Embed Size (px)
Citation preview

C O M P U T A T I O N A L R E S E A R C H D I V I S I O N
BIPSBIPS
Investigation of Leading HPC I/O Performance Using a Scientific Application Derived Benchmark
Julian Borrill, Leonid Oliker, John Shalf, Hongzhang Shan
Computational Research Division/
National Energy Research Scientific Computing Center (NERSC)Lawrence Berkeley National Laboratory

BIPSBIPS Overview
Motivation Demands for computational resources growing at rapid rate
Racing toward very high concurrency petaflop computing Explosion of sensor & simulation data make I/O critical component
Overview Present MADbench2: lightweight, portable, parameterized I/O benchmark
Derived directly from CMB analysis package Allows study under realistic I/O demands and patterns Discovered optimizations can be fed back into scientific code Tunable code allows I/O exploration of new and future systems
Examine I/O performance across 7 leading HEC systems Luster (XT3, IA-64 cluster), GPFS (Power5, AMD-cluster)
BG/L (GPFS and PVFS2), CXFS (SGI Altix) MORE???? (what is different about this from other I/O benchmarks)
Schtick: this is application driven (cannot understand results of other benchmarks in the context of application requirements)

BIPSBIPS Cosmic Microwave Background
After Big Bang, expansion of space cools the Universe until it falls below the ionization temperature of hydrogen when free electrons combine with protons
With nothing to scatter off, the photons then free-stream; the CMB is therefore a snapshot of the Universe at the moment it first becomes electrically neutral about 400,000 years after the Big Bang
Tiny anisotropies in CMB radiation aresensitive probes of cosmology
Cosmic - primordial photons filling all space
Microwave - red-shifted by the continued expansion of the Universe from 3000K at last scattering to 3K today
Background - coming from “behind” all astrophysical sources.
BIPSBIPS CMB Science
The CMB is a unique probe of the very early Universe
Tiny fluctuations in its temperature (1 in 100K) and polarization (1 in 100M) encode the fundamental parameters of cosmology, including the geometry, composition (mass-energy content), and ionization history of the Universe
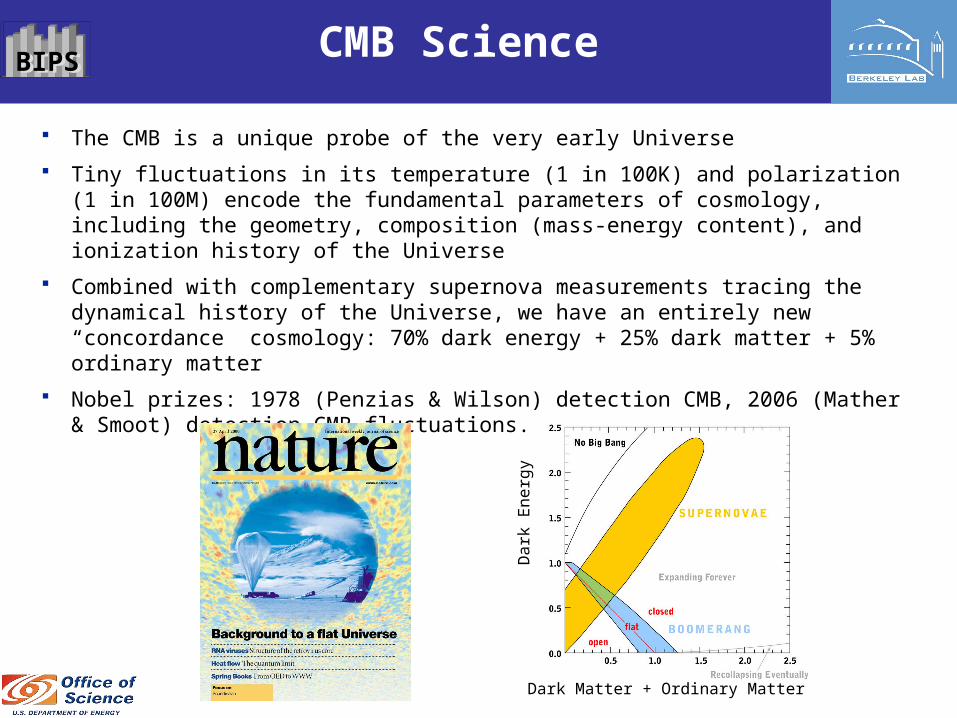
Combined with complementary supernova measurements tracing the dynamical history of the Universe, we have an entirely new “concordance” cosmology: 70% dark energy + 25% dark matter + 5% ordinary matter
Nobel prizes: 1978 (Penzias & Wilson) detection CMB, 2006 (Mather & Smoot) detection CMB fluctuations.
