Embed Size (px)
Citation preview

7/30/2019 Artificial Neural Network Weights Optimization Using ICA GA ICAGA and RICAGA SSCI2011 IEEE Conference Paris France
http://slidepdf.com/reader/full/artificial-neural-network-weights-optimization-using-ica-ga-icaga-and-ricaga 1/7
Artificial Neural Network Weights Optimization
Using ICA, GA, ICA-GA and R-ICA-GA: Comparing
Performances
Vahid Khorani
Islamic Azad University, Qazvin Branch
Qazvin, Iran
Nafiseh Forouzideh
University of Tehran, Kish International
Campus
Kish Island, Iran
Ali Motie Nasrabadi
Shahed University, Biomedical
Engineering Department
Tehran, Iran
Abstract —Artificial neural networks (ANN) and evolutionary
algorithms are two relatively young research areas that were
subject to a steadily growing interest during the past years. This
paper examines the use of different evolutionary algorithms,imperialist competitive algorithm (ICA), genetic algorithm (GA),
ICA-GA and recursive ICA-GA (R-ICA-GA) to train a
classification problem on a multi layer perceptron (MLP) neural
network. All of named evolutionary training algorithms are
compared together in this paper. The first goal of the paper is to
apply new evolutionary optimization algorithms ICA-GA and R-
ICA-GA for training the ANN and the second goal of the paper is
to compare different evolutionary algorithms. It is shown that the
ICA-GA has the best performance, in number of epochs,
compared to the other algorithms. For this purpose, learning
algorithms are applied on six known datasets (WINE, PIMA,
WDBC, IRIS, SONAR and GLASS) which are used for
classification problems.
ICA, GA, ICA-GA, R-ICA-GA, ANN, optimization, hybrid evolutionary algorithms.
I. I NTRODUCTION
Artificial neural networks are successful tools which areused in many problems such as pattern recognition,classification problems and regression problems [1]. Neuralnetwork learning in general is a nonlinear minimization problem with many local minima [2] which depends onnetwork weights, architecture (including number of hiddenlayers, number of hidden neurons and node transfer functions)and learning rules [3]. Many methods such as back propagation[4], pruning algorithms [5], simulated annealing [6], particleswarm optimization algorithm (PSO) [7], GA [8] and ICA [9]were used to determine the ANN parameters because of importance of this problem. For the complexity of ANNresearch, it is very necessary to still do some work in this field[10].
Many learning algorithms find their roots in functionminimization algorithms that can be classified into localminimization and global minimization. Local minimizationalgorithms, such as gradient-descent algorithms, are fast butusually converge to local minimums. In contrast, global
minimization algorithms have heuristic strategies to helpescape from local minimums [2]. Evolutionary optimizationalgorithms such as GA and ICA are global minimization
algorithms which are used to train the neural networks [9].
The optimization method used to determine weightadjustments has a large influence on the performance of neuralnetworks [11]. In this paper two new hybrid evolutionaryalgorithms ICA-GA and R-ICA-GA are tested and compared toother evolutionary algorithms in classification problems.Results of four algorithms ICA, GA, ICA-GA and R-ICA-GAare compared together to show which algorithm has better performance in training the ANN.
This paper is organized as follow: Section II provides a brief description of evolutionary algorithms ICA, GA, ICA-GAand R-ICA-GA. Section III surveys how much it needs to testmore evolutionary algorithms for training ANNs. Section IV
describes the research data and experiments. Section Vcompares test results of all different algorithms together andsection VI discusses the conclusions and future research issues.
II. I NTRODUCTION OF LEARNING ALGORITHMS
A. ICA
ICA optimizes the objective function via imperialisticcompetition idea. This algorithm uses the assimilation policywhich the imperialistic countries have reached after the 19th century. Based on this policy the imperialists try to improve theeconomy, culture and political situations of their colonies. This policy makes the colony’s enthusiasm toward the imperialists.
