Embed Size (px)
Citation preview

Beatinghumansincomplexboardgames
Seminar„NeuesteTrendsinBigDataAnalytics“
Wintersemester2017/18
Dozenten:Dr.JulianKunkel,JakobLüttgau
B.A.Informatik
UniversitätHamburg
EikeNilsKnoppOsterstraße6820259Hamburg
Matrikelnr.:[email protected]

2
Inhaltsübersicht
1 Einleitung.........................................................................................................................................................3
2 Historie.............................................................................................................................................................3
2.1 IBMDeepBlue...........................................................................................................................................3
2.2 IBMWatson...............................................................................................................................................4
2.3 DeepMindAlphaGo................................................................................................................................4
3 Hauptteil...........................................................................................................................................................4
3.1 RelevanzvonAlphaGo..........................................................................................................................4
3.2 WiespielteDeepBlueSchach?..........................................................................................................7
3.2.1 DieEvaluate-Funktion.....................................................................................................................8
3.3 DieUnterschiedezwischenSchachundGo................................................................................8
3.4 WiekonnteAlphaGoLeeSedolschlagen?..................................................................................9
3.4.1 MonteCarloTreeSearch................................................................................................................9
3.4.2 DeepNeuralNetworks..................................................................................................................10
3.4.3 PolicyNetwork..................................................................................................................................11
3.4.4 PolicyNetworkTraining..............................................................................................................11
3.4.5 ValueNetwork...................................................................................................................................12
3.4.6 ValueNetworkTraining...............................................................................................................12
3.5 KombinationderMonteCarloTreeSearchundderneuronalenNetze.....................13
3.5.1 Schritt1:Selection...........................................................................................................................14
3.5.2 Schritt2:Expansion........................................................................................................................14
3.5.3 Schritt3:Evaluation.......................................................................................................................15
3.5.4 Schritt4:Backup..............................................................................................................................15
4 Ausblick:WiekanndasneueWissenweitergenutztwerden?...........................................16
Quellen......................................................................................................................................................................17

3
1 Einleitung
KünstlicheIntelligenzenfindenimmermehrAnwendunginunseremAlltag.Obinunse-
renSmartphones,Smarthome-GegenständenwieAmazonsEchooderauchindermedizi-
nischenForschung.DochdieserVormarschderkünstlichenIntelligenzenisterstkürzlich
durcheinigeDurchbrücheindemGebietderneuronalenNetzwerkeermöglichtworden.
IndieserArbeitwirddieGeschichtederEntwicklungderkünstlichenIntelligenzanhand
von verschiedenenBrettspielen aufgezeigt. Eswerden dieMöglichkeiten undGrenzen
ausgelotetundvorallemihreFunktionsweisenerläutert.Abschließendwerdenineinem
AusblickdieEinsatzmöglichkeitendieserFormvonkünstlichenIntelligenzendiskutiert.
2 Historie
DieGeschichtederkünstlichenIntelligenzinBrettspielenkannimWesentlichenanver-
schiedenenMeilensteinenfestgemachtwerden.DieseMeilensteinewerdenimFolgenden
kurzvorgestellt.Künstliche Intelligenzen inBrettspielen sinddabei insofernvon Inte-
resse,dasichdortHandlungeninklardefiniertenRäumenundRegelnbewegenundso
sichmöglicheHandlungennichtimendlosenverlaufen.DennochkannvonsolchenSpiele-
SzenariosabstrahiertwerdenunddiekünstlicheIntelligenz(KI)soAnwendung inder
realenWeltfinden.
2.1 IBMDeepBlueDerSupercomputernamensDeepBluewarderersteComputer,derjeeinenamtierenden
menschlichenWeltmeister unterWettkampfbedingungen in einemSchachspiel schlug.
Im Jahre1997schlugderSupercomputerdendamalsamtierendenSchachweltmeister
GarryKasparovmiteinemEndergebnisvon31/2zu21/2.DasProjektbegannalsDisser-
tationsprojektdesStudentenFenghsiungHsuimJahre1985undwurdespätervomUn-
ternehmenIBMübernommen.DieKompositionausTreeSearchundeinervonSchachpro-
fisfeinjustiertenEvaluate-FunktionwarzurdamaligenZeitrevolutionärundkonnteso,
alsersteMaschine,einenmenschlichenWeltmeisterschlagen.

