22
∑∑∑∑ ⋅−+⋅++−= tttt eYbXaeYY )(2)ˆ( 22 (2-11)
ところで、パラメータは最小二乗法(OLS)で推定されている。その目的関数は、
第 2 章.E-Views による OLS 推定
24
[ ]∑=
⋅+−=T
ttt XbaYQ
1
2)(min (2-12)
よって、aに関する最小化の 1階の条件は
01
=∂∂∑=
aQt
T
t
⇒ ∑∑ ==⋅+− 0))(( ttt eXbaY (2-13)
(2-13)式を(2-11)式に代入して整理すると、
222 )ˆ()( ∑∑∑ +−=− ttt eYYYY
つまり「全変動」は、「推計式によって説明できる部分」と「それ以外の部分」に分解さ
れる。決定係数(R2)は「全変動のうち推計式で説明できる変動の割合」である。
2
2
2
)(
)ˆ(
∑∑
−
−=
YY
YYR
t
t
E-Virews で OLS を実施すると決定係数がデフォルトで表示される。(表 A中の“R-squared”)
2)自由度修正済み決定係数
元の推計式から説明変数を増やしていくと、(付加した説明変数が経済理論からみて妥当であ
るか否かには関係なく)決定係数は少なくとも付加以前と同じか、より高くなる性質がある。
換言すれば、決定係数を高めるためにはやみくもに説明変数を増やしていけばよいことになっ
てしまう。しかし、実際には、説明変数が増加するほど、推計の自由度(=標本数-説明変数
の数)は小さくなる。低い自由度のもとでは推定されたパラメータの信頼性は低下する。
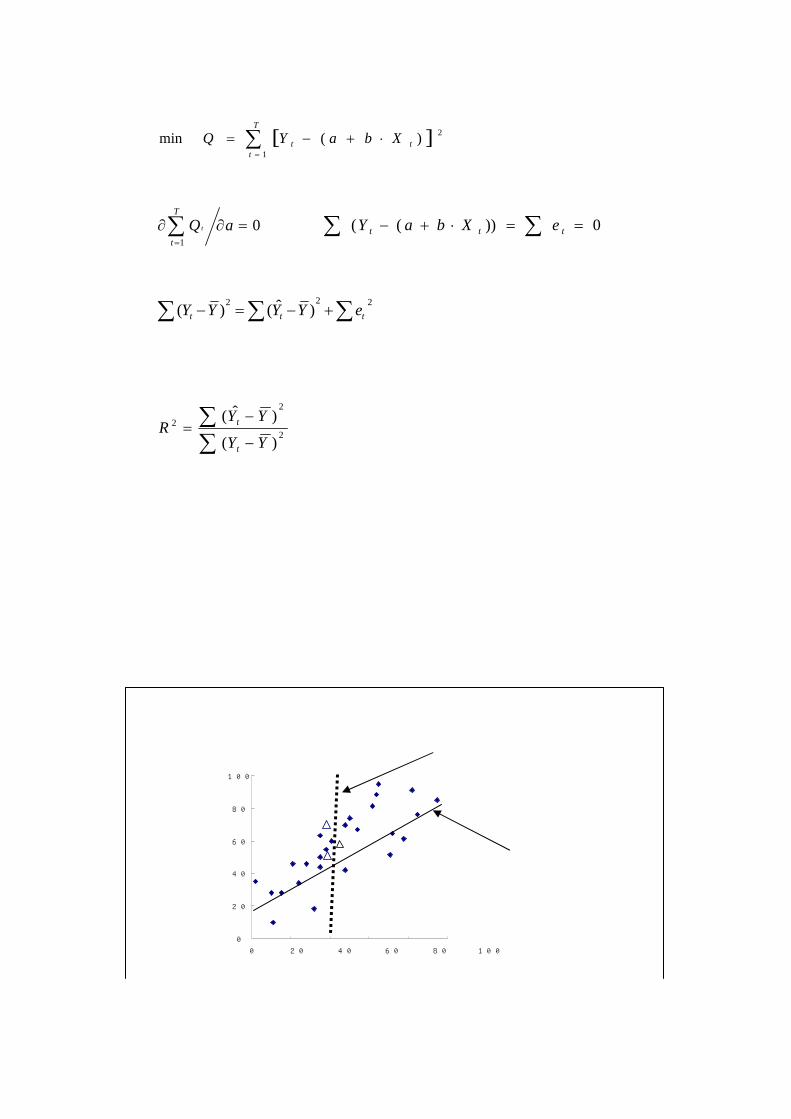
【参考:自由度と推計値の信頼性】
0
20
40
60
80
100
0 20 40 60 80 100
変数 X
変数 Y
多くの標本を利用できた場合
(自由度が大きい場合)
3 つの標本(△)しか利用できなかった場合
(自由度が小さい場合)

第 2 章.E-Views による OLS 推定
25
上の散布図において、 XとYの関係をもっともよく反映する切片(a)と傾き(b)を決めたい(つ
まり推計式は y=a+b・X +ε)。 このとき、もし無作為に選ばれた3つの標本しか推定に利用
できなかったとしたら(自由度 1 に相当)、信頼に足るパラメータを推定できるであろうか?
