Embed Size (px)
DESCRIPTION
Belief space planning assuming maximum likelihood observations. Robert Platt Russ Tedrake, Leslie Kaelbling, Tomas Lozano-Perez Computer Science and Artificial Intelligence Laboratory, Massachusetts Institute of Technology June 30, 2010. Planning from a manipulation perspective. - PowerPoint PPT Presentation
Citation preview

Belief space planning assuming maximum likelihood observations
Robert Platt
Russ Tedrake, Leslie Kaelbling, Tomas Lozano-Perez
Computer Science and Artificial Intelligence Laboratory,Massachusetts Institute of Technology
June 30, 2010

Planning from a manipulation perspective
(image from www.programmingvision.com, Rosen Diankov )
• The “system” being controlled includes both the robot and the objects being manipulated.
• Motion plans are useless if environment is misperceived.
• Perception can be improved by interacting with environment: move head, push objects, feel objects, etc…

The general problem: planning under uncertainty
Planning and control with:
1. Imperfect state information2. Continuous states, actions, and
observations
most robotics problems
N. Roy, et al.

Strategy: plan in belief space
1. Redefine problem:
“Belief” state space
2. Convert underlying dynamics into belief space dynamics
start
goal
3. Create plan
(underlying state space) (belief space)

Related work
1. Prentice, Roy, The Belief Roadmap: Efficient Planning in Belief Space by Factoring the Covariance, IJRR 2009
2. Porta, Vlassis, Spaan, Poupart, Point-based value iteration for continuous POMDPs, JMLR 2006
3. Miller, Harris, Chong, Coordinated guidance of autonomous UAVs via nominal belief-state optimization, ACC 2009
4. Van den Berg, Abeel, Goldberg, LQG-MP: Optimized path planning for robots with motion uncertainty and imperfect state information, RSS 2010

Simple example: Light-dark domain
11 ttt uxxUnderlying system:
ttt xwxz Observations:
underlying state
action
observation
observation noise
start
goal
25,0;~ xxNxw tt
State dependent noise:“dark” “light”

Simple example: Light-dark domain
start
goal
11 ttt uxxUnderlying system:
ttt xwxz Observations:
underlying state
action
observation
observation noise
“dark” “light”
25,0;~ xxNxw tt
State dependent noise:
Nominal information gathering plan

Belief system
ttt uxfx ,1
ttt xwxgz
Underlying system:
Belief system:• Approximate belief state as a Gaussian
ttt mb ,
(deterministic process dynamics)
state
(stochastic observation dynamics)
action
observation
ttt mxNbxP ,;|
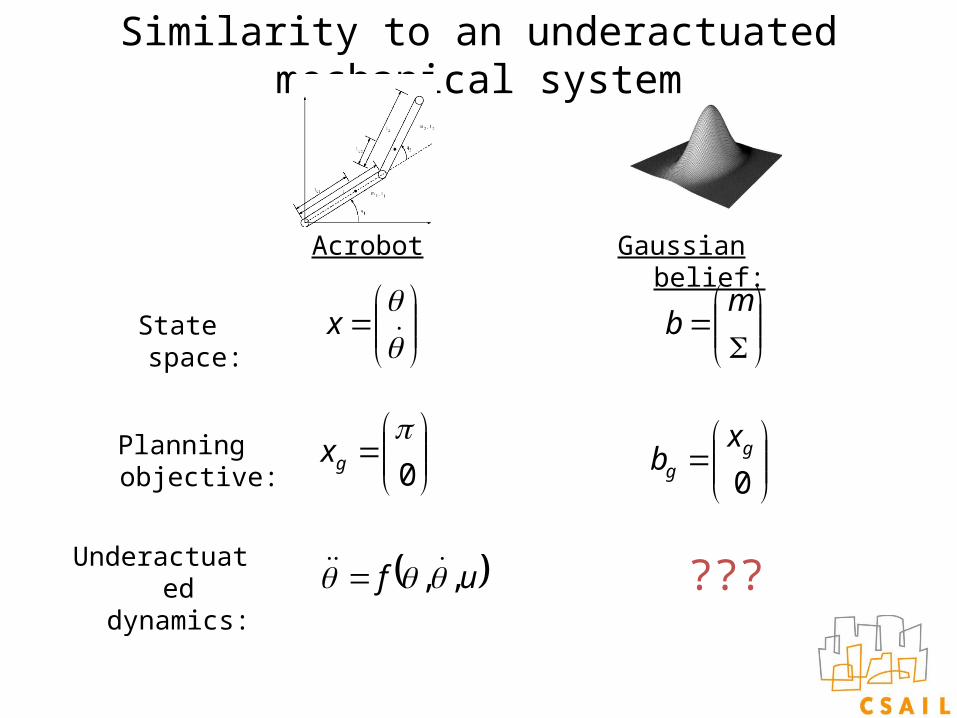
Similarity to an underactuated mechanical system
x
Acrobot
m
b
Gaussian belief:
State space:
Underactuated dynamics: uf ,, ???
Planning objective:
0
gx
0g
g
xb

Belief space dynamics
start
goal
tttttt muzFm ,,,, 11Generalized Kalman filter:

Belief space dynamics are stochastic
unexpected observation
BUT – we don’t know observations at planning time
start
goal
Generalized Kalman filter: tttttt muzFm ,,,, 11

Plan for the expected observation
Plan for the expected observation:
Generalized Kalman filter:
Model observation stochasticity as Gaussian noise
tttttt muzFm ,,,, 11
nmuzFm tttttt ,,,ˆ, 11
We will use feedback and replanning to handle departures from expected observation….

