Embed Size (px)
Citation preview

Assessing Writing 15 (2010) 100–117
Available online at www.sciencedirect.com
Bringing reading-to-write and writing-only assessmenttasks together: A generalizability analysis
Atta Gebril ∗United Arab Emirates University, Department of Linguistics, 17771 Alain, United Arab Emirates
Abstract
Integrated tasks are currently employed in a number of L2 exams since they are perceived as an addition tothe writing-only task type. Given this trend, the current study investigates composite score generalizabilityof both reading-to-write and writing-only tasks. For this purpose, a multivariate generalizability analysis isused to investigate the effect of both the task and rater facets on composite score reliability. In addition, acomparison of two different rating schemes is presented—two different groups of raters scoring each tasktype versus the same raters scoring both task types. The researcher collected data from 115 examinees whocompleted two writing-only and two reading-to-write tasks. mGENOVA (Brennan, R.L. (1999). Manual formJENOVA (version 2.0). Iowa City, IA: CASMA) a program mainly designed for multivariate generalizabilitywas used to analyze the study data. The results showed that a composite score of both task types is as reliableas scores obtained from either writing-only or reading-to-write tasks. The results also demonstrated thathaving different raters score each task type would produce reliable scores similar to those obtained fromhaving the same raters score both task types. Implications and limitations of the study are presented.© 2010 Elsevier Ltd. All rights reserved.
Keywords: L2 writing assessment; Reading–writing connections; Academic writing; Score reliability; Generalizabilitytheory; Integrated tasks; Independent tasks
1. Introduction
Recent developments in writing assessment have resulted in introducing new test methods inL2 exams (Cumming et al., 2005; Weigle, 2002). Examples of these new assessment innovationsinclude reading-to-write and listening-to-write tasks. For instance, the TOEFL iBT test, whichwas released in 2005, includes both a writing-only and an integrated task, based on reading andlistening texts. Cumming et al. (2005) claim that such integrated writing tasks would enhance
∗ Tel.: +971 50 1389550.E-mail address: [email protected].
1075-2935/$ – see front matter © 2010 Elsevier Ltd. All rights reserved.doi:10.1016/j.asw.2010.05.002

A. Gebril / Assessing Writing 15 (2010) 100–117 101
authenticity and also diversify and refine the writing assessment practices. A number of researchers(Cho, 2003; Gebril, 2009; Gebril & Plakans, 2009; Hamp-Lyons & Kroll, 1996; Lewkowicz,1997; Plakans, 2007; Plakans, 2008) reiterated the same idea. Weigle (2002) refers to backgroundknowledge as another advantage of integrated tasks where test takers depend on external sourcesin their writing instead of drawing solely on their memory.
In spite of these advantages, the introduction of integrated tasks comes with a host of chal-lenges adding to the already complicated nature of writing assessment. In writing assessment, ascore is confounded by a number of variables (Cooper, 1984; Gebril, 2009; Huot, 1990; Lee &Kantor, 2005; Schoonen, 2005) such as tasks, raters, scoring scales, writing mode. As a result, thescore reliability of writing exams is relatively lower than other assessment types. Hence, whenintroducing new test methods, there is a potential risk that this new practice would additionallylower writing score reliability and increase the sources of measurement error (Lee & Kantor,2005). Compromising score reliability is a serious issue in language testing and eventually wouldcast doubt on any exam results.
Traditionally, classical test theory (CTT) has been consistently used to investigate score relia-bility (Feldt & Brennan, 1989). However, classical test theory falls short of accounting for differentsources of error in test scores. This is because CTT offers only one error term, which cannot pro-vide any further details about the relative contribution of different variables to this error value.For example, in a writing assessment context, CTT estimates the amount of error in the data butdoes not show the impact of different sources of error, such as raters, tasks, and scoring rubrics.Fortunately, generalizability theory (G-theory) provides an alternative methodology where mul-tiple sources of measurement error are accounted for (Brennan, 2001; Shavelson & Webb, 1991).Van Leeuwen (1997) maintains that the G-theory has the following advantages over CTT:
• G-theory provides information about different sources of error as it is able to partition the errorterm into different parts.
• G-theory provides a unified approach to measurement error regardless of the facets involved inthe assessment process.
• G-theory provides a unified approach for assessing the reliability of measurement designed formaking either relative (norm-referenced) or absolute (criterion-referenced) decisions.
• G-theory makes no assumptions about the overlap of different sources of error, but simultane-ously estimates these different sources.
G-theory is ‘a measurement model that enables us to investigate the relative effects of multiplesources of variance in test scores’ (Bachman, 2004, p. 176). Shavelson and Webb (1991) defineG-theory as a statistical theory about the accuracy of generalizing from a person’s observed scoreon a test to the average score that person would have obtained under all possible test conditions.In a language assessment context, the main purpose is to develop test tasks replicating the targetlanguage use (TLU) situations that language learners encounter on a daily basis (Bachman &Palmer, 1996).
Messick (1996) considers generalizability as “an aspect of construct validity“ that includestwo perspectives: reliability and transfer. Generalizability as transfer reflects the basic tenet ofassessment that a specific ability or skill is measured through randomly selecting a very smallnumber of tasks from a larger domain. For example, testers judge one’s academic writing abilitythrough one or two writing tasks, and not through all potential academic writing tasks. Kane,Crooks, and Cohen (1999) argue that inferences are made from the actual observed behavior(test tasks) to a wider domain of performance which they call the target domain (e.g., academic

