Embed Size (px)
Citation preview

Backtracking and Game Trees
15-211: Fundamental Data Structures and Algorithms
April 17, 2003
Backtracking
X O XO X OX O O C D
B
A
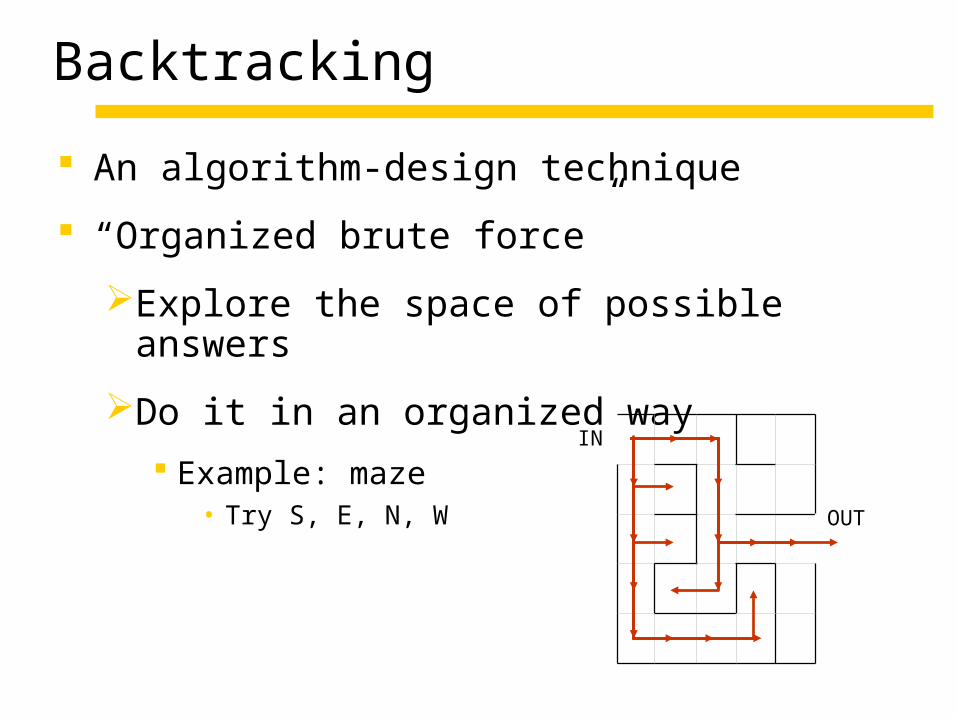
Backtracking
An algorithm-design technique
“Organized brute force”
Explore the space of possible answers
Do it in an organized way
Example: maze• Try S, E, N, W
IN
OUT

Backtracking is useful …
… when a problem is too hard to be solved directlyMaze traversal8-queens problemKnight’s tour
… when we have limited time and can accept a good but potentially not optimal solutionGame playing (second part of lecture)Planning (not in this class)

Basic backtracking
Develop answers by identifying a set of successive decisions.
Maze
Where do I go now: N, S, E or W?
8 Queens
Where do I put the next queen?
Knight’s tour
Where do I jump next?

Basic backtracking 2
Develop answers by identifying a set of successive decisions.
Decisions can be binary: ok or impossible (pure backtracking)
Decisions can have goodness (heuristic backtracking):
Good to sacrifice a pawn to take a bishop
Bad to sacrifice the queen to take a pawn
A B C D E
F G H I J
K L M N O
P Q R S T
U V X Y Z
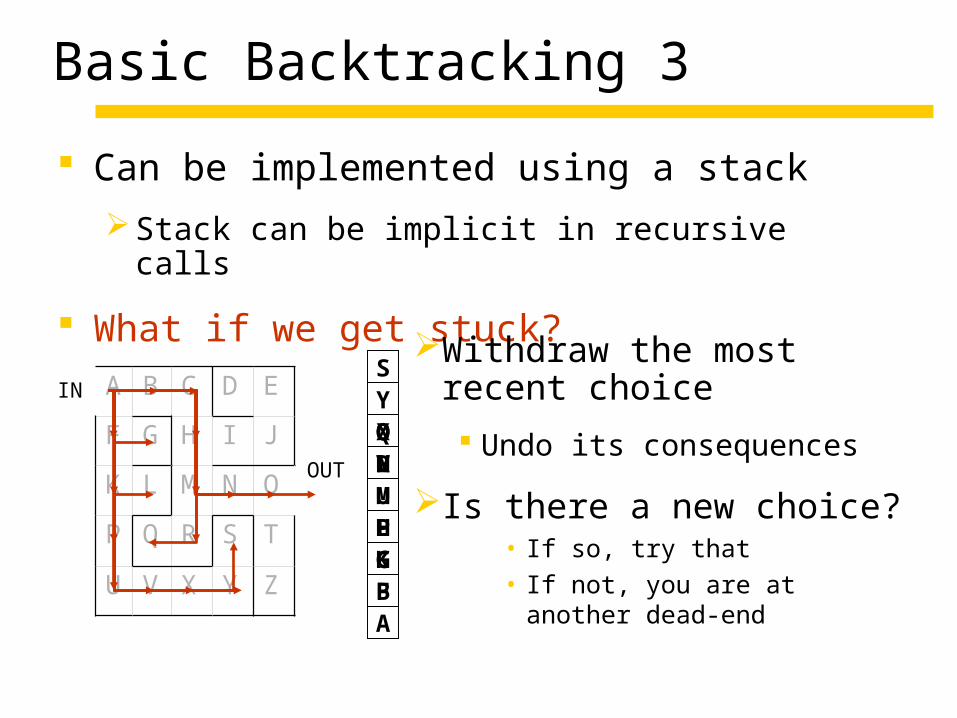
Basic Backtracking 3
Can be implemented using a stack
Stack can be implicit in recursive calls
What if we get stuck?Withdraw the most
recent choice
Undo its consequences
Is there a new choice?• If so, try that• If not, you are at another
dead-end
IN
OUT
AFKPUVXYS
LGBCHMRQNO

