Embed Size (px)
Citation preview

CADSL
Beyond Pipelining
Virendra Singh
Associate Professor Computer Architecture and Dependable Systems Lab
Department of Electrical Engineering Indian Institute of Technology Bombay
http://www.ee.iitb.ac.in/~viren/ E-mail: [email protected]
CP-226: Computer Architecture Lecture 23 (19 April 2013)

CADSL 19 Feb 2013 Computer Architecture@MNIT 2
Instr. mem. PC
Add
Reg
. File
Data mem. 1
mux
0
1 m
ux 0
0 m
ux 1
4
1 m
ux 0
Sign ext.
Shift left 2
ALU Cont.
CO
NTR
OL
opcode
MemWrite MemRead
ALU
Branch
zero
0-15
0-5
11-15
16-20
21-25
26-31
ALU
0 m
ux 1
Shift left 2
0-25 Jump
Combined Datapaths
Reg
Dst
MemtoReg
CADSL 19 Feb 2013 Computer Architecture@MNIT 3
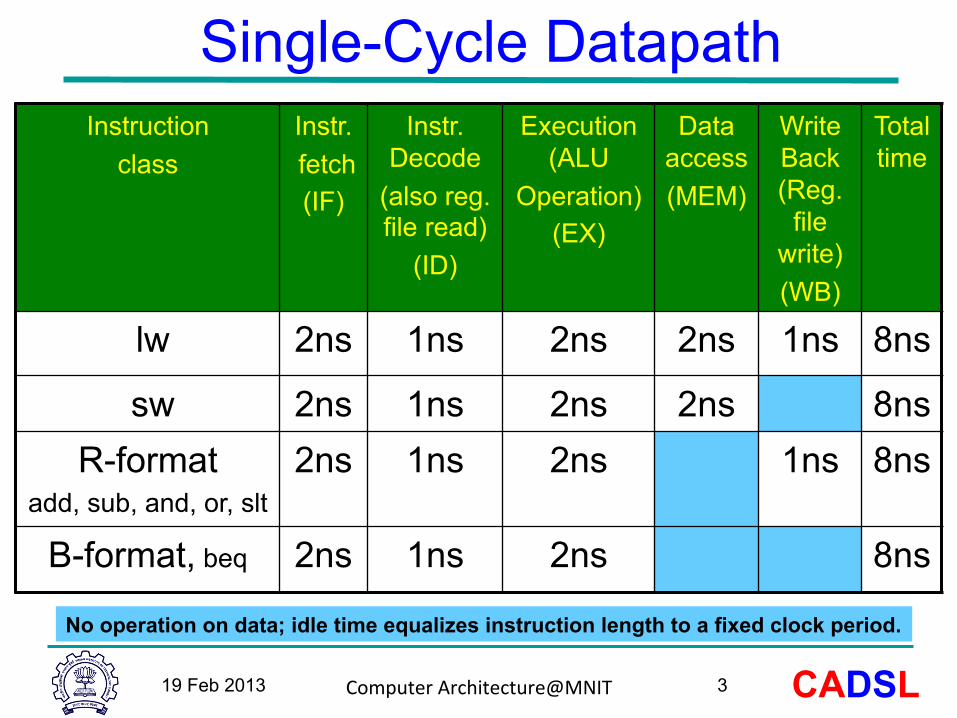
Single-Cycle Datapath Instruction
class Instr. fetch (IF)
Instr. Decode
(also reg. file read)
(ID)
Execution (ALU
Operation) (EX)
Data access (MEM)
Write Back (Reg.
file write) (WB)
Total time
lw 2ns 1ns 2ns 2ns 1ns 8ns
sw 2ns 1ns 2ns 2ns 8ns R-format
add, sub, and, or, slt 2ns 1ns 2ns 1ns 8ns
B-format, beq 2ns 1ns 2ns 8ns
No operation on data; idle time equalizes instruction length to a fixed clock period.

