Embed Size (px)
Citation preview

Aprendizaje de Similitudes
Aprendizaje de Similitudes
Emilio Parrado HernandezMLG
Departamento de Teorıa de la Senal y ComunicacionesUniversidad Carlos III de Madrid
1 de febrero de 2013
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 1 / 31

Aprendizaje de Similitudes
Vista General de la presentacion
Referencias
1. Learning Multimodal SimilarityB. McFee, G. LanckrietJMLR 12 (2011)
2. Metric and Kernel Learning Using a Linear TransformationP. Jain, B. Kulis, J. V. Davis, I. S. DhillonJMLR 13 (2012)
3. Large Scale Online Learning of Image Similarity ThroughRankingG. Chechik, V. Sharma, U. Shalit, S. BengioJMLR 11 (2010)
4. Learning Discriminative Metrics via Generative Models andKernel LearningY. Shi, Y.K. Noh, F. Sha, D. D. LeearXiv:1109.3940v1, 19 Sep. 2011.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 2 / 31

Aprendizaje de Similitudes
Vista General de la presentacion
Contenidos
Vista General de la presentacion
Planteamiento del problema
Aprendizaje de metricas desde informacion perceptual
Aprendizaje de metrica y kernel usando una transformacion lineal
OASIS
Aprendizaje de metricas discriminativas con modelos generativos yaprendizaje de kernels
Resumen
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 3 / 31
Aprendizaje de Similitudes
Planteamiento del problema
Motivacion
I Comparar dos objetos es una tarea fundamental en AprendizajeMaquina (AM).
I Relacion inmediata con clasificacion por similitudes (vecinos masproximos, metodos nucleo)
I Relacion con agrupamiento a traves de restricciones sobre parejas deejemplos que deberıan estar (o no) en el mismo grupo.
I ¿Similitud o metrica? Metrica implica imponer restricciones de PSD,lo que implica mayor coste computacional
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 4 / 31

Aprendizaje de Similitudes
Planteamiento del problema
Motivacion
I Comparar dos objetos es una tarea fundamental en AprendizajeMaquina (AM).
I Relacion inmediata con clasificacion por similitudes (vecinos masproximos, metodos nucleo)
I Relacion con agrupamiento a traves de restricciones sobre parejas deejemplos que deberıan estar (o no) en el mismo grupo.
I ¿Similitud o metrica? Metrica implica imponer restricciones de PSD,lo que implica mayor coste computacional
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 4 / 31

Aprendizaje de Similitudes
Planteamiento del problema
Motivacion
I Comparar dos objetos es una tarea fundamental en AprendizajeMaquina (AM).
I Relacion inmediata con clasificacion por similitudes (vecinos masproximos, metodos nucleo)
I Relacion con agrupamiento a traves de restricciones sobre parejas deejemplos que deberıan estar (o no) en el mismo grupo.
I ¿Similitud o metrica? Metrica implica imponer restricciones de PSD,lo que implica mayor coste computacional
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 4 / 31

Aprendizaje de Similitudes
Planteamiento del problema
Motivacion
I Comparar dos objetos es una tarea fundamental en AprendizajeMaquina (AM).
I Relacion inmediata con clasificacion por similitudes (vecinos masproximos, metodos nucleo)
I Relacion con agrupamiento a traves de restricciones sobre parejas deejemplos que deberıan estar (o no) en el mismo grupo.
I ¿Similitud o metrica? Metrica implica imponer restricciones de PSD,lo que implica mayor coste computacional
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 4 / 31
Aprendizaje de Similitudes
Planteamiento del problema
Metodos para comparar dos objetos en AM
1. Coger una metrica generica: coseno, euclıdea, etc.
2. Aprender una metrica de Mahalanobis para el problema concreto(equivale a buscar una transformacion lineal de los datos).
Pegas:I Numero de parametros cuadratico con la dimensionI Falla en escenarios no lineales. Se puede kernelizar, aunque tiene
limitaciones importantesI Limitado al escenario transductivoI Opciones para escenarios inductivos son muy restrictivas o de difıcil
optimizacion:Multiple kernel learning, hyperkernels.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 5 / 31

Aprendizaje de Similitudes
Planteamiento del problema
Metodos para comparar dos objetos en AM
1. Coger una metrica generica: coseno, euclıdea, etc.
2. Aprender una metrica de Mahalanobis para el problema concreto(equivale a buscar una transformacion lineal de los datos). Pegas:
I Numero de parametros cuadratico con la dimensionI Falla en escenarios no lineales. Se puede kernelizar, aunque tiene
limitaciones importantesI Limitado al escenario transductivoI Opciones para escenarios inductivos son muy restrictivas o de difıcil
optimizacion:Multiple kernel learning, hyperkernels.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 5 / 31

Aprendizaje de Similitudes
Planteamiento del problema
Metodos para comparar dos objetos en AM
1. Coger una metrica generica: coseno, euclıdea, etc.
2. Aprender una metrica de Mahalanobis para el problema concreto(equivale a buscar una transformacion lineal de los datos). Pegas:
I Numero de parametros cuadratico con la dimension
I Falla en escenarios no lineales. Se puede kernelizar, aunque tienelimitaciones importantes
I Limitado al escenario transductivoI Opciones para escenarios inductivos son muy restrictivas o de difıcil
optimizacion:Multiple kernel learning, hyperkernels.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 5 / 31
Aprendizaje de Similitudes
Planteamiento del problema
Metodos para comparar dos objetos en AM
1. Coger una metrica generica: coseno, euclıdea, etc.
2. Aprender una metrica de Mahalanobis para el problema concreto(equivale a buscar una transformacion lineal de los datos). Pegas:
I Numero de parametros cuadratico con la dimensionI Falla en escenarios no lineales.
Se puede kernelizar, aunque tienelimitaciones importantes
I Limitado al escenario transductivoI Opciones para escenarios inductivos son muy restrictivas o de difıcil
optimizacion:Multiple kernel learning, hyperkernels.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 5 / 31
Aprendizaje de Similitudes
Planteamiento del problema
Metodos para comparar dos objetos en AM
1. Coger una metrica generica: coseno, euclıdea, etc.
2. Aprender una metrica de Mahalanobis para el problema concreto(equivale a buscar una transformacion lineal de los datos). Pegas:
I Numero de parametros cuadratico con la dimensionI Falla en escenarios no lineales. Se puede kernelizar, aunque tiene
limitaciones importantesI Limitado al escenario transductivoI Opciones para escenarios inductivos son muy restrictivas o de difıcil
optimizacion:Multiple kernel learning, hyperkernels.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 5 / 31

