Embed Size (px)
Citation preview

Karlsruher Institut fur Technologie (KIT)Fakultat fur Physik
Institut fur Experimentelle Kernphysik
Bayes-Statistikund
konjugierte Verteilungen
Bayesian Statistics
andConjugate Distributions
Bachelorarbeitvorgelegt von
Paul Schnabeleam
19. Mai 2011
Referent: Prof. Dr. Michael FeindtKorreferent: Dr. Thomas Kuhr


Abstract
Diese Arbeit stellt in Kurze relevante Ergebnisse aus der Wahrscheinlichkeits-theorie zusammen, um darauf aufbauend mit einfachen Beispielen die Ideedes Satzes von Bayes zu erklaren. Danach wird der Satz fur mehrdimensiona-le Parametermodelle aufgestellt. Es schließt sich eine Gegenuberstellung vonklassischen (frequentistischen) Methoden und Bayes-Statistik an. Ein weitererHauptbestandteil der Arbeit ist die Diskussion von konjugierten Verteilungen.Im letzten Kapitel wird die Relevanz der bayesianischen Methoden fur diePhysik aufgezeigt.


Inhaltsverzeichnis
Einleitung 1
1 Grundlagen 31.1 Wahrscheinlichkeitsdefinitionen . . . . . . . . . . . . . . . . . . 3
1.1.1 Laplace-Wahrscheinlichkeit . . . . . . . . . . . . . . . . . 31.1.2 Frequentistischer Wahrscheinlichkeitsbegriff . . . . . . . 41.1.3 Bernoullisches Gesetz der großen Zahlen . . . . . . . . . 51.1.4 Wahrscheinlichkeitsdefinition von Kolmogorow . . . . . . 71.1.5 Anwendbarkeit der Wahrscheinlichkeitsbegriffe . . . . . . 10
1.2 Zufallsvariablen und Dichten . . . . . . . . . . . . . . . . . . . . 111.2.1 Zufallsvariablen in einer Dimension . . . . . . . . . . . . 111.2.2 Multivariate Verteilungen . . . . . . . . . . . . . . . . . 12
1.3 Bedingte Wahrscheinlichkeiten . . . . . . . . . . . . . . . . . . . 131.3.1 Baumdiagramme . . . . . . . . . . . . . . . . . . . . . . 131.3.2 Formale Herleitung des Satzes von Bayes . . . . . . . . . 14
2 Der Satz von Bayes 162.1 Interpretation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.2 Ausfuhrliche Beispiele . . . . . . . . . . . . . . . . . . . . . . . 17
2.2.1 Diagnostik seltener Ereignisse . . . . . . . . . . . . . . . 172.2.2 Priori- und posteriori-Verteilungen . . . . . . . . . . . . 182.2.3 Gefangenenparadoxon . . . . . . . . . . . . . . . . . . . 20
2.3 Satz von Bayes fur Dichten . . . . . . . . . . . . . . . . . . . . . 212.4 Qualitative Analyse am Beispiel des Munzwurfs . . . . . . . . . 25
3 Parametermodelle 283.1 Parameterschatzung . . . . . . . . . . . . . . . . . . . . . . . . 283.2 Die frequentistische Antwort . . . . . . . . . . . . . . . . . . . . 29
3.2.1 Munzwurf . . . . . . . . . . . . . . . . . . . . . . . . . . 293.2.2 Das Konfidenzintervall am Beispiel eines t-Tests . . . . . 30
3.3 Die bayesianische Antwort . . . . . . . . . . . . . . . . . . . . . 313.4 Vorteile der Bayes-Analyse . . . . . . . . . . . . . . . . . . . . . 33
4 Konjugierte Verteilungen 364.1 Theoretische Einfuhrung . . . . . . . . . . . . . . . . . . . . . . 36
4.1.1 Suffizienz- und Likelihoodprinzip . . . . . . . . . . . . . 364.1.2 Konjugierte Familie . . . . . . . . . . . . . . . . . . . . . 384.1.3 Exponentialfamilie . . . . . . . . . . . . . . . . . . . . . 384.1.4 Konjugierte Verteilungen bei Exponentialfamilien . . . . 40
i

ii Inhaltsverzeichnis
4.2 Konjugierte Analysen fur stetige Großen . . . . . . . . . . . . . 414.2.1 Exponentialverteilung, λ unbekannt . . . . . . . . . . . . 414.2.2 Normalverteilung, µ unbekannt und σ2 bekannt . . . . . 42
4.3 Konjugierte Analysen fur diskrete Großen . . . . . . . . . . . . 444.3.1 Poissonverteilung, λ unbekannt . . . . . . . . . . . . . . 444.3.2 Binomialverteilung, θ unbekannt . . . . . . . . . . . . . . 46
4.4 Nicht-informative Dichten . . . . . . . . . . . . . . . . . . . . . 47
5 Bayes-Analysen in der Physik 495.1 Warum Bayes-Analysen in der Physik? . . . . . . . . . . . . . . 495.2 Poisson-Statistik bei radioaktiver Strahlung . . . . . . . . . . . 515.3 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
Anhang 55
A Grunddefinitionen der Wahrscheinlichkeitstheorie 55
B Wahrscheinlichkeitsverteilungen 57B.1 Diskrete Verteilungen . . . . . . . . . . . . . . . . . . . . . . . . 57
B.1.1 Bernoulli-Verteilung . . . . . . . . . . . . . . . . . . . . 57B.1.2 Binomialverteilung . . . . . . . . . . . . . . . . . . . . . 57B.1.3 Poissonverteilung . . . . . . . . . . . . . . . . . . . . . . 59
B.2 Stetige Verteilungen . . . . . . . . . . . . . . . . . . . . . . . . 59B.2.1 Gleichverteilung . . . . . . . . . . . . . . . . . . . . . . . 59B.2.2 Normalverteilung . . . . . . . . . . . . . . . . . . . . . . 59B.2.3 Gammaverteilung . . . . . . . . . . . . . . . . . . . . . . 60B.2.4 Betaverteilung . . . . . . . . . . . . . . . . . . . . . . . . 60B.2.5 Student-t-Verteilung . . . . . . . . . . . . . . . . . . . . 61

Einleitung
Die Bayes-Statistik ist eine Moglichkeit, Wahrscheinlichkeitstheorie zu inter-pretieren. Jedoch ist sie deutlich unbekannter und in der Praxis weniger ver-breitet als ihr klassisches Pendant, der Frequentismus. Zwischen den beidenSchulen gab es im Laufe der Entwicklung dieses Teilgebiets der Mathematikheftige Auseinandersetzungen. Man konnte von einer Art Glaubenskrieg spre-chen, der in zwei Lager spaltete - die Bayesianer auf der einen und die Frequen-tisten auf der anderen Seite. Das Wort Glaubenskrieg erscheint ubertrieben,bringt allerdings tatsachlich den eigentlichen Grund der Auseinandersetzungauf den Punkt. Es geht letztlich darum, festzulegen, was Wahrscheinlichkeit ist.Welche Anschauung kann man sich von diesem Begriff machen? Die Antwortender beiden Lager unterscheiden sich deutlich. Wahrend Frequentisten Wahr-scheinlichkeit als eine relative Haufigkeit ansehen, halten Bayesianer Wahr-scheinlichkeit fur ein Maß fur Wettbereitschaft. Man spricht auch vom soge-nannten subjektiven Wahrscheinlichkeitsbegriff, bei dem es um den Grad anpersonlicher Uberzeugung bzw. um die Starke des Glaubens an das Eintre-ten eines bestimmten Ereignisses geht. Es mag dann nicht mehr verwundern,dass Thomas Bayes1, der die Grundlagen fur die Bayes-Statistik legte, ein eng-lischer Geistlicher war. Seine nach seinem Tod von einem Freund veroffentlichteArbeit (1763) gab den Anstoß fur die Entwicklung der Theorie. Die Ideen vonBayes wurden dann insbesondere von Pierre-Simon Marquis de Laplace2 wei-terentwickelt. Er stellte den sogenannten Satz von Bayes in der auch heutenoch ublichen Form auf (1812).Naturlich klingt dieser subjektive Wahrscheinlichkeitsbegriff dem ersten An-schein nach nicht nach serioser Wissenschaft. Welche sinnvolle Theorie solltesich auf Subjektivitat stutzen konnen? Ein Ziel der vorliegenden Arbeit ist es,die Idee, welche die Bayes-Statistik verkorpert, herauszuarbeiten. Dabei wirdklar werden, welche nutzlichen Vorteile von ihr bereit gestellt werden. Den ub-lichen statistischen Prufverfahren (Tests) wird mit dem Satz von Bayes eine insich schlussige und plausible Alternative gegenubergestellt.
In einem ersten Kapitel werden mathematische Grundlagen zusammengefasst,welche fur alles Weitere unabdingbar sind. Die darauf folgenden drei Kapi-tel beschaftigen sich mit der Bayes-Statistik. Es wird zunachst viel Wert da-rauf gelegt, grundlegende Erkenntnisse, die sich mit Hilfe des Bayes-Theoremserschließen, anschaulich zu machen. Weiterhin werden Parametermodelle imRahmen der Bayes-Statistik betrachtet. Generell wird ein Fokus auf die Anwen-dung fur die Forschung gelegt, welche sich die Bayes-Statistik fur komplizierte
1*um 1702 in London; †17. April 1761 in Tunbridge Wells2*28. Marz 1749 in Beaumont-en-Auge in der Normandie; †5. Marz 1827 in Paris
1

2 Inhaltsverzeichnis
Versuchsauswertungen zu Nutze machen kann. Ein weiteres Augenmerk wirdauf die Diskussion sogenannter konjugierter Verteilungen gelegt. Sie stellen,bei gunstigen Voraussetzungen, eine Moglichkeit dar, bayesianische Analysenanalytsisch durchzufuhren. Im abschließenden Kapitel wird vertieft auf die An-wendung im Rahmen der Physik eingegangen. Ziel dieses letzten Kapitels istes, weniger die konkreten Methoden als vielmehr die Grundlagen verstandlichzu machen, sodass eine Implementierung bayesianischer Uberlegungen in dieAuswertungen oft hochkomplizierter Versuche moglich wird.

1 Grundlagen
In diesem ersten Kapitel werden im Uberblick wichtige Grundzuge der Wahr-scheinlichkeitstheorie zusammengetragen, die fur die folgende Diskussion vonkonjugierten und nicht-informativen priori-Verteilungen unabdingbar sind. Die-ses Kapitel kann allerdings nicht als Ersatz fur mathematische Grundvorle-sungen bzw. Fachliteratur im Bereich Wahrscheinlichkeitstheorie und Statis-tik stehen. Es sollen viel eher Anhaltspunkte gegeben und Notationen festge-legt werden. Im Folgenden werden einige grundlegende Fachbegriffe der Wahr-scheinlichkeitstheorie benutzt. Um den Textfluss nicht zu storen, erfolgt dieErlauterung dieser zentralen Begrifflichkeiten im Anhang A. Bei Bedarf kanndort nachgeschlagen werden.
1.1 Wahrscheinlichkeitsdefinitionen
1.1.1 Laplace-Wahrscheinlichkeit
Die erste Frage, die es zu beantworten gilt, ist die nach einer sinnvollen De-finition von Wahrscheinlichkeit. Eine erste Festlegung erlaubt die sogenannteLaplace-Wahrscheinlichkeit (auch: klassische Wahrscheinlichkeit). Ihr Gultig-keitsbereich beschrankt sich auf Laplace-Experimente.
Definition 1.1 (Laplace-Wahrscheinlichkeit)Fur Laplace-Experimente ist
P (A) :=|A||Ω|
=Anzahl der fur A gunstigenF alle
Gesamtzahl der Elementarereignisse(1.1)
die Wahrscheinlichkeit des Ereignisses A.
Dabei ist die Anzahl der fur A gunstigen Falle identisch mit der Anzahl derin A enthaltenen Elementarereignissen. Zum Beispiel ist die Wahrscheinlich-keit beim einmaligen Wurfeln eines fairen Wurfels, eine gerade Augenzahl zuerhalten (Ereignis A) wegen Ω = 1, 2, 3, 4, 5, 6 und A = 2, 4, 6 gleich 50%.Mit dieser Festlegung und unter zur Hilfenahme von Kenntnissen aus der Kom-binatorik, lassen sich etwa Glucksspiele oder sonstige Situationen beschreiben,denen ein endlicher Ergebnisraum zugeschrieben werden kann und dessen Ele-mentarereignisse gleich haufig auftreten. Es ist klar, dass dieser begrenzte Gul-tigkeitsbereich fur die Wissenschaft nicht zufriedenstellend ist, da nicht jedestochastische Situation uber Ausgange verfugt, die allesamt die gleichen Vor-aussetzungen haben. In den meisten Fallen gibt es Ergebnisse, denen man einehohere Eintrittswahrscheinlichkeit einraumt als anderen.
3

4 1 Grundlagen
1.1.2 Frequentistischer Wahrscheinlichkeitsbegriff
Die zentrale Große der frequentistischen Wahrscheinlichkeitsinterpretation (auch:statistischer Wahrscheinlichkeitsbegriff) ist die relative Haufigkeit.
Definition 1.2 (Relative Haufigkeit)Sei Ω der Ergebnisraum und E ein Ereignis auf diesem Ergebnisraum. Fuhrtman ein Zufallsexperiment n-mal unabhangig voneinander durch und tritt dasEreignis E dabei genau Hn(E) mal ein, so ist
hn(E) :=Hn(E)
n(1.2)
die relative Haufigkeit des Ereignisses E.
Die Große Hn(E) bezeichnet man als absolute Haufigkeit. In Tab 1.1 ist einBeispiel zur Berechnung relativer Haufigkeiten zu sehen.
Tabelle 1.1: Ergebnis eines 30-fachen Wurfelwurfs
Es ist eine Erfahrungstatsache, dass sich bei genugend großer Anzahl an Wie-derholungen eines Zufallsexperiments die relative Haufigkeit um einen be-stimmten Wert einpendelt. Das heißt man erkennt empirisch, dass sich beimehreren jeweils umfangreichen Versuchsreihen in etwa der gleiche stabile Wertergibt.
Beispiel: Es wird sehr oft gewurfelt und die relative Haufigkeit des Ereignisses
”Augenzahl=6“ wird standig neu berechnet. In diesem Fall liegt ein Laplace-
Experiment vor; d. h. man kann die Wahrscheinlichkeit P(”Augenzahl 6”) auchberechnen. Man erhalt naturlich 1
6. Die Stabilisierung der relativen Haufigkeit
sollte also etwa um den Wert 0,167 erfolgen. In Abb. 1.1 ist die relative Haufig-keit hn uber der Anzahl der Versuchsdurchfuhungen n aufgetragen. Es werdensehr viele Versuchsreihen dargestellt.
Es war Richard Edler von Mises1 - einer der bekanntesten Frequentisten -, derdiesen statistischen Wahrscheinlichkeitsbegriff 1919 vorschlug.2 Seine Uberle-gungen fuhrten allerdings nicht zum vollen Erfolg ([Hin72] S. 20).Der frequentistische Wahrscheinlichkeitsbegriff zielt auf die Konvergenz derrelativen Haufigkeit fur n → ∞ ab. Die Wahrscheinlichkeit ware dann mitdem Grenzwert gleichzusetzen. Es stellt sich naturlich die Frage, ob man dieseVermutung auf eine stabile mathematische Basis stellen kann. Im folgendenAbschnitt wird auf eben diese Fragestellung eingegangen.
1*19. April 1883 in Lemberg, Osterreich-Ungarn, heute: Lwiw, Ukraine; †14. Juli 1953 inBoston, Massachusetts
2s. insbesondere fur geschichtliche Entwicklung der von Mises-Theorie: [Kre90] S. 461-466
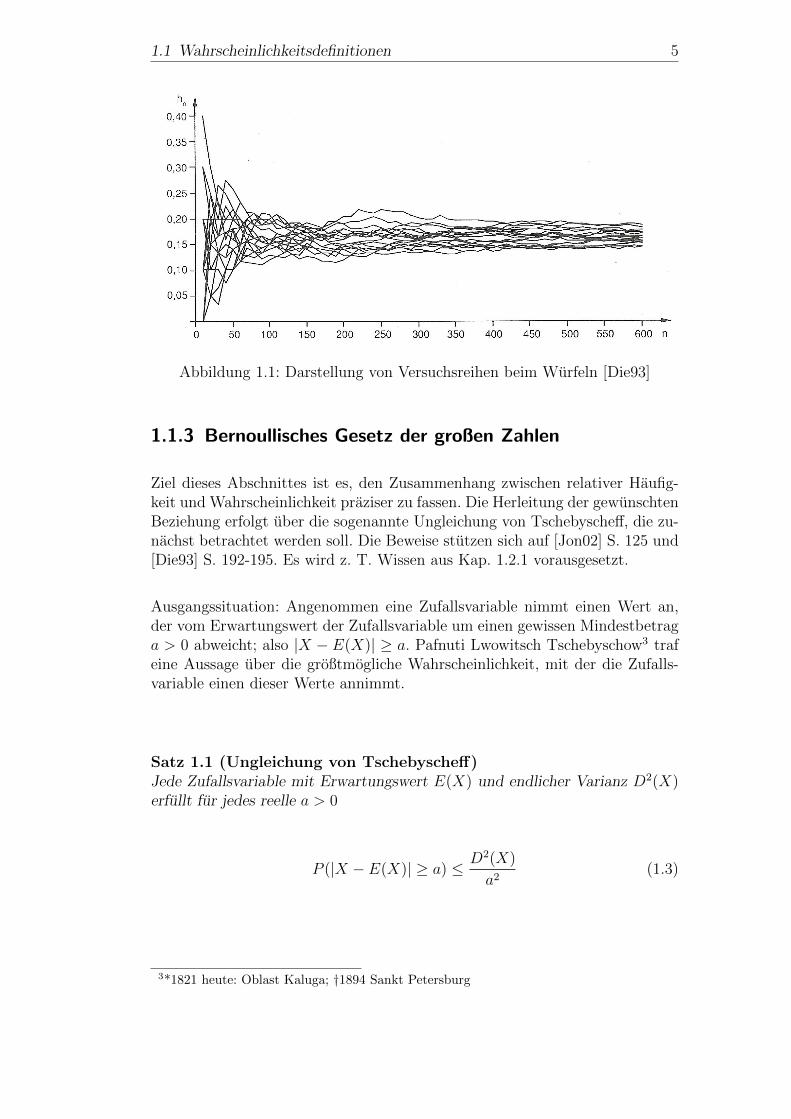
1.1 Wahrscheinlichkeitsdefinitionen 5
Abbildung 1.1: Darstellung von Versuchsreihen beim Wurfeln [Die93]
1.1.3 Bernoullisches Gesetz der großen Zahlen
Ziel dieses Abschnittes ist es, den Zusammenhang zwischen relativer Haufig-keit und Wahrscheinlichkeit praziser zu fassen. Die Herleitung der gewunschtenBeziehung erfolgt uber die sogenannte Ungleichung von Tschebyscheff, die zu-nachst betrachtet werden soll. Die Beweise stutzen sich auf [Jon02] S. 125 und[Die93] S. 192-195. Es wird z. T. Wissen aus Kap. 1.2.1 vorausgesetzt.
Ausgangssituation: Angenommen eine Zufallsvariable nimmt einen Wert an,der vom Erwartungswert der Zufallsvariable um einen gewissen Mindestbetraga > 0 abweicht; also |X − E(X)| ≥ a. Pafnuti Lwowitsch Tschebyschow3 trafeine Aussage uber die großtmogliche Wahrscheinlichkeit, mit der die Zufalls-variable einen dieser Werte annimmt.
Satz 1.1 (Ungleichung von Tschebyscheff)Jede Zufallsvariable mit Erwartungswert E(X) und endlicher Varianz D2(X)erfullt fur jedes reelle a > 0
P (|X − E(X)| ≥ a) ≤ D2(X)
a2(1.3)
3*1821 heute: Oblast Kaluga; †1894 Sankt Petersburg

6 1 Grundlagen
Beweis:Stellt man |x− E(X)| ≥ a auf (x−E(X))2
a2 ≥ 1 um, so kann man abschatzen:
P (|X − E(X)| ≥ a) =
∫|x−E(X)|≥a
f(x) dx
≤∫
|x−E(X)|≥a
(x− E(X))2
a2f(x) dx
≤ 1
a2
∞∫−∞
(x− E(X))2f(x) dx
=D2(X)
a2
2
Beispiel: Eine Munze werde 50 mal geworfen und X zahle das Elementarer-eignis Kopf (=Treffer k). Wie wahrscheinlich ist es hochstens, dass k dasIntervall [20, 30] verlasst? Wie groß ist also P (|X − E(X)| ≥ 6)?Es handelt sich um eine Bernoulli-Kette (s. Anhang B.1.2) mit p = 0, 5und n=50; d. h. E(X) = np = 25 und D2(X) = np(1 − p) = 12, 5. Also:P (|X−25| ≥ 6) ≤ 12,5
62 . Die gefragte Wahrscheinlichkeit betragt also hochstensca. 35%.Man kann sich in diesem Falle noch uberlegen, wie grob die Abschatzung aus-fallt, da bekannt ist, dass es sich um eine Binomialverteilung handelt. Es giltfur die Gegenwahrscheinlichkeit (fur die ein Wert ≥65% ewartet wird):
P (20 ≤ X ≤ 30) = P (19 < X ≤ 30) = F (30)− F (19) = 88, 1%
Die Werte sind entsprechenden Tabellen entnommen, die man z. B. in [Die93]auf S. 246 findet. Man sieht: Die Abschatzung kann sehr grob sein. Allerdingshat die Tschebyscheff-Ungleichung den großen Vorteil, dass sie unabhangig vonder zu Grunde gelegten Verteilung ist.
Mit Hilfe der Tschebyscheff-Ungleichung kann nun auf das Gesetz der großenZahlen von Jakob I. Bernoulli4 geschlossen werden. Es wird ein Ereignis E einesZufallsexperimentes betrachtet, das mit der unbekannten WahrscheinlichkeitP (E) =: p eintritt. Dieses Ereignis stellt den Treffer dar; die Nietenwahr-scheinlichkeit ist also q = 1− p. Fuhrt man das Experiment n-mal unabhangigvoneinander durch, so kann man sagen, dass die absolute Haufigkeit Hn(E)von E eine binomialverteilte Zufallsvariable ist. Die Wahrscheinlichkeit, dassein gewisser Wert k (0 ≤ k ≤ n) angenommen wird, ist nach Bernoulli durchdie im Anhang B.1.2 angegebene Verteilung bestimmt. Damit ist der Erwar-tungswert E(Hn) = np und die Varianz D2(Hn) = npq und es gilt mit (1.3)fur jedes reelle positive a:
P (|Hn − np| ≥ a) ≤ np(1− p)a2
4*1654 in Basel; †16. August 1705 in Basel

