Embed Size (px)
Citation preview

Building a high scale machine learning pipeline
with Apache Spark and Kafka
https://www.flickr.com/photos/sanjayaprime/5013115478Bedő Dániel

• biggest community-driven question & answer website in Germany
• 20 million questions, 70 million answers
• similar to Quora, Yahoo Answers

Google Update Impact

Ordering of answers

supervised machine learning
determine the type of the training data
gather a training set
find a representation of the data
pick a learning algorithm
run the training algorithm
evaluate the accuracy
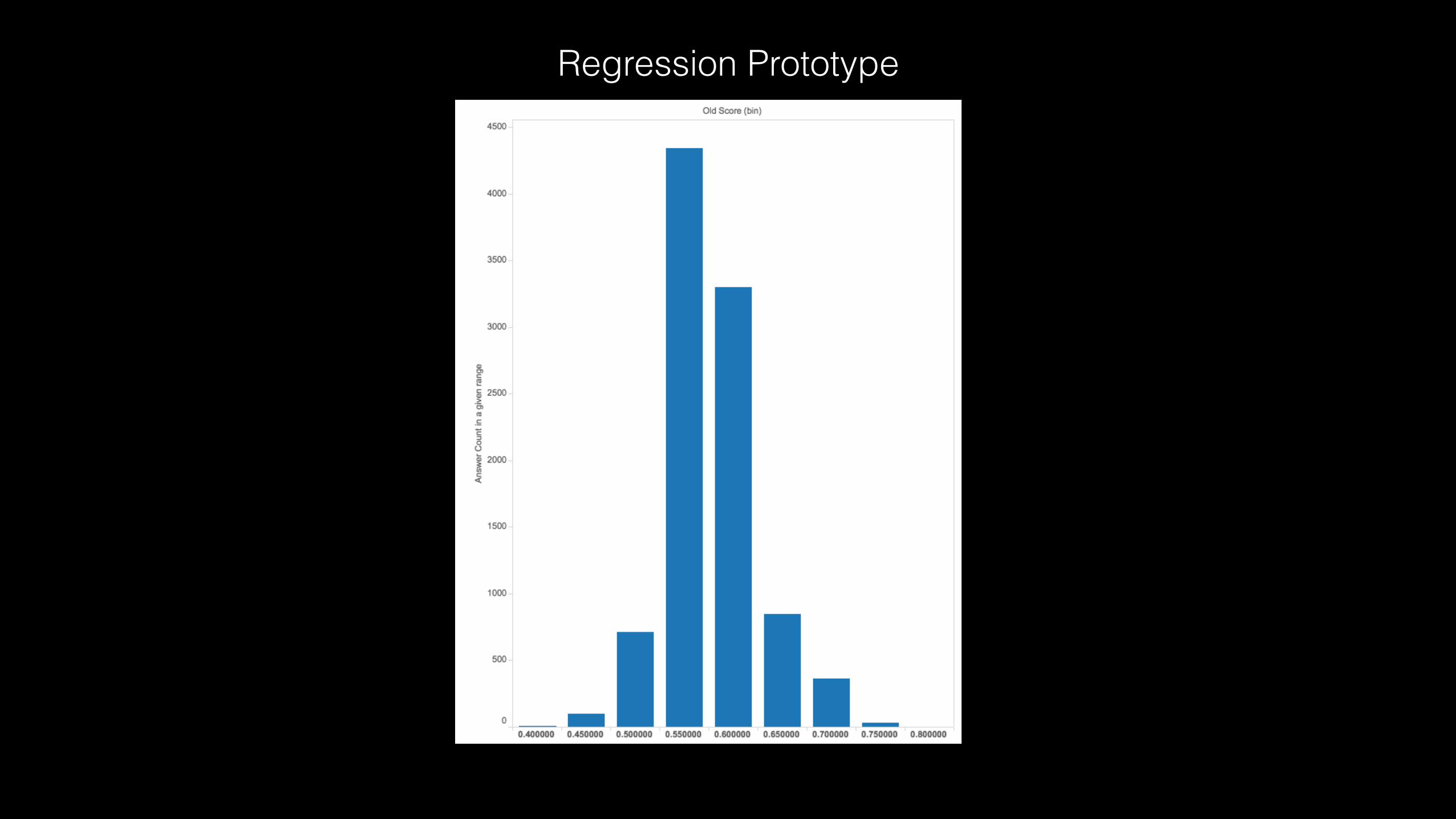
Regression Prototype

