Embed Size (px)
Citation preview

INLINING JAVA NATIVE CALLS AT RUNTIME
by
Levon S. Stepanian
A thesis submitted in conformity with the requirementsfor the degree of Masters of Science
Graduate Department of Computer ScienceUniversity of Toronto
Copyright c© 2005 by Levon S. Stepanian

Abstract
Inlining Java Native Calls at Runtime
Levon S. Stepanian
Masters of Science
Graduate Department of Computer Science
University of Toronto
2005
Despite the overheads associated with the Java Native Interface (JNI), its opaque and binary-
compatible nature make it the preferred interoperability mechanism for Java applications that
use legacy, high-performance and architecture-dependent native code.
This thesis addresses the performance issues associated with the JNI by providing a strategy
that transforms JNI callbacks into semantically equivalent but significantly cheaper operations
at runtime. In order to do so, the strategy first inlines native functions into Java applications us-
ing a Just-in-time (JIT) compiler. Native function inlining is performed by leveraging the abil-
ity to store statically-generated intermediate language alongside native binaries. Once inlined,
transformed native code can be further optimized due to the availability of runtime information
to the JIT compiler.
Preliminary evaluations on a prototype implementation of our strategy show that it can sub-
stantially reduce the overhead of performing native calls and JNI callbacks, while preserving
the opaque and binary-compatible characteristics of the JNI.
ii

Dedication
Jack, Maggy and Hovan,
Rose and Eugenie,
Saro, Christian, Krikor, Sabine, Vicky, Paul and Corine
Paul Gries,
and all those who have helped me along the way
your names go unmentioned but unforgotten
iii

Acknowledgements
I should start off by thanking Angela Demke Brown for taking me under her wings and
being my mentor and an incredible supervisor. Thank you for providing me with support and
guidance, but most importantly, for teaching me how to become a more analytical and efficient
researcher.
Allan Kielstra, just as Angela did, made me dive head-first into my research question. I
wouldn’t be here if it wasn’t for the W-Code conversion mechanism he masterminded, and of
course, the patience he showed with my sometimes inept if not aloof modes of inquiry.
I’d like to thank Kevin Stoodley for the idea that inspired this work, his unrelenting support
through it all, and his help in speeding up the otherwise nauseating patent filing process.
Many thanks go not only to Kelly Lyons and Marin Litoiu and IBM’s Centers For Advanced
Studies for providing me with an impeccable working environment, but to the countless TR JIT
and J9 engineers that steered me in the right direction.
To the guys and gals in syslab - despite being away most of the time, I’ll never forget the
times we shared. Best of luck in the future and hopefully our paths cross again.
And last but certainly not least, my parents. You are the reason why I am here today,
standing proud, fearless and humble in this beautiful world.
iv

Contents
1 Introduction 1
1.1 Java and the JNI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2.1 JNI Performance Issues . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2.2 Pervasiveness of the JNI . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.3 Approach and Challenges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.4 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Design 12
2.1 Assumptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2 Requirements of an IL Conversion Mechanism . . . . . . . . . . . . . . . . . 13
2.3 Inlining Native Calls . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3.1 Enhancements to a Java JIT Compiler’s Inliner . . . . . . . . . . . . . 14
2.4 Optimizing JNI Callbacks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4.1 Identifying Inlined JNI Callbacks . . . . . . . . . . . . . . . . . . . . 16
2.4.2 JNI Argument Use/Def Analysis . . . . . . . . . . . . . . . . . . . . . 18
2.4.3 Callback Transformations . . . . . . . . . . . . . . . . . . . . . . . . 19
2.5 Other Callback Transformations . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.6 Design Concerns . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.6.1 Synthesizing Opaque Calls . . . . . . . . . . . . . . . . . . . . . . . . 22
v

2.6.2 Shared Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.7 Design Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3 Tools 25
3.1 The TR JIT Compiler and J9 virtual machine . . . . . . . . . . . . . . . . . . 25
3.1.1 Inlining in the TR JIT compiler . . . . . . . . . . . . . . . . . . . . . 27
3.2 TR Intermediate Language . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.3 W-Code and The IL Conversion Mechanism . . . . . . . . . . . . . . . . . . . 28
4 Implementation 31
4.1 General Modifications to the TR JIT Compiler . . . . . . . . . . . . . . . . . . 31
4.2 Modifications to the TR JIT Compiler’s Inliner . . . . . . . . . . . . . . . . . 32
4.3 Introducing the Inlined CallHandlers . . . . . . . . . . . . . . . . . . . . . . . 32
4.3.1 The JNICallHandler . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.3.2 The ExternalCallHandler . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.4 Changes to the TR JIT Code Generator . . . . . . . . . . . . . . . . . . . . . . 38
4.5 Current Status . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5 Results and Analysis 40
5.1 Experimental Platform . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.2 W-Code Conversion Costs . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.3 Native Inlining Benefits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.4 Callback Transformation Benefits . . . . . . . . . . . . . . . . . . . . . . . . 44
5.5 Eliminating Data-Copy Costs . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.6 Optimizing Inlined Native Code . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.7 Synthesis Decisions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
6 Related Work 55
6.1 Alternative Language Interoperability Frameworks . . . . . . . . . . . . . . . 55
vi

6.2 Programmer-Based Optimizations . . . . . . . . . . . . . . . . . . . . . . . . 56
6.3 Restricting Functionality in Native Code . . . . . . . . . . . . . . . . . . . . . 56
6.4 Proprietary Native Interfaces . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
6.5 Unmanaged Memory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6.6 Optimizing the JNI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
6.7 Compiler IL as Runtime Program Data . . . . . . . . . . . . . . . . . . . . . . 61
7 Conclusions 62
7.1 Engineering Issues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
7.2 Performance Issues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
7.3 Future Directions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
7.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
Appendix 67
Bibliography 73
vii

List of Tables
4.1 Current support for callbacks and external function calls . . . . . . . . . . . . 39
5.1 Microbenchmark runtimes and improvements with native inlining . . . . . . . 44
5.2 Microbenchmark runtimes and improvements with native inlining and callback
transformations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.3 Moving data from Java to C - improvements with native inlining and callback
transformations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.4 hash: Performance improvements with other JIT compiler optimizations . . . . 49
5.5 GetArrayLength: Improvements with native inlining and callback trans-
formations and other JIT compiler optimizations . . . . . . . . . . . . . . . . . 51
5.6 Synthesizing calls to opaque functions . . . . . . . . . . . . . . . . . . . . . . 53
A.1 Cost of W-Code to TR-IL conversion for SPEC CINT2000 benchmarks . . . . 68
A.2 Raw timing measurements for Table 5.1 . . . . . . . . . . . . . . . . . . . . . 69
A.3 Raw timing measurements for Table 5.2 . . . . . . . . . . . . . . . . . . . . . 71
A.4 Raw timing measurements for Table 5.3 and Figure 5.2 . . . . . . . . . . . . . 72
A.5 Raw timing measurements for Table 5.4 and Figure 5.3 . . . . . . . . . . . . . 74
A.6 Raw timing measurements for Table 5.5 . . . . . . . . . . . . . . . . . . . . . 74
A.7 Raw timing measurements for Table 5.6 . . . . . . . . . . . . . . . . . . . . . 75
viii

List of Figures
1.1 Interactions between Java and non-Java (native) code . . . . . . . . . . . . . . 3
1.2 The JNIEnv pointer (JNIEnv *) . . . . . . . . . . . . . . . . . . . . . . . 4
2.1 The native function inlining process . . . . . . . . . . . . . . . . . . . . . . . 15
2.2 Sample inlined native code before callback transformations . . . . . . . . . . . 21
2.3 Sample inlined native code after callback transformations . . . . . . . . . . . . 21
2.4 Synthesizing opaque function calls . . . . . . . . . . . . . . . . . . . . . . . . 23
3.1 The TR JIT compiler’s architecture . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2 Sample TR-IL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.3 The IL conversion process . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.1 The TR inliner: Handling native functions . . . . . . . . . . . . . . . . . . . . 33
4.2 The Inlined Call Handler class hierarchy . . . . . . . . . . . . . . . . . . . . . 34
4.3 Pseudocode for JNICallHandler::transformCalls . . . . . . . . . . 36
4.4 Pseudocode for JNICallHandler::synthesize . . . . . . . . . . . . . 37
5.1 Cost of W-Code to TR-IL conversion for SPEC CINT2000 benchmarks . . . . 42
5.2 Moving data from Java to C - a graphical representation of the improvements
with native inlining and callback transformations . . . . . . . . . . . . . . . . 48
5.3 Exposing inlined native code to other JIT optimizations . . . . . . . . . . . . . 51
ix

Chapter 1
Introduction
Currently, there is no single programming language that is universally suitable for all tasks, nor
is one likely to emerge. Rather than focusing on a one-size-fits-all approach to programming
language design, support for language interoperability is the preferred solution. In addition to
allowing programmers to choose the right tool for the job, interoperability allows the reuse of
legacy applications and libraries that may have been written in a different language.
Most high-level languages support interoperability by providing some mechanism for call-
ing code written in a low-level language (such as C). These mechanisms typically impose both
time and space overheads at each cross-language function invocation because arguments and
results must be packaged carefully to bridge the boundary between the languages involved.
In this thesis, we focus on optimizing the Java Native Interface (JNI) [28], the interoper-
ability interface used by the JavaTM programming language [21]. Our goal is to reduce the
space and time overheads involved in crossings between Java and non-Java (native) program-
ming languages. We do this by providing a Just-in-time (JIT) compiler optimization that inlines
compiled native code into compiled Java code at runtime. Our strategy also performs optimiz-
ing transformations on inlined JNI function calls, and allows the JIT compiler to perform other
optimizations on inlined native code.
The rest of this chapter provides background information and the motivation behind our
1

CHAPTER 1. INTRODUCTION 2
work. It also summarizes our approach and the challenges we encounter, and concludes with a
description of our research contributions.
1.1 Java and the JNI
Java is a high-level programming language that features object-orientation, platform indepen-
dence and type safety, as well as automatic memory management via garbage collection. These
and other characteristics have led to its widespread adoption in many settings.
The JNI is Java’s interoperability mechanism. It is a two-way application programming
interface (API) that provides interoperability at the function-level, permitting Java programs
to invoke functions written in native languages (which we refer to as callouts), at the same
time allowing native programs to access and modify data and services from an executing Java
virtual machine (JVM) (performed via functions which we refer to as callbacks).
Generally speaking, callouts provide Java applications with the ability to leverage legacy,
high-performance and architecture-dependent native code. Callbacks, on the other hand, pro-
vide native code with access to JVM managed objects (i.e., strings and arrays) and perform a
host of other operations including reference management, exception handling, synchronization
and reflection, as well as JVM instantiation and invocation. The latter feature can be used to
embed a JVM implementation into a native application in order to execute software written in
Java. Figure 1.1 demonstrates the interactions between a Java program, a JVM and its JNI im-
plementation, native code and a host architecture. Host architecture refers to a host operating
system, a set of native libraries and the host CPU instruction set.
Native code performs callbacks by calling JNI functions, which are made accessible by the
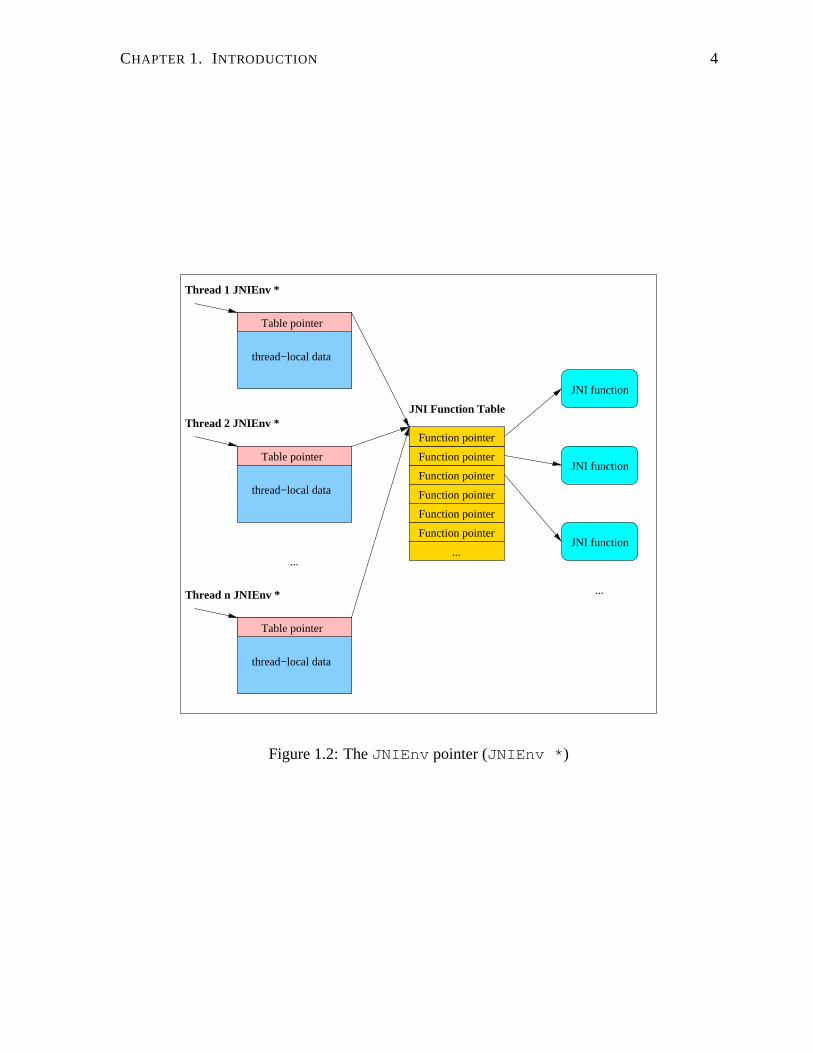
JNIEnv pointer that is passed as the first argument to every Java native function. As depicted
in Figure 1.2, each Java thread that invokes a native function receives its own JNIEnv pointer
containing thread−local data, as well as a pointer to a table of JNI function pointers. The two
levels of pointer indirection allow native code to link to any JVM implementation, and provides

CHAPTER 1. INTRODUCTION 3
Callout
Callback
ArchitectureHost
JNIJVM
JavaApplication
NativeBinary
Figure 1.1: Interactions between Java and non-Java (native) code
the JVM implementor with the flexibility of choosing between different function tables, as well
as different function implementations at runtime.
The JNI is designed to provide opaque access to JVM internals, by hiding JVM data struc-
tures and the binary layouts of heap-allocated objects. It is also binary-compatible, allowing
programmers to address interoperability issues once, and expect their software solutions to
function with all implementations of the Java platform (for a particular host environment).
We recognize that there exist alternative ways to introduce native code to a Java application.
Some of the alternatives separate Java applications and native code into separate processes
thereby exacerbating interoperability overheads. Others tightly couple JVMs and native code,
reducing overheads, but breaking the binary compatibility property essential to the JNI. A full
discussion of such alternatives is provided in Chapter 6.
We also acknowledge the fact that JNI-dependent Java code breaks the compile-once, run-
anywhere paradigm that has made Java the programming language of choice. Furthermore,
we recognize that JNI-dependent Java programs are limited by the type-unsafe nature of the
very native code they incorporate. Our work, however, mitigates this by implicitly performing
CHAPTER 1. INTRODUCTION 4
Thread 2 JNIEnv *
Thread 1 JNIEnv *
JNI Function Table
...
Function pointer
...
Thread n JNIEnv * ...
JNI function
JNI function
JNI function
Table pointer
thread−local data
Table pointer
thread−local data
Function pointer
Function pointer
Function pointer
Function pointer
Function pointer
Table pointer
thread−local data
Figure 1.2: The JNIEnv pointer (JNIEnv *)

CHAPTER 1. INTRODUCTION 5
runtime checks on inlined native code.
Having said this, we now examine the performance aspects of the JNI which our work
addresses.
1.2 Motivation
Our work is motivated by interoperability space and time overheads that afflict Java applica-
tions containing native function calls. We are also motivated by the JNI’s pervasive nature.
Since the JNI is used in a large number of applications, we believe any runtime benefit that
results from minimizing Java interoperability overheads will have a widespread effect.
1.2.1 JNI Performance Issues
The JNI’s strength lies in decoupling native code from a specific JVM implementation by pro-
viding opaque access to JVM internals, data, and services. The cost of this property is lost
efficiency, namely large runtime overheads during callouts to native functions, and even larger
ones during callbacks to access Java code and data. Furthermore, JIT compilers are not able
to perform aggressive optimizations on Java code containing native function calls because they
are forced to make pessimistic assumptions about the side-effects of these opaque calls.
Callout Overheads
Generally speaking, the traditional costs associated with a function call include setting up an
activation record, branching to the callee, branching on return and restoring the call stack. Java
callouts are very similar to traditional function calls, but bear a number of unique overheads:
• A native library containing the function called by a Java application must be loaded on
or before the function’s first invocation. The class containing the native call, as well
as the call itself must be resolved (resolution may require multiple passes over the ex-
ported functions of a native library). These are one-time costs that can be amortized if a

CHAPTER 1. INTRODUCTION 6
particular native function is invoked repeatedly.
• During each individual native function invocation, the JVM must also set up the native
stack (and possibly registers) to copy primitive-typed arguments, and add a layer of indi-
rection to passed reference arguments. There also exist JVM handshaking requirements
that must be met by each Java thread leaving the JVM’s context and entering a native
context, including handshaking for garbage collection and synchronization.
• Upon returning from native code, the return value must be pushed onto the Java stack
and the native stack must be restored. In addition, handshaking requirements for Java
threads re-entering the JVM context, which might include checking exception statuses
and garbage collecting local references created by native code, must be met. JVMs
with Just-in-time (JIT) compilers, however, may reduce these overheads by generating
specialized code segments to perform the required work at native call sites, as is done
in the IntelTM Open Runtime Platform [12] and in the IBM JIT compiler which we use
for our work. These code segments are further discussed in Section 4.4 and Chapter 6
respectively.
Sunderam and Kurzinyec [41] have studied the performance of different types of native calls
using different JVM implementations. The slowdowns they report when using native functions
range from a factor of 1.05 to a factor of 16 in the worst case. Similar results are produced in
overhead-measuring experiments performed by Murray et al. [32]. Liang [28] also reports a
factor of three slowdown when comparing native function calls to regular Java function calls.
Callback Overheads
Although callouts are reasonably expensive, the more significant source of overhead occurs
when native code invokes JNI callbacks. As described earlier, JNI functions are only callable
through a reference to the JNIEnv pointer. A callback thus pays an immediate performance

CHAPTER 1. INTRODUCTION 7
penalty because two levels of indirection¶ are used - one to obtain the appropriate function
pointer through the JNIEnv pointer, and one to invoke the function using that pointer. Other,
more specific callback overheads depend on the JNI function being called:
• Heap-allocated native function parameters - To make use of certain JVM heap-allocated
objects that are passed to native code as arguments (i.e., strings and arrays), native code
must first acquire access to them. Unfortunately, JVMs with garbage collectors that do
not support object pinning must perform expensive runtime copy operations to first pro-
vide native code with its own copy of the objects, and then to later update the JVM heap
with modifications to the copied objects. The JNI, however, also provides callbacks that
claim to increase the chances of receiving direct references to heap-allocated data, but
supporting such callbacks is left to the JVM’s discretion and also places certain restric-
tions on the programmer’s freedom. Because JVMs may implement these callbacks in
any way they choose, there is no guarantee that better performance will actually result
from their use. Sunderam and Kurzinyec [41] demonstrate that the achieved performance
for these types of callbacks varies widely across different JVM implementations.
• Fields and methods - Using Java data types, modifying object data, calling methods
and accessing JVM services from native code are also performed via callbacks. Reading
or modifying an instance or static field, as well as calling an instance or static function
first requires retrieving a handle to it and then performing the required operation via an-
other callback. Handle retrieval is commonly implemented as a traversal on the JVM’s
reflective data structures, in addition to expensive string-based signature comparison op-
erations performed at runtime [9]. Results in [41] highlight these callback overheads.
For example, field accesses in Java are orders of magnitude faster than those via the JNI.
Other JNI callbacks (such as those dealing with reference management, exception handling,
synchronization, reflection and JVM instantiation and invocation) share costs similar to those
¶Only one level of indirection is required for C++ native functions.

