Embed Size (px)
Citation preview

B-Trees
Size and Lookup

B-Trees (I)Suppose:• Blocks can hold either:
- 10 records or- 99 keys and 100 pointers
• B-Tree nodes are 70% full- 69 keys and 70 pointers
• 1,000,000 records
• For each structure described below, determine - The total number of blocks- The average # of I/O for
lookup given the search key.
A. Records sorted on search key, with 10 records per blocks. The B-tree is a dense index.
• 1,000,000 /10 = 100,000 blocks to hold the records
• For the B-tree we reason as follows:– We need 1,000,000 pointers at the
leaves to point to each record. They can be packed into
1,000,000 / 70 = 14,286 leave blocks.
– We need 14,286 pointers in the above level. Packed into 14,286/70=204
blks
– We need 204 pointers in the above Packed into 204/70 = 3 blocks
• Total: 100,000 + 14,286 + 204 + 3 1(root) = 114,494 blocks
• Since the tree has 4 levels, we need 5 I/O’s for a lookup.

B-Trees (II)Suppose:• Blocks can hold either:
- 10 records or- 99 keys and 100 pointers
• B-Tree nodes are 70% full- 69 keys and 70 pointers
• 1,000,000 records
• For each structure described below, determine - The total number of blocks- The average # of I/O for
lookup given the search key.
B Same as (A), but the records aren’t sorted. Still, records packed 10 to a block.
• Same as (A) = 114,494 blocks• Same as (A) = 5 I/O’s for a lookup.

B-Trees (III)Suppose:• Blocks can hold either:
- 10 records or- 99 keys and 100 pointers
• B-Tree nodes are 70% full- 69 keys and 70 pointers
• 1,000,000 records
• For each structure described below, determine - The total number of blocks- The average # of I/O for
lookup given the search key.
C Same as (A), but B-tree is a sparse index.
• 1,000,000 /10 = 100,000 blocks to hold the records
• For the sparse B-tree:– We need 100,000 pointers at the
leaves to point to each data block. They can be packed into 100,000
/ 70 = 1,429 leave blocks.
– We need 1,429 pointers in the above level.
Packed into 1429/70=21 blocks
– We need 21 pointers in the above Packed into 21/70 = 1 block
(root)
• Total: 100,000 + 1,429 + 21 + 1 = 101,451blocks
• Since the tree has 3 levels, we need 4 I/O’s for a lookup.

B-Trees (IV)Suppose:• Blocks can hold either:
- 10 records or- 99 keys and 100 pointers
• B-Tree nodes are 70% full- 69 keys and 70 pointers
• 1,000,000 records
• For each structure described below, determine - The total number of blocks- The average # of I/O for
lookup given the search key.
D Instead of the B-Tree leaves having pointers to data records, the B-Tree leaves hold the records themselves. A block can hold 10 records, but a leaf block is in fact 70% full, i.e. there are 7 records per leaf.
• 1,000,000 /7 = 142,857 blocks to hold the records. These blocks will be the leaves of the B-tree.
• We need 142,857 pointers at the next level.
– They can be packed into 142,857/ 70 = 2,040 blocks.
• We need 2,040 pointers in the above next level.
– Packed into 2040/70=30 blocks
• We need 30 pointers in the above…
– Packed into 30/70 = 1 block (root)
• Total: 142857 + 2040 +30 +1 = 144,928 blocks
• Since the tree has 4 levels, we need 4 I/O’s for a lookup.

B-Trees
Range Queries:
Repeat the exercise in the case that the query is a range query that is matched by 1000 records.

B-Trees (I)Suppose:• Blocks can hold either:
- 10 records or- 99 keys and 100 pointers
• B-Tree nodes are 70% full- 69 keys and 70 pointers
• 1,000,000 records
• For each structure described below, determine - The total number of blocks- The average # of I/O for
lookup given the search key.
A. Records sorted on search key, with 10 records per blocks. The B-tree is a dense index.
• Since the tree has 4 levels, we need 4 I/O’s to go to the leaf where the pointer to start of the range is located.
• Then, by following the sibling pointers we retrieve all the leaves holding the pointers to the matching records. • 1000 pointers are packed in
1000/70 = 14 blocks.• Now, by following each of the 1000
pointers we read the 1000 records. – Since the records are sorted the
1000 range records will occupy (almost) as few blocks as possible, i.e. 1000 / 10 = 100 blocks.
• In total, we need 4 + 14 + 100 = 118 I/O’s.

B-Trees (II)Suppose:• Blocks can hold either:
- 10 records or- 99 keys and 100 pointers
• B-Tree nodes are 70% full- 69 keys and 70 pointers
• 1,000,000 records
• For each structure described below, determine - The total number of blocks- The average # of I/O for
lookup given the search key.
B Same as (A), but the records aren’t sorted. Still, records packed 10 to a block.
• As in (A) we need 4+14 I/O’s to locate the 1000 pointers.
• However, since the records aren’t sorted, it might be that the 1000 records are located in 1000 different blocks. So, we might end up reading 1000 blocks.
• In total, we need 4 + 14 + 1000 = 1018 I/O’s.