In this theory, an imperialist with its colonies is called anempire. In this approach, the power of an empire depends onthe power of its imperialist and its colonies. By imperialisticcompetitions the imperialists which are weaker lose their colonies. These colonies would join a more powerful empirefor greater supports. After a while, the weaker empires will loseall their colonies and their imperialists will transform to thecolonies of the other empires; at the end, all the weak empireswill be collapsed and only one powerful empire will be left.
978-1-4244-9908-3/11/$26.00 ©2011 IEEE 61

7/30/2019 Artificial Neural Network Weights Optimization Using ICA GA ICAGA and RICAGA SSCI2011 IEEE Conference Paris France
http://slidepdf.com/reader/full/artificial-neural-network-weights-optimization-using-ica-ga-icaga-and-ricaga 2/7
Fig. 1 depicts the flowcharts of the ICA [12]. For codingthis algorithm, an initial population is created randomly. Eachmember of this population is a vector of random numberswhich is called a country. The cost of objective function will becalculated for each of these countries and shows their power.Countries which have more optimized costs are selected as theimperialists and other countries are selected as colonies andwould be divided between the imperialists. Imperialists withtheir relevant colonies are named empires. Cost of each empiredetermines its power.
Figure 1. Flowchart of ICA
Equation (1) shows how the power of empires can becalculated:
where T.C.n is the total cost of the nth empire and ξ is a positive number which is considered to be less than 1 andcoloniesn presents colonies of nth empire. The colonies move
toward their imperialists, in each iteration. Fig. 2 depicts howcolonies move toward their relevant imperialists. In this figure, x is a random variable with uniform distribution between 0 and β ×d . Equation (2) shows how x is calculated:
where β is a number greater than 1, and d is the distance between colony and imperialist. To search different points
around the imperialist, a random amount of deviation is addedto the direction of movement which is showed by θ in Fig. 2. In
this figure, θ is a random number with uniform distribution
between -γ and +γ . Equation (3) shows how to calculate θ:
where γ is a number that adjusts the deviation from the originaldirection.
In this method, colonies will exchange their positions bytheir imperialists when they earn a cost more optimized incomparison to them. Fig. 3 depicts how the positions can beexchanged.
Figure 2. Moving colonies toward their relevant imperialists
Figure 3. Exchanging positions of the imperialists and a colony
62

7/30/2019 Artificial Neural Network Weights Optimization Using ICA GA ICAGA and RICAGA SSCI2011 IEEE Conference Paris France
http://slidepdf.com/reader/full/artificial-neural-network-weights-optimization-using-ica-ga-icaga-and-ricaga 3/7
Next step is imperialistic competition. All empires try totake possession of colonies of the other empires and controlthem. So, the most powerful empire must take possession of acolony from the weakest empire. Fig. 4 depicts how it can bemodeled.
Figure 4. Imperialistic competition. The most powerful empire will possess
the weakest colony of the weakest empire.
After a few iterations, powerless empires will be collapsedin the imperialistic competition and their colonies will bedivided among other empires. At the end, all the empiresexcept the most powerful one will be collapsed and thecolonies will be under the control of this unique empire. In thisnew world all the colonies have the same position and samecosts and they are controlled by an imperialist with the same position and cost as themselves. In this condition theimperialistic competition ends and the algorithm stops. Positionand cost of remained imperialist respectively show theoptimized variables of the problem and optimized result of the
problem [13].
B. GA
By noticing the Darwin theory about evolution, GA iscreated. Fig. 5 shows the flowchart of this algorithm. For aspecific problem, the GA codes a solution as an individualchromosome. It then defines an initial population of thoseindividuals that represent a part of the solution space of the problem. The search space therefore, is defined as the solutionspace in which each feasible solution is represented by adistinct chromosome. Before the search starts, a set of chromosomes is randomly chosen from the search space toform the initial population. Next, through computations theindividuals are selected in a competitive manner, based on their fitness as measured by a specific objective function. Thegenetic search operators such as selection, mutation andcrossover are then applied one after another to obtain a newgeneration of chromosomes in which the expected quality over all the chromosomes is better than that of the previousgeneration. This process is repeated until the terminationcriterion is met, and the best chromosome of the last generationis reported as the final solution [13].
