Embed Size (px)
Citation preview

C++
Dipl. Math. F. Braun
Universität Regensburg � Rechenzentrum
svn/doku/trunk/cpp/cpp.tex
https://homepages.uni-
regensburg.de/~brf09510/EDV/kurs_info/brf09510/kurs_info/cpp/cpp.html
https://homepages.uni-
regensburg.de/~brf09510/EDV/kurs_info/brf09510/kurs_info/cpp/cpp.pdf
July 8, 2019


CHAPTER 1
Einführung in C++
1. Kursübersicht
ausgeteilt:
2. Designer
Stroustrup, AT&T
3. Literatur und Internet
Frank B. Brokken: C++ Annotations, 10.9.2, 2018, 90-367-0470-7http://www.icce.rug.nl/documents/cplusplus/
Ulrich Breymann: Der C++-Programmierer, Carl Hanser, 4. Au�age, 2015, 3-446-44346-0
Nicolai M. Josuttis: The C++ Standard Library, Addison Wesley Longman, 2012, 0-321-62321-5
David Vandevoorde, Nicolai M. Josuttis, Douglas Gregor: C++ Templates, Addison-Wesley, 2018, 978-0-321-71412-1
Scott Meyers: E�ective Modern C++ , C++11 and C++14, O'Reilly, 2014, 9781491903995Weitere Titel: E�ective C++, More E�ective C++, E�ective STL,
Herb Sutter: Exceptional C++ , 1999, 0201615622
Paul Deitel, Harvey Deitel: C++11 for Programmers, 2014, 978-0-13-343985-4 (Detailliert; rigider coding standard)
Lippman, Lajoie, Moo: C++ Primer, 2013, 978-0-321-71411-4
Torsten T. Will: C++11 programmieren, 2012, 978-3-8362-1732-3
ISO/IEC JTC1/SC22/WG21 - The C++ Standards Committee - ISOCPPhttp://www.open-std.org/JTC1/SC22/WG21/
ISO/IEC 14882, 2014-12-15, C++
Standardisierunghttps://isocpp.org/std/status
Compiler-Standhttp://en.cppreference.com/w/cpp/compiler_support
Internet basierte Nachschlagewerkehttp://en.cppreference.com/
http://www.cplusplus.com/
Artikel über C++https://www.fluentcpp.com/
3

4 1. EINFÜHRUNG IN C++
4. Geschichte
1956-1968 Fortran, 1960 Algol, 1960 Cobol, 1967 Pascal, 1965-67 PL/1, 1968 Algol-681965-1993 Simula, 1980 Smalltalk, 1980 Ada, 1985-87 Oberon, 1986 Ei�el, 1993 Java1970 C, Kernighan, Ritchie1980 C with classes, Bjarne Stroustrup, AT&T1982 ACM Sigplan notizes Vol 17 nr 11983/84 C++: der Name steht fest1985 erster Compiler: CFront1986 Stroustrup: The C++ programming language ("Bible")1989 Ansi-C (C89, C90)1989 ANSI Komitee ISO/IEC JTC1, Subkomitee SC221989 C++ 2.0, CFront 2.01990 Java1990 Ellis/Stroustrup: The Annotated C++ Reference Manual1993/94 Stepanov/Musser: STL Proposal1995 C++ Draft: ISO Entwurf1996 CD2 Second commenting draft1998-9-1 C++98 ISO/IEC 14882:1998 Standard mit der STL1999 C991999 Boost Library2003 C++ (03) ISO/IEC 14882:2003 (2. edition)2006 ISO/IEC TR 18015:2006 C++ Performance2007 ISO/IEC TR 19768:2007 C++ Library2010 ISO/IEC TR 29124:2010 C++ Library: Mathematical functions2011 C112011-9-01 C++11 ISO/IEC 14882:2011 (3. edition)2011 ISO/IEC TR 24733:2011 C++ Decimal Floating Point Arithmetic2012 The Standard C++ Foundation2014-12-15 C++14 ISO/IEC 14882:2014 (4. edition)2015 ISO/IEC TR 18822:2015 C++ The Filesystem Library2015 ISO/IEC TR 19570:2015 C++ Parallelism2015 ISO/IEC TR 19841:2015 C++ Transactional Memory2015 ISO/IEC TR 19568:2015 C++ Library Fundamentals2015 ISO/IEC TR 19217:2015 C++ Concepts2016 ISO/IEC TR 19571:2016 C++ Concurrency2017 N4659 �nal Draft http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2017/n4659.pdf2017-12 C++17 ISO/IEC 14882:2017 (5. edition)2020 C++20
5. Ziele und Eigenschaften
C++ sollte ein ungeändertes, verbessertes C mit Objektorientierung werden. Es wurzelt in den Sprachen C,Smalltalk und Ada. Schon kurz nach den ersten Entwürfen wurde es verstärkt in der professionellen Software-Produktion eingesetzt. Von dieser Seite wurden die Ziele schnell - korrekt - ökonomisch vorgegeben. Objektori-entierung ist Datenkapselung, Zugri�s-Rechte und Vererbung. Industriell ist graphische Software-Entwicklung mitUML von Bedeutung. C++ hat ein Standbein in der HPC-Programmierung. Verbreitete Libraries erleichtern dieSoftware-Entwicklung.
6. Compiler und Tools
6.1. Arbeiten auf Servern. Zum Arbeiten auf Servern (pc55556) wird ssh/scp oder unter Windows put-ty/pscp benötigt.
Installation: http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html

6. COMPILER UND TOOLS 5
6.2. JEdit und IDEs. Als Programm-Editor wird JEdit empfohlen. Software-Entwicklung mit IDEs wieEclipse in Projekten unterstützt C++.
Webseite: http://www.jedit.org/Download: http://www.jedit.org/index.php?page=download
6.3. Gnu. Aufruf: g++Manual: https://gcc.gnu.org/onlinedocs/gcc/index.htmlStatus: https://gcc.gnu.org/projects/cxx-status.htmlStatus Library: https://gcc.gnu.org/onlinedocs/libstdc++/manual/status.html
6.4. LLVM. Aufruf: clang++Manual: http://clang.llvm.org/docs/UsersManual.htmlStatus: http://clang.llvm.org/cxx_status.htmlStatus Library: https://libcxx.llvm.org/
6.5. Intel. Aufruf: ipcpManual: https://software.intel.com/en-us/compiler_15.0_ug_cStatus: https://software.intel.com/en-us/articles/c0x-features-supported-by-intel-c-compilerStatus Library: https://software.intel.com/en-us/articles/c14-features-supported-by-intel-c-compiler
6.6. Portland group. Aufruf: pgc++Manual: http://www.pgroup.com/doc/pgiug.pdf
6.7. MS Visual C++. Aufruf: cl /EHsc hello.cppManual: https://blogs.msdn.microsoft.com/vcblog/2014/11/17/c111417-features-in-vs-2015-preview/
6.8. Online Compiler. Es gibt mehrere online-Compiler, die Übersetzung und Start von kleineren C++-Programmen ermöglichen. Sie erlauben vor allem das Ausprobieren aktuellster Sprachkonstrukte.
https://isocpp.org/get-started Linkshttps://isocpp.org/blog/2013/01/online-c-compilers Linkshttp://coliru.stacked-crooked.com/ Coliruhttp://ideone.com/zjXGRo Ideonehttp://comeaucomputing.com/tryitout/ Comeauhttp://gcc.godbolt.org/ godbolt; kurze maximale Compile-Zeithttp://melpon.org/wandbox/ Wandbox
6.9. Debugger. Fehlerhafte Programmen werden mit Debuggern wie gdb und idb analysiert. Werkzeuge wielint/splint existieren in C++ kaum.
6.10. Make, cmake. Zur schnellen und bequemen Übersetzung und Montage von Programmen aus mehrerenDateien.
6.11. Libraries. http://de.cppreference.com/w/cpp/links/libs
http://en.cppreference.com/w/cpp/links/libs
https://github.com/fffaraz/awesome-cpp
https://stackoverflow.com/questions/777764/what-modern-c-libraries-should-be-in-my-toolbox
STL: Klassische objektorientierte Library; angepasst an C++; Teil des Standards seit 1998.
Boost: Freie C++-Quellcode Libraries (peer-reviewed); insgesamt über 80 Themen; einege Boost-Lizenz ähnlichBSD, MIT und GPL
ICU: C-C++-Java-Library für Unicode-Verarbeitung

6 1. EINFÜHRUNG IN C++
7. Die Beziehungskiste von C und C++
C++ hat prinzipiell das komplette C von 1988 übernommen. Da es ein besseres C sein sollte, wurde diesesPrinzip durchbrochen. Noch schlimmer: seit 1990 entwickelten sich C und C++ in verschiedene Richtungen.Seit 1999 arbeiten die Standardisierungskomitees beider Sprachen zusammen und versuchen die entstandenenInkompatibilitäten zu minimieren. Trotzdem soll sich C nicht zu einem zweiten C++ entwickeln; Zitat aus dem"Rationale for International Standard Programming Languages C Revision 5.10 April-2003": The Committee iscontent to let C++ be the big and ambitious language. While some features of C++ may well be embraced, it isnot the Committee's intention that C become C++.
C und C++ sind also zwei verschiedene Sprachen, die man auseinanderhalten muss. Der gröÿere Teil von C kanntrotzdem mit gleicher Syntax und Semantik fast identisch in C und C++ geschrieben werden.
Die eigentlich notwendige, sorgfältige Di�erenzierung der beiden Sprachen wird oft verwischt (Microsoft, NVidia,qd-package) oder ist für den Programmierer unsichtbar, weil die Compiler �exibel umschalten (gcc).
Nicht jeder C-Compiler ist ein C++-Compiler (lcc), aber jeder C++-Compiler kann C übersetzen (gcc, clang,icc, pg). Nicht jeder C++-Compiler, der C übersetzt, macht das für die gesamte Sprache C und korrekt nachC-Standard (Nvidia, Microsoft).
7.1. C und C++ sind trotz verschiedener Syntax gleich. Die folgende Tabelle enthält Sprachkonstrukte,die absolut identisch wirken, auch wenn sie anders geschrieben werden müssen.
Table 1. Syntaxunterschiede
C C++Jede C lib ist C++-lib #include<stdlib.h> #include<cstdlib>
Lib-Objekte sind im rand (); std::rand();
Namespace stdrand (); using namespace std; rand();
main ohne arg int main (void) int main ()
Hello World #include <stdio.h> #include <iostream>
int main (void) int main ()
{ printf ("Hello"); { std::cout << "Hello";}
return 0; }
Logik _Bool bool
Komplexe Zahlen float _Complex complex<float>
Konstante const int * p; int const * p;
struct typedef struct x {} name; struct name {};
struct typedef struct x {} name; class name {};
enum enum name {}; enum name x; enum name {}; name x;
union union name {}; union name x; union name {}; name x;
cast (int)x static_cast<int>(x)
dynamic memory malloc realloc free new deleteauto result int add(int a, int b) auto add(int a, int b) -> int
auto result template <type T, type U>
auto add(T t, U u) -> decltype(t+u)
{return t+u;}
7.2. C und C++ sind trotz gleicher Syntax verschieden. Die folgende Tabelle enthält Sprachkonstrukte,die in C++ weiter funktionieren, aber dort nicht mehr verwendet werden sollten, weil sie durch ein C++-eigenesKonstrukt ersetzt worden sind. Oft sind die C-Konstrukte in C++ deprecated (veraltet; von der Benutzung wirdabgeraten) und werden nur noch mit Warnungen übersetzt.
7.3. C++ hat wichtige Verbesserungen. Die folgende Tabelle enthält Sprachkonstrukte, denen in C nurein magerer Ersatz entspricht.

7. DIE BEZIEHUNGSKISTE VON C UND C++ 7
Table 2. Semantikunterschiede
C C++ deprecated C++iostream statt stdio #include<stdio.h> #include<cstdio> #include<iostream>
cin/cout/cerr/clog printf ("Hallo"); std::printf ("Hallo"); std::cout << "Hallo";
statt printfstring statt cstring #include<string.h> #include<cstring> #include<string>
string statt char* char * s = "Hallo"; char * s = "Hallo"; string s = "Hallo";
char*s=(char*)"hello";
Container statt Felder double v [100]; vector<double> v;
auto statt Typen _Bool b = true; bool b = true; auto b = true; // bool
templates statt Typen double _Complex complex<double>
Referenzen statt Zeiger void f (char * s) void f (string & s)
inline ist anders immer explizit in Klassen implizitstattFehlerende exit(1) exit(1) main-function-try-block
catch-return-1
Table 3. C++, a better C
C C++namespaces Namensprä�xe namespacesEllipse, vararg void f (...) overloading, default argumentsMacros #define x(a) sqrt (a++) inlineexceptions exceptionsexceptions exceptions
7.4. Beide Sprachen enthalten auch Unsinn. Ohne drastischere Worte verwenden zu wollen, �nden sichhier Beispiele, die man weder in C noch in C++ bei guten Programmierern jemals �nden wird.
Table 4. Unsinn
C C++trigraphs ??< ??<
bigraphs <: <:
getsstrtokDu�s devicefor (int i = 0. . .
Und ja, ich halte die schleifenlokalen Variablen in den meisten Fällen für eine schlechte Wahl und ein Hindernisbei der Programmentwicklung und -p�ege.
7.5. Mängel von C++. Schlieÿlich kann man für C++ viele Mängellisten aufstellen. Es gibt teilweise heftigeDiskussionen, ob solche Einträge bugs oder features sind, ob sie vielleicht sogar positive Eigenschaften sind. Einekleinere für den Anfänger:
• kein garbage collector• Das Wort unde�ned taucht im Standard viel zu oft auf• Name (de-)mangling ist nicht standardisiert (und: vernünftige Sprachen brauchen es gar nicht)• Zeiger• Der Präprozessor• keine Feldgrenzenüberwachung (segmentation faults)• C++-Programme sind schwerer lesbar als C und oft schwerer verständlichstd::vector<int> v; auto n = std::count(begin(v), end(v)); verbessert die Lesbarkeit seit 2011
• Schwierige Fehlersuche; Compilermeldungen sind schwer verstehbar• Schwierige Fehlersuche; Laufzeitmeldungen sind schwer verstehbar• kein finally

8 1. EINFÜHRUNG IN C++
• Unicode support gewöhnungsbedürftig• Der Quellcode in .h muss in groÿen Projekten immer wieder übersetzt werden• Code bloat• Übersetzungszeiten• T t; ist Konstruktoraufruf, T t(); ist Funktionsdeklaration und T t(1); ist wieder Konstruktoraufruf.• char * p; p = nullptr; cout << *p; erzeugt keine Exception sondern segmentation fault.• string und complex sind in der Bibliothek de�niert und damit langsamer und ohne Compiler-Optimierung.• Konzeptlos aus Einzelteilen zusammengeschusterte Sprachteile, jedes gut, aber im Zusammenspiel schlecht
(overloading, default args, templates).• Raw-Strings sind ein reiner Murks und führen zu ähnlich gut lesbaren C++-Programmen wie Perl.
8. Ein erster Eindruck
itor0.c ist ein C-Programm, dass die in einem String vorkommenden Schriftzeichen ermittelt. Es kann auch mitC++ übersetzt werden.
itor0/1/3/4/5 demonstrieren die sehr verschiedenen Sprachdialekte von C++.
itor0 benutzt praktisch keine C++-Fähigkeiten.
itor1 enthält C-Libraries, namespace std, main ohne void, C++-Ausgabe, new und delete.
itor3 verwendet C++-Mengen (set) zur Ermittling des Ergebnisses und Algorithmen (foreach) zur Ausgabe. Frap-pierend ist das Verschwinden der eigentlichen Arbeit in den Deklarationen.
itor4 demonstriert λ-Funktionen aus C++14.
itor5 ermittelt nicht die Schriftzeichen, sondern die Wörter mit regular expressions aus C++14.
Schon hier sieht man einen Nachteil von C++: die längeren Übersetzungszeiten. Bei diesem Programm erkenntman in der Laufzeit praktisch keine Unterschiede, weder zwischen den Compilern, noch zwischen den doch sehrverschiedenen Methoden. (Die Arbeit muss halt in jedem Fall irgendwie gemacht werden!) Nicht eimnal dieine�ziente Programmierung der Sortierung in itor0 und itor1 ist erkennbar.
Die erste Zahl ist die Compile-Zeit, die zweite die Laufzeit des Programms. Eingetragen wurde der Median vonjeweils drei Messungen. Alle Übersetzungen sind optimiert. Die Messung wurde mit Strings der Länge 10000durchgeführt. Der Test lief 2015 auf der Athene (Quad-Core AMD Opteron Processor 2354)
Table 5. Rechenzeiten
Programm Gnu gcc LLVM IntelC -o2 itor0.c 0.132/34.466 0.125/34.449 0.343/34.848C++ -o2 itor0.c 0.194/34.486 0.184/34.450 0.416/34.471C++ -o2 itor1.cpp 0.397/34.477 0.391/34.470 0.585/34.471C++ -o2 itor3.cpp 0.605/34.080 0.493/34.487 0.769/34.464C++ -o2 -std=C++11 itor4.cpp 0.964/34.438 1.174/34.551C++ itor5
9. Und ein ganz anderer Einsatz
Für die Programmierung von Mikrocontrollern existiert eine standardkompatible C17-Bibliothek modm.io, die einesehr konfortable Programmierung erlaubt. Dieser Einsatz liegt jedoch auÿerhalb des Rahmens dieses Kurses.
https://modm.io/
https://xpcc.io/ (alte Version)

CHAPTER 2
Prozedurale Programmierung
Paradigmen: Maschinenorientiert (Assembler), Formelorientiert (FORTRAN, mathematische Formeln), Prozedural(Algol-Familie), Funktional (LISP, λ-Kalkül von Church), Deskriptiv (Prolog, Prädikatenlogik), Objektorientiert(Smalltalk, Ei�el, C++, bezogen auf die Datenobjekte), Generisch (Ada, C++)
1. Struktur von C++-Programmen
1.1. main. Jedes C++-Programm muÿ genau eine globale Funktion mit dem Namen main enthalten, mitdem die Programmausführung beginnt.
Zwei Formen eines C++-Hauptprogramms sind im Standard de�niert; weitere Formen sind implementierungsab-hängig und sollten für portable Programme vermieden werden. Da argumentlose Funktionen in C++ ohne dasWort void deklariert werden, fehlt void selbstverständlich auch bei main. In main darf die return-Anweisungentfallen, wenn sie eine 0 erzeugt. Ein C++-Programm lautet daher:
1 // main1.cpp
2 int main () { }
Werden die Programmparameter argc und argv vom Betriebssystem übernommen, schreibt man wie in C:
1 // main2.cpp
2 int main (int argc , char * argv []) { }
3 // alternativ:
4 //int main (int argc , char ** argv) { }
Die Argumente argc und argv sind wie in C de�niert. (argc≥ 0, argv [0] . . . argv [argc-1], argv [argc] ≡ 0,argv [i] ist NTMBS � null terminated multibyte string). Da die Argumente besser als C++-Strings weiterverar-beitet werden, folgt ein kleines Rezept zur Konversion (es sollte eigentlich in der STL sein!):
1 // main2a.cpp
2 #include <iostream >
3 #include <vector >
4 #include <string >
5 using namespace std;
6 int main (int argc , char * argv [])
7 {
8 for (int i = 0; i < argc; i++) cout << argv [i] << endl;
9 vector <string > args (static_cast <size_t >(argc));
10 for (int i = 0; i < argc; i++) args [static_cast <size_t >(i)] = string (argv [i]);
11 for (size_t i = 0; i < args.size(); i++) cout << args [i] << endl;
12 }
Folgen implementierungsabhängige weitere Parameter von main, so müssen sie nach den Standardparameternstehen. Beliebt, aber nicht standardisiert, und deshalb zu vermeiden, ist hier char ** env.
Jede Funktion, auch main, darf als Rumpf einen function-try-block haben:1 // maintry.cpp
2 #include <exception >
3 int main (int argc , char** argv)
4 try
5 {
6 return 0;
7 }
8 catch (std:: exception e)
9

10 2. PROZEDURALE PROGRAMMIERUNG
9 {
10 return 1;
11 }
Der Ergebnistyp von main ist implementierungsabhängig, jede Implementierung muÿ jedoch int zulassen. Dasint-Ergebnis wird von vielen Betriebssystemen als Information über das Programmende interpretiert; 0 ist dannimmer fehlerfreies Programmende, Werte > 0 sind programmde�nierte Fehlernummern bei unvorhergesehenenProgrammstops.
main ist nicht überladbar und nicht rekursiv aufrufbar. Die Adresse von main kann nicht ermittelt werden. main
darf nicht inline oder static sein. Der Name main ist trotzdem nicht reserviert und darf als Bezeichnung fürandere Gröÿen (z.B. Memberfunktionen, Klassen, Aufzählungen, . . . ) verwendet werden, wenn keine Verwechslungmit dem Hauptprogramm möglich ist.
Die programmbeendende Anweisung return 0; darf in C++ entfallen. Sie wirkt wie in C, d.h. ein Programm kannaus main heraus mit der Anweisung return e;beendet werden. Dabei ist e die dem Betriebssystem übergebeneFehlernummer. Steht die Anweisung return e; nicht explizit im Hauptprogramm, so wird das Programm mit derFehlernummer 0 beendet.
Wie in C darf in C++ an jeder Stelle eines Programms mit der in <cstdlib> deklarierten Funktion exit (e); einProgramm beendet werden. Das sollte jedoch immer vermieden werden, da der Compiler bei exit() wie bei jederFunktion annimmt, dass sie nach ihrem Ende zurückkehrt und dass das Programm danach normal endet. Dadurchentfällt die eigentlich notwendige Blockabschluÿarbeit (Destruktoren. . . ). Das ist im Grunde ein Programmierfehler,so dass exit() in C++ eigentlich nichts verloren hat! Die korrekte Lösung ist ein function-try-block mit return 1;
im catch.
Wer exit() trotzdem verwenden will, sollte dem Compiler anzeigen, dass die exit() aufrufende Funktion nichtzurückkehrt:
1 // mainexit.cpp
2 #include <iostream >
3 #include <cstdlib >
4
5 [[ noreturn ]]
6 int error (int i)
7 {
8 std::cout << std::endl << "Fehler " << i << std::endl;
9 std::exit (1);
10 }
11
12 int main (int argc , char * argv [])
13 {
14 if (argc < 3) error (2);
15 std::cout << "doing whatever now" << std::endl;
16 }
1.2. Kommentare. C++ kennt dieselben Kommentarformen wie C99: nicht verschachtelbare, mit /* ... */
geklammerte Kommentare haben die Form/* ... /* ... * ... */
Weiter gibt es Zeilenendkommentare, die mit // eingeleitet werden und dem nächsten Zeilenende enden. Sie habendie Form:
// ...
Auch in C99 wurde diese Kommentarart übernommen. C++ und C99 auf der einen Seite und C89 auf der anderenführen die folgende Anweisung unterschiedlich aus:
x = a//* Kommentar */ b
+ c;
In C89 wird x = a/b + c; berechnet, während in C++ und C99 die Division im Kommentar verschwindet.x = a + c;

