Embed Size (px)
Citation preview

ORI GIN AL PA PER
Question answering at the cross-language evaluationforum 2003–2010
Anselmo Penas • Bernardo Magnini • Pamela Forner • Richard Sutcliffe •
Alvaro Rodrigo • Danilo Giampiccolo
� Springer Science+Business Media B.V. 2012
Abstract The paper offers an overview of the key issues raised during the 8 years’
activity of the Multilingual Question Answering Track at the Cross Language
Evaluation Forum (CLEF). The general aim of the track has been to test both
monolingual and cross-language Question Answering (QA) systems that process
queries and documents in several European languages, also drawing attention to a
number of challenging issues for research in multilingual QA. The paper gives a
brief description of how the task has evolved over the years and of the way in which
the data sets have been created, presenting also a short summary of the different
types of questions developed. The document collections adopted in the competitions
are outlined as well, and data about participation is provided. Moreover, the main
A. Penas � A. Rodrigo
NLP & IR Group, UNED, Madrid, Spain
e-mail: [email protected]
A. Rodrigo
e-mail: [email protected]
B. Magnini
Fondazione Bruno Kessler (FBK-irst), Trento, Italy
e-mail: [email protected]
P. Forner (&) � D. Giampiccolo
Center for the Evaluation of Language and Communication Technologies (CELCT), Trento, Italy
e-mail: [email protected]
D. Giampiccolo
e-mail: [email protected]
R. Sutcliffe
University of Limerick, Limerick, Ireland
e-mail: [email protected]
123
Lang Resources & Evaluation
DOI 10.1007/s10579-012-9177-0

measures used to evaluate system performances are explained and an overall
analysis of the results achieved is presented.
Keywords Question answering � Evaluation � CLEF
1 Introduction
Under the promotion of the TREC-8 (Voorhees and Tice 1999) and TREC-9
(Voorhees 2000) Question Answering tracks, research in Question Answering (QA)
received a strong boost. The aim of the TREC QA campaigns was to assess the
capability of systems to return exact answers to open-domain English questions. The
QA track at TREC represented the first attempt to emphasise the importance and
foster research on systems that could extract relevant and precise information rather
than documents. QA systems are designed to find answers to open domain questions
in a large collection of documents and the development of such systems has
acquired an important status among the scientific community because it entails
research in both Natural Language Processing (NLP) and Information Retrieval
(IR), putting the two disciplines in contact. In contrast to the IR scenario, a QA
system processes questions formulated into natural language (instead of keyword-
based queries) and retrieves answers (instead of documents). During the years at
TREC from 1999 to 2007 and under the TAC conference in 2008, the task has
evolved, providing advancements and evaluation evidence for a number of key
aspects in QA, including answering factual and definition questions, questions
requiring complex analysis, follow-up questions in a dialog-like context, and mining
answers from different text genres, including blogs. However, despite the great deal
of attention that QA received at TREC, multilinguality was outside the mainstream
of QA research.
Multilingual QA emerged as a complementary research task, representing a
promising direction for at least two reasons. First, it allowed users to interact with
machines in their native languages, contributing to easier, faster, and more equal
information access. Second, cross-lingual capabilities enabled QA systems to access
information stored only in language-specific text collections.
Since 2003, a multilingual question answering track has been carried out at the
Cross-Language Evaluation Forum (CLEF).1 The introduction of multilinguality
represented not only a great novelty in the QA research field, but also a good chance
to stimulate the QA community to develop and evaluate multilingual systems.
During the years, the effort of the organisers was focused on two main issues.
One aim was to offer an evaluation exercise characterised by cross-linguality,
covering as many languages as possible. From this perspective, major attention was
given to European languages, adding at least one new language each year. However,
the offer was also kept open to languages from all over the world, as the inclusion of
Indonesian shows.
1 http://www.clef-campaign.org.
A. Penas et al.
123

The other important issue was to maintain a balance between the established
procedure—inherited from the TREC campaigns—and innovation. This allowed
newcomers to join the competition and, at the same time, offered ‘‘veterans’’ more
challenges.
This paper is organised as follows: Sect. 2 outlines the outcomes and the lessons
learned in 8 years of CLEF campaigns; Sect. 3 gives a brief description of how the
task has evolved over the years, and the of way in which the data sets were created,
and presents the document collections adopted and data about participation.
Section 4 gives a short explanation of the different measures adopted to evaluate
system performance. In Sect. 5, annual results are discussed highlighting some
important features. In Sect. 6 the main techniques adopted by participants are
described. Sect. 7 addresses some relevant research directions on QA which have
been explored in the last years outside the scope of QA at CLEF. Finally, in Sect. 8
some conclusions are drawn. In ‘‘Appendix’’ a brief overview of the different types
of question developed is also given.
2 Outcomes and lessons learned
The main outcomes of the Question Answering Track along these years
(2003–2010) are:
1. Development of reusable benchmarks in several languages. Although it is not
possible to compare different systems across languages, developers can
compare their systems across languages thanks to the use of comparable and
parallel document collections, and parallel translations of all questions into
many different languages.
2. Development of the methodologies for creating these multilingual benchmarks.
3. Diversity of types of questions (all of them are classified in the available
resources) and diversity of collections (from newswire or Wikipedia to
legislative texts).
4. A general methodology for QA evaluation. This methodology has
evolved thanks to the output generated for many pilot exercises attached to
the track.
During these years, some lessons attached to the goals of each particular
campaign have been learned. From the very beginning in 2003, the track had a
strong focus on multilinguaility and tried to promote the development of
translingual systems. Despite all the efforts made in this direction—translating
questions in many different languages and using comparable and parallel
corpora—systems targeting different languages cannot be strictly compared and
no definite conclusions can be drawn. Nevertheless, the resources developed
allow the comparison of the same system across different languages, which is
very important for QA developers that work in several languages, as the
performances of different systems targeting the same language can be assessed
comparatively.
Cross-language evaluation forum 2003–2010
123

The final methodology was implemented in 2009 and 2010 (Penas et al. 2009,
2010), where both questions and documents had parallel translations. Thus, the
systems that participated in several languages served as reference points for
comparison across languages.
Another lesson learned concerned how the evaluation setting determines the
participant systems architecture. By 2005 it became clear that there was an upper
bound of 60% of accuracy in systems performance, although more than 80% of the
questions were answered by at least one participant. It emerged that there was a
problem of error propagation in the most used QA pipeline (Question Analysis,
Retrieval, Answer Extraction, Answer Selection/Validation). Thus, in 2006 a pilot
task called Answer Validation Exercise (AVE) was proposed, aimed at fostering a
change in QA architectures by giving more relevance to the validation step (Penas
et al. 2006). In AVE, the assumption was that after a preliminary step of hypothesis
over-generation, the validation step decides whether the candidate answer is correct
or not. This is a kind of classification task that could take advantage of Machine
Learning. The same idea is behind the architecture of IBM’s Watson (DeepQA
project) that successfully participated at Jeopardy (Ferrucci et al. 2010).
After the three campaigns of AVE an attempt was made to transfer the conclusions
to the QA main task at CLEF 2009 and 2010. The first step was to introduce the option
of leaving questions unanswered, which is related to the development of validation
technologies necessary to develop better QA systems. A suitable measure was also
needed, which was able to reward systems that reduce the number of questions
answered incorrectly without affecting system accuracy, by leaving unanswered those
questions whose answers the system is not confident about. The measure was an
extension of accuracy called c@1 (Penas and Rodrigo 2011), tested during 2009 and
2010 QA campaigns at CLEF, and used also in subsequent evaluations.
However, this was not the change in the architecture that was expected, as almost
all systems continued using indexing techniques to retrieve relevant passages and
tried to extract the exact answer from that. Moreover results did not go beyond the
60% pipeline upper bound.
Therefore, the conclusion was that, in order to foster a real change in the QA system
architecture, a previous development of answer validation/selection technologies was
required. For this reason, the new formulation of the task after 2010 leaves the retrieval
step aside to focus on the development of technologies able to work with a single
document, answering questions about it and using the reference collections as sources
of background knowledge that help the answering process.
3 Track evolution
The QA task since 2003 up to 2010 consisted of taking a short question and a
document collection as input and producing an exact answer as output. In the
Multiple Language QA Main Task at CLEF, the systems were fed with a set of
questions and were asked to return one or more exact answers per question—where
exact means that neither more nor less than the information required must be
returned.
A. Penas et al.
123

