Embed Size (px)
Citation preview

Assignment 3• Out: 5 October• Due: 26 October 23:59• Grace period: 27 October 13:00• No cheating!!!

Final Project• Milestone 2:• Please read the description:
https://cs.anu.edu.au/courses/comp3600/finalPrj-m2.pdf• M2 description is in p.4
• Due: 8 Oct 23:59• Grace period: 9 Oct 13:00

Marking• A2 XOR A3 is redeemable by Final Project • Total Score = max(0.15*A1 + 0.2*max(A2, FinalProject)
+ 0.25*A3 + 0.4*FinalProject ; 0.15*A1 + 0.2*A2 + 0.25*max(A3, FinalProject) + 0.4*FinalProject)
• But, note that Final Project, Milestone-1 marking is extremely lenient. This leniency will decrease in the marking of Milestone-2 and further decrease in the marking of the final deliverables• Hence, skipping A3 to work solely on the Final Project
may not be a good idea

COMP3600/6466 – Algorithms Dynamic Programming Cont.
[CLRS sec.15.2]
Hanna Kurniawati
https://cs.anu.edu.au/courses/comp3600/[email protected]

TopicsüWhat is it?üExample: Fibonacci SequenceüHow to develop DP algorithms?üExample: Shortest PathüExample: Chain matrix multiplication• Example: Longest Common Subsequence• Example: Decision-making under uncertainty

Longest Common Subsequence (LCS)• The Problem: Given two strings X and Y, find a
subsequence of the strings that appear in both X and Y and has the longest length• Note: Here, the subsequence does not need to be
continuous, but the order must be the same• Example: • Suppose X = (A, B, C, B, D, A, B) and Y = (B, D, C, A,
B, A). Then, LCS(X, Y) = (B, C, A, B) OR (B, D, A, B)• Applications:• Computational biology, e.g., comparing DNA• diff function in Linux

LCS – DP Steps1. Sub-problems:
• Recall the heuristic: When the problem requires processing of a sequence, there’s generally 3 possibilities to divide the problem into sub-problems: Prefix (subproblems from start to index-k), Suffix (subproblems from index-k to end), Substrings (subproblems from index-i to index-j)
• In this case, the sub-problems are the LCS of pairs of prefixes of the original strings and its length

LCS – DP Steps2. Relation between sub-problems• On LCS (optimal sub-structure of LCS)
Suppose X = (x1, x2, …, xm) and Y = (y1, y2, …, yn) be the input sequences and suppose Z = (z1, z2, …, zk) be any LCS of X and Y, then there’s 3 cases:• If xm = yn and zk = xm = yn then Zk-1 is an LCS of Xm-1 and
Yn-1
• If xm ≠ yn and zk ≠ xm then Zk-1 is an LCS of Xm-1 and Y• If xm ≠ yn and zk ≠ yn then Zk-1 is an LCS of X and Yn-1
• Xi, Yi, and Zi are continuous subsequences of X, Y, and Z respectively, starting from index-1 to index-i

LCS – DP Steps2. Relation between sub-problems• On the length of the LCS
𝑐 𝑖, 𝑗 = '0 𝑖 = 0 𝑂𝑅 𝑗 = 0
𝑐 𝑖 − 1, 𝑗 − 1 + 1 𝑖, 𝑗 > 0 𝑎𝑛𝑑 𝑥! = 𝑦"max(𝑐 𝑖, 𝑗 − 1 , 𝑐[𝑖 − 1, 𝑗]) 𝑖, 𝑗 > 0 𝑎𝑛𝑑 𝑥! ≠ 𝑦"
• 𝑐 𝑖, 𝑗 : The length of LCS of Xi and Yj

LCS – DP Steps3. Constructing the recurrence/topological order:
a. Is the sub-problem graph a DAG? Yes, because the sub-problem dependency goes one way, which is to the prefixes.

LCS – DP Steps3. Constructing the recurrence/topological order:
b. Top-down recurrence is straight forward. Topological order for bottom-up? Starts from LCS of X0 and Y0 to LCS of Xm and Yn
Maintain a 2D matrix to keep the length of the LCS and direction on where does the LCS come from
[CLRS] p. 395

Pseudo-code[CLRS] p. 394

LCS – DP Steps4. Compute solution to the original problem: • c[m, n] is the length of the LCS of the original
problem.• To get the LCS itself, traverse the matrix, starting from
b[m, n], following the directions. Whenever the direction is diagonal, we put the character corresponding to the particular cell into the LCS (e.g., a diagonal at b[i, j] means we’ll add xi to the LCS. This strategy will output the LCS from its last character