この問題を是正するため、説明変数の増加による見せかけのフィットの向上に対して、自
由度が減少したことによるペナルティを課した指標が「自由度修正済み決定係数」である。
)1()(
)(1 2
22
−−
−−=∑∑
nYY
kneRadj
t
t
E-Virews で OLS を実施すると自由度修正済決定係数がデフォルトで表示される。(表 A中の
“Adjusted R-squared”)
2-5.古典的線形回帰モデルの諸仮定が成立しているか否かの検定
2-2 節で示された「古典的線形回帰モデルの諸仮定」が満たされているとき、OLS 推定値は最
小分散不偏推定量(BLUE:Best Linear Unbiased Estimator)という望ましい性質をもつ。逆
に言えば、OLS によって得られた係数推定値が BLUE であることを確認するためには、「古典的
線形回帰モデルの諸仮定」が成立しているか否かを検定する必要がある。
2-5-1.検定することが可能な条件
「古典的線形回帰モデルの諸仮定」は以下の5つである。
① 推計モデルの誤差項の平均は 0 である。
② 推計モデルの誤差項は自己相関していない。
③ 推計モデルの誤差項は均一分散σ2をもつ。
④ 説明変数行列は非確率変数である。もしくは、各説明変数は誤差項と無相関である。
⑤ モデルの誤差項は正規分布する。(様々な仮説検定を行ううえで必要)
※⑤は OLS 推定量が BLUE であるために直接的に必要な条件ではないが、得られた推定量に対して様々
な仮説検定を行うことを正当化するうえで必要。
これら①~⑤はいずれもモデルの誤差項に関連した条件である。よって、これらの条件が成

第 2 章.E-Views による OLS 推定
26
立しているか否かを検定するには、推定された誤差項の系列、すなわち、残差項(実績値と
推定値の差)について分析すればよいように思われる。実際、条件②・③・⑤については、
残差系列を用いた検定を行う。
他方で、条件①・④については残差を用いた検定は不可能である。その理由は以下のとお
りである。第 1に、2-4-4 節の(2-13)式で示されたように、OLS では残差平方和最小化の 1
階の条件として「残差の和がゼロ」という制約が課される。よって、残差(つまり誤差の推
定値)については条件①が必ず満たされる。第 2 に、2-4-4 節の(2-12)式で示された最小
二乗法の目的関数について、パラメータ bについての最小化の 1 階の条件を導出すると以下
のようになる。
01
=∂∂∑=
bQt
T
t
⇒ [ ] ( )∑∑ =⋅=⋅⋅+− 0))(( ttttt eXXXbaY (2-14)
これは「説明変数と残差が必ず無相関になる」という制約が課されていることを意味する。
よって、OLS の残差は必ず条件④を満たす。つまり、OLS では、事前に条件①・④が成立して
いるか否とは関係なく、事後的にこの条件が必ず満たされるようにパラメータが推計される。
条件①・④の成立の可否について厳密に議論しようとすると、残念ながら第Ⅰ部で学ぶ内容
を超える統計学の知識が必要になる。よって、以下では、さしあたり分析者が事前に条件①・
④を満たすように被説明変数・説明変数を選んでいることを前提とし、OLS 残差を用いて条
件②・③・⑤の成立の可否について検定する方法について紹介する。 そのうえで、最後に「事
前に条件①・④が満たされているか否か」の確認手段について若干の補足を行う。
2-5-2.誤差項の自己相関の有無に関する検定(Durbin-Watson 検定)
1)自己相関(ないし系列相関)
ある時系列変数 Xtが過去の自身の値 Xt-nと相関を有しているとき、「系列 Xtは自己相関し
ている」ないし「系列 Xtには系列相関がある」という。特に、1 期前の自身の値との相関を
「1階の系列相関」といい、最大で m期前の自身の値との相関がある場合には「m階の系列相
関」があるといわれる。また、2 階を越える系列相関については、ひとまとめにして「高階
の自己相関」と呼ばれることもある。
2)誤差項の系列相関の検定
「古典的線形回帰モデルの諸仮定」の条件②は、モデルの誤差項に 1階ないし高階の系列相関
があってはならないことを意味する。E-Views で OLS を実行すると、誤差項の 1 階の自己相関の
第 2 章.E-Views による OLS 推定
27
有無を検定する Durbin-Watson 検定の結果がデフォルトで表示される。
※ Durbin-Watson 検定
推計された残差を et とすると DW統計量は、
∑
∑
=
=−−
= T
tt
T
ttt
e
eed
1
2
2
21 )(
(2-15)
誤差項の 1階の自己相関過程を以下のように表記する。
ttt ee ερ +⋅= − 1 (2-16)
近似的には(2-15)式を以下のように表すことが可能である。
)1(2 ρ−≈d (2-17)
推計された残差系列を用いると、自己相関係数ρを OLS 推定することができる。
∑∑ −⋅
= 21
t
tt
eee
ρ (2-18)
推計されたρを(2-17)式に代入したものが Durbin-Watson 統計量(DW 値)である。(表
A中の“Durbin-Watson stat”) ここで、DW値には以下のような性質がある。
ρ= 0 ⇒ 誤差項に自己相関なし ⇒ 2≈d
ρ= 1 ⇒ 誤差項に正の自己相関 ⇒ 0≈d
ρ=-1 ⇒ 誤差項に負の自己相関 ⇒ 4≈d
したがって、DW 値が2に近い値をとるほど「誤差項に 1 階の自己相関がない」と
いう強い根拠が得られる。
※ DW 統計量の棄却域