In all the campaigns, the QA track was structured in both monolingual and
bilingual tasks. The success of the track showed an increasing interest in both
monolingual non-English QA—where questions and answers were in the same
language—and in cross-lingual QA—where the question was posed in a language
and the answer must be found in a collection of a different language. Until 2009, the
target collections consisted of newspaper articles, which were comparable but not
parallel and, as a consequence, the answer might be present in more than one
language collection, even though not in all. On the contrary, in 2009 and 2010
campaigns a parallel aligned corpus was used, which made the task completely
multilingual, i.e. questions had an answer in all target languages.
Tables 1 and 2 summarise all the novelties that have been introduced in the main
task over the years, in order to make the exercise more challenging and realistic.
3.1 Task and question types
In 2003 (Magnini et al. 2003) consisted of returning automatically—i.e. with no
manual intervention—a ranked list of [docid, answer] pairs per question such that
the retrieved document supported the answer. Participants were given 200 questions
for each language sub-task, and were allowed to submit up to three responses per
query. They were asked to retrieve either a 50-byte snippet of text extracted from
the document collections, which provided exactly the amount of information
required, or an exact answer. Each returned run consisted either of entirely 50-byte
answers or exact answers, but not a mixture. Twenty questions had no known
answer in the target corpora: systems indicated their confidence that there was no
answer in the document collection by returning ‘‘NIL’’ instead of the [docid,
answer] pair. There was general agreement about their usefulness in assessing the
systems’ performances, so a certain number of NIL questions were created in all QA
campaigns until 2008. In the first year of the track, only Factoid questions were
considered, i.e. fact-based questions, asking for the name of a person, a location, the
extent of something, the day on which something happened, etc. Participants were
not required to return a supporting context for their answer until 2006. ‘‘Appendix’’
includes examples showing contexts (with the document ID in brackets) to illustrate
the source of the answer given for all the different question types used along these
years (see summary in Table 2).
In 2004 (Magnini et al. 2004), the task was repeated without changes but for the
addition of four new languages, and two new question types: Definition and a new
answer type for Factoid, namely Manner.
Despite the demand for radical innovation, a conservative approach was also
preferred in 2005 (Vallin et al. 2005), as the procedures consolidated in the last two
campaigns seemed to need further investigation before moving to the next stage.
Although the task remained basically the same as that of 2004, some minor changes
were made: the question types Manner and Object were discontinued and, at the
same time, the concept of Temporal Restriction was introduced. This was the
property of restricting answers to a given question (of any type) to those which were
valid only when associated with an event, when occurring on a particular date, or
Cross-language evaluation forum 2003–2010
123

Ta
ble
1C
oll
ecti
ons,
ques
tions
and
answ
erst
yle
sat
CL
EF
cam
pai
gns
1994
new
spap
ers
1995
new
spap
ers
2006
Wik
iped
ias
JRC
Acq
uis
EU
RO
PA
RL
Tar
get
Lan
guag
es
Num
ber
of
ques
tions
Ques
tions
Gro
uped
50
Byte
answ
er
Exac
t
answ
er
Par
agra
ph
answ
er
NIL
answ
er
Support
ing
docu
men
t
Support
ing
snip
pet
Support
ing
par
agra
ph
2003
Y3
200
YY
YY
2004
YY
7200
YY
Y
2005
YY
8200
YY
Y
2006
YY
9200
YY
Y
2007
YY
Y10
200
YY
YY
2008
YY
Y11
200
YY
YY
2009
Y9
500
Y
2010
YY
7200
YY
Y
A. Penas et al.
123

Tab
le2
Ques
tion
types
atC
LE
Fca
mpai
gns
Count
Defi
nit
ion
Lis
tL
oca
tion
Man
ner
Mea
sure
Obje
ctO
pin
ion
Org
anis
atio
nO
ther
Per
son
Pro
cedure
Purp
ose
Rea
son
Rea
son-
purp
ose
Tim
eT
empora
l
rest
rict
ion
2003
YY
YY
YY
Y
2004
YY
YY
YY
YY
Y
2005
YY
YY
YY
YY
2006
YY
YY
YY
YY
Y
2007
YY
YY
YY
YY
YY
Y
2008
YY
YY
YY
YY
YY
Y
2009
YY
YY
YY
YY
YY
YY
YY
2010
YY
YY
YY
YY
YY
YY
YY
Cross-language evaluation forum 2003–2010
123

when taking place within a time interval. Temporal restrictions have since been used
in a subset of CLEF questions in all years up until the present.
In 2006 (Magnini et al. 2006), the most significant innovation was the
introduction of List questions, which had also been considered for previous
competitions, but had been avoided due to the issues that their selection and
assessment implied. In contrast to TREC where each answer was listed as a
separate, self contained response to the question, at CLEF the list was contained
within a single response; this means that the answer was found in one passage of the
document set that spelled out the entire list. Under this aspect, these single response
List questions did not differ from a traditional Factoid question. Moreover, such
questions could require either ‘‘closed lists’’ as answers, consisting in a number of
specified items, or ‘‘open lists’’, where an unspecified number of correct answers
could be returned. In case of closed lists, correct partial answers, where only some
of the expected items were present, were evaluated as inexact. This kind of
questions was introduced in order to allow a multilingual investigation of List
questions without requiring a separate evaluation procedure.
Other important innovations of the 2006 campaign were the possibility to return
up to ten exact answers per question, and the requirement to additionally provide up
to ten text snippets—i.e. substrings of the specified documents giving the actual
context of the exact answer in order to justify it.
In 2007, the questions were grouped into clusters, each of which referred to the
same topic. This meant that co-reference could be used between entities mentioned
in questions—a well known phenomenon within NLP which nevertheless had not
been considered in previous QA exercises at CLEF. In these cases, the supporting
document for the second answer could be not the same as that for the first answer.
Another major novelty for 2007 concerned the documents. Up to 2006, each data
collection comprised a set of newspaper articles provided by ELRA/ELDA (see
Table 3). Then, in 2007, Wikipedia dated 2006 was used as well, capitalising on the
experience of the WiQA pilot task (Jijkoun and de Rijke 2007). Thus, for example,
the answer to a question in French could be found in a French newspaper article (as
in previous years), in a French Wikipedia entry, or both. One of the main reasons for
using the Wikipedia collections was to make a first step towards Web-formatted
corpora; as a huge amount of information was available on the Web, this was
considered a desirable next level in the evolution of QA systems.
The 2007 task proved to be much more difficult than expected because of the
grouped questions. Not only did groups include co-reference (See Example 9 in the
‘‘Appendix’’) but, in addition, the questions became intrinsically more complicated
because they were no longer semantically self-contained, as the simple factoids of
earlier campaigns had been. Instead, they effectively developed a theme cumula-
tively. In order to allow participants more time to further study this problem, the
exercise was repeated almost without changes in 2008.
The 2009 evaluation track, called ResPubliQA, represented a radical change with
respect to the previous QA campaigns at CLEF. The exercise was aimed at
retrieving answers to a set of 500 questions. The required output was not an exact
answer but an entire paragraph, and the collection—JRC-Acquis—was from a
specific domain, i.e. European legislation. Moreover, three new questions types
A. Penas et al.
123