CADSL 19 Feb 2013 Computer Architecture@MNIT 4
Multicycle Datapath PC
Inst
r. re
g. (I
R)
Mem
. Dat
a (M
DR
)
ALU
Out
Reg
.
A R
eg.
B R
eg.
A
LU
Reg
iste
r file
Mem
ory
Add
r.
Data
4
Sign extend
Shift left 2
ALU control 0-5
0-15
16-20 21-25
IorD
MemtoReg ALUOp
ALU
SrcB
ALU
SrcA
RegDst IRWrite
RegWrite
MemWrite MemRead
in1 in2
out control MUX
Shift left 2 0-25
28-31
PCSource PC
Writ
e e
tc.
26-31 to Control
FSM
11-1
5

CADSL
Traffic Flow
19 Apr 2013 Computer Architecture@MNIT 5

CADSL 19 Apr 2013 Computer Architecture@MNIT 6
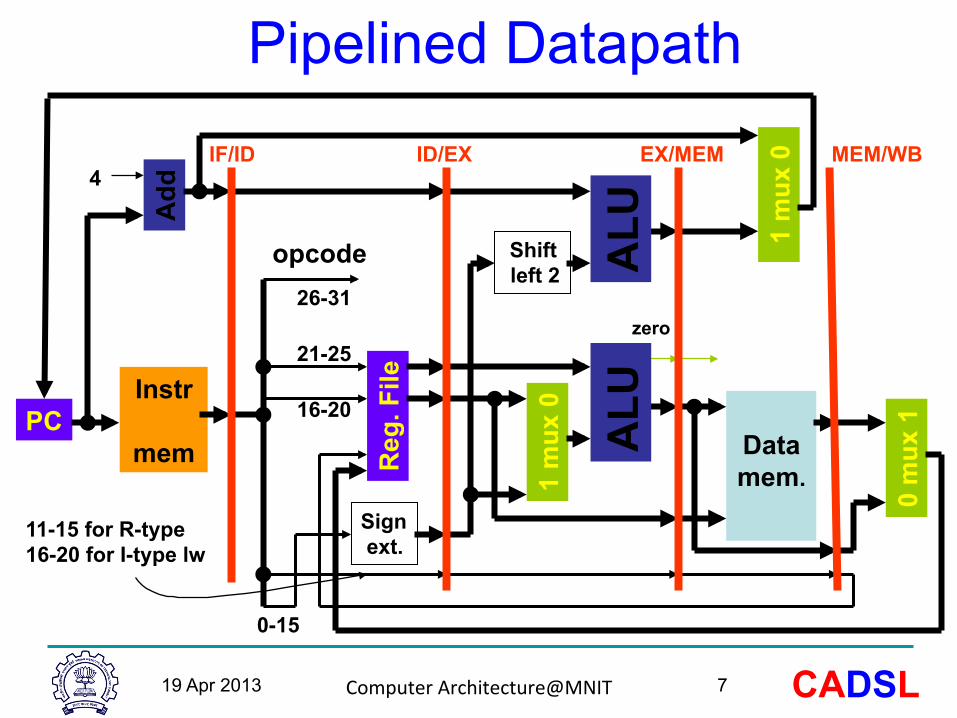
Pipelined Datapath Instruction
class Instr. fetch (IF)
Instr. Decode
(also reg. file read)
(ID)
Execu-tion
(ALU Opera-
tion) (EX)
Data access (MEM)
Write Back (Reg.
file write) (WB)
Total time
lw 2ns 1ns 2ns
2ns 2ns 1ns 2ns
10ns
sw 2ns 1ns 2ns
2ns 2ns 1ns 2ns
10ns
R-format: add, sub, and, or, slt 2ns
1ns 2ns
2ns 2ns 1ns 2ns
10ns
B-format: beq
2ns 1ns 2ns
2ns 2ns 1ns 2ns
10ns
No operation on data; idle time inserted to equalize instruction lengths.
CADSL 19 Apr 2013 Computer Architecture@MNIT 7
Instr
mem PC
Add
Reg
. File
Data mem.
1 m
ux 0
1 m
ux 0
0 m
ux 1
4
Sign ext.
Shift left 2
opcode
ALU
zero
0-15
16-20
21-25
26-31
ALU
Pipelined Datapath
IF/ID ID/EX EX/MEM MEM/WB
11-15 for R-type 16-20 for I-type lw

