Embed Size (px)
Citation preview

Beyond NounsBeyond Nouns
Abhinav Gupta and Larry S. DavisUniversity of Maryland, College Park
Exploiting Prepositions and Comparative Adjectives for Learning Visual Classifiers

Beyond NounsGupta and Davis
What this talk is aboutWhat this talk is about• Richer linguistic descriptions of images makes learning of
object appearance models from weakly labeled images more reliable.
• Constructing visually-grounded models for parts of speech other than nouns provides contextual models that make labeling new images more reliable.
• So, this talk is about simultaneous learning of object appearance models and context models for scene analysis.
car officer road
A officer on the left of car checks the speed of other cars on the road
AB
Larger (B, A)
Larger (tiger, cat)
cat
tigerBear Water Field
AB
Larger (A, B)
A
B
Above (A, B)

Beyond NounsGupta and Davis
What this talk is aboutWhat this talk is about• Prepositions – A preposition usually indicates the temporal, spatial or logical
relationship of its object to the rest of the sentence
• The most common prepositions in English are "about," "above," "across," "after," "against," "along," "among," "around," "at," "before," "behind," "below," "beneath," "beside," "between," "beyond," "but," "by," "despite," "down," "during," "except," "for," "from," "in," "inside," "into," "like," "near," "of," "off," "on," "onto," "out," "outside," "over," "past," "since," "through," "throughout," "till," "to," "toward," "under," "underneath," "until," "up," "upon," "with," "within," and "without” where indicated in bold are the ones (the vast majority) that have clear utility for the analysis of images and video.
• Comparative adjectives and adverbs– relating to color, size, movement- “larger”, “smaller”, “taller”, “heavier”, “faster”………
• This presentation addresses how visually grounded (simple) models for prepositions and comparative adjectives can be acquired and utilized for scene analysis.

Beyond NounsGupta and Davis
Learning Appearances – Weakly Labeled Learning Appearances – Weakly Labeled DataData
• Problem: Learning Visual Models for Objects/Nouns
• Weakly Labeled Data – Dataset of images with associated text or captions
Before the start of the debate, Mr. Obama and Mrs. Clinton met with the moderators,
Charles Gibson, left, and George Stephanopoulos, right, of ABC News.
A officer on the left of car checks the speed of other cars on the road.

Beyond NounsGupta and Davis
Captions - Bag of NounsCaptions - Bag of Nouns
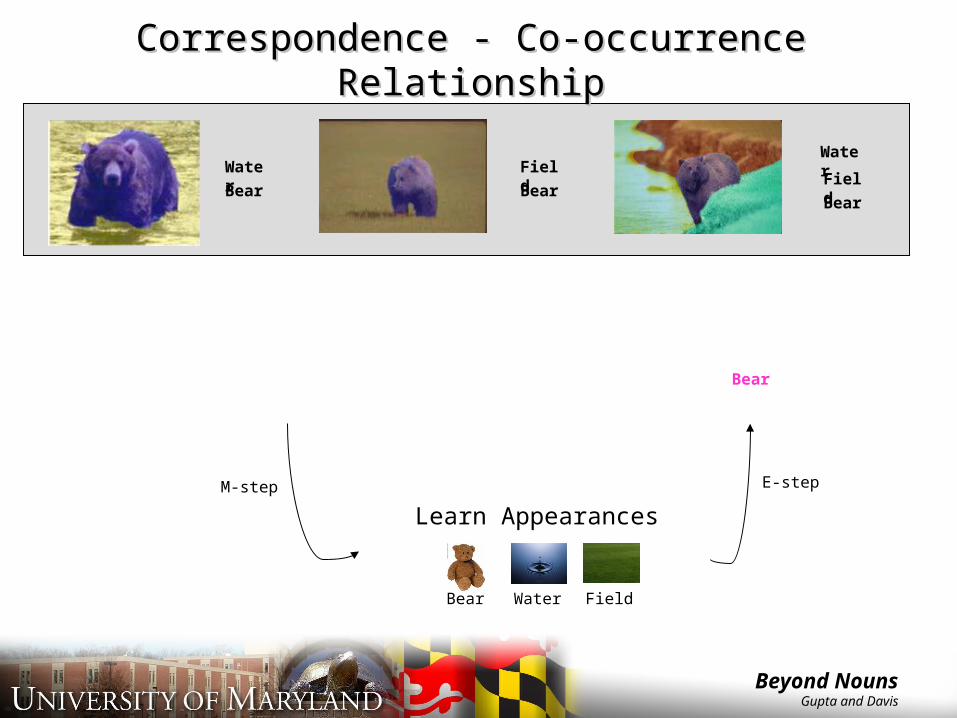
Learning Classifiers involves establishing correspondence.
road.A officer on the left of car checks the speed of other cars on the
officercar
road
officer
car
road
Beyond NounsGupta and Davis
Correspondence - Co-occurrence Correspondence - Co-occurrence RelationshipRelationship
Bear
Water
Bear
Field
Learn AppearancesM-step E-step
Bear Water Field
Water
Bear
Field
Bear