1.1 Wahrscheinlichkeitsdefinitionen 7
Wir setzen a := nη mit η > 0:
P (|Hn − np| ≥ nη) = 1− P (|Hn − np| < nη) ≤ np(1− p)(nη)2
⇐⇒ P (|Hn − np| < nη) ≥ 1− p(1− p)nη2
Außerdem gilt mit (1.2) und n > 0: |Hn − np| < nη ⇔ |hn − p| < η, sodassletztlich
P (|hn − p| < η) ≥ 1− p(1− p)nη2
(1.4)
resultiert. Im Grenzprozess fur n → ∞ geht die linke Seite von (1.4) gegen1. Das ist aber gerade die maximal mogliche Wahrscheinlichkeit, sodass ausdem Ungleichheitszeichen ein Gleichheitszeichen wird. Damit ist das Gesetzder großen Zahlen von Bernoulli gefunden:
Satz 1.2 (Bernoullisches Gesetz der großen Zahlen)Sei p die Wahrscheinlichkeit und hn die aus n unabhangigen Versuchsreihen re-sultierende relative Haufigkeit eines Ereignisses, dann gilt fur beliebiges reellesη > 0:
limn→∞
P (|hn − p| < η) = 1 (1.5)
Die Aussage, die hier getroffen wird, ist die Folgende: Im Grenzprozess n→∞wird die Wahrscheinlichkeit dafur, dass der Unterschied zwischen relativer Hau-figkeit und Trefferwahrscheinlichkeit p beliebig klein wahlbar ist, 100%. DerMathematiker sagt, die relative Haufigkeit hn(E) konvergiere in Wahrschein-lichkeit gegen P (E). Es handelt sich keineswegs um eine herkommliche Konver-genz - die Wahrscheinlichkeit ist nicht der Grenzwert der relativen Haufigkeitfur n→∞! Dennoch konnte der Zusammenhang zwischen beiden Großen aufeine solidere Basis gestellt werden.
Die empirische Bestimmung von frequentistischen Wahrscheinlichkeiten erfolgtin der Praxis approximativ durch Berechnen der relativen Haufigkeit fur aus-reichend großen Stichprobenumfang n.
1.1.4 Wahrscheinlichkeitsdefinition von Kolmogorow
Die Laplace’sche Auffassung von Wahrscheinlichkeit setzt die Gleichwahrschein-lichkeit der Elementarereignisse voraus; sie stellt also Voraussetzungen an denBegriff, der festgelegt werden soll. Dennoch bleibt dieses Verstandnis von Wahr-scheinlichkeit im Falle eines Laplace-Experimentes sehr intuitiv. UberzeugendeGrunde fur die Berechtigung der Annahme von Gleichwahrscheinlichkeit wer-den in [Siv06] auf S. 103 ff. gegeben.
Die Begriffsfindung, die zur frequentistischen Wahrscheinlichkeit fuhrt, ist eben-falls zirkular: Um den Begriff Wahrscheinlichkeit festzulegen, bedarf es des

8 1 Grundlagen
Zusammenhangs mit der relativen Haufigkeit (s. Kap. 1.1.3). Das Bernouill-sche Gesetz der großen Zahlen (1.5) trifft allerdings ebenfalls eine Wahrschein-lichkeitsaussage. Der zu definierende Begriff wird demnach fur die Definitionherangezogen.
Der Wahrscheinlichkeitstheorie fehlte noch zu Beginn des 20. Jahrhundertsdas Fundament. David Hilbert5 nannte die fehlende Axiomatisierung diesesTeilbereichs der Mathematik als eines seiner 23 ungelosten Probleme der Ma-thematik in seinem beruhmt gewordenen Vortrag auf dem InternationalenMathematiker-Kongress im August 1900 in Paris.Im Jahre 1933 gelang es dann dem sowjetischen Mathematiker Andrei Nikola-jewitsch Kolmogorow6 drei Axiome aufzustellen, die eine eindeutige Festlegungerlauben und oben genannte Definitionsprobleme umgehen. Um dieses Axio-mensystem verstehen zu konnen, muss man sich jedoch zunachst einem Pro-blem zuwenden, das bei Zufallsexperimenten mit unendlichem Ergebnisraumzum Tragen kommt. Ein solches Zufallsexperiment ware z. B. das Messen einerkontinuierlichen physikalischen Große, dessen Messergebnis aus quantenmecha-nischen Grunden dem Zufall unterliegt. Die kontinuierliche Skala sorgt dafur,dass uberabzahlbar unendlich viele Elementarereignisse denkbar sind. Ordnetman jedem Wert eine positive Wahrscheinlichkeit zu, so divergiert die Summeuber eben diese Wahrscheinlichkeiten ([Jon02] S. 12). Man betrachtet deswe-gen nur sinnvoll zu wahlende Teilmengen des Ereignisraumes P(Ω). Gemeintsind sogenannte σ-Algebren, die wie folgt definiert sind:
Definition 1.3 (σ-Algebra [Jon02])Ein nichtleeres System B von Teilmengen eines Ergebnisraums Ω heißt σ-Algebra, wenn gilt:
(i) A ∈ B ⇒ A ∈ B
(ii) An ∈ B mit n = 1, 2, .. ⇒∞⋃n=1
An ∈ B
Diese Definition erlaubt es, auch bei uberabzahlbaren Systemen sinnvoll Wahr-scheinlichkeiten zuzuordnen und damit oben beschriebenes Problem zu umge-hen. Weitere Details zu σ-Algebren finden sich in entsprechender Fachliteratur(z. B. in [Kle08] ab S. 2). Es wurden nun alle erforderlichen Grundlagen furdas Aufstellen des Axiomensystems vorgestellt.
Axiome von Kolmogorow [Jon02]:Gegeben seien ein Ergebnisraum Ω und eine geeignete σ-Algebra B uber Ω.Die Elemente von B sind die Ereignisse des Zufallsexperiments. Eine FunktionP, die jedem Ereignis A ∈ B eine reelle Zahl zuordnet, erfulle:
Axiom 1 ∀A ∈ B : P (A) ≥ 0
Axiom 2 P (Ω) = 1
5deutscher Mathematiker, *23. Januar 1862; †14. Februar 19436*1903 in Tambow; †20. Oktober 1987 in Moskau

1.1 Wahrscheinlichkeitsdefinitionen 9
Axiom 3 Fur paarweise disjunkte Ereignisse An ∈ B mit n = 1, 2, ...
P
(∞∑n=1
An
)=∞∑n=1
P (An)
Man beachte, dass fur Axiom 3 die fur disjunkte Mengen ubliche SchreibweiseA ∪ B = A + B verwendet wurde. Die Zahl P (A) bezeichnet die Wahrschein-lichkeit fur das Eintreten von A. Die Eigenschaften die Axiom 1, Axiom 2 bzw.Axiom 3 beschreiben, nennt man Nichtnegativitat, Normiertheit bzw. Addi-tivitat. Das Axiomensystem hat aufgrund der Einschrankung auf σ-Algebrenauch fur uberabzahlbare Systeme Gultigkeit. Die gestellten Forderungen kom-men unserer Intuition in vielen Aspekten entgegen: Es gibt keine negativenWahrscheinlichkeiten und Ereignisse mit P = 1 treten mit Sicherheit ein. DasBesondere ist, dass man dieses Axiomensystem fur alle hier vorgestellten Wahr-scheinlichkeitsbegriffe zu Grunde legen kann. Die Laplace-Wahrscheinlichkeiterfullt alle drei Axiome. Auch frequentistische Wahrscheinlichkeitsangaben er-folgen im Sinne von Kolmogorow, da relative Haufigkeiten offenbar folgendeEigenschaften erfullen:
1. Fur alle A ⊆ Ω gilt 0 ≤ hn(A) ≤ 1
2. hn(Ω) = 1
3. Fur alle A,B ⊆ Ω mit A,B disjunkt: hn(A ∪B) = hn(A) + hn(B)
Zu 3.: Diese Eigenschaft ist sofort einsehbar, wenn man sich klarmacht, dassfur die absoluten Haufigkeiten zweier sich ausschließender Ereignisse A und Bdie Beziehung Hn(A ∪B) = Hn(A) +Hn(B) gelten muss.Es werden an dieser Stelle noch zwei kurze Beispiele fur Gesetzesmaßigkeitenals Folgerungen aus dem Axiomensystem gegeben.
Satz 1.3 (Satz uber die Wahrscheinlichkeit des Gegenereignisses)Ist P (A) die Wahrscheinlichkeit fur das Eintreten des Ereignisses A, so ist
P (A) = 1− P (A) (1.6)
die Wahrscheinlichkeit fur das Eintreten des Gegenereignisses A.
Beweis:Da Ω = A∪A und A, A disjunkt, ergibt sich mit Axiom 3: P (Ω) = P (A∪A) =P (A) + P (A). Aus Axiom 2 folgt dann fur die sogenannte Gegenwahrschein-lichkeit:
P (A) = 1− P (A)
2
Da das unmogliche Ereignis ∅ das Gegenereignis zu Ω ist, muss P (∅) = 0gelten.

10 1 Grundlagen
Satz 1.4 (Additionssatz)Fur zwei im Allgemeinen nicht disjunkte Ereignisse A und B gilt:
P (A ∪B) = P (A) + P (B)− P (A ∩B) (1.7)
Beweis:Man mache sich die beiden Absorptionsgesetze A ∩ (A ∪ B) = A und A ∪(A ∩ B) = A grafisch oder anhand von Wahrheitstafeln klar und uberzeugesich damit und mit Hilfe des Distributiv- und Kommutativgesetzes von derRichtigkeit der Aussagen:
• A = (A ∩B) ∪ (A ∩ B)
• B = (A ∩B) ∪ (A ∩B)
Daraus folgt dann A ∪ B = (A ∩ B) ∪ (A ∩ B) ∪ (A ∩ B). Dabei sind A ∩ B,A ∩ B und A ∩ B drei paarweise disjunkte Aussagen (mit Hilfe einer Grafikveranschaulichen), sodass man Axiom 3 anwenden kann:
P (A) + P (B) = P (A ∩B) + P (A ∩ B) + P (A ∩B)︸ ︷︷ ︸=P (A∪B)
+ P (A ∩B)
2
1.1.5 Anwendbarkeit der Wahrscheinlichkeitsbegriffe
Bislang wurden zwei Wahrscheinlichkeitsbegriffe vorgestellt. Aber welche Be-dingungen stellen diese an die stochastische Situation, uber die Aussagen ge-troffen werden sollen? Inwiefern sind sie also anwendbar?Es wurde bereits erwahnt, dass der klassischen Wahrscheinlichkeit die Annah-me der Gleichwahrscheinlichkeit zu Grunde liegt und sich ihr Anwendungsbe-reich damit auf Laplace-Experimente beschrankt.7 Der Frequentismus wieder-um setzt - ungeachtet mathematischer Probleme - die Wiederholbarkeit desExperiments voraus. Es handelt sich jeweils um starke Einschrankungen.Aussagen wie z. B.
• 2012 wird Deutschland Fußball-Europameister.
• Demnachst wird am KIT wieder das Diplom eingefuhrt.
• Michael Phelps bleibt auch nach London 2012 erfolgreichster Olympionik.
kann eine stochastische Situation zu Grunde gelegt werden. Eine (subjektivgepragte) Wahrscheinlichkeitsangabe, die Kolmogorows Axiome erfullt, kannauch hier getroffen werden. Allerdings lassen sich weder die klassische noch diefrequentistische Theorie anwenden. Der Satz von Bayes wird an dieser Stelleweiterhelfen.7Man sollte an dieser Stelle zu Ehren von Pierre-Simon Marquis de Laplace, der die Wahr-
scheinlichkeitstheorie entscheidend pragte, erwahnen, dass dieser sich uber die beschrank-te Einsetzbarkeit der Laplace-Wahrscheinlichkeit im Klaren war. In seiner 1812 erschie-nenen Theorie Analytique des Probabilites formulierte er das Bayes-Theorem. Zudemkonnte er es auf einige Sachverhalte anwenden (außerst lesenswert sind dazu die Seiten8-11 in [Siv06]). Laplace war also ein Bayesianer.

1.2 Zufallsvariablen und Dichten 11
1.2 Zufallsvariablen und Dichten
1.2.1 Zufallsvariablen in einer Dimension
Um eine mathematische Analyse eines Zufallsexperimentes moglich zu machen,muss man den moglichen Ergebnissen des Experiments Zahlen zuordnen. Die-se Zuordnung ubernimmt eine sogenannte Zufallsvariable bzw. Zufallsgroße.Unter einer Zufallsvariablen versteht man ein Funktion X, die jedem ω ∈ Ωgenau eine reelle Zahl x = X(ω) zuordnet. Bei einem Wurfelwurf ware z. B.X() = 1 eine intuitive Wahl fur die Zuordnung einer Zahl zum EreignisAugenzahl 1 wird gewurfelt.Man unterscheidet diskrete und stetige Zufallsgroßen: X heißt diskret, wennsie nur endlich viele oder abzahlbar unendlich viele Werte annimmt. Sie heißtstetig oder kontinuierlich, wenn sie jeden Wert aus einem reellen endlichen bzw.unendlichen Intervall annehmen kann.
Definition 1.4 (Verteilungsfunktion [Jon02])Die Funktion
F (x) := P (X ≤ x) (1.8)
der reellen Variablen x heißt Verteilungsfunktion der Zufallsvariablen.
Die Verteilungsfunktion bildet die reellen Zahlen auf das Intervall [0, 1] ab:F : R → [0, 1]. Sie konvergiert fur x → ∞ gegen 1 und fur x → −∞ gegen 0und ist zudem monoton steigend ([Jon02] S. 39 f.).
Um mit stetigen Zufallsvariablen arbeiten zu konnen, bedarf es eines weiterenBegriffes. Die sogenannte Dichte f einer Zufallsvariablen X gibt an, wie sichdie Wahrscheinlichkeitsmasse uber der reellen Achse verteilt ([Jon02] S. 41).Es gilt f(x) ≥ 0 ∀x ∈ R. Man sagt, die Dichte sei auf 1 normiert:
∞∫−∞
f(x) dx = 1 (1.9)
Uber die Beziehung
F (x) =
x∫−∞
f(x′) dx′ (1.10)
ist die Dichte zudem mit der Verteilungsfunktion und damit mit der Wahr-scheinlichkeit P (X ≤ x) verknupft.Es gibt viele wichtige univariate, d. h von einer Variable abhangige, Dichte-funktionen, von denen die fur diese Arbeit relevanten im Anhang B aufgefuhrtsind.Der Hauptsatz der Differential- und Integralrechnung erlaubt den folgenden,sehr nutzlichen Zusammenhang:
P (x1 < X ≤ x2) = F (x2)− F (x1) =
x2∫x1
f(x) dx (1.11)

12 1 Grundlagen
Fur stetige Zufallsvariablen verschwinden jegliche Wahrscheinlichkeiten derForm P (X = x).
1.2.2 Multivariate Verteilungen
Um den Satz von Bayes fur Dichten verstehen konnen, bedarf es Kenntnis-se uber multivariate, d. h. von mehreren Variablen abhangigen, Verteilungen.Naturlich gibt es Zufallsexperimente, die in einer Dimension nicht mehr zu be-schreiben sind. Man fuhrt dafur mehrdimensionale ZufallsvariablenXT = (X1 X2 ... Xn) ein. Die Wahrscheinlichkeitsmasse 1 ist nun auf denRn verteilt, sodass gelten muss:∫
Rn
f(x) dnx = 1 (1.12)
Ein Beispiel fur eine multivariate Verteilung ware die zweidimensionale Nor-malverteilung.
Definition 1.5 (Verteilungsfunktion [Jon02])Die Funktion
F (x) := P (X1 ≤ x1, X2 ≤ x2, ..., XN ≤ xn) (1.13)
der mehrdimensionale Zufallsvariablen X heißt Verteilungsfunktion von X.
Es seien noch folgende, fur die weitere Diskussion relevante, Definitionen an-gegeben.
Definition 1.6 (Randdichte [Jon02])X sei eine zweidimensionale Zufallsvariable mit der Dichte f(x) = f(x1, x2).Dann heißen
• fX1(x1) :=∞∫−∞
f(x1, x2) dx2
• fX2(x2) :=∞∫−∞
f(x1, x2) dx1
Randdichten von X.
Definition 1.7 (Unabhangigkeit von Zufallsvariablen [Jon02])Zwei Zufallsvariablen X und Y mit gemeinsamer Dichte f(x, y) heißen stochas-tisch unabhangig, wenn gilt:
f(x, y) = fX(x) · fY (y) (1.14)
Unabhangige Zufallsvariablen sind nicht korreliert. Allerdings sind unkorrelier-te Großen im Allgemeinen nicht unabhangig ([Jon02] S. 112). Fur eine ausfuhr-liche Diskussion des Konzeptes der stochastischen Unabhangigkeit sei hier auf[Fin81] verwiesen. Im Folgenden wird oft von unabhangig identisch verteiltenVersuchsdurchfuhrungen ausgegangen.

1.3 Bedingte Wahrscheinlichkeiten 13
1.3 Bedingte Wahrscheinlichkeiten
1.3.1 Baumdiagramme
Definition 1.8 (Bedingte Wahrscheinlichkeit)Sind A und B Ereignisse einer σ-Algebra und P (B) 6= 0, so heißt
P (A|B) :=P (A ∩B)
P (B)(1.15)
die bedingte Wahrscheinlichkeit von A unter der Bedingung B.
Stellt man (1.15) um, so ergibt sich das sogenannte Produktgesetz:
P (A ∩B) = P (B) · P (A|B) (1.16)
Im Prinzip ist jede Wahrscheinlichkeit eine bedingte Wahrscheinlichkeit. Dennauch wenn vom Werfen eines fairen Wurfels die Rede ist, trifft man die Aus-sage, eine 6 trete mit der Wahrscheinlichkeit 1
6auf, stets unter der Bedingung
C, dass der Wurfel nicht gefalscht ist, die außeren Bedingungen bei Wieder-holung gleich bleiben, o. A. Streng genommen musste man also schreiben:P(”Augenzahl6”|C)=1
6. Bedingte Wahrscheinlichkeiten bilden die Grundlage
fur den Satz von Bayes. Zunachst wird der Begriff mit Hilfe von Baumdia-grammen (oder: Ereignisbaumen) veranschaulicht.Uber viele stochastische Situationen gewinnt man am besten den Uberblick,wenn man sie sich in einer Skizze strukturiert darstellt. Bei Erstellung dieserSchemata sind die Pfadregeln zu beachten:
1. Pfadregel: Die Wahrscheinlichkeit eines Elementarereignisses in einemmehrstufigen Zufallsexperiment ist gleich dem Produkt der Wahrschein-lichkeiten entlang des Pfades, der dieses Elementarereignis im Baumdia-gramm darstellt.
2. Pfadregel: Die Wahrscheinlichkeit eines Ereignisses (Zusammenfassungmehrerer Elementarereignisse) ist gleich der Summe der Wahrscheinlich-keiten der Pfade, die im Baumdiagramm dieses Ereignis bilden.
Die erste Regel entspricht dem Produktgesetz, wie Abb. 1.2 veranschaulicht.Regel 2 spiegelt den Satz uber die totale Wahrscheinlichkeit wider, welche sichfur ein Ereignis A wie folgt berechnet:
P (A) =n∑i=1
P (Bi) · P (A|Bi) (1.17)
Dabei zerlegen die paarweise disjunkten Bi den Ergebnisraum (also B1 ∪B2 ∪...∪Bn = Ω). Sie stellen die Bedingungen dar, unter denen A jeweils eintretenkann. Es muss fur i = 1, .., n gelten: P (Bi) 6= 0.
Beispiel: Drei gleiche Urnen seien mit jeweils 10 Kugeln gefullt. Es gibt roteund grune Kugeln. Das Ereignis
”rote Kugel ziehen“ sei mit A bezeichnet. In

14 1 Grundlagen
Abbildung 1.2: Exemplarisches Schema eines Baumdiagrammes
Urne U1 sind 6, in Urne U2 8 und in Urne U3 9 rote Kugeln. Der Experimen-tator bittet eine Person, die diese Informationen nicht kennt, eine Kugel zuziehen. Wir gehen also von Gleichwahrscheinlichkeit aus, was die Wahl derUrne anbelangt: P (U1) = P (U2) = P (U3) = 1
3. Wie hoch ist nun die Wahr-
scheinlichkeit P (A) fur das Ziehen einer roten Kugel? Die bedingten Wahr-scheinlichkeiten, nach Wahl einer bestimmten Urne eine rote Kugel zu ziehen,lauten P (A|U1) = 0, 6, P (A|U2) = 0, 8 und P (A|U3) = 0, 9, sodass sich fur dietotale Wahrscheinlichkeit P (A) = 1
3· 0, 6 + 1
3· 0, 8 + 1
3· 0, 9 ≈ 77% ergibt.
Jeder Ast in einem Baumdiagramm wird mit der entsprechenden Wahrschein-lichkeit beschriftet. Die Gesamtwahrscheinlichkeit aller Aste, die von einemEreignis ausgehen, ist immer 100%.
1.3.2 Formale Herleitung des Satzes von Bayes
Die Herleitung des Bayes-Theorems gelingt formal leicht mit dem Produkt-gesetz. Das Entscheidende wird jedoch die Interpretation der entstandenenFormel sein. Notiert man also das Produktgesetz (1.16) fur zwei Ereignisse Hi
und D, nutzt dabei die Kommutivitat aus
P (Hi ∩D) = P (D) · P (Hi|D) = P (Hi) · P (D|Hi) = P (D ∩Hi)
und stellt auf P (Hi|D) um, so erhalt man:
P (Hi|D) =P (Hi) · P (D|Hi)
P (D)(1.18)
Die Ereignisse der Menge Hk mit k = 1, 2, ..., i, ..., n sollen eine vollstandigeEreignisdisjunktion des Ergebnisraums bilden. Man hat dann paarweise dis-junkteHk, die gemeinsam den Ergebnisraum bilden (alsoH1∪H2∪...∪Hn = Ω),

1.3 Bedingte Wahrscheinlichkeiten 15
sodass mit Sicherheit eines der Ereignisse Hk eintritt. Wir identifizieren P (D)mit der totalen Wahrscheinlichkeit fur das Ereignis D. Es ergibt sich mit (1.17):
P (D) =n∑k=1
P (Hk) · P (D|Hk) (1.19)
Wenn man (1.19) in (1.18) einsetzt, erhalt man den Satz von Bayes:
Satz 1.5 (Bayes-Theorem)
P (Hi|D) =P (Hi) · P (D|Hi)
P (H1) · P (D|H1) + ...+ P (Hn) · P (D|Hn)(1.20)
Bezeichnungen:
• H1, H2, ..., Hn sind die Hypothesen, von denen mit Sicherheit eine ein-trifft.
• P (H1), P (H2), ..., P (Hn) heißen A-priori-Wahrscheinlichkeiten (auch:Anfangswahrscheinlichkeit), fur die
∑nk=1 P (Hk) = 1 gilt.
• Datum D (lateinisch: datum=Gegebenes)
• P (D|H1), P (D|H2), ..., P (D|Hn) sind die Likelihoods.
• Das Ergebnis nennt sich A-posteriori-Wahrscheinlichkeit P (Hi|D)(auch: Endwahrscheinlichkeit).