CADSL
Single Lane Traffic
19 Apr 2013 Computer Architecture@MNIT 8
CADSL Computer Architecture@MNIT
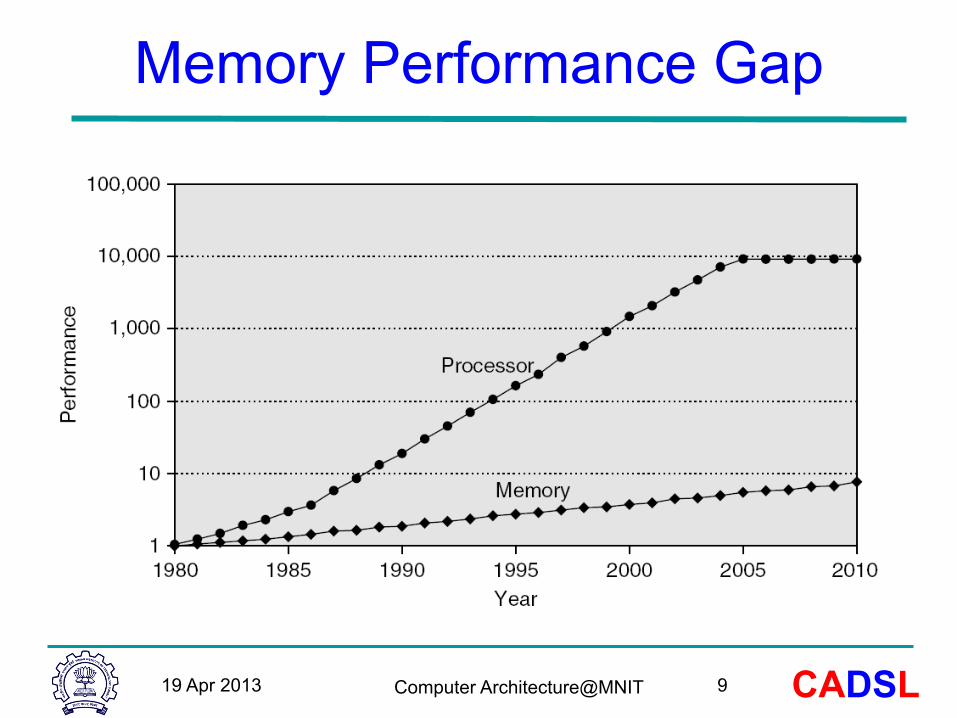
Memory Performance Gap
19 Apr 2013 9

CADSL Computer Architecture@MNIT 10
Memory Hierarchy
CPU
I & D L1 Cache
Shared L2 Cache
Main Memory
Disk
Temporal Locality • Keep recently referenced items at higher levels • Future references saHsfied quickly
SpaHal Locality • Bring neighbors of recently referenced to higher levels • Future references saHsfied quickly
19 Apr 2013

CADSL
Limits of Pipelining
• IBM RISC Experience – Control and data dependences add 15% – Best case CPI of 1.15, IPC of 0.87 – Deeper pipelines (higher frequency) magnify dependence penalHes
• This analysis assumes 100% cache hit rates – Hit rates approach 100% for some programs – Many important programs have much worse hit rates
19 Apr 2013 Computer Architecture@MNIT 11

CADSL
Processor Performance
• In the 1980’s (decade of pipelining): – CPI: 5.0 => 1.15
• In the 1990’s (decade of superscalar): – CPI: 1.15 => 0.5 (best case)
• In the 2000’s (decade of mulHcore): – Marginal CPI improvement
Processor Performance = --------------- Time
Program
Instructions Cycles Program Instruction
Time Cycle
(code size)
=! X! X!
(CPI) (cycle time)
19 Apr 2013 Computer Architecture@MNIT 12

CADSL
Limits on InstrucHon Level Parallelism (ILP)
Weiss and Smith [1984] 1.58 Sohi and Vajapeyam [1987] 1.81 Tjaden and Flynn [1970] 1.86 (Flynn’s bottleneck) Tjaden and Flynn [1973] 1.96 Uht [1986] 2.00 Smith et al. [1989] 2.00 Jouppi and Wall [1988] 2.40 Johnson [1991] 2.50 Acosta et al. [1986] 2.79 Wedig [1982] 3.00 Butler et al. [1991] 5.8 Melvin and Patt [1991] 6 Wall [1991] 7 (Jouppi disagreed) Kuck et al. [1972] 8 Riseman and Foster [1972] 51 (no control dependences) Nicolau and Fisher [1984] 90 (Fisher’s optimism)
19 Apr 2013 Computer Architecture@MNIT 13

