Embed Size (px)
Citation preview

Matei Zaharia@matei_zaharia
Apache Spark 2.0

What is Apache Spark?
Open source data processing engine for clusters• Generalizes MapReduce model
Rich set of APIs and libraries• In Scala, Java, Python and R
Large community of 1000+contributors
SQLStreaming ML Graph
…
Apache Spark, Spark and Apache are trademarks of the Apache Software Foundation

Relationship with Apache Mesos
The two projects go back a long time!
2008: Mesos started as UC Berkeley research project



Relationship with Apache Mesos
The two projects go back a long time!
2008: Mesos started as UC Berkeley research
2009: Spark started as example framework for iterative apps• About 3 hours’ drive from here

Apache Spark Vision
1) Concise, high-level API• Functional programming in Scala, Python, Java, etc
2) Unified engine for big data processing• Combines batch, interactive, and streaming

Motivation: Concise API
Much of data analysis is exploratory / interactive
Spark solution: Resilient Distributed Datasets (RDDs)• “Distributed collection” abstraction with simple functional API
lines = spark.textFile(“hdfs://...”) // RDD[String]
points = lines.map(line => parsePoint(line)) // RDD[Point]
points.filter(p => p.x > 100).count()
Higher level APIs: DataFrames, ML pipelines

MapReduce
General batchprocessing
Pregel
DremelPresto
Storm
GiraphDrill
ImpalaS4 . . .
Specialized systemsfor new workloads
Motivation: Unification
Hard to manage, tune, deployHard to combine in pipelines

MapReduce
Pregel
DremelPresto
Storm
GiraphDrill
ImpalaS4
Specialized systemsfor new workloads
General batchprocessing
Unified engine
Motivation: Unification
?. . .

Built-In Libraries
SQL + DataFrames Streaming MLlib
Spark Core (RDDs)
GraphX

Combining Libraries# Load data using SQLctx.jsonFile(“tweets.json”).registerTempTable(“tweets”)val points = ctx.sql(“select latitude, longitude from tweets”)
# Train a machine learning modelval model = KMeans.train(points, 10)
# Apply it to a streamctx.twitterStream(...)
.map(t => (model.predict(t.location), 1))
.reduceByWindow(“5s”, (a, b) => a+b)

Apache Spark 2.0
Next major release, coming in June• In development since January of this year
Remains highly compatible with Spark 1.X• Small changes to reduce binary dependencies

Major Features in 2.0
Project Tungsten5-10x speedups
for structured APIs
Structured Streaminghigher-level
streaming engine
Machine LearningModel Export

Major Features in 2.0
Project Tungsten5-10x speedups
for structured APIs
Structured Streaminghigher-level
streaming engine
Machine LearningModel Export

What are Structured APIs?
New set of high-level APIs (DataFrames and Datasets) that act on structured data, i.e. records with a known schema
• Enable much more efficient implementation
Original API: Java functions on Java objects (hard to analyze!)
Structured APIs: declarative operators on structured records

Example: DataFrames
DataFrames hold rows with a known schema and offer relational operations on them through a DSL
val c = new HiveContext()val users = c.sql(“select * from users”)
val maUsers = users(users(“state”) === “MA”)
maUsers.count()
maUsers.groupBy(“name”).avg(“age”)
maUsers.as[User] // Dataset[User].map(u => u.name.toUpper) // Dataset[String]
Expression AST

What Structured APIs Enable
1. Compact binary representation• Compressed columnar format; storage outside Java heap
2. Optimization across operators (join ordering, pushdown, etc)
3. Runtime code generation