Aprendizaje de Similitudes
Planteamiento del problema
Metodos para comparar dos objetos en AM
1. Coger una metrica generica: coseno, euclıdea, etc.
2. Aprender una metrica de Mahalanobis para el problema concreto(equivale a buscar una transformacion lineal de los datos). Pegas:
I Numero de parametros cuadratico con la dimensionI Falla en escenarios no lineales. Se puede kernelizar, aunque tiene
limitaciones importantesI Limitado al escenario transductivoI Opciones para escenarios inductivos son muy restrictivas o de difıcil
optimizacion:Multiple kernel learning, hyperkernels.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 5 / 31

Aprendizaje de Similitudes
Planteamiento del problema
Maneras de expresar una similitud implıcita
El aprendizaje de la metrica debe estar guiado por restricciones querecogen conocimiento a priori
I Etiquetas de clases: Los ejemplos pertenecientes a una misma clasedeben estar mas cerca entre sı que de los ejemplos de las otras clases
I Supervision en forma derestricciones por parejas de similitud odisimilitud
I Valor exacto de similitud entre ejemplos (no suele darse)
La similitud es una supervision mas debil que la clasificacion porque nohacen falta etiquetas.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 6 / 31

Aprendizaje de Similitudes
Planteamiento del problema
Distancia de Mahalanobis en el espacio de caracterısticas
I Datos X = {xi}ni=1 ∈ Rd
I Proyeccion no lineal a un espacio de caracterısticas φ(xi ) inducidamediante un kernel conocido κ0(xi , xj) = 〈φ(xi ), φ(xj)〉
I Distancia de Mahalanobis en el espacio de caracterısticas
dW (φ(xi ), φ(xj)) = φ(xi )TWφ(xj) = κ(xi , xj)
I Aprender dW (·, ·)/κ(·, ·) incorporando restricciones en forma desimilitudes entre pares de datos.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 7 / 31
Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Vista General de la presentacion
Planteamiento del problema
Aprendizaje de metricas desde informacion perceptual
Aprendizaje de metrica y kernel usando una transformacion lineal
OASIS
Aprendizaje de metricas discriminativas con modelos generativos yaprendizaje de kernels
Resumen
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 8 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Extraccion de similitudes a partir de etiquetados humanos
La similitud puede ser un concepto subjetivo.Multiples etiquetadores pueden no estar de acuerdo.
Es mas robusto preguntar por ordenes que por cantidades absolutas
“¿Son i y j mas parecidos que k y l?”“¿el elemento i es mas parecido a j o a k?”
Multidimensional Scaling (MDS)
Encontrar un espacio euclıdeo de representacion de los datos que respetelas distancias “percibidas” por los etiquetadores
MDS No metricoEncontrar un espacio euclıdeo de representacion de los datos que respeteuna ordenacion parcial “percibida” por los etiquetadores
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 9 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Extraccion de similitudes a partir de etiquetados humanos
La similitud puede ser un concepto subjetivo.Multiples etiquetadores pueden no estar de acuerdo.
Es mas robusto preguntar por ordenes que por cantidades absolutas
“¿Son i y j mas parecidos que k y l?”“¿el elemento i es mas parecido a j o a k?”
Multidimensional Scaling (MDS)
Encontrar un espacio euclıdeo de representacion de los datos que respetelas distancias “percibidas” por los etiquetadores
MDS No metricoEncontrar un espacio euclıdeo de representacion de los datos que respeteuna ordenacion parcial “percibida” por los etiquetadores
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 9 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Extraccion de similitudes a partir de etiquetados humanos
La similitud puede ser un concepto subjetivo.Multiples etiquetadores pueden no estar de acuerdo.
Es mas robusto preguntar por ordenes que por cantidades absolutas
“¿Son i y j mas parecidos que k y l?”“¿el elemento i es mas parecido a j o a k?”
Multidimensional Scaling (MDS)
Encontrar un espacio euclıdeo de representacion de los datos que respetelas distancias “percibidas” por los etiquetadores
MDS No metricoEncontrar un espacio euclıdeo de representacion de los datos que respeteuna ordenacion parcial “percibida” por los etiquetadores
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 9 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Extraccion de similitudes a partir de etiquetados humanos
La similitud puede ser un concepto subjetivo.Multiples etiquetadores pueden no estar de acuerdo.
Es mas robusto preguntar por ordenes que por cantidades absolutas
“¿Son i y j mas parecidos que k y l?”“¿el elemento i es mas parecido a j o a k?”
Multidimensional Scaling (MDS)
Encontrar un espacio euclıdeo de representacion de los datos que respetelas distancias “percibidas” por los etiquetadores
MDS No metricoEncontrar un espacio euclıdeo de representacion de los datos que respeteuna ordenacion parcial “percibida” por los etiquetadores
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 9 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Orden Parcial Estricto
