Embed Size (px)
Citation preview

Are you doing what I think you are doing?Robust AI via Verification, Monitoring and Repair ∗
Francesco Leofante
RWTH Aachen University, Germany
University of Genoa, Italy
Munich, May 24th, 2017
∗joint work with E. Abraham, N. Jansen, L. Pulina, A. Tacchella, S.VuottoLeofante Robust AI PUMA Seminar 1 / 24

Why?
www.businnessinsider.com
www.science.howstuffworks.com
Leofante Robust AI PUMA Seminar 2 / 24

Why?
Leofante Robust AI PUMA Seminar 3 / 24

What?
. . . aka my Ph.D. in 3 questions:
Q1. How to learn formal models of robots’ behaviorsthat can be subject to automated verification?
Q2. How to employ formal methods for the automatedconstruction of safe and effective strategies?
Q3. How to detect and repair faulty models?
Leofante Robust AI PUMA Seminar 4 / 24

What?
. . . aka my Ph.D. in 3 questions:
Q1. How to learn formal models of robots’ behaviorsthat can be subject to automated verification?
Q2. How to employ formal methods for the automatedconstruction of safe and effective strategies?
Q3. How to detect and repair faulty models?
Leofante Robust AI PUMA Seminar 4 / 24

How?
ModelMLearning Safe?
Deploy
Discrepancies?Beyond repair?
Shut Down
RepairM
Static Verification
yes
Online Monitoring no
yesyes
no
Leofante Robust AI PUMA Seminar 5 / 24

Case Studies
Let’s get down to business:
Problem 1: Verifying learning systemsI Verifying Support Vector Machines via SMT solving [1, 2]
Problem 2: Safety at the deliberative levelI Safe Standing Up for Humanoid Robots via Model Checking [3]
Leofante Robust AI PUMA Seminar 6 / 24

Verifying Support Vector Machines via SMT solving
Leofante Robust AI PUMA Seminar 7 / 24

Learning in Physical Domains
Machine learning is pervasive, several applications to CPS
In this context, data samples are expensive
CPS are safety-critical
Central Question
? �∧
images courtesy of: scandinavianstudy.com, wikipedia.com
Leofante Robust AI PUMA Seminar 8 / 24

Learning in Physical Domains
Machine learning is pervasive, several applications to CPS
In this context, data samples are expensive
CPS are safety-critical
Central Question
? �∧
images courtesy of: scandinavianstudy.com, wikipedia.com
Leofante Robust AI PUMA Seminar 8 / 24

How?
⇒From domain ... infer automatically ... ... models as
interaction... (active learning) Support Vector Machines.
Kernel machines are funny beasts!
Statistical guarantees only (at best)
R→ R functions ⇒ no (easy) verification algos
Leofante Robust AI PUMA Seminar 9 / 24

How?
⇒From domain ... infer automatically ... ... models as
interaction... (active learning) Support Vector Machines.
Kernel machines are funny beasts!
Statistical guarantees only (at best)
R→ R functions ⇒ no (easy) verification algos
Leofante Robust AI PUMA Seminar 9 / 24

How? - cont’d
⇒From concrete ... extract ... ... conservative
machines... (automatically) abstractions.
Abstractions can be model checked!
Quantifier-Free Linear Arithmetic over RConcrete machine is safe if abstract one is safe
Leofante Robust AI PUMA Seminar 10 / 24

Building the abstraction
Support Vector Regression y =∑l
i=1(αi − α∗i )K (xi , x) + b
Radial Basis Function K (xi , x) = e−1
2σ2‖x−xi‖2
p
[min(G(x),G(x + p)),G(µ)] if
[min(G(x),G(x + p)),max(G(x),G(x + p))] if
[0,G(x0)] otherwise
And now...
QF LRA encoding for each Ki
Can be verified with SMT X
if (x ≤ x0)then (Ki ≥ 0) (Ki ≤ G(x0))
. . .if (0 < x)(x ≤ 0.5)
then (Ki ≥ min(G(0),G(0.5)) (Ki ≤ max(G(0),G(0.5)). . .if (x1 < x)
then (Ki ≥ 0) (Ki ≤ G(x0))
Leofante Robust AI PUMA Seminar 11 / 24

