Embed Size (px)
Citation preview

Bloom FiltersAn Introduction and Really Most Of It
CMSC 491Hadoop-Based Distributed Computing
Spring 2015Adam Shook

Agenda
• Discuss what a set data structure is using math terms• Discuss the concept of a Bloom filter• Explore the mathematical magic behind Bloom filters

Set!
• A set is an unsorted data structure containing unique values• Most common uses are:• Error-free set membership tests• Storing unique members of data (remove duplicates)• Iterating through data in no particular order• Other fun operations like unions, intersections, subsets, etceteras!
• Other sets support sorting and duplicate values• But we aren’t here to talk about those
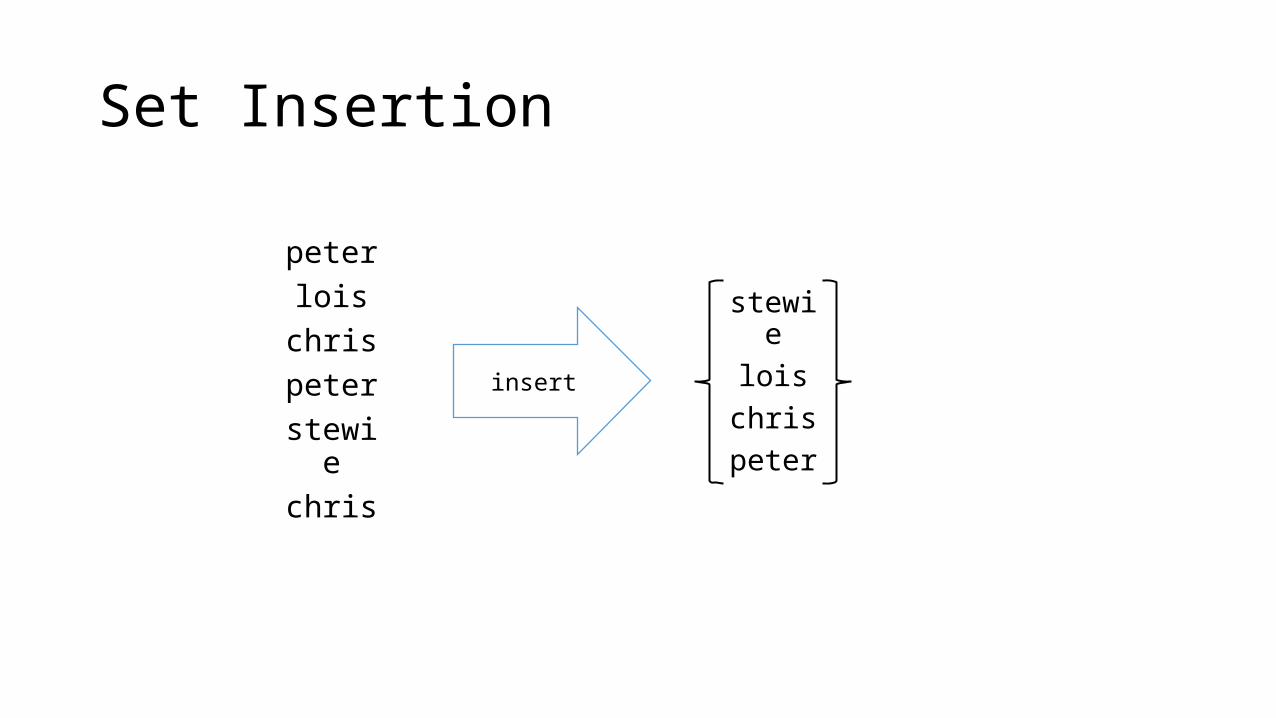
Set Insertion
peterlois
chrispeterstewiechris
stewielois
chrispeter
insert

is_member
Set Membership Test
peter
stewielois
chrispeter

is_member
Set Membership Test
adam
stewielois
chrispeter

Use Case!
• I’ve got a bunch of interesting keywords, A• I’ve got a data set B• I want to check if a record in B contains a word in A• Make a new data set C for some cool data science
for each record x in B
for each word w in x
if w in A
emit x