Relacion binaria R definida en un conjunto Z (R ⊆ Z 2) que satisface
I Irreflexiva: (a, a) /∈ R
I Transitiva: (a, b) ∈ R ∧ (b, c) ∈ R ⇒ (a, c) ∈ R
I Antisimetrica: (a, b) ∈ R ⇒ (b, a) /∈ R
Se puede capturar mediante un grafo acıclico dirigido (DAG) C dondecada nodo es un par de muestras y las aristas indican la relacion R
I Si hay ciclos, no hay una representacion que capture la relacion
I Si no hay ciclos, cualquier representacion que capture una reducciontransitiva de C captura al propio C .
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 10 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Simplificacion del grafo
La subjetividad y el desacuerdo entre etiquetadores provocan que el graforesultante de compilar todas las etiquetas presente ciclos.
Simplificacion del grafo
1. Romper ciclos. Algoritmo greedy de Berger and Shor, 1990
2. Eliminar aristas redundantes aplicando transitividad: Si dos nodosestan unidos a traves de un camino del grafo, se puede eliminar suconexion directa.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 11 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Simplificacion del grafo
La subjetividad y el desacuerdo entre etiquetadores provocan que el graforesultante de compilar todas las etiquetas presente ciclos.
Simplificacion del grafo
1. Romper ciclos. Algoritmo greedy de Berger and Shor, 1990
2. Eliminar aristas redundantes aplicando transitividad: Si dos nodosestan unidos a traves de un camino del grafo, se puede eliminar suconexion directa.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 11 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Partial Order Embedding
I Encontrar g : X −→ Rd tal que
∀(i , j , k , l) ∈ C : ‖g(i)− g(j)‖2 + 1 ≤ ‖g(k)− g(l)‖2
se da un margen unitario para estabilidad numerica
I Asumir que los datos ya estan en un cierto espacio RD y que lafuncion g es una proyeccion lineal
g(x) = Mx
I La matriz de Gram en el espacio imagen es K = XTMTMX
I Restricciones del grafo:(xi − xj)
TMTM(xi − xj) + 1 ≤ (xk − xl)TMTM(xk − xl)
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 12 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Partial Order Embedding
I Encontrar g : X −→ Rd tal que
∀(i , j , k , l) ∈ C : ‖g(i)− g(j)‖2 + 1 ≤ ‖g(k)− g(l)‖2
se da un margen unitario para estabilidad numerica
I Asumir que los datos ya estan en un cierto espacio RD y que lafuncion g es una proyeccion lineal
g(x) = Mx
I La matriz de Gram en el espacio imagen es K = XTMTMX
I Restricciones del grafo:(xi − xj)
TMTM(xi − xj) + 1 ≤ (xk − xl)TMTM(xk − xl)
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 12 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Partial Order Embedding
I Encontrar g : X −→ Rd tal que
∀(i , j , k , l) ∈ C : ‖g(i)− g(j)‖2 + 1 ≤ ‖g(k)− g(l)‖2
se da un margen unitario para estabilidad numerica
I Asumir que los datos ya estan en un cierto espacio RD y que lafuncion g es una proyeccion lineal
g(x) = Mx
I La matriz de Gram en el espacio imagen es K = XTMTMX
I Restricciones del grafo:(xi − xj)
TMTM(xi − xj) + 1 ≤ (xk − xl)TMTM(xk − xl)
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 12 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Partial Order Embedding
I Encontrar g : X −→ Rd tal que
∀(i , j , k , l) ∈ C : ‖g(i)− g(j)‖2 + 1 ≤ ‖g(k)− g(l)‖2
se da un margen unitario para estabilidad numerica
I Asumir que los datos ya estan en un cierto espacio RD y que lafuncion g es una proyeccion lineal
g(x) = Mx
I La matriz de Gram en el espacio imagen es K = XTMTMX
I Restricciones del grafo:(xi − xj)
TMTM(xi − xj) + 1 ≤ (xk − xl)TMTM(xk − xl)
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 12 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Optimizacion para encontrar M
1. slack variables ξijkl para que haya solucion al problema.
2. empirical hinge loss para las violaciones de las restricciones
3. Regularizacion con tr(MTM) para evitar sobreajuste
Optimizacion
mınM,ξijkl
tr(MTM) +β
|C |∑C
ξijkl
sujeto a (xi − xj)TMTM(xi − xj) + 1 ≤ (xk − xl)
TMTM(xk − xl) + ξijkl yξijkl ≥ 0
Resolver para W = MTM con W PSD, que es convexo
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 13 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Optimizacion para encontrar M
1. slack variables ξijkl para que haya solucion al problema.
2. empirical hinge loss para las violaciones de las restricciones
3. Regularizacion con tr(MTM) para evitar sobreajuste
Optimizacion
mınM,ξijkl
tr(MTM) +β
|C |∑C
ξijkl
sujeto a (xi − xj)TMTM(xi − xj) + 1 ≤ (xk − xl)
TMTM(xk − xl) + ξijkl yξijkl ≥ 0
Resolver para W = MTM con W PSD, que es convexo
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 13 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Version kernelizada
Asumir que la funcion g es una transformacion no lineal con dcomponentes
g(x) = M(φ(x)) = [〈wp, φ(x)〉H]dp=1
donde φ(·) es una proyeccion inducida por un kernel κ0(·, ·)No resoluble en dim. infinita...
Regularizar en un Espacio de Hilbert
‖M‖2HS =
d∑p=1
〈wp,wp〉H
Representer Theorem: M = NΦT → ‖M‖2HS = traza(NTNK )
