Embed Size (px)
Citation preview

Boosting CSC 411/2515 Tutorial
Wenjie Luo Nov {24th, 26th, 27th}, 2015
Slides adapted from last year’s version by Shenlong Wang

Example: Raptors• Imagine you are going to bet on Raptors, but don’t know much
about it.
• What you might do: ask one expert
• Hard to give a ‘decision boundary’
• Easy to give thumbs up or thumbs down
• Which expert to ask..
• Question:
• How to combine/take advantage of suggestions from multiple experts

Ensemble Methods• Bagging
• Parallel training with different training sets.
• Boosting
• Sequential training, re-weight training examples to focus on misclassified examples.
• Mixture of experts • Parallel training with objective encouraging
division of labor.

Input:
• Training set examples {xn,tn}, n = 1,2,…,N; tnϵ{-1,+1}
• WeakLearn: learning procedure, produces classifier y(x)
Initialize example weights: wnm(x) = 1/N
For m=1:M
• ym(x) = WeakLearn({x},t,w) – fit classifier to training data, minimizing weighted error function:
• error rate:
• classifier coefficient:
• update data weights:
Final model:
AdaBoost algorithm
])([1 nn
N
n m
m
nm tywJ !"# "x
])([1 nn
N
n m
m
nm tyw !"# "x$
}/)1log{(2
1mmm $$% &"
# "
'
''
&"
&"N
n nmnm
m
n
m
m
nmnm
m
n
m
n
ytwZ
Zytww
1
1
11
)}(exp{
/)}(exp{
x
x
%
%
# """
M
m mm
MM yyY1
))((sign))((sign)( xxx %

AdaBoost is equivalent to fitting a greedy forward additive model with this cost function:
At each round of boosting, minimize:
AdaBoost: Derivation
)}(exp{)](,[cost xx tyyt !"
)}exp{])([})exp{}((exp{
)])([}exp{])([}(exp{
)}(exp{
)}(exp{})(exp{
})(exp{
)}(exp{
1
1' ''
1' ''
1
####
## #
# #
#
!$%!!"
"!$%"
!"
!!"
!"
!"
!
"
"
"
n
m
nmn nnm
m
nmm
m
n nnm
m
nmn nnm
m
nm
m
n nmnm
m
n
m
n nmnm
m
m nmnm
n
m
m nmnm
N
n n
m
nm
m
wtyw
tywtyw
ytw
ytyt
yt
ytE
&&&'
&&'
&'
&&
&
&
x
xx
x
xx
x
x
Boosting
Exponential loss function
Another surrogate: exponential loss
L(H(x), y) = e�y·H(x)
L(H,X) =
NX
i=1
L(H(xi), yi)
=
NX
i=1
e�yi·H(xi)
−1.5 −1 −0.5 0 0.5 1 1.50
0.5
1
1.5
2
2.5
3
Di↵erentiable approximation (bound) of 0/1 loss
• Easy to optimize!
Other choices of loss are possible.
Greg Shakhnarovich (TTIC) Lecture 8: Boosting October 24, 2013 13 / 32

From this cost function we derive the updates
Minimize wrtym(x): weak learner optimizes, gets error
Minimize wrtαm
Update example weights
AdaBoost: Derivation (cont.)
})exp(
])([)]exp(){[exp(
1
1
!
!
"
"
#$
%##"
N
n
m
nm
N
n nnm
m
nmm
m
m
w
tywE
&
&&' x
])([1 nn
N
n m
m
nm tywJ %"! "x
11
1
1' ''1
/)}(exp{
)}(exp{
)}(exp{})(exp{
$$
#
"
$
#"
#"
##( !
m
nmnm
m
n
m
n
nmnm
m
n
m
nmnm
m
m nmnm
m
n
Zytww
ytw
ytytw
x
x
xx
&
&'
&&
! "
$ #"N
n nmmn
m
n
m ytwZ1
1 )}(exp{ x&