4
2.2 IBMWatsonDerzweiteMeilensteinwurdeebenfallsvonderFirmaIBMerreicht,mitderkünstlichen
Intelligenz, genanntWatson. Diese künstliche Intelligenz konnte 2011 gleichmehrere
ChampionsimwissensbasiertenSpielJeopardyschlagen.DasinteressanteanWatsonist
dabeinicht,dasssieinderLagewardieAntwortenaufdieFragenzufinden,daWatson
unter anderem Zugriff auf ca. 200 Millionen strukturierte und unstrukturierte Doku-
mentehatte,inklusivedergesamtenDatenbasisderonlineEnzyklopädieWikipedia.Das
interessanteanWatsonist,dassdiekünstlicheIntelligenzinderLagewar,Fragen–ge-
stelltinnatürlicherSprache–zuverstehenunddieAntwortenbasierendaufeinemCon-
fidence-Levelabzuwägen.DiesesConfidence-Levelistdabeientscheidend:Watsonweiß,
wasesnichtweiß.IstWatsonsichineinerAntwortnichtsicher(derThresholddesCon-
fidence-Levelswurdealsonichterreicht),sowirdlieberkeineAntwortausgegebenals
einefalsche.
2.3 DeepMindAlphaGoDer letzte große Meilenstein ist die von Googles Tochterfirma DeepMind entwickelte
künstlicheIntelligenzAlphaGoausdemJahre2016.ImMärzdiesesJahresschlugsieden
18-fachenGo-WeltmeisterLeeSedolmit einemdeutlichüberlegenenEndergebnisvon
vierzueins.ImAnschlusserhieltdiekünstlicheIntelligenzalsersteSoftwaredenhöchs-
tenGoRang„Honory9Dan“,verliehenvonderKoreanBadukAssociation(KBA).
3 Hauptteil
3.1 RelevanzvonAlphaGoAlphaGosetztemitseinerTechnikneueMaßstäbefürkünstlicheIntelligenzenundkonnte
dasSpielknacken,waslangeZeitalsfürComputernichtlösbargalt:DasJahrhundertealte
Go.Umzuverstehen,warumdiessowar,mussmansichdenbisherigenAnsatzfürdas
Lösen solcherBrettspiele anschauen. Traditionell verwendetman einen so genannten
Full-Game-TreeumeineLösungzufinden.DafürwerdenallemöglichenKombinationen
derFigurenaufdemSpielfeldaufgeschlüsseltunddieaktuelleBrettkombinationindie-
semBaumgesucht.VondiesemaktuellenKnotenwerdenallemöglichenPfadebiszuden
Blätterntraversiert.AufdiesenPfadenwerdenallemöglichenKombinationenvonZügen
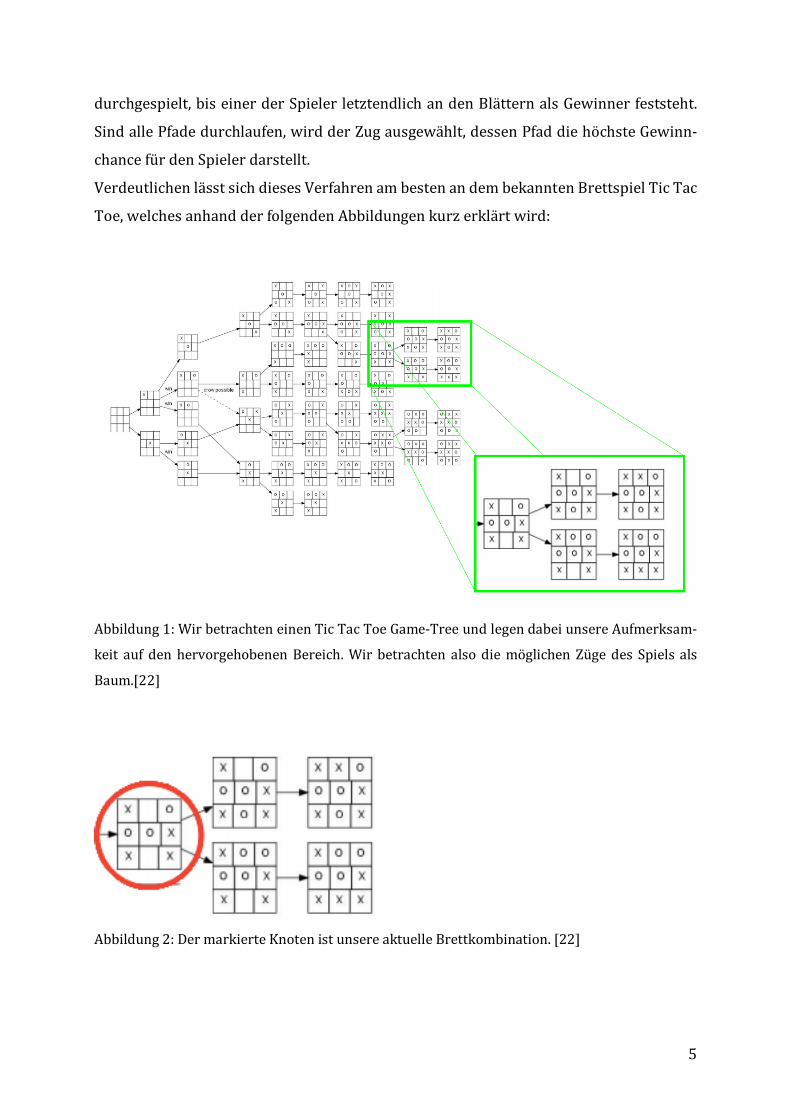
5
durchgespielt,biseinerderSpielerletztendlichandenBlätternalsGewinnerfeststeht.
SindallePfadedurchlaufen,wirdderZugausgewählt,dessenPfaddiehöchsteGewinn-
chancefürdenSpielerdarstellt.
VerdeutlichenlässtsichdiesesVerfahrenambestenandembekanntenBrettspielTicTac
Toe,welchesanhandderfolgendenAbbildungenkurzerklärtwird:
Abbildung1:WirbetrachteneinenTicTacToeGame-TreeundlegendabeiunsereAufmerksam-
keit aufdenhervorgehobenenBereich.Wirbetrachten alsodiemöglichenZügedes Spielsals
Baum.[22]
Abbildung2:DermarkierteKnotenistunsereaktuelleBrettkombination.[22]
6
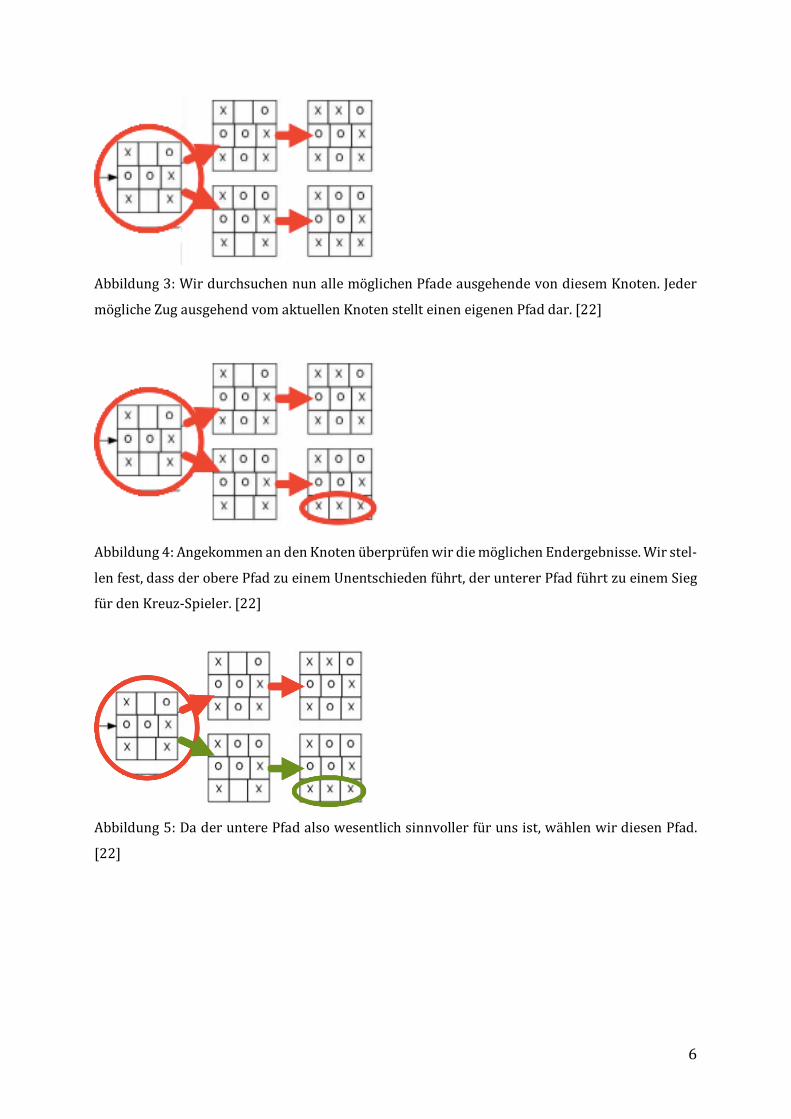
Abbildung3:WirdurchsuchennunallemöglichenPfadeausgehendevondiesemKnoten.Jeder
möglicheZugausgehendvomaktuellenKnotenstellteineneigenenPfaddar.[22]
Abbildung4:AngekommenandenKnotenüberprüfenwirdiemöglichenEndergebnisse.Wirstel-
lenfest,dassderoberePfadzueinemUnentschiedenführt,deruntererPfadführtzueinemSieg
fürdenKreuz-Spieler.[22]
Abbildung5:DaderunterePfadalsowesentlichsinnvollerfürunsist,wählenwirdiesenPfad.
[22]

