Embed Size (px)
Citation preview

#Dataflow @martin_gorner
“No one at Google uses MapReduce anymore”
Cloud Dataflow,the Dataflow model and
parallel processing in 2016.
Martin Görner

#Dataflow @martin_gorner
Before we start...
(QuickGoogle BigQuery
demo)

#Dataflow @martin_gorner
Flume Java (2010)The Dataflow Model (2015) Millwheel (2013)
#Dataflow @martin_gorner
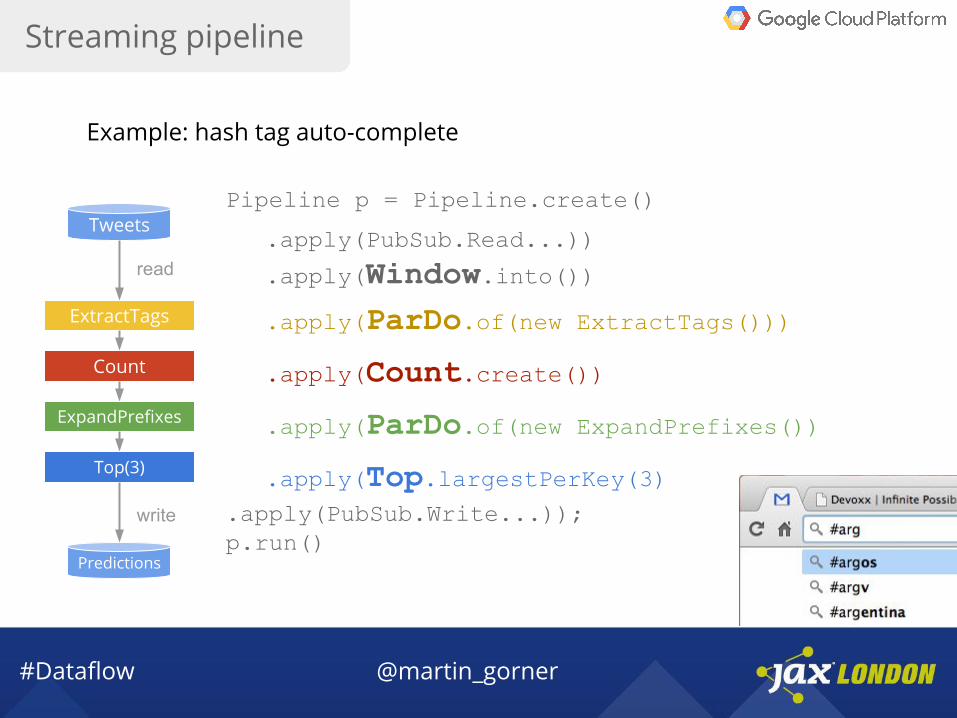
Streaming pipeline
Example: hash tag auto-complete
Tweets
Predictions
read #argentina scores, my #art project, watching #armenia vs #argentina
ExtractTags #argentina #art #armenia #argentina
Count (argentina, 5M) (art, 9M) (armenia, 2M)
ExpandPrefixes a->(argentina,5M) ar->(argentina,5M) arg->(argentina,5M) ar->(art, 9M) ...
Top(3)
write
a->[apple, art, argentina] ar->[art, argentina, armenia]
.apply(PubSub.Read...))
.apply(Window.into())
.apply(ParDo.of(new ExtractTags()))
.apply(Count.create())
.apply(ParDo.of(new ExpandPrefixes())
.apply(Top.largestPerKey(3)
Pipeline p = Pipeline.create()
.apply(PubSub.Write...));p.run()
#Dataflow @martin_gorner
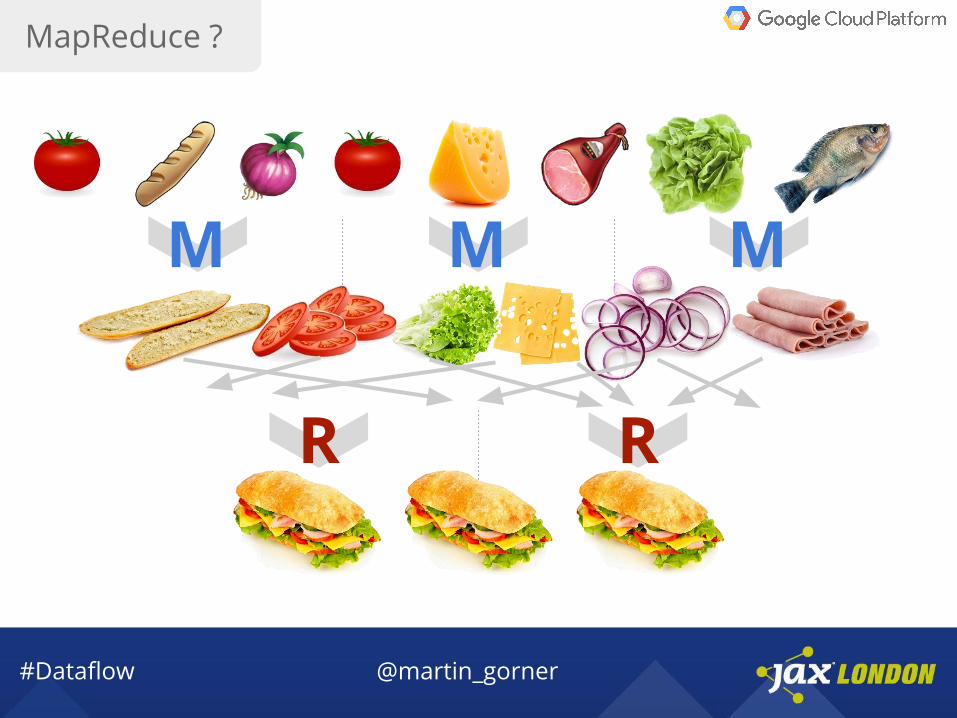
MapReduce ?
M M M
R R
#Dataflow @martin_gorner
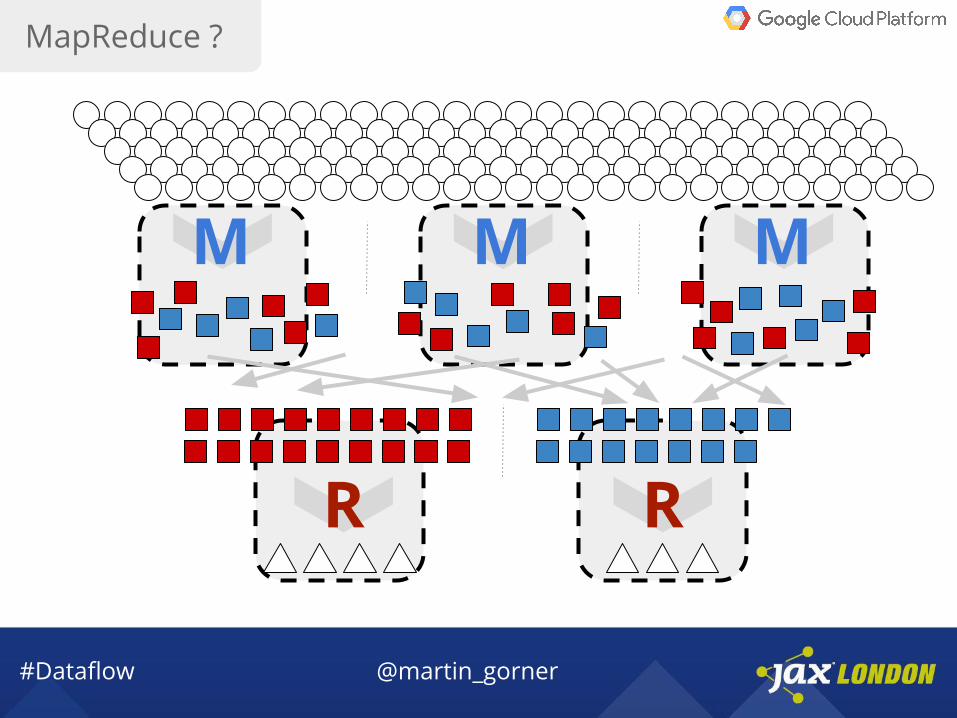
M M M
R R
MapReduce ?