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 14 / 31
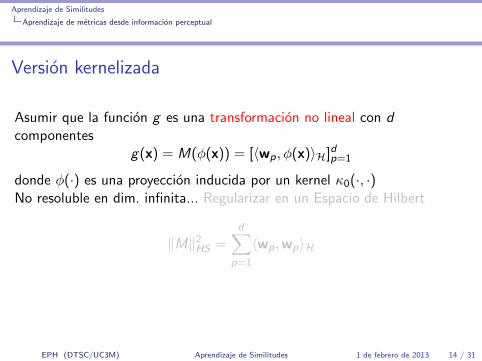
Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Version kernelizada
Asumir que la funcion g es una transformacion no lineal con dcomponentes
g(x) = M(φ(x)) = [〈wp, φ(x)〉H]dp=1
donde φ(·) es una proyeccion inducida por un kernel κ0(·, ·)No resoluble en dim. infinita... Regularizar en un Espacio de Hilbert
‖M‖2HS =
d∑p=1
〈wp,wp〉H
Representer Theorem: M = NΦT → ‖M‖2HS = traza(NTNK )
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 14 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Version kernelizada
Asumir que la funcion g es una transformacion no lineal con dcomponentes
g(x) = M(φ(x)) = [〈wp, φ(x)〉H]dp=1
donde φ(·) es una proyeccion inducida por un kernel κ0(·, ·)No resoluble en dim. infinita... Regularizar en un Espacio de Hilbert
‖M‖2HS =
d∑p=1
〈wp,wp〉H
Representer Theorem: M = NΦT → ‖M‖2HS = traza(NTNK )
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 14 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Version kernelizada
Asumir que la funcion g es una transformacion no lineal con dcomponentes
g(x) = M(φ(x)) = [〈wp, φ(x)〉H]dp=1
donde φ(·) es una proyeccion inducida por un kernel κ0(·, ·)No resoluble en dim. infinita... Regularizar en un Espacio de Hilbert
‖M‖2HS =
d∑p=1
〈wp,wp〉H
Representer Theorem: M = NΦT → ‖M‖2HS = traza(NTNK )
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 14 / 31
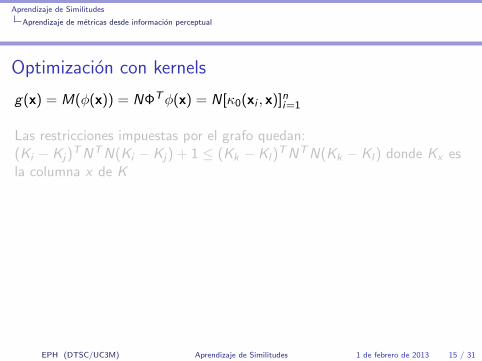
Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Optimizacion con kernels
g(x) = M(φ(x)) = NΦTφ(x) = N[κ0(xi , x)]ni=1
Las restricciones impuestas por el grafo quedan:(Ki − Kj)
TNTN(Ki − Kj) + 1 ≤ (Kk − Kl)TNTN(Kk − Kl) donde Kx es
la columna x de K
Optimizar
mınN,ξijkl
tr(NTNK ) +β
|C |∑C
ξijkl
sujeto a (Ki −Kj)TNTN(Ki −Kj) + 1 ≤ (Kk −Kl)
TNTN(Kk −Kl) + ξijkly ξijkl ≥ 0
Resolver para W = NTN, W PSD que es convexo.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 15 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Optimizacion con kernels
g(x) = M(φ(x)) = NΦTφ(x) = N[κ0(xi , x)]ni=1
Las restricciones impuestas por el grafo quedan:(Ki − Kj)
TNTN(Ki − Kj) + 1 ≤ (Kk − Kl)TNTN(Kk − Kl) donde Kx es
la columna x de K
Optimizar
mınN,ξijkl
tr(NTNK ) +β
|C |∑C
ξijkl
sujeto a (Ki −Kj)TNTN(Ki −Kj) + 1 ≤ (Kk −Kl)
TNTN(Kk −Kl) + ξijkly ξijkl ≥ 0
Resolver para W = NTN, W PSD que es convexo.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 15 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Optimizacion con kernels
g(x) = M(φ(x)) = NΦTφ(x) = N[κ0(xi , x)]ni=1
Las restricciones impuestas por el grafo quedan:(Ki − Kj)
TNTN(Ki − Kj) + 1 ≤ (Kk − Kl)TNTN(Kk − Kl) donde Kx es
la columna x de K
Optimizar
mınN,ξijkl
tr(NTNK ) +β
|C |∑C
ξijkl
sujeto a (Ki −Kj)TNTN(Ki −Kj) + 1 ≤ (Kk −Kl)
TNTN(Kk −Kl) + ξijkly ξijkl ≥ 0
Resolver para W = NTN, W PSD que es convexo.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 15 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Optimizacion con kernels
g(x) = M(φ(x)) = NΦTφ(x) = N[κ0(xi , x)]ni=1
Las restricciones impuestas por el grafo quedan:(Ki − Kj)
TNTN(Ki − Kj) + 1 ≤ (Kk − Kl)TNTN(Kk − Kl) donde Kx es
la columna x de K
Optimizar
mınN,ξijkl
tr(NTNK ) +β
|C |∑C
ξijkl
sujeto a (Ki −Kj)TNTN(Ki −Kj) + 1 ≤ (Kk −Kl)
TNTN(Kk −Kl) + ξijkly ξijkl ≥ 0
Resolver para W = NTN, W PSD que es convexo.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 15 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas desde informacion perceptual
Consideraciones
I Equivale a aprender una metrica de Mahalanobis con ΦWΦT en HI Equivale a aprender un kernel KWK con W PSD
I K = I quiere decir que no hay conocimiento a priori sobre lasimilitud entre puntos. La regularizacion tr(W ) equivale a minimizaruna cota en el rango de W , denotando preferencia por proyeccionesde baja dimension
I Extension para Multiple Kernel Learning util en problemas condiversas modalidades. Se aprende una combinacion ponderada de losdistintos kernels.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 16 / 31
Aprendizaje de Similitudes
Aprendizaje de metrica y kernel usando una transformacion lineal
Vista General de la presentacion
Planteamiento del problema
Aprendizaje de metricas desde informacion perceptual
Aprendizaje de metrica y kernel usando una transformacion lineal
OASIS
Aprendizaje de metricas discriminativas con modelos generativos yaprendizaje de kernels
Resumen
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 17 / 31
Aprendizaje de Similitudes
Aprendizaje de metrica y kernel usando una transformacion lineal
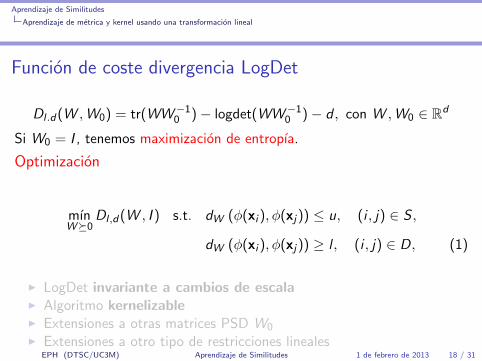
Funcion de coste divergencia LogDet
Dl .d(W ,W0) = tr(WW−10 )− logdet(WW−1
0 )− d , con W ,W0 ∈ Rd
Si W0 = I , tenemos maximizacion de entropıa.
Optimizacion
mınW�0
Dl ,d(W , I ) s.t. dW (φ(xi ), φ(xj)) ≤ u, (i , j) ∈ S ,
dW (φ(xi ), φ(xj)) ≥ l , (i , j) ∈ D, (1)
I LogDet invariante a cambios de escalaI Algoritmo kernelizableI Extensiones a otras matrices PSD W0
I Extensiones a otro tipo de restricciones linealesEPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 18 / 31

