Embed Size (px)
Citation preview

8/7/2019 Best Practices for Synchronizing Data
http://slidepdf.com/reader/full/best-practices-for-synchronizing-data 1/9
Best Practices for synchronizing data
SQL Data Compare version 6,73 September, 2008
SQL Data Compare is a tool that can be used to inspect the contents of
similar tables in a database, for instance, to make sure that the data is identicalafter a synchronization, to inspect a database after a software upgrade, or toperform Quality Assurance on data. Additionally, it can synchronize the data sothat the tables in both databases contain exactly the same information.
When using Data Compare as a data synchronization tool, there are anumber of issues that may occur because of the way that Data Compare works.
The diagram shows a few important things. One is that rows are matchedtogether using the column of a table on which there is a primary key, uniqueindex, or unique constraint. This can be bypassed by manually setting thecomparison key column, but the performance is degraded as compared to acolumn with a primary key or unique index. Another important thing to note isthat the data comparison and storage of the results is done on the localworkstation’s hard disk. This could potentially limit the scalability of the
comparison.
Once a comparison is complete, the results can be reviewed, and if desired, a synchronization SQL script can be saved or run from within the
program. There are various methods that can be used to manage the datasynchronization in some cases.
A common problem that can be solved using SQL Data Compare’s datasynchronization is synchronizing data from various off-line sources into a centraldata repository. Because the client machines are potentially not connected to anetwork, this makes some other data replication techniques unfeasible or difficult.

8/7/2019 Best Practices for Synchronizing Data
http://slidepdf.com/reader/full/best-practices-for-synchronizing-data 2/9
One such example exists at a fire station. The station has a central server with aMicrosoft SQL Server database that logs the activities of the firefighters. The
firefighters carry a laptop in the cab of the truck when they are called to thescene of a fire. After the fire has been extinguished, the details are logged intothe laptop, and when the truck returns to the station, the data is synchronizedinto the main server, and new data from any other units at other scenes is
synchronized back from the main server to the firefighters’ laptop. The schema of
one of the tables is similar to this:
CREATE TABLE Response (
RecordID int PRIMARY KEY IDENTITY(1,1),
UnitId int NOT NULL,
CaptainID int NOT NULL,
Address NVARCHAR(255)
)
This causes a problem when the data is synchronized with the station’s server,because of conflicting identity values: remember that Data Compare uses the
primary key column to match rows of data! To illustrate:
In this situation, two units had been dispatched at the same time, and
they had both returned with a new record to insert into the station’s database.Once the new record from Unit 1 had been inserted, the new record from Unit 2cannot be inserted because the RecordID of 4 already exists.
Designing a database for synchronization
There are a number of changes that could be made to the database
schema to prevent this conflict. The easiest and most obvious option wouldsimply be to assign a range of RecordIDs for each unit. After synchronizing theschema to the laptops, it would be relatively simple to adjust the schema on eachlaptop to change the identity seed. This would not help with data that already
exists. There is also a risk that the identities could overlap, given time.
USE FireUnit1
DBCC CHECKIDENT (Response, RESEED, 1000)
Use FireUnit2
DBCC CHECKIDENT (Response, RESEED, 2000)
Another idea would be create a compound primary key from RecordID and
UnitID, which should still uniquely identify each response. If the table had arelationship with another table, then the second table would also need to have a
RecordID UnitID CaptainID Address1 2 1 1 Main Street2 1 2 59 Elm Street3 3 4 315 Bowery
StationHouse
RecordID UnitID CaptainID Address 4 1 1 1060 W Addison
RecordID UnitID CaptainID Address 4 2 2 1600 Pennsylvania Av
Unit 1 Unit 2

8/7/2019 Best Practices for Synchronizing Data
http://slidepdf.com/reader/full/best-practices-for-synchronizing-data 3/9
UnitID column and a compound foreign key created in order to ensure referentialintegrity:
CREATE TABLE [dbo].[ResponseDetails](
[ResponseID] [int] NOT NULL,
[UnitID] [int] NOT NULL,
[Details] [ntext] NULL,
CONSTRAINT [PK_ResponseDetails] PRIMARY KEY CLUSTERED (
[UnitID] ASC,
[ResponseID] ASC
)
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE [dbo].[ResponseDetails] WITH CHECK ADD CONSTRAINT
[FK_ResponseDetails_Response] FOREIGN KEY([ResponseID], [UnitID])
REFERENCES [dbo].[Response] ([RecordID], [UnitId])
GO
ALTER TABLE [dbo].[ResponseDetails] CHECK CONSTRAINT
[FK_ResponseDetails_Response]
This is assuming that the individual firefighters only add new data at thescene. If they were allowed to change existing data, there would be more to payattention to.