were introduced, in an attempt to move away from the factoid paradigm—
Procedure, Purpose and Reason. Finally, the choice of a specific domain represented
a first step towards the definition of a realistic user model. The issue of identifying
potential users of QA systems had been a matter of discussion among the track
organizers for long, but in the campaigns held so far, the focus was on proposing a
general task in order to allow systems to perfect the existing techniques. In 2009,
time seamed ripe to make the task more realistic and introduce a user model. While
looking for a suitable context, improving the efficacy of legal searches in the real
world seemed an approachable field, as the retrieval of information from legal texts
was an issue of increasing importance given the vast amount of data which had
become available in electronic form in the previous years.
The design of the ResPubliQA 2010 evaluation campaign was to a large extent a
repetition of the previous year’s exercise. However, this year participants had the
opportunity to return both paragraph and exact answers as system output. Another
novelty was the addition of a portion of the EuroParl collection which contains
transcribed speeches from the European Parliament. Moreover, Reason and Purpose
questions, which had been found to be too similar to one another, were duly merged
into one category, Reason-Purpose. At the same time, two new question types were
introduced, Other and Opinion. In the case of the latter, it was thought that speeches
within EuroParl might express interesting opinions.
3.2 Multilingual question sets
The procedure for generating questions did not significantly change over the years.
For each target language, a number of questions (ranging from 100 to 200
depending on the campaign) were manually produced, initially using the topics of
the Ad-Hoc track at CLEF. The use of topics was originally introduced to reduce the
number of duplicates in the multilingual question set. Together with the questions, a
Gold Standard was also produced, by manually searching for at least one answer in
a document collection. The questions were then translated into English, which acted
as lingua franca, so that they could be understood and reused by all the other groups.
Once the questions were collected in a common format, native speakers of each
source language, with a good command of English, were recruited to translate the
English version of all questions into their own languages, trying to adhere as much
as possible to the original.
The introduction of back translation to create cross-lingual question–answer
pairs—a paradigm developed in 2003 and used ever since—is one of the most
remarkable features of QA at CLEF.
In 2007 (Giampiccolo et al. 2007), with the introduction of topic-related
questions, the procedure followed to prepare the test set changed slightly. First of
all, each organising group, responsible for a target language, freely chose a number
of topics. For each topic, one to four questions were generated. The topic-related
questions consisted of clusters of questions which referred to the same topic. The
requirement for related questions on a topic necessarily implies that the questions
refer to common concepts and entities within the domain in question. Unlike in the
Cross-language evaluation forum 2003–2010
123
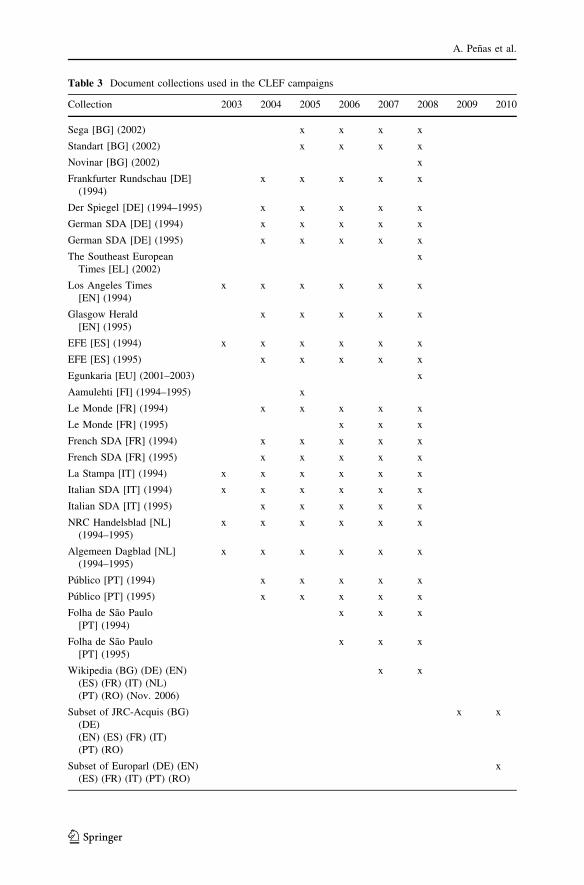
Table 3 Document collections used in the CLEF campaigns
Collection 2003 2004 2005 2006 2007 2008 2009 2010
Sega [BG] (2002) x x x x
Standart [BG] (2002) x x x x
Novinar [BG] (2002) x
Frankfurter Rundschau [DE]
(1994)
x x x x x
Der Spiegel [DE] (1994–1995) x x x x x
German SDA [DE] (1994) x x x x x
German SDA [DE] (1995) x x x x x
The Southeast European
Times [EL] (2002)
x
Los Angeles Times
[EN] (1994)
x x x x x x
Glasgow Herald
[EN] (1995)
x x x x x
EFE [ES] (1994) x x x x x x
EFE [ES] (1995) x x x x x
Egunkaria [EU] (2001–2003) x
Aamulehti [FI] (1994–1995) x
Le Monde [FR] (1994) x x x x x
Le Monde [FR] (1995) x x x
French SDA [FR] (1994) x x x x x
French SDA [FR] (1995) x x x x x
La Stampa [IT] (1994) x x x x x x
Italian SDA [IT] (1994) x x x x x x
Italian SDA [IT] (1995) x x x x x
NRC Handelsblad [NL]
(1994–1995)
x x x x x x
Algemeen Dagblad [NL]
(1994–1995)
x x x x x x
Publico [PT] (1994) x x x x x
Publico [PT] (1995) x x x x x
Folha de Sao Paulo
[PT] (1994)
x x x
Folha de Sao Paulo
[PT] (1995)
x x x
Wikipedia (BG) (DE) (EN)
(ES) (FR) (IT) (NL)
(PT) (RO) (Nov. 2006)
x x
Subset of JRC-Acquis (BG)
(DE)
(EN) (ES) (FR) (IT)
(PT) (RO)
x x
Subset of Europarl (DE) (EN)
(ES) (FR) (IT) (PT) (RO)
x
A. Penas et al.
123

previous campaigns, topics could be not only named entities or events, but also
other categories such as objects, natural phenomena, etc. Topics were not given in
the test set, but could be inferred from the first question/answer pair.
For the ResPubliQA tasks in 2009 and 2010, the questions were once again
ungrouped. The collection was also changed (see next section) but the same
principle of back-translation was used to create a completely parallel set of
questions, identical in all source languages.
3.3 Document collections
Before 2009, the target corpora in all languages, released by ELRA/ELDA,
consisted of large, unstructured, open-domain text collections. The texts were
SGML tagged and each document had a unique identifier (docid) that systems had to
return together with the answer, in order to support it. As regards the sources of
these collections, they remained practically unchanged during the years. Table 3
gives an overview of all the collections used in the QA campaigns.
In the first QA exercise, where only three languages were considered, the
collections were taken from news of 1994 and 1995. In the following year, the
number of languages increased and new collections from news sources were added
for each language, all covering the same time span, i.e. 1994–1995.
On the one hand, the fact that the newspaper and news agency articles referred to
the same period of time, with the exception of Bulgarian, assured that a certain
number of topics in the documents were shared in the different collections, making
them comparable, at least to some degree. On the other hand, the collections were
not really homogenous, and, what is more important, were of different size, ranging
from a minimum of 69,195 documents (213 MB) for Bulgarian to 454,045
documents (1,086 MB) for Spanish, which implied that the systems had to deal with
considerably different amount of data depending on the language of the task they
had to perform.
To reduce the difference between collections, and improve the comparability of
systems’ performances, the necessity of adopting other collections was debated for a
long time, but copyright issues represented a major obstacle.
A step towards a possible solution was made by the proposal of the WiQA pilot
task, which represented a first attempt to set the QA competitions in their natural
context, i.e. the Internet. An important advantage of Wikipedia was that it was
freely available in all languages considered, and presented a fairly high number of
entries containing comparable information. As this new source of data appeared to
be a promising field to explore in the attempt to gain a larger comparability among
languages, Wikipedia corpora were added in 2007. ‘‘Snapshots’’ of Wikipedia pages
for each language, as found in the November 2006 version, were made available for
download both in XML and HTML versions. However, the significant variations in
the size of the Wikipedia data in the different languages still represented a major
shortcoming, as the misalignment of the information about the same topic made it
difficult to create questions which could have answers in all the languages of the
competition, and to balance up questions by type across languages.
Cross-language evaluation forum 2003–2010
123