7
Abbildung6:NachdemwirunsfüreinenPfadentschiedenhaben,wählenwiralsaktuellenZug
jenenaus,derunserenausgewähltenPfadinitiiert.[22]
VordemHintergrunddiesesVerfahrensstellenwirnunalsofest,dassderbenötigeSpei-
cherplatzunddiebenötigteRechenleistunginstarkerAbhängigkeitzurKomplexitätdes
Spielssteht.JekomplexereinSpielist,destomehrmöglicheBrettkombinationgibtes.Je
mehrKombinationenesgibt,destogrößerwirdderComplete-Game-Tree.DawirzurLö-
sungunseresnächstenZugsdengesamtenBaumdurchsuchenmüssen,stehtdieGröße
desBaumesalsoimdirektenVerhältniszurbenötigtenRechenleistung.Fürkleine,einfa-
cheSpielewiezumBeispielTicTacToeistdiesesVerfahrenkeinProblem,dadasTicTac
ToeSpielfeldnuraus9Feldernbesteht,welchemitnur2TypenvonFigurenbefülltwer-
den.EinesimpleobereSchrankefürdieGrößedesBaumesistdaher9!,alsogeradeeinmal
362.880Knoten (der erste Spieler hat 9Möglichkeiten, seine Figur zu platzieren, der
zweite8usw.bisdaskompletteSpielfeldbefülltist).FürGame-TreesdiesesAusmaßes
istdiebenötigteRechenleistungdefinitivnochüberschaubar.JedochsindSpiele,diediese
Komplexitätdeutlichüberschreiten,mitsolcheinemAnsatznichtmehrzubewältigen.
3.2 WiespielteDeepBlueSchach?DerSupercomputerDeepBluewarmitseinerRechenleistunginderLagebiszu200Mil-
lionen Schachpositionen zu berechnen. Auf Basis der Regeln des Schachspiels konnte
DeepBlue,anhanddesaktuellenSpielbretts,Zügeberechnen.JederZugwirddanachvon
derspeziellenEvaluate-Funktionevaluiert.AnhandderErgebnissekannderbestmögli-
cheZugausgewähltwerden.
DadieGrößedesGame-TreesfürSchachdieGrenzendesMöglicheninBezugaufdieRei-
chenleistungüberschreitet,wirdderBaum,ausgehendvoneinerBrettkombination,nur
soweitwiemöglichdurchsucht.Jeweitererdurchsuchtwird,destogenauerwirddabei