The next step, once all of the firefighting units have synchronized to thefire station’s database, would be to synchronize all of the data back to the
firefighters’ laptops using SQL Data Compare.
Data merging
There may also be situations where the type of replication required is tomerge data from several sources into one – a hub and spoke topology. This
introduces several new challenges: how to manage new records from multiplesources, how to manage the deletion of records, and how to design strategies forelecting updates when the same record is being updated from several sources.
Unlike in the first example, the ‘hub’ database may have had some records
deleted, and these deletions need to be applied to the databases at the end of the ‘spoke’. Any record that exist at the end of the spoke, but not on the hub,however, must be prevented from deletion. The way to prevent this is to useData Compare’s Actions menu, and choose to exclude all on the right.

8/7/2019 Best Practices for Synchronizing Data
http://slidepdf.com/reader/full/best-practices-for-synchronizing-data 4/9
If records have been updated at the spoke database and need to besynchronized to the hub database, then you can click synchronize. To preventupdates from being sent upwards, exclude all different objects. Now click
synchronize, and run the synchronization against the hub database.
The next step would be to get the changes made at the hub database andpull them down to the spoke database. The synchronization direction can be
changed by double-clicking the ‘synchronization direction’ arrow, causing it topoint at the ‘spoke’ database. If, as mentioned in the previous paragraph,
updates are allowed only at the hub database, select Include all, then excludeall on the left. If updates are allowed only from the spoke database to the hub,also choose exclude all different objects. Now click the synchronize button,which will cause a synchronization to happen on the ‘spoke’ database.
Congratulations! The databases have effectively been merged!
One of the more advanced topics regarding data merging is how to elect awinner when two updates to the same row of data occur at both data sources.
Data Compare’s default behaviour is simply to overwrite the row, meaning it’s alast-update-wins strategy for the whole row. In some cases, this is too simplistic.The Red Gate SQL Tools do offer a solution for choosing which changes will be
applied on a row-by-row basis. This requires the SQL Toolkit programming API,
which will allow you to write code to choose records based on their content, forinstance, automatically choose rows of data in which a certain datetime fieldcontains a newer date than in the second database. Please see the
SelectionDelegate object in the SQL Comparison and Synchronization Toolkit helpfile that comes with SQL Bundle for more information.
