Embed Size (px)
Citation preview

8/6/2019 Assn Rule Mining
http://slidepdf.com/reader/full/assn-rule-mining 1/9
Rule Acquisition in Data Mining Using GeneticAlgorithm
K.Indira#1, Dr. S. Kanmani *2, Gaurav Sethia.D $3, Kumaran.S$3, Prabhakar.J $3
# Research Scholar, Department of Computer Science,* Professor, Department of Information Technology,
$ Final Year IT, Department of Information Technology, Pondicherry Engineering College,
Puducherry,
Abstract: Association Rule mining is a technique of data mining that is verywidely used in many areas. It is used to deduce results that prove to be veryhelpful in the field as they provide some inferences from possibly largedatabases. These inferences cannot be noticed without data mining. Also,Genetic Algorithm can be applied to different areas of applications as Biology, biometrics, Education, Manufacturing Information System, Application Protocolinterface records from Computers for Intrusion Detection, Software Engineering,Virus information from Computer data, Image data base, Finance information,
Students Information etc. It is seen that by altering representations and operatorsthe Genetic algorithm could be applied for any fields without compromising theefficiency.
Keywords : Association rule mining, Genetic algorithm, Crossover, Mutation,Fitness value, Population size..
I. I NTRODUCTION
Data mining is concerned with the analysis of data and the use of softwaretechniques for drawing conclusions from the large sets of data. This includes finding
patterns and regularities in sets of data. Association rule mining is a type of data mining.It is the method of finding the relations between entities in databases. Association rulemining is mainly used in market analysis, transaction data analysis or in the medicalfield. For example, all of the transactions occurring in a super market are stored in a largedatabase, and if a customer buys bread in a supermarket, then there is a chance that he
buys butter. Such inferences can be used for making decisions, and such inferences aredrawn using association rule mining.
Many algorithms for generating association rules were developed over time.Some of the well known algorithms are Apriori, Eclat and FP-Growth tree. There have
been several attempts for mining association rules using Genetic Algorithm.
This paper analyses the mining of Association Rules by applying GeneticAlgorithms. The suitability of Genetic algorithms in the field of data mining is studied in
the paper [7]. The main reason for choosing a genetic algorithm for data mining is that aGA performs global search and copes better with attribute interaction when comparedwith the traditional greedy methods, based on induction.
Genetic algorithm is evolved from Charles Darwin’s ‘Survival of the fittest’theory. It is based on individual’s fitness and genetic similarity between the individuals.Breeding occurs in every generation and eventually it leads to better and optimal group inthe later generations.
Combining natural immune evolution theory and relevant bionic mechanism, [1] proposes an IOGA (Immune Optimization based Genetic Algorithm) approach for

8/6/2019 Assn Rule Mining
http://slidepdf.com/reader/full/assn-rule-mining 2/9
incremental association rules mining for large and frequently updating data sets. Theexperiment demonstrates the method’s efficiency, its good performance in pruningredundant rules, discovering meaningful rules and perceiving low support rules inadditional data set.
A fitness function is presented in [2] by proposing an efficient rule generator for denial of services of network intrusion detection. More chromosomes with relevantfeatures are used thereby resulting in generation of more rules. As such, the rules
generated by this algorithm are suitable for continuously changing misuse detection.
[3] presents a genetic algorithm based approach for mining classification rulesfrom large database. It emphasizes on predictive accuracy, comprehensibility andinterestingness of the rules and simplifying the implementation of a GA. The paper discusses in detail the design of encoding, genetic operators and fitness function of genetic algorithm for this task.
[4],[5] discuss some variations of the traditional Genetic algorithms in the fieldof data mining. [4] is based on a evolutionary strategy and [5] adopts a self adaptiveapproach
The main functional concepts in data mining process are
i. Data cleaning: also so known as data cleansing, is a phase in which noise data
and irrelevant data are removed from the collection.
ii. Data selection: at this step, the data relevant for the analysis is decided on and
retrieved from the large data collection.
iii. Data mining: it is the crucial step in which clever techniques are applied to
extract patterns potentially useful.