Figures from Yoav Freund and Rob Schapire
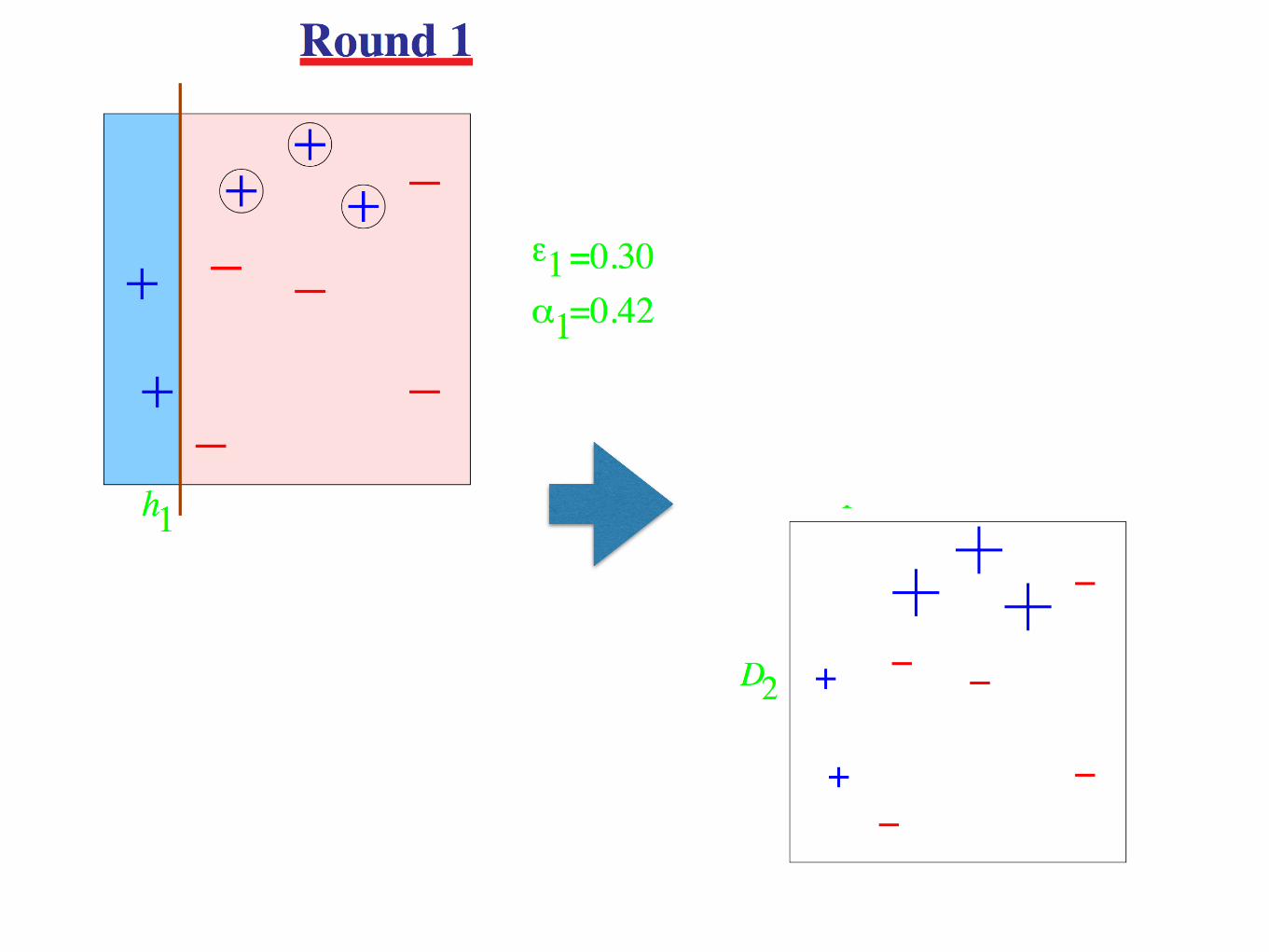