1. STRUKTUR VON C++-PROGRAMMEN 11
1.3. Präprozessor. Der Präprozessor ist wie in C de�niert und funktioniert unverändert weiter.
Es gibt einen Unterschied in den Include-Anweisungen der Standardbibliotheken in C: Die veraltete C-Form(stdlib.h) bringt die Deklarationen ohne Namespace ein; die C++-Form (cstdlib) von 1999 erzeugt die Dekla-rationen im Namespace std und erfordert die explizite Namespaceangabe (using namespace std;).
Wird mit einem C++-Compiler übersetzt, dann ist das Präprozessorsymbol __cplusplus (2 Unterstriche!) mitden Werten 1, 199711L, 201103L, 201402L oder 201703L de�niert. Es kann mit der Präprozessoranweisung
#ifdef __cplusplus
...
#endif
im Programm abgefragt werden.
Weitere Präprozessorsymbole sind
__STDC_HOSTED__, wenn das Programm unter einem Betriebssystem arbeitet und kompletten Zugang zu allen Bib-liotheken hat (Gegenteil: freestanding)__STDC_MB_MIGHT_NEQ_WC__ char und wchar_t Codes können beim selben Zeichen verschiedene Werte haben__STDC_ISO_10646__ yyyymmL, Unicode required wchar_t-Zeichen des angegebenen Datums haben alle den richti-gen Code; Beispiele: 200910L, 201605L__STDCPP_STRICT_POINTER_SAFETY__ genau das (ISO/IEC 14882 3.7.4.3); gedacht für in C++ inexistente garbagecollection; Gegenteil: relaxed__STDCPP_THREADS__ mehr als 1 Thread erlaubt__STDCPP_DEFAULT_NEW_ALIGNMENT__ std::size_t-Wert, der das von new garantierte Feldalignment enthält
__DATE__ Übersetzungsdatum__FILE__ Quelldatei__LINE__ Quellzeile__TIME__ Übersetzungsuhrzeit__STDC__ kann existieren und hat in C++ nichts verloren__STDC_VERSION__ kann existieren und hat in C++ nichts verloren
1.4. Bestandteile von C++, Zeichen und tokens. Der Begri� token beschreibt in Programmiersprachendie Elemente, aus denen sich der Programmtext zusammensetzt. Für C++ werden sie in diesem Kapitel beschrieben.Es sind Operatorsymbole, Namen und Literale. Für Anfänger ist dieses Kapitel ein Nachschlageteil und kein Start-punkt zum Erlernen der Sprache.
1.4.1. Schriftzeichen und Operatoren. C++-Programme werden mit einer Schriftzeichenmenge (Zeichensatz)mit der Bezeichnung source character set geschrieben. Nach der Übersetzung verarbeitet das laufende ProgrammSchriftzeichen einer zweiten Menge, der execution character set. In beiden Fällen muss eine Minimalmenge vor-liegen, die basic character set, die durch eine extended character set erweitert sein kann.
Die Minimalmenge besteht aus den 52 Buchstaben des englischen Alphabets, den zehn Zi�ern, 29 Sonderzeichenund fünf nichtsichtbaren Gliederungszeichen. Bei der Ausführung kommen drei weitere Zeichen zur Textgestaltungdazu:
Buchstaben ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz
Zi�ern 0123456789
Sonderzeichen _ { } [ ] # ( ) < > % : ; . ? * + - / ^ & | ~ ! = , \ " '
Gestaltungszeichen: \t\v\f\n und zusätzlich \a\b\r
Mit diesen Schreibweisen sind das Leerzeichen ( ), der Tabulator (\t), der Vertikaltabulator (\v), der Seiten-vorschub (\f) und der Zeilenvorschub (\n) gemeint. Die Zusatzzeichen bei der Ausführung sind der Alarm, (\a)die Rücktaste (\b) und der Wagenrücklauf (\r).
Der Zeilenvorschub \n muss nicht durch ein Zeichen dargestellt werden.
Mit sehr tastenarmen Tastaturen kann man neun dieser Zeichen durch Trigraphs ersetzen, die immer mit einem doppeltenFragezeichen beginnen:
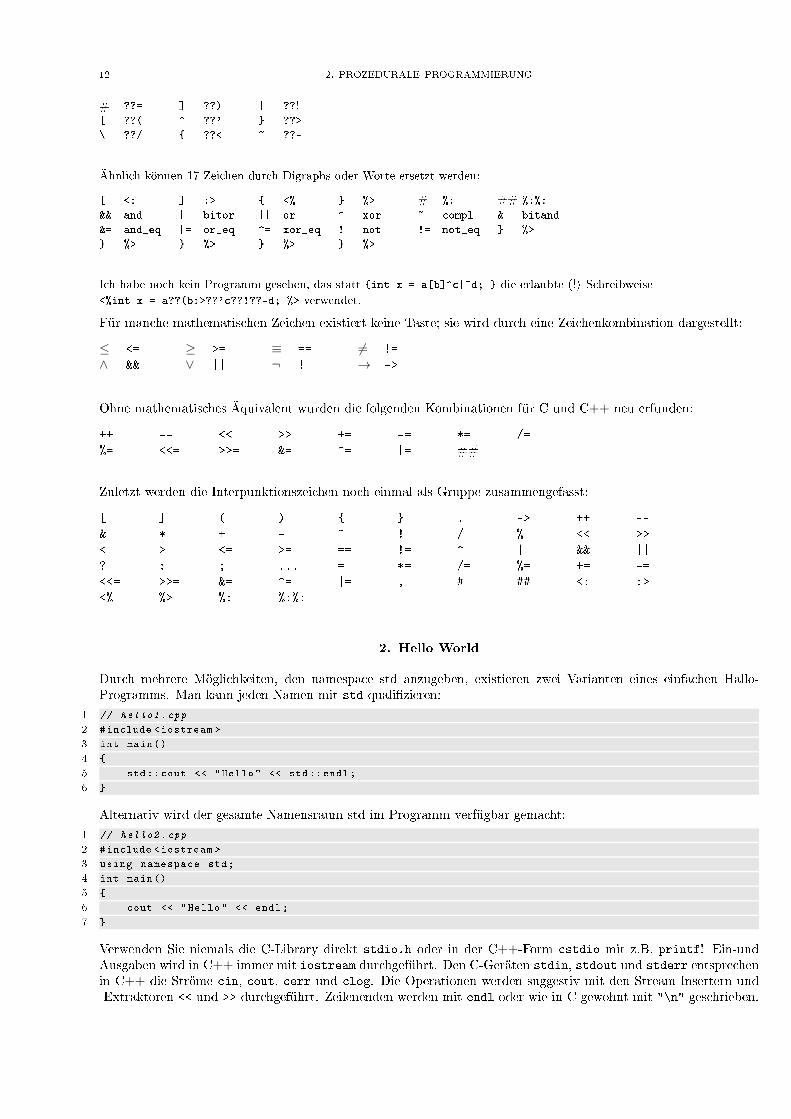
12 2. PROZEDURALE PROGRAMMIERUNG
# ??= ] ??) | ??![ ??( ^ ??' } ??>
\ ??/ { ??< ~ ??-
Ähnlich können 17 Zeichen durch Digraphs oder Worte ersetzt werden:
[ <: ] :> { <% } %> # %: ## %:%:
&& and | bitor || or ^ xor ~ compl & bitand
&= and_eq |= or_eq ^= xor_eq ! not != not_eq } %>
} %> } %> } %> } %>
Ich habe noch kein Programm gesehen, das statt {int x = a[b]^c|~d; } die erlaubte (!) Schreibweise<%int x = a??(b:>??'c??!??-d; %> verwendet.
Für manche mathematischen Zeichen existiert keine Taste; sie wird durch eine Zeichenkombination dargestellt:
≤ <= ≥ >= ≡ == ̸= !=
∧ && ∨ || ¬ ! → ->
Ohne mathematisches Äquivalent wurden die folgenden Kombinationen für C und C++ neu erfunden:
++ -- << >> += -= *= /=
%= <<= >>= &= ^= |= ##
Zuletzt werden die Interpunktionszeichen noch einmal als Gruppe zusammengefasst:
[ ] ( ) { } . -> ++ --
& * + - ~ ! / % << >>
< > <= >= == != ^ | && ||
? : ; ... = *= /= %= += -=
<<= >>= &= ^= |= , # ## <: :>
<% %> %: %:%:
2. Hello World
Durch mehrere Möglichkeiten, den namespace std anzugeben, existieren zwei Varianten eines einfachen Hallo-Programms. Man kann jeden Namen mit std quali�zieren:
1 // hello1.cpp
2 #include <iostream >
3 int main()
4 {
5 std::cout << "Hello" << std::endl;
6 }
Alternativ wird der gesamte Namensraum std im Programm verfügbar gemacht:
1 // hello2.cpp
2 #include <iostream >
3 using namespace std;
4 int main()
5 {
6 cout << "Hello" << endl;
7 }
Verwenden Sie niemals die C-Library direkt stdio.h oder in der C++-Form cstdio mit z.B. printf! Ein-undAusgaben wird in C++ immer mit iostream durchgeführt. Den C-Geräten stdin, stdout und stderr entsprechenin C++ die Ströme cin, cout, cerr und clog. Die Operationen werden suggestiv mit den Stream-Insertern und-Extraktoren << und >> durchgeführt. Zeilenenden werden mit endl oder wie in C gewohnt mit "\n" geschrieben.

3. DATENTYPEN, VARIABLE UND WERTE 13
3. Datentypen, Variable und Werte
3.1. Typprüfung. Typprüfungen sind strenger als in C.
3.2. Fundamentale Typen. Datentyp für die leere Menge: void.
Logische Gröÿen: bool.
Schriftzeichen: drei verschiedene Typen für Schriftzeichen der basic character set char, signed char und unsigned char
mit dem gemeinsamen Obergegri� narrow character types. Ein zusätzlicher Type wchar_t für eine extended≡widecharacter set. Zwei zusätzliche Typen char16_t und char32_t für Unicodezeichen in UTF-16/UCS-2 und UTF-32≡UCS-4 ()wide character types.
Ganze Zahlen mit Vorzeichen: signed char short long und long long. int ist der natürliche Type der Rech-nerarchitektur.
Ganze Zahlen ohne Vorzeichen: unsigned char unsigned short unsigned long und unsigned long long. unsigned int
ist der natürliche Type der Rechnerarchitektur.
Reelle Zahlen: float, double und long double.
Zeiger: int * v.
decltype: ein vom Compiler aus einem Ausdruck ermittelter Typ.class X { double a; }; const X * x; decltype(x->a) var;
auto: ein vom Compiler automatisch aus dem Umgebung ermittelter Typ.
3.3. Namen (Identi�er). Namen bezeichnen Programmeinheiten wie Variable, Funktionen, Klassen, Mem-ber und ähnliches.
C++ ist case-sensitiv und formatfrei.
Namen beginnen mit einem Buchstaben und bestehen aus beliebig vielen Buchstaben und Zi�ern. Der Unterstrichzählt als Buchstabe.
Ein Unterstrich (_Hans) am Anfang ist erlaubt, dient jedoch für zukünftige Spracherweiterungen und sollte prinzip-iell vermieden werden, damit das Programm auch in Zukunft nach möglichen Sprachänderungen garantiert über-setzbar bleibt. Das schlieÿt einen Doppelunterstrich am Anfang ein (__Otto).
Mit der universal character name-Schreibweise können alle Unicode-Buchstaben und -Zi�ern verwendet werden.Diese Liste ist abschlieÿend im Unicode-Standard (ISO 10646) und im C++-Standard aufgeführt. Compiler müssenbei der Übersetzung oft speziell eingestellt werden. Auch wegen der internationalen Lesbarkeit sollte man tschechis-che oder chinesische Variablennamen eher vermeiden.
int i\u00c4\u5c71; // Ä und shan (chin.)
Solche Programme sind nur mit Zusatzoptionen übersetzbar:
g++ -fextended-identifiers -finput-charset=utf8 x.cpp
Schlüsselwörter als Namen sind verboten. Namen mit spezieller Bedeutung (override, �nal) sind nicht überallerlaubt. Alternative Darstellungen sind ebenfalls reserviert. Die folgenden Namen sind Schlüsselwörter und dürfennur in ihrer festgelegten Bedeutung verwendet werden:
alignas alignof asm auto bool break case catch char char16_t char32_t class const const_cast constexpr continuedecltype default delete do double dynamic_cast else enum explicit export extern false �oat for friend goto if inlineint long mutable namespace new noexcept nullptr operator private protected public register reinterpret_cast returnshort signed sizeof static static_assert static_cast struct switch template this thread_local throw true try typedeftypeid typename union unsigned using virtual void volatile wchar_t while
3.4. Werte und Literale.

14 2. PROZEDURALE PROGRAMMIERUNG
4. Rechenausdrücke
5. Anweisungen
6. Funktionen
6.1. Überladung.
6.2. Default Argumente.
6.3. void/variable arguments.
6.4. C-Funktionen.
7. Header
8. Namespaces
Namespaces sollen in groÿen Programmen, die manchmal aus Teilen verschiedener Herkunft zusammengesetztsind, Namenskon�ikte vermeiden. Der Klassiker ist eine in C und C++ fehlende ganzzahlige Potenz, die oft adhoc in verschiedenen Programmteilen unter dem Namen ipow eingeführt wird. Die Kollision entsteht, wenn beideProgrammteile gemeinsam übersetzt werden und beide Funktionen vielleicht sogar leicht verschieden de�nierteLeistungen erbringen.
Namespace-Blöcke werden mit einem Namespace-Namen versehen, ihr Inhalt wird zusätzlich mit dem Namespace-Namen quali�ziert.
namespace name { De�nitionen und Deklarationen wie int i; }
Auÿerhalb des Namespace heiÿt die Variable name::i. So können verschiedene gleichnamige Entities durch ver-schiedene Namespace-Namen unterschieden werden.
Mehrere Namespace-Blöcke mit demselben Namespace sind erlaubt und werden als gemeinsamer Namespace be-handelt. Solche Blöcke dürfen sich sogar über verschiedene Übersetzungseinheiten erstrecken.
Namespaces dürfen beliebig tief verschachtelt sein, also innere Namespaces enthalten. Die Bezeichnungen folgendann den Verschachtelungen.
namespace n1 { int i; namespace n2 { int j; j = 1; } i = 2; n2::j = 3; }
n1::i = 4; n1::n2::j = 5;
Will man die Namespace-Entities ohne den namespace-namen benutzen, kann man das mit using-Direktive tun.
using namespace n1; //Alle Namen in n1 dürfen mit und ohne Namespace-Angabe benutzt werden: n1::i = 5; i = 1;
Mit der using-Deklaration kann man einzelne Entities ohne Namespace-Angabe benutzen.
using n1::i; // Der Name i darf mit und ohne Namespace-Angabe benutzt werden: n1::i = 5; i = 1;
Ein mit inline markierter Namespace überträgt seinen Inhalt in den umgebenden Namespace. Dabei dürfen keineNamenskollisionen auftreten. Verschachtelte inlines sind erlaubt.
namespace n1 { int i; inline namespace n2 { int j; j = 1; } i = 2; n2::j = 3; j = 4; }
n1::i = 5; n1::n2::j = 6; n1::j = 6;
Namespaces ohne Namen sind erlaubt und generieren einen mit unique bezeichneten Namespace mit impliziterusing-Direktive mit der storage-Klasse internal linkage. Die Namen sind also nur in einer Übersetzungseinheitsichtbar.
namespace { int i; i = 1; } i = 2; unique::i=3;
Namespaces dürfen in einzelnen Programmteilen umbenannt werden. Ihre Entities können dann unter einemanderen Names (alias-name) benutzt werden.
using zweitname=namespacename;
Schlieÿlich werden ab 2017 für verschachtelte Namespaces Kurzschreibweisen erlaubt.
namespace A::B::C { } ersetzt namespace A { namespace B { namespace C { }}}

10. SCHRIFTZEICHEN, STRINGS UND UNICODE 15
9. Referenzen
10. Schriftzeichen, Strings und Unicode
10.1. Schriftzeichen. C++ hat vier Schreibweisen für Schriftzeichen, die sich im Typ unterscheiden:'x' (narrow literal), Typ: charu'x' Typ: char16_tU'x' Typ: char32_tL'x' Typ: wchar_t
Die Schriftzeichen selbst dürfen aus der source character set sein. Sie wird vom Compiler implementierungsabhängigauf die execution character set abgebildet, falls Schriftzeichen verwendet werden, die nicht aus der Grundzeichen-menge stammen (basic source character set, 96 Zeichen: a-z A-Z 0-9 _{}[]()#<>%:;.? *+-/^&|~!=,\"').
Wie in C sind Escape-Schreibweisen erlaubt: \' \" \? \\ \a \b \f \n \t \v. Auch die oktalen und sedezimalenEscapes A ≡ \101 ≡\x41 sind problemlos. Der in C sehr häu�ge Stringabschluss \0 wird verstanden, wurde inC++ natürlich durch echte Strings ersetzt.
Unicode-Zeichen dürfen (auch im normalen Programm) mit zwei unicode-Escapes geschrieben werden: \uxxxx
und \Uxxxxxxxx. Hier sind ausschlieÿlich sedezimale vier- oder achtstellige code-points aus dem Unicode erlaubt,surrogate-Schreibweisen sind verboten; verwenden Sie statt dessen die achtstellige Variante mit groÿem U.
Mehr als ein Schriftzeichen ist erlaubt, wird als int ausgewertet und der Wert ist implementierungsabhängig(multicharacter literal, 'ab', u'2e'). Zwischen Apostrophen sollte in portablen Programmen niemals mehr als einSchriftzeichen stehen. Wegen der Probleme gibt gcc eine Warnung aus.
Anders als in C sind char, char16_t, char32_t und wchar_t in C++ Schlüsselworte.
Faustregel: Wenn Sie nur ASCII verwenden, machen Sie weiter wie bisher! Wenn Sie andere Zeichen brauchen(ÄÖÜäöüÿÑñéèe. . . ), benutzen Sie konsequent UTF-8-Strings, die Unicode-Escape-Schreibweisen und die C++-Stringlibrary. UTF-16 ist ebenfalls brauchbar. Wenn Sie die Strings im Programm verarbeiten wollen, benutzenSie eine gute Unicode-Library (ICU)!
10.2. Strings. Für Strings stehen fünf Grundschreibweisen in zwei Varianten zur Verfügung:
"Hallo" Inhalt: ASCII, ISO-8859-1, CP1252 oder what you will1
u8"Hallo" Inhalt: UTF-8 in char
u"Hallo" Inhalt: UTF-16 in char16_t
U"Hallo" Inhalt: UTF-32 in char32_t
L"Hallo" Inhalt: compiler-de�ned in wchar_t
Mit Ausnahme der 96 Zeichen der basic source character set ist die Abbildung der source character set auf die exe-cution character set implementierungsabhängig, also ist nicht eindeutig klar, was ein Compiler mit L"2e" wirklichanfängt. Besser ist in jedem Fall u8"2\u20AC" oder U"2\U000020AC". Ob der Compiler oder das Betriebssystembei der Programmausführung mit den Strings klarkommen, ist eine weitere spannende Frage.
Überraschenderweise erzeugt <iostream> bei der Ausgabe nur bei ASCII- und UTF-8-Strings eine Zeichenfolge,bei allen anderen Stringvarianten eine Adresse.
Alle Strings können auch als Raw-Strings geschrieben werden, diese Form erlaubt keine Escapes und jedes Zeichenaus der source character set wird eins zu eins in den String übernommen. Zwischen Pre�x und String steht dannnoch ein R:
u8R"abc( 2 efür meinen Kommentar\n
)abc"
steht für u8" 2 \u20AC\nfür meinen Kommentar\n\\n\n". Gänsefüÿchen, abc und die Klammern begrenzen denString. Der Text abc als Begrenzer ist frei wählbar und darf auch fehlen.
1Shakespeare: Thwelfth Night

16 2. PROZEDURALE PROGRAMMIERUNG
10.3. STL-Strings. Die STL-Library bietet eine ausgefeilte, jedoch noch an klassischem C orientierte String-Library in <string>. Sie setzt fälschlicherweise Schriftzeichen ≡ code unit voraus.
Das folgende Beispiel demonstriert die Leistungen und Grenzen, sowie die wichtigsten Funktionen von string.h>.Dabei werden verschiedene Strings von rechts nach links geschrieben:
1 // str1.cpp
2 #include <iostream >
3 #include <string >
4 #include <algorithm >
5
6 using namespace std;
7
8 int main ()
9 { string s, stmp;
10 int i, j;
11
12 getline (cin , s); // input line from keyboard
13 stmp = s; // copy string to another variable
14 cout << stmp << endl;
15
16 cout << "backwards: ";
17 for (i = s.length () - 1; i >= 0; --i) // first solution
18 { cout << s [i];
19 }
20 cout << endl;
21
22 s = stmp;
23 for (j = 0, i = s.length () - 1; j < i; ++j, --i) // K&R
24 { char tmp = s [i];
25 s [i] = s [j];
26 s [j] = tmp;
27 }
28 cout << "swap pairs: " << s << endl;
29
30 s = stmp;
31 reverse (s.begin(), s.end()); // using algorithm
32 cout << "reverse: " << s << endl;
33
34 s = string(stmp.rbegin (), stmp.rend()); // reverse iterator
35 cout << "rev. it.: " << s << endl;
36
37 stmp = string(u8"1 $ = 0.8122 \u20ac = 107.680 \u00a5 = 0.7141 \u00a3 (23.4.2018)"); // UTF
-8 reverse
38 // Euro Yen Pound
39 cout << stmp << endl;
40 cout << stmp.length () << endl;
41 s = string(stmp.rbegin (), stmp.rend()); // reverse iterator
42 // without auto abbreviates
43 /*
44 std:: string :: iterator ib , ie;
45 ib = s.begin ();
46 ie = s.end();
47 */
48 auto ib = s.begin ();
49 auto ie = s.end();
50 while (ib != ie)
51 {
52 if (((*ib) & 0xc0) == 0x80) // revert multi -unit -chars
53 { // a second time
54 auto i = ib;
55 while (i != ie && (((*i) & 0xc0) == 0x80)) i++;
56 i++; // i = end of muc

10. SCHRIFTZEICHEN, STRINGS UND UNICODE 17
57 reverse (ib, i);
58 ib = i;
59 }
60 else
61 {
62 ib++;
63 }
64 }
65 cout << "UTF -8 rev.: " << s << endl;
66 }
10.3.1. Grundprinzip. Gilt für string und auch für vector: Mehrere Funktionsklassen werden scharf unter-schieden: 1. string bleibt unverändert (size()); 2. bestehender string-Bereich wird manipuliert (s[0]='A'); 3.String erweitert ();
Eine bereichsmanipulierende Funktion kann nicht erweitern (s[10000000]='A';)
10.3.2. Variable und Initialisierung. string s, s1(s), s2("Hallo"), s3(10, 'A'); strinf s4(s2,1,3), s5(s2.begin(),s2.end());
10.3.3. Iteratoren. auto b = s.begin();
auto e = s.end();
auto b1 = s.rbegin();
auto e1 = s.rend();
10.3.4. Operatoren. s1=s2; s[i]; s+s1; s==s1; s<s1;
10.3.5. Funktionen. s1.assign(s2);
10.3.6.
10.4. C++ und Unicode. C++ hat C komplett übernommen (char); beide Sprachen haben zweimal ver-sucht, den Unicode mühsam zu integrieren: einmal ca. 1999 (wchar_t, wprint, "%ls", towupper) und einmal2011 (char16_t, char32_t). Beide Sprachen sind hier nicht kompatibel: in C muss bei wchar_t-Verwendung<stdlib.h> inkludiert werden, bei char16_t- oder char32_t-Verwendung jedoch <uchar.h>. In C++ sind alledrei Typen Sprachschlüsselworte!
Auch die Leistungen von wchar_t (C++98) und char16_t/char32_t (C++11) sind nicht äquivalent.
Der Unicode de�niert den Code und mehrere encodings, macht aber keine Vorgaben, welche encodings verwendetwerden sollten. Er sagt nichts aus über die Schnittstellen zwischen Tastatur, Betriebssystem und Programm, undes gibt keinerlei Aussagen über die Darstellung der Zeichen auf Papier oder Bildschirm.
In Java und JavaScript ist für die interne Verarbeitung als code-unit eine Zwei-Byte-Einheit mit encoding UTF-16festgelegt, in Javascript engineabhängig auch nur UCS-2. Das encoding-scheme (endianess) steht der CPU frei.
C und C++ enthalten keine Vorgaben über encodings. Diese Entscheidung muss prinzipiell der Programmierertre�en; er sollte jedoch möglicherweise Randbedingungen berücksichtigen. Die meisten encodings (UTF-1, UTF-4,UTF-5, UTF-7, SCSU, BOCU) können heute erfreulicherweise ignoriert werden; wichtig sind eigentlich nur nochASCII, UTF-8, UTF-16 und UTF-32. Das encoding-scheme regelt auch hier die CPU.
Randbedingungen sind die Inkompatibilität zwischen Microsoft-Compilern und Windows-Rechnern auf der einenSeite (sizeof(wchar_t)==2 und UTF-16) und Gnu-C, Intel-C und LLVM-C auf der anderen (sizeof(wchar_t)==4und UTF-32). wchar_t ist nicht portabel und sollte vermieden werden!
char16_t und char32_t sollten portabel sein, werden jedoch nur von aktuellen Compilern beherrscht (gcc -std=c11,g++ -std=c++11, g++ -std=c++14).
Damit zeichnen sich folgende brauchbare Empfehlungen ab:
1. Eine gute Wahl ist die Verwendung von char und UTF-8 als interne Darstellung.
2. Eine Alternative ist char16_t und UTF-16 oder char32_t und UTF-32. Hier ist einschränkend zu beachten,dass <iostream> nur Adressen ausgibt (cout<<u"Hallo";).
3. Wer wirklich vielsprachige Texte verarbeiten muss, kommt um die Library ICU von IBM nicht herum. Siehat einen eigenen Datentyp für Schriftzeichen UChar (intern UCHAR_TYPE) und verwendet UTF-16, kann aber alleencodings konvertieren.