A final approach to the problem of data comparability was attempted in 2009,
when a subset of the JRC-Acquis Multilingual Parallel Corpus was used. JRC-
Acquis2 is a freely available parallel corpus of European Union (EU) documents,
mostly of a legal nature, covering various subject domains, such as economy, health,
information technology, law, agriculture, food, and politics. This collection of
legislative documents offered the opportunity to test QA systems on the same set of
questions in all the languages—allowing a real comparison of the performances—
and represented a change from the news domain to the legal domain.
As the ResPubliQA task was repeated in 2010, a subset of JRC-Acquis was used
again, together with a subset of EuroParl3—a collection of the Proceedings of the
European Parliament dating back to 1996—in order to assure a wider variety of
questions and make the exercise more challenging.
3.4 Participation and languages involved
The first years of the QA evaluation exercises at CLEF registered a steady increment
not only in the number of participants, but also of the languages involved, which is
encouraging, as multi-linguality is one of the main aims of these exercises. From
2007 on, the number of participants started to decrease, presumably because the task
underwent major modifications which made it more challenging. Anyway, the
number of languages involved in the exercise remained stable, as new languages
were added replacing others which were no longer adopted. It is worth noticing that
participants seemed to be less and less inclined to carry out cross-lingual tasks,
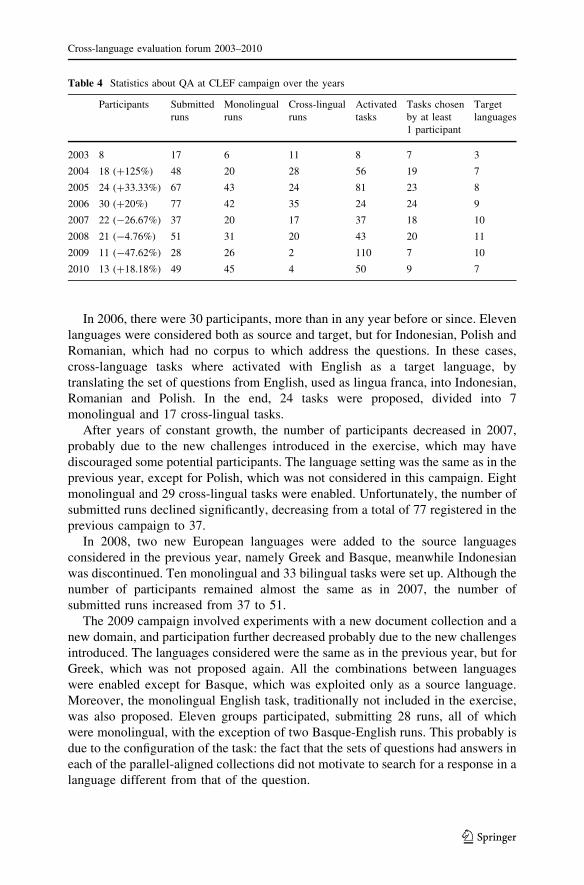
especially in the last two campaigns. Table 4 gives an overview of participation,
languages and runs, showing at a glance how the exercise has evolved during
8 years of QA campaigns.
When the track was proposed for the first time in 2003, eight tasks were set up—
three monolingual and five bilingual—and eight groups from Europe and North
America participated in seven tasks. The details of the distribution between
monolingual and bilingual tasks in all QA campaigns is shown in Table 5.
In 2004, the CLEF QA community grew significantly, as the spectrum of the
languages widened. In fact, nine source languages and 7 target languages were
exploited to set up more than 50 tasks, both monolingual and bilingual. The
monolingual English task was not offered, as it appeared to have been sufficiently
investigated at TREC, a policy retained in the following campaigns, until 2009.
The response of the participants was very positive, and eighteen groups—twice
as many as in the previous year—tested their systems in the QA exercise, submitting
a total of 48 runs.
In 2005, the positive trend in terms of participation was confirmed, as the number
of participants rose to 24, and 67 runs were submitted. The addition of Indonesian
introduced for the first time a non-European language in the task, enhancing the
multilingual character of the exercise, and experimenting with cross-linguality
involving languages outside the European boundaries.
2 http://wt.jrc.it/lt/Acquis/.3 http://www.europarl.europa.eu.
A. Penas et al.
123
In 2006, there were 30 participants, more than in any year before or since. Eleven
languages were considered both as source and target, but for Indonesian, Polish and
Romanian, which had no corpus to which address the questions. In these cases,
cross-language tasks where activated with English as a target language, by
translating the set of questions from English, used as lingua franca, into Indonesian,
Romanian and Polish. In the end, 24 tasks were proposed, divided into 7
monolingual and 17 cross-lingual tasks.
After years of constant growth, the number of participants decreased in 2007,
probably due to the new challenges introduced in the exercise, which may have
discouraged some potential participants. The language setting was the same as in the
previous year, except for Polish, which was not considered in this campaign. Eight
monolingual and 29 cross-lingual tasks were enabled. Unfortunately, the number of
submitted runs declined significantly, decreasing from a total of 77 registered in the
previous campaign to 37.
In 2008, two new European languages were added to the source languages
considered in the previous year, namely Greek and Basque, meanwhile Indonesian
was discontinued. Ten monolingual and 33 bilingual tasks were set up. Although the
number of participants remained almost the same as in 2007, the number of
submitted runs increased from 37 to 51.
The 2009 campaign involved experiments with a new document collection and a
new domain, and participation further decreased probably due to the new challenges
introduced. The languages considered were the same as in the previous year, but for
Greek, which was not proposed again. All the combinations between languages
were enabled except for Basque, which was exploited only as a source language.
Moreover, the monolingual English task, traditionally not included in the exercise,
was also proposed. Eleven groups participated, submitting 28 runs, all of which
were monolingual, with the exception of two Basque-English runs. This probably is
due to the configuration of the task: the fact that the sets of questions had answers in
each of the parallel-aligned collections did not motivate to search for a response in a
language different from that of the question.
Table 4 Statistics about QA at CLEF campaign over the years
Participants Submitted
runs
Monolingual
runs
Cross-lingual
runs
Activated
tasks
Tasks chosen
by at least
1 participant
Target
languages
2003 8 17 6 11 8 7 3
2004 18 (?125%) 48 20 28 56 19 7
2005 24 (?33.33%) 67 43 24 81 23 8
2006 30 (?20%) 77 42 35 24 24 9
2007 22 (-26.67%) 37 20 17 37 18 10
2008 21 (-4.76%) 51 31 20 43 20 11
2009 11 (-47.62%) 28 26 2 110 7 10
2010 13 (?18.18%) 49 45 4 50 9 7
Cross-language evaluation forum 2003–2010
123

Ta
ble
5L
ang
uag
esat
QA
@C
LE
F
Yea
rM
ono
lin
gual
run
sC
ross
-lin
gual
run
s
20
03
IT(2
),N
L(2
),S
P(2
)E
S-E
N(2
),F
R-E
N(6
),IT
-EN
(2),
DE
-EN
(1)
2004
DE
(1),
ES
(8),
FR
(2),
IT(3
),N
L(2
),P
T(3
)B
G-E
N(1
),B
G-F
R(2
),E
N-F
R(2
),E
N-N
L(1
),E
S-F
R(2
),D
E-E
N(3
),D
E-F
R(2
),F
I-
EN
(1),
FR
-EN
(6),
IT-E
N(2
),IT
-FR
(2),
NL
-FR
(2),
PT
-FR
(2)
20
05
BG
(2),
DE
(3),
ES
(13
),F
I(2
),F
R(1
0),
IT(6
),N
L(3
),P
T(4
)B
G-E
N(1
);D
E-E
N(1
),E
N-D
E(3
),E
N-E
S(3
),E
N-F
R(1
),E
N-P
T(1
),E
S-E
N(1
),
FI-
EN
(2)
FR
-EN
(4),
IN-E
N(1
),IT
-EN
(2),
IT-E
S(2
),IT
-FR
(2),
PT
-FR
(1)
20
06
BG
(3),
DE
(6),
ES
(12
),F
R(8
),IT
(3),
NL
(3),
PT
(7)
EN
-DE
(2),
EN
-ES
(3),
EN
-FR
(6),
EN
-IT
(2),
EN
-NL
(3),
EN
-PT
(3),
ES
-EN
(3),
FR
-EN
(4),
FR
-ES
(1),
DE
-EN
(1),
ES
-PT
(1),
IT-E
N(1
),P
T-E
S(1
),R
O-E
N(2
),
IN-E
N(1
)P
L-E
N(1
),P
T-F
R(1
)
20
07
DE
(3),
ES
(5),
FR
(1),
IT(1
),N
L(2
),P
T(7
),R
O(3
)D
E-E
N(1
),E
N-D
E(1
),E
N-F
R(1
),E
N-N
L(2
),E
N-P
T(1
),E
S-E
N(1
),F
R-E
N(2
),
IN-E
N(1
),N
L-E
N(2
),P
T-D
E(1
),R
O-E
N(1
)
20
08
BG
(1),
DE
(6),
ES
(6),
EU
(1),
FR
(1),
NL
(2),
PT
(9),
RO
(4)
DE
-EN
(3),
EN
-DE
(3),
EN
-EU
(1),
EN
-ES
(2),
EN
-FR
(1),
EN
-NL
(2),
ES
-DE
(2),
ES
-EU
(2),
FR
-ES
(1),
NL
-EN
(1),
PT
-FR
(1),
RO
-EN
(1)
20
09
DE
(2),
EN
(10
),E
S(6
),F
R(3
),IT
(1),
RO
(4)
EU
-EN
(2)
2010
DE
-4,0
EN
-16,3
ES
-6,1
FR
-5,2
IT-2
,1P
T-1
,0R
O-4
,0E
N-R
O-2
,0E
U-E
N-2
,0
Nu
mb
ero
fru
ns
for
each
mo
no
ling
ual
lan
gu
age
and
for
each
cro
ss-l
ing
ual
lan
gu
age
pai
r
A. Penas et al.
123