8
dasErgebnis.DurchschnittlichwirdderBaumdabei6Zügeweitdurchsucht.Dernachfol-
gendeSub-BaumwirdersetztdurchdiespezielleEvaluate-Funktion.Dabeiwirddieak-
tuelleBrettkombinationalsInputverwendet.VieleFaktorenwerdendabeimiteinbezo-
gen:DieverfügbarenFigurenundihrePositionen,diePositiondesKönigsundseineVer-
teidigung,derFortschrittdesSpielsundzusätzlichesExpertenwissen.DasErgebnisder
FunktionisteineZahl,diedenWerteinesmöglichenZugsbeschreibt.NachderPrüfung
vonmehrerenZügenwirdderZugausgewählt,derdenhöchstenWerterhaltenhat.
3.2.1 DieEvaluate-FunktionDieEvaluate-Funktionbestehtausüber8.000Teilen,dabeisindvieleTeileextraaufbe-
stimmtePositionenabgestimmt.AlleinedasOpening-Bookbestehtausüber4.000Positi-
onenausüber700.000SpielenvonGrandmasterSpielern.AuchfürdenspäterenVerlauf
desSpielshatDeepBlueVorgaben für festePositionen:FürvieleBoardkombinationen
vonsechsoderwenigerFigurensinddienachfolgendenZügegenaufestgelegt.
Wirstellenalsofest,dassDeepBlueseineLösungmiteinemVerfahrenerreicht,daseher
anBrute-ForceerinnertalsaneinesmartekünstlicheIntelligenz,diedurch"überlegen"
undabschätzeneineLösung findet.DadieEvaluate-Funktionzudemauch speziell auf
DeepBluesGegnerGarryKasparovundseinenSpielstilabgestimmtwurde,kommteszu
einemstarkenoverfitting.EinenanderenGegner,überdenDeepBluekeineInformatio-
nen bezüglich seines Spielstils besitzt, hätte die künstliche Intelligenzmöglicherweise
nichtgeschlagen.Zudem istderAlgorithmusnicht inderLagezu lernen. SeineStärke
zieht das System aus der vonMenschen geschaffenenEvaluate-Funktion. ImUmkehr-
schlusskannalsodasSystemniestärkerwerden,alsdieMenschen,dieesentwickeltha-
ben.AuchwenndieseMenschenübergroßesSchachwissenverfügtenkanndieserAnsatz
nurschwerzuneuenErkenntnissenführen.AuchkanndiesekünstlicheIntelligenzauf
keineandereSituationalsaufSchachangewendetwerden,dasienichtgeneralisierbarist.
SieistnurdaraufausgelegtSchachzuspielen.
3.3 DieUnterschiedezwischenSchachundGoBetrachtenwiralsnächstesdieUnterschiedezwischendenSpielenSchachundGo,insbe-
sonderedieUnterschiedeinderKomplexität.BeiSchachhatjederSpieler16Figurenaus
6verschiedenenArtenzurVerfügung.DabeidarfjedeArtvonFigursichaufunterschied-
licheArtaufdemSpielfeldbewegen.DasSpielfeldbestehtdabeiaus64einzelnenFeldern.