Basic Backtracking 4
No optimality guarantees
If there are multiple solutions, simple backtracking will find one of them, but not necessarily the optimal
No guarantees that we’ll reach a solution quickly

Backtracking Summary
Organized brute force
Formulate problem so that answer amounts to taking a set of successive decisions
When stuck, go back, try the remaining alternatives
Does not give optimal solutions
Games
X O XO X OX O O

Why Make Computers Play Games?
People have been fascinated by games since the dawn of civilization
Idealization of real-world problems containing adversary situations
Typically rules are very simple
State of the world is fully accessible
Example: auctions

No, not Quake (although interesting research there, too)
Simpler Strategy Games:Deterministic
Chess
Checkers
Othello
Go
Non-determinstic Poker
Backgammon
What Kind of Games?

So let’s take a simple game
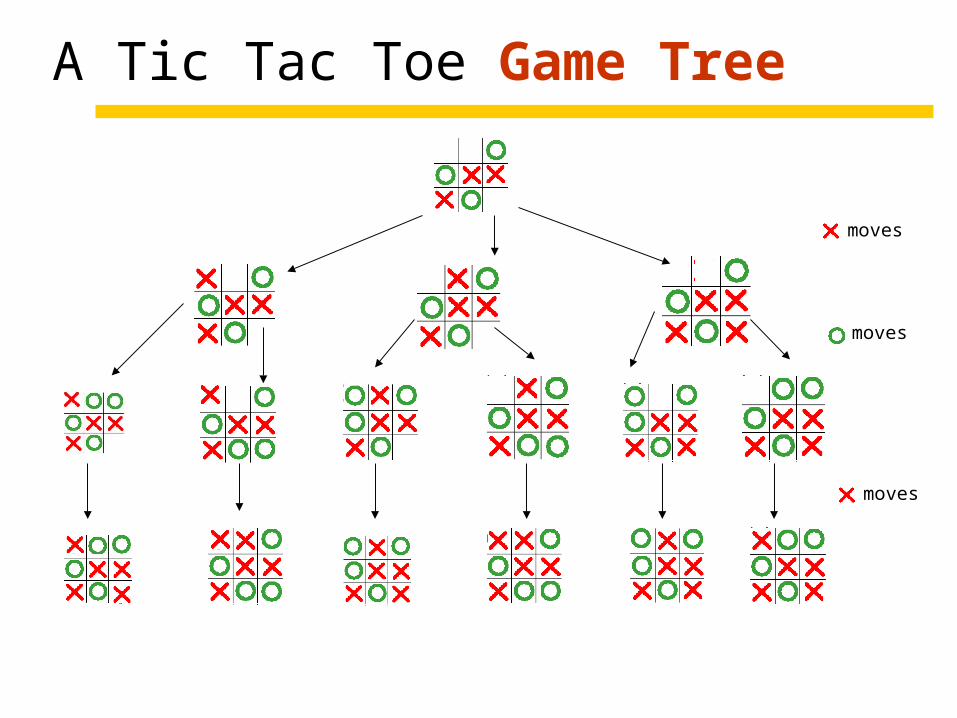
A Tic Tac Toe Game Tree
moves
moves
moves

A Tic Tac Toe Game Tree
moves
moves
moves
Nodes•Denote board configurations•Include a score
Edges•Denote legal moves
Path•Successive moves by the players