2 Der Satz von Bayes
Im vorliegenden Kapitel steht die Interpretation des Satzes von Bayes im Vor-dergrund. Anhand einiger Beispiele wird illustriert, welche - der menschlichenIntuition zunachst zuwider laufenden - Ergebnissse die bayesianische Heran-gehensweise oft liefert. Dabei wird deutlich, von welcher zentralen Bedeutungdie von Thomas Bayes gemachten Erkenntnisse sind. Schließlich wird am En-de des Kapitels der Satz von Bayes fur stetige Großen formuliert, womit diebayesianische Theorie auch fur wissenschaftliche Zwecke nutzbar wird. Die zen-tralen Aussagen des Theorems bleiben dabei die gleichen. Es wird allerdingsdas Tor geoffnet fur die Behandlung statistischer parameterbehafteter Modelleauf Grundlage der Bayes-Statistik.
2.1 Interpretation
Der Satz von Bayes wurde im vorangehenden Kapitel formal hergeleitet. Vielwichtiger als der uberschaubare Beweis, uber den es in Fachkreisen keine Dis-kussion gibt, ist jedoch die Interpretation der Formel. Sie sorgt seit Jahrzehn-ten fur Meinungsverschiedenheiten unter den Wissenschaftlern und spaltet dieFachwelt in zwei Lager - die Frequentisten und die Bayesianer.Die zentrale Formel von Bayes sei hier noch einmal aufgefuhrt:
P (Hi|D) =P (Hi) · P (D|Hi)n∑k=1
P (Hk) · P (D|Hk)(2.1)
Um dem ganzen Konzept Gestalt zu geben, schließen sich nun ein paar Wor-te zur Interpretation an. Die Beispiele in Kap. 2.2 sind fur das Verstandnisebenfalls unerlasslich.Summiert man alle A-posteriori-Wahrscheinlichkeiten auf, so erhalt man denWert 1. Man erkennt dabei, dass der Nenner im Satz von Bayes die Rolle einerNormierungskonstanten ubernimmt. Man kann den Satz von Bayes also auchdurch die Proportionalitat
A-posteriori-Wahrscheinlichkeit ∝ A-priori-Wahrscheinlichkeit · Likelihood
charakterisieren. Diese Darstellung bietet gemeinsam mit der Benennung dereinzelnen Großen einen ersten Hinweis: Offenbar andert sich die A-posteriori-Wahrscheinlichkeit gegenuber der A-priori-Wahrscheinlichkeit unter gewissenRegeln. Wir ordnen den Großen einen Zeitaspekt zu. Zum Zeitpunkt t0 bewer-tet man das Eintreten von Hypothese Hi mit der AnfangswahrscheinlichkeitP (Hi). Anschließend - also zeitlich gesehen danach - tritt das Datum D ein. Die-ser Vorgang kann als eine Zeitperiode (t0, t1) angesehen werden, wahrend der
16

2.2 Ausfuhrliche Beispiele 17
Daten gesammelt und Tests durchgefuhrt werden. Nach Ende dieses Lernpro-zesses wird zum Zeitpunkt t1 > t0 unter Berucksichtigung des Bayes-Theoremsdie Endwahrscheinlichkeit P (Hi|D) angegeben. Formel (2.1) wird somit zu ei-ner Regel zur Revision der Wahrscheinlichkeit von Hypothesen auf Grundvon Daten ([Kle80] S. 115).
Man beachte hierbei den großen Unterschied zur eingeschrankt einsetzbarenTheorie der Frequentisten. Bayes traf mit seiner Formel eine bedeutende Aussa-ge uber die Bewertung von Hintergrundinformationen. Zum Ausdruck kommt,dass erworbenes Wissen Einfluss nehmen sollte auf die (personliche) Einschat-zung von Situationen. Es handelt sich also nicht nur um eine mathematischeFormel; vielmehr wird eine Aussage getroffen, die viele (natur)wissenschaftlicheoder ganz alltagliche, lebenspraktische Bereiche beruhrt.
Das Bayes-Theorem bietet die Moglichkeit, Rollen zu vertauschen: AusP (Ereignis|Ursache) wird P (Ursache|Ereignis). Naiverweise konnte manannehmen, dass es dafur keines speziellen Satzes bedarf. Auf diesen wichti-gen Punkt wird im Rahmen des ersten Beispiels eingegangen.
2.2 Ausfuhrliche Beispiele
2.2.1 Diagnostik seltener Ereignisse
Die im Folgenden vorgestellte Aufgabe ist typisch fur den Satz von Bayes undwird in der Literatur meist als Beispiel aufgefuhrt. Die folgenden Ausfuhrungenlehnen sich stark an [Die93] S. 114-115 an.
Situation: Ein Mann lasst sich bei seinem Hausarzt auf eine gewisse Krankheitohne dringenden Tatbestand vorsorglich untersuchen. Uber die Krankheit istbekannt, dass 0,1% der mannlichen Bevolkerung mit ihr infiziert ist. Weiterhinwandte der Arzt ein Testverfahren an, dessen Gute bekannt ist: Bei einer tat-sachlich erkrankten Person wird die Krankheit mit 95%-ger Wahrscheinlichkeitdiagnostiziert. Das Ergebnis fallt hingegen mit gar 98%-ger Wahrscheinlichkeitnegativ aus, falls die Person gesund ist. Nach Auswertung des Tests befindetsich der Arzt in der misslichen Situation, seinem Patienten mitteilen zu mussen,dass das Ergebnis positiv ausgefallen ist. Wie groß ist die Wahrscheinlichkeit,dass er tatsachlich krank ist?
Man konnte intuitiv dazu neigen, die Wahrscheinlichkeit mit 95% zu beziffern.Schließlich werden 95% der kranken Personen positiv getestet. Dann wurdeman aber, wie am Ende von Abschnitt 2.1 beschrieben, Ursache und Ereignisvertauschen und P (D|H1) gleich P (H1|D) setzen. Die Rollen sind allerdingsnicht einfach vertauschbar - man muss das Bayes-Theorem anwenden!
Zunachst notieren wir alle gegebenen Informationen:
• Der Ergebnisraum teilt sich in zwei HypothesenH1=“Der Mann ist krank“und H2=“Der Mann ist gesund“.
• Das Datum D ist das positive Testergebnis.

18 2 Der Satz von Bayes
• Die A-priori-Wahrscheinlichkeit dafur, die Krankheit zu haben, lautet:P (H1) = 0, 001. Damit ist P (H2) = 0, 999.
• Außerdem ist uber das Testverfahren bekannt: P (D|H1) = 0, 95und P (D|H2) = 1− 0, 98 = 0, 02 - das sind die Likelihoods!
• Gesucht ist die A-posteriori-Wahrscheinlichkeit P (H1|D).
Abbildung 2.1: Baumdiagramm zum Prufverfahren [Die93]
Daraus folgt die Berechnung mit (2.1):
P (H1|D) =P (H1) · P (D|H1)
P (H1) · P (D|H1) + P (H2) · P (D|H2)
=0, 001 · 0, 95
0, 001 · 0, 95 + 0, 999 · 0, 02
≈ 5%
Sieht man sich das erste Mal mit einer solchen Analyse konfrontiert, so stellt ei-ne derart kleine Wahrscheinlichkeit eine Uberraschung dar. Man kann sich dasErgebnis erklaren, indem man mit Hilfe eines Zahlenbeispiels absolute Großenausrechnet. Angenommen die Bevolkerung umfasse 1.000.000 Manner. Dannsind davon 1.000 krank und 999.000 gesund. Von den 1.000 Kranken werden950 als krank erkannt und 50 als gesund eingestuft. Die wichtige Zahl ist nunaber die Anzahl der Manner, die als krank eingestuft werden, obwohl sie gesundsind; das sind 999.000·0, 02 = 19.980 - also sehr viele! Die gesuchte Wahrschein-lichkeit erhalt man dann auch uber 950
19.980≈ 5%. Es sei noch angemerkt, dass
bei der Berechnung der Zahlenwerte hier die relativen Haufigkeiten mit denWahrscheinlichkeiten gleichgesetzt wurden. Das ist naturlich falsch. Allerdingswar das Ziel lediglich, das uberraschend klein ausfallende Ergebnis plausibelzu machen.
2.2.2 Priori- und posteriori-Verteilungen
In diesem Beispiel geht es um die Bestimmung einer Posteriori-Verteilung beieiner diskreten Zufallsvariable. Das Beispiel stammt aus [Die93] S. 119-121.Fur ein Glucksspiel gebe es folgende Regeln: In sechs Urnen befinden sichjeweils 6 Kugeln, die rot oder schwarz sein konnen. Dabei sind die Farbenso einsortiert, wie Abb. 2.2 zeigt. Der Spielleiter zieht immer 6 Kugeln mit

2.2 Ausfuhrliche Beispiele 19
Zurucklegen aus einer Urne, wobei er die Urne zufallig durch Wurfeln einesfairen Wurfels auswahlt. Die Spielteilnehmer wissen nicht, welche Augenzahlder Wurfel anzeigt, also aus welcher Urne gezogen wird. Sie sehen nur dieKugeln, die gezogen werden und kennen die Verteilung der schwarzen Kugelnauf die Urnen. Anschließend wetten sie auf die Urne, aus der ihrer Meinungnach gezogen wurde. Das Ergebnis einer konkreten Durchfuhrung seien dreirote und drei schwarze Kugeln. Wie hat sich die Verteilung der Wahrschein-lichkeiten auf die einzelnen Urnen nun verandert? Auf welche Urne sollte mansetzen?
Abbildung 2.2: Verteilung der schwarzen Kugeln auf die sechs Urnen [Die93]
Die sechs Hypothesen H1, H2, ..., H6 stehen fur das Ziehen aus Urne 1 bis 6,wobei die A-priori- Wahrscheinlichkeiten P (H1) = P (H2) = ... = P (H6) = 1
6
allesamt gleich sind. Weiterhin beschreibe das Datum D das genannte konkreteVersuchsergebnis (3 rote und 3 schwarze Kugeln). Man erhalt die Likelihoodsmit der Formel fur eine Bernoulli-Kette der Lange 6 mit der Trefferwahrschein-lichkeit p1 = 1
6fur Urne 1, p2 = 2
6fur Urne 2, .... und p6 = 6
6fur Urne 6. Also:
P (D|Hk) =
(6
3
)· p3
k · (1− pk)3
Im Einzelnen ergibt sich: P (D|H1) ≈ 0, 0536, P (D|H2) ≈ 0, 2195, P (D|H3) ≈0, 3125, P (D|H4) ≈ 0, 2195, P (D|H5) ≈ 0, 0536 und P (D|H6) = 0.1 Die A-posteriori-Wahrscheinlichkeit berechnet sich dann z. B. fur H1, wie folgt:
P (H1|D) =16· 0, 0536
16· 0, 0536 + 1
6· 0, 2195 + 1
6· 0, 3125 + 1
6· 0, 2195 + 1
6· 0, 0536 + 1
6· 0
Die Ergebnisse lauten:
• P (H1|D) = 0, 0624
• P (H2|D) = 0, 2556
• P (H3|D) = 0, 3639
• P (H4|D) = 0, 2556
• P (H5|D) = 0, 0624
• P (H6|D) = 0
1Summation uber alle Likelihoods fuhrt nicht auf 1.
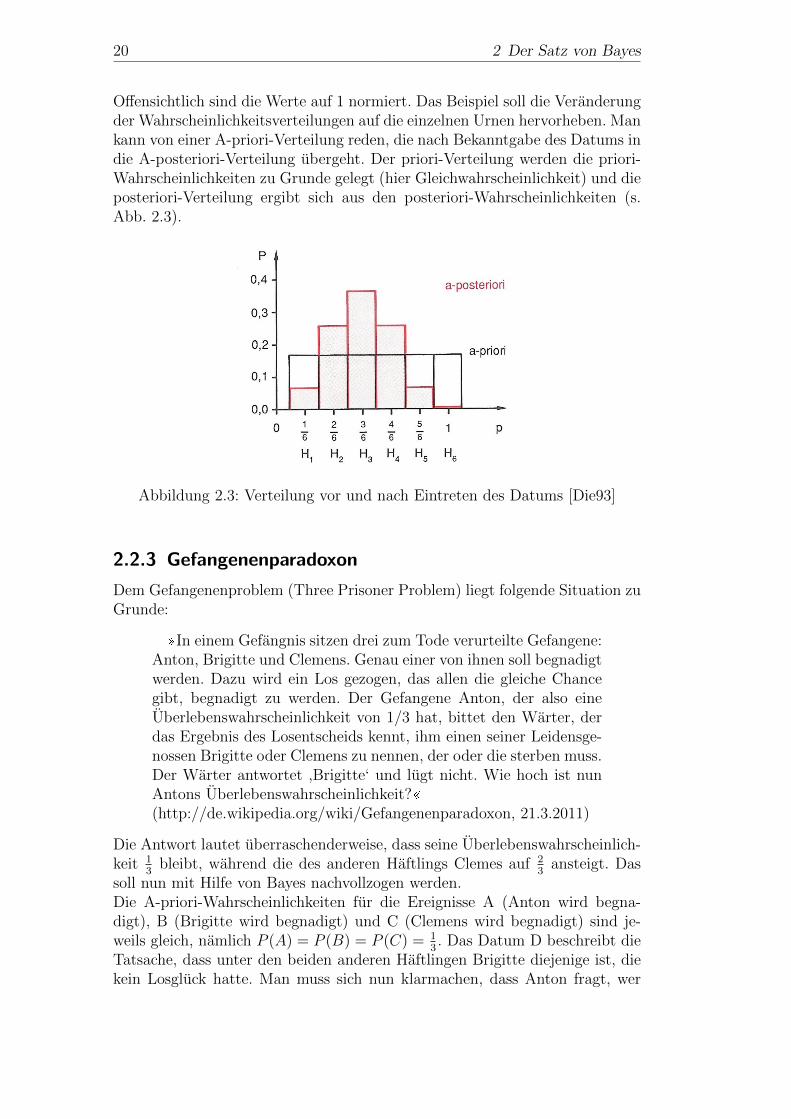
20 2 Der Satz von Bayes
Offensichtlich sind die Werte auf 1 normiert. Das Beispiel soll die Veranderungder Wahrscheinlichkeitsverteilungen auf die einzelnen Urnen hervorheben. Mankann von einer A-priori-Verteilung reden, die nach Bekanntgabe des Datums indie A-posteriori-Verteilung ubergeht. Der priori-Verteilung werden die priori-Wahrscheinlichkeiten zu Grunde gelegt (hier Gleichwahrscheinlichkeit) und dieposteriori-Verteilung ergibt sich aus den posteriori-Wahrscheinlichkeiten (s.Abb. 2.3).
Abbildung 2.3: Verteilung vor und nach Eintreten des Datums [Die93]
2.2.3 Gefangenenparadoxon
Dem Gefangenenproblem (Three Prisoner Problem) liegt folgende Situation zuGrunde:
In einem Gefangnis sitzen drei zum Tode verurteilte Gefangene:Anton, Brigitte und Clemens. Genau einer von ihnen soll begnadigtwerden. Dazu wird ein Los gezogen, das allen die gleiche Chancegibt, begnadigt zu werden. Der Gefangene Anton, der also eineUberlebenswahrscheinlichkeit von 1/3 hat, bittet den Warter, derdas Ergebnis des Losentscheids kennt, ihm einen seiner Leidensge-nossen Brigitte oder Clemens zu nennen, der oder die sterben muss.Der Warter antwortet ,Brigitte‘ und lugt nicht. Wie hoch ist nunAntons Uberlebenswahrscheinlichkeit?(http://de.wikipedia.org/wiki/Gefangenenparadoxon, 21.3.2011)
Die Antwort lautet uberraschenderweise, dass seine Uberlebenswahrscheinlich-keit 1
3bleibt, wahrend die des anderen Haftlings Clemes auf 2
3ansteigt. Das
soll nun mit Hilfe von Bayes nachvollzogen werden.Die A-priori-Wahrscheinlichkeiten fur die Ereignisse A (Anton wird begna-digt), B (Brigitte wird begnadigt) und C (Clemens wird begnadigt) sind je-weils gleich, namlich P (A) = P (B) = P (C) = 1
3. Das Datum D beschreibt die
Tatsache, dass unter den beiden anderen Haftlingen Brigitte diejenige ist, diekein Losgluck hatte. Man muss sich nun klarmachen, dass Anton fragt, wer

2.3 Satz von Bayes fur Dichten 21
von den beiden anderen mit Sicherheit nicht begnadigt wird. Der Warter hatalso nur dann die Moglichkeit Brigitte oder Clemens zu nennen, wenn Antonselbst begnadigt wird. Das ist aber nur eine von drei Moglichkeiten!Formal druckt sich das uber Likelihoods folgendermaßen aus:
• P (D|A) = 12⇒ Falls Anton begnadigt wird, hat der Warter die Wahl;
er kann Anton oder Brigitte nennen (D und D).
• P (D|B) = 0 ⇒ Falls Brigitte begnadigt wurde, ist D das unmoglicheEreignis!
• P (D|C) = 1⇒ Falls Clemens begnadigt wird, muss D eintreten. Schließ-lich kann, falls Anton der Gluckliche ist, der Warter dies nicht verraten!
Fur die Posteriori-Wahrscheinlichkeit erhalt man dann:
P (A|D) =P (A)P (D|A)
P (A)P (D|A) + P (B)P (D|B) + P (C)P (D|C)=
1
3
2.3 Satz von Bayes fur Dichten
Der Nutzen der Bayes-Formel wurde bereits verdeutlicht. Allerdings entziehtsie sich in der Form (2.1) noch der Anwendbarkeit fur wissenschaftliche Zwe-cke. Das Ziel muss es sein, die Aussage in einem allgemeineren Bayes-Theoremunterzubringen, sodass auch mit stetigen Zufallsvariablen gearbeitet werdenkann. Dafur bedarf es der in Kap. 1.2.2 definierten Randdichten. Außerdemwird der Begriff der bedingten Dichte benotigt, welcher das Konzept der be-dingten Wahrscheinlichkeit auf uberabzahlbare Systeme ubertragt.
Definition 2.1 (Bedingte Dichte [Zuc04])Seien X und Y stetige Zufallsvariablen mit der gemeinsamen Dichte fXY (x, y)sowie den positiven Randdichten fX(x) > 0 und fY (y) > 0. Die bedingteDichtefunktion von Y gegeben X = x ist definiert durch
fY |X(y|x) :=fXY (x, y)
fX(x)(2.2)
und die bedingte Dichtefunktion von X gegeben Y = y ist definiert durch
fX|Y (x|y) :=fXY (x, y)
fY (y)(2.3)
Die Indizes der bedingten Dichten und Randdichten werden oft weggelassen.
Satz 2.1 (Satz von Bayes fur Dichten)Es gilt fur zwei Zufallsvariablen X und Y
f(y|x) =f(x|y)f(y)
∞∫−∞
f(x|y)f(y) dy
(2.4)
wobei f(x, y) die gemeinsame Dichte ist.

