Embed Size (px)
Citation preview

BalancingDesignOptionswith Sherpa
TimothySherwood�
Mark Oskin�
BradCalder�
[email protected] [email protected] [email protected]
�Departmentof ComputerScienceandEngineering,Universityof California,SanDiego
�Departmentof ComputerScienceandEngineering,Universityof Washington
Abstract
Applicationspecificprocessorsoffer thepotentialof rapidly designedlogic specificallyconstructedto meettheperformanceandareademandsof the taskat hand. Recently, therehave beenseveral major projectsthat attemptto automatethe processof transforminga predeterminedprocessorconfigurationinto a low level descriptionforfabrication.Theseprojectseitherleave thespecificationof theprocessorto thedesigner, which canbea significantengineeringburden,or handleit in a fully automatedfashion,whichcompletelyremovesthedesignerfrom theloop.
In thispaperweintroduceatechniquefor guidingthedesignandoptimizationof applicationspecificprocessors.Thegoalof theSherpadesignframework is to automatecertaindesigntasksandprovide earlyfeedbackto helpthedesignernavigatetheirwaythroughthearchitecturedesignspace.Ourapproachis to decomposetheoverallproblemof choosinganoptimalarchitectureinto asetof sub-problemsthatare,to thefirst order, independent.For eachsub-problem,we createa modelthat relatesperformanceto area.From this, we build a constraintsystemthat canbesolvedusinginteger-linearprogrammingtechniques,andarrive at an idealparameterselectionfor all architecturalcomponents.Our approachonly takesa few minutesto explorethedesignspaceallowing thedesigneror compilerto seethe potentialbenefitsof optimizationsrapidly. We show that the expectedperformanceusing our modelcorrelatesstronglyto detailedpipelinesimulations,andpresentresultsshowing designtradeoffs for severaldifferentbenchmarks.
1 Intr oduction
Thecontinuingexpansionof theembeddedmarket hascreateda significantdemandfor low-costhigh-performance
computingsolutionsthatcanberealizedwith aminimumof engineeringeffort. While dieareaandpowerconsump-
tion is aconcernwhendevelopingadesktop-processor, in theembeddeddesignworld thesefactorshaveasignificant
impacton thecost-pointandultimatefunctionalityof a product. Applicationspecificprocessorsallow a designer
to meetthesegoalsby specializingthefeaturesof theprocessorto aparticularembeddedapplication.Architectural
1

choicessuchascachesizes,issuewidth, andfunctionalunit mix canbetradedoff in thecost-energy-performance
spaceon a per-applicationbasis. Customizationmay alsoincludeextensionsin the form of customaccelerators,
for instancethe inclusionof encryptioninstructions[32]. Building embeddedprocessorstunedto a specificappli-
cationenablesa designthatminimizesareaandpower while still meetingperformancerequirements.At thesame
time,becausethedesignis basedon acarefullytestedtemplate,thedesigntime is reducedandreliability increased
significantlyover apureASIC basedapproach.
In the desktopprocessingrealmonemight take an “everythingandthe kitchensink” approach,focusingonly
onbottom-lineperformance.But in thefiercelycompetitive embeddeddomainsystemcost(area)is thedominating
factor. Smallerprocessorsmeansmoreintegrationresultingin lesspackagingcost,andlessareameansmorechips
perdieandlessdefectsperchip.
In thisspace,it is vital to determinehow to effectively divideyourareabetweentheinstructioncache,datacache,
branchpredictor, additionalfunctionalunits,andothercomponents.Thisis becausecostis thesinglemostimportant
attribute for embeddedapplications.Whendesigninga customprocessorthedesignerneedsto find thelowestcost
implementationthatmeetsthetargetperformanceconstraints,andthis problemby it’s very naturerequiresthatall
optimizationsbeviewed in concertwith all otherpartsof theprocessor. Facedwith this extremelyimportantgoal
of minimizing areaandpower, anda combinatorialnumberof designoptions,how shouldanembeddedprocessor
engineerproceed?
Thegoalof thispaperis to introducea techniquethatassiststhisprocessorengineer(or automatedcompiler)in
thenavigationof thevastapplicationspecificprocessordesignspace.It is not practicalto evaluateevery possible
alternative throughdetailedsimulation.But by building asetof estimatorsandsolversa verygoodcharacterization
of the designspacecanbe built andexplored. We presentthe Sherpaframework asa guidefor this application
specificprocessorexploration. Sherpaefficiently exploresthe custom-processordesignspacebecause,while the
spaceis non-linearandfull of localminimait is, to first order, decomposable.Customprocessorsarecurrentlybuilt
from in-orderprocessingcores[13, 26, 4, 1], andthedesignfeaturesof these,aswe will show in Section5, canbe
brokenapartandmodeledasindependentoptimizationproblems.
Sherpais a framework for exploring thesesub-problemsandrecombiningthemto find idealparametersfor the
usualprocessorfeaturessuchascaches,andbranchpredictors.It is fully general,however, andcanalsoexplore
2

whetheror not to usecustominstructionaccelerators,or variationson functionalunit type,for instancewhetherto
useaslow or fastmultiplier, or nohardwaremultiplier atall. Moresignificantly, it optimizestheseselectionsagainst
all of theotherdesignpossibilities.
The Sherpaframework begins with an applicationandcarvesup the entireprocessordesignspaceinto a set
of looselyindependentregions. Eachregion representsa logical architecturalcomponent,suchasthe data-cache
hierarchy, branchpredictor, customaccelerator, etc.Theseregionsarethentreatedasseparatesub-problemsandare
exploredusingdata-drivenanalyticalmodelsorhigh-level simulation.Theresultof theseindependentexplorationsis
asetof characterizingfunctionsthatarecombinedto form amodelof theentiredesignspacesuitablefor constrained
minimization.Thisglobalmodelis thenoptimizedthroughstandardinteger-linearprogrammingtechniquesto arrive
atdesirableparameterselectionsfor eacharchitecturalcomponent.
While integer-linear programminghasbeenwidely usedin theASIC designcommunityto automatedataflow
graphpartitioning,to ourknowledgewearethefirst to applythispowerful optimizationtechniqueto total-processor
designspaceexploration.Thesignificantresearchadvancewe contribute in this paperis thecharacterizationof the
processordesignspaceintocomponentmodels,theconstraintformalismto combinethem,andthevalidationof these
techniquesin thisenvironment.Theresearchin thispaperbridgesthegapbetweenoptimizingsmallASIC dataflow
graphs,and completeprocessordesigns;it lays the foundationfor optimizationof more complex architectures.
Additionalcontributionsof thispaperare:
� An automateddesignspacesurveyor for embeddedin-ordercustom-processors.
� A methodologyto approximatevariousdesignoptionsfor processorfeatureswith piece-wiselinearfunctions
relatingareato performance.
� An integer-linearprogrammingformulationfor combiningthesesub-problemsusingthesepiece-wiselinear
functions.Thisprovidesanapproachfor rapidlyfinding idealparametersfor theprocessorarchitecture.
� An in-depthanalysisof tradingoff performanceandareaagainsteachother. This leadsto theresultthatwhen
holistically designinga processor, insteadof focusingonly on a singlecomponent,areaand performance
optimizationscanbeusedto thesameeffect.
3

� A demonstrationof usingSherpato decidewhetherto usea custominstructionaccelerator. For our purposes
weillustratethiswith thedesignchoiceof whetheror not to useahardwaremultiplier, however, thetechnique
generalizesto any custominstructiononeis trying to decidewhetheror not to includein adesign,andseveral
differentalternativescanbeevaluatedat thesametime.
� A demonstrationof how to useSherpato quickly evaluatethepotentialbenefitof anarchitecturaloptimiza-
tion. As a casestudywe examinethe useof applicationspecificfinite statemachinepredictorsfor branch
prediction[25].
2 DesignNavigation
Therearecurrentlyseveral commercialventuresthat offer customizableRISC processors[13, 26, 4] suchasthe
XTensaprocessorfrom Tensilica[13]. Tensilicaprovidessupportfor XTensain termsof compilation,synthesis,and
verification[21]. Embeddeddesignersusethesetoolsby providing a high level specificationfor a processorcore.
Producedfrom themis a componentreadyfor integrationontoa systems-on-a-chip(SOC)product.While this is a
significantadvancementfor customizedprocessors,thedesigneris still for themostpartunassistedin determining
theoptimalprocessorspecificationfor their embeddedapplication.This is whereour researchis focusedwith the
Sherpaframework.
In thissectionwediscussthetypicaldesignflow usedwhengeneratingacustomizedprocessor. Wethenillustrate
whereSherpaintegratesinto thisworkflow to provide rapidfeedbackanddesignoptimization.
2.1 ProcessFlow for Creatingan Application SpecificProcessor
We will discussthe workflow usedto createan applicationspecificprocessor, andthenhow Sherpaenhancesit.
For concretenessour discussionwill focuson the processusedfor systemssimilar to the XTensaprocessorfrom
Tensilica,however, Sherpacanalsobeusedby moreautomatedtool-chainssuchasthoseproposedfor thePICO[1,
2] customprocessor(discussedfurtherin Section6). Thecurrentdesignprocess,asfollows,involvesseveraliterated
stepsto find anoptimizedprocessorconfiguration:
4

A�
ppl i�cation S
�ource Code Binary Re q� uirements
S�
he r� pa De s� ign G
uide
S�
ynthe s� is E m u lation
costl y� feedbac k
earl y� feedback
earl y� use of requi r� ements
Figure1: TheApplicationSpecificProcessordesignflow with theSherpadesignguide.Sherpaminimizesthenum-berof timesthedesignmustbe iteratedon. This allows thedesignerto spendtheir time optimizingthealgorithmsusedor theway they arecodedinsteadof having to iterateover thedesignspace.
Auto mated Profi li n g
S�
ub-Pro b�
le m C�
harac t�erizat ion
Data Lineariz a� tion
C�
onst r� aint S�
yste m� Buildin g
Arch it e� c� tura l Te m p� late
S�
ub-Pro b�
le m Pe rformance Mapp ing
C�
onst raint Ex p� loration
ILP S�
olve r� Post-S o� lve
Visua lizatio n
S�
pe c� if icat ions
From Bin ary Req uire ments
Feedb ack from De taile d Evalu ation
Figure2: Overview of theSherpadesignguideimplementation.Thesystemstartswith theinput binaryandthesetof requirements.Thebinaryis profiledandthedifferentsub-problemsareanalyzed.In thedatalinearizationstagea setof piecewise linear functionsarebuilt for eachsub-problem.These,alongwith anautomaticallyconstructedperformancemodel,areconvertedinto a constraintsystemwhich is solved usinginteger-linear programming.Asetof differentconstraintscanthenbe iteratedover. The outputof the solver canthenbe visualizedfor humanexaminationandconvertedinto asetof processorspecificationsfor useby synthesis.
1. The embeddedapplicationis provided in a high-level sourcelanguage,suchasC or Java. Thedesignteam
determinesperformancetargets,e.g.pagerendersperminute,or framespersecond.
2. Theapplicationis compiledto a binary, or in somecasesseveraldifferentbinariesdependinguponthearchi-
tecturaloptions(availableregisters,instructions,etc).
3. Profilesof the applicationon the target platform are generatedfrom simulation. Theseprofiles focus the
designteamseffort on applicationand architecturalbottlenecks.Architecturalchangesinvolve a lengthy,
manualenumerationof thepotentialoptionssuchascacheandbranchtablesizesin anattemptto find anideal
configuration.
4. Thedesignteamthencreatesa new binarycompiledto thepotentialarchitecturalchoicesfrom theprevious
step.Theprocessorspecificationis passedthroughthebackendtoolset,which generatesanRTL description
5