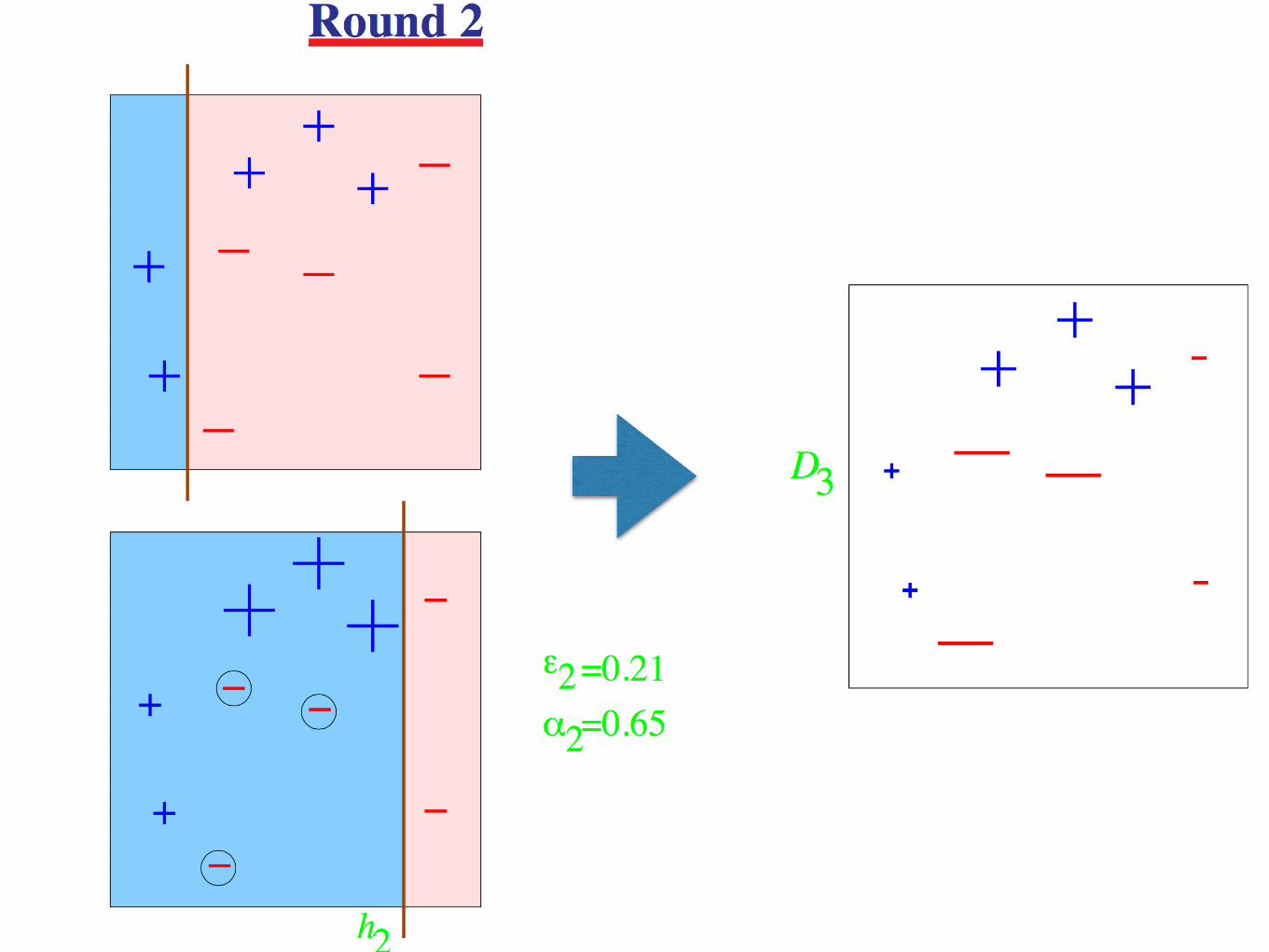