CHAPTER 1. INTRODUCTION 8
of field and method access callbacks, but have their own unique set of overheads. Liang [28]
recognizes the inability of JVMs to optimize callbacks, and hypothesizes that the overhead of
any callback can be as much as an order of magnitude greater than a normal Java function call.
Furthermore, callbacks also perform JVM handshaking (since callbacks require Java threads
to re-enter and then exit the JVM’s context), and may sometimes block if the JVM is in the
midst of performing a blocking task (such as garbage collection). The latter is dependent on
the specific JVM implementation and lies outside the scope of the JNI specification.
1.2.2 Pervasiveness of the JNI
What makes JNI overheads more troubling is the fact that there is widespread adoption and
usage of Java applications that depend on the JNI for functionality. We are concerned by the
high overheads associated with the JNI, especially since a prime motivator for using it in Java
applications is to access high-performance native code. Performance critical routines can be
written in low-level native code, and incorporated into Java applications by wrapping them
as Java native functions. More specifically, the JNI has been used in I/O implementations
to improve the performance of object serialization for distributed computing [11], to provide
bindings for low-level parallel computing libraries [4, 19], and to implement high-speed net-
work interfaces [42].
Bik and Gannon [7] make strong arguments in favor of implementing numerical routines
as Java native functions, and despite improvements in pure Java numerical libraries, interfaces
to widely-used but platform-dependent optimized native linear algebra packages are still being
developed [23].
Besides performance-critical routines, the JNI is also used to implement features that are
not available in Java. The graphical components of Java-based user interface libraries, in-
cluding the Standard Widgets Toolkit [34] and the Abstract Window Toolkit [39], as well as
other Java-based multimedia APIs [31] rely on the JNI to make use of underlying architecture
functionality. Native code is also used to compensate for other functionality unavailable in

CHAPTER 1. INTRODUCTION 9
Java, including low-level hardware performance measuring tools [37], and accurate timers and
system resource monitors [5].
The JNI has also been used to implement various JVM frameworks and APIs, such as the
Java 5.0 class libraries, the reflective, Java-based OpenJIT compiler from Ogawa et al. [35] and
the MicrosoftTM Marmot JVM’s class libraries [17].
Java applications also use the JNI as a software engineering tool to leverage and utilize
functionality provided by large sets of legacy code. Without the JNI, this code would have
to be re-written and re-engineered using the Java programming language if they were to be
incorporated into Java applications. Liang [28] devotes an entire chapter of the JNI specifica-
tion to techniques one might use when “wrapping” native functions for integration with Java
applications.
Having provided the background and motivation behind our work, we provide a description
of a strategy that reduces the callout and callback overheads experienced by JNI-dependent Java
applications.
1.3 Approach and Challenges
This thesis describes the design, implementation and evaluation of a strategy that inlines com-
piled native code into compiled Java code, thereby removing function call and return overheads.
More specifically, our strategy inlines native calls performed by Java applications at runtime,
and also performs optimizing transformations on inlined JNI callbacks, further improving the
performance of inlined native code.
We have implemented a prototype of this native function inlining strategy inside a production-
quality Java JIT optimizing compiler. Our proof-of-concept implementation operates as part
of the JIT compiler’s runtime optimization strategy, and utilizes an intermediate language (IL)
conversion mechanism to translate native code to JIT compiler IL during inlining. Our strategy
reduces JNI overheads while maintaining the JNI’s opaque and binary compatible nature.

CHAPTER 1. INTRODUCTION 10
Once native code has been inlined, the JIT compiler can also remove pessimistic assump-
tions it may have maintained about opaque native function calls, and performs aggressive run-
time optimizations on inlined native code.
As with any runtime optimization, we wish to amortize the cost of performing the opti-
mization by obtaining significant benefits from native function inlining and callback transfor-
mations. Our inlining strategy, however, must also deal with native code that is non-inlineable
and callbacks that are non-transformable. Furthermore, it must provide correct linkages for
program data that is shared between Java and native code as a byproduct of inlining, and most
importantly, it should enforce both native language and JNI semantics on all inlined and opti-
mized code.
1.4 Contributions
Our research contribution is a JIT compiler based native function inlining and optimizing call-
back transformation framework that reduces JNI overheads, and makes Java a more attractive
solution for cross-language application and system development.
Our implementation shows significant performance increases from inlining native code and
optimizing JNI callbacks for simple microbenchmarks. In spite of the prototypical-nature of
our work, we expect these benefits to translate into performance improvements in real applica-
tions that make extensive use of the JNI.
To be more specific, our contribution includes methods that:
• identify native function calls in a JIT compiler’s IL
• convert the statically generated and optimized IL of a native function to a JIT compiler’s
IL at runtime (while preserving the semantics of the native programming language)
• inline native function calls at runtime
• identify JNI function calls in a JIT compiler’s IL

CHAPTER 1. INTRODUCTION 11
• transform JNI function calls to JIT compile-time constants
• transform JNI function calls to cheaper but semantically equivalent operations
• handle non-inlineable function calls found in inlined native code
• share data between inlined and non-inlined native code
In essence, our work can be viewed as a first step to provide a framework that transmutes
statically compiled code to dynamic environments where runtime information guides optimiza-
tions that are otherwise not profitable or possible to perform statically.
The rest of this thesis is organized as follows: Chapter 2 details a complete JIT compiler
native inlining and callback transformation design. Chapter 3 describes the software tools we
use for our implementation. Chapter 4 describes our implementation. We verify our hypothesis
and contributions by showcasing our experimental results in Chapter 5. Chapter 6 compares
our work to others in the field. Finally, we conclude by discussing limitations and future work
in Chapter 7.

Chapter 2
Design
Given the extensive use of the JNI in existing applications, we believe JNI performance penal-
ties must be addressed directly, rather than by introducing changes to the interface, or intro-
ducing a new interoperability mechanism for Java. Furthermore, since high-performance JVMs
include JIT compilers, we believe it is appropriate to leverage JIT optimizations to reduce the
overheads incurred as a result of using the JNI for interoperability. Instead of simply generat-
ing efficient code to perform the extra work required at JNI invocation points, however, we aim
to eliminate this extra work entirely.
Our approach is to extend a JIT compiler’s function inlining optimization to handle native
function calls. Once native code has been inlined at its callsite in a Java program, it is no longer
necessary to set up and tear down a native stack, or perform other expensive operations to pass
arguments. More importantly, the callbacks, designed to gain access to internal JVM state, can
now be transformed into JIT compile-time constants or lightweight Bytecodes that preserve the
semantics of the original source program and the JNI.
Our native inlining design consists of three phases: The first phase requires the inliner to
convert native code to a representation understood by the JIT compiler. This permits the in-
lining of native code and the elimination of the overheads associated with making callouts.
The second phase performs optimizing transformations on inlined JNI callbacks, thereby elim-
12

CHAPTER 2. DESIGN 13
inating much of the overhead associated with performing JNI function calls in native code.
The final phase processes and fixes up inlined function calls that are not amenable to inlining,
thereby making our design robust. The following is a description of our design assumptions
and each design phase in more detail.
2.1 Assumptions
Our design assumes the existence of:
1. an optimizing Java JIT compiler that can perform Java function inlining
2. an intermediate language (IL) conversion mechanism that can perform a one-way map-
ping from statements in the compiler IL of a native language to the IL of the Java JIT
compiler mentioned in 1
The availability of a JIT compiler is a reasonable assumption to make since there are many
open-source JIT compilers available for academic research purposes. Our assumption of the
existence of an IL conversion mechanism might seem unusual at first, but is also reasonable
because it is part of the tool-set we have decided to use for implementation. Chapter 3 provides
a description of the actual JIT compiler and IL conversion mechanism used in our proof-of-
concept implementation.
2.2 Requirements of an IL Conversion Mechanism
Instead of using source-code text or low-level assembly instructions as a representation of
native code, our design uses the IL generated by a compiler for the native language. Using
source code text would require translating from a source language to a target language, making
sure that the semantics of the source language are captured in the target language. Due to
significant syntax and semantical differences between most programming languages, this might

CHAPTER 2. DESIGN 14
require substantial additions or modifications to the target language. Representing native code
in low-level assembly has the advantage of being a small, tightly-packed representation, but
suffers from being architecture-dependent.
Our choice in using the IL generated by a compiler as a representation of native code pro-
vides us with the right amount of abstraction between a high-level and low-level representation.
Furthermore, the IL representation encodes static optimizations that are performed by a native
compiler. Our only requirements from the IL conversion mechanism is that it should perform a
mapping of statements from native IL to the JIT compiler’s IL, and maintain correct semantic
information about the native code.
2.3 Inlining Native Calls
Our design for native function inlining consists of two major components, the first of which
is the already described IL conversion. The second component is an extension to the assumed
Java JIT compiler’s function inliner, permitting it to inline native functions.
2.3.1 Enhancements to a Java JIT Compiler’s Inliner
Upon successful native to JIT compiler IL conversion for a Java-callable native function, the
JIT inliner inlines the IL and recursively inlines function calls that are inlined. The inliner
considers non-Java callable native functions as potential inlineable candidates as well (i.e.,
native calls by native code).
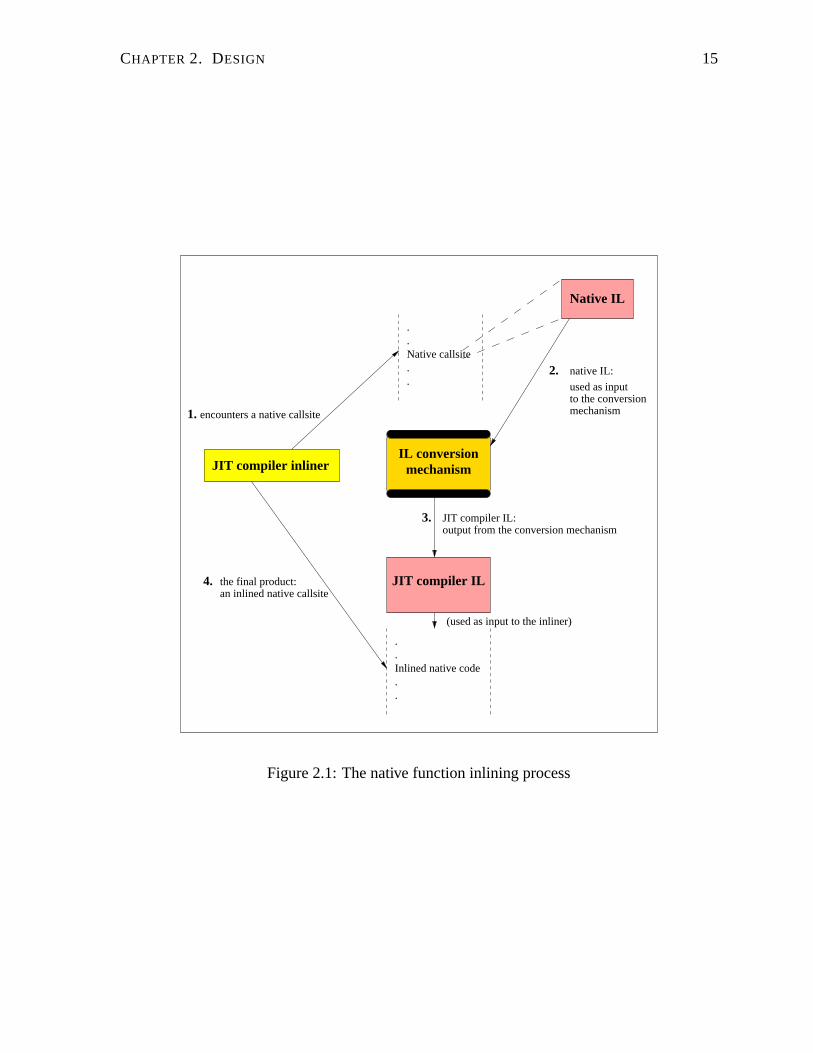
Figure 2.1 depicts this process for a terminal native function (i.e., one containing no other
function calls): Upon (1) encountering a native callsite, the JIT inliner (2) feeds the native IL
to the IL conversion mechanism which then (3) generates JIT IL for the native method. The
inliner finishes (4) by producing an inlined native callsite using the converted IL. Inlined native
methods clearly execute in a Java context, therefore, the code must be conditioned to interact
with all appropriate JVM requirements. In particular, instructions to perform handshaking with
CHAPTER 2. DESIGN 15
JIT compiler IL:3.
IL conversionJIT compiler inliner
Native IL
.
.Inlined native code..
.
.Native callsite..
mechanism
JIT compiler IL
(used as input to the inliner)
encounters a native callsite1.
2. native IL:
used as inputto the conversionmechanism
output from the conversion mechanism
an inlined native callsitethe final product:4.
Figure 2.1: The native function inlining process

CHAPTER 2. DESIGN 16
JVM components such as garbage collection, as well as exception handling are inserted at the
appropriate locations in the inlined native code.
The IL for a native method cannot, in most cases, proceed directly through the rest of JIT
compiler processing. This is because it may contain “opaque” calls to non Java-callable native
functions. Such “opaque” calls occur in two situations: (1) calls through function pointers, and
(2) calls to functions in binaries where native IL is unavailable. Both situations require special
handling and we defer discussing them until Section 2.6.1.
The inliner recursively inlines functions called by a Java-callable native method until it
either encounters a call to an “opaque” function or a termination condition (e.g., a maximum
inlined code size limit) is reached. The inliner then continues with normal JIT compiler pro-
cessing only after it has performed optimizing callback transformations and satisfied require-
ments for inlined “opaques”, as described in the following sections.
2.4 Optimizing JNI Callbacks
The native inlining process is extended by callback transformations that optimize inlined JNI
function calls. Inlined native code executes in the JVM’s context, thus there is no need for the
JNIEnv pointer and the JNI function pointer table to obtain access to internal JVM services
and data. Once the native inlining technique has converted native IL to the JIT compiler’s IL, it
performs two tasks to transform callbacks. These tasks include identifying callbacks and per-
forming JNI argument use/def analysis. Whenever possible, inlined callbacks are transformed
into compile-time constants, and new semantically equivalent JIT compiler IL that represents
faster, more direct access to JVM services and data.
2.4.1 Identifying Inlined JNI Callbacks
The first step in transforming inlined callbacks is to identify them in the converted IL. The
JIT compiler’s IL makes it hard to distinguish a JNI callback from an arbitrary function call

CHAPTER 2. DESIGN 17
via a pointer. For this reason, our technique scans the generated IL for sequences of IL state-
ments that constitute function calls via pointers, and then attempts to match them against a
well known set of pre-constructed IL shapes (i.e., sequences of IL statements) that represent
JNI callbacks. In order to construct the set of well known IL shapes, we require a preliminary
step that renders each callback defined by the JNI API in terms of the JIT compiler’s IL.
Building JNI Callback Shapes
As part of identifying JNI callbacks, the JIT compiler needs to understand the expected “shape”
of each JNI callback as it scans the inlined IL looking for statements representing JNI callbacks.
The shape encodes how each callback uses the JNIEnv pointer and other arguments, thereby
uniquely identifying a callback. The JIT compiler uses a set of well known pre-constructed
shapes for subsequent analysis (and avoids recursively inlining callbacks).
Pre-constructing these shapes can be performed in a variety of ways, including:
• dynamically performed at the start of a Java program execution
• performed as part of the process of building the JIT compiler itself
• statically performed by encoding each callback’s shape in the compiler
The only requirement is that the IL used to pre-construct IL shapes must be correct for both the
current version of the JIT compiler (where the IL definition may change over time) and for the
JVM being targeted (because each JVM is free to define how the JNI specification is actually
implemented).
Pattern Matching JNI Callbacks
When a native function is inlined, care is taken to record uses of the JNIEnv pointer within
the IL. Recursive inlining is expected and the JNIEnv pointer may be passed to recursively in-
lined functions. However, before recursive inlining, the IL representing the callsite is examined
as follows:

CHAPTER 2. DESIGN 18
1. If the JNIEnv pointer is used in the same position in the IL as it appears in any of
the pre-constructed shapes, the inliner proceeds to Step 2. Otherwise, inlining continues
normally.
2. For each pre-constructed shape in which the JNIEnv pointer appears in the same posi-
tion as it does in the IL for an inlined callsite under consideration, the inliner attempts to
match the entire shape to the IL for the callsite. A match occurs if the shape and the IL
share the same number and compatible types of arguments. If there is a match, the call-
site is not eligible for inlining but might be transformable. Otherwise, inlining continues
normally.
As part of Step 2, the inliner records the callsites that it has determined do correspond to
JNI callbacks and remembers them later when performing optimizing transformation on them.
Thus, the result of the transformation of the first call can be used in the transformation of later
calls.
2.4.2 JNI Argument Use/Def Analysis
Once inlined callbacks have been identified, the values and types of variables passed to them
as arguments must be deciphered in order to replace callbacks with JIT compile-time constants
or cheaper but semantically equivalent operations. A pass of JNI argument use/def analysis is
performed to track the definitions of variables to the points where they are used as arguments
to callbacks.
In general, each callback argument is represented by a set of possible objects as dictated
by the control flow in the native method. Definitions of variables include incoming argu-
ments to the native function (i.e., passed in from Java code), or results of other callbacks. For
example, the values returned by the JNI callbacks GetObjectClass, GetSuperClass,
FindClass, Get[Static]‖MethodID and Get[Static]FieldID are treated as def-
‖[Static] is shorthand notation that allows us to encode the static version of the JNI callback function as well

CHAPTER 2. DESIGN 19
initions.
When the analysis cannot conclusively determine the class that an object must be an in-
stance of, it produces sufficient information to allow the transformation phase to consider all
possible classes that the object may be an instance of. It is possible, however, that the analy-
sis is unable to compute even conditional results if, for example, arguments to a callback are
fetched from storage.
The use/def analysis also tracks literal or constant arguments to FindClass,
Get[Static]MethodID and Get[Static]FieldID and by doing so, the JIT compiler
may positively resolve some of these calls while a more naive implementation would be unable
to do so.
2.4.3 Callback Transformations
Once the identification of callbacks and JNI argument use/def analysis is complete, the proce-
dure continues by iterating over all of the identified callbacks and attempts to transform them to
compile-time constant values or new JIT compiler IL that is semantically equivalent and results
in the generation of a smaller number of CPU instructions at code generation time. Generally
speaking, callbacks that result in definitions are transformed to constants, whereas callbacks
using such definitions are transformed to cheaper IL. Using some of the same callbacks men-
tioned in the previous section, the following transformation outcomes are possible:
• If all of the possible argument definitions reaching a GetObjectClass are of the same
class, the call is replaced by an appropriate constant.
• If all possible classes reaching a Get[Static]FieldID or Get[Static]MethodID
are compatible and the string arguments can be uniquely determined, the call is replaced
by an appropriate constant
as the instance version using only one identifier