B-Trees (III)Suppose:• Blocks can hold either:
- 10 records or- 99 keys and 100 pointers
• B-Tree nodes are 70% full- 69 keys and 70 pointers
• 1,000,000 records
• For each structure described below, determine - The total number of blocks- The average # of I/O for
lookup given the search key.
C Same as (A), but B-tree is a sparse index.
• Since the tree has 3 levels, we need 3 I/O’s to go to the leaf where the pointer to start of the range is located.
• How many pointers to data we need to follow?
• 1000 records are packed into 1000/10 = 100 blocks. So, we need to follow 100 pointers.
• How many leaves are needed to pack 100 pointers?
• 2 leaves. • Total: 3 + 2 + 100 = 105 I/O’s

B-Trees (IV)Suppose:• Blocks can hold either:
- 10 records or- 99 keys and 100 pointers
• B-Tree nodes are 70% full- 69 keys and 70 pointers
• 1,000,000 records
• For each structure described below, determine - The total number of blocks- The average # of I/O for
lookup given the search key.
D Instead of the B-Tree leaves having pointers to data records, the B-Tree leaves hold the records themselves. A block can hold 10 records, but a leaf block is in fact 70% full, i.e. there are 7 records per leaf.
• Since the tree has 4 levels, we need 4 I/O’s to go to the leaf where the start record of the range is located.
• By following the sibling pointers we need to retrieve as many leaves as are needed to hold 1000 records.
– 1000 records are packed in 1000 /7 = 143 leaves.
• Total: 4 + 143 = 147 I/O’s
Hash Tables
Extensible Hash Tables

Dynamic Hashing Framework• Hash function h produces a sequence of k bits. • Only some of the bits are used at any time to determine
placement of keys in buckets.
Extensible Hashing (Buckets may share blocks!)• Keep parameter i = number of bits from the beginning of h(K)
that determine the bucket. • Bucket array now = pointers to buckets.
- A block can serve as several buckets. - For each block, a parameter ji tells how many bits of
h(K) determine membership in the block. - I.e., a block represents 2i-j buckets that share the first j bits
of their number.

Example• An extensible hash table when i=1:

Extensible Hash table Insert• If record with key K fits in the block pointed to by h(K), put it
there. • If not, let this block B represent j bits.
1. j<i: a) Split block B into two and distribute the records (of B)
according to (j+1)st bit; b) set j:=j+1; c) fix pointers in bucket array, so that entries that formerly
pointed to B now point either to B or the new block How? depending on…(j+1)st bit
2. j=i: 1. Set i:=i+1; 2. Double the bucket array,
so it has now 2i+1 entries; 3. proceed as in (1).
Let w be an old array entry. Both the new entries w0 and w1 point to the same block that w used to point to.
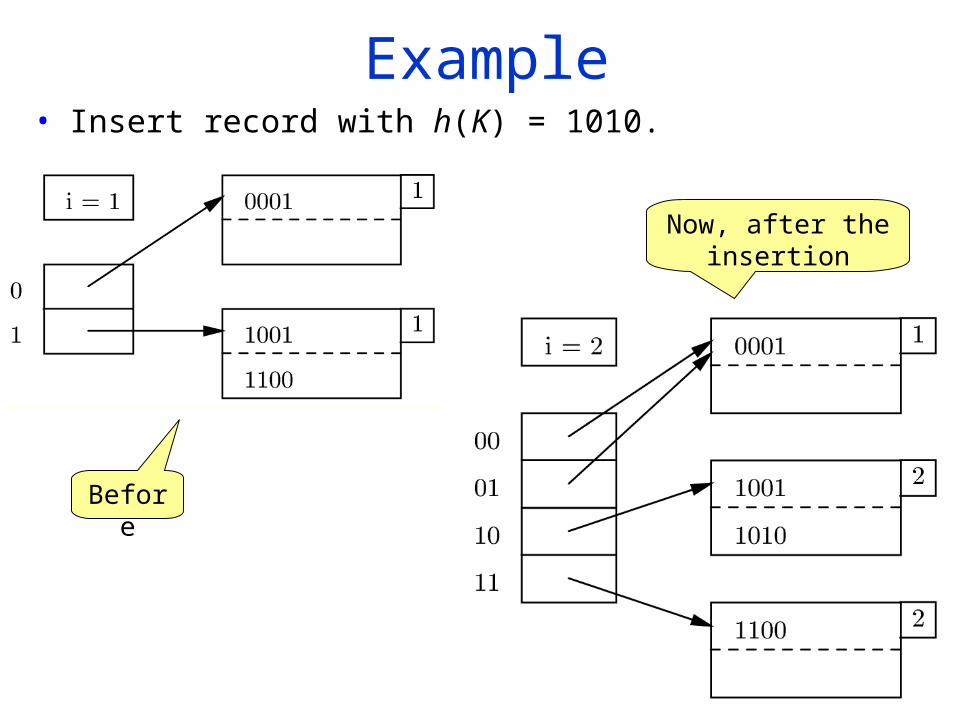
Example• Insert record with h(K) = 1010.
Before
Now, after the insertion
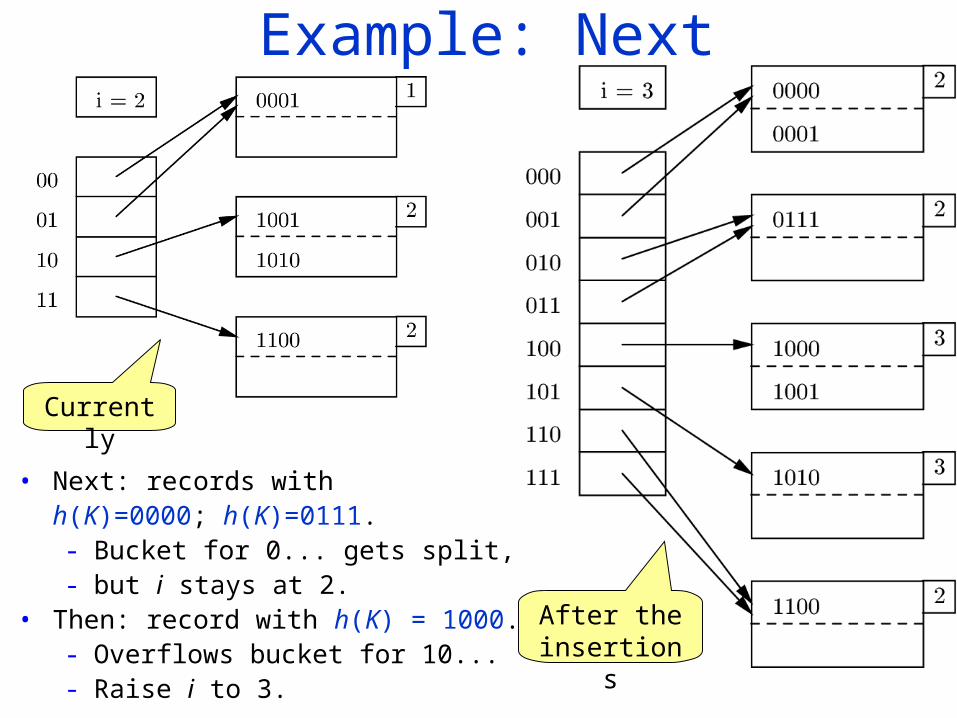
Example: Next
• Next: records with h(K)=0000; h(K)=0111. - Bucket for 0... gets split, - but i stays at 2.
• Then: record with h(K) = 1000. - Overflows bucket for 10... - Raise i to 3.
After the insertions
Currently