#Dataflow @martin_gorner
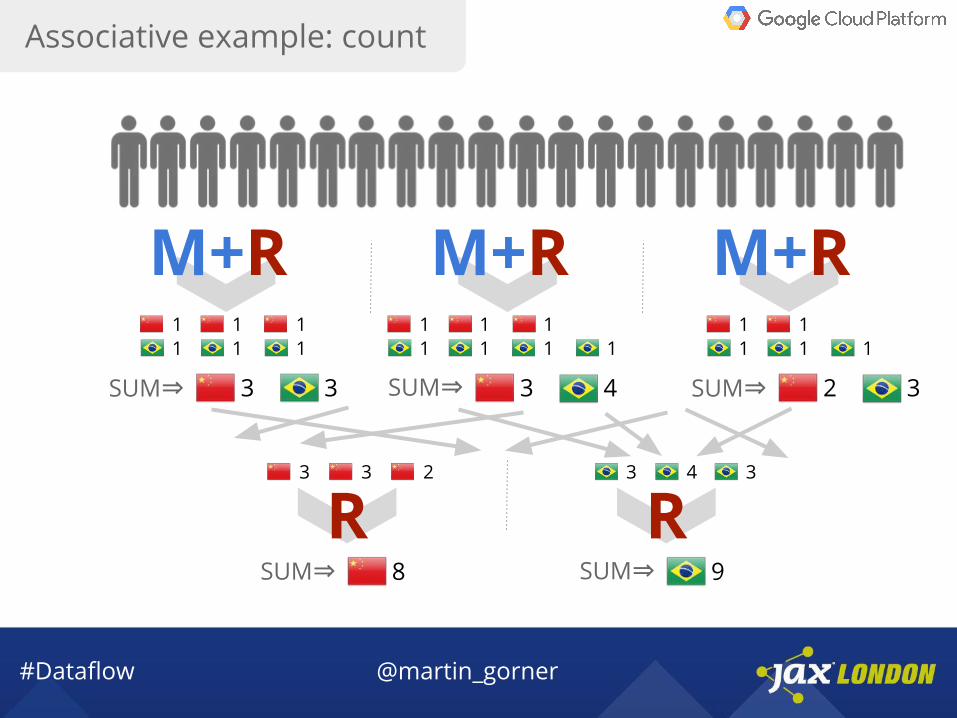
Associative example: count
SUM⇒ SUM⇒ 2SUM⇒3 4 33 3
R RSUM⇒ SUM⇒ 98
M+RM+RM+R1 1 1 1 1 1 11
1111111 111
3 3 2 3 4 3

#Dataflow @martin_gorner
Dataflow programming model
PCollection<T>
PaDo(DoFn) in: PCollection<T>out: PCollection<S>
GroupByKeyin: PCollection<KV<K,V>> //multimapout: PCollection<KV<K,Collection<V>>> //unimap
Combine(CombineFn)in: PCollection<KV<K,Collection<V>>> //unimapout: PCollection<KV<K,V>> //unimap
Flatten in: PCollection<T>, PCollection<T>, ...out: PCollection<T>

#Dataflow @martin_gorner
reinventing Count
Count in: PCollection<T>out: PCollection<KV<T,Integer>> //unimap
ParDo: T => KV<T, 1>
GroupByKey: PCollection<KV<<T, 1>> // multimap => PCollection<KV<<T,Collection<1>>> // unimap
Combine(Sum): => PCollection<KV<<T,Integer>>

#Dataflow @martin_gorner
reinventing JOIN
joinin: two multimaps with same key typePCollection<KV<<K,V>>, PCollection<KV<<K,W>>out: a unimapPCollection<KV<<K, Pair<Collection<V>,Collection<W>>>>
ParDo: KV<K,V> => KV<K, TaggedUnion<V,W>> KV<K,W> => KV<K, TaggedUnion<V,W>>