Dark Matter + Ordinary Matter
Dark
Energ
y
BIPSBIPS
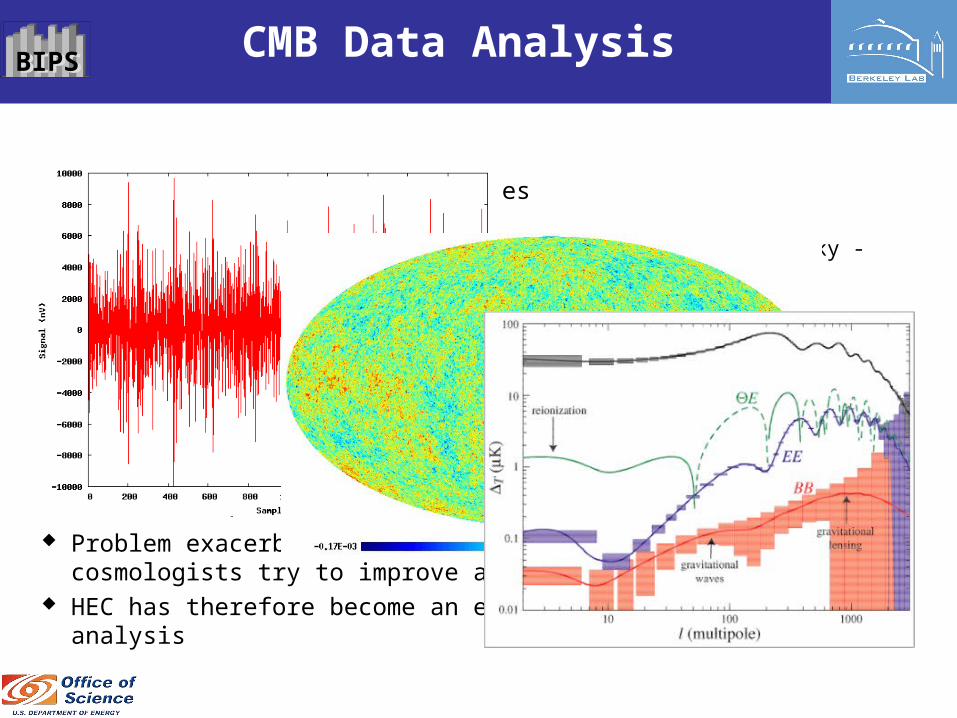
CMB analysis progressively moves from the time domain:
precise high-resolution measurements of the microwave sky - O(1012) to the pixel domain:
pixelized sky map - O(108) and finally to the multipole domain:
angular power spectrum (most compact sufficient statistic for CMB) - O(104)
calculating the compressed data and their reduced error bars (data correlations for error/uncertainity analysis) at each step
Problem exacerbated by an explosion in dataset sizes as cosmologists try to improve accuracy
HEC has therefore become an essential part of CMB data analysis
CMB Data Analysis

BIPSBIPS
Lightweight version of the MADCAP maximum likelihood CMB angular power spectrum estimation code
Unlike most I/O benchmarks, MADbench2 is derived directly from important app
Benchmark retains operational complexity and integrated system requirements of the full science code
Eliminated special-case features, preliminary data checking, etc.
Out-of-core calculation because of large size of pixel-pixel correlation matrices Holds at most three matrices in memory at any one time
MADbench2 used for Procuring supercomputers and filesystems Benchmarking and optimizing performance of realistic scientific applications Comparing various computer system architectures
MADbench2 Overview

BIPSBIPS Computational Structure
Derive spectra from sky maps by: Compute, Write (Loop): Recursively build sequence of Legendre polynomial
based CMB signal pixel-pixel correlation component matrices Compute/Communicate: Form and invert CMB signal & noise correlation matrix Read, Compute, Write (Loop): Read each CMB component signal matrix,