CHAPTER 2. DESIGN 20
• If all possible field ids reaching a Get[Static]<Type>‡Field or a
Put[Static]<Type>Field are the same and all possible objects reaching the call
are of compatible class types, the call is replaced by a new, simpler sequence of JIT
compiler IL. More generally, if the offset of the data member from the beginning of the
object is the same for all possible types that can reach the call, then the same code can
be used for all the objects, allowing the callback to be “strength reduced”.
• Similar transformations are performed for the various Call[Static]<Type>Method
callbacks by replacing the existing IL with new IL that makes a more direct call to the
method.
We display the complete callback transformation process using the annotated inlined native
code in Figure 2.2, which is transformed to the code in Figure 2.3.
If use/def analysis produces known but inconclusive information for any arguments to a
callback, conditional logic may be inserted along with the appropriate IL that represents the
semantics of the callback being transformed. When the transformed callback is executed, ap-
propriate behavior can be selected based on actual values. Furthermore, all transformed IL
defers throwing exceptions in accordance with the Java rules for executing native methods.
Theoretically, an optimization such as the one described here should follow uses of data
defined in terms of the JNIEnv pointer to track all possible callsites that may correspond
to JNI function calls. However, it is harmless to perform this optimization on some callsites
and decline to perform it on others. Any inlined callbacks that are not handled by the steps
above are treated as an ordinary call to an appropriate VM service routine and are described in
Section 2.6.1.
‡<Type> represents any one of Void, Object, Boolean, Byte, Char, Short, Int, Long, Float or
Double

CHAPTER 2. DESIGN 21
}
inlined_native_function(JNIEnv *env, jobject obj) {
/* inlined callbacks look like: */(A) jclass cls = (*env)−>GetObjectClass(env, obj);(B) jmethodID mid = (*env)−>GetMethodID(env, cls, "power", "(II)I"); if (mid == NULL) return;
(C) jint ret = (*env)−>CallIntMethod(env, obj, mid, 2, 2);(D) if ((*env)−>ExceptionCheck(env)) return;
/* use ret in rest of inlined function */ ...
Figure 2.2: Sample inlined native code before callback transformations
}
inlined_native_function() {
/* (A) is transformed to a compile−time constant */
/** * (B) is transformed to a compile−time constant and return * semantics are preserved by generating IL for the case where * the constant can not be generated (i.e. an invalid argument * to the callback) */
/** * (C) is replaced with IL that performs an invocation of the * power function on the object with the given constant * arguments */
/** * (D) IL is generated to check for pending exceptions, as well * as the required return statement */
/* use ret in rest of inlined function */ ...
Figure 2.3: Sample inlined native code after callback transformations

CHAPTER 2. DESIGN 22
2.5 Other Callback Transformations
In certain situations, it might be possible to do away with transforming inlined callbacks all
together. For example, if the character conventions used by the JVM and the host architecture
are the same, there is no need to transform an inlined GetStringUTFChars. Its resulting
definition can be replaced by the original Java String it was destined to copy and convert.
A favorable side-effect of inlining native code that declares and uses local references is
that inlined callbacks can potentially be eliminated by implicitly shifting responsibilities to the
JVM’s garbage collector. These include NewLocalRef, DeleteLocalRef,
PushLocalFrame and PopLocalFrame callbacks.
We exclude an exhaustive analysis of all the JNI API functions, but recognize similarities
that might exist with other callbacks.
2.6 Design Concerns
Before describing an implementation of this proposed design, we bring to light two issues
that surface when inlining native code into Java programs. The first of these are “opaque”
function calls that can not, under any circumstance, be inlined and must be dealt with in a
special manner. The second one concerns data that is accessed or modified by both inlined and
non-inlined native code.
2.6.1 Synthesizing Opaque Calls
As mentioned earlier, “opaque” calls occur in two situations:
1. calls through function pointers, and
2. calls to functions in binaries where native IL is unavailable
For example, inlined but non-transformable JNI callbacks are opaque calls through function
pointers, whereas inlined system calls are opaque calls to functions in binaries that do not have

CHAPTER 2. DESIGN 23
native function
Synthesizednative function ‘a’
Synthesizednative function ‘b’
Synthesizednative function ‘c’
a
b
c
Java function (caller)
Calls to appropriatenative implementations afterproper linkage and function
Inlined
context established
"opaque"function calls
Inlined
Figure 2.4: Synthesizing opaque function calls
IL available.
We solve this problem by performing calls to “synthesized” functions whose purpose is to
call the said opaque function after having set up the proper linkages and context to make the
call. The effect is to bridge the Java application to the previously-buried native function. This
situation is depicted in Figure 2.4. Inlining a single Java-callable native function may require
the synthesis of multiple calls to opaque functions. Inlining, however, creates the opportunity
to remove the much-higher overhead of callbacks, and reduces the need for conservative as-
sumptions about the behavior of native code in the JIT optimizer. We expect that it will often
be profitable to synthesize multiple callouts to opaques, provided callbacks can be transformed
into cheaper operations as previously discussed in Section 2.4.3.
2.6.2 Shared Data
A second design concern is the situation that arises when inlining results in data that is accessed
or modified by both inlined and non-inlined native code. We define shared data as data shared
between an inlined native function and any other native function (e.g., a synthesized native
function, another function in the same library, or a function defined somewhere else), static
data, as well as addresses of variables (automatics or parameters) that may be passed by an
inlined native to one of its synthesized calls.

CHAPTER 2. DESIGN 24
In such cases, our strategy ensures that correct linkage is used and the inlined native code
is able to read and write to the same block of memory as non-inlined functions. Furthermore,
because the resolution of addresses is performed at JIT compile-time, and the original native
function is now inlined rather than called explicitly, additional care is taken to ensure that the
dynamic loading of new libraries is handled correctly.
2.7 Design Summary
To summarize, our strategy for improving the performance of JNI-dependent Java applications
is based on inlining native function calls at runtime, and performing a number of steps that
allow for the transformation of inlined JNI callbacks to cheaper but semantically-equivalent
operations. The following chapter describes the tools we use to implement our proposed de-
sign.

Chapter 3
Tools
Our strategy for native function inlining has been prototyped and evaluated in the context of
a high-performance production JVM and JIT compiler from IBM. In this chapter, we describe
the IBM Java JIT compiler and JVM that provide the starting point of our implementation. We
also describe JNI overheads specific to the JIT compiler and JVM implementation. Following
this is a description of the JIT compiler’s IL, as well as a concrete native to JIT compiler IL
conversion mechanism that will be used in the realization of our design.
3.1 The TR JIT Compiler and J9 virtual machine
The IBM R© TR JIT compiler is a high-quality, high-performance optimizing compiler, con-
ceived and developed at the IBM Toronto Software Lab. Designed with a high level of config-
urability in mind, it supports multiple Java Virtual Machines and class library implementations,
targets many architectures, can achieve various memory footprint goals and has a wide range
of optimizations and optimization strategies.
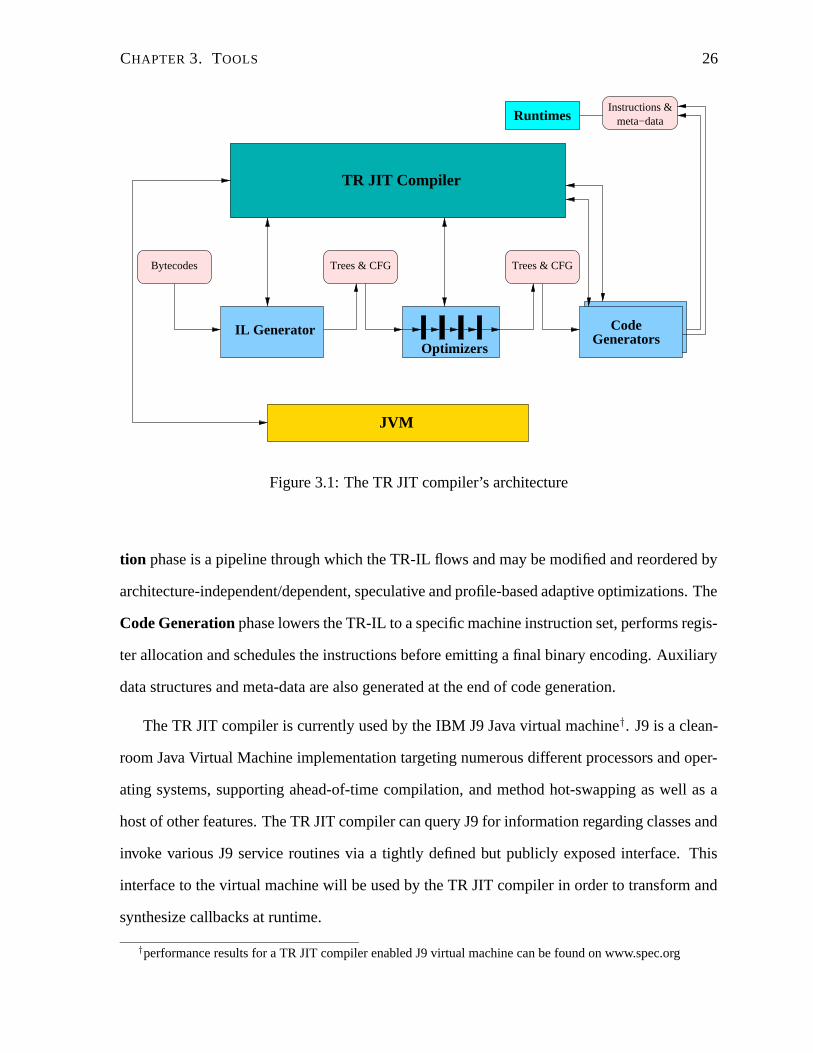
A single pass of the TR JIT compiler consists of phases for IL generation, optimization
and code generation as depicted in Figure 3.1. When compiling a method, the IL Generator
walks the method’s Bytecodes and generates tree-based JIT compiler IL (known as TR-IL)
that also encodes the control flow graph (see Section 3.2 for sample TR-IL). The Optimiza-
25
CHAPTER 3. TOOLS 26
JVM
TR JIT Compiler
IL Generator
Bytecodes Trees & CFG Trees & CFG
RuntimesInstructions &
meta−data
GeneratorsOptimizers
Code
Figure 3.1: The TR JIT compiler’s architecture
tion phase is a pipeline through which the TR-IL flows and may be modified and reordered by
architecture-independent/dependent, speculative and profile-based adaptive optimizations. The
Code Generation phase lowers the TR-IL to a specific machine instruction set, performs regis-
ter allocation and schedules the instructions before emitting a final binary encoding. Auxiliary
data structures and meta-data are also generated at the end of code generation.
The TR JIT compiler is currently used by the IBM J9 Java virtual machine†. J9 is a clean-
room Java Virtual Machine implementation targeting numerous different processors and oper-
ating systems, supporting ahead-of-time compilation, and method hot-swapping as well as a
host of other features. The TR JIT compiler can query J9 for information regarding classes and
invoke various J9 service routines via a tightly defined but publicly exposed interface. This
interface to the virtual machine will be used by the TR JIT compiler in order to transform and
synthesize callbacks at runtime.
†performance results for a TR JIT compiler enabled J9 virtual machine can be found on www.spec.org

CHAPTER 3. TOOLS 27
3.1.1 Inlining in the TR JIT compiler
The TR JIT compiler optimization we are interested in is the function inlining optimization.
This optimization reduces the overhead of function invocations by inlining entire functions at
their callsites. The primary purpose of this inlining, however, is to expose more TR-IL to the
optimizer and to eliminate pessimistic assumptions that must be made about the behaviour of
function calls. Like most inlining strategies, it uses a variety of heuristics to determine if a
given function call should be inlined. Once the decision has been made to inline a function,
the inliner generates TR-IL for the callee, and completes the process by performing all the
required transformations on both the caller and callee functions, including mapping parameters
to arguments, generating temporaries, as well as merging caller and callee IL and control flow
graphs.
TR currently handles native function invocation Bytecodes by generating code that transfers
the native call setup and tear-down work to J9, or by using a proprietary mechanism known
as Direct2JNI. Direct2JNI uses compile-time signature parsing to produce compiled glue code
tailored to perform the native call to each unique native target. We describe Direct2JNI in more
detail in Chapter 4. Independent of the type of dispatch mechanism used, Java threads leaving
the JVM context must indicate they are no longer mutators of the JVM heap. Conversely, Java
threads re-entering the JVM context must indicate they are mutators once again. Besides the
generic JNI callout and callback overheads and the JVM handshaking requirements mentioned
in Section 1.2.1, the notification mechanism is comprised of expensive CPU instructions that
can be eliminated if the originating native call is inlined.
Our implementation extends the inlining strategy in the TR JIT compiler to native function
calls. Our focus is on providing this novel functionality, rather than exploring new heuristics
that might be more suitable for native code. We thus use the existing heuristics to decide when
a native call should be inlined.

CHAPTER 3. TOOLS 28
load auto 3
load auto 2
next tree top
store auto 1
previous tree top
integer add
Figure 3.2: Sample TR-IL
3.2 TR Intermediate Language
As mentioned earlier, the IL generated and used by the TR JIT compiler is tree-based and
encodes the control flow graph for the function being compiled. More specifically, TR-IL is a
linked list of tree-tops, where each tree-top represents an instruction and each child to a tree-
top represents an argument to the instruction. Aliasing information is explicit in TR-IL, which
facilitates the native to JIT IL conversion mechanism.
Figure 3.2 is an example of the TR-IL for a function adding two local variables together
and storing them in a third.
3.3 W-Code and The IL Conversion Mechanism
The first phase of our native inlining design requires the conversion of native code into the same
IL used by the JIT compiler. To do this efficiently, we exploit the ability to store IL alongside
native executable code in the same binary object file or library.

CHAPTER 3. TOOLS 29
Native Code
TR−IL as in Figure 4.2
a = b + c;W−Code producing
front−ends conversion mechanismW−Code to TR−IL
W−Code
STORE aADD
LOAD cLOAD b
Figure 3.3: The IL conversion process
In our case, the native IL is W-Code, a mature stack-based representation generated by IBM
compiler front-ends for C, C++, FORTRAN, COBOL, PL/1 and other programming languages.
Because W-Code is designed to support a large number of languages, aliasing is made explicit
in the IL itself. As mentioned earlier, aliasing is also explicit in TR-IL, making it possible to
preserve alias information from the W-Code of native functions when they are converted to
TR-IL.
As depicted in Figure 3.3, the W-Code to TR-IL conversion mechanism operates by iterat-
ing through the W-Code opcodes of a native function, and generating TR-IL for each encoun-
tered statement. Once W-Code opcodes have been processed, the TR JIT compiler can treat the
generated TR-IL as if it were derived from Java Bytecodes. Care, however, must be taken to
provide appropriate linkages and preserve the semantics of the original language with respect
to opaque function calls and shared data as discussed in Section 2.6.
As will be described in Chapter 4, our implementation converts IL at runtime, when the
inliner decides to inline a particular native function. In principle, the conversion could also be
done offline, storing TR-IL along with the native executable. TR-IL, however, is an in-memory
IL and is not suitable for efficient serialization to disk. In contrast, W-Code (like Bytecode)
is a suitable disk format by design, and the conversion to TR-IL is a single-pass, lightweight
operation. The alternative of storing the tree-based IL directly would take more space to store

CHAPTER 3. TOOLS 30
and would still require a similar amount of work to reconstruct an in-memory representation.
In essence, we are interfacing the TR JIT compiler with a new virtual machine. This new
W-Code virtual machine is an oracle providing answers to queries made by the TR JIT compiler
regarding native symbols, but most importantly, it functions as an IL generator, generating TR-
IL from W-Code opcodes (instead of Java Bytecodes).
Having described the software framework available to use, including a JVM, JIT compiler
and IL conversion mechanism, we proceed to describe the details of our implementation in the
chapter that follows.

Chapter 4
Implementation
In this chapter, we present details of a prototype implementation of the design described in
Chapter 2. Our implementation targets the POWER4TM line of IBM processors, and is com-
posed of general modifications to the TR JIT compiler, changes to the TR JIT compiler’s in-
liner, as well as modifications to the TR JIT code generator to support synthesis. We conclude
this chapter by summarizing the current status of our prototype.
4.1 General Modifications to the TR JIT Compiler
Two significant changes were made to the TR JIT compiler to support the compilation of W-
Code-based languages. The first was to extend its data type set to include unsigned types (since
it was originally designed for Java which does not define unsigned types). The second was
modifying its optimizations that depend on alias analysis (e.g., copy and value propagation),
since aliasing in Java is much simpler than in C. As noted in Section 3.3, alias information
for the native code is explicit in the W-Code IL, and is preserved during the transformation to
TR-IL.
31

CHAPTER 4. IMPLEMENTATION 32
4.2 Modifications to the TR JIT Compiler’s Inliner
The TR JIT inliner was modified to permit function inlining of a small subset of native func-
tions. If the inliner encounters a native callsite during its heuristical analysis stage, it proceeds
via two steps to process the callsite:
1. it instantiates a W-Code virtual machine and associates with it the W-Code file containing
the IL for the native function under consideration
2. it requests the native function’s TR-IL (this initiates a W-Code to TR-IL conversion)
Once TR-IL for the native function is made available, the inliner instantiates two callback han-
dler objects that process the generated IL, transforming JNI callbacks and synthesizing opaque
function calls, respectively. Once transformations are complete and synthesis requirements
have been met, the inliner continues and completes the inlining process. Figure 4.1 displays
this entire native inlining process. We now describe the implementation of these two callback
handlers in detail.
4.3 Introducing the Inlined CallHandlers
We have implemented two callback handler classes that analyze and process inlined function
calls in the TR-IL generated from W-Code. Figure 4.2 represents a class diagram for the JNI-
CallHandler and ExternalCallHandler. The JNICallHandler is in charge of
transforming and synthesizing JNI callbacks, whereas the ExternalCallHandler syn-
thesizes all other opaque calls (i.e., function calls with no accompanying W-Code), and both
implement the interface defined by the InlinedCallHandler.
4.3.1 The JNICallHandler
As mentioned in Chapter 2, transforming inlined JNI callbacks requires callback identification
and JNI argument use/def analysis. Synthesis is also required for inlined callbacks that are
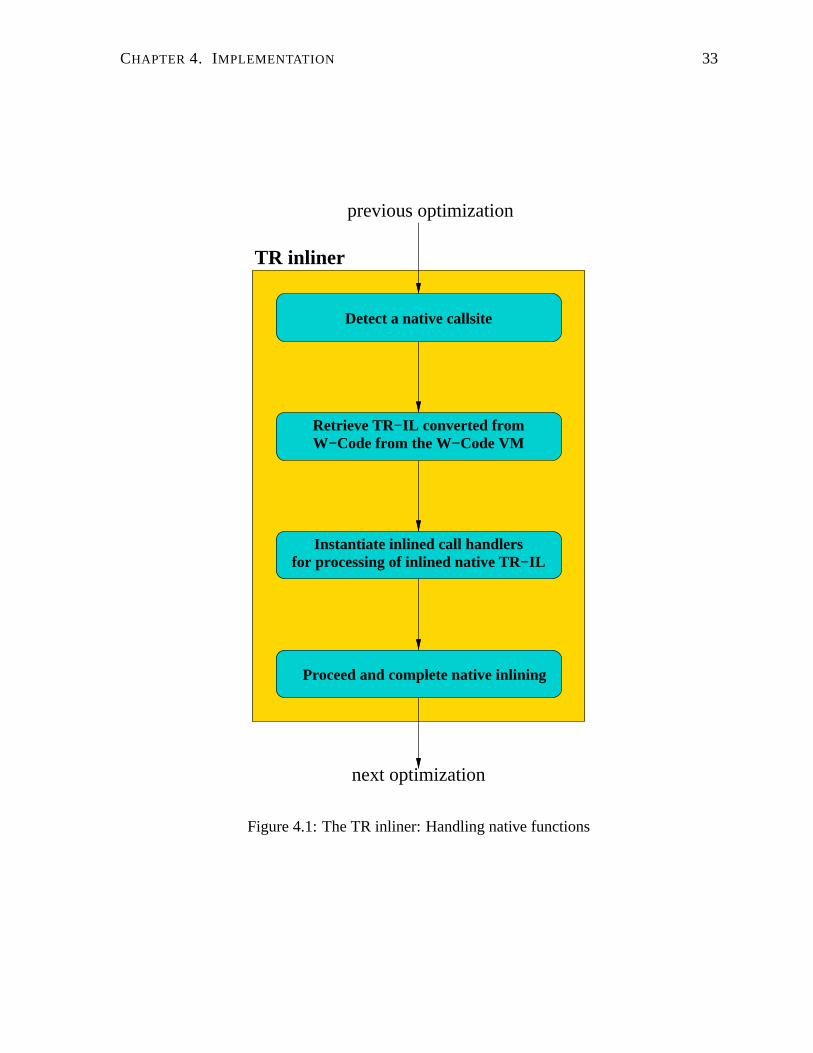
CHAPTER 4. IMPLEMENTATION 33
previous optimization
Retrieve TR−IL converted fromW−Code from the W−Code VM
for processing of inlined native TR−ILInstantiate inlined call handlers
Proceed and complete native inlining
next optimization
TR inliner
Detect a native callsite
Figure 4.1: The TR inliner: Handling native functions