AdaBoost
• Adaptive in the sense that subsequent weak learners are tweaked in favor of those instances misclassified by previous classifiers.
• Sensitive to noisy data and outliers.
• Primarily reducing bias, and also variance.

Boos$ng'Varia$ons'
• Different'surrogate'loss'func$on'– E.g.'LogitBoost:'
'Minimize''
• Removal'previous'added'classifiers'– E.g.'FloatBoost'
• Confidence'rated'version'– E.g.'Realboost'''

Famous application of boosting: detecting faces in images
Two twists on standard algorithm
1) Pre-define weak classifiers, so optimization=selection
2) Change loss function for weak learners: false positives less costly than misses
AdaBoost in face detection

ViolaMJones'Detector'
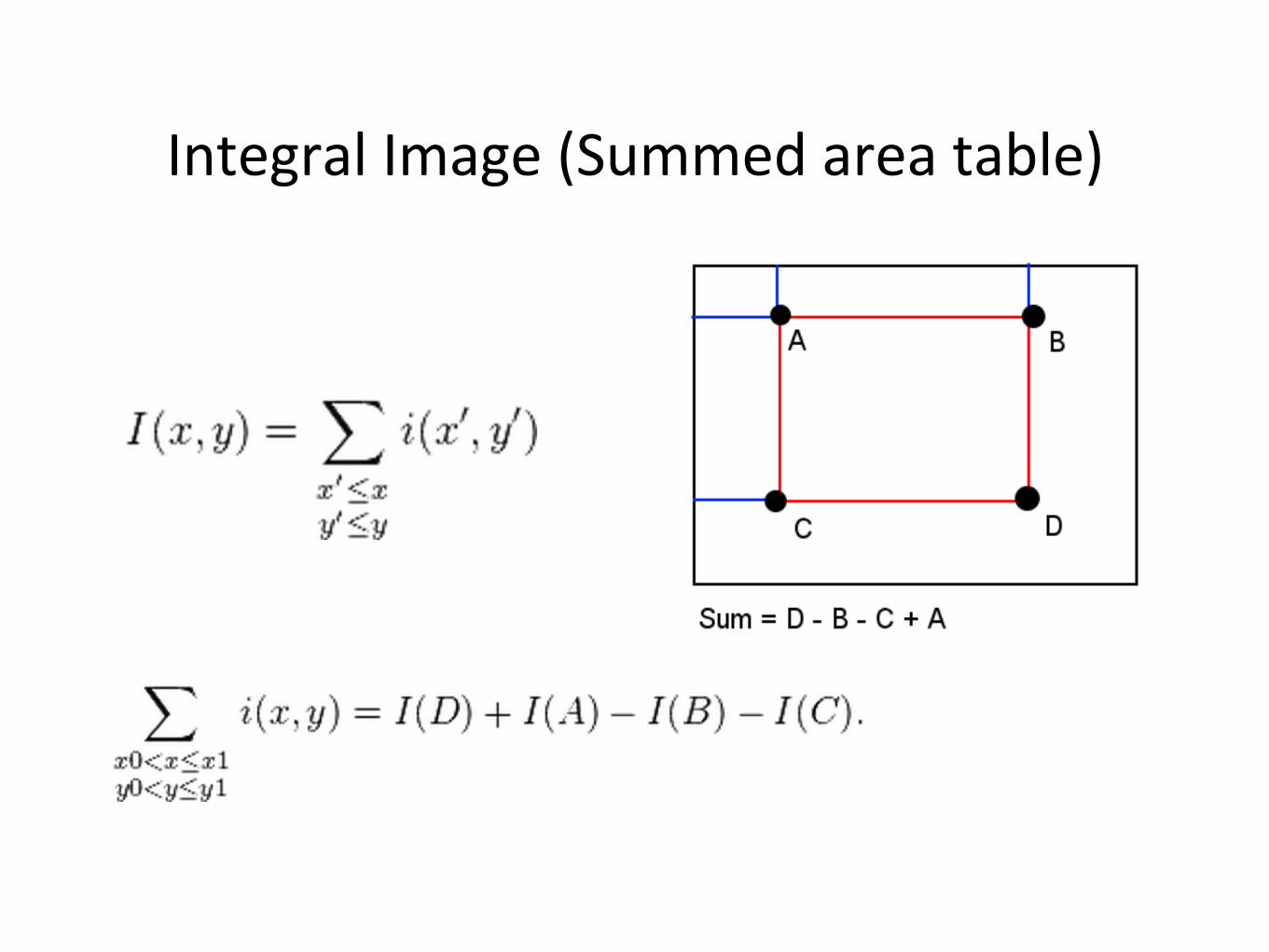
Integral'Image'(Summed'area'table)'





