102 A. Gebril / Assessing Writing 15 (2010) 100–117
writing tasks). In this context, assessment scores are interpreted in terms of the target domainand not in terms of the observed tasks. Generalizability as reliability refers to the consistency ofscores across different conditions, as the traditional concept of reliability suggests. The reliabilityor dependability of a test score can be defined as ”the accuracy of generalizing from a person’sobserved score on a test to the average score that a person would have received under all possibleconditions that the test user would be equally willing to accept” (Shavelson & Webb, 1991, p. 1).
There are two types of studies in a generalizability analysis: a generalizability study (G-study)and a decision study (D-study). A G-study is used to compute the different variance componentsin an assessment context. Once these variance components are estimated, they are used in anumber of scenarios to estimate the different coefficients under various test conditions: this is aD-study. In other words, the results obtained from a G-study are used to design D-studies that willprovide more details about the possible estimates of reliability that would be obtained in differentassessment contexts (Gao & Brennan, 2001; Shavelson & Webb, 1991).
The characteristics of G-theory make it extremely effective in performance assessment ingeneral and writing assessment in particular where numerous sources of measurement error areinvolved (Brennan, 2001). In the study reported here, a generalizability analysis is employedto address two main sources of variability in a writing score: tasks and raters. Lee and Kantor(2005), discussing the design of new writing task types for the TOEFL, advocate the inclusionof integrated tasks in language exams as an addition to independent tasks, but also refer to thesubstantial impact of task and rater facets particularly in the context of integrated tasks:
. . . some concerns could be also raised regarding the incorporation of integrated tasks inwriting assessment. One important issue is the low score generalizability that could beexacerbated by the dependency created by common stimulus materials shared betweenthe writer and the comprehension sections . . . A similar argument could be made about therating process. Raters are expected to apply somewhat different scoring criteria for differenttask types. When they rate examinee responses for independent tasks, raters mostly focuson language and ideas developed by the writer. When they rate examinee responses fromintegrated tasks, however, raters also have to attend to content accuracy to make sure thatthe examinees have adequately understood and conveyed ideas presented in the lecture ortext. (Lee & Kantor, 2005, p. 3)
The current study investigates the effect of these two important facets, the task and the rater,on the composite score dependability of both independent and integrated task types. The studyalso attempts to investigate measurement accuracy when different rating schemes are used. Sincecurrent best practice in writing assessment employs more than one task, rater availability andworkload are issues that need consideration. That is, the increasing demand for raters requirestesting programs to use creative rating schemes to lower the costs and reduce rater workload.
A number of studies have used generalizability theory in L2 writing research (Breland, Camp,Jones, Morris, & Rock, 1987; Dunbar, Koretz, & Hoover, 1991; Gebril, 2009; Lee & Kantor, 2005;Reckase, 1995; Schoonen, 2005; Stuhlmann, Daniel, Dellinger, Denny, & Powers, 1999). Fromthis literature, only the studies of Gebril (2009) and Lee and Kantor (2005) have compared thescore generalizability of independent tasks and integrated tasks. For example, Gebril (2009) useda univariate generalizability analysis to investigate the score generalizability of both independentand integrated writing tasks. A univariate analysis looks into each task type separately, while amultivariate generalizability analysis looks into these task types as subsections of the same testthat could be analyzed simultaneously. Gebril (2009) used a fully crossed design—a fully crosseddesign in this context means that all test takers have to work on the same tasks and all tasks have

A. Gebril / Assessing Writing 15 (2010) 100–117 103
to be scored by the same raters. Hence, the participants completed four writing tasks and all thefour tasks were scored by all raters involved in this study. The results showed that both task typesyielded similar reliability indices. In addition, the results indicated that reliability was very lowwhen one writing task was used.
Lee and Kantor (2005) employed a multivariate generalizability analysis with both integratedand independent tasks to investigate the dependability of scores obtained from the TOEFL inte-grated and independent tasks. They used two types of integrated tasks: listening-based andreading-based. Four hundred eighty eight L2 students were recruited from the US, Australia,Canada, Hong Kong, Mexico and Taiwan. Those test takers were divided into three groups witheach subgroup taking a different combination of six writing tasks out of eight tasks. The resultsshowed that relatively larger gains in composite score reliability were obtained when using morelistening-to-write tasks than reading-to-write tasks. In addition, single-rating designs that haddifferent tasks for the same examinee and were rated by different raters yielded relatively higherscore reliability than other single-rating designs. Lee and Kantor (2005) conclude that it is easierto maximize the TOEFL writing score accuracy by increasing the number of tasks rather than byincreasing the number of raters.
Gebril (2009) used a univariate analysis to investigate the score generalizability of both tasktypes. This study design could not provide information about composite score reliability; inaddition, Gebril’s study did not address the impact of using different rating schemes on scoreaccuracy. In the current study a multivariate analysis with both independent and integrated tasksis used—Lee and Kantor’s (2005) TOEFL study did not fully include independent tasks in themultivariate analysis since only one independent task was included in some phases of the analysis(a minimum of two tasks is needed to run the analysis). Second, the current study uses a balanceddesign with the same number of tasks in each task type. Furthermore, for the current study ahomogenous group of students who come from the same ethnic and linguistic background wasrecruited. More importantly, the current study is interested in a specific university context and notas large-scale testing program. Given these differences, the current study attempts to address anumber of issues that have not been tackled in the literature. More specifically, this study attemptsto investigate the score generalizability of a composite writing score based on two task types:writing-only and reading-to-write tasks. In addition, the study looks into the impact of using twodifferent rating schemes on score dependability. For this purpose, a multivariate generalizabilityanalysis is conducted to investigate these issues. The research questions will address these issuesbased on four generalizability indices:
- Absolute error variance.- Relative error variance.- Generalizability coefficient.- Phi coefficient.
The results section of the paper discusses these concepts, and the interested reader is referredto Brennan (2003) and Johnson and Johnson (2010).
2. Research questions
The study attempts to answer the following questions in relation to the use of both reading-to-write and writing-only tasks as part of a composite score in an Egyptian University:

104 A. Gebril / Assessing Writing 15 (2010) 100–117
1. What percentage of the total score variance/covariance can be attributed to persons, tasks, andraters based on a multivariate generalizability analysis? (G-study)
2. What is the score generalizability of the composite score obtained from both the independentand integrated task types? (D-study)
3. What is the score generalizability of two different rating schemes: same raters scoring bothtask types and different raters scoring each task type? (D-study)
3. Instruments
The study used four writing tasks; two independent tasks and two reading-to-write tasks (thetasks are available from the author upon request). The prompts used with the four tasks wereselected from TOEFL materials. A panel of university professors selected these prompts from alarger pool of topics. Two reading passages were attached to each of the integrated tasks since thistask type requires test takers to use reading sources in their writing. The researcher made sure thetwo passages in each task were of equal difficulty and length. For this purpose, both readabilityformulas and feedback from writing instructors were employed. To score the essays, two holisticTOEFL rating scales were adapted for this purpose: one for the independent task type and theother one for the integrated type.
4. Data collection and analysis
One hundred and fifteen Egyptian university students, seniors majoring in English language,were recruited for this study. The students were given the four tasks over two days. On the firstday, they were given an independent task followed by an integrated task. On the second day, theresearcher changed the order so the students started with an integrated task and were then given anindependent task. Before working on these tasks, students were given the chance to ask questionsand also signed a consent form.
Three raters were selected to score the four essays. The three raters are native speakers ofEnglish who have worked for a major US testing company for between three and five years. Thoseraters were selected because they have had extensive experiences with scoring L2 writing examsand also they needed minimal training. Before scoring, the three raters went through a trainingsession to familiarize them with the scoring rubrics and the writing tasks. During the trainingsession, the researcher provided the raters with sample essays representing different proficiencylevels; the raters scored a number of essays corresponding to each level of the scoring rubricsand then extensive discussions followed in cases of disagreement among the three raters. Theresearcher made sure that the raters had thorough understanding of the different issues involvedin this process before they started scoring. Each rater scored all the essays collected in this studyin order to have two fully crossed univariate designs (p × t × r). As mentioned earlier, a fullycrossed design (p × t × r) implies that all test takers (p) took the same tasks (t) and all tasks werescored by the same raters (r).
In order to answer questions 1–3, a multivariate G-theory analysis was conducted to investigatethe relative effect of tasks and raters. Multivariate generalizability analysis is used when a testincludes a number of subsections or subtests and consequently investigating the reliability of thecomposite of these subsections is of interest (Brennan, 2001). For example, in a writing assessmentcontext, where both independent and integrated tasks are used, multivariate generalizability allowstest developers to investigate the score reliability of each task type separately and also provideinformation about the accuracy of the composite score. Univariate generalizability analysis cannot

A. Gebril / Assessing Writing 15 (2010) 100–117 105
examine score reliability of both task types simultaneously, nor can it provide any informationabout composite score reliability.
The study used a multivariate P• × I◦ × R• (• means that a facet is crossed and◦ refers to a fixedfacet) design where the persons and raters are crossed and the task type is considered as a fixedfacet. More specifically, the integrated and independent writing tasks in this study are consideredas levels of a fixed facet. A fixed facet in this context means that both task types (integrated andindependent tasks) cannot be changed. However, under each level of this fixed facet, a differentset of items are nested within each level. The items nested within each level are random indicatingthat each item in the universe of admissible observations has the same probability to be selected.Brennan (2001) compares this situation to the content categories in a specifications table. If thisdesign is converted to a univariate design, it will produce two fully crossed univariate designs(p × t × r), one for the independent tasks and the other one for the integrated tasks. For the purposeof the analysis, mGENOVA (Brennan, 1999) a program that was mainly designed to deal withmultivariate generalizability analysis was used to execute both the G- and D-studies and thencompute the variance/covariance components, the relative and absolute error variance as well asthe generalizability and dependability coefficients.
5. Results
Table 1 shows that the participants exhibited similar overall performances on both task types,although integrated task performances had relatively higher means. With regard to raters, theresults demonstrated that their mean ratings are almost equal. A more detailed discussion of theresults is presented in the following section.
5.1. Question 1: the variance/covariance components obtained from the multivariategeneralizability analysis (G-study)
The results of the multivariate generalizability analysis, which includes both the independentand integrated task types, show that the largest variance component among the seven values is thethree-way interaction of persons, raters, and tasks (ptr) (Table 2).
This ptr component has a relatively similar value in both the independent and integrated tasktypes (40% and 41%, respectively). The second largest variance component is related to the persons(p) in both the independent and integrated task types (33% and 27%, respectively). The third
Table 1Descriptive statistics for both integrated and independent task types.
Independent tasks Integrated tasks
Task 1 Task 2 Task 3 Task 4
Task mean 3.55 3.57 3.68 3.72Task SD 0.52 0.59 0.56 0.53Rater 1 mean 3.54 3.57 3.74 3.63Rater 1 SD 0.06 0.06 0.12 0.06Rater 2 mean 3.65 3.53 3.73 3.86Rater 2 SD 0.06 0.06 0.05 0.05Rater 3 mean 3.46 3.60 3.57 3.66Rater 3 SD 0.05 0.05 0.06 0.05