A path in a game tree
KARPOV-KASPAROV, 1985
1.e4 c52.Nf3 e63.d4 cxd44.Nxd4 Nc6 5.Nb5 d6 6.c4 Nf6 7.N1c3 a6 8.Na3 d5!? 9.cxd5 exd5 10.exd5 Nb4 11.Be2!?N Bc5! 12.0-0 0-0 13.Bf3 Bf5 14.Bg5 Re8! 15.Qd2 b5 16.Rad1 Nd3! 17.Nab1? h6! 18.Bh4 b4! 19.Na4 Bd6 20.Bg3 Rc8
21.b3 g5!! 22.Bxd6 Qxd6 23.g3 Nd7! 24.Bg2 Qf6! 25.a3 a5 26.axb4 axb4 27.Qa2 Bg6 28.d6 g4! 29.Qd2 Kg7 30.f3 Qxd6 31.fxg4 Qd4+ 32.Kh1 Nf6 33.Rf4 Ne4 34.Qxd3 Nf2+ 35.Rxf2 Bxd3 36.Rfd2 Qe3! 37.Rxd3 Rc1!! 38.Nb2 Qf2! 39.Nd2 Rxd1+40.Nxd1 Re1+ White resigned
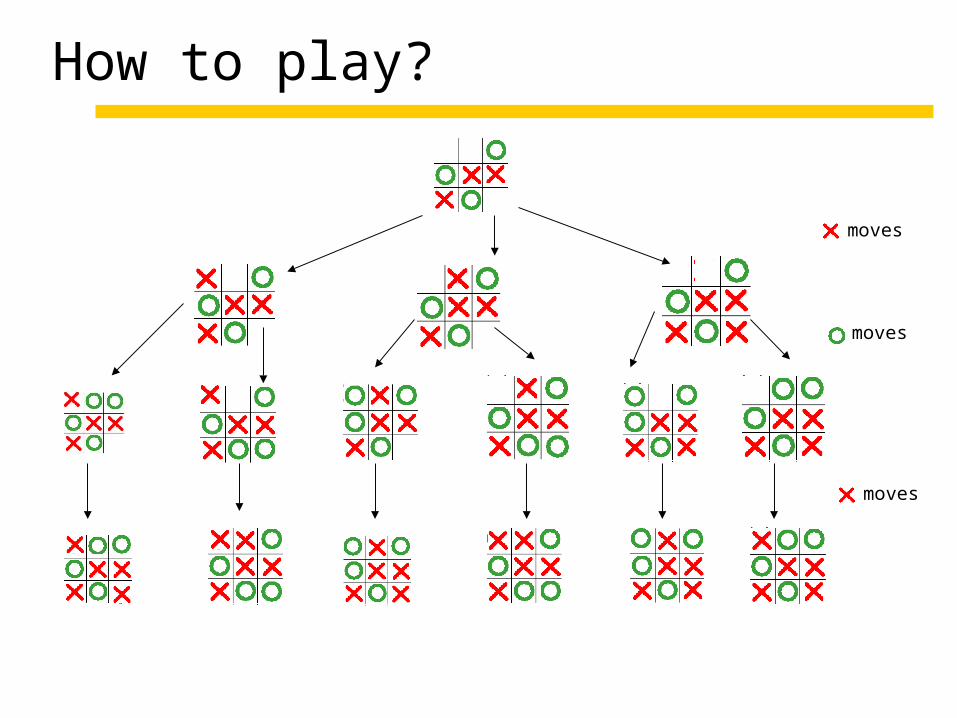
