Embed Size (px)
Citation preview

Brașov, 2011
Universitatea Transilvania din Braşov
Facultatea de Inginerie Electrică și Stiința Calculatoarelor
Aplicat ii ale inteligent ei computat ionale in Data Mining
Applications of Computational Intelligence in Data Mining
de
Ioan Bogdan CRIVA T
Rezumat al tezei de doctorat
Conduca tor s tiint ific: prof. univ. dr. Ra zvan Andonie

Brașov, 2011
MINISTERUL EDUCAŢIEI, CERCETARII, TINERETULUI ŞI SPORTULUI
UNIVERSITATEA “TRANSILVANIA” DIN BRAŞOV BRAŞOV, B-DUL EROILOR NR. 29, 500036, TEL. 0040-268-413000, FAX 0040-268-
410525 RECTORAT
___________________________________________________________________
ANUNŢ
Vă aducem la cunoştinţă că în ziua de sâmbătă, 03.09.2011, ora 11,00, în sala N.II.1, corp
N, la FACULTATEA DE INGINERIE ELECTRICĂ ŞI ŞTIINŢA CALCULATOARELOR, va avea loc
susţinerea publică a tezei de doctorat intitulată: APLICAŢII ALE INTELIGENŢEI
COMPUTAŢIONALE ÎN DATA MINING, elaborată de domnul CRIVĂŢ I. Ioan Bogdan în
vederea obţinerii titlului ştiinţific de DOCTOR, în domeniul domeniul CALCULATOARE ŞI
TEHNOLOGIA INFORMAŢIEI.
COMISIA DE DOCTORAT
PREŞEDINTE: - Prof. univ. dr. ing. Sorin Aurel MORARU
DECAN - Fac. de Inginerie Electrică şi Ştiinţa Calculatoarelor Universitatea “Transilvania” din Braşov
CONDUCĂTOR ŞTIINŢIFIC: - Prof. univ. dr. Răzvan ANDONIE Universitatea “Transilvania” din Braşov
REFERENŢI: - Prof. univ. dr. ing. Lucian VINŢAN Universitatea „Lucian Blaga” din Sibiu
- Prof. univ. dr. ing. Costin BĂDICĂ Universitatea din Craiova
- Prof. univ. dr. Ioan DZIŢAC Universitatea “Aurel Vlaicu” din Arad
Vă rugăm să luaţi parte la şedinţa publică de susţinere a tezei de doctorat
RECTOR, SECRETAR DEP. DOCTORAT, Prof. univ. dr. ing. Ion VIŞA Maria NICOLAE

Brașov, 2011
Cuprins Cuprins ............................................................................................................ iii Table of Contents ............................................................................................. v
Diagrame și desene ......................................................................................... 1
1 Introducere ............................................................................................... 2
1.1 Contribuții ..................................................................................... 2
1.2 Structura tezei ............................................................................... 3
2 Utilizarea regulilor in data mining ............................................................ 4
2.1 Reguli în data mining .................................................................... 4
2.1.1 Reguli de asociere ....................................................................................... 5
2.1.2 Problema coșului de cumpărături ............................................................... 7
2.1.3 Grupuri de elemente și reguli în reprezentare densă ................................ 8
2.1.4 Despre echivalența reprezentărilor densă și rară ...................................... 9
2.2 Reguli Fuzzy ................................................................................. 10
2.2.1 Concepte de modelare fuzzy .................................................................... 10
2.2.2 Modelarea fuzzy ........................................................................................ 10
3 Metode de extracție a regulilor .............................................................. 12
3.1 Extracția regulilor de asociere .................................................... 12
3.1.1 Algoritmul Apriori...................................................................................... 12
3.1.2 Algoritmul FP-Growth ............................................................................... 15
3.1.3 Probleme ridicate de algoritmii de extracție ce folosesc o limită de suport minim ......................................................................................................... 15
3.2 Reguli ca exprimare a șabloanelor detectate de alți algoritmi ... 16
3.2.1 Reguli din arbori de decizie ...................................................................... 16
3.2.2 Reguli din rețele neuronale ...................................................................... 17
4 Contribuții la generalizarea sistemelor de reguli .................................... 19
4.1 Generalizarea sistemelor de reguli de tip fuzzy.......................... 19
4.1.1 Redundanța mulțimilor fuzzy .................................................................... 19
4.1.2 Similaritatea mulțimilor fuzzy ................................................................... 20
4.2 Tehnici de simplificare a modelelor de reguli fuzzy ................... 20
4.3 Generalizarea Regulilor ............................................................... 21
4.3.1 Problemă și context .................................................................................. 21
4.3.2 Algoritmul de generalizare a regulilor (RGA) ............................................ 21
4.3.3 Aplicarea RGA la un set de reguli extrase de algoritmi de tip apriori ...... 24
4.3.4 Direcții de dezvoltare a algoritmului RGA ................................................ 26
4.3.5 Direcții de dezvoltare a varietății apriori a algoritmului RGA ................... 29
5 Măsurarea acurateții predicțiilor de utilizare produse de sisteme de recomandare ................................................................................................. 30
5.1 Evaluarea sistemelor de recomandare ....................................... 30

Brașov, 2011
5.2 Intrumente pentru evaluarea deconectată a acurateții predicțiilor de utilizare ................................................................................................... 30
5.2.1 Măsurători de acuratețe pentru un singur utilizator ............................... 31
5.3 Curba de acuratețe detaliată ...................................................... 32
5.3.1 O interpretare vizuală a curbei detaliate de acuratețe ............................ 36
5.3.2 Impactul parametrului N asupra măsurilor de Lift și Area Under Curve 37
5.4 Note de implementare a curbei detaliate de acuratețe ............. 38
5.4.1 Măsuri de acuratețe .................................................................................. 38
5.4.2 Algoritmul de construire a curbei detaliate de acuratețe ........................ 38
5.5 Concluzii și direcții de cercetare ulterioare ................................ 40
6 Concluzii și direcții de cercetare ............................................................. 41
6.1 Direcții de cercetare .................................................................... 41
Bibliografia tezei ........................................................................................... 43
Publicații, brevete și cereri de brevet de autor ............................................ 53
Cărţi ......................................................................................................... 53
Articole .................................................................................................... 53
Brevete Emise (USPTO) ........................................................................... 53
Cereri de brevet în aşteptare (USPTO) ................................................... 54

Brașov, 2011
Table of Contents Cuprins ............................................................................................................ iii Table of Contents ............................................................................................. v
List of figures ................................................................................................... 1
1 Introduction .............................................................................................. 2
1.1 Contributions ................................................................................ 2
1.2 The Structure of the Thesis ........................................................... 3
2 Rules in the Data Mining Context ............................................................. 4
2.1 Rules in Data Mining ..................................................................... 4
2.1.1 Association Rules ........................................................................................ 5
2.1.2 The Market Basket Analysis Problem ......................................................... 7
2.1.3 Itemsets and Rules in dense representation .............................................. 8
2.1.4 Equivalence of dense and sparse representations ..................................... 9
2.2 Fuzzy Rules .................................................................................. 10
2.2.1 Conceptualizing in Fuzzy Terms ................................................................ 10
2.2.2 Fuzzy Modeling ......................................................................................... 10
3 Methods for Rules Extraction ................................................................. 12
3.1 Extraction of Association Rules ................................................... 12
3.1.1 The Apriori Algorithm ............................................................................... 12
3.1.2 The FP-Growth Algorithm ......................................................................... 15
3.1.3 Problems raised by Minimum Support itemset extraction systems ........ 15
3.2 Rules as expression of patterns detected by other algorithms .. 16
3.2.1 Rules based on Decision Trees .................................................................. 16
3.2.2 Rules from Neural Networks ..................................................................... 17
4 Contributions to Rule Generalization ..................................................... 19
4.1 Fuzzy Rules Generalization ......................................................... 19
4.1.1 Redundancy .............................................................................................. 19
4.1.2 Similarity ................................................................................................... 20
4.2 Rule Model Simplification Techniques ....................................... 20
4.3 Rule Generalization ..................................................................... 21
4.3.1 Problem and Context ................................................................................ 21
4.3.2 The Rule Generalization Algorithm (RGA) ................................................ 21
4.3.3 Applying the RGA to an apriori-derived set of rules ................................. 24
4.3.4 Development directions for basic RGA ..................................................... 26
4.3.5 Development directions for the apriori specialization of RGA ................. 29
5 Measuring the Usage Prediction Accuracy of Recommendation Systems30
5.1 Evaluating Recommendation Systems ........................................ 30
5.2 Instruments for offline measuring the accuracy of Usage Predictions 30
5.2.1 Accuracy measurements for a single user ................................................ 31

Brașov, 2011
5.3 The Itemized Accuracy Curve ...................................................... 32
5.3.1 A visual interpretation of the itemized accuracy curve ............................ 36
5.3.2 Impact of the N parameter on the Lift and Area Under Curve measures ............................................................................................................... 37
5.4 Implementation Notes for the Itemized Accuracy Curve ........... 38
5.4.1 Accuracy Measures ................................................................................... 38
5.4.2 The algorithm for constructing the Itemized Accuracy Curve .................. 38
5.5 Directions for further research ................................................... 40
6 Conclusions and directions for further research .................................... 41
6.1 Directions for further research ................................................... 41
Bibliography for the Thesis ........................................................................... 43
Publications, Patents and Pending Patent Applications ............................... 53
Books ....................................................................................................... 53
Articles .................................................................................................... 53
Patents (USPTO) ...................................................................................... 53
Pending Patent Applications (USPTO) .................................................... 54

Diagrame și desene Figura 4-1 O reprezentare vizuală a RGA .......................................................................... 23
Figura 4-2 O abordare mai fină a RGA .............................................................................. 27
Figura 4-3 Nivelul de încredere al unei reguli fuzzy ca măsură a similarității cu setul universal ................................................................................................................ 29
Figura 5-1 Curba de acuratețe detaliată pentru un sistem top-N recommender și pentru un sistem de referință teoretic ideal ........................................................ 36
Figura 5-2 Evoluția măsurilor de Lift și Area Under Curve pentru valori diferite ale numărului de recomandări N ................................................................................ 37
Figura 5-3 Curba detaliată de acuratețe, agregată peste atributul Categorie al filmelor din setul de date Movie Recommendations (pentru N=5 ) .................... 40

2
1 Introducere
In mare parte datorită dezvoltărilor computaţionale majore din ultimele decenii, un volum mare de cercetare a dus la dezvoltarea multor clase de algoritmi de extracție de șabloane și regularități din date. Acești algoritmi oferă adesea o foarte bună performanță predictivă, dar șabloanele si regularitățile detectate sunt deseori dificil de interpretat. O consecință directă a acestei dificultăți de interpretare este rezistența întâmpinată de data mining la acceptarea în setul uzual de instrumente al analiștilor din diverse domenii.
Autorul a petrecut cea mai mare parte a ultimului deceniu implicat in design-ul si implementarea platformei Microsoft SQL Server Data Mining, un produs conceput cu scopul de a face mai accesibilă tehnologia data mining. Lucrarea este puternic influențată de această perspectivă industrială.
Obiectivul acestei lucrări este realizarea unei sinteze a eforturilor recente în domeniul extracției si prelucrării de reguli predictive, precum şi prezentarea unor contribuții originale în domeniu.
1.1 Contribuții Sistemele de reguli sunt colecţii de șabloane ușor de înțeles care adesea pot fi traduse în limbaj comun. Începând aproximativ în jurul anului 1990, comunitatea de cercetare a produs diferiți algoritmi pentru extracția de reguli din date, precum şi multe tehnici pentru conversia la reguli a șabloanelor detectate de alți algoritmi.
În capitolul 4 investigăm unele dintre rezultate in domeniul simplificarii si generalizării regulilor. Contribuțiile noastre originale includ:
- O metodă nouă de prelucrare a unui set de reguli cu scopul de a imbunătăți capacitatea acestuia de generalizare. Metoda este dezvoltată special pentru reguli extrase dintr-un sistem Fuzzy ARTMAP de invățare incrementală, sistem folosit uzual pentru probleme de clasificare. Această metodă a fost introdusă în (1), o lucrare premiată la conferința internațională IJCNN 2009 organizată de IEEE.

3
O dezvoltare a metodei menționate anterior pentru seturi de reguli extrase cu algoritmi concepuți special pentru extracția de reguli, cum ar fi apriori. Rezultatele experimentale sugerează reduceri de 5 până la 10 ori a numărului de reguli dintr-un set prin aplicarea acestei metode de generalizare.
Capitolul 5 discută problema evaluării sistemelor de recomandare. Contribuțiile originale includ:
Curba de acuratețe detaliată, un instrument nou de evaluare a calităţii sistemelor de recomandare. Instrumentul a fost introdus, ca brevet, în (1).
1.2 Structura tezei
Capitolul al doilea, „Utilizarea regulilor în data mining”, prezintă tehnologia data mining cu accent pe extracţia de reguli. Vom discuta despre regulile de asociere şi proprietăţile lor, precum şi despre unele noţiuni de modelare fuzzy şi reguli de tip fuzzy.
Capitolul al treilea, „Metode de extracție a regulilor”, prezintă cele mai frecvent
utilizate metode pentru extracția de reguli. Vom începe cu prezentarea unor
algoritmi special concepuți pentru extracția de reguli, cum ar fi apriori şi FP-
Growth. Vom discuta unele dintre problemele ridicate de acești algoritmi, precum
şi soluţii pentru aceste probleme. Prezentăm apoi câteva tehnici pentru extracția
de reguli din șabloane detectate de alți algoritmi, in special din rețelele neuronale,
un subiect de interes în capitolul următor.
Capitolul al patrulea, „Contribuții la generalizarea sistemelor de reguli”, descrie
eforturi recente pentru simplificarea sistemelor de reguli, cu accent pe analiza
similarității dintre reguli. Este propusă o metodă nouă de simplificare a sistemelor
de reguli, metodă dezvoltată inițial pentru reguli detectate de un predictor Fuzzy

4
ARTMAP. Metoda este apoi extinsă pentru sisteme de reguli extrase de clase mai
largi de algoritmi cum ar fi apriori.
Sistemele de recomandare constituie una dintre cele mai frecvente aplicații pentru
extracția de reguli. Capitolul al cincilea, „Măsurarea acurateții predicțiilor de
utilizare produse de sisteme de recomandare”, analizează metricile existente de
evaluare a acestor sisteme de recomandare și introduce un instrument intutiv de
evaluare și comparare a performanței lor.
Capitolul al șaselea al tezei (exclus din acest rezumat) conține rezultate experimentale atât pentru metodele de generalizare de reguli cât și pentru instrumentul de evaluare a sistemelor de recomandare.
Ultimul capitol prezintă concluziile tezei cât și direcții promițătoare de cercetare deschise de rezultatele prezentate in teză.
2 Utilizarea regulilor in data mining
În această lucrare, expresia data mining este folosită pentru a descrie procesul de analiză automată a datelor cu scopul de a detecta șabloane și regularități ascunse. Acest proces (sau părți ale sale) poate fi referit, în unele din lucrările citate și in literatura de specialitate, cu alți termeni cum ar fi învățare automata (machine learning) sau analiză predictivă (predictive analytics) – în special atunci când șabloanele detectate sunt utilizate în scopuri predictive. Acest capitol descrie modelarea pe bază de reguli în cadrul procesului data mining.
2.1 Reguli în data mining
Regulile consituie o manieră naturală de a descrie șabloane extrase din date. O regulă este o relație de implicație între două propoziții logice. Una dintre propoziții se numește antecedent, premiză sau precondiție iar cealaltă se numește consecință sau concluzie. Antecedentul este de obicei introdus prin conjuncția “dacă” (IF) iar

5
consecința este introdusă prin adverbul cu rol de conjuncție “atunci” (THEN). Datorită poziției antecedentului și a consecinței în topica uzuală, cele două componente ale unei reguli sunt referite în literatura de specialitate și ca “partea stângă” (left hand side ori LHS), respectiv “partea dreaptă” (right hand side ori RHS).
Atât antecedentul cât și consecința unei reguli sunt propoziții logice evaluate peste puncte dintr-un spațiu de date, de obicei multidimensional. Coordonatele acestor puncte pe diversele dimensiuni ale acestui spațiu constituie atribute ale acestor puncte. Spre exemplu, un tabel al unei baze de date relaționale este un astfel de spațiu iar fiecare coloană este un atribut.
Antecedentul este, de obicei, o conjuncție (în sens logic, de astă data) a mai multor predicate simple, fiecare astfel de predicat descriind unul dintre atributele spațiului de date. Consecința este un tot un astfel de predicat simplu.
Literatura de specialitate descrie și alte tipuri de reguli, spre exemplu reguli cu predicate complexe în antecedent (cum ar fi negații de predicate simple) sau reguli cu maimulte predicate simple în concluzie (combinate prin conjuncție, disjuncție sau alte operații logice). Astfel de reguli nu fac obiectul acestei lucrări.
Această secțiune oferă o definiție formală a regulilor și a unor proprietăți asociate cu regulile. Discutăm două moduri de representare a datelor (reprezentare densă și rară) și modurile asociate de definire a regulilor (asociative și predictive), apoi discutăm echivalența celor două prezentări.
2.1.1 Reguli de asociere
Regulile de asociere au fost introduse de Agrawal în (2) cu scopul de a analiza baze de date ample conținând tranzacții comerciale ale unor companii mari de vânzări.
Fir o mulțime de elemente (spre exemplu, catalogul produselor văndute). Fir D o mulțime de tranzacții comerciale cu aceste elemente. Fiecare
tranzacție T este o submulțime de elemente, T I. Tranzacțiile sunt, de obicei, descrise de un identificator de tranzacție, Transaction Id (TxId).
O regulă de asociere este o propoziție logică de forma A B, unde A B = iar A,
B I. A este antecedentul, iar B consecința regulii. Atât A cât și B sunt grupuri de elemente, submulțimi ale lui I (itemset).