CADSL
Superscalar Proposal • Go beyond single instrucHon pipeline, achieve IPC > 1
• Dispatch mulHple instrucHons per cycle • Provide more generally applicable form of concurrency (not just vectors)
• Geared for sequenHal code that is hard to parallelize otherwise
• Exploit fine-‐grained or instrucHon-‐level parallelism (ILP)
19 Apr 2013 Computer Architecture@MNIT 14

CADSL
Classifying ILP Machines [Jouppi, DECWRL 1991] • Baseline scalar RISC
– Issue parallelism = IP = 1 – OperaHon latency = OP = 1 – Peak IPC = 1
12 3 4
5 6
IF DE EX WB
1 2 3 4 5 6 7 8 90
TIME IN CYCLES (OF BASELINE MACHINE)
SUCC
ESSI
VEIN
STRU
CTIO
NS
19 Apr 2013 Computer Architecture@MNIT 15

CADSL
Classifying ILP Machines [Jouppi, DECWRL 1991] • Superpipelined: cycle Hme = 1/m of baseline
– Issue parallelism = IP = 1 inst / minor cycle – OperaHon latency = OP = m minor cycles – Peak IPC = m instr / major cycle (m x speedup?)
12
345
IF DE EX WB6
1 2 3 4 5 6
19 Apr 2013 Computer Architecture@MNIT 16

CADSL
Classifying ILP Machines [Jouppi, DECWRL 1991] • Superscalar:
– Issue parallelism = IP = n inst / cycle – OperaHon latency = OP = 1 cycle – Peak IPC = n instr / cycle (n x speedup?)
IF DE EX WB
123
456
9
78
19 Apr 2013 Computer Architecture@MNIT 17

CADSL
Classifying ILP Machines [Jouppi, DECWRL 1991] • VLIW: Very Long InstrucHon Word
– Issue parallelism = IP = n inst / cycle – OperaHon latency = OP = 1 cycle – Peak IPC = n instr / cycle = 1 VLIW / cycle
IF DE
EX
WB
19 Apr 2013 Computer Architecture@MNIT 18

CADSL
Classifying ILP Machines [Jouppi, DECWRL 1991] • Superpipelined-‐Superscalar
– Issue parallelism = IP = n inst / minor cycle – OperaHon latency = OP = m minor cycles – Peak IPC = n x m instr / major cycle
IF DE EX WB
123
456
9
78
19 Apr 2013 Computer Architecture@MNIT 19

CADSL
Superscalar vs. Superpipelined
• Roughly equivalent performance – If n = m then both have about the same IPC – Parallelism exposed in space vs. Hme
Time in Cycles (of Base Machine)0 1 2 3 4 5 6 7 8 9
SUPERPIPELINED
10 11 12 13
SUPERSCALARKey:
IFetchDcode
ExecuteWriteback
19 Apr 2013 Computer Architecture@MNIT 20

CADSL
LimitaHons of Scalar Pipelines • Scalar upper bound on throughput
– IPC <= 1 or CPI >= 1 • Inefficient unified pipeline
– Long latency for each instrucHon • Rigid pipeline stall policy
– One stalled instrucHon stalls all newer instrucHons
19 Apr 2013 Computer Architecture@MNIT 21

CADSL Computer Architecture@MNIT
Instruction-Level Parallelism • When exploiHng instrucHon-‐level parallelism, goal is to maximize IPC – Pipeline IPC =
• Ideal pipeline IPC + • Structural stalls -‐ • Data hazard stalls -‐ • Control stalls -‐
• Parallelism with basic block is limited – Typical size of basic block = 3-‐6 instrucHons – Must opHmize across branches
19 Apr 2013 22

CADSL
LimitaHons of Scalar Pipelines • Scalar upper bound on throughput
– IPC <= 1 or CPI >= 1 • Inefficient unified pipeline
– Long latency for each instrucHon • Rigid pipeline stall policy
– One stalled instrucHon stalls all newer instrucHons
19 Apr 2013 Computer Architecture@MNIT 23