Beyond NounsGupta and Davis
Co-occurrence Relationship (Problems)Co-occurrence Relationship (Problems)
RoadCar RoadCar RoadCarRoadCar RoadCar RoadCarCar Road RoadCar
Hypothesis 1
Hypothesis 2
Car Road
Beyond NounsGupta and Davis
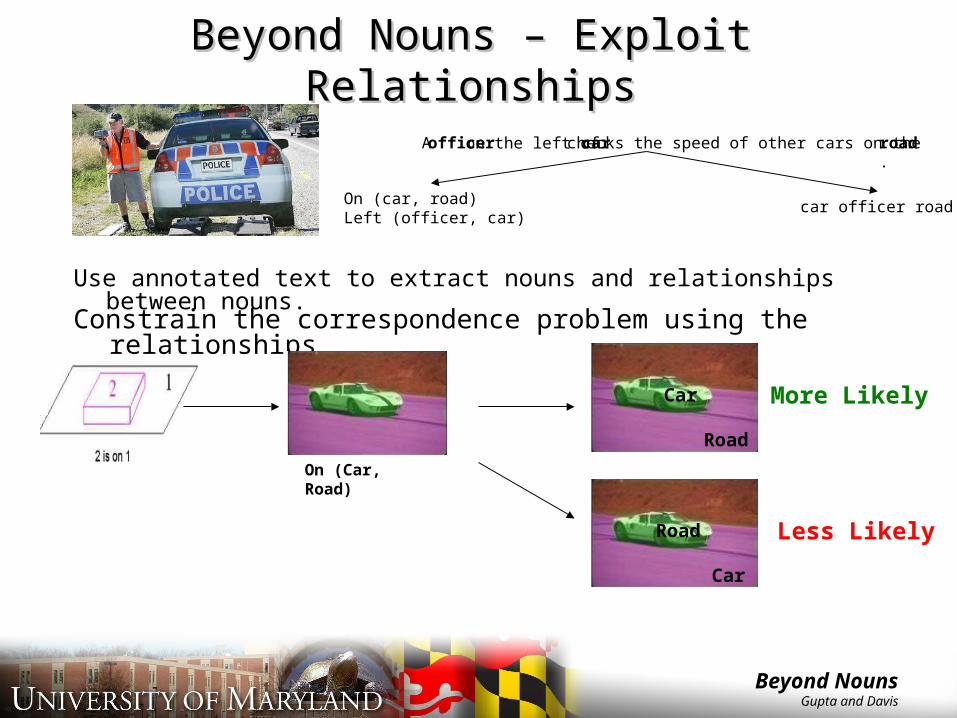
Beyond Nouns – Exploit RelationshipsBeyond Nouns – Exploit Relationships
Use annotated text to extract nouns and relationships between nouns.
road.officer on the left of carchecks the speed of other cars on theA
On (car, road)Left (officer, car)
car officer road
Constrain the correspondence problem using the relationships
On (Car, Road)
Road
Car
Road
Car
More Likely
Less Likely

Beyond NounsGupta and Davis
Beyond Nouns - OverviewBeyond Nouns - Overview• Learn classifiers for both Nouns and Relationships
simultaneously.– Classifiers for Relationships based on differential features.
• Learn priors on possible relationships between pairs of nouns – Leads to better Labeling Performance
above (sky , water)
above (water , sky)
sky
water sky
water