Exercise• Suppose we want to insert keys with hash values: 0000…
1111 in an extensible hash table.• Assume that a block can hold three records.

0000
i=1
0
1
1
1
0000
0001
i=1
0
1
1
1
Insertion of 0011.No room
0000
0001
0010
i=1
0
1
1
1

0000
0001
0010
i=2
00
01
2
2
10
11
1
This is the new block.
0000
0001
i=3
000
001
3
0010
0011
3
010
011
2
100
101
110
111
1
This is the new block.

0000
0001
i=3
000
001
3
0010
0011
3
010
011
2
100
101
110
111
1
0000
0001
i=3
000
001
3
0010
0011
3
010
011
0100 2
100
101
110
111
1

0000
0001
i=3
000
001
3
0010
0011
3
010
011
0100
0101
2
100
101
110
111
1
0000
0001
i=3
000
001
3
0010
0011
3
010
011
0100
0101
0110
2
100
101
110
111
1

0000
0001
i=3
000
001
3
0010
0011
3
010
011
0100
0101
3
100
101
110
111
1
0110
0111
3
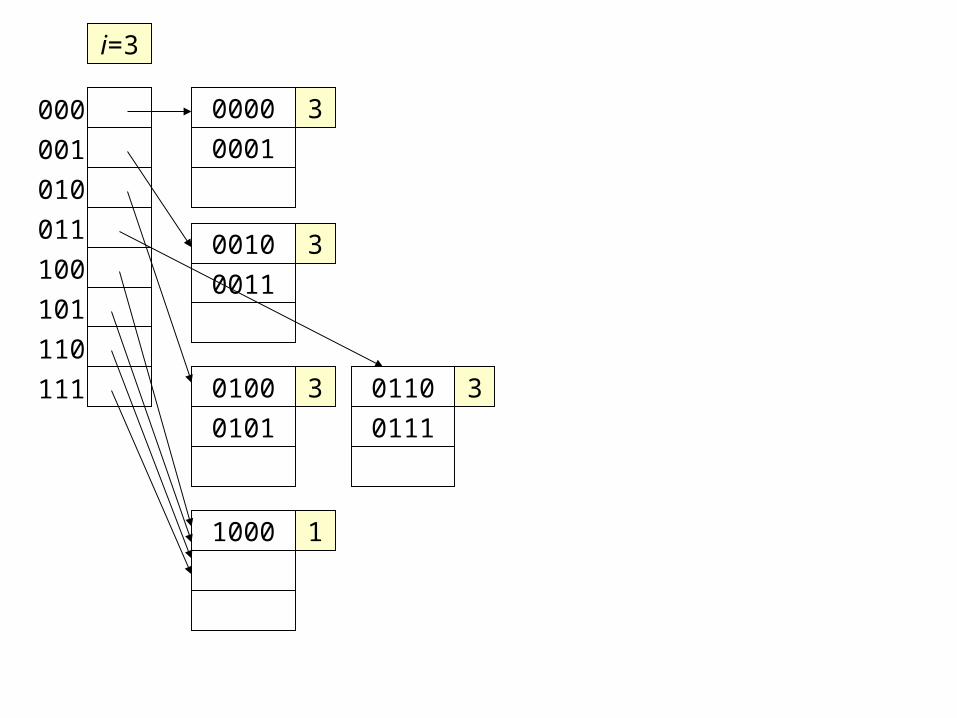
0000
0001
i=3
000
001
3
0010
0011
3
010
011
0100
0101
3
100
101
110
111
1000 1
0110
0111
3