A brief introduction about Association Rule Mining and GA is given in Section2, followed by methodology in section 3, which describes the basic implementationdetails of Association Rule Mining with GA. In section 4 the Parameters that decides onefficiency of the algorithm is presented. Section 5 presents the experimental resultsfollowed by conclusion in the last section.
II. ASSOCIATION R ULES AND GENETIC ALGORITHMS
A. Association Rules
Association rule mining finds interesting associations and/or correlation relationshipsamong large set of data items. Association rules show attributes value conditions thatoccur frequently together in a given dataset.
Typically the relationship will be in the form of a rule:
IF {antecedent} THEN {consequent}
There are two types of Association rule levels:Support Level- The minimum percentage of instances in the database that contain allitems listed in a given association rule andConfidence Level- “If A then B”, rule confidence is the conditional probability that B istrue when A is known to be true.
B. Genetic Algorithm
Genetic Algorithm is based on Charles Darwin’s theory of ‘The survival of thefittest’. Algorithm is started with a set of solutions (represented by chromosomes) called
population. Solutions from one population are taken and used to form a new population.This is motivated by a hope, that the new population will be better than the old one.

8/6/2019 Assn Rule Mining
http://slidepdf.com/reader/full/assn-rule-mining 3/9
Solutions which are selected to form new solutions(offspring) are selected according totheir fitness - the more suitable they are the more chances they have to reproduce.If thefitness of the new individuals is better than the fitness of the individuals in the previousgeneration, the individuals are replaced. This is carried out till the termination conditionis reached.
The chromosome should in some way contain information about solution whichit represents. The most used way of encoding is a binary string. Each chromosome has
one binary string. Each bit in this string can represent some characteristic of the solution.Or the whole string can represent a number. But there are many other ways of encoding.
The outline of the algorithm is
A. [Start] Generate random population of n chromosomes.
B. [Fitness] Evaluate the fitness f(x) of each chromosome x in the population.
C. [New population] Create a new population by repeating the following steps