CHAPTER 4. IMPLEMENTATION 34
virtual bool isCallOfInterest(CallNode)=0;
public: void identifyCalls(); void transformCalls();
protected: bool isCallOfInterest(CallNode);
public:
JNICallHandler ExternalCallHandler
void redo*(...);
virtual void identifyCalls()=0; virtual void transformCalls()=0;
protected:
public:
void identifyCalls(); void transformCalls();
protected: bool isCallOfInterest();
private: void handle*(...);
void synthesize(CallNode);
InlinedCallHandler
Figure 4.2: The Inlined Call Handler class hierarchy
opaque. We now describe how the transformation and synthesis of callbacks is realized.
Identifying JNI Callbacks
The JNICallHandler relies on the W-Code VM to identify and flag callback symbols dur-
ing IL conversion. The W-Code VM does so by checking to see if a function call by pointer
targets a legal function table offset in the JNI interface. These function table offsets are doc-
umented in the JNI specification [28]. Furthermore, the W-Code VM maintains a listing of
transformable callbacks, thereby allowing the handler to differentiate between transformable
and synthesizable callbacks.
Once the JNICallHandler has been instantiated, it iterates through the generated IL
probing for callbacks, and adding them to a list for later processing. The same is done if the
handler encounters any callbacks that are deemed non-transformable (i.e., requiring synthesis).
This represents the work performed in the JNICallHandler::identifyCalls routine.
By flagging known callback symbols, our implementation differs from the design in Chapter 2

CHAPTER 4. IMPLEMENTATION 35
which detailed an approach that scans the generated JIT compiler IL, pattern matching IL state-
ments against a set of well-known JNI callback IL shapes.
JNI Argument Use/Def Analysis
Our implementation avoids a detailed JNI argument use/def analysis by assuming straight line
control flow in native code. The use/def analysis is similar to that required for other optimiza-
tions, but building one specifically for JNI arguments is an engineering issue we believe can
be addressed by future work, and one that does not diminish the novelty of our idea. Instead,
the set of argument definitions is restricted to values passed in from Java code (i.e., arguments
to the native function call) as well as values returned by any of the JNI functions presented in
Section 2.4.2.
Callback Transformation
Having identified all transformable calls, the JNICallHandler::transformCalls rou-
tine proceeds by iterating through them and transforming each constant-generating callback
into a compile-time constant by querying the J9 virtual machine. For example, JNI functions
that return field or method ids are converted to JIT compile-time constant addresses and field
offsets. Transformable JNI calls that use the results of these constant-generating callbacks as
arguments (i.e., Get<Type>Field or CallStatic<Type>method) are transformed
into cheaper but semantically equivalent TR-IL. Get<Type>Field, for example, is trans-
formed to TR-IL representing a direct field access, whereas CallStatic<Type>method
is transformed to a direct function call.
Figure 4.3 shows pseudocode for the JNICallHandler::transformCalls func-
tion. Each transformable callback is provided a “handle” method that takes in the TR-IL rep-
resenting the callback, along with required “definitions” from previous transformations and
returns the TR-IL result of the transformation. A natural side-effect of querying the J9 virtual
machine for data at JIT compile-time is the ability to filter native code that performs illegal

CHAPTER 4. IMPLEMENTATION 36
*/
JNICallHandler::transformCalls() {
for (each tree top X representing an inlined JNI callback) { switch(callType(X)) {
break; case GetObjectClass: constClass = handle_GetObjectClass(X); break; case GetFieldID: redoPool.add(X); offset = handle_GetFieldID(X, constClass); break; case GetIntField: handle_GetIntField(X, offset); break; case ...: ... default:
break; } }}
case FindClass: constClass = handle_FindClass(X); // transform to a constant
// transform to a constant
// transform to an offset
// transform to a direct read
synthesize(X); // synthesize a call to the opaque JNI callback
/**
// add to the redo pool in case the transformation needs to be undone
* Attack the JNI callback tree tops as they first appear in the inlined native code’s IL
Figure 4.3: Pseudocode for JNICallHandler::transformCalls

CHAPTER 4. IMPLEMENTATION 37
}
... transformed_call = redoPool.getDependentTransformations(X);
JNICallHandler::synthesize(X) {
correct_data = redo(transform_call); handle_callback(X, correct_data); ...
Figure 4.4: Pseudocode for JNICallHandler::synthesize
operations on JVM data (i.e., querying the field id of a non-existent field). An appropriate
response to such an unchecked error would be to halt the JVM, thereby preventing it from en-
tering an indeterministic state, or possibly avoiding a crash.
Synthesizing Opaque Callbacks
Since both transformable and non-transformable callbacks are stored in the same list, there
exists the possibility of encountering an opaque callback during the transformation stage. If a
callback can not be transformed, but takes arguments that were defined by a previously trans-
formed callback, special care must be taken to ensure the definition of arguments to the opaque
callback are of the correct type. For example, if the virtual function table offset constant
generated from transforming a non-opaque GetMethodID callback is then passed as an argu-
ment to an opaque CallStaticObjectMethod callback, the GetMethodID transformation must
be ”redone” to produce the expected type of data which is then passed as an argument to Call-
StaticObjectMethod. The expected type of data in this case is jmethodID rather than a virtual
function table offset.
Once dependent transformations are redone, the opaque call is synthesized by adding a
layer of indirection to all the reference arguments that originate from the argument list to the
inlined native function (a semantic enforced by the JNI to support copying garbage collectors).
Figure 4.4 gives pseudocode for synthesizing opaque callbacks.

CHAPTER 4. IMPLEMENTATION 38
4.3.2 The ExternalCallHandler
The ExternalCallHandler relies on the W-Code VM to identify and flag external sym-
bols during IL conversion. The W-Code VM does so by checking to see if the function call
targets an externally defined symbol (i.e., a symbol outside the module being processed).
Once the ExternalCallHandler has been instantiated, it scans the generated IL for
external calls, and adds them to a list that will be processed by the code generator.
4.4 Changes to the TR JIT Code Generator
Once the native function inlining and callback transformation optimizations have taken place,
the code generator must handle any side-effects that result from changes to the inlined native
function’s TR-IL. Since we are targeting the POWER4TMline of processors, the POWER4 code
generator needs to be able to generate specialized dispatch code for synthesized callbacks and
external calls, as well as code for accesses to shared data residing in native libraries. The code
generator evaluates synthesized function calls by adapting and modifying the Direct2JNI call-
out mechanism described in Section 3.1.1. Direct2JNI is a specialized snippet of high-speed
assembly that sets up the correct linkages and context when making a native call from Java. It
enforces the linkage conventions specified by the AIX [13] Application Binary Interface [14]
(ABI). It also encodes the handshaking required between native code and the J9 virtual ma-
chine.
Furthermore, when evaluating TR-IL load trees, the code generator must handle loads of
shared data accessible to both inlined and non-inlined native functions. When generating CPU
instructions for such loads, the code generator uses the AIX dlopen and dlsym system calls [15]
to load and resolve the runtime addresses of intra-module defined symbols.
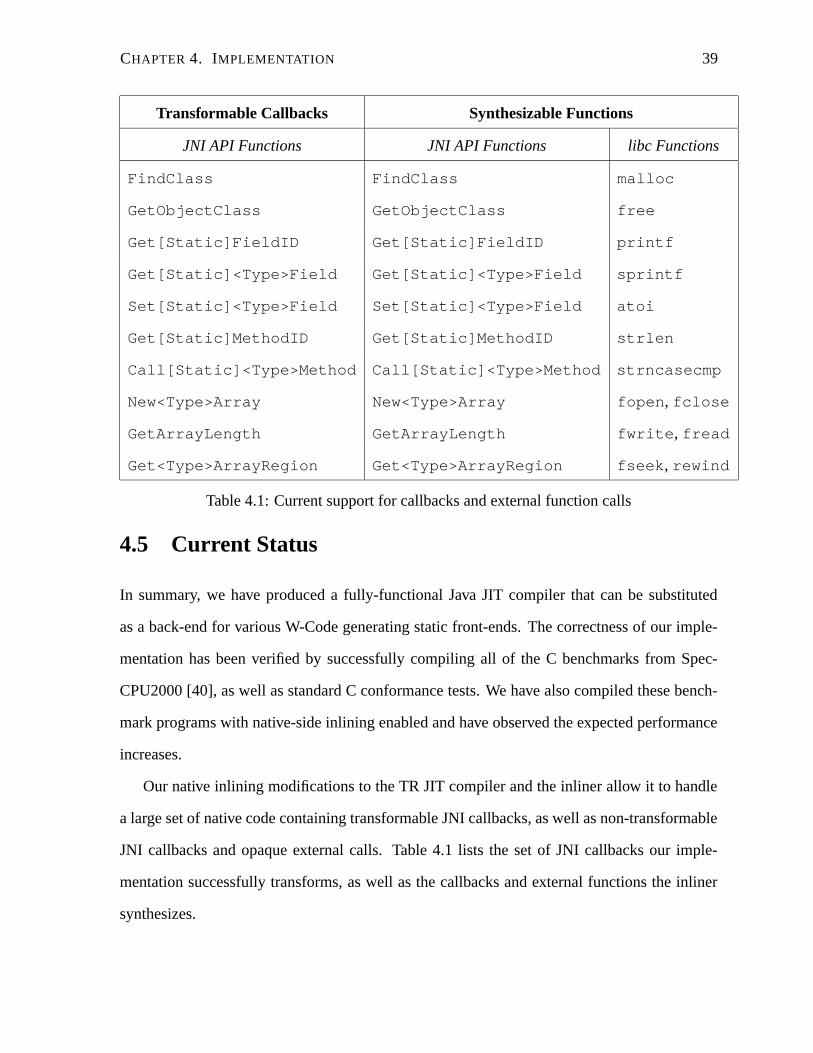
CHAPTER 4. IMPLEMENTATION 39
Transformable Callbacks Synthesizable Functions
JNI API Functions JNI API Functions libc Functions
FindClass FindClass malloc
GetObjectClass GetObjectClass free
Get[Static]FieldID Get[Static]FieldID printf
Get[Static]<Type>Field Get[Static]<Type>Field sprintf
Set[Static]<Type>Field Set[Static]<Type>Field atoi
Get[Static]MethodID Get[Static]MethodID strlen
Call[Static]<Type>Method Call[Static]<Type>Method strncasecmp
New<Type>Array New<Type>Array fopen, fclose
GetArrayLength GetArrayLength fwrite, fread
Get<Type>ArrayRegion Get<Type>ArrayRegion fseek, rewind
Table 4.1: Current support for callbacks and external function calls
4.5 Current Status
In summary, we have produced a fully-functional Java JIT compiler that can be substituted
as a back-end for various W-Code generating static front-ends. The correctness of our imple-
mentation has been verified by successfully compiling all of the C benchmarks from Spec-
CPU2000 [40], as well as standard C conformance tests. We have also compiled these bench-
mark programs with native-side inlining enabled and have observed the expected performance
increases.
Our native inlining modifications to the TR JIT compiler and the inliner allow it to handle
a large set of native code containing transformable JNI callbacks, as well as non-transformable
JNI callbacks and opaque external calls. Table 4.1 lists the set of JNI callbacks our imple-
mentation successfully transforms, as well as the callbacks and external functions the inliner
synthesizes.

Chapter 5
Results and Analysis
Native inlining is an optimization that interacts with the performance dynamics of the TR JIT
compiler, as well as with the running Java program performing native function calls. As with
any JIT optimization, the runtime costs of performing native inlining and callback transforma-
tions must be balanced against the expected benefits of removing overhead and exposing more
IL to the JIT optimizer. Ultimately, we believe the true power of our approach lies in the ability
to treat native and Java code together during JIT compilation, particularly since we have the
opportunity to eliminate pessimistic assumptions that the optimizer must make in the presence
of native function calls.
Our results and experiments focus on the costs and benefits of inlining callouts and trans-
forming callbacks. First, we examine the cost of converting native functions from native W-
Code IL into TR-IL. We also demonstrate the benefits of eliminating native call and return
overhead and record performance gains from transforming heavyweight callbacks into sub-
stantially cheaper operations. Furthermore, we measure and validate runtime improvements
in the performance of native code as the result of exposing them to additional JIT optimiza-
tions once inlined. To conclude, we quantify the performance results of synthesis when inlined
native code contains calls to opaque native functions.
To confirm the applicability of native inlining and callback transformations on real-world
40

CHAPTER 5. RESULTS AND ANALYSIS 41
code, we profiled a run of SPEC JAppServer2004 using IBM Websphere R© Application Server
6.0. We found that 4.07% of all function calls made during the run were calls to 71 unique
native functions, accounting for roughly 23% of the running time. Of these, 19 unique native
functions were called at least 5000 times, and out of those, six were called at least 50,000
times. A single native function, Object.hashCode(), was called more than 300,000 times. This
suggests that the runtime cost of inlining can be amortized over a large number of uses for
important native functions. If the native function is well-understood by the compiler, semantic
expansion [44] or a related inlining technique could be used to create a special version. These
approaches, however, are less general than our solution.
5.1 Experimental Platform
Due to the protypical nature of our implementation, we are limited to evaluating critical aspects
of our proposed system using microbenchmarks. Although this limits us from investigating the
impact of our work on a large-scale system, the microbenchmark results provide us with a
realistic sense of the costs and benefits of our implementation. All our timing measurements
are performed on an IBM 7038-6M2 with eight 1.4 GHz POWER4TM CPUs. We use the
following legend when describing our microbenchmark results:
• NoOpt - unless otherwise mentioned, no optimizations are performed on microbench-
mark tests calling native functions
• N-inlining - native functions called by microbenchmark tests are only inlined
• N-inlining+ - native functions called by microbenchmark tests are inlined and contained
JNI callbacks are transformed
Detailed descriptions of our microbenchmark tests, as well as the raw data used to generate the
results in this chapter, can be found in Appendix A.
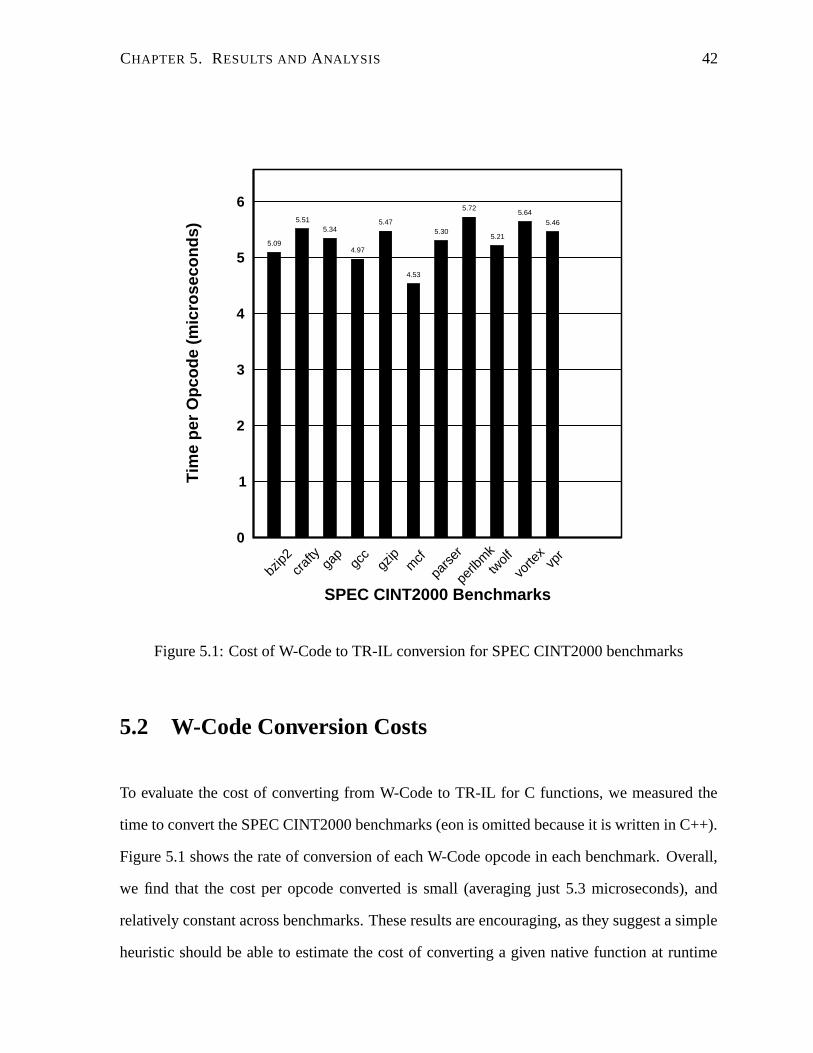
CHAPTER 5. RESULTS AND ANALYSIS 42
bzip2
5.09
craf
ty
5.51
gap
5.34
gcc
4.97
gzip
5.47
mcf
4.53
pars
er
5.30
perlb
mk
5.72
twolf
5.21
vorte
x
5.64
vpr
5.46
0
1
2
3
4
5
6T
ime
per
Op
cod
e (m
icro
seco
nd
s)
SPEC CINT2000 Benchmarks
Figure 5.1: Cost of W-Code to TR-IL conversion for SPEC CINT2000 benchmarks
5.2 W-Code Conversion Costs
To evaluate the cost of converting from W-Code to TR-IL for C functions, we measured the
time to convert the SPEC CINT2000 benchmarks (eon is omitted because it is written in C++).
Figure 5.1 shows the rate of conversion of each W-Code opcode in each benchmark. Overall,
we find that the cost per opcode converted is small (averaging just 5.3 microseconds), and
relatively constant across benchmarks. These results are encouraging, as they suggest a simple
heuristic should be able to estimate the cost of converting a given native function at runtime

CHAPTER 5. RESULTS AND ANALYSIS 43
based on its size in W-Code opcodes. Such a heuristic would then be able to guide native
inlining decisions in the JIT compiler. Furthermore, the cost of conversion only needs to be
paid once, when the function is inlined, whereas the benefits of removing callout overhead will
be obtained on every subsequent use of the inlined code.
5.3 Native Inlining Benefits
We then implemented a set of microbenchmark tests to evaluate the benefits of inlining native
functions.
A portion of the test included calls to empty native functions. The motivation behind this
was to confirm the complete removal of native call and return overheads as a result of perform-
ing native inlining. Empty-bodied instance and static native functions were implemented with
varying number of parameters (0, 1, 3 and 5 parameters) and JIT compiled at NoOpt and N-
inlining optimization levels. As shown in Table 5.1, the speedup that resulted from performing
native inlining for each test was infinite because inlining completely removed the overhead in
performing the native call and then returning from the native call. In general, the NoOpt results
also show the incremental cost of passing arguments to native functions. They also show that
static microbenchmark tests ran faster than their corresponding instance versions due to the
fact that Direct2JNI was used to create compiled glue code for the native calls.
We also implemented a microbenchmark test that contains real code. This test will clearly
demonstrate that the benefits of inlining depend on the amount of time spent executing native
code in the function. To see the benefits that occur in realistic uses of native code, we wrote a
native hash function§. Inlining our hash function gives a speedup of 3.6.
In summary, our microbenchmark tests show that native inlining can easily result in speedups
that range from effectively infinite (as for the empty bodied native function calls), to effectively
§we based this hash function on Wang’s 32-bit mix function athttp://www.concentric.net/ Ttwang/tech/inthash.htm