Space Usage
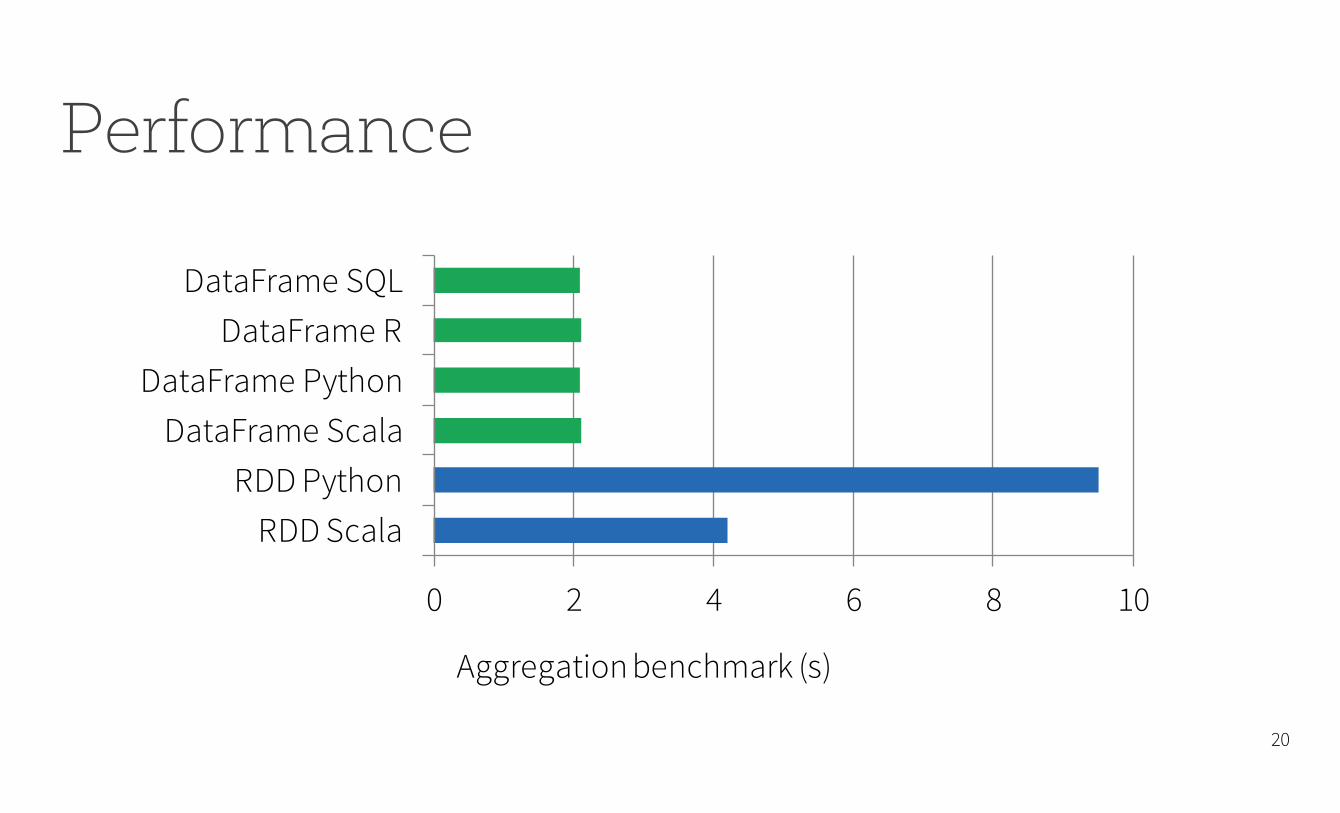
Performance
20
0 2 4 6 8 10
RDD ScalaRDD Python
DataFrame ScalaDataFrame Python
DataFrame RDataFrame SQL
Aggregation benchmark (s)

New in 2.0
Whole-stage code generation• Fuse across multiple operators
Spark 1.6 14Mrows/s
Spark 2.0 125Mrows/s
Parquetin 1.6
11Mrows/s
Parquetin 2.0
90Mrows/s
Optimized input / output• Apache Parquet + built-in cache
Automatically applies to SQL, DataFrames & Datasets

Major Features in 2.0
Project Tunsgten5-10x speedups
for structured APIs
Structured Streaminghigher-level
streaming engine
Machine LearningModel Export