C. ICA-GA
Using combination of the two evolutionary algorithms ICAand GA, these algorithms can be used next to each other for covering their disabilities. The suggested method is based onusing the ICA in the first iterations of optimization. This leadsthat the ability of ICA in the first iterations of optimization beused. At the second part of optimization the developed population calculated by the ICA is given to the GA. So the
ability of GA in finding the global optimum without forgettingother regions will be used in this section of algorithm. Fig. 6shows flowchart of the algorithm [13].
Figure 5. Flowchart of GA
Figure 6. Flowchart of ICA-GA
63

7/30/2019 Artificial Neural Network Weights Optimization Using ICA GA ICAGA and RICAGA SSCI2011 IEEE Conference Paris France
http://slidepdf.com/reader/full/artificial-neural-network-weights-optimization-using-ica-ga-icaga-and-ricaga 4/7
Figure 7. Behavior of R-ICA-GA to getting close to the global optimum
D. R-ICA-GA
This algorithm proposes to combine two basic algorithmsICA and GA based on recursive repetition of them. GA always prevents increasing the concentration on talent full regions of
optimization area. On the other hand, ICA always sends thecolonies toward the imperialists and gathers a big percentage of population near the imperialists. The global optimum usually isnear the local optimums in most of the problems. So the populations which are gathered near to the imperialists of ICA(which may be near the global optimum), will expand andtwitch, by recursive combination of these two algorithms. Infact, this algorithm behaves based on ICA, but it uses the helpof GA to expand the population of colonies which are gatherednear the imperialists [13]. Fig. 7 shows the behavior of coloniesin this algorithm.
As shown in Fig. 7 this algorithm, uses ICA to move the population toward the imperialists with the difference that the population movement is done in a billowy way. This billowy
movement leads to a fast decrease in the convergence curve inthe times which algorithm switches from ICA to GA and viceversa. This fast decrease shows the more optimized regionsnext to the imperialists are found. Fig. 8 shows the flowchart of the R-ICA-GA algorithm.
III. PROBLEM STATEMENT
As mentioned in section I the optimization method used todetermine weight adjustments has a large influence on the performance of neural networks. Using new hybridevolutionary algorithms ICA-GA and R-ICA-GA, andcomparing their performances to other evolutionary algorithmsICA and GA leads to find the best algorithm in weight
optimization for a classification problem.
IV. EXPERIMENTAL STUDIES
Test results are presented in this part of the paper. Threegroups of datasets are used for simulation which areclassification problems. The ANN which is used in thissimulation is a MLP network. At first a simple dataset is usedto learn the ANN, second is a complicated dataset and at thethird group, other standard datasets are studied in the ANN. All
datasets which are used in this paper, are Known datasetsavailable for download fromhttp://archive.ics.uci.edu/ml/datasets.html. These datasets are presented as follow:
• WINE
• PIMA
• WDBC
• IRIS
• SONAR
• GLASS
WINE is used as a simple dataset to test algorithms whichare used to train the ANN. PIMA is used as a complicateddataset and other datasets are used to assay the differentlearning methods which are used in this paper. All four algorithms ICA, GA, ICA-GA and R-ICA-GA are used to learnnamed datasets and are compared to each other.
Figure 8. Flowchart of R-ICA-GA
A. Using WINE as a Simple Dataset
WINE includes data from wine chemical analysis that belongs to 3 classes. It contains 178 samples with 13 attributes.The named dataset is divided to two subsets containing trainand test samples. Sizes of train and test subsets are chosen 124and 54 respectively. The samples are categorized to train and
64
7/30/2019 Artificial Neural Network Weights Optimization Using ICA GA ICAGA and RICAGA SSCI2011 IEEE Conference Paris France
http://slidepdf.com/reader/full/artificial-neural-network-weights-optimization-using-ica-ga-icaga-and-ricaga 5/7
test subsets randomly. The best topology of MLP network tolearn the WINE dataset is determined as (7,4,3) [9].