Building the abstraction
Support Vector Regression y =∑l
i=1(αi − α∗i )K (xi , x) + b
Radial Basis Function K (xi , x) = e−1
2σ2‖x−xi‖2
p
[min(G(x),G(x + p)),G(µ)] if
[min(G(x),G(x + p)),max(G(x),G(x + p))] if
[0,G(x0)] otherwise
And now...
QF LRA encoding for each Ki
Can be verified with SMT X
if (x ≤ x0)then (Ki ≥ 0) (Ki ≤ G(x0))
. . .if (0 < x)(x ≤ 0.5)
then (Ki ≥ min(G(0),G(0.5)) (Ki ≤ max(G(0),G(0.5)). . .if (x1 < x)
then (Ki ≥ 0) (Ki ≤ G(x0))
Leofante Robust AI PUMA Seminar 11 / 24

Building the abstraction
Support Vector Regression y =∑l
i=1(αi − α∗i )K (xi , x) + b
Radial Basis Function K (xi , x) = e−1
2σ2‖x−xi‖2
p
[min(G(x),G(x + p)),G(µ)] if
[min(G(x),G(x + p)),max(G(x),G(x + p))] if
[0,G(x0)] otherwise
And now...
QF LRA encoding for each Ki
Can be verified with SMT X
if (x ≤ x0)then (Ki ≥ 0) (Ki ≤ G(x0))
. . .if (0 < x)(x ≤ 0.5)
then (Ki ≥ min(G(0),G(0.5)) (Ki ≤ max(G(0),G(0.5)). . .if (x1 < x)
then (Ki ≥ 0) (Ki ≤ G(x0))
Leofante Robust AI PUMA Seminar 11 / 24

Building the abstraction
Support Vector Regression y =∑l
i=1(αi − α∗i )K (xi , x) + b
Radial Basis Function K (xi , x) = e−1
2σ2‖x−xi‖2
p
[min(G(x),G(x + p)),G(µ)] if
[min(G(x),G(x + p)),max(G(x),G(x + p))] if
[0,G(x0)] otherwise
And now...
QF LRA encoding for each Ki
Can be verified with SMT X
if (x ≤ x0)then (Ki ≥ 0) (Ki ≤ G(x0))
. . .if (0 < x)(x ≤ 0.5)
then (Ki ≥ min(G(0),G(0.5)) (Ki ≤ max(G(0),G(0.5)). . .if (x1 < x)
then (Ki ≥ 0) (Ki ≤ G(x0))
Leofante Robust AI PUMA Seminar 11 / 24

Building the abstraction
Support Vector Regression y =∑l
i=1(αi − α∗i )K (xi , x) + b
Radial Basis Function K (xi , x) = e−1
2σ2‖x−xi‖2
p
[min(G(x),G(x + p)),G(µ)] if
[min(G(x),G(x + p)),max(G(x),G(x + p))] if
[0,G(x0)] otherwise
And now...
QF LRA encoding for each Ki
Can be verified with SMT X
if (x ≤ x0)then (Ki ≥ 0) (Ki ≤ G(x0))
. . .if (0 < x)(x ≤ 0.5)
then (Ki ≥ min(G(0),G(0.5)) (Ki ≤ max(G(0),G(0.5)). . .if (x1 < x)
then (Ki ≥ 0) (Ki ≤ G(x0))
Leofante Robust AI PUMA Seminar 11 / 24

Building the abstraction
Support Vector Regression y =∑l
i=1(αi − α∗i )K (xi , x) + b
Radial Basis Function K (xi , x) = e−1
2σ2‖x−xi‖2
p
[min(G(x),G(x + p)),G(µ)] if
[min(G(x),G(x + p)),max(G(x),G(x + p))] if
[0,G(x0)] otherwise
And now...
QF LRA encoding for each Ki
Can be verified with SMT X
if (x ≤ x0)then (Ki ≥ 0) (Ki ≤ G(x0))
. . .if (0 < x)(x ≤ 0.5)
then (Ki ≥ min(G(0),G(0.5)) (Ki ≤ max(G(0),G(0.5)). . .if (x1 < x)
then (Ki ≥ 0) (Ki ≤ G(x0))
Leofante Robust AI PUMA Seminar 11 / 24