multiply by inverse CMV data correlation matrix, write resulting matrix to disk Read, Compute/Communicate (Loop): In turn read each pair of these result
matrices and calculate trace of their product
Recast as benchmarking tool: all scientific detail removed, allows varying busy-work component to measure balance between computational method and I/O
BIPSBIPS
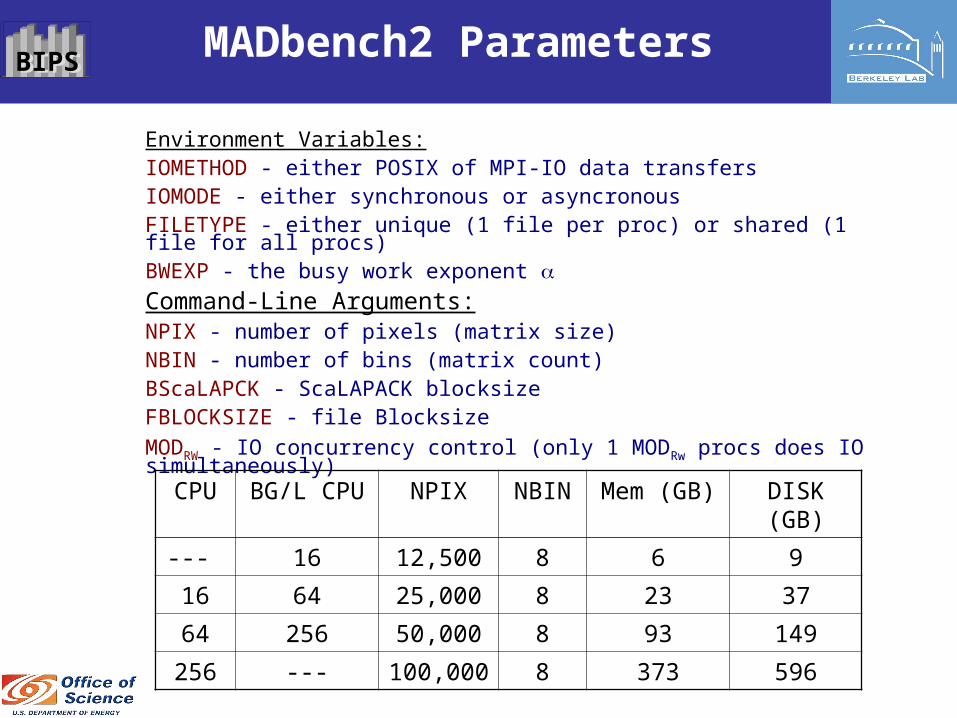
Environment Variables:IOMETHOD - either POSIX of MPI-IO data transfersIOMODE - either synchronous or asyncronousFILETYPE - either unique (1 file per proc) or shared (1 file for all procs)BWEXP - the busy work exponent Command-Line Arguments:NPIX - number of pixels (matrix size)NBIN - number of bins (matrix count)BScaLAPCK - ScaLAPACK blocksizeFBLOCKSIZE - file Blocksize
MODRW - IO concurrency control (only 1 MODRw procs does IO simultaneously)
MADbench2 Parameters
CPU BG/L CPU NPIX NBIN Mem (GB) DISK (GB)
--- 16 12,500 8 6 9
16 64 25,000 8 23 37
64 256 50,000 8 93 149
256 --- 100,000 8 373 596
BIPSBIPS Parallel Filesystem Overview
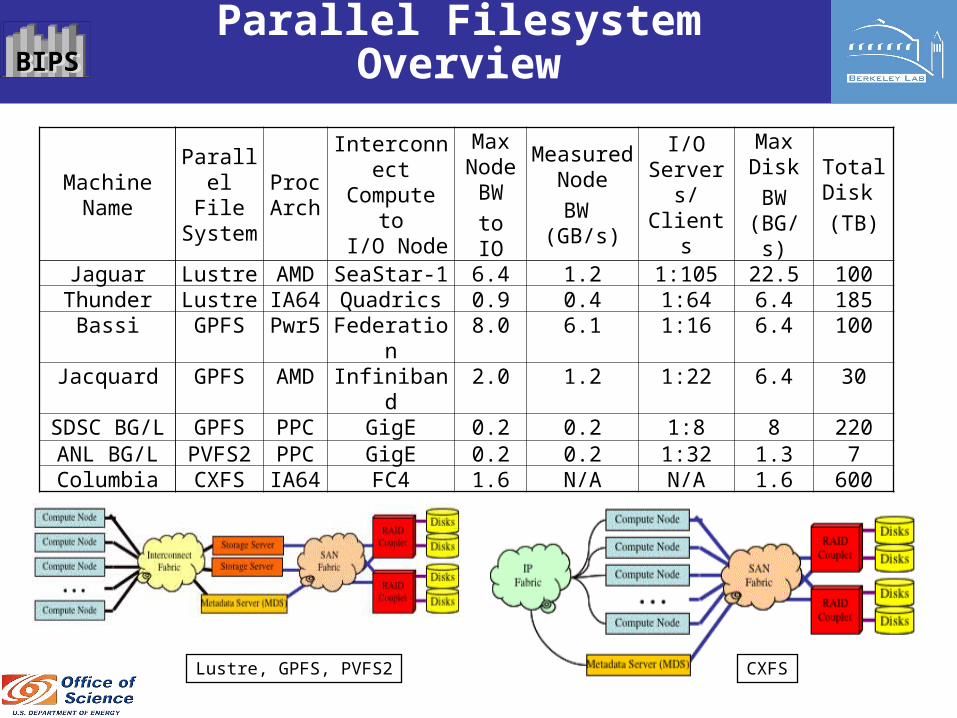
MachineName
Parallel File
System
ProcArch
InterconnectCompute to I/O Node
MaxNode BW
to IO
MeasuredNode
BW (GB/s)
I/OServers/Clients
MaxDisk
BW(BG/s)
TotalDisk
(TB)
Jaguar Lustre AMD SeaStar-1 6.4 1.2 1:105 22.5 100Thunder Lustre IA64 Quadrics 0.9 0.4 1:64 6.4 185
Bassi GPFS Pwr5 Federation 8.0 6.1 1:16 6.4 100Jacquard GPFS AMD Infiniband 2.0 1.2 1:22 6.4 30
SDSC BG/L GPFS PPC GigE 0.2 0.2 1:8 8 220ANL BG/L PVFS2 PPC GigE 0.2 0.2 1:32 1.3 7Columbia CXFS IA64 FC4 1.6 N/A N/A 1.6 600
Lustre, GPFS, PVFS2 CXFS
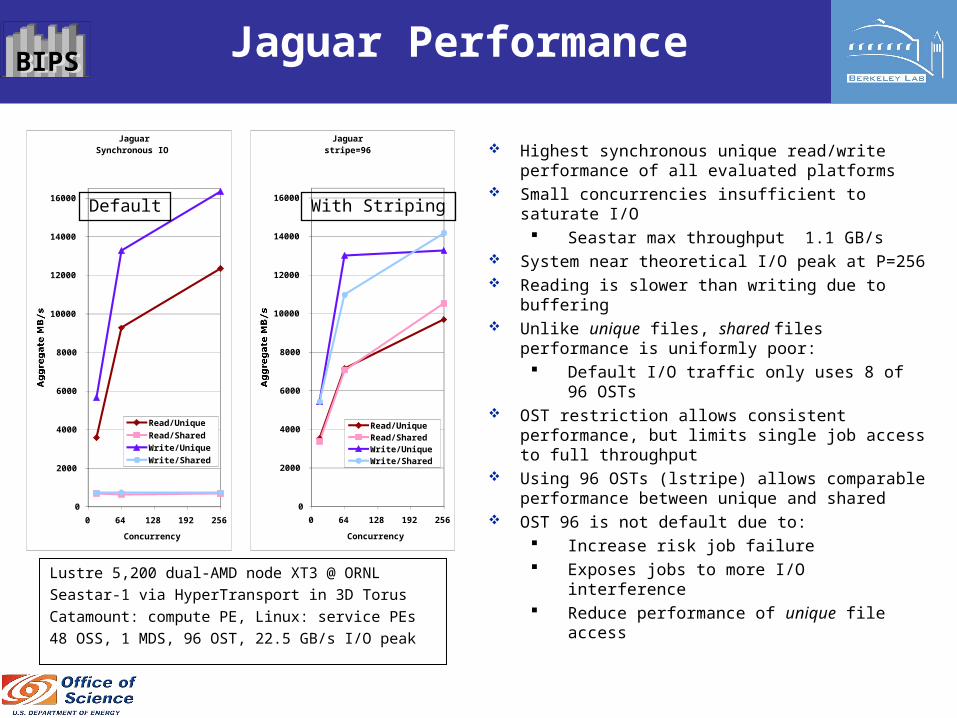
BIPSBIPS Jaguar Performance
Highest synchronous unique read/write performance of all evaluated platforms
Small concurrencies insufficient to saturate I/O Seastar max throughput 1.1 GB/s