9
Bei Go hingegen besitzt jeder Spieler nur eineArt von Spielfiguren,welche auf einem
Spielbrettmit361einzelnenFelderngesetztwerden.Wirstellenalsofest,dassGowe-
sentlichwenigerEinschränkung inBezug aufdieKombinationsmöglichkeiten hat. Das
Spielfeldistfast6-malsogroßwiedasSchachfeldunddieFigurenkönnenzujederZeit
aufjedesfreieFeldaufdemSpielfeldplatziertwerden.
EinSchach-Spielkannauf20Arteneröffnetwerden,einGo-Spielauf361Arten.Durch-
schnittlichkannmanzujedemMomentineinemSchach-Spielaus35möglichenZügen
auswählen,beiGosindesdurchschnittlich250.AuchdieSpiellängeistbeieinemGo-Spiel
durchschnittlichwesentlichlängeralsbeieinemSchach-Spiel.80ZügebeimSchachspiel
stehenungefähr150ZügebeiGogegenüber.
DieseUnterschiedemanifestierensichschlussendlichinderKomplexitätderSpiele:Es
gibtungefähr10^120verschiedenMöglichkeitendieFigurenauf einemSchachfeld im
LaufeeinsSpielszuplatzieren.BeiGosindesüberwältigende10^170Möglichkeiten.Um
kurzeinenÜberblickzuschaffen,inwelchenGrößenordnungenwirunshierbewegen:Es
gibtungefähr10^80AtomeimUniversum.EinComplete-Game-TreefürGobesitztalso
10^170Knoten.
Wirstellenalsofest,dassGovielzukomplexistumvoneinemähnlichenAnsatzwiebei
IBMsDeepBluegelöstzuwerden,geschweigedennvomtraditionellenAnsatzwiebeiei-
nemeinfachenSpielwieTicTacToe.
3.4 WiekonnteAlphaGoLeeSedolschlagen?UmdieserFrageaufdenGrundzugehenschauenwirunszuerstdenAufbauderkünstli-
chen Intelligenz an. AlphaGo besteht aus zweiHauptkomponenten: EinerMonte Carlo
TreeSearchunddreiDeepNeuralNetworks.DieKomponentenkönnenzwaraucheinzeln
verwendetwerden,umeineGospielendeKIzuerzeugen.DocheinzelnkommendieSys-
temenichtübereinAmateurniveauhinaus.ErstdieKombinationausbeidenSystemen
vermachtAlphaGodieStärkedieesbenötigt,ummehrfacheWeltmeisterwieLeeSedol
zuschlagen.BetrachtenwirzuerstdieKomponentenimEinzelnen:
3.4.1 MonteCarloTreeSearchEineMonteCarloTreeSearchisteinealternativeArt,einenGameTreezudurchsuchen.
ImGegensatzzumtraditionellenAnsatzmussdafürnichtdergesamteBaumvorliegen,
was enormen Speicherplatz undRechenleistung spart. Ausgehend von einer aktuellen
BrettkombinationwerdenSpielesimuliert.DabeiwerdenzuerstzufälligeZügegewählt,

10
bisletztendlicheinSpielergewinnt.NachjederSimulationwerdendieWertegespeichert,
welcheZügegewähltwurdenundobsiezueinemSiegführtenodernicht.JedeSimulation
ziehtbeiderAuswahleinesZugsdieSiegchancendesselbenausdenvorigenSimulationen
inBetracht.SowerdenausdenzuBeginnnochzufälligenZügennachundnachZüge,die
einesehrhoheGewinnchancehaben.Dabeigilt:JemehrSimulationendurchgeführtwer-
den,destobesserwerdendieZüge.ErhöhtmandieAnzahlanSimulationeninsunendli-
che,sokonvergierteineMonteCarloTreeSearchtatsächlichzumbestmöglichenZug.Die
MonteCarloTreeSearchlässtsichinfolgendeEinheitenaufgliedern:
1.Selection:DerBaumwirdvonderWurzelbiszueinemBlattdurchlaufen.Dabeiwerden
beiderAuswahleinesKnotensdiejeweiligenSiegchancendesKnotensinBetrachtgezo-
gen.
2.Expansion:IstdasBlattkeinSiegfüreinenderbeidenSpieler,sowirdeinodermehrere
neueZüge(Knoten)zufälliggewählt.
3.Simulation:VondiesenneuenKnotenwirdeineSimulationgestartet.DasSpielwird
simuliert,biseinerderSpielergewinnt(auchRolloutgenannt).
4.Backpropagation:IstdieSimulationbeendet,sowirddasErgebnisderSimulationzu-
rückandenKnotengegeben,derwährendderExpansionerzeugtwurdeundvondort
hochbiszuderWurzeldesBaumes.WardieSimulationeinSieg,sowirddieserPfadin
zukünftigenDurchläufenstarkergewichtetwerden,alsdieKnoteneinesPfades,derletzt-
endlichineinerNiederlageendet.
Systeme,welchesichnuraufMonteCarloTreeSearchfüreineGo-KIverlassenundsolche,
dieMonteCarloTreeSearchmitmenschlichemFachwissenkombinierenerreichendas
NiveaueinesstarkenAmateurSpieles.EinBeispielfürsolcheinSystemistdieSoftware
Pachi,welcheZügeausschließlichmitungefähr100.000MonteCarloTreeSearchSimu-
lationenproZugauswählt.
3.4.2 DeepNeuralNetworksAlphaGobesitztnichtnureinneuronalesNetz,sonderngleichdrei:EinValue-Network
undzweiPolicy-Networks.DabeiübernimmtjedesNetzunterschiedlicheAufgaben.

