Embed Size (px)
Citation preview

Automated Finite Element Computations in theFEniCS Framework using GPUs
Florian Rathgeber ([email protected])
Advanced Modelling and Computation Group (AMCG)Department of Earth Science & Engineering
Imperial College London
2nd UK GPU Computing ConferenceDecember 13th 2010
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Outline
Introduction: The FEniCS Project
Parallel Finite Element Assembly
Avoiding Global Assembly
Benchmarks and Pro�ling Results
Automating Finite Element Assembly
Conclusions
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Outline
Introduction: The FEniCS Project
Parallel Finite Element Assembly
Avoiding Global Assembly
Benchmarks and Pro�ling Results
Automating Finite Element Assembly
Conclusions
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

The FEniCS Project
http://www.fenicsproject.org
Automation of Computational Mathematical Modeling (ACMM)
DOLFIN
⇐
FEniCS
⇒
UNICORN
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Automating �nite element assembly
UFL DOLFIN UnicornFFC UFCweak form
mathematicalproblem
formimplementation
UFCinterface
global matrixassembly
PDEsolver
UFL, FFC, and UFC:
the link betweenvariational form in mathematical notation
andassembly in DOLFIN
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Modular DOLFIN library architecture
source: Logg and Wells - DOLFIN: Automated �nite element computing (2010)
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

The missing link
source: NVIDIA
GoalsI GPU backend for DOLFIN
I Performance gain
I No sacri�ce in degree ofautomation
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

The missing link
source: NVIDIA
GoalsI GPU backend for DOLFIN
I Performance gain
I No sacri�ce in degree ofautomation
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Outline
Introduction: The FEniCS Project
Parallel Finite Element AssemblyThe Finite Element Method (FEM)Finite Element AssemblyFinite Element Assembly on the GPUA Question of Data Layout
Avoiding Global Assembly
Benchmarks and Pro�ling Results
Automating Finite Element Assembly
ConclusionsFlorian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

The Finite Element Method (FEM)
FEMTriangulation
⇒
FEM Assembly
⇒
Sparse matrix
⇒
FEM Solution
source: Wikimedia Commons
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Finite Element Assembly
Assembling a 3× 3 element matrix into the global system matrixsource: Alnaes et al. - Uni�ed Framework for Finite Element Assembly (2009)
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Finite element assembly on the GPU
tabulate_dofsinterpolate_func
eval_expressiontabulate_tensor matrix_addto
assembly time
tabulation ofdegrees of freedom
tabulation ofelement matrices
assembly ofglobal system matrix
evaluation of coe�cients(constants, expressions, functions)
entityindices
DOFmapping
vertexcoords
functionvalues
coe�cientvalues
elementmatrices
globalmatrix
assemblykernels
globalmemory
assemblyphase
A data �ow diagram showing input and output of kernels for the di�erentassembly stages and how data is streamed between them
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

A question of data layout
123
n-2n-1n
threadID
threadID
consecutive
consecutive
1 2 3 n-2 n-1 n
GPU data layout to achieve coalesced transfers from and to global devicememory (right) compared to a corresponding layout in CPU memory
(left)
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Outline
Introduction: The FEniCS Project
Parallel Finite Element Assembly
Avoiding Global Assembly
Benchmarks and Pro�ling Results
Automating Finite Element Assembly
Conclusions
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Sparse matrix-vector product without assembling thematrix
== MeA AAT
Linear algebra representation of the sparse matrix-vector multiplication:
I Me block-diagonal matrix of element matrices
I A sparse matrix corresponding to local-to-global mappingrows: all local degrees of freedomcolumns: global degrees of freedom
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Outline
Introduction: The FEniCS Project
Parallel Finite Element Assembly
Avoiding Global Assembly
Benchmarks and Pro�ling ResultsPro�ling GPU AssemblyAssembly BenchmarksAssembly and Solve BenchmarksInterpreting Speedup Figures
Automating Finite Element Assembly
ConclusionsFlorian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Pro�ling GPU assembly
0 10 20 30 40 50 60 70 80
tabulate_dofs
tabulate_tensor
matrix_addto
memcpy
GPU kernel execution time (%)
Poisson's equation (P1)
0 10 20 30 40 50 60 70 80
tabulate_dofs
GPUVelSource
GPUSource
tabulate_tensor
matrix_addto
memcpy
GPU kernel execution time (%)
Stabilized Navier-Stokes momentumterm(P1)
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs
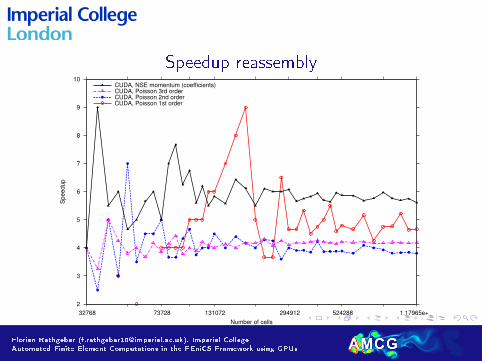
Speedup reassembly
2
3
4
5
6
7
8
9
10
32768 73728 131072 294912 524288 1.17965e+06
Speedup
Number of cells
CUDA, Poisson 1st orderCUDA, Poisson 2nd orderCUDA, Poisson 3rd orderCUDA, NSE momentum (coefficients)
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Total runtime assembly and solve
0.25
0.5
1
2
4
8
16
32
64
2 4 8 16 32 64 128
Runtim
e [s]
Number of iterations
Poisson 1st order, PETSc assemblePoisson 1st order, PETSc LMAPoisson 1st order, CUDA assemblePoisson 1st order, CUDA LMAPoisson 3rd order, PETSc assemblePoisson 3rd order, PETSc LMAPoisson 3rd order, CUDA assemblePoisson 3rd order, CUDA LMA
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Interpreting speedup �gures
I Computations in double precision
→ factor 8 penalty for �oating point computation, factor 2 for memorytransfer
→ 78 GFlop/s peak performance, on par with Intel Nehalem 8-core CPU→ Fermi architecture improves double precision penalty to factor 2
I High speedup �gures
→ often: mediocre CPU against highly optimized GPU implementations→ here: highly optimized linear algebra (PETSc) and tensor contraction
(generated by FFC) against generated GPU kernels without anyhand-optimization
I Performance comparisons include data transfer between host anddevice→ true one-to-one comparisons including all transfer and setup times
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Outline
Introduction: The FEniCS Project
Parallel Finite Element Assembly
Avoiding Global Assembly
Benchmarks and Pro�ling Results
Automating Finite Element Assembly
Conclusions
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