System near theoretical I/O peak at P=256 Reading is slower than writing due to buffering Unlike unique files, shared files performance is
uniformly poor: Default I/O traffic only uses 8 of 96 OSTs
OST restriction allows consistent performance, but limits single job access to full throughput
Using 96 OSTs (lstripe) allows comparable performance between unique and shared
OST 96 is not default due to: Increase risk job failure Exposes jobs to more I/O interference Reduce performance of unique file access
Jaguar Synchronous IO
0
2000
4000
6000
8000
10000
12000
14000
16000
0 64 128 192 256
Concurrency
Aggregate MB/s
Read/UniqueRead/SharedWrite/UniqueWrite/Shared
Jaguar stripe=96
0
2000
4000
6000
8000
10000
12000
14000
16000
0 64 128 192 256
Concurrency
Aggregate MB/s
Read/UniqueRead/SharedWrite/UniqueWrite/Shared
Default With Striping
Lustre 5,200 dual-AMD node XT3 @ ORNL
Seastar-1 via HyperTransport in 3D Torus
Catamount: compute PE, Linux: service PEs
48 OSS, 1 MDS, 96 OST, 22.5 GB/s I/O peak
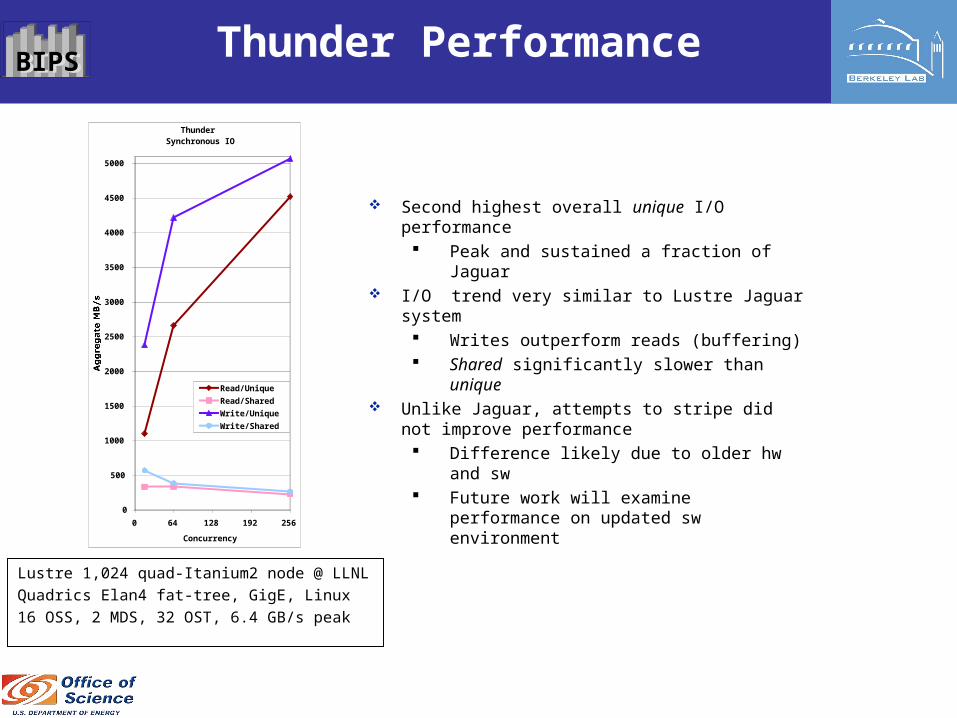
BIPSBIPS Thunder Performance
Second highest overall unique I/O performance Peak and sustained a fraction of Jaguar
I/O trend very similar to Lustre Jaguar system Writes outperform reads (buffering) Shared significantly slower than unique
Unlike Jaguar, attempts to stripe did not improve performance Difference likely due to older hw and sw Future work will examine performance on
updated sw environment
Thunder Synchronous IO
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 64 128 192 256
Concurrency
Aggregate MB/s
Read/Unique
Read/Shared
Write/Unique
Write/Shared
Lustre 1,024 quad-Itanium2 node @ LLNL
Quadrics Elan4 fat-tree, GigE, Linux
16 OSS, 2 MDS, 32 OST, 6.4 GB/s peak
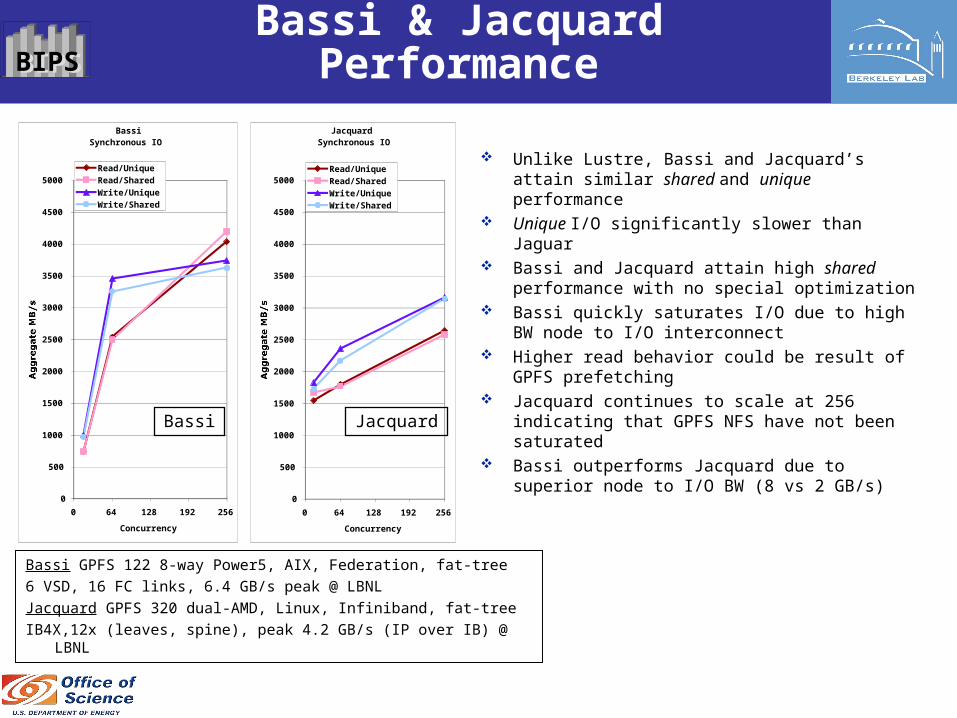