CHAPTER 5. RESULTS AND ANALYSIS 44
Microbenchmark Test NoOpt (ns) N-inlining (ns) Speedup (X)
instance
0 args 423 0 ∞
1 args 458 0 ∞
3 args 490 0 ∞
5 args 579 0 ∞
static
0 args 128 0 ∞
1 args 137 0 ∞
3 args 138 0 ∞
5 args 143 0 ∞
Table 5.1: Microbenchmark runtimes and improvements with native inlining
0 (for very long-running native functions). The primary motivation for inlining native code,
however, is to create the opportunity to transform inlined JNI callbacks that are much more
expensive to perform. We consider the effect of these transformations in the following section.
5.4 Callback Transformation Benefits
To measure the overheads involved with performing callbacks in native code, we implemented
a series of microbenchmark tests and ran them at NoOpt and N-inlining+ optimization levels.
Table 5.2 contains a complete listing of the microbenchmark tests and our experimental results.
Our microbenchmark test names are encoded as follows:
• CVMethod - Call a void instance Java function from native code
• CSVMethod - Call a void static Java function from native code
• CIMethod - Call an integer returning instance Java function from native code

CHAPTER 5. RESULTS AND ANALYSIS 45
• CSIMethod - Call an integer returning static Java function from native code
• GIField - Read an integer field from a Java object
• GSIField - Read a static integer field from a Java class
• SIField - Write to an integer field in a Java object
• SSIField - Write to an integer field in a Java class
• E - empty function (i.e., in the context of native code calling Java functions)
Because callbacks are more expensive than callouts, we see that the benefit of transforming
them is correspondingly greater, with a minimum achieved speedup of nearly 12X in our mi-
crobenchmark tests.
For example, the native code in the CVoidMethodE test ultimately calls an empty Java
method, but does so by calling the GetObjectClass, GetMethodID, and
CallVoidMethod JNI functions. By performing native inlining and then transforming each
of these callbacks (i.e., running at N-inlining+), our strategy is able to reclaim the order of mag-
nitude slowdown experienced when running the same microbenchmark test at NoOpt. More
specifically, the three callbacks are transformed to two compile-time constants, and a JNI-
independent virtual function call (using the constants from the previous two transformations),
respectively.
Our results also indicate what at first appears to be anomalous infinite speedups for four
microbenchmark tests that perform reads or writes to instance or static fields. For example,
inlining the native call in GIntField inlines a JNI callback which reads an instance field. The
callback, however, even after being transformed (to a more direct read operation) is still present
and contributes to work performed at runtime. In other words, inlining and transforming the
callbacks does not result in the complete removal of work. The infinite speedup results from the
superscalar pipelined CPU (like the POWER4) being able to find a slot to schedule the single
read CPU instruction along with other instructions. The read instruction is scheduled alongside
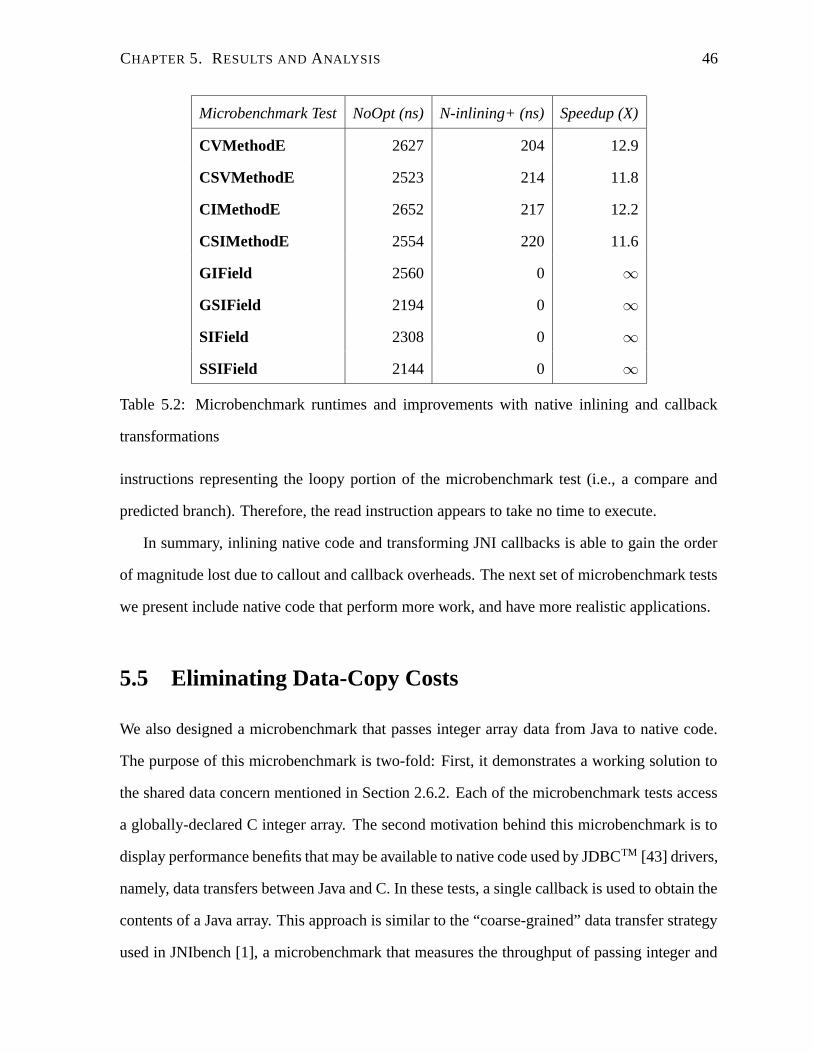
CHAPTER 5. RESULTS AND ANALYSIS 46
Microbenchmark Test NoOpt (ns) N-inlining+ (ns) Speedup (X)
CVMethodE 2627 204 12.9
CSVMethodE 2523 214 11.8
CIMethodE 2652 217 12.2
CSIMethodE 2554 220 11.6
GIField 2560 0 ∞
GSIField 2194 0 ∞
SIField 2308 0 ∞
SSIField 2144 0 ∞
Table 5.2: Microbenchmark runtimes and improvements with native inlining and callback
transformations
instructions representing the loopy portion of the microbenchmark test (i.e., a compare and
predicted branch). Therefore, the read instruction appears to take no time to execute.
In summary, inlining native code and transforming JNI callbacks is able to gain the order
of magnitude lost due to callout and callback overheads. The next set of microbenchmark tests
we present include native code that perform more work, and have more realistic applications.
5.5 Eliminating Data-Copy Costs
We also designed a microbenchmark that passes integer array data from Java to native code.
The purpose of this microbenchmark is two-fold: First, it demonstrates a working solution to
the shared data concern mentioned in Section 2.6.2. Each of the microbenchmark tests access
a globally-declared C integer array. The second motivation behind this microbenchmark is to
display performance benefits that may be available to native code used by JDBCTM [43] drivers,
namely, data transfers between Java and C. In these tests, a single callback is used to obtain the
contents of a Java array. This approach is similar to the “coarse-grained” data transfer strategy
used in JNIbench [1], a microbenchmark that measures the throughput of passing integer and
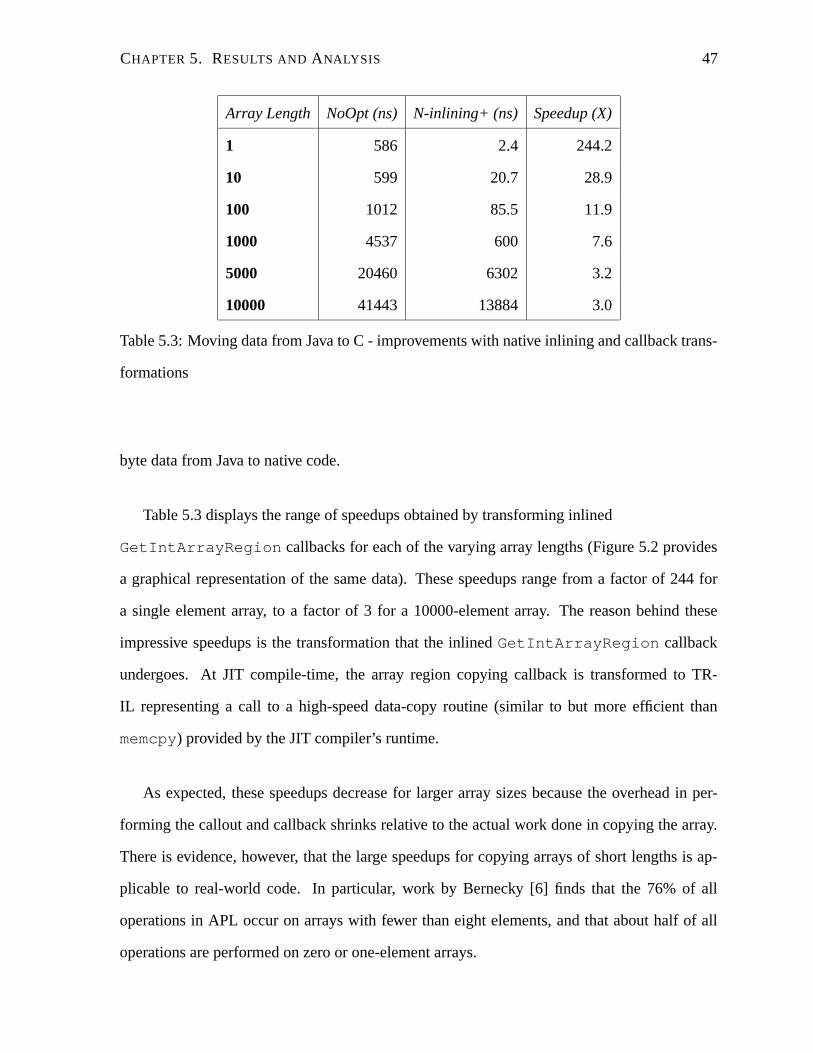
CHAPTER 5. RESULTS AND ANALYSIS 47
Array Length NoOpt (ns) N-inlining+ (ns) Speedup (X)
1 586 2.4 244.2
10 599 20.7 28.9
100 1012 85.5 11.9
1000 4537 600 7.6
5000 20460 6302 3.2
10000 41443 13884 3.0
Table 5.3: Moving data from Java to C - improvements with native inlining and callback trans-
formations
byte data from Java to native code.
Table 5.3 displays the range of speedups obtained by transforming inlined
GetIntArrayRegion callbacks for each of the varying array lengths (Figure 5.2 provides
a graphical representation of the same data). These speedups range from a factor of 244 for
a single element array, to a factor of 3 for a 10000-element array. The reason behind these
impressive speedups is the transformation that the inlined GetIntArrayRegion callback
undergoes. At JIT compile-time, the array region copying callback is transformed to TR-
IL representing a call to a high-speed data-copy routine (similar to but more efficient than
memcpy) provided by the JIT compiler’s runtime.
As expected, these speedups decrease for larger array sizes because the overhead in per-
forming the callout and callback shrinks relative to the actual work done in copying the array.
There is evidence, however, that the large speedups for copying arrays of short lengths is ap-
plicable to real-world code. In particular, work by Bernecky [6] finds that the 76% of all
operations in APL occur on arrays with fewer than eight elements, and that about half of all
operations are performed on zero or one-element arrays.
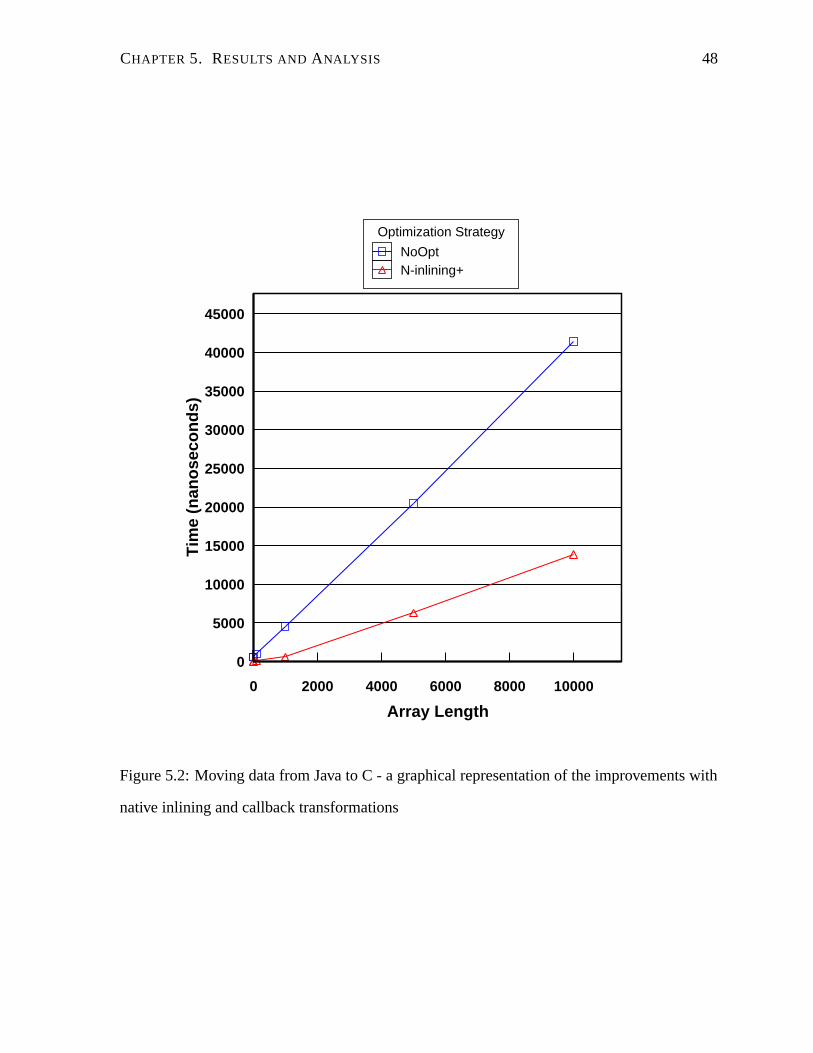
CHAPTER 5. RESULTS AND ANALYSIS 48
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
Tim
e (n
ano
seco
nd
s)
0 2000 4000 6000 8000 10000
Array Length
Optimization Strategy
NoOptN-inlining+
Figure 5.2: Moving data from Java to C - a graphical representation of the improvements with
native inlining and callback transformations

CHAPTER 5. RESULTS AND ANALYSIS 49
Microbenchmark N-inlining+ HighOpt HigherOpt
Test Speedup (X) Speedup (X) Speedup (X)
hash 3.58 36.49 23.91
Table 5.4: hash: Performance improvements with other JIT compiler optimizations
5.6 Optimizing Inlined Native Code
Our microbenchmark tests have thus far exposed the overheads of performing callouts and
callbacks. We have (except for hash) completely ignored the effects of native inlining and
callback transformations on native code that perform useful work. In this section, we present
the speedups obtained by exposing inlined and transformed native code to other optimizations
in the TR JIT compiler. Most notably, we inline native functions, and JIT-compile them at
increasingly higher optimization levels (HighOpt, HigherOpt) which perform a large set of
inter-procedural optimizations. We avoid a detailed explanation of these optimization strate-
gies, but focus on their effect on inlined native code.
For example, in Table 5.4, exposing hash to more JIT compiler optimizations improves
the runtime performance by a factor of almost 37. Exposing the same test, however, to a
higher level of optimizations dampens the runtime benefits from compiling at HighOpt. This
is because of very aggressive and experimental optimizations that do not pay off.
In Figure 5.3, four microbenchmark tests contain native code that use the JNI to ultimately
call Java functions that perform lookups on Java HashMap objects. These microbenchmark
tests are labeled:
• CVMethod - Call a void instance Java method
• CSVMethod - Call a void static Java method
• CIMethod - Call an integer returning instance Java method
• CSIMethod - Call an integer returning static Java method

CHAPTER 5. RESULTS AND ANALYSIS 50
Of interest here is the relatively small N-inlining+ baseline speedups (relative to the NoOpt
optimization strategy) these tests experienced compared to the infinite speedups observed be-
fore with other microbenchmark tests (Table 5.1). This is because the amount of work per-
formed by native code (or Java functions called from native code) dominates the overhead in
performing the callout and callbacks. This is especially apparent in the N-inlining++ strategy
which recursively inlines both the Java-callable native function, as well as the Java function
called via a JNI Call[Static]<Type>Method callback. There is no significant speedup
even though the entire callout-callback path is eliminated.
Modest performance gains, however, are attributable to exposing recursively inlined func-
tions to other JIT compiler optimizations, as can be seen with compiling with the HigherOpt
optimization strategy. Our initial expectations were for larger gains, given the Java-centric
nature of the JIT compiler’s optimization strategy, and the fact that the inlined code contains
operations on Java objects. We, however, do not believe this is generalizable to other mi-
crobenchmark tests. As long as the additional optimizations keep the performance of the gen-
erated code at par, and the overhead in performing additional aggressive optimizations is not
excessive, we do not see any harm in performing them.
Another interesting result comes from the GArrayLength microbenchmark test. This test
creates an array of characters using NewCharArray and returns its length using
GetArrayLength. As reported in Table 5.5, the 94.7 speedup factor is due to the trans-
formation and further optimization of two callbacks. The first is a call to NewCharArray,
which is ultimately transformed to a call to a specialized JIT compiler object allocation rou-
tine which makes use of runtime information unavailable to the JVM. The second call is to
GetArrayLength, which is ultimately transformed from an expensive JNI callback to the
JVM, to a fast array object header field lookup.
In summary, our results indicate that it will often be profitable for a JIT compiler to perform
aggressive runtime optimizations on inlined native code.
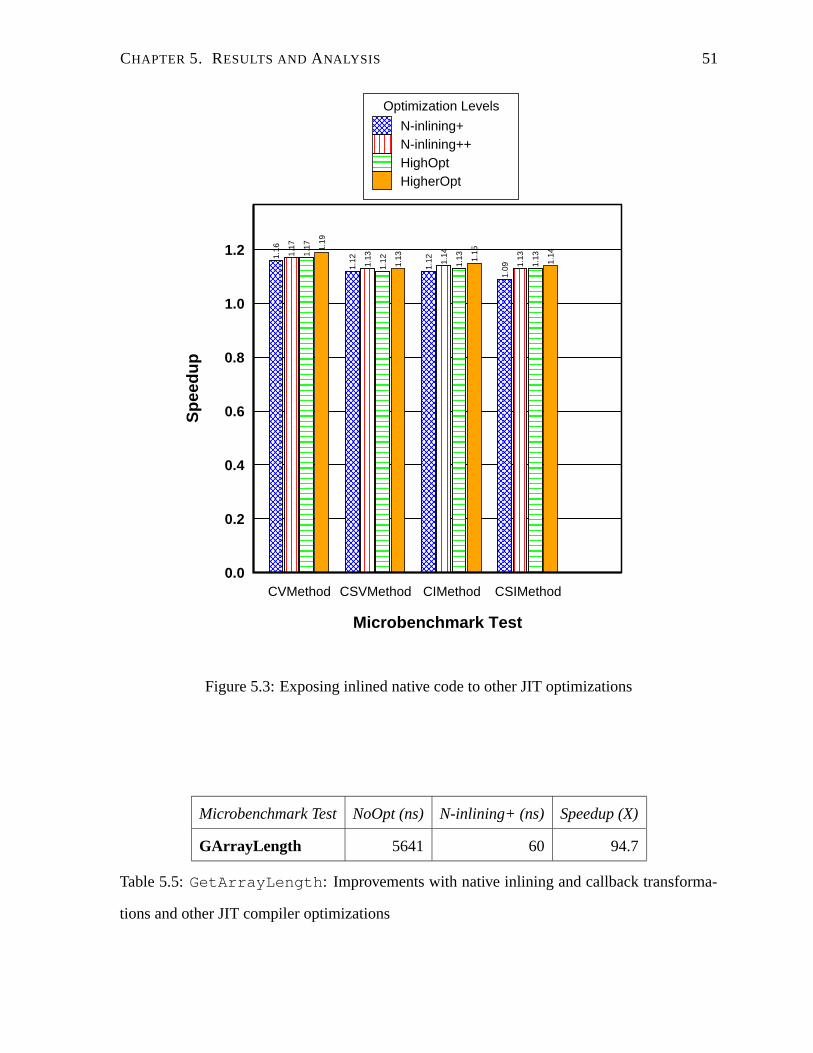
CHAPTER 5. RESULTS AND ANALYSIS 51
1.16 1.17
1.17 1.
19
CVMethod
1.12 1.13
1.12 1.13
CSVMethod
1.12 1.
14
1.13 1.
15
CIMethod
1.09 1.
13
1.13 1.14
CSIMethod0.0
0.2
0.4
0.6
0.8
1.0
1.2
Sp
eed
up
Microbenchmark Test
Optimization Levels
N-inlining+N-inlining++HighOptHigherOpt
Figure 5.3: Exposing inlined native code to other JIT optimizations
Microbenchmark Test NoOpt (ns) N-inlining+ (ns) Speedup (X)
GArrayLength 5641 60 94.7
Table 5.5: GetArrayLength: Improvements with native inlining and callback transforma-
tions and other JIT compiler optimizations