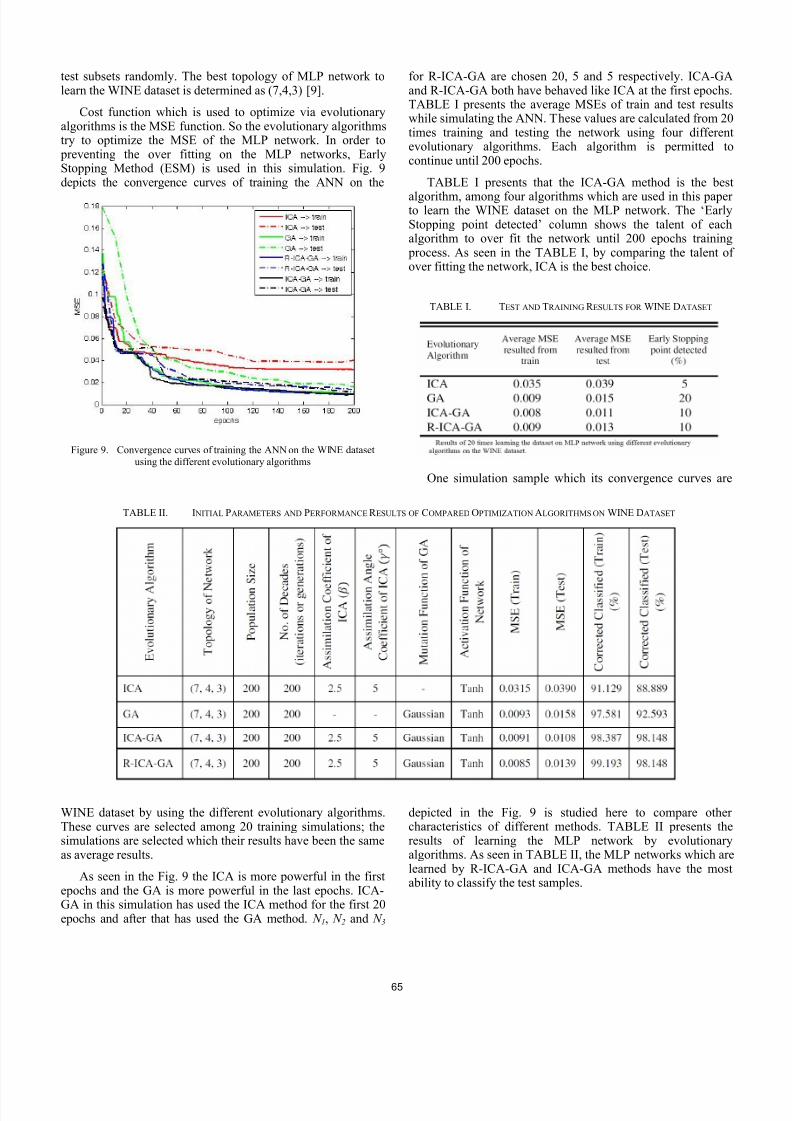
Cost function which is used to optimize via evolutionaryalgorithms is the MSE function. So the evolutionary algorithmstry to optimize the MSE of the MLP network. In order to preventing the over fitting on the MLP networks, EarlyStopping Method (ESM) is used in this simulation. Fig. 9depicts the convergence curves of training the ANN on the
Figure 9. Convergence curves of training the ANN on the WINE dataset
using the different evolutionary algorithms
WINE dataset by using the different evolutionary algorithms.These curves are selected among 20 training simulations; thesimulations are selected which their results have been the sameas average results.
As seen in the Fig. 9 the ICA is more powerful in the firstepochs and the GA is more powerful in the last epochs. ICA-GA in this simulation has used the ICA method for the first 20epochs and after that has used the GA method. N 1, N 2 and N 3
for R-ICA-GA are chosen 20, 5 and 5 respectively. ICA-GAand R-ICA-GA both have behaved like ICA at the first epochs.TABLE I presents the average MSEs of train and test resultswhile simulating the ANN. These values are calculated from 20times training and testing the network using four differentevolutionary algorithms. Each algorithm is permitted tocontinue until 200 epochs.