BIPSBIPS Bassi & Jacquard Performance
Unlike Lustre, Bassi and Jacquard’s attain similar shared and unique performance
Unique I/O significantly slower than Jaguar Bassi and Jacquard attain high shared
performance with no special optimization Bassi quickly saturates I/O due to high BW
node to I/O interconnect Higher read behavior could be result of GPFS
prefetching Jacquard continues to scale at 256 indicating
that GPFS NFS have not been saturated Bassi outperforms Jacquard due to superior
node to I/O BW (8 vs 2 GB/s)
BassiSynchronous IO
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 64 128 192 256
Concurrency
Aggregate MB/s
Read/UniqueRead/SharedWrite/UniqueWrite/Shared
Jacquard Synchronous IO
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 64 128 192 256
Concurrency
Aggregate MB/s
Read/UniqueRead/SharedWrite/UniqueWrite/Shared
Bassi GPFS 122 8-way Power5, AIX, Federation, fat-tree
6 VSD, 16 FC links, 6.4 GB/s peak @ LBNL
Jacquard GPFS 320 dual-AMD, Linux, Infiniband, fat-tree
IB4X,12x (leaves, spine), peak 4.2 GB/s (IP over IB) @ LBNL
Bassi Jacquard
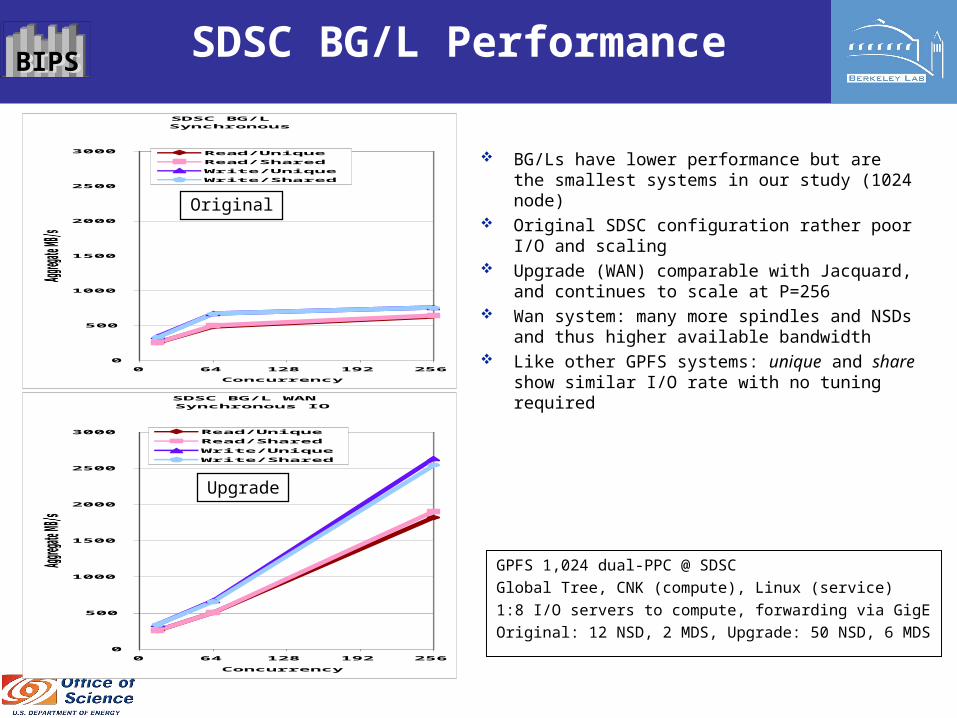
BIPSBIPS SDSC BG/L Performance
BG/Ls have lower performance but are the smallest systems in our study (1024 node)
Original SDSC configuration rather poor I/O and scaling
Upgrade (WAN) comparable with Jacquard, and continues to scale at P=256
Wan system: many more spindles and NSDs and thus higher available bandwidth
Like other GPFS systems: unique and share show similar I/O rate with no tuning required
GPFS 1,024 dual-PPC @ SDSC
Global Tree, CNK (compute), Linux (service)
1:8 I/O servers to compute, forwarding via GigE
Original: 12 NSD, 2 MDS, Upgrade: 50 NSD, 6 MDS
SDSC BG/L Synchronous
0
500
1000
1500
2000
2500