Durbin-Watson 検定では、帰無仮説は「ρ=0(誤差項に 1階の系列相関なし)」であ
る。では、この検定において帰無仮説の棄却域はどのように設定されるのだろうか。
実は、DW 統計量は①(定数項を除く)説明変数の数、②標本のサイズ、③説明変数の
第 2 章.E-Views による OLS 推定
28
観測値に応じて異なる分布をとる。 特に③に関してはほぼ無限の可能性が考えられるの
で、(E-Views に限らず)計量経済分析アプリケーションがあらかじめ全ての可能性に対
して P 値(帰無仮説が正しい確率)を算出できるようなプログラムを用意しておくこと
は不可能に近い。
しかし、幸いなことに Durbin-Watson 統計量には、①(定数項を除く)説明変数の数
と②標本のサイズが同じであれば、③説明変数の観測値に影響を受けない上限分布と下
限分布が存在することが知られている(下図参照)。
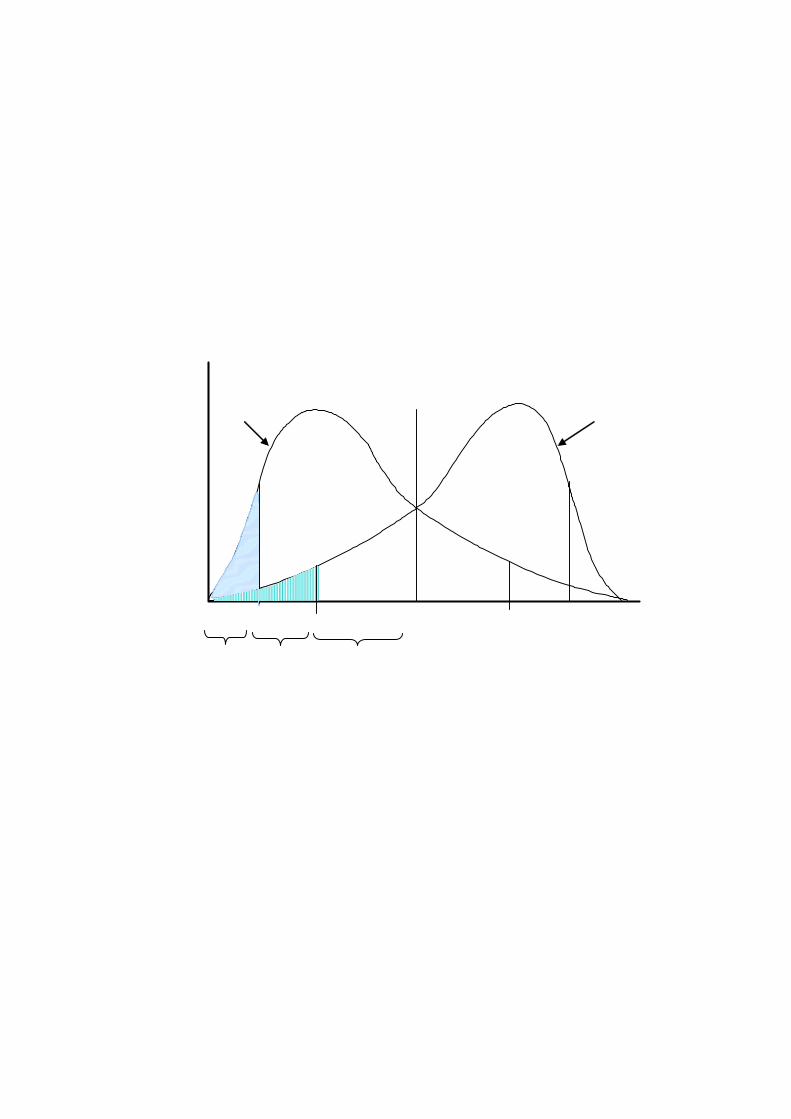
図 2-3.Durbin-Watson 統計量の上限分布と下限分布(イメージ)
2 0 4 4-L 4-U U L
上限分布 下限分布
DW
最初に正の自己相関(ρ>0)が発生しているか否かを検討する。“0<ρ≦1”のとき、
DW 値は 0から 2の間をとりうる。したがって、帰無仮説(ρ=0)の棄却域は左側に設定さ
れる。いま上限分布において有意水準 5%で帰無仮説が棄却される臨界値を U、同じく下限
①上限・下限両分布とも「ρ=0」を棄却
↓
正の自己相関あり
②上限分布でのみ「ρ=0」を棄却
↓
結論は保留される
③上限・下限両分布とも「ρ=0」を棄却せず
↓
誤差項に1階自己相関なし

第 2 章.E-Views による OLS 推定
29
分布において有意水準 5%で帰無仮説が棄却される臨界値を Lと定める。
図 2-3 の①にも示されるように、DW 値が Lより小さいとき、明らかに上限分布でも下限
分布でも“ρ=0”の帰無仮説は棄却される。よって、誤差項に正の1階の系列相関ありと
いう結論が得られる。他方、図 2-3 の③に示されるように、DW 値が Uと 2の間に入ってい
るとき、明らかに上限分布でも下限分布でも“ρ=0”の帰無仮説は棄却されない。よって、
誤差項に正の1階の系列相関なしとみなされる。では、DW 値が Lと Uの間に入った場合は
どうであろうか? このとき上限分布では“ρ=0”の帰無仮説は棄却されるが、下限分布
では棄却されない。よって、この範囲では誤差項に正の1階の系列相関があるか否かの結
論は保留される(図 2-3 の②)。まとめると以下のようになる。
【Durbin-Watson 検定による判定:誤差項における正の1階の系列相関の有無】
帰無仮説:ρ=0(誤差項に1階の系列相関なし)
DW < L ⇒ 「帰無仮説:ρ=0」を棄却 ⇒ ρ>0(正の自己相関)
L < DW < U ⇒ 1階の正の自己相関の有無について結論を保留
U < DW < 2 ⇒ 「帰無仮説:ρ=0」は棄却されず ⇒ 正の自己相関なし
※ DW:Durbin-Watson 値, U:上限分布での臨界値, L:下限分布での臨界値
なお、誤差項に負の1階の自己相関が疑われるとき(-1≦ρ<0)、DW値は 2から 4の間
の値を取りうる。Durbin-Watson 検定においては、誤差項に負の1階の系列相関があるか否
かの判定は以下のように下される。
【Durbin-Watson 検定による判定:誤差項における負の1階の系列相関の有無】
帰無仮説:ρ=0(誤差項に1階の系列相関なし)
2 < DW< 4-U ⇒ 「帰無仮説:ρ=0」は棄却されず ⇒ 負の自己相関なし
4-U < DW < 4-L ⇒ 1階の負の自己相関の有無について結論を保留
4-L < DW < 2 ⇒ 「帰無仮説:ρ=0」を棄却 ⇒ ρ<0(負の自己相関)
したがって、“U < DW < 4-U”が満たされる限りにおいて、誤差項に1階の系列相関
はないとみなすことができる。表 2-1 には、Durbin-Watson 統計における有意水準 5%の棄
却域の臨界値が示されている。実習問題 Q2-1(表 A)では DW 値が約 1.36 となっている。

第 2 章.E-Views による OLS 推定
30
この推計の標本サイズは 22、定数項を除く説明変数の数は 3(タイムトレンド、民間資本、
労働)である。表中の該当欄を見ると、上限分布の臨界値(U)は 1.664、下限分布の臨界
値(L)は 1.053 となっている。ゆえに、“L<DW<U”となるから結論は保留される。
表 2-1.Durbin-Watson 統計における有意水準 5%の境界値 (帰無仮説:ρ=0)
下限 上限 下限 上限 下限 上限 下限 上限 下限 上限 下限 上限 下限 上限
20 1.201 1.411 1.100 1.537 0.998 1.676 0.894 1.828 0.792 1.991 0.692 2.162 0.595 2.339
22 1.239 1.429 1.147 1.541 1.053 1.664 0.958 1.797 0.863 1.940 0.769 2.090 0.677 2.246
30 1.352 1.489 1.284 1.567 1.214 1.650 1.143 1.739 1.071 1.823 1.020 1.920 0.950 2.018
40 1.442 1.544 1.391 1.600 1.338 1.659 1.285 1.721 1.230 1.786 1.175 1.854 1.120 1.924