TABLE I presents that the ICA-GA method is the best
algorithm, among four algorithms which are used in this paper to learn the WINE dataset on the MLP network. The ‘EarlyStopping point detected’ column shows the talent of eachalgorithm to over fit the network until 200 epochs training process. As seen in the TABLE I, by comparing the talent of over fitting the network, ICA is the best choice.
One simulation sample which its convergence curves are
depicted in the Fig. 9 is studied here to compare other characteristics of different methods. TABLE II presents theresults of learning the MLP network by evolutionaryalgorithms. As seen in TABLE II, the MLP networks which arelearned by R-ICA-GA and ICA-GA methods have the mostability to classify the test samples.
TABLE I. TEST AND TRAINING R ESULTS FOR WINE DATASET
TABLE II. I NITIAL PARAMETERS AND PERFORMANCE R ESULTS OF COMPARED OPTIMIZATION ALGORITHMS ON WINE DATASET
65
7/30/2019 Artificial Neural Network Weights Optimization Using ICA GA ICAGA and RICAGA SSCI2011 IEEE Conference Paris France
http://slidepdf.com/reader/full/artificial-neural-network-weights-optimization-using-ica-ga-icaga-and-ricaga 6/7
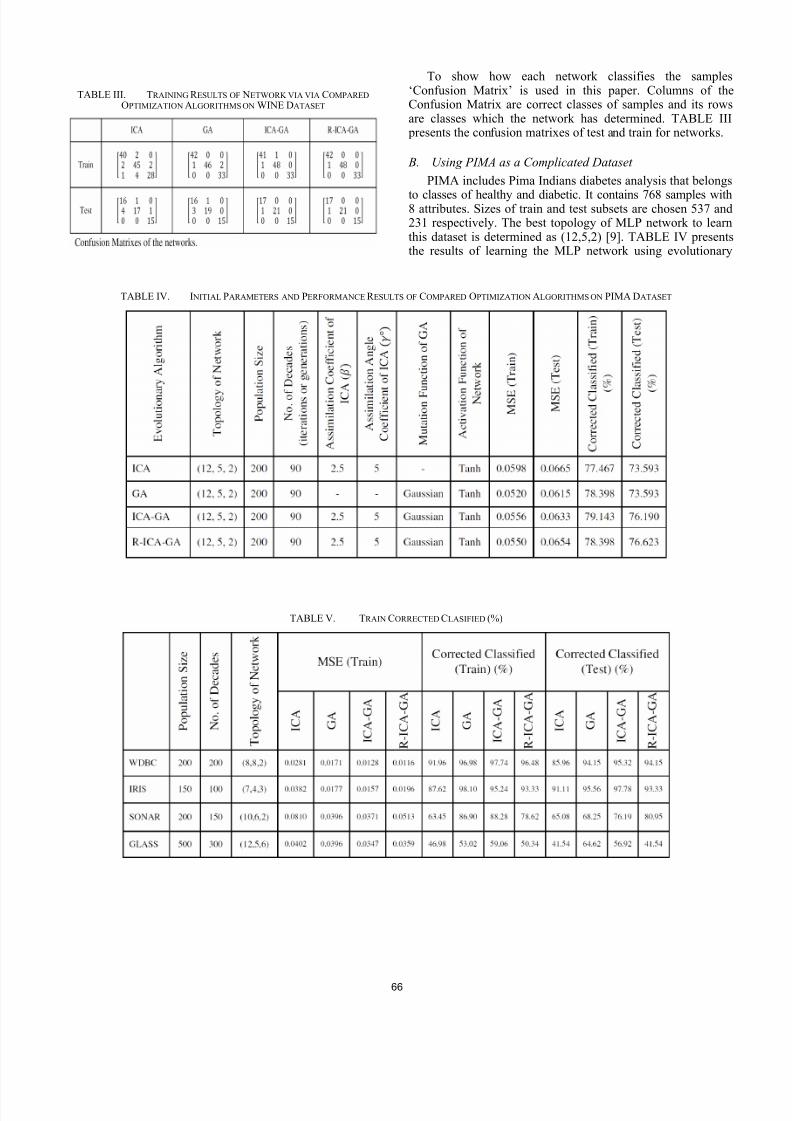
To show how each network classifies the samples‘Confusion Matrix’ is used in this paper. Columns of theConfusion Matrix are correct classes of samples and its rowsare classes which the network has determined. TABLE III presents the confusion matrixes of test and train for networks.