Flatten: => PCollection<KV<<K, TaggedUnion<V,W>>> //multimap
GroupByKey: => PCollection<KV<K, Collection<TaggedUnion<V,W>>>>//unimap
ParDo: final type transform => PCollection<KV<<K, Pair<Collection<V>, Collection<W>>>>
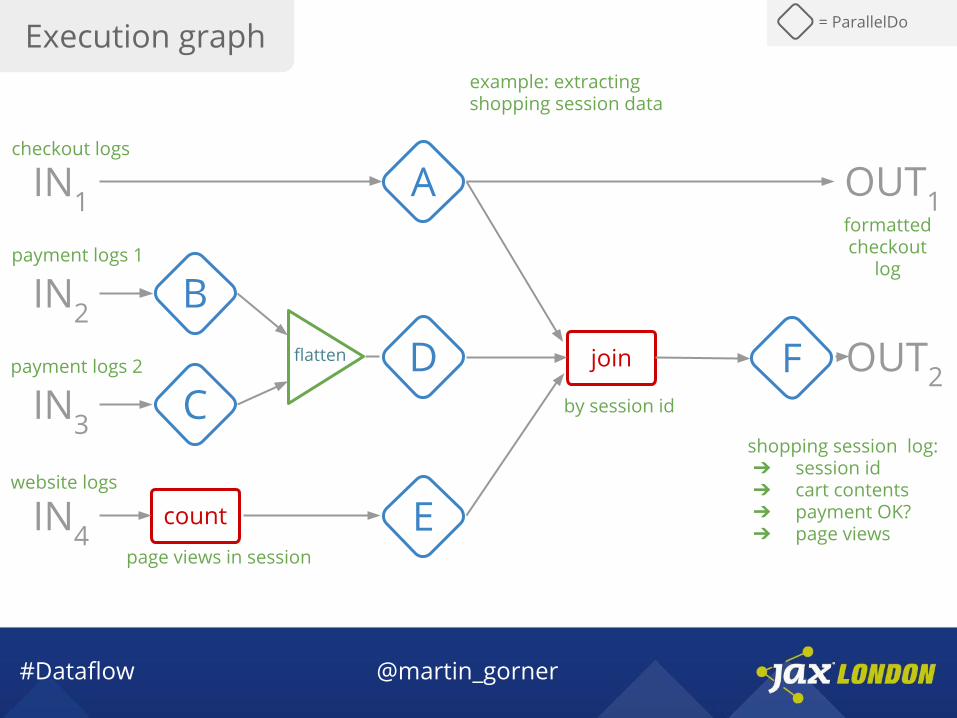
#Dataflow @martin_gorner
join
IN1
IN2
IN3
IN4
OUT1
OUT2C
A
Dflatten FB
= ParallelDo
count E
payment logs 1
payment logs 2
website logs
page views in session
formatted checkout
log
shopping session log:➔ session id➔ cart contents➔ payment OK?➔ page views
by session id
checkout logs
example: extracting shopping session data
Execution graph
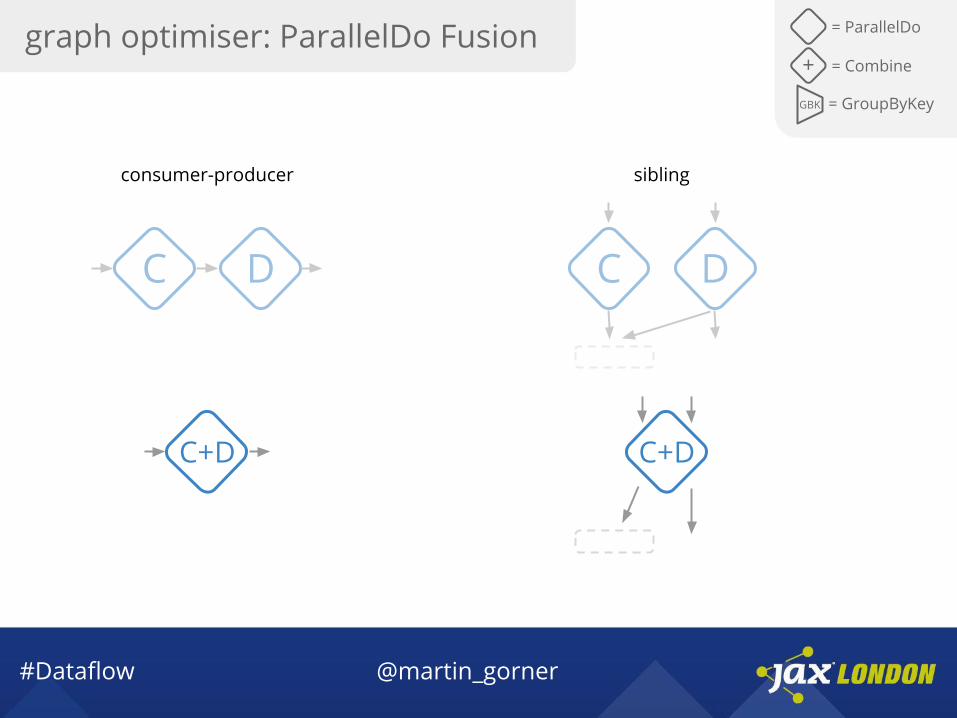
#Dataflow @martin_gorner
= ParallelDo
GBK = GroupByKey
+ = Combine
C D
C+D
consumer-producer sibling
C D
C+D
graph optimiser: ParallelDo Fusion
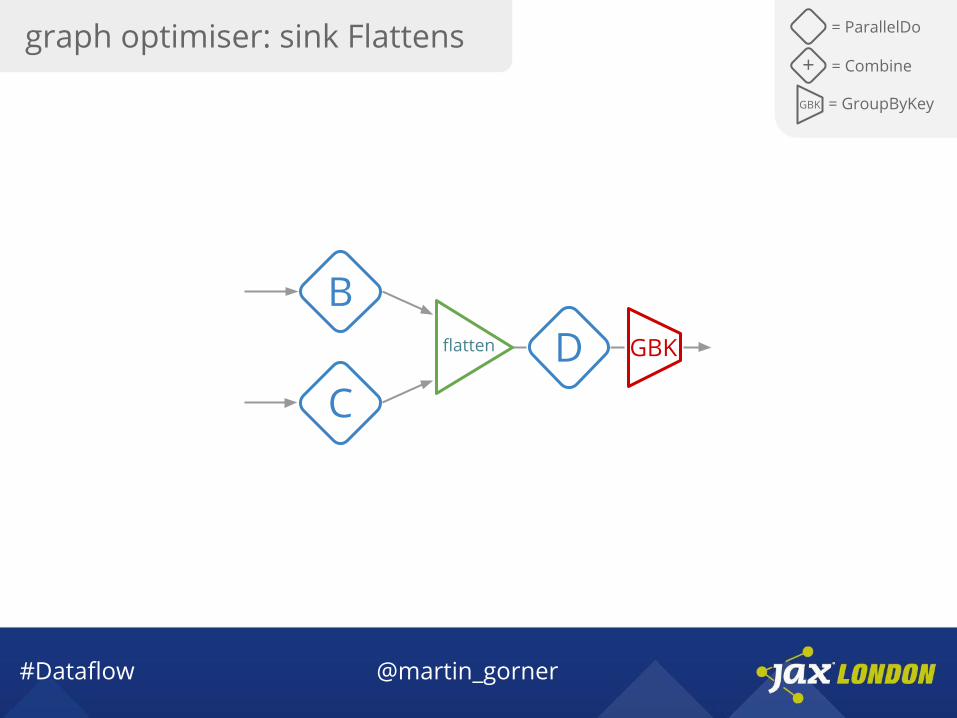
#Dataflow @martin_gorner
B
CDflatten GBK
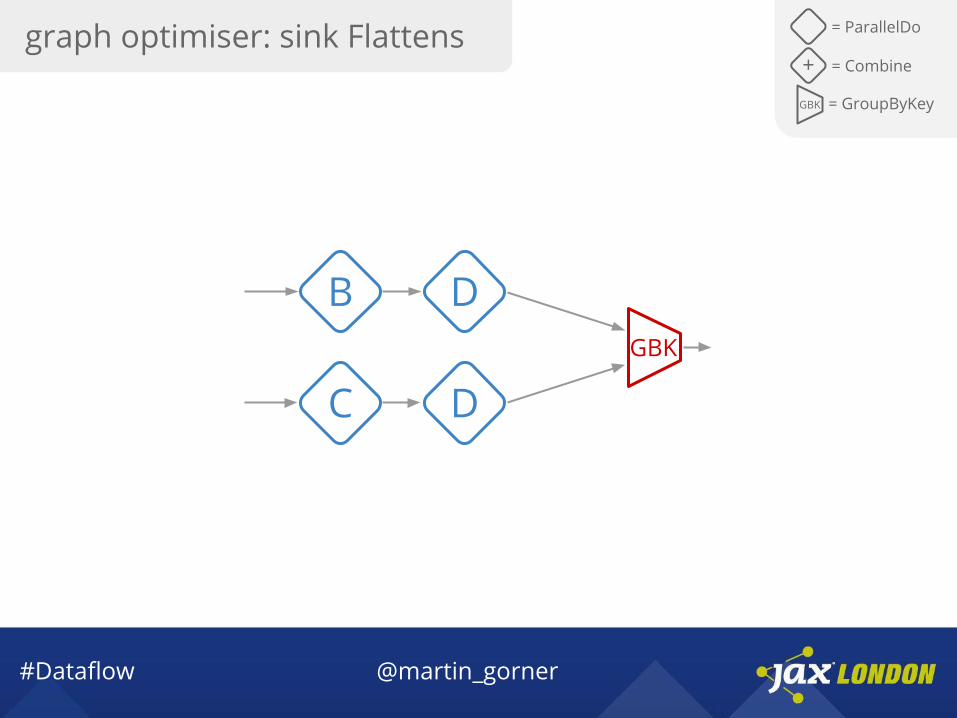
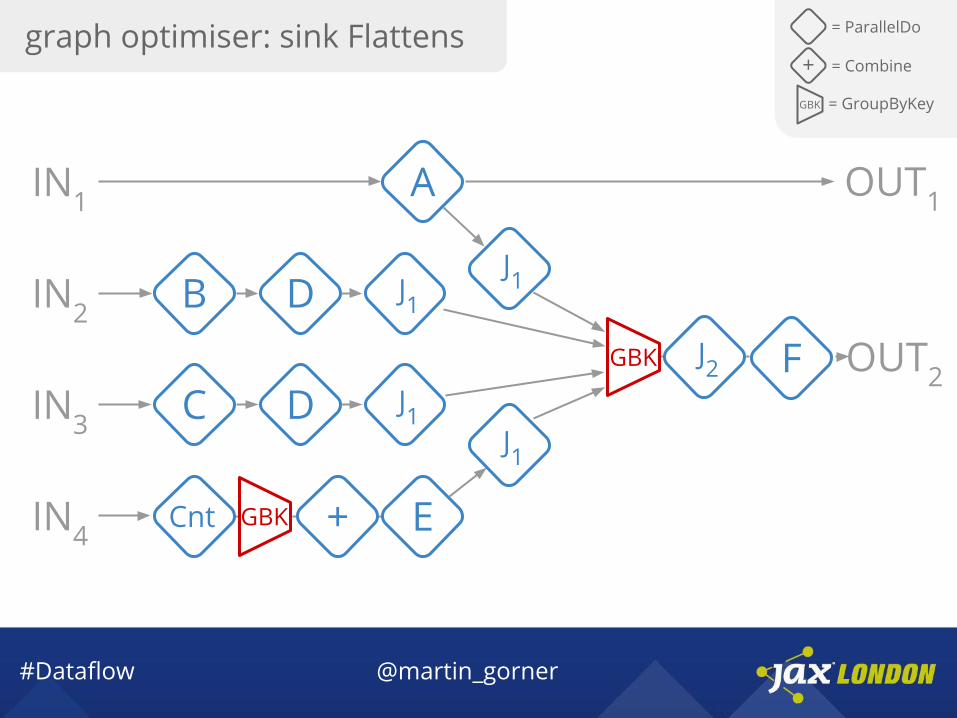
graph optimiser: sink Flattens = ParallelDo
GBK = GroupByKey
+ = Combine
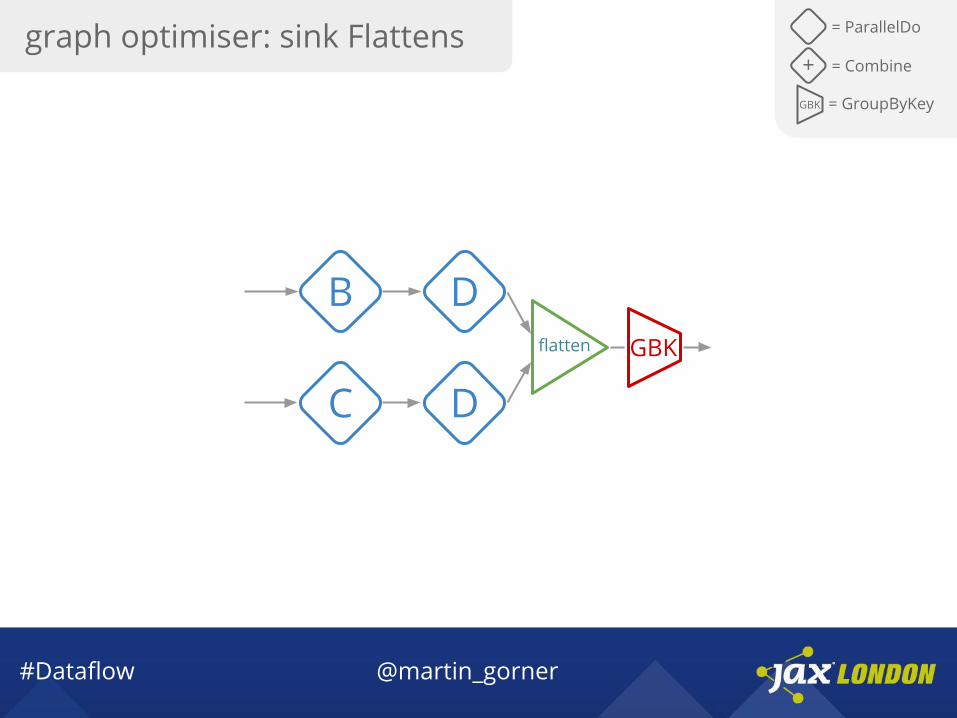
#Dataflow @martin_gorner
B
C D
flatten GBK
D
graph optimiser: sink Flattens = ParallelDo