What do we verify?
We are interested in the stability of the SVR ς, i.e.,
∀x1, x2 ∈ I : ||x1 − x2|| ≤ δ → ||ς(x1)− ς(x2)|| ≤ ε
and compare the results with Gaussian Process Regression (GPR).
Why?GPR is a higher order kernel method natively providing statistical boundson predictions
Samples MAE p ε CPU Time (s)SVR 10 samples 0.036 0.09 0.38 465.201
+ 20 samples 0.032 0.09 0.40 2041.645SMT 40 samples 0.030 0.06 0.42 7480.110
Samples MAE σ Time10 samples 0.106 0.291 3.336
GP 20 samples 0.095 0.303 6.80540 samples 0.099 0.280 14.035
Leofante Robust AI PUMA Seminar 12 / 24

What do we verify?
We are interested in the stability of the SVR ς, i.e.,
∀x1, x2 ∈ I : ||x1 − x2|| ≤ δ → ||ς(x1)− ς(x2)|| ≤ ε
and compare the results with Gaussian Process Regression (GPR).
Why?GPR is a higher order kernel method natively providing statistical boundson predictions
Samples MAE p ε CPU Time (s)SVR 10 samples 0.036 0.09 0.38 465.201
+ 20 samples 0.032 0.09 0.40 2041.645SMT 40 samples 0.030 0.06 0.42 7480.110
Samples MAE σ Time10 samples 0.106 0.291 3.336
GP 20 samples 0.095 0.303 6.80540 samples 0.099 0.280 14.035
Leofante Robust AI PUMA Seminar 12 / 24

What do we verify?
We are interested in the stability of the SVR ς, i.e.,
∀x1, x2 ∈ I : ||x1 − x2|| ≤ δ → ||ς(x1)− ς(x2)|| ≤ ε
and compare the results with Gaussian Process Regression (GPR).
Why?GPR is a higher order kernel method natively providing statistical boundson predictions
Samples MAE p ε CPU Time (s)SVR 10 samples 0.036 0.09 0.38 465.201
+ 20 samples 0.032 0.09 0.40 2041.645SMT 40 samples 0.030 0.06 0.42 7480.110
Samples MAE σ Time10 samples 0.106 0.291 3.336
GP 20 samples 0.095 0.303 6.80540 samples 0.099 0.280 14.035
Leofante Robust AI PUMA Seminar 12 / 24

What do we verify?
We are interested in the stability of the SVR ς, i.e.,
∀x1, x2 ∈ I : ||x1 − x2|| ≤ δ → ||ς(x1)− ς(x2)|| ≤ ε
and compare the results with Gaussian Process Regression (GPR).
Why?GPR is a higher order kernel method natively providing statistical boundson predictions
Samples MAE p ε CPU Time (s)SVR 10 samples 0.036 0.09 0.38 465.201
+ 20 samples 0.032 0.09 0.40 2041.645SMT 40 samples 0.030 0.06 0.42 7480.110
Samples MAE σ Time10 samples 0.106 0.291 3.336
GP 20 samples 0.095 0.303 6.80540 samples 0.099 0.280 14.035
Leofante Robust AI PUMA Seminar 12 / 24

Safe Standing Up for Humanoid Robots via Model Checking
Leofante Robust AI PUMA Seminar 13 / 24

Standing up for humanoid robots
Bipedal locomotion is a challenging task for a humanoid robot
Reliable standing-up routines are fundamental in case of a fall
Conventional motion-planning is difficult to apply
Scripted strategies are often used:I lack flexibility (by definition)I reliability and robustness issuesI daunting task
Learning offers an elegant solution
Leofante Robust AI PUMA Seminar 14 / 24

Standing up for humanoid robots
Bipedal locomotion is a challenging task for a humanoid robot
Reliable standing-up routines are fundamental in case of a fall
Conventional motion-planning is difficult to apply
Scripted strategies are often used:I lack flexibility (by definition)I reliability and robustness issuesI daunting task
Learning offers an elegant solution
Leofante Robust AI PUMA Seminar 14 / 24

Standing up for humanoid robots
Bipedal locomotion is a challenging task for a humanoid robot
Reliable standing-up routines are fundamental in case of a fall
Conventional motion-planning is difficult to apply
Scripted strategies are often used:I lack flexibility (by definition)I reliability and robustness issuesI daunting task
Learning offers an elegant solution
Leofante Robust AI PUMA Seminar 14 / 24

Objectives
Problem: Synthesize a standing-up procedure that minimizesthe expected number of falls, self-collisions and actions.
?
Simulated Bioloid humanoid in V-REP
Leofante Robust AI PUMA Seminar 15 / 24