Managing the temporary disk storage
Because SQL Data Compare heavily uses disk storage to hold comparisonresults, it may be sensible to consider limiting the amount of data actually being
8/7/2019 Best Practices for Synchronizing Data
http://slidepdf.com/reader/full/best-practices-for-synchronizing-data 5/9
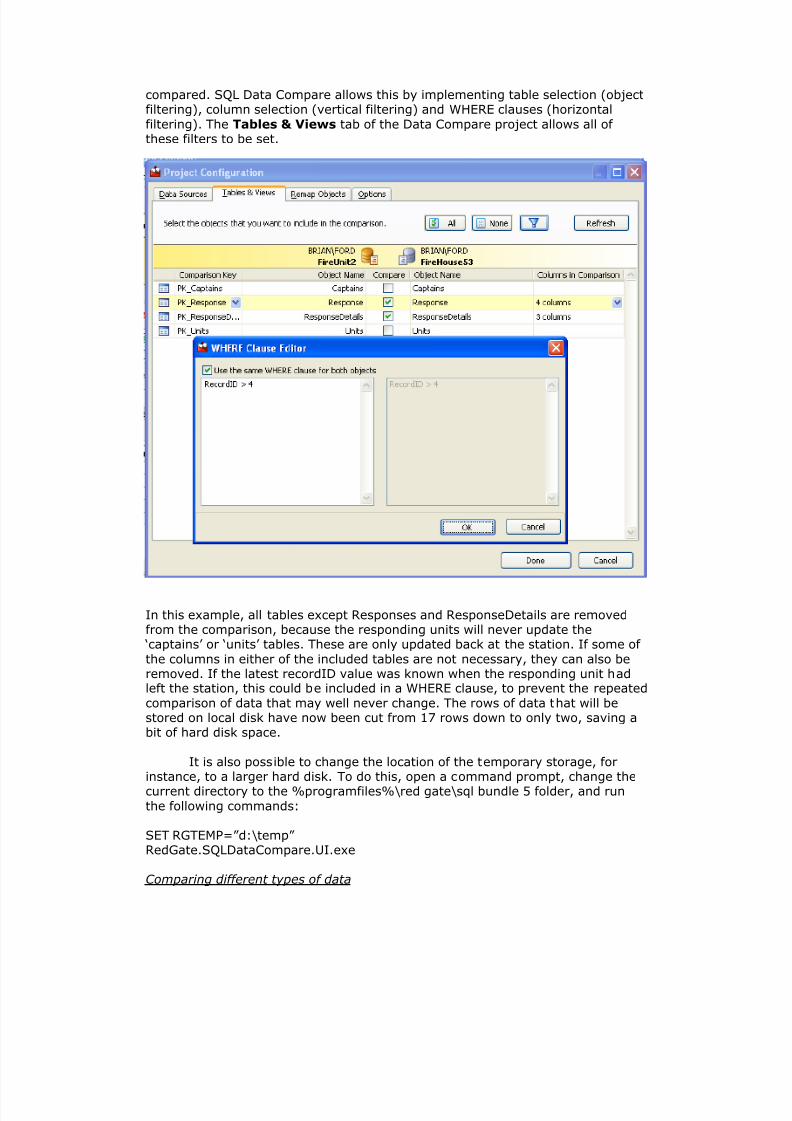
compared. SQL Data Compare allows this by implementing table selection (objectfiltering), column selection (vertical filtering) and WHERE clauses (horizontal
filtering). The Tables & Views tab of the Data Compare project allows all of these filters to be set.
In this example, all tables except Responses and ResponseDetails are removedfrom the comparison, because the responding units will never update the
‘captains’ or ‘units’ tables. These are only updated back at the station. If some of
the columns in either of the included tables are not necessary, they can also beremoved. If the latest recordID value was known when the responding unit hadleft the station, this could be included in a WHERE clause, to prevent the repeated
comparison of data that may well never change. The rows of data that will bestored on local disk have now been cut from 17 rows down to only two, saving abit of hard disk space.
It is also possible to change the location of the temporary storage, forinstance, to a larger hard disk. To do this, open a command prompt, change thecurrent directory to the %programfiles%\red gate\sql bundle 5 folder, and run
the following commands:
SET RGTEMP=”d:\temp” RedGate.SQLDataCompare.UI.exe
Comparing different types of data

8/7/2019 Best Practices for Synchronizing Data
http://slidepdf.com/reader/full/best-practices-for-synchronizing-data 6/9
In some cases, columns containing different types of data must becompared. This could potentially cause some problems. The first concerns NULL
data.