Beyond NounsGupta and Davis
Related Work
• Generative Approaches– Duygulu, P., Barnard, K., Freitas, N., Forsyth, D.: Object recognition as machine translation:
Learning a lexicon for a fixed image vocabulary. ECCV (2002)– Barnard, K., Duygulu, P., Freitas, N., Forsyth, D., Blei, D., Jordan, M.I.: Matching words and
pictures. Journal of Machine Learning Research (2003) 1107–1135– Barnard K and Forsyth D., Learning the semantics of Words and Pictures. ICCV 2001
• Relevance Language Models– Lavrenko, V., Manmatha, R., Jeon, J.: A model for learning the semantics of pictures. NIPS (2003) – Feng, S., Manmatha, R., Lavrenko, V.: Multiple Bernoulli relevance models for image and video
annotation. CVPR (2004)
• Classification Based Approaches– Li, J., Wang, J.: Automatic linguistic indexing of pictures by statistical modeling approach. IEEE
PAMI (2003)– Andrews, S., Tsochantaridis, I., Hoffman, T.: Support vector machines for multiple-instance learning.
NIPS (2002)

Beyond NounsGupta and Davis
Related Work – [1]
• Model the problem of learning object models as a machine translation problem.– Nouns in the caption (English) have to be translated into visual
words (Visual Language).
• Use statistical machine translation approaches to obtain the correspondence or translation probabilities.

Beyond NounsGupta and Davis
RepresentationRepresentation
• Each image is first segmented into regions.
• Regions are represented by feature vectors based on:– Appearance (RGB, Intensity)– Shape (Convexity, Moments)
• Models for nouns are based on features of the regions
• Relationship models are based on differential features:– Difference of avg. intensity – Difference in location
• Assumption: Each relationship model is based on one differential feature for convex objects. Learning models of relationships involves feature selection.
• Each image is also annotated with nouns and a few relationships between those nouns.
B
B
A
A
B below A
Beyond NounsGupta and Davis
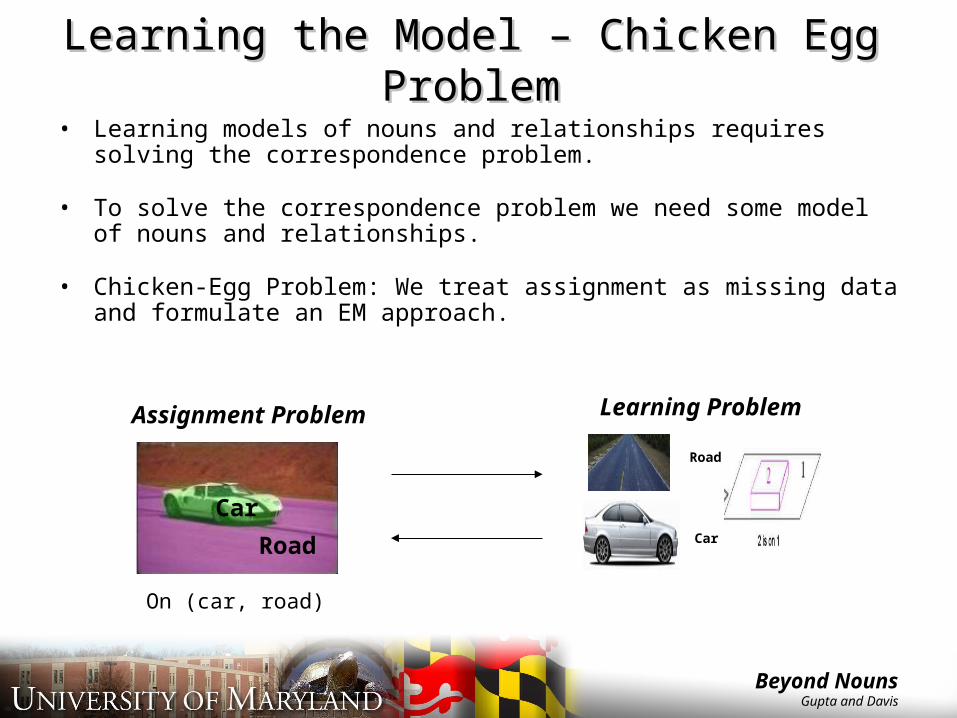
Learning the Model – Chicken Egg Learning the Model – Chicken Egg ProblemProblem
• Learning models of nouns and relationships requires solving the correspondence problem.
• To solve the correspondence problem we need some model of nouns and relationships.
• Chicken-Egg Problem: We treat assignment as missing data and formulate an EM approach.
Road
Car
Car
Road
Assignment Problem Learning Problem
On (car, road)