CADSL 19 Apr 2013 Computer Architecture@MNIT 24
Superscalar Architecture Ø Simple concept Ø Wide pipeline Ø InstrucHons are not independent Ø Superscalar architecture is natural descendant of pipelined scalar RISC
Ø Superscalar techniques largely concern the processor organizaHon, independent of the ISA and the other architectural features
Ø Thus, possibility to develop a processor code compaHble with an exisHng architecture
CADSL 19 Apr 2013 Computer Architecture@MNIT 25
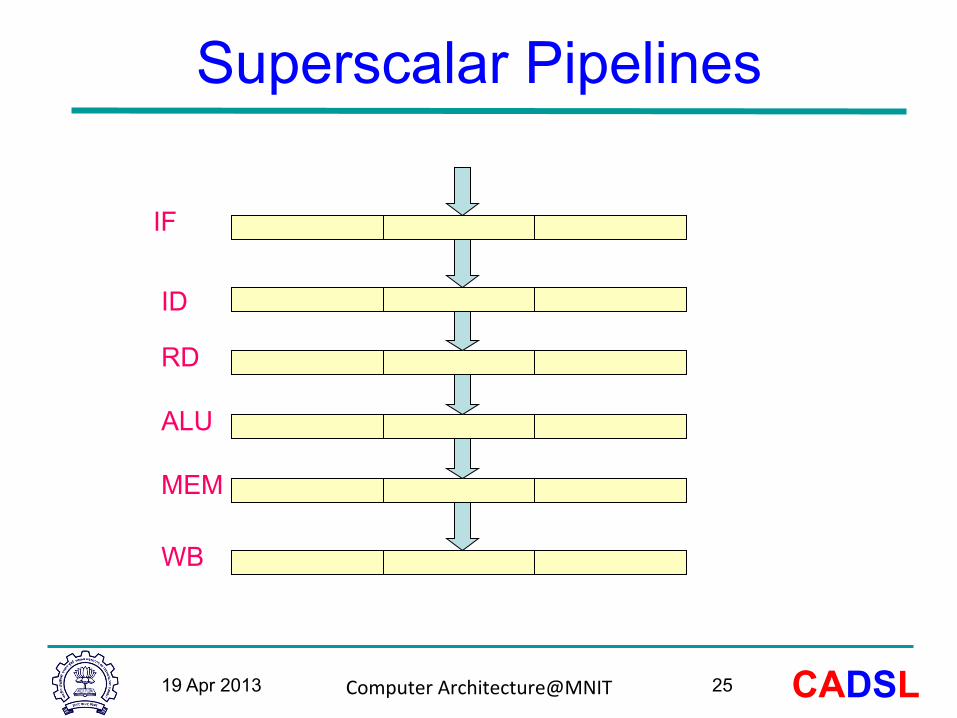
Superscalar Pipelines
IF
ID
RD
ALU
MEM
WB

CADSL
Highway
19 Apr 2013 Computer Architecture@MNIT 26

CADSL 19 Apr 2013 Computer Architecture@MNIT 27
Instruction Level Parallelism
Ø InstrucHon parallelism of a program is a measure of the average number of instrucHons that a superscalar processor might be able to execute at the same Hme
Ø Mostly, ILP is determined by the number of true dependencies and the number of branches in relaHon to other instrucHons

CADSL 19 Apr 2013 Computer Architecture@MNIT 28
Machine Level Parallelism
Ø Machine parallelism of a processor is a measure of the ability of processor to take advantage of the ILP
Ø Determined by the number of instrucHons that can be fetched and executed at the same Hme
Ø A challenge in the design of superscalar processor is to achieve good balance between instrucHon parallelism and machine parallelism

CADSL 19 Apr 2013 Computer Architecture@MNIT 29
Superscalar Pipelines
IF
ID
RD
ALU
MEM
WB