How to play?
moves
moves
moves
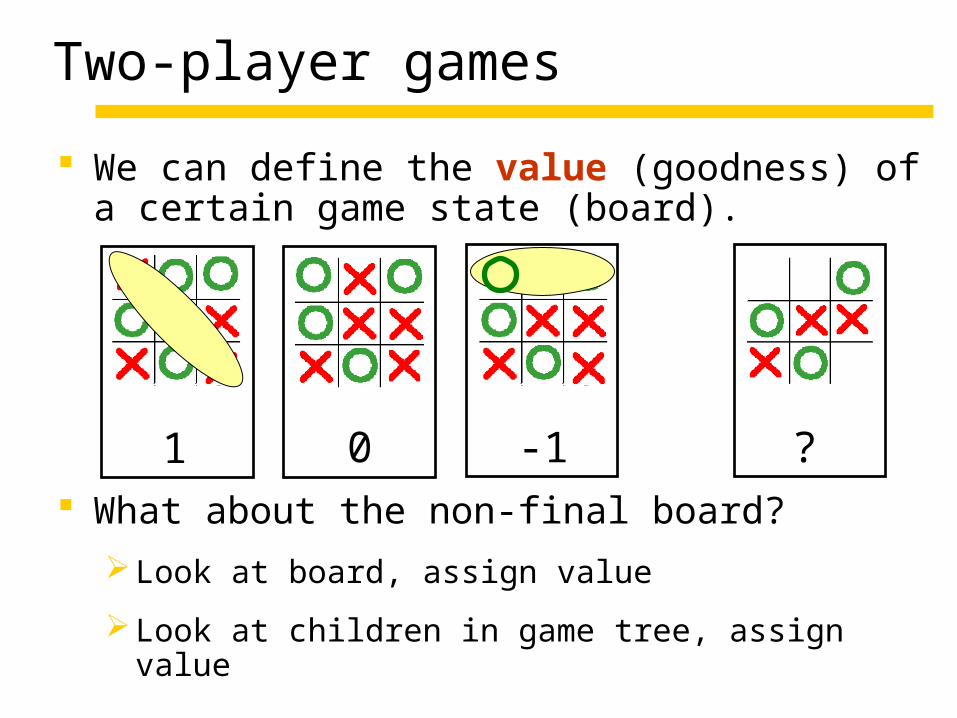
Two-player games
We can define the value (goodness) of a certain game state (board).
What about the non-final board?
Look at board, assign value
Look at children in game tree, assign value
1 0 -1 ?

How to play?
moves
moves
moves
1 0 0 0 0 1
1 0 0 0 0 1
0 00
0
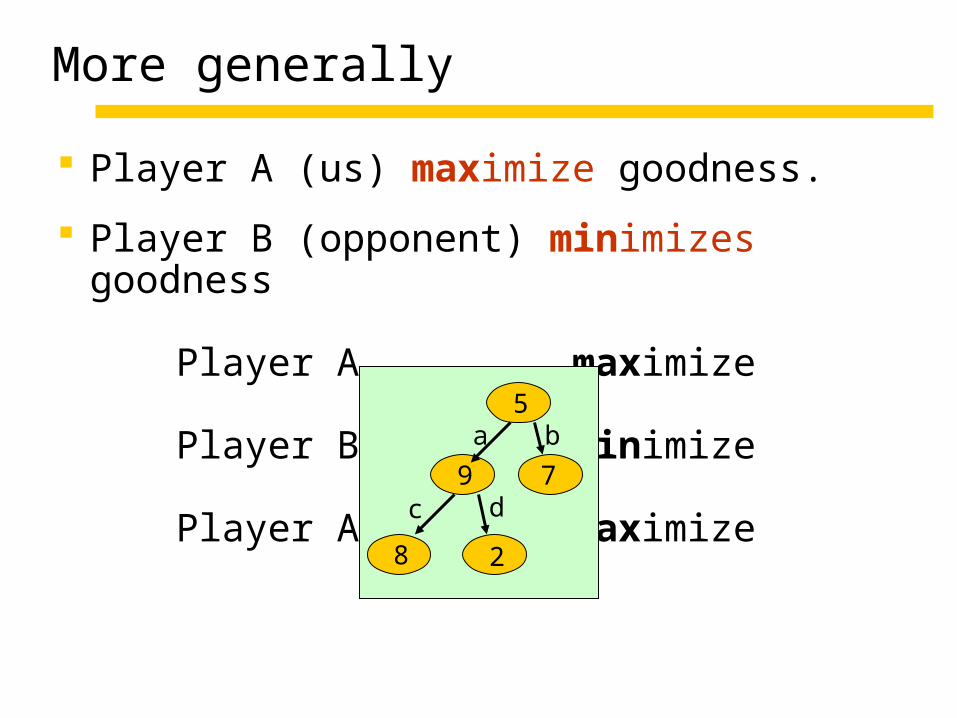
More generally
Player A (us) maximize goodness.
Player B (opponent) minimizes goodness
Player A maximize
Player B minimize
Player A maximize
5
9 7
8 2
a b
c d