11
3.4.3 PolicyNetworkDasPolicy-NetworkhatdieAufgabedieMonteCarloTreeSearchbeiderAuswahlneuer
Zügezuleiten.DabeiwirddasaktuelleBrettalsBildalsInputverwendet.JederZug,der
durchlaufenwird,bekommteineWertigkeitvondiesemPolicy-Networkzugewiesen.An-
handdieserWertigkeit,kannsoderbestmöglicheZugausgewähltwerden.DiesesNetz
reduziertdieBreitedesSuchbaums,dasoZüge,dienichtzielführendsind,direktausge-
schlossenwerden können und keineRessourcen auf derenBerechnung verschwendet
werdenmüssen.
DasPolicy-NetworkgibtesinzweiAusführungen:Alslangsameaberdafürsehrpräzise
Variante,demHeavyRolloutPolicyNetwork,undalsschnelleaberdafürwenigerpräzise
Variante,demFastRolloutPolicyNetwork.
3.4.4 PolicyNetworkTrainingDasTrainingdesneuronalenNetzesbestehtaus2Phasen.IndererstenPhasewirddas
NetzmittelsSupervisedLearningtrainiert.InderzweitenPhasewirddasbereitsgelernte
mittelsReinforcementLearningvertieft.BeimSupervisedLearningwerdenungefähr30
MillionenPositionenausSpielenzwischenmenschlichenSpielernverwendet.Diesesind
aufdeminternationalenKGSGoServergespeichertundfürjedermanneinsehbar.Dabei
werdendiePositionenalsTrainingsSetverwendetunddervommenschlichenSpieler
tatsächlichausgeführteZugalsLabeldesValidationSets.DasPolicyNetworkversucht
nunalsoanhandeinerPositiondennächstenbestmöglichenZugdesSpielsvorauszusa-
genundüberprüftseinErgebnismitdemLabelausdemValidationSet.AnhandderKor-
rektheitderVoraussagedesNetzespasstdasNetzseineGewichtunginnerhalbderSy-
napsenanundkannsoseineVoraussagenimmerweiterverbessern.Nachdemdie30Mil-
lionenTrainingsdatenverarbeitetwurden,wardasHeavyPolicyNetworkinderLageden
nächstenZugdesmenschlichenSpielersmiteinerGenauigkeitvon57%vorherzusagen.
DabeibenötigtdasNetzdurchschnittlichdreiMillisekundenfürdieBerechnungdesZugs.
DasFastRolloutPolicyNetworkkommtmitseinerwesentlichgeringerenAnzahlanNeu-
ronenzwarnuraufeineGenauigkeitvon24%,kanndafürdiesenaberauchbereitsinner-
halb von durchschnittlich 2 Mikrosekunden berechnen und ist damit rund 1500-mal
schnelleralsdasHeavyRolloutPolicyNetwork.InderzweitenPhasedesTrainingswird
dieGenauigkeitdesneuronalenNetzesmittelsReinforcementeLearningweiterverbes-
sert.HierbeispieltdasPolicyNetworkgegenzufälligeIterationenvonsichselbst,umdie
Wahrscheinlichkeit eines Overfittings zu reduzieren. Overfitting bezeichnet dabei ein

12
Phänomen,beidemsichdasNetzzustarkandasTrainingssetannähert.DasNetzerzeugt
dannzwarfürdasTrainingssetsehrguteErgebnisse,dochtauschtmandasTrainingsset
gegenneue,unbekannteDatenaus,soerzieltdasNetzwesentlichschlechtereErgebnisse.
DasModeldesneuronalenNetzeshatsichzustarkandasTrainingssetangepasstumgute
Ergebnissezuerzielen,anstattvondenDatenzuabstrahierenundübergeordneteStruk-
turen zu erkennen. Durch stetig wechselnde Trainingssets unterschiedlicher Qualität
lässtsichdiesesPhänomenreduzieren.DeswegenführenGegnerauszufälligenIteratio-
nendesneuronalenNetworkszubesserenErgebnissenalswenndasNetworknurgegen
eineVersionseinerselbstspielenwürde.BeidiesenSpielengegensichselbstwirddas
EndergebnisdesSpielsalsTrainingssignalfürdenjeweiligenZuggenommen.Insgesamt
spieltesodasNetzmehrals1,2MillionenPartiengegensichselbst.
SokonntenGo-KIswelchenuraufdemPolicyNetworkbasierennachdemReinforcement
LearningbereitseineWinratevon80%gegenKIsverzeichnen,welchenuraufdemPolicy
NetworknachdemSupervisedLearningbasieren.GegenüberderGo-KIPachi,welchenur
aufderMonteCarloTreeSearchmit100.000SimulationenproZugbasiert,konntesogar
eineWinratevon85%erzieltwerden.
3.4.5 ValueNetworkDasValueNetworkgibtAufschlussüberdie"Qualität" einesaktuellenBretts, alsowie
wahrscheinlichesist,dassderschwarzeSpieler,ausgehendvomaktuellenBrett,gewinnt.
DabeiwirddasBrettalsBildalsInputfürdasneuronaleNetzverwendetundgibteine
Zahlzurück,welchedieGewinnchancedesschwarzenSpielersrepräsentiert.DiesesNetz
istvergleichbarmitderEvaluate-FunktiondesDeepBlueSchachsupercomputervonIBM,
miteinementscheidendenUnterschied:DasValue-Networkwirdtrainiertundistsomit
erlerntundnichtdefiniert.SowirdzumeinenkeindirektesmenschlichesWissenbenötigt
undzumanderenwirddasNetworknichtdurchmenschlichesWissenlimitiert.Dieses
NetworkreduziertdieTiefedesSuchbaums.
3.4.6 ValueNetworkTrainingTrainiertwurdedasValueNetworkzuerstebenfallsmitPositionenausderDatenbank
desKGSGoServers.Dochschnellstelltemanfest,dasseszueinemOverfittingdieserDa-
tenkommt.DasNetzlerntedenAusgangvonbestimmtenPositionenauswendig,anstatt
diePositionenzugeneralisieren.Mangingdazuüber,dasValueNetworkmit30Millionen