of thecustomprocessor.
5. The binary is then re-simulatedon the new customprocessorand the entire processis iteratedto further
optimizetheconfiguration.
The above process,whendonemanually, can be tediousand time consuming. It leaves to the designerthe
choiceof whatarchitecturaloptionsto modify by guessingthepossibleoutcomeprior to executinga lengthytool-
chainandsimulationstep.Unfortunately, theentirespaceof designoptionsfor a configurablecoreis vastin both
performanceandcost. Furthermore,this searchspaceis filled with local optimasrequiringsomethingmoreclever
thanastraightforwardgreedyapproach.
2.2 UsingSherpa to Guide Design
While engineerscanperformtheabove processby hand,they needto first spendsignificanttimebecomingfamiliar
with thetargetapplication,andthenmustquantifythebehavior of theprogramthroughexhaustive experimentation
andanalysis.We insteadprovide Sherpaasanautomatedsystemto examineprogrambehavior andsuggestnear-
optimal (which areoften optimal) designdecisions,allowing the designerto make informeddecisionsearly and
experimentwith different optimizations. In addition, Sherpaalso allows the designerto more easily deal with
processordesigntradeoffs resultingfrom latechangesto theapplication.
Figure1 shows theapplicationspecificdesignflow whenusingtheSherpadesignguide.Thegoalof theSherpa
designnavigator is to allow its userto make designtradeoffs early in the explorationphaseandquickly narrow
in on thebottlenecksof a system.Sherpaanalyzestheapplicationcodefrom theexisting customprocessordesign
workflow andquickly searchestheentirearchitecturaldesignspacefor globaloptima.Theembeddedproductdesign
teamthenusesthis informationto narrow in on thefinal customprocessorarchitecture.
Figure2 shows theinternalprocessof theSherpaDesignGuide(thegraybox)shown in Figure1. Sherpatakes
the input application,andprofilesit to generatea setof representative traces.Next, Sherpadecomposesthe vast
customprocessordesignspaceinto a setof independentsub-problems(e.g.,datacache,branchpredictor, etc). The
applicationtraceis thenusedto initiate thesemodels.Finally, Sherpacombinesthemodelsusinganinteger-linear
program(ILP) solver to locatea globally ideal customprocessorarchitectureconfiguration. This configuration,
6

alongwith thedesigntradeoffs Sherpamade,is thenpassedbackto thedesignerfor examination.Thedesignercan
thenfocusattentionon thesignificantarchitecturalcomponentsandapplicationsections.
3 Implementation
We now describethe implementationof a DesignNavigator, Sherpa,beginning with a descriptionof our overall
approachand a descriptionof the target architecture,and finishing with a detailedevaluationof the algorithms
used.We usethedesignnavigator to find idealsizingsfor instructionanddatacache,branchpredictionlogic, and
multiplier settings.
3.1 Overall Approach
Our initial implementationis basedon a constraintsystemthatexpressestheentirerangeof architecturaloptions.
The constraintsystemis structuredso that a integer-linear solver will find an optimal solutionfrom the possible
designoptionswhile maintaininghardconstraints,suchasperformanceneeds,but at thesametime optimizingfor
designgoals(suchasarea).
Ourapproachinitially treatseachcustomizablecomponentseparately. Foreachcomponent,anarea-performance
modelis developedby simulatingavarietyof componentconfigurationswith arepresentative instructiontrace.This
collectionof area-performancemodelsis thencombinedwith integer-linearprogrammingandsolvedtoyieldanideal
overall processorconfiguration.Beforediscussingthedetailsof this processwe wish to describethecustomizable
processorwearetargetingin moredetail.
Thispaperoptimizesa customizablearchitecturesimilar to thein-orderXTensaProcessor[13]. Thereasonthat
we have chosento usethis processormodelis that the work doneby Tensilicais matureenoughthat they have a
workabledesignpathfrom processorspecificationall thewaydown to silicon. They areableto dothisbecausethey
work with theCAD tool designsfurtherdown thedesignchainto insurethattheparameterizedprocessorsthey build
will beableto besynthesizedinto anefficient form. TheSherpaguidecanbeusedasanautomatedfront endto the
XTensadesignprocessto guidetheselectionof idealparametersof thedifferentcomponents.
The parameterizedprocessorwe model is a single issuein-order32-bit RISC corewith parameterizabledata
7
MINra
Are
a
Penalty
raMAXra
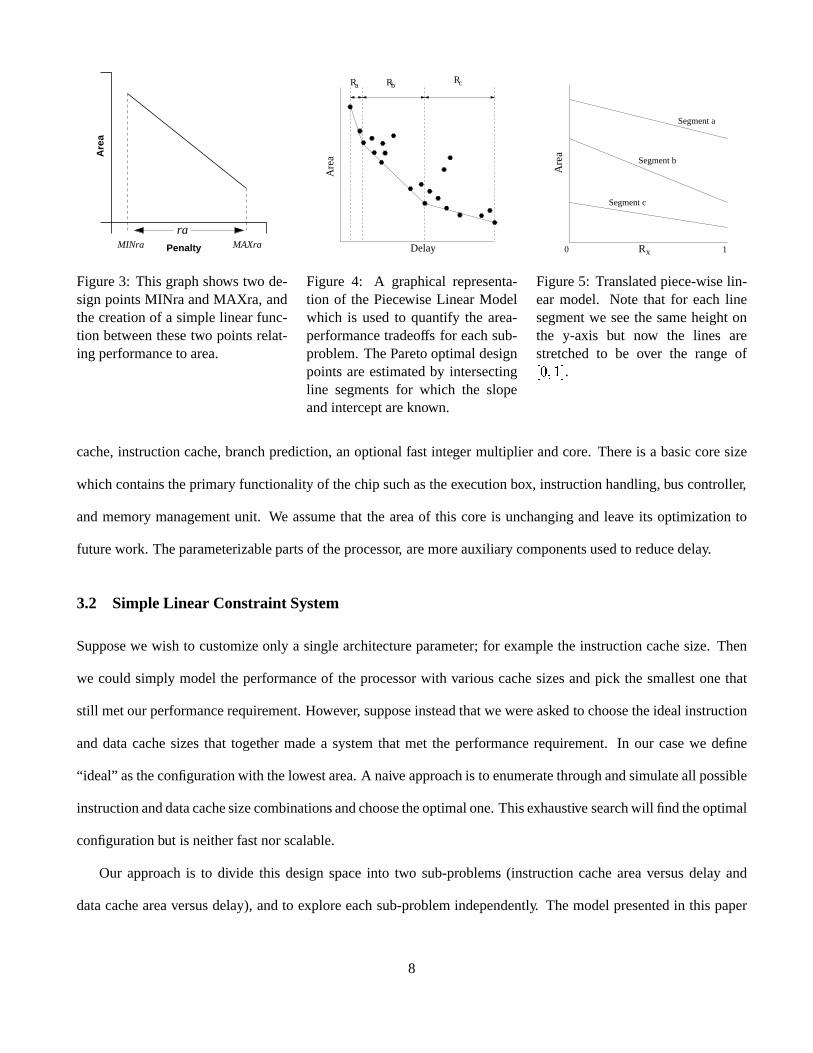
Figure3: This graphshows two de-signpointsMINra andMAXra, andthecreationof a simplelinear func-tion betweenthesetwo pointsrelat-ing performanceto area.
aR c
Are
a
Delay
RbR
Figure 4: A graphical representa-tion of the Piecewise Linear Modelwhich is usedto quantify the area-performancetradeoffs for eachsub-problem.TheParetooptimaldesignpointsareestimatedby intersectingline segmentsfor which the slopeandinterceptareknown.
x
Are
a
0 1R
Segment a
Segment b
Segment c
Figure5: Translatedpiece-wiselin-ear model. Note that for eachlinesegmentwe seethe sameheightonthe y-axis but now the lines arestretchedto be over the range of� ����� �
.
cache,instructioncache,branchprediction,anoptionalfastinteger multiplier andcore. Thereis a basiccoresize
which containstheprimaryfunctionalityof thechipsuchastheexecutionbox, instructionhandling,buscontroller,
andmemorymanagementunit. We assumethat the areaof this coreis unchangingandleave its optimizationto
futurework. Theparameterizablepartsof theprocessor, aremoreauxiliarycomponentsusedto reducedelay.
3.2 SimpleLinear Constraint System
Supposewe wish to customizeonly a singlearchitectureparameter;for examplethe instructioncachesize. Then
we could simply modelthe performanceof the processorwith variouscachesizesandpick the smallestonethat
still metourperformancerequirement.However, supposeinsteadthatwewereaskedto choosetheidealinstruction
anddatacachesizesthat togethermadea systemthat met the performancerequirement. In our casewe define
“ideal” astheconfigurationwith thelowestarea.A naiveapproachis to enumeratethroughandsimulateall possible
instructionanddatacachesizecombinationsandchoosetheoptimalone.Thisexhaustivesearchwill find theoptimal
configurationbut is neitherfastnorscalable.
Our approachis to divide this designspaceinto two sub-problems(instructioncacheareaversusdelay and
datacacheareaversusdelay),andto exploreeachsub-problemindependently. Themodelpresentedin this paper
8

approximatestheperformancepenaltyfrom a sub-problemasa fixedlengthprocessorstall,wherethis stall affects
theentirepipeline. For example,a cachemisscanberepresentedasa fixed50 cycle processorstall, anda branch
mispredictionasa 6 cycle stall. Even thoughall of thesub-problemswe examinearenot completelyindependent
(e.g.,branchpredictionand instructioncachedelays)the probability of thesedelaysoverlappingfor an in-order
processoris small for theprogramswe examined.We measuredtheamountof dependencebetweenthedifferent
subproblemsusingdetailedcycleaccuratesimulationandfoundit to benegligible. This issueis discussedfurtherin
Section5.
By allowing ourselvesthesimplifying assumptionthat theseareindependentsub-problemswe canexpressthe
overallperformanceof ourexampletwo parameterprocessorby Equation1:
!#"�$&%('*),+-!�./'10&2435!#67'*%('189%('*):);35!#<>=90?%A@>89%('*)B)(1)
where CEDGF>HAIKJ is the total executiontime of the program, CML IONQP is the time to executethe programassuming
a perfectmemory, and the stalls for both the datacacheand instructioncacheare addedfor the corresponding
configurationsbeingconsidered.
In orderto comparethedifferentconfigurations,we needto createa functionthat relatesareato performance.
Figure3 shows theperformanceversusareafor two cacheconfigurationschosenfor thedatacache.For purposesof
illustration,we assumethis is a simplelinearfunction;thenext sectionintroducesmorerealisticmodels.Giventhe
two pointsin Figure3, thecontribution to processorstall from thecachecanbeexpressedin termsof its structurevia
theequationC4RSHAIKJTJGUWVYX[Z]\S^�_ , whereV is aconstant.Performingthisoperationonbothsub-problemscreatestwo
independentlinearfunctionsthatrelateperformanceto areathatmustbecombinedto find theidealbalancebetween
thetwo. Rewriting Equation1 weget:
! "�$&%('*) +`! ./'10&2 3badc 67'*%('fehgjilknmo6p'*%('lq 3badc <>=90?%A@rehgjilknmo<*=s0t%A@ q(2)
UsingthisequationwesetaperformanceconstraintCGDEFQHAIOJMuvC/w IKx , andsolve for thetwo unknowns: Z]\S^�_�y I1HAI9