18 2. PROZEDURALE PROGRAMMIERUNG
Lesen und Schreiben von Dateien setzt für eine Datei voraus, dass Sie ihr encoding (UTF-8. . . ) und ihr encoding-scheme (big/little endian) kennen. Interne Strings und Datei-Format müssen eventuell konvertiert werden. Auchhier leistet ICU gute Dienste.
Ausgaben auf den Bildschirm oder Drucker benötigen installierte Fonts zur Darstellung der Glyphen.
Eingaben von der Tastatur gehen nur, wenn die Tastatur Vielsprachigkeit ermöglicht, das Betriebssystem die Ze-ichen überträgt und das Programm das alles richtig versteht. In Unices sind die Locale-Einstellung hilfreich:setlocale(LC_ALL, "Russian");
_wsetlocale(LC_ALL, L"Russian");
Wichtigste Regel für alle Programmierer:
char ist kein Schriftzeichen mehr, sondern nur noch code-unit. Ein oder mehrere code-units können ein Schriftze-ichen sein, das hängt von encoding und vom Schriftzeichen selbst ab.
wchar_t oder char16_t ist ebenfalls kein Schriftzeichen, sondern nur code-unit. Ein oder zwei code-units könnenein Schriftzeichen sein, das hängt von encoding und vom Schriftzeichen selbst ab.
Nur mit char32_t fallen code-units und Schriftzeichen wieder zusammen. Dafür werden alle Schriftzeichen in vierBytes gespeichert.
Die in den Sprachstandards de�nierten Libraries verarbeiten keine Schriftzeichen mehr, auch wenn ihre Namen dassuggerieren. Sie verarbeiten lediglich code-units! std::string s = u8"2e"; s.size() liefert nicht die Anzahlder Schriftzeichen (2), sondern die Anzahl der code-units (1+3=4). Insbesondere gilt das für <cstring> und<string>, hier für string, wstring und u16string. Für u32string sind Zeichen und Codeunits wieder identisch.
Microsoft benutzt in Windows für den Unicode wchar_t mit UTF-16. Nicht portabel ist gcc mit wchar_t =UTF-32.
10.5. Übersicht. Die folgende Tabelle gibt eine Übersicht über die De�nitionen im Standard:
char string
wchar_t wstring
char16_t u16string
char32_t u32string
Null-terminated sequence <cctype>
Null-terminated sequence <cwctype>
Null-terminated sequence <cstring>
Null-terminated sequence <cwchar>
Null-terminated sequence <cuchar>
10.6. Beispiel. Im folgenden Beispiel werden Funktionen vorgestellt, die mit Sprachmitteln die verschiedenenStringvarianten auÿer wchar_t konvertieren. Mit dem optional übersetzbaren main können sie gleich getestetwerden.
Die seit C++11 vorhandene Library codecvt (im C++14-Standard unter 22.3.3.2 beschrieben) enthält ähnlicheLeistungen; sie ist jedoch vorläu�g ohne Ersatz ab C++17 deprecated. O�zielle Empfehlung: selbst implemen-tieren!
Die Funktionen sind so kurz wie möglich implementiert und arbeiten korrekt für unicode-korrekte Eingabestrings.Sie prüfen nicht alle im Unicode verbotenen Darstellungen. Bei nicht korrekten Darstellungen liefern sie unde�nierteErgebnisse (UTF-8-Zeichen, die als Fortsetzung starten, halbe UTF-16-Paare, verbotene Zeichen). Spezielle Uni-codeprobleme wie combining characters werden hier nicht bearbeitet.
Man kann die Bearbeitung von UTF-8- und UTF-16-Strings gut erkennen und nachvollziehen.
1 // uconvert.cpp
2 // g++ -std=c++11 -Dtestmain uconvert.cpp
3 // g++ -std=c++11 -c uconvert.cpp
4
5 #include <iostream >
6 #include <fstream >
7 #include <string >

10. SCHRIFTZEICHEN, STRINGS UND UNICODE 19
8 #include <locale >
9 #include <iomanip >
10 //#include <codecvt > introduced 2011, deprecated 2017
11 #include <vector >
12
13 #include "uconvert.h"
14
15 std:: string toUtf8 (std:: u16string s) // u16 -> u32 -> u8
16 { std:: u32string t = toUtf32 (s);
17 return toUtf8 (t);
18 }
19
20 std:: u16string toUtf16 (std:: string s) // u8 -> u32 -> u16
21 { std:: u32string t = toUtf32 (s);
22 return toUtf16 (t);
23 }
24
25 // recursivly generate UTF -8 bytes from c to v
26 // 10000000=n (marks 0 bit in 1st byte) bits n ~(2n-1)
27 // 0xxxxxxx 7 bit 0x80 0x00
28 // 110 xxxxx 10 xxxxxx 11 bit 0x20 0xc0
29 // 1110 xxxx 10 xxxxxx 10 xxxxxx 16 bit 0x10 0xe0
30 // 11110 xxx 10 xxxxxx 10 xxxxxx 10 xxxxxx 21 bit 0x08 0xf0
31 void u8enter (std::vector <char > & v, int c, int n)
32 { int m;
33 if (c < n) // rest of char in c fits into first byte
34 { m = ((~(2*n-1)) & 0xff) | c;
35 v.push_back (static_cast <char >(m));
36 return;
37 }
38 u8enter (v, c >> 6, n==0x80 ? n>>2 : n>>1);
39 v.push_back (static_cast <char >((c & 0x3f) | 0x80));
40 }
41 std:: string toUtf8 (std:: u32string s) // u32 -> u8
42 { std::vector <char > v;
43 for (int i = 0; i < s.size(); ++i) u8enter (v, s [i], 0x80);
44 return std:: string (v.begin (), v.end());
45 }
46
47 void u32enter (std::vector <char32_t > & v, char32_t & c, int & n, int s)
48 { if ((s & 0x80) == 0x00) { v.push_back (s & 0x7f); c = U'\0'; n = 0; }
49 else if ((s & 0xe0) == 0xc0) { c = s & 0x1f; n = 1; } // 110 xxxxx
50 else if ((s & 0xf0) == 0xe0) { c = s & 0x0f; n = 2; } // 1110 xxxx
51 else if ((s & 0xf8) == 0xf0) { c = s & 0x07; n = 3; } // 11110 xxx
52 else if ((s & 0xc0) == 0x80) // 10 xxxxxx
53 { c = (c << 6) | (s & 0x3f);
54 n--;
55 if (n <= 0) { v.push_back (c); c = U'\0'; n = 0; }
56 } }
57 std:: u32string toUtf32 (std:: string s) // u8 -> u32
58 { std::vector <char32_t > v;
59 char32_t c;
60 int n;
61 c = U'\0'; n = 0;
62 for (int i = 0; i < s.size(); ++i)
63 { u32enter (v, c, n, s [i]);
64 }
65 return std:: u32string (v.begin(), v.end());
66 }
67
68 // the 10 bits of c-0 x10000 are stored in two surrogate code units
69 // 110110 xxxxxxxxxx 110111 xxxxxxxxxx

20 2. PROZEDURALE PROGRAMMIERUNG
70 // 0xd800 -0xdbff 0xdc00 -9 xdfff
71 std:: u16string toUtf16 (std:: u32string s) // u32 -> u16
72 { std::vector <char16_t > v;
73 for (int i = 0; i < s.size(); ++i)
74 { if (s [i] < 0xd800 || (0xe000 <= s [i] && s [i] < 0x10000))
75 { v.push_back (static_cast <char16_t >(s [i]));
76 }
77 else
78 { char32_t c = s [i];
79 c -= 0x10000;
80 v.push_back (static_cast <char16_t >((c >> 10) | 0xd800));
81 v.push_back (static_cast <char16_t >((c & 0x3ff) | 0xdc00));
82 } }
83 return std:: u16string (v.begin(), v.end());
84 }
85
86 std:: u32string toUtf32 (std:: u16string s) // u16 -> u32
87 { std::vector <char32_t > v;
88 for (int i = 0; i < s.size(); ++i)
89 { if ((s [i] & ~0x3ff) == 0xd800 && i < s.size() - 1 && (s [i+1] & ~0x3ff) == 0xdc00)
90 { v.push_back (0 x10000 + (((s [i] & 0x3ff) << 10) | (s [i+1] & 0x3ff)));
91 ++i;
92 }
93 else
94 { v.push_back (s [i]);
95 }
96 }
97 return std:: u32string (v.begin(), v.end());
98 }
99
100 #ifdef testmain
101 int main()
102 { std:: string s8 (u8"z\u00df\u6c34\U0001f34c\u20ac"); // z ß shui emoticon euro
103 std:: u16string s16 (u"\u4f60\u597d"); // ni hao
104 std:: u16string s16a (u"z\u00df\u6c34\U0001f34c\u20ac"); // z ß shui emoticon euro
105 std:: u32string s32 (U"z\u00df\u6c34\U0001f34c\u20ac"); // z ß shui emoticon euro
106
107 std::vector <char > v;
108 u8enter (v, 65, 0x80); std::cout << std:: string (v.begin(), v.end()) << std::endl;
109 u8enter (v, 0xdf , 0x80); std::cout << std:: string (v.begin(), v.end()) << std::endl;
110 u8enter (v, 0x6c34 , 0x80); std::cout << std:: string (v.begin(), v.end()) << std::endl;
111 u8enter (v, 0x1f34c , 0x80); std::cout << std:: string (v.begin(), v.end()) << std::endl;
112
113 std:: string x;
114 std:: u32string y;
115 std:: u16string z;
116
117 x = toUtf8 (s32); std::cout << x << std::endl;
118 y = toUtf32 (x);
119 if (s32 != y) std::cout << "wtf" << std::endl;
120
121 x = toUtf8 (s16a); std::cout << x << std::endl;
122 z = toUtf16 (x);
123 if (s16a != z) std::cout << "wtf" << std::endl;
124
125 x = toUtf8 (s16); std::cout << x << std::endl;
126 z = toUtf16 (x);
127 if (s16 != z) std::cout << "wtf" << std::endl;
128
129 y = toUtf32 (s16a); std::cout << toUtf8(y) << std::endl;
130 z = toUtf16 (y);
131 if (s16a != z) std::cout << "wtf" << std::endl;

10. SCHRIFTZEICHEN, STRINGS UND UNICODE 21
132
133 y = toUtf32 (s16); std::cout << toUtf8(y) << std::endl;
134 z = toUtf16 (y);
135 if (s16 != z) std::cout << "wtf" << std::endl;
136
137 z = toUtf16 (s32); std::cout << toUtf8(z) << std::endl;
138 y = toUtf32 (z);
139 if (s32 != y) std::cout << "wtf" << std::endl;
140 }
141 #endif
Im nächsten Beispiel wird uconvert.cpp verwendet, um verschiedene Dateiformate mit Unicode-Text zu lesen undnach UTF-8 zu konvertieren. Alle Dateien müssen mit einer Byte-Order-Mark (BOM) markiert sein, andernfallswird UTF-8 angenommen. Streng genommen ist die BOM in UTF-8 verboten.
Alle Casts müssen stehen, sonst werden Vorzeichen beim Schieben falsch dupliziert. Alle Klammern müssen stehen,sonst klammert der Compiler falsch.
UTF-8 wird als Ein- und Ausgabeformat für die Konsole verwendet. UTF-32 ist als Zwischenformat für die schnelleStringverarbeitung geeignet.
Die C++-Fähigkeiten werden ausgenutzt (vector, iterator), aber nur gemäÿigt, um den Code nicht zu unlesbar zumachen. In auskommentierten Debug-Anweisungen kommen λ-Funktionen und for_each vor.
1 // unicode.cpp
2 // clang ++ -std=c++11 -c uconvert.cpp
3 // clang ++ -std=c++11 -Wall -pedantic unicode.cpp uconvert.o
4
5 #include <iostream >
6 #include <fstream >
7 #include <string >
8 #include <algorithm >
9 #include <iterator >
10 #include <vector >
11 //#include <codecvt > introduced 2011, deprecated 2017
12
13 #include "uconvert.h"
14
15 std:: string doutf32be (char const * fn)
16 { std::cout << "utf32be" << std::endl;
17 std:: ifstream f (fn , std::ios::in | std::ios:: binary);
18 std::vector <char > b (std:: istreambuf_iterator <char >(f), (std:: istreambuf_iterator <char >()));
19 f.close ();
20 std::vector <char32_t > v;
21 for (int i = 0; i < b.size() -3; i += 4)
22 { v.push_back (static_cast <char32_t >(((((((( unsigned char)b[i+0]<<8) | (unsigned char)b [i+1])
<<8)
23 | (unsigned char)b [i+2]) << 8) | (unsigned char)b [i
+3])));
24 }
25 // std:: for_each (v.begin(), v.end(), []( char32_t & c){ std::cout << " " << std::hex << (
unsigned int) c << std::dec; });
26 // std::cout << std::dec << std::endl;
27 return toUtf8 (std:: u32string (v.begin(), v.end()));
28 }
29
30 std:: string doutf32le (char const * fn)
31 { std::cout << "utf32le" << std::endl;
32 std:: ifstream f (fn , std::ios::in|std::ios:: binary);
33 std::vector <char > b (std:: istreambuf_iterator <char >(f), (std:: istreambuf_iterator <char >()));
34 f.close ();
35 std::vector <char32_t > v;
36 for (int i = 0; i < b.size() -3; i += 4)

22 2. PROZEDURALE PROGRAMMIERUNG
37 { v.push_back (static_cast <char32_t >(((((((( unsigned char)b[i+3]<<8) | (unsigned char)b [i+2])
<<8)
38 | (unsigned char)b [i+1]) << 8) | (unsigned char)b [i
+0])));
39 }
40 std::cout << b.size() << " " << v.size() << std::endl;
41 return toUtf8 (std:: u32string (v.begin(), v.end()));
42 }
43
44 std:: string doutf16be (char const * fn)
45 { std::cout << "utf16be" << std::endl;
46 std:: ifstream f (fn , std::ios::in|std::ios:: binary);
47 std::vector <char > b (std:: istreambuf_iterator <char >(f), (std:: istreambuf_iterator <char >()));
48 f.close ();
49 std::vector <char16_t > v;
50 for (int i = 0; i < b.size() -1; i += 2)
51 { v.push_back (static_cast <char16_t >((((( unsigned char)b [i+0]) << 8) | (unsigned char)b [i+1])
));
52 }
53 std::cout << b.size() << " " << v.size() << std::endl;
54 return toUtf8 (std:: u16string (v.begin(), v.end()));
55 }
56
57 std:: string doutf16le (char const * fn)
58 { std::cout << "utf16le" << std::endl;
59 std:: ifstream f (fn , std::ios::in|std::ios:: binary);
60 std::vector <char > b (std:: istreambuf_iterator <char >(f), (std:: istreambuf_iterator <char >()));
61 f.close ();
62 std::vector <char16_t > v;
63 for (int i = 0; i < b.size() -1; i += 2)
64 { v.push_back (static_cast <char16_t >((((( unsigned char)b [i+1]) << 8) | (unsigned char)b [i+0])
));
65 }
66 std::cout << b.size() << " " << v.size() << std::endl;
67 return toUtf8 (std:: u16string (v.begin(), v.end()));
68 }
69
70 std:: string doutf8 (char const * fn)
71 { std::cout << "utf8" << std::endl;
72 std:: ifstream f (fn , std::ios::in|std::ios:: binary);
73 std::vector <char > b (std:: istreambuf_iterator <char >(f), (std:: istreambuf_iterator <char >()));
74 f.close ();
75 std::cout << b.size() << std::endl;
76 return std:: string(b.begin(), b.end());
77 }
78
79 std:: string filetype (char const * fn)
80 { std:: ifstream f (fn , std::ios::in|std::ios:: binary);
81 if (!f) return std:: string ();
82 if (!f.is_open ()) return std:: string ();
83 char c [4];
84 f.read (c, 4);
85 for (int i = f.gcount (); i < 4; ++i) c [i] = '\0';
86 for (int i = 0; i < 4; ++i) std::cout << std::hex << (unsigned int )(unsigned char) c [i] << "
| ";
87 std::cout << std::dec << std::endl;
88 f.close ();
89 if (c[0] == (char)0 && c[1] == (char)0 && c[2] == (char)0xfe && c[3] == (char)0xff)
90 { return doutf32be (fn);
91 }
92 if (c[0] == (char)0xff && c[1] == (char)0xfe && c[2] == (char)0 && c[3] == (char)0)
93 { return doutf32le (fn);

11. EIN- UND AUSGABE 23
94 }
95 if (c[0] == (char)0xfe && c[1] == (char)0xff)
96 { return doutf16be (fn);
97 }
98 if (c[0] == (char)0xff && c[1] == (char)0xfe)
99 { return doutf16le (fn);
100 }
101 if (c[0] == (char)0xef && c[1] == (char)0xbb && c[2] == (char)0xbf)
102 { return doutf8 (fn);
103 }
104 return doutf8 (fn);
105 }
106
107 int utf8Chars (std:: string const & s)
108 { int n = 0;
109 for (int i = 0; i < s.size(); ++i)
110 { if ((s [i] & 0xc0) != 0x80) ++n;
111 }
112 return n;
113 }
114
115 std:: string toline (std:: string const & s)
116 { std:: string t (s);
117 for (int i = 0; i < t.size(); ++i)
118 { if (static_cast <unsigned char >(t [i]) < ' ') t [i] = '/';
119 }
120 return t;
121 }
122
123 int main (int argc , char** argv)
124 { std:: string s;
125 for (int i = 1; i < argc; ++i)
126 { s = filetype (argv [i]); // filetype analyses BOM and processes file content to UTF -8 string
127 std::cout << argv [i] << ": s=" << s.size () << "/c=" << utf8Chars (s) << std::endl;
128 std::cout << toline(s) << std::endl;
129 std::cout << std::endl;
130 } }
Beide Beispiele machen Gebrauch von ganzzahligen Bitoperationen. In aller Kürze (mit . werden unwichtige 0-Bitsmarkiert):
1 &: Bitweises Und , 01110100 & 11001100 -> 01000100 0x74 & 0xcc -> 0x44
2 |: Bitweises Oder , 01110100 | 11001100 -> 11111100 0x74 | 0xcc -> 0xfc
3 ~: Bitweises Nicht , ~01110100 -> 10001011 ~0x74 -> 0x8b
4 <<: Links schieben , 01110100 << 2 -> 11010000 0x74 << 2 -> 0xd0
5 >>: Rechts schieben , 01110100 >> 2 -> 00011101 0x74 >> 2 -> 0x1d
6 >>: unsigned , 11001100 >> 3 -> 00011001 0xcc >> 3 -> 0x19
7 >>: signed , 11001100 >> 3 -> 11111001 0xcc >> 3 -> 0xf9
8 & als Bitmaske: 10101010 & 00011100 -> ...010.. 0xaa & 0x1c -> 0x08
9 | als Bitkombination: 10101... | .....101 -> 10101101 0xa8 | 0x05 -> 0xad
11. Ein- und Ausgabe
Ein- und Ausgaben werden statt von der Bibliothek <cstdio> (früher <stdio>) von der objektorientiert program-mierten Bibliothek <iostream> abgewickelt. Die Leistungen beider Bibliotheken sind sehr ähnlich; die Schreib-weisen der Anweisungen sind jedoch gravierend verschieden. Die Ein- und Ausgabefunktionen der Bibliotheken<cstdio> und <iostream> sollten nicht im selbem Programm zusammen verwendet werden; grundsätzlich sollten inC++-Programmen die Ein- und Ausgabenfunktionen der C-Bibliothek <cstdio> überhaupt nicht mehr verwendetwerden.
1 // io.cpp
2 #include <iostream >

24 2. PROZEDURALE PROGRAMMIERUNG
3
4 using namespace std;
5
6 int main ()
7 { int a, b, summe;
8
9 cout << "\nBerechnung von a + b; Gib a und b: ";
10 cin >> a >> b;
11 summe = a + b;
12 cout << "\n" << a << "+" << b << "=" << summe;
13
14 cerr << "\nNormales Programmende";
15 return 0;
16 }
Die Ein- und Ausgabe in C und C++ ist stromorientiert gestaltet. Jedes Gerät oder jede Datei wird als Zeichen-oder Byte-Strom interpretiert, der im Fall der Ausgabe erzeugt wird und im Fall der Eingabe gelesen und ab-schnittsweise interpretiert wird.
Die Funktionen der C-Bibliothek <cstdio> sind auch in C++ verfügbar und können dort aufgerufen werden, obwohldas kein guter C++-Stil ist. Für C++ existieren neu gestaltete C++-Bibliotheken <iostream>, <iomanip>,<fstream> und <sstream> (früher <strstream>), welche die C-Bibliothek ersetzen. Sie stellen ausgezeichneteBeispiele für Klassen dar und sollten statt der C-Bibliothek verwendet werden. Weiter gibt es Krücken undSpezialbibliotheken wie <iosfwd>, <streambuf>, <istream> und <ostream>.
Wer auf hohe Compilergeschwindigkeit Wert legt, sollte in jeder Übersetzungseinheit sehr genau nur die benötigtenBibliotheken angeben, da sonst in C++ jedesmal sehr viel unnötiger Ballast mitübersetzt wird, der nicht unbe-trächtliche Übersetzungszeit beansprucht. Oft genügt einfach <iosfwd>, aber das können Sie selbst leider erst danngenauer beurteilen, wenn Sie den objektorientierten Teil des Kurses beherrschen.
11.1. Standardströme und Ein-/Ausgabeoperatoren. Tastatureingabe und Bildschirmausgabe werdenüber vier in <iostream> vorde�nierte Ströme cin, cout, cerr und clog abgewickelt. Weitere vier Ströme stehenfür Zeichenströme mit mehr als acht Bit pro Zeichen bereit. In der C-Bibliothek gibt es nur drei verschiedeneÄquivalente.
i/ostream wi/ostr. cstdio Bedeutung Gerätcin wcin stdin Standardeingabe normalerweise Tastatureingabecout wcout stdout Standardausgabe normalerweise Bildschirmausgabecerr wcerr stderr Fehlermeldungen normalerweise Bildschirmausgabeclog wclog stderr Protokollmeldungen normalerweise Bildschirmausgabe
Für char16_t und char32_t fehlen entsprechende Ströme.
In einigen Betriebssystemen (Unix) oder speziellen Situationen (MS-DOS bei der Ausgabeumlenkung) könnenNormalausgaben und Fehlermeldungen getrennt behandelt werden. Innerhalb des Programms werden sie danndurch cout und cerr unterschieden.
Ausgaben werden mit dem Ausdruck strom << e1 << e2 << ... << en erstellt, Eingaben mit dem Ausdruckstrom >> v1 >> v2 >> ... >> vn gelesen. Es gelten die C-Vorrangregeln, so daÿ manchmal � bei Vergleichen �geklammert werden muÿ. Die Gröÿen ei sind Rechenausdrücke, die Gröÿen vi die zu füllenden Variablen.
Bei der Eingabe können Adressen (l-Werte!) von Variablen mit den elementaren Typen
char * non-white-space Zeichenfolge (mit '\0')(signed/unsigned) char Einzelzeichen(short/long) (signed/unsigned) int Ganze Zahl�oat/(long) double Reelle Zahlbool logische Gröÿenchar/wchar_t Schriftzeichenvoid * Zeiger
gelesen werden.