60 1.549 1.616 1.514 1.652 1.480 1.689 1.444 1.727 1.408 1.767 1.372 1.808 1.335 1.850
80 1.611 1.662 1.586 1.688 1.560 1.715 1.534 1.743 1.507 1.772 1.480 1.801 1.453 1.831
100 1.654 1.694 1.634 1.715 1.613 1.736 1.592 1.758 1.571 1.780 1.550 1.803 1.528 1.826
150 1.720 1.746 1.706 1.760 1.693 1.774 1.679 1.788 1.665 1.802 1.651 1.817 1.637 1.832
200 1.758 1.778 1.748 1.789 1.738 1.799 1.728 1.810 1.718 1.820 1.707 1.831 1.697 1.841
標本数 k=5 k=6 k=7
定数項を除く説明変数の数
k=1 k=2 k=3 k=4
N.E.Savin and Kenneth J.White(1977)“The Durbin-Watson Test for Serial Correlation with Extreme Size
or Many Regressors”,Econometrica,Vol.45,No.8 より抜粋
※ 蓑谷(2003)にはより詳細な 5%有意水準、1%有意水準の臨界値の表がある。
【補足】
① E-Views では DW 値の上限分布・下限分布の値が表示されない。したがって、厳密に
Durbin-Watson 検定を行いたい場合には、蓑谷(2003)の巻末表などを利用し、自分
の推計に応じた臨界値を把握されたい。
② Theil and Nagar(1961)によれば、説明変数が緩やかに変化しながら推移している
場合には、DW 統計の分布は上限分布に近い形状になるという。これに該当する変数の
セットで回帰を行うのであれば、例えば“L<DW<U”となったときには誤差項に1階
の正の自己相関があると疑ったほうがよいと言える。
③ 回帰式の説明変数として被説明変数のラグ項が含まれるとき、実際には誤差項に正
の1階の自己相関があるにもかかわらず、DW値は2に近くなるバイアスをもっている。
このケースにおける代替的な検定については第3章で扱う。
④ Durbin-Watson 検定では誤差項の1階の自己相関の有無しか判定できない。誤差項の
高階の自己相関の検定については第3章で扱う。

第 2 章.E-Views による OLS 推定
31
2-5-3.誤差項の不均一分散性に関する検定(White 検定)
E-Views で OLS 推定を実施後、簡単な操作によって誤差項に不均一分散が発生しているか否
かを検定できる。
1)White 検定
① OLS 推定によって得られた残差の 2乗の系列を作成する。OLS では残差系列の平均はゼロ
となるから、残差の 2乗系列は、残差のばらつき具合(つまり分散)の尺度とみなせる。
② 残差の 2乗系列を被説明変数としたうえで、定数項、もとの回帰式の説明変数、説明変数
の二乗項(場合によってはさらに説明変数どうしのクロス項)で回帰する。
③ 定数項以外の説明変数の係数推定値が有意にゼロと異なり、さらに、②の OLS 推定の決定
係数が高いときには、残差項の分散はある変数(ないしはその 2 乗や他変数とのクロス項)
の変動に応じて規則的に変動しているとみなされる。したがって、「誤差項の分散が均一であ
る」という帰無仮説は棄却される。
④ 統計学的に厳密にいえば、②の OLS 推定の決定係数に標本数を乗じた値(N×R2)は、「誤
差項の分散が均一である」という帰無仮説のもとで自由度を「補助回帰の説明変数の数(除:
定数項)」とする χ2(カイ二乗)分布に従う。 (カイ二乗分布の詳細は章末補論の 2a-Ⅲ
-2 節を参照せよ)
⑤ この検定では、分析者にとって帰無仮説が棄却されないことが望ましい。一般に、P値(帰
無仮説が棄却されない確率)が 0.10(10%)より高ければ、帰無仮説は棄却されないとみな
される。
2)E-Views での操作
E-Views では簡単な操作によって White 検定を実施し、検定統計量および P値を算出する。
⇒ 「View → Residual Tests」と進む。
⇒ 上記②の回帰において
A.変数どうしのクロス項を含めない → White Heteroscedasticity(no cross terms)
B.変数どうしのクロス項を含める → White Heteroscedasticity(cross terms)
~ 実習問題 Q2-1 における、変数どうしのクロス項を含めない White 検定の結果が表 2-2 に示さ
れている。

第 2 章.E-Views による OLS 推定
32
表 2-2.クロス項を含めない White 検定の結果(実習 Q2-1)
White Heteroskedasticity Test:
F-statistic 0.365467 Prob. F(5,16) 0.864732
Obs*R-squared 2.255040 Prob. Chi-Square(5) 0.812847
Test Equation: Dependent Variable: RESID^2 Method: Least Squares Date: 11/08/05 Time: 12:01 Sample: 1979 2000 Included observations: 22
Variable Coefficient Std. Error t-Statistic Prob.
