Embed Size (px)
Citation preview

BİL711 Natural Language Processing 1
Statistical Parse Disambiguation
Problem:– How do we disambiguate among a set of parses of a given sentence?
– We want to pick the parse tree that corresponds to the correct meaning.
Possible Solutions:– Pass the problem onto Semantic Processing
– Use principle-based disambiguation methods.
– Use a probabilistic model to assign likelihoods to the alternative parse trees and select the best one (or at least rank them).
– Associating probabilities with the grammar rules gives us such a model.

BİL711 Natural Language Processing 2
Probabilistic CFGs
• Associate a probability with each grammar rule.
• The probability reflects relative likelihood of using the rule in generating the LHS constituent.
• Assume for a constituent C we have k grammar rules of form C i.
• We are interested in calculating P(C i|C) -- the probability of using rule i for deriving C.
• Such probabilities can be estimated from a corpus of parse trees:
)(
)(
)(
)()|(
1
Ccount
Ccount
Ccount
CcountCCP i
k
jj
ii

BİL711 Natural Language Processing 3
Probabilistic CFGs (cont.)
• Attach probabilities to grammar rules
• The expansions for a given non-terminal sum to 1
VP -> Verb .55
VP -> Verb NP .40
VP -> Verb NP NP .05

BİL711 Natural Language Processing 4
Assigning Probabilities to Parse Trees
• Assume that probability of a constituent is independent of context in which it appears in the parse tree.
• Probability of a constituent C’ that was constructed from A1’,…,An’ using the rule C A1,…,An is:
P(C’)=P(C A1,…,An|C) P(A1’) … P(An’)
• At the leafs of the tree, we use the POS probabilities P(C|wi).

BİL711 Natural Language Processing 5
Assigning Probabilities to Parse Trees (cont.)
• A derivation (tree) consists of the set of grammar rules that are in the tree
• The probability of a derivation (tree) is just the product of the probabilities of the rules in the derivation.

BİL711 Natural Language Processing 6
Assigning Probabilities to Parse Trees (Ex. Grammar)
S -> NP VP 0.6
S -> VP 0.4
NP -> Noun1.0
VP -> Verb 0.3
VP -> Verb NP 0.7
Noun -> book 0.2
.
Verb-> book 0.1
.

BİL711 Natural Language Processing 7
Parse Trees for An Input: book book
• [S [NP [Noun book]] [VP [Verb book]]]P([Noun book])=P(Noun->book)=0.1
P([Verb book])=P(Verb->book)=0.2
P([NP [Noun book]])=P(NP->Noun)P([Noun book])=1.0*0.1=0.1
P([VP [Verb book]])=P(VP->Verb)P([Verb book])=0.3*0.2=0.06
P [S [NP [Noun book]] [VP [Verb book]]])
=P(S->NP VP)*0.1*0.06=0.6*0.1*0.06=0.0036
• [S [VP [Verb book] [NP [Noun book]]]]P([VP [Verb book] [NP [Noun book]]])=P(VP->Verb NP)*0.2*0.1=0.7*0.2*0.1=0.014
P([S [VP [Verb book] [NP [Noun book]]]])=P(S->VP)*0.014=0.4*.014=0.0056

BİL711 Natural Language Processing 8
Problems with Probabilistic CFG Models
• Main problem with Probabilistic CFG Model: it does not take contextual effects into account.
• Example: Pronouns are much more likely to appear in the subject position of a sentence than an object position.
• But in a PCFG, the rule NPPronoun has only one probability.
• One simple possible extension -- make probabilities dependent on first word of the constituent.
• Instead of P(C i|C), use P(C i|C,w) where w is the first word in C.
• Example: the rule VP V NP PP is used 93% of the time with the verb put, but only 10% of the time for like.
• Requires estimating a much larger set of probabilities, and can significantly improve disambiguation performance.

BİL711 Natural Language Processing 9
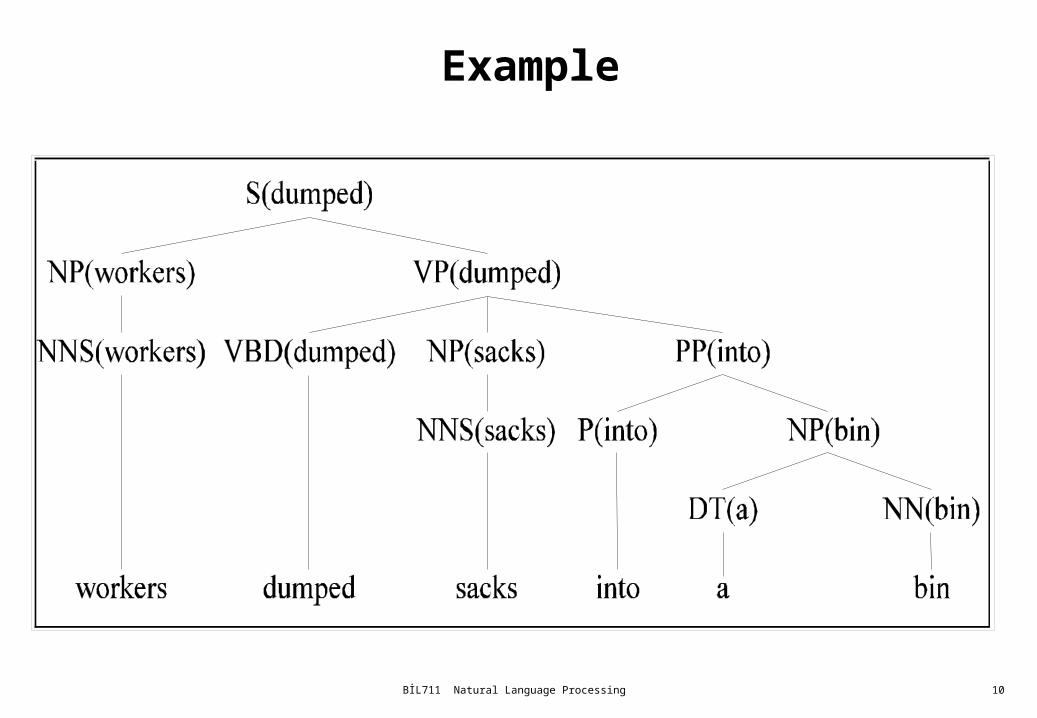
Probabilistic Lexicalized CFGs
• A solution to some of the problems with Probabilistic CFGs is to use Probabilistic Lexicalized CFGs.
• Use the probabilities of particular words in the computation of the probabilities in the derivation
BİL711 Natural Language Processing 10
Example

BİL711 Natural Language Processing 11
How to find the probabilities?
• We used to have– VP -> V NP PP P(r|VP)
• That’s the count of this rule divided by the number of VPs in a treebank
• Now we have– VP(dumped)-> V(dumped) NP(sacks)PP(in)
– P(r|VP ^ dumped is the verb ^ sacks is the head of the NP ^ in is the head of the PP)
– Not likely to have significant counts in any treebank

BİL711 Natural Language Processing 12
Subcategorization
• When stuck, exploit independence and collect the statistics you can…
• We’ll focus on capturing two things– Verb subcategorization
• Particular verbs have affinities for particular VPs
– Objects affinities for their predicates (mostly their mothers and grandmothers)• Some objects fit better with some predicates than others
• Condition particular VP rules on their head… so r: VP -> V NP PP P(r|VP)
Becomes
P(r | VP ^ dumped)
What’s the count?
How many times was this rule used with dump, divided by the number of VPs that dump appears in total





