Use Case, Solved!
• Stuff all the data in A into a set• Get an A+ on your computer science project• Impress the boss
• But what if A is stupid big?
credit to mr. squarepants

Memory Footprint
• A contains 1 billion unique strings, average of 32 characters in length• 8 bits per character• 32 characters per string• 1 billion of them• 8 bits * 32 * 1,000,000,000 …• Roughly 29.8 GB of raw storage required to hold these elements
• + overhead• + even more if you are using Java
• For the sake of argument, let’s all agree that A doesn’t fit comfortably on a computer…

credit to xkcd and paint

Making a Set Smaller
• What two ‘features’ of a set can we relax to meet our requirements and have a reasonable memory footprint?
• Functionality• Only want set membership operations
• Accuracy• Don’t really need to be 100% accurate

Use Case, Revised!
• I’ve got a bunch of interesting keywords, A• I’ve got a data set B• I want to check if a record in B contains a word in A• Make a new data set C for some cool data science• I don’t really care if some stuff in C doesn’t contain words from A
for each record x in B
for each word w in x
if w is likely in A with false positive p
emit x

Let me paint you a story…
• We travel back to 1970…• Burton Howard Bloom was investigating means to eliminate
unnecessary disk accesses for particular algorithms• Came up with the a probabilistic data structure for set membership• Useful for programs with expensive operations where the operation is
often unnecessary• A structure only 15% of the size of the original can eliminate 85% of
unnecessary disk accesses

Bloom Filter
• A space-efficient means to test if an element is a member of a set• Elements can be added, but cannot be removed• Storage cost for a single element is independent of the element size• The members are not stored, so they cannot be retrieved• There are no false negatives, but false positives are possible

How It’s Made – Training a Bloom FilterGiven
An array of bits size m, initialized to 0k hash functionsn elements
foreach element ni in n
foreach function ki in k
m[ki(ni) % m] = 1
Training a Bloom filter is O(n)
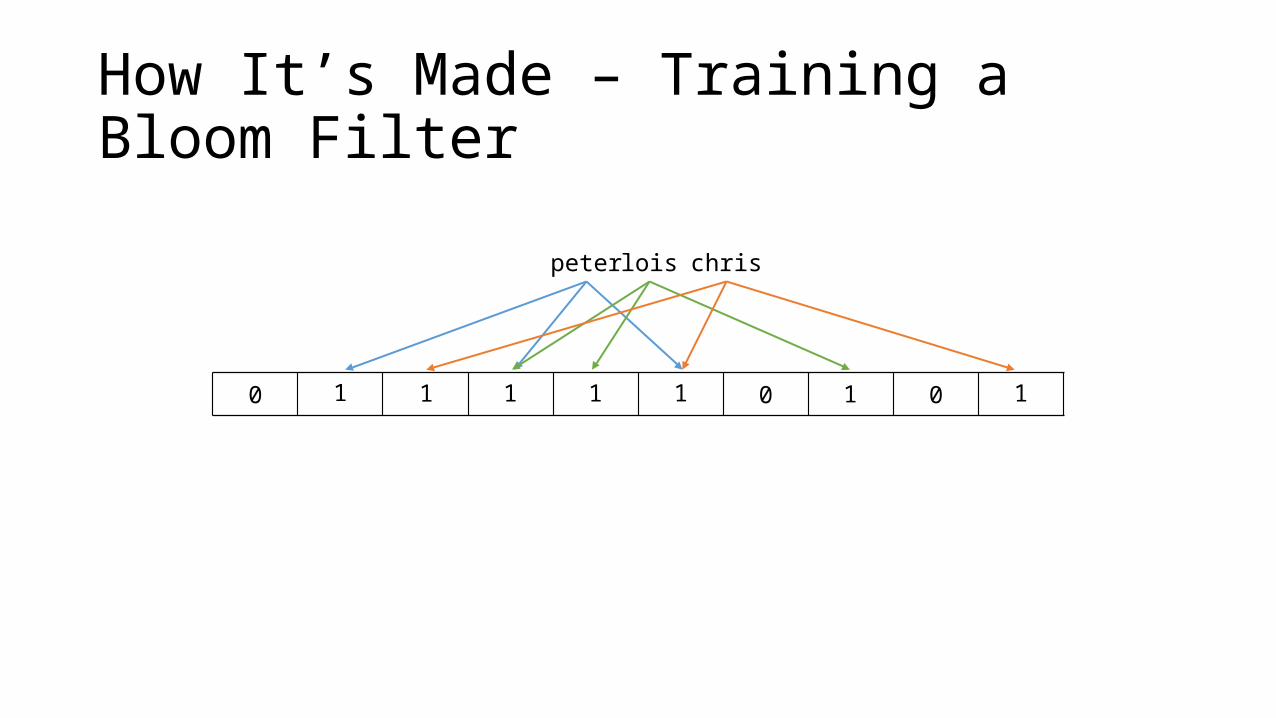
How It’s Made – Training a Bloom Filter
0 0 0 0 0 0 0 0 0 0
peter lois chris
11 1 1 1 11