6
Un grup de elemente conținând k elemente este numit k-itemset. Numărul tranzacțiilor ce conțin un grup A constituie suportul acelui grup și se notează supp(A). Suportul unui grup de elemente poate fi exprimat ca număr întreg (suport absolut) ori ca procent (de tranzacții, dintr-o bază de date, ce conțin acel grup). În restul lucrării, dacă nu menționăm explicit suportul absolut, notația supp este folosită pentru a exprima suportul ca procent.
Este important să observăm că ficărei reguli îi corespunde un grup de elemente dub I, grup ce conține elementele din .
Regulile sunt caracterizate de mai multe proprietăți, dintre care următoarele sunt folosite pe parcursul lucrării:
- Nivelul de încredere(Confidence):
(2.1)
Nivelul de încredere al unei reguli poate fi interpretat ca fiind o estimare a probabilității condiționale de a găsi elementele din consecința regulii în tranzacțiile ce conțin antecedentul ei, P(B|A)
- Lift:
(2.2)
Măsura de lift a unei reguli este raportul dintre suportul observat al regulii și cel de așteptat (în cazul în care A și B ar fi independente)
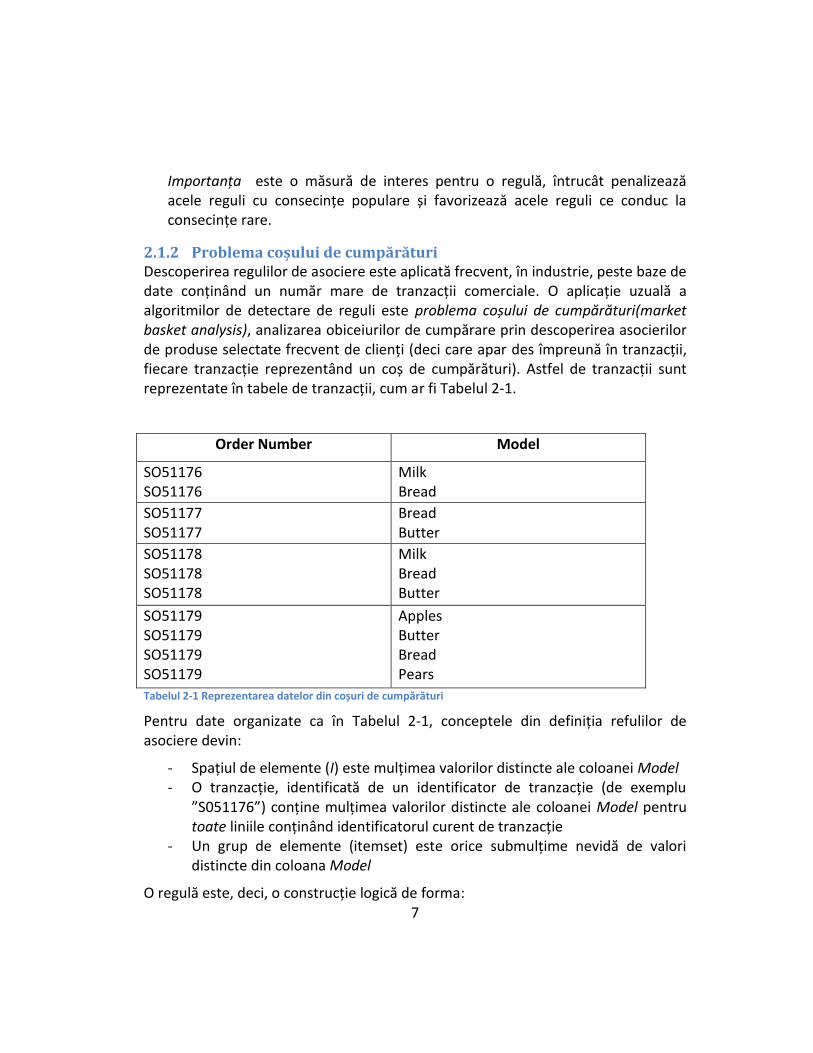
- Importanța , definită (3) ca:
(2.3)
7
Importanța este o măsură de interes pentru o regulă, întrucât penalizează acele reguli cu consecințe populare și favorizează acele reguli ce conduc la consecințe rare.
2.1.2 Problema coșului de cumpărături Descoperirea regulilor de asociere este aplicată frecvent, în industrie, peste baze de date conținând un număr mare de tranzacții comerciale. O aplicație uzuală a algoritmilor de detectare de reguli este problema coșului de cumpărături(market basket analysis), analizarea obiceiurilor de cumpărare prin descoperirea asocierilor de produse selectate frecvent de clienți (deci care apar des împreună în tranzacții, fiecare tranzacție reprezentând un coș de cumpărături). Astfel de tranzacții sunt reprezentate în tabele de tranzacții, cum ar fi Tabelul 2-1.
Order Number Model
SO51176 SO51176
Milk Bread
SO51177 SO51177
Bread Butter
SO51178 SO51178 SO51178
Milk Bread Butter
SO51179 SO51179 SO51179 SO51179
Apples Butter Bread Pears
Tabelul 2-1 Reprezentarea datelor din coșuri de cumpărături
Pentru date organizate ca în Tabelul 2-1, conceptele din definiția refulilor de asociere devin:
- Spațiul de elemente (I) este mulțimea valorilor distincte ale coloanei Model - O tranzacție, identificată de un identificator de tranzacție (de exemplu
”S051176”) conține mulțimea valorilor distincte ale coloanei Model pentru toate liniile conținând identificatorul curent de tranzacție
- Un grup de elemente (itemset) este orice submulțime nevidă de valori distincte din coloana Model
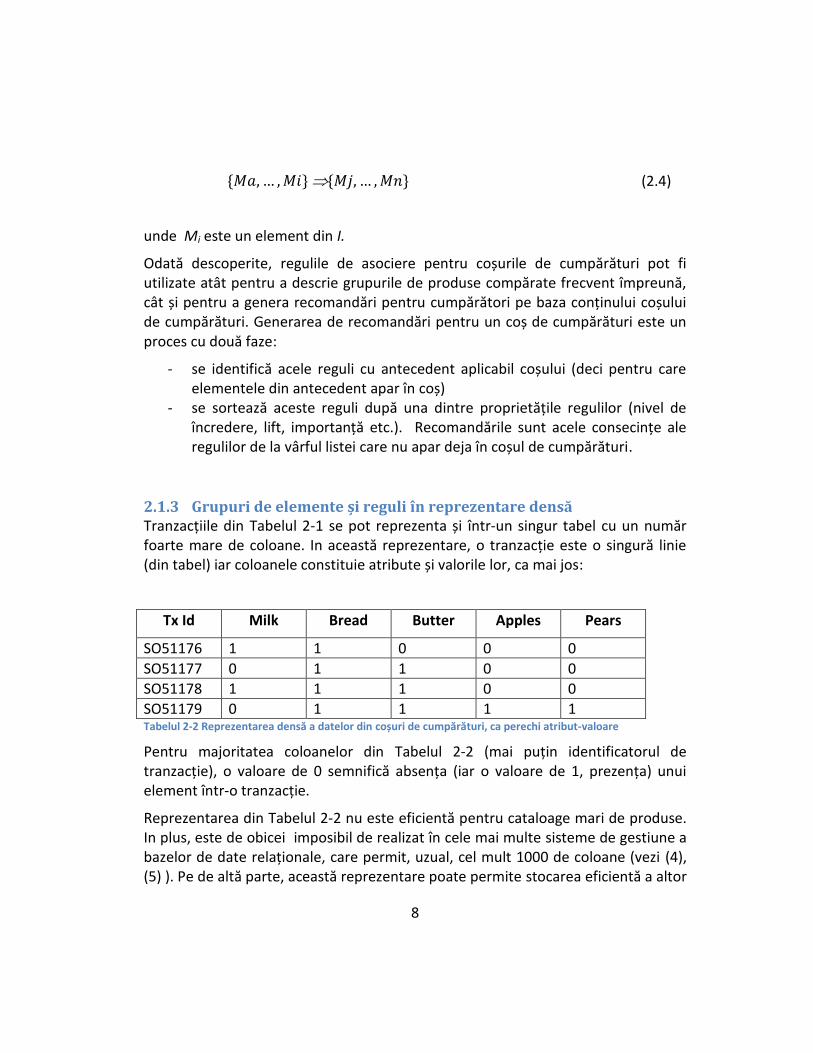
O regulă este, deci, o construcție logică de forma:
8
(2.4)
unde Mi este un element din I.
Odată descoperite, regulile de asociere pentru coșurile de cumpărături pot fi utilizate atât pentru a descrie grupurile de produse compărate frecvent împreună, cât și pentru a genera recomandări pentru cumpărători pe baza conținului coșului de cumpărături. Generarea de recomandări pentru un coș de cumpărături este un proces cu două faze:
- se identifică acele reguli cu antecedent aplicabil coșului (deci pentru care elementele din antecedent apar în coș)
- se sortează aceste reguli după una dintre proprietățile regulilor (nivel de încredere, lift, importanță etc.). Recomandările sunt acele consecințe ale regulilor de la vârful listei care nu apar deja în coșul de cumpărături.
2.1.3 Grupuri de elemente și reguli în reprezentare densă Tranzacțiile din Tabelul 2-1 se pot reprezenta și într-un singur tabel cu un număr foarte mare de coloane. In această reprezentare, o tranzacție este o singură linie (din tabel) iar coloanele constituie atribute și valorile lor, ca mai jos:
Tx Id Milk Bread Butter Apples Pears
SO51176 1 1 0 0 0
SO51177 0 1 1 0 0
SO51178 1 1 1 0 0
SO51179 0 1 1 1 1 Tabelul 2-2 Reprezentarea densă a datelor din coșuri de cumpărături, ca perechi atribut-valoare
Pentru majoritatea coloanelor din Tabelul 2-2 (mai puțin identificatorul de tranzacție), o valoare de 0 semnifică absența (iar o valoare de 1, prezența) unui element într-o tranzacție.
Reprezentarea din Tabelul 2-2 nu este eficientă pentru cataloage mari de produse. In plus, este de obicei imposibil de realizat în cele mai multe sisteme de gestiune a bazelor de date relaționale, care permit, uzual, cel mult 1000 de coloane (vezi (4), (5) ). Pe de altă parte, această reprezentare poate permite stocarea eficientă a altor

9
atribute ale tranzacției, ce nu sunt necesar legate de elementele din coșul de cumpărături. Spre exemplu, informații demografice (despre client) sau geografice (despre magazinul unde tranzacția a fost înregistrată) pot fi adăugate la tabel. Astfel de atribute constituie o altă dimensiune a tranzacției. O discuție detaliată a sistemelor de tip data-warehouse multidimensionale nu face decât tangențial obiectul acestei teze, dar lucrările citate (15) și (16) discută in detaliu problem de data mining în general (și reguli de asociere, în special) peste astfel de sisteme.
O reprezentare a tranzacțiilor ca cea din Tabelul 2-2 este descrisă ca fiind densă, doarece toate atributele sunt explicit exprimate, cu valori specifice ce exprimă prezența sau absența unui element dintr-o tranzacție. Prin contrast, o reprezentare ca cea din tabelul Tabelul 2-1 este descrisă ca fiind rară, deoarece numai acele element din catalog care sunt prezente într-o tranzacție apar explicit în tabel.
2.1.4 Despre echivalența reprezentărilor densă și rară Reprezentările densă și rară ale tranzacțiilor sunt similare în ceea ce privește regulile și grupurile de elemente.
Fie A={Ai} mulțimea tuturor atributelor ce descriu o tranzacție în reprezentare densă, atribute ce pot fi grupate semantic în mai multe dimensiuni. Din punct de vedere al stocării datelor, fiecare astfel de atribut este o coloană din tabel.
Fie Vi={vij}, mulțimea tuturor valorilor posibile ale atributului Ai .
Un predicat descriind o stare a unui atribut, Ai=vij , constituie un element în sensul
folosit de definiția rară a regulilor de asociere. Cu astfel de elemente, regulile de asociere pot fi descrise peste reprezentări dense ca mai jos:
- Spațiul de elemente (I) este mulțimea tuturor prerechilor distincte atribut-valoare
- Identificatorul de tranzacție este o valoare distinctă descriind o linie de date în reprezentare densă (în exemplu, valoarea coloanei Order Number )
- O tranzacție, identificată de un identificator de tranzacție (de exemplu ”S051176”) conține, ca elemente, acele perechi atribut-valoare asociate cu linia respectivă din tabel.
Cu aceste definiții, o regulă (ecuația (2.4) ) devine o propoziție logică de forma:
{A1=v1, …, Ai=vi} {Aj=vj, …, An=vn} (2.5)

10
Este interesant de observat că, în cazul particular când numărul de elemente din consecință este exact 1, regula de asociere devine regulă de clasificare și poate fi folosită pentru a prezice cu o anume probabilitate (nivelul de încredere) valoarea unui singur atribut.
Pe baza acestei echivalențe între reprezentările densă și rară, algoritmi concepuți pentru extracția regulilor de asociere pot fi utilizați pentru a produce reguli de clasificare.
2.2 Reguli Fuzzy Modelarea fuzzy este una din tehnicile de descriere a sistemelor complexe neliniare. Modelele fuzzy partiționează spațiul variabilelor din sistem în regiuni numite mulțimi fuzzy (6). Pentru fiecare astfel de regiune, caracteristicile sistemului pot fi descrise cu o regulă. Aplicarea acestor reguli permite modelarea sistemelor complexe neliniare cu acuratețe globală satifăcătoare.
Regulile din modelele fuzzy sunt transparente la interpretare și analiză. Modelele de reguli fuzzy, însă, nu sunt întotdeauna ușor de interpretat. Unele sisteme complexe sunt reprezentate de un număr mare de mulțimi fuzzy, in mare masură suprapuse, ce fac interpretarea dificilă.
2.2.1 Concepte de modelare fuzzy Pentru concepte care nu sunt clar definite, o funcție poate fi utilizată pentru a descrie măsura în care un punct este parte a unui concept. Spre exemplu, conceptul “astăzi este o zi ploioasă” poate avea o valoare joasă pentru zile însorite, una mai mare pentru o zi de toamnă și o valoare foarte mare pentru zilele cu ploi torențiale.
Astfel de funcții de apartenență la un concept sunt de obicei definite cu valori în spațiul [0,1]. Valoarea 0 are semnificația că un punct nu aparține deloc unui concept, iar 1 are semnificația că un punct aparține în totalitate unui concept. Un concept, împreună cu o funcție de apartenență, formează o mulțime fuzzy.
2.2.2 Modelarea fuzzy Modelarea fuzzy constă în descoperirea mulțimilor fuzzy și estimarea parametrilor funcțiilor de apartenență. Rezultatul modelării fuzzy este un grup de reguli de forma DACĂ-ATUNCI (IF-THEN), reguli care stabilesc relații între variabilele

11
sistemului peste care se face modelarea. Predicatele fuzzy sunt asociate cu etichete lingvistice, așa că modelul este o descrie calitativă a sistemului, cu reguli cum ar fi:
DACĂ temperatura este moderată și volumul este mic
ATUNCI presiunea este joasă
Semnificația termenilor moderat, mic și joasă este dată de mulțimi fuzzy peste domeniul variabilelor de sistem respective (în exemplu, temperatura, volum, presiune). Pentru ca asociază o etichetă lingvistică cu predicatele fuzzy, modelele bazate pe acest fel de reguli se numesc modele lingvistice. Modelele lingvistice pot fi clasificate ca mai jos:
- Modelul Mamdani (7) folosește reguli lingvistice la care atât premiza cât și
consecința sunt de tip fuzzy
- Modelul Takagi Sugeno (TS) (8) folosește reguli pentru care consecințele
sunt funcții matematice în loc de mulțimi fuzzy.
Într-un model Mamdani, inferența este consecința regulii ce se aplică la un anume punct. Setul de reguli este, deci, o corespondență statică între antecedente și consecință.
Modelul TS este bazat pe ideea că regulile din model au forma de mai jos:
Ri: wi(IF X1 is Ai1 AND … AND Xn is Ain THEN Yi = fi(.)) (2.6)
unde:
- wi – este ponderea regulii (de obicei 1, dar care poate fi variabilă)
- fi – o funcție, de obicei liniară, peste spațiul variabilelor premiză, x1 … xn
Inferența (predicția) cu un model TS se calculează după formula:
∑
∑
(2.7)
Ecuația 2.7 este media ponderată a consecințelor regulilor, unde N este numărul de reguli, Yi consecința unei reguli iar βi gradul de activare al premizei regulii curente. Pentru un punct oarecare X=(x1, x2, … xn) din spațiul modelat, βi