13
PositionenausSelf-PlayData zu trainieren.DiesePositionenwurdenausSpielenzwi-
schenzweiVariantendesPolicyNetworksentnommen,diesichinderPhasedesRein-
forcementLearningbefanden.Dabeiwurdeaus jedemSpielnureinePositionentnom-
men,umdieDiversitätderDatenzuerhöhen.Wenige,aufeinanderfolgendeZügeinner-
halbeinesSpielsverändernmeistdenAusgangeinesSpielsnicht,solangemannichtzu-
fälligeinigewenige,kritischeZügebetrachtet(dieWahrscheinlichkeitdafüristsehrge-
ring).Sokannespassieren,dassauchhierdasNetzdenAusgangdesSpielsauswendig
lernt,anstattvondenPositionenzugeneralisieren.UmsolcheinOverfittingzuvermeiden
wirdalsoausjedemSpielnureinePositionverwendet.
DasValueNetworkistdabeiwesentlichgenaueralseineMonteCarloTreeSearchkombi-
niertmitdemFastRolloutPolicyNetworkundähnlichgenauwieeineMonteCarloTree
SearchkombiniertmitdemHeavyRolloutPolicyNetwork,benötigtdabeiallerdingsfast
15.000-malwenigerRechenleistungalsdasHeavyRolloutPolicyNetwork.
EinzelnkommendieKomponentenvonAlphaGoalsoaufdasNiveaueinesstarkenAma-
teurspielers.ErstdieKombinationausderMonteCarloTreeSearchunddenneuronalen
NetzenverleihtAlphaGoseineStärke.
3.5 KombinationderMonteCarloTreeSearchundderneuronalenNetzeDieStärkenderverschiedenenneuronalenNetzewerdenineinemMonteCarloTreeSe-
archAlgorithmuskombiniert.JedermöglicheZug,dersichvonderWurzeldesBaumes
ausergibt,wirdaufzweiArtenevaluiert.EinmalmitdemValueNetworkundeinmalmit
demFastRolloutPolicyNetwork:DasValueNetworkevaluiertdiePositionnachdemZug
undgibteineentsprechendeWertigkeitaus.DasFastRolloutPolicyNetworkführt,aus-
gehendvondemneuausgewähltenZug,eineSimulationaus,bisdasSpielterminiertist.
ObderZugletztendlichzueinemSiegodereinerNiederlageführtentscheidetüberdie
WertigkeitdiesesZugs.DieerrechnetenWertewerdenmitdenWertenderKantenver-
rechnet.AusdiesemVerfahrenergibtsichletztendlicheinvondemSystemalsbestmög-
licheingestufterZug.DochbetrachtenwirdieeinzelnenSchritteetwasgenauer:

14
3.5.1 Schritt1:Selection
Abbildung7:JedeSimulationdurchläuftdenBaumundwähltdabeiimmerdieKanteaus,dieden
höchstenWerthat.DerWertderKanteistdabeidieSummeausdemberechnetenWertausvor-
herigenSimulationenQundeineminitialenprobabilityWertu(P).DieserprobabilityWertwird
durchdasHeavyRolloutPolicyNetworkbestimmt.DerZugmitdemhöchstenprobabilityWert
spiegeltdabeialsodenZugwieder,deneinmenschlicherSpieleramwahrscheinlichstenwählen
würde.Dabeiwirdu(P)durchdieAnzahlgeteilt,wiehäufigdieseKantebereitsausgewähltwurde.
u(P)wirdmitderZeitalsoimmergeringer,wasdieExplorationvonAlphaGofördertundverhin-
dert,dasssichdasSystemzufrühaufwenigebestimmteZügefestlegtundandere,möglicherweise
bessereZügeaußerAchtlässt.[1]
3.5.2 Schritt2:Expansion
Abbildung8:ErreichenwireinBlatt,sowirdeinneuerZugerzeugtundvomPolicyNetworkmit
eineminitialenprobabilityWertversehen.[1]

15
3.5.3 Schritt3:Evaluation
Abbildung9:DerneuerzeugteZugwirdnunaufzweiArtenevaluiert.ZumeinenwirddiePosition
vomValueNetworkV0bewertet.Zumanderenwird,ausgehendvomneuenZug,eineSimulation
gestartet,beiderdasSpielmittelsdesFastRolloutPolicyNetworkPπweitergespieltwird,bisdas
Endeerreichtwird.DerAusgangdesSpielsbestimmtdieWertigkeitdesneuerzeugtenZuges.
AnhanddieserbeidenWertewirddieWertigkeitQdesneuenZugsberechnet.[1]
3.5.4 Schritt4:Backup
Abbildung10:DieerrechneteWertigkeitQdesZugeswirdaktualisiert.DesWeiterenwerdenalle
WerteQderZügeaktualisiert,dieindemPfadvonderWurzelbiszumneuenBlattenthaltenwa-
ren.FührtederZugzueinemSiegerhöhtsichderWert,führtederZugzueinerNiederlageso
verringertsichderWert.Auchwirddieaktualisiert,wiehäufigeineKanteausgewähltwurdeund
soauchderWertu(P)angepasst.[1]