C 0.699405 1.623158 0.430892 0.6723 TIME -0.000136 0.000449 -0.303677 0.7653
TIME^2 3.86E-06 1.57E-05 0.246461 0.8085
LH 0.002616 0.008994 0.290865 0.7749
LK(-1) -0.087378 0.191255 -0.456868 0.6539
LK(-1)^2 0.002616 0.005573 0.469361 0.6451
R-squared 0.102502 Mean dependent var 0.000464 Adjusted R-squared -0.177966 S.D. dependent var 0.000577 S.E. of regression 0.000627 Akaike info criterion -11.68553 Sum squared resid 6.28E-06 Schwarz criterion -11.38797 Log likelihood 134.5408 F-statistic 0.365467 Durbin-Watson stat 2.181640 Prob(F-statistic) 0.864732
1)E-Views は独自の判断(一定の自由度を確保するなどの理由か)で、全ての説明変数とそ
の 2乗項を回帰に含めないことがある。このケースでは変数 LHの 2乗項が捨象された。
2)この結果、定数項を除く説明変数の数は 5 となる。よって、「誤差項の分散が均一」とい
う帰無仮説が正しいもとで、「標本数×決定係数」は自由度 5のカイ二乗分布に従う。
3)この回帰において、標本数は 22、決定係数は 0.1025 である。よって、検定統計量は 2.25
(=22×0.1025)となる。
4)このときp値は 81%(0.81)となり、判断基準となる 10%を大きく上回る。
5)よって、帰無仮説は棄却されない、つまり「誤差項の分散は均一」と結論づけられる。
②の回帰式の OLS 推定の結果
(各係数は有意ではなく、
決定係数も低い)
p値(帰無仮説が正しい確率)
は 81%
(帰無仮説は棄却されない)

第 2 章.E-Views による OLS 推定
33
2-5-4.誤差項の正規性に関する検定(Jarque and Bera 検定)
E-Views で OLS 推定を実施後、やはり簡単な操作によって誤差項が正規分布しているか否かを
検定できる。
1)歪度と尖度
確率変数 y の分布の特徴をあらわすとき、一般には平均(1次のモーメント)と分散(2
次のモーメント)が示される。
平均: ∑=
=N
iiy
Ny
1
1
分散: ∑=
−=N
ii yy
NV
1
2)(1 → 標準偏差 : V=σ̂
※ ただし、分散と標準偏差の不偏推定量は ∑=
−−
=′N
ii yy
NV
1
2)()1(
1 , VS ′=
しかし、より厳密に特徴をあらわしたい場合には、さらに、歪度(3次のモーメント)と尖
度(4次のモーメント)が用いられる。
◆歪度(Skewness): 分布の対称度(非対称度)をあらわす指標
3
1 ˆ1 ∑
=
−=
N
i
i yyN
Sσ
⇒ S=0 → 対称な分布、 S>0 → 右裾が長い分布、 S<0 → 左裾が長い分布
◆尖度(Kurtosis): 正規分布と比較した分布の中心まわりの尖り具合をあらわす指標
∑=
−=
N
i
i yyN
K1
4
ˆ1
σ
⇒ K=3 → 正規分布、 K>3 → より尖っている、 K<3 → より尖っていない

第 2 章.E-Views による OLS 推定
34
2)Jarque & Bera 検定
残差系列から歪度(S)と尖度(K)を算出し、これが正規分布からどれだけ乖離しているか
を検定する。具体的には、以下の Jarque & Bera 統計量を定義する。
−
+⋅−
=4
36
2 KSkNJB k:説明変数の数
直観的にみると、残差項の分布が正規分布に近いほど、JB はゼロに近づくことがわかるだろ
う。より厳密に言えば、統計量 JB は「誤差項が正規分布をとる」という帰無仮説のもとで自
由度 2のχ2分布に従う。
この検定の場合も「帰無仮説が棄却されない(=誤差項が正規分布)」ほうが望ましい。一般
には、p値(帰無仮説が正しい確率)が 0.10(10%)を上回れば、帰無仮説が棄却されないと
みなされる。
3)E-Views での操作
E-Views では簡単な操作で Jarque&Bera 検定を実施し、検定統計量および P値を算出できる。
⇒「View → Residual Test → Histgram ‐ Normality Test」とすすむ。
~ 実習問題 Q2-1 における Jarque&Bera 検定の結果が図 2-4 に示される。
図 2-4.Jarque&Bera 検定の結果(実習 Q2-1)
0
1
2
3
4
5
6
7
8
-0.04 -0.02 0.00 0.02 0.04
Series: ResidualsSample 1979 2000Observations 22