GBK = GroupByKey
+ = Combine
#Dataflow @martin_gorner
B
C DGBK
D
graph optimiser: sink Flattens = ParallelDo
GBK = GroupByKey
+ = Combine
#Dataflow @martin_gorner
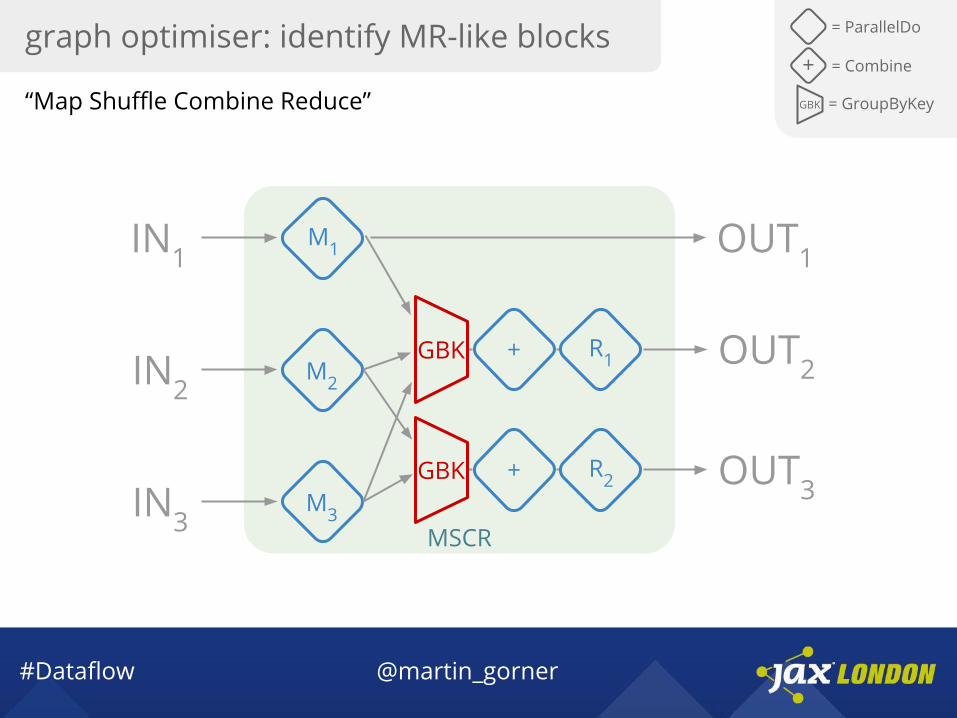
“Map Shuffle Combine Reduce”
OUT1
OUT3GBK R2+
M3
M2
M1
GBK R1+ OUT2
IN1
IN2
IN3 MSCR
graph optimiser: identify MR-like blocks = ParallelDo
GBK = GroupByKey
+ = Combine
#Dataflow @martin_gorner
B
C
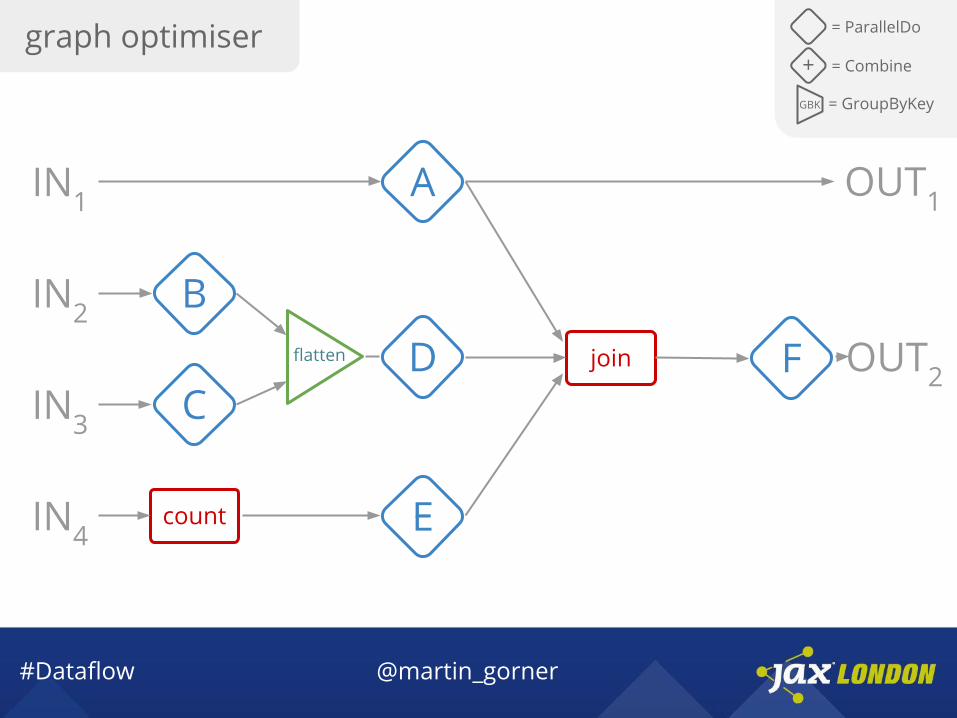
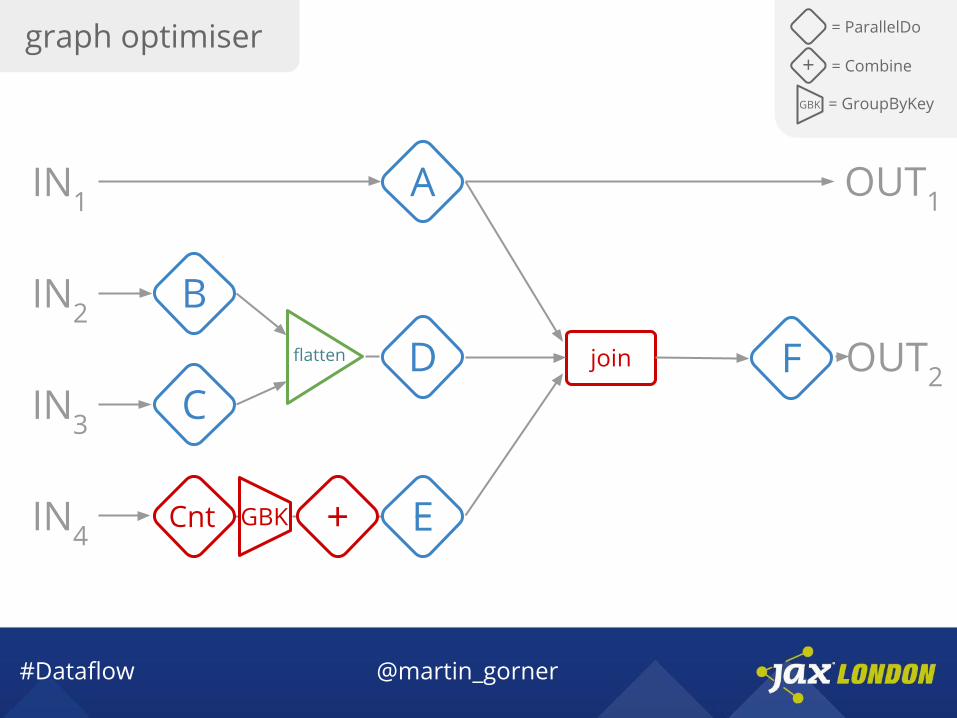
count
join
IN1
IN2
IN3
IN4
OUT1A
Dflatten F OUT2
E
graph optimiser = ParallelDo
GBK = GroupByKey
+ = Combine
#Dataflow @martin_gorner
B
Cjoin
IN1
IN2
IN3
IN4
A
D
E
flatten
Cnt GBK +
F OUT2
OUT1
graph optimiser = ParallelDo
GBK = GroupByKey
+ = Combine
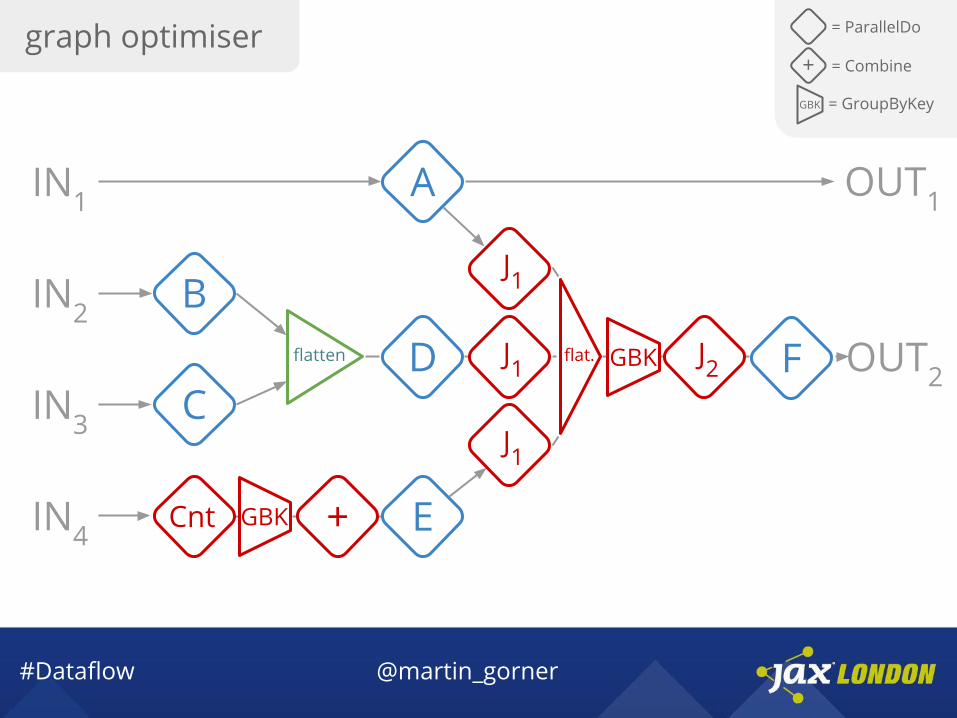
#Dataflow @martin_gorner
A
B
CD F
IN1
IN2
IN3
IN4
flatten
OUT1
OUT2
J1
GBKflat.J1
J1
J2
ECnt GBK +
graph optimiser = ParallelDo
GBK = GroupByKey
+ = Combine
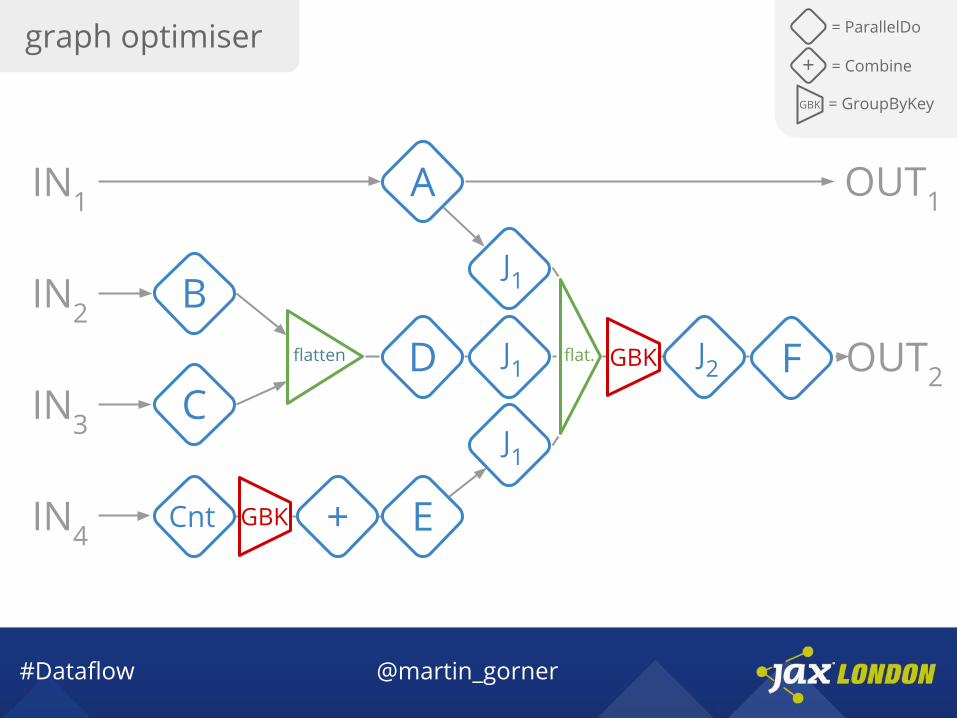
#Dataflow @martin_gorner
A
B
CD F
IN1
IN2
IN3
IN4
flatten
OUT1
OUT2
J1
GBKflat.J1
J1
J2
ECnt GBK +
graph optimiser = ParallelDo
GBK = GroupByKey