Beyond NounsGupta and Davis
EM Approach- Learning the ModelEM Approach- Learning the Model
• E-Step: Compute the noun assignment for a given set of object and relationship models from previous iteration ( ).
• M-Step: For the noun assignment computed in the E-step, we find the new ML parameters by learning both relationship and object classifiers.
• For initialization of the EM approach, we can use any image annotation approach with localization such as the translation based model described in [1].
[1] Duygulu, P., Barnard, K., Freitas, N., Forsyth, D.: Object recognition as machine translation: Learning a lexicon for a fixed image vocabulary. ECCV (2002)

Beyond NounsGupta and Davis
Relationships modeledRelationships modeled
• Most relationships are learned “correctly”– Above, behind, below, left, right, beside, bluer, greener,
nearer, more-textured, smaller, larger, brighter
• But some are associated with the wrong features– In (topological relationships not captured by color,
shape and location)– on-top-of– taller (most tall objects are thin and the segmentation
algorithm tends to fragment them)
Beyond NounsGupta and Davis
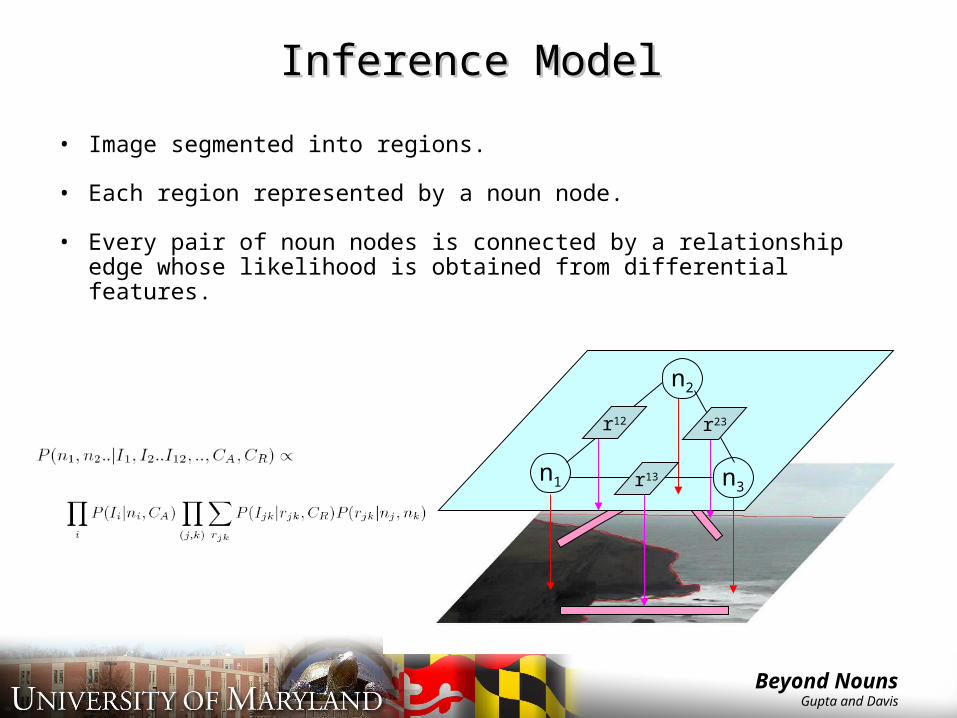
Inference ModelInference Model
• Image segmented into regions.
• Each region represented by a noun node.
• Every pair of noun nodes is connected by a relationship edge whose likelihood is obtained from differential features.
n1
n2
n3
r12
r13
r23

Beyond NounsGupta and Davis
Experimental Evaluation – Corel 5k Experimental Evaluation – Corel 5k DatasetDataset
• Evaluation based on Corel5K dataset [1].
• Used 850 training images with tags and manually labeled relationships.
• Vocabulary of 173 nouns and 19 relationships.
• We use the same segmentations and feature vector as [1].
• Quantitative evaluation of training based on 150 randomly chosen images.
• Quantitative evaluation of labeling algorithm (testing) was based on 100 test images.