In 2010 the exercise of the previous campaign was replicated almost identically,
considering the same languages, with the exception of Bulgarian. A slight increase
in participation was registered, passing from 11 to 13 participants, who submitted 49
runs, twice as many as in the previous year. The preference for monolingual tasks
was confirmed, as only two participating teams attempted cross-lingual tasks,
namely Basque-English and English-Romanian. This trend, and the fact that 22 out
of 49 submitted runs were monolingual English, suggests that multilinguality was
not perceived as a priority in the last two campaigns.
3.5 Pilot exercises
QA at CLEF was also an opportunity to experiment with several pilot tasks, as
Table 6 shows, whose common goal was to investigate how QA systems and
technologies are able to cope with different types of questions from those proposed
in the main task, experimenting with different scenarios. The following pilot tasks
have been proposed over the years:
• Real Time Question Answering (Noguera et al. 2007): an exercise for the
evaluation of QA systems within a time constraint, carried out in the 2006
campaign, and proposing new measures which combine Precision with the
answer time.
• Answer Validation (Penas et al. 2006): a voluntary exercise to promote the
development and evaluation of sub-systems aimed at validating the correctness
of the answers given by a QA system. The basic idea was that once an
[answer ? snippet] pair is returned to a question by a QA system, an Answer
Validation module has to decide whether the answer is correct according to the
supporting snippet.
• Question Answering over Speech Transcripts (Lamel et al. 2007): the aim was to
evaluate QA technology in a real multilingual speech scenario in which written
and oral questions (factual and definitional) in different languages were
Table 6 Pilot tasks at QA at CLEF campaigns over the years
Answer
Validation
Exercise
(AVE)
Extraction
of Novel
Wikipedia
Information
(WiQA)
Geographic
Wikipedia IR
(GikiCLEF)
QA over
Speech
Transcriptions
(QAST)
Real
Time QA
Word Sense
Disambiguation
QA (WS-QA)
2003
2004
2005
2006 Y Y Y
2007 Y Y
2008 Y Y Y
2009 Y Y
2010
Cross-language evaluation forum 2003–2010
123

formulated against a set of audio recordings related to speech events in those
languages. The scenario was the European Parliament sessions in English,
Spanish and French.
• Word Sense Disambiguation for Question Answering (see Forner et al. 2008,
Section 3.6): a pilot task which provided the questions and collections with
already disambiguated word senses in order to study their contribution to QA
performances.
• Question Answering using Wikipedia (Jijkoun & de Rijke 2007): the purpose
was to see how IR and NLP techniques could be effectively used to help readers
and authors of Wikipedia pages to access information spread throughout
Wikipedia rather than stored locally on the pages. Specifically, the task involved
detecting whether a snippet contained new information or whether it duplicated
what was already known.
• GikiCLEF (Santos and Cabral 2009): following the previous GikiP pilot at
GeoCLEF 2008, the task focused on open list questions over Wikipedia that
require geographic reasoning, complex information extraction, and cross-lingual
processing, for Bulgarian, Dutch, English, German, Italian, Norwegian,
Portuguese, Romanian and Spanish.
4 Performance assessment
The evaluation performed for a specific QA track depended on the concrete
objectives of each year: once these were set, the organisers tried to choose an
appropriate evaluation method. This implied determining specific features of the
collections, as well as selecting the measures for assessing the performance of
participating systems.
For each question in the test set systems were required to return at least one
answer along with a text supporting the correctness of that answer. Until 2005, the
supporting information was the id of a document, while starting from 2006, systems
had to return a supporting snippet (no more than 500 bytes) containing the answer.
Answers were judged by native language human assessors, who assigned to each
response a unique judgment following the schema already established in TREC
(Voorhees 2000):
• Right (R): the answer string consisted of nothing more than an exact answer and
it was supported by the accompanying text;
• Wrong (W): the answer string did not contain a correct answer;
• Unsupported (U): the answer was correct, but it was impossible to infer its
correctness from the supporting text;
• IneXact (X): the answer was correct and supported, but the answer string
contained either more or less characters than the exact answer.
Once the answers had been manually assessed, the following step in the
evaluation was to give a set of numeric values summarising the performance of each
system. These values were given with two purposes:
A. Penas et al.
123

1. To compare the performance of different systems. In fact, numeric scores
permit not only to judge which system is best, but also to study the same system
with different configurations, by analysing the effect of including new features
on the performance of the systems.
2. To predict the performance of a system in future real scenarios. One of the
objectives of such an evaluation as that performed in QA at CLEF is to predict
in a controlled environment the behavior that a system would have in the real
world.
The scores assessing the performances of QA systems at CLEF were calculated
using different evaluation measures, each of which was based on the information
derived from human assessments. As each measure is generally aimed at analysing
only a specific aspect of the behavior of a system, one should be careful when
drawing conclusions on the basis of a single metric, since it is probably appropriate
only to assess a particular system feature.
4.1 Evaluation measures applied
Several evaluation measures have been used in the QA at CLEF campaigns. In each
competition a main measure was selected to rank the results of the participating
systems, while several additional measures were adopted in order to provide more
information about the systems’ performances.
Mean Reciprocal Rank (MRR) was used in the first campaign (2003) as the main
evaluation measure, while in the following years it was employed as a secondary
measure whenever more than one answer per question was requested. MRR is
related to the Average Precision used in Information Retrieval (Voorhees and Tice
1999) and was used at CLEF when systems had to return up to three answers per
question ranked by confidence, putting the surest answer in the first place.
According to MRR, the score for each question is the reciprocal of the rank at
which the first correct answer is given. That is, each question can be scored 1; 0.5;
0.333; or 0 (in the case where none of the three answers given is correct). The final
evaluation score is the mean over all the questions. Thus, MRR allows to evaluate
systems giving more than one answer per question, acknowledging the precision of
systems that place correct answers in the first positions in the answer ranking.
The most used evaluation measure in the QA at CLEF was accuracy, which is the
proportion of questions correctly answered. In the case of having more than one
answer per question, accuracy takes into consideration only the first answer.
Accuracy acknowledges a more precise behaviour than MRR, since it only takes into
account one answer per question. This is why it was used as the main evaluation
measure from 2004 to 2008 (inclusive), while it was exploited as a secondary
measure in 2009, where c@1 was introduced.
With c@1 (Penas and Rodrigo 2011), systems can either respond to a question, or
leave it unanswered if they are not confident about finding a correct answer. The
main rationale behind c@1 is that, in some scenarios (for instance in medical
diagnosis), to leave a question unanswered is preferable to giving an incorrect one.
In fact, c@1 rewards the ability of a system to maintain the number of correct
Cross-language evaluation forum 2003–2010
123