16
NachnDurchläufendiesesVerfahrensergibtsichalsoeinZug,dereinehöhereWertigkeit
aufweistalsalleanderenZüge.SofindetAlphaGoseinennächstenZugundderGegenspie-
leristanderReihe.
DurchdieseKombinationausMonteCarloTreeSearchundderverschiedenenNeurona-
lenNetzeerlangteAlphaGoseinebekannteStärke,mitderdasSystemauchden18-fachen
Go-WeltmeisterLeeSedolschlagenkonnte,undüberwindetsodieSchrankenderSpei-
cher-undRechenkapazität,dieeinesolchstarkeGo-KIfürlangeZeitverhinderten:Die
neuronalenNetzereduzierendieBreiteundTiefedesSuchbaumesinsolcheinemMaße,
dassAlphaGodurchschnittlichnur5SekundenproZugbenötigt.
4 Ausblick:WiekanndasneueWissenweitergenutztwerden?
AnwendungfindendieneunenErkenntnisseausderkünstlichenIntelligenzüberwiegend
indermedizinischenForschung.BesondersimThemengebietderErforschungderFal-
tungvonProteineneröffnetdieProblemlösungvonAlphaGoneuePfade.Dabeiwirddas
SystemzumErkennenundVerstehenvonfehlgeformtenProteinenverwendetumneue
ErkenntnisseundBehandlungsformenfürbeispielsweiseKrankheitenwieAlzheimerzu
finden.AuchfindetdieAnfangserwähntekünstlicheIntelligenzWatsonvonIBMbereits
AnwendungKrebsforschung.WatsonforOncologykanneineVielzahlvonKrebsartenan-
handvonRöntgenbildernerkennenundinKombinationmiteinemgroßenPoolanKran-
kenakten und Patientendaten speziell auf den Patienten zugeschnitteneBehandlungs-
pläneerstellen.
EinweitererinteressanterPunktistdieaufAlphaGobasierendeWeiterentwicklungAl-
phaGoZero.ImGegensatzzuAlphaGoverwendetAlphaGoZeroeinsogenanntes"Tabula
rasa"learning.DemSystemwurdennurdieRegelndesSpielsGobeigebracht.Ohnejedes
weiteremenschlicheWissenspieltAlphaGoZerogegenIterationvonsichselbstundent-
wickeltsoeigenständigeineSpielweiseundeigeneTaktiken,völliglosgelöstvonbereits
bekanntenTaktikenmenschlicherSpieler.Soistesmöglich,ohnemenschlichesVorwis-
senneueErkenntnissezugewinnen.MittelsdiesesVerfahrenserreichteAlphaGoZero
bereitsnach3TagendiegleicheStärkewiedieVersionvonAlphaGo,diedenWeltmeister

17
LeeSedolschlug.Nach40TagenübertrumpfteAlphaGoZerojeglicheVersionenvonAl-
phaGoundwirdderbesteGoSpielerderWelt.AlldiesohnemenschlichesVorwissenund
ausschließlichdurchSelf-Play.
DieseröffnetzudemneueMöglichkeitenfür"generalpurpose"KIs,dieaufvieleverschie-
deneAnwendungsgebieteanwendbarsindundnichtnuraufeinzelneTätigkeiten.
Quellen
Journals:
[1]MasteringtheGameofGowithDeepNeuralNetworksandTreeSearchGoogle,GoogleDeepMind|PusblishedinNature529,Januar2016[2]MasteringthegameofGowithouthumanknowledgeGoogle,GoogleDeepMind|PusblishedinNature550,April2017
Online-Quellen:
[3]https://jeffbradberry.com/posts/2015/09/intro-to-monte-carlo-tree-search/
[4]https://www.tastehit.com/blog/google-deepmind-alphago-how-it-works/
[5]http://ccg.doc.gold.ac.uk/research-mcts/
[6]https://machinelearnings.co/understanding-alphago-948607845bb1
[7]https://deepmind.com/blog/alphago-zero-learning-scratch/
[8]https://deepmind.com/research/alphago/
[9]https://blog.google/topics/machine-learning/alphago-machine-learning-game-go/
[10]http://ccg.doc.gold.ac.uk/research-mcts/
[11]https://www.tastehit.com/blog/google-deepmind-alphago-how-it-works/
[12]https://en.wikipedia.org/wiki/Monte_Carlo_tree_search
[13]http://www.businessinsider.com/how-ibm-watson-is-transforming-healthcare-
2015-7?IR=T
[14]https://sciencebasedmedicine.org/tag/watson/
[15]https://www.newscientist.com/article/2079871-im-in-shock-how-an-ai-beat-the-
worlds-best-human-at-go/

18
[16]http://www.businessinsider.com/r-ibms-watson-to-guide-cancer-therapies-at-14-
centers-2015-5?IR=T
[17]https://www.engadget.com/2017/06/01/ibm-watson-cancer-treatment-plans/
[18]http://www.telegraph.co.uk/science/2017/10/18/alphago-zero-google-deep-
mind-supercomputer-learns-3000-years/
[19]https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4828734/
[20]https://en.wikipedia.org/wiki/Deep_Blue_versus_Garry_Kasparov
[21]https://en.wikipedia.org/wiki/Watson_(computer)
[22]https://commons.wikimedia.org/wiki/File:Tic-tac-toe-full-game-tree-x-rational.jpg





