3000
0 64 128 192 256
Concurrency
Aggregate MB/s
Read/Unique
Read/Shared
Write/Unique
Write/Shared
Original
SDSC BG/L WANSynchronous IO
0
500
1000
1500
2000
2500
3000
0 64 128 192 256
Concurrency
Aggregate MB/s
Read/Unique
Read/Shared
Write/Unique
Write/Shared
Upgrade
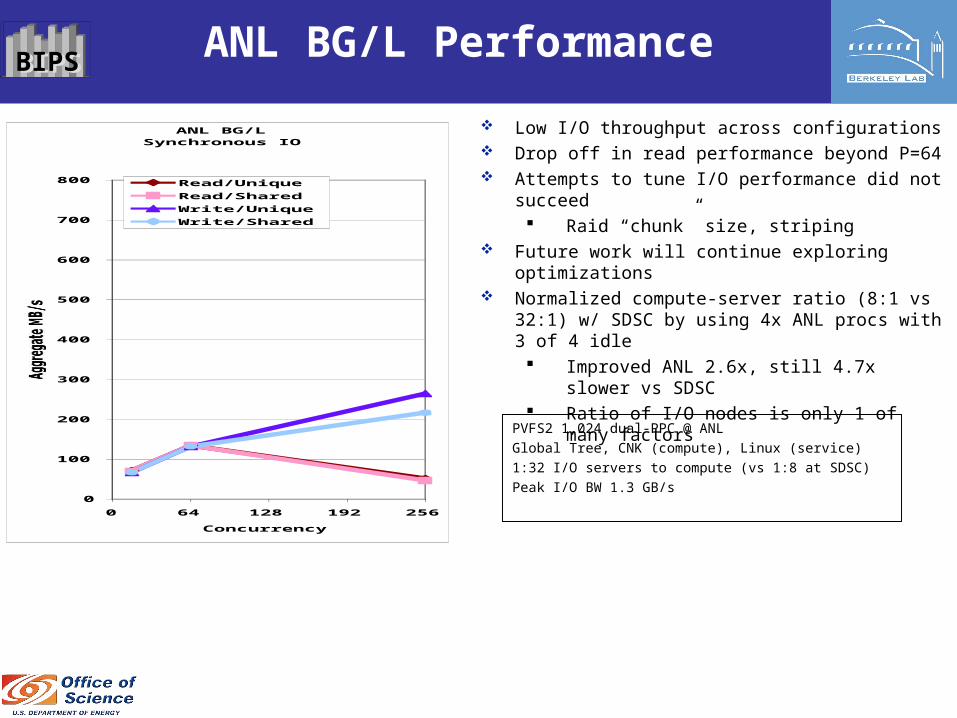
BIPSBIPS ANL BG/L Performance
ANL BG/L Synchronous IO
0
100
200
300
400
500
600
700
800
0 64 128 192 256
Concurrency
Aggregate MB/s
Read/Unique
Read/Shared
Write/Unique
Write/Shared
Low I/O throughput across configurations Drop off in read performance beyond P=64 Attempts to tune I/O performance did not succeed
Raid “chunk” size, striping Future work will continue exploring optimizations Normalized compute-server ratio (8:1 vs 32:1) w/
SDSC by using 4x ANL procs with 3 of 4 idle Improved ANL 2.6x, still 4.7x slower vs
SDSC Ratio of I/O nodes is only 1 of many factors
PVFS2 1,024 dual-PPC @ ANL
Global Tree, CNK (compute), Linux (service)
1:32 I/O servers to compute (vs 1:8 at SDSC)
Peak I/O BW 1.3 GB/s
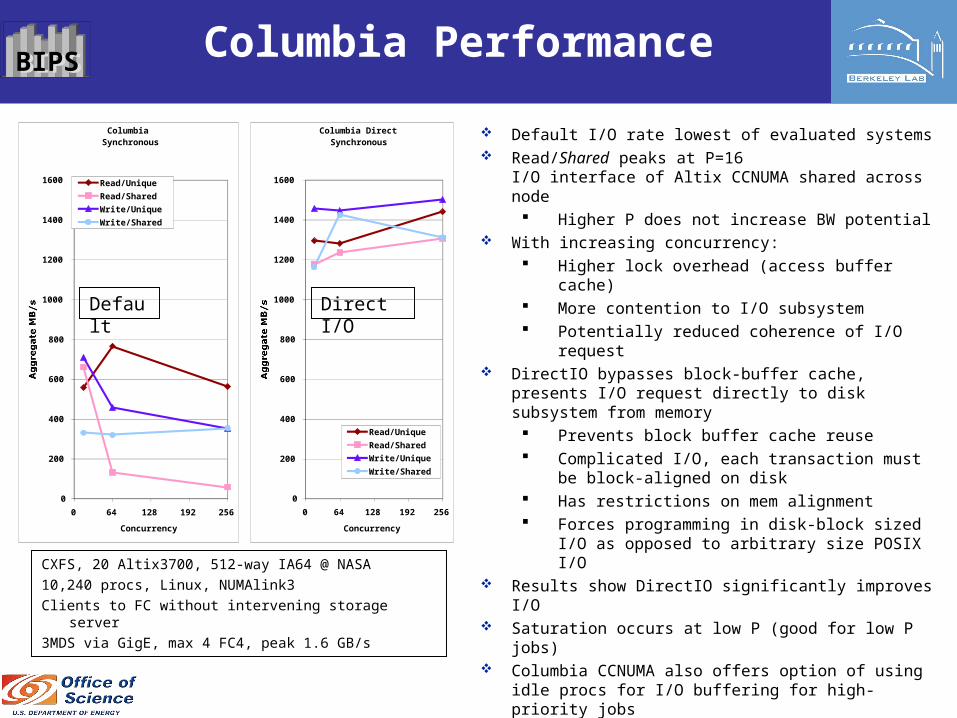
BIPSBIPS Columbia Performance
Default I/O rate lowest of evaluated systems Read/Shared peaks at P=16
I/O interface of Altix CCNUMA shared across node Higher P does not increase BW potential
With increasing concurrency: Higher lock overhead (access buffer cache) More contention to I/O subsystem Potentially reduced coherence of I/O
request DirectIO bypasses block-buffer cache, presents
I/O request directly to disk subsystem from memory Prevents block buffer cache reuse Complicated I/O, each transaction must be
block-aligned on disk Has restrictions on mem alignment Forces programming in disk-block sized I/O