11. EIN- UND AUSGABE 25
Vorsicht: Das folgende Beispiel mit einer wohlbekannten C-Falle zeigt, daÿ der Programmierer sicherstellen muÿ,daÿ bereitgestellter Speicherplatz nicht überbeansprucht wird. Das Programm wird korrekt übersetzt und vonmanchen Compilern sogar noch ausgeführt. GNU-C erzeugt einen Laufzeitfehler; Borland-C überschreibt jedenSpeicherbereich, auf den p zufällig zeigt, sogar den setup-Bereich.
1 // io3.cpp
2 #include <iostream >
3 #include <iomanip >
4
5 using namespace std;
6
7 int main ()
8 { char * p; // string ist immer besser!
9 // cin >> p; // geht , ist aber ein Fehler , da ins Nirwana geschrieben wird
10 // fuehrt zu segmentation fault
11 // keine exception
12 p = static_cast <char*>("12345678");
13 cout << p << endl;
14 cin >> p; // geht , wenn maximal 8 Zeichen getippt werden und *p nicht readonly
15 cout << p << endl;
16 char w [1000];
17 cin >> w >> ws; // geht wahrscheinlich , wenn space vor dem 1000. Zeichen kommt
18 cout << w << endl;
19 cin.getline (w, 1000); // ist 100%ig korrekt
20 cout << w << endl;
21 cin >> std::setw (1000) >> w; // ist ebenfalls 100%ig korrekt
22 cout << w << endl;
23 return 0;
24 }
In die Ausgabe können Ausdrücke mit den Typen
char * Zeichenfolge mit \0(signed/unsigned) char Einzelzeichen(short/long) (signed/unsigned) int Ganze Zahl�oat/(long) double Reelle Zahlbool logische Gröÿenchar/wchar_t Schriftzeichenvoid * Zeiger (Maschinenadresse)
geschrieben werden.
Beispiele:1 // io1.cpp
2 #include <iostream >
3
4 using namespace std;
5
6 int main ()
7 { char ch;
8
9 do
10 { cin >> ch;
11 cout << "Gelesen wurde Zeichen " << ch
12 << " in die Variable auf Adr. " << (const void*) &ch << endl;
13 } while (ch != '.'); /* Abfrage auf '\n' geht nur ohne "eatws" */
14 return 0;
15 }
Die obige Beschreibung bezieht sich auf <iostream>. Weitere Inserter sind in anderen Libraries de�niert. AlsBeispiel können natürlich auch Strings übertragen werden:
1 // io5.cpp
2 #include <iostream >

26 2. PROZEDURALE PROGRAMMIERUNG
3 #include <string >
4
5 using namespace std;
6
7 int main ()
8 { string s;
9 cout << "Gib Namen:" << endl;
10 cin >> s;
11 cout << "Hallo " << s << "!" << endl;
12 return 0;
13 }
11.2. Fehlerbehandlung. Jedem Strom ist ein Stromzustand zugeordnet, der die Stromfehler der vorherge-henden Stromzugri�e speichert und für den Erfolg der nächsten Stromzugri�e abgefragt werden sollte. Prinzipiellexistieren drei Möglichkeiten, diesen Stromzustand abzufragen:
Stromname oder -operation Erfolg oder MiÿerfolgZustandsabfragen Genaue InformationBitzugri� auf die Stromzustandsvariable Direkte Manipulation
Die einfachste Möglichkeit ist die Verwendung des Stromnamens oder einer Stromoperation als Bedingung. DerWert Null (false, == 0) signalisiert einen Übertragungsfehler, ein Wert verschieden von Null (true, != 0) der Erfolgder letzten Operation.
Damit sind Eingabeschleifen der Formwhile (cin � x) cout � endl � x;
und Prüfungen der Formif (!(cout � x)) /* Ausgabe klappt nicht */
möglich.
Alternativ kann man Funktionen zur direkten Abfrage des Stromzustandes aufrufen. Der Aufruf erfolgt immer inder Form strom.frage (). Die Funktionen liefern Informationen über den Ablauf der vergangenen Operationenund (wichtiger) einen Hinweis auf die Durchführbarkeit weiterer Operationen. Für bestimmte Fragen müssen dieElementaroperationen kombiniert werden.
cin.eof () end of �le seen Dateiende erreichtcin.fail () next will fail keine Operationen mehr möglichcin.bad () stream corrupted Schwerer Fehlercin.good () next might succeed "cin.good () || cin.eof () last succeed letzte Operation ok
Falls ein nicht allzu schwerer Fehler in einer der vergangenen Operationen aufgetreten ist, kann der Strom miteinem Aufruf von cin.clear () wieder in einen arbeitsfähigen Zustand gebracht werden. Ob das sinnvoll ist, muÿder Programmierer entscheiden. Nach einem Dateiende von der Tastatur (Windows: ^Z, Linux: ^D) ermöglichtcin.clear () manchmal weitere Eingaben.
Die letzte Möglichkeit der Zustandsabfragen sind direkte Manipulationen der Zustandsbits. Die Funktion cin.rdstate ()
liefert den momentanen Stromzustand als ganze Zahl vom Typ int. Da die Interpretation der einzelnen Zustands-bits nicht festgelegt ist, wohl aber die Zustände und Zustandsnamen, sollen Zustandsabfragen nur mit Hilfe derZustandsnamen erfolgen. Es gibt die folgenden Zustände
ios::goodbit
ios::eofbit
ios::failbit
ios::badbit
Beispiel:
1 // io2.cpp
2 #include <iostream >
3
4 using namespace std;
5

11. EIN- UND AUSGABE 27
6 int main ()
7 { ios:: iostate s;
8 s = cin.rdstate ();
9 if (s & ios:: eofbit) { cout << "cin Dateiende bei Start" << endl; }
10 int i;
11 cin >> i;
12 cout << "i=" << i << endl;
13 s = cin.rdstate ();
14 if (s & ios:: eofbit) { cout << "cin Dateiende" << endl; }
15 }
Die Methode wird nicht empfohlen und entspricht eigentlich einem schon um 1960 veralteten Programmierstil!
Parallel existiert natürlich cin.setstate (s).
Seit 1998 sind Exceptions in iostream eingearbeitet; sie fehlen jedoch noch hier.
11.3. Formatierung. Ohne weitere Angaben wird bei der Eingabe an Stellen, an denen dies sinnvoll ist,Leerraum (whitespace) übergangen. Die Ausgabe wird ähnlich vorformatiert, wie dies schon in C die Funktionprintf durchführt.
Diese Vorformatierung kann vom Programmierer jederzeit geändert werden. Auch dazu stehen drei Möglichkeitenzur Auswahl: Der Aufruf von Stromfunktionen zur Änderung des Formatierungszustandes, die Verwendung vonsog. Manipulatoren in einem Ausdruck mit einer Stromoperation und die direkte bitweise Änderung des Formatzu-standes. Prinzipiell kann für jeden Strom jedwede Einstellung erzeugt werden. Jedoch sind viele Kombinationensinnlos und haben daher keine Wirkung. So wird ein Ausgabestrom nicht gelesen und kann daher auch keinenLeerraum überlesen. Durch cin und cout wird angezeigt, bei welchem Strom ein Aufruf sinnvoll ist.
Am einfachsten ist der Aufruf von Formatierungsfunktionen.
Die Funktionssignaturen (Argumente und Ergebnisse) folgen einer Systematik: Alle Funktionen liefern als Ergebnisden alten Zustand zurück, der ignoriert oder gespeichert werden kann (char ch = cout.fill(); ch = cout.fill ('*'); cout.fill ('x');).
Ohne Argumente bewirkt die Funktion eine Abfrage des eingestellten Zustandes.
Mit Argumenten wird zusätzlich der neue Zustand gemäÿ den Argumenten eingestellt.
cout.flags (l) stellt genau den übergebenen Zustand l ein. cout.setf(l) setzt lediglich die übergebenenTeilzustände l. cout.setf(l, f) setzt nur die übergebenen Teilzustände l in der Zustandsgruppe f.
cout.unsetf(l) und cout.unsetf(l, f) löscht die übergebenen Teilzustände l (ev. in der Zustandsgruppe f).
Bei Funktionen mit identischer Wirkung existiert lediglich eine. (cout.flags() statt cout.setf()).
Bei der Beschreibung der Wirkung bedeuted fmtfl den internen Zustand.
Funktion Wirkungcin.getline (char *, int) Lesen einer Zeile mit beschränktem Platzcout.tie (cin) Koppeln von Eingabestrom an Ausgabestromcout.width (n) Einstellung der Feldbreite der nächsten Ausgabecout.width () Abfrage der Feldbreitecout.fill ('#') Einstellung des Füllzeichenscout.fill () Abfrage des Füllzeichenscout.precision (n) Einstellung der Nachkommastellencout.precision () Abfrage der Nachkommstellencout.flags (l) Einstellung des kompletten Formatzustandes auf den Wert l
Wirkung: fmtfl = l
l = cout.flags () Abfrage des Formatzustandescout.setf (l) Setzen einzelner Formatzustände
Wirkung: fmtfl |= l
cout.setf (l, f) Löschen von Zustandsgruppen undSetzen einzelner FormatzuständeWirkung: fmtfl = (l & f) | (fmtfl & ~f)
Bsp. cout.setf (ios::left, ios::basefield)
cout.unsetf (l) Löschen einzelner FormatzuständeWirkung: fmtfl &= ~l

28 2. PROZEDURALE PROGRAMMIERUNG
Innerhalb eines Ein- oder Ausgabeausdruckes können wichtige dieser Einstellungen auch durch Manipulatorenerfolgen. In der Tabelle ist die mittlere Spalte verkürzt wiedergegeben. In Programmen muss selbstverständlichstatt setf (boolalpha) ausführlich cout.setf (ios_base::boolalpha) stehen.
Manipulator Ersatzfunktion Bedeutungboolalpha setf (boolalpha) bool alphabetisch (false, true)noboolalpha unsetf (boolalpha) bool numerisch (0, 1)showbase setf (showbase) Basis-Prä�x 0 oder 0xnoshowbase unsetf (showbase) kein Basis-Prä�xshowpoint setf (showpoint) Dezimalpunkt auch ohne Nachkommastellennoshowpoint unsetf (showpoint)
showpos setf (showpos) Vorzeichen auch bei positiven Zahlennoshowpos unsetf (showpos)
skipws setf (skipws) Whitespace vor Eingabe erlaubtnoskipws unsetf (skipws)
uppercase setf (uppercase) 0X1A und 1.0E8nouppercase unsetf (uppercase)
unitbuf setf (unitbuf) �ush nach jeder Operationnounitbuf unsetf (unitbuf)
internal setf (internal, adjustfield) links- und rechtsbündigleft setf (left, adjustfield) linksbündigright setf (right, adjustfield) rechtsbündigdec setf (dec, basefield) int dezimalhex setf (hex, basefield) int sedezimaloct setf (oct, basefield) int oktalfixed setf (fixed, floatfield) �oat ohne Exponentscientific setf (scientific, floatfield) �oat mit Exponentendl Neue Zeile und �ushends '\0'
flush Pu�er leeren und alles Vorhandene transportierensetw (n) Einstellung der Feldbreite der nächsten Ausgabesetprecision (n) Einstellung der Nachkommastellensetfill ('#') Einstellung des Füllzeichenssetbase (b) Einstellung des Zahlenbasis (8, 10, 16)setiosflags (l) Setzen einzelner Formatzuständeresetiosflags (l) Löschen einzelner Formatzustände
Die bitweisen Änderungen stellen eigentlich veralteten Programmierstil dar und sollten vermieden werden. Dieeinzelnen Bits werden durch einen Namen bezeichnet, falls sie doch verwendet werden müssen. Aber für alle, diees nicht lassen können, folgen in der letzten Tabelle die Bitnamen:

14. ATTRIBUTE 29
ios::skipws Überspringen von Leerraumios::left Linksbündige Ausgabe (Leerraum rechts)ios::right Rechtsbündige Ausgabe (Leerraum links)ios::internal Links- und rechtsbündige Ausgabe (Leerraum in die Mitte)ios::adjustfield Alle Bits zur Bündigkeit
ios::dec Dezimale Ein- und Ausgabeios::oct Oktale Ein- und Ausgabeios::hex Sedezimale Ein- und Ausgabeios::basefield Alle Bits zur Zahlenbasis
ios::showbase Anzeige der Zahlenbasisios::showpoint Dezimalpunkt bei reellen Zahlenios::uppercase Buchstaben in Zahlen groÿ schreibenios::showpos Pluszeichen immer schreibenios::scientific Gleitpunktschreibweise bei reellen Zahlenios::fixed Festpunktschreibweise bei reellen Zahlenios::floatfield Bits zur Schreibweise von reellen Zahlen
ios::unitbuf sofortige Ausgabeios::boolalpha bool alphabetisch (false, true)
12. Ergänzungen
13. struct union enum
14. Attribute
Zeichensatz, digraphs, trigraphs, alternative tokensu
keywords


CHAPTER 3
Objektorientierte Programmierung
Für vollständige Objektorientierung benötigt eine Programmiersprache drei Elemente:
• Datenkapselung: Klassen (class/struct/union/enum) in C++• Rechte: public/private/protected in C++• Polymorphie: Vererbung in C++
Der dritte Punkt wird in einem eigenen Kapitel behandelt.
1. Kapselung
Klassen in C++ werden verwendet, um neue Datentypen mit eigenen Wertebereichen zu erstellen. Mit diesen neuenDatentypen werden Variable zur Speicherung dieser Werte erzeugt. Diese Variablen heiÿen in der objektorientiertenProgrammierung Objekte1, manchmal selten auch Instanzen. Dieser Begri� darf mit der zweiten Bedeutung vonInstanz bei Templates nicht verwechselt werden.
Anders als Strukturen in C werden die Funktionen zur Verarbeitung dieser neuen Typen in der Klasse de�niertoder deklariert2.
Die Werte einer neuen Klasse können aus elementaren Datentypen oder anderen Klassen (einschlieÿlich aus STL-Klassen) zusammengesetzt sein.
Alle Elemente einer Klasse werden als Member bezeichnet. Membervariable (data members) werden in der objek-torientierten Programmierung auch Felder (�elds) genannt; Memberfunktionen heiÿen auch Methoden (methods).Neben den Membervariablen und Methoden kommen in Klassen weitere Membergruppen vor: Konstruktoren zumErzeugen neuer Objekte, der Destruktor zur Speicherfreigabe nicht mehr benötigter Objekte, Memberoperatorenzur bequemen Programmierung der Operationen mit den neuen Typen, statische Member für klassenbezogene In-formationen und friends mit Zugri� auf private member als Zwischenstufe zwischen globalen (kein private Zugri�)und Membern. Von untergeordneter Bedeutung sind in normalen Klassen die Membergruppen verschachtelte Klassen,member templates, sowie aus C stammende und selten gebrauchte member wie bit �elds.
the this pointer using-declarations member access speci�ers default member initializer(C++11) explicit speci�erconverting constructor
default constructor copy constructor move constructor(C++11) copy assignment operator move assignment oper-ator(C++11) InheritancSpecial membe
Neben dieser eher klassentechnisch orientierten Einteilung der Member verwendet man in der Programmierung ofteine eher zielorientierte Gliederung: Hier bleiben Membervariable, Konstruktoren und der Destruktor erhalten;die übrigen Member werden unterteilt in die Zugri�soperationen (accessors) zum Abfragen der Variablenwerte,in die Manipulatoren (manipulators) zum gezielten Ändern der Variablenwerte, Konversionen zur Erzeugung an-derer Datentypen mit gleichen oder ähnlichen Werten, arithmetischen oder arithmetikähnlichen Operationen zurVerknüpfung mehrerer Werten des neuen Typs/mehrerer neuer Typen, Ein- und Ausgabeoperationen, Iteratorenfür Klassen mit Datenmengen.
Eine Sonderstellung nehmen wegen ihrer technischen Probleme und ihrer hohen Bedeutung die sog. Big Zero/Three-/Five ein: der Copy-Konstruktor, der Move-Konstruktor, der Destruktor, der der Wertzuweisungsoperator und derMove-Wertzuweisungsoperator. Der Begri� Big Five meint in C++ immer genau diese fünf speziellen Operationen.Vor 2011 waren es drei; die beiden Move-Operationen wurden erst 2011 eingeführt. Mit Big Zero bezeichnet man
1In C sind Objekte speicherverbrauchende Sprachelemente, also Variable oder Funktionen. In C++ sind Objekte Variable von als
Klassen de�nierter Datentypen2Wie in C ist eine Deklaration die Bekanntgabe der Existenz einer Gröÿe. Eine De�nition ist die vollständige Beschreibung einer
Gröÿe mit allen ihren Eigenschaften.
31

32 3. OBJEKTORIENTIERTE PROGRAMMIERUNG
Figure 1. Klassen in C++
den Fall, dass Big Five an eine andere Klasse delegiert werden. Dann dürfen sie nicht vorkommen; sie solltenimplizit oder besser explizit vom Compiler generiert werden.
2. Operatorfunktionen
Die in C und C++ vorhandenen Operatoren können gröÿtenteils in C++ mit neuen Bedeutungen versehen wer-den. Dieser Vorgang heiÿt Überladen von Operatoren (operator overloading). Damit ergibt sich die bequemeMöglichkeit, auch bei neuen Datentypen die üblichen Rechenoperationen verwenden zu können, ohne wie in C aufFunktionsaufrufe zurückgreifen zu müssen.
Beispiel:
1 matrix A, B, C, D, h;
2 ...
3 D = A / 2 + B * C; // statt: h = MatMulDbl (A, 0.5); D = MatMul (B, C); D =

2. OPERATORFUNKTIONEN 33
4 MatAdd (h, D);
2.1. Operatorfunktionen. In C++ gilt jede Operatorverwendung (x⊙y, ⊙x, x⊙) als Funktionsaufruf einerdem Operator ⊙ zugeordneten Operatorfunktion. Diese Operatorfunktion wird mit operator⊙ bezeichnet. DasWort operator ist ein Schlüsselwort. Statt x⊙ y kann man also auch operator⊙ (x, y) schreiben.
Beispiel:
1 int i, j, k;
2 ...
3 operator = (k, operator $+$ (i, j)); // wirkt wie k = i $+$ j;
Diese Operator-Funktionen können wie normale Funktionen überladen werden. Damit der Compiler die aufzu-rufende Funktion eines überladenen Operators eindeutig feststellen kann, muÿ lediglich mindestens ein Argumentdes Operators ein neuer Datentyp, also eine C++-Klasse oder eine Aufzählung sein. Alternativ kann der Operatoreine member-Funktion sein.
Die überladbaren Operatoren sindnew delete new [] delete []
+ - * / % ^ & | ~
! = < > += -= *= /= %=
^= &= |= << >> >>= <<= == !=
<= >= && || ++ -- , ->* ->
() [] ""id (typ)
Nicht überladen werden dürfen die Operatoren . .* :: ?: und die Präprozessorsymbole # ##.
Beim Überladen wird lediglich die Bedeutung der Operatoren auf neue Datentypen erweitert; die schon in Cvorgegebene Stellung, die Priorität, die Assoziativität und die Argumentanzahl bleibt unverändert. Es ist also nichtmöglich, einen binären Operator ! (zwei Argumente statt eines), einen Post�x-Operator ! als Fakultätsoperator(not ist Prä�x), einen Prä- oder Post�x-Operator % (% ist binär) zu erzeugen; genausowenig kann � von rechtsnach links klammern oder eine Operatorfunktion operator + (int, complex, int) mit drei Argumenten erzeugtwerden.
Die beiden in C miteinander verwandten Operatoren x ⊙ y und x ⊙= y gelten nach einer Überladung als ver-schiedene Operatoren. Wenn die C-Relation weiter gelten soll, muÿ sie getrennt und korrekt für x ⊙ y und für x⊙= y programmiert werden.
Ein überladener Operator wird wie eine normale Funktion deklariert und de�niert, nämlich mitreturntyp operator ⊙ (Argumentliste) { Funktionscode }
Beispiel:
class X {
int i; public:
int operator + (int);
X operator + (X);
};
int X::operator + (int j)
{ return i + j;
}
X X::operator + (X x)
{ X h; h.i = i + x.i; return h;
}
X operator + (X x)
{ return x;
}