22 2 Der Satz von Bayes
Beweis:Verwendet man beide Gleichungen aus Def. 2.1, so erhalt man
f(y|x) =f(x, y)
f(x)=f(x|y)f(y)
f(x)
Im Nenner steht die Randdichte (s. Def. 1.6):
f(x) =
∞∫−∞
f(x, y) dy =
∞∫−∞
f(x|y)f(y) dy
2
Die Kernaussage kommt auch weiterhin durch die Proportionalitat
posteriori-Dichte ∝ priori-Dichte · Likelihoodfunktion
zum Ausdruck.
Außerdem gibt es naturlich Mischfalle, in denen sowohl stetige als auch dis-krete Großen auftreten. Man kann zwar mit Hilfe von Delta-Distributionenauch Dichten fur diskrete Großen formulieren. Dennoch sei hier, zwecks An-wendung in einem der kommenden Beispiele, das Bayes-Theorem (im eindi-mensionalen Fall) fur Y stetig und X diskret angegeben:
f(y|X = x) =P (X = x|y)f(y)
∞∫−∞
P (X = x|y)f(y) dy
(2.5)
Naturlich ist auch die Form (2.4) des Bayes-Theorems nicht ausreichend fur dieWissenschaft. Ublicherweise hat man es mit einer ganzen Reihe an Parameterneines Modells und einer großen Datenmenge zu tun. Das hat zur Folge, dassdas Integral im Nenner mehrdimensional wird. Bevor die endgultige Form desBayes-Theorems formuliert wird, sei zunachst eine Festlegung bezuglich derNotation getroffen.Normalerweise greift fur Zufallsvariablen und deren konkreten Werte folgendeRegel: Zufallsvariablen werden mit Großbuchstaben bezeichnet und Versuch-sergebnisse mit Kleinbuchstaben. Wird also beispielsweise die ZufallsvariableX untersucht, so schreibt man typischerweise X = x fur den beobachtetenWert. Diese Konvention wurde bislang und wird auch weiterhin fur lateini-sche Buchstaben in dieser Arbeit verwendet. Parameter einer Theorie werdenublicherweise mit griechischen Buchstaben bezeichnet. Fur sie wird keine Un-terscheidung zwischen Groß- und Kleinbuchstaben gemacht, sodass θ sowohleine mehrdimensionale Zufallsvariable als auch eine bestimmte Realisierungdes Zufallsvektors sein kann, sprich eine Konstante. Aus dem Kontext sollteersichtlich werden, was jeweils gemeint ist.

2.3 Satz von Bayes fur Dichten 23
Satz 2.2 (Satz von Bayes in mehreren Dimensionen)Sei der Parametervektor θ Element des endlichdimensionalen Vektorraums Θ(genannt Parameterraum), so ist die Dichte von θ unter der Bedingung derBeobachtung X = x (posteriori-Dichte) durch den Satz von Bayes in derForm
π(θ|x) =f(x|θ) π(θ)∫
Θf(x|θ)π(θ) dθ
(2.6)
gegeben. Dabei ist π(θ) die priori-Dichte von θ. Die Integration erfolgt uberden gesamten Parameterraum.
Im nun folgenden Abschnitt zur Interpretation der endgultigen Form des Bayes-Theorems (2.6) wird die Sichtweise eines Wissenschaftlers eingenommen, derdurch das Experiment eine Theorie auf den Prufstand stellen mochte.
Man interessiert sich fur die k Parameter einer Theorie, die im Parametervektor
θ = (θ1, θ2, ..., θk)
zusammengefasst werden. Dabei sind grundsatzlich Falle, in denen manche derParameter (z. B aus fruheren Messungen oder Angaben des Herstellers einesMessgerates) bekannt sind von Situationen zu unterscheiden, bei denen alleParameter unbekannt sind.
Vor Durchfuhrung der Experimente mussen bei einer bayesianischen Analyseimmer Voruberlegungen gemacht werden, deren Resultate dann im Prior π(θ)in quantifizierter Form zum Ausdruck kommen. Dabei gibt es durchaus ver-schiedene Ansatze zur Bildung von priori-Dichten. Grundsatzlich ist zwischeninformativen und nichtinformativen Prioren zu unterscheiden. Es geht um dieFrage, ob die Versuchsergebnisse die a priori-Uberlegungen moglichst starkdominieren sollen, man also sehr wenig Informationen in π(θ) unterbringenmochte, oder ob Expertenwissen erhoben wird. Die Kritik am bayessiani-schen Paradigma wird bei eben diesem Teil der Bayes-Statistik am lautesten.Neben dem bereits in der Einleitung erwahnten Vorwurf des unwissenschaft-lichen Arbeitens durch Berucksichtigung subjektiver Einschatzungen wird vorallem angefochten, dass die Wahl des Priors uneindeutig ist. Es gibt keineallgemeine Vorgehensweise, die den Prior fur jede beliebige Analyse festlegenwurde. Der Wissenschaftler, der sich mit der Aufgabe der Auswertung von Ver-suchsdaten konfrontiert sieht, muss fur jedes Problem separat Uberlegungenanstellen und die am besten passende Methode zur Wahl des Priors anwen-den. Der Vorwurf des unwissenschaftlichen Arbeitens ist unberechtigt (s. Kap.3.4). Was die Wahl des Priors angeht, hilft vor allem eine moglichst ehrlicheEntscheidung und, wie im nachsten Abschnitt klar werden wird, viel Statis-tik, also ein großer Stichprobenumfang. Naturlich kann man priori-Dichten sofestlegen, dass sich Voruberlegungen bestatigen, Versuchsergebnisse also nichtzum Tragen kommen. Allerdings wird der serios arbeitende Wissenschaftlerimmer davon absehen, gegebenenfalls teure Experimente auf diese Art undWeise nutzlos zu machen.

24 2 Der Satz von Bayes
Abbildung 2.4: Schematische Darstellung einer Bayes-Analyse
Zuruck zur Beschreibung der in (2.6) auftauchenden mathematischen Großen:Die Versuchsergebnisse bilden ebenfalls einen Vektor, wobei die n gemachtenBeobachtungen die Eintrage bilden.
x = (x1,x2, ...,xn)
Dabei sollte man beachten, dass die Beobachtungen wiederum mehrdimensio-nal sein konnen. Die Dimension des Raumes χ der Messergebnisse ist danngroßer als eins (im Allgemeinen dimχ ≥ 1).Der Einfluss der Versuchsdaten wird durch die Likelihood f(x|θ) gewahrleistet,welche auf Grundlage in der Regel bereits gesicherter Theorien bestimmt wird.Hier kann es aufgrund uneindeutiger Notation manchmal zu Missverstandnis-sen kommen. Man konnte dazu verleitet sein, Likelihoods als Funktion derVersuchsergebnisse fur festen Parametervektor aufzufassen. Likelihoods sind- fur unsere Zwecke - allerdings wie folgt zu interpretieren: Fur festes Ver-suchsergebnis x ist f(x|θ) eine Funktion von θ und damit keine Dichte imeigentlichen Sinne mehr. Ein Integral (bzw. eine Summe) uber die Likelihoodsergibt im Allgemeinen nicht 1. Diese Interpretation wird in der fur diese Arbeitgewahlten Notation f(x|θ) durch oben genannte Konvention nahe gelegt: Beix handelt es sich um eine konkrete Realisierung von X und damit um einenkonstanten Vektor. Oft findet man in der Literatur fur Likelihoods auch dieSchreibweise
l(θ|x) = f(x|θ)
was fur zusatzliche Verwirrung sorgen kann, da der Parametervektor den Platzgetauscht hat. Oft werden Likelihoods auch als Likelihoodfunktionen be-zeichnet (s. auch (3.3)).Insgesamt ergibt sich damit folgendes Bild: Die A-priori-Vorstellungen uberdie Parameter einer Theorie werden uber die Likelihood mit den Messdatenverknupft. Die Division mit dem Integral im Nenner - die sogenannten Evi-denz - sorgt fur Normiertheit der posteriori-Dichte. Abb. 2.4 zeigt noch einmal

2.4 Qualitative Analyse am Beispiel des Munzwurfs 25
schematisch den Ablauf einer Bayes-Analyse. Die Idee zu dieser Darstellungstammt aus [Bor10].
2.4 Qualitative Analyse am Beispiel desMunzwurfs
In diesem Beispiel geht es um den Einfluss von priori-Annahmen. In der fre-quentistischen Theorie gibt es das nicht; die Daten allein sollen die Grundlagefur wissenschaftliche Ruckschlusse bilden. Frequentisten sehen die Objektivitatwissenschaftlichen Arbeitens durch bayesianische Methoden gefahrdet. Es wirdkritisiert, dass Uberzeugungen quantifiziert werden, um sie als Priorwissenmit in die Berechnungen einzubeziehen. In Abschnitt 3.4 wird ein Fazit in Be-zug auf Kritikpunkte an der Bayes-Statistik formuliert. Mit dem nun folgendenBeispiel wird ein erstes Argument, das fur die Sinnhaftigkeit der bayesianischenVorgehensweise spricht, formuliert. Es stammt aus [Siv06] (S. 14 ff.) und veran-schaulicht die Tatsache, dass die priori-Annahmen mit zunehmender Statistik,d. h. bei vielen Versuchsdurchfuhrungen, Einfluss verlieren.
Es sollen die Auswirkungen verschiedener priori-Annahmen auf die Entwick-lung des posteriori-Geschehens beim mehrfachen Munzwurf untersucht wer-den. Dabei ist θ die Wahrscheinlichkeit fur Kopf (head, Ereignis H). Ange-nommen man weiß nicht, ob man es mit einer fairen Munze θ = 0, 5 zu tunhat, oder ob man von zwielichtigen Spielkameraden betrogen wird, die Munzealso gefalscht ist. Welchen Prior soll man also wahlen?Mogliche Szenarien waren beispielsweise:
1. Befindet man sich in einem fragwurdigen Spielkasino, ist man vielleichtgeneigt, eine Verteilung zu wahlen, die beide Moglichkeiten der Verfal-schung (es fallt fast nur Kopf / fast nur Zahl) berucksichtigt.
2. Oder aber man bedient sich einer Verteilung um θ = 0, 5, die im Rahmeneiner Standardabweichung gewisse Streuung berucksichtigt, sonst aberbesonders hohe und niedrigere Werte fur θ fast ausschließt. Wahlt mandie Standardabweichung besonders klein, so geht man von einer fairenMunze aus.
3. Es ware auch die Wahl einer Gleichverteilung denkbar. Sie druckt aus,dass man in seiner Umwelt keine Hinweise in Bezug auf die Natur derMunze wahrnimmt, oder diese nicht zu deuten weiß.
Bei θ handelt es sich um den Parameter, der in der Likelihood auftritt. Er stellteine stetige Zufallsvariable mit Wertebereich [0, 1] dar. In diesem speziellenFall kennt man die Funktion, die die Likelihoods beschreiben: Es handelt sichum eine Binomialverteilung (s. Anhang B.1.2). Es soll anhand des Priors derGleichverteilung (3. Szenario) illustriert werden, wie sich die Verteilung nachder ersten und zweiten Versuchsdurchfuhrung andert. Das Experiment ergebe

26 2 Der Satz von Bayes
dabei zwei Mal hintereinander Kopf, sodass das Datum die Ereignisse D1 :>”1Treffer und dann D2 :>”2 Treffer darstellt.Wir wissen, dass die posteriori-Dichte proportional zum Produkt aus Like-lihood und Prior ist. Es wird hier bewusst die Proportionalitatsbeziehung ver-wendet, da es an dieser Stelle nur um ein qualitatives Verstandnis gehen soll.Die mathematischen Vorgehensweisen werden in Kap. 4 erlautert. Da der Prioreine Konstante ist, kann man ihn, dank der Proportionalitat, weglassen. Furdie Likelihoods gilt bei k Treffern
(nk
)θk(1 − θ)n−k, wobei n und k zunachst 1
und dann 2 sind. Die Beziehung zwischen posteriori- und priori-Dichten werdenalso durch folgende Proportionalitaten beschrieben:
• nach dem ersten Munzwurf (n=k=1): f(θ|D1) ∝ θ
• nach dem zweiten Munzwurf (n=k=2): f(θ|D2) ∝ θ2
Abb. 2.5 dient zur Veranschaulichung der Enwicklung des Wissens uber denParameter θ. Dort wird Szenario 1 als gepunkteter Graph dargestellt. Szena-rio 2 wird durch die gestrichelte Linie reprasentiert und die Gleichverteilungdurch den durchgezogenen Strich. Im ersten Diagramm links oben sind diepriori-Dichten zu sehen. In jedem Diagramm steht rechts oben die Anzahl derVersuchsdurchfuhrungen. Auf der y-Achse wird die posteriori-Dichte und aufder x-Achse der Parameter θ aufgetragen, wobei die posteriori-Dichte dem je-weils folgenden Munzwurf als Prior dient. Fur Szenario 3 erkennt man fur dieersten beiden Wurfe sehr schon die oben gefundenen Proportionalitaten. ImFalle von Szenario 1 wird der Ausschlag bei θ = 0 direkt nach dem erstenMunzwurf revidiert.Man sieht: Nach vielen Versuchsdurchfuhrungen spielt das eingespeiste Prior-Wissen keine Rolle mehr. Alle drei Szenarien - so unterschiedlich sie auch sind- fuhren zum gleichen Ergebnis, namlich θ ≈ 0, 25.
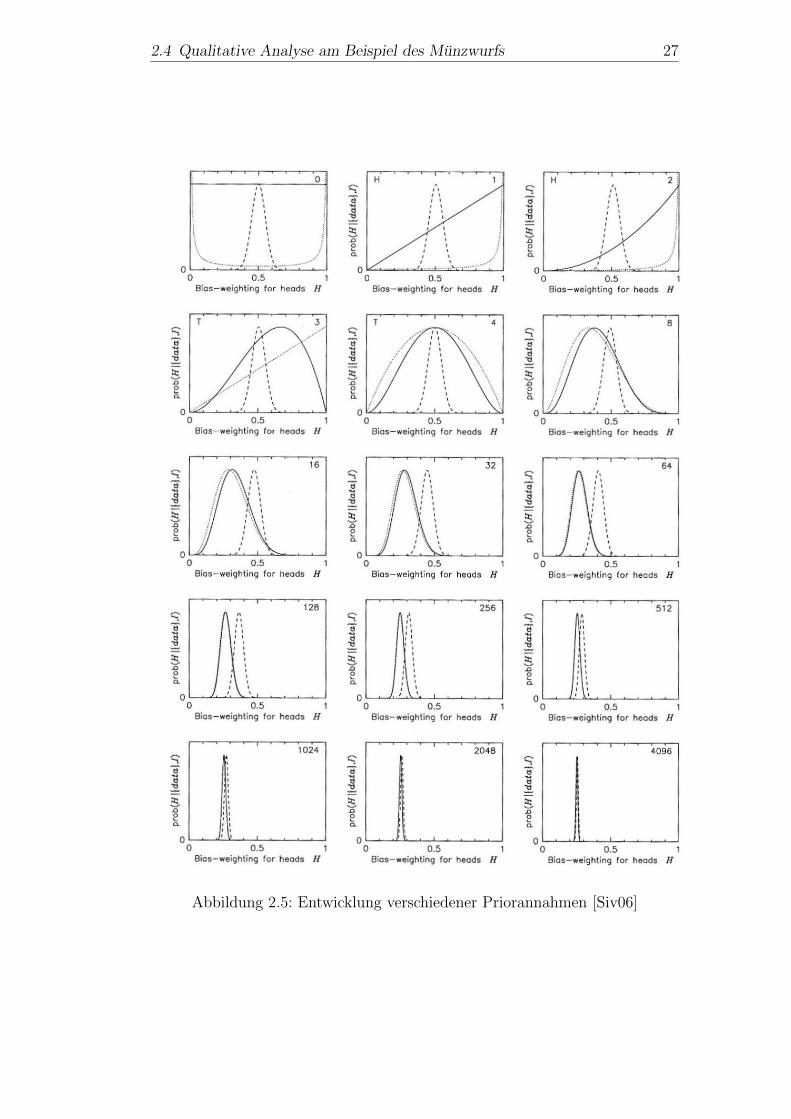
2.4 Qualitative Analyse am Beispiel des Munzwurfs 27
Abbildung 2.5: Entwicklung verschiedener Priorannahmen [Siv06]

3 Parametermodelle
Dieses Kapitel beschaftigt sich mit parameterbehafteten statistischen Model-len und geht insbesondere auf Unterschiede zwischen klassischer und baye-sianischer Sichtweise ein. Als Konklusion aus dem Beispiel zum mehrfachenMunzwurf und den im Folgenden aufgefuhrten Erlauterungen zum ThemaEstimation wird am Ende dieses Kapitels ein Fazit uber die Vorteile undKritikpunkte an der Bayes-Statistik formuliert.
3.1 Parameterschatzung
Es ist ublich den Schatzwert eines Parameters θ mit θ bezeichnet. Zwei Stan-dardmethoden der Punktschatzung sind die Momentmethode sowie der ma-ximum likelihood estimator (MLE). Den folgenden Beschreibungen der ange-sprochenen Methoden liege jeweils eine Beobachtung x1, ..., xn zu Grunde,die man aus unabhangig identisch verteilten Zufallsvariablen X1, ..., Xn ent-standen weiß.
Momentmethode Die Parameter der Theorie, welche es zu schatzen gilt, mus-sen zunachst durch die k-ten Momente
E(Xk) :=
∞∫−∞
xkf(x) dx (3.1)
der Zufallsvariablen ausgedruckt werden (f(x) ist die zugehorige Wahr-scheinlichkeitsdichte). Der Schatzwert ergibt sich dann durch das Erset-zen der k-ten Momente durch die k-ten Stichprobenmomente
mk :=1
n
n∑i=1
xki (3.2)
Das erste Stichprobenmoment ist z. B. der Mittelwert x.Beispiel: Fur X ∼ N (µ, σ2) schatzt man den Erwartungswert E(X) = µmit µ = m1 und die Varianz D2(X) = σ2 = E(X2) − (E(X))2 mitσ = m2 −m2
1.
Maximum-Likelihood-Methode Der MLE θ ist der Wert des Parameters θ,der dem Ausgang des Experiments - also der Beobachtung x1, ..., xn- die großte Wahrscheinlichkeit zuordnet. Er maximiert also die Like-lihoodfunktion
L(θ;x1, x2, ..., xn) :=n∏i=1
P (θ;xi) (3.3)
28

3.2 Die frequentistische Antwort 29
welche die Wahrscheinlichkeit fur das Eintreten der Beobachtung angibt.Sie ist eine Funktion des Parameters. In der Praxis maximiert man -zwecks Vereinfachung der Rechnung - die Loglikelihoodfunktion, also denLogarithmus zu einer beliebigen Basis von L(θ; xi).
Von einem Schatzer θ fordert man, dass er konsistent, erwartungstreu undeffizient ist. Das bedeutet in dieser Reihenfolge:
• limn→∞
θ = θ
• E(θ) = θ
• Varianz D2(θ) moglichst klein
Nicht immer kann ein Schatzwert alle Anforderungen erfullen. Der MLE, z. B.,ist zwar meist konsistent aber fur kleinen Stichprobenumfang n oft nicht er-wartungstreu (biased) [Bar89].
Es soll wieder das Beispiel des mehrfachen Munzwurfs betrachtet werden; ei-nerseits um dem Verfahren der Berechnung von posteriori-Verteilungen naherzu kommen und andererseits um einen Vergleich mit den Vorgehensweisen derklassischen Theorie zu ziehen. Angenommen es wurde bereits 10-mal geworfen,wobei
H, H, T, T, H, T, T, T, H, T
die Beobachtung umschreibe und H weiterhin fur Kopf und T fur Zahl (tail)stehe. Genau wie in Abschnitt 2.4 interessiert der Parameter θ, der die Treffer-wahrscheinlichkeit fur Kopf angibt. Welchen Schatzwert wurde ein Frequentistausrechnen? Was fur eine Antwort hatte man von einem Bayesianer zu erwar-ten? In den folgenden beiden Abschnitten wird u. a. anhand dieses Beispielsdetailliert auf die unterschiedlichen Vorgehensweisen eingegangen.
3.2 Die frequentistische Antwort
3.2.1 Munzwurf
Eine Moglichkeit dem Problem aus frequentistischer Sicht zu begegnen, waredie Anwendung der Maximum-Likelihood-Methode. Die Likelihoodfunktion,welche die Wahrscheinlichkeit fur oben genanntes Versuchsergebnis ausdruckt,lautet unter der berechtigten Annahme, dass die Munzwurfe unabhangig iden-tisch verteilt sind:
L(θ) = θ · θ · (1− θ) · (1− θ) · θ · (1− θ) · (1− θ) · (1− θ) · θ · (1− θ) = θ4(1− θ)6
Das heißt, es muss ln(L(θ)) = 4 ln θ + 6 ln(1 − θ) maximiert werden, was aufθ = 0, 4 fuhrt.

30 3 Parametermodelle
3.2.2 Das Konfidenzintervall am Beispiel eines t-Tests
Frequentisten behandeln den Parameter als unbekannte Konstante (bzw. immehrdimensionalen Falle als konstanten Vektor). Diese klassische Betrach-tungsweise hat Folgen fur die methodischen Vorgehensweisen: Es wird einPunktschatzer berechnet, fur den ein Konfidenz- bzw. Vertrauensintervall an-gegeben wird, um einen Eindruck von der Gute der Schatzung zu vermitteln.Das soll an folgendem Beispiel noch einmal verdeutlicht werden (in Anlehnungan [Bor10] S. 7-8).
Das Versuchsergebnis eines Experimentes seien die Werte x1, x2, ..., xn, diekonkrete Werte der unabhangig identisch verteilten Zufallsvariablen X1, ..., Xn
darstellen. Es werden folgende Bezeichnungen benutzt:
E(Xi) = µ <∞ und D2(Xi) = σ2 <∞ ∀i ∈ 1, 2, ..., n
In diesem Beispiel soll ein Konfidenzintervall fur den Parameter µ gefundenwerden, welcher mit Hilfe der Momentmethode zu
µ = x = m1 =1
n
n∑i=1
xi
geschatzt wird. Untersucht werden muss die neue Zufallsvariable
X :=1
n
n∑i=1
Xi
Dabei hilft der zentrale Grenzwertsatz (s. z. B. [Jon02] S. 129), welcher be-
sagt, dass Zn := Sn−nµ√nσ
mit Sn :=n∑i=1
Xi fur n → ∞ standardnormalverteilt
ist. Dem ist so, da die Xi unabhangig identisch verteilt sind.1 Es kann dem-nach festgehalten werden, dass Zn ∼ N (0; 1) falls der Strichprobenumfang nausreichend groß gewahlt wird.Damit konnte man nun - bei bekanntem σ - bereits auf ein Vertrauensintervall[x− ξ, x+ ξ] fur ξ > 0 schließen, indem man
X =1
nSn =
1
n(Zn√nσ + nµ)
inP (µ− ξ < X ≤ µ+ ξ) ≥ 1− α
einsetzt. Die letzte Gleichung druckt dabei die Forderung aus, dass die Wahr-scheinlichkeit, dass der Erwartungswert innerhalb des Konfindenzintervalls liegt,mindestens 1 − α sein soll. Typischerweise setzt man α = 5%. Die konkreteBerechnung stellt nun kein Problem mehr da, zumal die Verteilung von Znbekannt ist.
1Bemerkenswerterweise konnen die einzelnen Zufallsvariablen sogar uber diskrete Vertei-lungen verfugen.