106 A. Gebril / Assessing Writing 15 (2010) 100–117
Table 2The G-study estimated variance and covariance components.
Effects Independent tasks Integrated tasks
Variance Percentage Covariance Variance Percentage Covariance
Person (p) 0.148 33% .147 0.119 27% .147Task (t) 0.00 0.00% 0.00 0.00%Rater (r) 0.00 0.00% .002 .003 0.8% .002pt 0.097 22% 0.116 26.2%pr 0.015 3.5% 0.015 0.013 3% 0.015tr 0.006 1.5% 0.007 2%ptr 0.181 40% 0.183 41%
Total 0.450 100% 0.445 100%
largest variance component in both task types is the person-by-task (pt) effect. This componentaccounts for 22% of the variance in the independent tasks and 26.2% in the integrated task. Theother variance components each account for a small amount of the variance. For example, theperson-by-rater (pr) effect accounts for 3.5% in the independent tasks and 3.0% in the integratedtasks.
The value of multivariate G-studies is their ability to identify when two variables or effectsvary together—their covariance. It is worth noting that these two effects should be linked in orderto produce this covariance component. Effects that are not linked cannot have a covariance valuein a multivariate G-study. In this study, covariance looks into how both independent and integratedtasks vary simultaneously. In the current study, it was found that the person and rater effects werelinked, while the task effect was not. Consequently, only the following effects are considered inthe covariance analysis: persons (p), raters (r), and the interaction of persons and raters (pr).
The results showed that the covariance between the persons’ universe scores for the integratedand independent task types is very large (0.147), even larger than the universe score of theintegrated task type (0.119) and almost equal to the universe score of the independent task type(0.148). In generalizability theory, the term ‘universe score’ is used to refer to the person (p)effect since it reflects the ‘ability’ estimates of examinees. This large covariance may indicatethat the two task types rank-ordered the students similarly. The next largest covariance is theperson-by-rater (pr) covariance. This value is slightly larger than the person-by-rater covariancein both tasks. This result suggests that the raters are roughly similar in the way they scored theessays in both task types. The smallest covariance is found among the three raters in the two tasktypes.1
5.2. Question 2: score generalizability of the composite (D-study)
In a multivariate analysis, the independent variables – reading-to-write and writing-only taketypes in this study – are considered as levels of a fixed facet. In this context, each test taker hasa number of universe (i.e., ability) scores, while in univariate generalizability each test taker hasonly one universe score. In this section, the analysis examines the composite score for the different
1 A full explanation of G-theory is beyond the scope of this paper. More information about how to interpret these valuesmay be found in Brennan (2003) and Johnson and Johnson (2010).

A. Gebril / Assessing Writing 15 (2010) 100–117 107
universe scores. Consequently, relative and absolute errors of the composite score are computedfollowed by the multivariate generalizability and Phi coefficients.
5.2.1. Relative error variance of the compositeIn general, error variance refers to the “error involved in using an examinee’s observed mean
score” (Brennan, 2003, p. 9). The index of relative error variance is used in situations wherenorm-referenced score interpretation is of interest. In this analysis, scores from the independentand integrated task types were collapsed to produce this multivariate analysis. The minimumnumber of tasks in each analysis was two (one from each task type). The results showed that therelative error variance was close to zero (.02) when the D-study has eight tasks and four raters.As Appendix A and Fig. 2 indicate, the biggest reduction in the relative error (.072) occurredwhen the number of tasks increased from two to four while holding the raters constant (nt = 1).The second largest increase (.052) occurred when the number of raters increased from one to twowhile holding the number of tasks constant (nt = 2). This result showed that it is possible to obtaina relatively similar relative error either by increasing the number of raters from one to two withtwo tasks or by increasing the number of tasks from two to four with one rater. Making a decisionto go either way depends upon a number of factors including testing time, availability of raters,and types of information the test attempts to gather.
5.2.2. Absolute error variance of the compositeAbsolute error variance is of interest when criterion-referenced interpretations are involved.
Absolute error variance is usually larger than relative error variance. Similar to the results reportedin the section describing relative error, the absolute variance was almost close to zero (.023) whenthe D-study had eight tasks and four raters. As Appendix A and Fig. 1 show, the biggest reductionin the absolute error (.074) occurred when the number of tasks increased from two to four whileholding the raters constant (nt = 1). The second largest increase (.05) occurred when the numberof raters increased from one to two while holding the number of tasks constant (nt = 2).
5.2.3. Multivariate generalizability coefficientA generalizability coefficient is similar to a reliability coefficient in CCT and is used in situ-
ations where norm-referenced interpretations are of interest. Relative error variance is employedwhen estimating this index. Fig. 3 shows the multivariate generalizability coefficients for the
Fig. 1. Absolute error variance of the composite.