34 3. OBJEKTORIENTIERTE PROGRAMMIERUNG
2.2. Übersicht über die Operator-Funktionen. Die folgende Übersicht zeigt alle Möglichkeiten, Opera-toren zu überladen. Post�xoperatoren müssen mit einem zusätzlichen künstlichen int-Parameter versehen werden,um sie von den Prä�xoperatoren zu unterscheiden. Dieser int-Parameter hat jedoch keine weitere Bedeutung.
Die speziell aufgeführten Memberoperatoren (typ, =, [], (), →) dürfen nicht global de�niert werden.
Table 1. Globale und Member-Operatoren
Scope des Operators Deklaration Operator-Aufruf Funktionsaufrufglobaler Operator T1 operator ⊙ (T2, T3) t2 ⊙ t3 operator ⊙ (t2, t3)globaler Operator T1 operator ⊙ (T2) ⊙ t2 operator ⊙ (t2)globaler Operator T1 operator ⊙ (T2, int) t2 ⊙ operator ⊙ (t2, 0)member-Operator T1 X::operator ⊙ (T2) x ⊙ t2 x.operator ⊙ (t2)member-Operator T1 X::operator ⊙ () ⊙ x x.operator ⊙ ()member-Operator T1 X::operator ⊙ (int) x ⊙ x.operator ⊙ (0)member-Operator X::operator typ () (typ) x x.operator typ ()member-Operator T1 X::operator = (T2) x = t2 x.operator = (t2)member-Operator T1 X::operator [] (T2) x [t2] x.operator [] (t2)member-Operator T1 X::operator () (T2, T3, ...) x (t2, t3, ...) x.operator () (t2, t3, ...)member-Operator T1 X::operator → () x → m (x.operator → ()) → m
Die Tabelle zeigt, daÿ die Symmetrie der kommutativen Operatoren (+ *) gestört wird, wenn sie als member-Funktionen de�niert werden. x + y (x.operator + (y)) und y + x (y.operator + (x)) sind nicht notwendiggleich, wenn X x; und Y y; aus verschiedenen Klassen oder Typen kommen.
2.3. Empfehlungen. Alle überladenen Operatoren sollten mit möglichst wenig Überraschungse�ekten pro-grammiert werden. Wenn der Operatorcomplex complex::operator * (complex c)
{ complex h; h.r = r - c.r; h.i = i - c.i; return h; }
die komplexe Subtraktion durchführt, werden die darauf beruhenden Programme völlig unverständlich.
Selbst geübte C-Programmierer werden verwirrt sein, wenn der Operatorcomplex complex::operator + (complex c)
{ r += c.r; i += c.i; return *this; }
sein Argument zum Klassenobjekt addiert; diese Leistung sollte dem Operator += vorbehalten bleiben.
Ein Grenzfall ist sicherlich eine Klasse integer für ganze Zahlen (mit gröÿerer Länge als long), wenn member-Operatoren für den ggT und das kgV benötigt werden. Beide Funktionen haben zwei Operanden, so daÿ sichdie binären Operatoren anbieten. Die arithmetischen (+-*/%) und relationalen (< > <= >= == =!) Operatoren,die Zuweisungsoperatoren (= += -= *= /= %= ^= &= |= <<= >>=) und die Ein- und Ausgabeoperatoren (<< >>)scheiden aus, da sie in ihrer Normalbedeutung gebraucht werden. So bleiben die Operatoren ^ & | && || , ->* -> () []
übrig, von denen sich aus verbandtheoretischen Gründen ({N, ggT (x, y) = x ⊓ y = x · y = x&y, kgV (x, y) =x ⊔ y = x + y = x∥y} ist ein distributiver Verband) die Operatoren & | && || anbieten. Wahrscheinlich hängtdie Entscheidung von der Zielgruppe ab, für die diese Klasse programmiert wird: Falls sie von Mathematikern be-nutzt wird, ist die Wahl dieser Operatoren bei guter Kommentierung unproblematisch; falls sie jedoch auch vonNicht-Mathematikern angewendet wird, ist die Verwendung von member-Funktionen integer ggT (integer,
integer) und integer kgV (integer, integer) vorzuziehen, da vor allem C-Programmierer bei (integer & |)an eine bitweise Operation und bei (integer && ||) an eine boolsche Operation denken.
2.4. Arithmetische Operatoren. Arithmetische Operatoren (+ - * / %) sollten nur für Klassen program-miert werden, in denen analoge mathematische Verknüpfungen bestehen. Beispiele sind numerische Klassen fürBrüche, komplexe Zahlen oder Quaternionen, und algebraische Klassen für Vektorräume oder Polynome. Dabeisollten sowohl die C-Eigenschaften dieser Operatoren als auch die Eigenschaften der programmierten Verknüpfun-gen berücksichtigt werden. In nichtmathematischen Klassen können natürlich einzelne Operatoren programmiertwerden, die für diese Klassen sinnvoll sind (+ als Konkatenation in Stringklassen, || als Parallelitätsabfrage ingeometrischen Klassen).
Meistens sollten dann die zugehörigen Zuweisungs-Operatoren (+= -= *= /= %=) ebenfalls programmiert werden.

2. OPERATORFUNKTIONEN 35
Oft müssen Verknüpfungen verschiedener Datentypen (complex + int) oder Datenquali�kationen (complex +
const int) möglich sein , um ein bequemes Arbeiten mit der Klasse zu ermöglichen.
Die Addition und Multiplikation in C ist kommutativ; a + b darf vom Compiler sogar als b + a ausgeführt werden.Damit ist ein member-Operator eigentlich schon ausgeschlossen. Denn mit dem Objekt X x der Klasseclass X { public: X operator + (int); };
kann man x + 3 ≡ x.operator + (3), aber nicht 3 + x ≡ 3.operator + (x) schreiben. Dieser Operator müÿtemember-Operator von int sein � int ist jedoch keine Klasse und könnte auch keine nachträglich eingefügtenweiteren Operatoren haben.
Am elegantesten ist meistens die Lösung, die Zuweisungsoperatoren als member-Operatoren zu programmieren,die arithmetischen Operatoren als globale Operatoren auf die Zuweisungsoperatoren zurückzuführen und andereDatentypen mit Hilfe geeigneter Konstruktoren zu konvertieren.
class X {
public:
X (const long) { *this = (X) l; }
X operator += (X);
};
X X::operator += (X x)
{ *this += x; return *this; }
X operator + (const X a, const X b)
{ X h; h = a; h += b; return h; }
Denn jetzt sind im aufrufenden Programm alle folgenden Aufrufe erlaubt:
int i; long l; X x; const X y;
x + y;
x + i; i + x;
x + l; l + x;
x + 3; 3 + x;
Ein weiterer Vorteil ist, daÿ die Addition nur noch einmal, nämlich bei += programmiert werden muÿ.
Die Vorteile werden mit einem leichten Geschwindigkeitsverlust erkauft, weil bei jedem Operator-Aufruf von + zweiOperator-Funktionen aufgerufen werden.
2.5. Increment und Decrement.
2.6. Bitoperatoren. C und C++ verfügen über überladbare bitweise Verknüpfungen ^ | & ~ << >>. DieSchiebeoperatoren sind in C++ der Ein- und Ausgabe gewidmet. Sie können trotzdem in anderen Klassen eigeneAufgaben übernehmen. Schon in C sind sie nicht kommutativ (a<<b ̸= b<<a); diese Eigenschaft dürfen in eigenenImplementierungen übernommen werden.
Manchmal kommt die Idee auf, den operator^ als Potenzoperator zu überladen (a^b = ab). Leider verstossendabei die Klammerungsregeln gegen die mathematischen Gewohnheiten; deshalb bewährt sich diese Überladungnicht:
a^b + c = a^(b + c) ̸= ab + c
a^b^c = (a^b)^c ̸= abc
Die Bitoperatoren werden selten überladen.
2.7. Ein- und Ausgabeoperatoren. Seit Entwicklung der iostream-Library wurden die beiden Operatoren<< und >> für die Ein- und Ausgabe überladen. Ihre genauen Bezeichnungen sind stream-inserter und stream-extractor. In neuen Klassen X sollten sie keine Member-Operatoren sein, da sie dann mit X-Objekten x aufgerufenwerden müssten: x.operator<<(rs) oder x << rs; Die linke Seite sollte jedoch immer der Stream sein.
Die Operatoren sollten also global de�niert werden. Dann haben sie keinen Zugri� auf die privaten Member von Xmehr; statt dessen sind sie auf Accessor-Funktionen angewiesen. Die Möglichkeit, sie als friend in den Klassen-Scopeaufzunehmen, gilt als unschön und veraltet.

36 3. OBJEKTORIENTIERTE PROGRAMMIERUNG
Die globale De�nition hat einen Nachteil bei der Vererbung: Globale Funktionen werden nicht vererbt und müssenauch in Subklassen neugeschrieben werden, in denen eigentlich keine Neuimplementierung notwendig wäre.
Die stream-Operatoren sind also global, haben als linkes Argument einen Stream und als rechtes Argument einObjekt einer Klasse X. Es ist üblich, sie kaskadieren zu können: cout << x << y << z;. Der Operator klammertvon links nach rechts (((cout << x) << y) << z;) � also muss jeder Aufruf das Streamobjekt zurückgeben. Dabeidürfen keinesfalls Duplikate der Streamobjekte entstehen: Zwei Filedeskriptoren auf dieselbe Datei können dieseDatei zerstören. Die Streamobjekte müssen also Referenzen sein und sie werden manipuliert, also verändert. DieReferenzen dürfen nicht konstant sein.
Die Stream-Operatoren verwenden prinzipiell Sentry-Objekte, um zu verhindern, dass notwendige Vor- und Nachar-beiten vergessen werden.
Exkurs: Das Sentry-Muster
Mehrere Funktionen (f, g, . . . ) benötigen manchmal gemeinsame Vor- und Nacharbeiten (hier prework und postworkgenannt). Die Schreibweise
1 void f (void)
2 {
3 prework ();
4 // work of f
5 postwork ();
6 }
ist fehlerträchtig, weil die Gefahr besteht, bei vielen verschiedenen Implementierungen der Funktionen den Aufruf vonprework und postwork zu vergessen. Dieses Risiko kann halbiert werden, wenn man statt prework und postwork eine neueKlasse Sentry einführt, die im Konstruktor das prework und im Destruktor das postwork enthält. Erzeugt man am Beginnvon f ein Sentry-Objekt, wird das prework automatisch durch den Konstruktor aufgerufen. Das Postwork kann nicht mehrvergessen werden, da es mit Funktionsende automatisch im Destruktor des Sentry-Objekts aufgerufen wird.
1 class Sentry
2 {
3 public:
4 Sentry () { /* do prework here */ }
5 ~Sentry () { /* do postwork here */ }
6 };
7
8 void f (void)
9 {
10 Sentry s;
11 // work of f() is always prefixed with s-ctor
12 // and postfixed with s-dtor
13 } // implicit call of s-dtor
Sentries können Klassen ohne Daten sein; sind Daten zu speichern, werden sie im Konstruktor übergeben, im Objektgespeichert und im Destruktor verwendet.
Vorteil: Weniger Schreibarbeit (eine Zeile statt zwei an verschiedener Stelle); weniger Fehlermöglichkeiten (postwork kannnicht vergessen werden);
Stream-Klassen nutzen Sentries.
In den Stream-Klassen istream und ostream sind Sentry-Klassen vorgesehen, die bei jeder Inserter- und Extractor-Überladung benutzt werden müssen. Sie benutzen die Streams als Datenobjekt. Die Sentry-Objekte haben einencast-operator nach bool, der der Benutzbarkeit der Streamoperatoren anzeigt. Er sollte immer abgefragt werden.
Damit sind jetzt alle Inserter- und Extractor-Bedürfnisse vollständig. Ein- und Ausgabe-Überladungen habenimmer die folgende Form:
1 ostream & operator << (ostream & s, X const & rs) // insert a const rs to stream s
2 {
3 ostream :: sentry se (s); // ctor does prework of s, dtor does postwork
4 if (se) // cast to bool signals noncorrupt stream
5 {
6 // do output of rs with getter -menbers to s
7 }

2. OPERATORFUNKTIONEN 37
8 return s; // enable cascading of output operators cout << x << y << z;
9 }
1 istream & operator >> (istream & s, X & rs) // extract data from stream s to nonconst object rs
2 {
3 istream :: sentry se (s); // ctor does prework of s, dtor does postwork
4 if (se) // cast to bool signals noncorrupt stream
5 {
6 // do input to rs with setter -menbers from s
7 }
8 return s; // enable cascading of input operators cin >> x >> y;
9 }
Wenn der Inserter selbst die Manipulatoren benutzt, sollte er sie am Ende wieder in den Originalzustand versetzen,der dazu gespeichert werden muss.
1 std::ios:: fmtflags f = s.setf (ios::right , ios:: adjustfield);
2 // h << setw (7) << ...
3 s.flags (f);
Manchmal sind Textdarstellungen eines Objekts komplexer und müssen aus mehreren Teilen zusammengesetztwerden. Wenn das mit mehreren Inserter-Aufrufen geschieht, wirken Manipulatoreinstellungen nur auf den er-sten. Damit die gesamte Textdarstellung von den Manipulatoreinstellungen erfasst wird, darf also nur ein einzigerInserter-Aufruf statt�nden. Damit wird es zwingend, die Textdarstellung erst in einem String komplett zu er-fassen, der am Ende einmal ausgegeben wird. C++ folgt aus historischen Gründen demselben eigentlich unl-ogischen Prinzip wie C, die Stringerzeugung in Streams zu erledigen, statt wie Java einfach eigene Funktionenbereitzustellen. Der Mechanismus wurde einmal überarbeitet und verbessert, die ältere, obsolete und deprecatedVariante heiÿt strstream, die aktuelle stringstream.
1 #include <sstream >
2
3 std:: ostringstream h;
4 std:: string t;
5 // h stores the text in possibly several calls
6 h <<
7 h <<
8 h <<
9 // at the end h is once converted to a string
10 t = h.str ();
11 // and inserted to the stream s
12 s << t;
Zusammengefasst kann ein Inserter etwa wie folgt aussehen:
1 ostream & operator << (ostream & s, X const & rs) // insert a const rs to stream s
2 {
3 ostream :: sentry se (s); // ctor does prework of s, dtor does postwork
4 if (se) // cast to bool signals noncorrupt stream
5 {
6 std::ios:: fmtflags f = s.setf (ios::right , ios:: adjustfield);
7 std:: ostringstream h;
8 std:: string t;
9 // h stores the text in possibly several calls
10
11 // insert text representation to stringstream h
12
13 // at the end h is once converted to a string
14 t = h.str ();
15 // and inserted to the stream s
16 s << t;
17 s.flags (f);
18 }
19 return s; // enable cascading of output operators cout << x << y << z;
20 }

38 3. OBJEKTORIENTIERTE PROGRAMMIERUNG
2.8. Logische Operatoren. Für die logischen Operatoren ! && || gelten analoge Regeln wie für die arith-metischen Operatoren.
Ausnahme: Für überladene Logikoperationen wird kein logischer Shortcut durchgeführt; der gesamte geschriebeneAusdruck wird immer ausgewertet.
Wichtig: Vor C++17 gelten die Logikoperatoren als kommutativ; d.h. es ist nicht garantiert, dass die linke Seitevor der rechten ausgewertet wird.
2.9. The Big Five/Three. Three or Five: Vor 2011 waren es nur drei, da die zwei Move-Operatoren gefehlthaben.
Generalregel: Wenn einer dieser fünf Operatoren in einer Klasse existiert, müssen alle fünf implementiert werden(rule of �ve).
Wenn einer fehlt (X() = delete;) oder durch den default ersetzt wurde (X() = default;), darf kein weitererdieser fünf existieren. (rule of zero oder rule of �ve defaults)
Kurz: Alle oder Keiner! Alles oder Nichts!
Vor 2011 fehlten die Move-Operationen, deshalb hieÿ die Regel damals rule of three. Sind die Move-Operationennicht de�niert, handelt es sich mit hoher Wahrscheinlichkeit um ein älteres legacy-Programm.
Der sog. default-Konstruktor ohne Argumente wird ebenfalls vom Compiler erzeugt und sollte aus diesem Grund im-mer gleich wie die anderen fünf behandelt werden. Umgekehrt gilt das nicht: die Existenz des default-Konstruktorszieht nicht die anderen fünf nach sich!
Die Wertzuweisungsoperatoren müssen Memberoperatoren sein. Sie dürfen nicht global de�niert werden. IhreAufgabe ist es, geschickt das this-Objekt vom alten Inhalt leerzuräumen (eigentlich dtor-Aufgabe) und anschlieÿendmit einem neuen Inhalt aus der rechten Seite der Wertzuweisung zu füllen (eigentlich ctor-Aufgabe). Dabei sindauch die C-Regeln zu beachten (Kaskadierbarkeit x = y = z = X(), x = x.
Die Konstruktoren werden implizit und explizit aufgerufen; die impliziten Aufrufe können mit der Spezi�kationexplicit vom Programmieren unterbunden werden.
Der dtor � es gibt genau einen � wird nur implizit aufgerufen.
2.9.1. Copy ctor.
2.9.2. Move ctor.
2.9.3. Copy assignment. Der Wertzuweisungsoperator einer Klasse X folgt fast immer dem Muster:
1 X const & operator= (X const & rs) // references accelerate , const must be correct
2 {
3 if (this != & rs) // to allow x = x
4 {
5 free existing content of *this // dtor behaviour
6 generator new content from rs // copy ctor behaviour
7 }
8 return *this; // to allow cascading assignments x = y = z = X();
9 }
2.9.4. Move assignment.
2.9.5. Destructor. Wertzuweisung
o1 = o2
o = o
2.10. Konversionen. In Klassen können zwei Memberarten als Konversionen interpretiert werden: Kon-struktoren konvertieren Typen von auÿerhalb der Klasse in ein neues Objekt. Castoperatoren konvertieren einKlassenobjekt in einen anderen Datentyp. Die Konversionen sollten keine Informationen verlieren, in manchenEinzelfällen ist ein Informationsverlust jedoch erlaubt. Beim cast double x = (double) 3 können alle 32 Bitder int 3 in den 53 Bit der double gespeichert werden =⇒ kein Informationsverlust. Umgekehrt gehen beiint n = (int) 3.14 alle Nachkommstellen verloren =⇒ partieller gewünschter Informationsverlust. Dasselbe

2. OPERATORFUNKTIONEN 39
gilt für if (x): aus der 64 Bit reichen Information einer double wird die schwache Information Null oder nichtNull.
Spezielle Konversionen sind:
1 class X
2 {
3 X (std:: string) { konvertiert string in X-Objekt }
4 operator std:: string () const { konvertier X-Objekt in string }
5 operator bool () const { true fuer Objekte , die als ungleich 0 interpretiert werden }
6 bool operator ! () const { true fuer Objekte , die als gleich 0 interpretiert werden }
7 }
2.11. Vergleichsoperatoren. < > <= >=
2.12. Äquivalenzoperatoren. == !=
2.13. Wertveränderungen. += -=. . .
2.14. Kommaoperator. , a, b res X::operator, (T rs) {} res operator,(X x, T rs)
Wichtig: Vor C++17 gilt der Kommaoperator als kommutativ; d.h. es ist nicht garantiert, dass die linke Seite vorder rechten ausgewertet wird.
In älteren Programmen wird ein Kommaausdruck serialisiert durch
a, void(), b
void() ist explizit erlaubt (ISO 14882 5.2.3) und castet "nichts" in void.
2.15. Indexoperator. operator[]
1 class X
2 {
3 X const & operator [] (size_t i) const
4 { liefert Wert dessen , was als i-te Komponente des Objekts interpretiert werden kann. }
5 X & operator [] (size_t i)
6 { liefert Referenz auf i-te Komponente des Objekts }
7 };
2.16. Funktionsoperator. operator()
1 class X
2 {
3 returntype operator () ()
4 { frei programmierbare Leistung wenn ein Objekt als Funktion aufgerufen wird }
5 returntype operator () (int i)
6 { ueberladbar }
7 };
8
9 // Aufruf:
10
11 X x;
12 x ();
13 x (4);
2.17. Adressoperator. operator&
2.18. Dereferenzoperator. operator*
2.19. Struktur-Dereferenzoperator. operator->

40 3. OBJEKTORIENTIERTE PROGRAMMIERUNG
2.20. Pointer-to-member Operator. operator->*
Exkurs: Zeiger auf Funktionen: C++ beherrscht wie C Zeiger auf Funktionen. Das sind normale Zeiger, die Adressenenthalten und deren Dereferenzierung eine Funktion mit einer de�nierten Signatur ist. Sie sind nützlich als Argumente vonFunktionen, die andere Funktionen benutzen.
1 double f (double x) { return x*x; } // square
2 double g (double x) { return 1/x; } // reciprocal
3 double h (double x) { return sin (x); } // intrinsics may have no address
4
5 double integral (double (*f) (double), double a, double b, int n)
6 // *f is real function
7 // f is pointer to real function
8 { // trapezoidal rule (quick and poorly implemented)
9 double s, h, xi;
10 int i;
11 h = (b-a) / n;
12 s = ((*f) (a) + (*f) (b)) / 2;
13 for (int i = 1; i < n; ++i)
14 {
15 xi = ((n-i)*a + i*b) / n; // = a + i*h = a + i*(b-a)/n = a + i/n*b - i/n*a
16 s += f (xi); // f (x) == (*f) (x)
17 }
18 return s * h;
19 }
20
21 std::cout << "Int (x^2, 0, 1) = " << integral (&f, 0, 1, 10) << std::endl;
22 std::cout << "Int (x^2, 0, 1) = " << integral (&f, 0, 1, 100) << std::endl;
23 std::cout << "Int (x^2, 0, 1) = " << integral (&f, 0, 1, 1000) << std::endl;
24 std::cout << "Int (1/x, 0, 1) = " << integral (&g, 1, 2, 1000) << std::endl;
25 std::cout << "Int (sin x, 0, 3.14) = " << integral (h, 0, 3.141592653589793 , 1000) << std::endl;
26 // &h == h
Man beachte insbesondere die explizite Erlaubnis, bei Funktionszeigern jeweils beide Schreibweisen zu verwenden: &f ≡ f
und (*f) (x) ≡ f (x).
Man beachte weiter, dass die Klammern wegen der C-Klammerregeln in (*f) (x) stehen müssen, sonst wäre das eineFunktion mit einem Zeigerergebnis und dessen Bezugsvariable.
Ähnlich gibt es in C++ Zeiger auf Member von Klassen. Zum Aufwärmen erst ein einfaches Beispiel:
1 class X
2 {
3 public:
4 int i;
5 int j;
6 int k;
7 void f () { std::cout << " f()"; }
8 void g () { std::cout << " g()"; }
9 void h () { std::cout << " h()"; }
10 };
11
12 X * p = new X;
13
14 int X::* pi;
15 p->i = 5; p->j = 6; p->k = 7;
16 pi = &X::i; cout << p->*pi << endl;
17 pi = &X::j; cout << p->*pi << endl;
18 pi = &X::k; cout << p->*pi << endl;
19 void (X::* pf) ();
20
21 pf = &X::f; (p->*pf)(); cout << endl;
22 pf = &X::g; (p->*pf)(); cout << endl;
23 pf = &X::h; (p->*pf)(); cout << endl;

2. OPERATORFUNKTIONEN 41
p zeigt auf ein neu erzeugtes Objekt der Klasse X. pi zeigt auf ein int-member dieser Klasse - nicht etwas des neuenObjekts. pf zeigt auf eine Member-Funktion dieser Klasse mit der Signatur void () (). Die Member-Zeiger werdenjetzt konkret gefüllt und dann durch Dereferenzierung mit ->* zur Ausgabe benutzt. Mit einer direkten Variablenfunktioniert ein analoger Mechanismus auch mit dem Operator .*
Merke: Die Memberzeiger zeigen auf ein Member der Klasse. Erst in Kombination mit einem Objekt und einemder beiden Operatoren .* ->* können sie dereferenziert werden.
Und damit zu einem komplexeren Beispiel:
Ein idealer Student wechselt zwischen Lernen, Vergnügen und Schlaf. Wenn er das etwa 1000 Tage (3 Jahre)gemacht hat, ist er fertig und bekommt seinen Bachelor.
1 class Student {
2 public:
3 void learn () { cout << "learning" << endl; }
4 void party () { cout << "partying ..." << endl; }
5 void sleep () { cout << "sleeping ..." << endl; }
6 };
7
8 class Do_Call_Of_Pointer_To_Member_Function {
9 public:
10 typedef std::pair <Student*, void (Student ::*)()>
Object_With_Pair_Of_Student_And_Member_Function_Pointer;
11
12 Do_Call_Of_Pointer_To_Member_Function(const
Object_With_Pair_Of_Student_And_Member_Function_Pointer& p)
13 : pair_object(p) {}
14
15 void operator ()() const
16 { (pair_object.first ->* pair_object.second)(); }
17
18 private:
19 Object_With_Pair_Of_Student_And_Member_Function_Pointer pair_object;
20 };
21
22 class Student_Pointer {
23 public:
24 Student_Pointer(Student *p): ptr(p) {}
25 Student_Pointer(Student_Pointer && p) : ptr(nullptr) { swap (p.ptr , ptr); }
26 ~Student_Pointer () { delete ptr; }
27
28 Do_Call_Of_Pointer_To_Member_Function const operator ->*(void (Student ::*p)()) const
29 { return std:: make_pair(ptr , p); } // implicit constructor call
30 private:
31 Student* ptr;
32 };
33
34 int main()
35 {
36 typedef void (Student ::* pointer_to_member_function)();
37
38 Student_Pointer stud = new Student;
39
40 pointer_to_member_function activity = &Student ::learn; // freshman don't party
41 (stud ->*activity)();
42 activity = &Student :: sleep;
43 (stud ->*activity)();
44
45 pointer_to_member_function pa [3]; // older students do
46 pa [0] = &Student ::learn;
47 pa [1] = &Student ::party;
48 pa [2] = &Student ::sleep;