Mean 1.07e-15Median 0.001703Maximum 0.041271Minimum -0.039887Std. Dev. 0.022042Skewness 0.186119Kurtosis 2.479302
Jarque-Bera 0.375547Probability 0.828802
E-Views では残差項のヒストグラムとともに Jarque&Bera 検定の検定統計量とそのp値が
示される。この例ではp値は 0.83(83%)であり、判断基準となる 10%を大きく上回る。よ
って、帰無仮説は棄却されない、つまり「誤差項は正規分布している」と結論づけられる。

第 2 章.E-Views による OLS 推定
35
2-5-5.「古典的線形回帰モデルの諸仮定」の①および④について(若干の補足)
「古典的線形回帰モデルの諸仮定」の①および④とは、
① 推計モデルの誤差項の平均は 0 である。
④ 説明変数行列は非確率変数である。もしくは、各説明変数は誤差項と無相関である。
既に 2-5-1 で述べたように、OLS では残差平方和最小化の1階の条件より、(1)残差系列
の平均がゼロ、(2)残差系列と説明変数系列の無相関が事後的に必ず満たされるようにパラ
メータが推定される。したがって、残差系列を使って条件①・④が事前に満たされているか
否かを検定することはできなかった。では、この問題にどのように対処すべきだろうか。
モデルの誤差項の分布とは、すなわち被説明変数の分布を意味する。よって、条件①を満
たすためには、事前に発散過程にない系列を被説明変数として選択することが重要になろう。
もっとも、この点については第Ⅰ部の範囲を超える。興味のある読者は、第Ⅱ部において時
系列データの「定常性」の概念について学んでほしい。
他方、条件④については変数の「外生性」の概念が重要になる。いま推計したい式が、複
数の式によって記述される経済モデルのうちの 1本の構造方程式であるとしよう。 このと
き推計式の説明変数としてモデルの他の内生変数が含まれていると、当該説明変数は誤差項
と相関をもってしまうことが知られている(同時方程式バイアス)。 したがって、条件④を
満たすためには、経済理論のうえでも、統計理論のうえでも「外生」とみなせる変数を説明
変数として選ぶことが重要になる。実は、説明変数の外生性を検定する方法は存在する。し
かし、これも第Ⅰ部の範囲を超えるので、興味のある読者は第Ⅱ部の第 5章で学んでほしい。
第 2 章.E-Views による OLS 推定
36
2-6.OLS 推定の工夫:ダミー変数の導入
ここからは統計理論を離れ、推計モデルの説明力を高めるためのひとつの工夫として、ダミ
ー変数の活用方法について説明する。
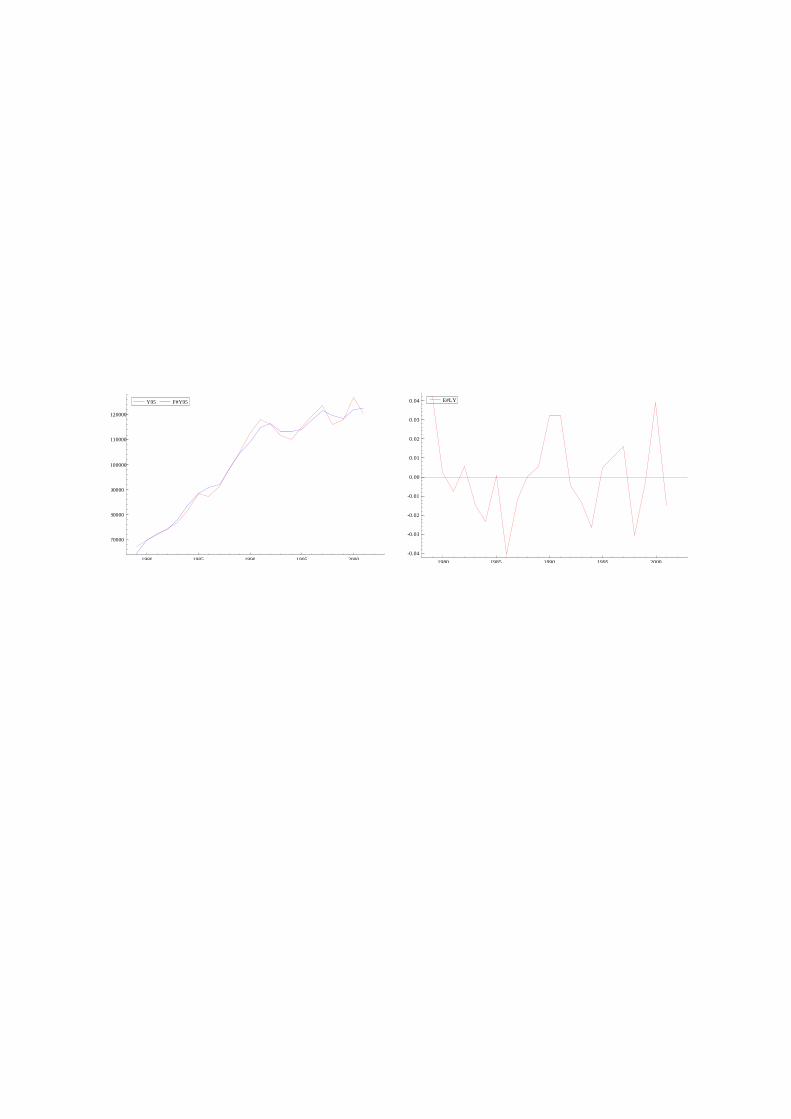
1)推計結果の視覚的把握
実習問題 Q2-1 について、①実績値と推計値の時系列プロット、②残差系列のプロットは以
下の図 2-5、図 2-6 のようにあらわされる。
図 2-5.実績値 と 推計値 図 2-6.残差のプロット
すると以下のような特徴が見出せる。
① バブル期の説明力が低い、 ② 1998 年の推計値は、実績値から大きく乖離
上記 2箇所の実績値と推計値の乖離の理由として、以下のような推論を立てた
a)バブル期(1987~91 年)に資本の生産性が高まった。
b)1998 年は外的ショック(アジア金融危機、大手銀行破綻など)で生産が減少した。
ダミー変数を導入すれば、a)と b)を反映させた推計を行うことができる。
2)定数項ダミーと係数ダミー
ある特定の状況(時系列データであれば「特定の時期」)にだけ1をとり、その他の状況では 0
の値をとる変数を「ダミー変数」という。ダミー変数を推計モデルに組み込む方法としては、①
定数項ダミーと②係数ダミーがある。
1980 1985 1990 1995 2000
70000
80000
90000
100000
110000
120000
Y95 F#Y95
1980 1985 1990 1995 2000-0.04
-0.03
-0.02
-0.01
0.00
0.01
0.02
0.03
0.04 E#LY
第 2 章.E-Views による OLS 推定
37
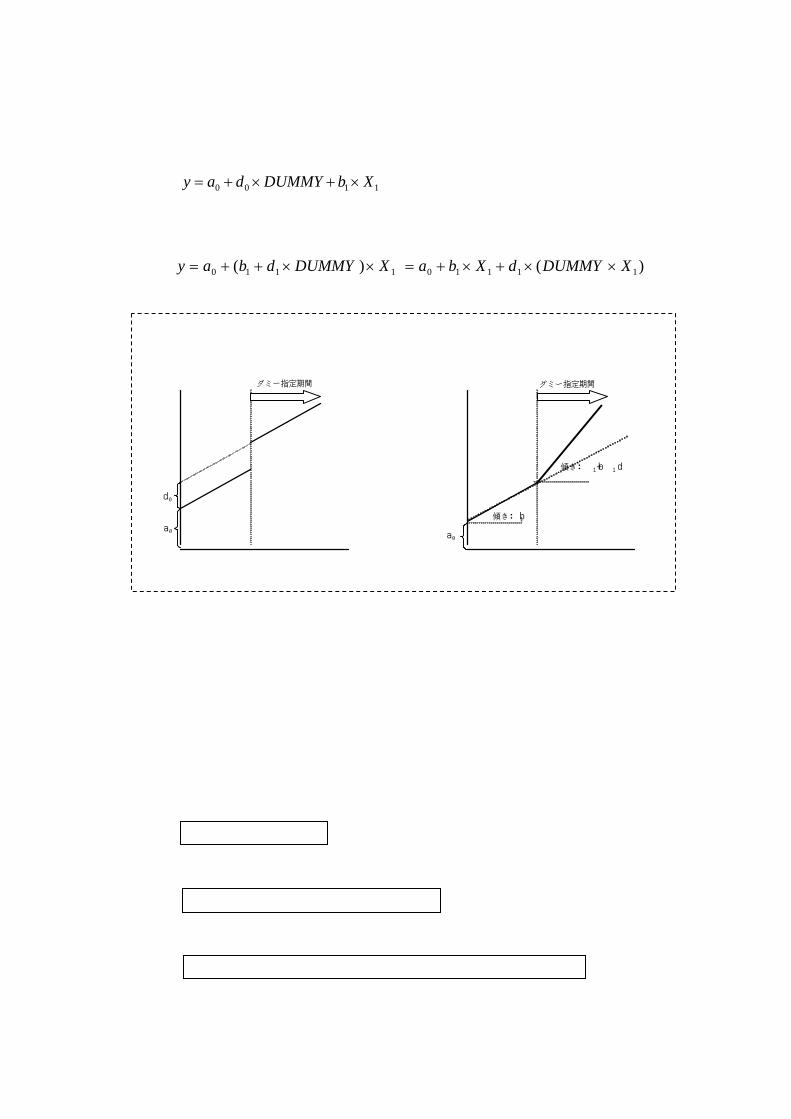
① 定数項ダミー :指定期間でのみ「切片」が変化する。(図 A参照)
1100 XbDUMMYday ×+×+=
② 係数ダミー ⇒ 指定期間でのみ「傾き」が変化する。(図 B参照)
)()( 111101110 XDUMMYdXbaXDUMMYdbay ××+×+=××++=
【定数項ダミーと係数ダミー】
3)ダミー変数の作成
Excel でデータセットを作成する際、経済変数とともに“Year”などの名前で時間変数(例:
1978,1979,・・・,2000)も作成しておき、これを E-Views に読み込んでおくと、後で簡単にダミ
ー変数を作成することができる。具体的な方法は以下のとおりである。
⇒ Workfile ウィンドウより“Genr”を押し、“Enter Equation”欄に