0000
0001
i=3
000
001
3
0010
0011
3
010
011
0100
0101
3
100
101
110
111
1000
1001
1
0110
0111
3

0000
0001
i=3
000
001
3
0010
0011
3
010
011
0100
0101
3
100
101
110
111
1000
1001
1010
1
0110
0111
3

0000
0001
i=3
000
001
3
0010
0011
3
010
011
0100
0101
3
100
101
110
111
1000
1001
1010
2
0110
0111
3
2
Still no room for 1011
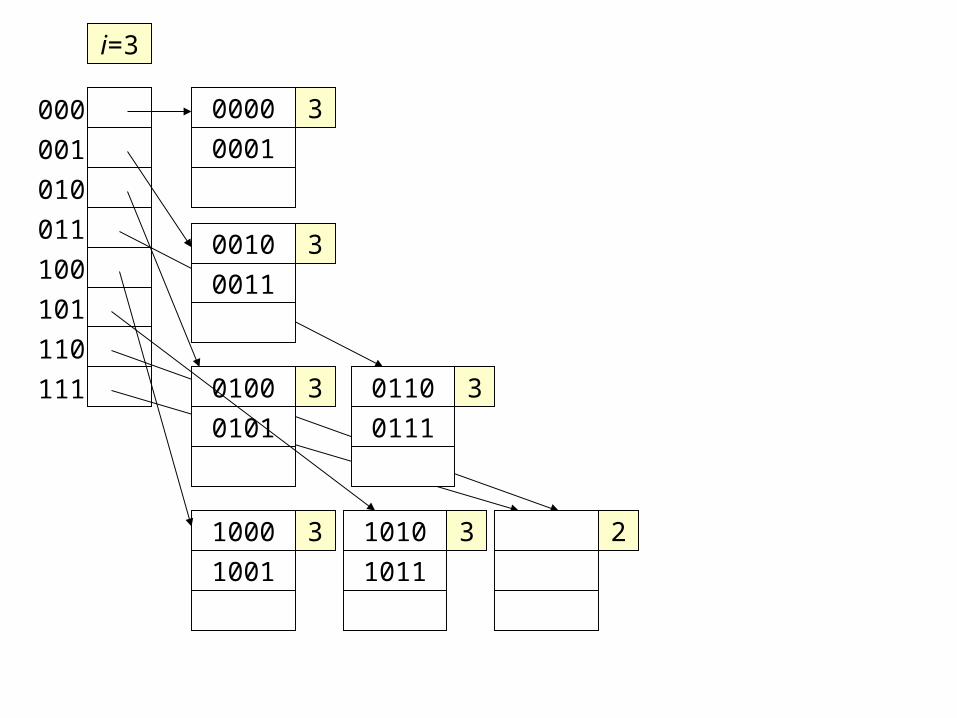
0000
0001
i=3
000
001
3
010
011
100
101
110
111
1000
1001
3
0110
0111
3
21010
1011
3
0100
0101
3
0010
0011
3
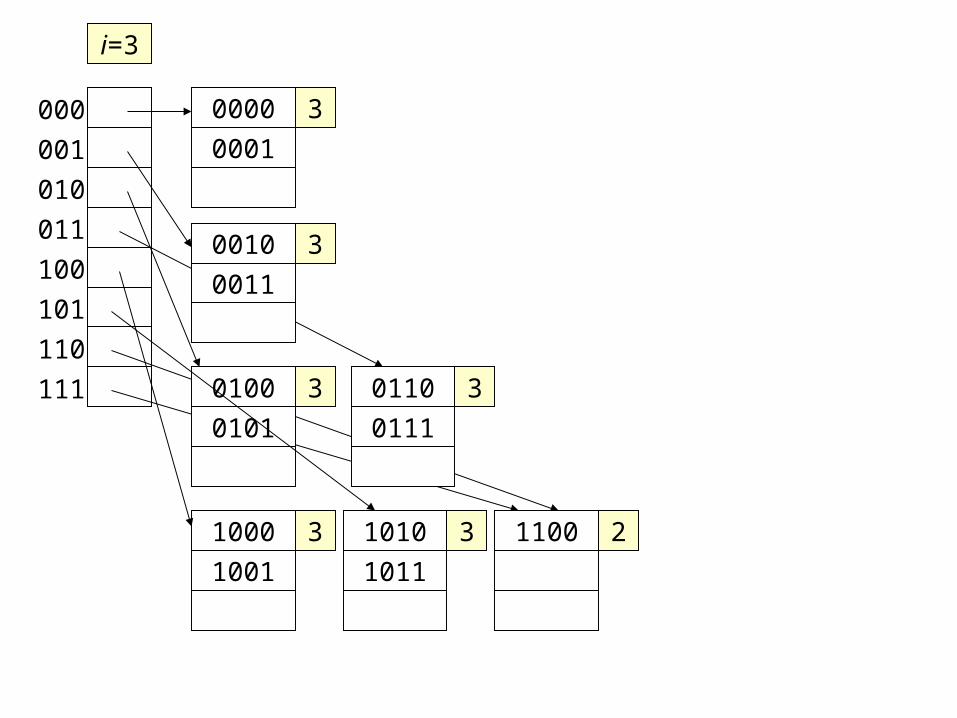
0000
0001
i=3
000
001
3
010
011
100
101
110
111
1000
1001
3
0110
0111
3
1100 21010
1011
3
0100
0101
3
0010
0011
3