How It’s Made – Membership Testing
GivenA trained Bloom filter of size mThe same k hash functionsAn element x
foreach function ki in k
if m[ki(x) % m] is 0
return false
return true
Testing a Bloom filter is O(1)
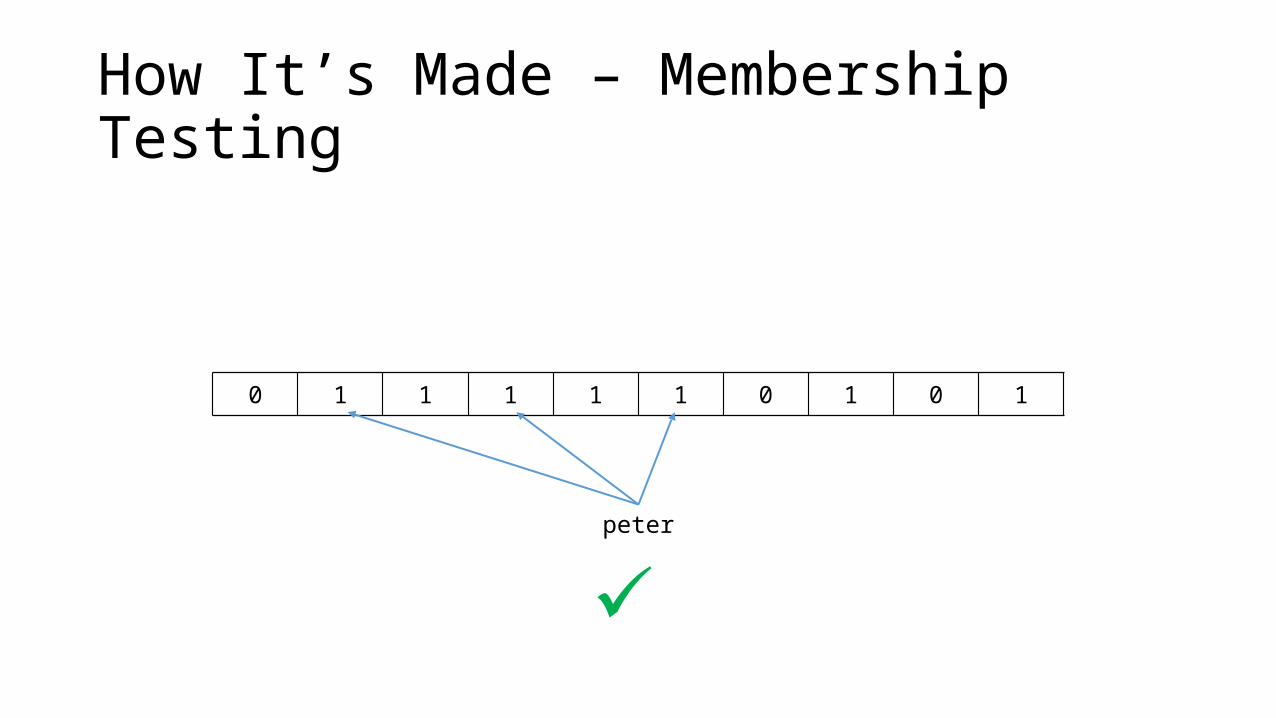
How It’s Made – Membership Testing
0 1 1 1 1 1 0 1 0 1
peter