3.3 Die bayesianische Antwort 31
Nun ist allerdings in der Regel nicht nur µ sondern auch σ unbekannt; d. h.θ = (µ, σ). Es liegt nahe, auch fur die Schatzung der Standardabweichung dieMomentmethode zu benutzen. Man setzt dann:
σ2 =1
n− 1
n∑i=1
(xi − x)2 n > 1
Dabei sollte man sich von dem im Nenner auftauchenden Term n − 1 nichtverwirren lassen (erwarten wurde man zunachst lediglich die Division mit n).Er gewahrleistet Erwartungstreue (Bessel’s correction, s. [Bar89] S. 77). DerUnterschied zum Fall mit bekanntem σ ist allerdings, dass nun statt einer Nor-malverteilung eine Student-t-Verteilung mit n − 1 Freiheitsgraden zu Grundeliegt ([Bro06] S. 801). Das liegt daran, dass auch die Standardabweichung ausden Messdaten geschatzt werden musste. Auf die exakten mathematischen Ur-sachen wird hier nicht weiter eingegangen.
3.3 Die bayesianische Antwort
Nun wird der Munzwurf im Rahmen der Bayes-Statistik behandelt. Die baye-sianische Methodik verlangt Voruberlegungen; es bedarf eines Priors, der dasVorwissen von Experten quantifiziert. Die Ausgangssituation wird in den Ent-scheidungsprozess einbezogen. In Abschnitt 2.4 wurden dazu drei Szenarienbeschrieben. Angenommen die der Datenerhebung vorangehende Analyse ver-mittle ein Bild, das gut zu Szenario 2 passt. Dann ware eine BetaverteilungBe(20; 20) eine naheliegende Wahl fur den Prior (s. Abb. 3.1).
Sei X die Anzahl der Treffer (H), dann gilt, da X = 4 das Versuchsergebnisdarstellt:
P (X = 4|θ) = θ4(1− θ)6 (3.4)
Das Bayes-Theorem besagt
P (θ|X = 4) =P (X = 4|θ)f(θ)
1∫0
P (X = 4|θ)f(θ) dθ
(3.5)
wobei a priori θ ∼ Be(20; 20) gilt, sodass die Dichte durch (B.14) gegeben ist.Das oft schwierige Integral im Nenner ist in diesem Fall problemlos analytischlosbar. Die Rechnung wird hier fur allgemeine Parameter α, β der Betaver-teilung und Versuchsergebnis X = x sowie allgemeine Stichprobengroße ndurchgefuhrt.
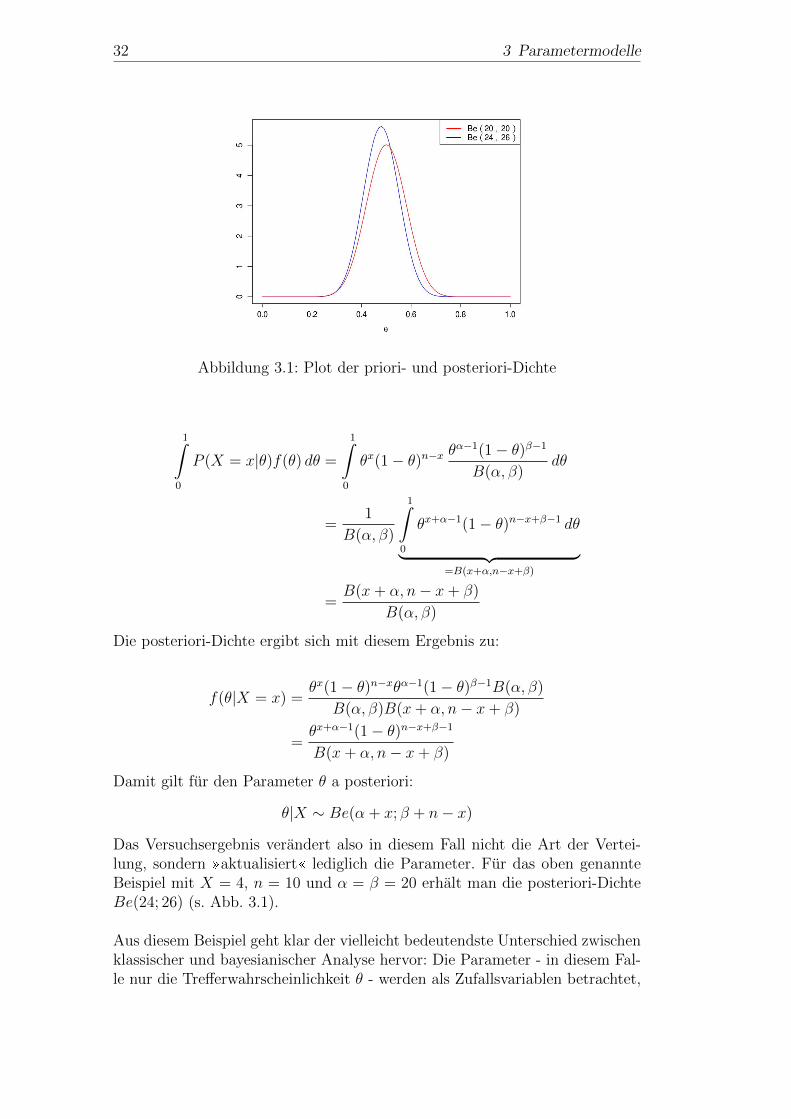
32 3 Parametermodelle
Abbildung 3.1: Plot der priori- und posteriori-Dichte
1∫0
P (X = x|θ)f(θ) dθ =
1∫0
θx(1− θ)n−x θα−1(1− θ)β−1
B(α, β)dθ
=1
B(α, β)
1∫0
θx+α−1(1− θ)n−x+β−1 dθ
︸ ︷︷ ︸=B(x+α,n−x+β)
=B(x+ α, n− x+ β)
B(α, β)
Die posteriori-Dichte ergibt sich mit diesem Ergebnis zu:
f(θ|X = x) =θx(1− θ)n−xθα−1(1− θ)β−1B(α, β)
B(α, β)B(x+ α, n− x+ β)
=θx+α−1(1− θ)n−x+β−1
B(x+ α, n− x+ β)
Damit gilt fur den Parameter θ a posteriori:
θ|X ∼ Be(α + x; β + n− x)
Das Versuchsergebnis verandert also in diesem Fall nicht die Art der Vertei-lung, sondern aktualisiert lediglich die Parameter. Fur das oben genannteBeispiel mit X = 4, n = 10 und α = β = 20 erhalt man die posteriori-DichteBe(24; 26) (s. Abb. 3.1).
Aus diesem Beispiel geht klar der vielleicht bedeutendste Unterschied zwischenklassischer und bayesianischer Analyse hervor: Die Parameter - in diesem Fal-le nur die Trefferwahrscheinlichkeit θ - werden als Zufallsvariablen betrachtet,

3.4 Vorteile der Bayes-Analyse 33
wahrend in oben beschriebener klassischer Vorgehensweise Parametern zwarunbekannte aber dennoch feste Werte zugeordnet werden.
Das in Abschnitt 3.2.2 nach klassischer Vorgehensweise behandelte Beispiel derNormalverteilung wird in Kap. 4 sein bayesianisches Analogon erhalten.
3.4 Vorteile der Bayes-Analyse
In den vorangehenden Kapiteln wurde versucht, ein Bild der bayesianischenWahrscheinlichkeitsinterpretation herauszuarbeiten. Dem bisher Erarbeitetenschließt sich mit vorliegendem Abschnitt eine kurze Diskussion der Bayes-Analyse an. Die kontroversen Standpunkte sind nicht in aller Ausfuhrlichkeitund Vollstandigkeit dargestellt. Viele der im Literaturverzeichnis angegebenenBucher bieten eine Abwagung zwischen klassischen und bayesianischen Ver-fahren. Bei Bedarf konnen dort weitere Uberlegungen nachgelesen werden.
Mit der Gegenuberstellung von bayesianischer und frequentistischer Antwortim letzten Kapitel wurde deutlich, dass bei statistischen Tests der Parame-tervektor als fest angesehen wird, wahrend ein Bayesianer ihn als Set vonZufallsvariablen begreift. Dieser zentrale Unterschied hat zur Folge, dass furFrequentisten das Konfidenzintervall den Charakter einer Zufallsvariable an-nimmt. Doch was bedeutet das im Sinne einer statistischen Wahrscheinlich-keit - also einer relativen Haufigkeit fur moglichst großen Stichprobenumfang?Fuhrt man die Versuchsreihe (des Stichprobenumfangs n) 100 mal unter glei-chen außeren Bedingungen durch und berechnet jedes Mal das Konfidenzin-tervall neu, so liegt der wahre Wert in 1 − α Prozent der 100 Falle innerhalbder jeweiligen Konfidenzintervalle. Die Wahrscheinlichkeitsangabe 1−α ist so-mit, wie es die frequentistische Theorie verlangt, eine relative Haufigkeit. Manmuss dazu sagen, dass wohl in der Regel nur eine Versuchsreihe des Umfangsn durchgefuhrt wird und die restlichen 99, welche hier nur zur Erklarung her-angezogen wurden, lediglich der Vorstellung entspringen ([Bor10] S. 9). Dasbereits in Abschnitt 1.1.5 angesprochene Problem, dass Experimente oft nichtunter gleichen außeren Bedingungen durchfuhrbar sind, taucht hier wieder auf.Der Standard-Ansatz gerat ins Wanken, wenn es sich um besonders selten auf-tretende Ereignisse handelt. Wie z. B. soll die Ausfallwahrscheinlichkeit ei-nes Atomkraftwerkes auf dieser Basis berechnet werden? Die Berucksichtigungbayesianischer Ansatze bei Risikobewertungen ist mit Sicherheit sinnvoll. Ei-nige ausfuhrlich behandelte Beispiele dieser Art, wie z. B. das Lawinenrisikoanhand der Lawine von Montroc (9. Februar 1999), finden sich in [Bor10].
Die Bayes-Analyse stellt eine deutlich naturlicher wirkende Vorgehensweise be-reit: Da die Parameter als Zufallsvariablen behandelt werden, unterliegen sieWahrscheinlichkeitsverteilungen. Die priori-Verteilung geht dabei durch Kennt-nis der Versuchsergebnisse in die posteriori-Verteilung uber. Von dieser Dichtekonnen dann der Erwartungswert oder sonstige Kenngroßen berechnet werden.Auch die Bestimmung eines Intervalls, in dem der Erwartungswert mit z. B.

34 3 Parametermodelle
95%-ger Wahrscheinlichkeit liegt, ist einfach moglich. Zwecks Abgrenzung zumklassischen Konfidenzintervall wird dieses nun Kredibilitatsintervall genannt.
Es wurde bereits erwahnt, dass Kritiker die subjektiven Einflusse durch denPrior anprangern. Doch was ist falsch daran, Expertenwissen zu Rate zu zie-hen, insbesondere wenn die Datenlage allein nicht besonders aussagekraftigist? Widerspricht es tatsachlich dem Grundsatz des objektiven wissenschaftli-chen Arbeitens, Voruberlegungen als Priorwissen zu berucksichtigen? Fur denFranzosisch sprechenden Leser sei dazu folgende treffend formulierte Antwortgegeben:
Evaluer des chances sur la base de son experience est une ac-tivite intellectuelle recurrente partagee par la majorite des etrespensants. [Bor10] S. 17
Die bayesianische Denkweise lehnt sich an den gesunden Menschenverstandan. Die Bewertung von Sachverhalten auf Grundlage von Erfahrungen bzw.des aktuellen Wissensstandes ist ein absolut naturlicher Vorgang. Das Re-sultat solcher Voruberlegungen ist die Wettbereitschaft auf die verschiede-nen moglichen Resultate von Versuchen. Damit wird das Bild der subjektivenWahrscheinlichkeit als Maß fur Wettbereitschaft ([Die93] S. 54) aufgegriffen.Man sollte sich stets klarmachen, dass Priorwissen kein vages Unterfangen seinmuss. Wird z. B. eine extrem kleine Lebensdauer gemessen und ist durch dieMessapparatur, welche die Berechnung der Zeitdauer indirekt durch das Be-stimmen mehrerer Messgroßen ermoglicht, die Gefahr gegeben, ein negativesErgebnis zu erhalten, so ware ein Prior, der solche negativen Lebensdauern ver-bietet, von Vorteil. Die Tatsache, dass Lebensdauern nur positiv sein konnen,stellt dabei gesichertes Vorwissen dar und verfalscht in keinster Weise moglicheRuckschlusse aus dem Experiment. Die Richtlinien wissenschaftlichen Arbei-tens konnen also von Bayesianern sehr gut eingehalten werden - und zwar durchEhrlichkeit was die Wahl des Priors anbelangt. Zudem kann man umgekehrtauch der frequentistischen Theorie eine gewisse Subjektivitat unterstellen. Oftgibt es eine Vielzahl an moglichen Auswertungsmethoden (MLE, Momentme-thode,...), die zu unterschiedlichen Ergebnissen fuhren. Zwar kann man ihreQualitat durch Konsistenz, Erwartungstreue und Effektivitat bewerten, aberes wird Situationen geben, in denen man sich fur das kleinere Ubel entscheidenmuss. Eine solche Wahl unterliegt wiederum den personlichen Einschatzungen.Man kann die Diskussion uber die Rolle der Subjektivitat - auch in philosophi-schen Dimensionen - noch weiter verfolgen. Das ist allerdings nicht Aufgabedieser Arbeit.
Zum Schluss seien hier noch ausdrucklich zwei Hinweise gegeben, die bei Miss-achtung zu katastrophal falschen Ergebnissen fuhren konnen:
• Man konnte dazu neigen, das Ergebnis einer Bayes-Analyse wieder alsPrior fur die gleichen Versuchsergebnisse zu verwenden. Diese Vorgehens-weise ist nicht konsistent! Resultate, welche sich auf diese Weise ergeben,entsprechen nicht mehr der Aussage des Experimentes.

3.4 Vorteile der Bayes-Analyse 35
• Setzt man den Prior an manchen Stellen gleich null, so schließt man dieseWerte kategorisch aus. In der posteriori-Verteilung bleiben sie dann -unabhangig von den Daten - ebenfalls ohne Beachtung. Man sollte dasalso nur tun, wenn man sich dabei absolut sicher ist (s. obiges Beispielzur Lebensdauer).

4 Konjugierte Verteilungen
In manchen Fallen wird vorhandenes Priorwissen sinnvoll durch eine bekann-te Wahrscheinlichkeitsverteilung beschrieben. So erschien beispielsweise beimMunzwurf aus Abschnitt 3.3 eine Betaverteilung als Prior gerechtfertigt. DerVorteil, der dadurch zu Stande kommen kann, liegt auf der Hand: Die Eigen-schaften der Verteilungen sind sehr gut bekannt und das Bayes-Theorem lasstsich unter Umstanden mit Hilfe analytischer Berechnungen anwenden. Manspricht von einer zur Likelihood konjugierten priori-Dichte, wobei die hier ver-wendeten Begriffe im Rahmen dieses Kapitels noch exakt definiert werden.Sind die Herleitungen fur interessierende Verteilungen erstmal durchgefuhrt,reduziert sich, wie wir sehen werden, das Anwenden von (2.6) auf ein Upda-te der Parameter. Das vermeidet aufwendige numerische Methoden, wie z. B.Monte-Carlo-Methoden mit Markoff-Ketten, die viel Rechenzeit in Anspruchnehmen. Der hohe Rechenaufwand ist der Evidenz, dem mehrdimensionalenIntegral im Nenner von (2.6), geschuldet.Man kann wohl nur in den seltensten Fallen von ganzlicher Ubereinstimmungdes Vorwissens mit einer bekannten Verteilung ausgehen. Im Folgenden wirddeswegen nur auf Situationen eingegangen, in denen man den Informations-verlust durch Annaherung der eigentlichen priori-Dichte an einen bekanntenkonjugierten Prior in Kauf nimmt, oder nur unzureichende Informationen zurVerfugung hat, allerdings eine bekannte Verteilung findet, die zumindest imPrinzip den Vorstellungen entspricht. Nachdem im letzten Kapitel bereits einBeispiel fur eine konjugierte Verteilung behandelt wurde, sollen nun zunachsttheoretische Grundlagen gelegt werden.
4.1 Theoretische Einfuhrung
4.1.1 Suffizienz- und Likelihoodprinzip
Die Stochastik beruft sich oft auf allgemein akzeptierte Prinzipien. Zwei solcherGrundsatze, die vom bayesianischen Ansatz erfullt werden, sind das Suffizienz-und das Likelihoodprinzip.
Definition 4.1 (Suffizienz [Rob06])Eine Funktion T von Beobachtungen x heißt suffizient fur θ, wenn die bedingteDichte von X gegeben T (X) nicht von θ abhangt.
Die Funktion T wird suffiziente Statistik (sufficient statistic) genannt. An-schaulich bedeutet Suffizienz die Reduktion eines (hochdimensionalen) Daten-vektors auf einige Kennzahlen. Das heißt, die posteriori-Dichte hangt nicht vonsamtlichen Messwerten ab, sondern lediglich von charakteristischen Großen,
36

4.1 Theoretische Einfuhrung 37
welche die Daten umschreiben. Diese Rolle der suffizienten Statistik wird bei-spielsweise vom ersten Stichprobenmoment x in Abschnitt 4.2.2 ubernommen.Bei Reduktion der Daten auf Statistiken kommt es nicht zu Informationsver-lust, falls Suffizienz vorliegt (Beweis s. unten).Aus obiger Definition lasst sich folgendes Theorem ableiten (Beweis s. [Lee04]S. 52).
Satz 4.1 (Neyman’s factorization theorem [Lee04])Eine Statistik T ist eine suffiziente Statistik fur θ gegeben X = x, genau dannwenn es Funktionen m und n gibt, sodass:
f(x|θ) = m(T (x),θ)n(x) (4.1)
Die posteriori-Verteilung unterliegt aufgrund des Satzes von Bayes der Pro-portionalitat π(θ|x) ∝ f(x|θ)π(θ). Verwendet man (4.1) und lasst die fur dieProportionalitat unnotige Konstante n(x) weg, ergibt sich
π(θ|x) ∝ m(T (x),θ)π(θ) (4.2)
Daraus wird direkt ersichtlich, dass die suffiziente Statistik T alle relevantenInformationen der Versuche enthalt. Der Statistiker, der einen Versuch aus-wertet, benotigt also vom Experimentator lediglich die suffizienten Statistikenund nicht alle Messergebnisse.
Suffizienzprinzip [Rob06] Sei T eine suffiziente Statistik. Das Suffizienzprin-zip besagt, dass zwei Beobachtungen x und y, fur die T (x) = T (y) gilt,auf die gleichen Schlussfolgerungen fur θ fuhren mussen.
Das Likelihoodprinzip wird hier nicht ausfuhrlich diskutiert. Es besagt in Kurz-fassung, dass die Information, die durch Versuchsergebnisse x gewonnen wird,vollstandig in der Likelihoodfunktion enthalten ist. Sind insbesondere zwei Be-obachtungen x und y gemacht worden, die sich auf den gleichen Parameter-raum Θ beziehen und deren Likelihoods proportional zueinander sind, d. h.
f(θ|x) = c · f(θ|y) mit 0 < c <∞ (4.3)
so mussen beide Beobachtungen auf die gleichen Schlussfolgerungen fur θ fuh-ren ([Kle80] S. 226). Birnbaum1 stellte 1962 einen Satz auf, der besagt, dass dasLikelihoodoprinzip aus dem sogenannten conditionality principle und demSuffizienzprinzip folgt ([Lee04] S. 195). Beide Prinzipien entsprechen dem ge-sunden Menschenverstand. Das conditionality principle besagt grob, dassstatistische Schlussfolgerungen nicht von nicht beobachteten Werten abhangendurfen. Dem Bayes-Theorem (2.6) sieht man leicht an, dass sich die Konstantec kurzt und man tatsachlich fur beide Likelihoods in (4.3) dieselbe posteriori-Dichte erhalt.
Ausfuhrlichere Diskussionen des Suffizienz- und Likelihoodprinzips finden sichbeispielsweise in [Sch95] S. 82 ff. oder [Lee04] S. 194 ff. Wir werden aber sehen,dass die betrachteten Aspekte ausreichen, um einen Zugang zu konjugiertenVerteilungen zu erhalten.
1*27. Mai 1923; 1. Juli 1976

38 4 Konjugierte Verteilungen
4.1.2 Konjugierte Familie
Im Folgenden wird die konjugierte Familie definiert. Dabei ist der Begriff Fa-milie im Prinzip ein Synonym fur Funktion ([Ebb03] S. 60).
Definition 4.2 (Konjugierte Familie [Rob06])Eine Familie von Wahrscheinlichkeitsverteilungen F auf Θ heißt - durch eineLikelihood f(x|θ) - konjugiert, falls fur alle priori-Dichten π ∈ F die posteriori-Dichte π(·|x) ebenfalls zu F gehort.
Ein Prior f(θ) heißt konjugierte Verteilung fur die Likelihood f(x|θ), fallsPrior und posteriori-Dichte zur selben konjugierten Familie gehoren ([Zuc04]S. 196).Ein triviales Beispiel fur eine konjugierte Familie ware naturlich die Familiealler Wahrscheinlichkeitsverteilungen. Es ist allerdings offensichtlich, dass diesfur die Praxis irrelevant ist. Um eine fur konkrete Berechnungen notwendigeGrundlage zu erarbeiten, wird im nachsten Abschnitt die Exponentialfamiliebetrachtet.
4.1.3 Exponentialfamilie
Die Exponentialfamilie ist uber die Beziehung
f(xi|θ) := g(xi)ξ(θ) · exp(
(φ(θ))T · h(xi))
(4.4)
definiert. In einer Bayes-Analyse ist es die Likelihood, welche dieser Festlegunggenugen muss, um eine Analyse mit konjugierter Verteilung zu ermoglichen.Die einzelnen in (4.4) auftretenden Großen haben folgende Eigenschaften:
• Die Parameter sind im Parametervektor θ zusammengefasst, wobei θ ∈Θ und dim Θ =: k. Eine spezielle Wahl des Parametervektors legt, wieweiter unten anhand von Beispielen klar werden wird, ein spezifischesMitglied der Exponentialfamilie fest.
• Ein Datenvektor xi beschreibt die Messergebnisse einer konkreten Mes-sung. So konnten pro Versuchsdurchfuhrung in einem Experiment derklassischen Physik beispielsweise gleichzeitig Ort und Impuls eines Teil-chens registriert werden. Der Raum der Messergebnisse χ ware dannzweidimensional und xi = (Ort, Impuls). Es sei hier die Notation dimχ =:d gewahlt und darauf hingewiesen, dass im Allgemeinen naturlich d 6= kgilt. Der Stichprobenumfang, d. h. die Anzahl der Versuchsdurchfuhrun-gen, wird auch weiterhin mit n bezeichnet.
• g und ξ sind eindimensionale Funktionen, deren Wertebereiche die posi-tiven reellen Zahlen und null umfassen.
• Die Funktionen φ und h sind im Allgemeinen mehrdimensional mit Wer-tebereich in Rk. Im Exponenten der Exponentialfunktion steht dahereinfach eine Zahl.