as opposed to arbitrary size POSIX I/O Results show DirectIO significantly improves I/O Saturation occurs at low P (good for low P jobs) Columbia CCNUMA also offers option of using idle
procs for I/O buffering for high-priority jobs
Columbia Synchronous
0
200
400
600
800
1000
1200
1400
1600
0 64 128 192 256
Concurrency
Aggregate MB/s
Read/Unique
Read/Shared
Write/Unique
Write/Shared
Columbia Direct Synchronous
0
200
400
600
800
1000
1200
1400
1600
0 64 128 192 256
Concurrency
Aggregate MB/s
Read/Unique
Read/Shared
Write/Unique
Write/Shared
CXFS, 20 Altix3700, 512-way IA64 @ NASA
10,240 procs, Linux, NUMAlink3
Clients to FC without intervening storage server
3MDS via GigE, max 4 FC4, peak 1.6 GB/s
Default Direct I/O
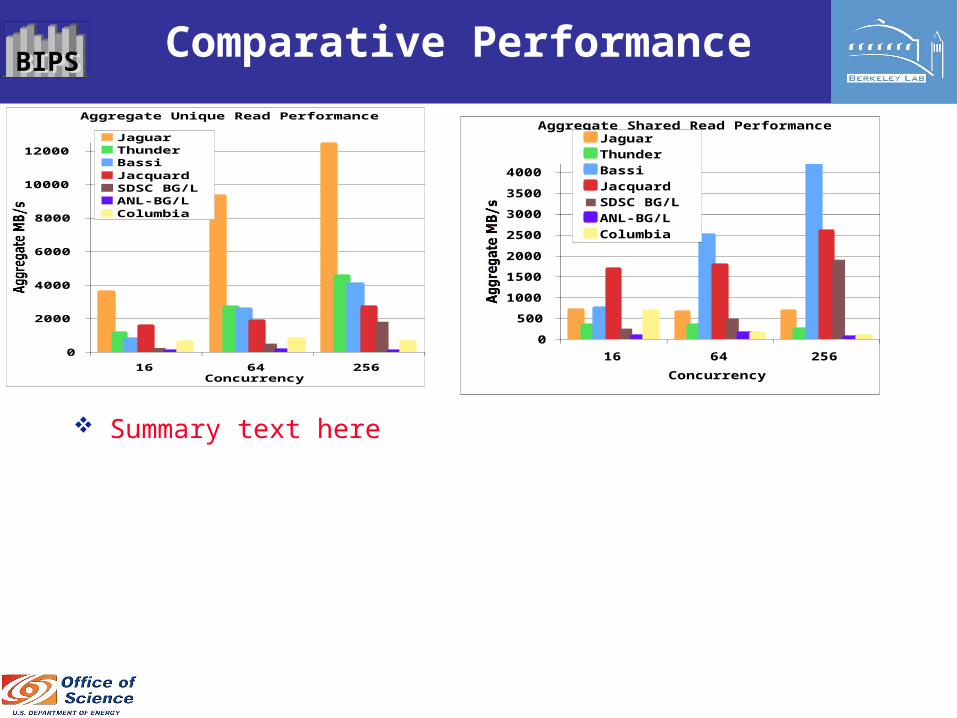
BIPSBIPS Comparative Performance
Summary text here
Aggregate Unique Read Performance
0
2000
4000
6000
8000
10000
12000
16 64 256Concurrency
Aggregate MB/s
JaguarThunderBassiJacquardSDSC BG/LANL-BG/LColumbia
Aggregate Shared Read Performance
0
500
1000
1500
2000
2500
3000
3500
4000
16 64 256
Concurrency
Aggregate MB/s
JaguarThunderBassiJacquardSDSC BG/LANL-BG/LColumbia
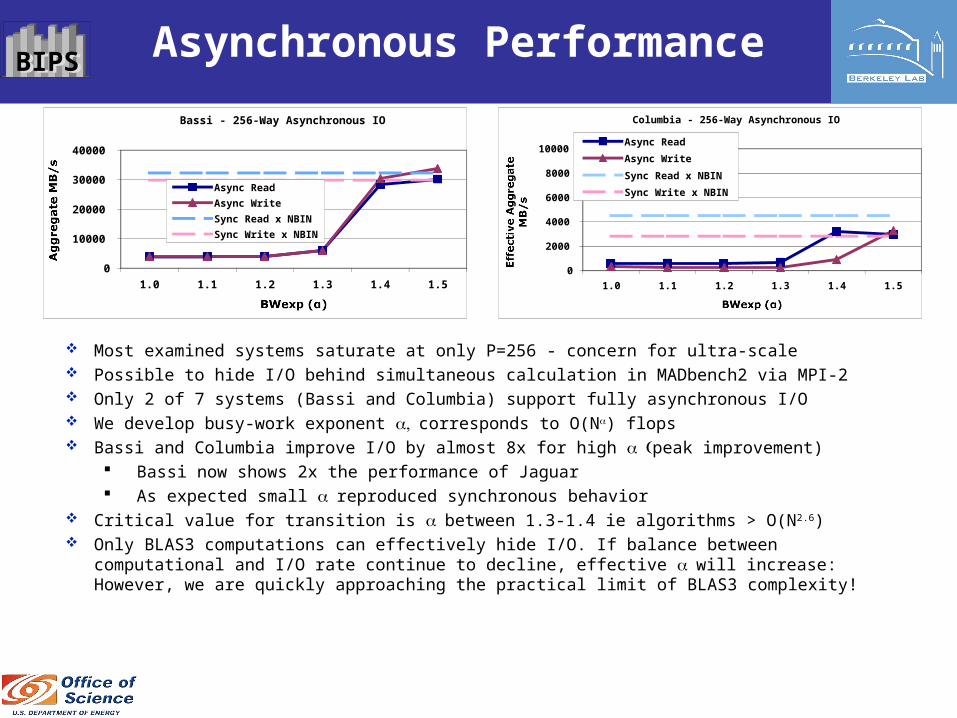
BIPSBIPS Asynchronous Performance
Most examined systems saturate at only P=256 - concern for ultra-scale Possible to hide I/O behind simultaneous calculation in MADbench2 via MPI-2 Only 2 of 7 systems (Bassi and Columbia) support fully asynchronous I/O We develop busy-work exponent corresponds to O(N) flops Bassi and Columbia improve I/O by almost 8x for high peak improvement)
Bassi now shows 2x the performance of Jaguar As expected small reproduced synchronous behavior
Critical value for transition is between 1.3-1.4 ie algorithms > O(N2.6) Only BLAS3 computations can effectively hide I/O. If balance between