answers, while reducing the number of incorrect ones by leaving some questions
unanswered. This is effectively a strategy of increasing precision while maintaining
recall, an essential provision for any system which is expected to be employed by
real users. The formulation of c@1 is given in (1), where:
nR: number of questions correctly answered
nU: number of unanswered questions
n: total number of questions
c@1 ¼ 1
nnR þ nU
nR
n
� �ð1Þ
It must be noticed that the concept of leaving a question unanswered is different
from giving a NIL answer. In the former case, a system shows that it is not able to
find a correct answer to the question, while in the latter the system’s conclusion is
that there is not correct answer to the question in the target collection.
The adoption of c@1 was a consequence of the Answer Validation Exercises4
(AVE) carried out as a subtask of QA at CLEF from 2006 to 2008 (Penas et al.
2006, 2007; Rodrigo et al. 2008). In AVE, the development of Answer Validation
technologies was sustained by the effort of improving the ability of QA systems to
determine the correctness of their answers, and therefore, to reduce the number of
incorrect answers. Because AVE showed that it was possible to improve QA results
by including deeper analysis concerning the correctness of answers, it was decided
to transfer this idea to the main task by using the c@1 measure.
The rest of the measures used in QA@CLEF evaluations (always as secondary
measures) were focused on evaluating systems’ confidence in the correctness of
their responses. Confidence Weighted Score (CWS) (Voorhees 2002), which had
already been used for evaluating QA systems at TREC could be applied when
systems ordered their answers from the most confident response to the least
confident one. CWS rewards a system for a correct answer early in the ranking, more
than for a correct answer later in the ranking. The formulation of CWS is given in
(2), where n is the number of questions, and C(i) (Eq. 3) is the number of correct
answers up to the position i in the ranking. I(j) is a function that returns 1 if answer jis correct and 0 if not. CWS gives more value in the final score to some questions
over other ones. Specifically, questions whose correct answers are in the highest
positions of the ranking contribute significantly to the final score, while questions
with answers at the bottom of the ranking do not contribute so much.
CWS ¼ 1
n
Xn
i¼1
CðiÞi
ð2Þ
CðiÞ ¼Xi
j¼1
IðjÞ ð3Þ
4 http://nlp.uned.es/clef-qa/ave/.
A. Penas et al.
123

Other two measures focused on the evaluation of systems’ self-confidence, K and
K1, were adopted in a pilot task at CLEF 2004 (Herrera et al. 2005). In order to
apply K and K1, QA systems had to return a real number between 0 and 1 associated
to each answer that indicated their confidence in the given answer. When a system
gave value 1, it meant that the system was totally sure about the correctness of its
answer, while 0 meant that the system did not have any evidence supporting the
correctness of the answer.
K and K1 are based on a utility function that returns -1 if the answer is incorrect
and 1 if it is correct. This positive or negative value is weighted with the normalised
confidence self-score given by the system to each answer. The formulation of K1 is
shown in (4), while the formulation of K (a variation of K1 for use where there is
more than one answer per question) is shown in (5). In these formulas, R(i) is the
total number of known answers to question i that are correct and distinct;
answered(i) is the number of answers given by a system for question i; self_score (r)
is the confidence score assigned by the system to answer r and eval (r) depends on
the judgement given by a human assessor:
• eval(r) = 1 if r is judged as correct
• eval(r) = 0 if r is a repeated answer
• eval(r) = -1 if r is judged as incorrect
K1 ¼P
i2fcorrect answersÞ self scoreðiÞ �P
i2fincorrect answersÞ self scoreðiÞn
ð4Þ
K ¼ 1
#questions
Xi2questions
Pr2answersðiÞ self scoreðrÞ � evalðrÞ
maxfRðiÞ; answeredðiÞg ð5Þ
K and K1 ranks between -1 and 1. However, the final value given by K and K1 is
difficult to interpret: a positive value does not indicate necessarily more correct
answers than incorrect ones, but that the sum of scores of correct answers is higher
than the sum of scores of incorrect ones.
5 Discussion of results
The QA campaigns can be divided into three eras as it can be seen from Table 1.
The division has been made considering the collections used and the type of
questions:
• Era I: 2003–2006. Ungrouped mainly factoid questions asked against monolin-
gual newspapers; Exact answers returned.
• Era II: 2007–2008. Grouped questions asked against newspapers and Wikipe-
dias; Exact answers returned.
• Era III: 2009–2010. Ungrouped questions against multilingual parallel-aligned
EU legislative documents; Passages or exact answers returned.
Cross-language evaluation forum 2003–2010
123
In considering results from different years at CLEF, we need to bear in mind the
following points: Firstly, the task to be performed may differ from year to year; the
task in a particular year may be easier or harder than that of the previous year, and
this could result in a general level of performance which is higher or lower
respectively. Secondly, in Eras I and II the document collections used were
necessarily different for each target language. Naturally this affects results, though it
does not invalidate general comparisons between languages. Thirdly, even if
questions and documents are identical, as in Era III, there may be intrinsic
differences between languages which preclude exact comparison (see further
discussion later). Nevertheless, performance figures and comparisons between them
give an important indication of the state of the field, the activity in different
countries and the issues in language processing which need to be tackled—all
important and substantive matters.
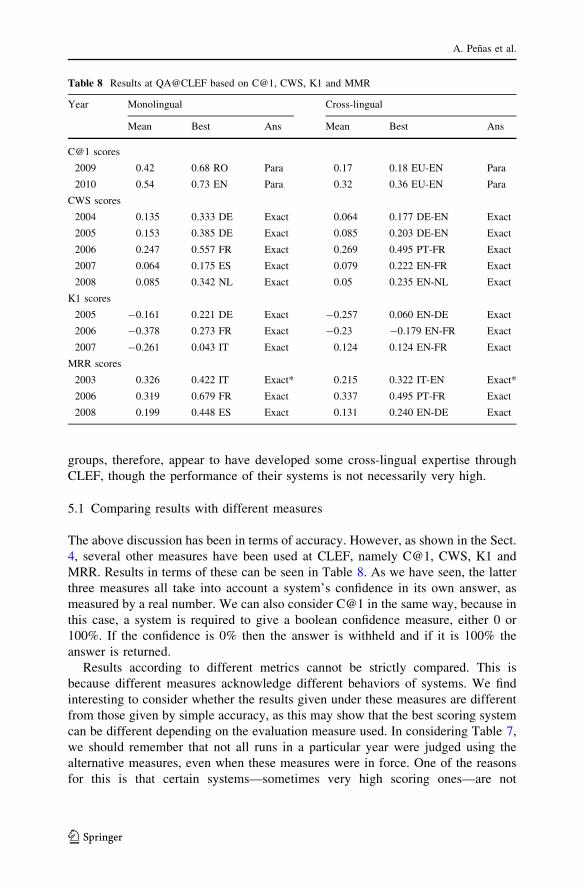
Table 7 summarises the results from 2003 to 2010 in terms of accuracy; these are
given as the percent of questions which were answered correctly, to the nearest 1%.
Since the task was quite different in each of the above eras, we need to consider the
evaluation results separately.
In the first era (2003–2006), monolingual factoid QA showed a steady
improvement, starting at 49% in the first year and increasing to 68% in the fourth
(2006). Interestingly, the best system was for a different language in each of those
years—Italian, Dutch, Portuguese and French respectively. The improvement can be
accounted for by the adoption of increasingly sophisticated techniques gleaned from
other monolingual tasks at TREC and NTCIR, as well as at CLEF. However, during
the same time, cross-lingual QA showed very little improvement, remaining in the
range 35–49%. The bottleneck for cross-lingual QA is Machine Translation and
Table 7 Results at QA@CLEF based on accuracy
Year Monolingual Cross-lingual
Mean (%) Best Ans Mean (%) Best Ans
Era I
2003 29 49% IT Exact 17 45% IT-EN Exact
2004 24 46% NL Exact 15 35% EN-NL Exact
2005 29 65% PT Exact 18 40% EN-FR Exact
2006 28 68% FR Exact 25 49% PT-FR Exact
Era II
2007 23 54% FR Exact 11 42% EN-FR Exact
2008 24 64% PT Exact 13 19% RO-EN Exact
Era III
2009 41 61% EN Para 16 18% EU-EN Para
2010 51 72% EN Para 28 30% EN-RO Para
These are given as the percent of questions answered exactly right, to the nearest 1%. In 2003, three
attempts were allowed at each question and if one of these was correct, the answer was ‘‘exactly right’’.
For results in terms of the other measures C@1 (2009-10), CWS (2004-8), K1 (2005-7) and MRR (2003,
2006 and 2008) see the next table
A. Penas et al.
123