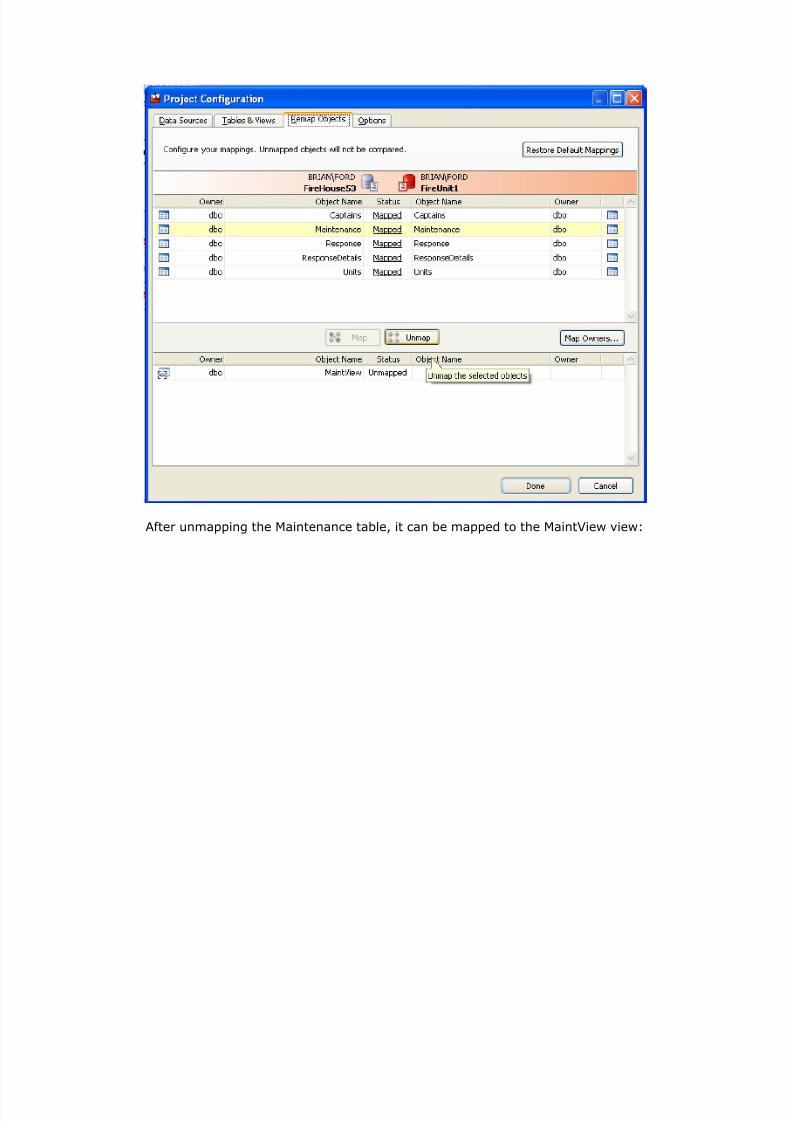
The Maintenance table in one database allows NULL data for theMaintCode column, and the other does not. If NULLS are synchronized to the
second database, the update will fail. One solution would be to replace all of theNULL data in the first database, but possibly the owner of this data would object.In that case, a view could be used rather than a table. The view could CAST dataor replace it with a value. Creating a view on database 1 is the first
step:
This view will replace any NULL data with the word ‘NONE’. The next stepis to instruct Data Compare to map the view to the Maintenance table on theother database:
CREATE VIEW [dbo].[MaintView]
AS
SELECT CASE WHEN MaintCode IS NULL THEN 'NONE' ELSE MaintCode END AS
MaintCode, Date, MaintenenceID
FROM dbo.Maintenance
CREATE TABLE [dbo].[Maintenance](
[MaintenenceID] [int] PRIMARY KEY
NOT NULL,