Belief space planning problem
T
tt
Tt
k
iiT
TiT RuunnubJ
11:11,Minimize:
Minimize covariance at final state
• Minimize state uncertainty along the directions.in
Find finite horizon path, , starting at that minimizes cost function:
Action cost• Find least effort path
Subject to:
Trajectory must reach this final state
goalT xm
Tu :1 1b

Existing planning and control methods apply
Now we can apply:• Motion planning w/ differential constraints (RRT, …)• Policy optimization• LQR• LQR-Trees

Planning method: direct transcription to SQP
1. Parameterize trajectory by via points:
2. Shift via points until a local minimum is reached:• Enforce dynamic constraints during
shifting
3. Accomplished by transcribing the control problem into a Sequential Quadratic Programming (SQP) problem.• Only guaranteed to find locally optimal solutions

Example: light-dark problem
• In this case, covariance is constrained to remain isotropic
X
Y

Replanning
goal
• Replan when deviation from trajectory exceeds a threshold:
r
2rmmmm T
m
m
New trajectory
Original trajectory

Replanning: light-dark problem
Planned trajectory
Actual trajectory
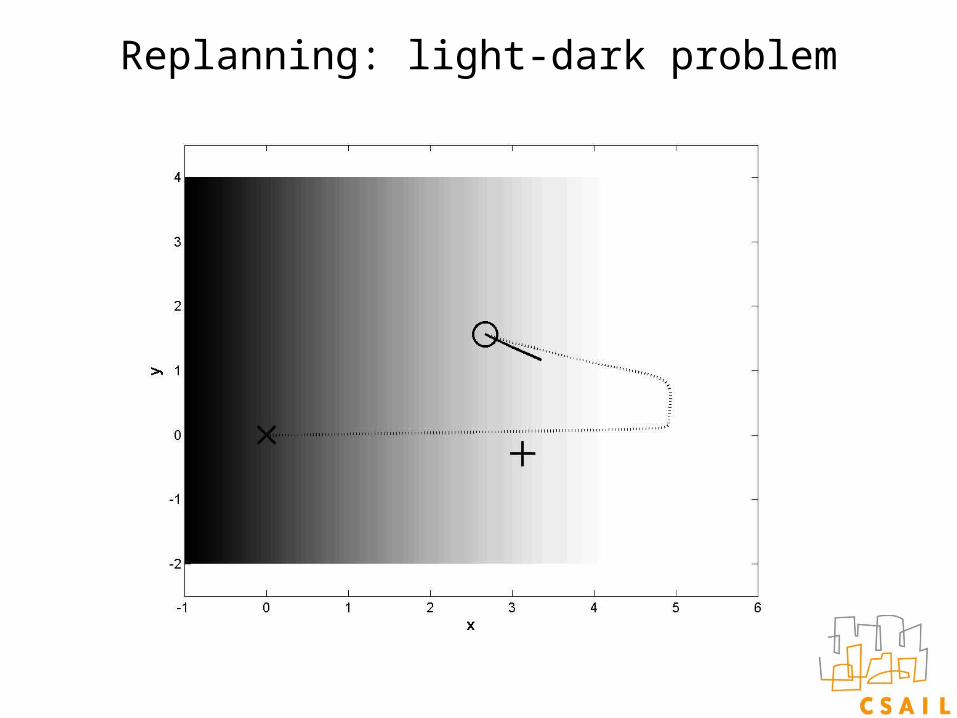
Replanning: light-dark problem

Replanning: light-dark problem

Replanning: light-dark problem

Replanning: light-dark problem

Replanning: light-dark problem

Replanning: light-dark problem

Replanning: light-dark problem

Replanning: light-dark problem

Replanning: light-dark problem

Replanning: light-dark problem

Replanning: light-dark problem

Replanning: light-dark problem

Replanning: light-dark problem

Replanning: light-dark problem
Originally planned path
Path actually followed by system

Planning vs. Control in Belief Space
A plan A control policy
Given our specification, we can also apply control methods:
• Control methods find a policy – don’t need to replan
• A policy can stabilize a stochastic system

Control in belief space: B-LQR
In general, finding an optimal policy for a nonlinear system is hard.
• Linear quadratic regulation (LQR) is one way to find an approximate policy
• LQR is optimal only for linear systems w/ Gaussian noise.
Belief space LQR (B-LQR) for light-dark domain:

Combination of planning and control
Algorithm:
1. repeat
2.
3. for
4.
5. if then break
6. if belief mean at goal
7. halt
1:1:1 _, bplancreatebu TT
Tt :1
tttt bubcontrollqru ,,_
0 tt bb

Conditions:
1. Zero process noise.2. Underlying system passively critically stable3. Non-zero measurement noise.4. SQP finds a path with length < T to the goal belief region from
anywhere in the reachable belief space.5. Cost function is of correct form (given earlier).
Theorem:
• Eventually (after finite replanning steps) belief state mean reaches goal with low covariance.
Analysis of replanning with B-LQR stabilization

Laser-grasp domain

Laser-grasp: the plan

Laser-grasp: reality
Initially planned path
Actual path

Conclusions
1. Planning for partially observable problems is one of the keys to robustness.
2. Our work is one of the few methods for partially observable planning in continuous state/action/observation spaces.
3. We view the problem as an underactuated planning problem in belief space.





