and Zz\S^�_|{~} N&H�� . Thegoal is to maintainthis performanceconstraintwhile minimizing thearea,which is expressed
as:
�����#�?���t� k��sg�ilk m "�$&%('~),+ gjilknm 67'*%('j3 gjilknm <*=s0t%A@(3)
Theresultof this formulationis asystemof linearequationsandanoptimizationcriteria.Thiscanbeeffectively
solved usinglinear programmingtools. Commercialsolvers from CPLEX areavailable,but we found the freely
availablelpsolvetool to besufficient [6].
3.3 Data Linearization
The previous exampleof finding the ideal balancebetweena setof instructionanddatacacheconfigurationsre-
lied uponthe assumptionthat thereis a strict linearequationto representcacheareato performance.Clearly this
assumptionis simplisticandwemustsupportamorecomplex area-performancemodel.
For this we turn to a piece-wiselinear approximationof the actualfunction. To form this approximationwe
begin by identifying Pareto-optimaldesignpoints. A point � is saidto bePareto-optimal(on theaxis in Figure4)
if thereis no point ��� suchthat ��� requireslessareaandincurslessstall time. Intuitively, if a point is not Pareto-
optimal thenthereis anotherdesignpoint that will achieve asgoodor betterperformancewith lessarea.We use
thesePareto-optimalpointsto helpform a piece-wiselinearapproximationof thearea-performancefunction.
Startingfrom thePareto-optimaldesignpointswegreedilyconstructstraightline segments.A point is addedto
a line segmentif thecorrelationbetweenthatline segmentandall thepointsthatapproximateit doesnotdropbelow
a threshold.The correlationcoefficient, \ , providestheextent to which theboundingPareto-optimalpointsbeing
consideredlie onastraightline. For theresultswepresentin thispaperwe insurethat \ is alwaysgreaterthan0.98.
Whenthe correlationcoefficient dropsbelow this threshold,a new line segmentis started.To insurethat the line
segmentsalwaysintersect,thelastdatapoint includedin a givensegmentis alsoincludedin thenext segment.
Theresultof piecewise linearizationcanbeseenin Figure4. ThepointsthatarePareto-optimalareconnected
by line segmentsthatcapturetheoverallarea-performancetrend.In thisexamplethreeline segments� I , ��� and ���
10

make up theentirepiece-wiselinearapproximation.Ourgoalnow is goingto beto modify theconstraintsystemto
usethesefar moreprecisesub-problemmodels,whichwedescribenext.
3.4 Final Constraint System
A mixedinteger-linearprogramis similar to a linearprogramexceptthatsomevariablesareoptionallyconstrained
to bewholenumbers.Solvinga mixed integer-linear programasopposedto a linearprogramis a straightforward
process.Werefertheinterestedreaderto [17] for detailson theinternalsof this algorithm.
Tocreateourmixedinteger-linearconstraintsystem,thefirst stepis to includeeachpiece-wiselinearfunctionfor
eachsub-probleminto theconstraintsystem.This is performedby breakingupeachline-segmentof thepiece-wise
linearapproximationsinto separatecomponents.Theseline segmentsarethentranslatedto have a uniform length
andstartingpointalongthehorizontalaxis.Figure5 depictsthesamepiece-wiselinearfunctionfrom Figure4 after
translationis performed.For eachpiece,we generatethe functionsfor delayandareawherethe functionfor area
anddelayhasbeennormalizedbetweenzeroandone.
Thelinearfunctionfor areais calculatedas
Zz\�^s_ x U��h_��9^sZ]\S^�_ x������?� �E^�Zz\S^�_ x�� � x , andthefunctionfor delayis calculatedas C]�& ¡^ x U��h_��9^lC]�& ¡^ xf����?� �E^nCz�& ¡^ x�� � x . In bothof theseequations,� x is adesignpointwith avaluebetweenzeroandone. ��_��o^�Zz\�^s_ xand �h_|�o^nC]�¢ ¡^ x arethestartareaandtime for eachlinearpiecein Figure4.
Oncedistilled into separateline-segmentsweconstructamixedinteger-linearprogramwhereonly asingleline-
segment(from thepiece-wiselinear function) is selectedfor eachsub-problem.Thesingleline-segmentis chosen
using integer programming.To illustrate,Figure6 depictsa new constraintsystemwith theseconstraints.This
constraintsystemworks by choosinga tuple £��¢� x � � x;¤ with Equation4. �Q� x is an integer valueof either zero
or one. � x is a linear valuebetweenzeroandone. This tuple selectswhich line segmentto usewith the integer
variable�¢� x , andthedesignpointwithin thatline-segmentto examineusingthevariable� x . Equation4 cannotbe
implementeddirectly, andwedescribenext how to constructit usingintegerandlinearconstraints.
Equations5 and6 performa line segmentselectionfor thesub-problemby ensuringthatonly oneline segment
is selected,sinceeach�¢� x canonly have a valueof 0 or 1. Equation5 insuresthatonly one �Q� x will beequalto
one,andall therestwill beequalto zero.Sincewe normalizedthelinearfunctionsto representtheareaanddelay
11

a(�?¥§¦�¨>¥©¦ q +-ªr«¬l¬�® kn¯ � k a¢°oa��t¥r±n¨Q¥r± q ¨Oa(�?¥§²�¨>¥©² q ¨K³´³´³T¨ aA�t¥©=�¨>¥©= q~µnq(4)
�t¥ ± 3¡�t¥ ² 3¶³´³T³n35�t¥ = +¸·(5)�?¥r±©¹`ºS¨��?¥§²�¹»º;¨¼³´³´³r¨��t¥§=�¹`º(6)
º�½ ¥ ± ½»�t¥ ±(7)º�½ ¥§² ½»�t¥§²(8)³T³´³
º�½ ¥©= ½»�t¥§=(9)
º�½ !j�?� k @*2&¾¢¿ À´@*2&Á�ÂÃ!���� k*Ä 2t@*Ån2&Æ�%(10) a(Ç m ® k !j�?� k ±EÈp�t¥r±43¡ÉMÊ(¬*Ë k !j�?� k ±GÈÌ¥r± q
 a(Ç m ® k !j�?� k ²4Èp�t¥§²73¡ÉMÊ(¬*Ë k !j�?� k ²/ÈÌ¥§² q ³T³´³Â a(Ç m ® k !j�?� kn= Èp�t¥ = 3»É4Ê(¬*Ë k !���� kn= ÈÌ¥ =q
�����#�?���t� k§� a(Ç m ® kngjilknm ±7Èp�t¥�±43»É4Êd¬*Ë kngjilknm ±4ÈÌ¥�± q(11)3 a(Ç m ® kngjilknmͲ Èp�t¥ ² 3»É4Êd¬*Ë kngjilknmͲ ÈÌ¥ ² q
3 ³´³T³3 a(Ç m ® kngjilknmÍ= Èp�?¥ = 3¡É4Êd¬*Ë kngjilknmÍ= ÈÌ¥ =Sq
Figure6: Constraintsystemfor apiece-wiselinearsub-subproblemmodel.
usingavariablebetween0 and1, weareableto reusethevariable�¢� x to subtlyconstraintheselectionof thedesign
point � x . This is shown in Equations7 - 9, wherethedesignpointsalongthechosenline segmentareexamined.
Oncea given tuple is selected,the translated�h_|�o^ IK�*P>IlÎ H�Ï w P and ���?� �E^ I1�~PQI�Î H�Ï w P valuesareusedto determine
performanceimpactandareacostof thechoice.Themodifiedperformanceboundis illustratedin Equation10 and
thenew minimizationgoalis shown in Equation11.
Figure 6 shows only the constraintsystemfor one sub-problem. To generatethe overall constraintsystem
to examinethe trade-offs betweenmultiple sub-problems,eachsub-problemhasits own constraintsto choosean
�¢� x and � x particularto that sub-problemusingequationssimilar to thoseshown in Equations5 - 9. The time
delayfor eachsub-problemis subtractedfrom Equation10, andtheareadelayfor eachsub-problemis addedinto
Equation11. Thentheoverall systemis run throughtheconstraintsolver to minimize thearea,while meetingthe
12