4.1 Theoretische Einfuhrung 39
Generell soll angenommen werden, dass die Betrachtung von Einheiten separaterfolgt - Messergebnisse und Parameter also nur durch Zahlen reprasentiert indie Berechnungen einfließen.Bei (4.4) handelt sich zunachst einmal um eine willkurlich erscheinende Fest-legung einer Familie von Wahrscheinlichkeitsverteilungen. Folgende Auflistungaber zeigt, dass einige der bekannten Verteilungen der Exponentialfamilie an-gehoren. Dabei wird statt der, bereits in Hinblick auf die weiterfuhrende Dis-kussion gewahlten, Notation xi schlicht x verwendet, da es sich um univariateVerteilungen handelt (d = 1).
Normalverteilung: Die Normalverteilung hat zwei Parameter, den Erwartungs-wert µ und die Standardabweichung σ. Wir wahlen also den Parameter-vektor
θ = (θ1, θ2) = (µ, σ)
Der im Exponenten der Dichtefunktion (B.7) auftauchende Term (x−µ)2
kann ausmultipliziert werden, was auf
f(x|θ) =1√2πσ
exp
(− µ2
2σ2
)exp
(µσ−2x− 1
2x2σ−2
)fuhrt. Setzt man g(x) = 1√
2πund ξ(θ) = 1
θ2exp
(− θ2
1
2θ22
), sowie
φ(θ) =
(θ1θ−22
12θ−2
2
)h(x) =
(x−x2
)sieht man, dass die Normalverteilung der Exponentialfamilie angehort.
Gammaverteilung: Schreibt man die Dichte (B.11) folgendermaßen um
f(x|ν, λ) = f(x|θ) =λν
Γ(ν)e(ν−1) lnxe−λx =
λν
Γ(ν)exp ((ν − 1) lnx− λx)
so kann man die einzelnen Funktionen direkt ablesen:
• g(x) = 1 und ξ(θ) = λν
Γ(ν)
• φ(θ) =
(ν − 1λ
)und h(x) =
(lnx−x
)Poissonverteilung: Die mit einem Parameter θ = λ behaftete Poissonvertei-
lung (B.5) lasst sich folgendermaßen notieren (k = 1):
f(x|λ) =λx
x!e−λ =
1
x!e−λex lnλ
Dann sind die Funktionen aus (4.4) gegeben durch:
• g(x) = 1x!
und ξ(λ) = e−λ
• φ(λ) = lnλ und h(x) = x
Die Poissonverteilung gehort also zur Exponentialfamilie.
Außerdem gehoren z. B. noch die Binomial-, Exponential-, Beta- und die geo-metrische Verteilung zur Exponentialfamilie.

40 4 Konjugierte Verteilungen
4.1.4 Konjugierte Verteilungen bei Exponentialfamilien
Aufgabe ist es nun, die Ergebnisse der letzten drei Abschnitte sinnvoll zu-sammenzufugen, um eine Aussage uber konjugierte Verteilungen fur die Ex-ponentialfamilie herauszuarbeiten. Laut [Fin97] S. 4 muss die Likelihood derExponentialverteilung angehoren, damit eine konjugierte Analyse uberhauptmoglich ist.
Im Folgenden steht x reprasentativ fur alle xi mit i = 1, .., n. Es ist wichtig,sich klar zu machen, dass x nun ein Vektor mit vektorartigen Eintragen ist,also x = (x1, ...,xn). Bei identisch unabhangig verteilten Beobachtungen kannman mit Hilfe von (1.14) fur die der Exponentialfamilie angehorigen Likelihoodnotieren:
f(x|θ) = f(x1,x2, ...,xn|θ)
=n∏i=1
g(xi)ξ(θ) · exp(
(φ(θ))T · h(xi))
=
(n∏i=1
g(xi)
)[ξ(θ)]n exp
((φ(θ))T
n∑i=1
h(xi)
)(4.5)
Diese Gleichung hat die Form von (4.1), wobei
n(x) =n∏i=1
g(xi)
und der zweite Faktor gleich m(T (x),θ) ist. Es mussen nun die Eintrage desVektors der suffizienten Statistik in (4.5) gefunden werden. Fur beliebiges ngibt es immer gleich viele solcher Komponenten, namlich k + 1. Dabei wirdhier auch der Stichprobenumfang n hinzugezahlt.2 Die restlichen Statistikensind die Eintrage des k-dimensionalen Vektors
T (x) :=n∑i=1
h(xi) (4.6)
Die Likelihood steht damit fest:
f(x|θ) = [ξ(θ)]n exp(
(φ(θ))T T (x))
(4.7)
Die Konstante∏n
i=1 g(xi) wurde weggelassen, da man sie im Bayes-Theorem(2.6) kurzen kann.Schaut man sich (4.2) und (4.7) an, so erscheint folgende Festlegung fur denPrior sinnvoll, damit priori- und posteriori-Dichte, wie bei konjugierten Fami-lien notwendig, von gleicher Form sind:
π(θ) ∝ [ξ(θ)]a0 exp(
(φ(θ))T a)
(4.8)
2Ob man n hinzuzahlt oder nicht, ist irrelevant.

4.2 Konjugierte Analysen fur stetige Großen 41
Dabei ist a ∈ Rk, wobei eine Normierung des Priors dazu fuhren kann, dassDefinitionsbereiche der Parameter des Priors eingeschrankt werden mussen.Man erhalt die posteriori-Dichte gemaß des Satzes von Bayes:
π(θ|x) ∝ [ξ(θ)]n+a0 exp(
(φ(θ))T (a+ T (x)))
(4.9)
Man kann folgende Regeln fur das Parameter-Update ablesen:
1. a0 → n+ a0
2. a→ a+ T (x) bzw. aj → aj + Tj(x) fur j = 1, ..., k
Dabei symbolisiert der Pfeil den Ubergang von priori- zu posteriori-Parametern.Im nachsten Abschnitt geht es darum, ein paar Beispiele zu betrachten und diejeweiligen Regeln fur das Update der Parameter aufzustellen. Dabei kannoft auf die hier vorgestellte allgemeine Theorie zuruckgegriffen werden. Allebetrachteten Beispiele haben einen eindimensionalen Parametervektor.
4.2 Konjugierte Analysen fur stetige Großen
4.2.1 Exponentialverteilung, λ unbekannt
Angenommen eine Likelihood sei durch eine ExponentialverteilungX|λ ∼ Exp(λ) gegeben. Man hat es mit einem einparametrigen Modell zutun, wobei der unbekannte Parameter durch θ = λ > 0 beschrieben wird(k = 1). Es soll hier die allgemeine Theorie aus dem vorigen Abschnitt zurAnwendung kommen.Die Likelihood lautet fur eine Messung nach (B.12):
f(xi|λ) =
0 xi ≤ 0
λe−λxi xi > 0(4.10)
Naturlich gehort die Exponentialverteilung der Exponentialfamilie an, wobeidie einzelnen Funktionen aus (4.4) durch
• g(xi) = 1
• ξ(θ) = ξ(λ) = λ
• φ(θ) = φ(λ) = −λ
• h(xi) = xi
gegeben sind. Daraus ergibt sich sofort T (x) =∑n
i=1 xi = nx. Der Vorteilder theoretischen Voruberlegungen ist nun der Folgende: Mit Hilfe von (4.8)erschließt sich die priori-Verteilung, die auf eine konjugierte Familie fuhrt -man muss demnach nicht blind ausprobieren. Setzt man in (4.8) ein, so ergibtsich:
π(λ) ∝ λa0e−a1λ (4.11)

42 4 Konjugierte Verteilungen
An dieser Stelle muss man sehr genau auf die Wahl der Notation achten. DieVariable der priori-Dichte ist naturlich λ, da uber eben diese Große Priorwissengesammelt wurde. Die Parameter der Verteilung heißen zunachst einmal a0 unda1. Durch Normieren von (4.11) kann man erkennen, um welche Verteilung essich handelt.
∞∫0
π(λ) dλ =
∞∫0
λa0e−a1λ dλ
Subst.
t := a1λ
dλ = dta1
= a−(a0+1)1
∞∫0
t(a0+1)−1e−t dt a1 > 0
= a−(a0+1)1 Γ(a0 + 1)
Benennt man die beiden Parameter folgendermaßen um
α := a0 + 1 und β := a1
und teilt durch den Normierungsfaktor erhalt man fur λ > 0 folgende priori-Dichte:
π(λ) =βαλα−1
Γ(α)e−βλ (4.12)
Ein Vergleich mit (B.11) macht klar, dass es sich um eine Gammaverteilunghandelt. Die posteriori-Verteilung ist dann auch eine Gammaverteilung, wobeidie Parameter sich folgendermaßen andern
1. α→ n+ α
2. β → β + nx
Dabei handelt es sich lediglich um die Anwendung der oben aufgestellten Re-geln.
4.2.2 Normalverteilung, µ unbekannt und σ2 bekannt
Angenommen eine Likelihood folge einer Normalverteilung, wobei der Erwar-tungswert µ unbekannt und die Varianz σ2 bekannt seien. Das ist ein durchausrealistisches Szenario fur einen Versuch, dessen Messapparatur unter vielenEinflussen steht, sodass man die Messergebnisse als gaußverteilt annehmenkann. Die Varianz ist dann aus alteren Messungen, Vergleichen mit anderenMessgeraten oder der Herstellerangabe bekannt. Wir halten also fest, dassX|µ ∼ N (µ, σ2). Es sei an dieser Stelle noch einmal darauf hingewiesen, dassdie Likelihood nach Einsetzen der Messergebnisse als Funktion vom Parameterzu interpretieren ist.

4.2 Konjugierte Analysen fur stetige Großen 43
Die Ergebnisse der n durchgefuhrten Messungen seien im Datenvektor x zu-sammengefasst, wobei die pro Messung aufgenommenen Werte hier jeweils ein-dimensional sind. Man kann die einzelnen Messungen als unabhangig identischverteilt auffassen, sodass nach (1.14) gilt:
f(x|µ) = f(x1, x2, ..., xn|µ) = f(x1|µ) · f(x2|µ) · ... · f(xn|µ)
Setzt man die Dichte der Normalverteilung (B.7) ein, so nimmt die Likelihoodfolgende Gestalt an:
f(x|µ) =
(1
2πσ2
)n2
exp
−n∑i=1
(xi − µ)2
2σ2
(4.13)
Es ist erstrebenswert, den Einfluss der Daten moglichst kompakt mit einerKenngroße zu realisieren. Hierfur bietet sich das erste Stichprobenmoment xan (suffiziente Statistik). Zur Vereinfachung des Exponenten von (4.13) dientfolgende kurze Rechnung [Kle80]:
n∑i=1
(xi − µ)2 =n∑i=1
[(xi − x)− (µ− x)]2
=n∑i=1
(xi − x)2 +n∑i=1
(µ− x)2
︸ ︷︷ ︸=n(µ−x)2
−2n∑i=1
(xi − x)(µ− x)︸ ︷︷ ︸=0
(4.14)
Der letzte Term verschwindet, da
n∑i=1
(xi − x)(µ− x) = nxµ− nx2 − nxµ+ nx2 = 0
Setzt man (4.14) in die Likelihood (4.13) ein und vernachlassigt die Konstanten(2πσ2)−n/2 und exp (−(2σ2)−1
∑ni=1(xi − x)2), so erhalt man:
f(x|µ) ∝ exp
[− (µ− x)2
2(σ/√n)2
](4.15)
Zur Normierung der Likelihood kann man mittels Substitution integrieren unddiese durch das Ergebnis teilen:
∞∫−∞
exp
[−(
µ− x√2σ/√n
)2]dµ =
√2π
σ√n
Das bedeutet, dass eine Normalverteilung der Form N (x, ( σ√n)2) vorliegt. Die
Normierung ist keinesfalls von Noten. Allerdings erkennt man hier sehr schondas wohlbekannte Ergebnis, dass die Abweichung auf den Mittelwert mit
√n
fallt (Standardabweichung des Mittelwertes).

44 4 Konjugierte Verteilungen
Der nachste Schritt ist die Festlegung eines Priors. Wahlt man hier ebenfalls ei-ne Normalverteilung, so sind die Rechnungen analytisch durchfuhrbar und manerhalt als posteriori-Verteilung ebenfalls eine Gaußkurve. Man hat es dann, wiebeabsichtigt, mit einer konjugierten Familie zu tun.Der Prior legt das Wissen uber den Parameter µ fest. Die Standardabweichungwird hier mit s und der Erwartungswert mit m bezeichnet.
π(µ) =1√2πs
exp
(−(µ−m)2
2s2
)(4.16)
Gemaß Bayes-Theorem gilt dann folgende Proportionalitat:
π(µ|x) ∝ exp
[−1
2
(µ−ms
)2]
exp
[−n
2
(µ− xσ
)2]
= exp
[−1
2
((µ−m)2
s2+n(x− µ)2
σ2
)](4.17)
Ausmultiplizieren ergibt zwei konstante Summanden, die man als Exponen-tialfunktionen separat schreiben und aufgrund der Proportionalitat in (4.17)weglassen kann. Nach kurzer Rechnung ergibt sich fur den Rest der innerenKlammer:
µ2
(1
s2+
n
σ2
)︸ ︷︷ ︸
=σ2+ns2
s2σ2
−2µ(ms2
+nx
σ2
)︸ ︷︷ ︸
=mσ2+ns2x
s2σ2
(4.18)
Setzt man
µ′ :=mσ2 + ns2x
σ2 + ns2und σ′2 :=
s2σ2
σ2 + ns2(4.19)
und fugt in (4.17) den konstanten Faktor exp(−µ′2/(2σ′2)) ein, was wegen derProportionalitat in (4.17) erlaubt ist, so folgt:
π(µ|x) ∝ exp
(− µ′2
2σ′2
)exp
[− 1
2σ′2(µ2 − 2µµ′
)]= exp
(− 1
2σ′2(µ− µ′)2
)(4.20)
Man erkennt leicht, dass es sich um eine noch nicht normierte Form einerNormalverteilung handelt. Die posteriori-Dichte ist demnach N (µ′, σ′2), wobeiµ′ und σ′2 durch (4.19) gegeben sind.
4.3 Konjugierte Analysen fur diskrete Großen
4.3.1 Poissonverteilung, λ unbekannt
In Abschnitt 4.1.3 wurde bereits gezeigt, dass die Poissonverteilung zur Ex-ponentialfamilie gehort. Dort wurden auch die Funktionen ξ, φ und h notiert.

4.3 Konjugierte Analysen fur diskrete Großen 45
Fur die suffiziente Statistik gilt:
T (x) =n∑i=1
xi = nx
Wieder kann man mit Hilfe von (4.8) und Normierung die priori-Dichte be-stimmen. Wir integrieren also mit Hilfe einer Substitution:
∞∫0
π(λ) dλ =
∞∫0
(e−λ)a0
ea1 lnλ dλ
=
∞∫0
λa1e−λa0 dλ
= a−(a1+1)0 Γ(a1 + 1) a0 > 0
Wir dividieren den nicht-normierten Prior mit dem Ergebnis dieses Integralsund benennen die Parameter a0 und a1 folgendermaßen um: α = a1 + 1 undβ = a0. Das fuhrt auf eine Gammaverteilung mit den positiven Parametern αund β.
π(λ) =βα
Γ(α)λα−1e−βλ
Somit ist die posteriori-Dichte ebenfalls durch eine Gammaverteilung mit denneuen Parametern β → β + n sowie α→ α + nx gegeben.
Bei diesem Ergebnis ist jedoch Vorsicht geboten! Es handelt sich hier um ei-ne sogenannte Poisson-Statistik. Da eine Binomialverteilung fur die Lange derBernoulli-Kette n → ∞ gegen eine Poissonverteilung konvergiert, wenn mandie Trefferwahrscheinlichkeit p = λ
nsetzt, werden Poissonverteilungen oft ahn-
lich wie Binomialverteilungen verwendet (s. z. B. [Jon02] S. 80 f.). Ein Beispieldafur, das in Kapitel 5 genauer untersucht wird, ist der radioaktive Zerfall einerProbe. Die aufgestellten Regeln fur den Parameterupdate implizieren nun, dassman die Ereignisse (z. B. radioaktive Zerfalle) jeweils in n voneinander unab-hangigen und gleichlangen Zeitintervallen 4t zahlt, um das erste Stichproben-moment x bilden zu konnen. Allerdings folgt die Summe zweier unabhangiger,poissonverteilter Zufallsvariablen X1 und X2 ebenfalls einer Poissonverteilung.Um das einzusehen, setzen wir die Gesamttrefferzahl gleich m und berechnenunter Ausnutzung der Unabhangigkeit die Wahrscheinlichkeit fur X = m mitX := X1 +X2. Die Bedingung, welche von X1 = x1 und X2 = x2 erfullt werdenmuss, lautet x1 + x2 = m.

46 4 Konjugierte Verteilungen
P (X1 +X2 = m) =m∑k=1
P (X1 = k)P (X2 = m− k)
=m∑k=1
λk1k!e−λ1
λm−k2
(m− k)!e−λ2
=e−(λ1+λ2)
m!
m∑k=0
(m
k
)λk1λ
m−k2
=(λ1 + λ2)m
m!e−(λ1+λ2)
Das heißt, dass X ∼ Po(λ1 + λ2). Das Ergebnis lasst sich auf die Summe nunabhangiger poissonverteilter Zufallsvariablen verallgemeinern.Das Resultat dieser Herleitung lautet: Um eine prazisere Aussage zu treffen,wurde man im Beispiel der radioaktiven Probe einfach langer messen. Insbe-sondere sieht man durch Vergleich oben formulierter Regeln fur den Parame-terupdate mit den nun folgenden, dass in der hier vorgestellten konjugiertenBayes-Analyse eine Messzeit der Lange n · 4t das gleiche Ergebnis wie n Ein-zelmessungen der Zeitdauer 4t liefert.
1. β → β + 1
2. α→ α + x
Diese zweite Version des Parameterupdates, in der X = x die Anzahl der Tref-fer beschreibt, ist, wie bereits erwahnt, aquivalent zur ersten Fassung, zeugtaber von einem besseren Verstandnis der Poisson-Statistik.
Generell seien als Fazit aus der konjugierten Analyse der Poissonverteilung zweiWarnungen formuliert. Erstens sollte man bei Anwendung konjugierter Vertei-lungen aus tabellarischen Auflistung immer genau studieren, welchen Großenwelche Bedeutung zugemessen wird, wenn man ihre Herleitung nicht kennt.Zweitens konnen auch bei Verwendung der allgemeinen Theorie aus Abschnitt4.1.4 Anpassungen notig sein, da Eigenschaften der jeweiligen Likelihood zuberucksichtigen sind. Dafur dient die Betrachtung der Poissonverteilung alsBeispiel.
4.3.2 Binomialverteilung, θ unbekannt
In Abschnitt 3.3 wurde im Rahmen der quantitativen Analyse des Munzwurfsdieser Fall bereits betrachtet. Der einzige Unterschied zwischen einer geome-trischen Verteilung, welche dort als Likelihood verwendet wurde, und einerBinomialverteilung, ist der konstante Binomialkoeffizient ist. Nach dem Like-lihoodprinzip mussen die Ruckschlusse auf den unbekannten Parameter danndieselben sein. Das Ergebnis lautet also: Ist die Likelihood durch eine Bino-mialverteilung B(n; p) gegeben und wahlt man als Prior eine Betaverteilung

4.4 Nicht-informative Dichten 47
Be(α; β) fur die unbekannte Trefferwahrscheinlichkeit θ, so ist die priori-Dichteebenfalls eine Betaverteilung mit den neuen Parametern
1. α→ α + x
2. β → β + n− x
In diesem Falle wird der Versuch n-mal durchgefuhrt und x ist die Anzahl derbeobachteten Treffer.
4.4 Nicht-informative Dichten
Zum Schluss dieses Kapitels wird noch kurz auf alternative Methoden zur Be-stimmung von priori-Dichten eingegangen. Dieser Abschnitt dient allerdingslediglich dazu, einen Uberblick zu geben. Keines der hier angesprochenen Ver-fahren wird ausfuhrlich diskutiert.
Bei unzureichendem Priorwissen ist es wunschenswert, so wenig wie mog-lich Information in der priori-Dichte unterzubringen. Man spricht von nicht-informativen Dichten. Wann also tragt eine Dichte besonders wenig Informa-tion?
Einen ersten Ansatz haben bereits die Erfinder der Bayes-Statistik gemacht,namlich Thomas Bayes und Pierre-Simon Marquis de Laplace. Das sogenannteBayes-Postulat formuliert, dass eine Gleichverteilung fur eine nicht-informativenPrior geeignet ist ([Kle80] S. 204). Eine andere Idee ist es, die Entropie als Maßfur Informationsgehalt zu verwenden. Eine gute Einfuhrung in dieses Verfah-ren findet sich in [Siv06] auf S. 110-121. Zudem befasst sich das ganze Buchvon Nailong Wu [Wu97] mit dieser Thematik.Ein anderer Ansatz ist die Verwendung eines sogenannten Jeffrey’s prior.Hier wird die sogenannte Fisher-Information als Maß fur den Informations-gehalt herangezogen. Ohne diese Vorgehensweise weiter motivieren zu wollen,seien hier die notigen Beziehungen angegeben, welche fur die Berechnung vonJeffrey-Prioren zu Grunde liegen. Die Formeln sind aus [Rob06] S. 140-141entnommen. Dort konnen auch weitere Informationen bezuglich des Verfah-rens nachgelesen werden.
Im Falle eines eindimensionalen Parameterraums ist die Fisher-Informationfolgendermaßen definiert:
I(θ) := E
[(∂ ln[f(x|θ)]
∂θ
)2]
(4.21)
Sie ist also der Erwartungswert der Ableitung der Loglikelihoodfunktion zumQuadrat. Der Erwartungswert bezieht sich auf die Daten und nicht auf die Pa-rameter. Das heißt, die Integration erfolgt uber den Raum der Messergebnisse.Die Beziehung (4.21) kann auch folgendermaßen notiert werden:

48 4 Konjugierte Verteilungen
I(θ) = −E[∂2 ln[f(x|θ)]
∂θ2
](4.22)
Fur den Prior gilt dann folgende Proportionalitatsbeziehung:
π(θ) ∝√I(θ) (4.23)
Im mehrdimensionalen Fall, d. h. θ ∈ Rk, ist die Fisher-Information eine Ma-trix mit den Eintragen:
Iij(θ) := −E[∂2
∂θi∂jln[f(x|θ)]
]mit i, j = 1, ..., k (4.24)
Der Prior ist dann proportional zur Wurzel aus der Fisher-Determinante.
π(θ) ∝√
det I(θ) (4.25)
Um dem Konzept etwas Gestalt zu geben, wird hier beispielhaft der zur Pois-sonverteilung gehorige Jeffrey-Prior abgeleitet. Die Dichte der Poissonvertei-lung (B.5) stellt die Likelihood dar. Wegen
ln
(λx
x!e−λ)
= x lnλ− ln x!− λ ⇒ ∂
∂λ(x lnλ− ln x!− λ) =
x− λλ
ist die Fisher-Information durch
I(λ) =1
λ2
∞∑x=0
(x− λ)2P (X = x) =1
λ2D2(X) =
1
λ
gegeben, sodass fur den Jeffrey-Prior
π(λ) ∝ 1√λ
(4.26)
gilt.