0000
0001
i=3
000
001
3
010
011
100
101
110
111
1000
1001
3
0110
0111
3
1100
1101
21010
1011
3
0100
0101
3
0010
0011
3

0000
0001
i=3
000
001
3
010
011
100
101
110
111
1000
1001
3
0110
0111
3
1100
1101
1110
21010
1011
3
0100
0101
3
0010
0011
3

0000
0001
i=3
000
001
3
010
011
100
101
110
111
1000
1001
3
0110
0111
3
1100
1101
31010
1011
3
0100
0101
3
0010
0011
3
1110
1111
3

Hash Tables
Linear Hash Tables

Linear Hashing• Use i bits from right (low order) end of h(K). • Buckets numbered [0…n-1], where 2i-1<n2i.
• Let last i bits of h(K) be m = (a1,a2,…,ai)
1. If m < n, then record belongs in bucket m.
2. If nm<2i, then record belongs in bucket m-2i-1, that is the bucket we would get if we changed a1 (which must be 1) to 0.
i=1
n=2
r=3
This is also part of the structure
#of records
#of buckets

Linear Hash Table Insert• Pick an upper limit on capacity,
- e.g., 85% (1.7 records/bucket in our example). • If an insertion exceeds capacity limit, set n := n + 1.
- If new n is 2i + 1, set i := i + 1. No change in bucket numbers needed --- just imagine a leading 0.
- Need to split bucket n - 2i-1 because there is now a bucket numbered (old) n.

Example• Insert record with h(K) = 0101.
- Capacity limit exceeded; increment n.
r=3
n=2
i=1
#of records
#of buckets
r=4
n=3
i=2
#of records
#of buckets

Example • Insert record with h(K) = 0001.
- Capacity limit not exceeded. - But bucket is full; add overflow bucket.
r=5
n=3
i=2

Example• Insert record with h(K) = 1100.
- Capacity exceeded; set n = 4, add bucket 11. - Split bucket 01.
r=7
n=4
i=2

Lookup in Linear Hash Table• For record(s) with search key K, compute h(K); search the
corresponding bucket according to the procedure described for insertion.
• If the record we wish to look up isn’t there, it can’t be anywhere else.
• E.g. lookup for a key which hashes to 1010, and then for a key which hashes to 1011.
r=4
n=3
i=2

Exercise• Suppose we want to insert keys with hash values: 0000…
1111 in a linear hash table with 100% capacity threshold. • Assume that a block can hold three records.
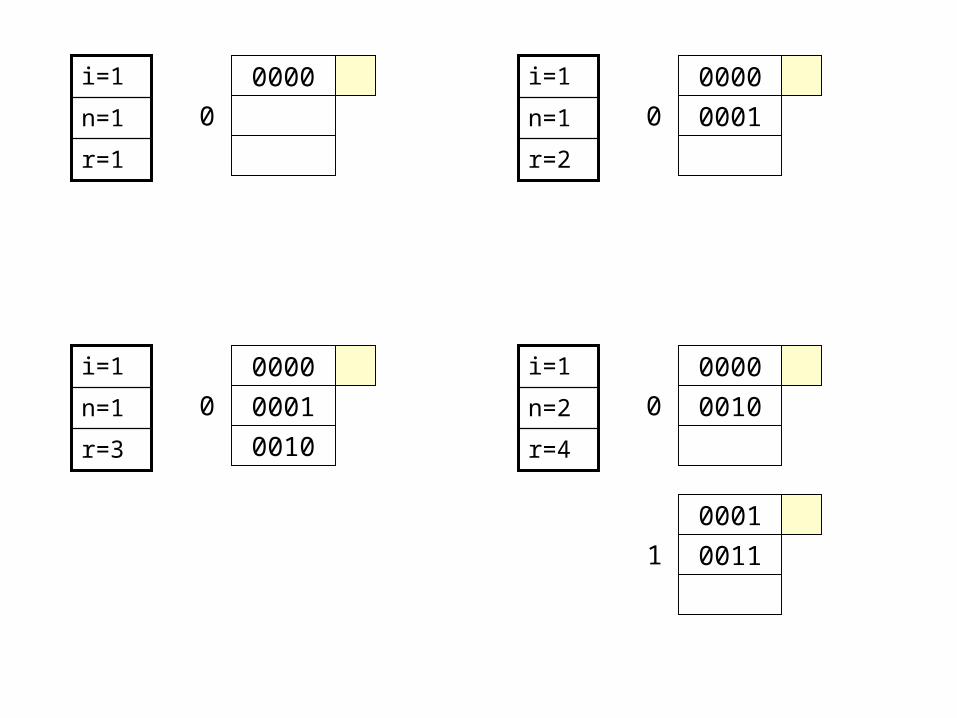
r=1
n=1
i=1 0000
0
r=2
n=1
i=1 0000
00010
r=3
n=1
i=1 0000
0001
0010
0
r=4
n=2
i=1 0000
00100
0001
00111