FFC code generation
FIAT FERARI
parser compiler
formatPoisson.u� Poisson.h
Compilation of a variational form given as a UFL �le to a UFC compliantheader using FFC
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Integration of generated code with a user program
libdol�n.souser
programlink
compile
compile
include
gcc
�c -l dol�n
dol�n.hPoisson.u� Poisson.h
main.cpp
using DOLFIN library
libdol�n-gpu.so userprogram
Poisson.o
link compile
compile
compile includenvcc
gcc
�c -l dol�n-gpudol�n-gpu.h
Poisson.u�
Poisson.hPoisson.cu
main.cpp
using DOLFIN-GPU library
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Outline
Introduction: The FEniCS Project
Parallel Finite Element Assembly
Avoiding Global Assembly
Benchmarks and Pro�ling Results
Automating Finite Element Assembly
ConclusionsConclusionsFuture work
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Conclusions
Code generation for Finite Element Computations on GPUs
1. Finite element computations in the FEniCS framework on the GPU,showing a speedup of up to 9 over PETSc on single CPU
2. Automated assembly from a variational form in mathematicalnotation using the FEniCS Form Compiler FFC
Current limitations:
1. Only cell integral assembly
2. No support for strongly enforced boundary conditions
3. Only conjugate gradient solver → symmetric positive de�nitematrices
4. Bugs in nvcc compiler prohibit complex forms
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Conclusions
Code generation for Finite Element Computations on GPUs
1. Finite element computations in the FEniCS framework on the GPU,showing a speedup of up to 9 over PETSc on single CPU
2. Automated assembly from a variational form in mathematicalnotation using the FEniCS Form Compiler FFC
Current limitations:
1. Only cell integral assembly
2. No support for strongly enforced boundary conditions
3. Only conjugate gradient solver → symmetric positive de�nitematrices
4. Bugs in nvcc compiler prohibit complex forms
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Future work
I Integrate with OP2 and Fluidity
I Optimise generation of CUDA kernels
I MPI-parallelisation (distributed memory)
I Fully implement UFC
I Port to OpenCL
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Thank You!
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

The NVIDIA Tesla GPU architecture
SM
TCP0 1 9
DRAMDRAMDRAMDRAMDRAMDRAM
interconnect network
texture unittexture unit texture unit
shared mem
const. cache
instr. cache
MT scheduler
DP-SP
SFU SFU
SP SP
SP SP
SP SP
SP SP
NVIDIA Tesla C1060
I 30 multiprocessors
(MP)
I 8 streamprocessors (SPs)
I 16384 registersI 16 KB shared
memory
I 1.30 GHz shader clock
I 4096 MB globalmemory (frame bu�er)
I 933.0 GFlop/sarithmetic peak
I 102.4 GB/s memorybandwidth
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Finite element assembly on the GPU
GPUFunctionSpace GPUMesh GPUForm GPUAssembler GPUMatrixGPUVector
Function
tabulate_dofsinterpolate_func
eval_expressiontabulate_tensor matrix_addto
assembly time
entityindices
DOFmapping
vertexcoords
functionvalues
coe�cientvalues
elementmatrices
globalmatrix
assemblykernels
globalmemory
referencingclasses
A data �ow diagram showing input and output of the assembly kernels,how data is streamed between them, and where it is stored
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Speedup assembly
1.2
1.4
1.6
1.8
2
2.2
2.4
32768 73728 131072 294912 524288 1.17965e+06
Speedup
Number of cells
CUDA, Poisson 1st orderCUDA, Poisson 2nd orderCUDA, Poisson 3rd orderCUDA, NSE momentum (coefficients)
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs

Speedup assembly and solve
0.5
1
1.5
2
2.5
3
3.5
4
2 4 8 16 32 64 128
Speedup (
facto
r)
Number of iterations
Poisson 1st order, PETSc LMAPoisson 1st order, CUDA assemblePoisson 1st order, CUDA LMAPoisson 3rd order, PETSc LMAPoisson 3rd order, CUDA assemblePoisson 3rd order, CUDA LMA
Florian Rathgeber ([email protected]), Imperial CollegeAutomated Finite Element Computations in the FEniCS Framework using GPUs









![IRaaS: A Cloud Implementation of an Interface Relaxation ...to the IaaS model [27]. B. FEniCS The FEniCS project is a collection of free, open source software components forming an](https://img.pdfslide.us/doc/110x75/6021b767d0bc1368f873beb7/iraas-a-cloud-implementation-of-an-interface-relaxation-to-the-iaas-model-27.jpg)



