until the new population is complete.
i. [Selection] Select two parent chromosomes from a population according to
their fitness.
ii. [Crossover] With a crossover probability alter the parents to form a new
offspring (children).
iii. [Mutation] With a mutation probability mutate new offspring at each
locus.
iv. [Accepting] Place new offspring in a new population
D. [Replace] Use newly generated population for a further run of the algorithm
E. [Test] If the end condition is satisfied, stop, and return the best solution in
current population
F. [Loop] Go to step B
III. METHODOLOGY
A new population is first initialized. For every individual in the population, afitness function is applied and the fitness is calculated. Then based on the crossover andmutation rates, the crossover and mutation functions are performed. The new individual’sobtained are again subjected to the fitness function. If the fitness of the new individuals is
better than the fitness of the individuals in the previous generation, the individuals arereplaced. This is carried out till the termination condition is reached. The following are
the steps of a Genetic Algorithm:
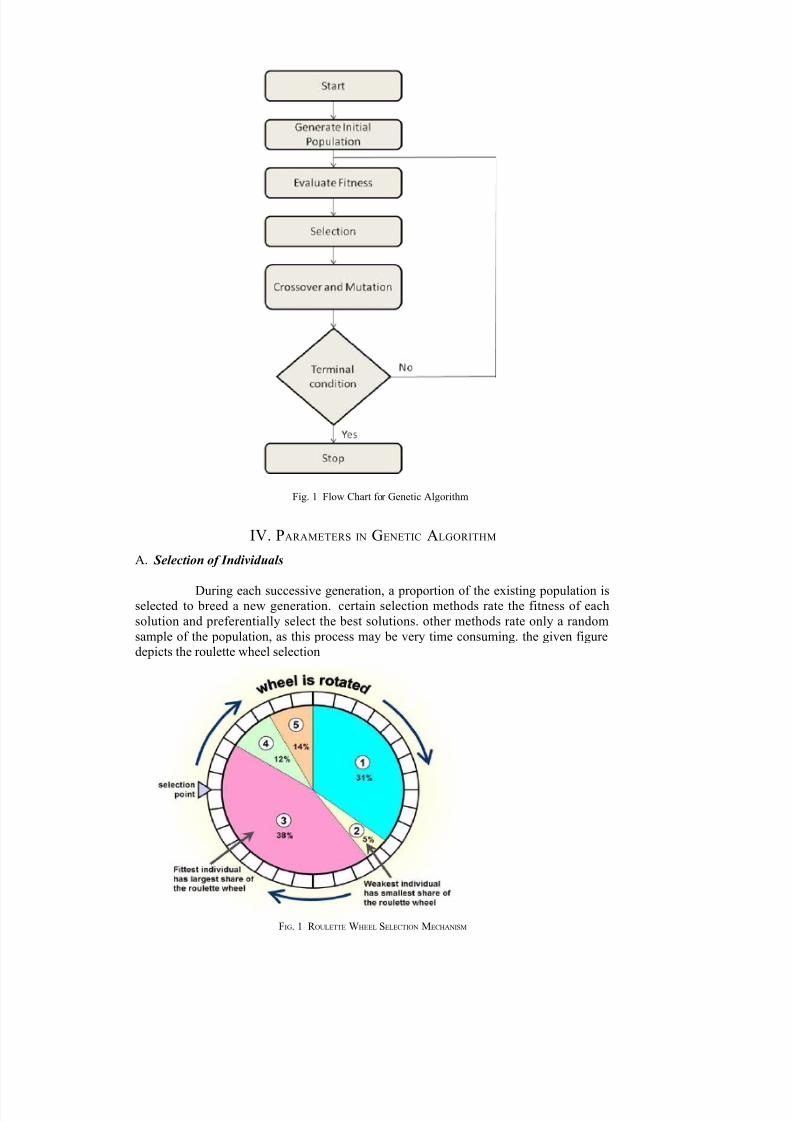
8/6/2019 Assn Rule Mining
http://slidepdf.com/reader/full/assn-rule-mining 4/9
Fig. 1 Flow Chart for Genetic Algorithm
IV. PARAMETERS IN GENETIC ALGORITHM
A. Selection of Individuals
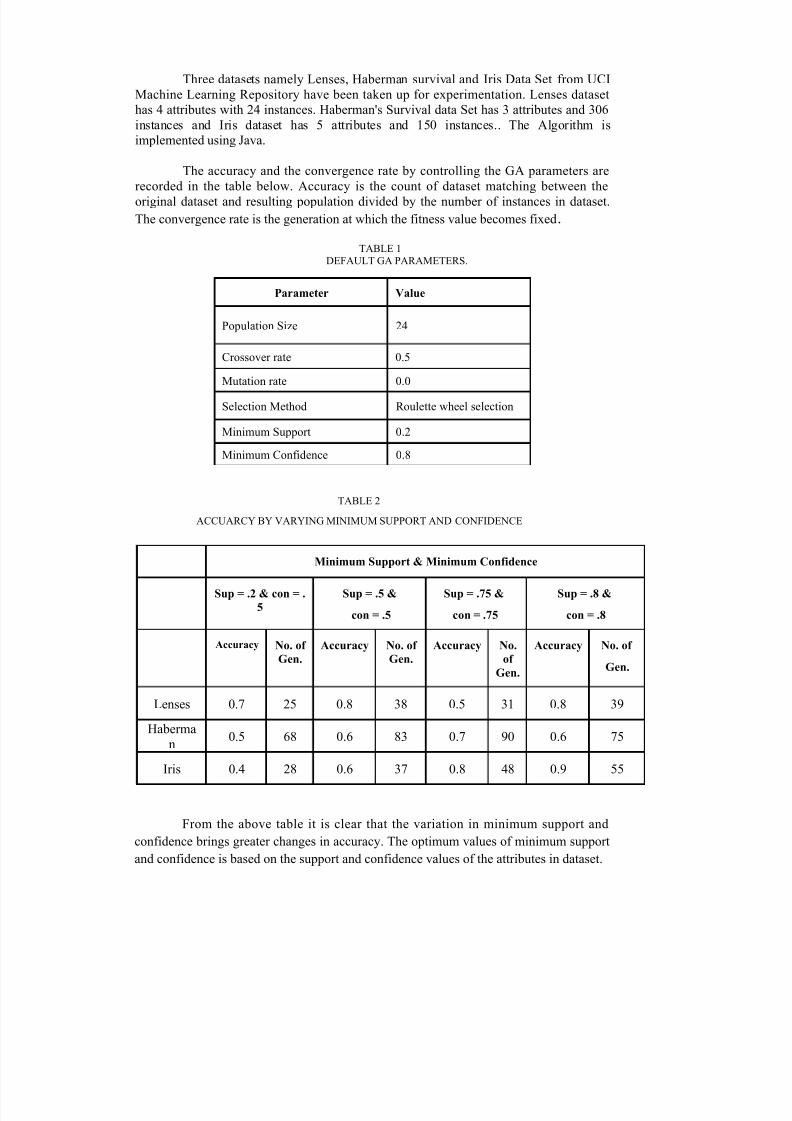
During each successive generation, a proportion of the existing population isselected to breed a new generation. certain selection methods rate the fitness of eachsolution and preferentially select the best solutions. other methods rate only a randomsample of the population, as this process may be very time consuming. the given figuredepicts the roulette wheel selection
FIG. 1 R OULETTE WHEEL SELECTION MECHANISM

8/6/2019 Assn Rule Mining
http://slidepdf.com/reader/full/assn-rule-mining 5/9
B. Fitness Function
A fitness function must be devised for each problem to be solved. Given a particular chromosome, the fitness function returns a single numerical "fitness," or "figure of merit," which is supposed to be proportional to the "utility" or "ability" of theindividual which that chromosome represents. For many problems, particularly functionoptimisation, the fitness function should simply measure the value of the function.