Games Trees are useful…
Provide “lookahead” to determine what move to make next
Build whole tree = we know how to play
5
9 7
8 2
a b
c d

But there’s one problem…
Games have large search trees:
Tic-Tac-Toe
There are 9 ways we can make the first move and opponent has 8 possible moves he can make.
Then when it is our turn again, we can make 7 possible moves for each of the 8 moves and so on….
9! = 362,880

Or chess…
Suppose we look at 16 possible moves at each step
And suppose we explore to a depth of 50 turns
Then the tree will have 1650=10120 nodes!
DeepThought (1990) searched to a depth of 10

So…
Need techniques to avoid enumerating and evaluating the whole tree
Heuristic search

Heuristic search
1. Organize search to eliminate large sets of possibilities Chess: Consider major moves first
2. Explore decisions in order of likely success Chess: Use a library of known strategies
3. Save time by guessing search outcomes Chess: Estimate the quality of a situation
Count pieces
Count pieces, using a weighting scheme
Count pieces, using a weighting scheme, considering threats

Mini-Max Algorithm
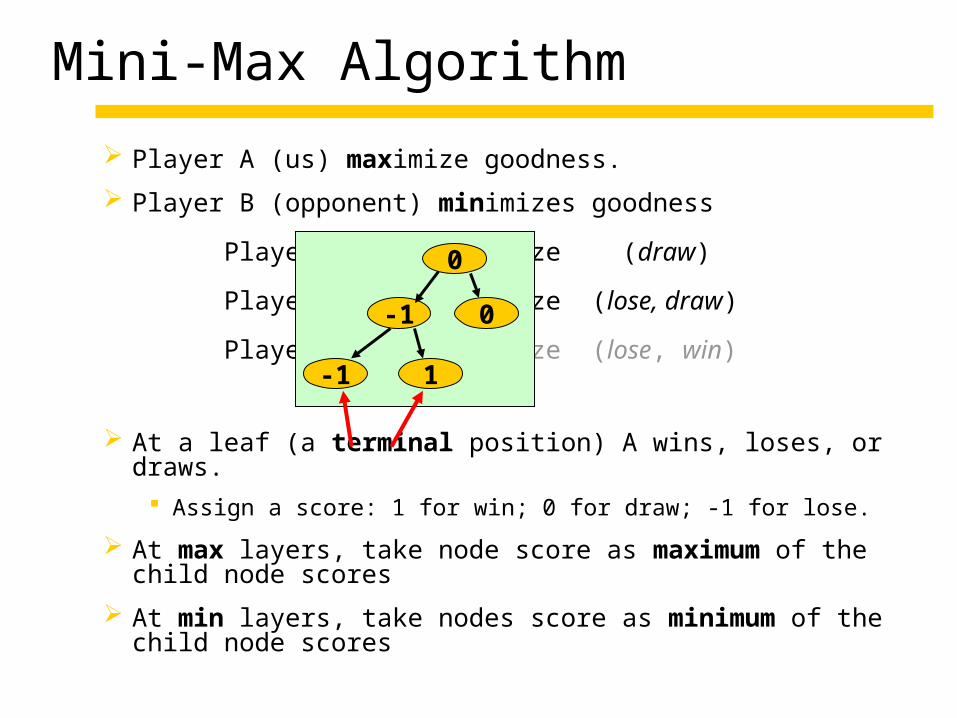
Mini-Max Algorithm
Player A (us) maximize goodness.