Beyond NounsGupta and Davis
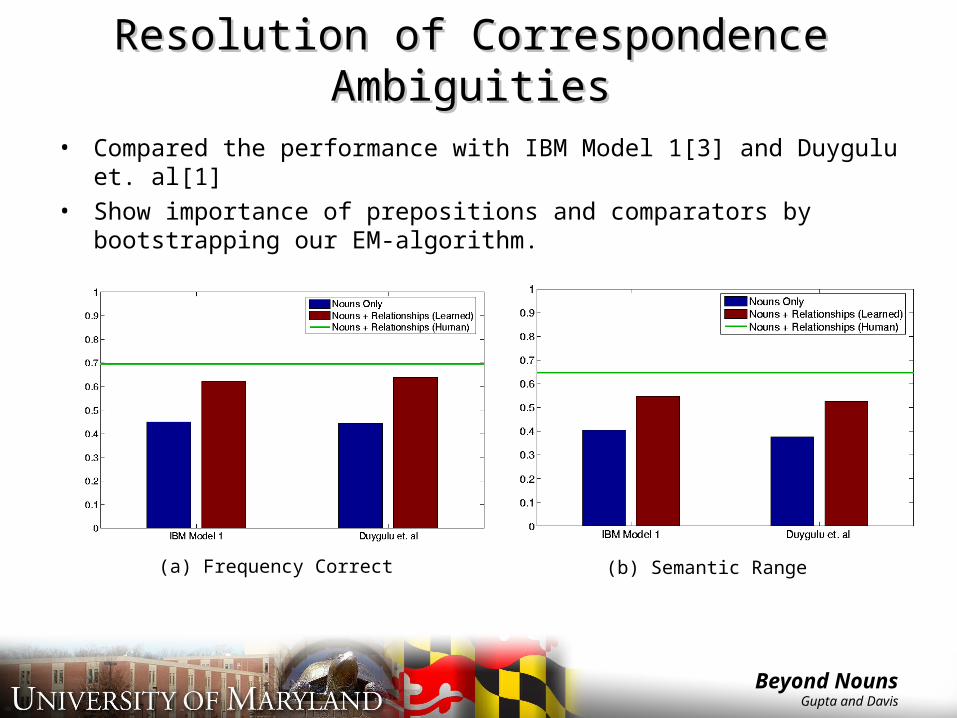
Resolution of Correspondence Resolution of Correspondence AmbiguitiesAmbiguities
• Evaluate the performance of our approach for resolution of correspondence ambiguities in training dataset.
• Evaluate performance in terms of two measures [2]:– Range Semantics
• Counts the “percentage” of each word correctly labeled by the algorithm• ‘Sky’ treated the same as ‘Car’
– Frequency Correct• Counts the number of regions correctly labeled by the algorithm• ‘Sky’ occurs more frequently than ‘Car’
[2] Barnard, K., Fan, Q., Swaminathan, R., Hoogs, A., Collins, R., Rondot, P., Kaufold, J.: Evaluation of localized semantics: data, methodology and experiments. Univ. of Arizona, TR-2005 (2005)
Duygulu et. al [1] Our Approach
[1] Duygulu, P., Barnard, K., Freitas, N., Forsyth, D.: Object recognition as machine translation: Learning a lexicon for a fixed image vocabulary. ECCV (2002)
below(birds,sun) above(sun, sea) brighter(sun,sea) below(waves,sun)
above(statue,rocks);ontopof(rocks, water); larger(water,statue)
below(flowers,horses); ontopof(horses,field); below(flowers,foals)
Beyond NounsGupta and Davis
Resolution of Correspondence Resolution of Correspondence AmbiguitiesAmbiguities
• Compared the performance with IBM Model 1[3] and Duygulu et. al[1]
• Show importance of prepositions and comparators by bootstrapping our EM-algorithm.
(b) Semantic Range(a) Frequency Correct

Beyond NounsGupta and Davis
Examples of labeling test imagesExamples of labeling test images
Duygulu (2002)
Our Approach