Structured Streaming
High-level streaming API built on DataFrames• Event time, windowing, sessions, sources & sinks
Also supports interactive & batch queries• Aggregate data in a stream, then serve using JDBC• Change queries at runtime• Build and apply ML models Not just streaming, but
“continuous applications”
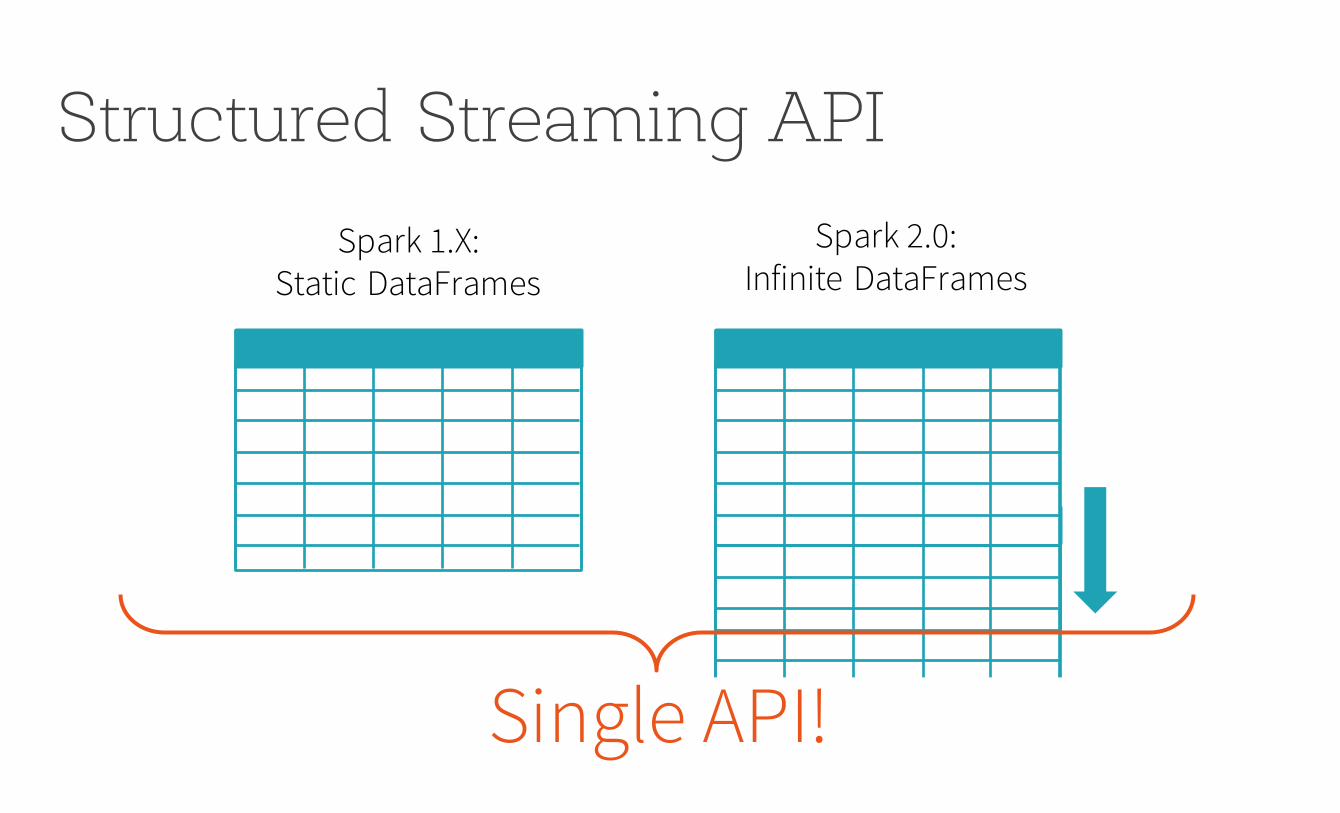
Spark 2.0:Infinite DataFrames
Spark 1.X:Static DataFrames
Single API!
Structured Streaming API

logs = ctx.read.format("json").open("s3://logs")
logs.groupBy(“userid”, “hour”).avg(“latency”)
.write.format("jdbc")
.save("jdbc:mysql//...")
Example: Batch Aggregation