108 A. Gebril / Assessing Writing 15 (2010) 100–117
different D-studies. As expected, the multivariate generalizability coefficient increases with theincrease in both the number of tasks and the number of raters. The highest increase (.135) resultedfrom increasing the number of tasks from two to four while holding the number of raters constant(nr = 2). The second largest (0.1) increase resulted from increasing the number of raters from oneto two while holding the number of tasks constant. As Appendix A and Fig. 3 show, when thereare more than two raters and two tasks, the amount of increase in the multivariate generalizabilitycoefficient is not substantial.
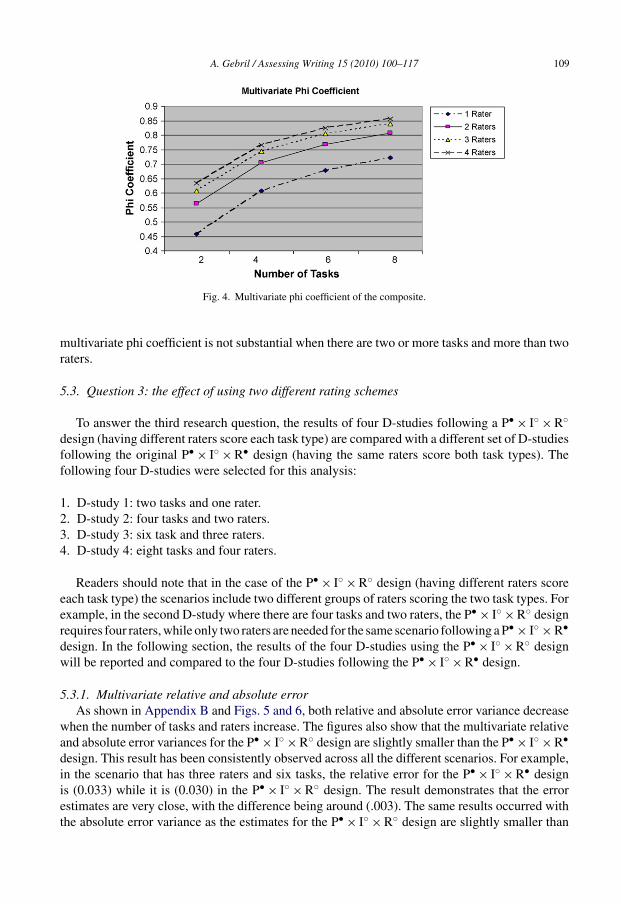
5.2.4. Multivariate phi coefficientA phi coefficient, which is also called a dependability coefficient, is similar to CTT reliability
coefficients used in criterion-referenced assessment contexts. For this reason, absolute error vari-ance is used in estimating this index. It is always the case that the multivariate phi coefficient issmaller than the multivariate generalizability coefficient. Following the same pattern exhibited bythe generalizability coefficient, the multivariate phi coefficient improves with the increase in boththe number of tasks and raters. As Fig. 4 shows, the highest increase (.147) resulted from increas-ing the number of tasks from two to four while holding the number of raters constant (nr = 2).Also, similar to the multivariate generalizability coefficient results, the amount of increase in the
Fig. 2. Relative error variance of the composite.
Fig. 3. Multivariate generalizability coefficient of the composite.
A. Gebril / Assessing Writing 15 (2010) 100–117 109
Fig. 4. Multivariate phi coefficient of the composite.
multivariate phi coefficient is not substantial when there are two or more tasks and more than tworaters.
5.3. Question 3: the effect of using two different rating schemes
To answer the third research question, the results of four D-studies following a P• × I◦ × R◦design (having different raters score each task type) are compared with a different set of D-studiesfollowing the original P• × I◦ × R• design (having the same raters score both task types). Thefollowing four D-studies were selected for this analysis:
1. D-study 1: two tasks and one rater.2. D-study 2: four tasks and two raters.3. D-study 3: six task and three raters.4. D-study 4: eight tasks and four raters.
Readers should note that in the case of the P• × I◦ × R◦ design (having different raters scoreeach task type) the scenarios include two different groups of raters scoring the two task types. Forexample, in the second D-study where there are four tasks and two raters, the P• × I◦ × R◦ designrequires four raters, while only two raters are needed for the same scenario following a P• × I◦ × R•design. In the following section, the results of the four D-studies using the P• × I◦ × R◦ designwill be reported and compared to the four D-studies following the P• × I◦ × R• design.
5.3.1. Multivariate relative and absolute errorAs shown in Appendix B and Figs. 5 and 6, both relative and absolute error variance decrease
when the number of tasks and raters increase. The figures also show that the multivariate relativeand absolute error variances for the P• × I◦ × R◦ design are slightly smaller than the P• × I◦ × R•design. This result has been consistently observed across all the different scenarios. For example,in the scenario that has three raters and six tasks, the relative error for the P• × I◦ × R• designis (0.033) while it is (0.030) in the P• × I◦ × R◦ design. The result demonstrates that the errorestimates are very close, with the difference being around (.003). The same results occurred withthe absolute error variance as the estimates for the P• × I◦ × R◦ design are slightly smaller than

110 A. Gebril / Assessing Writing 15 (2010) 100–117
Fig. 5. Absolute error variance of two rating schemes.
Fig. 6. Relative error variance of two rating schemes.
the P• × I◦ × R• design. A closer look at Figs. 5 and 6 indicates that the estimates are relativelysimilar across different numbers of tasks and raters.
5.3.2. Multivariate generalizability and phi coefficientsAppendix B and Figs. 7 and 8 show the multivariate generalizability and phi coefficients
for both rating schemes. The analysis demonstrates that the generalizability and phi coefficientsimprove when the number of tasks and raters increase. For both designs, the coefficients improvedsubstantially when the number of tasks increased to four and the number of raters increased to two.For example, the phi coefficient for the first D-study (nr = 1 and nt = 2) was (0.473). However, whennr = 2 and nt = 4, the phi coefficient increased substantially to (0.72). This substantial improvementis mainly due to having two raters rather than one. In addition, the increase of the number of tasksfrom two to four contributed to having a larger coefficient.
As for the differences between the two scenarios, the results indicate that both coefficientswere slightly higher in the P• × I◦ × R◦ design. This pattern was consistent across the differentscenarios. For example, in the scenario that had two raters and four tasks, the generalizabil-