Identify the problems
• Model not complex enough
• Similar inputs, different outputs?
• Not enough training data
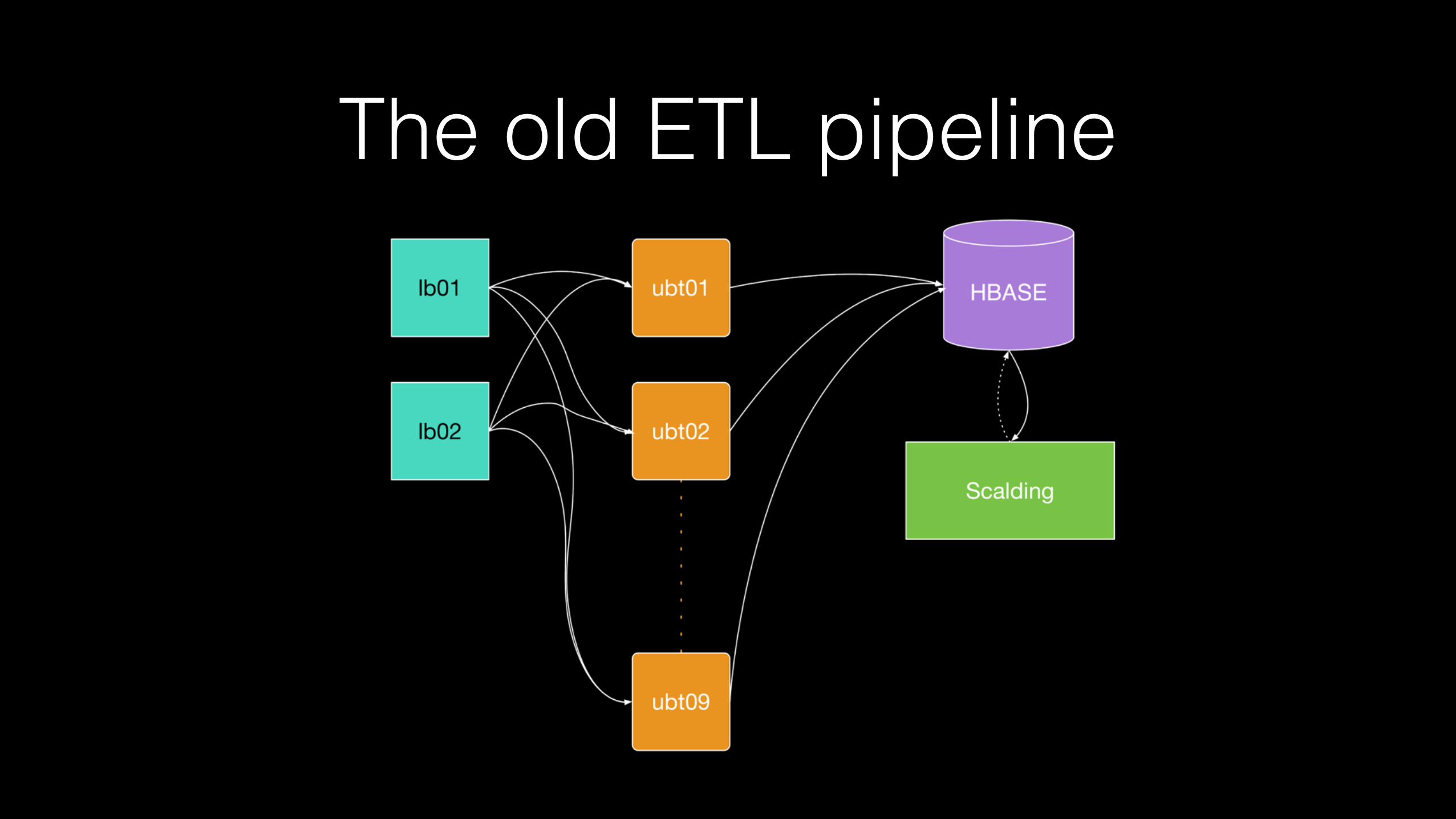
The old ETL pipeline
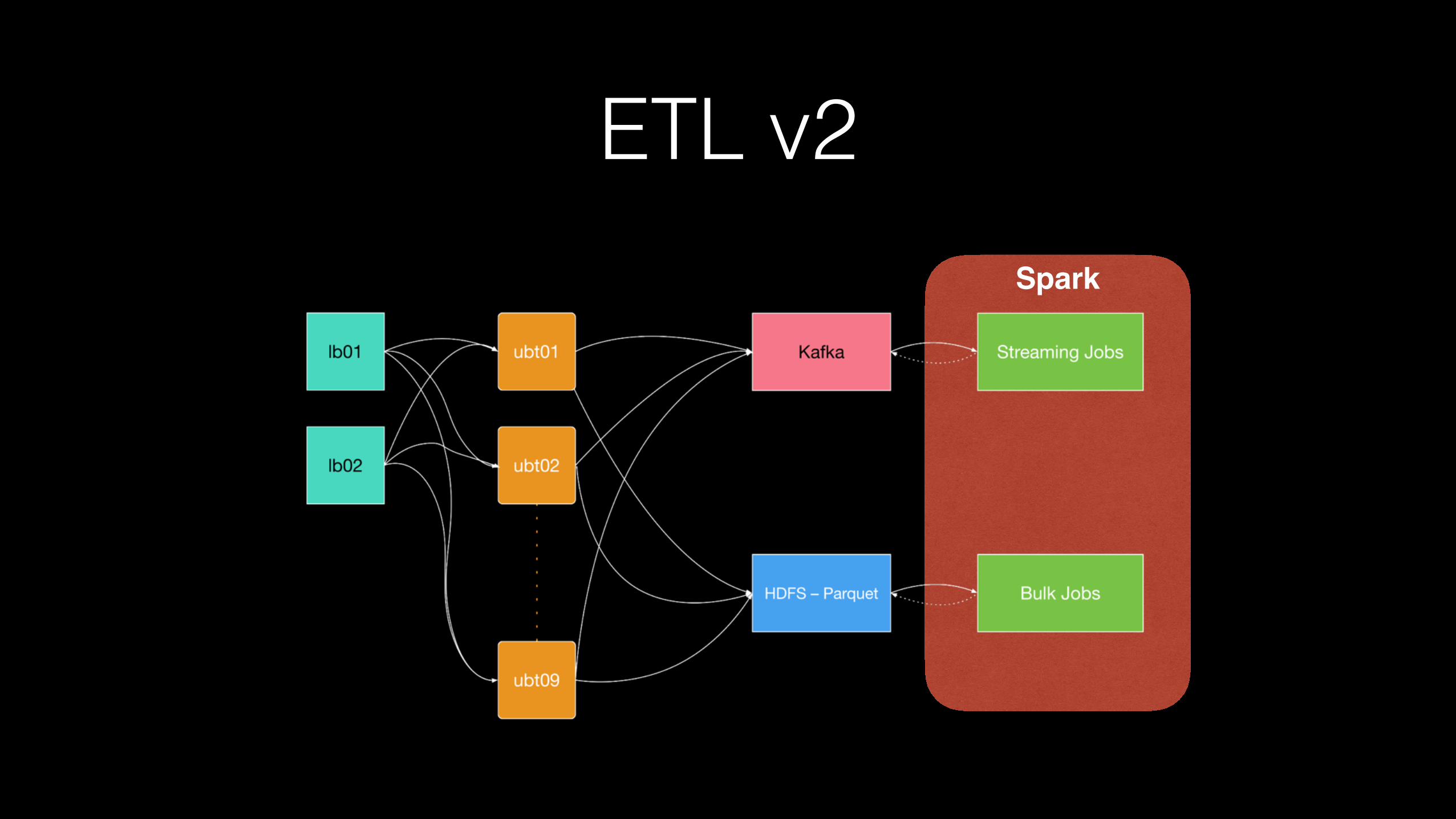
ETL v2Spark