This paper adopts minimum support and minimum confidence for filtering rules.Then correlative degree is confirmed in rules which satisfy minimum support-degree andminimum confidence degree. After support-degree and confidence-degree aresynthetically taken into account, fit degree function is defined as follows.
In the above formula, Rs + Rc = 1 ( Rs ≥ 0_ Rc ≥ 0) and Suppmin, Conf min arerespective values of minimum support and minimum confidence. By all appearances_ if the Suppmin and Conf min are set to higher values, then the value of fitness function is alsofound to be high.
C. Crossover Operator
Crossover selects genes from parent chromosomes and creates a new offspring.The simplest way how to do this is to choose randomly some crossover point andeverything before this point copy from a first parent and then everything after a crossover
point copy from the second parent. Common form of crossover is single point crossover where randomly one position in the chromosomes is chosen and child 1 is head of chromosome of parent 1 with tail of chromosome of parent 2 and child 2 is head of 2with tail of 1. There are other ways to make crossover, for example we can choose morecrossover points. Crossover can be rather complicated and depends on encoding of theencoding of chromosome.
D. Mutation Operator
Mutation changes randomly the new offspring. For binary encoding we canswitch a few randomly chosen bits from 1 to 0 or from 0 to 1. Mutation provides a smallamount of random search, and helps ensure that no point in the search has a zero
probability of being examined.
E. Number of Generations
The generational process of mining association rules by Genetic algorithm isrepeated until a termination condition has been reached. Common terminating conditionsare:
• A solution is found that satisfies minimum criteria• Fixed number of generations reached• The highest ranking solution's fitness is reaching or has reached a plateau such that
successive iterations no longer produce better results• Manual inspection• Combinations of the above
V. EXPERIMENTAL STUDIES
The objective of this study is to compare the accuracy achieved in datasets byvarying the GA Parameters. The encoding of chromosome is binary encoding with fixedlength. As the crossover is performed on attribute level the mutation rate is set to zero soas to retain the original attribute values. The fitness function adopted is as given.