5 Bayes-Analysen in der Physik
Im Schlusskapitel wird der Nutzen bayesianischer Sichtweisen fur die Physikthematisiert. Dabei wird es zunachst darum gehen, exemplarisch verstandlichzu machen, an welchen Stellen Bayes-Analysen von Noten sind. Im Anschlusswird ein uberschaubares und konkretes Beispiel beschrieben, bei dem es umdie Messung von Zahlraten radioaktiver Proben geht.
5.1 Warum Bayes-Analysen in der Physik?
Abgesehen von den bereits in Abschnitt 3.4 diskutierten Vorwurfen an derBayes-Statistik gibt es einen zweiten Grund dafur, dass der Satz von Bayes erstin neuerer Zeit wieder Anerkennung findet, obwohl er bereits im 18. Jahrhun-dert aufgestellt wurde. Die in den letzten Jahren immer verfugbarer und effekti-ver gewordene computergestutzte Rechenleistung ermoglicht die Durchfuhrungkomplizierter numerischer Berechnungen. Numerische Verfahren sind auch furdie Bayes-Statistik enorm relevant, da den meisten stochastischen Situationenkeine besonders gut bekannten und einfachen Strukturen zu Grunde liegen.Das fuhrt dazu, dass die analytisch berechenbaren konjugierten Verteilungennur begrenzt Anwendung finden. Fur die Auswertung komplexer Versuche -z. B. aus dem Bereich der Hochenergiephysik - reichen die in Kapitel 4 vorge-stellten Methoden nicht aus. Das liegt daran, dass Likelihoods, welche diesenVersuchen zu Grunde liegen, mittels umfangreicher Monte-Carlo-Simulationendes Versuchaufbaus bestimmt werden. Es ist klar, dass das Ergebnis solcherStudien nicht durch eine bekannte Wahrscheinlichkeitsverteilung beschriebenwird. Die Anwendung des Bayes-Theorems wird dann zu einer anspruchsvollenAufgabe, da die Evidenz bestimmt werden muss. Die Methoden, die dafur zurVerfugung stehen, sind, wie bereits erwahnt, numerischer Natur. Ublicherweisehandelt es sich um Monte-Carlo-Methoden mit Markoff-Ketten.
Es ist naturlich interessant, abschatzen zu konnen, wann man den Aufwand ei-ner Bayes-Analyse dennoch nicht scheuen sollte. Im Grunde mussen die beidenfolgenden Fragen beantwortet werden:
1. Wann nimmt der Fehler, den man durch Anwenden konventioneller Aus-wertungsmethoden begeht, Ubermaß?
2. Was bedeutet Fehler in diesem Fall?
Zunachst wird auf die zweite Frage eingegangen.
49

50 5 Bayes-Analysen in der Physik
Bislang wurde der z. T. auf philosophischer Ebene zu diskutierende Unterschiedzwischen der klassischen und der bayesianischen Schule betrachtet, sowie Vor-zuge der Bayes-Methoden aufgezeigt. Aber es ist zudem moglich, dass durchAnwendung frequentistischer Theorie tatsachlich signifikante Fehler begangenwerden. Es geht dann nicht mehr darum, welcher Philosophie man sich an-schließt. So stellt sich z. B bei der Suche nach neuen Teilchen die Frage, obein Versuchsergebnis die Entdeckung neuer Physik bedeutet oder nicht. DasProblem liegt nun darin, dass man von den interessierenden Ereignissen meistweiß, dass sie sehr selten auftreten - sie haben also einen kleinen Prior. Schnellkann man sich dazu verleitet sehen, neue Erkenntnisse zu postulieren. Die mitHilfe des Satzes von Bayes erhaltene Antwort auf solche Situationen kann al-lerdings ganz anders aussehen: Ein kleiner Prior verhindert bei wenig Statistikeine hohe Wahrscheinlichkeit fur die Entdeckung eines neuen Teilchens. DieseSituation entspricht genau dem in Kapitel 2 besprochenen Beispiel zur Diagno-stik seltener Ereignisse. Zudem sind bei kleinen Ereignisraten im Rahmen derfrequentistischen Theorie oft keine statistisch signifikanten Aussagen moglich.Man ist dann auf die Verwendung von Vorwissen angewiesen.
Um die erste Frage zu beantworten, sei hier zunachst ein simples Beispiel ge-nannt. Angenommen man mochte eine Strecke messen; z. B. den Abstandeines Maximums hoherer Ordnung zum Maximum nullter Ordnung in einemInterferenzmuster. Frequentisten wurden die Messung der Strecke durchfuh-ren und gegebenenfalls einige Male wiederholen. Die Vorgehensweise, welchedie bayesianische Theorie vorsieht, erscheint in diesem Fall uberzogen. Dieposteriori-Verteilung, welche man nach Aufstellen von Likelihood und Priormit Hilfe der Messdaten ermitteln wurde, ware wohl kaum aussagekraftigerals das Ergebnis der ublichen Vorgehensweise. Das liegt daran, dass man insolchen Fallen, eine gaußformige Auflosung der Messapparatur annimmt. Mangeht dabei davon aus, dass viele Einflusse bei der Messung eine Rolle spielen,sodass man mit Hilfe des Zentralen Grenzwertsatzes argumentieren kann. Dasbedeutet, dass die posteriori-Verteilung bereits annaherungsweise bekannt ist:Es handelt sich in etwa um eine Normalverteilung. Der Zentrale Grenzwertsatzstoßt oft an seine Grenzen, wenn es um die Auslaufer der Verteilung geht (alsobildlich gesprochen die Schwanze der glockenformigen Kurve). Im genanntenBeispiel spielen diese außeren Bereiche der Verteilung allerdings eine absolutuntergeordnete Rolle, da die Bestimmung der als makroskopisch angenomme-nen Strecke keinen derartigen Schwankungen unterliegt. Handelt es sich umein ubliches, mit dem bloßen Auge gut erkennbares Interferenzbild, so liefernfrequentistische und bayesianische Analyse gleiche Ergebnisse. Die klassischeVorgehensweise bedeutet allerdings deutlich weniger Aufwand, da man ledig-lich einen besten Schatzwert (in diesem Beispiel das 1. Stichprobemoment)ermittelt und eine Fehler unter Annahme einer Normalverteilung berechnet(hier ebenfalls mit Hilfe der Momentmethode).
Sind die Messwerte also weit von den physikalischen Grenzen entfernt, dieStandardabweichung klein und die Annahme einer Gaußverteilung gerechtfer-tigt, so wird keine Bayes-Analyse benotigt, falls die Datenlage gut ist.

5.2 Poisson-Statistik bei radioaktiver Strahlung 51
In Abschnitt 3.4 wurde bereits ein mogliches Beispiel genannt, bei dem dieMessergebnisse physikalische Grenzen verletzen konnen: Die (indirekte) Mes-sung einer extrem kleinen Lebensdauer, konnte negative Werte ergeben. Aberwelches Teilchen zerfallt, bevor es entstanden ist? Ein sinnvoller Prior wurdenegative Werte verbieten.Stochastische Situationen, bei denen die Datenlage unzureichend ist, gibt esimmer wieder in der naturwissenschaftlichen Forschung. Haufig hat man esdamit z. B. in der Klimaforschung zu tun.
5.2 Poisson-Statistik bei radioaktiver Strahlung
Die Behandlung eines komplexen Beispiels aus der modernen Forschung wurdeden Rahmen dieser Arbeit sprengen. Es gibt jedoch auch im Kleinen sinnvol-le Anwendungen des Satzes von Bayes in der Physik. Ein solches Beispiel wirdnun betrachtet. Die hier vorgestellten Berechnungen lehnen sich an [Gre05]S. 376-380.
Angenommen es wird der Zerfall einer radioaktiven Quelle untersucht, wo-bei die Ereignisse - also Zerfalle - gezahlt werden. Die Anzahl an EreignissenX folgt einer Poisson-Statistik. Das bedeutet, dass die Likelihood der Bayes-Analyse einer Poissonverteilung entspricht. Fur diese Anwendung ist es sinn-voll, die Dichte (B.5) in einer etwas anderen Form zu notieren.
f(x|r) =(rT )x
x!e−rT (5.1)
Dabei wurden folgende Bezeichnungen gewahlt:
• Der ublichen Konvention folgend bezeichnet der Kleinbuchstabe x eineRealisierung der mit dem Großbuchstaben X bezeichneten Zufallsvaria-ble.
• Die Zahlrate r ist die erste zeitliche Ableitung von X. Gleichzeitig ist rauch der Parameter der Theorie, uber den es mit Hilfe des Versuchsergeb-nisses Ruckschlusse zu ziehen gilt. An dieser Stelle wird von der bisherverwendeten Konvention, die Parameter mit griechischen Buchstaben zubezeichnen, abgesehen.
• T bezeichnet die Messzeit. Der Faktor rT ist also dimensionslos. Weiter-hin ist T kein Parameter der Theorie.
Es wird die Abwesenheit von Hintergrundstrahlung angenommen.
Naturlich bedarf es eines angemessen Priors π(r). Kann das Vorwissen durcheine Gammaverteilung beschrieben werden, so ware eine konjugierte priori-Dichte eine Moglichkeit (s. Abschnitt 4.3.1). Hier wollen wir jedoch einen nicht-informativen Prior ansetzen; also zum Ausdruck bringen, dass nichts uber dieZahlrate bekannt ist.

52 5 Bayes-Analysen in der Physik
Eine Moglichkeit ware die Verwendung des Jeffrey-Priors (4.26). Wir wollenallerdings berucksichtigen, dass kein Ereignis registriert wird; d. h. x = 0.Welche posteriori-Dichte hatte das bei Annahme eines Jeffrey-Priors π(r) = 1√
r
zur Folge? Wegen
∞∫0
π(r) · f(x = 0|r) dr =
∞∫0
1√re−rT dr
= 2
∞∫0
e−ξ2T dξ
=
√π
T
ist die posteriori-Dichte normierbar. Allerdings bleibt die Polstelle bei r = 0bestehen. Da das Integral
∫ r0π(r′|x = 0) dr′ nicht elementar integrierbar ist,
sind Aussagen uber die Wahrscheinlichkeit, dass die Zahlrate kleine Werte (in[0, r]) annimmt, schwierig.Wir wahlen deswegen hier eine andere Vorgehensweise, namlich das bereits inAbschnitt 4.4 erwahnte Bayes-Postulat. Eine plausibel erscheinende Annahmeist es, die Randdichte der Zufallsvariablen X als eine Konstante anzunehmen,d. h. f(x) = const.. Diese Randdichte stellt den Nenner des Bayes-Theoremsdar (s. Beweis zu Satz 2.1). Wir konnen also notieren, dass
f(x) =
∞∫0
π(r) f(x|r) dr
=1
x!T
∞∫0
(rT )xe−rTπ(r) d(rT ) = const.
Man erkennt, dass das Integral eine Gammafunktion ergibt, falls der Prior π(r)eine Konstante ist.
π(r) = const. r ∈ [0,∞)
Auffallig ist naturlich, dass dieser Prior nicht normierbar ist. Es handelt sichum eine sogenannte uneigentliche Dichte (improper prior). Oft ist die pos-teriori-Dichte allerdings dennoch normierbar, sodass das kein Problem darstellt(s. beispielsweise [Siv06] S. 124-125).Unter Verwendung von (B.10) wird der Nenner im Satz von Bayes zu 1
T. Fur
die posteriori-Dichte ergibt sich damit fur r ≥ 0:
π(r|x) =T (rT )x
x!e−rT (5.2)
Diese Verteilung sieht auf den ersten Blick wie eine Poissonverteilung aus, diemit der Messzeit multipliziert wird. Man muss sich allerdings klarmachen, dassfur x ein konkreter Wert - namlich das Versuchsergebnis - eingesetzt wird. Die
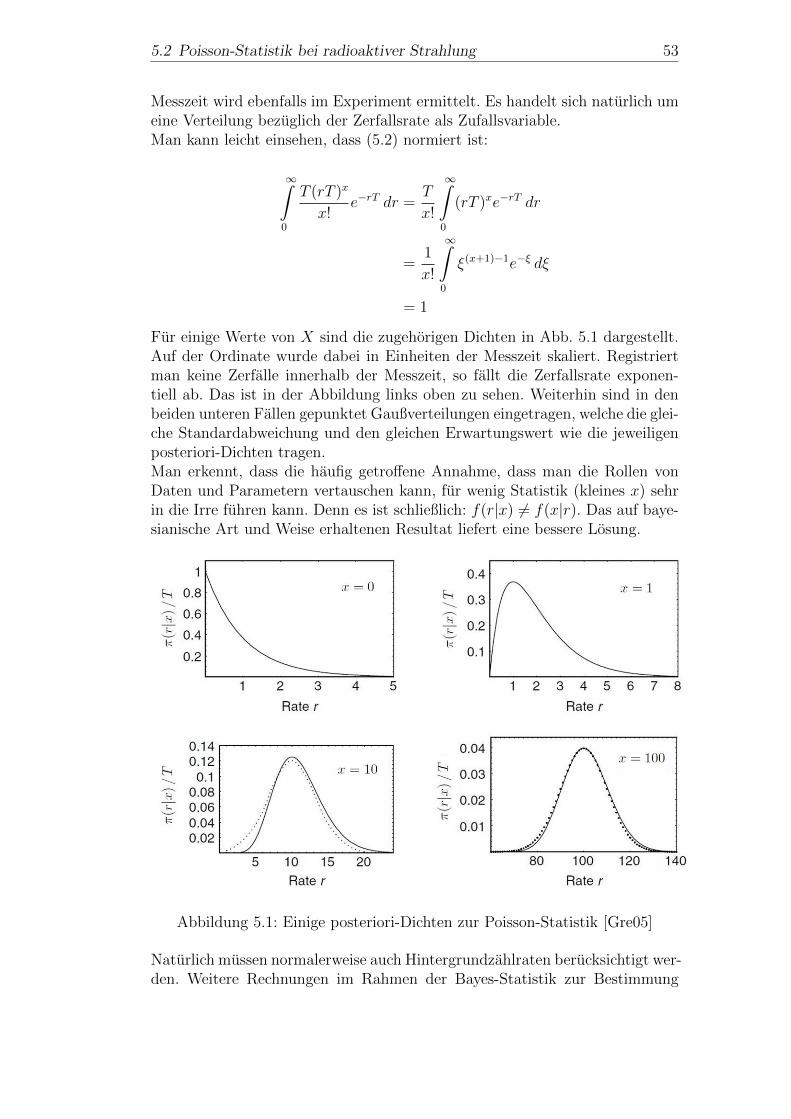
5.2 Poisson-Statistik bei radioaktiver Strahlung 53
Messzeit wird ebenfalls im Experiment ermittelt. Es handelt sich naturlich umeine Verteilung bezuglich der Zerfallsrate als Zufallsvariable.Man kann leicht einsehen, dass (5.2) normiert ist:
∞∫0
T (rT )x
x!e−rT dr =
T
x!
∞∫0
(rT )xe−rT dr
=1
x!
∞∫0
ξ(x+1)−1e−ξ dξ
= 1
Fur einige Werte von X sind die zugehorigen Dichten in Abb. 5.1 dargestellt.Auf der Ordinate wurde dabei in Einheiten der Messzeit skaliert. Registriertman keine Zerfalle innerhalb der Messzeit, so fallt die Zerfallsrate exponen-tiell ab. Das ist in der Abbildung links oben zu sehen. Weiterhin sind in denbeiden unteren Fallen gepunktet Gaußverteilungen eingetragen, welche die glei-che Standardabweichung und den gleichen Erwartungswert wie die jeweiligenposteriori-Dichten tragen.Man erkennt, dass die haufig getroffene Annahme, dass man die Rollen vonDaten und Parametern vertauschen kann, fur wenig Statistik (kleines x) sehrin die Irre fuhren kann. Denn es ist schließlich: f(r|x) 6= f(x|r). Das auf baye-sianische Art und Weise erhaltenen Resultat liefert eine bessere Losung.
Abbildung 5.1: Einige posteriori-Dichten zur Poisson-Statistik [Gre05]
Naturlich mussen normalerweise auch Hintergrundzahlraten berucksichtigt wer-den. Weitere Rechnungen im Rahmen der Bayes-Statistik zur Bestimmung

54 5 Bayes-Analysen in der Physik
der Signalzahlrate bei Berucksichtigung von Untergrundstrahlung werden hiernicht mehr gefuhrt. Man findet sie in [Gre05] auf S. 379-386.
5.3 Ausblick
Zur Zeit finden bayesianische Methoden noch keine breite Anwendung in derphysikalischen Forschung. Dem Thema wird allerdings immer mehr Bedeu-tung zugerechnet, nicht zuletzt weil moderne Versuche oft geschickte Auswer-tungsmethoden verlangen. So entwickelte z. B. das Max-Planck-Institut furPlasmaphysik (IPP) ein Verfahren zur Losung von inversen Problemen, dasGebrauch von Bayes-Statistik macht [IPP99]. Das Bayes-Theorem spielte da-bei eine zentrale Rolle, da es sich bei einem inversen Problem letzten Endes umden bereits im zweiten Kapitel angesprochenen Rollentausch handelt; sprichum die Bestimmung der Wahrscheinlichkeit P (Parameter|Daten) ausgehendvon der Likelihoodfunktion P (Daten|Parameter). Ein kurzer Artikel zu die-sem Verfahren findet man auf der Internetseite des Instituts1.
Eine weiteres Anwendungsbeispiel fur bayesianische Methoden manifestiertsich in der Software NeuroBayesr. In den vielseitig einsetzbaren Algorith-men kommen sogar konjugierte Verteilungen zum Einsatz. Naheres findet sichin [Fei04].
Abschließend bleibt zu sagen, dass standardmaßige, zur Routine gewordeneAuswertungsmethoden immer wieder auf Sinnhaftigkeit zu prufen sind. Diewichtige Frage, die es zu stellen gilt, lautet: Welche Fehler konnen durch fehlen-de Beachtung des Satzes von Bayes entstehen? Um diese Frage fur den jeweilsdurchzufuhrenden Versuch beantworten zu konnen, fuhrt - meiner Ansicht nach- kein Weg an der Auseinandersetzung mit den Grundzugen der frequentisti-schen und bayesianischen Wahrscheinlichkeitstheorie vorbei. Ich hoffe, mit derhier vorliegenden Arbeit diesbezuglich einen kleinen Beitrag geleistet zu haben.
1www.ipp.mpg.de/ippcms/de/presse/archiv/06 99 pi.html (Stand: 6.5.2011)