Spark ecosystem
API
Scala Python Java R
Spark Streaming
Spark SQL MLLib GraphX
K
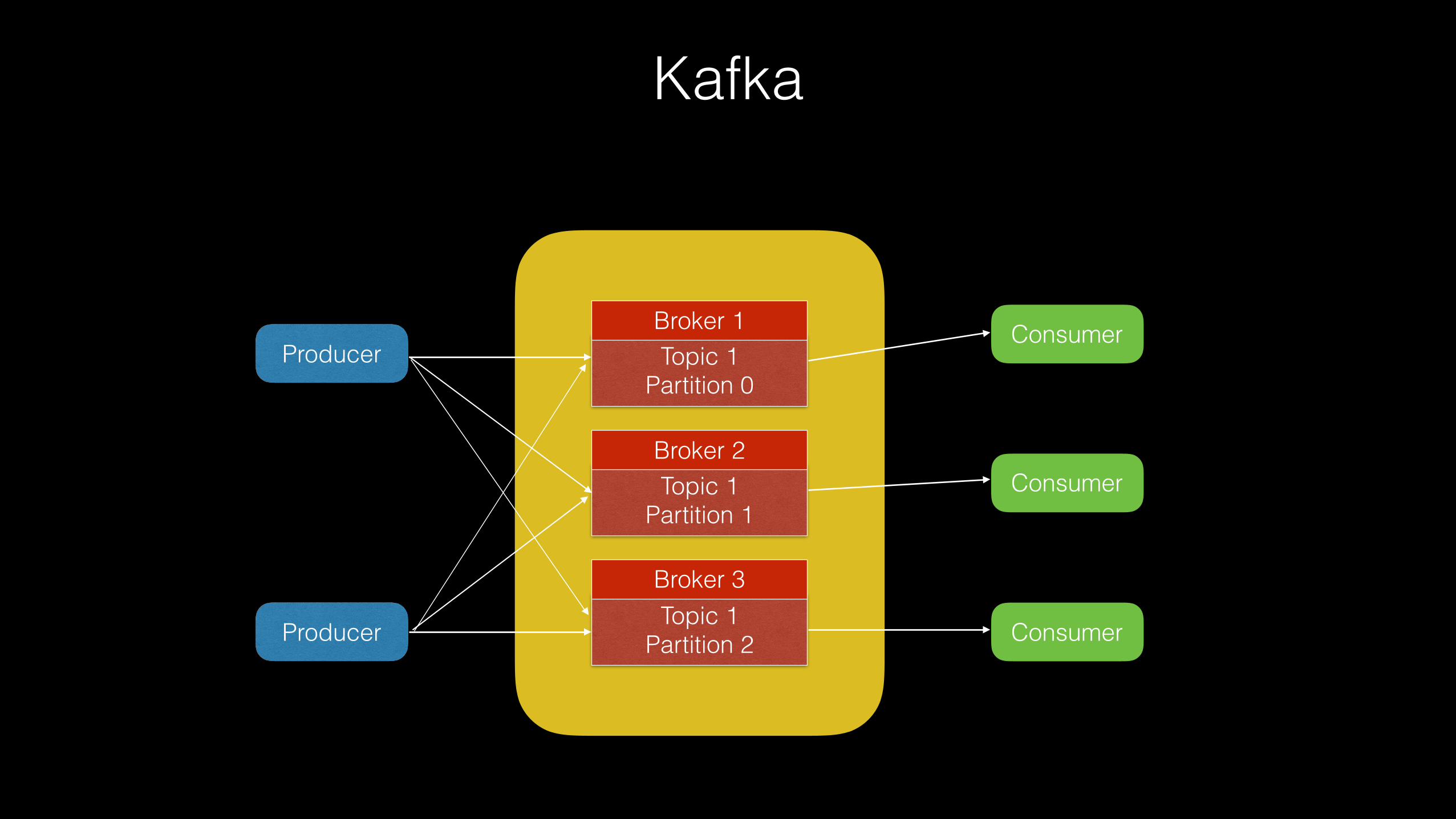
Kafka
Producer
Producer
Consumer
Consumer
Consumer
Topic 1 Partition 0
Broker 1
Topic 1 Partition 1
Broker 2
Topic 1 Partition 2
Broker 3
Kafka Cluster