Player B (opponent) minimizes goodness
Player A maximize (draw)
Player B minimize (lose, draw)
Player A maximize (lose, win)
At a leaf (a terminal position) A wins, loses, or draws. Assign a score: 1 for win; 0 for draw; -1 for lose.
At max layers, take node score as maximum of the child node scores
At min layers, take nodes score as minimum of the child node scores
0
-1
-1 1
0
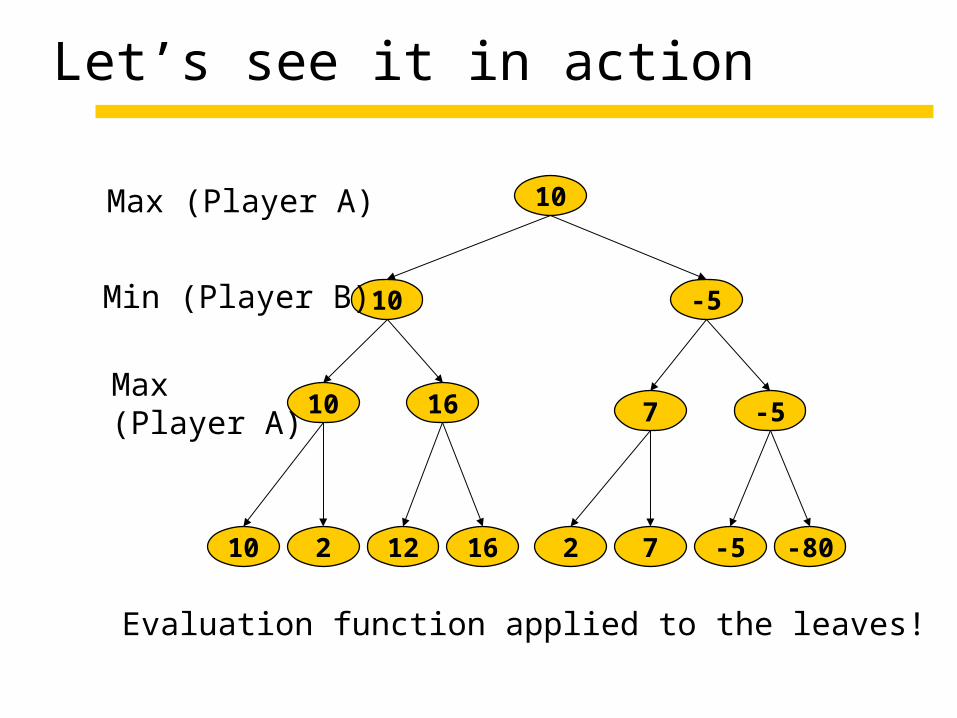
Let’s see it in action
10 2 12 16 2 7 -5 -80
10 16 7 -5
10 -5
10Max (Player A)
Max(Player A)
Min (Player B)
Evaluation function applied to the leaves!
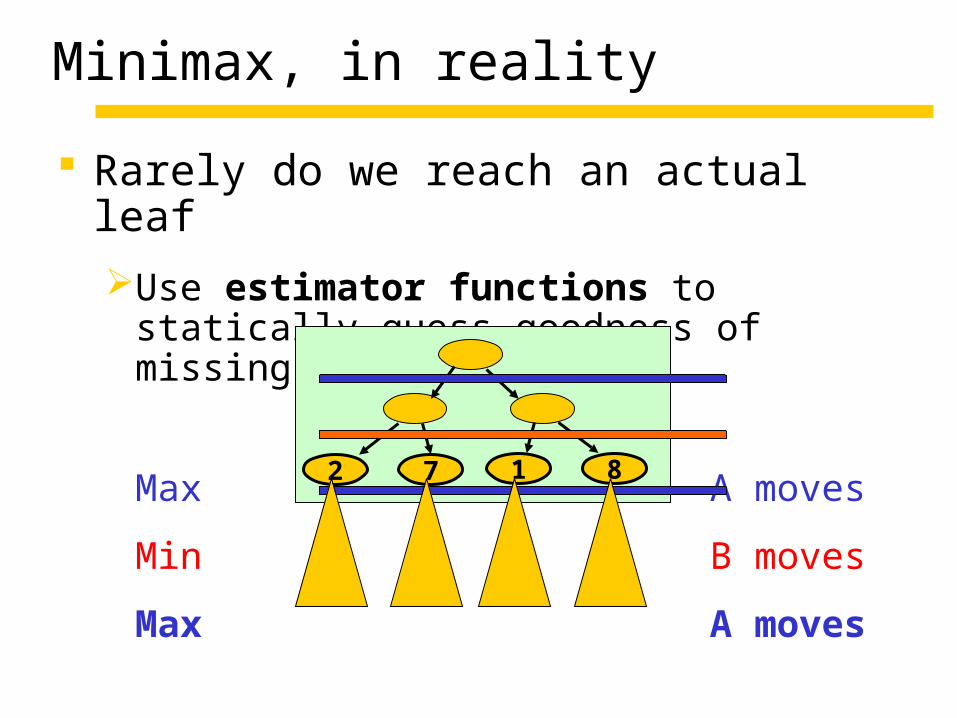
Minimax, in reality
Rarely do we reach an actual leaf
Use estimator functions to statically guess goodness of missing subtrees
Max A moves
Min B moves
Max A moves
2 7 1 8
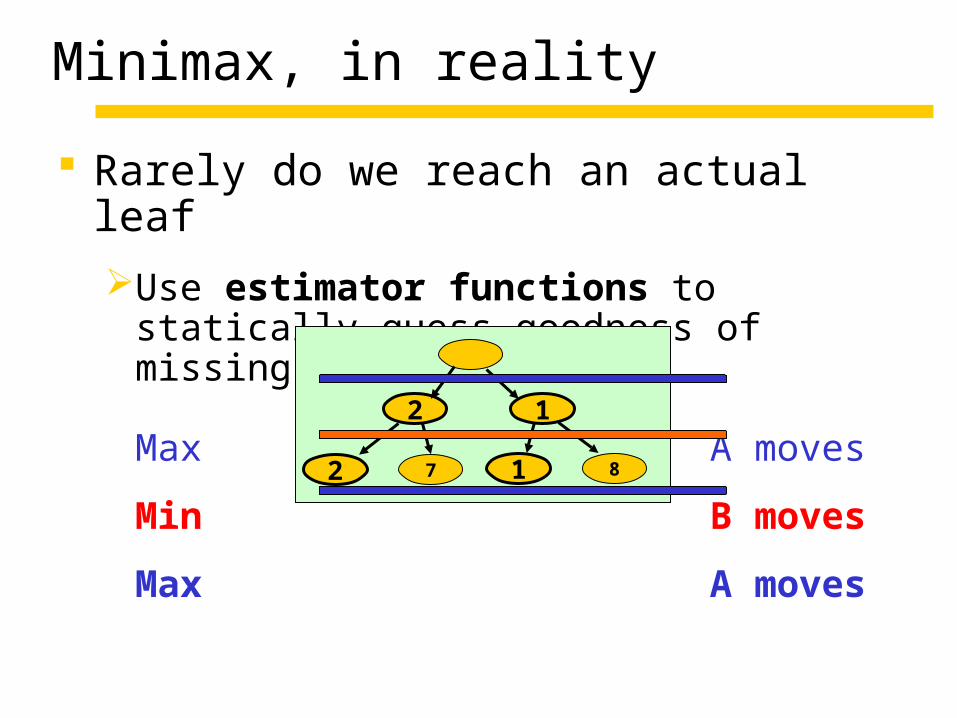
Minimax, in reality
Rarely do we reach an actual leaf
Use estimator functions to statically guess goodness of missing subtrees
Max A moves
Min B moves
Max A moves
2
2 7
1
1 8
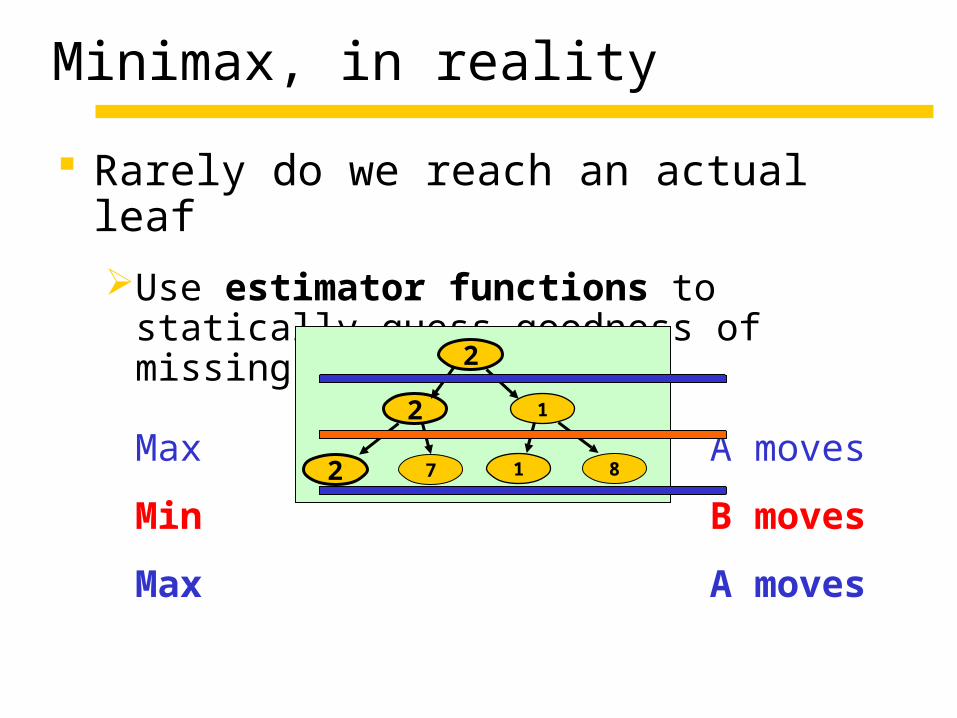
Minimax, in reality
Rarely do we reach an actual leaf
Use estimator functions to statically guess goodness of missing subtrees
Max A moves
Min B moves
Max A moves
2
2
2 7
1
1 8