8/6/2019 Assn Rule Mining
http://slidepdf.com/reader/full/assn-rule-mining 6/9
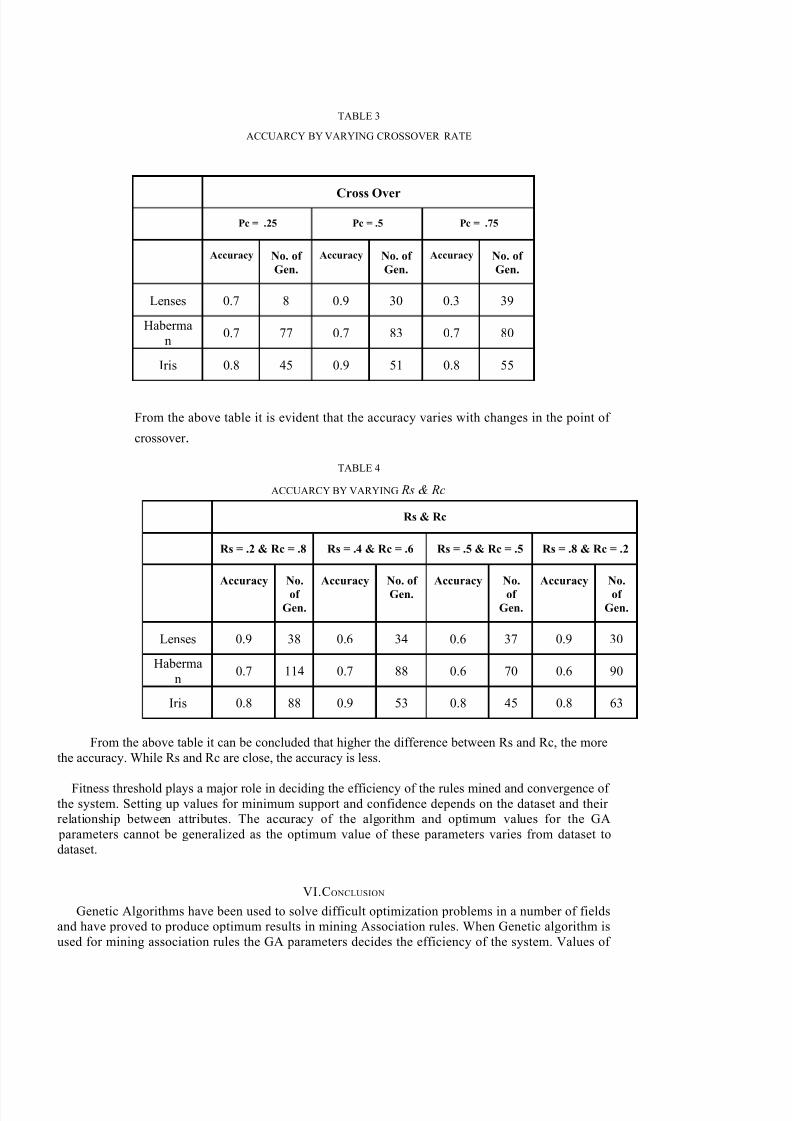
Three datasets namely Lenses, Haberman survival and Iris Data Set from UCIMachine Learning Repository have been taken up for experimentation. Lenses datasethas 4 attributes with 24 instances. Haberman's Survival data Set has 3 attributes and 306instances and Iris dataset has 5 attributes and 150 instances.. The Algorithm isimplemented using Java.
The accuracy and the convergence rate by controlling the GA parameters arerecorded in the table below. Accuracy is the count of dataset matching between the
original dataset and resulting population divided by the number of instances in dataset.
The convergence rate is the generation at which the fitness value becomes fixed.
TABLE 1DEFAULT GA PARAMETERS.
Parameter Value
Population Size 24
Crossover rate 0.5
Mutation rate 0.0
Selection Method Roulette wheel selection
Minimum Support 0.2
Minimum Confidence 0.8
TABLE 2
ACCUARCY BY VARYING MINIMUM SUPPORT AND CONFIDENCE
Minimum Support & Minimum Confidence
Sup = .2 & con = .
5
Sup = .5 &
con = .5
Sup = .75 &
con = .75
Sup = .8 &
con = .8
Accuracy No. of
Gen.
Accuracy No. of
Gen.
Accuracy No.
of
Gen.
Accuracy No. of
Gen.
Lenses 0.7 25 0.8 38 0.5 31 0.8 39
Haberman
0.5 68 0.6 83 0.7 90 0.6 75
Iris 0.4 28 0.6 37 0.8 48 0.9 55
From the above table it is clear that the variation in minimum support and
confidence brings greater changes in accuracy. The optimum values of minimum support
and confidence is based on the support and confidence values of the attributes in dataset.
8/6/2019 Assn Rule Mining
http://slidepdf.com/reader/full/assn-rule-mining 7/9
TABLE 3
ACCUARCY BY VARYING CROSSOVER RATE
Cross Over
Pc = .25 Pc = .5 Pc = .75
Accuracy No. of
Gen.