A. Gebril / Assessing Writing 15 (2010) 100–117 111
Fig. 7. Generalizability coefficient of two rating schemes.
Fig. 8. Phi coefficient of two rating schemes.
ity coefficient for the P• × I◦ × R• design was (0.711) while it was (0.725) in the P• × I◦ × R◦design. These values suggest that the coefficients are relatively similar with only a differenceof approximately .015. The same pattern also occurred with the phi coefficients across thedifferent D-studies. For example, in the scenario that had four raters and eight tasks, the phicoefficient for the P• × I◦ × R• design was (0.856) while it was (0.868) for the P• × I◦ × R◦design.
6. Discussion
The results showed that the triple interaction of persons, tasks, and raters (ptr) variancecomponents and the persons (p) variance components had the largest values. This result isin agreement with a number of generalizability studies that showed these two components asthe largest among all variance components (Brennan, Goa, & Colton, 1995; Lee & Kantor,2005; Schoonen, 2005; Shavelson, Baxter, & Goa, 1993). The analysis also demonstrates

112 A. Gebril / Assessing Writing 15 (2010) 100–117
that the person-by-task (pt) variance component was noticeably large. This result is com-mon in performance assessment in general and writing assessment in particular as shownin a number of studies (Brennan et al., 1995; Schoonen, 2005; Shavelson et al., 1993). Asfor the covariance components, the analysis revealed that the covariance between the per-sons’ universe scores for the integrated and independent tasks was relatively large. Most L2performance assessment studies have had very high correlations between the two task types(Lee, 2006; Lee & Kantor, 2005). This large value may suggest that the two task types rank-ordered examinees similarly; it may also suggest that the two task types measure a similarconstruct.
The present analysis raises a number of issues that merit further discussion. The resultsshowed that the composite coefficients had values similar to those reported in the univariategeneralizability analysis conducted in Gebril (2009) for both independent and integrated writ-ing tasks—that study used the same data to conduct the univariate analysis. This outcomesupports having a composite score in writing tests based on both independent and integratedtasks. In this context, test takers could be given both independent and integrated tasks on thesame test while assuring that their composite score would yield adequately reliable values.This conclusion supports the use of this model in testing programs such as the TOEFL iBTtest. The same conclusion was reached by Lee and Kantor (2005) in their TOEFL generaliz-ability study. In addition, this trend could enhance university teaching practices that employboth integrated and independent tasks and consequently result in positive washback in writingclasses. In such a context, teachers and students would give more attention to discourse synthe-sis and related reading-to-write activities. Some might argue that it is time-consuming to useboth task types on one test. Hughes (2003) provides a very interesting counterargument in thefollowing:
Before we decide what we cannot afford to test in a way that will promote beneficialwashback, we have to ask ourselves a question: What will be the cost of not achievingbeneficial washback? When we compare the cost of the test with the waste of effort andtime on the part of teachers and students in activities quite inappropriate to their true learninggoals (and in some circumstances, with the potential loss to the national economy of nothaving more people competent in foreign languages), we are likely to decide that we cannotafford not to introduce a test with a powerful washback effect. (p. 56)
So, as Hughes (2003) argues, decision makers have to count the cost correctly and be convincedthat achieving the targeted learning outcomes is more important than practicality considerations,especially in high-stakes contexts.
Question three has addressed the use of two different rating schemes: same raters scoring bothtask types and different raters scoring each task type. The results of the multivariate analysisindicated that the rating schemes with different raters for each task type had smaller multivariaterelative and absolute error variances. In addition, the results by default showed that the ratingscheme with different raters for each task type had higher generalizability and dependabilitycoefficients. It is important to mention that these differences were not substantial as the coef-ficients across the different selected scenarios were almost identical. The rating scheme withdifferent raters had higher coefficients because the error variance for this scheme is smaller thanthe design with same raters. As a rule, when the error values in a certain design are smaller thantheir counterparts in another design, score reliability will be larger in that design (Brennan, 2001;Shavelson & Webb, 1991). Therefore, the rating scheme with different raters scoring each tasktype yielded scores that are more reliable than the other scheme. One could conclude based on

A. Gebril / Assessing Writing 15 (2010) 100–117 113
the data analysis that using any of these schemes would yield scores that would have similarreliability coefficients.
This result can provide support for using a larger pool of raters where one group of ratersworks on a specific task type, while the other group works on the other task type. This prac-tice is useful because it would speed up the rating process and minimize rater workload. Inaddition, instead of having one group of raters struggling with two different scoring rubrics,this suggested rating scheme could help each group of raters focus on only one rubric. Fur-thermore, the training of raters would not take more time even if there are two groups ofraters. This is simply because training one group of raters on using both rubrics would takeapproximately the same amount of time to train each group of raters on only one rubric. How-ever, the decision to use one group of rater or two groups mainly depends on the availableresources in a testing program. In some situations, it is hard to find a large pool of raters, soemploying one group of raters would be the optimal solution. In other contexts, it is hard tofind one group of raters who work full-time or who are committed to working for extendedhours, so hiring a larger number of raters who work for a shorter time would be a possiblesolution.
7. Implications
The first implication of the current study is that a composite score of both the independentand integrated task types is as reliable as univariate scores for either the integrated tasks or theindependent tasks. This implication provides support for many of the testing programs that adoptan integrated approach to language test development. This type of information would also behelpful for university administrators when they make admission or placement decisions. In otherwords, having a composite score involving different writing tasks would provide a more accuratepicture of a student’s writing ability and also could be a good predictor of the success of thisstudent in university classes. This issue is closely related to authenticity since employing bothtask types would reflect the actual teaching practices in university classes that require studentsto integrate information from sources as well as work on independent writing tasks (Hale et al.,1996; Hamp-Lyons, 1991). The following quotation by Hamp-Lyons (1991) eloquently speaks tothis issue:
The need to consider the wider context is particularly real for college-level writers. Tolook only at processes is to see writing as existing solely for the writer, while we knowin fact much, if not most, of writing at the college level is done in response to specificassignments set by faculty. . . As teachers, if we are to help our college-level nonnativestudents, we need to pay attention to the academic context in which they find themselvesand for which they are writing. We need to be sure that the writing tasks we set andthe responses we offer our students’ writing are meaningful within the specific contextswhere our students will apply what we teach them. As evaluators of writing and designersof writing tests, we need to be sure that the tests we design and/or use match with thecontextual expectations in initiation and follow-up—the response is up to the students.(p. 128)
This quotation reflects the attention of writing educators to a number of issues including writingin an academic context, the writing tasks assigned to students, and the types of test methods usedin universities to evaluate students’ writing abilities.