Minimax
Trade-off
Quality vs. Speed
Quality: deeper search
Speed: use of estimator functions
Balancing
Relative costs of move generation and estimator functions
Quality and cost of estimation function

Mini-Max Algorithm
Definitions
Terminal position is a position where the game is over
In TicTacToe a game may be over with a tie, win or loss
Each terminal position has some value
The value of a non-terminal position P, is given by
v(P) = max - v(P') P' in S(P)
Where S(P) is the set of all successor positions of P
Minus sign is there because the other player is moving into position P’

Mini-Max algorithm - pseudo code
min-max(P){ if P is terminal, return v(P) m = -
for each P' in S(P) v = -(min-max(P')) if m < v then m = v return m
}

Game Tree search techniques
Min-max search
Assume optimal play on both sides
Pruning
The alpha-beta procedure: Next!

Alpha-Beta Pruning
Track expectations.
Use 2 variables and to prune the tree
– Best score so far at a max node
Value increases as we see more children
– Best score so far at a min node
Value decreases as we see more children
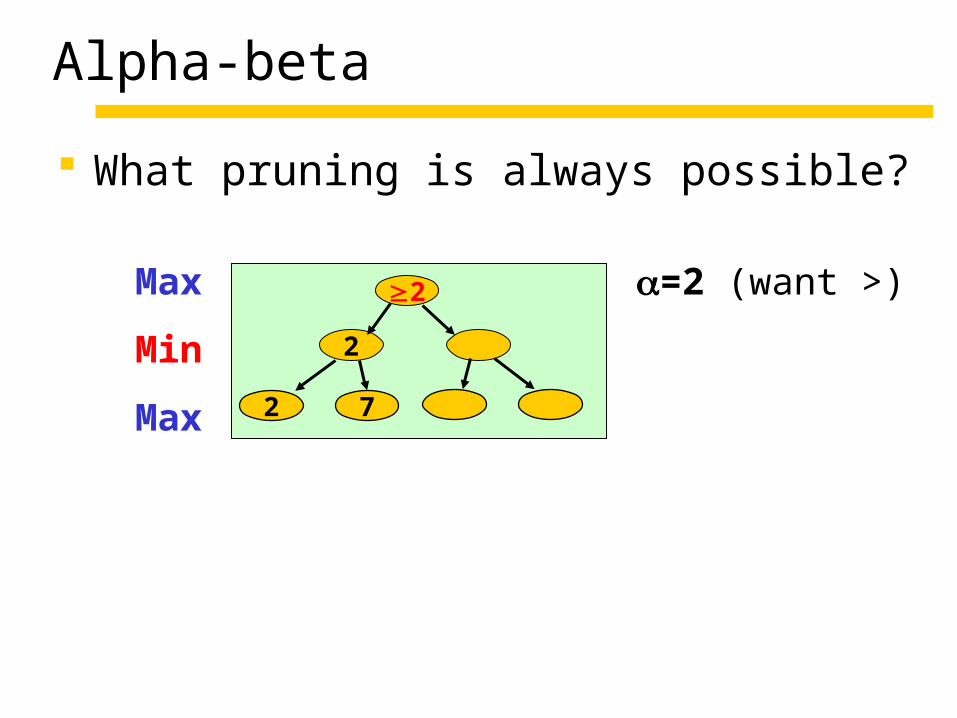
Alpha-beta
What pruning is always possible?
Max =2 (want >)
Min
Max
2
2
2 7

Alpha-beta
What pruning is always possible?
Max =2 (want >)
Min =1 (want <)
Max
The root already has a value larger than the current minimizing value .
Therefore there is no point in finding a better minimum. Prune!
2
2
2 7
1
1
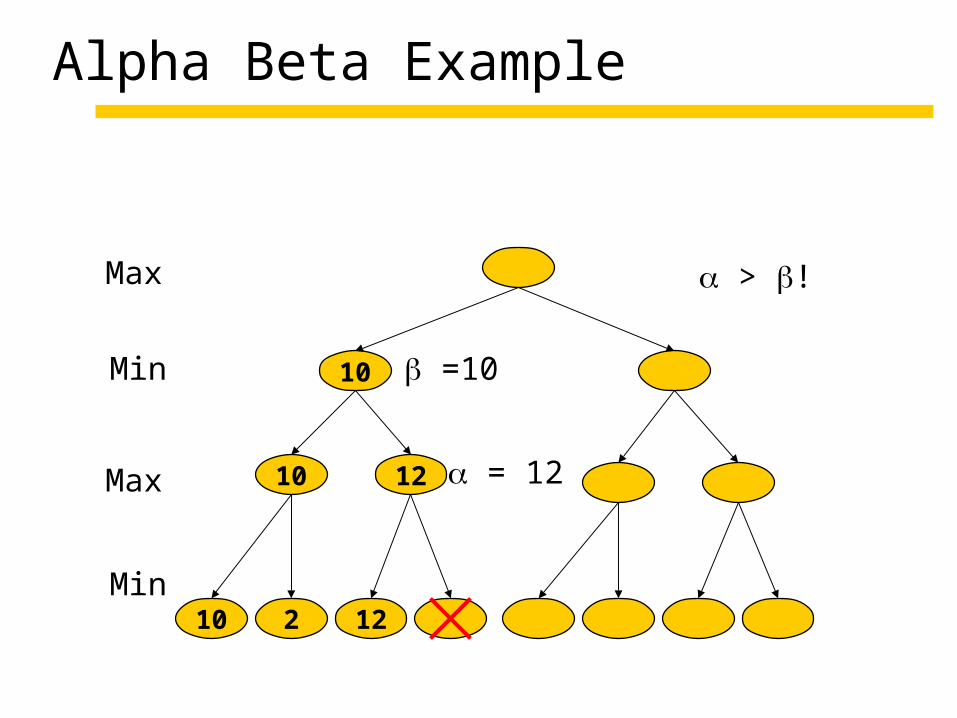
10 2 12
10 12
10
Alpha Beta Example
Max
Max
Min
Min
=10
= 12
> !
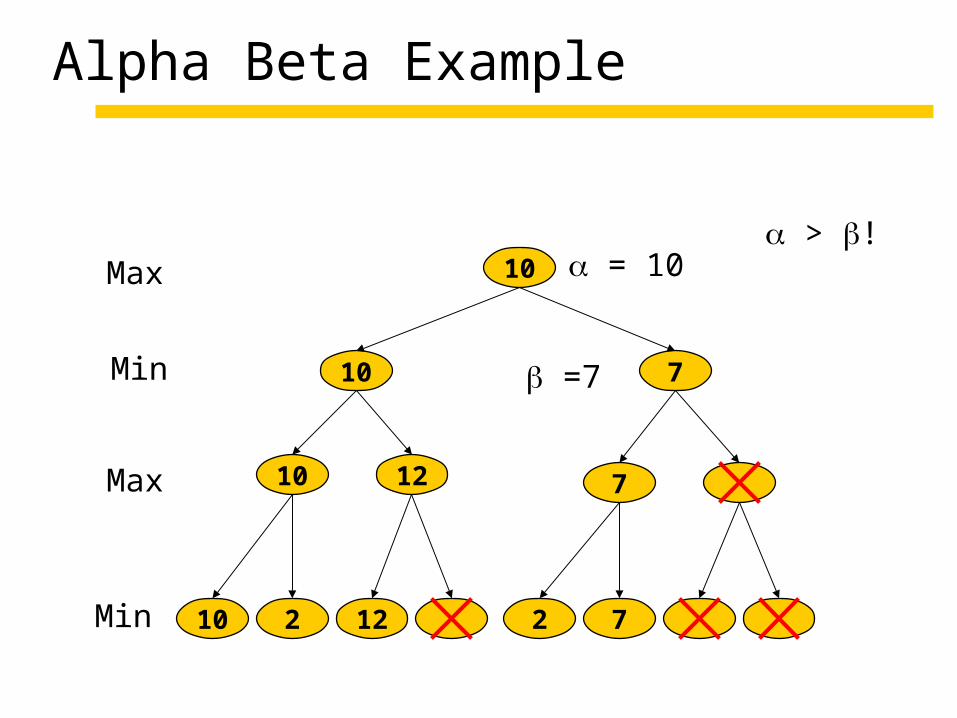
Alpha Beta Example
10 2 12 2 7
10 12 7
10 7
10Max
Max
Min
Min
= 10
=7
> !

