Embed Size (px)
Citation preview

UW Adoption of the Public Cloud for Research
Rob FatlandMay 28, 2020
AWS Education: Online Seminar

AWS has been the preponderant cloud platform adopted by research groups at the University of Washington by far.
I will discuss cloud-based research at UW and the NSF-sponsored Cloudbank project (http://cloudbank.org) today, primarily in relation to AWS.
● Tim Durham (Noble lab, Genome Sciences)● Guarav Bhardwaj (formerly Baker lab, MolES)● Tychele Turner (Eichler lab, Genome Sciences)
○ Tara Madhystha “Test everything at scale” maxim● Jeanelle Ariza (Keene lab, Department of Pathology)● Andy Connolly (UW Astronomy, LSST)
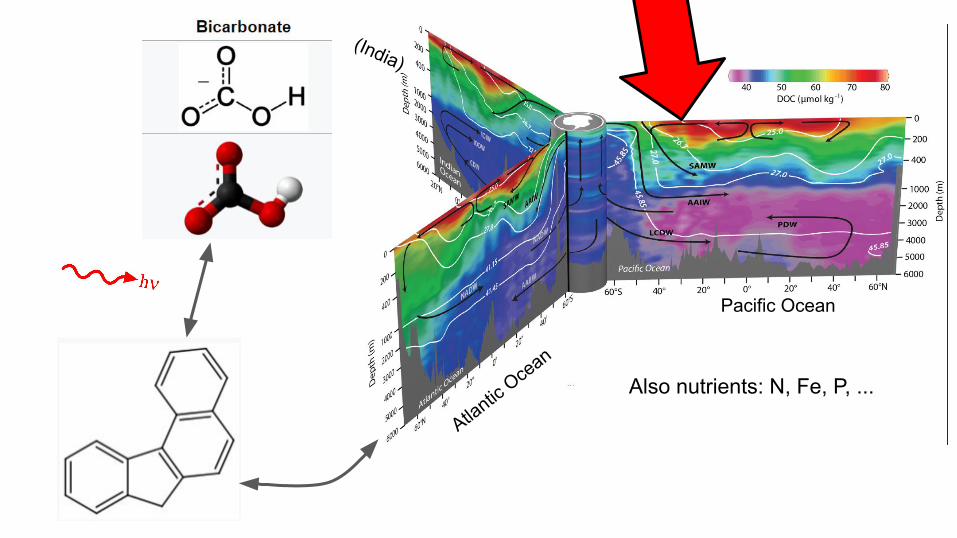
Two groups studying energy transport: Oceans, atmosphere ● Peter Gaube works from models to empirical (robots)
○ ocean circulation > GCC○ gliders cruise about, dive, surface, report in○ power ~ data ~ cost ~ ruggedization
(India)
Atlantic Ocean
Pacific Ocean
Also nutrients: N, Fe, P, ...
slide courtesy Chelle Gentemann, thanks!

“I am not plankton!”
more complicated organic carbon...

Returning to that story of two groups studying energy transport in the oceans and atmosphere
● Peter Gaube: From models to empirical data○ ocean circulation > GCC○ gliders cruise about, dive, surface, report in○ power ~ data ~ cost ○ (self-powered gliders would be nice)

(Sadly no more sharks…)
● Brian Green, Lauren Kuntz: Remote sensing: Tropical Rainfall Measuring Mission (TRMM)● Latent heat vertical profiles coincident with rain storms: Atmospheric energy transport● Ambitious mid-latitude global over 17 years: Atmospheric energy budget in ESS● Needs compute horsepower for data reduction (AWS) and help with implementation (P.Shivraj)
x10

“I don't think we could have done this without [UW eScience] and Shiv to help with both cloud and computer science. There are a lot of ropes to get the hang of (S3, EC2 and all the instance type options, etc) and that would have 100% seemed like an impossible task…”
TRMM continued...

‘Small team’ narrativeWe replace computers as physical boxes with the cloud as a programmable resource pool. Your goal in life is to 3D map the neurons that wind through a thousand cicadas.You generated 47 PB of electron microscope data.You need a stack of computers… path of inquiry… maybe we do this on the cloud?
So there is a ‘start over’ task to learn Cloud Formation and the AWS CLI. Then: Map your analysis software to compute instances via machine images. That’s cool.Data > object storage Test on a small scale, gradually turn up the volume(Be sure to use full capacity)Convinced? Throw that third switch!
Map those neurons! Then think about the results…...plus you have the skill to do it again in five months
(take notes)