Beyond NounsGupta and Davis
Evaluation of labeling test imagesEvaluation of labeling test images
• Evaluate the performance of labeling based on annotation from Corel5K dataset Set of Annotations from Ground Truth from Corel
Set of Annotations provided by the algorithm
• Choose detection thresholds to make the number of missed labels approximately equal for two approaches, then compare labeling accuracy
Beyond NounsGupta and Davis
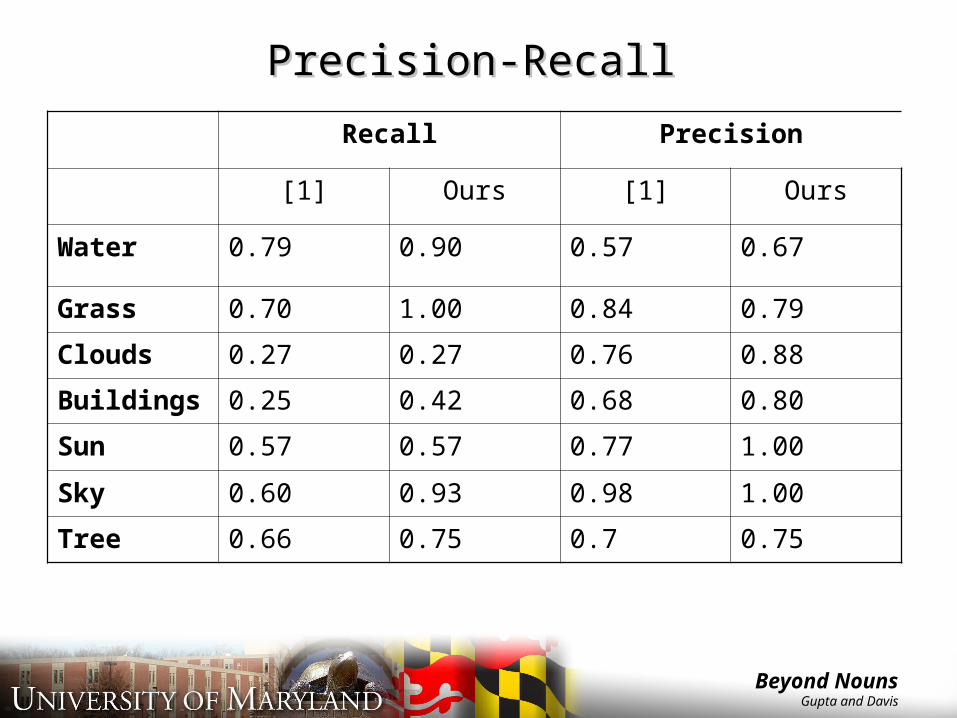
Precision-RecallPrecision-Recall
Recall Precision
[1] Ours [1] Ours
Water 0.79 0.90 0.57 0.67
Grass 0.70 1.00 0.84 0.79
Clouds 0.27 0.27 0.76 0.88
Buildings 0.25 0.42 0.68 0.80
Sun 0.57 0.57 0.77 1.00
Sky 0.60 0.93 0.98 1.00
Tree 0.66 0.75 0.7 0.75
Beyond NounsGupta and Davis
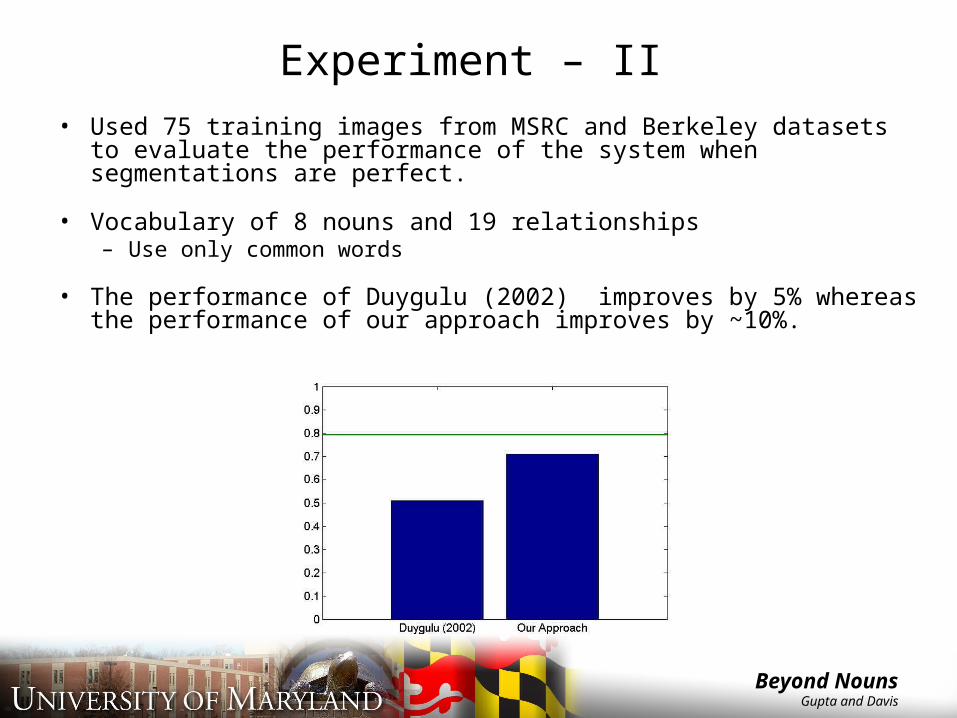
Experiment – II• Used 75 training images from MSRC and Berkeley datasets to
evaluate the performance of the system when segmentations are perfect.
• Vocabulary of 8 nouns and 19 relationships– Use only common words
• The performance of Duygulu (2002) improves by 5% whereas the performance of our approach improves by ~10%.
Beyond NounsGupta and Davis
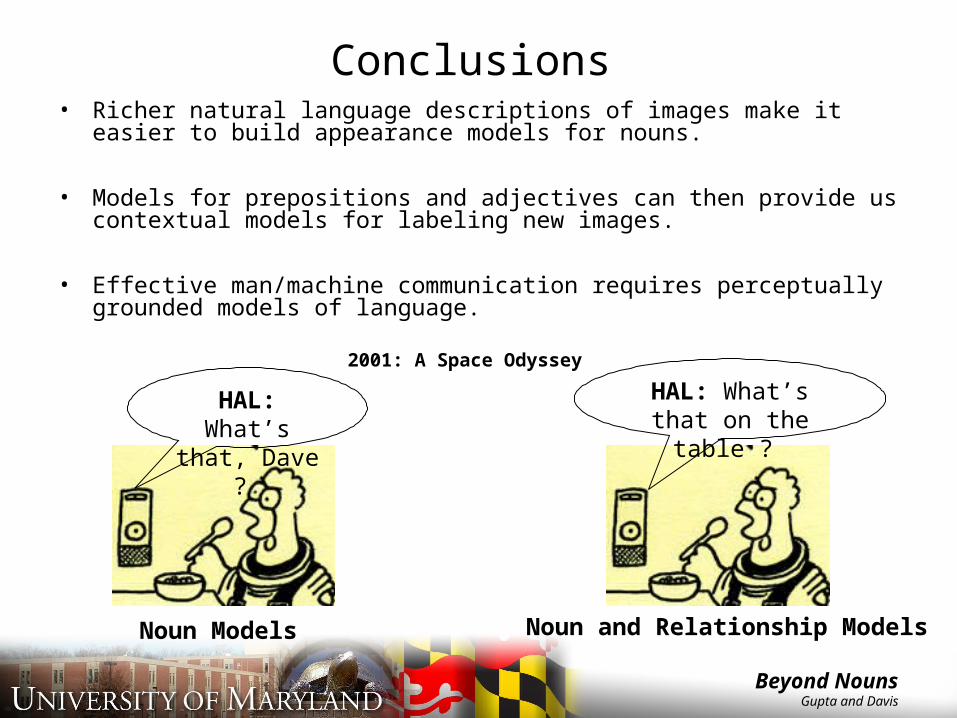
Conclusions• Richer natural language descriptions of images make it easier to
build appearance models for nouns.
• Models for prepositions and adjectives can then provide us contextual models for labeling new images.
• Effective man/machine communication requires perceptually grounded models of language.
HAL: What’s that, Dave ?
HAL: What’s that on the table ?
2001: A Space Odyssey
Noun Models Noun and Relationship Models