Reinforcement learning
Goal: Learn an optimal strategy for a non-deterministic probabilisticsystem
Given:I state set S , initial state s init
I action set ActI a possibility to observe the successor state when executing a given
action in a given stateI a reward function R : S × Act × S → R
Method: Q-learning
Leofante Robust AI PUMA Seminar 16 / 24

Reinforcement learning
Goal: Learn an optimal strategy for a non-deterministic probabilisticsystem
Given:I state set S , initial state s init
I action set ActI a possibility to observe the successor state when executing a given
action in a given stateI a reward function R : S × Act × S → R
Method: Q-learning
Leofante Robust AI PUMA Seminar 16 / 24

Reinforcement learning
Goal: Learn an optimal strategy for a non-deterministic probabilisticsystem
Given:I state set S , initial state s init
I action set ActI a possibility to observe the successor state when executing a given
action in a given stateI a reward function R : S × Act × S → R
Method: Q-learning
Leofante Robust AI PUMA Seminar 16 / 24

Reinforcement learning
Goal: Learn an optimal strategy for a non-deterministic probabilisticsystem
Given:I state set S , initial state s init
I action set ActI a possibility to observe the successor state when executing a given
action in a given stateI a reward function R : S × Act × S → R
Method: Q-learning
Leofante Robust AI PUMA Seminar 16 / 24

Q-learning: Learning through simulation
Leofante Robust AI PUMA Seminar 16 / 24

Q-learning on an example
s0
s1
a1
Rewards:
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
Q-matrix:
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 50 0
s1 0 0 0
s2 0 0 0
. . .
Qk+1(s0, a1) = 0.5 · Qk(s0, a1)+0.5 · (100 + 1 ·maxai∈ActQk(s1, ai ))
Leofante Robust AI PUMA Seminar 17 / 24

Q-learning on an example
s0
s1
a1
Rewards:
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
Q-matrix:
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 50 0
s1 0 0 0
s2 0 0 0
. . .
Qk+1(s0, a1) = 0.5 · Qk(s0, a1)+0.5 · (100 + 1 ·maxai∈ActQk(s1, ai ))
Leofante Robust AI PUMA Seminar 17 / 24

Q-learning on an example
s0
s1
a1
Rewards:
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
Q-matrix:
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 50 0
s1 0 0 0
s2 0 0 0
. . .
Qk+1(s0, a1) = 0.5 · Qk(s0, a1)+0.5 · (100 + 1 ·maxai∈ActQk(s1, ai ))
Leofante Robust AI PUMA Seminar 17 / 24

Q-learning on an example
s0
s1
a1
Rewards:
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
Q-matrix:
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 50 0
s1 0 0 0
s2 0 0 0
. . .
Qk+1(s0, a1) = 0.5 · Qk(s0, a1)+0.5 · (100 + 1 ·maxai∈ActQk(s1, ai ))
Leofante Robust AI PUMA Seminar 17 / 24

Q-learning on an example
s0
s1
a1
Rewards:
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
Q-matrix:
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 50 0
s1 0 0 0
s2 0 0 0
. . .
Qk+1(s0, a1) = 0.5 · Qk(s0, a1)+0.5 · (100 + 1 ·maxai∈ActQk(s1, ai ))
Leofante Robust AI PUMA Seminar 17 / 24

Q-learning on an example
s0
s1
a1
Rewards:
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
Q-matrix:
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 50 0
s1 0 0 0
s2 0 0 0
. . .
Qk+1(s0, a1) = 0.5 · Qk(s0, a1)+0.5 · (100 + 1 ·maxai∈ActQk(s1, ai ))
Leofante Robust AI PUMA Seminar 17 / 24

Q-learning on an example
s0
s1
a1
Rewards:
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
Q-matrix:
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 50 0
s1 0 0 0
s2 0 0 0
. . .
Qk+1(s0, a1) = 0.5 · Qk(s0, a1)+0.5 · (100 + 1 ·maxai∈ActQk(s1, ai ))
Leofante Robust AI PUMA Seminar 17 / 24

Q-learning on an example
s0
s1
a1
Rewards:
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
Q-matrix:
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 50 0
s1 0 0 0
s2 0 0 0
. . .
Qk+1(s0, a1) = 0.5 · Qk(s0, a1)+0.5 · (100 + 1 ·maxai∈ActQk(s1, ai ))
Leofante Robust AI PUMA Seminar 17 / 24