114 A. Gebril / Assessing Writing 15 (2010) 100–117
Another implication of this research addresses whether to have each rater score both task typesor to have different raters score each task type. The results showed that having different raters scoreeach task type would produce as reliable scores as having the same raters score both task types.Hence, the decision to employ either rating scheme would depend on the available resources, asdiscussed above.
More importantly, at least in the Egyptian university context, the study results provide supportfor the inclusion of reading-to-write tasks in writing exams. Many Egyptian writing instructorshave recently voiced concerns about the inability of students to use reading sources appropriately intheir writing. Based on the data collected in this study, it is evident that L2 writers can handle thesetasks effectively if given clear instructions. With regard to score reliability, the results showed areasonably reliable composite score of both reading-to-write and writing-only tasks. Furthermore,the data revealed that different rating schemes could provide similar reliability values; a result thatgives more flexibility to university programs in the scoring process. It is hoped that the inclusionof reading-to-write tasks in writing exams would lead to positive washback in writing classes inEgyptian universities where more time is assigned to source-based writing.
8. Limitations of the study
There are a number of limitations of this study that have to be considered when interpreting theresults. First, the data were collected from Egyptian students with relatively advanced proficiency.In addition, the raters were English native speakers with L2 rating experience. Furthermore, onlytwo tasks were used at each level of the fixed facet. Future research needs to focus on the effect ofusing raters from different linguistic and cultural backgrounds. Also, it would be useful to lookat other writing modes and how these modes affect writing score generalizability.
9. Conclusion
The current study attempted to examine the composite score generalizability obtained from bothwriting-only and reading-to-write tasks. In addition, the impact of two different rating schemes onscore accuracy was investigated. The study showed that composite score reliability of both tasktypes was relatively similar to that obtained from both task types when used independently. Also,the results demonstrated that having different raters score each task type would yield reliablescores similar to those obtained from having the same raters score both task types. Hopefully,these results would encourage university writing programs to use both writing-only and reading-to-write tasks in assessing L2 students, which would eventually achieve beneficial washback inacademic writing classes.
Acknowledgements
I would like to thank Dr. Liz Hamp-Lyons, editor of this journal, for her support and patienceduring the reviewing process. My thanks are also extended to the anonymous reviewers for theirinvaluable feedback on the first draft of this paper.

A. Gebril / Assessing Writing 15 (2010) 100–117 115
Appendix A.
Error variance and generalizability and phi coefficients of the composite.
Multivariate absolute error variance
D-studies nr = 1 nr = 2 nr = 3 nr = 4
nt = 2 .165 .109 .090 .081nt = 4 .091 .059 .048 .042nt = 6 .066 .042 .0341 .030nt = 8 .054 .033 .026 .023
Multivariate relative error variance
D-studies nr = 1 nr = 2 nr = 3 nr = 4
nt = 2 .159 .106 .089 .080nt = 4 .087 .057 .047 .041nt = 6 .063 .040 .033 .029nt = 8 .051 .032 .026 .022
Multivariate generalizability coefficients
D-studies nr = 1 nr = 2 nr = 3 nr = 4
nt = 2 .468 .568 .612 .637nt = 4 .616 .711 .749 .770nt = 6 .689 .776 .810 .828nt = 8 .733 .813 .844 .860
Multivariate phi coefficients
D-studies nr = 1 nr = 2 nr = 3 nr = 4
nt = 2 .459 .562 .607 .633nt = 4 .606 .704 .744 .766nt = 6 .679 .769 .805 .824nt = 8 .722 .806 .839 .856
Appendix B.
Error variance and generalizability and phi coefficients for the two rating schemes.
P• × I◦ × R• design (same raters) P• × I◦ × R◦ design (different raters)
Relative error Absolute error G coeff. Phi coeff. Relative error Absolute error G coeff. Phi coeff.
nr = 1 nt = 2 .159 .165 .468 .459 .152 .156 .480 .473nr = 2 nt = 4 .0571 .059 .711 .704 .053 .054 .725 .720nr = 3 nt = 6 .033 .034 .810 .805 .030 .031 .822 .818nr = 4 nt = 8 .022 .023 .860 .856 .020 .021 .870 .868
References
Bachman, L. (2004). Statistical analyses for language assessment. Cambridge: Cambridge University Press.