[Date] [datetime] NULL CONSTRAINT [DF_Maintenence_Date] DEFAULT
(getdate()),
[MaintCode] [nchar](10) NULL
)
CREATE TABLE [dbo].[Maintenance](
[MaintenenceID] [int] PRIMARY KEY
NOT NULL,
[Date] [datetime] NULL CONSTRAINT [DF_Maintenence_Date] DEFAULT (getdate()),
[MaintCode] [nchar](10) NOT NULL
)
8/7/2019 Best Practices for Synchronizing Data
http://slidepdf.com/reader/full/best-practices-for-synchronizing-data 7/9
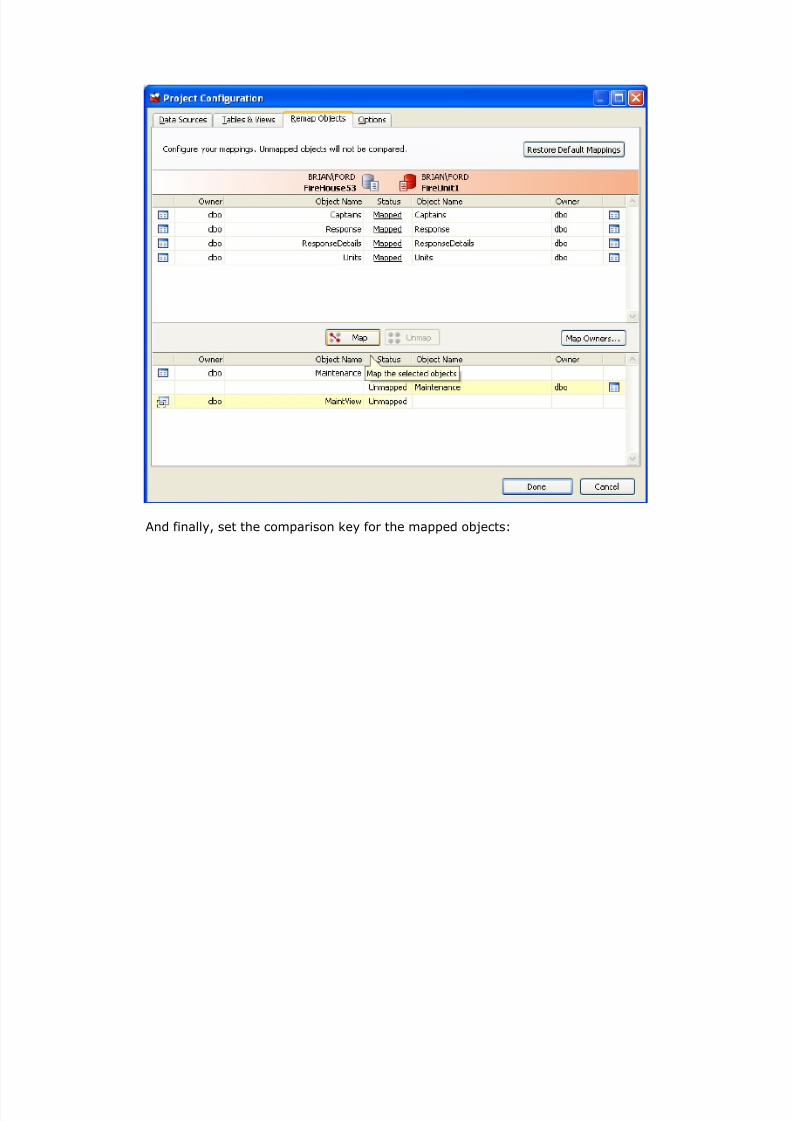
After unmapping the Maintenance table, it can be mapped to the MaintView view:
8/7/2019 Best Practices for Synchronizing Data
http://slidepdf.com/reader/full/best-practices-for-synchronizing-data 8/9
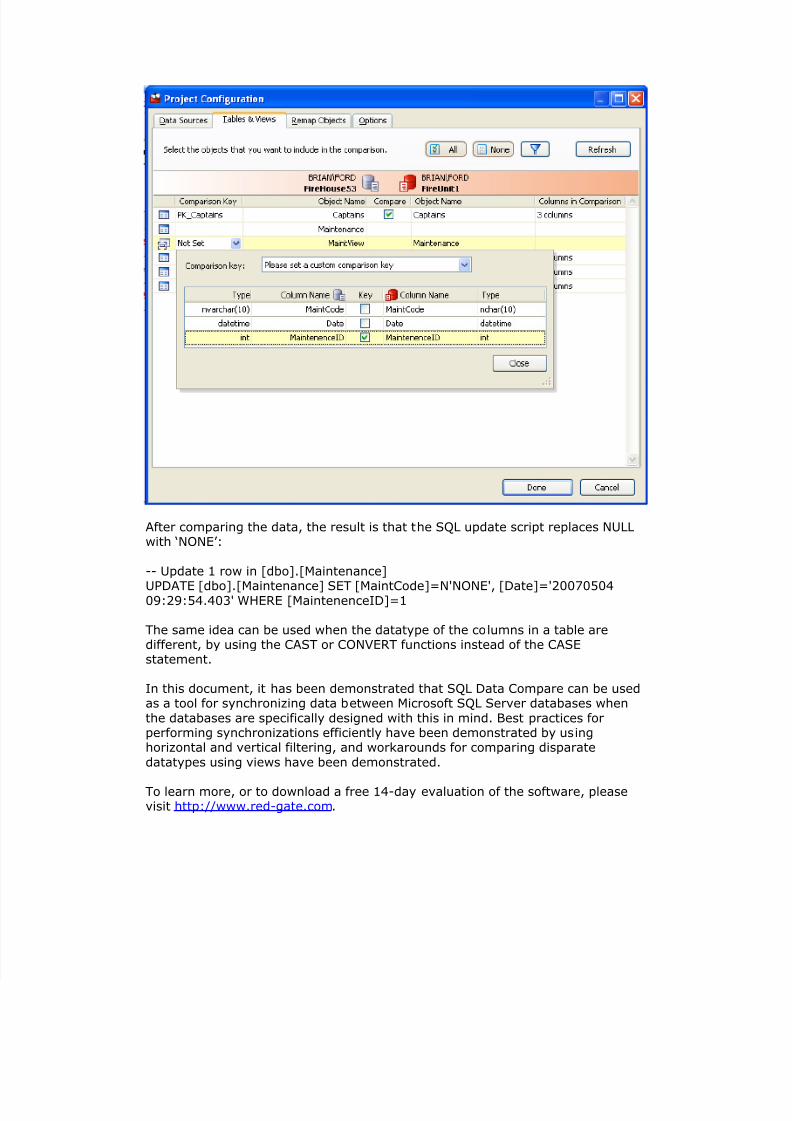
And finally, set the comparison key for the mapped objects:
8/7/2019 Best Practices for Synchronizing Data
http://slidepdf.com/reader/full/best-practices-for-synchronizing-data 9/9
After comparing the data, the result is that the SQL update script replaces NULLwith ‘NONE’:
-- Update 1 row in [dbo].[Maintenance]
UPDATE [dbo].[Maintenance] SET [MaintCode]=N'NONE', [Date]='2007050409:29:54.403' WHERE [MaintenenceID]=1
The same idea can be used when the datatype of the columns in a table aredifferent, by using the CAST or CONVERT functions instead of the CASEstatement.
In this document, it has been demonstrated that SQL Data Compare can be usedas a tool for synchronizing data between Microsoft SQL Server databases when
the databases are specifically designed with this in mind. Best practices forperforming synchronizations efficiently have been demonstrated by usinghorizontal and vertical filtering, and workarounds for comparing disparate
datatypes using views have been demonstrated.
To learn more, or to download a free 14-day evaluation of the software, pleasevisit http://www.red-gate.com.





