B. Using PIMA as a Complicated Dataset
PIMA includes Pima Indians diabetes analysis that belongs
to classes of healthy and diabetic. It contains 768 samples with8 attributes. Sizes of train and test subsets are chosen 537 and231 respectively. The best topology of MLP network to learnthis dataset is determined as (12,5,2) [9]. TABLE IV presentsthe results of learning the MLP network using evolutionary
TABLE III. TRAINING R ESULTS OF NETWORK VIA VIA COMPARED
OPTIMIZATION ALGORITHMS ON WINE DATASET
TABLE IV. I NITIAL PARAMETERS AND PERFORMANCE R ESULTS OF COMPARED OPTIMIZATION ALGORITHMS ON PIMA DATASET
TABLE V. TRAIN CORRECTED CLASIFIED (%)
66
7/30/2019 Artificial Neural Network Weights Optimization Using ICA GA ICAGA and RICAGA SSCI2011 IEEE Conference Paris France
http://slidepdf.com/reader/full/artificial-neural-network-weights-optimization-using-ica-ga-icaga-and-ricaga 7/7
algorithms.
C. Using Other Datasets
Four datasets WDBC, IRIS, SONAR and GLASS arestudied in this section. Test results are presented in TABLE V.these results will be used in section V to compare performanceof each algorithm.
V. COMPARING THE TEST R ESULTS
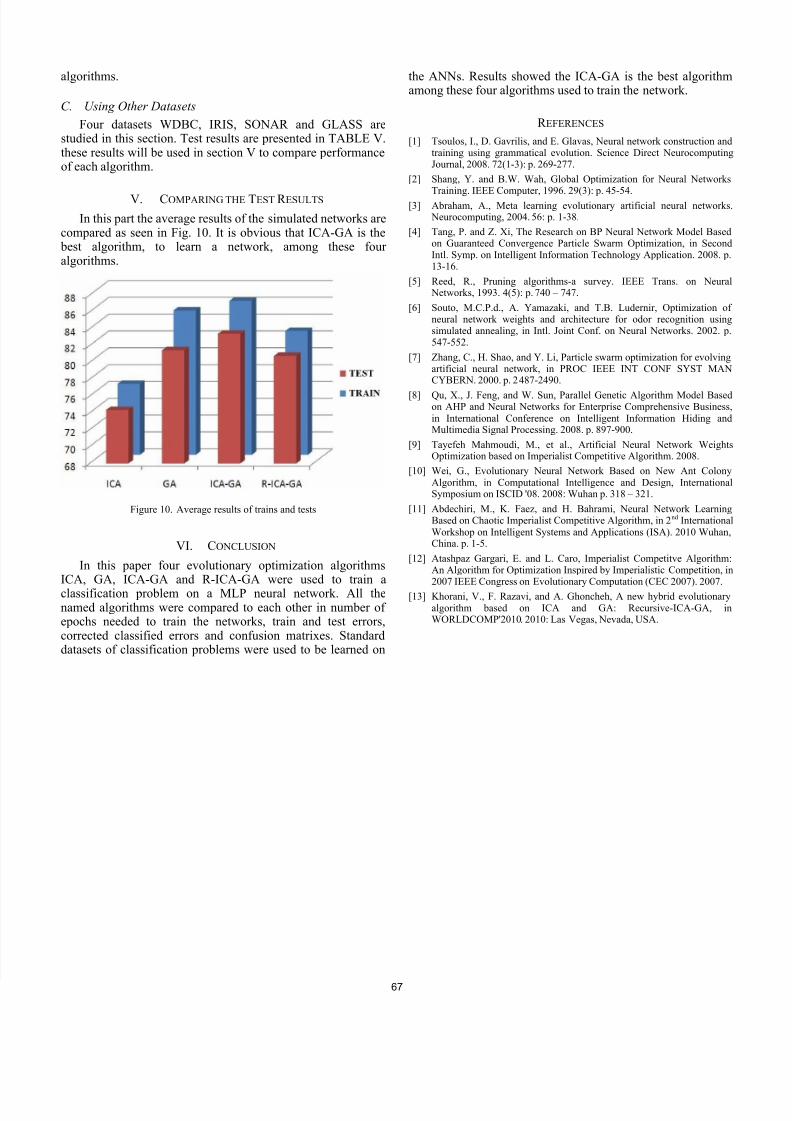
In this part the average results of the simulated networks arecompared as seen in Fig. 10. It is obvious that ICA-GA is the best algorithm, to learn a network, among these four algorithms.