CHAPTER 5. RESULTS AND ANALYSIS 52
5.7 Synthesis Decisions
The last set of results we present quantify the benefits and costs of performing synthesis on in-
lined opaque function calls. We created two sets of microbenchmark tests (shown in Table 5.6)
to demonstrate the need for an inlining heuristic that can estimate performance degradation
when native inlining generates synthesized opaque function calls.
The first set of tests (Fully Transformed) consists of native code that only contain opaque
function calls. All the tests except for File I/O contain a single synthesizable call to the libc
function encoded in the test’s name (i.e. printfS calls printf, atoiS calls atoi). File I/O
performs a sequence of file-system calls (fopen, fread, fwrite, fseek, rewind and
fclose). The difference between the S and L Fully Transformed microbenchmark tests lies
in the length of data passed to the libc function: S tests pass shorter lengthed data, whereas L
pass longer lengthed data (and therefore have longer runtimes).
Inlining a single callout for each of these tests results in the synthesis of a single call and
a respectable speedup. For the printf*, atoi*, strlen* tests, a synthesis heuristic should guide
the inliner into performing the optimization on the native functions. In contrast, inlining the
native callsite in File I/O results in the generation of 13 synthesized calls, and no significant
increase in performance. A synthesis heuristic should advise the inliner to refrain from inlining
this native call because the runtime benefit from performing the optimization would not offset
its runtime cost.
The second set (Partially Transformed) contains the exact same native code from before
(Section 5.4) except that some of the callbacks are synthesized instead of transformed. We
conclude that a synthesis heuristic should approve inlining Partially Transformed native code.
In the four tests (G[Static]IntField, S[Static]IntField) the inliner is able to transform all the
JNI functions that provide definitions (in the JNI argument use/def sense) to the synthesized
call that reads or writes to the instance or static variable. Although the speedups obtained
in these four tests are lower then those recorded in Table 5.2, they still represent substantial
speedups when compared to compiling them with the NoOpt optimization strategy.
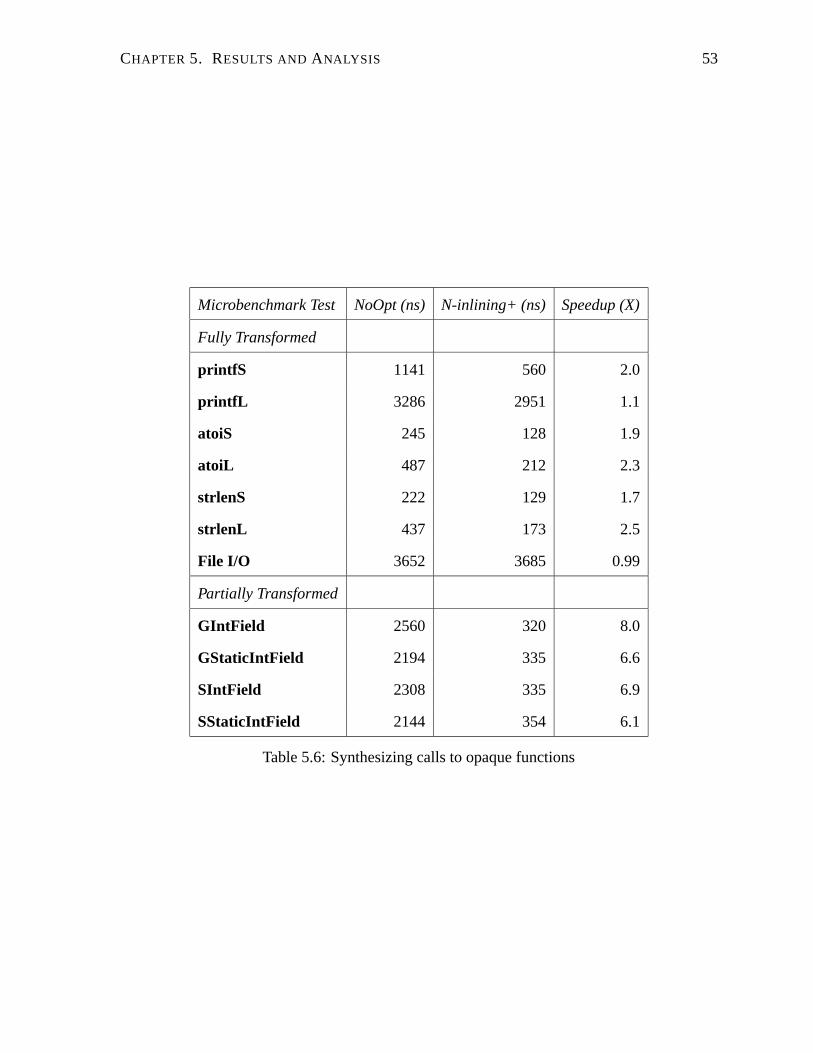
CHAPTER 5. RESULTS AND ANALYSIS 53
Microbenchmark Test NoOpt (ns) N-inlining+ (ns) Speedup (X)
Fully Transformed
printfS 1141 560 2.0
printfL 3286 2951 1.1
atoiS 245 128 1.9
atoiL 487 212 2.3
strlenS 222 129 1.7
strlenL 437 173 2.5
File I/O 3652 3685 0.99
Partially Transformed
GIntField 2560 320 8.0
GStaticIntField 2194 335 6.6
SIntField 2308 335 6.9
SStaticIntField 2144 354 6.1
Table 5.6: Synthesizing calls to opaque functions

CHAPTER 5. RESULTS AND ANALYSIS 54
In general, our experiments have focused on the costs and benefits of inlining callouts
and transforming callbacks. The relatively small overheads and impressive gains attributable
to native inlining and callback transformations provides us with motivation to see through a
complete implementation of our strategy. In Chapter 6, we compare our strategy with other
approaches at minimizing JNI-related overheads, and Chapter 7 outlines other performance
and engineering issues that need to be taken into consideration when moving forward.

Chapter 6
Related Work
This chapter provides context to our strategy by describing research on general and Java-centric
approaches to language interoperability, as well as optimizations of Java native functions and
callbacks.
6.1 Alternative Language Interoperability Frameworks
Examples of language interoperability frameworks that operate across languages, processes
and machine boundaries include CORBA [38], Remote Procedure Calls [8] and the Compo-
nent Object Model [30]. These frameworks use interface definition languages (IDLs) to specify
common types, and depend on proxy stubs to help clients translate between machine architec-
tures, execution models and programming languages.
A more recent advance in language interoperability is Microsoft .NET [20] which claims
complete language interoperability between the family of .NET-labeled languages. .NET com-
pilers for each language transform source to a common IL, the Microsoft Intermediate Lan-
guage (MSIL). It also requires additional language features, for example, inheritance, over-
loading and exception handling in Visual Basic (VB) 6.0 .NET. This, unfortunately, may re-
quire revision and modifications to existing VB applications if these programs wish to take
advantage of the power of the CLR and CLS [22]. Furthermore, C and C++, two widely-used
55

CHAPTER 6. RELATED WORK 56
languages are not fully supported within the framework.
The JNI is not the only way to bridge Java programs with native code. Liang [28] mentions
a number of ways to utilize inter-process communication to marshal data between processes
independently hosting the Java application and native code. These solutions, however, have
unacceptable performance characteristics (i.e., large memory footprints).
6.2 Programmer-Based Optimizations
Programmer-based optimizations to the JNI put the onus on the application programmer to
practice efficient coding techniques when writing native code that uses the JNI. A former IBM
developerWorks R© article [25] advised batching native calls and passing as much data as pos-
sible per native call, as well as a number of other recommendations to amortize overhead,
including using the ExceptionCheck call instead of ExceptionOccured because it is
less computationally expensive. Although this article is no longer available through develop-
erWorks, the recommended JNI programming practices are still valid.
Similarly, the JNI specification [28] suggests ways to avoid making JNI callbacks, by
caching field and method ids during static initialization of classes.
By reducing the overhead of the JNI automatically, our approach obviates these program-
ming practices, removing the added burden from the application programmer.
6.3 Restricting Functionality in Native Code
Restricting native code functionality is another way to reduce overhead and minimize the de-
pendence on JNI callbacks. The Intel ORP [12] gives JIT compilers the freedom to lay out
stack frames and use registers in any manner they want, thereby making them responsible
for unwinding the stack and enumerating roots for garbage collection (GC). Such unmanaged
code, however, requires the core virtual machine to generate special wrapper code for native

CHAPTER 6. RELATED WORK 57
methods which provide support for unwinding past native frames, and enumerating JNI ref-
erences during GC. The wrappers also include synchronization code for synchronized native
methods. In order to avoid the work performed by these wrappers, the ORP supports a “direct
call” mechanism that bypasses the construction of the wrappers. The speedup that results from
not having to perform maintenance work in the wrappers comes at the expense of not being
able to unwind the stack. Therefore, direct calls can only be used for native methods that are
guaranteed not to require garbage collection, exception handling, synchronization or any type
of security support.
The JNI specification [28] provides a set of “critical” functions that may return direct ref-
erences to JVM data and objects at the cost of limiting the programmer’s freedom (code that
lies within associated GetCritical and ReleaseCritical callbacks can not invoke any
functions that might potentially block the running JVM thread and result in indeterminate JVM
behaviour).
Bacon [3] has implemented a JVM-specific JNI “trap-door” which simplifies reference
management for garbage collection, based on the observation that his native code only accesses
primitive parameters and never performs any JNI callbacks.
Although these strategies might improve performance in certain circumstances, they are
not general solutions, severely restrict native code functionality and cannot be used for most
existing JNI code.
6.4 Proprietary Native Interfaces
Proprietary native interfaces that are coupled with JVMs take advantage of knowing the inter-
nals of the JVM in order to mitigate the overheads of native calls and callbacks.
The PERC Native Interface [33] (PNI) is a native code calling interface that ships with the
PERC VM. Although PERC claims that it runs three times faster than the JNI, the PNI doesn’t
provide some of the key safety features of the JNI.

CHAPTER 6. RELATED WORK 58
Microsoft’s now-supplanted Raw Native Interface [16] (RNI) exposed the binary layout of
Java objects, and returned pointers to underlying JVM data, providing efficient access to JVM
data at the cost of being JVM dependent.
More recently, gcj [10] from Cygnus Solutions compiles Java source code ahead of time
to native binary code. The Cygnus Native Interface (CNI) can be used to call C++ code from
Java source. This solution, however, restricts native code to CNI-supporting compilers.
JNIWrapper [29] is a commercially available API that addresses the programmer-unfriendly
nature of writing JNI code, but does little else. It does not provide a solution to the overheads
involved in using the native interface.
According to [32], the original Native Method Interface was deprecated because it coupled
native code to a specific JVM implementation too closely. As a side-effect, this restricted the
JVM to using conservative garbage collection algorithms.
In summary, all of these approaches closely couple the native interface with the specific
virtual machine, and thus seriously restrict portability. The JNI, in contrast, is a cleaner and
more portable solution because all JVM internals are represented in an opaque manner and can
only be accessed via JNI callbacks. This, ironically, lies at the heart of JNI-related overheads.
Our work is independent of the JVM being used and our technique can be utilized by those
who wish to support it.
6.5 Unmanaged Memory
A different approach to native code involves extending the JVM to support features for which
native functions are commonly used. One example is incorporating unmanaged memory into
the JVM. The provision of high-speed access to unmanaged memory can be used to implement
shared memory segments, memory-mapped files, communication and I/O buffers, and even
memory-mapped hardware devices.
Jaguar [42] implements Bytecode-to-assembly code mappings in a JIT compiler to generate

CHAPTER 6. RELATED WORK 59
inlined assembly code for limited sequences of machine code. The main use of the mappings
is to map object fields to memory outside the managed Java heap. The benefit of this approach
is that the performance obtained for various Java-based latency and bandwidth simulations ap-
proaches that recorded by native implementations. However, there are a number of limitations
with this approach, including the inability to recognize and map long, complex sequences of
Bytecodes, as well as the inability to apply mappings to virtual method invocations, since code
mappings can’t handle runtime class loading.
Buffers in the Java new I/O libraries [24] improve performance in the areas of primitive
type buffer management, scalable network and file I/O, character-set support, and regular-
expression matching. Buffers are allocated outside the garbage-collected heap, and can be
accessed by the JVM without having to perform any time-consuming copy operations. The
general recommended usage of direct buffers is for large, long-lived buffers that are subject to
the underlying system’s native I/O operations.
The PERC Native Interface (PNI) [33] also provides an alternative solution to unmanaged
memory by providing DirectMemory, consisting of static methods for reading and writing
data to external memory. The methods look just like regular Java functions, but are treated
separately by the PERCS Ahead-of-time and JIT compilers. These methods can further be
optimized by inlining them, disabling any array-bounds checking, and performing processor-
specific optimizations - resulting in machine instructions generated by a native compiler.
Generally speaking, our thesis is orthogonal to work on unmanaged memory.
6.6 Optimizing the JNI
Optimizations that target native functions and the JNI specifically include IBM’s enhancements
to the Java 2 Platform mentioned in [25] and inlining of helper code that sets up JNI stack
frames as mentioned in [12]. IBM also reuses existing Java stack frames to reduce the native
stack frame setup overhead.

CHAPTER 6. RELATED WORK 60
Andrews’ [1] optimizations include native memory mirroring, which effectively registers
static Java memory with native code, making writes to these statics immediately visible to
native code. Andrews also suggests provisioning the JNI for lightweight calls similar to what
Bacon [3] suggests.
The Intel ORP also speeds up the performance of native calls by using an inlined sequence
of instructions to allocate and initialize outgoing JNI reference handles directly. This is very
similar to IBM’s Direct2JNI mechanism (Section 3.1.1).
From the work described in [32], code generated by SGI’s IRIX Java JIT compiler uses
the same calling convention as native code. This minimizes the overhead in making transitions
from a JIT compiler’s calling convention to a native calling convention.
Work on efficient object serialization [36] also proposes changes to the JNI. It argues that
some benchmarks clearly advocate extending the JNI to provide a routine that can copy all
primitive type instance variables of an object into a buffer at once.
No known implementations of native function inlining exist, but they have been referred to
by Andrews [1] and by Liang [28] as a powerful, yet difficult-to-implement optimization.
Our solution demonstrates that native function inlining is feasible with a JIT compiler and
a mature native IL, and that the benefits of removing overhead alone may make it worthwhile.
Furthermore, native inlining enables more aggressive optimizations, similar to traditional in-
lining techniques, as we have shown in Section 5.6.

CHAPTER 6. RELATED WORK 61
6.7 Compiler IL as Runtime Program Data
Our strategy of retaining the IL generated by a traditional static compiler to support future opti-
mizations is similar to strategies used to support link-time cross-module inlining optimizations
in several commercial compilers, include those from HP [2] and IBM [26]. It is also remi-
niscent of the strategy for supporting “life-long” program optimization used in LLVM [27].
Storing the more compact representation (i.e., W-Code instead of TR-IL) and converting at
runtime is in keeping with the “slim binaries” strategy proposed by Franz and Kistler [18].