12
se calculează ca mai jos (ca produs al funcțiilor de apartenență pentru toate predicatele din regula curentă)
∏ ( )
(2.8)
Datorită structurii liniare a consecințelor acestor reguli, metode cunoscute de estimare a parametrilor (cum ar fi metoda celor mai mici pătrate) pot fi folosite pentru a estima parametrii consecinței.
3 Metode de extracție a regulilor Prezentăm, în acest capitol, metodele cel mai frecvent folosite pentru extragerea
regulilor. Secțiunea 3.1 de mai jos descrie algoritmi dezvoltați special pentru extracția de reguli, cum ar fi apriori și FP-Growth. Apoi, în secțiunea 3.2, prezentăm câteva metode de extracție a regulilor din șabloane detectate de alți algoritmi. Tratăm cu atenție specială extracția de reguli din rețele neuronale, o zonă de interes pentru capitolul următor.
O secțiune specială a tezei (neinclusă din acest rezumat) descrie aspecte specifice ale prelucrării de reguli în produsul Microsoft SQL Server.
3.1 Extracția regulilor de asociere
3.1.1 Algoritmul Apriori Algoritmul apriori este un algoritm influent de extracție a grupurilor frecvente de elemente în vederea descoperirii regulilor de asociere între elemente. Algoritmul a fost introdus de Agrawal în (9). Principiul algoritmului este să evite numărarea tuturor grupurilor de elemente ce pot rezulta din combinații ale catalogului I și să ia în considerare doar acele grupuri de elemente care apar frecvent. Algoritmul exploatează o proprietate a grupurilor de elemente numită închidere descendentă (downward closure) sau proprietatea apriori: dacă un grup de n elemente (un n-itemset) este frecvent, atunci oricare din subgrupurile sale trebuie sa fie de asemenea frecvent. Frecvent, în acest context, înseamnă că suportul grupului depășește un minim specific ca parametru al algoritmului (și notat minsup). Grupuri de elemente care apar mai puțin frecvent decât suportul minim specificat sunt considerate infrecvente și sunt ignorate de algoritm. Un algoritm de generarea a

13
grupurilor de elemente și de testare a suportului, algoritm care nu folosește proprietatea apriori a fost introdus tot de Agrawal în (2).
Algoritmul apriori se inițializează prin numărarea aparițiilor fiecărui element individual, deci prin calcularea frecvențelor grupurilor de elemente de dimensiune 1. Algoritmul face asta printr-o traversare a datelor în cadrul căreia se contorizează aparițiile fiecărui element. Grupurile de elemente de dimensiune 1 cu frecvență mai mică decât minsup sunt excluse din analiză. Grupurile de dimensiune 1 (1-itemset) rămase constituie L1, mulțimea de grupuri frecventede dimensiune 1 interesante pentru algoritm.
Odată inițializat, algoritmul execută iterativ următorii pași:
1. Pasul de sinteză (join): se generează o mulțime de grupuri candidat de elemente de dimensiune n, n-itemsets, mulțime notată Cn. Această mulțime de grupuri candidat este sintetizată prin combinarea mulțimii Ln-1 cu ea insăși. Prin convenție, apriori presupune că elementele unei tranzacții sunt sortate lexicografic. Combinarea elementelor mulțimii Ln-1 cu ele însele se face pe baza unui prefix comun de lungime (n-2). Fie A și B două grupuri de lungime (n-1) (deci membrii ai Ln-1), definite ca mai jos:
A = {a1, a2, …, an-2, an-1}
B = {b1, b2, …, bn-2, bn-1} (3.1)
A și B vor fi combinate dacă au acelașsi prefix de lungime (n-2), deci dacă
⋀
(3.2)
Rezultatul combinării elementelor A și B este un nou grup, de data asta de n elemente, care este adăgat la mulțimea de grupuri candidat Cn:
C = {a1, a2, …, an-2, an-1, bn-1} (3.3)

14
Primul predicat din condiția de combinare, , nu face decât să asigure păstrarea ordinii lexicografice și faptul că operația de combinare generează doar grupuri candidat unice.
2. Pasul de rafinare (pruning): Nu toate grupurile candidat din mulțimea Cn
îndeplinesc criteriul minsup. Determinarea acelor grupuri care respectă acest criteriu se poate face cu o traversare a datelor. Această opțiune nu este, însă, întotdeauna posibilă ori eficientă, căci mulțimea Cn poate avea extrem de multe elemente. Aici intervine proprietatea apriori și rafinează mulțimea Cn prin eliminarea unor grupuri candidat. Dacă oricare dintre subgrupurile de dimensiune (n-1) al unui grup candidat nu este frecvent, atunci candidatul nu poate fi nici el frecvent. Acest test se poate realiza rapid, prin stocarea grupurilor frecvente descoperite anterior într-o structură de date ce permite căutarea rapidă, cum ar fi o tabelă de dispersie sau un arbore de prefix. Pentru acest pas, de fapt, doar grupurile frecvente de dimensiune (n-1) trebuie să fie păstrate în memorie.
Odată ce pasul de rafinare este complet, grupurile candidat rămase în mulțimea Cn devin grupuri frecvente de dimensiune n, constituind mulțimea Ln, ce va fi folosită în iterația următoare. Procesul iterativ se încheie atunci când fie Ln este mulțimea vidă, fie lungimea (n+1) a grupurilor ce urmează a fi detectate depășește o limită definită de utilizator.
Pe baza grupurilor frecvente detectate, se pot extrage ușor regulile de asociere. În general, numai acele reguli cu un nivel de încredere suficient de mare sunt interesante. Fie minconf limita minimă acceptabilă pentru nivelul de încredere al unei reguli, limită introdusă ca un parametru al algoritmului. Cum am menționat în
secțiunea 2.1.1 de mai sus, nivelul de încredere al unei reguli A B e definit ca:
(3.4)
Pentru fiecare grup frecvent de elemente G, regulile de asociere pot fi extrase ca mai jos:
- Se generează toate submulțimile nevide {Si G} ale grupului

15
- Pentru fiecare submulțime, Si, se calculează nivelul de încredere al regulii Ri:
Si{G-Si}:
supp(Ri) =
(3.5)
- Dacă supp(Ri)>minconf atunci se adaugă Ri la mulțimea de reguli interesante
Metoda apriori de detectare a a grupurilor frecvente poate să producă, în timpul pasului de sinteză, un număr mare de grupuri candidat. Algoritmul pe care îl analizăm mai departe, FP-Growth, adresează această problemă. Alte probleme ridicate de algoritmul apriori (și, în general, de algoritmi care se bazează pe o limită inferioară de suport, minsup), sunt discutate în secțiunea 3.1.3 mai jos.
3.1.2 Algoritmul FP-Growth Algoritmul FP-Growth (Dezvoltarea șabloanelor frecvente, sau Frequent Pattern Growth) a fost introdus de Jiawei Han în (10) și apoi rafinat în (11), cu scopul de a extrage întreaga mulțime de grupuri frecvente fără generarea de grupuri candidat.
Algoritmul utilizează a structură de date nou-introdusă, arborele de șabloane frecvente (Frequent pattern tree, ori FP-Tree). Un arbore este un arbore de prefix care stochează informații despre șabloanele frecvente. Grupurile frecvente de dimensiune 1 formează noduri ale arborelui. Aceste noduri sunt aranjate în așa fel încât să crească șansele de reutilizare a nodurilor frecvente. Algoritmul este prezentat în detaliu in secțiunea 3.1.2 a tezei.
Odată ce un arbore FP este construit, extragerea grupurilor frecvente este redusă la traversări ale acestui arbore. Rzultate experimentale, spre exemplu (10), sugerează ca un astfel de arbore poate fi câteva ordine de mărime mai mic decât setul de date reprezentat.
Spre deosebire de apriori, care execută atât o sintetizare de grupuri candidat cât și o testare a acestor grupuri, algoritmul FP-Growth execută doar o testare a grupurilor candidat descoperite în arborele FP.
3.1.3 Probleme ridicate de algoritmii de extracție ce folosesc o limită de suport minim
Algoritmii de extragere de reguli cel mai frecvent utilizați, apriori și FP-Growth, reduc numărul de grupuri din care se extrag reguli prin excluderea grupurilor

16
infrecvente (care apar mai rar decât limita minsup specificată). Reguli cu nivel ridicat de încredere pot avea, însă, un suport relativ mic (mai mic decât valoarea minsup). Astfel de reguli, potențial valoroase, nu vor fi detectate de acești algoritmi. Detecția regulilor rare este una din ariile de interes în cercetarea actuală.
O colecție a celor mai semnificative rezultate legate de reguli rare poate fi găsită în lucrarea (12). O parte din abordări utilizează un parametru minsup variabil, care poate fi definit pentru diverse elemente sau care poate fi modificat dinamic pentru a permite includerea grupurilor rare. Algoritmi folosind un suport minim variabil include metodele Multiple Support Apriori (MSApriori) (13), Relative Support Apriori, introdusă în (14), Adaptive Apriori (15) ori LPMiner (16), care se bazează pe FP-Growth. Algoritmii bazați pe suport minim variabil sunt, de obicei, foare influențați de apriori sau FP-Growth.
Abordări radical diferit constau în eliminarea completă a noțiunii de suport minim. Algoritmi ca MinHashing (17), Apriori Inverse (18) și Apriori Rare (19) extrag grupuri frecvente de elemente fără a folosi nici un fel de suport minim.
.
3.2 Reguli ca exprimare a șabloanelor detectate de alți algoritmi Puterea descriptivă a regulilor face din ele o alegere uzuală pentru exprimarea șabloanelor descoperite cu alți algoritmi de data mining.
3.2.1 Reguli din arbori de decizie Algoritmii de construcție ai arborilor de decizie sunt frecvent folosiți pentru extracția de reguli, pentru că șabloanele detectate de acești algoritmi pot fi reprezentate natural ca reguli.
Fiecare nod dintr-un arbore de clasificare (cum are fi ID3, divizorul dihotomic iterativ, ori Iterative dichotomiser 3, introdus de Quinlan (20)) sau dintr-un arbore de clasificare și regresie (classification-and-regression-trees, CART, introduși de Breiman și alții în (21)) poate fi convertit la o regulă. Calea de la rădăcina arborelui la nodul respectiv constituie antecedentul regulii iar histogram nodului, consecința acesteia.
Colecțiile de arbori (păduri) pot fi utilizate pentru extragerea unor reguli de asociere similare cu cele detectate de algoritmi de tip apriori. Un exemplu din industrie este implementarea produsului Microsoft SQL Server, după cum arătăm în lucrarea citată (3). Într-o astfel de implemntare, câte un arbore este construit pentru fiecare element din catalog, cu scopul de extracție a regulilor care conțin, în consecință, prezența respectivului element.

17
3.2.2 Reguli din rețele neuronale O rețea neuronală artificială (artificial neural network, ori ANN) este un model matematic inspirat din aspecte funcționale ale rețelelor neuronale biologice. O ANN constă din grupuri de neuroni artificiali interconectați. O descriere amănunțită a rețelelor neuronale artificiale nu face obiectul acestei lucrări, dar poate fi găsită în lucrearea (22). O parte din conceptele și proprietățile ANN descrise în (22) și care sunt relevante pentru această lucrare sunt sumarizate mai jos.
Într-o ANN, un neuron primește mai multe informații de intrare și le combină cu scopul de a produce o informație de ieșire. De obicei, combinarea informațiilor se face cu sume ponderate iar rezultatul este trecut printr-o funcție neliniară numită funcție de activare sau de transfer.
Informație de ieșire a unui neuron este, deci, descrisă de ecuația de mai jos:
∑
(3.6)
unde:
- m este numărul de intrări pentru neuron - wkj este ponderea asociată cu conexiunea dintre intrarea j și neuronal
curent - xj este valoarea de intrare j
- este funcția de activare a neuronului.
Funcția scară sau funcția sigmoid sunt exemple tipice de funcții de activare.
O rețea neuronală artificială este, deci, definită de:
- Topologia rețelei (neuronii și conexiunile dintre ei) - Procesul de învățare pe baza căruia se calculează ponderile conexiunilor - Funcțiile de activare ale neuronilor
Tipuri complexe de rețea neuronală au fost propuse pentru modelarea proceselor biologice complexe, cum ar fi dezvoltarea corticală sau învățarea prin repetiție (reinforcement learning). Teoria Adaptive Resonance (ART), spre exemplu, descrisă în detaliu în (23), este un caz special de rețea neuronală cu abilități speciale de învățare.

18
Complexitatea internă a rețelelor neuronale face șabloanele învățate de acestea greu de descris. Reguli sunt adesea utilizate pentru a descrie procesul din cadrul rețelei. Regulile extrase pot fi exacte sau fuzzy.
O trecere în revistă a mecanismelor de extracție de reguli, lucrarea citată (24), introduce o taxonomie de referință a acestor metode, taxonomie ce ia în considerare puterea de expresie a regulilor, translucența acestora (măsura în care regulile expun structura internă a rețelei), calitatea regulilor (acuratețe, fidelitate față de rezultatele ANN, comprehensibilitate), complexitate algoritmică și tratamentul variabilelor. Taxonomia a fost modificată în 1998 în lucrarea (25), devenind aplicabilă și la tipuri mai complex de ANN neacoperite inițial, cum ar fi rețelele recurente.
Una dintre primele metode de extracție de reguli dintr-o rețea neuronală a fost propusă de Saito și Nakano in 1988, în (26). Este vorba de o abordare bazată pe analiza sensibilității rețelei (sensitivity analysis), observarea efectelor pe care schimbări în datele de intrare le cauzează în rezultatele rețelei .
În 1999 se arată, în (27), că rețelele cu mai multe straturi de neuroni și propagare anterioară (multilayer feed-forward) sunt aproximatori universali, deci pot aproxima uniform orice funcție reală continuă pe un domeniu compact. Același rezultat este obținut în 1994, în (28), pentru anumite sisteme bazate pe reguli fuzzy, și anume sisteme aditive fuzzy, bazate pe reguli ca mai jos:
⇒
(3.8)
unde pjk este o funcție liniară definită pe domeniul datelor de intrare.
Aceste rezultate au dus la ipoteza echivalenței dintre rețelele neuronale și sisteme expert de tip fuzzy ((29)). În 1998, Benitez și alții oferă o demonstrație constructivă, în (30), pentru echivalența dintre anumite rețele și anumite sisteme fuzzy. Autorii arată cum se poate construi un sistem aditiv fuzzy dintr-o rețea neuronală cu 3 straturi (un singur strat ascuns) care folosește o funcție de activare logistică în neuroni. Domeniul sistemelor neuro-fuzzy este de interes deosebit pentru această teză deoarece oferă contextul unor rezultate prezentate în capitolul 4.

19
Alte rezultate legate de echivalența sistemelor fuzzy cu rețelele neuronale sunt prezentate în (31), o trecere în revistă a algoritmilor de generare de reguli neuro-fuzzy. Lucrarea este apoi folosită în 2005 în (32) pentru extracția de reguli de tip DACĂ-ATUNCI dintr-o rețea neuronală fuzzy și pentru a explica apoi proiectanților de medicamente, într-o formă ușor de înțeles, cum ajunge o rețea la o anume concluzie.
Mai recent, în 2011, Chorowski și Zurada introduc, în (33), o metodă nouă de extracție de reguli, metodă numită LORE (Extracția de reguli locale, Local Rule Extraction). Această metodă se aplică rețelelor multi-strat cu date de intrare logice sau discrete (categoriale). Metoda descrie o structură nouă de date numită Diagramă de Decizie, ce permite fuzionarea eficientț de reguli parțiale. Totodată, lucrarea introduce un format nou de regulă ce diferențiază între combinații de intrare la care concluzia este cunoscută și cele cu concluzie nedeterminată.
4 Contribuții la generalizarea sistemelor de reguli
4.1 Generalizarea sistemelor de reguli de tip fuzzy Simplicitatea conceptului de regulă fuzzy crează, intuitiv, impresia că modelele bazate pe reguli fuzzy sunt transparente la interpretare și analiză, dar această transparență nu este garantată. Unele sisteme complexe pot fi descrise de reguli puține ce folosesc mulțimi fuzzy distincte și ușor de interpretat, dar pot fi descrise și de un număr mare de mulțimi fuzzy in mare masură suprapuse, ce fac orice interpretare dificilă.
4.1.1 Redundanța mulțimilor fuzzy Modelele fuzzy, in special cele extrase direct din date, fără postprocesare, pot conține informație redundantă sub forma de mulțimi fuzzy similare. Trei situații nedorite de redundanță pot fi identificate:
1) Similaritatea între două sau mai multe mulțimi fuzzy din model;
2) Similaritatea între o mulțime fuzzy și mulțimea universală, întreg domeniul de definiție al funcției de apartenență;
3) Similaritatea unei mulțimi fuzzy cu un singleton, o mulțime fuzzy definită de un singur punct. (Este interesant de observat ca acest caz, fără valoare de generalizare, poate fi totuși util in descrierea excepțiilor)

20
4.1.2 Similaritatea mulțimilor fuzzy Diferite metrici au fost propuse pentru măsurarea similarității a două mulțimi fuzzy. In general, aceste metrici pot fi clasificate ca:
- Metrici de similaritate geometrice (ex. clasa de distanțe Minkowski)
∑
⁄ (1.1)
- Metrici de similaritate bazate pe teoria mulțimilor (ex. indicele de
consistență):
[ ] (1.2)
unde ˄ este operatorul minimum
Setnes et al., în (34), definesc un număr de criterii pentru o măsură de similaritate și propun o astfel de măsură. Masura definită este utilizată intr-un algoritm de simplificare a unui sistem de reguli fuzzy, algoritm prezentat in detaliu in aceeași lucrare.
4.2 Tehnici de simplificare a modelelor de reguli fuzzy Tehnicile de simplificare a modelelor de reguli pot ținti atributele luate in considerație in timpul extracției de reguli sau definiția mulțimilor fuzzy care apar in reguli .
Tehnicile de modificare a atributelor urmăresc să reducă setul de atribute luate in considerare de procesul de inferență de reguli. Sintetizarea de atribute (Feature Extraction) constă in crearea unui set de atribute nou, de dimensiune mai mică, dar care acoperă varianța setului original de atribute în totalitate sau în mare măsură. Tehnicile de sintetizare de atribute includ metoda Principal Component Analysis (transformarea Karhunen-Loewe), descrisă in (35), sau metoda de proiecție neliniară a lui Sammon (36). Selecția de atribute (Feature Selection) constă in identificarea celor mai semnificative atribute pe baza unor criterii cum ar fi câștigul de informație (information gain). O analiză exhaustivă a tehnicilor de selecție de atribute este prezentată de Dash și Liu, in (37).