+ = Combine
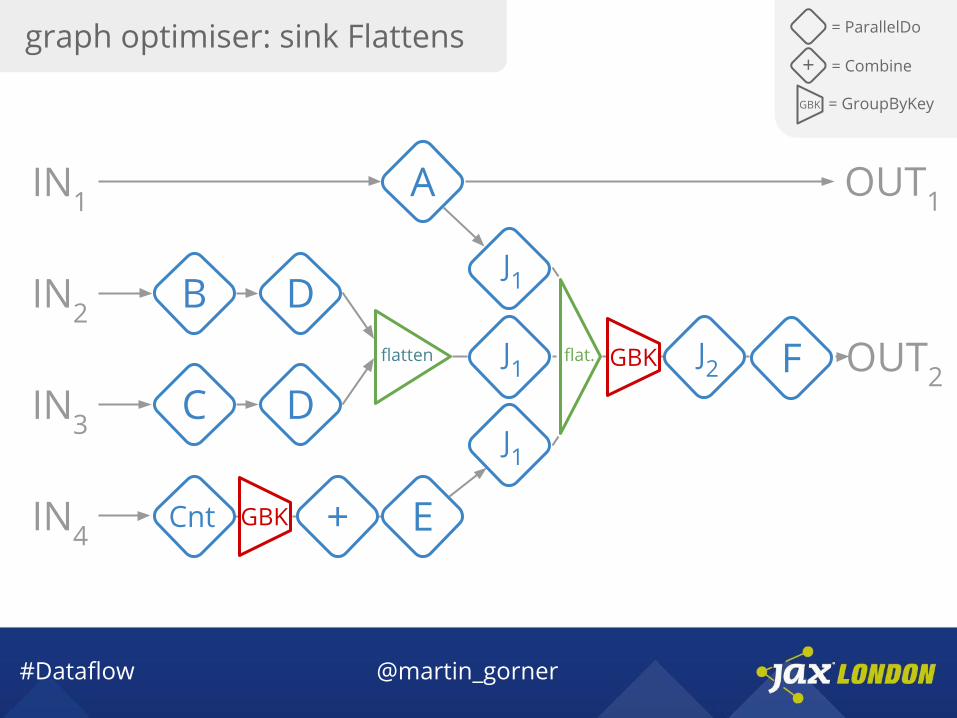
#Dataflow @martin_gorner
A
B
C DF
IN1
IN2
IN3
IN4
flatten
OUT1
OUT2
J1
GBKflat.J1
J1
J2
ECnt GBK +
D
graph optimiser: sink Flattens = ParallelDo
GBK = GroupByKey
+ = Combine
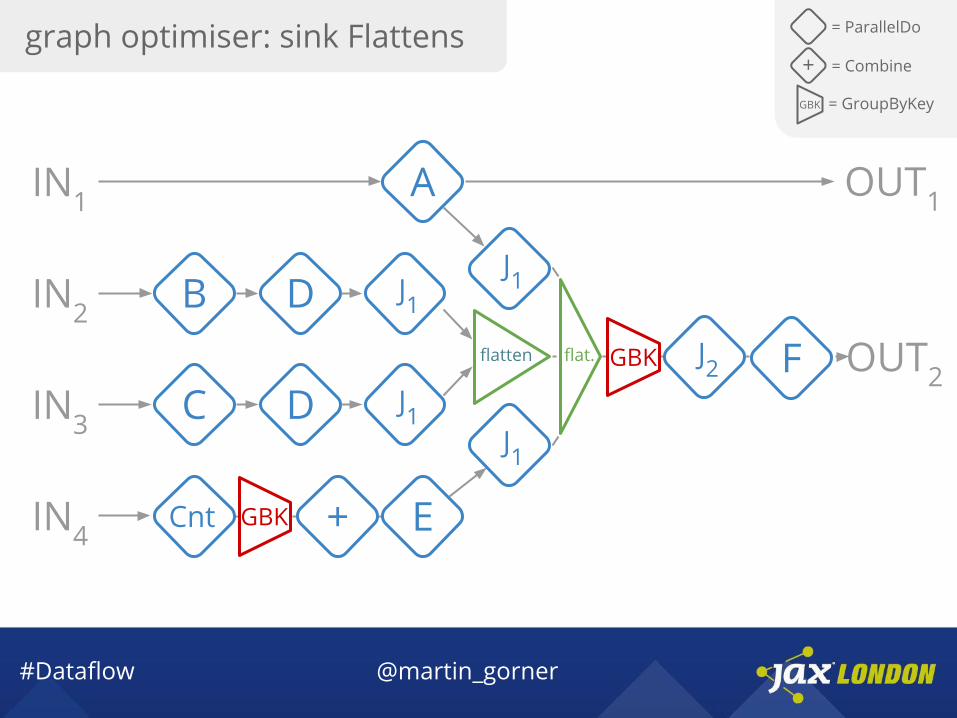
#Dataflow @martin_gorner
A
C DF
IN1
IN2
IN3
IN4
flatten
OUT1
OUT2
J1
GBKflat.
J1J1
J2
ECnt GBK +
B D J1
graph optimiser: sink Flattens = ParallelDo
GBK = GroupByKey
+ = Combine
#Dataflow @martin_gorner
A
C DF
IN1
IN2
IN3
IN4
OUT1
OUT2
J1
GBK
J1J1
J2
ECnt GBK +
B D J1
graph optimiser: sink Flattens = ParallelDo
GBK = GroupByKey
+ = Combine
#Dataflow @martin_gorner
C DF
IN1
IN2
IN3
IN4
OUT1
OUT2GBK
J1J1
J2
ECnt GBK +
B D J1
A+J1
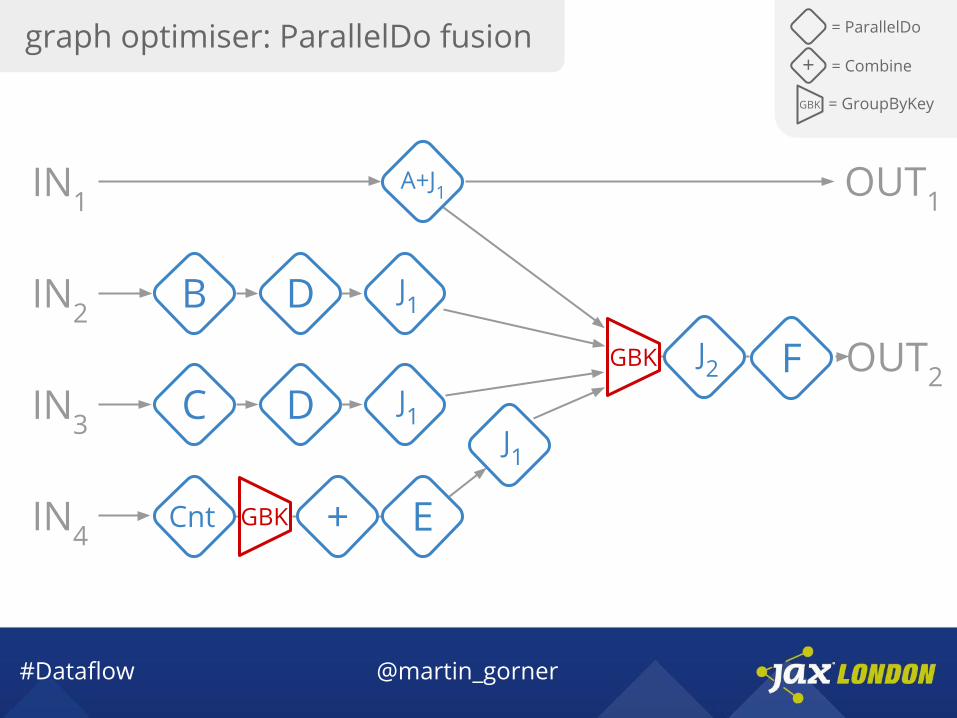
graph optimiser: ParallelDo fusion = ParallelDo
GBK = GroupByKey
+ = Combine
#Dataflow @martin_gorner
C DF
IN1
IN2
IN3
IN4
OUT1
OUT2GBK
J1J1
J2
ECnt GBK +
B+D+J1
A+J1
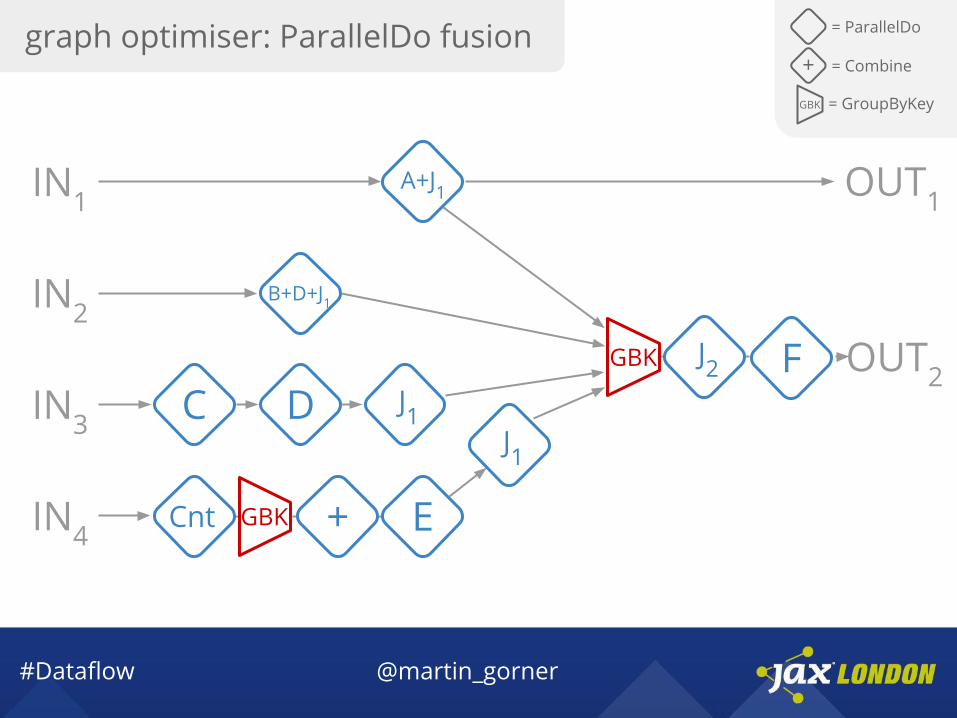
graph optimiser: ParallelDo fusion = ParallelDo
GBK = GroupByKey
+ = Combine
#Dataflow @martin_gorner
C+D+J1
F
IN1
IN2
IN3
IN4
OUT1
OUT2GBK
J1
J2
ECnt GBK +
B+D+J1
A+J1