Chapter 7
Conclusions
This chapter describes the engineering issues that make our design harder to generalize, per-
formance issues that need to be accounted for, and directions that can be taken to further our
prototype implementation.
7.1 Engineering Issues
Some of the language features of Java that our implementation does not support include native
callsite polymorphism (i.e., overriding and overloading of native functions, including dynam-
ically changing the target of a native function call by using the RegisterNatives JNI
callback). These can be addressed by using virtual guards or other runtime assumption-based
techniques that require validation and ensure the execution of the correct version of native code.
Synchronized native functions also fall outside the scope of this thesis but can be handled
via simple synchronization handshaking with the JVM before, inside and after the inlined
callsite.
For the purposes of generating a proof-of-concept prototype, we have ignored handling
JNI callbacks that deal with string parameter access, reference creation, exception handling,
the Reflection-related functions, monitors and the invocation interface. Although these are
important features that must be handled in a full implementation, we believe this is a matter
62

CHAPTER 7. CONCLUSIONS 63
of engineering, and one that will not substantially alter the applicability of our native function
inlining optimization.
We have not yet built the generalized shape-matching or the control-flow dependent use/def
analysis required to automatically detect and transform all callbacks. Although the pattern-
matching nature of our callback identification mechanism is restrictive, we believe that it
handles a sufficient amount of native functions especially if written in the style suggested by
Liang [28]. Certain J9 virtual machine data structures might also need to be altered in order to
identify arguments to JNI callbacks that originate from cached storage.
Our implementation ignores inlining native functions with variable length parameter lists
and parameters whose addresses are taken. Our inliner wasn’t able to guarantee the preser-
vation of the stack-semantics for these C language-based features. We also don’t handle any
of the Call[Static]<Type>Method callbacks that accept arguments in array or variable
list form.
Finally, there is a need for a robust infrastructure that maps native functions to their ap-
propriate libraries (containing W-Code data). As it stands, the path and names of many native
libraries are hard-coded into our copy of the JIT compiler source. A side-effect of this is our
inability to recursively inline non-opaque native functions declared in external modules. The
simplest solution is a lookup-table based approach for the mapping. A more elegant solution
would see this be part of a dynamic library loading scheme that would invalidate JIT compiled
code dependent on unloaded native modules.
7.2 Performance Issues
Although a JIT compiler is unlikely to be able to compete with a static native code optimizer,
the W-Code IL stored alongside our native binaries is the output of a sophisticated interpro-
cedural optimizer and loop transformer. This provides the TR JIT compiler with some of the
benefits of static analysis that could not be contained in the compile-time budget of a dynamic

CHAPTER 7. CONCLUSIONS 64
compiler. We have also demonstrated (in Section 5.6) that some of the runtime information
unavailable to static optimizers helps further improve the quality of the inlined native code. At
this time, however, we do not have results that allow us to compare the performance of our
inlined native code against their statically compiled counterparts.
As with any JIT optimization, we wish to amortize the cost of performing the optimization
by obtaining significant runtime benefits from native function inlining and optimizing call-
back transformation. Our inlining strategy, however, must also deal with native code that is
non-inlineable and callbacks that are non-transformable. Furthermore, it must provide correct
linkages for program data that becomes shared between Java and native code as a byproduct
of inlining, and most importantly, it should enforce both native language and JNI semantics on
any inlined and transformed code. By focusing on microbenchmark results, we have omitted a
comprehensive analysis of the costs of these runtime decisions and interactions. Furthermore,
the use of microbenchmarks implies a lower than expected level of stress on the JVM and JIT
compiler, making our results potentially more favorable.
We should also note that we have completely ignored the eight-way nature of the test system
we used to run our microbenchmark tests, as well as the level of stress on the system during
our runs. Even though our microbenchmark tests are all single-threaded, the JVM we use in
our implementation is multi-threaded. Our results therefore ignore any processor scheduling
effects on JVM performance. We have also run our tests multiple times to eliminate any noise
that may result from varied stress levels on our system. Our raw results are consistent across
all runs.
7.3 Future Directions
Besides the previously mentioned engineering and performance issues, our implementation
wasn’t overly concerned with modifying the TR JIT inliner’s heuristics, except for some fine-
tuning that recognized a number of differences between Java and native functions (i.e., function

CHAPTER 7. CONCLUSIONS 65
size).
Explorable heuristics include the IL-conversion cost heuristic mentioned in Chapter 5 as
well as a heuristic that uses the number of opaque calls contained in a potentially-inlineable
native function to guide runtime native inlining decisions. Developing and examining the out-
come of using heuristics such as these and others make for interesting future work.
Another heuristic that could be used during the callback transformation phase is one that
examines the context of the callback with respect to the host architecture. For example, if the
character conventions used by the JVM and the host architecture are different (i.e., Unicode
vs. Unicode Transformation Format-8), an inlined GetStringUTFChars callback which
provides a value that is used in a synthesized call to printf will still require an expensive
copy and string format conversion. In such a situation, it may be more profitable to leave the
original Java-callable native callsite alone.
One might also want to extend our work to cover a larger set of native languages (i.e., those
that have W-Code emitting front ends) and derive a larger infrastructure for cross language
interoperability. Looking at it from another perspective, this would mean an infrastructure that
makes static languages more “dynamic”.
7.4 Conclusion
In this thesis we presented a novel strategy that reduces the performance penalties incurred
by Java applications invoking native functions, as well as native code performing JNI call-
backs. By using an optimizing JIT compiler to inline native function calls at runtime, the cost
of calling and returning from native code is completely eliminated. Our strategy also per-
forms optimizing transformations on expensive JNI callbacks, transforming them to cheaper
but semantically-equivalent operations.
Our solution preserves the semantics of the native language when inlining by converting
native code IL to the JIT compiler’s internal representation. This is done by extracting native

CHAPTER 7. CONCLUSIONS 66
IL that is stored alongside statically optimized native binaries. When performing inlining, the
JIT compiler is also able to remove pessimistic assumptions on the side-effects of Java code
containing opaque native function calls, and performs an aggressive suite of optimizations to
further increase the performance of inlined native code.
Microbenchmark tests measuring performance indicate our prototypical implementation
significantly speeds up Java applications containing native function calls. In most cases, our
strategy is able to reclaim the overheads attributed to native calls and JNI callbacks.
We have also identified opportunities to extend our work to a full implementation. Besides
a number of engineering issues and performance concerns, we have highlighted heuristics that
may guide the JIT compiler in making better runtime inlining decisions.

Appendix
This appendix describes each microbenchmark test and presents the raw data used to derive
our experimental results. The following tables represent the time to perform 100 million calls
for each microbenchmark test. The calls were made from a loop, which was timed using
System.currentTimeMillis(). The overhead of the loop was then subtracted from
the recorded time by recording the length of time an empty loop iterates 100 million times.
Each test was run three times for accuracy. The results reported in Chapter 5 are the average of
each set of three runs converted to nanoseconds and divided by 100 million.
W-Code Conversion Costs - Measurements
Table A.1 contains the raw data used to derive the results of Figure 5.1 in Chapter 5. We report
the total number of opcodes converted, the total time for the conversion, and the average time
per opcode for each benchmark.
Inlining Callouts - Measurements
Table A.2 contains the raw data used to derive the results of Section 5.3. The microbenchmark
tests that were run include:
• 0 args, 1 arg, 3 args and 5 args are empty native method calls with the indicated number
of parameters
67
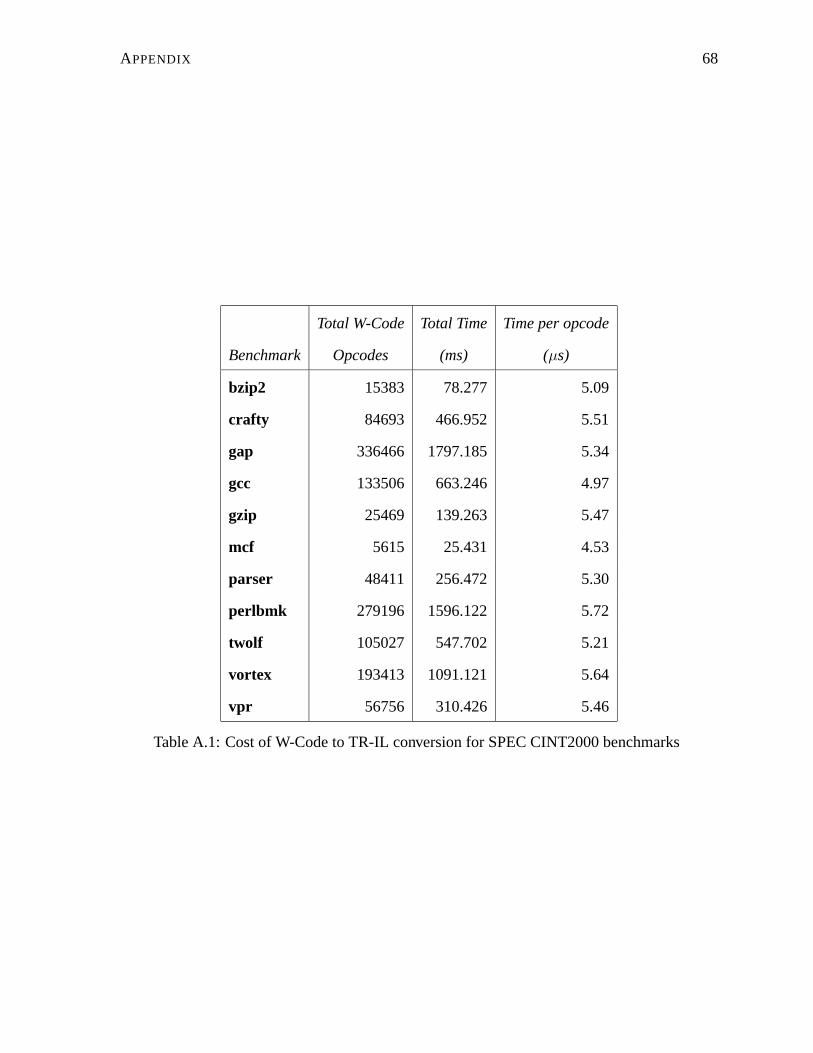
APPENDIX 68
Total W-Code Total Time Time per opcode
Benchmark Opcodes (ms) (µs)
bzip2 15383 78.277 5.09
crafty 84693 466.952 5.51
gap 336466 1797.185 5.34
gcc 133506 663.246 4.97
gzip 25469 139.263 5.47
mcf 5615 25.431 4.53
parser 48411 256.472 5.30
perlbmk 279196 1596.122 5.72
twolf 105027 547.702 5.21
vortex 193413 1091.121 5.64
vpr 56756 310.426 5.46
Table A.1: Cost of W-Code to TR-IL conversion for SPEC CINT2000 benchmarks
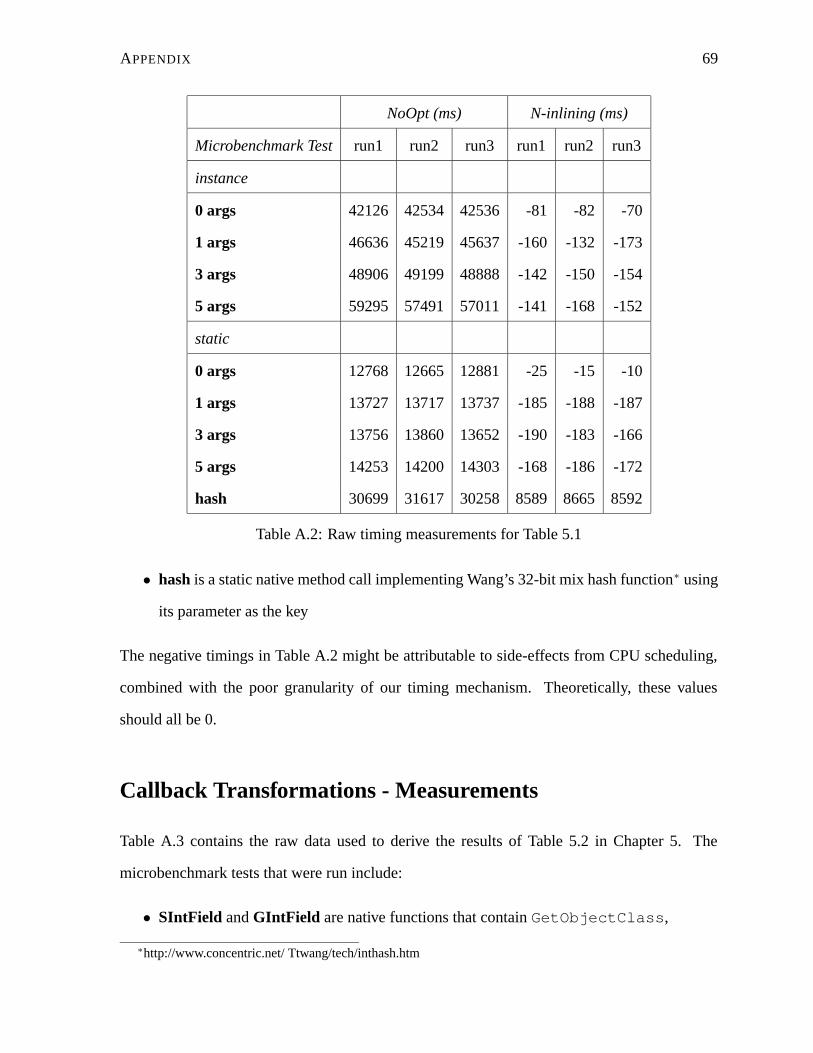
APPENDIX 69
NoOpt (ms) N-inlining (ms)
Microbenchmark Test run1 run2 run3 run1 run2 run3
instance
0 args 42126 42534 42536 -81 -82 -70
1 args 46636 45219 45637 -160 -132 -173
3 args 48906 49199 48888 -142 -150 -154
5 args 59295 57491 57011 -141 -168 -152
static
0 args 12768 12665 12881 -25 -15 -10
1 args 13727 13717 13737 -185 -188 -187
3 args 13756 13860 13652 -190 -183 -166
5 args 14253 14200 14303 -168 -186 -172
hash 30699 31617 30258 8589 8665 8592
Table A.2: Raw timing measurements for Table 5.1
• hash is a static native method call implementing Wang’s 32-bit mix hash function∗ using
its parameter as the key
The negative timings in Table A.2 might be attributable to side-effects from CPU scheduling,
combined with the poor granularity of our timing mechanism. Theoretically, these values
should all be 0.
Callback Transformations - Measurements
Table A.3 contains the raw data used to derive the results of Table 5.2 in Chapter 5. The
microbenchmark tests that were run include:
• SIntField and GIntField are native functions that contain GetObjectClass,
∗http://www.concentric.net/ Ttwang/tech/inthash.htm

APPENDIX 70
GetFieldID, SetIntField and GetIntField callbacks, respectively, which are
transformed to compile-time constants and direct field reads and writes.
• SStaticIntField and GStaticIntField contain GetStaticFieldID,
SetStaticIntField and GetStaticIntField callbacks, respectively, which
are transformed to compile-time constants and direct field reads and writes
• CVoidMethodE contains GetObjectClass, GetMethodID and
CallVoidMethod callbacks which are transformed to compile-time constants and a
virtual function call. The void method being called assigns its arguments to local vari-
ables.
• CStaticVoidMethodE contains GetMethodID and CallStaticVoidMethod call-
backs which are transformed to a compile-time constant and a direct function call. The
void method being called assigns its arguments to local variables.
• CIntMethodE contains GetObjectClass, GetMethodID and CallIntMethod
callbacks which are transformed to compile-time constants and a virtual function call.
The integer returning method being called performs a simple algebraic operation on its
arguments and returns its result.
• CStaticIntMethodE contains GetMethodID and CallStaticIntMethod call-
backs which are transformed to a compile-time constant and a direct function call. The
integer returning method being called performs a simple algebraic operation on its argu-
ments and returns its result.
The negative timings in Table A.3 might be attributable to side-effects from CPU scheduling,
combined with the poor granularity of our timing mechanism. Theoretically, these values
should all be 0.
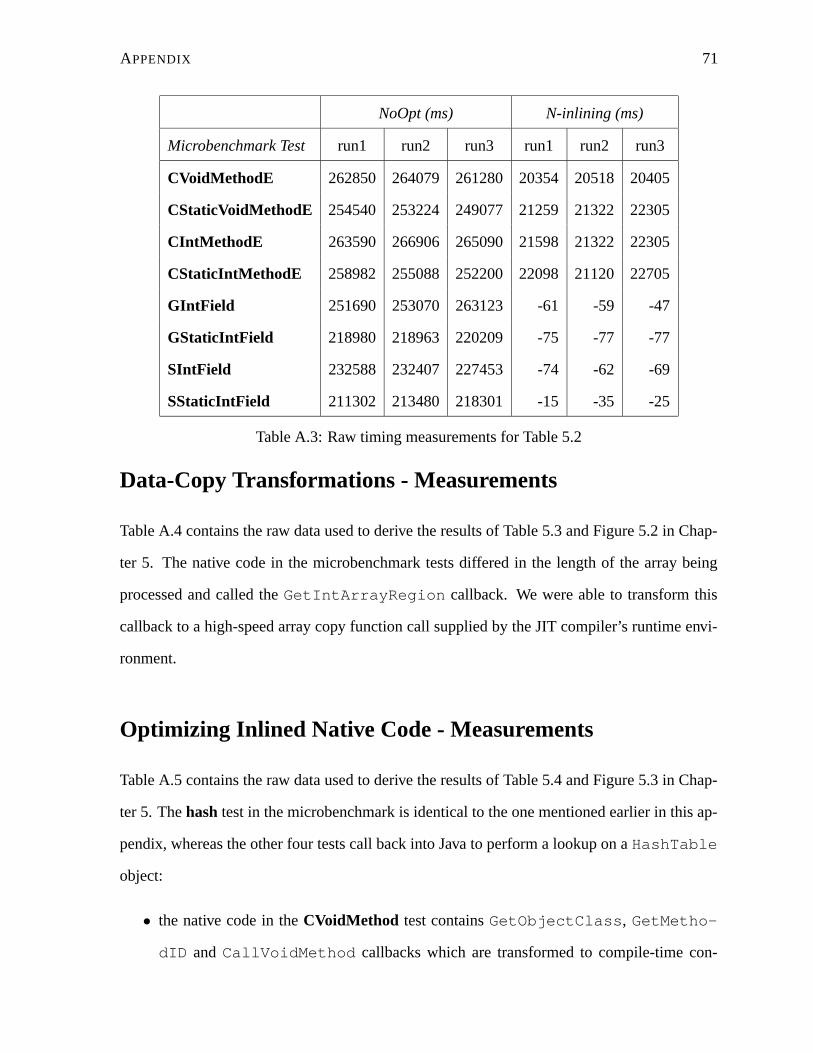
APPENDIX 71
NoOpt (ms) N-inlining (ms)
Microbenchmark Test run1 run2 run3 run1 run2 run3
CVoidMethodE 262850 264079 261280 20354 20518 20405
CStaticVoidMethodE 254540 253224 249077 21259 21322 22305
CIntMethodE 263590 266906 265090 21598 21322 22305
CStaticIntMethodE 258982 255088 252200 22098 21120 22705
GIntField 251690 253070 263123 -61 -59 -47
GStaticIntField 218980 218963 220209 -75 -77 -77
SIntField 232588 232407 227453 -74 -62 -69
SStaticIntField 211302 213480 218301 -15 -35 -25
Table A.3: Raw timing measurements for Table 5.2
Data-Copy Transformations - Measurements
Table A.4 contains the raw data used to derive the results of Table 5.3 and Figure 5.2 in Chap-
ter 5. The native code in the microbenchmark tests differed in the length of the array being
processed and called the GetIntArrayRegion callback. We were able to transform this
callback to a high-speed array copy function call supplied by the JIT compiler’s runtime envi-
ronment.
Optimizing Inlined Native Code - Measurements
Table A.5 contains the raw data used to derive the results of Table 5.4 and Figure 5.3 in Chap-
ter 5. The hash test in the microbenchmark is identical to the one mentioned earlier in this ap-
pendix, whereas the other four tests call back into Java to perform a lookup on a HashTable
object:
• the native code in the CVoidMethod test contains GetObjectClass, GetMetho-
dID and CallVoidMethod callbacks which are transformed to compile-time con-
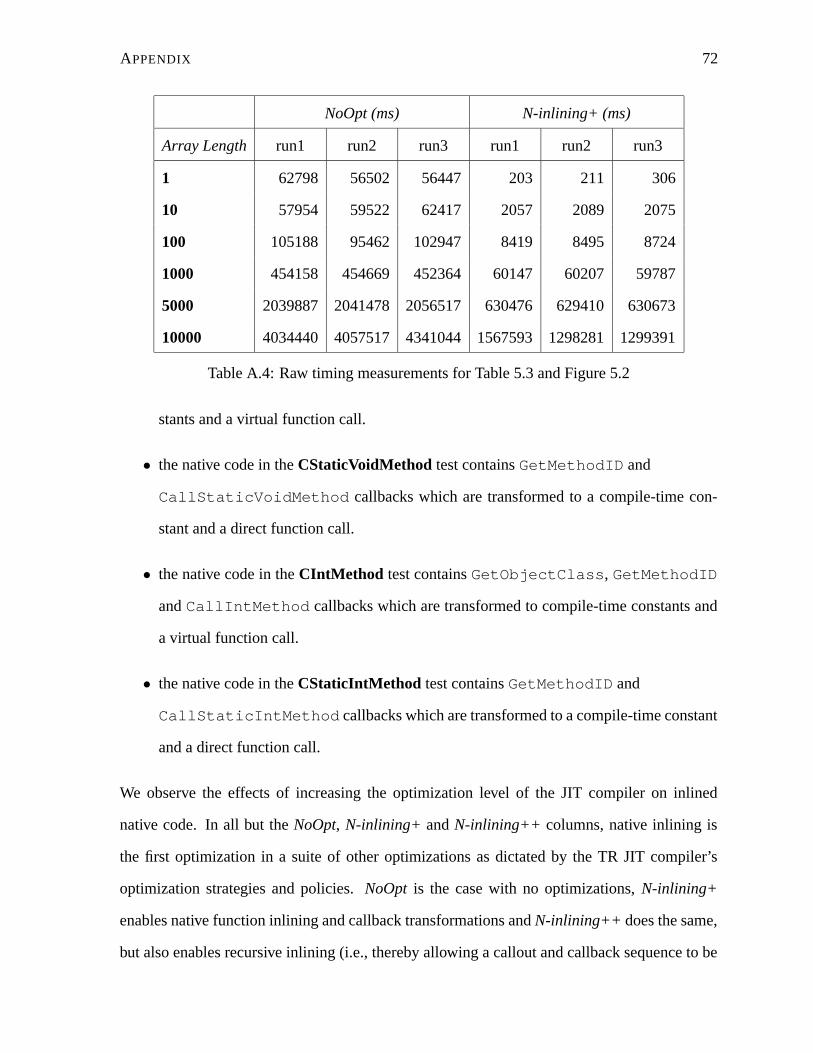
APPENDIX 72
NoOpt (ms) N-inlining+ (ms)
Array Length run1 run2 run3 run1 run2 run3
1 62798 56502 56447 203 211 306
10 57954 59522 62417 2057 2089 2075
100 105188 95462 102947 8419 8495 8724
1000 454158 454669 452364 60147 60207 59787
5000 2039887 2041478 2056517 630476 629410 630673
10000 4034440 4057517 4341044 1567593 1298281 1299391
Table A.4: Raw timing measurements for Table 5.3 and Figure 5.2
stants and a virtual function call.
• the native code in the CStaticVoidMethod test contains GetMethodID and
CallStaticVoidMethod callbacks which are transformed to a compile-time con-
stant and a direct function call.
• the native code in the CIntMethod test contains GetObjectClass, GetMethodID
and CallIntMethod callbacks which are transformed to compile-time constants and
a virtual function call.
• the native code in the CStaticIntMethod test contains GetMethodID and
CallStaticIntMethod callbacks which are transformed to a compile-time constant
and a direct function call.
We observe the effects of increasing the optimization level of the JIT compiler on inlined
native code. In all but the NoOpt, N-inlining+ and N-inlining++ columns, native inlining is
the first optimization in a suite of other optimizations as dictated by the TR JIT compiler’s
optimization strategies and policies. NoOpt is the case with no optimizations, N-inlining+
enables native function inlining and callback transformations and N-inlining++ does the same,
but also enables recursive inlining (i.e., thereby allowing a callout and callback sequence to be