LCS – Time complexity• #sub-problems: Θ(𝑚𝑛)• Time/sub-problem: Θ(1)• Total time for the DP (i.e., constructing the
matrix): #sub-problems X time/sub-problem=Θ(𝑚𝑛)

TopicsüWhat is it?üExample: Fibonacci SequenceüHow to develop DP algorithms?üExample: Shortest PathüExample: Chain matrix multiplicationüExample: Longest Common Subsequence• Example: Decision-making under uncertainty

Dynamic Programming in Robust Planning / Decision-Making• Dynamic Programming is a well-known approach (in
fact one of two major approaches) in robust control and planning (aka. sequential decision-making)• Robust: The system is affected by uncertainty• Sequential decision-making: The problem of deciding what
should a system do now, so as to get good long-term performance
• Rely on Bellman’s Principle of Optimality: An optimal solution from the initial state must constitute an optimal solution from the state resulting from the first decision
• The notion of dynamic programming in algorithm and in planning and control are the same. In fact, dynamic programming approach to algorithm design started exactly from the control and planning domain

An Example: Solving a Markov Decision Processes (MDP) Problem• A framework to find the best mapping from states
to actions when the outcome of each action is non-deterministic.• Many applications:• Games: Tic Tac Toe, Chess, Go• Robots: Pedestrian avoidance in self-driving cars• Navigation:

Markov Decision Processes• The non-determinism must be 1st order Markov.• 1st order Markov means given the present state, the
future states are independent from the past states.• P(st+1 | st, at) = P(st+1 | st, at, st-1, at-1, .., s1, a1, s0)

Defining an MDP Problem• Formally defined as 4-tuples
(S, A, T, R):• S: State space• A: Action space• T: transition function
T(s, a, s’) = P(St+1 = s’ | St = s, At = a)• R: Reward function
R(s) or R(s, a) or R(s, a, s’)
G

Solving an MDP problem• Is finding an optimal policy, usually
denoted as π*.• Policy = strategy• A mapping from states to actions π : S à A.• Meaning for any state s in S, π(s) wil tell us the best
action the system should perform.• Example: +1
-1

Using a Policy
Policy
Action
Observation (state)
G
1. Starts from the initial state.2. Move according to the policy.3. The system moves to a new
state and receives a reward Some notes:The new state the system ends up may be different in different runs.The goal of the system is to get the maximum possible total reward
4. Repeat to step-2 until stopping criteria is satisfied (e.g., goal is reached)

𝑉∗ 𝑠 = max$
𝑅 𝑠 + 𝛾>%&
𝑇 𝑠, 𝑎, 𝑠′ 𝑉∗ 𝑠′
Solving an MDP is Solving an Optimization Problem
• Recall optimal policy maps states to the best action. Best here means maximizing the following
• Theorem: There is a unique function V* satisfying the above function
Q(s, a)Bellman equation
Notice the optimal sub-structure property

Solving an MDP is Solving an Optimization Problem
• Optimal policy?• If we know V*, the optimal policy can be generated
easily.
𝜋∗ 𝑠 = argmax$
𝑅 𝑠 + 𝛾>%&
𝑇 𝑠, 𝑎, 𝑠′ 𝑉∗ 𝑠′

Value Iteration: A way to compute the optimal value function• Iterate calculating the optimal value of a state until
convergence.• Algorithm:
Initialize for all s.Loop
For all s {
}t = t + 1
Until Vt+1(s)=Vt(s) for all s (impl: maxs |Vt+1(s)-Vt(s)| < 1e-7)• Essentially, bottom-up dynamic programming
Often called value update or Bellman update or Bellman backup.
𝑉'() 𝑠 = max$
𝑅 𝑠 + 𝛾>%&
𝑇 𝑠, 𝑎, 𝑠′ 𝑉' 𝑠′
𝑉* 𝑠 = 𝑅 𝑠