Scientists are very resourceful when it comes to generating new datasets
Scientists are notorious when it comes to analysis
But they are having so much fun they attract the computer scientists and information technologists…
...and best case everybody wins…
...until the scientists can’t find that computer scientist
This has led to a second wave of cloud innovation for research: Science infrastructure on the cloud
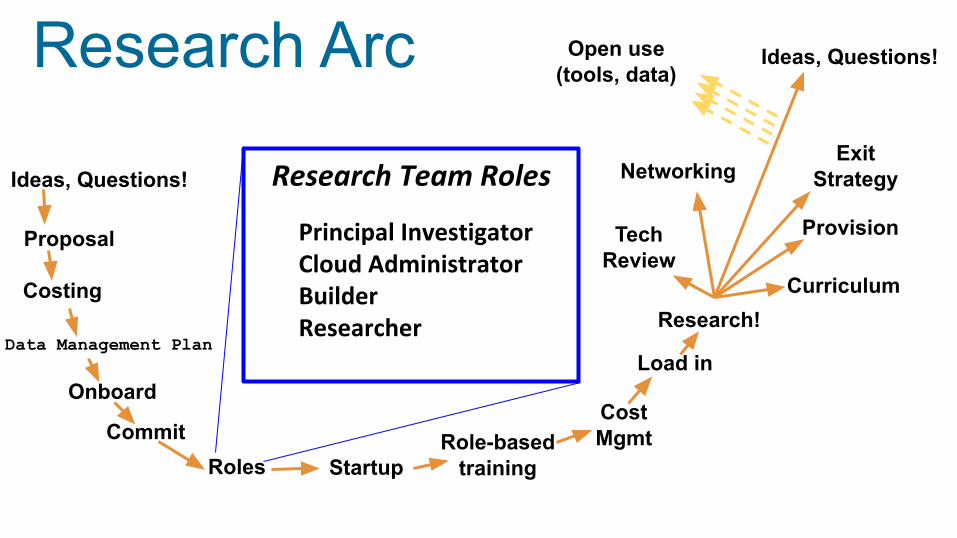
Research Arc
Proposal
Ideas, Questions!
Data Management Plan
Costing
CommitStartup
Onboard
Role-basedtrainingRoles
Research!
Load in
Open use(tools, data)
Ideas, Questions!
CostMgmt
TechReview
Networking
Provision
ExitStrategy
Curriculum

NSF Solicitation 19-519: Enabling Access to Cloud Computing Resources for CISE Research and Education (Cloud Access)
Mission: Easier for computer science researchers and educators to use public cloud resourcesInitial: CISE research and education communityPIs request cloud resources via specific NSF proposals with request budgetFunds are part of CloudBank’s cooperative agreement: Used to procure cloud resources on behalf of researchersProject roles: UCSD/SDSC leads portal development and cloud negotiations; UofW leads education outreach and training; UCB is lead for student data science infrastructure (e.g., Data 8)
What is CloudBank?


A new model for a public/private partnership in service to research enterprise
Key element: Partnering with cloud solution provider Strategic Blue
Service and sustainability vision: Broaden the impact of public cloud computing across all sciences, help ensure students entering the workforce and research enterprise will be able to contribute and compete in the global economy
Address the ‘last mile’ problem for the cloud providers: providing cloud support for researchers spread across universities and democratizing access to cloud
A Public/Private Partnership to Expand Research

OverbuyingUnused instances on-demand, excessive purchase of reserved instances, buying for timeframes not utilized at start-upMismatched instance sizing (actual memory/CPU utilization)
Billing and pricing difficultiesInaccurate or obfuscated vendor metering. Are we actually getting what they say they are giving? Can we understand our bills enough to control costs? Billing errors. Application of discounts, rebates or even price terms causing billing irregularities
Resale market IlliquidityResell markets often have too little volume, strong deflationary price pressuresInstitutions can lose too much money in not being able to reuse excess capacity purchased
Cloud financial issues from a CIO’s perspective

Service opportunitiesImmediate
CISE-funded researchers via “certain CISE solicitations”
Near termCISE researchers with non-CISE fundingCB partnering institution researchers
FutureOther NSF-funded researchNIH-funded researchCorporate- and foundation-funded researchInternational collaborations
CloudBank
••
••••

● Help learn about the cloud, write proposals
● Liaison with providers

23 cents per hourModest Virtual Machine + GPU
AWS preemptible; 2 cores; 30GB RAM; Tesla M60
$23 per monthOne Month One Terabyte
fast access object storage
Cloudbank EOT Z-matchingExample of ‘Rule 23’

git basics, existence of GitHub% git config -global user.name “kilroy”% git init my_amino_acid_repository% git clone https://github.com/hashicorp/terraform.git% git commit -m “added bbh ringdown”
GitHub logo
EOT
Tim Durham: Genome sciences