①1998 年に「1」、その他の期間を「0」とするダミー変数“D98”
D98 = (YEAR=1998)
②1987~91 年に「1」、その他の期間を「0」とするダミー変数“D8791”
D8791 = (YEAR>=1987 AND YEAR<=1991)
Cf. 1987~91 年および 1998 年に「1」、その他の期間を「0」とするダミー変数“D8791_98”
D8791_98 = (YEAR>=1987 AND YEAR<=1991) OR (YEAR=1998)
図 A:定数項ダミー 図 B:係数ダミー
a0
d0
傾き:b1
ダミー指定期間 ダミー指定期間
傾き: b1+ d1
a0
第 2 章.E-Views による OLS 推定
38
3)ダミー変数を加えた推計
いま想定している経済環境の変化は、
a)バブル期(1987~91 年)に資本の生産性が高まった。
b)1998 年は外的ショック(アジア金融危機、大手銀行破綻など)で生産が減少した。
である。このうち a)は資本のみに関係するので「係数ダミー」として定式化するのが適当であ
ろう。他方、b)については経済全体を襲った 1次的なショックであるから「定数項ダミー」と
して定式化するのが適切である。よって、元の被説明変数、説明変数に対して以下の2つの項
を加えて OLS 推定すればよい。
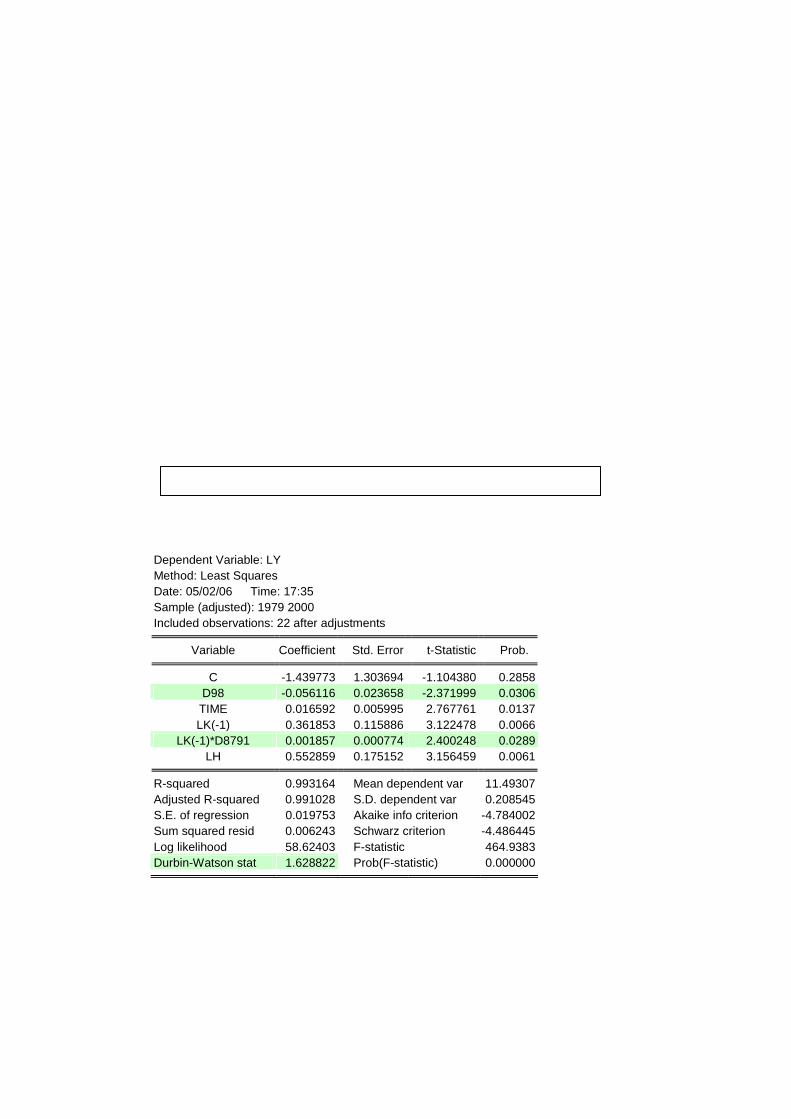
[方法] Workfile ウィンドウより“Object”を押し、“New Object → Equation”と進んで
LY C D98 TIME LK(-1) LK(-1)*D8791 LH
⇒ 推計結果は改善されているか? (推計結果を“EQ02”という名前で保存)
Dependent Variable: LY Method: Least Squares Date: 05/02/06 Time: 17:35 Sample (adjusted): 1979 2000 Included observations: 22 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C -1.439773 1.303694 -1.104380 0.2858D98 -0.056116 0.023658 -2.371999 0.0306TIME 0.016592 0.005995 2.767761 0.0137LK(-1) 0.361853 0.115886 3.122478 0.0066
LK(-1)*D8791 0.001857 0.000774 2.400248 0.0289LH 0.552859 0.175152 3.156459 0.0061
R-squared 0.993164 Mean dependent var 11.49307Adjusted R-squared 0.991028 S.D. dependent var 0.208545S.E. of regression 0.019753 Akaike info criterion -4.784002Sum squared resid 0.006243 Schwarz criterion -4.486445Log likelihood 58.62403 F-statistic 464.9383Durbin-Watson stat 1.628822 Prob(F-statistic) 0.000000

第 2 章.E-Views による OLS 推定
39
2-7.経済理論との整合的な推計:係数制約の妥当性の検定
実証分析の主な目的は、理論モデルの現実妥当性の検証にある。ゆえに、もとの理論モデルで関数
の形状に何らかの制約が課されている場合、回帰分析でもその制約を考慮する必要がある。
1)コブ=ダグラス型生産関数における係数の 1次同次制約
実習問題 Q2-1 ではコブ=ダグラス型の生産関数を推定した。経済理論において、この生産関
数にはしばしば「1次同次」の制約が課される。1
生産関数の 1次同次性: 全ての生産要素を n 倍増やすと、産出量も n 倍増加する。
(いわゆる規模に関する収穫一定)
⇒ ),,,( ,3,2,1 Lttttt XXXFAY ⋅= において、 ttttt nYnXnXnXFA =⋅ ),,,( ,3,2,1 L が成立
コブ=ダグラス型生産関数が以下のように定式化されるときに「1 次同次性」が満たされ、
資本と労働に関して収穫一定となる。
( ) ββα −−
⋅ ⋅⋅⋅= 11
~tt
Tt LKeAY (2-18)
これを対数変換して表記すると、
ttt MHLaKaTimeaaY log)1(95log95log 21210 ⋅−+⋅+⋅+= − (2-19)
Where ttt ORIKPK ×= 9595 , ttt AHWELFMHL ×=
ところでもとの推計式は以下の〈2-5〉式である。
ttt MHLaKaTimeaaY log95log95log 31210 ⋅+⋅+⋅+= − (2-5)
よって、コブ=ダグラス型生産関数の「1次同次性」を満たされるためには、
132 =+ aa
という係数制約が成立している必要がある。