Aprendizaje de Similitudes
Aprendizaje de metrica y kernel usando una transformacion lineal
Funcion de coste divergencia LogDet
Dl .d(W ,W0) = tr(WW−10 )− logdet(WW−1
0 )− d , con W ,W0 ∈ Rd
Si W0 = I , tenemos maximizacion de entropıa.
Optimizacion
mınW�0
Dl ,d(W , I ) s.t. dW (φ(xi ), φ(xj)) ≤ u, (i , j) ∈ S ,
dW (φ(xi ), φ(xj)) ≥ l , (i , j) ∈ D, (1)
I LogDet invariante a cambios de escalaI Algoritmo kernelizableI Extensiones a otras matrices PSD W0
I Extensiones a otro tipo de restricciones linealesEPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 18 / 31
Aprendizaje de Similitudes
Aprendizaje de metrica y kernel usando una transformacion lineal
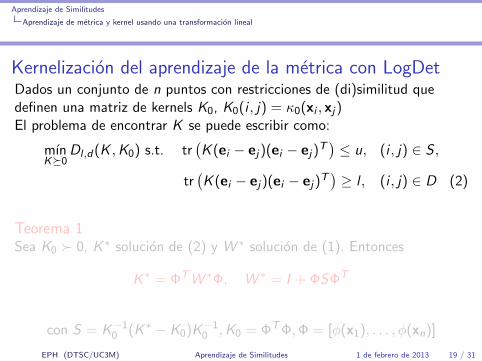
Kernelizacion del aprendizaje de la metrica con LogDetDados un conjunto de n puntos con restricciones de (di)similitud quedefinen una matriz de kernels K0, K0(i , j) = κ0(xi , xj)El problema de encontrar K se puede escribir como:
mınK�0
Dl ,d(K ,K0) s.t. tr(K (ei − ej)(ei − ej)
T)≤ u, (i , j) ∈ S ,
tr(K (ei − ej)(ei − ej)
T)≥ l , (i , j) ∈ D (2)
Teorema 1Sea K0 � 0, K ∗ solucion de (2) y W ∗ solucion de (1). Entonces
K ∗ = ΦTW ∗Φ, W ∗ = I + ΦSΦT
con S = K−10 (K ∗ − K0)K−1
0 ,K0 = ΦTΦ,Φ = [φ(x1), . . . , φ(xn)]
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 19 / 31
Aprendizaje de Similitudes
Aprendizaje de metrica y kernel usando una transformacion lineal
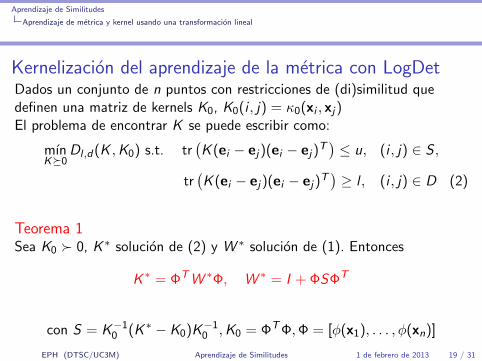
Kernelizacion del aprendizaje de la metrica con LogDetDados un conjunto de n puntos con restricciones de (di)similitud quedefinen una matriz de kernels K0, K0(i , j) = κ0(xi , xj)El problema de encontrar K se puede escribir como:
mınK�0
Dl ,d(K ,K0) s.t. tr(K (ei − ej)(ei − ej)
T)≤ u, (i , j) ∈ S ,
tr(K (ei − ej)(ei − ej)
T)≥ l , (i , j) ∈ D (2)
Teorema 1Sea K0 � 0, K ∗ solucion de (2) y W ∗ solucion de (1). Entonces
K ∗ = ΦTW ∗Φ, W ∗ = I + ΦSΦT
con S = K−10 (K ∗ − K0)K−1
0 ,K0 = ΦTΦ,Φ = [φ(x1), . . . , φ(xn)]
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 19 / 31