alphaBeta (, )
The top level call: Return alphaBeta (- , ))
alphaBeta (, ):
At leaf level (depth limit is reached):
Assign estimator function value (in the range (- .. ) to the leaf node.
Return this value.
At a min level (opponent moves):
For each child, until :
Set = min(, alphaBeta (, ))
Return .
At a max level (our move):
For each child, until :
Set = max(, alphaBeta (, ))
Return .

Alpha-Beta Pseudo Code
AB(, ,P){
if P is terminal, return v(P) 1 =
for each P' in S(P) v = -AB(- , - 1 , P') if 1 < v then 1 = v if 1 >= then return 1
return 1
}

Heuristic search techniques
Alpha-beta is one way to prune the game tree…

Heuristic search techniques
1. Organize search to eliminate large sets of possibilities Pruning strategies remove
subtrees (alpha-beta)
Transposition strategies combine multiple states, exploiting symmetries
Memoizing techniques remember states previously explored Also, eliminate loops
X O O
X O X O OX O
OX
X O X O O

Heuristic search techniques
2. Explore decisions in order of likely success
Guide search with estimator functions that correlate with likely search outcomes
3. Save time by guessing search outcomes
Use estimator functions

Heuristic search techniques
4. Put resources into promising approaches
Go deeper for more promising moves
5. Consider progressive deepening
Breadth-first: find a most plausible move;
then do deeper search to improve confidence.

Summary
Backtracking
Organized brute force
Answer to problem = set of successive decisions
When stuck, go back, try the remaining alternatives
No optimality guarantees

Summary
Game playing
Game trees
Mini-max algorithm
Optimization
Heuristics search
Alpha-beta pruning

Homework 6 Reminder !
HW6 is out !
Build an Othello Player
Part I: Build a board (game state) class
Part II: Build a player which uses mini-max and alpha-beta
Part III: Competition

State-of-the-art: Backgammon
Gerald Tesauro (IBM)
Wrote a program which became “overnight” the best player in the world
Not easy!
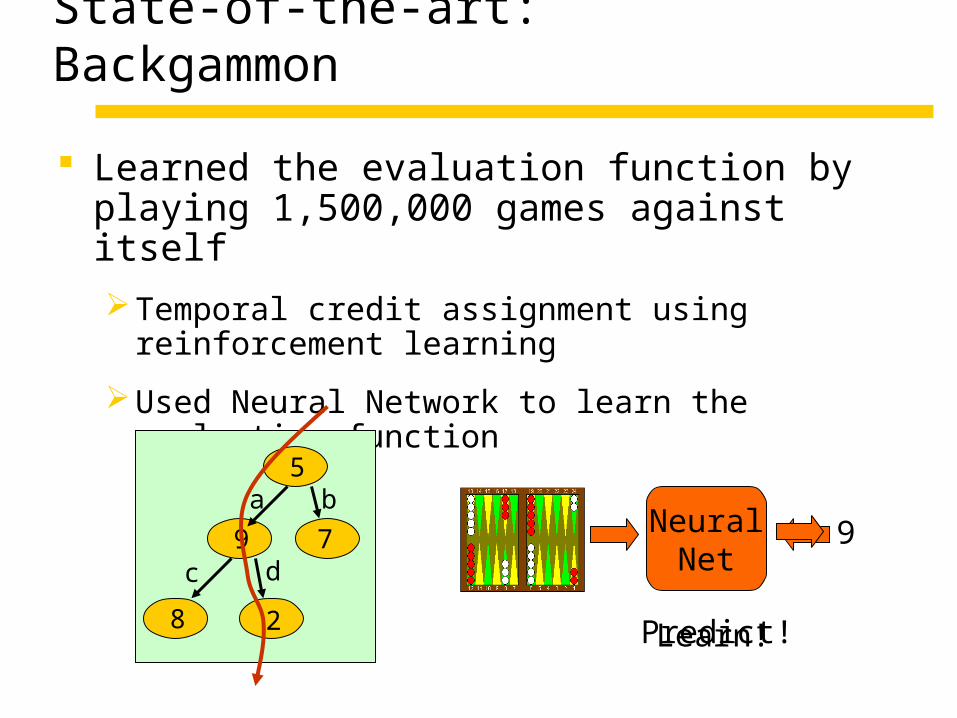
State-of-the-art: Backgammon
Learned the evaluation function by playing 1,500,000 games against itself
Temporal credit assignment using reinforcement learning
Used Neural Network to learn the evaluation function
5
9 7
8 2
a b
c d
NeuralNet
9
Learn!Predict!

State-of-the-art: Go
Average branching factor 360
Regular search methods go bust !
People use higher level strategies
Systems use vast knowledge bases of rules… some hope, but still play poorly
$2,000,000 for first program to defeat a top-level player