A Grunddefinitionen derWahrscheinlichkeitstheorie
Die folgende Liste fuhrt Grundbegriffe auf, die immer wieder benutzt werden.Sie ist jedoch keinesfalls vollstandig. Es sollen lediglich die Sachverhalte, welchefur das Verstandnis des Kernthemas dieser Arbeit von Interesse sind, erklartwerden. Die Auflistung ist in Teilen direkt aus [Sch10] entnommen (S. 4-6).
Zufallsexperiment: Ein Zufallsexperiment erfullt die Bedingung, dass es prin-zipiell beliebig oft wiederholbar ist und uber mogliche sich gegenseitigausschließende Ausgange verfugt, die allesamt bekannt sind. Dabei bleibtdas Ergebnis einer konkreten Durchfuhrung des Experimentes dem Zufalluberlassen. Typische Beispiele sind: Wurfeln, Munzwurf, Lotto-Ziehung.Es kann endlich viele, abzahlbar unendlich viele oder uberabzahlbar un-endlich viele Ergebnisse eines Zufallsexperimentes geben.
Elementarereignis: Die moglichen, sich aber gegenseitig ausschließenden Er-gebnisse eines Zufallsexperimentes heißen Elementarereignisse ω1, ω2, ...Beim Munzwurf gibt es z. B. zwei solcher Elementarereignisse - namlichKopf und Zahl.
Ergebnisraum: Die Menge aller Elementarereignisse eines Zufallsexperimentsnennt man Ergebnisraum Ω. Die Machtigkeit |Ω| bezeichnet dann dieAnzahl an Elementarereignissen.
Ereignis: Eine Teilmenge A ⊆ Ω heißt Ereignis. Ein Ereignis A kann sein:Das unmogliche Ereignis ∅ (A enthalt kein ω ∈ Ω), ein Elementarer-eignis, eine Zusammenfassung mehrerer Elementarereignisse aus Ω oderdas sichere Ereignis (A = Ω). Das Ereignis A tritt ein, wenn sich einVersuchsergebnis ω einstellt mit ω ∈ A.
Ereignisraum: Die Menge aller denkbaren Ereignisse, die sich aus dem Er-gebnisraum Ω ergeben konnen, nennt sich Ereignisraum P. Fur den Falleines endlichen oder abzahlbar unendlichen Ergebnisraums entspricht derEreignisraum P der Potenzmenge Pot(Ω) = A : A ⊂ Ω ([Jon02] S. 12).Die Anzahl an moglichen Ereignissen bei endlichen Ergebnisraumen mitN Elementarereignissen ist
|P(Ω)| =N∑n=0
(N
n
)= 2N
da es das unmogliche Ereignis ∅, das sichere Ereignis Ω und(N1
)einele-
mentige,(N2
)zweielementige,...,
(NN−1
)(N-1)-elementige Ereignisse gibt.
55

56 A Grunddefinitionen der Wahrscheinlichkeitstheorie
Zur Bestimmung des Reihenwertes wurde die Binomische Reihe verwen-det.
Laplace-Experiment: Wiederholt man ein Zufallsexperiment mit endlichemErgebnisraum Ω oft und stellt sich dabei heraus, dass alle Elementa-rereignisse nahezu gleich haufig auftreten, so spricht man von einemLaplace-Experiment.
Bernoulli-Experiment: Unter Bernoulli-Experimenten versteht man Zufalls-experimente, bei denen zwei Ausgange unterschieden werden konnen- namlich Treffer und Niete. Die Trefferwahrscheinlichkeit wird mit pbezeichnet und die Gegenwahrscheinlichkeit ist wegen (1.6) durch q =1 − p gegeben. Wichtig ist, dass p immer gleich bleibt. Bei n unabhan-gigen Durchfuhrungen eines solchen Experiments spricht man von einerBernoulli-Kette der Lange n. Ein Beispiel ware der n-fache Munzwurfmit p = 0, 5, wenn man z. B. mit Kopf den Treffer identifiziert.
Zerlegung: Die paarweise disjunkten Ereignisse An (n ∈ N) eines Ereignis-raums zu einem hochstens abzahlbaren System zerlegen den Ergebnis-raum, falls
∞⋃n=1
An = Ω
Eine andere Bezeichnung ist: Vollstandige Ereignisdisjunktion.
Unabhangigkeit von Ereignissen: Falls P (A|B) = P (A) und damit P (B|A) =P (B) fur zwei Ereignisse A, B gilt, so sind die beiden Ereignisse vonein-ander stochastisch unabhangig. Aufgrund der Definition 1.8 sind zweiEreignisse auch dann voneinander unabhangig, wenn gilt: P (A ∩ B) =P (A) · P (B), falls P (B) > 0 bzw. P (A) > 0.

B Wahrscheinlichkeitsverteilungen
Im Folgenden werden knapp die Definitionen der fur diese Arbeit relevantenWahrscheinlichkeitsverteilungen angegeben und gegebenenfalls um einige nutz-liche Informationen erganzt. Fur die grafische Veranschaulichung der Wahr-scheinlichkeitsdichten s. [Zuc04].
B.1 Diskrete Verteilungen
B.1.1 Bernoulli-Verteilung
Folgende Definition wird im Hinblick auf die Binomialverteilung angegeben.
Definition B.1 (Bernoulli-Verteilung [Zuc04])Die Bernoulli-Verteilung ist gegeben durch
PX(x) :=
1− p x = 0
p x = 1
0 sonst
(B.1)
wobei 0 < p < 1 und die Zufallsvariable X nur die Werte X = 1 (Treffer)und X = 0 (Niete) annehmen kann.
Notation: X ∼ Ber(p)
B.1.2 Binomialverteilung
Die Binomialverteilung einer Zufallsvariablen X ist gegeben durch:
P (X = k) :=
(nk
)pk(1− p)n−k k = 0, 1, 2, ..., n
0 sonst(B.2)
Notation: X ∼ B(n; p)Fur die beiden Parameter muss gelten: n ∈ N und 0 < p < 1. Am Beispiel derBinomialverteilung wird hier exemplarisch die Normierung uberpruft, sowietypische Kennwerte berechnet. Die Wahrscheinlichkeit fur das sichere Ereignismuss 1 ergeben, also:
n∑k=0
(n
k
)pk(1− p)n−k !
= 1
Mit dem binomischen Lehrsatz (a+b)n =∑n
k=0
(nk
)akbn−k kann man das sofort
einsehen.
57

58 B Wahrscheinlichkeitsverteilungen
Satz B.1 (Erwartungswert und Varianz einer B(n; p)-Verteilung)Falls X ∼ B(n; p), so gilt fur Erwartungswert und Varianz von X:
E(X) = np und D2(X) = np(1− p) (B.3)
Beweis:
Erwartungswert:
E(X) =n∑k=0
k
(n
k
)pk(1− p)n−k = np
n∑k=1
k(n− 1)!
k!(n− k)!pk−1(1− p)n−k︸ ︷︷ ︸
=1
Die Summe wird 1, da
n∑k=1
k(n− 1)!
k!(n− k)!pk−1(1− p)n−k =
n∑k=1
k · (n− 1)!
k!(n− k)!pk−1(1− p)n−1−(k−1)
=n∑k=1
(n− 1
k − 1
)pk−1(1− p)(n−1)−(k−1)
=n′∑k′=0
(n′
k′
)pk′(1− p)n′−k′
= (p+ (1− p))n′
Standardabweichung:
D2(X) =n∑k=0
(k − np)2
(n
k
)pk(1− p)n−k
=n∑k=0
k2
(n
k
)pk(1− p)n−k︸ ︷︷ ︸
np((n−1)p+1)
−2npn∑k=0
k
(n
k
)pk(1− p)n−k︸ ︷︷ ︸np
+ n2p2
n∑k=0
(n
k
)pk(1− p)n−k︸ ︷︷ ︸=1
= np((n− 1)p+ 1)− n2p2 = np(1− p)
Der erste Term berechnet sich folgendermaßen:
n∑k=0
k2
(n
k
)pk(1− p)n−k = np
n∑k=1
k(n− 1)!
(k − 1)!(n− k)!pk−1(1− p)(n−1)−(k−1)
= npn−1∑k=0
(k + 1)
(n− 1
k
)pk(1− p)(n−1)−k
= np((n− 1)p+ 1)
2

B.2 Stetige Verteilungen 59
Es gilt zudem folgender Satz (s. auch Anhang A Bernoulli-Experiment):
Satz B.2 (Bernoullisches Versuchsschema [Zuc04])Sind X1, X2, ..., Xn unabhangig und identisch Bernoulli-verteilt mit dem Para-meter p, so gilt fur die Zufallsvariable X:
X =n∑i=1
Xi ∼ B(n; p) (B.4)
B.1.3 Poissonverteilung
Definition B.2 (Poissonverteilung [Jon02])Eine Zufallsvariable X, die die Werte x = 0, 1, 2, ... mit den Wahrscheinlich-keiten
P (X = x) :=λx
x!e−λ (B.5)
annimmt, ist mit dem Parameter λ > 0 poissonverteilt.
Notation: X ∼ Po(λ)Fur Erwartungswert und Varianz gilt: E(X) = D2(X) = λ. Die Poissonvertei-lung wird bei großem λ gut durch eine Gaußverteilung approximiert.
B.2 Stetige Verteilungen
B.2.1 Gleichverteilung
Definition B.3 (Gleichverteilung [Zuc04])Eine stetige Zufallsvariable X heißt uber [a, b] gleichverteilt, falls sie folgenderDichte genugt:
f(x) =
1b−a a ≤ x ≤ b
0 sonst(B.6)
Notation: X ∼ U(a; b)
B.2.2 Normalverteilung
Die Normal- bzw. Gaußverteilung ist von uberragender Bedeutung fur die Wis-senschaft. Ein Grund dafur ist der zentrale Grenzwertsatz. Die Dichte der Nor-malverteilung lautet (x, µ ∈ R und σ > 0):
f(x) :=1√2πσ
exp
(−(x− µ)2
2σ2
)(B.7)
Notation: X ∼ N (µ;σ2)Man kann leicht zeigen, dass der Erwartungswert dieser Verteilung gleich µund die Standardabweichung gleich σ ist. Ein wichtiger Spezialfall der Nor-malverteilung ist die Standardnormalverteilung N (0; 1)

60 B Wahrscheinlichkeitsverteilungen
B.2.3 Gammaverteilung
Definition B.4 (Gammafunktion [Zuc04])Die Gammafunktion ist fur ν > 0 reell gegeben durch
Γ(ν) :=
∞∫0
tν−1e−t dt (B.8)
Die Gammafunktion hat fur reelle Zahlen x > 0 folgende Eigenschaft:
Γ(x+ 1) = x · Γ(x) (B.9)
Insbesondere gilt fur n ∈ N:
Γ(n) = (n− 1)! (B.10)
Definition B.5 (Gammaverteilung [Zuc04])Die Dichtefunktion der Gammaverteilung definiert sich, wie folgt
f(x) :=
λνxν−1e−λx
Γ(ν)x ≥ 0
0 x < 0(B.11)
Dabei gilt fur den shape-Parameter ν und fur den scale-Parameter λ:
ν > 0 , λ > 0
Notation: X ∼ G(ν;λ)
Shape-Parameter beeinflussen die Form des Graphen und scale-Parameter be-stimmen die Breite der Verteilung.Als Spezialfall der Gammaverteilung ergibt sich fur ν = 1 die Exponentialver-teilung. Sie besitzt die Dichte
f(x) =
0 x ≤ 0
λe−λx x > 0(B.12)
Notation: X ∼ Exp(λ)
B.2.4 Betaverteilung
Definition B.6 (Betafunktion [Zuc04])Die Betafunktion ist definiert durch
B(α, β) :=
1∫0
tα−1(1− t)β−1 dt (B.13)
wobei α > 0 und β > 0.

B.2 Stetige Verteilungen 61
Man kann zeigen, dass gilt:
B(α, β) =Γ(α)Γ(β)
Γ(α + β)
Definition B.7 (Betaverteilung [Zuc04])Die Dichteverteilung der Betaverteilung ist gegeben durch
f(x) :=
xα−1(1−x)β−1
B(α,β)0 < x < 1
0 sonst(B.14)
Fur die Parameter α und β muss gelten: α > 0 und β > 0
Notation: X ∼ Be(α; β)
Fur α = β erhalt man eine Verteilung die symmetrisch um die Parallele zury-Achse durch x = 0, 5 liegt.
B.2.5 Student-t-Verteilung
Definition B.8 (t-Verteilung [Zuc04])Eine Zufallsvariable X mit Dichte
f(x) :=Γ(n+1
2
)√nπ Γ
(n2
) (1 +x2
n
)−(n+1)/2
x ∈ R, n ∈ N (B.15)
besitzt eine t-Verteilung bzw. Student-t-Verteilung. Man sagt, dass X einet-Verteilung mit n Freiheitsgraden besitzt.
Notation: X ∼ tnDer Erwartungswert fur n > 1 ist null. Die t-Verteilung findet insbesonderebeim sogenannten t-Test Anwendung (s. 3.2.2).


Literaturverzeichnis
[Alb09] ALBERT, Jim (2009): Bayesian Computation with R. 2. Aufl.Dordrecht: Springer.
[Bar89] BARLOW, Roger (1989): Statistics. A Guide to the Use of StatisticalMethods in the Physical Sciences. Chichester: John Wiley & Sons Ltd.
[Bor10] BOREUX, Jean-Jacques/PARENT, Eric/BERNIER, Jacques (2010):Pratique du calcul bayesien. Paris: Springer.
[Bro06] BRONSTEIN, I. N. et al. (2006): Taschenbuch der Mathematik. 6.Aufl. Frankfurt am Main: Verlag Harri Deutsch.
[Car09] CARLIN, Bradley P./LOUIS, Thomas A. (2009): Bayesian Methodsfor Data Analysis. 3. Aufl. Boca Raton: Chapman & Hall/CRC.
[Cra09] CRAIG, Peter (2009): Bayesian Statistics III/IV. Handout on expo-nential family populations and canonical conjugate prior distributi-ons.
[Die93] DIEPGEN, Raphael/KUYPERS, Wilhelm/RUDIGER, Karlheinz(1993): Mathematik Sekundarstufe II. Stochastik. Berlin: Cornelsen.
[Dud06] DUDEN (2006): Die schriftliche Arbeit - kurz gefasst. Eine Anleitungzum Schreiben von Arbeiten in Schule und Studium. 4. Aufl. Mann-heim: Dudenverlag.
[Ebb03] EBBINGHAUS, Heinz-Dieter (2003): Einfuhrung in die Mengenlehre.4. Aufl. Heidelberg/Berlin: Spektrum Akademischer Verlag.
[Fei04] FEINDT, Michael (2004): A Neural Bayesian Estimator for Con-ditional Probability Densities. Karlsruher Institut fur Technologie(KIT). Institut fur experimentelle Kernphysik. IEKP-KA/04-05.
[Fin81] FINETTI, Bruno de (1981): Wahrscheinlichkeitstheorie. Munchen: Ol-denburg.
[Fin97] FINK, Daniel (1997): A Compendium of Conjugate Priors.
[Gel04] GELMAN, Andrew et al. (2004): Bayesian Data Analysis. 2. Aufl.Boca Raton: Chapman & Hall/CRC.
[Gho06] GHOSH, Jayanta/DELAMPADY, Mohan/SAMANTA, Tapas(2006): An Introduction to Bayesian Analysis. Theory and Models.New York: Springer.
63

64 Literaturverzeichnis
[Gre05] GREGORY, P. C. (2005): Bayesian Logical Data Analysis for thePhysical Sciences. Cambridge: Cambridge University Press 2005.
[Gro10] GROSS, Jurgen (2010): Grundlegende Statistik mit R. Eine anwen-dungsorientierte Einfuhrung in die Verwendung der Statistik SoftwareR. Wiesbaden: Vieweg+Teubner Verlag.
[Hin72] HINDERER, Karl (1972): Grundbegriffe der Wahrscheinlichkeitstheo-rie. Berlin/Heidelberg: Springer.
[IPP99] DOSE, Volker et al. (1999): Depth profile determination with confi-dence intervals from Rutherford backscattering data. In: New Jour-nal of Physics 1, 11.1-11.13.
[Jon02] JONDRAL, Friedrich/WIESLER, Anne (2002): Wahrscheinlichkeits-rechnung und stochastische Prozesse. Grundlagen fur Ingenieure undNaturwissenschaftler. 2. Aufl. Stuttgart/Leipzig/Wiesbaden: Teub-ner.
[Kle80] KLEITER, Gernot (1980): Bayes-Statistik. Grundlagen und Anwen-dungen. Berlin/New York: de Gruyter.
[Kle08] KLENKE, Achim (2008): Wahrscheinlichkeitstheorie. 2. Aufl. Ber-lin/Heidelberg: Springer.
[Koc00] KOCH, Karl-Rudolf (2000): Einfuhrung in die Bayes-Statistik. Ber-lin/Heidelberg: Springer.
[Koc07] KOCH, Karl-Rudolf (2007): Introduction to Bayesian Statistics. 2.Aufl. Berlin/Heidelberg: Springer.
[Kre90] KRENGEL, Ulrich (1990): Wahrscheinlichkeitstheorie. In: Fischer,Gerd et al. (Hg.): Ein Jahrhundert Mathematik. Festschrift zum Ju-bilaum der DMV. Braunschweig/Wiesbaden: Vieweg, S.457-489.
[Lee04] LEE, Peter M. (2004): Bayesian Statistics. An Introduction. 3. Aufl.London: Hodder Arnold.
[Mic11] MICHEAUX, Pierre Lafaye de/DROUILHET, Remy/LIQUET, Be-noıt (2011): Le logiciel R. Maıtriser le langage Effectuer des analysesstatistiques. Paris: Springer.
[Pap08] PAPULA, Lothar (2008): Mathematik fur Ingenieure und Naturwis-senschaftler Band 3. Vektoranalysis Wahrscheinlichkeitsrechnung Ma-thematische Statistik Fehler- und Ausgleichsrechnung. 5. Aufl. Braun-schweig/Wiesbaden: Vieweg.
[Pra10] HEITZ, Simon/SCHNABELE, Paul (2010): Beta-Spektroskopie.Protokoll im Rahmen des Fortgeschrittenen-Praktikums, KarlsruherInstitut fur Technologie (KIT).

Literaturverzeichnis 65
[Rob06] ROBERT, Christian P. (2006): Le choix bayesien. Principes et prati-que. Paris: Springer.
[Sch95] SCHERVISH, Mark (1995): Theory of the Statistics. New York: Sprin-ger.
[Sch10] SCHNABELE, Paul (2010): Hauptseminar: Methoden der experi-mentellen Teilchenphysik. Frequentistische und Bayes’sche Statistik.Handout zum Hauptseminarvortrag, Karlsruher Institut fur Technol-gie (KIT).
[Siv06] SIVIA, D. S./SKILLING J. (2006): Data Analysis. A Bayesian Tuto-rial. 2. Aufl. Oxford: Oxford University Press.
[Wag10] WAGNER, Helga (2010): Einfuhrung in die Bayes-Statistik. Skriptzur Vorlesung Einfuhrung in die Bayes-Statistik des Instituts fur Sta-tistik, Ludwig-Maximilians-Universitat Munchen (LMU).
[Wu97] WU, Nailong (1997): The Maximum Entropy Method. Ber-lin/Heidelberg: Springer.
[Zuc04] ZUCCHINI, Walter/BOKER, Fred/STADIE, Andreas (2004): Sta-tistik III. Skript zur Vorlesung Statistik III der Wirtschaftswissen-schaftlichen Fakultat, Georg-August-Universitat Gottingen.
Zusatzliche Quellenangaben:
• Alle nicht mit einer Angabe versehenen Grafiken in dieser Arbeit wurdenmit dem Softwareprogramm R oder Microsoft Visio erstellt.
• Aus dem eigenen Handout [Sch10] sind einige Passagen wortlich uber-nommen.


Index
σ-Algebra, 8
Additionssatz, 10Additivitat, 9Axiomensystem, 7
Baumdiagramm, 13Bernoulli-Experiment, 56Betafunktion, 60
Datenvektor, 38Dichte
bedingte, 21eindimensional, 11Rand-, 12
Effizienz, 29Ereignis
Definition, 55Elementarereignis, 55Gegen-, 9
Ereignisraum, 55Ergebnisraum, 55Erwartungstreue, 29Evidenz, 24Exponentialverteilung, 60
FamilieExponential-, 38konjugierte, 38
Gammafunktion, 60Gefangenenparadoxon, 20Gesetz der großen Zahlen, 5
Haufigkeitabsolute, 4relative, 4
Konfidenzintervall, 30Konsistenz, 29
Laplace-Experiment, 56Likelihood
Likelihoodfunktion, 28Likelihoodprinzip, 36
Likelihoodprinzip, 37
Maximum-Likelihood, 28Moment
Definition, 28Methode, 28
Nichtnegativitat, 9Normiertheit, 9
ParameterRaum, 23scale-, 60Schatzung, 28shape-, 60Vektor, 23
Parametervektor, 38Pfadregeln, 13Produktgesetz, 13
Raum der Messergebnisse, 24
Satz von Bayesfur Dichten, 21fur diskrete Großen, 15mehrdimensional, 22
Statistik, 36Suffizienz, 36Suffizienzprinzip, 37
Unabhangigkeitbei Ereignissen, 56bei Zufallsvariablen, 12
Ungleichung von Tschebyscheff, 5
VerteilungBernoulli-, 57
67

68 Index
Beta-, 60Binomial-, 57Gamma-, 60Gleich-, 59Normal-, 59Poisson-, 59Student-t, 61
Verteilungsfunktion, 11Vollstandige Ereignisdisjunktion, 56
Wahrscheinlichkeitbedingte, 13frequentistische, 4Laplace, 3totale, 13
Zufallsexperiment, 55Zufallsvariable, 11

Erklarung
Hiermit erklare ich, dass ich die vorliegende Bachelorarbeit selbststandig undnur mit Hilfe der angegebenen Quellen angefertigt habe. Dabei habe ich michan die Satzung des KIT zur Sicherung guter wissenschaftlicher Praxis in dergultigen Fassung (Stand: 12.1.2000) gehalten. Wortlich ubernommene Stellensind als solche kenntlich gemacht.
Karlsruhe, den 19. Mai 2011
















![Philosophische Aufsdtze: Eduard Zeller zu seinem funf- · 2015. 12. 24. · ['O n he pt of ] , in Philosophische Aufsdtze: Eduard Zeller zu seinem funf-zigjdhrigen Doctorjubilaum](https://img.pdfslide.us/doc/110x75/611de9219a783e1e040ac163/philosophische-aufsdtze-eduard-zeller-zu-seinem-funf-2015-12-24-o-n-he.jpg)