Aprendizaje de Similitudes
Aprendizaje de metrica y kernel usando una transformacion lineal
Generalizacion a puntos nuevos
Supongase que K es la solucion al problema (2).
Distancia entre puntos del conjunto de entrenamiento
d(φ(xi ), φ(xj)) = K (i , i) + K (j , j)− 2K (i , j)
Distancia entre puntos del conjunto de test
d(φ(z1), φ(z2)) = φ(z1)TWφ(z2) = φ(z1)T (I + ΦSΦTφ(z2)
= κ0(z1, z2) + kT1 Sk2, conki = [κ0(x1, zi ), . . . , κ0(xn, zi )]T
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 20 / 31

Aprendizaje de Similitudes
Aprendizaje de metrica y kernel usando una transformacion lineal
Generalizacion a puntos nuevos
Supongase que K es la solucion al problema (2).
Distancia entre puntos del conjunto de entrenamiento
d(φ(xi ), φ(xj)) = K (i , i) + K (j , j)− 2K (i , j)
Distancia entre puntos del conjunto de test
d(φ(z1), φ(z2)) = φ(z1)TWφ(z2) = φ(z1)T (I + ΦSΦTφ(z2)
= κ0(z1, z2) + kT1 Sk2, conki = [κ0(x1, zi ), . . . , κ0(xn, zi )]T
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 20 / 31

Aprendizaje de Similitudes
Aprendizaje de metrica y kernel usando una transformacion lineal
Extension para conjuntos grandes de datosHemos presentado dos alternativas equivalentes:
I Aprender W , complejidad O(d2)I Aprender K , complejidad O(n2)
Se puede considerar queW = I + ULUT
con L = F − I de tamano k × k definida positiva y U conocida de tamanod × k (k << mın(d , n)).
Se resuelve para F un problema de tamano O(k2)
Elecciones para UI k primeros vectores singulares de ΦI Centroides de un clustering de las columnas de ΦI Centroides de un clustering de las medias de cada clase
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 21 / 31

Aprendizaje de Similitudes
Aprendizaje de metrica y kernel usando una transformacion lineal
Extension para conjuntos grandes de datosHemos presentado dos alternativas equivalentes:
I Aprender W , complejidad O(d2)I Aprender K , complejidad O(n2)
Se puede considerar queW = I + ULUT
con L = F − I de tamano k × k definida positiva y U conocida de tamanod × k (k << mın(d , n)).
Se resuelve para F un problema de tamano O(k2)
Elecciones para UI k primeros vectores singulares de ΦI Centroides de un clustering de las columnas de ΦI Centroides de un clustering de las medias de cada clase
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 21 / 31

Aprendizaje de Similitudes
Aprendizaje de metrica y kernel usando una transformacion lineal
Extension para conjuntos grandes de datosHemos presentado dos alternativas equivalentes:
I Aprender W , complejidad O(d2)I Aprender K , complejidad O(n2)
Se puede considerar queW = I + ULUT
con L = F − I de tamano k × k definida positiva y U conocida de tamanod × k (k << mın(d , n)).
Se resuelve para F un problema de tamano O(k2)
Elecciones para UI k primeros vectores singulares de ΦI Centroides de un clustering de las columnas de ΦI Centroides de un clustering de las medias de cada clase
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 21 / 31

Aprendizaje de Similitudes
Aprendizaje de metrica y kernel usando una transformacion lineal
Extension para conjuntos grandes de datosHemos presentado dos alternativas equivalentes:
I Aprender W , complejidad O(d2)I Aprender K , complejidad O(n2)
Se puede considerar queW = I + ULUT
con L = F − I de tamano k × k definida positiva y U conocida de tamanod × k (k << mın(d , n)).
Se resuelve para F un problema de tamano O(k2)
Elecciones para UI k primeros vectores singulares de ΦI Centroides de un clustering de las columnas de ΦI Centroides de un clustering de las medias de cada clase
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 21 / 31

Aprendizaje de Similitudes
OASIS
Vista General de la presentacion
Planteamiento del problema
Aprendizaje de metricas desde informacion perceptual
Aprendizaje de metrica y kernel usando una transformacion lineal
OASIS
Aprendizaje de metricas discriminativas con modelos generativos yaprendizaje de kernels
Resumen
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 22 / 31
Aprendizaje de Similitudes
OASIS
Motivacion
I Problemas de escalabilidad: recursos computacionales y de memoriacrecen cuadraticamente con el numero de datos
I Etiquetados basados en humanos pueden no ser apropiados enescenarios big data
I La similitud se puede inferir a traves de parejas de resultados que sondevueltas ante la misma query
I Inferir similitud de las etiquetas de clases
OASIS aprende similitud (no garantiza semidefinida positiva)independiente de las etiquetas de las clases
Esta basado en los algoritmos Passive-Aggressive para aprendizaje en lınea.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 23 / 31

Aprendizaje de Similitudes
OASIS
Motivacion
I Problemas de escalabilidad: recursos computacionales y de memoriacrecen cuadraticamente con el numero de datos
I Etiquetados basados en humanos pueden no ser apropiados enescenarios big data
I La similitud se puede inferir a traves de parejas de resultados que sondevueltas ante la misma query
I Inferir similitud de las etiquetas de clases
OASIS aprende similitud (no garantiza semidefinida positiva)independiente de las etiquetas de las clases
Esta basado en los algoritmos Passive-Aggressive para aprendizaje en lınea.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 23 / 31