APPENDIX 73
inlined). The values contained in the table are milliseconds (ms).
Table A.6 contains the raw data used to derive the GArrayLength results of Table 5.5
in Chapter 5. GArrayLength contains FindClass GetMethodID, NewCharArray, and
GetArrayLength, used to instantiate a new character array and return its length - these calls
are transformed to compile-time constants as well as a more direct array length function call.
Synthesis Benefits - Measurements
Table A.7 contains the raw data used to derive the results of Table 5.6 in Chapter 5. The
microbenchmark tests include:
• printfS contains a function call to printf passing an empty string
• printfL contains a function call to printf passing the string “Hello World”
• atoiS contains a function call to atoi passing the string “123”
• atoiL contains a function call to atoi passing the string “1234567890”
• strlenS contains a function call to strlen passing the string “I”
• strlenL contains a function call to strlen passing the string “IEEEEEEEEEEEEEE”
• File I/O contains a sequence of fopen, fread, fwrite, fseek, rewind, fclose
and printf function calls
The four other tests (G[Static]Intfield and S[Static]IntField are identical to the ones men-
tioned earlier, except that the JNI function call involving the Java function is synthesized in-
stead of transformed.
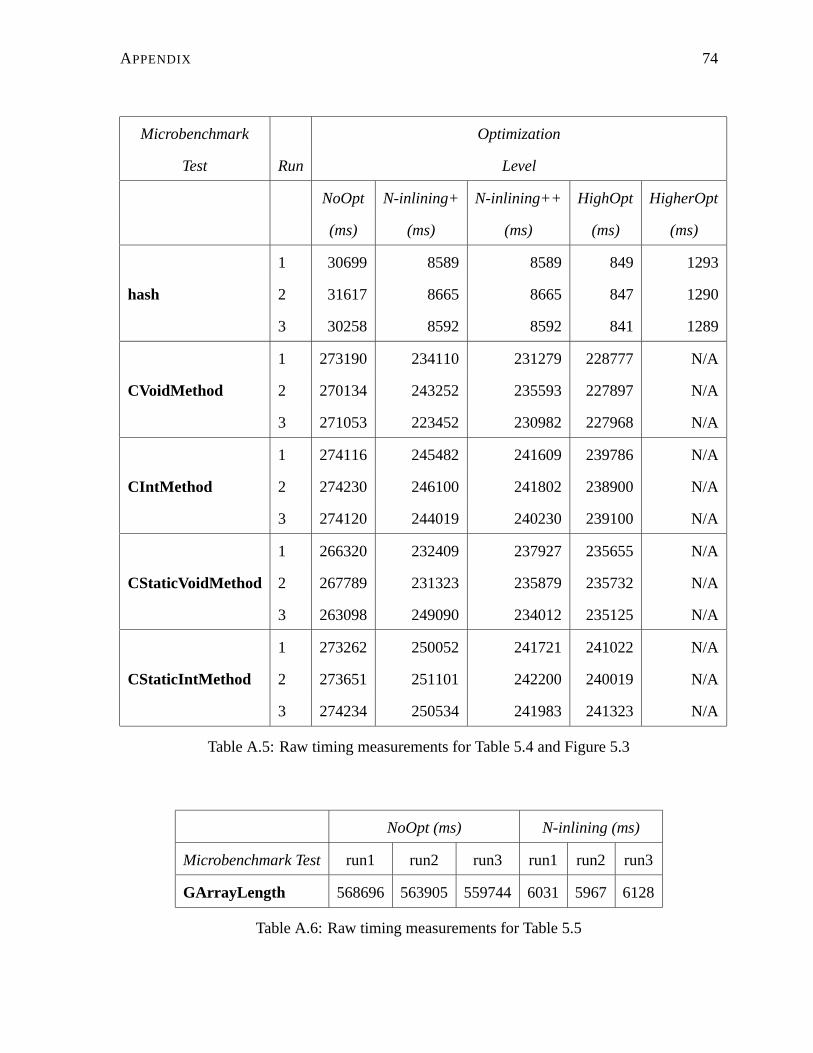
APPENDIX 74
Microbenchmark Optimization
Test Run Level
NoOpt N-inlining+ N-inlining++ HighOpt HigherOpt
(ms) (ms) (ms) (ms) (ms)
hash
1 30699 8589 8589 849 1293
2 31617 8665 8665 847 1290
3 30258 8592 8592 841 1289
CVoidMethod
1 273190 234110 231279 228777 N/A
2 270134 243252 235593 227897 N/A
3 271053 223452 230982 227968 N/A
CIntMethod
1 274116 245482 241609 239786 N/A
2 274230 246100 241802 238900 N/A
3 274120 244019 240230 239100 N/A
CStaticVoidMethod
1 266320 232409 237927 235655 N/A
2 267789 231323 235879 235732 N/A
3 263098 249090 234012 235125 N/A
CStaticIntMethod
1 273262 250052 241721 241022 N/A
2 273651 251101 242200 240019 N/A
3 274234 250534 241983 241323 N/A
Table A.5: Raw timing measurements for Table 5.4 and Figure 5.3
NoOpt (ms) N-inlining (ms)
Microbenchmark Test run1 run2 run3 run1 run2 run3
GArrayLength 568696 563905 559744 6031 5967 6128
Table A.6: Raw timing measurements for Table 5.5
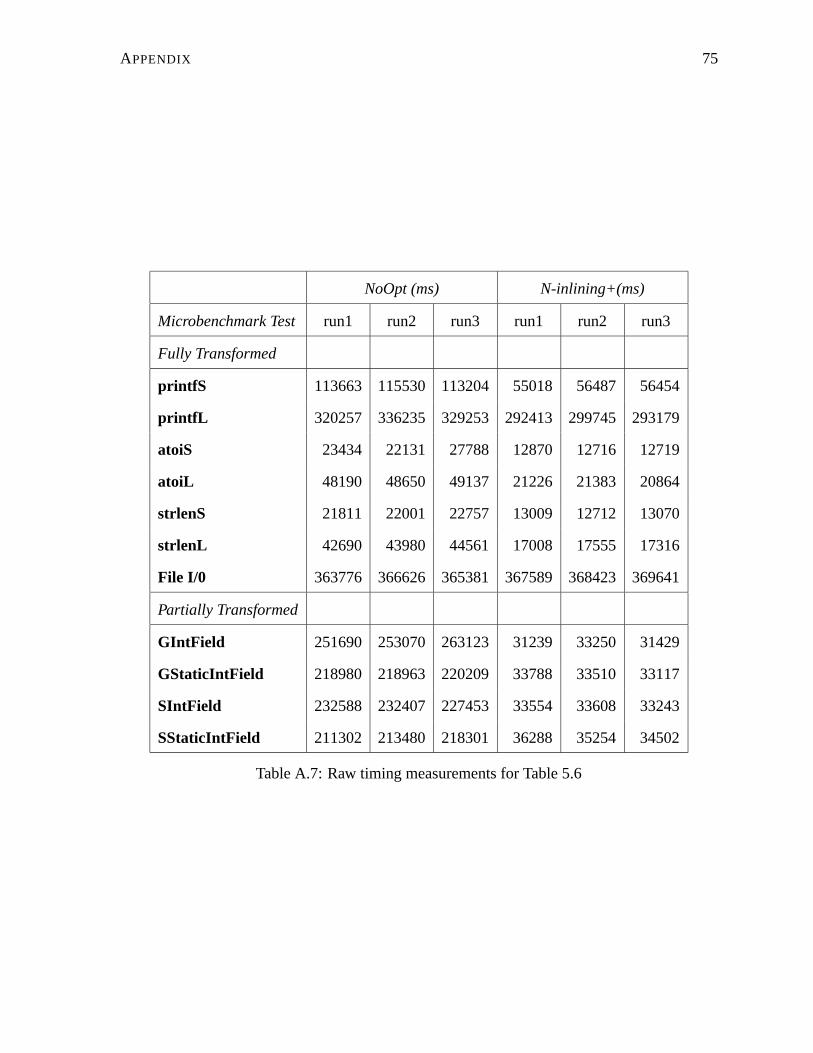
APPENDIX 75
NoOpt (ms) N-inlining+(ms)
Microbenchmark Test run1 run2 run3 run1 run2 run3
Fully Transformed
printfS 113663 115530 113204 55018 56487 56454
printfL 320257 336235 329253 292413 299745 293179
atoiS 23434 22131 27788 12870 12716 12719
atoiL 48190 48650 49137 21226 21383 20864
strlenS 21811 22001 22757 13009 12712 13070
strlenL 42690 43980 44561 17008 17555 17316
File I/0 363776 366626 365381 367589 368423 369641
Partially Transformed
GIntField 251690 253070 263123 31239 33250 31429
GStaticIntField 218980 218963 220209 33788 33510 33117
SIntField 232588 232407 227453 33554 33608 33243
SStaticIntField 211302 213480 218301 36288 35254 34502
Table A.7: Raw timing measurements for Table 5.6

Bibliography
[1] Jack Andrews. Interfacing Java with native code: Performance limits. IT-
toolbox for Java Technologies Knowledge Base web site, Peer Publishing section.
http://java.ittoolbox.com/documents/document.asp?i=780#, 2000. Also available at
http://www.str.com.au/jnibench.
[2] Andrew Ayers, Stuart de Jong, John Peyton, and Richard Schooler. Scalable cross-module
optimization. In PLDI ’98: Proceedings of the ACM SIGPLAN 1998 conference on Pro-
gramming language design and implementation, pages 301–312. ACM Press, 1998.
[3] David F. Bacon. JaLA: A Java package for linear algebra. Presented at the Computer
Science Division, University of California, Berkeley, 1998. IBM T.J. Watson Research
Center.
[4] Mark Baker, Bryan Carpenter, Geoffrey Fox, Sung Hoon Ko, and Xinying Li. mpiJava:
A Java interface to MPI. In Proceedings of the First UK Workshop, Java for High Perfor-
mance Network Computing at EuroPar, Southampton, UK, September 1998.
[5] Paolo Bellavista, Antonio Corradi, and Cesare Stefanelli. How to Monitor and Control
Resource Usage in Mobile Agent Systems. In Proceedings of the Third IEEE Interna-
tional Symposium on Distributed Objects and Applications, pages 65–75, Rome, Italy,
September 17–20 2001.
[6] Robert Bernecky. Apex: The apl parallel executor. Master’s thesis, University of Toronto,
1997.
76

BIBLIOGRAPHY 77
[7] Aart J. C. Bik and Dennis Gannon. A Note on Native Level 1 BLAS in Java. Concurrency:
Practice and Experience, 9(11):1091–1099, 1997.
[8] Andrew D. Birrell and Bruce Jay Nelson. Implementing remote procedure calls. ACM
Transactions on Computer Systems, 2(1):39–59, 1984.
[9] Per Bothner. Java/C++ integration - writing native Java methods in natural C++.
http://gcc.gnu.org/java/papers/native++.html, November 1997.
[10] Per Bothner. Compiling Java with GCJ. Linux Journal, 105, January 1 2003.
http://www.linuxjournal.com/print.php?sid=4860.
[11] Fabian Breg and Constantine D. Polychronopoulos. Java virtual machine support for
object serialization. In Proceedings of the 2001 Joint ACM-ISCOPE Conference on Java
Grande, pages 173–180, Palo Alto, California, June 2–4 2001.
[12] Michal Cierniak, Marsha Eng, Neal Glew, Brian Lewis, and James Stichnoth. The Open
Runtime Platform: A Flexible High-Performance Managed Runtime Environment. Intel
Technology Journal, 7(1), February 2003.
[13] IBM Corporation. Ibm aix 5l - unix operating system. http://www-
1.ibm.com/servers/aix/.
[14] IBM Corporation. The PowerPC Compiler Writer’s Guide. Warthman Associates, 1996.
[15] IBM Corporation. Aix 5l version 5.3 - technical reference: Base operating system and
extensions, volume 1 (a-p), December 2004.
[16] Bruce Eckel. Thinking in Java. Prentice-Hall, 1st edition, 1998.
[17] Robert Fitzgerald, Todd B. Knoblock, Erik Ruf, Bjarne Steensgard, and David Tarditi.
Marmot: An optimizing compiler for Java. Technical Report MSN-TR-99-33, Microsoft
Inc., June 16 1999.

BIBLIOGRAPHY 78
[18] Michael Franz and Thomas Kistler. Slim binaries. Communications of the ACM,
40(12):87–94, December 1997.
[19] Vladimira Getov, Susan Flynn Hummel, and Sava Mintchev. High-performance parallel
programming in Java: exploiting native libraries. Concurrency: Practice and Experience,
10(11–13):863–872, 1998.
[20] Andrew D. Gordon and Don Syme. Typing a multi-language intermediate code. ACM
SIGPLAN Notices, 36(3):248–260, March 2001.
[21] James Gosling, Bill Joy, and Guy Steele. The Java Language Specification. Addison-
Wesley, 1996.
[22] Mark Hammond, Brad Abrams, and Damien Watkins. Programming in the .NET Envi-
ronment. Addison-Wesley, 2003.
[23] Bjørn-Ove Heimsund. Native Numerical Interface (NNI).
http://www.math.uib.no/ bjornoh/mtj/nni/, November 2004.
[24] Ron Hitchens. Java NIO. O’Reilly and Associates, Inc., August 2002.
[25] IBM Corporation. IBM rewrites the book on Java performance.
http://www.developer.ibm.com/java/j2/j2perfpaper.html.
[26] IBM Corporation. XL FORTRAN: Eight ways to boost performance. White Paper, 2000.
[27] Chris Lattner and Vikram Adve. LLVM: A compilation framework for lifelong program
analysis & transformation. In Proceedings of the 2004 International Symposium on Code
Generation and Optimization, pages 75–87, San Jose, California, March 20–24 2004.
[28] Sheng Liang. The Java Native Interface. Programmer’s Guide and Specification.
Addison-Wesley, 1999.
[29] MIIK Ltd. Jniwrapper. http://www.jniwrapper.com/index.jsp.

BIBLIOGRAPHY 79
[30] Microsoft Inc. Com: Component object model technologies.
http://www.microsoft.com/com/default.mspx.
[31] Michael Lazar Milvich. JavaCAVE: A 3D immersive environment in Java. Master’s
thesis, Montana State University, July 13 2004.
[32] Paul M. Murray, Todd Smith, Suresh Srinivas, and Mattias Jacob. Performance issues
for multi-language Java applications. In Proceedings of the 15 International Parallel and
Distributed Processing Symposium 2000 Workshops, volume 1800 of Lecture Notes in
Computer Science, pages 544–551, Cancun, Mexico, May 1–5 2000. Springer.
[33] NewMonics Inc. Best practices for native code integration with perc.
http://www.newmonics.com/perceval/native whitepaper.shtml, February 26 2003.
[34] Steve Northover. SWT: The Standard Widget Toolkit, Part 1: Implementation Strategy
for JavaTM Natives. http://www.eclipse.org/articles/Article-SWT-Design-1/SWT-Design-
1.html, March 2001.
[35] Hirotaka Ogawa, Kouya Shimura, Satoshi Matsuoka, Fuyuhiko Maruyama, Yukihiko So-
hda, and Yasunori Kimura. OpenJIT: An Open-Ended, Reflective JIT Compiler Frame-
work For Java. In Proceedings of the 14th European Conference on Object-Oriented Pro-
gramming, volume 1850 of Lecture Notes in Computer Science, pages 362–387, Sophia
Antipolis and Cannes, France, June 12–16 2000. Springer.
[36] Michael Philippsen and Bernhard Haumacher. More efficient object serialization. In
Proceedings of the 11 IPPS/SPDP’99 Workshops Held in Conjunction with the 13th In-
ternational Parallel Processing Symposium and the 10th Symposium on Parallel and Dis-
tributed Processing, volume 1586 of Lecture Notes in Computer Science, pages 718–732,
San Juan, Puerto Rico, April 12–16 1999. Springer.

BIBLIOGRAPHY 80
[37] Vladimir Roubtsov. Profiling cpu usage from within a Java application.
http://www.javaworld.com/javaworld/javaqa/2002-11/01-qa-1108-cpu.html, November
2002.
[38] Todd Scallan. a corba primer. http://www.omg.org/news/whitepapers/seguecorba.pdf,
June 3 2002.
[39] Davanum Srinivas. Java tip 86: Support native rendering in jdk 1.3.
http://www.javaworld.com/javaworld/javatips/jw-javatip86.html.
[40] Standard Performance Evaluation Corporation. SPEC CPU2000 V1.2.
http://www.spec.org/cpu2000.
[41] Vaidy Sunderam and Dawid Kurzyniec. Efficient cooperation between Java and native
codes – JNI performance benchmark. In Proceedings of the 2001 International Confer-
ence on Parallel and Distributed Processing Techniques and Applications, Las Vegas,
Nevada, June 25–28 2001.
[42] Matt Welsh and David Culler. Jaguar: Enabling efficient communication and I/O in Java.
Concurrency: Practice and Experience, 12(7):519–538, May 2000.
[43] Seth White, Maydene Fisher, Rick Cattell, Graham Hamilton, and Mark Hapner. JDBCTM
API Tutorial and Reference: Universal Data Access for the JavaTM 2 Platform (2nd Edi-
tion). Pearson Education, June 1999.
[44] Peng Wu, Samuel P. Midkiff, Jose E. Moreira, and Manish Gupta. Efficient support for
complex numbers in java. In Proceedings of the ACM 1999 Java Grande Conference,
pages 109–118, San Francisco, California, June 1999.