How It’s Made – Membership Testing
0 1 1 1 1 1 0 1 0 1
adam

I know what you’re thinking
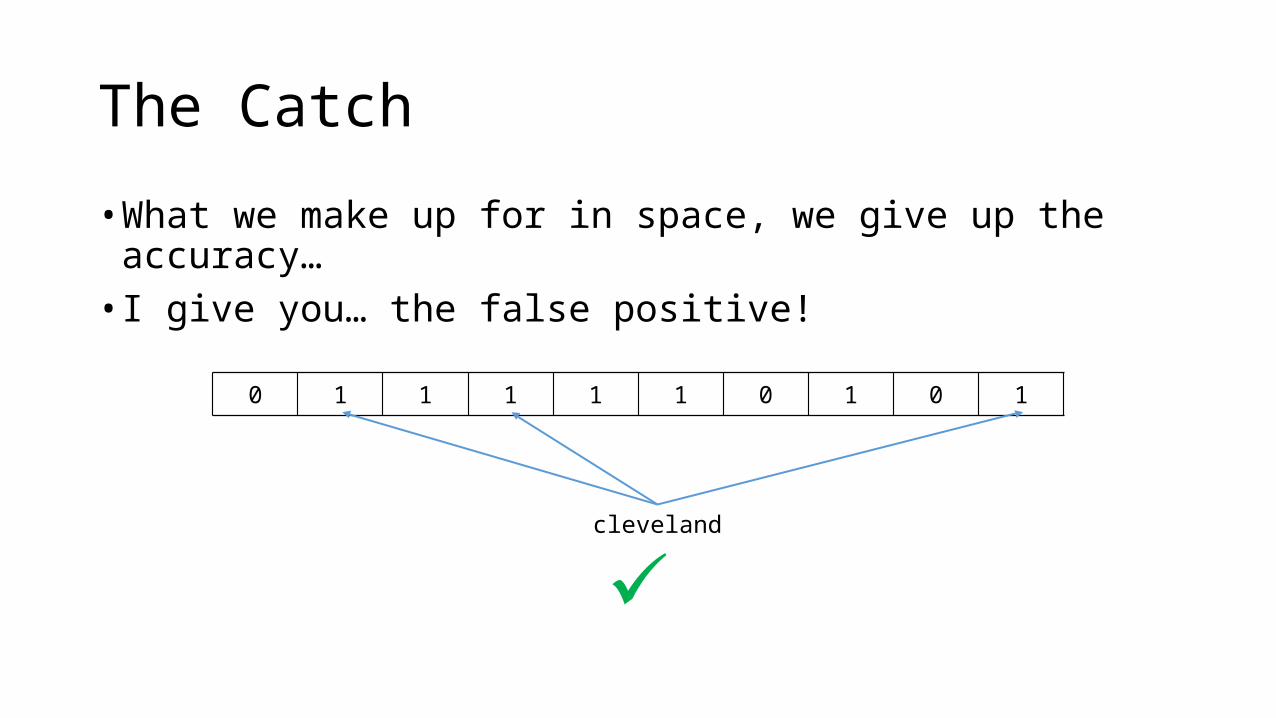
The Catch
• What we make up for in space, we give up the accuracy…• I give you… the false positive!
0 1 1 1 1 1 0 1 0 1
cleveland

credit to xkcd and paint

Controlling the False Positive Rate
GivenApproximate number of elements in A, nA willingness to tolerate a percent p of false positivesk is the optimal number of hash functions
We can approximate m
If you want the full details, read the paper or Wikipedia

Back to our use case…
n = 1,000,000,000p = .1
After dusting off the calculators….
m = 4.792 x109 bits or 0.558 GB
An improvement of 29.8/0.558 = 53.4!

And now that we have m…
We can use n and m to calculate k = m/n * ln(2)
But I haven’t heard of 3.32 hash functions so let’s call it 4

References
• Wikipedia