Aprendizaje de Similitudes
OASIS
Motivacion
I Problemas de escalabilidad: recursos computacionales y de memoriacrecen cuadraticamente con el numero de datos
I Etiquetados basados en humanos pueden no ser apropiados enescenarios big data
I La similitud se puede inferir a traves de parejas de resultados que sondevueltas ante la misma query
I Inferir similitud de las etiquetas de clases
OASIS aprende similitud (no garantiza semidefinida positiva)independiente de las etiquetas de las clases
Esta basado en los algoritmos Passive-Aggressive para aprendizaje en lınea.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 23 / 31

Aprendizaje de Similitudes
OASIS
Motivacion
I Problemas de escalabilidad: recursos computacionales y de memoriacrecen cuadraticamente con el numero de datos
I Etiquetados basados en humanos pueden no ser apropiados enescenarios big data
I La similitud se puede inferir a traves de parejas de resultados que sondevueltas ante la misma query
I Inferir similitud de las etiquetas de clases
OASIS aprende similitud (no garantiza semidefinida positiva)independiente de las etiquetas de las clases
Esta basado en los algoritmos Passive-Aggressive para aprendizaje en lınea.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 23 / 31

Aprendizaje de Similitudes
OASIS
Motivacion
I Problemas de escalabilidad: recursos computacionales y de memoriacrecen cuadraticamente con el numero de datos
I Etiquetados basados en humanos pueden no ser apropiados enescenarios big data
I La similitud se puede inferir a traves de parejas de resultados que sondevueltas ante la misma query
I Inferir similitud de las etiquetas de clases
OASIS aprende similitud (no garantiza semidefinida positiva)independiente de las etiquetas de las clases
Esta basado en los algoritmos Passive-Aggressive para aprendizaje en lınea.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 23 / 31

Aprendizaje de Similitudes
OASIS
Algoritmo OASISSimilitud: SW (xi , xj) = xTi W xjRestricciones: dada una tripleta de datos xi , xj , xk tales quer(xi , xj) > r(xi , xk), se establece la restriccion
SW (xi , xj) > SW (xi , xk) + 1
Funcion de perdidas tipo hinge
lW (xi , xj , xk) = max{0, 1− SW (xi , xj) + SW (xi , xk)}
OASIS
W i = arg mınW
1
2‖W −W i−1‖2
F + Cξ
sujeto a lW (xi , xj , xk) ≤ ξ y ξ ≥ 0
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 24 / 31

Aprendizaje de Similitudes
OASIS
Algoritmo OASISSimilitud: SW (xi , xj) = xTi W xjRestricciones: dada una tripleta de datos xi , xj , xk tales quer(xi , xj) > r(xi , xk), se establece la restriccion
SW (xi , xj) > SW (xi , xk) + 1
Funcion de perdidas tipo hinge
lW (xi , xj , xk) = max{0, 1− SW (xi , xj) + SW (xi , xk)}
OASIS
W i = arg mınW
1
2‖W −W i−1‖2
F + Cξ
sujeto a lW (xi , xj , xk) ≤ ξ y ξ ≥ 0
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 24 / 31

Aprendizaje de Similitudes
OASIS
Algoritmo OASISSimilitud: SW (xi , xj) = xTi W xjRestricciones: dada una tripleta de datos xi , xj , xk tales quer(xi , xj) > r(xi , xk), se establece la restriccion
SW (xi , xj) > SW (xi , xk) + 1
Funcion de perdidas tipo hinge
lW (xi , xj , xk) = max{0, 1− SW (xi , xj) + SW (xi , xk)}
OASIS
W i = arg mınW
1
2‖W −W i−1‖2
F + Cξ
sujeto a lW (xi , xj , xk) ≤ ξ y ξ ≥ 0
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 24 / 31