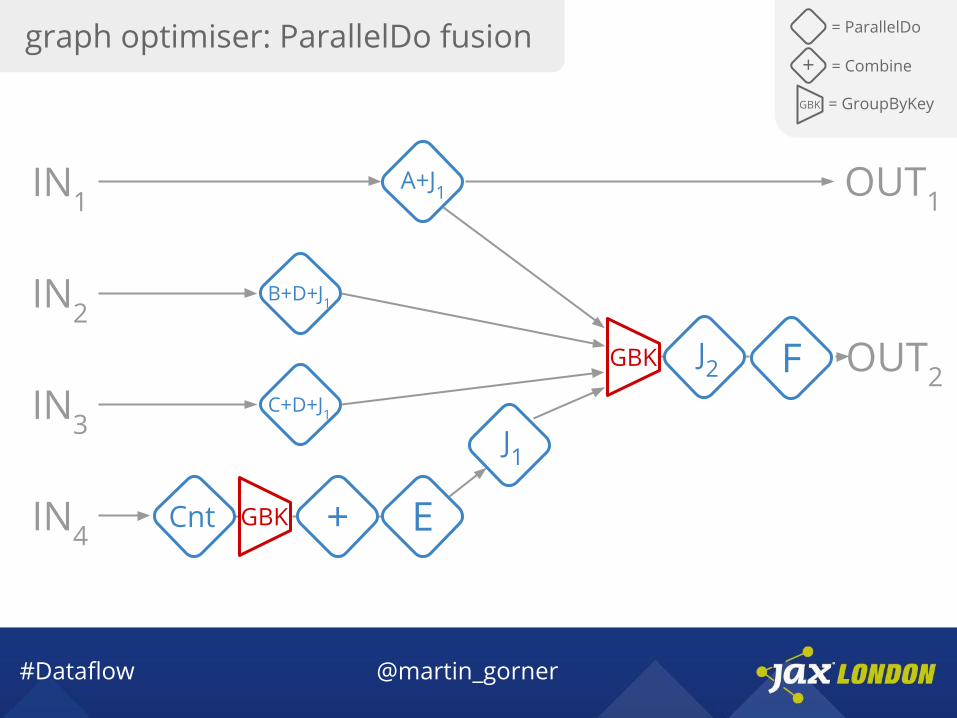
graph optimiser: ParallelDo fusion = ParallelDo
GBK = GroupByKey
+ = Combine
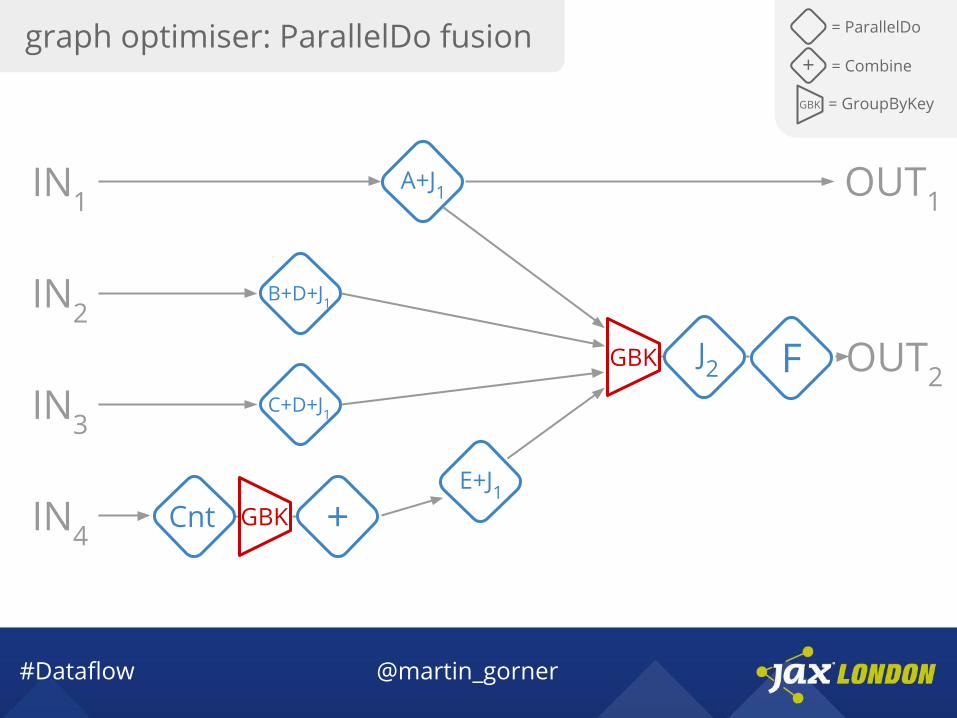
#Dataflow @martin_gorner
C+D+J1
F
IN1
IN2
IN3
IN4
OUT1
OUT2GBK J2
Cnt GBK +
B+D+J1
A+J1
E+J1
graph optimiser: ParallelDo fusion = ParallelDo
GBK = GroupByKey
+ = Combine
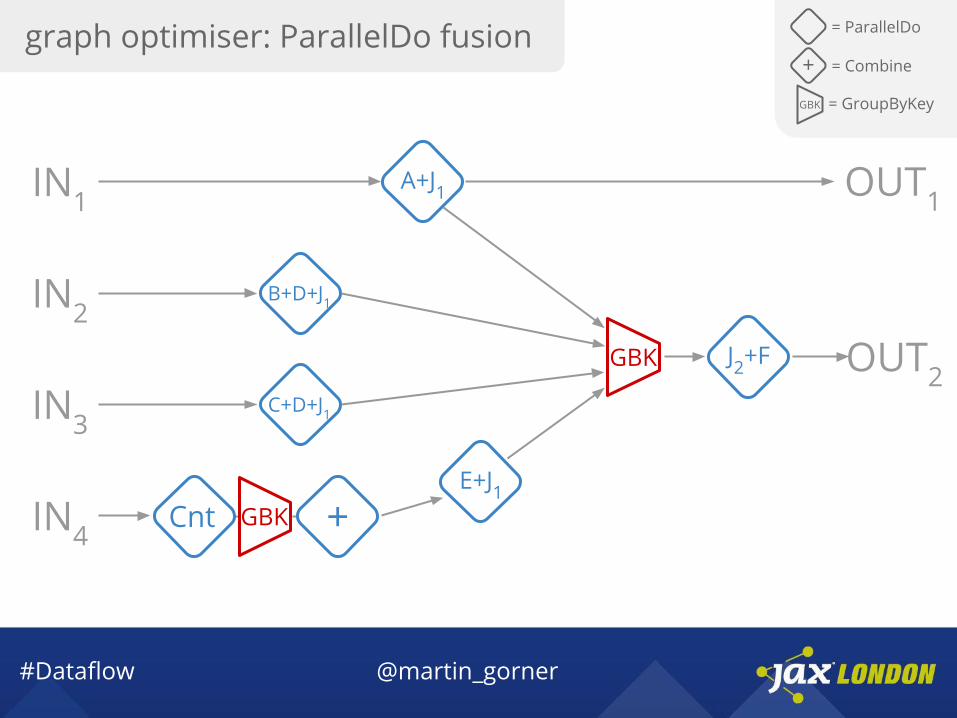
#Dataflow @martin_gorner
C+D+J1
IN1
IN2
IN3
IN4
OUT1
OUT2GBK
Cnt GBK +
B+D+J1
A+J1
E+J1
J2+F
graph optimiser: ParallelDo fusion = ParallelDo
GBK = GroupByKey
+ = Combine
#Dataflow @martin_gorner
C+D+J1
IN1
IN2
IN3
IN4
OUT1
OUT2GBK
B+D+J1
A+J1
E+J1
J2+F
Cnt GBK +
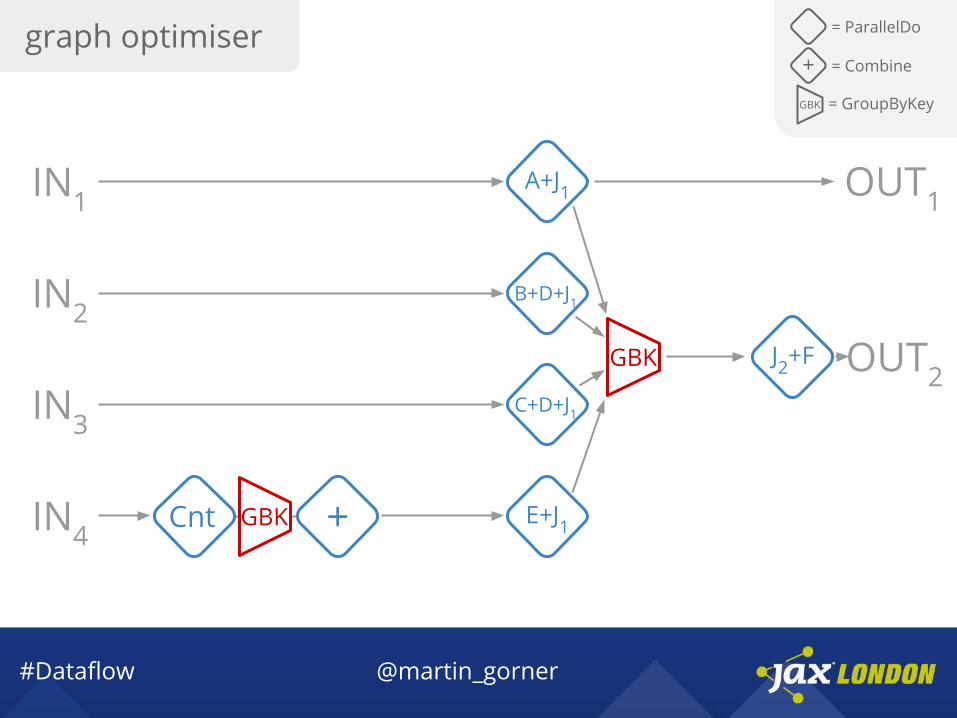
graph optimiser = ParallelDo
GBK = GroupByKey
+ = Combine
#Dataflow @martin_gorner
IN1
IN2
IN3
IN4
OUT1
OUT2GBK J2+F+
Cnt GBK +
C+D+J1
B+D+J1
A+J1
E+J1
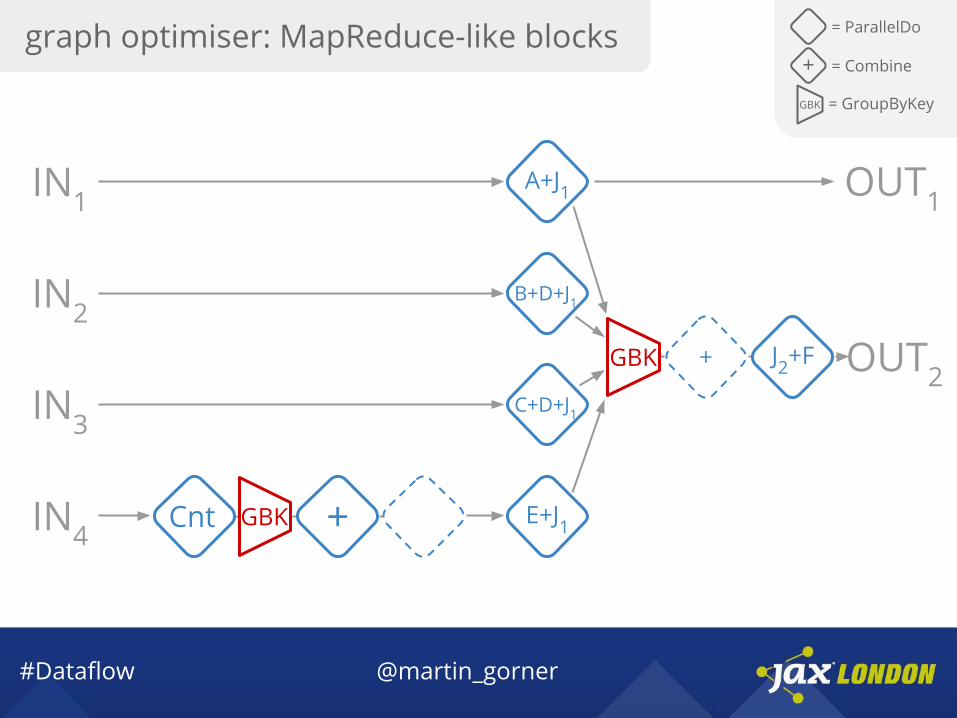
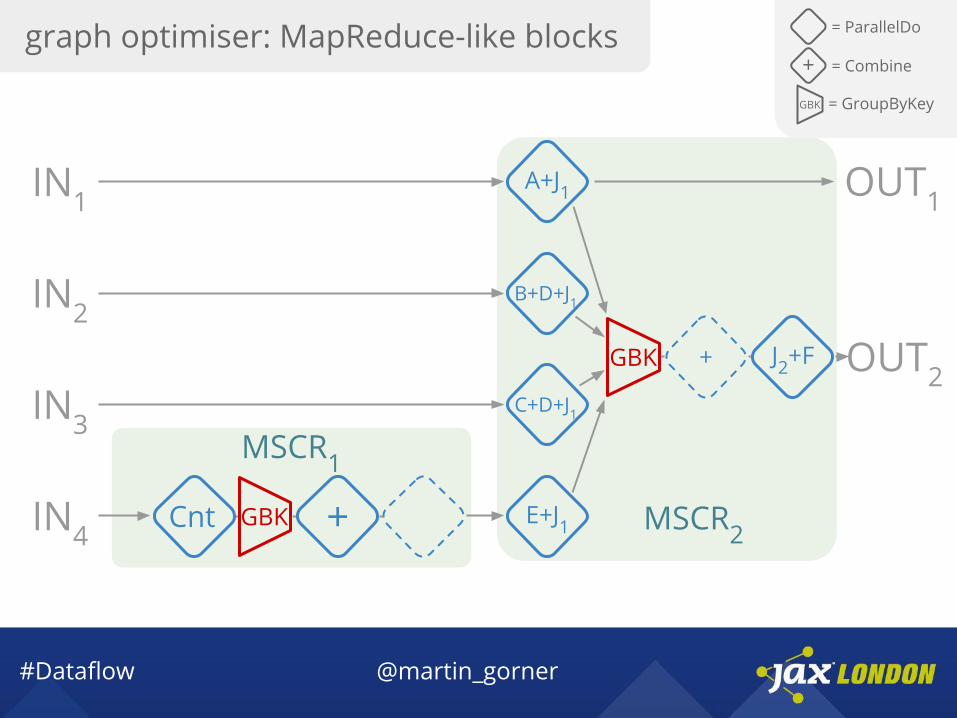
graph optimiser: MapReduce-like blocks = ParallelDo
GBK = GroupByKey
+ = Combine
#Dataflow @martin_gorner
IN1
IN2
IN3
IN4
OUT1
OUT2GBK J2+F+
Cnt GBK +
C+D+J1
B+D+J1
A+J1
E+J1
MSCR1
MSCR2
graph optimiser: MapReduce-like blocks = ParallelDo