Example: Simple Navigation• An agent moves in 4X3 grid cells.• It can move to one of four neighboring
cells. The actions’ accuracy is 70%.30% of the time, the agent ends up at the left or right of its intended cell, or at the current cell, with equal probability. If there’s no cell in the left or right of its intended cell, the probability mass is added to staying where it is.• Collision with obstacle/boundary will result in no
movement.• Two terminal states, with reward +1 and -1. Being in all
other valid states incur a cost of -0.04. Being in invalid states incur a cost of -10
+1-1
S
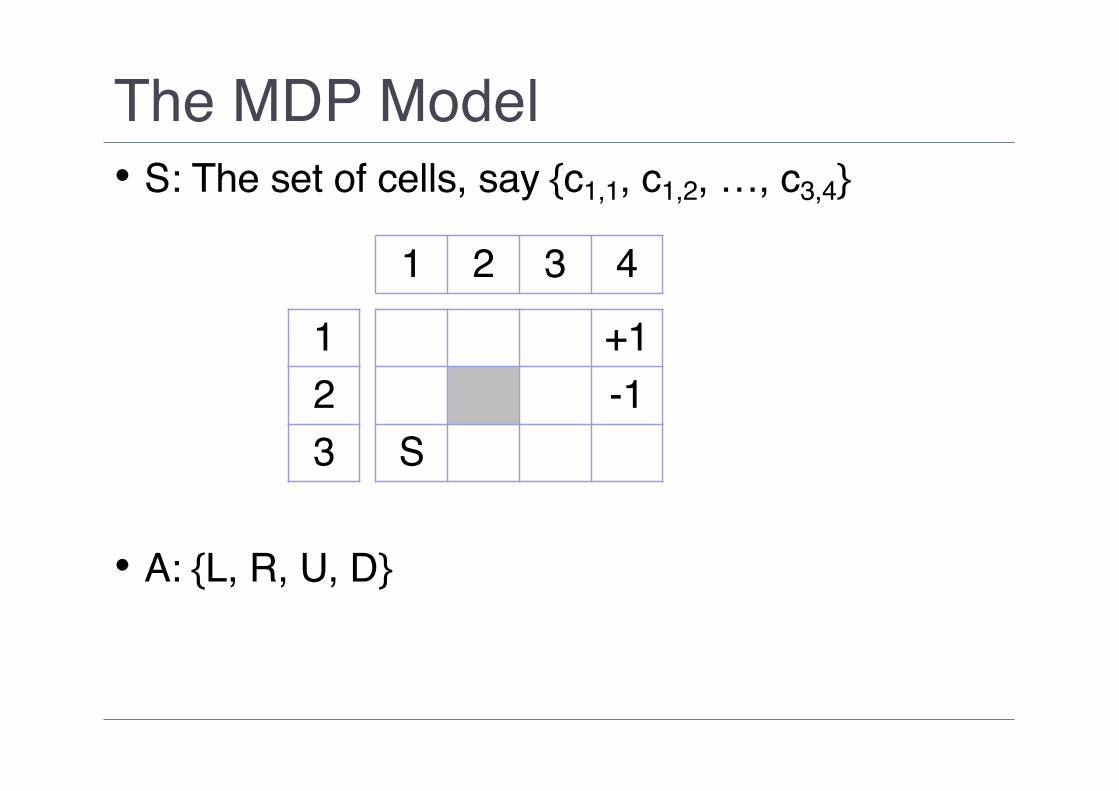
The MDP Model• S: The set of cells, say {c1,1, c1,2, …, c3,4}
• A: {L, R, U, D}
+1-1
S
123
1 2 3 4

The MDP Model• T(s, a, s’): For each action, we’ll have the probability matrix
C1,1
C1,2
C1,3
::
C3,4
C1,1 C1,2 C1,3 … C3,4
s
s’Left

The MDP Model• Reward function R(s): Parameterized by states
-0.04 -0.04 -0.04 +1-0.04 -10 -0.04 -1-0.04 -0.04 -0.04 -0.04
123
1 2 3 4

Computing the Optimal Policy?• Run the value iteration algorithm on the
information about transition and reward function that have been defined earlier
• Time complexity? 𝑂(𝑇 𝑆 D 𝐴 ), where T is #time steps to convergence.

TopicsüWhat is it?üExample: Fibonacci SequenceüHow to develop DP algorithms?üExample: Shortest PathüExample: Chain matrix multiplicationüExample: Longest Common SubsequenceüExample: Decision-making under uncertainty
Next: Greedy Approach for Designing Algorithms

If time permits, W9 Tutorial Q1• How many ways can you roll a sum of n by throwing
a 6-sided dice at most n times? Note that in this question, order matters1. Sub-problems: Number of ways to roll a sum of 𝑠 by
throwing the dice 𝑘 times, let’s denote this as 𝑊(𝑠, 𝑘)2. Relation between sub-problems:
𝑊 𝑠, 𝑘 =
0 𝑘 = 0, 𝑠 ≤ 0
>!+)
,
𝑊(𝑠 − 𝑖, 𝑘 − 1) 𝑘 > 0, 𝑠 > 0

If time permits, W9 Tutorial Q1• How many ways can you roll a sum of n by throwing
a 6-sided dice at most n times? Note that in this question, order matters3. Recurrence / topological order
a. Is the sub-problem graph a DAG? Yes, because the sub-problem dependency goes one way, which is to smaller 𝑠 and 𝑘
b. Top down + memorization, simply transform the recurrence in step-2 to pseudo-code
4.Compute solution to the original problem: 𝑊(𝑛, 𝑛)





