Aprendizaje de Similitudes
OASIS
Algoritmo OASISSimilitud: SW (xi , xj) = xTi W xjRestricciones: dada una tripleta de datos xi , xj , xk tales quer(xi , xj) > r(xi , xk), se establece la restriccion
SW (xi , xj) > SW (xi , xk) + 1
Funcion de perdidas tipo hinge
lW (xi , xj , xk) = max{0, 1− SW (xi , xj) + SW (xi , xk)}
OASIS
W i = arg mınW
1
2‖W −W i−1‖2
F + Cξ
sujeto a lW (xi , xj , xk) ≤ ξ y ξ ≥ 0
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 24 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas discriminativas con modelos generativos y aprendizaje de kernels
Vista General de la presentacion
Planteamiento del problema
Aprendizaje de metricas desde informacion perceptual
Aprendizaje de metrica y kernel usando una transformacion lineal
OASIS
Aprendizaje de metricas discriminativas con modelos generativos yaprendizaje de kernels
Resumen
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 25 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas discriminativas con modelos generativos y aprendizaje de kernels
Aprendizaje de una metrica local discriminativa
Para cada punto de entrenamiento xi se obtienen dos conjuntos de datos:objetivos x+
i , cuya etiqueta coincide con la de xi e impostores x−i , cuyaetiqueta no coincide
Metrica local basada en NN
mınM,ξ≥0
∑i
∑j∈x+
i
d2M(xi , xj) + γ
∑ijl
ξijl
sujeto a 1 + d2M(xi , xj)− d2
M(xi , xl) ≤ ξijl , ∀j ∈ x+i , l ∈ x−i
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 26 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas discriminativas con modelos generativos y aprendizaje de kernels
Metrica Generativa
Cuando el numero de datos es finito, el error del 1-NN se desvıa del errorasimptotico un termino de sesgo que es independiente de la metrica.Si se asume una metrica basada en transformacion lineal, el termino desesgo se optimiza con
mın(tr(M−1i Φi )
2 sujeto a |Mi | = 1,MiPSD
El optimo es una matriz PSD cuyos autovectores sean los mismos que losde Φi
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 27 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas discriminativas con modelos generativos y aprendizaje de kernels
Aprendizaje discriminativo con multiples metricasgenerativasMetrica generativa local funciona pero hace falta una Mi por cada punto.
Resultados dependen de la pdf usada para el modelado generativo.
Mejora combinando metricas locales Ki (xm, xn) = xTmMixn
Cada Mi se aprende en la vecindad de xi y es una estimacion sesgada deun kernel global.
Promediar los kernels locales resulta en un estimador insesgado
κ(xm, xn) =∑i
αiκi (xm, xn) = xTm
(∑i
αiMi
)xn = xTmMxn
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 28 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas discriminativas con modelos generativos y aprendizaje de kernels
Aprendizaje discriminativo con multiples metricasgenerativasMetrica generativa local funciona pero hace falta una Mi por cada punto.
Resultados dependen de la pdf usada para el modelado generativo.
Mejora combinando metricas locales Ki (xm, xn) = xTmMixn
Cada Mi se aprende en la vecindad de xi y es una estimacion sesgada deun kernel global.
Promediar los kernels locales resulta en un estimador insesgado
κ(xm, xn) =∑i
αiκi (xm, xn) = xTm
(∑i
αiMi
)xn = xTmMxn
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 28 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas discriminativas con modelos generativos y aprendizaje de kernels
Aprendizaje discriminativo con multiples metricasgenerativasMetrica generativa local funciona pero hace falta una Mi por cada punto.
Resultados dependen de la pdf usada para el modelado generativo.
Mejora combinando metricas locales Ki (xm, xn) = xTmMixn
Cada Mi se aprende en la vecindad de xi y es una estimacion sesgada deun kernel global.
Promediar los kernels locales resulta en un estimador insesgado
κ(xm, xn) =∑i
αiκi (xm, xn) = xTm
(∑i
αiMi
)xn = xTmMxn
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 28 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas discriminativas con modelos generativos y aprendizaje de kernels
Aprendizaje discriminativo con multiples metricasgenerativasMetrica generativa local funciona pero hace falta una Mi por cada punto.
Resultados dependen de la pdf usada para el modelado generativo.
Mejora combinando metricas locales Ki (xm, xn) = xTmMixn
Cada Mi se aprende en la vecindad de xi y es una estimacion sesgada deun kernel global.
Promediar los kernels locales resulta en un estimador insesgado
κ(xm, xn) =∑i
αiκi (xm, xn) = xTm
(∑i
αiMi
)xn = xTmMxn
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 28 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas discriminativas con modelos generativos y aprendizaje de kernels
Aprendizaje discriminativo con multiples metricasgenerativasMetrica generativa local funciona pero hace falta una Mi por cada punto.
Resultados dependen de la pdf usada para el modelado generativo.
Mejora combinando metricas locales Ki (xm, xn) = xTmMixn
Cada Mi se aprende en la vecindad de xi y es una estimacion sesgada deun kernel global.
Promediar los kernels locales resulta en un estimador insesgado
κ(xm, xn) =∑i
αiκi (xm, xn) = xTm
(∑i
αiMi
)xn = xTmMxn
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 28 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas discriminativas con modelos generativos y aprendizaje de kernels
Consideraciones
I Caso sencillo αi = 1, entonces MUNI = 1N
∑i Mi
I Extension no lineal. Kernel local
Kil(xm, xn) = exp{−(xm − xn)TMi (xm − xn)/σ2l }
I Kernel como combinacion convexa de kernels locales
K (xm, xn) =∑i ,l
αilKil(xm, xn)
y los αil cumplen las restricciones de ser convexos.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 29 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas discriminativas con modelos generativos y aprendizaje de kernels
Consideraciones
I Caso sencillo αi = 1, entonces MUNI = 1N
∑i Mi
I Extension no lineal. Kernel local
Kil(xm, xn) = exp{−(xm − xn)TMi (xm − xn)/σ2l }
I Kernel como combinacion convexa de kernels locales
K (xm, xn) =∑i ,l
αilKil(xm, xn)
y los αil cumplen las restricciones de ser convexos.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 29 / 31

Aprendizaje de Similitudes
Aprendizaje de metricas discriminativas con modelos generativos y aprendizaje de kernels
Consideraciones
I Caso sencillo αi = 1, entonces MUNI = 1N
∑i Mi
I Extension no lineal. Kernel local
Kil(xm, xn) = exp{−(xm − xn)TMi (xm − xn)/σ2l }
I Kernel como combinacion convexa de kernels locales
K (xm, xn) =∑i ,l
αilKil(xm, xn)
y los αil cumplen las restricciones de ser convexos.
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 29 / 31

Aprendizaje de Similitudes
Resumen
Vista General de la presentacion
Planteamiento del problema
Aprendizaje de metricas desde informacion perceptual
Aprendizaje de metrica y kernel usando una transformacion lineal
OASIS
Aprendizaje de metricas discriminativas con modelos generativos yaprendizaje de kernels
Resumen
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 30 / 31

Aprendizaje de Similitudes
Resumen
Resumen
I Breve exposicion de cuatro artıculos sobre aprendizaje de metricas
I Incorporar restricciones sobre parejas, trıos o cuadruplas de elementosque contienen informacion de dominio del problema
I Poda de grafo para limpiar la supervision basada en etiquetadoshechos por humanos
I Aprendizaje de metrica es equivalente a un aprendizaje de kernel, loque permite extension a conjuntos de test
I Aprendizaje de similitud OASIS
I Aprendizaje de metricas globales a partir de metricas locales
EPH (DTSC/UC3M) Aprendizaje de Similitudes 1 de febrero de 2013 31 / 31





