GBK = GroupByKey
+ = Combine
#Dataflow @martin_gorner
IN4
IN1IN2IN3
OUT1
OUT2
A+B+C+D+E+J1
A+B+C+D+E+J1
A+B+C+D+E+J1
A+B+C+D+E+J1
A+B+C+D+E+J1
A+B+C+D+E+J1
F+J2
F+J2
F+J2
Cnt
Cnt
Cnt
+
+
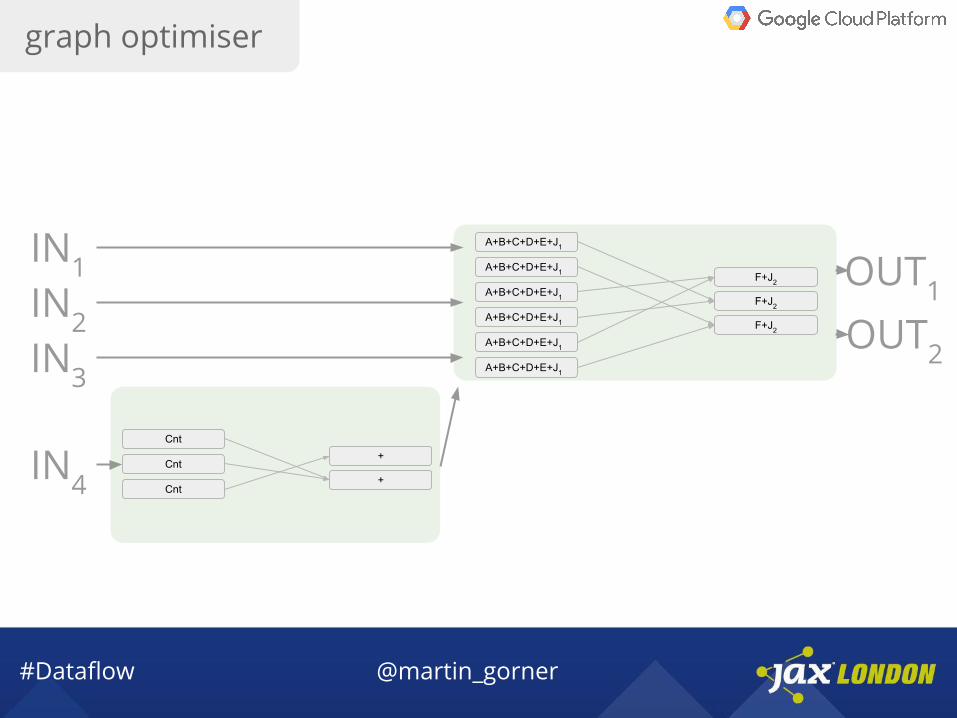
graph optimiser

#Dataflow @martin_gorner
Dataflow model
What are you computing?
Where in event time?
When are results emitted?
How do refinements relate?Wind
owing

#Dataflow @martin_gorner
Dataflow model: windowing
Windowing divides data into event-time-based finite chunks.
Often required when doing aggregations over unbounded data.
What Where When How
Fixed Sliding1 2 3
54
Sessions
2
431
Key 2
Key 1
Key 3
Time
1 2 3 4

#Dataflow @martin_gorner
Event-time windowing: out-of-order
What Where When How
11:0010:00 15:0014:0013:0012:00Event Time
11:0010:00 15:0014:0013:0012:00Processing Time
Input
Output
#Dataflow @martin_gorner
What Where When How
Proc
essi
ng T
ime
Event Time
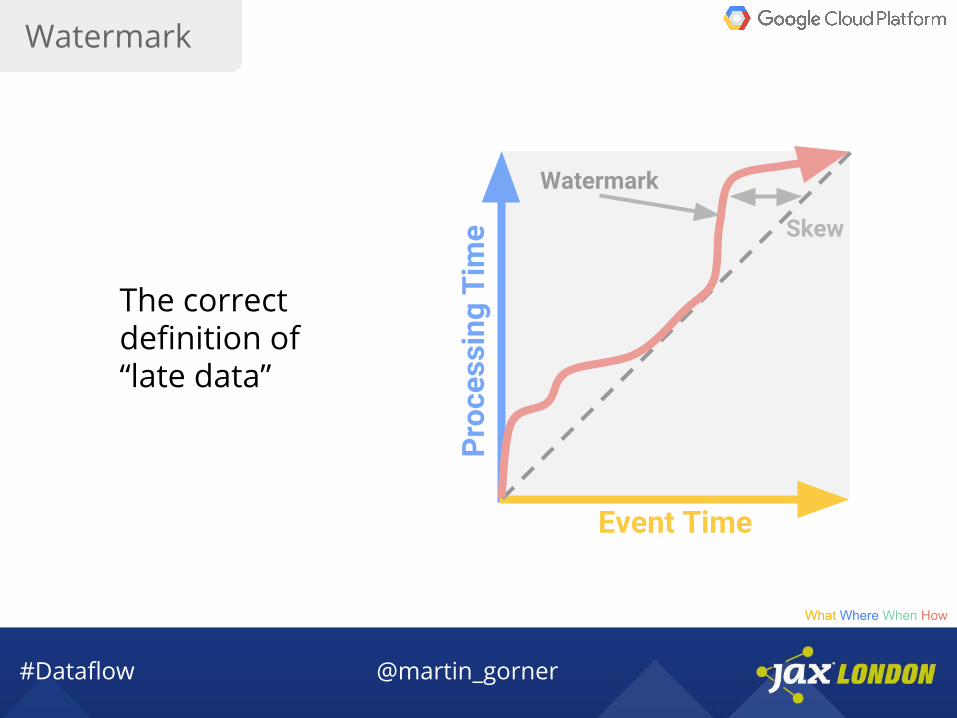
Skew
Watermark
The correct definition of “late data”
Watermark
#Dataflow @martin_gorner
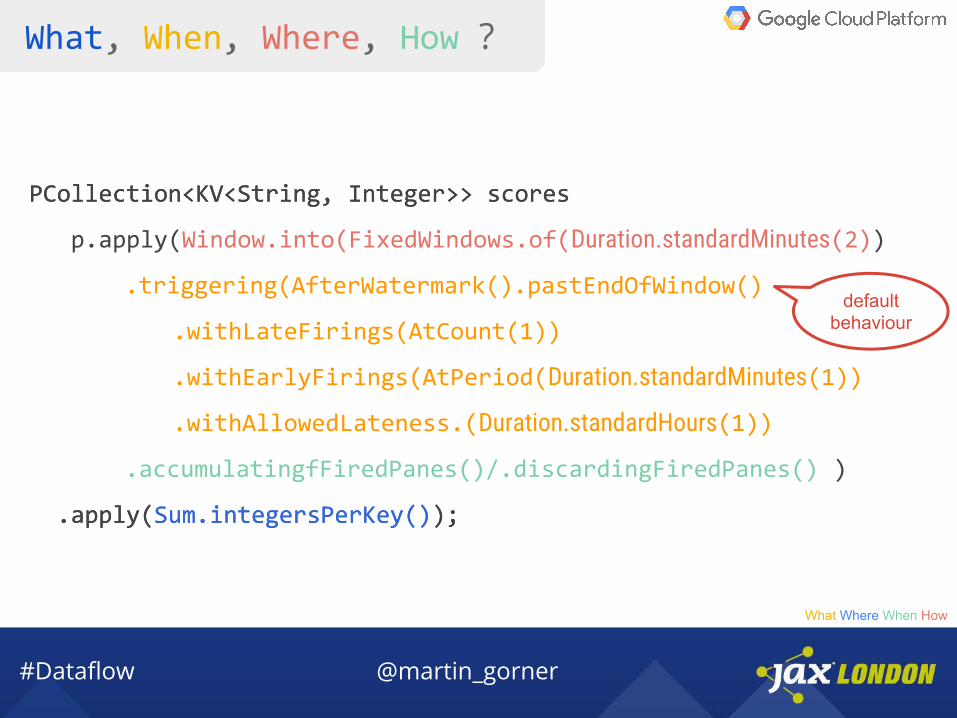
What, When, Where, How ?