42 3. OBJEKTORIENTIERTE PROGRAMMIERUNG
49 for (int i = 0; i < 20; ++i) (stud ->*pa[i%3])();
50 }
2.21. Arrow-Operator. ->
2.22. Speicherverwaltung. new new[] delete delete[]
2.23. Programmiererliterale. Erste Frage: Wer hat die denn gerufen? Zweite Frage: Wer liebt sie und werbenutzt sie? Dritte Frage: Wer hasst sie?
Ein kontroverses neues Feature von C++ mit Haken und Ösen und vielen positiven Beispielen, die sich (meinerMeinung nach) erst im Gebrauch als negativ herausstellen werden, weil eine weitere klare Sprachstruktur verdunkeltwird.
Seit 2011 kann man für ganzzahlige und reelle Literale, für Zeichenliterale und für Stringliterale ein beliebiges Su�xverwenden. Das geht selbstverständlich nicht für Variable (a + b_i).
Eigene Su�xe müssen mit einem Unterstrich beginnen; Su�xe ohne Unterstrich sind dem Standard vorbehalten.Diese Regel ist genau gegenteilig zu der bei Namen (identi�ern). Hier sind die mit Unterstrich beginnenden Namenfür den Standard reserviert.
Die Bedeutung der folgenden Beispiele ist suggestiv, jedoch hier nicht nicht festgelegt. Suggestionen könnenkatastrophale Irrlichter sein!
1 double x = 1.3 _miles;
2 x = 2.0_km;
3 if (1_kg == 2.2046226 _lb)
4 std::complex <double > z = 1 + 2_i;
5 Point p = 25_x + 34_y + 3_z;
6 Date d1 = 20170731 _ad;
7 Date d2 = 15821005 _ad;
8 Date d3 = 10101bc;
9 Date d4 = "1954 -06 -07"_ad;
10 Date d5 = "12/24/2017"_ad;
11 font_size fs = 12_pt;
12 double angle = 60 _degrees;
Verwendete Su�xe müssen als Operatorfunktion de�niert werden. Als Argumente sind unsigned long long int,long double, char, wchar_t, char16_t, char32_t, const char *, const wchar_t *, const char16_t * undconst char32_t *, zugelassen.
Die Operatorfunktion wird mit
returntype operator "" identifier (argument) { conversion code }
de�niert.
1 long double operator "" _miles (long double x) { return x * 1.609; }
2 long double operator "" _km (long double x) { return x; }
3 long double operator "" _lb (long double x) { return x * 0.4535923; }
4 complex <long double > operator "" _i (long double x) { return complex <long double > (0, x); }
5 long long operator "" _ad (long long n) { return Date (n%100, (n/100) %100, n/10000); }
6 long long operator "" _ad (char * p) { return /* zu kompliziert */ }
7 long long operator "" _bc (long long n) { return Date (n%100, (n/100) %100, -n/10000); }
8 double operator "" _degrees (long double n) { return n / 180.0L * 3.14L; }
"a"_b res operator""_b (T a) {}
Seit 2014 können in der De�nition der Operatorfunktion auch sogenannte user-de�ned-string-literal(e) stehen -achten sie auf das fehlende Leerzeichen zwischen den Gänsefüÿchen und dem identi�er! Jetzt sind beliebige Wörter,auch Schlüsselwörter erlaubt. Die Unterstrichregel bleibt gültig, so dass das folgende Beispiel im User-code nichtauftauchen sollte.

4. ÜBERSICHT ÜBER DIE C++-DATENTYPEN 43
1 float operator ""if (float x) { };
2 double operator ""i (double x) { };
3 long double operator ""i (long double x) { };
4 std:: complexfloatdouble > zf = 1 + 2if;
5 std::complex <double > z = 1 + 2i;
6 std::complex <long double > zl = 1 + 2il;
Die Sprache C++ wird mit diesem Feature nicht klarer und durchsichtiger.
In der Library gibt es neben den drei gerade genannten Schreibweisen für imaginäre Zahlen vorde�nierte Program-miererliterale im Namespace std::literals::complex_literals:
Uhrzeiten: operator ""h operator ""min operator ""s operator ""ms operator ""us operator ""ns
Character array to basic_string: operator ""s
Character array to string_view: operator ""sv
3. Beispiel: Schnitt zweier Geraden
Figure 2. Schnitt zweier Geraden
4. Übersicht über die C++-Datentypen
Das folgende Diagramm gibt eine Übersicht über wichtige Begri�e im Zusammenhang mit C++-Datentypen undüber die Datentypen selbst. Alle Abgrenzungen lassen sich leider nicht in einem einzigen zweidimensionalen Dia-gramm darstellen.
Der Begri� Aggregat umfasst neben Aggregat-Klassen auch Arrays. Er taucht im Diagramm zweimal auf. Aggregat-Variable können mit geschweiften Klammern und/oder Gleichheitszeichen initialisiert werden.
struct Aggregat {
int i;
double x;
};
Aggregat a = { 2, 3.14, };

44 3. OBJEKTORIENTIERTE PROGRAMMIERUNG
Die De�nition einer Aggregat-Klassen verbietet neben eigenen Konstruktoren, privaten Daten-Membern, Basis-Klassen und virtuellen Funktionen vor allem die Initialisierung von Membervariablen:
struct KeinAggregat {
int i = 2;
std::vector<int> s {2, 3, 5};
};
Im Diagramm fehlen die Begri�e
• Trivially copyable type: Alle skalaren Typen zusammen mit trivially copyable classes• Trivial type: Alle skalaren Typen zusammen mit trivial classes• Standard-layout type: Alle skalaren Typen zusammen mit standard-layout classes• POD-type: Alle skalaren Typen zusammen mit POD classes• Literal type: Alle skalaren Typen, Referenzen, Arrays und Klassen
Trivial kopierbar sind alle Typen, deren Variable byteweise in ein char-Array kopiert und von dort zurückkopiertwerden können, ohne dass der Inhalt korrumpiert wird.
Triviale Typen können statisch initialisiert werden.
Standard-layout bezeichnet die Eigenschaft einer festgelegten Darstellung in einer Bytefolge, die sogar kompatibelzu C ist.
Das Akronym POD steht für plain old data und bezeichnet Typen mit beiden Eigenschaften, trivial und standard-layout.
Der Standard benutzt die Begri�e class, struct und union als Oberbegri�e und als konkrete Typenbezeichnungenclass, struct und union. class als Typenbezeichnung ist eine Klasse, die mit privaten membern beginnt. structbeginnt mit public membern. union ist eine Klasse mit alternativen membern, von denen zu einem Zeitpunkt nureines gespeichert sein kann.
class als Oberbegri� bezeichnet alle drei Typen class, struct und union. struct als Oberbegri� bezeichnet classund struct. union als Oberbegri� bezeichnet nur union.
(Diese Darstellung ist gegenüber dem Standardtext stark vereinfacht und versucht die wesentlichen Punkte vorzustellen.)
5. Beispiele
5.1. Datum und Uhrzeit; Zeitachse.
5.2. Punktmenge.
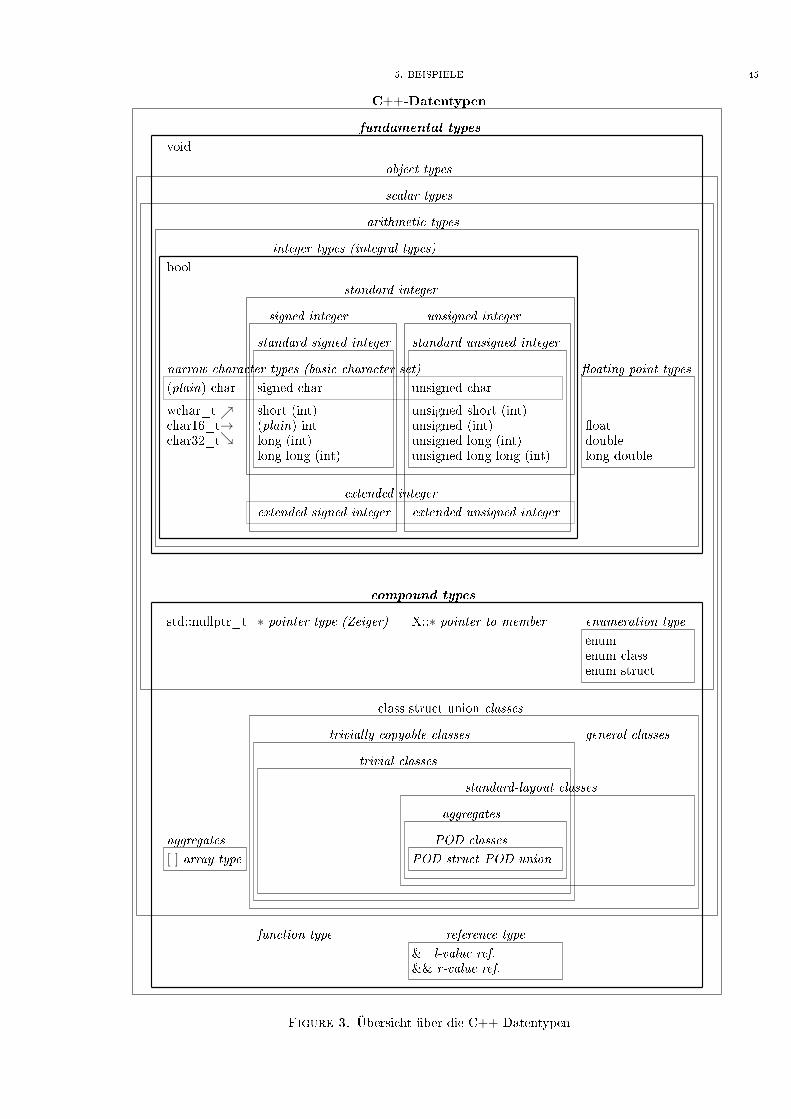
5. BEISPIELE 45
C++-Datentypen
fundamental types
void
object types
scalar types
arithmetic types
integer types (integral types)bool
standard integer
signed integer unsigned integer
standard signed integer standard unsigned integer
narrow character types (basic character set)(plain) char signed char unsigned char
wchar_t short (int) unsigned short (int)char16_t→
↗
↘(plain) int unsigned (int)
char32_t long (int) unsigned long (int)long long (int) unsigned long long (int)
extended integerextended signed integer extended unsigned integer
�oating point types
�oatdoublelong double
compound types
std::nullptr_t ∗ pointer type (Zeiger) X::∗ pointer to member enumeration typeenumenum classenum struct
class struct union classes
general classestrivially copyable classes
trivial classes
standard-layout classes
aggregates[ ] array type
aggregates
POD classesPOD struct POD union
function type reference type& l-value ref.&& r-value ref.
Figure 3. Übersicht über die C++-Datentypen


CHAPTER 4
Polymorphie (Vererbung - inheritance)
1. Vererbung
Skizze
Vererbung Inheritance Polymorphie
Erblasser Basisklasse Superklasse
Erbe abgeleitete Klasse (derived), Subklasse Erweiterung (extension)
Konzept
Gleichnamige Variable: shadowing/ausgrauen
Gleichnamige Funktionen: "
Virtuelle Funktionen: Überschreiben
Notwendige Bedingungen der Überschreibung: Zeiger + gleichnamig + virtuell
Anwendung: Shape
2. Abstrakte Klassen
Abstrakte Klassen generieren keine Objekte (können nicht instanziiert werden). Ihr einziger Zweck ist die Be-nutzung als Superklasse.
Eine pure virtual function ist eine speziell gekennzeichnete Funktion ohne Implementierung (ohne Code).
virtual void f () = 0;
Eine Klasse ist abstrakt, wenn sie mindestens eine pvf enthält.
Eine (direkte oder indirekte) Subklasse einer abstrakten Klasse ist konkret, wenn alle geerbten pvf überschriebensind.
pvf de�nieren also Interface-Teile (Funktionssignaturen).
Abstrakte Klassen dürfen Daten und Nicht-pvf für deren Verarbeitung enthalten.
Dann brauchen sie ctor, dtor, Big Five, Operatoren.
3. Mehrfachvererbung
class X: A, B
virtual
4. Interfaces
Interface: Klasse mit nur pvf. Sie enthalten nur Funktionssignaturen und stellen ein reines Interface dar. Siede�nieren Schnittstellen für klar umgrenzte Zwecke.
ISP: Interface segregation principle: Zu groÿe Interfaces werden so zerlegt, dass eine implementierende Klassejeden Teil unabhängig verwenden kann. Die implementierenden Klassen müssen dann nur noch die Funktionenüberschreiben, die sie wirklich benötigen. Ziel: Schlanke Interfaces.
Gekoppelte Systeme werden so entkoppelt.
47

48 4. POLYMORPHIE (VERERBUNG - INHERITANCE)
Figure 1. Polymorpie in C++
Beispiel: Geometrisches Objekt mit Interface zur Position in Ebene, auf Bildschirm, Fläche, Darstellungsfarbe. . .
class geo { point getPos () =0; screenpoint getSPos () = 0; ... };

5. SPEZIALTHEMEN 49
Schon zum Testen der Rechnungen muss man auch die Zeichenfunktionen überschreiben.
Bessere Lösung:
class computable { point getPos () =0; ... };
class drawable { screenpoint getSPos () = 0; ... };
class geo: computable, drawable { ... }
class testcompute: computable { ... }
class testdraw: drawable { ... }
5. Spezialthemen
Objekterzeugung: globale Objekte (auÿerhalb von geschweiften Klammern im globalen Speicher) Wer/wann ruftden Konstruktor?)
X x (3) auÿerhalb von {}
Felder von Objekten:
X x [n] nur default ctor möglich
X *p = new X* [n]; for (i = 0; i < n; ++i) p[i] = new X(i);
globale Objekte
direkte Objekte im Stack (Konstruktoren X x;)
indirekte Objekte im Heap (Konstruktoren X = new X();)
Factories: Objekterzeugende Funktionen
class X { X(){}; public: X * getX () { return new X(); } };
Private Konstruktoren?
Virtuelle Destruktoren??? ja!!!
Virtuelle Konstruktoren?? ctor immer Klassenbezogen!!!
Vererbung globaler Funktionen???
Vererbung der wichtigen Inserter und Extractor Operatoren???
Modern C++ Design, by Andei Alexandrescu


CHAPTER 5
Entwurfsmuster (Design patterns)
1. UML
2. Framework
3. Strategy
4. Singleton
5. Factory
6. Klassendesign für das Newton-Verfahren
51


CHAPTER 6
Generische Programmierung (Templates)
Allgemein sind Templates in C++ Entities mit variablen Typen, die durch Typparameter spezi�ziert werden.
1. De�nition von Template-Variablen
Template-Variable existieren seit C++14. Sie de�nieren eine zusammengehörende Menge von Variablen verschiede-nen Typs.
template<parlist>var-declaration
Als Beispiel wird die Zahl π in verschiedenen Typen erzeugt. Die angegebene Genauigkeit reicht auch aus, wennlong double eine IEEE-754 quad-zahl ist.
template<typename T>constexpr T pi = T(3.1415926535897932384626433832795028841971L);
Instanziierungen erfolgen erst, wenn die Template-Variable benutzt wird:
double x = pi<double>;
complex<long double> z = pi<complex<long double>>;
Von Template-Variablen wird hauptsächlich bei Klassenvariablen (static member) in Template-Klassen Gebrauchgemacht.
2. Funktionen
Literatur:
David Vandevoorde, Nicolai M. Josuttis, Douglas Gregor: C++ Templates, Addison-Wesley, 2018, 978-0-321-71412-1
http://www.icce.rug.nl/documents/cplusplus/, Frank B. Brokken, C++ Annotations Version, University ofGroningen, 9036704707, Kapitel 21, 22
2.1. De�nition von Funktionstemplates. Funktionen haben oft ähnlichen oder sogar identischen Code,auch wenn sie für verschiedene Datentypen de�niert werden.
1 int abs (int x) { return x < 0 ? -x : x; }
2 double abs (double x) { return x < 0 ? -x : x; }
3 std::complex <double > abs (std::complex <double > x) { return hypot (x.real(), x.imag());}
C++ hat für solche Fälle die Möglichkeit der Funktionsüberladung. Alle drei Funktionen können gleichzeitig ineinem Programm de�niert und ausgeführt werden. Dass die ersten beiden Funktionen sogar praktisch identisch sind,ist trotzdem ärgerlich. Mit Templates (Muster, Schablone) erhalten beide Funktionen eine gemeinsame De�niton.Dabei wird der Typ der Funktionsargumente durch einen Typparameter (hier T) ersetzt.
1 template <typename T>
2 T abs (T x) { return x < 0 ? -x : x; }
Die erste Zeile ist der Template-Header und erlaubt in spitzen Klammern ein oder mehrere Typparameter. DasSchlüsselwort typename kann auch durch class ersetzt werden; diese Möglichkeit gilt allerdings als veraltet.
1 template <typename T1, typename T2...>
Ein Funktionstemplate wird vom Compiler zunächst nur registriert. Der Compiler erzeugt noch keinen Code.Manche Fehler werden schon angezeigt, aber der folgende Fehler wird zunächst noch nicht registriert:
53

54 6. GENERISCHE PROGRAMMIERUNG (TEMPLATES)
1 template <typename T>
2 T abs (T x) { return x<<1 < 0 ? -x : x; } // dieser Fehler wird noch nicht erkannt
Ein Template wird erst aktiv, wenn die dadurch de�nierte Funktion benutzt wird. Das kann durch Aufruf derFunktion (oder auch durch Ermittlung ihrer Adresse mit &) geschehen.
1 std::cout << abs (-3) << "\n";
2 std::cout << abs ( -3.14) << "\n";
Beim ersten Aufruf wird die Funktion abs für den Typ T =int erstellt, beim zweiten Aufruf ist T =double. Es istjeder Typ zugelassen, der einen Vergleich < 0 und eine Prä�x-Negation −x erlaubt, auch Typen selbstgeschriebenerKlassen. In der obigen fehlerhaften Variante würde der Compiler erst bei der Erzeugung der Funktion für T =doubleeinen Fehler melden; der Schiebeoperator ist hier nicht erlaubt.
template<typename T, typename T1...>
template<class T>
Funktion mit T, T1 in den Argumenten (nicht im Ergebnis).
2.2. Template Typparameter. T const & x
T darf im Ergebnis und im Rumpf auftauchen.
Alle Operationen im Rumpf müssen für T erlaubt sein.
2.3. Instanziierung. erst Funktionsaufrufe generieren Template-Code (Instanziierung):
template<typename T> T abs(T x) { return x < 0 ? -x : x; }
x = abs (-5); y = abs (-3.14); s = abs ("Hans");
Das letzte Beispiel geht nicht, da in std::string kein operator-() existiert.
template<typename T> T abs(T const & x) { return x < 0 ? -x : x; }
Vorteile/Nachteile?
2.4. Template Return-Typen. template<typename T1, typename T1> T add(T1 const & x, T2 const & y) { return x + y; }
T= T1, T2???
template<typename T1, typename T1> decltype(x+y) add(T1 const & x, T2 const & y) { return x + y; }
template<typename T1, typename T1> auto add(T1 const & x, T2 const & y) -> decltype (x + y);
2.5. Code bloat mit HeaderDateien. Templates in Header → Compiler langsam:
1 #include <cmath >
2 #include <algorithm >
3 #include <string >
4 #include <iostream >
5
6 int main()
7 {
8 }
1 time g++ x.cpp
2 real 0m5.622s alle 4
3 real 0m0.674s "
4 real 0m0.704s "
5 real 0m0.300s keine
6 real 0m0.341s cmath
7 real 0m0.399s algorithm
8 real 0m0.444s string
9 real 0m0.604s iostream
10
11 time clang ++ x.cpp

3. KLASSEN 55
12 real 0m1.250s alle vier
13 real 0m1.218s
14 real 0m0.476s keine
15 real 0m0.492s
16 real 0m0.576s cmath
17 real 0m0.729s
18 real 0m0.862s algorithm
19 real 0m0.670s
20 real 0m0.744s string
21 real 0m0.742s
22 real 0m1.057s iostream
23 real 0m0.994s
Instanziierungen von Templates bei Funktionsaufrufen.
Mehrfachinstanziierungen derselben Instanz werden vom Linker entsorgt. → linker langsam
Sowenig wie möglich header�les. So kleine wie möglich Header�les.
iosfwd statt iostream
2.6. Deklaration von Funktionstemplates. template<typename T> T abs(T x);
2.7. Deklaration von Instanziierungen. template int abs<int>(int x);
template double abs<double>(double x);
2.8. Instanziierungen. Explizite Instanziierung von Templates
abs<int>
Instanziierung, wenn Funktion augerufen wird.
wenn Adressen der Funktion gebildet werden.
(Stelle ist Instanziierungspunkt)
Problem:
int f (int x){}
int f (int x, int y = 3){}
template<typename T> T f (T x){}
f(3)???
ambiguity
2.9. Überladung von Template-Funktionen. template<typename T> T abs(T x) { return x < 0 ? -x : x; }
template<typename T> T abs(T x, T y) { return hypot (x, y); }
x = abs (-5); y = abs (-3.14); z = abs (3.14, 2.71);
template<typename T> T abs(std::vector<T> const & v) { }
2.10. Spezialisierung von Template-Funktionen. template<> unsigned char abs(signed char c) { if (c < 0) return c + 128; return c; }
3. Klassen
3.1. De�nition von Template-Klassen. template<typename T> class X { T * p; ...};
X<int> o;
X<Y> o;
3.2. Member Templates. template<typename T> X<T>::X(T t) : i(t) { ... }

56 6. GENERISCHE PROGRAMMIERUNG (TEMPLATES)
3.3. Default template parameter. template<typename T = int> class X { ... };
X<> o;
3.4. Deklaration von Template-Klassen. template<typename T> class X;
3.5. Instanziierungen verhindern. extern template class std::vector<int>;
Beschleunigt Übersetzungen