21
Modificări ale definiției mulțimilor fuzzy pot să conducă la fuziunea funcțiilor de apartenență și, astfel, la simplificări ale sistemelor de reguli fuzzy, după cum arată Song et al., în (38).
4.3 Generalizarea Regulilor In (1), patru descriptori moleculari (molecular weight, number of H-bond donors și acceptors, și ClogP) sunt folosiți pentru a prezice activitatea biologică (IC50). Lucrarea propune un algoritm nou de generalizare a regulilor extrase dintr-o rețea neuronală. Această secțiune prezintă in detaliu algoritmul din (1), apoi il extinde la reguli extrase de alți algoritmi (ex apriori), discută rezultatele obținute și propune noi direcții de cercetare.
4.3.1 Problemă și context Problema tratată de (1) este legată de biochimie. Un model de tip Fuzzy ARTMAP
with Relevance (FAMR) este antrenat pentru a prezice indicatorul IC50. Șabloanele detectate de FAMR sunt extrase sub formă de reguli iar sistemul de reguli rezultat este procesat pentru a fi mai ușor de interpretat. Scopul final constă in a explica, intr-o formă ușor de înțeles, cum ajunge rețeaua la o anume concluzie și care este influența unui descriptor molecular asupra țintei.
Teoria Adaptive Resonance (ART), descrisă in detaliu în (23), propune un tip special de rețea neuronală cu capacități de invățare secvențială. Capacitățile de invățare ale rețelelor ART sunt îmbunătățite cu logică de tip fuzzy în modelul Fuzzy ART, introdus în (39). Modelul FAMR, un rafinament al Fuzzy ART, este un sistem de învățare incremental, bazat pe o rețea neuronală, ce poate fi folosit pentru probleme de clasificare, estimare de probabilitate și aproximare de funcții, introdus în (40). Șabloanele detectate de rețelele de tip FAM pot fi expuse sub forma unor reguli fuzzy de tip IF/THEN.
Mai mulți autori au tratat problema extragerii de reguli din rețele FAM pentru probleme de clasificare, spre exemplu (41), (42) și (43). In (1), adaptăm metoda propusă de Carpenter și Tan, în (41), la problema aproximării de funcții.
4.3.2 Algoritmul de generalizare a regulilor (RGA)
Fie O mulțimea regulilor extrase din modelul FAMR cu algoritmul de extracție
menționat mai sus. In această secțiune, analizăm calitatea regulilor din O prin

22
perspectiva nivelului de incredere (conf) și a suportului (supp) regulilor, proprietăți descrise in capitolul 2 mai sus.
Suportul regulilor inițiale din O ia valori între 0.0% și 16.47%, iar nivelul de
încredere ia valori între 0.00% și 100.00%. Pentru a asigura un nivel de calitate al setului de reguli, se folosesc două criterii: nivel minim de încredere și suport minim. Regulile ce nu îndeplinesc aceste criterii sunt excluse din set.
Regulile inițiale din O au următoarele caracteristici (consecințe ale mecanismului de extracție):
Toate regulile sunt complete, în sensul că antecedentul fiecărei reguli conține câte un predicat pentru fiecare descriptor.
Unele valori ale descriptorilor moleculari (variabile independente) nu apar in nici una dintre reguli.
Introducem două noi măsuri peste un set de date de tipul celor descrise de regulile din O:
- Coverage: Procentajul punctelor, din setul de date, cu următoarea proprietate: există cel puțin o regulă pentru care punctul este descris de antecedent (procentajul de puncte pentru care cel puțin o regulă se poate aplica).
- Accuracy: Procentajul punctelor, din setul de date, cu următoarea proprietate: există cel puțin o regulă pentru care punctul este descris de antecedent și, în plus, indicatorul IC50 asociat (variabila dependentă) aparține zonei descrise de consecința regulii (procentajul de puncte pentru care cel puțin o regulă corectă se poate aplica).
Atât peste setul de date folosit la antrenarea modelului FAMR, cât și peste setul de date de test (neutilizat in antrenarea FAMR), valorile joase pentru măsurile Coverage și Accuracy sugerează ca regulile sunt prea specifice setului de antrenare (overfitting). Pentru generalizarea acesto reguli, propunem algoritmul de generalizare a regulilor (RGA), de tip greedy, de mai jos, algoritm ce se aplică fiecărei reguli din O.
Algoritm de generalizare a regulilor(RGA). Fie R o regulă reprezentată ca mai jos:

23
R: (X1 = x1,X2 = x2, . . . ,Xn = xn) ⇒ (Y = y) (4.12)
Se relaxează regula R prin eliminarea câte unui predicat. In descrierea regulii, se înlocuiește (Xi = xi) cu (Xi = ), cu semnificația că atributul Xi poate lua orice valoare. Antecendentul regulii nou formate este mai puțin restrictiv, deci suportul va fi cel puțin egal cu cel al regulii originale.
Dacă regula nou formată are un nivel de încredere mai mare sau egal cu criteriul minim de încredere, se păstrează această regulă intr-un set de generalizări ce candidează pentru înlocuirea regulii inițiale.
Procedura este aplicată pentru toate predicatele din regulă, rezultând în cel mult n generalizări, toate cu suport mai mare sau egal cu regula inițială și nivele de încredere ce depășesc minimum acceptabil. Dacă setul de generalizări conține cel puțin un candidat, atunci se înlucuiește regula inițială cu acea generalizare care oferă cel mai mare nivel de încredere.
Algoritmul se aplică recursiv regulii rezultate, până când nu se poate găsi o generalizare mai bună.
Scopul algoritmului RGA este să generalizeze regulile relaxând condițiile din antecedente, încercând să îmbunătățească, la fiecare pas, suportul regulii, fără a reduce nivelul de încredere sub un minim acceptabil.
Figura 4-1 O reprezentare vizuală a RGA

24
Figura 4-1 oferă o reprezentare vizuală a modului in care RGA funcționează: Fie o regulă R: (X=High, Y=High)⇒ (Target = t). Dacă, după relaxarea condiției Y=High noua regulă R’: (X=High, Y=*)⇒ (Target = t) are un nivel de încredere suficient (suportul e garantat ), atunci R’ devine un candidat pentru înlocuirea lui R.
In cel mai complex caz, numărul de înlocuiri de predicate pentru fiecare regulă este în O(n2).
4.3.3 Aplicarea RGA la un set de reguli extrase de algoritmi de tip apriori Ordinea comună de sortare a atributelor in reguli, de obicei lexicografică, aceeași pentru toate regulile extrase de apriori poate fi exploatată pentru aplicarea eficientă a algoritmului RGA , descris anterior, pe seturi de reguli extrase de apriori. Următoarea proprietate a regulilor justifică aplicare algoritmului RGA pe seturi de reguli caracterizate de aceeași ordine de sortare a atributelor in antecedent.
Proprietatea 4.1: Fie două reguli dintr-un set, cu aceeași consecință C, fiecare regulă definită de un număr de predicatePi în antecedentul său: R1: ({P1}->C}, R2:
({P2}->C}. Dacă P1 P2 atunci R1 este o generalizare a lui R2, generalizare similară cu cele obținute in RGA prin relaxarea predicatelor.
Demonstrație: Dacă P1 este o submulțime proprie P2, atunci P2 conține cel puțin un
predicat Ci:Xi=xi, CiP1. Fiecare asftel de predicat Ci din definiția lui P2 poate fi
relaxat, rezultând în P2’={P1, Xi=*}. Repetând relaxarea pentru fiecare Ci P2, CiP1 se obține o relaxare a lui P2 care este identică cu P1.
Pe baza proprietății 4.1 propunem un algoritm de simplificare a seturilor de reguli de tip apriori (reguli de dimensiuni variabile, cu aceeași ordine de sortare a atributelor in antecedent). Algoritmul traversează regulile sortate, menținând o stivă de antecedente detectate în timpul scanării. Dacă antecedentul unei reguli noi conține unul dintre prefixele stocate pe stivă, atunci regula nouă poate fi generalizată de una din regulile anterioare. Prefixele de pe stivă care nu sunt conținute de regula curentă sunt eliminate (ordinea de sortare comună garantează ca ele nu pot servi ca prefix regulilor ce nu au fost incă citite).
Algoritmul e prezentat mai jos:
Parametrii:
T – Set de reguli cu aceeași ordine a predicatelor in antec.
Intrare
Un set T’ de reguli generalizate

25
Initializare:
Se sortează regulile după consecință (rezultând în subgrupuri GiT,
cu toate regulile dintr-un astfel de subgrup, Gi , având aceeași
consecință).
For each group Gi Reset prefix stack S
for each rule RGi(cum toate regulile din Gi au aceeași consecință,
doar antecedentul lui R este luat in considerare)
while S (se traversează stiva)
if S.topR then
if S.confidence is satisfactory then
S.top e o generalizare a lui R (iar R poate fi exclus din set)
break
end if
else Pop(S) // prefixul de pe stivă nu descrie R, poate fi șters
end while // traversarea stivei e completă
if R has not been dismissed then
copy R to T’
push R onto stack S
End if
End for Each
Pentru un exemplu simplu, fie un set de reguli trivial, ca mai jos:
R1: X1=a⇒ Y = Excellent
R2: X1=a AND X2=b ⇒ Y = Excellent
R3: X1=c ⇒ Y = Excellent
(4.13)
Regula R1 este prima regulă citită. Stiva este goală, deci R1 nu poate fi exclusă din set. R1 se adaugă atât la stivă cât și la setul de reguli generalizate, T’.
Când regula R2 este citită, stiva conține antecedentul lui R1, X1=x1, care este un prefix al lui R2. R1 este, deci, o generalizare a lui R2 iar R2 poate fi exclusă din setul generalizat.
La citirea regulii R3, stiva nu conține nici un prefix al acestei reguli, așa ca stiva va fi golită.

26
După cum se arată in capitolul de rezultate experimentale din teză acest algoritm produce generalizări semnificative ale sturilor de reguli. Experimentele sugerează o reducere a numărului de reguli din sistem la 10%-20%. Complexitatea de calcul e relativ mică, cu cel mult O(n2) operații (folosind stiva) unde n este cardinalitatea inițială a setului de reguli.
Câteva puncte slabe ale algoritmului sunt ușor de detectat. De exemplu, natura sa greedy previne detectarea tuturor generalizărilor posibile dintr-un set. Să considerăm, spre exemplu, setul următor de reguli
R1: X1=a AND X2=b ⇒ Y = Excellent
R2: X2=b ⇒ Y = Excellent (4.14)
Deși R2 este o generalizare a lui R1, nu va fi detectată de algoritm pentru ca apare, in ordinea lexicografică, după R1. O soluție posibilă pentru această problemă este sugerată mai jos.
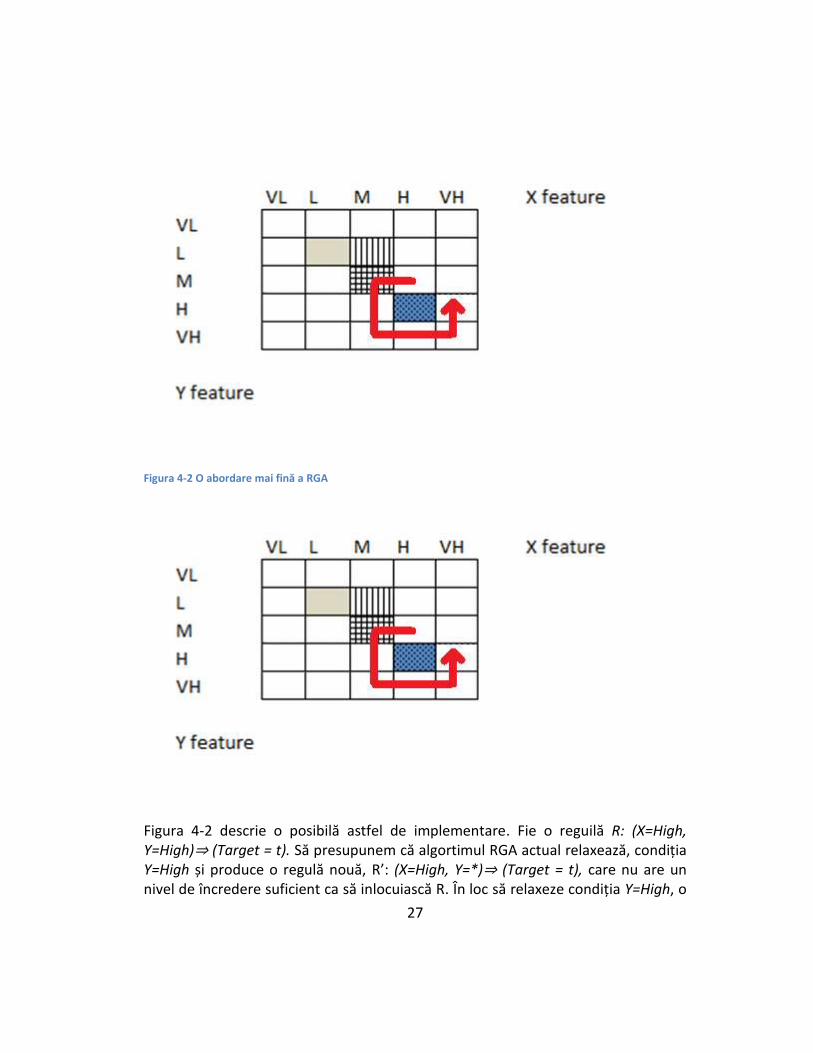
4.3.4 Direcții de dezvoltare a algoritmului RGA Algoritmul RGA descris anterior funcționează prin eliminarea unor benzi întregi din domeniul de definiție al antecedentelor setului de reguli. Această abordare produce rezultate bune in experimentele efectuate, dar este probabil prea grosieră. O soluție mai rafinată, deși computațional mai intensă, ar putea fi testarea a vecinătăților antecedentului inițial și fuziunea cu acele zone care, adăugate la antecedent, mențin nivelul de încredere al regulii deasupra nivelului minim acceptabil.
27
Figura 4-2 O abordare mai fină a RGA
Figura 4-2 descrie o posibilă astfel de implementare. Fie o reguilă R: (X=High, Y=High)⇒ (Target = t). Să presupunem că algortimul RGA actual relaxează, condiția Y=High și produce o regulă nouă, R’: (X=High, Y=*)⇒ (Target = t), care nu are un nivel de încredere suficient ca să inlocuiască R. În loc să relaxeze condiția Y=High, o