PCollection<KV<String, Integer>> scores
.apply(Sum.integersPerKey());
What Where When How
PCollection<KV<String, Integer>> scores
p.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))
.triggering(AfterWatermark().pastEndOfWindow()
.withLateFirings(AtCount(1))
.withEarlyFirings(AtPeriod(Duration.standardMinutes(1))
.withAllowedLateness.(Duration.standardHours(1))
.accumulatingfFiredPanes()/.discardingFiredPanes() )
.apply(Sum.integersPerKey());
default behaviour
#Dataflow @martin_gorner
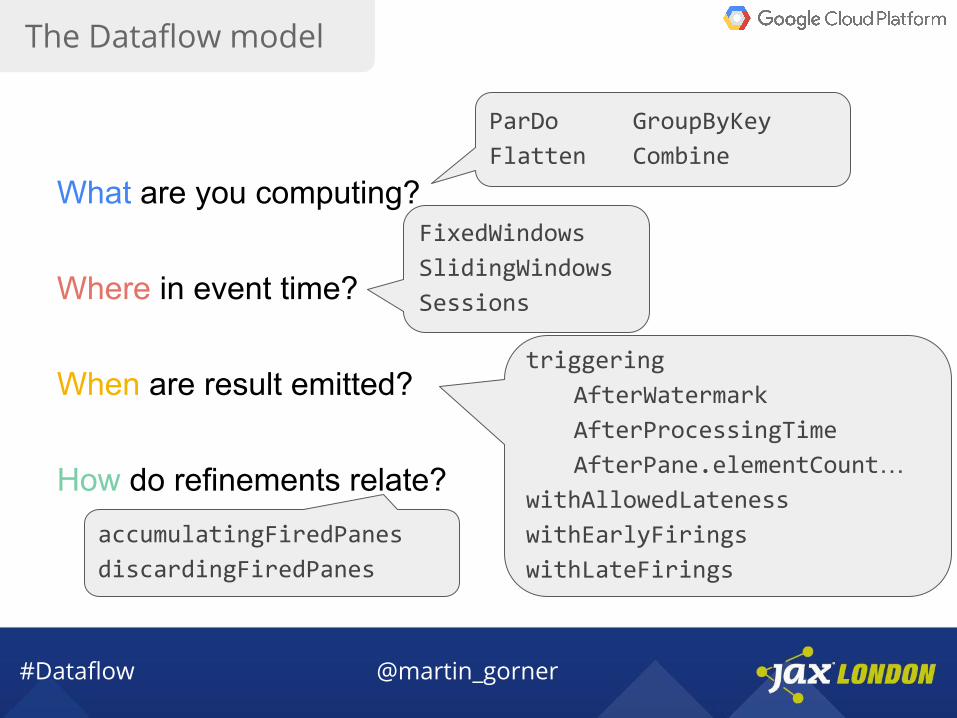
The Dataflow model
What are you computing?
Where in event time?
When are result emitted?
How do refinements relate?
ParDo GroupByKey
Flatten Combine
FixedWindows
SlidingWindows
Sessions
triggering
AfterWatermark
AfterProcessingTime
AfterPane.elementCount…withAllowedLateness
withEarlyFirings
withLateFirings
accumulatingFiredPanes
discardingFiredPanes
#Dataflow @martin_gorner
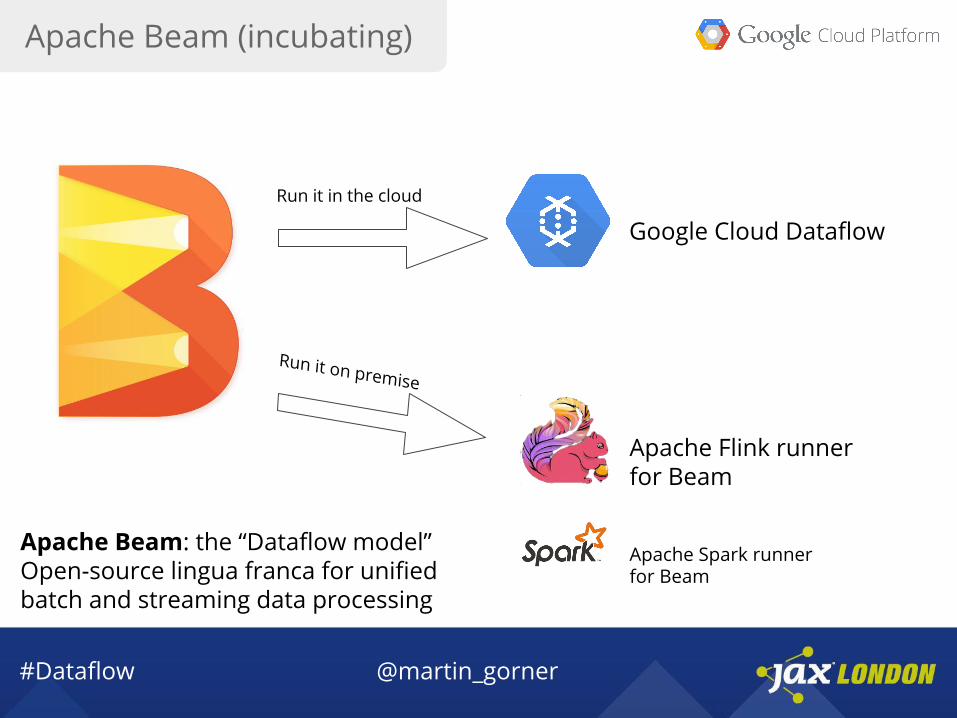
Apache Beam: the “Dataflow model”Open-source lingua franca for unified batch and streaming data processing
Google Cloud DataflowRun it in the cloud
Run it on premise
Apache Flink runner for Beam
Apache Spark runner for Beam
Apache Beam (incubating)

#Dataflow @martin_gorner
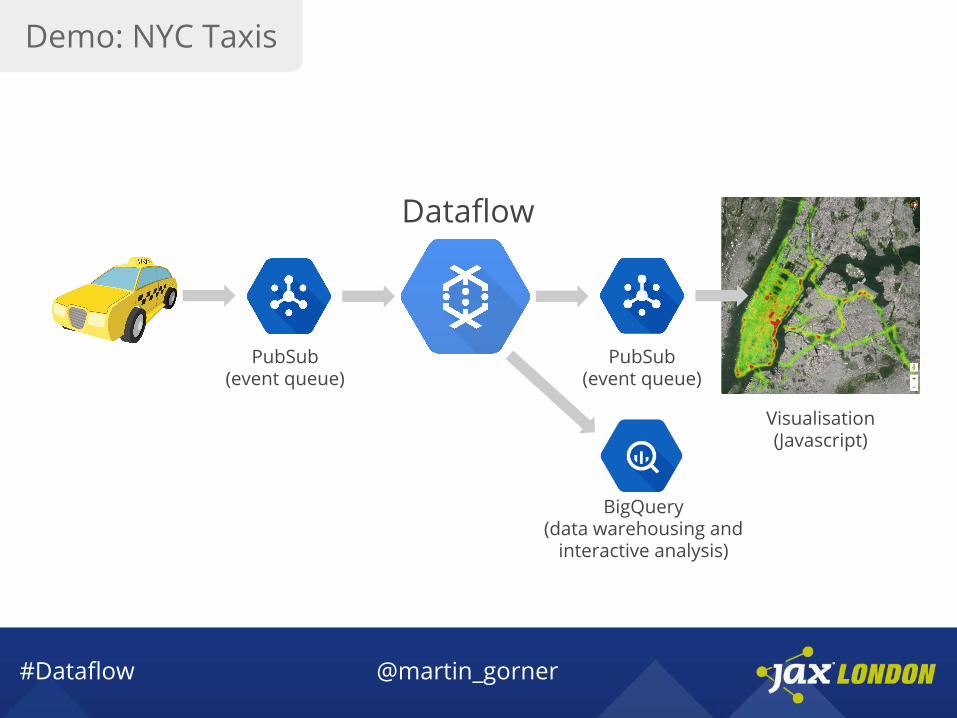
Demo time
1 week of data
3M taxi rides
One point every 2s on each ride
Accelerated 8x
20,000 events/s
Streamed from Google Pub/Sub
#Dataflow @martin_gorner
Demo: NYC Taxis
PubSub(event queue)
PubSub(event queue)
Visualisation(Javascript)
BigQuery(data warehousing and
interactive analysis)
Dataflow

#Dataflow @martin_gorner
cloud.google.com/dataflowbeam.incubator.apache.org
Thank you !
Martin Görner
Google Developer relations@martin_gorner





