CHAPTER 7
Exceptions
1. Problemsituationen in Programmen
In moderner Programmentwicklung betrachtet man immer einzelne in sich abgeschlossene Programmabschnittemit einer klar de�nierten, abgegrenzten Tätigkeit. Damit der Abschnitt erfolgreich ablaufen kann, benötigt ervorher bestimmte Voraussetzungen (preconditions). Nach dem Ablauf hat er einen neuen Zustand erzeugt, derdurch weitere Bedingungen charakterisiert ist (postconditions). Im Normalfall sind bei Beginn des Abschnitts allepreconditions erfüllt, der Abschnitt erledigt seine Arbeit und hinterläÿt erfüllte postconditions.
Sehr häu�g werden solche Abschnitte als eigene Funktionen implementiert, das ist jedoch nicht zwingend.
Hier kann man drei Problemfälle erkennen: Vor Beginn des Abschnitts sind die preconditons nicht erfüllt; das istVerantwortung des oder der zeitlich vorangehenden Abschnitte. Nach dem Abschnitt sind die postconditions nichterfüllt; dann ist ein auf ungenügende Analyse zurückzuführender Programmierfehler passiert. Der Abschnitt mussneu analysiert und programmiert werden. Noch schlimmer sind während des Abschnittes auftretende unerwarteteSituationen.
2. Reaktionsmöglichkeiten in Problemsituationen
Die (leider) häu�gste und einfachste Reaktion auf Probleme ist es, nichts zu tun. Der Programmierer setzt voraus,dass preconditions und postconditions nie verletzt werden und nichts unerwartetes geschieht. Ist das nicht derFall, stürzen solche Programme meist mit völlig unvorhersehbaren Konsequenzen ab. Wie heiÿt dieses Verhaltenso schön? �Unde�ned behaviour�!
Ist ein Programmabschnitt als Funktion implementiert, dann erzeugt diese Funktion meist Resultate. Alle Problemekönnen durch diese Resultate übermittelkt werden. Das geschieht dann in Form von speziellen Resultatwerten(= 0 ist Fehler - fopen, malloc in C; ̸= 0 ist Fehlernummer - fclose in C) oder bei komplexeren Ergebnissen durchzusätzliche Fehlermember in einer Resultatklasse mit de�niertem Inhalt. Bei dieser Methode ist ein Problem, dassoft vergessen wird, diese Fehlermeldungen auch abzufragen und adäquat darauf zu reagieren.
Man kann eine globale (schlecht, Namensraumverschmutzung) oder halbglobale (Namespace-Variable, static Klassen-variable) bereitstellen, die mit dem Wert fehlerfrei initialisiert wird und bei jeder Problemsituation einen Vermerkerhält. Das erlaubt es, auch nach längeren Abschnitten auf die angesammelten Fehler mit einer Abfrage zu reagieren(errno in der C-Library). Auch hier besteht die Gefahr, dass die im Fehlerfall notwendige Reaktion vergessen wird.
Und man kann Exceptions verwenden.
3. Exceptions
In fast allen modernen Sprachen (C++, Java, JavaScript, . . . ) hat sich in fast identischer Form ein Exception-Mechanismus durchgesetzt.
Dabei wird ein Programmabschnitt mit einer speziellen Syntax, der try-Anweisung, markiert (try { ... }). SeineFormulierung erfolgt so klar und einfach wie möglich, ohne dass Problemanalysen das Lesen und Verstehen erschw-eren. Auch die Ausführung erfolgt im Normalfall genauso, wie es der Code vorschreibt.
Natürlich müssen an entsprechenden Stellen eventuelle Probleme (Verletzung von pre- und postconditions, uner-wartete Situationen) erkannt werden. Treten solche Probleme konkret auf, wird mit einer weiteren Spezialanweisung(throw) eine Exception erzeugt (man sagt geworfen). Jede erzeugte Exception unterbricht den normalen Ablaufund setzt das Programm an einer de�nierten Stelle, nämlich nach einer einschlieÿenden try-Anweisung fort. JederCode zwischen Exception-Erzeugung und dieser Stelle wird dabei übersprungen, die Programmreaktion auf einenFehler erfolgt unmittelbar.
57

58 7. EXCEPTIONS
Am Ende der try-Anweisung kann der Programmierer Analysecode für alle Problemsituationen einfügen und Reak-tionen vorsehen. Verschiedene Probleme sollten dabei unterschieden werden können. Diese Analyse erfolgt incatch-Anweisungen. Die Argumente der catch-Anweisungen erlauben die Erkennung der verschiedenen Probleme,der Rumpf die spezi�schen Reaktionen. Das kann durch verschiedene Datentypen oder auch durch verschiedeneWerte erfolgen.
Um generell Speicher und andere Resourcen wieder freigeben zu können, haben manche Sprachen einen Teil (�nally),der ohne und mit Exceptions in jedem Fall durchlaufen wird. In C++ fehlt er, denn Code, der Resourcen freigibt,sollte immer in den Destruktoen stehen.
In speziellen Situationen kann man entscheiden, eine Exception weiterzugeben (rethrow). Sie kann erneut in dernächstäuÿeren try-Anweisung aufgegri�en (gecatcht) werden.
Exceptions, die nie aufgegri�en werden, beenden das Programm.
4. Exception-Syntax
Erzeugen einer Exception (Werfen):
1 throw "C-String mit Typ char const *";
2 throw std:: string("C-String mit Typ char const *");
3 throw 3.14; /// schmeissen Sie doch was Sie wollen! ///
4 throw new T ("Hallo");
5 throw domain_error("Bessel -function with wrong argument");
Der sarkastische Satz im Kommentar ist nicht wörtlich zu verstehen: Man sollte nichts werfen, was beim Erzeugen(Konstruktoraufruf) selbst eine weitere Exception werfen könnte (bad_alloc?)! Räumen Sie Ihre Exception-Klassenauf, minimieren Sie diese und verwenden Sie brauchbare std::exceptions! Da diese Standardexceptions selbstvom Programm oder der Library geworfen werden können, sollte man für eigene Exceptions Subklassen dieserStandardexceptions de�nieren.
Programmabschnitt mit problematischen Teilen:
1 try
2 { // very complicated code
3 // will call functions in several depths
4 f ();
5 }
6 catch (T t)
7 { // handle exceptions (plural) with type T
8 }
9 catch (T * t)
10 { // handle exceptions (plural) with pointer type T*
11 }
12 catch (T1 t)
13 { // handle exceptions (plural) with type T1
14 }
15 ...
Weitergabe einer Exception (rethrow):
1 catch (T t)
2 { // handle exceptions (plural) with type T
3 throw; // rethrow this exception
4 }
Die C++-Library enthält eine Reihe vorgegebener Exception-Klassen. Die Mutter aller Klassen ist dabei std::exception:
1 exception
2 logic_error
3 invalid_argument
4 domain_error
5 length_error
6 out_of_range
7 future_error(C++11)

6. EXCEPTION-BEISPIEL 59
8 bad_optional_access(C++17)
9 runtime_error
10 range_error
11 overflow_error
12 underflow_error
13 regex_error(C++11)
14 tx_exception(TM TS)
15 system_error(C++11)
16 ios_base :: failure(C++11)
17 filesystem :: filesystem_error(C++17)
18 bad_typeid
19 bad_cast
20 bad_any_cast(C++17)
21 bad_weak_ptr(C++11)
22 bad_function_call(C++11)
23 bad_alloc
24 bad_array_new_length(C++11)
25 bad_exception
26 ios_base :: failure(until C++11)
27 bad_variant_access(C++17)
(aus http://en.cppreference.com/w/cpp/error/exception)
Die std::exceptions werden mit einem (C-)String initialisiert, der nach dem catch mit der Funktion what ermitteltwerden kann.
1 catch (std:: invalid_argument e)
2 { std::cout << "Exception " << e.what() << std::endl;
3 }
5. Programmverhalten
Programmfragmente lassen sich je nach Umgang mit Exceptions in mehrere Klassen einteilen. Von oben nachunten wird das Verhalten schwächer, also schlechter:
1. nothrow exception guarantee: Ein Programmfragment wirft keine Exceptions und produziert keine unerwartetenSituationen. Fehler werden mit anderen Mechanismen gemeldet. Da während des stack unwindings bei der Suchenach einer catch-Anweisung Destruktoren aufgerufen werden, sollten Destruktoren niemals Exceptions werfen undimmer in diese Gruppe gehören. Seit C++11 können solche Funktionen als nothrow markiert werden.
2. strong exception guarantee: Nach einer Exception wird der gesamte Programmzustand zurück zu dem vor derStelle, die die Exception ausgelöst hat, zurückgesetzt. Das ist Aufgabe der catch-Anweisungen. Das Programmkann selbst nach Auftreten von Exceptions bedenkenlos fortgesetzt werden.
3. weak exception guarantee: Das Programm bleibt in einem gültigen Zustand, auch wenn es nicht den vor derException erreicht. Auch hier kann es fortgesetzt werden.
4. no exception guarantee: Das Programm verbleibt nach der Exception in einem unde�nierten Zustand. Der dieException auslösenden Fehler produziert unbehobene Allokationsfehler (verbliebene locks), Speicherlöcher (nichtfreigegebene Speicherbereiche) und ähnliches.
6. Exception-Beispiel
Arbeiten mit Dateien sind sehr fehlerträchtig und damit gute Beispiele für Verwendung von Exceptions. Eingabe-dateien müssen nicht existieren oder enthalten falsche Daten. Ausgabedateien kommen auf ein volles oder gesperrtes(read-only) Medium.
Im folgenden Programm werden Zahlen aus einer Liste von Dateien gelesen und deren Wurzel am Bildschirmausgegeben. Die Dateien können Textdateien (UTF-8 mit Byte-oder-mark) oder Binärdateien sein. Die BOMist in UTF-8 eigentlich nicht gestattet, wird hier aber zur Unterscheidung verwendet. Weitere Unterscheidungenkönnten UTF-16 und UTF-32 sein.

60 7. EXCEPTIONS
Katastrophale Fehöler beendet das Programm, leichtere Fehler werden abgefangen und setzen das Programmsinnvoll fort.
Diese Beispiel ist ein Exception-Beispiel und nicht als Muster für Unicode-Verarbeitung zu sehen. BOM in UTF-8ist falsch; für die Zahlen würde ASCII ausreichen; es fehlt UTF-16 und UTF-32; es fehlt BOM-Erkennung; es fehlteine brauchbare Binärerkennung und es fehlen nach der Erkennung weitere Plausibilitätsprüfungen während desLesens der Dateien. Glauben Sie mir: Sie wollen das alles hier nicht lesen!
1 // excpt.cpp
2 #include <cmath >
3 #include <iostream >
4 #include <fstream >
5 #include <string >
6 #include <algorithm >
7 #include <exception >
8
9 void dotext (std:: string fn) throw (std:: logic_error , std:: string)
10 {
11 std:: ifstream f (fn);
12 if (!f) throw std:: logic_error("1");
13 if (!f.is_open ()) throw std:: logic_error("2");
14 unsigned char c0=0, c1=0, c2=0;
15 f >> c0 >> c1 >> c2;
16 if (!(c0 == 0xef && c1 == 0xbb && c2 == 0xbf)) throw std:: logic_error("3");
17 while (f)
18 {
19 double x;
20 f >> x;
21 if (x < 0) { f.close (); throw std:: string("file has wrong data"); return; }
22 std::cout << sqrt (x) << std::endl;
23 }
24 }
25
26 void dobinary (std:: string fn) throw (std:: logic_error , std:: invalid_argument)
27 {
28 std:: ifstream f (fn , std::ios::in|std::ios:: binary);
29 if (!f) throw std:: logic_error("wtf");
30 if (!f.is_open ()) throw std:: logic_error("wtf");
31 double x;
32 while (f)
33 {
34 f.read (reinterpret_cast <char*>(&x), sizeof (double));
35 if (x < 0) { f.close (); throw std:: invalid_argument ("negative value in binary"); return; }
36 std::cout << x << ": " << sqrt (x) << std::endl;
37 }
38 }
39
40 void filetype (std:: string fn)
41 throw (std:: logic_error , std::string , std:: logic_error , std:: invalid_argument , char const *)
42 {
43 std:: ifstream f (fn.c_str (), std::ios::in|std::ios:: binary);
44 if (!f) throw "file does not exist";
45 if (!f.is_open ()) throw "file does not exist";
46 char c0=0, c1=0, c2=0;
47 f.read (&c0, 1); f.read (&c1, 1); f.read (&c2 , 1);
48 f.close ();
49 if (c0 == (char)0xef && c1 == (char)0xbb && c2 == (char)0xbf)
50 {
51 dotext (fn);
52 return;
53 }
54 dobinary (fn);
55 }

6. EXCEPTION-BEISPIEL 61
56
57 int main (int argc , char** argv)
58 try
59 {
60 /* generate a binary file:
61 std:: ofstream f("ex3", std::ios::out|std::ios:: binary);
62 double x;
63 x = 2; f.write (reinterpret_cast <char*> (&x), sizeof x);
64 x = 5; f.write (reinterpret_cast <char*> (&x), sizeof x);
65 x = -5; f.write (reinterpret_cast <char*> (&x), sizeof x);
66 x = 7; f.write (reinterpret_cast <char*> (&x), sizeof x);
67 f.close ();
68 */
69 for (int i = 1; i < argc; ++i)
70 {
71 try
72 {
73 filetype (std:: string(argv [i]));
74 }
75 catch (std:: string e)
76 {
77 std::cout << "std:string: file " << argv [i] << "; something wrong; " << e << std::endl;
78 }
79 catch (char const * e)
80 {
81 std::cout << "char*: file " << argv [i] << "; something wrong; " << e << std::endl;
82 }
83 catch (std:: invalid_argument e)
84 {
85 std::cout << "x<0: " << argv [i] << "; " << e.what() << std::endl;
86 }
87 }
88 return 0;
89 }
90 catch (std:: exception e)
91 {
92 std::cout << "Abnormal end with " << e.what() << std::endl;
93 return 1;
94 }
Das Programm wurde mit den Testdateien gstartet und liefert nach der Übersetzung
./excpt.exe ex1.txt ex2.txt ex33 ex1.txt ex3 > excpt.res
das folgende Ergebnis:1 4.79583
2 6
3 3
4 3
5 2
6 3
7 4
8 5
9 6
10 std:string: file ex2.txt; something wrong; file has wrong data
11 char*: file ex33; something wrong; file does not exist
12 4.79583
13 6
14 3
15 3
16 2: 1.41421
17 5: 2.23607
18 x<0: ex3; negative value in binary

62 7. EXCEPTIONS
Bemerkungen:
1. Eigentlich sollte man keine Strings als Exceptions verwenden. Wenn man das trotzdem tut, müssen String-Literale als char const * gecatcht werden.
2. Will man C++-Strings verwenden, braucht man einen std::string-Konstruktor.
3. Besser sind die in <stdexcept> de�nierten Exception-Klassen.
4. Für weitere Unterscheidungen kann man in den Exception-Objekten String-Informationen unterbringen und/oderselbstde�nierte Subklassen verwenden.
7. assert
Genauso wie in C existiert in C++ die assert-Anweisung. Sie ist abschaltbar (#define NDEBUG vor #include<cassert>)und dient zum Testen während der Programmentwicklung, jedoch niemals zur Fehlererkennung.
Bedingungen, die man während der Programmentwicklung sicherstellen will, kann man mit assert(bedingung)prüfen. Das Programm bricht bei nichterfüllter Bedingung ab und der Entwickler kann die Ursache suchen. NachAbschalten wird diese Bedingung nicht mehr geprüft.
Preconditions kann man mit assert testen, wenn durch den Programmablauf sichergestellt ist, dass die preconditionimmer erfüllt ist.
Die Existenz von Dateien sollte niemals mit assert geprüft werden, da nach Abschalten des assert eine unklareSituation über den Dateizustand vorliegt.

CHAPTER 8
Reguläre Ausdrücke
Einerseits sind reguläre Ausdrücke (regex) ein bedeutendes Element der Textverarbeitung. In C und C++ jedochwurden sie schon immer sehr nachrangig behandelt.
Wegen ihrer Unverzichtbarkeit gibt es externe Libraries, die reguläre Ausdrücke auch für C und C++ bereitstellen.Wie wir noch sehen werden, haben sie nichts von ihrer Wichtigkeit verloren.
Hochwertige reguläre Ausdrücke mit Unicode-Unterstützung �nden sich in der ICU:http://site.icu-project.org/
http://userguide.icu-project.org/strings/regul\"are Ausdr\"uckep
Die C++-Library boost enthält eine Implementierung der Posix-reguläre Ausdrücke:http://www.boost.org/doc/libs/1_61_0/libs/regul\"are Ausdr\"ucke/doc/html/index.html
Wer Perlen vorzieht, kann auch die PCRE verwenden:http://www.pcre.org/
Die gute Nachricht ist, dass C++ seit 2011 reguläre Ausdrücke in der STL enthält. Sie sind sogar verwendbar � wennIhre Ansprüche nicht allzu hoch sind. Schlechter klingt die Botschaft, dass hier fast alles, was den Unicode betri�t,falsch gemacht wurde, auch wenn stolz gleich sechs reguläre Ausdrucksvarianten vorgeschrieben sind, darunter dievon ECMAScript. Das Problem beginnt damit, dass als Spezialisierungen nur char- und wchar_t-Strings de�niertsind und char16_t- und char32_t-Strings fehlen. In char kann man zwar UTF-8 speichern, die reguläre Ausdrückeanalysieren dann jedoch nur Codeunits und keine Schriftzeichen. wchar_t ist compilerabhängig und ebenfalls fürportable Programme ungeeignet. gcc speichert in wchar_t UTF-32 und ist inkompatibel zu Microsoft mit UTF-16.
Kurz: C++ enthält seit C++11 eine reguläre Ausdrucks-Library, die mit hohem Qualitätsstandard auf dem Standdes Jahres 1988 reguläre Ausdrücke de�niert, die nicht Unicode-aware sind.
#include<regex>
1. Wahlmöglichkeiten
Die folgenden Wahlmöglichkeiten suggerieren fälschlicherweise, dass C++ kompatibel zu den jeweiligen Vorbildernist. Dem ist nicht so, C++ ist bestenfalls jeweils ähnlich. Eigentlich ist es eine gute Sache, wenn sich ein Standardin Details auf andere Standards bezieht, die dieses Detail schon ausreichend de�niert haben (Beispiel: reelle Zahlensind in IEEE-754 de�niert). C++ bezieht sich jedoch im Jahr 2011 auf den Posix-Standard, der 1985 entstandenist und damit nichts vom Unicode wissen kann..
ECMAScript ist ähnlich zu JavaScript.basic ist ähnlich zu Posix BRE.extended ist ähnlich zu Posix ERE.grep ist wie Posix grep.egrep ist wie Posix egrep.awk ist wie Posix awk.
Verlinkung der Originalde�nitionen:ECMAScript:www.ecma-international.org/publications/files/ECMA-ST/ECMA-262.pdfECMA-262 7th Edition / June 2016Posix:http://pubs.opengroup.org/onlinepubs/9699919799/nframe.html POSIX.1-2008 (auch IEEE Std 1003.1-2008und The Open Group Technical Standard, Base Speci�cations, Issue 7)
63

64 8. REGULÄRE AUSDRÜCKE
ECMAScript: ECMA-262 7th Edition / June 2016, 21.2 RegEXP Objects, p. 409basic: Posix , 9.3 Basic Regular Expressions,http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_03
grep: http://pubs.opengroup.org/onlinepubs/9699919799/utilities/grep.htmlawk: http://pubs.opengroup.org/onlinepubs/009695399/utilities/awk.html
2. Objekte für reguläre Ausdrücke
Ähnlich wie bei Strings sind reguläre Ausdrücke eine Template-Klassebasic_regex<charT,regexT> mit default basic_regex<charT,regex_traits<charT> de�niert, die neben zweiStandardspezialisierungenregex ≡ basic_regex<char> undwregex ≡ basic_regex<wchar_t> weitere Spezialisierungen zuläÿt.
Die beiden weiteren Spezialisierungentypedef basic_regex<char16_t> regex16; und typedef basic_regex<char32_t> regex32; sind leicht zu erzeu-gen und könnten nützlich sein. Die Namen wurden so gewählt, dass sie mit voraussichtlichen Namen kommenderStandardversionen wahrscheinlich nicht kollidieren.
Die Erzeugung eines regulären Ausdruck-Objektes erfolgt mit einem Konstruktor, der reguläre Ausdrücke ausC/C++-Strings erzeugt und weitere Parameter hat.
regex(const char* p, size_t len, flag_type f);
regex(const string & s, flag_type f);
String-Literale enthalten bei regulären Ausdrücken viele Backslashes, so dass sich hier Raw-Literale anbieten(Denken Sie and die zu verdoppelnden Backslashes in C- und C++!)-Strings:
regex r("\\w+"); // Wörter mit mindestens einem Zeichen
regex r(R"re(\w+)re"); // als Raw-String
char * p; p = (char*)"\\w+"; regex r(p, strlen (p)); // als C-String
regex r("\\w+", std::regex_constants::ECMAScript); // Explizit: JavaScript-Regeln
regex r("\\w+", std::regex_constants::basic); // Posix BRE
regex r("\\w+", std::regex_constants::extended); // Posix ERE
regex r("\\w+", std::regex_constants::grep); // BRE mit \n-Erweiterung
regex r("\\w+", std::regex_constants::egrep); // ERE mit \n-Erweiterung
regex r("\\w+", std::regex_constants::awk);
\n-Erweiterung: Wenn der reguläre Ausdruck den String ohne das abschlieÿende Zeilenende matcht, gilt das alsZeilentre�er.
Weitere Flags werden geodert:
regex r("\\w+", std::regex_constants::ECMAScript | std::regex_constants::icase);
regex r("\\w+", std::regex_constants::ECMAScript | std::regex_constants::nosubs);
regex r("\\w+", std::regex_constants::ECMAScript | std::regex_constants::optimize);
regex r("\\w+", std::regex_constants::ECMAScript | std::regex_constants::collate);
3. Verwendung regulärer Ausdrücke
Typische Anwendungen regulärer Ausdrücke sind einfache und globale Tre�ersuche und Ersetzungen.
Einfache Tre�ersuche erfolgt mit std::regex_match() und std::regex_search() . Die Tre�er werden in geeignetenSpezialisierungen der Tre�erklassen gespeichert.
In C++ wird zwischen den regex-Spezialisierungen und den C/C++-Strings unterschieden, so dass sich jeweils vierTre�erklassen ergeben:
std::cmatch
std::smatch

4. ICU 65
std::wcmatch
std::wsmatch
Für globale Tre�ersuchen benötigt man Iteratoren:
std::cregex_iterator
std::sregex_iterator
std::wcregex_iterator
std::wsregex_iterator
Zur Ersetzung dient die Funktion std::regex_replace().
4. ICU
ICU bietet das beste aus der Perl-, Java- und Unicode-Welt.
http://site.icu-project.org/
http://userguide.icu-project.org/strings/regexp
1 // regexicu.cpp
2 // source: http :// userguide.icu -project.org/strings/regexp
3 // debian compile (pc55556):
4 // g++ regexicu.cpp `icu -config --ldflags `
5 // g++ regexicu.cpp -licudata -licui18n -licuio -licule -liculx -licutest -licutu -licuuc
6 // corrected: find without arguments!
7 // results:
8 /*
9 The result of find & replace is "Here_is_some_text ."
10 The number of replacements is 3
11 */
12
13 #include <iostream >
14 #include "unicode/regex.h"
15
16 int
17 main ()
18 {
19 UErrorCode status = U_ZERO_ERROR;
20 RegexMatcher m (UnicodeString (" +"), 0, status);
21 UnicodeString text ("Here is some text.");
22 m.reset (text);
23
24 UnicodeString result;
25 UnicodeString replacement ("_");
26 int replacement_count = 0;
27
28 while (m.find (/* status */) && U_SUCCESS (status))
29 {
30 m.appendReplacement (result , replacement , status);
31 replacement_count ++;
32 }
33 m.appendTail (result);
34
35 char result_buf [100];
36 result.extract (0, result.length (), result_buf , sizeof (result_buf));
37 std::cout << "The result of find & replace is \"" << result_buf << "\"" << std::endl;
38 std::cout << "The number of replacements is " << replacement_count << std::endl;
39 }