specifiedC]�¢ ¡^l�~PQÐ>Ñ�ÏÒ�~P>Ó .
4 Sub-problem Characterization
In the previous sectionswe presentedour generalmethodologyof partitioningthe completeapplicationspecific
processordesignspaceinto a setof looselyindependentsub-problems.In this sectionwe discussthesub-problems
we exploredandhow we modeledthem. Thesub-problemsof thedesignspacethatwe choseto explore in depth
aretheinstructionanddatacaches,thebranchpredictorconfiguration,andwhetheror not to includea fasthardware
multiplier. Thegeneralmethodologyfor constructingeachof thesemodelsis to exploreasamplingof pointsthrough
directsimulationandthenconstructpiece-wiselinearmodelsfrom theParetooptimaldesignpoints.
For a givensubproblem(e.g.,branchpredictor)we cantradeoff multiple designs(gshare,bimodal,2-level) by
plotting themall on thesameParetograph.Thepiece-wiselinearmodelbuilt from thatgraphrepresentsthe ideal
designto usefor a givenperformance/areapoint. Thesameapproachwould betakenif we wereto have theoption
of differenttypesof acceleratorsfor agiveninstructionor setsof instructions.
In thissectionwedescribehow weestimatetheareafor eachdesignpointconsideredaswell ashow to calculate
theperformancepenaltyfor thatconfigurationfor thetracebeingexamined.
4.1 Data and Instruction Cache
We startwith anexaminationof thecachesin our architecture.As will beseenlater in Section5.2, thecachesare
thedominantconfigurableareaof anapplicationspecificprocessor. Becauseof this it is imperative thatthemodels
correctlycapturethearea-performancetradeoffs sincethey arethefirst orderdeterminantof theoverallaccuracy of
our technique.
Cachedesignis a well-studiedproblemin computerarchitecture,andwe wish to build uponpastwork in this
areawhereappropriate.ReinmanandJouppi[23] presenta very detailedcachedesignspacewalker basedon the
work presentedin [31]. CACTI, whengiven a setof cacheparameters,suchasassociativity andcachesize,will
find the delayoptimal cachearraypartitioningscheme(i.e. the fastedphysicaldevice layout for the given cache
parameters).Mulder [20] presentsa validatedareamodelfor cachesandregisterfiles. For our researchwe usethe
13
0Ô
500Ô
1000Ô
1500Ô
2000Ô
Delay (ps)Õ0
2000
4000
6000
8000
10000
12000
Are
a (r
be)
Pareto Optimal Points
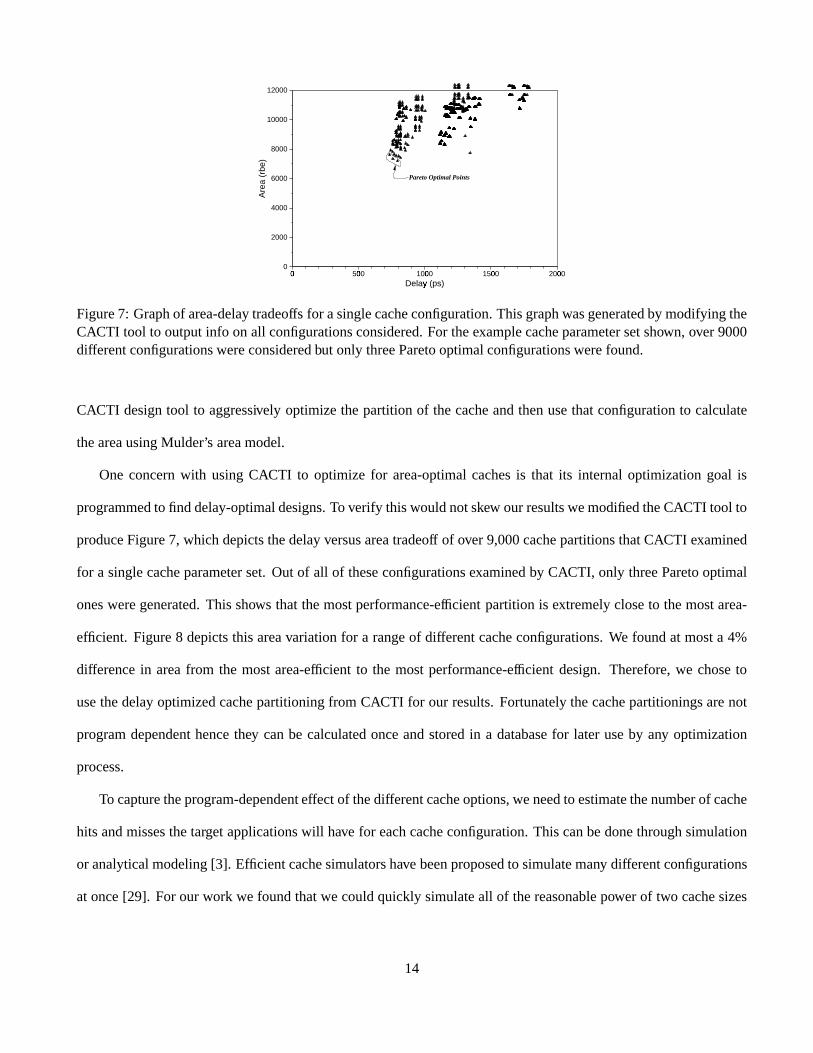
Figure7: Graphof area-delaytradeoffs for asinglecacheconfiguration.Thisgraphwasgeneratedby modifyingtheCACTI tool to outputinfo on all configurationsconsidered.For theexamplecacheparametersetshown, over 9000differentconfigurationswereconsideredbut only threeParetooptimalconfigurationswerefound.
CACTI designtool to aggressively optimizethe partitionof thecacheandthenusethatconfigurationto calculate
theareausingMulder’s areamodel.
One concernwith using CACTI to optimize for area-optimalcachesis that its internal optimizationgoal is
programmedto find delay-optimaldesigns.To verify thiswouldnotskew ourresultswemodifiedtheCACTI tool to
produceFigure7, which depictsthedelayversusareatradeoff of over 9,000cachepartitionsthatCACTI examined
for a singlecacheparameterset. Out of all of theseconfigurationsexaminedby CACTI, only threeParetooptimal
onesweregenerated.This shows that themostperformance-efficient partitionis extremelycloseto themostarea-
efficient. Figure8 depictsthis areavariationfor a rangeof differentcacheconfigurations.We foundat mosta 4%
differencein areafrom the mostarea-efficient to the mostperformance-efficient design. Therefore,we choseto
usethedelayoptimizedcachepartitioningfrom CACTI for our results.Fortunatelythecachepartitioningsarenot
programdependenthencethey canbe calculatedonceandstoredin a databasefor later useby any optimization
process.
To capturetheprogram-dependenteffectof thedifferentcacheoptions,weneedto estimatethenumberof cache
hits andmissesthetargetapplicationswill have for eachcacheconfiguration.This canbedonethroughsimulation
or analyticalmodeling[3]. Efficientcachesimulatorshave beenproposedto simulatemany differentconfigurations
at once[29]. For our work we foundthatwe couldquickly simulateall of thereasonablepower of two cachesizes
14
Size/Assoc 1 2 4 8
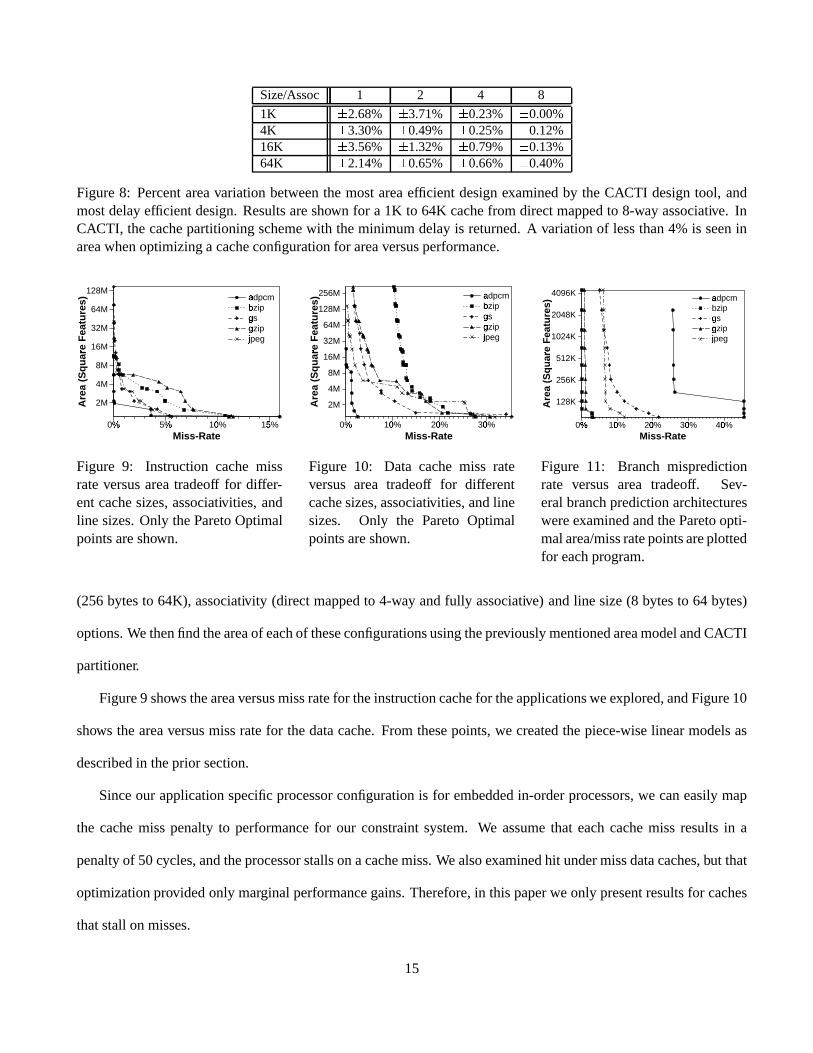
1K Ö 2.68% Ö 3.71% Ö 0.23% Ö 0.00%4K Ö 3.30% Ö 0.49% Ö 0.25% Ö 0.12%16K Ö 3.56% Ö 1.32% Ö 0.79% Ö 0.13%64K Ö 2.14% Ö 0.65% Ö 0.66% Ö 0.40%
Figure8: Percentareavariationbetweenthe mostareaefficient designexaminedby the CACTI designtool, andmostdelayefficient design.Resultsareshown for a 1K to 64K cachefrom directmappedto 8-way associative. InCACTI, thecachepartitioningschemewith theminimumdelayis returned.A variationof lessthan4% is seeninareawhenoptimizinga cacheconfigurationfor areaversusperformance.
0%× 5%× 10%Ø 15%ÙMiss-Rate
2M
4M
8M
16M
32M
64M
128M
Are
a (S
qu
are
Fea
ture
s)
Ú
adpcmÛbzipÜgsÝgzipÝjpegÞ
Figure 9: Instruction cachemissrateversusareatradeoff for differ-entcachesizes,associativities, andline sizes.Only theParetoOptimalpointsareshown.
0%× 10%Ø 20%Ø 30%ØMiss-Rate
2M
4M
8M
16M
32M
64M
128M
256M
Are
a (S
qu
are
Fea
ture
s)
Ú
adpcmÛbzipÜgsÝgzipÝjpegÞ
Figure 10: Data cachemiss rateversus area tradeoff for differentcachesizes,associativities,andlinesizes. Only the Pareto Optimalpointsareshown.
0%ß 10%à 20%à 30%à 40%àMiss-Rate
128K
256K
512K
1024K
2048K
4096K
Are
a (S
qu
are
Fea
ture
s)
á
adpcmâbzipgsãgzipãjpegä
Figure 11: Branch mispredictionrate versus area tradeoff. Sev-eralbranchpredictionarchitectureswereexaminedandtheParetoopti-malarea/missratepointsareplottedfor eachprogram.
(256bytesto 64K), associativity (directmappedto 4-way andfully associative) andline size(8 bytesto 64 bytes)
options.Wethenfind theareaof eachof theseconfigurationsusingthepreviouslymentionedareamodelandCACTI
partitioner.
Figure9 showstheareaversusmissratefor theinstructioncachefor theapplicationsweexplored,andFigure10
shows theareaversusmissratefor thedatacache.Fromthesepoints,we createdthepiece-wiselinearmodelsas
describedin theprior section.
Sinceour applicationspecificprocessorconfigurationis for embeddedin-orderprocessors,we caneasilymap
the cachemisspenaltyto performancefor our constraintsystem. We assumethat eachcachemiss resultsin a
penaltyof 50cycles,andtheprocessorstallsonacachemiss.Wealsoexaminedhit undermissdatacaches,but that
optimizationprovidedonly marginal performancegains.Therefore,in this paperwe only presentresultsfor caches
thatstall onmisses.
15