28
abordare mai fină poate investiga vecinătățile antecedentului original (cum ar fi Y=M or Y=VH). Generalizarea va rezulta atunci in reguli cu forma de mai jos:
R’’:(X=High, Y{High, Medium, Very High})⇒
(Target = t).
(4.15)
O astfel de abordare constă, deci, în fuziunea antecedentelor a două reguli atâta timp cât antecedentele sunt adiacente, regulile au aceeași consecință, iar regula rezultantă satisface criteriul de nivel minim de încredere.
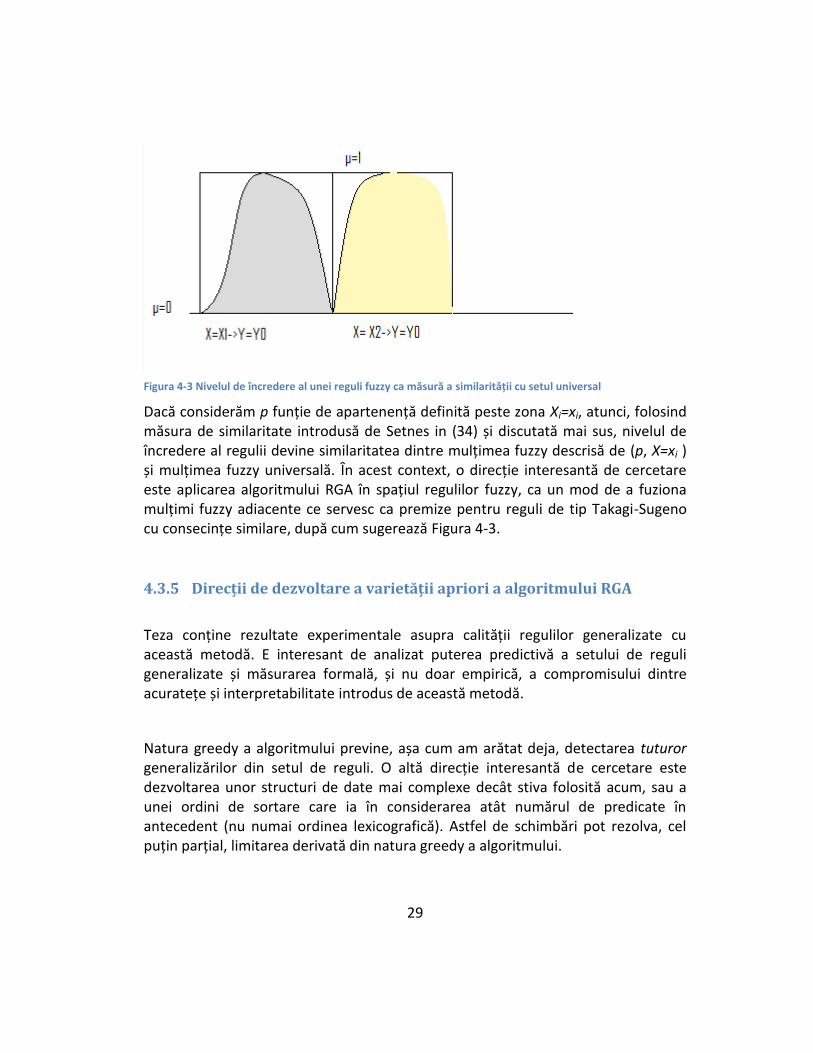
In problema tratată in (1), ca și în multe aplicații reale ale extracției de reguli, atât predicatele din antecedente cât și cele din consecințe descriu intervale de discretizare a unor variabile continue. In acest caz, pentru o regulă de forma R:(Xi=xi Y=yi) se poate defini o funcție p:(Xi=xi )[0,1] ce descrie densitatea de probabilitate pentru predicatul Y=yi peste felia Xi=xi a spațiului. Nivelul de încredere al regulii poate fi gândit, atunci, ca raportul dintre integrala acestei funcții ce descrie probabilitatea și integrala unei funcții constante, u=1, definită ăe aceeași zonă, (Xi=xi)
∫
∫
(4.16)
29
Figura 4-3 Nivelul de încredere al unei reguli fuzzy ca măsură a similarității cu setul universal
Dacă considerăm p funție de apartenență definită peste zona Xi=xi, atunci, folosind măsura de similaritate introdusă de Setnes in (34) și discutată mai sus, nivelul de încredere al regulii devine similaritatea dintre mulțimea fuzzy descrisă de (p, X=xi ) și mulțimea fuzzy universală. În acest context, o direcție interesantă de cercetare este aplicarea algoritmului RGA în spațiul regulilor fuzzy, ca un mod de a fuziona mulțimi fuzzy adiacente ce servesc ca premize pentru reguli de tip Takagi-Sugeno cu consecințe similare, după cum sugerează Figura 4-3.
4.3.5 Direcții de dezvoltare a varietății apriori a algoritmului RGA
Teza conține rezultate experimentale asupra calității regulilor generalizate cu această metodă. E interesant de analizat puterea predictivă a setului de reguli generalizate și măsurarea formală, și nu doar empirică, a compromisului dintre acuratețe și interpretabilitate introdus de această metodă.
Natura greedy a algoritmului previne, așa cum am arătat deja, detectarea tuturor generalizărilor din setul de reguli. O altă direcție interesantă de cercetare este dezvoltarea unor structuri de date mai complexe decât stiva folosită acum, sau a unei ordini de sortare care ia în considerarea atât numărul de predicate în antecedent (nu numai ordinea lexicografică). Astfel de schimbări pot rezolva, cel puțin parțial, limitarea derivată din natura greedy a algoritmului.

30
5 Măsurarea acurateții predicțiilor de utilizare produse de sisteme de recomandare
După numărul de beneficiari, sistemele de recomandare sunt probabil printre cele mai populare aplicații ale tehnologiei data mining. Astfel de sisteme sunt concepute pentru a identifica, pe baza experienței colective a unei comunități, conținut de interes pentru alți utilizatori.
5.1 Evaluarea sistemelor de recomandare Cea mai mare parte a lucrărilor legate de evaluarea sistemelor de recomandare se concentrează pe acuratețea recomandărilor generate. Măsurile de acuratețe sunt foarte diferite atunci când un sistem prezice opiniile utilizatorilor ca scoruri (evaluări numerice) sau ca probabilități de utilizare (spre exemplu, probabilități de cumpărare). Evaluările de acuratețe pot fi realizate intr-o manieră deconectată de sistem, offline, (pe baza recomandărilor efectuate), in experimente controlate cu utilizatori reali ai sistemului, cum este arătat în (44), cât și cu combinații ale acestor două metode.
In evaluările offline, recomandările produse de sistem sunt comparate cu valori reținute de evaluator, pe baza unor metrici prezentate in secțiunea următoare. Acest gen de evaluări sunt ieftin de realizat și rapide, chiar pe mai multe sisteme de recomandare in același timp.
Seturi de date care conțin și data și ora înregistrărilor pot fi folosite pentru a relua utilizarea reală a sistemului: fiecare recomandare este comparată cu decizia utilizatorului real.
5.2 Intrumente pentru evaluarea deconectată a acurateții predicțiilor de utilizare
O evaluare deconectată tipică se realizează pe baza unui set de date care conține selecțiile mai multor utilizatori ai sistemului. Un test tipic incepe cu selectarea unui utilizator. Unele selecții ale utilizatorului sunt reținute de evaluator, altele sunt prezentate sistemului de recomandare, căruia i se cer recomandări pe baza selecțiilor prezentate. Elementele recomandate și cele reținute sunt apoi comparate. Comparația poate produce 4 tipuri de rezultate, prezentate in Tabelul 5-1
Recomandat Nerecomandat
Folosit (prezent in setul Adevărat Pozitiv (TP) Fals Negativ (FN)

31
reținut)
Nefolosit Fals Pozitiv (FP) Adevărat Negativ (TN)
Tabelul 5-1 Clasificarea rezultatelor posibile in urma recomandării unui element
5.2.1 Măsurători de acuratețe pentru un singur utilizator In urma numărării valorilor din fiecare celulă din Tabelul 5-1, următoarele cantități pot fi calculate:
(4.1)
(4.2)
Precizia (Precision) reprezintă probabilitatea ca un element recomandat să fie util (relevant), iar Recall reprezintă probabilitatea ca un element util să fie recomandat.
Măsurile de Precizie și Recall sunt invers corelate, cum este arătat in (45) : liste mai lungi de recomandări duc, de obicei, la recall mai bun și precizie mai slabă. Incercări de consolidare a celor două măsuri intr-una singură au dus la măsuri cum ar fi F1 (introdusă în (46), utilizată pentru clasificatori în (47) și mai apoi pentru sisteme de recomandare în (48)), definită mai jos:
(4.3)
In anumite aplicații, numărul de recomandări ce trebuie prezentate utilizatorilor este predefinit. Pentru astfel de aplicații, măsurile de interes sunt Precizia și Recall la N, unde N este numărul de recomandări prezentate. Pentru alte aplicații, numărul nu este predefinit ori o valoare optimă trebuie determinată. In acest ultim caz, se poate analiza valoarea metricilor pentru numere diferite de recomandări.

32
Diagrame (cum ar fi curvele ROC, descrise mai jos) pot fi utilizate pentru compararea mai multor măsuri, cum ar fi de precizie și recall, sau valorile TP și FP.
Diagramele ce compară valorile TP (adevărat pozitiv) și FP (fals pozitiv), cunoscute sub numele de curbe ROC, sunt frecvent utilizate. Curbele ROC au fost introdus in 1969 in (49), sub numele de “Relative Operating Characteristics” dar sunt mai frecvent cunoscute sub numele “Receiver Operating Characteristics”, evoluat din utilizarea acestor curbe în teoria detecției semnalelor(vezi (50)).
Mai multe sisteme de recomandare rezultă în multiple curbe ROC. Când o curbă le domină pe celelalte, este ușor de ales cel mai bun sistem. Când curbele se intersectează, decizia depinde de nevoile aplicației. Spre exemplu, o aplicație care poate prezenta doar un număr redus de recomandări va alege sistemul de recomandare ce produce curba dominantă in stânga. Hanley and McNeil, în (50), propun aria de sub curbă (Area under Curve) ca măsură de comparare a implementărilor, independent de aplicație.
5.3 Curba de acuratețe detaliată Măsurile de acuratețe a sistemelor de recomandare prezentate in secțiunea anterioară sunt utilizate frecvent în competiții academice sau pentru evaluarea unor sisteme noi. Instrumente de evaluare a modelelor de clasificare și regresie, cum ar fi diagramele de câștig cumulativ (lift charts), diagrame ROC și de tip scatter plot, sunt omniprezente în produsele comerciale de data mining, dar majoritatea acestor produse nu oferă un instrument intuitiv de evaluare a sistemelor de recomandare.
Propunem un nou instrument, introdus în (51), pentur evaluarea calității predicțiilor de utilizare generate de sisteme de recomandare pe seturi de date deconectate. Acest instrument constă intr-o familie de diagrame ce pot fi folosite pentru a calcula, spre exemplu, măsura de recall asociată cu fiecare element dintr-un catalog de produse, pentru o familie de sisteme de recomandare.
Curba de acuratețe detaliată a fost dezvoltată cu scopul de a oferi utilizatorilor unui produs data mining o diagramă ușor de înțeles care permite compararea sistemelor de recomandare la fel de ușor cum diagramele de câștig cumulativ permit compararea modelelor de clasificare.

33
Un top-N recommender este un sistem de recomandare configurat sa producă N elemente cele considerate cele mai importante în context. Asta poate însemna elementele care sunt cel mai probabil să fie selectate de utilizator, sau elementele care pot aduce cele mai mari beneficii. În implementări industriale, un astfel de sistem folosește, de obicei, informații despre utilizatorul curent, cum ar fi lista elementelor selectate deja de acesta.
Un exemplu simplu de astfel de sistem este Most-Frequent N-Item Recommender (MFnR). Un astfel de sistem produce, indiferemt de caracteristicile utilizatorului curent, acele N elemente care apar cel mai frecvent in tranzacțiile înregistrate istoric.
Un exemplu mai sofisticat poate fi un sistem de reguli de asociere, care analizează selecțiile anterioare ale utilizatorului, extrage acele reguli din set care se pot aplica utilizatorului curent apoi sortează consecințele acestor reguli pe baza unor măsuri cum ar fi nivelul de încredere, importanța sau lift-ul, apoi emite acele N consecințe ce apar in capul listei sortate.
Fie o mulțime de elemente și D un set de date consistând din
tranzacții. Fiecare tranzacție D este definită ca un tuplu = (C, I) unde:
- C este un set, opțional, de proprietăți specifice tranzacției. Aceste
proprietăți pot fi atribute ale tranzacției in alte dimensiuni ale datelor, cum
ar fi atribute demografice ale clientului sau atribute geografice ale locului
unde s-a executat tranzacția
- I I este un grup de elemente ce au apărut impreună în tranzacție și vor fi
folosite pentru testarea sistemului top-N recommender.
Procesul de testare a unui sistem top-N recommender folosind setul de date D
constă în a evalua cât de bine prezice sistemul de recomandare elementele care
apar in fiecare tranzacție D. Testarea pentru un element iI constă în a
prezenta sistemului de recomandare o tranzacție ’i derivată din , care exclude
cel puțin elementul i. Apoi, se evaluează relația dintre elementul i și recomandările
produse de sistem pe baza lui ’i , relații cum ar fi prezența lui i, poziția în lista de
recomandări etc. Mai multe metode de a construi ’i din sunt descrise în
secțiunea 5.5.2 a tezei, împreună cu avantajele lor.

34
Prin definiție, sistemul top-N recommender va produce n recomandări pe baza
datelor de intrare specificate. După analiza celor n recomandări:
- Un rezultat Adevărat Pozitiv (TP) este definit ca prezența elementului i în
lista de recomandări, deci in primele N rezultate
- Un rezultat Fals Negativ (FN) este definit ca absența elementului i din lista
de recomandări produsă de sistem
Fie o metrică pozitivă ce descrie acuratețea predicțiilor de utilizare și care poate
fi calculată pentru fiecare element din catalogul I. Exemple de astfel de metrici
includ numărul de rezultate adevărat pozitive (TP), recall, precizia, valoarea
asociată cu recall-ul (definită ca recall multiplicat cu valoarea nominală a unui
element) etc.
Curba de acuratețe detaliată pentru un sistem top-N recommender se calculează în
modul următor:
- Se calculează (peste setul de tranzacții de test) măsura de acuratețe pentru fiecare element individual din catalogul I.
- Se agregă măsura de acuratețe a sistemului peste întregul catalog. Agregarea poate fi bazată pe orice măsură aditivă, nu neapărat pe sumă, dar suma este un exemplu simplu:
∑
- Se compară măsura agregată M cu două măsuri teoretice de referință, una minimă Mmin și una maximă Mmax
- Se calculează două cantități noi
o
o
Lift-ul descrie performanța sistemului curent top-N recommender relativ la un minim de referință acceptabil. Măsura Area Under Curve descrie performanța sistemului curent relativ la un maxim teoretic de referință.
Dacă măsura minimă de referință este asociată cu un sistem top-N recommender, atunci lift-ul asociat cu acest sistem este prin definiție 1. Similar, dacă măsura

35
maximă de referință este asociată, la rândul ei, cu un sistem top-N recommender, atunci măsura Area Under Curve asociată cu acest sistem este prin definiție 1, indiferent de numărul de recomandări n pentru care se execută testul.
Trebuie observat ca măsura Area Under Curve nu este identică cu măsura omonimă asociată cu diagramele ROC, deși are niște proprietăți similare, cum ar fi faptul că e mărginită superior de 1, valoare asociată cu un model ideal.
Un sistem de referință pentru valoarea Mmax utilizată în calcule este un sistem teoretic ideal, care produce numai rezultate Adevărat Pozitive.
In implementări industriale, valoarea minimă teoretică de referință nu trebuie sa fie mai slabă decât valoarea produsă de sistemul Most-Frequent n-Item Recommender (MFnR). Motive de utilizare a acestui sistem ca referință includ:
- Costuld e implementare a sistemului MFnR este practic 0 (deci nu există motiv de acceptare a unui sistem mai slab decât MFnR)
- MFnR este utilizat in industrie ca sistem rudimentar de recomandări (sau atunci când un sistem mai avansat nu poate produce încă recomandări, cum ar fi cazul produselor nou introduse)
Pentru motivele menționate mai sus, folosim MFnR ca sistem de referință ce produce valoarea Mmin utilizată în calcule. O proprietate interesantă a acestui sistem este faptul ca acuratețea sa crește cu numărul de recomandări n pe care le emite de fiecare dată.
Lemma 5.1 Numărul agregat de rezultate Adevărat Pozitive (TP) produse de MFnR crește, iar numărul de rezultate Fals Negative (FN) scade pe măsură ce numărul de recomandări (valoarea parametrului n crește), până când n atinge cardinalitea catalogului de elemente I.
Demonstrație:
Fie , cardinalitatea catalogului de elemente. Pentru fiecare următoarele proprietăți derivă din definițiile noțiunilor de rezultat Adevărat Pozitiv (TP) și Fals Negativ (FN) pentru un sistem top-N recommender:
(4.4)
, (4.5)

36
Când n atinge X, FN devine 0, TP devine n iar sistemul MFnR devine un sistem de recomandare ideal din punctul de vedere al măsurilor TP și FN.
Odată ce măsurile sunt calculate detaliat (pentru fiecare element din catalogul I), diagrama de acuratețe detaliată se obține afișând, pe abscisă, toate elementele din
I și pe ordonată valorile asociate cu aceste elemente. Ordinea de sortare a elementelor din catalog îmbunătățește semnificative caritatea diagramei. Spre
exemplu, sortarea îm ordine descrescătoare a metricii max (calculate pentru un sistem de referință teoretic ideal) oferă o perspectivă intuitivă a acurateții sistemului analizat.
5.3.1 O interpretare vizuală a curbei detaliate de acuratețe
Figura 5-1 Curba de acuratețe detaliată pentru un sistem top-N recommender și pentru un sistem de referință teoretic ideal
Figura 5-1 prezintă o diagramă detaliată de acuratețe. Curba dominantă reprezintă
măsura max (calculată pentru sistemul de referință ideal), iar curba trasată cu linie
continuă reprezintă măsura pentru sistemul top-N recommender care este evaluat.
Agregarea metricii este echivalentă cu integrarea acestei valori peste catalogul de elemente I. În acest context, măsurile Lift și Area Under Curve pot fi definite ca
37
∫
∫
, ∫
∫
,
Ambele măsuri devin, astfel, rapoarte de arii sub curbele definite de metricile asociate cu diverse sisteme de recomandare. Ambele măsuri sunt definite absolut (relative la sisteme teoretice de referință), dar definițiile pot fi și relative permițând compararea mai multor sisteme.
5.3.2 Impactul parametrului N asupra măsurilor de Lift și Area Under Curve
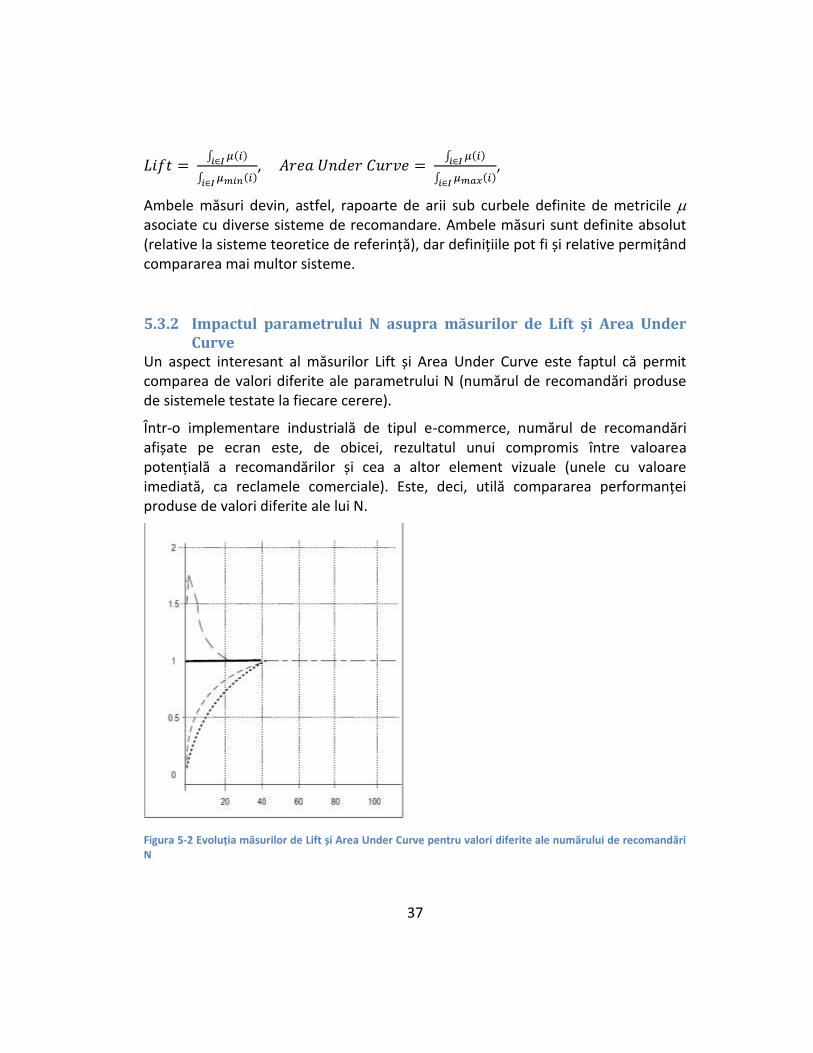
Un aspect interesant al măsurilor Lift și Area Under Curve este faptul că permit comparea de valori diferite ale parametrului N (numărul de recomandări produse de sistemele testate la fiecare cerere).
Într-o implementare industrială de tipul e-commerce, numărul de recomandări afișate pe ecran este, de obicei, rezultatul unui compromis între valoarea potențială a recomandărilor și cea a altor element vizuale (unele cu valoare imediată, ca reclamele comerciale). Este, deci, utilă compararea performanței produse de valori diferite ale lui N.
Figura 5-2 Evoluția măsurilor de Lift și Area Under Curve pentru valori diferite ale numărului de recomandări N