clearly the required improvement in MT systems has not been realised by
participants in the task.
As a general remark, systems which attempted a cross-language task in addition
to a monolingual one did not show a similar performance trend in the two tasks, the
cross-language task recording much lower scores. For example, the QRISTAL
system developed by Synapse Developpement in 2005 (Laurent et al. 2005)
participated in four tasks having French as target language—namely monolingual
French, English-French, Italian-French, and Portuguese-French. Meanwhile it
obtained good results in the monolingual task, reaching 64%, its performance
decreased in the cross-language tasks, scoring 39.50, 25.50, 36.50% respectively.
Another example is the 2006 Priberam system (Cassan et al. 2006): it performed
well in the monolingual Portuguese task, with an accuracy of 69%, but in cross-
lingual Spanish-Portuguese task its accuracy dropped to 29%. Similarly, the system
scored 51% in the monolingual Spanish task, but only 34.4% in the cross-lingual
Portuguese-Spanish task.
In the second era (2007–2008), the task became considerably more difficult
because questions were grouped around topics and in particular because, sometimes,
it was necessary to use coreference information across different questions.
Monolingual performance dropped 14%, from its previous high of 68% in 2006
to 54% in 2007, and then increased to 64% in 2008. Once again the language was
different in each year—first French and then Portuguese. At the same time, cross-
lingual performance decreased from the 2006 figure of 49% (PT-FR) in the previous
Era to 42% (EN-FR) in 2007. Relative to the change in monolingual system
performance, this was a smaller decrease. Then, in 2008, the figure fell to 19% (RO-
EN). This dramatic change can be explained by the fact that the monolingual
systems in Era II were the same as those in Era I, while the highest performing
cross-lingual system of 2007 was from a particularly important group which has
consistently achieved very good results at TREC. Unfortunately this group chose
not to participate in 2008.
In the third era (2009–2010), the task changed to one of paragraph retrieval while
at the same time the questions and document collection became more difficult.
Monolingual performance started at a similar level of 61% in 2009 and then rose to
72% in 2010. Cross lingual performance was 18% (EU-EN) in 2009 and rose to
30% (EN-RO) in 2010. These very low figures can be accounted for by the fact that
there was very little participation in the cross-lingual task during the third era.
Concerning monolingual performance taken over all 8 years, which language
scores the highest? Generally, the language of the best system tended to change
from year to year. Taken alphabetically and considering the top scoring system for
each year, we had one Dutch, two English, two French, one Italian and two
Portuguese. There are a number of factors which influence this, including the
languages which are allowed in any particular year, and also the groups which are
able to participate. Generally, however, we can conclude that very good systems
were developed in a number of different languages, a key aim of CLEF in contrast
to TREC. Concerning the language pairs of the best cross-lingual systems, they
changed every year and the only pair which occurred twice was EN-FR. Most
Cross-language evaluation forum 2003–2010
123
groups, therefore, appear to have developed some cross-lingual expertise through
CLEF, though the performance of their systems is not necessarily very high.
5.1 Comparing results with different measures
The above discussion has been in terms of accuracy. However, as shown in the Sect.
4, several other measures have been used at CLEF, namely C@1, CWS, K1 and
MRR. Results in terms of these can be seen in Table 8. As we have seen, the latter
three measures all take into account a system’s confidence in its own answer, as
measured by a real number. We can also consider C@1 in the same way, because in
this case, a system is required to give a boolean confidence measure, either 0 or
100%. If the confidence is 0% then the answer is withheld and if it is 100% the
answer is returned.
Results according to different metrics cannot be strictly compared. This is
because different measures acknowledge different behaviors of systems. We find
interesting to consider whether the results given under these measures are different
from those given by simple accuracy, as this may show that the best scoring system
can be different depending on the evaluation measure used. In considering Table 7,
we should remember that not all runs in a particular year were judged using the
alternative measures, even when these measures were in force. One of the reasons
for this is that certain systems—sometimes very high scoring ones—are not
Table 8 Results at QA@CLEF based on C@1, CWS, K1 and MMR
Year Monolingual Cross-lingual
Mean Best Ans Mean Best Ans
C@1 scores
2009 0.42 0.68 RO Para 0.17 0.18 EU-EN Para
2010 0.54 0.73 EN Para 0.32 0.36 EU-EN Para
CWS scores
2004 0.135 0.333 DE Exact 0.064 0.177 DE-EN Exact
2005 0.153 0.385 DE Exact 0.085 0.203 DE-EN Exact
2006 0.247 0.557 FR Exact 0.269 0.495 PT-FR Exact
2007 0.064 0.175 ES Exact 0.079 0.222 EN-FR Exact
2008 0.085 0.342 NL Exact 0.05 0.235 EN-NL Exact
K1 scores
2005 -0.161 0.221 DE Exact -0.257 0.060 EN-DE Exact
2006 -0.378 0.273 FR Exact -0.23 -0.179 EN-FR Exact
2007 -0.261 0.043 IT Exact 0.124 0.124 EN-FR Exact
MRR scores
2003 0.326 0.422 IT Exact* 0.215 0.322 IT-EN Exact*
2006 0.319 0.679 FR Exact 0.337 0.495 PT-FR Exact
2008 0.199 0.448 ES Exact 0.131 0.240 EN-DE Exact
A. Penas et al.
123

designed to return confidence scores, and without these values, some of these
measures cannot be computed.
Starting with C@1 (2009–2010, Era III) we can see that for monolingual QA the
best system was EN by both C@1 and accuracy in 2010 but that in 2009 it was RO
by C@1 and EN by accuracy. In fact, the same EN system in 2010 had the best
C@1 and the best accuracy. However, in 2009, the RO system with C@1 0.68 in
Table 7 had an accuracy of only 0.52 whereas the EN system with an accuracy of
0.61 in Table 6 only had a C@1 of 0.61. Concerning cross-lingual results, they
concurred in both 2009 and 2010 (EU-EN).
Turning to CWS during 2004–2008 (Era I 2004–2006 and Era II 2007–2008) the
results do not concur with those of accuracy except in 2006; the same FR system in
that year had the best CWS and the best accuracy. Similarly, cross-lingual results
only concurred in 2006 (PT–FR) and 2007 (EN–FR). In both cases it was in fact the
same system which had the best CWS and the best accuracy.
Concerning K1 during 2005–2007 (Era I 2005–2006 and Era II 2007) for
monolingual results these concurred with accuracy only in 2006 (as with CWS).
Once again the language was FR and it was the same French run. Cross-lingual
results only concurred in 2007 (EN–FR) where it was also the same EN-FR run.
Regarding MRR during 2003, 2006 and 2008 (Era I, Era I and Era II
respectively), the monolingual results concurred in 2003 (IT) and 2006 (FR) but not
in 2008. The best MRR in 2003 was the same Italian run which obtained the best
accuracy, and similarly for the French run in 2006. Cross-lingual results concurred
in 2003 (IT–EN) and in 2006 (PT–FR) but not in 2008.
Another question concerning different evaluation measures is, where there is an
increase in accuracy, is there a comparable increase in the measure? The answer for
C@1 appears to be yes—the trend for C@1 scores seems to be quite similar to that
for accuracy scores: monolingual C@1 (2009–2010) increased from 0.68 to 0.73 as
against an increase in accuracy from 0.61 to 0.72. Cross lingual results went from
0.18 to 0.36 by both measures.
Turning to CWS and K1, however, the trend is not clear-cut, but since not all
systems returned these scores, it is hard to draw a firm conclusion.
Regarding changes in MRR scores, the monolingual trend for the years 2003,
2006 and 2008 was 0.422, 0.679, 0.448 while accuracy figures were 0.49, 0.68, 0.64.
However, the anomaly of 0.448 is accounted for because it was for a system with
accuracy 0.43. The more accurate systems did not return MRR scores. So, generally,
MRR appears similar to accuracy.
5.2 Comparing results across languages
The number of runs submitted in each language (monolingual) and language pair
(cross-lingual) across the three eras is shown in Table 5. As can be seen, the main
interest has always been in the monolingual systems, with the majority of teams
building a monolingual system in just their own language. Naturally, most groups
are also capable of building a good English monolingual system, but these have not
been allowed at CLEF except in Era III. However, cross-lingual runs from or to
Cross-language evaluation forum 2003–2010
123