4.2 Branch Predictors
To examinethe customdesignspacefor branchpredictionwe examineselectingfrom the following well know
branchpredictors:(1) a tableof 2-bit counters,(2) a globalcorrelationpredictor, and(3) a metapredictorthatuses
bothlocalandglobalcorrelationinformation.
We examinethebranchpredictionmissratefor thesedifferentpredictorsfor a varietyof tablesizes.Figure11
shows the areaversusmissratefor the Paretooptimal points in the differentprogramsexamined. For all of the
programsexaminedthe mostareaefficient branchpredictordesignwasthe tableof 2-bit predictorssimilar to the
oneusedin theXScaleembeddedprocessor[18]. To achieve betterperformance,significantresourcesareneeded
by theotherpredictormethods.For example,the Paretocurve for adpcm choosesa per-branch2-bit for the low
areapoints,anda metapredictorfor higherarea. It shows that the per-branch2-bit countersgive the lowestmiss
ratefor anarealessthan128K squarefeatures,anda metapredictorgave thebestmissratefor anareagreaterthan
128K.In crossingthisdesignboundarytheareais increasedabove128K,but themispredictionrateis reducedfrom
45%down to 26%.
The mispredictionratemeasuredhereis usedto calculatethe performancepenaltyfor our in-orderprocessor
model.By assuminga6 cyclestall for eachbranchmisprediction,andknowing how many brancheswemispredict,
wecanestimatethetotal numberof stall cyclesincurredby thebranchpredictor.
4.3 Multiplier Unit
Thelastconfigurableoptionweexaminedwasaprocessorwith andwithouta largefasthardwaremultiplier instead
of themuchsmallerandslower iterativemultiplier. This is modeledby countingthenumberof multiply instructions
executedin eachprogram. The reasonthat we have chosenthis configurableoption is to show that our design
optimizationtechniquecanalsocleanlyhandlebinary decisionssuchaswhetheror not to includea specialized
functionalunit. While decidingwhetheror not to usea fastmultiplier is a binarydecision,in anoverall context the
decisionis complicatedby thefact that its usefulnessmustbetradedoff againstother, non-binarydecisions.Thus,
theactualdecisionis extremelydifficult to answerby conventionaltechniques.
We modela hardwaremultiplier in the following way: if the fasthardwaremultiplier is used,thena multiply
16
0å
2æ
4ç
6è
Estimated CPIé0
2
4
6
Act
ual
CP
I
ê
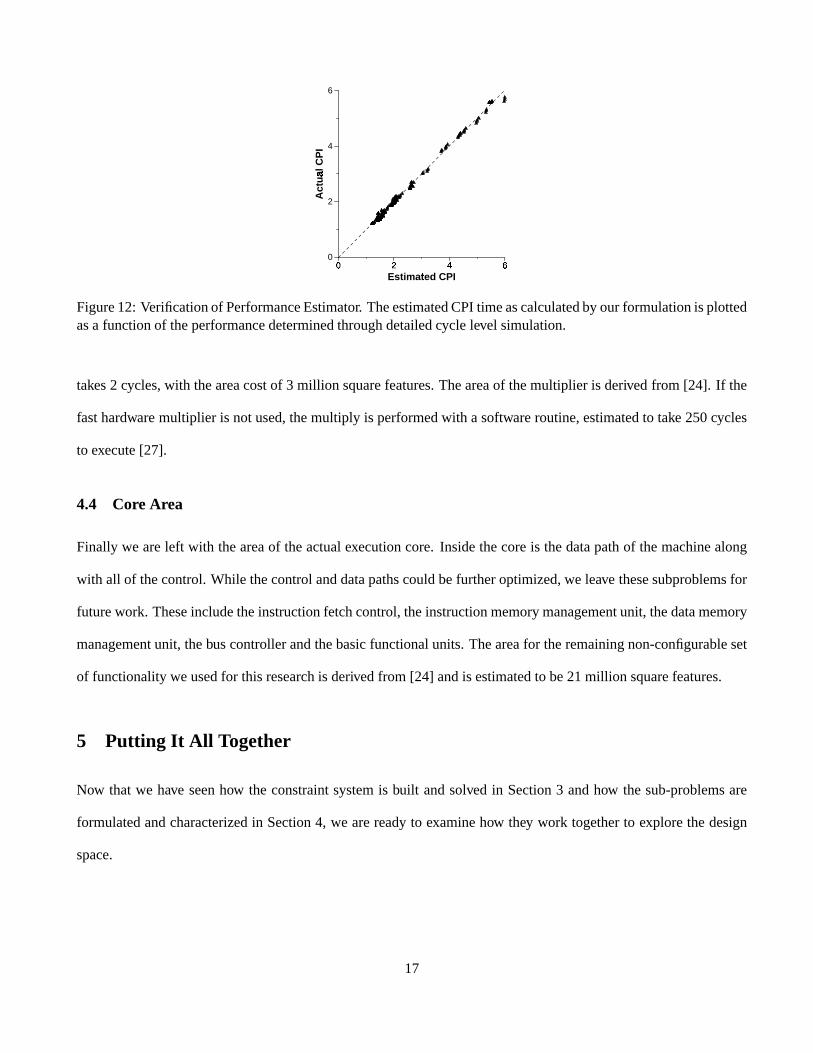
Figure12: Verificationof PerformanceEstimator. TheestimatedCPItimeascalculatedby ourformulationis plottedasa functionof theperformancedeterminedthroughdetailedcycle level simulation.
takes2 cycles,with theareacostof 3 million squarefeatures.Theareaof themultiplier is derivedfrom [24]. If the
fasthardwaremultiplier is notused,themultiply is performedwith a softwareroutine,estimatedto take 250cycles
to execute[27].
4.4 CoreAr ea
Finally we areleft with theareaof theactualexecutioncore. Insidethecoreis thedatapathof themachinealong
with all of thecontrol.While thecontrolanddatapathscouldbefurtheroptimized,we leave thesesubproblemsfor
futurework. Theseincludetheinstructionfetchcontrol,theinstructionmemorymanagementunit, thedatamemory
managementunit, thebuscontrollerandthebasicfunctionalunits.Theareafor theremainingnon-configurableset
of functionalityweusedfor this researchis derivedfrom [24] andis estimatedto be21million squarefeatures.
5 Putting It All Together
Now that we have seenhow the constraintsystemis built andsolved in Section3 andhow the sub-problemsare
formulatedandcharacterizedin Section4, we arereadyto examinehow they work togetherto explore thedesign
space.
17

5.1 Running the Overall Solution
When running the systemon a given programwe must go througha few steps. The first stepis sub-problem
characterizationaspresentedin theprevioussection.During thisstepweperformsimulationof thedifferentdesign
optionsfor eachsub-problem.FromthiswegeneratethePareto-optimalpointsandpiece-wiselinearapproximation
to beusedfor thenext stage.Thesimulationtime herevariesbothon what is beinginvestigatedandtheprogram
itself. We usefairly bruteforcemethodsfor examiningeachspace,andthis processis themosttime consumingof
all theoperations.
Webuilt oursimulationinfrastructureon topof ATOM [28] becauseit providesbothhighperformanceandease
of usefor a RISCarchitecturesimilar to thosesupportedby configurablecores.Thedesignpoint enumerationsfor
eachof thesubproblemsarecalculatedat run-time.For theprogramsweexaminedit takesanywherefrom a couple
of secondsto 10 minutesper simulation. However this processcanbe easilyspeedup thoughthe useof smarter
simulationalgorithms[29], or analyticalmodelingasdescribedin Section6.3.
In additionto generatingtheestimatedperformancesof thedifferentsub-problems,wealsoneedto estimatethe
totalareaconsumedby eachdesignpoint. This is doneoncefor eachgivensubproblem,andtheresultscanbeused
for eachof thedifferentprograms.Thissteptakeslessthan1 minuteto run.
Thefinal stepof theoptimizationprocessis theactualconstructionof theconstraintsystem.Thisstepis veryfast
sincemany differentdesignparameterscanbeexaminedquickly. To createchartsof thepareto-optimalsolutions,
shown in Figures13 and17, we generatedalmost50 designsolutionsin lessthan8 seconds.Eachoneof these
designsolutionsis theidealcombinationof thedifferentsub-problemsandrepresentsthebestdesignpointof many
hundredsof millions. Becauseof this fastturn aroundmany new designchoicescanbeevaluatedin real-time.For
example,onecouldanswerthequestion:whatwould theareaimpactbeof reducingthecachemisspenaltyby 30%.
Thiscouldbeansweredwithout re-runningany simulations.
5.2 Results
WeusedATOM [28] to profile theapplications,generatetracesandsimulatecacheandbranchmodels.All applica-
tionswerecompiledonaDECAlphaAXP-21264architectureusingtheDECC compilerunderOSF/1V4 operating
18
1ë 2ì
3í
Normalized Execution Timeî0M
50M
100M
150M
Are
a (S
qu
are
Fea
ture
s)
adpcmïbzipgsðgzipðjpegñ
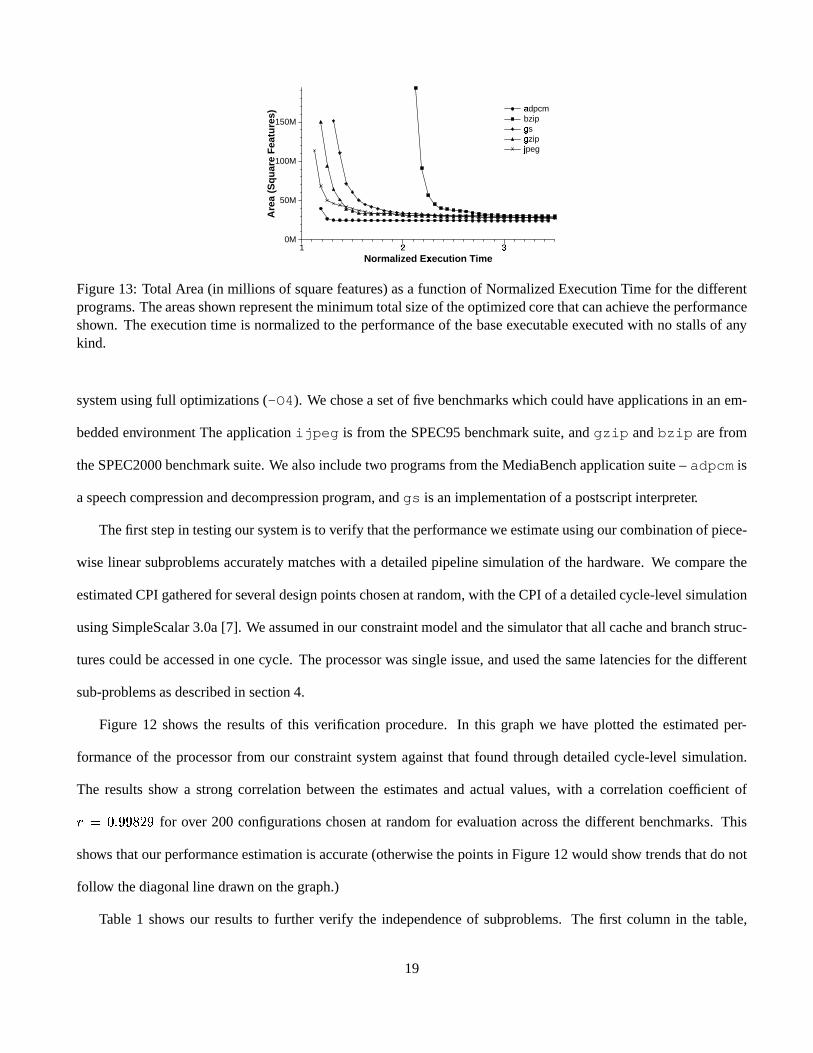
Figure13: Total Area(in millions of squarefeatures)asa functionof NormalizedExecutionTime for thedifferentprograms.Theareasshown representtheminimumtotalsizeof theoptimizedcorethatcanachieve theperformanceshown. Theexecutiontime is normalizedto theperformanceof thebaseexecutableexecutedwith no stallsof anykind.
systemusingfull optimizations(-O4). We chosea setof five benchmarkswhich couldhave applicationsin anem-
beddedenvironmentTheapplicationijpeg is from theSPEC95benchmarksuite,andgzip andbzip arefrom
theSPEC2000benchmarksuite.Wealsoincludetwo programsfrom theMediaBenchapplicationsuite– adpcm is
aspeechcompressionanddecompressionprogram,andgs is animplementationof apostscriptinterpreter.
Thefirst stepin testingoursystemis to verify thattheperformanceweestimateusingourcombinationof piece-
wise linearsubproblemsaccuratelymatcheswith a detailedpipelinesimulationof thehardware. We comparethe
estimatedCPIgatheredfor severaldesignpointschosenat random,with theCPIof adetailedcycle-level simulation
usingSimpleScalar3.0a[7]. Weassumedin our constraintmodelandthesimulatorthatall cacheandbranchstruc-
turescouldbeaccessedin onecycle. Theprocessorwassingleissue,andusedthesamelatenciesfor thedifferent
sub-problemsasdescribedin section4.
Figure 12 shows the resultsof this verificationprocedure. In this graphwe have plotted the estimatedper-
formanceof the processorfrom our constraintsystemagainstthat found throughdetailedcycle-level simulation.
The resultsshow a strongcorrelationbetweenthe estimatesand actualvalues,with a correlationcoefficient of
\`U ��òBó�ó�ô�õ�ófor over 200 configurationschosenat randomfor evaluationacrossthe differentbenchmarks.This
shows thatourperformanceestimationis accurate(otherwisethepointsin Figure12wouldshow trendsthatdonot
follow thediagonalline drawn on thegraph.)
Table1 shows our resultsto further verify the independenceof subproblems.The first column in the table,
19