Q-learning on an example
s0
s1
a1
Rewards:
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
R s0 s1 s2 . . .
(s0, a0) -10 100 -50
(s0, a1) -10 100 -50
. . .
(s1, a0) -50 -10 100
(s1, a1) -50 -10 100
. . .
Q-matrix:
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 0 0
s1 0 0 0
s2 0 0 0
. . .
Q a0 a1 a2 . . .
s0 0 50 0
s1 0 0 0
s2 0 0 0
. . .
Qk+1(s0, a1) = 0.5 · Qk(s0, a1)+0.5 · (100 + 1 ·maxai∈ActQk(s1, ai ))
Leofante Robust AI PUMA Seminar 17 / 24

Q-learning: The action space
The robot has 18 joints → intractable action space
Simplifying assumptions:
some joints are inhibited
joints operate symmetrically
action space is discretized
We end up with 730 actions:
3 upper limbs, 3 lower limbs, 3 actions each
→ action space {−1, 0, 1}6
additional action arestart for safe restart
Leofante Robust AI PUMA Seminar 18 / 24

Q-learning: The state space
Robot states: s = (x , y , z , q0, q1, q2, q3, ρ1, . . . , ρ18) ∈ R25
Infinite state space!
Full grid discretization is infeasible
Input: scripted trace A =(aA0 , . . . , a
Ak
)for standing-up
Explore states in a “tube” around A
s initaA0
a∈Act s initaA0 aA1
a∈Act s initaA0 aA1 aA2
a∈Act . . .
Discretize the so reachable states → 17614 states
Still, several adaptation of Q-learning were needed to achieveconvergence
Several additional paths to the goal could be identified (even shorter)
Leofante Robust AI PUMA Seminar 19 / 24

Q-learning: The state space
Robot states: s = (x , y , z , q0, q1, q2, q3, ρ1, . . . , ρ18) ∈ R25
Infinite state space!
Full grid discretization is infeasible
Input: scripted trace A =(aA0 , . . . , a
Ak
)for standing-up
Explore states in a “tube” around A
s initaA0
a∈Act s initaA0 aA1
a∈Act s initaA0 aA1 aA2
a∈Act . . .
Discretize the so reachable states → 17614 states
Still, several adaptation of Q-learning were needed to achieveconvergence
Several additional paths to the goal could be identified (even shorter)
Leofante Robust AI PUMA Seminar 19 / 24

Static and online methods: Our frameworkWait but... how to guarantee that our properties of interest are satisfied?
State space generation
Q-learning
Model generation
Greedy model repair
Online monitoring
stable strategy σ
stable strategy σ
safe stable strategy σ
new observations M,
current strategy σ
That’s why we combine it with static analysis and online monitoring
Leofante Robust AI PUMA Seminar 20 / 24

Static and online methods: Our frameworkWait but... how to guarantee that our properties of interest are satisfied?
State space generation
Q-learning
Model generation
Greedy model repair
Online monitoring
stable strategy σ
stable strategy σ
safe stable strategy σ
new observations M,
current strategy σ
That’s why we combine it with static analysis and online monitoring
Leofante Robust AI PUMA Seminar 20 / 24

Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24

Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24

Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24

Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24

Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24

Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24
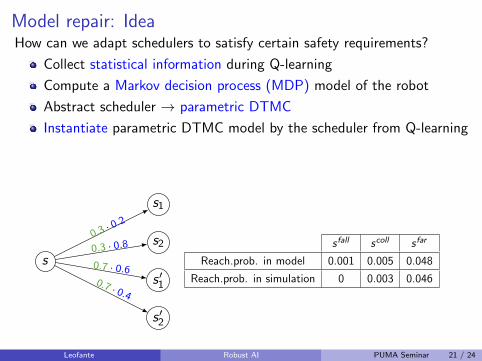
Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24

Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24

Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24

Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24

Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24

Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24

Model repair: IdeaHow can we adapt schedulers to satisfy certain safety requirements?
Collect statistical information during Q-learning
Compute a Markov decision process (MDP) model of the robot
Abstract scheduler → parametric DTMC
Instantiate parametric DTMC model by the scheduler from Q-learning
Check safety by probabilistic model checking
Repair the scheduler if unsafe
s
s1
s2
s ′1
s ′2
a1
0.2
0.8
a20.6
0.4
s
s1
s2
s ′1
s ′2
σ(s, a1
) · 0.2
σ(s, a1)· 0.8
σ(s, a2) · 0.6σ(s, a2 ) · 0.4
s
s1
s2
s ′1
s ′2
0.3· 0.2
0.3 · 0.8
0.7 · 0.60.7 · 0.4
s fall scoll s far
Reach.prob. in model 0.001 0.005 0.048
Reach.prob. in simulation 0 0.003 0.046
Pr s1(♦B)
Pr s2(♦B)
Pr s′1(♦B)
Pr s′2(♦B)
+
>+
s
s1
s2
s ′1
s ′2
0.28 · 0
.2
0.28 · 0.8
0.72 · 0.60.72 · 0.4
s fall scoll s far
Reach.prob. in model before repair 0.001 0.005 0.048
Reach.prob. in simulation before repair 0 0.003 0.046
Reach.prob. in model after repair 0.0003 6.8 · 10−6 0.02
Reach.prob. in simulation after repair 0 0 0
Leofante Robust AI PUMA Seminar 21 / 24

Online monitoring
So now we deploy our safe, repaired strategy on the real robot andeverything should be fine right?
WRONG
What if the assumptions on which the model was built change?
environmental changes, robot failures . . .
Looks like this is a problem we could solve using. . .
Online Monitoring
Leofante Robust AI PUMA Seminar 22 / 24

Online monitoring
So now we deploy our safe, repaired strategy on the real robot andeverything should be fine right?
WRONG
What if the assumptions on which the model was built change?
environmental changes, robot failures . . .
Looks like this is a problem we could solve using. . .
Online Monitoring
Leofante Robust AI PUMA Seminar 22 / 24

Online monitoring
So now we deploy our safe, repaired strategy on the real robot andeverything should be fine right?
WRONG
What if the assumptions on which the model was built change?
environmental changes, robot failures . . .
Looks like this is a problem we could solve using. . .
Online Monitoring
Leofante Robust AI PUMA Seminar 22 / 24

Online monitoring
So now we deploy our safe, repaired strategy on the real robot andeverything should be fine right?
WRONG
What if the assumptions on which the model was built change?
environmental changes, robot failures . . .
Looks like this is a problem we could solve using. . .
Online Monitoring
Leofante Robust AI PUMA Seminar 22 / 24

Online monitoring
So now we deploy our safe, repaired strategy on the real robot andeverything should be fine right?
WRONG
What if the assumptions on which the model was built change?
environmental changes, robot failures . . .
Looks like this is a problem we could solve using. . .
Online Monitoring
Leofante Robust AI PUMA Seminar 22 / 24

Online monitoring
We collect statistical observations during deployment
From time to time, we update the MDP model with the newobservations
Model check and repair the scheduler if needed
We simulated that a part of the robot was broken
Out of 300 simulation episodes only 2 reached the goal state
After a feedback loop, in further 300 episodes, 197 reached the goal
Leofante Robust AI PUMA Seminar 23 / 24

Online monitoring
We collect statistical observations during deployment
From time to time, we update the MDP model with the newobservations
Model check and repair the scheduler if needed
We simulated that a part of the robot was broken
Out of 300 simulation episodes only 2 reached the goal state
After a feedback loop, in further 300 episodes, 197 reached the goal
Leofante Robust AI PUMA Seminar 23 / 24

Thank you for your attention
In case you still want to speak with me after thistalk, you can find me at:
Francesco Leofante, Luca Pulina, and Armando Tacchella.
Learning with safety requirements: State of the art and open questions.
In Proc. of RCRA@AI*IA 2016), pages 11–25, 2016.
Francesco Leofante and Armando Tacchella.
Learning in physical domains: Mating safety requirements and costly sampling.
In Proc. of AI*IA 2016, pages 539–552, 2016.
Francesco Leofante, Simone Vuotto, Erika Abraham, Armando Tacchella, and NilsJansen.
Combining static and runtime methods to achieve safe standing-up for humanoidrobots.
In Proc. of ISoLA 2016, Part I, pages 496–514, 2016.Leofante Robust AI PUMA Seminar 24 / 24


















![AI pptX: Robust Continuous Learning for Document ......AI pptX understands human language instructions [Vittorio et al.,2015] by predicting labels [T. Kollar and Roy,2014] for every](https://img.pdfslide.us/doc/110x75/60b442f4cc505f7566444ee7/ai-pptx-robust-continuous-learning-for-document-ai-pptx-understands-human.jpg)