Kafka topic
• scale
• parallelism
0 1 2 3 4 5 6 7 8 9
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7 8
Producer
partition 0
partition 1
partition 2

Parquet
id cc votes
1 DE 2
2 DE 3
3 AT 1
4 DE 2
id cc votes
1 DE 2
2 DE 3
3 AT 1
4 DE 2
id cc votes
1 DE 2
2 DE 3
3 AT 1
4 DE 2
SELECT votes FROM logs WHERE cc = ‘AT’
push-down filters

Kafka
Rabbit MQServices
Tracking
Spark Cluster
KafkaKafka
HDFS(Tracking)
Stre
amin
g Worker
MySQL Read Slave
MySQL Master
Redis Master
Redis Read Slave
ElasticSearch
ETL v2

Project Moria
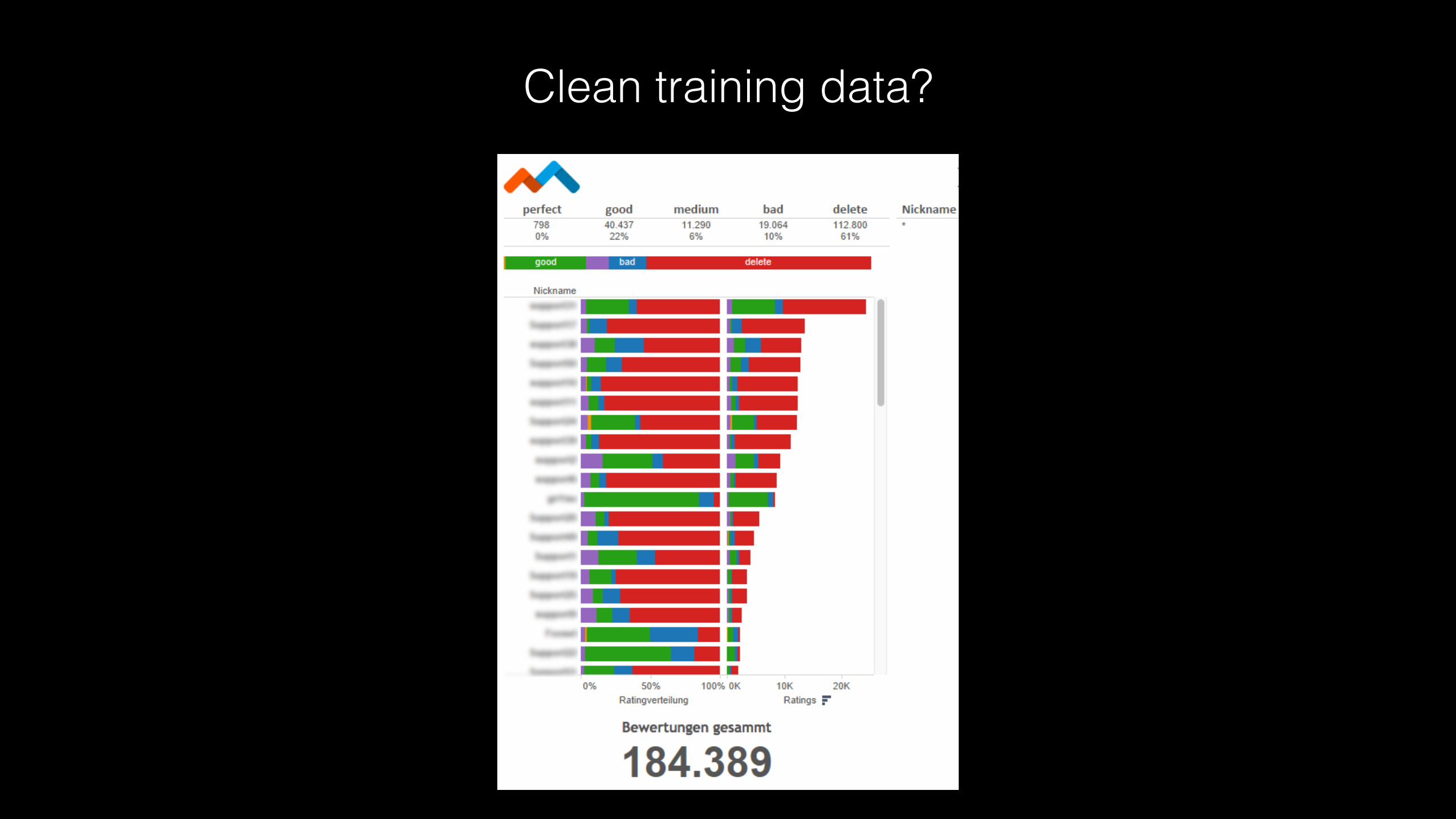
Clean training data?

Project Angmar
• tried lots of different supervised learning methods
• feature engineering - most crucial part
• analyse the domain, chart everything

FeaturesContent
length
syntactic complexity
number of links
probability of deletion
Social
votes
most helpful answer
number of comments
answered by expert
Author
gained votes
credibility score
role
deleted answer ratio
number of answers
number of comments
reported answer ratio

The structure of the network
21
3
1
0,2
0,4
0,1
2 0,8
Answer vector
AV normalized
0,9
0,6
0,2
0,1
Output