Fixed Vary Avg StdDev Max StdDevD-cache I-cache 0.000000% 0.000000%D-cache Branch 0.000000% 0.000000%I-cache D-cache 0.004775% 0.046030%I-cache Branch 0.001985% 0.038971%Branch D-cache 0.007916% 0.080000%Branch I-cache 0.006044% 0.095263%
Table1: Quantifyingthe independenceof subproblems.The first columnin the table, labeledFixed, shows thesubproblemunderexamination,andthesecondcolumn,labeledVary, is thesubproblemto which independenceisbeingevaluated.For example,thefirst row in thetablecomparestheindependenceof thedatacachemissratefromtheinstructioncachemissrate.For thefirst row this is determinedby holdingthedatacachesizeconstant,varyingthesizeof theinstructioncache,andanalyzingthechangein datacachemissrate.This is thenrepeatedfor severalsizesof datacache.Thenumbersreportedaretheaveragestandarddeviation andmaximumstandarddeviation inmissratesacrossall fixedsizesevaluated.
labeledFixed, shows thesubproblemunderexamination,andthesecondcolumn,labeledVary, is thesubproblem
to which independenceis beingevaluated.For example,the first row in the tablecomparesthe independenceof
the datacachemissratefrom the instructioncachemissrate. For the first row this is determinedby holding the
datacachesizeconstant,varyingthesizeof theinstructioncache,andanalyzingthechangein datacachemissrate.
This is thenrepeatedfor severalsizesof datacache.Thenumbersreportedaretheaveragestandarddeviation and
maximumstandarddeviation in missratesacrossall fixedsizesevaluated.Theresultsshow that thesubproblems
areindependentwith lessthana 0.1%standarddeviation at maximumwhenholdingonecomponentconstantand
varying the othercomponent. It can thereforebe concludedfrom this graphthat the datacachemiss rate does
not changesignificantlyas the instructioncachemissratevariesfor the cachesizesandprocessormodelwe are
exploring.
We now examinethe resultsof runningthe entiresystemon several programs.Figure13 shows the resulting
minimizedareafor eachprogramfor severalperformancedesignpoints.Theareais shown in squarefeatures.The
performanceconstraintis shown normalizedto thebaseexecutableexecutedwith nostallsfor any components.For
example,in orderfor gs to beexecutedin 1.5x theamountof time it would take to executeit with no stallsof any
sort,theprocessorwill needanareaof 60M (squarefeatures).
As expected,relaxingtheperformanceconstraintreducestheareaneededby theprocessor. All of theprograms
exhibit averystrongelbow in theirperformanceareaplot. Hence,themajorworkingsetsof theprogramarecaptured
20
1.12
1.19
1.25
1.31
1.38
1.44
1.50
1.56
1.62
1.69
1.75
1.81
1.88
1.94
2.00
Normalized Execution Time
0
50
100
Are
a (m
illio
ns
of
squ
are
feat
ure
s)Branch PredInstr CacheMultiplierData CacheCore
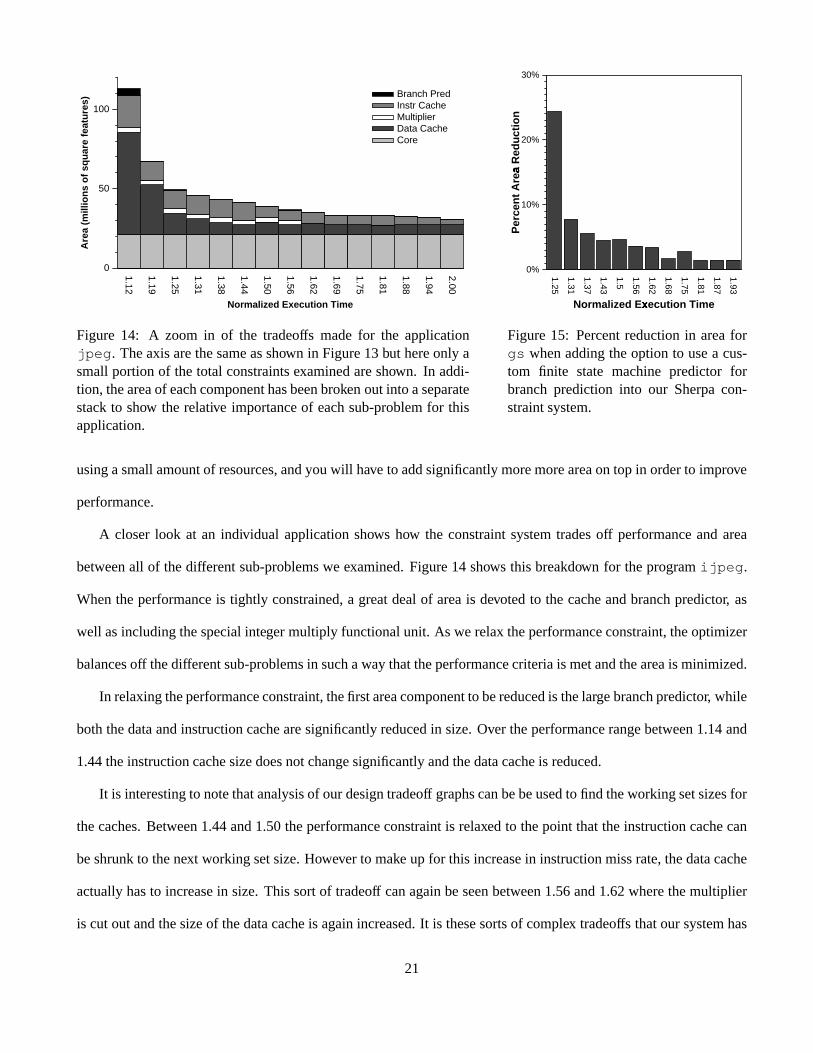
Figure 14: A zoom in of the tradeoffs madefor the applicationjpeg. Theaxisarethesameasshown in Figure13 but hereonly asmallportionof thetotal constraintsexaminedareshown. In addi-tion, theareaof eachcomponenthasbeenbrokenout into aseparatestackto show the relative importanceof eachsub-problemfor thisapplication.
1.25
1.31
1.37
1.43
1.5
1.56
1.62
1.68
1.75
1.81
1.87
1.93
Normalized Execution Timeö0%
10%
20%
30%
Per
cen
t A
rea
Red
uct
ion
÷
Figure15: Percentreductionin areaforgs whenaddingtheoption to usea cus-tom finite state machine predictor forbranchprediction into our Sherpacon-straintsystem.
usingasmallamountof resources,andyouwill have to addsignificantlymoremoreareaontop in orderto improve
performance.
A closerlook at an individual applicationshows how the constraintsystemtradesoff performanceand area
betweenall of thedifferentsub-problemswe examined.Figure14 shows this breakdown for theprogramijpeg.
Whentheperformanceis tightly constrained,a greatdealof areais devotedto the cacheandbranchpredictor, as
well asincludingthespecialintegermultiply functionalunit. As werelaxtheperformanceconstraint,theoptimizer
balancesoff thedifferentsub-problemsin suchawaythattheperformancecriteriais metandtheareais minimized.
In relaxingtheperformanceconstraint,thefirst areacomponentto bereducedis thelargebranchpredictor, while
boththedataandinstructioncachearesignificantlyreducedin size.Over theperformancerangebetween1.14and
1.44theinstructioncachesizedoesnotchangesignificantlyandthedatacacheis reduced.
It is interestingto notethatanalysisof ourdesigntradeoff graphscanbebeusedto find theworkingsetsizesfor
thecaches.Between1.44and1.50theperformanceconstraintis relaxedto thepoint that theinstructioncachecan
beshrunkto thenext workingsetsize.However to make up for this increasein instructionmissrate,thedatacache
actuallyhasto increasein size.This sortof tradeoff canagainbeseenbetween1.56and1.62wherethemultiplier
is cut outandthesizeof thedatacacheis againincreased.It is thesesortsof complex tradeoffs thatour systemhas
21
1 2 3ø
4Normalized Execution Timeù
20M
25M
30M
35M
40M
Are
a
Improvement atSame Performance
Optimization
Resultant Area
Performance
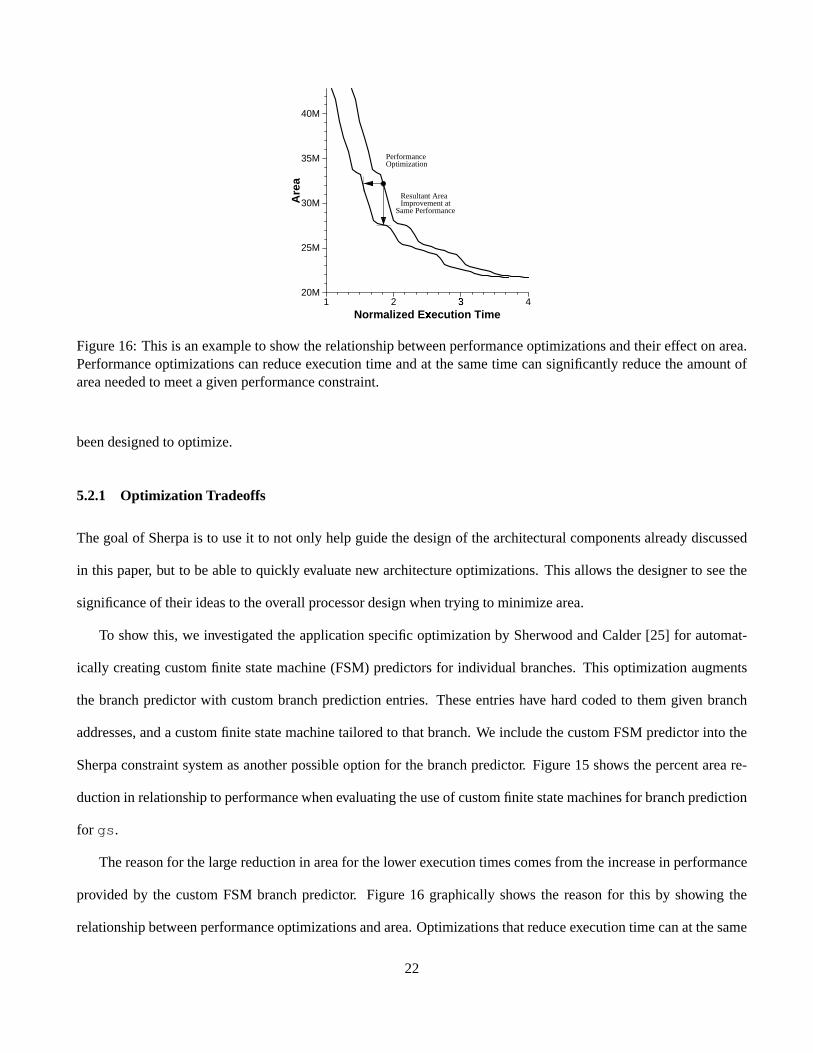
Figure16: This is anexampleto show therelationshipbetweenperformanceoptimizationsandtheir effect on area.Performanceoptimizationscanreduceexecutiontime andat thesametime cansignificantlyreducetheamountofareaneededto meetagivenperformanceconstraint.
beendesignedto optimize.
5.2.1 Optimization Tradeoffs
Thegoalof Sherpais to useit to not only helpguidethedesignof thearchitecturalcomponentsalreadydiscussed
in this paper, but to beableto quickly evaluatenew architectureoptimizations.This allows thedesignerto seethe
significanceof their ideasto theoverallprocessordesignwhentrying to minimizearea.
To show this, we investigatedtheapplicationspecificoptimizationby SherwoodandCalder[25] for automat-
ically creatingcustomfinite statemachine(FSM) predictorsfor individual branches.This optimizationaugments
the branchpredictorwith custombranchpredictionentries. Theseentrieshave hardcodedto themgiven branch
addresses,anda customfinite statemachinetailoredto thatbranch.We includethecustomFSM predictorinto the
Sherpaconstraintsystemasanotherpossibleoptionfor thebranchpredictor. Figure15 shows thepercentareare-
ductionin relationshipto performancewhenevaluatingtheuseof customfinite statemachinesfor branchprediction
for gs.
Thereasonfor thelargereductionin areafor thelowerexecutiontimescomesfrom theincreasein performance
provided by the customFSM branchpredictor. Figure16 graphicallyshows the reasonfor this by showing the
relationshipbetweenperformanceoptimizationsandarea.Optimizationsthatreduceexecutiontimecanat thesame
22
50 100ú 150ûArea
0.00
0.01
0.02
0.03
Per
form
ance
/Are
aü
adpcmbzipgsýgzipýjpegþ
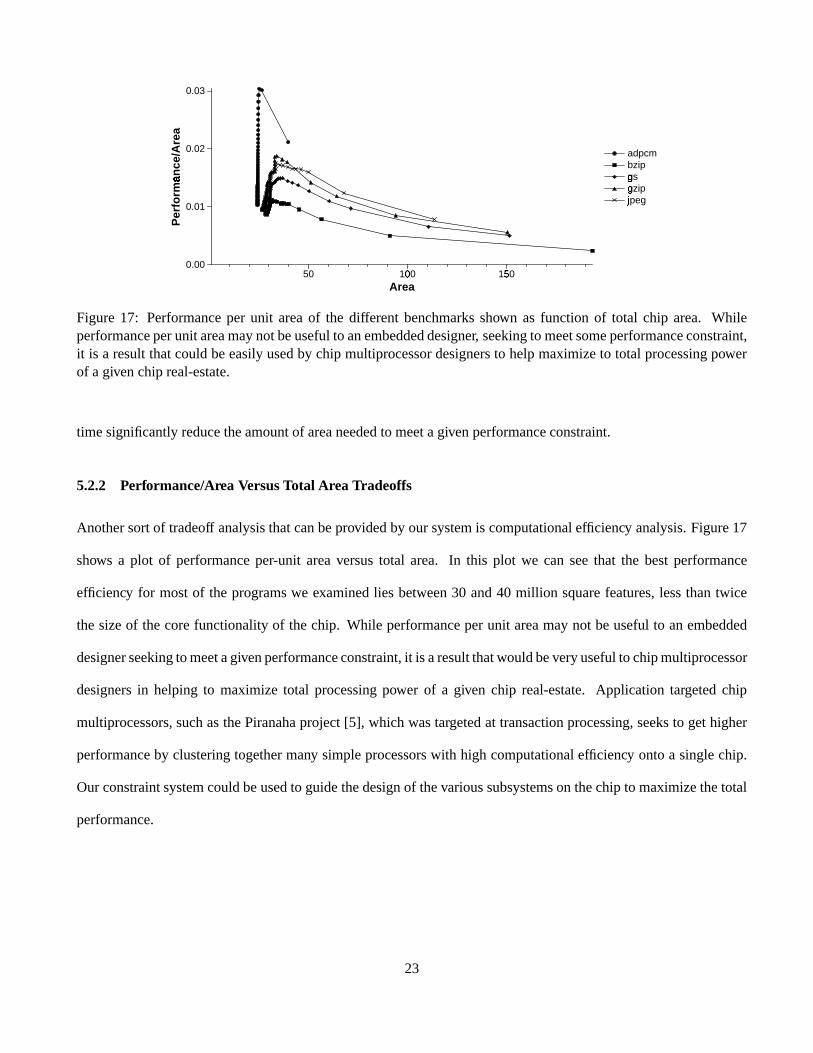
Figure 17: Performanceper unit areaof the different benchmarksshown as function of total chip area. Whileperformanceperunit areamaynotbeusefulto anembeddeddesigner, seekingto meetsomeperformanceconstraint,it is a resultthatcouldbeeasilyusedby chip multiprocessordesignersto helpmaximizeto total processingpowerof a givenchip real-estate.
timesignificantlyreducetheamountof areaneededto meetagivenperformanceconstraint.
5.2.2 Performance/AreaVersusTotal Ar eaTradeoffs
Anothersortof tradeoff analysisthatcanbeprovidedby oursystemis computationalefficiency analysis.Figure17
shows a plot of performanceper-unit areaversustotal area. In this plot we can seethat the bestperformance
efficiency for mostof the programswe examinedlies between30 and40 million squarefeatures,lessthantwice
thesizeof thecorefunctionalityof thechip. While performanceperunit areamaynot beusefulto anembedded
designerseekingtomeetagivenperformanceconstraint,it is aresultthatwouldbeveryusefulto chipmultiprocessor
designersin helping to maximizetotal processingpower of a given chip real-estate.Application targetedchip
multiprocessors,suchasthePiranahaproject[5], which wastargetedat transactionprocessing,seeksto gethigher
performanceby clusteringtogethermany simpleprocessorswith high computationalefficiency ontoa singlechip.
Ourconstraintsystemcouldbeusedto guidethedesignof thevarioussubsystemson thechip to maximizethetotal
performance.
23