CHAPTER 9
Die STL von C++
1. Zufallszahlen
C++ verfügt in der STL seit C++11 über einen ausgezeichneten Zufallsgenerator. Der aus C stammende rand
kann weiter benutzt werdn.
2. Zufall in C++
C++ trennt die Zufallserzeugung von der erwünschten Verteilung und bürdet nichts davon dem Programmiererauf.
2.1. Erzeugung. Für den Anfänger unübersichtlich, aber leicht durch Ignoranz zu vereinfachen. ErzeugterZufall ist immer gleichverteilt.
Es gibt zur Zufallserzeugung sog. engines (lc, mt, sc), engine adaptors (db, ib, so), non-deterministic devices(Entropie-Quelle) und zehn prede�ned engines (). Hier kann man sich eigentlich in fast allen Situationen mit dreiEmpfehlungen das Leben erleichtern:
random_device: Hier wird eine gute Entropie-Quelle angezapft.mt19937: Mersenne-Twister sind derzeit die mit Abstand besten Generatoren.mt19937_64: auch mit 64 Bit Ergebnissen.
Viele weitere sind in der Literatur erwähnte Generatoren (knuth_b), die nur benötigt werden, wenn man für einenLauf genau die Zahlen aus der entsprechenden Literaturangabe verwenden will.
Wenn Sie wissen, was Sie tun (das wissen Sie doch ho�entlich immer?), können sie die Zufallsquelle fein tunen.Wenn Ihre Kenntnisse über über hochwertigen Zufall jedoch eher geringer sind, z.B. nur das hier vorgestellteMinimalwissen, sollten Sie auf gar keinen Fall mit den Parametern spielen; die Gefahr der Verschlechterung derErgebnisse ist riesig groÿ. Um wirklich sinnvoll in die engines einzugreifen, sollten Sie mindestens das Wissen ausKnuth: The Art of Computer Programming beherrschen. Im Zweifelsfall immer beachten: don't mess with theengines!
2.2. Verteilungen. Aus der Zufallsquelle kann jede wichtige Verteilung generiert werden. Für wichtigeVerteilungen gibt es in C++ erzeugende Templates und Klassen:
2.2.1. Diskrete Verteilungen.
(1) Diskrete Gleichverteilung: uniform_int_distribution
P (i|a, b) = 1
b− a+ 1, a ≤ i ≤ b
, Münzwurf, Würfel, . . .(2) Bernoulli-Verteilung: (Null-Eins-Verteilung): bernoulli_distribution
P (b|p) =
{p b = true
1− p b = false
, Experimente mit zwei Ausgängen
67

68 9. DIE STL VON C++
(3) Binomialverteilung: binomial_distribution
P (i|t, p) =(t
i
)pi(1− p)t−i, i ≥ 0
, Erfolg bei mehreren Versuchen(4) Geometrische Verteilung, Miÿerfolge:
P (i|p) = p(1− p)i−1
Anzahl der Miÿerfolge bis zum ersten Erfolg bei mehreren Experimenten(5) Geometrische Verteilung, Versuche:
P (i|p) = p(1− p)i
Erfolg: geometric_distribution
, Anzahl der Versuche bis zum ersten Erfolg bei mehreren ExperimentenIn beiden Fällen ist die Ausgangssituation gleich: Wir warten aus ein bestimmtes Ereignis und zählen
die Miÿerfolge bez. Versuche bis zum ersten Erfolg. Wer unbedingt eine Tochter will, zählt seine Söhneoder alle seine Kinder bis er genau eine Tochter hat.
Der betrunkene Hausherr, der vergiÿt, welche Schlüssel er schon probiert hat, wenn er mit einemSchlüsselbund mit vielen Schlüssel versucht, die Türe aufzuschlieÿen.
(6) Poisson-Verteilung: poisson_distribution
P (i|µ) = e−µµi
i!
Anzahl von Ereignissen in einem festen Zeitintervall. Anzahl der Tore eines Vereins in seinen einzelnenSpielen.
9. Logarithmische Verteilung:
2.2.2. Stetige Verteilungen.
(1) Stetige Gleichverteilung: uniform_real_distribution
P (x|a, b) = 1
b− a, a ≤ x < b
Wartezeit auf einen Bus oder die Grünphase einer Ampel, wenn man zufällig ankommt.(2) Normalverteilung (Gauÿ-Verteilung): normal_distribution
P (x|µ, σ) = 1
σ√2π
e−(x−µ)2
2σ2
Die wichtigste Verteilung des Statistik. Alle summierten Variablen (Mittelwerte mehrerer Messungen)konvergieren gegen die Normalverteilung.
(3) Logarithmische Normalverteilung (Log-Normalverteilung): lognormal_distribution
P (x|m, s) =1
sx√2π
e−(lnx−m)2
2s2
(4) Exponentialverteilung: exponential_distribution
P (x|λ) = λe−λx, x ≥ 0
Durchschnittliche Wartezeiten auf Ereignisse, wenn die schon verstrichene Wartezeit keine Informationüber die zu erwartende Restwartezeit liefert (gedächtnisloses Warten)
(5) Chi-Quadrat-Verteilung (χ2-Verteilung): chi_squared_distribution
P (x|n) = xn2 −1e−
x2
Γ(n2 )2n2
(6) Studentsche t-Verteilung: student_t_distribution
P (x|n) = 1√nπ
Γ(n+12 )
Γ(n2 )(1 +
x2
n)−
n+12
Hypothesentests und Kon�denzintervalle bei Stichprobenversuchen

2. ZUFALL IN C++ 69
(7) F-Verteilung (Fisher-Verteilung): fisher_f_distribution
P (x|m,n) =Γ(m+n
2 )
Γ(m2 )Γ(n2 )
(m
n)
m2 · xm
2 −1 · (1 + mx
n)−
m+n2
(8) Gammaverteilung: gamma_distribution
P (x|α, β) = e−xβ
βαΓ(α)xα−1, x > 0
(9) Weibull-Verteilung: weibull_distribution
P (x|a, b) = a
b(x
b)a−1e−( x
b )a
(10) Cauchy-Verteilung (Cauchy-Lorentz-Verteilung, Lorentz-Verteilung): cauchy_distribution
P (x|a, b) = (πb(1 + (x− a
b)2))−1
(11) Extrem-Value-Distribution (Gumbel Type I, log-Weibull, Fisher-Tippet Type I) extreme_value_distribution
P (x|a, b) = 1
be(
a−xb )−e
a−xb
2.2.3. Empirische Verteilungen.
(1) discrete_distribution
P (i|p0, . . . pn−1) = pi
(2) piecewise_constant_distribution
(3) piecewise_linear_distribution
2.3. Beispiele. Zufallszahlen mit einem Standard-Mersenne-Twister, die bei jedem Lauf verschieden sind,benutzen einmal eine Entropiequelle:
1 #include <iostream >
2 #include <random >
3
4 int main ()
5 {
6 std:: random_device start_with_;
7 std:: mt19937 mt (start_with_ ());
8 std:: uniform_int_distribution <int > dice (1, 6);
9 for (int i = 0; i < 30; ++i)
10 {
11 std::cout << " " << dice (mt);
12 }
13 }
Reproduzierbare Zufallszahlen benutzen eine feste Initialisierung:
1 #include <iostream >
2 #include <random >
3
4 int main ()
5 {
6 std:: mt19937 mt (42);
7 std:: uniform_int_distribution <int > dice (1, 6);
8 for (int i = 0; i < 30; ++i)
9 {
10 std::cout << " " << dice (mt);
11 }
12 }
Warum werden die Entropie-Quellen nicht für alle Zufallszahlen verwendet? Sie sind deutlich langsamer als dieMersenne-Twister (typischer Faktor 1000).
Sie können das folgende Beispiel auf Ihrer Maschine ausprobieren:

70 9. DIE STL VON C++
1 #include <iostream >
2 #include <random >
3
4 int main ()
5 {
6 int n (100000000);
7 #ifdef nondeterministic
8 std:: random_device mt;
9 // n = 10000000;
10 std::cerr << "entropy = " << mt.entropy () << std::endl;
11 #else
12 std:: mt19937 mt (42);
13 #endif
14 std::cerr << "n = " << n << std::endl;
15 std:: uniform_int_distribution <int > dice (1, 6);
16 for (int i = 0; i < n; ++i)
17 {
18 std::cout << " " << dice (mt);
19 }
20 }
21 /*
22 Results on rex2 (6 '2019):
23 rex2 :... svn/doku/trunk/random/progs > g++ -std=c++11 entropy.cpp
24 rex2 :... svn/doku/trunk/random/progs > time ./a.out > /dev/null
25 n = 100000000
26 12.044u 0.012s 0:12.11 99.5% 0+0k 0+0io 0pf+0w
27 rex2 :... svn/doku/trunk/random/progs > g++ -std=c++11 -D nondeterministic entropy.cpp
28 rex2 :... svn/doku/trunk/random/progs > time ./a.out > /dev/null
29 entropy = 0
30 n = 100000000
31 20.100u 0.044s 0:20.27 99.3% 0+0k 0+0io 0pf+0w
32
33 Results on rrzvm034 (6 '2019):
34 brf09510@rrzvm034 :~/ temp/brf09510/svn/doku/trunk/random/progs > g++ -std=c++11 entropy.cpp
35 brf09510@rrzvm034 :~/ temp/brf09510/svn/doku/trunk/random/progs > time ./a.out > /dev/null
36 n = 100000000
37
38 real 0m13 .184s
39 user 0m12 .889s
40 sys 0m0.048s
41 brf09510@rrzvm034 :~/ temp/brf09510/svn/doku/trunk/random/progs > g++ -std=c++11 -D nondeterministic
entropy.cpp
42 brf09510@rrzvm034 :~/ temp/brf09510/svn/doku/trunk/random/progs > time ./a.out > /dev/null
43 entropy = 0
44 n = 100000000
45
46 real 0m22 .015s
47 user 0m21 .942s
48 sys 0m0.040s
49
50 Results on cygwin (6 '2019):
51 brf09510@pc1011802600 /cygdrive/r/svn/doku/trunk/random/progs
52 $ g++ -std=c++11 -D nondeterministic entropy.cpp
53
54 brf09510@pc1011802600 /cygdrive/r/svn/doku/trunk/random/progs
55 $ time ./a.exe > /dev/null
56 entropy = 0
57 n = 100000000
58
59 real 0m36 ,132s
60 user 0m36 ,031s
61 sys 0m0 ,046s

2. ZUFALL IN C++ 71
62
63 brf09510@pc1011802600 /cygdrive/r/svn/doku/trunk/random/progs
64 brf09510@pc1011802600 /cygdrive/r/svn/doku/trunk/random/progs
65 $ g++ -std=c++11 entropy.cpp
66
67 brf09510@pc1011802600 /cygdrive/r/svn/doku/trunk/random/progs
68 $ time ./a.exe > /dev/null
69 n = 100000000
70
71 real 0m25 ,680s
72 user 0m25 ,625s
73 sys 0m0 ,000s
74
75 $ g++ -v
76 Es werden eingebaute Spezifikationen verwendet.
77 ...
78 gcc -Version 7.4.0 (GCC)
79
80
81 */


CHAPTER 10
Guter Programmentwurf in C++
1. RAII
Resource Aquisition is Initialization
2. SOLID
SOLID
Single Responsibility Principle (SRP)
Open Closed Principle (OCP)
Liskov Substitution Principle (LSP)
Interface Segregation Principle (ISP)
Dependency Inversion Principle (DIP)
73


CHAPTER 11
Problemfälle von C++
1. Konstante wie π
Bruce Dawson diskutiert dieses Problem in:
https://randomascii.wordpress.com/2014/06/26/please-calculate-this-circles-circumference/
Ein schon seit 1969 existierendes Problem in C ist, dass es keine De�nition von π gibt. Der Wert M_PI ist nicht imStandard festgelegt. Auch ein vor der Header-De�nition #include<cmath> eingefügtes #define _USE_MATH_DEFINES
ist kein korrektes Programm.
Die ältesten Lösungen sind, die Zahl ins Programm zu schreiben
return d * 3.14159265358979323846L
oder eine de�ne-Direktive
#define pi 3.14159265358979323846L
In beiden Fällen spezi�ziert das Su�x L eine long double, um π mit maximaler Genauigkeit zu speichern. Nachteildieser Lösung sind die Konversionen auf den Zieltyp (�oat oder double). Mehrfache Konstanten pif, pi und pil
sind eigentlich in einer Sprache mit overloadad functions nicht mehr zeitgemäÿ. Und viele Compiler erzeugen beijeder Konversion eine Warnung vor verlorenen Stellen.
Weiter verschmutzen de�ne-Direktiven den Namensraum. Wie immer man auch π benennt, es kann in groÿenProgrammen mit dort vorhandenen Namen kollidieren und deren Übersetzung stören. de�ne-Direktiven könnennicht in Namespaces gekapselt werden.
Die o�ensichtliche Lösung in C++ ist
long double const pi = 3.14159265358979323846L
in einer Header-Datei. Überraschenderweise wird jetzt bei jedem include eine eigene (konstante) Variable für πerzeugt. Bei einer ganzzahligen Konstanten passiert dies noch überraschender nicht!
Seit 2011 gibt es constexpr, die der Compiler auswertet:
constexpr long double pi = 3.14159265358979323846L;
Wer für gute (!) Programme keinen Aufwand (!) scheut, kann π extern anmontieren:
mathconst.h:extern long double const pi;
mathconst.cpp:extern long double const pi = 3.14159265358979323846L
Jetzt wird wie bei ganzzahligen Konstanten nur ein Speicherplatz der Konstanten erzeugt. Allerdings kommt füreine einfache Zahl spätestens, wenn eine dynamische Bibliothek benutzt wird, der Export aus der dll oder so-Dateials Kostenfaktor ins Spiel.
Auch die folgende Lösung scheut keinen Aufwand, diesmal mit templates:1 // pi1.cpp
2 #include <iostream >
3
4 template < class T >
5 struct MathStruct
6 {
7 static long double const pil;
75

76 11. PROBLEMFÄLLE VON C++
8 };
9
10 template < class T >
11 long double const MathStruct <T>::pil = 3.14159265358979323846L;
12
13 using Math = MathStruct <void >;
14
15 int main(int argc , char* argv [])
16 {
17 std::cout << Math::pil;
18 }
Man kann π auch berechnen. Das scheint bei allen Schwierigkeiten die sauberste Lösung zu sein:
long double pi () { return 4 * atanl (1); }
Nur muss jetzt jede Verwendung von π berechnet werden. 2017 benötigte die Berechnung auf einerIntel Xeon CPU E5-2680 v2 @ 2.80GHz 136 Takte (gemessen mit qd_timer.cpp aus der qd-package). Das istsehr viel Zeit für eine Zahl.
Seit C++11 kann der Compiler diese Berechnung während der Compilation erledigen:
constexpr double pif() { return 4 * atanf(1); }
constexpr double pi() { return 4 * atan(1); }
constexpr double pil() { return 4 * atanl(1); }
Da C++ Überladungen nur an den Funktionsargumenten und niemals am Funktionsresultat unterscheidet, brauchtman die drei Namensvarianten.
Ob ein Template wirklich einfacher ist, entscheiden Sie selbst:1 // pi.cpp
2 #include <iostream >
3 #include <cmath >
4
5 template <typename T>
6 T atn (T x) { return atanl (x); }
7
8 template <>
9 double atn <double > (double x) { return atan (x); }
10
11 template <>
12 float atn <float > (float x) { return atanf (x); }
13
14 template <typename T>
15 T pi () { return 4 * atn <T> (1); }
16
17 int main(int argc , char* argv [])
18 {
19 float d = 2;
20 std::cout << pi <float >();
21 std::cout << pi <double >();
22 std::cout << pi <long double >();
23 }
Seit C++14 gibt es Template-Variable:1 // templ1.cpp
2
3 #include <iostream >
4 #include <iomanip >
5 #include <string >
6 #include <complex >
7
8 template <typename T>

3. NICHT GARANTIERTER DTOR-AUFRUF 77
9 constexpr T pi = T(3.1415926535897932385L);
10
11 int main ()
12 {
13 std::cout << std:: setprecision (20) << pi <float > << std::endl;
14 std::cout << std:: setprecision (20) << pi <double > << std::endl;
15 std::cout << std:: setprecision (20) << pi <long double > << std::endl;
16 }
Schlieÿlich kennt C++ ja auch noch inline:
inline long double pi() { return 3.14159265358979323846L; }
Die Boost-Library enthält nebenbei bemerkt π � auch hier mit templates:
#include <boost/math/constants.hpp> long double pi = boost::math::constants::pi<long double>();
Zusammenfassung: Viele Fragen bei einem trivialen Problem!
2. Reell und ganzzahlig
Im letzten Abschnitt wurde schon die unterschiedliche Behandlung reeller und ganzzahliger Typen angeschnit-ten. Für ganzzahlige Konstante stehen neben den oben diskutierten die folgenden drei einfachen Methoden zurVerfügung:
#define max 1000
enum typname { max=1000, };
int const max = 1000;
Die enum-Variante ist eine garantierte Compilezeit-Konstante; die const-Variante hat nicht die vorher diskutiertenNachteile der reellen Variante. Reelle enum-Werte existieren nicht.
3. Nicht garantierter dtor-Aufruf
1 void SomeMethod ()
2 {
3 ClassA *a = new ClassA;
4 SomeOtherMethod (); // it can throw an exception
5 delete a;
6 }
1 void SomeMethod ()
2 {
3 std::auto_ptr <ClassA > a(new ClassA); // deprecated , please check the text
4 SomeOtherMethod (); // it can throw an exception
5 }
1 #include <iostream >
2 #include <memory >
3
4 struct Foo {
5 Foo() { std::cout << "Foo::Foo\n"; }
6 ~Foo() { std::cout << "Foo ::~Foo\n"; }
7 void bar() { std::cout << "Foo::bar\n"; }
8 };
9
10 void f(const Foo &foo)
11 {
12 std::cout << "f(const Foo&)\n";
13 }
14
15 int main()
16 {

78 11. PROBLEMFÄLLE VON C++
17 std::unique_ptr <Foo > p1(new Foo); // p1 owns Foo
18 if (p1) p1->bar();
19
20 {
21 std::unique_ptr <Foo > p2(std::move(p1)); // now p2 owns Foo
22 f(*p2);
23
24 p1 = std::move(p2); // ownership returns to p1
25 std::cout << "destroying p2...\n";
26 }
27
28 if (p1) p1->bar();
29
30 // Foo instance is destroyed when p1 goes out of scope
31 }
4. scope resolution operator
Der scope resolution operator :: hat mehrere Funktionen:
1. als unärer Operator sucht er einen globalen Namen. ::i ist immer eine globale Gröÿe, hier wahrscheinlich dieglobale Variable i. So etwas verwenden Sie doch ho�entlich niemals!
2. als binärer Operator ordnet er einen Namen einer Klasse, einem Namespace oder einer Enumeration zu. Daskann in einer Verschachtelung (kaskadiert) erfolgen. Die Memberfunktion f() in der Klasse X im Namespace NS
wird in C++ geschrieben mit NS::X::f().
2.1 Ein Klassenname beschränkt die Suche nach einem Namen auf den zugehörigen Klassenscope: X::f()
2.2 Ein Namespacename beschränkt die Suche nach einem Namen auf den zugehörigen Namespace: X::f()
2.3 Ein Namespacename beschränkt die Suche nach einem Namen auf den zugehörigen Namespace: X::f()

CHAPTER 12
Überblick über die Entwicklung von C++
Übersicht:https://github.com/AnthonyCalandra/modern-cpp-features
https://www.quora.com/What-are-the-differences-between-C++11-and-C++14-C++17
Laufender Status der Standardentwicklung:
https://isocpp.org/std/status
Überblick über den Stand mehrere Compiler:
http://en.cppreference.com/w/cpp/compiler_support
Laufender Status der clang++ Compilerentwicklung:
http://clang.llvm.org/cxx_status.html
https://libcxx.llvm.org/
Laufender Status der Gnu g++ Compilerentwicklung:
https://gcc.gnu.org/projects/cxx-status.html
https://gcc.gnu.org/onlinedocs/libstdc++/manual/status.html
Laufender Status Intel icpc Compilerentwicklung:
https://software.intel.com/en-us/articles/c0x-features-supported-by-intel-c-compiler
https://software.intel.com/en-us/articles/c14-features-supported-by-intel-c-compiler
Laufender Status der Visual C++Compilerentwicklung:
https://blogs.msdn.microsoft.com/vcblog/2014/11/17/c111417-features-in-vs-2015-preview/
1. ARM
2. C++98
3. C++11
4. C++14
5. C++17
79


Inhalt
81


Contents
Chapter 1. Einführung in C++ 31. Kursübersicht 32. Designer 33. Literatur und Internet 34. Geschichte 45. Ziele und Eigenschaften 46. Compiler und Tools 47. Die Beziehungskiste von C und C++ 68. Ein erster Eindruck 89. Und ein ganz anderer Einsatz 8
Chapter 2. Prozedurale Programmierung 91. Struktur von C++-Programmen 92. Hello World 123. Datentypen, Variable und Werte 134. Rechenausdrücke 145. Anweisungen 146. Funktionen 147. Header 148. Namespaces 149. Referenzen 1510. Schriftzeichen, Strings und Unicode 1511. Ein- und Ausgabe 2312. Ergänzungen 2913. struct union enum 2914. Attribute 29
Chapter 3. Objektorientierte Programmierung 311. Kapselung 312. Operatorfunktionen 323. Beispiel: Schnitt zweier Geraden 434. Übersicht über die C++-Datentypen 435. Beispiele 44
Chapter 4. Polymorphie (Vererbung - inheritance) 471. Vererbung 472. Abstrakte Klassen 473. Mehrfachvererbung 474. Interfaces 475. Spezialthemen 49
Chapter 5. Entwurfsmuster (Design patterns) 511. UML 512. Framework 513. Strategy 514. Singleton 515. Factory 516. Klassendesign für das Newton-Verfahren 51
83

84 CONTENTS
Chapter 6. Generische Programmierung (Templates) 531. De�nition von Template-Variablen 532. Funktionen 533. Klassen 55
Chapter 7. Exceptions 571. Problemsituationen in Programmen 572. Reaktionsmöglichkeiten in Problemsituationen 573. Exceptions 574. Exception-Syntax 585. Programmverhalten 596. Exception-Beispiel 597. assert 62
Chapter 8. Reguläre Ausdrücke 631. Wahlmöglichkeiten 632. Objekte für reguläre Ausdrücke 643. Verwendung regulärer Ausdrücke 644. ICU 65
Chapter 9. Die STL von C++ 671. Zufallszahlen 672. Zufall in C++ 67
Chapter 10. Guter Programmentwurf in C++ 731. RAII 732. SOLID 73
Chapter 11. Problemfälle von C++ 751. Konstante wie π 752. Reell und ganzzahlig 773. Nicht garantierter dtor-Aufruf 774. scope resolution operator 78
Chapter 12. Überblick über die Entwicklung von C++ 791. ARM 792. C++98 793. C++11 794. C++14 795. C++17 79
Inhalt 81

CONTENTS 85
Erstellt mit LATEX und TTH:
TTH-Seite:http://hutchinson.belmont.ma.us/tth/
https://www.ctan.org/texarchive/support/tth/dist





