r=5
n=2
i=1 0000
0010
0100
0
0001
00111
r=6
n=2
i=1 0000
0010
0100
0
0001
0011
0101
1

r=7
n=3
i=2 0000
0100
00
0001
0011
0101
01
0010
011010
Continue at home…

Multidimensional Indexes

Grid files (hash-like structure)
Data:(25,60) (45,60) (50,75) (50,100)(50,120) (70,110) (85,140) (30,260)(25,400) (45,350) (50,275) (60,260)
• Divide data into stripes in each dimension
• Rectangle in grid points to bucket
• Example: database records (age,salary) for people who buy gold jewelry.

Grid file

OperationsLookup Find coordinates of point in each dimension ---
gives you a bucket to search. Nearest Neighbor Lookup point P . Consider points in that bucket. • Problem: there could be points in adjacent
buckets that are closer. - Example: NN of (45; 200).
• Problem: there could be no points at all in the bucket: widen search?
Range Queries Ranges define a region of buckets. • Buckets on border may contain points not in
range. • Example: 35 < age <= 45; 50 < salary <=
100. Queries Specifying Only One Attribute • Problem: must search a whole row or column
of buckets.
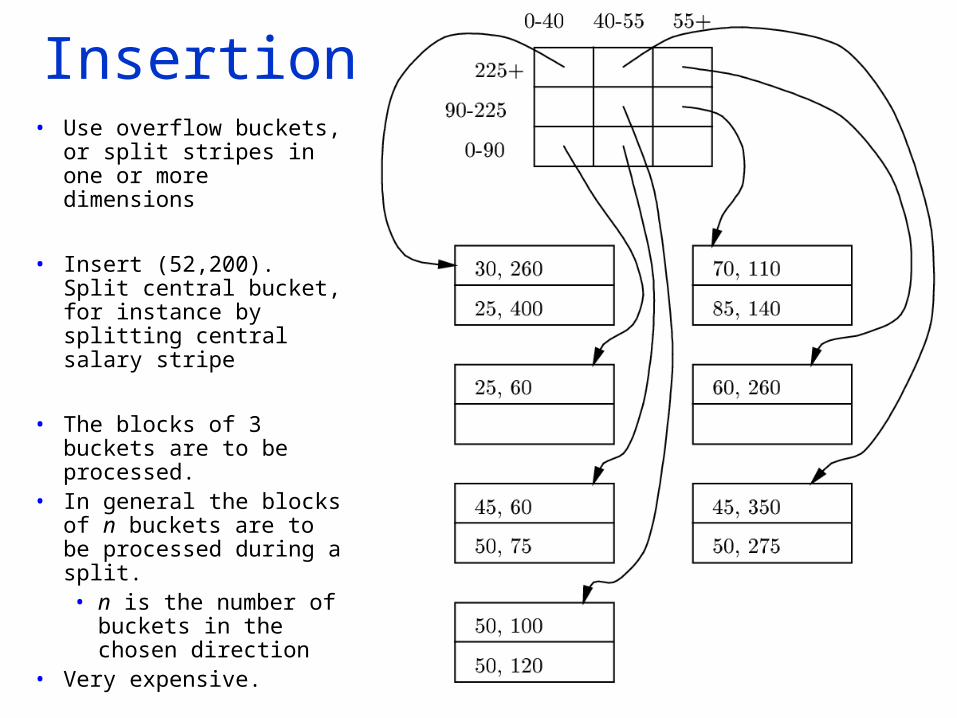
Insertion• Use overflow buckets,
or split stripes in one or more dimensions
• Insert (52,200). Split central bucket, for instance by splitting central salary stripe
• The blocks of 3 buckets are to be processed.
• In general the blocks of n buckets are to be processed during a split. • n is the number of
buckets in the chosen direction
• Very expensive.
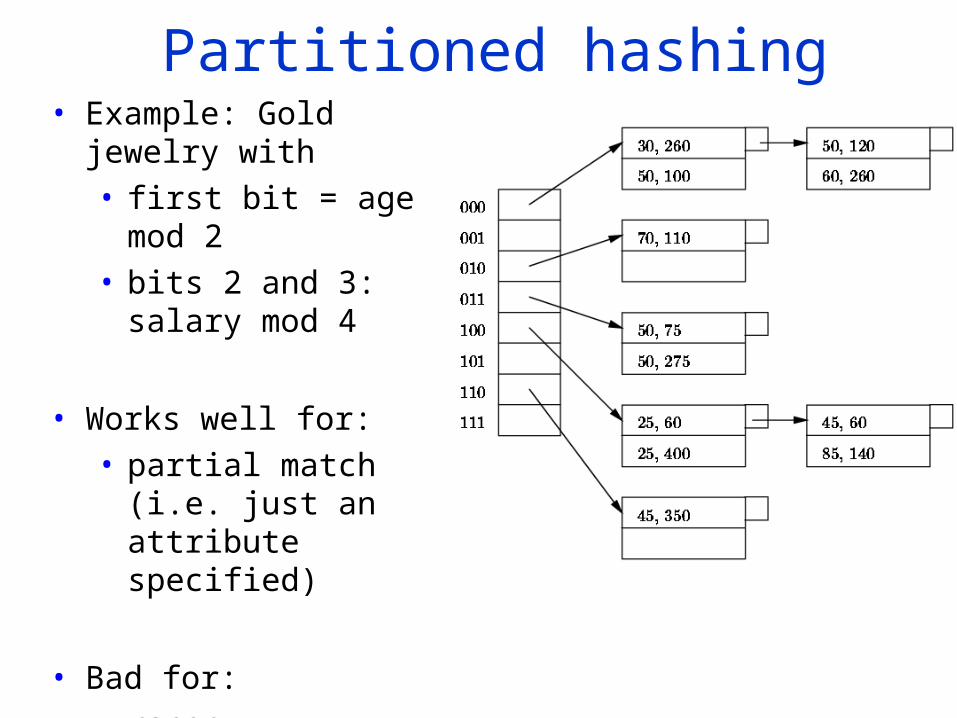
Partitioned hashing• Example: Gold jewelry
with• first bit = age mod 2• bits 2 and 3: salary
mod 4
• Works well for: • partial match (i.e. just
an attribute specified)
• Bad for: • range • Nearest Neighbors
queries
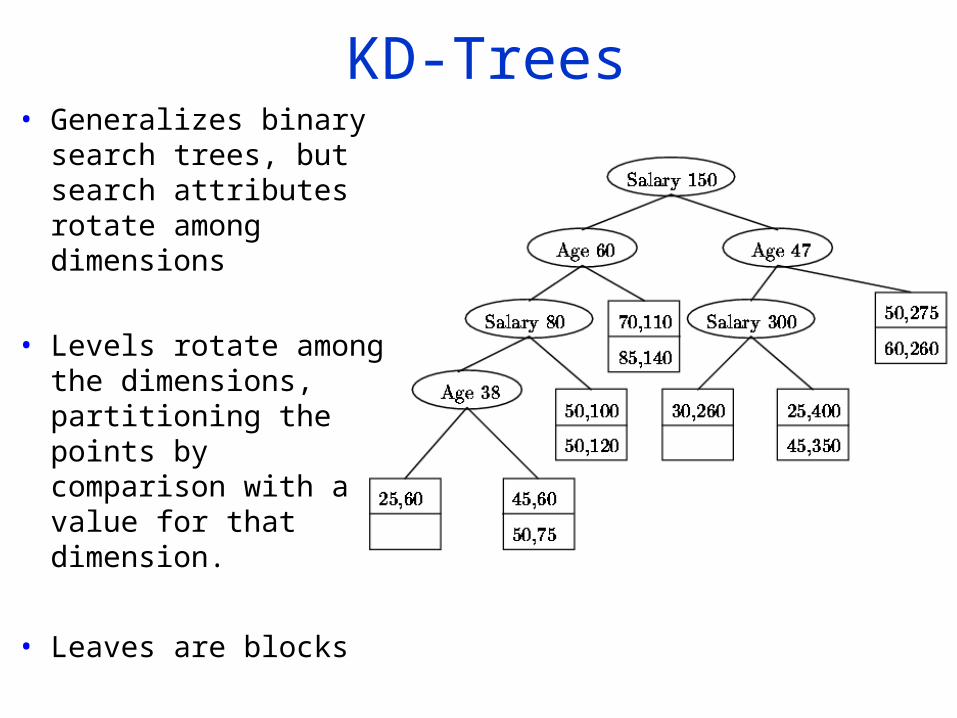
KD-Trees• Generalizes binary
search trees, but search attributes rotate among dimensions
• Levels rotate among the dimensions, partitioning the points by comparison with a value for that dimension.
• Leaves are blocks

Geometrically…• Remember we didn’t
want the stripes in grid files to continue all along the vertical or horizontal direction?
• Here they don’t.