1 この仮定のもとでは、完全競争市場で企業が利潤最大化した場合に、付加価値は余すところなく生産要素の提供者に
分配される。(例:生産要素が資本と労働のみであれば、GDP は雇用者所得と営業余剰に分配し尽くされ、このとき資
本分配率はβ、労働分配率は 1-βとなる。)

第 2 章.E-Views による OLS 推定
40
2)E-Views における係数制約の検定
① 既に 2-3 節で実施したコブ=ダグラス型生産関数の推計結果(EQ01)について、「View →
Representation」とすすみ、説明変数と係数記号の対応関係をを確認する。
ここでは資本の係数が C(3)、労働の係数が C(4)となるケースを想定
②「View → Coefficient Tests → Wald」を選択し、“Restriction”に以下を入力する。
C(3)+C(4)=1
③「帰無仮説:係数制約が有効である」が正しいとき、Wald 統計量は「自由度=制約の数」
とするχ2分布に従う。 なお、このケースでは制約式は「C(3)+C(4)=1」の 1本だけである。
④ 大標本検定2 の統計学的な背景を理解することは容易でない。よって、ここでは Wald 検定
の結果の見方だけ示す。E-Views で Wald 検定を実行すると、出力結果の“Chi-Square”の
Probability 欄に p 値(帰無仮説が棄却されない確率)が示される。ここでは帰無仮説が「係
数制約が妥当」なので、分析者にとっては帰無仮説が棄却されないほうが望ましい。一般に p
値が 0.10(10%)を上回るとき「帰無仮説は棄却されない」とみなされる。
⇒ この実習問題のケースでは係数制約は有効とみなされるか?
⇒ p 値は 0.166 であり、判断の基準となる 0.10 を上回っている。ゆえに「係数制約が妥当」と
いう帰無仮説は棄却されない。
3)あらかじめ 1次同次の係数制約をおいた推定
1 次同次制約の妥当性が確認できれば、あらかじめこの制約を考慮した推計を行える。
⇒ Object → New Object → Equation → OK
⇒ Equation Specification 欄に以下のように入力して推定(“EQ03”という名で保存)
LY = C(5)* TIME +C(6)*LK(-1) +(1-C(6))* LH +C(7)
※ パラメータを C(5)から定義しているのは、前の推定式の係数推定値と区別するため
2 Wald 検定,Lagrange 乗数検定,尤度比検定を指す。これらの検定について知りたければ、行列演算を学んだうえで蓑
谷(1996)『計量経済学の理論と応用』(日本評論社)の第 8 章を読むとわかりやすい。
Wald Test: Equation: EQ01 Test Statistic Value df Probability
F-statistic 1.914685 (1, 18) 0.1834Chi-square 1.914685 1 0.1664

第 2 章.E-Views による OLS 推定
41
《演習》都道府県別データを用いた消費関数の推計
(保存 Workfile 名:“Test2.wf1”)
“Test2 県別消費関数.xls”(=H12 年度の『県民経済計算』より)をもとに、以下の OLS
推定・仮説検定を行いなさい。ただし、沖縄県は大幅な外れ値となるので、推計時にはこ
れを除き、46都道府県を標本として OLS を実行すること。
1.消費と所得のデータを人口 1人当たりの金額に変換し、以下の2通りのケインズ型
消費関数を推計せよ(消費=定数項+β×所得)。
(a)東京都、愛知県、大阪府のそれぞれについて人口 1人あたり実質 GDP に関
する係数ダミーを作成し、説明変数に付加せよ。(“EQ01”として保存)
(b)「東京、愛知、大阪の3都府県が同時に 1の値をとるダミー」を作成し、人
口1人あたり実質GDPに関する係数ダミーをつくって説明変数に付加せよ。
(“EQ02”として保存) ※このダミーの作成にあたってはテキストの「応用」が必要
2.「東京、愛知、大阪の係数ダミーは同時にゼロである」という帰無仮説が棄却される
か否かを調べよ。(有意水準は 5%) ⇒ Freeze 後に“Table01”として保存
3.「東京、愛知、大阪の係数ダミーの大きさは全て同じである」という帰無仮説が棄却
されるか否か調べよ。(有意水準は 5%) ⇒ Freeze 後に“Table02”として保存
※このダミーの作成にあたってはテキストの「応用」が必要
[お断り] あくまでも実習例なので、モデルの全体的なフィットには目をつむってほしい。
⇒ 巻末〔P221〕に解答例が掲載されている。






















![Twitter の複数アカウント所持者を対象とした 投稿アカウント推 … · 奥野ら[8] は,文字n-gram を素性としたTwitter 著者推定の 手法を提案している.n](https://img.pdfslide.us/doc/110x75/5e61e71d837c5e6a436928e9/twitter-effoeee-cff.jpg)