computational and I/O rate continue to decline, effective will increase:However, we are quickly approaching the practical limit of BLAS3 complexity!
Bassi - 256-Way Asynchronous IO
0
10000
20000
30000
40000
1.0 1.1 1.2 1.3 1.4 1.5
Aggregate MB/s
Async Read
Async Write
Sync Read x NBIN
Sync Write x NBIN
Columbia - 256-Way Asynchronous IO
0
2000
4000
6000
8000
10000
1.0 1.1 1.2 1.3 1.4 1.5
Effective Aggregate
MB/s
Async Read
Async Write
Sync Read x NBIN
Sync Write x NBIN

BIPSBIPS Conclusions
I/O critical component due to exponential growth sensor & simulated data Presented one of most extensive I/O analyses on parallel filesystems Introduced MADbech2 derived directly from CMB analysis:
Lightweight, portable, generalized to varying computations () POSIX vs MPI-IO, shared vs unique, synch vs async
Concurrent accesses work properly with modern POSIX API (same as MPI-IO) It is possible to achieve similar behavior between shared and unique file access!
Default for all systems except Lustre which required trivial mod Varying concurrency can saturate underlying disk subsystem
Columbia saturates at P=16, while SDSC BG/L did not saturate even at P=256 Asynchronous I/O offers tremendous potential, but supported by few systems Defined amount of computation by I/O data via
Showed that computational intensity required to hide I/O is close to BLAS3 Future work: continue evaluating latest HEC, explore effect of inter-processor
communication on I/O behavior, conduct analysis of I/O variability.

BIPSBIPS Acknowledgments
We gratefully thank the following individuals for their kind assistance:
Tina Bulter, Jay Srinivasan (LBNL) Richard Hedges (LLNL) Nick Wright (SDSC) Susan Coughlan, Robert Latham, Rob Ross, Andrew Cherry (ANL) Robert Hood, Ken Taylor, Rupak Biswas (NASA-Ames)





