Accuracy No. of
Gen.
Accuracy No. of
Gen.
Lenses 0.7 8 0.9 30 0.3 39
Haberman
0.7 77 0.7 83 0.7 80
Iris 0.8 45 0.9 51 0.8 55
From the above table it is evident that the accuracy varies with changes in the point of
crossover .
TABLE 4
ACCUARCY BY VARYING Rs & Rc
Rs & Rc
Rs = .2 & Rc = .8 Rs = .4 & Rc = .6 Rs = .5 & Rc = .5 Rs = .8 & Rc = .2
Accuracy No.
of
Gen.
Accuracy No. of
Gen.
Accuracy No.
of
Gen.
Accuracy No.
of
Gen.
Lenses 0.9 38 0.6 34 0.6 37 0.9 30
Haberman
0.7 114 0.7 88 0.6 70 0.6 90
Iris 0.8 88 0.9 53 0.8 45 0.8 63
From the above table it can be concluded that higher the difference between Rs and Rc, the morethe accuracy. While Rs and Rc are close, the accuracy is less.
Fitness threshold plays a major role in deciding the efficiency of the rules mined and convergence of the system. Setting up values for minimum support and confidence depends on the dataset and their relationship between attributes. The accuracy of the algorithm and optimum values for the GA
parameters cannot be generalized as the optimum value of these parameters varies from dataset todataset.
VI.CONCLUSION
Genetic Algorithms have been used to solve difficult optimization problems in a number of fieldsand have proved to produce optimum results in mining Association rules. When Genetic algorithm isused for mining association rules the GA parameters decides the efficiency of the system. Values of

8/6/2019 Assn Rule Mining
http://slidepdf.com/reader/full/assn-rule-mining 8/9
minimum support, minimum confidence and population size decides upon the accuracy of the systemthan other GA parameters. The optimum value of crossover rate leads to earlier convergence while
playing minimum role in achieving better accuracy. The optimum value of the GA parameters variesfrom data to data and the fitness function plays a major role in optimizing the results. The size of thedataset and relationship between attributes in data contributes to the setting up of the parameters. Theefficiency of the methodology could be further explored on more datasets with varying attribute sizes.
REFERENCES
[1]. Genxiang Zhang, Haishan Chen, “Immune Optimization Based Genetic Algorithm for IncrementalAssociation Rules Mining”, International Conference on Artificial Intelligence and ComputationalIntelligence, AICI '09 Volume: 4, Page(s): 341 – 345, 2009.
[2]. Gonzales, E., Mabu, S., Taboada, K., Shimada, K., Hirasawa, K., “Mining Multi-class Datasetsusing Genetic Relation Algorithm for Rule Reduction”, IEEE Congress on EvolutionaryComputation,CEC’09 , Page(s): 3249 – 3255, 2009.
[3]. Hong Guo, Ya Zhou, “An Algorithm for Mining Association Rules Based on Improved GeneticAlgorithm and its Application”, 3rd International Conference on Genetic and EvolutionaryComputing, WGEC '09, Page(s): 117 – 120, 2009.
[4]. Jing Li, Han Rui Feng, “A self-adaptive genetic algorithm based on real code”, Capital NormalUniversity, CNU, 2010
[5]. Xiaoyuan Zhu, Yongquan Yu, Xueyan Guo, “Genetic Algorithm Based on Evolution Strategy andthe Application in Data Mining”, First International Workshop on Education Technology andComputer Science, ETCS '09, Volume: 1, Page(s): 848 – 852, 2009.
[6]. Xian-Jun Shi, Hong Lei, “A Genetic Algorithm-Based Approach for Classification Rule Discovery”,International Conference on Information Management, Innovation Management and IndustrialEngineering, ICIII '08, Volume: 1, Page(s): 175 – 178, 2008.
[7]. Martine Collard, Dominique Francisi, “Evolutionary Data Mining: an overview of Genetic-basedAlogrithms”, IEEE, 2001.

8/6/2019 Assn Rule Mining
http://slidepdf.com/reader/full/assn-rule-mining 9/9
A.