Figure 10. Average results of trains and tests
VI. CONCLUSION
In this paper four evolutionary optimization algorithmsICA, GA, ICA-GA and R-ICA-GA were used to train a
classification problem on a MLP neural network. All thenamed algorithms were compared to each other in number of epochs needed to train the networks, train and test errors,corrected classified errors and confusion matrixes. Standarddatasets of classification problems were used to be learned on
the ANNs. Results showed the ICA-GA is the best algorithmamong these four algorithms used to train the network.
R EFERENCES
[1] Tsoulos, I., D. Gavrilis, and E. Glavas, Neural network construction andtraining using grammatical evolution. Science Direct NeurocomputingJournal, 2008. 72(1-3): p. 269-277.
[2] Shang, Y. and B.W. Wah, Global Optimization for Neural NetworksTraining. IEEE Computer, 1996. 29(3): p. 45-54.
[3] Abraham, A., Meta learning evolutionary artificial neural networks. Neurocomputing, 2004. 56: p. 1-38.
[4] Tang, P. and Z. Xi, The Research on BP Neural Network Model Basedon Guaranteed Convergence Particle Swarm Optimization, in SecondIntl. Symp. on Intelligent Information Technology Application. 2008. p.13-16.
[5] Reed, R., Pruning algorithms-a survey. IEEE Trans. on Neural Networks, 1993. 4(5): p. 740 – 747.
[6] Souto, M.C.P.d., A. Yamazaki, and T.B. Ludernir, Optimization of neural network weights and architecture for odor recognition usingsimulated annealing, in Intl. Joint Conf. on Neural Networks. 2002. p.547-552.
[7] Zhang, C., H. Shao, and Y. Li, Particle swarm optimization for evolvingartificial neural network, in PROC IEEE INT CONF SYST MANCYBERN. 2000. p. 2487-2490.
[8] Qu, X., J. Feng, and W. Sun, Parallel Genetic Algorithm Model Basedon AHP and Neural Networks for Enterprise Comprehensive Business,in International Conference on Intelligent Information Hiding andMultimedia Signal Processing. 2008. p. 897-900.
[9] Tayefeh Mahmoudi, M., et al., Artificial Neural Network WeightsOptimization based on Imperialist Competitive Algorithm. 2008.
[10] Wei, G., Evolutionary Neural Network Based on New Ant ColonyAlgorithm, in Computational Intelligence and Design, InternationalSymposium on ISCID '08. 2008: Wuhan p. 318 – 321.
[11] Abdechiri, M., K. Faez, and H. Bahrami, Neural Network LearningBased on Chaotic Imperialist Competitive Algorithm, in 2nd InternationalWorkshop on Intelligent Systems and Applications (ISA). 2010 Wuhan,China. p. 1-5.
[12] Atashpaz Gargari, E. and L. Caro, Imperialist Competitve Algorithm:An Algorithm for Optimization Inspired by Imperialistic Competition, in2007 IEEE Congress on Evolutionary Computation (CEC 2007). 2007.
[13] Khorani, V., F. Razavi, and A. Ghoncheh, A new hybrid evolutionaryalgorithm based on ICA and GA: Recursive-ICA-GA, inWORLDCOMP'2010. 2010: Las Vegas, Nevada, USA.
67





