Durham, Timothy J., Maxwell W. Libbrecht, J. Jeffry Howbert, Jeff Bilmes, and William Stafford Noble. "PREDICTD parallel epigenomics data imputation with cloud-based tensor decomposition." Nature communications 9, no. 1 (2018): 1-15.
https://github.com/tdurham86/PREDICTD
PREDICTD Wiki: Spark cluster tutorial
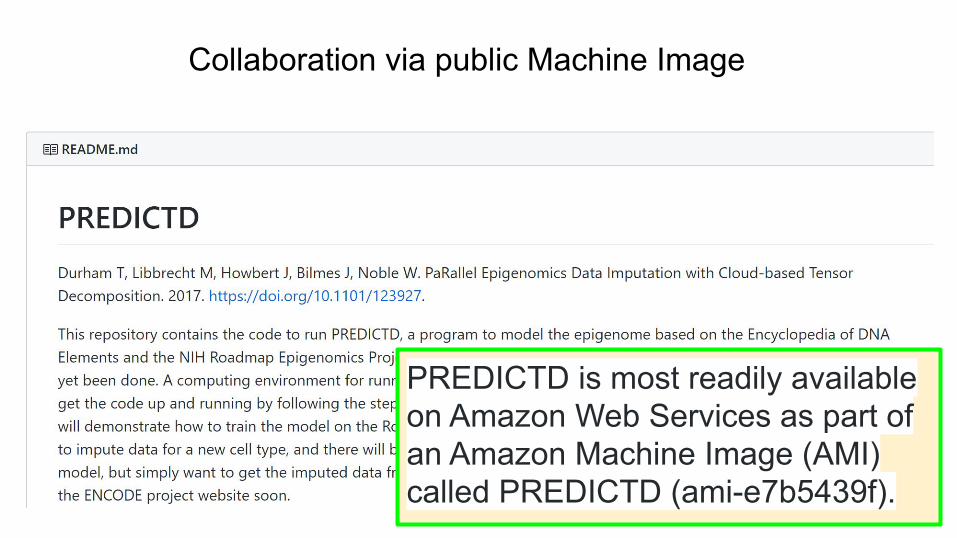
PREDICTD is most readily available on Amazon Web Services as part of an Amazon Machine Image (AMI) called PREDICTD (ami-e7b5439f).
Collaboration via public Machine Image
zombiescredits
(non-sus)
cost (GPU etc)
trust
complexity
TTL
security
contracts
$torage
desert
HPC
breakeven
turnkey
...or not
open/reprogit jupyter binder
iteration
MATLAB
Sub-topics of Navigating Cloud-based Research

KeysFalling OverZombiesLoad
Cloudbank EOT Failure Modes

● What is Pangeo?● Pangeo has real estate; needs people● The “what if we do this?” spirit is the core of Pangeo Dev● Debugging is a problem. Impatience is a problem. ● Important communication tools: Jupyter, Binder, Gallery

courtesy Chelle Gentemann

● Guarav Bhardwaj (formerly Baker lab, MolES)○ AWS Batch and Spot in concert to sift through an
HTC problem in protein synthesis: 5 million macrocycle peptides for $5300 (50 hrs)
○ Key idea: Background resource building
● Jeanelle Ariza (Keene lab, Department of Pathology)○ Key idea: “Third party question”: Microscope
analysis busting servers at the seams… do we need a cloud pro on our team to handle the transition?
● Andy Connolly (LSST)○ Six months benchmarking LSST processing on AWS (jury out) ○ Opportunity for change in philosophy: Major facilities look to
the cloud for their data management system
Last Three Stories

Concluding Remarks● IDC begone ● Tractable (fractal) research runs into data, time, relevance issues● Two failure modes that cloud addresses well: Raw processing power and democratization● The cloud does not address infrastructure such as turnkey processing power● AWS has been consistently incredibly supportive: credits, technical, “progressive
approach to human error”● Cloudbank, Pangeo, Teraform and the rise of the RSE are responses to this new frontier,
this infrastructure gap● Certain individuals do have the knack… and hiring them into research is a challenge
CTA 1: Research needs people. Recruitment problem. Contributors needed. Training paths needed. AWS is making great contributions; and I think this will prove to be a wise course.
CTA 2: The large dataset and the small dataset
CTA 3: Noise persists at the apex of the stack

* Will Cloudbank be available to researchers with cloud funding from other sources? * What if I get a new idea for a calculation (on the cloud) that isn't in my budget? (If I own the computer I just start it and run it.)* Any thoughts / considerations on wrangling large datasets into the cloud?* Are there any other good pitfalls to know beyond { zombies, fall-over, keys, load } ?* Any examples of surprising uses for cloud services one would not normally associate with research? * How does one use the cloud for PHI?
Potential Questions




