38
Figura 5-2 prezintă evoluția măsurilor de Lift și Area Under Curve pentru un sistem top-N recommender atunci când valoarea lui N evoluează de la 1 la 100.
Linia orizontală cu ordonata 1 este măsura de Lift minim asociată cu sistemul de referință MFnR. Curba cu linie punctată de deasupra acestei linii reprezintă măsura Lift (pentru valori diferite ale lui N) a sistemului top-N recommender testat. Cum am arătat in Lemma 5.1, acuratețea sistemului MFnR crește (deci măsura de Lift a sistemului testat scade) odată cu creșterea lui N.
Curbele din partea de jos a graficului reprezintă evoluția măsurii Area Under Curve. Prin definiție, Area Under Curve pentru sistemul de referință ideal este 1, iar pentru alte sisteme (inclusiv pentru MFnR) această valoare crește până la 1, cel târziu atunci când N atinge cardinalitatea catalogului de elemente.
5.4 Note de implementare a curbei detaliate de acuratețe
5.4.1 Măsuri de acuratețe Numărul de rezultate Adevărat Pozitive (TP), cât și câteva derivate ale acestui
număr sunt măsurile pe care le-am folosit pentru metrica calculată pentru fiecare element din catalogul I.
Cum am exemplificat anterior, considerăm un sistem de recomandare ideal ca sursă pentru agregarea Mmax , așadar un sistem care produce zero rezultate Fals Negative. Diferența între M și Mmax este, deci, numărul de rezultate Fals Negative produse de sistemul real testat. O consecință a alegerii metricii TP este faptul ca Area Under Curve este exact metrica de Recall asociată cu sistemul de recomandare.
O măsură înrudită ce poate fi utilizată pentru ia în considerare valoare nominală
(de catalog, sau specifică tranzacției) asociată cu un element, (i) = Valoare(i)*TP(i). Această metrică permite o evaluare mai flexibilă a valorii sistemului de recomandare.
5.4.2 Algoritmul de construire a curbei detaliate de acuratețe Algoritmul, prezentat mai jos, folosește o populație de test pentru a calcula numărul de rezultate Adevărat Pozitive și Fals Negative. Numărul de recomandări

39
este un parametru al algoritmului. Rezultatele sunt contorizate pentru fiecare element din catalogul I, în două structuri de date indexate după elementele din I, și anume GlobalCounts și TruePositives. Structura GlobalCounts contorizează numărul de apariții, în populația de test, a fiecarui element din catalog. Acest număr de apariții este considerat numărul absolute de rezultate Adevărat Pozitive, deci Mmax
Când iterația este completă, metricile de interes se pot calcula în felul următor:
- M – suma valorilor din colecția TruePositives - Mmax – suma valorilor din colecția GlobalCounts - Mmin – suma acelor valori din GlobalCounts care sunt indexate după cele
mai populare N elemente
O tabelă de frecvențe pentru detectarea celor mai frecvente elemente poate fi calculată în cadrul aceleiași iterații. Algoritmul nu execută acest pas deoarece sistemele de baze de date au, de obicei, metode mai performante de a produce cele mai frecvente N elemente.
Parametrii :
n – numărul de recomandări produse
D – set de tranzzacții de test
Inițializare:
Se inițializează cu 0 GlobalCounts, TruePositives pentru
fiecare element din catalog
for each transaction Tx=(Cx, Ix) in D
for each item i in the Ix
increment GlobalCounts[i]
Let Txi = (Cx, (Ix – i))
Let RIn = TopRecommendations(n, Txi)
if i RIn then
increment TruePositives[i]
IterationEnd: calculează metricile agregate
Algoritmul traversează spațiul tranzacțiilor de test și execută câte o cerere de recomandare pentru fiecare element testat (din fiecare tranzacție). Complexitatea algoritmului este, deci unde |D| este numărul de tranzacții iar
Avg(|I|) numărul mediu de elemente într-o tranzacție.
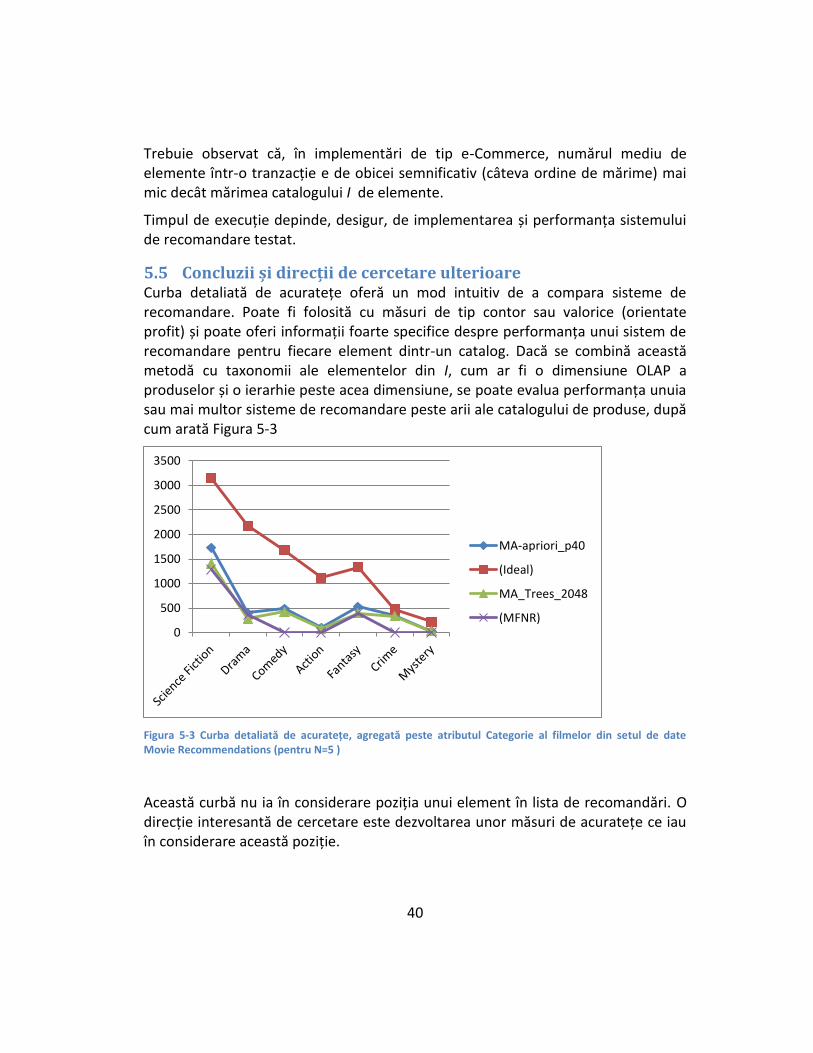
40
Trebuie observat că, în implementări de tip e-Commerce, numărul mediu de elemente într-o tranzacție e de obicei semnificativ (câteva ordine de mărime) mai mic decât mărimea catalogului I de elemente.
Timpul de execuție depinde, desigur, de implementarea și performanța sistemului de recomandare testat.
5.5 Concluzii și direcții de cercetare ulterioare Curba detaliată de acuratețe oferă un mod intuitiv de a compara sisteme de recomandare. Poate fi folosită cu măsuri de tip contor sau valorice (orientate profit) și poate oferi informații foarte specifice despre performanța unui sistem de recomandare pentru fiecare element dintr-un catalog. Dacă se combină această metodă cu taxonomii ale elementelor din I, cum ar fi o dimensiune OLAP a produselor și o ierarhie peste acea dimensiune, se poate evalua performanța unuia sau mai multor sisteme de recomandare peste arii ale catalogului de produse, după cum arată Figura 5-3
Figura 5-3 Curba detaliată de acuratețe, agregată peste atributul Categorie al filmelor din setul de date Movie Recommendations (pentru N=5 )
Această curbă nu ia în considerare poziția unui element în lista de recomandări. O direcție interesantă de cercetare este dezvoltarea unor măsuri de acuratețe ce iau în considerare această poziție.
0
500
1000
1500
2000
2500
3000
3500
MA-apriori_p40
(Ideal)
MA_Trees_2048
(MFNR)

41
6 Concluzii și direcții de cercetare
Lucrarea se axează pe contribuții originale cu tentă aplicativă in domeniul prelucrării sistemelor de reguli.
În capitolul 4 am investigat unele dintre rezultatele recente din domeniul simplificării și generalizării regulilor, apoi am prezentat contribuțiile noastre originale ce includ:
- o metodă nouă de prelucrare a unui set de reguli cu scopul de a imbunătăți capacitatea acestuia de generalizare. Metoda este dezvoltată special pentru reguli extrase dintr-un sistem Fuzzy ARTMAP de invățare incrementală, sistem folosit uzual pentru probleme de clasificare. Această metodă a fost introdusă în (1), o lucrare premiată la conferința internațională IJCNN organizată de IEEE.
- o dezvoltare a metodei menționate anterior pentru seturi de reguli extrase cu algoritmi concepuți special pentru extracția de reguli, cum ar fi apriori. Rezultatele experimentale sugerează reduceri de 5 până la 10 ori a numărului de reguli dintr-un set prin aplicarea acestei metode de generalizare.
Capitolul 5 a discutat problema evaluării sistemelor de recomandare, propunând curba de acuratețe detaliată, un instrument nou de evaluare a calităţii sistemelor de recomandare. Instrumentul a fost introdus, ca brevet, în (1).
6.1 Direcții de cercetare
Algoritmul RGA descris anterior funcționează prin eliminarea unor benzi întregi din domeniul de definiție al antecedentelor setului de reguli. Această abordare produce rezultate bune in experimentele efectuate, dar este probabil prea grosieră. O soluție mai rafinată, deși computațional mai intensă, ar putea fi testarea a vecinătăților antecedentului inițial și fuziunea cu acele zone care, adăugate la antecedent, mențin nivelul de încredere al regulii deasupra nivelului minim acceptabil.

42
O astfel de abordare constă, deci, în fuziunea antecedentelor a două reguli atâta timp cât antecedentele sunt adiacente, regulile au aceeași consecință iar regula rezultantă satisface criteriul de nivel minim de încredere.
Secțiunea “Direcții de dezvoltare a algoritmului RGA” prezintă o direcție nouă de cercetare a aplicabilității algoritmului RGA în spațiul regulilor fuzzy, ca un mod de a fuziona mulțimi fuzzy adiacente ce servesc ca premize pentru reguli de tip Takagi-Sugeno cu consecințe similare.
Dintr-o perspectivă de implementare, este interesant de observat că algoritmul permite evaluări de tip bloc a mai multor măsuri. Într-o bază de date relațională tipică, toate vecinătațile antecedentului unei reguli pot fi evaluate într-o singură citire a datelor, folosind construcții de tip GROUP BY. Dezvoltări recente în spațiul bazelor de date stocate în memorie (de exemplu (52), (53) ) vor fi probabil extrem de utile în a adresa costul computațional al estimării nivelului de încredere pentru reguli generalizate.
In secțiunea „Aplicarea RGA la un set de reguli extrase de algoritmi de tip apriori” am prezentat un algoritm de generalizare a regulilor extrase de algoritmi de tip apriori. Teza conține rezultate experimentale asupra calității regulilor generalizate cu această metodă. E interesant de analizat puterea predictivă a setului de reguli generalizate și măsurarea formală, și nu doar empirică, a compromisului dintre acuratețe și interpretabilitate introdus de această metodă.
Natura greedy a algoritmului previne, așa cum am arătat deja, detectarea tuturor generalizărilor din setul de reguli. O altă direcție interesantă de cercetare este dezvoltarea unor structuri de date mai complexe decât stiva folosită acum, sau a unei ordini de sortare care ia în considerarea atât numărul de predicate în antecedent (nu numai ordinea lexicografică). Astfel de schimbări pot rezolva, cel puțin parțial, limitarea derivată din natura greedy a algoritmului.
Capitolul 5 a discutat problema evaluării sistemelor de recomandare, propunând un instrument nou de evaluare a calităţii sistemelor de recomandare. Curba detaliată de acuratețe oferă un mod intuitiv de a compara sisteme de recomandare. Poate fi folosită cu măsuri de tip contor sau valorice (orientate profit) și poate oferi informații foarte specifice despre performanța unui sistem de

43
recomandare pentru fiecare element dintr-un catalog. Dacă se combină această metodă cu taxonomii ale elementelor din I, cum ar fi o dimensiune OLAP a produselor și o ierarhie peste acea dimensiune, se poate evalua performanța unuia sau mai multor sisteme de recomandare peste arii ale catalogului de produse.
Această curbă nu ia în considerare poziția unui element în lista de recomandări. O direcție interesantă de cercetare este dezvoltarea unor măsuri de acuratețe ce iau în considerare această poziție.
Bibliografia tezei 1. Fuzzy ARTMAP rule extraction in computational chemistry. Andonie, Razvan, .
2009. IJCNN. pg. 157-163. DOI: 10.1109/IJCNN.2009.5179007. 2. Agrawal, Rakesh, Imielinski, Tomasz și Swami, Arun N. Mining association rules
between sets of items in large databases. 1993, Vol. 22, pg. 207-216. p207-agrawal.pdf.
3. MacLennan, Jamie, Crivat, Bogdan și Tang, ZhaoHui. Data Mining with Microsoft SQL Server 2008. Indianapolis, Indiana, United States of America : Wiley Publishing, Inc., 2009. 978-0-470-27774-4.
4. Microsoft Corporation. Maximum Capacity Specifications for SQL Server. msdn.microsoft.com. [Interactiv] [Citat: 13 6 2011.] http://msdn.microsoft.com/en-us/library/ms143432.aspx.
5. Oracle. Logical Database Limits. oracle.com. [Interactiv] [Citat: 13 6 2011.] http://download.oracle.com/docs/cd/B19306_01/server.102/b14237/limits003.htm.
6. Kasabov, Nikola K. Foundations of Neural Networks, Fuzzy Systems, and Knowledge Engineering. s.l. : Massachusetts Institute of Technology, 1998. ISBN 0-262-11212-4.
7. Application of Fuzzy Logic to Approximate Reasoning Using Linguistic Synthesis. Mamdani, E.H. 12, IEEE Transactions on Computers - TC, Vol. 26, pg. 1182-1191. DOI: 10.1109/TC.1977.1674779 .
8. Fuzzy identification of systems and its applications to modelling and control. Takagi, T. și Sugeno, M. 15, 1985, IEEE Transactions on Systems, Man and Cybernetics, pg. 116-132. http://pisis.unalmed.edu.co/vieja/cursos/s4405/Lecturas/Takagi%20Sugeno%20Modelling.pdf.