6 RelatedWork
Thereis a greatdealof relatedwork in hardware/softwareco-design,applicationspecificprocessorgenerators,and
analyticperformanceestimation,but wehavefoundnonethataddresstheproblemweareattemptingto solve. While
afull listing of relatedwork is not feasiblein apaperof this length,wedopointoutsomerepresentative papersfrom
eachareaanddescribehow our researchfits into thebroadercontext.
6.1 Configurable Cores
Therearecurrentlymany configurablecoredesigns,that canbe customizedor otherwisemodifiedto application
specificrequirements.The XTensaprocessor[13] allows the designerto input specificationsthat they want in
a processor, and the XTensatools generatethe neededcomponentsreadyfor integration into a system-on-chip.
Anotherexampleof aconfigurableRISCcoreis theLX4380[26] processorcore.LX4380supportsaddingupto 12
new instructionsto thecoreasneededby a designer. TheARC processorcore[4] is similar in designandintentto
theLX4380. Thetoolsavailablefor thesethreeconfigurablecoresdonot assistthedesignerin findinggooddesign
pointsfor theirapplication.Weprovideanautomatedsystemthatwill examineprogrambehavior andsuggestnear-
optimal designdecisions,allowing the designerto make informeddecisionsearly andexperimentwith different
optimizations.
6.2 DesignExploration for Application SpecificProcessors
An approachbeingexaminedfor designingcustomizedprocessorsis to automaticallygeneratetrial processors(with
a machinedescriptionlanguage[14, 19], a GUI [15], or a templateasdescribedabove) for a specificapplication,
andthenexaminetheirperformanceandfeedthisevaluationbackinto theautomatedprocessorgenerator.
TheLx [9, 10, 8] customizableVLIW architecturebuilds customhardwarefor loop nestsin applications.They
have a clusteredVLIW architecturethat canbe customizedto a given applicationdomainwith a semi-automated
optimizationstep. Thesystemstartsby generatinga trial architecture,for which it generatescompilersandother
tools. Key partsof this applicationcodeare thencompiledand measured,andareusedto generatea new trial
architecture,andtheprocessis repeated.
24