CADSL
Highway
19 Apr 2013 Computer Architecture@MNIT 30

CADSL
Dream Highway
19 Apr 2013 Computer Architecture@MNIT 31

CADSL 19 Apr 2013 Computer Architecture@MNIT 32
Superscalar Pipelines
Dynamic Pipelines
1. Alleviate the limitaHons of pipelined implementaHon
2. Use diversified pipelines 3. Temporal machine parallelism
CADSL 19 Apr 2013 Computer Architecture@MNIT 33
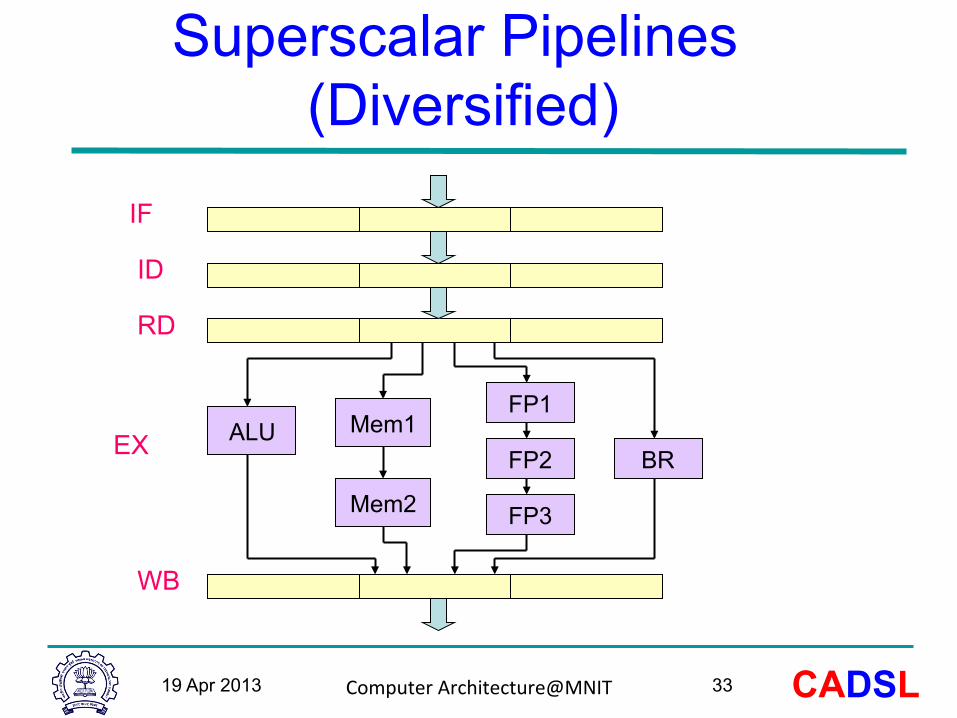
Superscalar Pipelines (Diversified)
IF
ID
RD
WB
ALU Mem1
Mem2
FP1
FP2
FP3
BR EX

CADSL 19 Apr 2013 Computer Architecture@MNIT 34
Superscalar Pipelines (Diversified) Diversified Pipelines
v Each pipeline can be customized for parHcular instrucHon type
v Each instrucHon type incurs only necessary latency
v Certainly less expensive than idenHcal copies v If all inter-‐instrucHon dependencies are resolved then
there is no stall aqer instrucHon issue
Require special consideraHon
Ø Number and Mix of funcHonal units

CADSL 19 Apr 2013 Computer Architecture@MNIT 35
Superscalar Architecture • InstrucHon issue and machine parallelism
Ø ILP is not necessarily exploited by widening the pipelines and adding more resources
Ø Processor policies towards fetching decoding, and execuHng instrucHon have significant effect on its ability to discover instrucHons which can be executed concurrently
Ø InstrucHon issue is refer to the process of iniHaHng instrucHon execuHon
Ø InstrucHon issue policy limits or enhances performance because it determines the processor’s look ahead capability

CADSL 19 Apr 2013 Computer Architecture@MNIT 36
Super-scalar Architecture Instruction buffer
Dispatch buffer
Reservation station
Re-order/Completion buffer
Store buffer
Fetch
Decode
Dispatch
Complete
Retire
Execute
finish
Issue

CADSL
Superscalar Pipeline Stages
Instruction Buffer
Fetch
Dispatch Buffer
Decode
Issuing Buffer
Dispatch
Completion Buffer
Execute
Store Buffer
Complete
Retire
In Program
Order
In Program
Order
Out of
Order
19 Apr 2013 Computer Architecture@MNIT 37

CADSL
Thank You
19 Apr 2013 Computer Architecture@MNIT 38
![Pipelining & Parallel Processing - ics.kaist.ac.krics.kaist.ac.kr/ee878_2018f/[EE878]3 Pipelining and Parallel Processing.pdf · Pipelining processing By using pipelining latches](https://img.pdfslide.us/doc/110x75/5d40e26d88c99391748d47fb/pipelining-parallel-processing-icskaistackricskaistackree8782018fee8783.jpg)




