44
9. Fast Algorithms for Mining Association Rules. Agrawal, Rakesh și Srikant, Ramakrishnan. 1994. Very Large Databases VLDB. http://www.eecs.umich.edu/~jag/eecs584/papers/apriori.pdf.
10. Mining frequent patterns without candidate generation. Han, Jiawei, Pei, Jian și Yin, Yiwen. 2000. International Conference on Management of Data - SIGMOD. Vol. 29, pg. 1-12. dami04_fptree.pdf. 10.1145/342009.335372.
11. Mining Frequent Patterns without Candidate: A Frequent-Pattern Tree Approach. Han, Jiawei, . s.l. : Kluwer Academic Publishers, 2004, Data Mining and Knowledge Discovery, Vol. 8, pg. 53-87. dami04_fptree.pdf.
12. Koh, Yun Sing și Rountree, Nathan. Rare Association Rule Mining And Knowledge Discovery - Technologies for Infrequent and Critical Event Detection. Hershey, PA : Information Science Reference, 2010. 978-1-60566-754-6.
13. Mining association rules with multiple minimum supports. Liu, Bing, Hsu, Wynne și Ma, Yiming. 1999. Knowledge Discovery and Data Mining - KDD. pg. 337-341. DOI: 10.1145/312129.312274 .
14. Mining association rules on significant rare data using relative support. Yun, Hyunyoon, . 3, 2003, Journal of Systems and Software - JSS, Vol. 67, pg. 181-191. DOI: 10.1016/S0164-1212(02)00128-0 .
15. Pushing Support Constraints Into Association Rules Mining. Wang, Ke, He, Yu și Han, Jiawei. 2003, IEEE Transactions on Knowledge and Data Engineering : TKDE, pg. 642-658. DOI: 10.1109/TKDE.2003.1198396 .
16. LPMiner: An Algorithm for Finding Frequent Itemsets Using Length-Decreasing Support. Seno, Masakazu și Karypis, George. 2001. IEEE: International Conference on Data Mining ICDM. DOI: 10.1109/ICDM.2001.989558.
17. Finding interesting associations without support pruning. Cohen, E., . 1, 2001, IEEE Transactions on Knowledge and Data Engineering - TKDE, Vol. 13, pg. 64-78. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.96.7294&rep=rep1&type=pdf. DOI:10.1109/69.908981 .
18. Koh, Yun Sing și Rountree, Nathan. Finding Sporadic Rules Using Apriori-Inverse. Lecture Notes in Computer Science. 2005, Vol. 3518/2005, pg. 153-168.
19. Towards Rare Itemset Mining. Szathmary, L., . 2007. IEEE International Conference on Tools with Artificial Intelligence - ICTAI 2007. pg. 305-312. http://hal.archives-ouvertes.fr/docs/00/18/94/24/PDF/szathmary-ictai07.pdf. 10.1109/ICTAI.2007.30.
20. Induction of Decision Trees. Quinlan, J. R. 1, 1986, Machine Learning - ML, Vol. 1, pg. 81-106. InductionOfDT.pdf. DOI 10.1007/BF00116251 .

45
21. Breiman, Leo, . Classification and Regression Trees. s.l. : Chapman & Hall, 1984. ISBN 0-412-04841-8.
22. Bishop, Cristopher M. Neural Networks for Pattern Recognition. New York : Oxford University Press, Inc, 1995.
23. Carpenter, G.A. și Grossberg, S. The Handbook of Brain Theory and Neural Networks. [ed.] Michael A. Arbib. Cambridge, MA : MIT Press, 2003. pg. 87-90. http://cns.bu.edu/Profiles/Grossberg/CarGro2003HBTNN2.pdf.
24. Survey and critique of techniques for extracting rules from trained artificial neural networks. Andrews, Robert, Diederich, Joachim și Tickle, Alan B. 6, 1995, Knowledge Based Systems - KBS, Vol. 8, pg. 373-389. DOI: 10.1016/0950-7051(96)81920-4 .
25. The Truth Will Come to Light: Directions and Challenges in Extracting the Knowledge Embedded Within Trained Artificial Neural Networks. Tickle, Alan B., . 6, 1998, IEEE TRANSACTIONS ON NEURAL NETWORKS, Vol. 9. TruthWillComeToLight.pdf.
26. Medical diagnosis expert system based on PDP model. Saito, K și Nakano, R. New York : IEEE Press, 1988. IEEE International Conference on Neural Networks. pg. 1255-1262.
27. Multilayer feedforward networks are universal approximators. Hornik, Kurt, Stinchcombe, Maxwell B. și White, Halbert. 5, 1989, Neural Networks, Vol. 2, pg. 359-366. DOI: 10.1016/0893-6080(89)90020-8 .
28. Fuzzy Systems as Universal Approximators. Kosko, Bart. 11, 1994, IEEE Transactions on Computers - TC, Vol. 43, pg. 1329-1333. http://sipi.usc.edu/~kosko/FuzzyUniversalApprox.pdf. DOI: 10.1109/12.324566 .
29. On the equivalence of neural nets and fuzzy expert systems. Buckley, J. J., Hayashi, Y. și Czogala, E. 2, 1993, Fuzzy Sets and Systems, Vol. 53, pg. 129-134. DOI: 10.1016/0165-0114(93)90167-G .
30. Are artificial neural networks black boxes? Benitez, J.M., Castro, J.L. și Requena, I. 1997, IEEE Transactions on neural Networks, pg. 1156 - 1164 . http://www.imamu.edu.sa/Scientific_selections/abstracts/Math/Are%20Artificial%20Neural%20Networks%20Black%20Boxes.pdf. DOI: 10.1109/72.623216 .
31. Neuro-fuzzy rule generation: survey in soft computing framework. Mitra, S. și Hayashi, Y. 3, 2000, IEEE Transactions on Neural Networks, Vol. 11, pg. 748-768. DOI: 10.1109/72.846746 .
32. Neuro-fuzzy Prediction of Biological Activity and Rule Extraction for HIV-1 Protease Inhibitors. Andonie, Razvan, . 2005. Symposium on Computational Intelligence in Bioinformatics and Computational Biology - CIBCB. pg. 113-120.

46
33. Extracting Rules from Neural Networks as Decision Diagrams. Chorowski, J. și Zurada, J. M. 99, 2011, IEEE Transactions on Neural Networks, Vol. PP, pg. 1 - 12. ExtRulesNNDecisionDiagrams.pdf. DOI: 10.1109/TNN.2011.2106163 .
34. Similarity Measures in Fuzzy Rule Base Simplification. Setnes, Magne, . 3, June 1998, IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS, Vol. 28.
35. Jolliffe, I.T. Principal Component Analysis . s.l. : Springer, 2002. ISBN-13: 978-0387954424.
36. A Nonlinear Mapping for Data Structure Analysis. Sammon, J.W. 5, 1969, IEEE Transactions on Computers - TC, Vol. C-18, pg. 401-409. http://www.mec.ita.br/~rodrigo/Disciplinas/MB213/Sammon1969.pdf. DOI: 10.1109/T-C.1969.222678 .
37. Feature Selection for Classification. Dash, Manoranjan și Liu, Huan. 1-4, 1997, Intelligent Data Analysis - IDA, Vol. 1, pg. 131-156. http://reference.kfupm.edu.sa/content/f/e/feature_selection_for_classification__39093.pdf.
38. Adaptive membership function fusion and annihilation in fuzzy if-then rules. Song, B.G., . 1993. Second IEEE International Conference on Fuzzy Systems. Vol. 2, pg. 961 - 967. Print ISBN: 0-7803-0614-7.
39. Fuzzy ART: Fast stable learning and categorization of analog patterns by an adaptive resonance system. Carpenter, Gail A., Grossberg, Stephen și Rosen, David B. 6, 1991, Neural Networks, Vol. 4, pg. 759-771. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.64.2379&rep=rep1&type=pdf. DOI: 10.1016/0893-6080(91)90056-B .
40. Fuzzy ARTMAP with input relevances. Andonie, R și Sasu, L. 2006, IEEE Transactions on Neural Networks, Vol. 17, pg. 929–941.
41. Rule Extraction: From Neural Architecture to Symbolic Representation. Carpenter, Gail și Tan, H. A. 1, 1995, Connection Science, Vol. 7, pg. 3-27.
42. A hybrid neural network model for rule generation and its application to process fault detection and diagnosis. Tan, S. C., Lim, Chee Peng și Rao, M. V. C. 2, 2007, Engineering Applications of Artificial Intelligence - EAAI, Vol. 20, pg. 203-213. DOI: 10.1016/j.engappai.2006.06.007.
43. Rule Extraction, Fuzzy ARTMAP and medical databases. Carpenter, G. A și Tan, A.-H. Portland, Oregon; Hillsdale, NJ : Lawrence Associates, 1993. Proceedings of the World Congress on Neural Networks. pg. 501-506. http://digilib.bu.edu/journals/ojs/index.php/trs/article/view/430.
44. Controlled experiments on the web: survey and practical guide. Kohavi, Ron, . 1, s.l. : Springer, Data Mining and Knowledge Discovery, Vol. 18, pg. 140-181.

47
http://www.springerlink.com/content/r28m75k77u145115/fulltext.pdf. DOI: 10.1007/s10618-008-0114-1Open Access.
45. Cleverdon, Cyril W. și Keen, Michael. Aslib Cranfield research project - Factors determining the performance of indexing systems; Volume 2, Test results. 1966. https://dspace.lib.cranfield.ac.uk/bitstream/1826/863/2/1966e.pdf.
46. Van Rijsbergen, C. J. Information Retrieval. s.l. : Butterworth-Heinemann, 1979. ISBN-13: 978-0408709293.
47. A re-examination of text categorization methods. Yang, Yiming și Liu, Xin. 1999. Research and Development in Information Retrieval - SIGIR. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.11.9519&rep=rep1&type=pdf.
48. Analysis of recommendation algorithms for e-commerce. Sarwar, Badrul, . 2000. ACM Conference on Electronic Commerce - EC. pg. 158-167. DOI: 10.1145/352871.352887.
49. Swets, John A. EFFECTIVENESS OF INFORMATION RETRIEVAL METHODS. 1969. http://www.dtic.mil/cgi-bin/GetTRDoc?AD=AD0656340&Location=U2&doc=GetTRDoc.pdf.
50. The Meaning and Use of the Area undera Receiver Operating Characteristics (ROC) Curve. Hanley, James A. și McNeil, Barbara J. 1, April 1982, Radiology, Vol. 143, pg. 29-36. http://www.medicine.mcgill.ca/epidemiology/hanley/software/Hanley_McNeil_Radiology_82.pdf.
51. Crivat, Ioan Bogdan, . Techniques for Evaluating Recommendation Systems. 20090319330 United States of America, 2009. Application.
52. Crivat, Ioan B, Petculescu, Cristian și Netz, Amir. Efficient Column Based Data Encoding for Large Scale Data Storage. 20100030796 United States of America, 2010.
53. —. Random access in run-length encoded structures. 7952499 United States of America, 2011.
54. CHARM: An Efficient Algorithm for Closed Itemset Mining. Zaki, Mohammed Javeed și Hsiao, Ching-jiu. 2002. SIAM International Conference on Data Mining - SDM. CHARM.pdf.
55. Crivat, Ioan B., . Extensible data mining framework . 7383234 United States of America, 2008.
56. Crivat, Ioan Bogdan, . Systems and methods that facilitate data mining. 7398268 United States of America, 2008.
57. Crivat, Ioan, B, . Using a rowset as a query parameter. 7451137 United States of America, 2008.

48
58. Crivat, Ioan, Bogdan, Cristofor, Elena, D. și MacLennan, C. James. Analyzing mining pattern evolutions by comparing labels, algorithms, or data patterns chosen by a reasoning component . 7636698 United States of America, 2009.
59. Crivat, Bogdan, . Systems and methods of utilizing and expanding standard protocol. 7689703 United States of America, 2010.
60. Crivat, Ioan B, Iyer, Raman și MacLennan, James. Partitioning of a data mining training set. 7756881 United States of America, 2010.
61. Crivat, Ioan, B, MacLennan, C, James și Iyer, Raman. Goal seeking using predictive analytics. 7788200 United States of America, 2010.
62. Crivat, Ioan B, Iyer, Raman și MacLennan, C James. Detecting and displaying exceptions in tabular data. 7797264 United States of America, 2010.
63. Crivat, Ioan B, Iyer, Raman și MacLennan, C. James. Dynamically detecting exceptions based on data changes. 7797356 United States of America, 2010.
64. Crivat, Ioan B, Petculescu, Cristian și Netz, Amir. Explaining changes in measures thru data mining. 7899776 United States of America, 2011.
65. Crivat, Ioan, Bogdan, . Unstructured data in a mining model language. 7593927 United States of America, 2009.
66. Fayyad, Usama, Grinstein, Georges, G. și Wierse, Andreas. Information Visualization in Data Mining and Knowledge Discovery. San Diego, CA, USA : Academic Press, 2002. ISBN: 1-55860-689-0.
67. Han, Jiawei și Kamber, Micheline. Data Mining Concepts and Techniques. San Diego, CA, USA : Academic Press, 2001. ISBN: 1-55860-489-8.
68. Witten, Ian, H. și Frank, Eibe. Data Mining - Practical Machine Learning Tools and Techniques. San Francisco, CA, USA : Morgan Kauffman, 2005. ISBN: 0-12-088407-0.
69. Murphy, Laura W. Testimony Regarding Civil Liberties and National Security: Stopping the Flow of Power to the Executive Branch. www.house.gov. [Interactiv] 2010. [Citat: 13 6 2011.] http://judiciary.house.gov/hearings/pdf/Murphy101209.pdf.
70. Davis, Jeff. Data Mining with Access Queries. www.techrepublic.com. [Interactiv] 30 7 2002. [Citat: 13 6 2011.] http://www.techrepublic.com/article/data-mining-with-access-queries/1043734.
71. devexpress. Pivot Table® Style Data Mining Control for ASP.NET AJAX. www.devexpress.com. [Interactiv] [Citat: 13 6 2011.] http://www.devexpress.com/Products/NET/Controls/ASP/Pivot_Grid/.
72. Intel Corporation. Excerpts from A Conversation with Gordon Moore: Moore’s Law. download.intel.com. [Interactiv] 2005. [Citat: 13 6 2011.]

49
ftp://download.intel.com/museum/Moores_Law/Video-Transcripts/Excepts_A_Conversation_with_Gordon_Moore.pdf.
73. Walter, Chip. Kryder's Law. www.scientificamerican.com. [Interactiv] 25 7 2005. [Citat: 13 6 2011.] http://www.scientificamerican.com/article.cfm?id=kryders-law.
74. Gantz, John și Reinsel, David. The Digital Universe Decade – Are You Ready? www.idcdocserv.com. [Interactiv] 5 2010. [Citat: 13 6 2011.] http://idcdocserv.com/925.
75. Bohn, Roger, E. și Short, James, E. How Much Information? 2009. hmi.ucsd.edu. [Interactiv] January 2010. [Citat: 13 6 2011.] http://hmi.ucsd.edu/pdf/HMI_2009_ConsumerReport_Dec9_2009.pdf.
76. Knowledge Discovery and Data Mining: Towards a Unifying Framework. Fayyad, Usama, Piatetsky-Shapiro, Gregory și Smyth, Padhraic. 1996. KDD.
77. Mining quantitative association rules in large relational tables. Srikant, Ramakrishnan și Agrawal, Rakesh. 1996. International Conference on Management of Data - SIGMOD. Vol. 25, pg. 1-12. srikant96.pdf. DOI: 10.1145/233269.233311 .
78. A Tree Projection Algorithm For Generation of Frequent Itemsets. Agarwal, Ramesh, C., Aggarwal, Charu C. și Prasad, V.V.V. 1999, Journal of Parallel and Distributed Computing .
79. Real world performance of association rule algorithms. Zheng, Zijian, Kohavi, Ron și Mason, Llew. 2001. Knowledge Discovery and Data Mining - KDD. pg. 401-406. RealWorldPerf01.pdf.
80. Amazon.com recommendations: item-to-item collaborative filtering. Linden, Greg, Smith, B. și York, J. 1, January 2003, Internet Computing, IEEE , Vol. 7, pg. 76 - 80. ISSN: 1089-7801.
81. The area above the ordinal dominance graph and the area below the receiver operating characteristic graph. Bamber, D. 1975, Journal of Mathematical Psychology, Vol. 12, pg. 387-415.
82. Methods and metrics for cold-start recommendations. Schein, Andrew I., . 2002. Research and Development in Information Retrieval - SIGIR. MethodMetricsColdStart.pdf.
83. Overview of the TREC 2002 Question Answering Track. Voorhees, Ellen M. 2002. Text Retrieval Conference - TREC. http://trec.nist.gov/pubs/trec11/papers/QA11.pdf.
84. Evaluating Performance of Recommender Systems: An Experimental Comparison. Fouss, François și Saerens, Marco. 2008. Web Intelligence - WI. pg. 735-738.