116 A. Gebril / Assessing Writing 15 (2010) 100–117
Bachman, L., & Palmer, A. (1996). Language testing in practice. Oxford: Oxford University Press.Breland, H. M., Camp, R., Jones, R. J., Morris, M. M., & Rock, D. A. (1987). Assessing writing skills. New York: College
Entrance Examination Board.Brennan, R. L. (1999). Manual for mJENOVA (version 2.0). Iowa City, IA: CASMA.Brennan, R. L. (2001). Generalizability theory. New York: Springer.Brennan, R. L. (2003). Coefficients and indices in generalizability theory. CASMA Research Report No. 1.
Iowa City: University of Iowa Center for Advanced Studies in Measurement and Assessment. Available onhttp://www.education.uiowa.edu/casma.
Brennan, R., Goa, X., & Colton, D. (1995). Generalizability analyses of WorkKeys listening and writing tests. Educationaland Psychological Measurement, 55 (2), 157–176.
Cho, Y. (2003). Assessing writing: Are we bound by only one method? Assessing Writing, 8, 165–191.Cooper, P. L. (1984). The assessment of writing ability: A review of research (GRE Board Research Report No. GREB
82-15R/ETS Research Report No. 84-12). Princeton, NJ: Educational Testing Service.Cumming, A., Kantor, R., Baba, K., Erdosy, U., Eouanzoui, K., & James, M. (2005). Differences in written discourse in
independent and integrated prototype tasks for next generation TOEFL. Assessing Writing, 10, 5–43.Dunbar, S. B., Koretz, D. M., & Hoover, H. D. (1991). Quality control in the development and use of performance
assessments. Applied Psychological Measurement, 4 (4), 289–303.Feldt, L. S., & Brennan, R. L. (1989). Reliability. In: R. L. Linn (Ed.), Educational measurement (3rd ed., pp. 105–146).
New York: Macmillan.Gao, X., & Brennan, R. (2001). Variability of estimated variance components and related statistics in a performance
assessment. Applied Measurement in Education, 14 (2), 191–203.Gebril, A. (2009). Score generalizability of academic writing tasks: Does one test method fit it all? Language Testing, 26,
507–531.Gebril, A., & Plakans, L. (2009). Investigating source use, discourse features, and process in integrated writing tests. In:
Spaan fellow working papers in second/foreign language assessment 7. Ann Arbor: The University of Michigan. pp.47–84.
Hale, G., Taylor, C., Bridgeman, J., Carson, J., Kroll, B., & Kantor, R. (1996). A study of writing tasks assigned inacademic degree programs. Princeton, NJ: Educational Testing Service.
Hamp-Lyons, L. (1991). Scoring procedures for ESL contexts. In: L. Hamp-Lyons (Ed.), Assessing second languagewriting in academic contexts (pp. 241–276). Norwood, NJ: Ablex Publishing Corp.
Hamp-Lyons, L., & Kroll, B. (1996). Issues in ESL writing assessment: An overview. College ESL, 6 (1), 52–72.Hughes, A. (2003). Testing for language teachers (2nd ed.). Cambridge: Cambridge University Press.Huot, B. A. (1990). The literature of direct writing assessment: Major concerns and prevailing trends. Review of Educational
Research, 60, 237–263.Johnson, S., & Johnson, R. (2010). Conceptualizing and interpreting reliability. In: Coventry: Qualifi-
cations and curriculum authority. (Available on http://www.excellencegateway.org.uk/pdf/2010 02 01Conceptualising%20and%20interpreting%20reliability.pdf).
Kane, M., Crooks, T., & Cohen, A. (1999). Validating measures of performance. Educational Measurement, Issues andPractice, 18 (2), 5–17.
Lee, Y. (2006). Dependability of scores for a new ESL speaking assessment consisting of integrated and independenttasks. Journal of Language Testing, 23 (2), 131–166.
Lee, Y., & Kantor, R. (2005). Dependability of new ESL writing test scores: Tasks and alternative rating schemes (TOEFLMonograph Series No. 31). Princeton, NJ: ETS.
Lewkowicz, J. (1997). The integrated testing of a second language. In: C. Clapham (Ed.), Encyclopedia of language andeducation, Vol. 7. Language testing and assessment (pp. 121–130). Dordrecht, The Netherlands: Kluwer AcademicPublishers.
Messick, S. (1996). Validity. In: R. L. Linn (Ed.), Educational measurement (3rd ed., pp. 13–103). New York: Macmillan.Plakans, L. (2007). Second language writing and reading-to-write assessment tasks: A process study. Unpublished Doctoral
Dissertation. Iowa City, IA: The University of Iowa.Plakans, L. (2008). Comparing composing processes in writing-only and reading-to-write test tasks. Assessing Writing,
13, 111–129.Reckase, M. (1995). Portfolio assessment: A theoretical estimate of score reliability. Educational Measurement: Issues
and Practice, 14 (1), 31. 12–14.Schoonen, R. (2005). Generalizability of writing scores: An application of structural equation modeling. Language Testing,
22 (1), 1–30.

A. Gebril / Assessing Writing 15 (2010) 100–117 117
Shavelson, R., Baxter, G., & Goa, X. (1993). Sampling variability of performance assessments. Journal of EducationalMeasurement, 30 (3), 215–232.
Shavelson, R. J., & Webb, N. M. (1991). Generalizability theory: A primer. Newbury Park, CA: Sage.Stuhlmann, J., Daniel, K., Dellinger, A., Denny, R., & Powers, T. (1999). A generalizability study of the effects of training
on teachers’ ability to rate children’s writing using a rubric. Journal of Reading Psychology, 20, 107–127.Van Leeuwen, D. M. (1997). Assessing reliability of measurements with generalizability theory: An application to inter-
rater reliability. Journal of Agricultural Education, 38, 36–42.Weigle, S. C. (2002). Assessing writing. Cambridge: Cambridge University Press.
Atta Gebril is an assistant professor & coordinator of the Applied Linguistics program at the United Arab EmiratesUniversity. He obtained his PhD in foreign language and ESL education from the University of Iowa (USA). Dr. Gebrilpreviously worked at the College of William and Mary in Virginia and at ACT, Inc. He is the winner of the 2008 Universityof Michigan Spaan Fellowship in L2 assessment and the 2009 TOEFL Committee of Examiners (COE) Grant. His researchinterests include score generalizability, L2 writing assessment, reading-writing connections, test validation, and fairnessin language assessment.