Embed Size (px)
Citation preview

Big Data Architecture for Enterprise
Wei Zhang Big Data Architect
Up up consultant, LLC

Design Principles
• Future-proof, scalable and auto recoverable, compatible with existing technologies, loose coupled and layered architecture

Centralized Data Governance service
• Build Schema catalog service to track all data entities and attributes for both structured and unstructured data sets
• Establish and enforce proper practices including solution patterns/design, coding, testing automation and release procedues
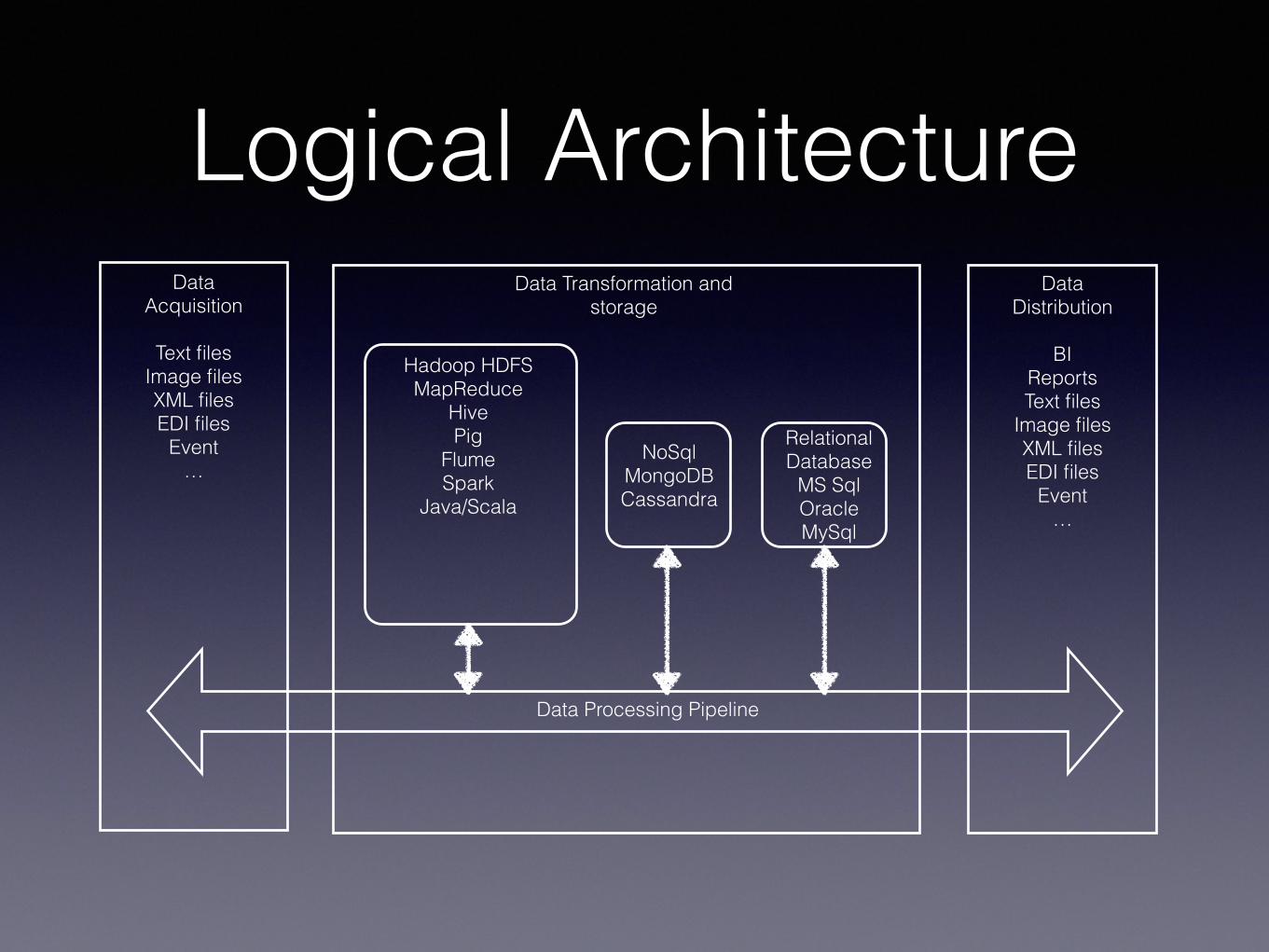
Logical ArchitectureData Transformation and
storageData
Acquisition
Text files Image files XML files EDI files
Event …
Data Distribution
BI Reports Text files
Image files XML files EDI files
Event …
Data Processing Pipeline
Hadoop HDFS MapReduce
Hive Pig
Flume Spark
Java/Scala
NoSql MongoDB Cassandra
Relational Database
MS Sql Oracle MySql

Logical Architecture• Data lifecycle control, access audit, replication
and DR
• On-desk and in-memory data processing technology stack - sql or nosql database, hadoop map reduce, Spark or ETL tool etc
• Central data inventory services for discovery, tracking and optimization

Technology Stack
• HDFS, MapReduce, Yarn
• Oozie, Hive, Spark, Kafka, Cassandra, MongoDB
• BI & Reporting, Data acquisition and distribution, Data inventory and data model

Schema Catalog
• MongoDB schema store
• Schemas, Entities, attributes defined using Arvo format
• Define all Data Sources, destinations including format, transfer protocol, file system, schedule etc

Data Ledger
• Ledger inventory of all business data set across enterprise
• data set producer and consumer registration
• Data set are tagged and can be queried for traceability and usages

Data Process and Persistent • Relational database for OLTP, data warehouse
and BI which need to access SQL database and existing systems
• HDFS for source, destination, staging, no structured document, large to huge data processing, data saved in either Arvo or Parquet format for better exchange and performance
• Cassanadra for high frequency, high write transaction systems and MongoDB for document

Automated and Regression Testing
• Maven, SBT, Junit, Scalatest

Physical Deployment
• Low End: 7.2 RPM / 75 IOPS, 16 core, 128G (data acquisition and distribution)
• Medium: 15k RPM / 175 IOPS, 24 core, 512G (batch processing)
• High End: 6K - 500K IOPS, 80 core, 1.5T (realtime processing/analytics)





