Beyond NounsGupta and Davis
ReferencesReferences[1] Duygulu, P., Barnard, K., Freitas, N., Forsyth, D.: Object recognition as machine translation: Learning a lexicon for a fixed
image vocabulary. ECCV (2002)
[2] Barnard, K., Fan, Q., Swaminathan, R., Hoogs, A., Collins, R., Rondot, P., Kaufold, J.: Evaluation of localized semantics: data, methodology and experiments. IJCV 2008
[3] Li, J., Wang, J.: Automatic linguistic indexing of pictures by statistical modeling approach. IEEE PAMI (2003)
[4] Barnard, K., Duygulu, P., Freitas, N., Forsyth, D., Blei, D., Jordan, M.I.: Matching words and pictures. Journal of Machine Learning Research (2003) 1107–1135
[5] Andrews, S., Tsochantaridis, I., Hoffman, T.: Support vector machines for multiple-instance learning. NIPS (2002)
[6] Brown, P., Pietra, S., Pietra, V., Mercer, R.: The mathematics of statistical machine translation: Parameter estimation. Computational Linguistics (1993)
[7] Lavrenko, V., Manmatha, R., Jeon, J.: A model for learning the semantics of pictures. NIPS (2003)
[8] Feng, S., Manmatha, R., Lavrenko, V.: Multiple Bernoulli relevance models for image and video annotation. CVPR (2004)
[9] Barnard K and Forsyth D., Learning the semantics of Words and Pictures. ICCV 2001

Beyond NounsGupta and Davis
Thank You !