OperationsLookup in KD Trees • Find appropriate leaf by binary search. Is the record there?
Insert Into KD Trees • Lookup record to be inserted, reaching the appropriate leaf. • If there is room, put record in that block. • If not, find a suitable value for the appropriate dimension and
split the leaf block.
Example • Someone 35 years old with a salary of $500K buys gold
jewelry. • Belongs in leaf with (25; 400) and (45; 350). • Too full: split on age. See figure next.
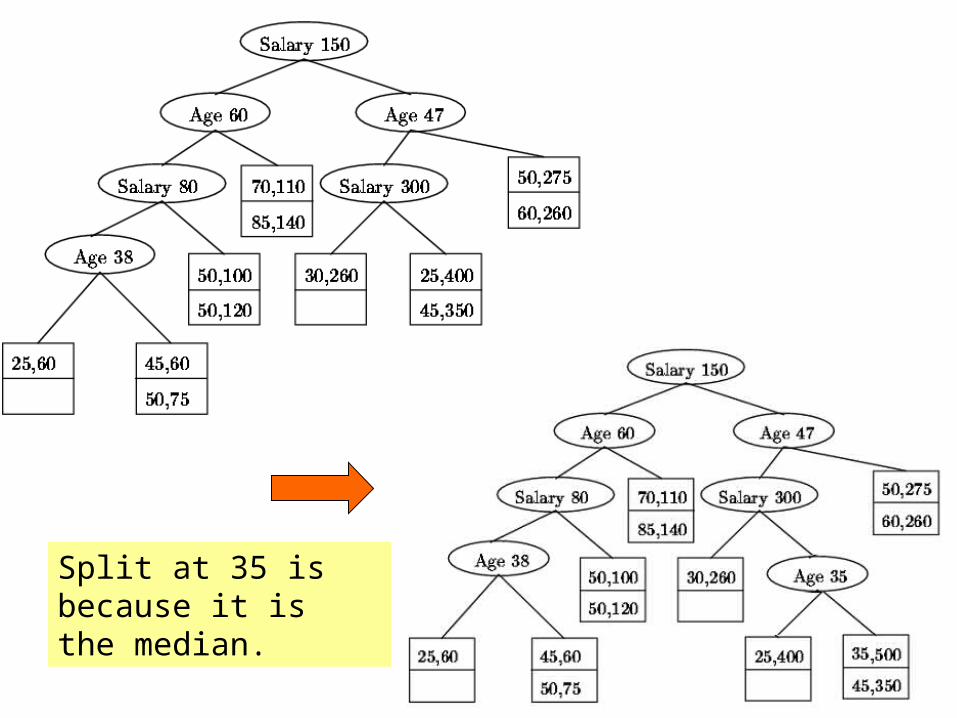
Split at 35 is because it is the median.

QueriesPartial match queries• When we don’t know
the value of the attribute at the node, we must explore both of its children.- E.g. find points with
age=50
Range Queries• Sometimes a range will
allow us to move to only one child of a node.
• But if the range straddles the splitting value then we must explore both children.

R-Tree Lookup (Where am I)• We start at the root, with which the
entire region is associated.
• We examine the subregions at the root and determine which children correspond to interior regions that contain point P.
• If there are zero regions we are done; P is not in any data region.
• If there are some subregions we must recursively search those children as well, until we reach the leaves of the tree.

R-Tree Insertion• We start at the root and try to find some subregion into R fits.
If more than one we pick just one, and repeat the process there.
• If there is no region, we expand, and we want to expand as little as possible. So, we pick the child that will be expanded as little as possible.
• Eventually we reach a leaf, where we insert the region R. • However, if there is no room we have to split the leaf. We
split the leaf in such a way as to have the smallest subregions.

Example• Suppose that the
leaves have room for six regions.
• Further suppose that the six regions are together on one leaf, whose region is represented by the outer solid rectangle.
• Now suppose that another region POP is added.

((0,0),(60,50)) ((20,20),(100,80))
Road1 Road2 House1 School House2 Pipeline Pop
Example (Cont’ ed)

Example (Cont’ ed)• Suppose now that
House3 ((70,5),(80,15)) gets added.
• We do have space to the leaves, but we need to expand one of the regions at the parent.
• We choose to expand the one which needs to be expanded the least.

Which one should we expand?((0,0),(80,50)) ((20,20),(100,80))
Road1 Road2 House1 House3 School House2 Pipeline Pop
((0,0),(60,50)) ((5,20),(100,80))
Road1 Road2 House1 School House2 Pipeline Pop House3

Bitmap Indexes• Suppose we have n tuples.• A bitmap index for a field F is a collection of bit vectors of
length n, one for each possible value that may appear in the field F.
• The vector for value v has 1 in position i if the i-th record has v in field F, and it has 0 there if not.
(30, foo)
(30, bar)
(40, baz)
(50, foo)
(40, bar)
(30, baz)
foo 100100
bar 0…
baz …

Motivation for Bitmap Indexes• They allow very fast evaluation of partial match queries.
SELECT title
FROM Movie
WHERE studioName=‘Disney’ AND year=1995;
If there are bitmap indexes on both studioName and year, we can intersect the vectors for the Disney value and 1995 value.
We should have another index to retrieve the tuples by number.





