50
85. Effective personalization based on association rule discovery from web usage data. Mobasher, Bamshad, . 2001. Web Information and Data Management - WIDM. pg. 9-15. DOI: 10.1145/502932.502935 .
86. Netflix. Netflix Prize. [Interactiv] Netflix. [Citat: 27 6 2011.] http://www.netflixprize.com.
87. A Survey of Collaborative Filtering Techniques. Su, Xiaoyuan și Khoshgoftaar, Taghi M. January 2009, New York, NY, USA : Hindawi Publishing Corp, 2009, Advances in Artificial Intelligence. http://www.hindawi.com/journals/aai/2009/421425/. 10.1155/2009/421425.
88. Using collaborative filtering to weave an information tapestry. Goldberg, David, . 12, 1992, Communications of the ACM - CACM, Vol. 35, pg. 61-70. http://www.ischool.utexas.edu/~i385d/readings/Goldberg_UsingCollaborative_92.pdf.
89. Item-based collaborative filtering recommendation algorithms. Sarwar, Badrul, . 2001. World Wide Web Conference Series - WWW. pg. 285-295. http://glaros.dtc.umn.edu/gkhome/fetch/papers/www10_sarwar.pdf. DOI: 10.1145/371920.372071 .
90. Robustness of collaborative recommendation based on association rule mining. Sandvig, Jeff J., Mobasher, Bamshad și Burke, Robin D. 2007. Conference on Recommender Systems - RecSys. pg. 105-112. http://maya.cs.depaul.edu/~mobasher/papers/smb-recsys07.pdf. DOI: 10.1145/1297231.1297249 .
91. Evaluating collaborative filtering recommender systems. Herlocker, Jonathan L., . 1, 2004, ACM Transactions on Information Systems - TOIS, Vol. 22, pg. 5-53. http://web.engr.oregonstate.edu/~herlock/papers/tois2004.pdf. DOI: 10.1145/963770.963772 .
92. A Survey of Accuracy Evaluation Metrics of Recommendation Tasks. Gunawardana, Asela și Shani, Guy. 2009, Journal of Machine Learning Research - JMLR, Vol. 10, pg. 2935-2962. http://research.microsoft.com/pubs/118124/gunawardana09a.pdf. DOI: 10.1145/1577069.1755883 .
93. Microsoft Corp. Data Mining Add-Ins for Office 2007. www.microsoft.com. [Interactiv] Microsoft Corporation, 2008. [Citat: 27 6 2011.] http://www.microsoft.com/sqlserver/2008/en/us/data-mining-addins.aspx.
94. Predixion Software. Predixion Insight for Excel. PredixionSoftware.com. [Interactiv] Predixion Software, 2011. [Citat: 27 6 2011.] https://www.predixionsoftware.com/predixion/Products.aspx.

51
95. 11 Ants Analytics. 11 Ants Model Builder. www.11antsanalytics.com. [Interactiv] 11 Ants Analytics. [Citat: 27 6 2011.] http://www.11antsanalytics.com/products/default.aspx.
96. IBM. CRISP-DM 1.0 -- Step by Step data mining guide. ftp://public.dhe.ibm.com. [Interactiv] IBM. [Citat: 27 6 2011.] ftp://public.dhe.ibm.com/common/ssi/ecm/en/ytw03084usen/YTW03084USEN.PDF.
97. Microsoft Corp. Data Mining Extensions (DMX) Reference. MSDN.microsoft.com. [Interactiv] [Citat: 28 6 2011.] http://msdn.microsoft.com/en-us/library/ms132058.aspx.
98. Learning Collaborative Information Filters. Billsus, Daniel și Pazzani, Michael J. 1998. International Conference on Machine Learning - ICML. pg. 46-54. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.40.4781&rep=rep1&type=pdf.
99. Jump-starting movielens: user benefits of starting a collaborative filtering system with "dead data". Dahlen, B. J., . s.l. : University of Minnesota, 1998.
100. Comparison of fuzzy reasoning methods. Mizumoto, M. și Zimmermann, H. J. 3, 1982, Fuzzy Sets and Systems - FSS, Vol. 8, pg. 253-283. DOI: 10.1016/S0165-0114(82)80004-3 .
101. Approximate reasoning by linear rule interpolation and general approximation. Kóczy, László T. și Hirota, Kaoru. 3, 1993, International Journal of Approximate Reasoning - IJAR , Vol. 9, pg. 197-225. DOI: 10.1016/0888-613X(93)90010-B .
102. Learning fuzzy classification rules from labeled data. Roubos, Johannes A., Setnes, Magne și Abonyi, János. 1-2, 2003, Information Sciences - ISCI, Vol. 150, pg. 77-93. http://sci2s.ugr.es/keel/pdf/specific/articulo/15-E.pdf.
103. Crossing the Rubicon: A Generic Intelligent Advisor. Andonie, R, Russo, J.E. și Dean, R. 2007, International Journal of Computers, Communications & Control, Vol. 2, pg. 5-16. http://www.cwu.edu/~andonie/MyPapers/Advisor%202005.pdf.
104. Efficient Mining of Association Rules Using Closed Itemset Lattices. Pasquier, Nicolas, . 1, 1999, Information Systems - IS, Vol. 24, pg. 25-46. http://cchen1.csie.ntust.edu.tw:8080/students/2009/Efficient%20mining%20of%20association%20rules%20using%20closed%20itemset%20lattices.pdf.
105. Discovering Frequent Closed Itemsets for Association Rules. Pasquier, Nicolas, . 1999, International Conference on Database Theory - ICDT, pg. 398-416. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.37.1102&rep=rep1&type=pdf. DOI: 10.1007/3-540-49257-7_25.

52
106. An Efficient Algorithm for Mining Association Rules in Large Databases. Savasere, Ashok, Omiecinski, Edward și Navathe, Shamkant B. 1995. Very large Databases VLDB. pg. 432-444. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.103.5437&rep=rep1&type=pdf.
107. CiteSeerX - Scientific Literature Digital Library and Search Engine. http://citeseerx.ist.psu.edu/. [Interactiv] U. of Arkansas, King Saud U., National U. of Singapore , 2011. http://citeseerx.ist.psu.edu/.
108. Microsoft Academic Search. Microsoft Academic Search. [Interactiv] Microsoft Corp. http://academic.research.microsoft.com/.
109. Google Scholar. Google Scholar. [Interactiv] Google. http://scholar.google.com/.
110. Reduction of fuzzy control rules by means of premise learning - method and case study. Xiong, N. și Litz, Lothar. 2, 2002, Fuzzy Sets and Systems - FSS, Vol. 132, pg. 217-231. http://www.sciencedirect.com/science/article/pii/S0165011402001124. DOI: 10.1016/S0165-0114(02)00112-4 .
111. Discovery of Multiple-Level Association Rules from Large Databases. Han, Jiawei și Fu, Yongjian. 1995. Very Large Databases - VLDB. pg. 420-431. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.64.3214&rep=rep1&type=pdf.

53
Publicații, brevete și cereri de brevet de autor
Cărţi 1. MacLennan Jamie, Crivat Bogdan and Tang ZhaoHui Data Mining with
Microsoft SQL Server 2008 [Book]. - Indianapolis, Indiana, United States of America : Wiley Publishing, Inc., 2009. - 978-0-470-27774-4, tradusă in limbile rusă (BHV-Petersburg Publishing House. Russia, 2009) și chineză
2. Crivat Bogdan, Grewal Jasjit Singh, Kumar Pranish and Lee Eric ATL Server: High Performance C++ on .Net [Book]. – Berkeley, CA, United States of America : APress, Inc., 2003. - 1-59059-128-3.
Articole 3. Andonie Razvan, Crivat B [et al.] Fuzzy ARTMAP rule extraction in
computational chemistry [Conference] // IJCNN. - 2009. - pp. 157-163. - DOI: 10.1109/IJCNN.2009.5179007. (Best Poster Award Runner-up Award.)
4. Crivat, Ioan Bogdan SQL Server Data Mining Programability [Online] March 2005 [Cited: 6 22, 2011.] http://msdn.microsoft.com/en-US/library/ms345148(v=SQL.90).aspx.
Brevete Emise (USPTO) 5. Crivat Ioan B, Petculescu Cristian and Netz Amir Explaining changes in
measures thru data mining [Patent] : 7899776. - United States of America, 2011.
6. Crivat Ioan B, Petculescu Cristian and Netz Amir Random access in run-length encoded structures [Patent] : 7952499. - United States of America, 2011.
7. Crivat Ioan B, Iyer Raman and MacLennan C James Detecting and displaying exceptions in tabular data [Patent] : 7797264. - United States of America, 2010.
8. Crivat Ioan B, Iyer Raman and MacLennan C. James Dynamically detecting exceptions based on data changes [Patent] : 7797356. - United States of America, 2010.

54
9. Crivat Ioan B, Iyer Raman and MacLennan James Partitioning of a data mining training set [Patent] : 7756881. - United States of America, 2010.
10. Crivat Ioan B, Petculescu Cristian and Netz Amir Efficient Column Based Data Encoding for Large Scale Data Storage [Patent] : 20100030796 . - United States of America, 2010.
11. Crivat Ioan B. [et al.] Extensible data mining framework [Patent] : 7383234. - United States of America, 2008.
12. Crivat Ioan Bogdan [et al.] Systems and methods that facilitate data mining [Patent] : 7398268. - United States of America, 2008.
13. Crivat Ioan, B [et al.] Using a rowset as a query parameter [Patent] : 7451137. - United States of America, 2008.
14. Crivat Ioan, B, MacLennan C, James and Iyer Raman Goal seeking using predictive analytics [Patent] : 7788200. - United States of America, 2010.
15. Crivat Ioan, Bogdan [et al.] Unstructured data in a mining model language [Patent] : 7593927. - United States of America, 2009.
16. Crivat Ioan, Bogdan, Cristofor Elena, D. and MacLennan C. James Analyzing mining pattern evolutions by comparing labels, algorithms, or data patterns chosen by a reasoning component [Patent] : 7636698. - United States of America, 2009.
17. Crivat Bogdan [et al.] Systems and methods of utilizing and expanding standard protocol [Patent] : 7689703. - United States of America, 2010.
Cereri de brevet în aşteptare (USPTO) 18. Crivat Ioan Bogdan [et al.] Techniques for Evaluating Recommendation
Systems [Patent Application] : 20090319330 - United States of America, 2009.

Aplicații ale inteligenței computaționale in Data Mining
CONDUCĂTOR ȘTIINȚIFIC
Prof.univ.dr.mat. Răzvan ANDONIE
DOCTORAND:
Ioan Bogdan CRIVĂȚ
Rezumat
Obiectivul acestei lucrări este realizarea unei sinteze a eforturilor recente în domeniul extracției si prelucrării de reguli predictive, precum şi prezentarea unor contribuții originale în domeniu.
Primele două capitole ale lucrării prezintă domeniul data mining și rezultate recente în aria extracției de reguli. Capitolul al doilea, „Utilizarea regulilor in Data Mining”, prezintă tehnologia data mining cu accent pe extracţia de reguli. Vom discuta despre regulile de asociere şi proprietăţile lor, precum şi despre unele noţiuni de modelare fuzzy şi reguli de tip fuzzy. Capitolul al treilea, „Metode de extracție a regulilor”, prezintă cele mai frecvent utilizate metode pentru extracția de reguli. Vom începe cu prezentarea unor algoritmi special concepuți pentru extracția de reguli, cum ar fi apriori şi FP-Growth. Vom discuta unele dintre problemele ridicate de acești algoritmi, precum şi soluţii pentru aceste probleme. Prezentăm apoi câteva tehnici pentru extracția de reguli din șabloane detectate de alți algoritmi, in special din rețelele neuronale, un subiect de interes în capitolul următor.
Următoarele capitole conțin conțin contribuțiile originale ale lucrării. Capitolul al patrulea, „Contribuții la generalizarea sistemelor de reguli” descrie eforturi recente pentru simplificarea sistemelor de reguli, cu accent pe analiza similarității dintre reguli. Este propusă o metodă nouă de simplificare a sistemelor de reguli, metodă dezvoltată inițial pentru reguli detectate de un predictor Fuzzy ARTMAP. Metoda este apoi extinsă pentru sisteme de reguli extrase de clase mai largi de algoritmi cum ar fi apriori. Sistemele de recomandare constituie una dintre cele mai frecvente aplicații pentru extracția de reguli. Capitolul al cincilea, „Măsurarea acurateții predicțiilor de utilizare produse de sisteme de recomandare”, analizează metricile existente de evaluare a acestor sisteme de recomandare și introduce un instrument intutiv de evaluare și comparare a performanței lor.
Capitolul al șaselea al tezei conține rezultate experimentale atât pentru metodele de generalizare de reguli cât și pentru instrumentul de evaluare a sistemelor de recomandare.
Ultimul capitol prezintă concluziile tezei cât și direcții promițătoare de cercetare deschise de rezultatele prezentate in teză.
CUVINTE CHEIE: data mining, reguli asociative, acuratețe, simplificarea regulilor, generalizarea regulilor, evaluarea sistemelor de recomandare

Applications of computational intelligence in data mining
ADVISOR
Prof.univ.dr.mat. Răzvan ANDONIE
AUTHOR
Ioan Bogdan CRIVĂȚ
Abstract
The objective of this work is a synthesis of some of the recent efforts in the domain of predictive rules extraction and processing as well as a presentation of certain original contributions to the area.
The first two chapters of the theses present data mining and the some recent results in the area of rule extraction. The second chapter, “Rules in the Data Mining Context” introduces data mining with a focus on rule extraction. The CRISP-DM standard for the life cycle of a data mining project is described, together with some business problems commonly approached with data mining techniques. We focus, then, on rules in data mining. We discuss association rules and their properties as well as some notions of fuzzy modeling and fuzzy rules. The third chapter, “Methods for Rules Extraction”, presents the most commonly used methods for extracting rules. We start with by presenting some algorithms designed specifically for rule extraction, such as apriori and FP-Growth. We discuss some of the problems raised by these algorithms as well as solutions identified for those problems. Next, we present some techniques for extracting rules from patterns detected by other algorithms and focus on rule extractions from neural networks, a topic of significant interest in the next chapter. A special section describes the specifics of rules analysis in Microsoft SQL Server.
The following chapters contain some original contributions in their context. The fourth chapter, “Contributions to Rules Generalization”, reviews some of the existing methods for simplifying rule models, and focuses on measures for detecting rules similarity. Similar rules can be merged, resulting in simpler rule systems. By interpreting one of these similarity measures from the data mining rules analysis perspective, a novel generalization method is proposed, which reduces the complexity of certain rule sets and improves the interpretability of the model. The method, introduced for very specific rules detected by a Fuzzy ARTMAP predictor, is extended for rule sets discovered by rule detection algorithms such as apriori. The fifth chapter, “Measuring the Usage Prediction Accuracy of Recommendation Systems”, presents the area of accuracy measurements for recommendation systems, one of the most common applications of association rules. A new instrument for assessing the accuracy of a recommender is presented, together with some experimental results. The sixth chapter presents some experimental results for the techniques introduced in the third and fourth chapters. The results are detailed for datasets used in presenting the methods or compared against results from other authors. The last chapter contains conclusions of this thesis as well as certain directions for further research.

Curriculum Vitae
Ioan Bogdan Criva t
Adresă de contact: [email protected]
Educație
2006-2011: Doctorand Universitatea “Transilvania” din Brașov, România
Facultatea de Inginerie Electrică și Știința Calculatoarelor Specializare: Data Mining, Inteligență computațională, învățare automată
1993-1997: Licențiat în informatică Facultatea de Matematică, secția Informatică, Universitatea București, București, România Specializare (lucrare de licență): Tehnici de compilare / Corectitudinea formală a algoritmilor
1997-1999: student la Facultatea de Ingineria și Managementul Sistemelor de Producție Universitatea “Politehnica”, București, România (studii întrerupte în 1999 ca urmare a plecării din țară)
Experiență profesională
2010 – 2011: Principal Software Architect, Predixion Software, Redmond, WA, USA
2001 – 2010:
Sr. Software Design Engineer / Principal. Software Design Engineer,
SQL Server Data Mining, Microsoft Corporation, Redmond, WA, USA
1999 – 2001:
Software Design Engineer, Visual C++ Product Unit,
Microsoft Corporation, Redmond, WA, USA 1997 – 1999:
Software Engineer / Project Manager,
SOFTWIN SRL, Bucharest, Romania
Realizări profesionale
- 13 brevete de invenție acordate de Biroul de Patente al Statelor Unite (USPTO), 3 aplicații de brevet în curs de acordare
- Două volume publicate de prestigioase edituri tehnice (APress/Wiley); lucrarea de Data Mining tradusă în limbile rusă și chineză
- Articole publicate la conferințe și în reviste tehnice, dintre care numeroase în domeniul SQL Server Data Mining, prezentări frecvente la conferințe profesionale organizate de Microsoft Corporation

Curriculum Vitae
Ioan Bogdan Criva t
Contact: [email protected]
Education
2006-2011: Ph.D. Student “Transilvania” University, Brașov, Romania
Faculty of Electrical Engineering and Computer Science Specialization: Data Mining, Computational Intelligence, Machine Learning
1993-1997: Bachelor of Science, Mathematics and Computer Science, University of Bucharest, Bucharest, Romania Specialization (graduation paper): Compilation Techniques, Formal Proof for Algorithm Correctness
1997-1999: Pursued an engineering degree in the Engineering and Management of Production Systems, “Politehnica” University, Bucharest, Romania (Interrupted in 1999 upon moving to USA)
Professional Experience
2010 – 2011: Principal Software Architect, Predixion Software, Redmond, WA, USA
2001 – 2010:
Sr. Software Design Engineer / Principal. Software Design Engineer,
SQL Server Data Mining, Microsoft Corporation, Redmond, WA, USA
1999 – 2001:
Software Design Engineer, Visual C++ Product Unit,
Microsoft Corporation, Redmond, WA, USA 1997 – 1999:
Software Engineer / Project Manager,
SOFTWIN SRL, Bucharest, Romania
Professional achievements
- 13 patents granted by United States Patent Office, 3 pending applications - Published two technical books with APress and Wiley publishing houses,
translations in Russian/Chinese - Numerous papers in technical magazines, frequent talks on data mining in
various professional conferences in the Microsoft Corporation evironment

![RELA}II SPORTIVE INTERNA}IONALE - anst.gov.ro International Sports... · Tot `n aceast\ perioad\ a continuat procesul de constituire `n cadrul federa]iilor interna]ionale a organismelor](https://img.pdfslide.us/doc/110x75/5e09d6803f9072767b2754de/relaii-sportive-internaionale-anstgovro-international-sports-tot-n-aceast.jpg)



