Beyond NounsGupta and Davis
Limitations and Future Work
• Assumes One-One relationship between nouns and image segments.– Too much reliance on image segmentation
• Can these relationships help in improving segmentation ?
• Use Multiple Segmentations and choose the best segment.
On (car, road) Left (tree, road)
Above (sky, tree)Larger (Road, Car) CarTreeroad
Beyond NounsGupta and Davis
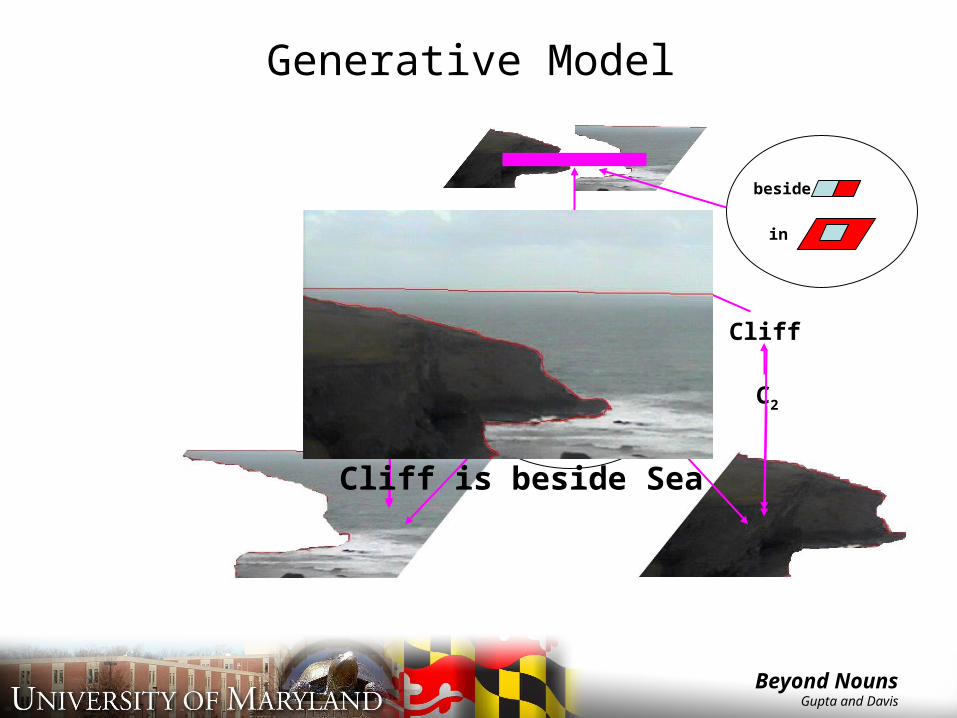
Generative Model
CliffSea Cliff
Sea
Bear
beside
beside
in
C1 C2
Cliff is beside Sea

Beyond NounsGupta and Davis
AcknowledgementsAcknowledgements
We wish to gratefully acknowledge :• Kobus Barnard (Univ. of Arizona) for
providing the Corel5K dataset.
We also acknowledge funding support provided by:
• DARPA VACE program

Beyond NounsGupta and Davis
Training Datasets – The Spectrum
Human Effort
Corel Unlabeled Images

Beyond NounsGupta and Davis
Related WorkRelated Work
• Generative Models [1,4]– Model joint distribution of nouns and image features. – Barnard et. al [9] presented a generative model for image
annotation that induces hierarchical structure from the co-occurrence data.
– Shared topic model : Both nouns and visual words are generated based on common topic.
θ
b
w

Beyond NounsGupta and Davis
Related Work – Contd.
• Classification Approaches [3, 6]– Classifiers learned from positive and negative samples
generated based on captions.
• Relevance Language Models [7, 8]– Find similar images in the training dataset.– Use annotations shared between extracted images to
annotate new image.





