The Result
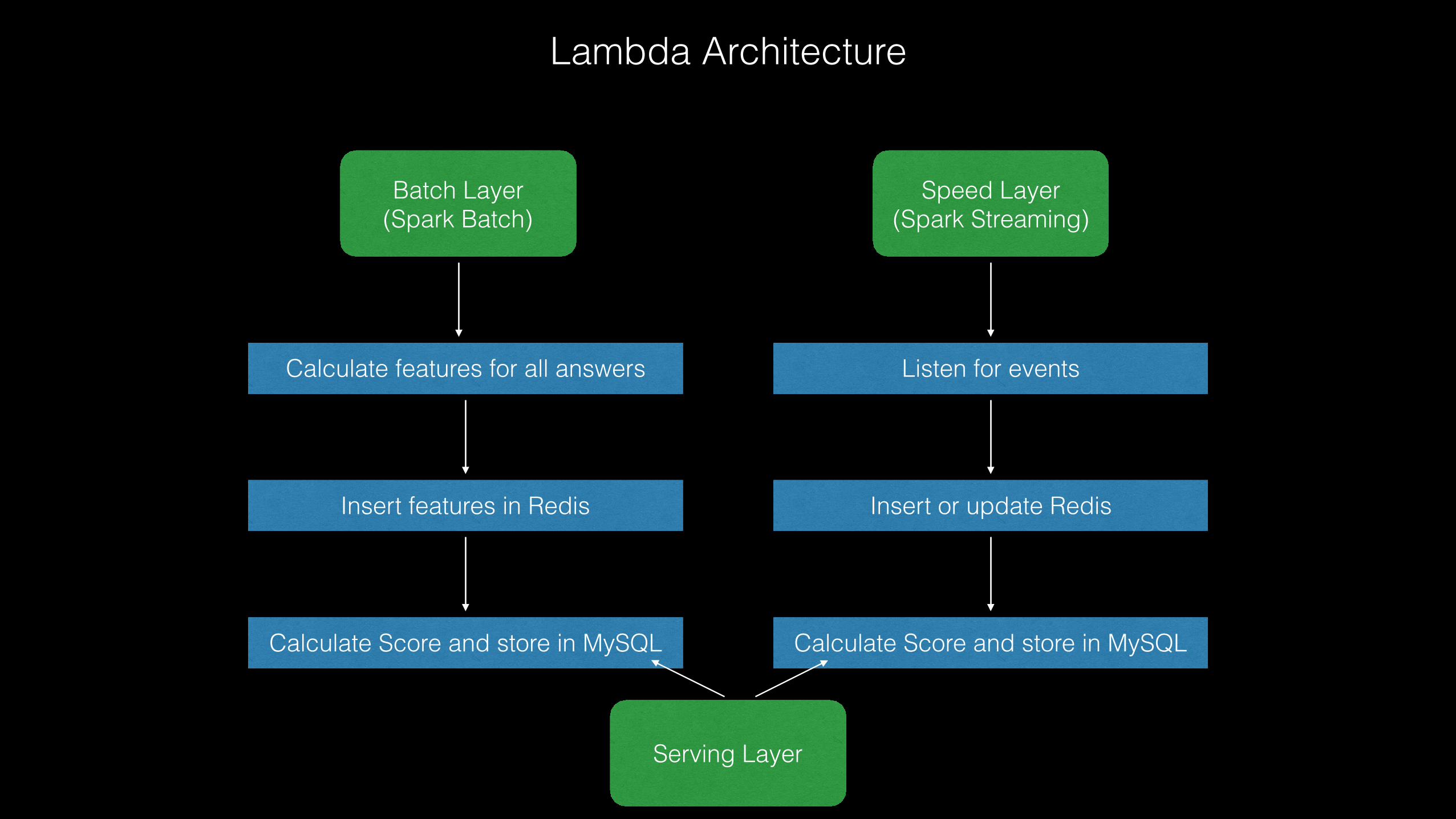
Calculate features for all answers
Batch Layer (Spark Batch)
Insert features in Redis
Calculate Score and store in MySQL
Speed Layer (Spark Streaming)
Listen for events
Insert or update Redis
Calculate Score and store in MySQL
Serving Layer
Lambda Architecture

Back pressure
• Bulk jobs insert too fast
• MySQL: sendQueue size, threads connected
• ElasticSearch: load on the instance creating the new index

Debugging the network
+1Change individual features

real world test (deleted vs non-deleted)
deletednon-deleted

Switching models
Amount of questions for a
score range
Old Score
New score


Insights
MenWomen

Learnings• If your use case is complex, you need a complex
model
• If you have a complex model, you need lots of data
• If you have lots of data, you need an ETL pipeline that can process huge amounts of data fast
• Think about your use case first, then design the pipeline

Questions?You can ask them on gutefrage too :)

























![[Pipeline] Inspecting Pipeline Installation](https://img.pdfslide.us/doc/110x75/55cf8d045503462b1391543e/pipeline-inspecting-pipeline-installation.jpg)