ThePICOproject[1, 2] usesa fully automatedapproachto creatingacustomizedprocessor. Theirsystemstarts
by designinga set of Paretooptimal memoryhierarchies,processors,andcustomhardware accelerators.Then,
different combinationsof thesepointsare testedby assemblingthe processorand simulatingits performancein
detail. Thebestcombinationsarenotedandcombinationsthataresimilar to theseareevaluated.They reportthat
thesystemtakesfrom 10hoursto severaldays.
The iterative approachesfor Lx andPICO yield very goodresults,but take too long to be usedinteractively.
We proposeto usea high level modelingof performancefirst via Sherpato allow the designerto very rapidly
examinecomplex designtradeoffs in realtime,andthenfeedthis informationinto theiterative processorgeneration
performedfor Lx andPICO.
The PlatuneSystem[12, 11] hasgoalssimilar to ours, in that it too seeksto reducethe numberof processor
configurationsthatmustbeexplored. ThePlatuneSystemmakesuseof thefact thatwhile someprocessorparam-
etersarecoupled,therearemany othersthat are independentor are just one-way dependent.They thenusethis
informationenteredby handby theuserto prunetheredesignspace,skippingover pointsthat theuserknows will
not be Paretooptimal. The major differencebetweenour two techniquesis that after Platuneprunesthe design
space,abruteforcesearchof aparametersis still requiredwhichlimits theoverallnumberof parametersettingsthat
canbesearched.Sherpa,on theotherhand,useslinearprogrammingto modelmany discretepointsthatarenear
linearasa line segmentwhichallows for thepointsto besearchedanalytically. Webelieve thatacombinationof the
two techniques,usingPlatuneto discover andgroupthedependentparametersandthenexploring thoseparameters
usingSherparatherthanexhaustive simulationcanprovideevenbetterresultsthaneithertechniqueby itself.
6.3 PerformanceEstimation
Anothercommonfield of studythatis closelyrelatedto ourwork is analyticalcacheperformanceestimation.Agar-
wal et. al. [3] presentananalyticalcachemodelthatcancapturethebehavior of cachesystemsbasedontheanalysis
of a trace. Both Whalley [30] andQuong[22] presentmodelsfor capturingthe expectedinstructioncachemiss
ratefor a givenapplicationondifferentcachesub-systemseitherat compiletimeor throughstatisticalanalysisof a
compressedtrace.Jacobet. al. presentwork thatusesa characterizationof workloadlocality built from LRU stack
distanceto take ananalyticalapproachto building memoryhierarchies[16].
25

Many of thesemodelscouldbeincorporatedinto Sherpato createthepiece-wiselinearfunctionsfor thedifferent
componentswe examined.Evenso,we foundusingtargetedsimulationto quickly walk pointsin thedesignspace
to beefficientwhengeneratingthepiece-wiselinearfunctions.
7 Summary
Ourapproachto exploring thisdesignspaceis to first divide it into separateregionsmappedby largely independent
parameters.Theseregionsform individual sub-problemsthatcanbeefficiently andaccuratelymodeledusingdata-
drivenanalyticaltechniques.We formulatetheresultsof thesemodelsinto a singlelargeconstraint-basedinteger-
linearprogramthatcanbeefficiently solvedusingconventionalmathematicaltechniques.
We showed that the resultsfrom solving of the constraintsystemlined up very closely with the actualper-
formancenumbersobtainedthroughdetailedsimulation. We examinedthe tradeoffs that weremadebetweenthe
differentcomponentsincludedin optimizationandsaw how they canplay off eachotherin a complex manner. We
furtherdemonstratedhow theSherpaframework canbeappliedto rapidlyevaluatepotentialoptimizationsandtheir
impactonboththeperformanceandareaof theprocessor.
A goalof this researchis to provide a morescientificallysoundmethodologyfor evaluatingnovel architectural
techniquesin theembeddedspace.The traditionalmethodof proposinga new technique,andthenexaminingthe
performanceenhancementrelative to asinglebaselinedata-pointis notverymeaningfulto overall systemdesignin
costsensitive domains.An architectneedsa wayof visualizingthewaynew techniquestrade-off againsta rangeof
potentialdesignoptions.Themethodologypresentedin thispaperprovidestheability to performthisrangeanalysis.
It placesarchitecturalchangesin aglobalsettingallowing thearchitectto gaina full pictureof its usefulness.
To our knowledgewe arethe first to apply integer-linear programmingto total-processordesignspaceexplo-
ration. Thesignificantresearchadvancewe contribute in this paperis thecharacterizationof theprocessordesign
spaceinto piece-wiselinearmodels,theconstraintformalismto combinethem,our formationof piece-wiselinear
functions,andthevalidationof thesetechniquesin thisenvironment.Theresearchin this paperlaysthefoundation
for optimizationof morecomplex architectures.
26

References
[1] S. Abraham,B. Rau,R. Schreiber, G. Snider, andM. Schlansker. Efficient designspaceexplorationin pico. In Proc.of InternationalConferenceon Compilers, Architecture, and Synthesisfor EmbeddedSystems, pages71–79,SanJose,California,November2000.
[2] S.G. AbrahamandS. A. Mahlke. Automaticandefficient evaluationof memoryhierarchiesfor embeddedsystems.In32ndInternationalSymposiumonMicroarchitecture, 1999.
[3] Anant Agarwal, Mark Horowitz, and JohnHennessy. An analyticalcachemodel. ACM Transactionson ComputerSystems, 7(2):184–215,1989.
[4] ARC. Whitepaper:Customizinga softmicroprocessorcore.http://www.arccores.com,2001.
[5] L. Barroso,K. Gharachorloo,R. McNamara,A. Nowatzyk, S. Qadeer, B. Sano,S. Smith, R. Stets,andB. Verghese.Piranha: A scalablearchitecturebasedon single-chipmultiprocessing. In 27th Annual InternationalSymposiumonComputerArchitecture, Vancouver, Canada,June2000.
[6] M. Berkelaar. lp solve: a mixedintegerlinearprogramsolver. ftp://ftp.es.ele.tue.nl/pub/lpsolve,September1997.
[7] D. C. BurgerandT. M. Austin. Thesimplescalartool set,version2.0. TechnicalReportCS-TR-97-1342,UniversityofWisconsin,Madison,June1997.
[8] PaoloFaraboschi,Geoffrey Brown, JosephA. Fisher, GiuseppeDesoli,andFredHomewood. Lx: a technologyplatformfor customizablevliw embeddedprocessing.In 27thAnnualInternationalSymposiumon ComputerArchitecture, pages203–213,2000.
[9] J. A. Fisher, P. Faraboschi,andG. Desoli. Custom-fitprocessors:Letting applicationsdefinearchitectures.In 29thInternationalSymposiumonMicroarchitecture, pages324–335,December1996.
[10] JosephA. Fisher. Customizedinstruction-setsfor embeddedprocessors. In Proceedingsof the DesignAutomationConference, 1999, pages253–257,1999.
[11] T. GivargisandF. Vahid. Platune:A tuningframework for system-on-a-chipplatforms.IEEETransactionsonComputerAidedDesign, 21(11),November2002.
[12] T. Givargis,F. Vahid,andJ.Henkel. System-levelexplorationfor pareto-optimalconfigurationsin parameterizedsystems-on-a-chip.In InternationalConferenceonComputerAidedDesign, November2001.
[13] R. E. Gonzalez.Xtensa:A configurableandextensibleprocessor. IEEEMicro, 20(2):60–70,March-April 2000.
[14] G. Hadjiyiannis,P. Russo,andS. Devadas.A methodologyfor accurateperformanceevaluationin architectureexplo-ration. In In Proceedingsof theDesignAutomationConference(DAC 99), pages927–932,1999.
[15] M. Itoh, S. Higaki, J. Sato,A. Shiomi,Y. Takeuchi,A. Kitajima, andM. Imai. Effectivenessof theasipdesignsystempeas-iii in designof pipelinedprocessors.In In Proceedingsof Asia andSouthPacific DesingAutomationConference2001(ASP–DAC 2001), pages649–654,2001.
[16] BruceL. Jacob,PeterM. Chen,SethR. Silverman,andTrevor N. Mudge. An analyticalmodelfor designingmemoryhierarchies.IEEETransactionsonComputers, 45(10):1180–1194,1996.
[17] E. Lawler andD. Wood. Branchandboundmethods:A survey. OperationsResearch, 14(291):699–719,1966.
[18] S.Leibson.Xscale(strongarm-2)musclesin. MicroprocessorReport, September2000.
[19] T. Morimoto,K. Saito,H. Nakamura,T. Boku,andK. Nakazawa. Advancedprocessordesignusinghardwaredescriptionlanguageaidl. In In Proceedingsof AsiaandSouthPacificDesingAutomationConference1997(ASP–DAC 1997), pages387–390,1997.
[20] J.Mulder. An areamodelfor on-chipmemoriesandits applications.IEEEJournalof SolidStatesCircuits, 26(2):98–106,February1991.
[21] M. Puig-Medina,G. Ezer, andP. Konas. Verificationof configurableprocessorcores. In Proceedingsof the DesignAutomationConference(DAC2000), pages426–431,2000.
27

[22] RussellW. Quong.Expectedi-cachemissratesvia thegapmodel.In 21stAnnualInternationalSymposiumonComputerArchitecture, pages372–383,1994.
[23] G. Reinmanand N. Jouppi. Cacti version2.0. http://www.research.digital.com/wrl/people/jouppi/CACTI.html, June1999.
[24] S.Santhanam.Strongarm110: A 160mhz32b0.5wcmosarmprocessor. In Proceedingsof HotChipsVIII , pages119–130,1996.
[25] T. SherwoodandB. Calder. Automateddesignof finite statemachinepredictorsfor customizedprocessors.In AnnualInternationalSymposiumonComputerArchitecture, June2001.
[26] C. Snyder. Synthesizablecoremakeover: Is lexra’sseven-stagepipelinedcorethespeedking? In MicroprocessorReport,June2001.
[27] C.D.Snyder. Fpgaprocessorscoresgetserious.MicroprocessorReport, 14(9),September2000.
[28] A. Srivastava andA. Eustace.ATOM: A systemfor building customizedprogramanalysistools. In Proceedingsof theConferenceonProgrammingLanguageDesignandImplementation, pages196–205.ACM, 1994.
[29] RabinA. SugumarandSantoshG. Abraham. Set-associative cachesimulationusinggeneralizedbinomial trees. ACMTransactionsonComputerSystems, 13(1):32–56,1995.
[30] D. B. Whalley. Fast instructioncacheperformanceevaluationusingcompile-timeanalysis. In Proc. 1992ACM SIG-METRICSandPERFORMANCE’92 Int’l. Conf. onMeasurementandModelingof ComputerSystems, page13,Newport,RhodeIsland,USA, 1-51992.
[31] S.Wilton andN. Jouppi.Cacti:An enhancedcacheaccessandcycletimemodel.In IEEEJournalof Solid-StateCircuits,May 1996.
[32] Lisa Wu, ChrisWeaver, andToddAustin. Cryptomaniac:a fastflexible architecturefor securecommunication.In 28thAnnualInternationalSymposiumonComputerArchitecture, pages110–119,2001.
28