logs = ctx.read.format("json").stream("s3://logs")
logs.groupBy(“userid”, “hour”).avg(“latency”)
.write.format("jdbc")
.startStream("jdbc:mysql//...")
Example: Continuous Aggregation
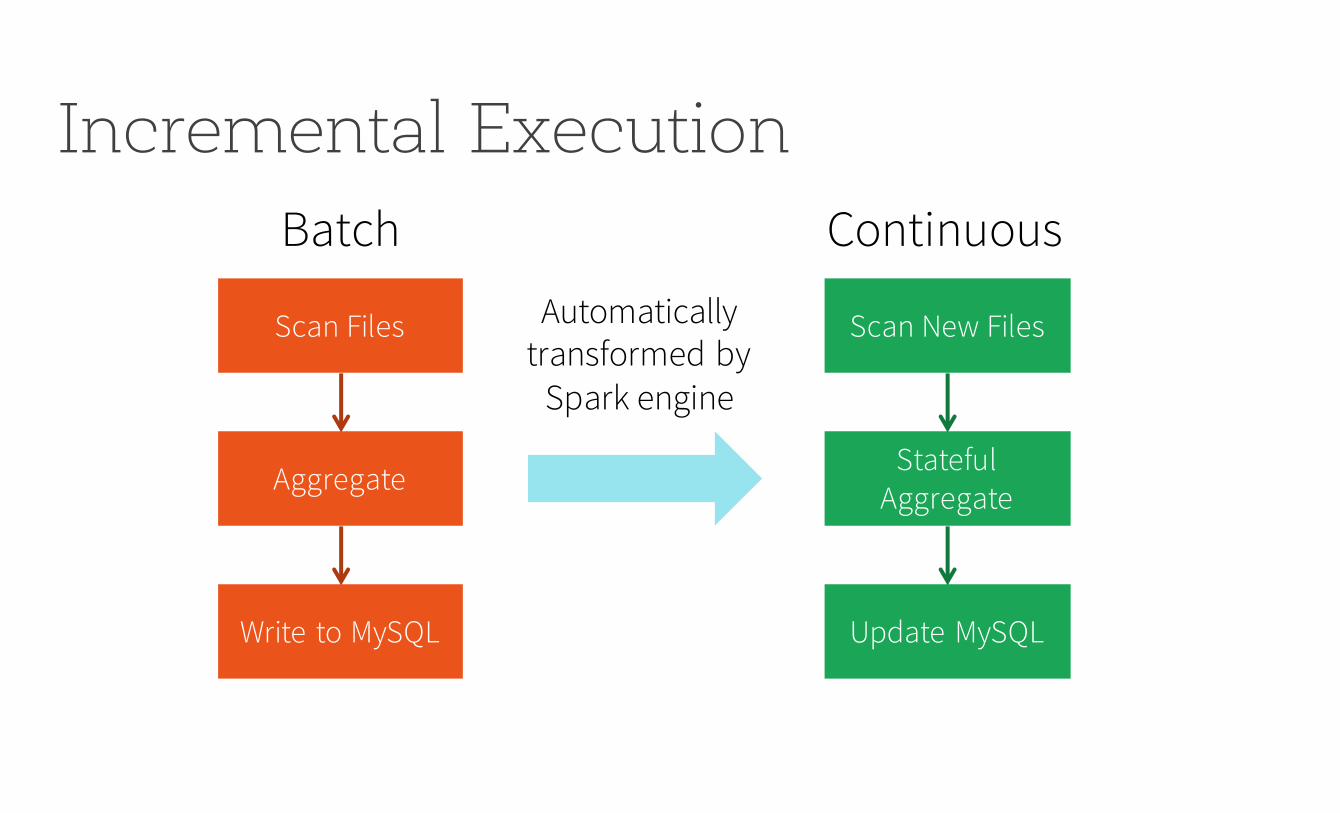
Incremental Execution
Scan Files
Aggregate
Write to MySQL
Scan New Files
StatefulAggregate
Update MySQL
Batch ContinuousAutomatically
transformed bySpark engine

Major Features in 2.0
Project Tunsgten5-10x speedups
for structured APIs
Structured Streaminghigher-level
streaming engine
Machine LearningModel Export

ML Model Export
I trained a great ML model… but how can I call it in production?
Model export allows saving & loading entire ML pipelines (including feature transformation steps)
tinyurl.com/ml-persistence, SPARK-6725

Conclusion
Apache Spark 2.0 continues goal of a unified, high level API for big data
Part of a great ecosystem with Apache Mesos, Cassandra, Kafka, …
Try the {unfinished, unstable} 2.0 preview release: spark.apache.org

Want to Learn Apache Spark?
Databricks Community Edition offers free hands-on tutorials
databricks.com/ce.





