English are allowed, and as the table shows, most of the runs between languages are
indeed either from English to the language of the team or the other way around. What
follows from this is that a relatively high number of cross-language tasks are activated
each year with a very small number of runs (often just one or two) being submitted for
each. This has led to some criticism of the QA track at CLEF, that there are too many
languages and language pairs involved and that results are therefore not comparable
between language pairs. We turn to this point next, but we should also note in passing
that Europe is a highly multilingual region with many more languages than are
represented here. It seems fitting therefore that CLEF should encourage the
development of systems in as many of these languages as possible.
If several systems perform the same task on the same language pair, direct
comparison is of course possible. However, as discussed above, the nature of CLEF
means that this is rarely possible. So, can performance on different tasks be
compared? Up until 2009 (i.e. in Eras I and II), each target language had its own
document collection and corresponding set of questions which were then back-
translated into the source languages. Thus all tasks of the form S–T (with a fixed
target language T) were answering the same questions (albeit in different source
languages S) against the same target collection in T. This made a measure of
comparison possible, mainly in the case where T was EN since this was a task which
was within the means of most groups through their familiarity with English.
In order to take this comparison further, a new strategy was adopted in 2009
whereby a parallel aligned collection was used (Acquis) meaning that the questions
and document collection were exactly the same for all monolingual tasks as well as
all cross-lingual tasks.
Moreover, some interesting additional experiments were performed at UNED
(Perez-Iglesias et al. 2009). Firstly, the document collections in all the various target
languages were indexed by paragraph, using the same IR engine in each case. The
queries in each language were then input to the corresponding IR system, and the
top ranking paragraphs returned were used as ‘baseline’ answers—this was possible
because the task that year was paragraph selection, not exact answer selection.
Interestingly, many systems returned results which were worse than the baseline, a
situation which probably arose because UNED tuned the parameters in their system
very carefully. Something similar was observed at TREC-8 (Voorhees and Tice
1999) where the AT&T system using passage retrieval techniques performed well
against those using QA techniques.
In the second experiment, UNED compared the performance of the baseline
systems across languages. Because all languages were answering the same questions
on the same collection, this enabled them to estimate the intrinsic difficulty of the
language itself. By applying the resulting difficulty coefficients to the various
submitted runs, they were able to make more accurate comparisons between them.
6 Techniques used by participants
In this section we outline some of the developments in QA which have taken place
during the various campaigns. As has already been mentioned, QA in the sense being
A. Penas et al.
123

discussed here started at TREC in 1999. It ran there for several years before commencing
at CLEF in 2003. It follows from this that most established groups had developed
sophisticated techniques in English before CLEF started. Moreover, most first-
generation QA systems evolved into a common architecture: Question analysis leading
to question type determination; document/passage selection; candidate answer extrac-
tion; and finally, answer selection. This architecture and a detailed discussion of QA can
be found in Hirschman and Gaizauskas (2001) and Prager (2006).
What follows relates specifically to QA at CLEF. For each year, the best three
monolingual systems, independent of language, were identified, as well as the single
best cross-lingual system. Descriptions of these systems were then studied in order
to observe general trends over the years of the evaluation exercise. We refer to a
group’s CLEF overview paper by the name of the group, the reference to the paper,
and the year of the campaign, e.g. Amsterdam; Jijkoun, et al. (2003).
Concerning monolingual systems, the first observation is that one key to success
has been the use of vast numbers of hand-tuned patterns in order to achieve high
performance. Systems include Priberam and Synapse, both of which have
repeatedly achieved very high scores. For example, Priberam uses Question
Patterns to assign queries to categories (possibly more than one), Answer Patterns to
assign document sentences to various categories at indexing time, depending on
what kind of question they could answer, and Question Answering Patterns to
extract an answer to a question. This work is labour-intensive. Priberam spent
twelve person-months converting a lexicon and associated rules from Portuguese
into Spanish (Priberam; Cassan et al. 2006). Conversion of question analysis rules to
Spanish took a further 2 months. The use of detailed answer patterns is of course not
new and goes back to Hovy et al. (2001).
In addition, vast resources—often hand compiled—are often used. For example,
in 2006, Synapse (Laurent et al. 2006) reported a nominal dictionary of 100,000
entries and a multilingual list of 5,000 proper names in a number of different
languages, as well as the use of 200,000 translations of words or expressions. These
materials were specially refined, checked and further developed on a continuous
basis. Information of interest can include lists of persons, places etc. with additional
information (such as a person’s occupation or a place’s population), lexical data,
ontologies and so on. Sometimes semi-automatic methods are used for creating
these, such as extracting them from document collections, Wikipedia or the Web.
However, hand-correction and refinement is always the key to top performance.
A second theme has been the rise in importance of answer validation techniques.
Given a list of likely correct answers, the correct one must be chosen. In early
systems, the answer was frequently there but was somehow missed.
An early form of answer validation involved the use of the web, as pioneered by
Magnini et al. (2002) and widely used by other systems thereafter. Here, an association
is sought on the web between terms from the query and the candidate answer. If this is
found, it suggests that the answer is correct. Systems at CLEF using this technique
include Alicante (Vicedo et al. 2003, 2004), ITC-irst (Negri et al. 2003), and Evora
(Saias and Quaresma 2007, 2008) and it was particularly suitable during the years
when the questions were of the ‘‘trivia’’ factoid type since information concerning the
answers was readily found outside the official document collections.
Cross-language evaluation forum 2003–2010
123

Another form of answer validation which has been widely adopted is the
comparison of n-grams between query and candidate document (Indonesia, Toba
et al. 2010; Romanian Academy, Ion et al. 2009; UNED, Rodrigo et al. 2009). This
of course takes into account both word occurrence and word order, and is no doubt
inspired by the BLEU automatic evaluation measure for machine translation
systems (Papineni et al. 2002). Typically 1-grams or 2-grams are used though one
approach uses up to 5-grams (UNED, Rodrigo et al. 2009).
A final popular form of answer validation is textual entailment (measured by
logical deduction, WordNet word chaining etc.) to link a query term to a candidate
paragraph term (Indonesia, Toba et al. 2010; Romanian Academy, Ion et al. 2009).
If such a chain is found, it supports the hypothesis that the answer is correct.
From an architectural perspective, a major innovation has been the multi-stream
approach of Amsterdam (Amsterdam, Jijkoun et al. 2003, 2004). They introduce
redundancy into the structure of their system by dividing it into a number of
different streams, each of which independently searches for answer candidates.
These are merged at the end before selecting the system’s response. In 2003 there
were five streams but by 2004 this had risen to eight.
The idea behind ‘‘Early Answering’’ is to mine possible answers to questions
from the document collection and elsewhere, prior to answering any questions
(Clarke et al. 2001). Answers are saved in a series of databases and can then be used
to determine the answer to certain questions prior to searching the document
collection. At CLEF a successful use of this technique can be seen in the systems of
Amsterdam (Jijkoun et al. 2003, 2004) and Avignon (Gillard et al. 2006).
CLEF has witnessed a number of interesting developments concerned with the
retrieval process. Firstly, there are different units which can be indexed—whole
documents (Avignon, Gillard et al. 2006; Cuza Romania, Iftene et al. 2009; Romanian
Academy, ion et al. 2009), blocks of arbitrary fixed size such as 1 kB (Synapse,
Laurent et al. 2005), paragraphs (Cuza Romania, Iftene et al. 2009; Romanian
Academy, Ion et al. 2009; Valencia, Correa et al. 2009), passages of variable size
(Avignon, Gillard et al. 2006) or sentences (Alicante, Vicedo et al. 2003; Priberam,
Amaral et al. 2008). In some cases, several different indices are used simultaneously—
Synapse (Laurent et al. 2005) reports the use of eight. Conversely, Indonesia (Toba
et al. 2010) have three indices of the same text units indexed using different
algorithms. Comparison between the results forms an important part of their
successful retrieval component. Aside from the number of indices and the amount of
text indexed, there is the question of what to index by, other than keywords. Prager’s
landmark work on Predictive Annotation (indexing by NE type) (Prager et al. 2000)
has been hugely influential and related ideas can be seen at CLEF. For example
Priberam (Amaral et al. 2005, Cassan et al. 2006) use Answer Patterns to assign
document sentences to various categories, depending on what kind of question they
could answer. Similarly, Synapse (Laurent et al. 2005, 2006, 2007, 2008) index by
named entity types but also be question type, answer type and field of study (e.g.
aeronautics).
Related to indexing is the broader issue of text representation, called the
‘‘Document Representative’’ by van Rijsbergen (1979). An information retrieval
system traditionally uses an inverted index based on keywords or phrases. The
A. Penas et al.
123

developments mentioned above extend this with named entities, query types etc.
However, the index often remains the sole remnant of the document collection.
However, there have been some interesting developments using representations of
parsed and disambiguated texts. These include deep parsing with WOCADI and
MULTINET (Hagen, Hartrumpf 2004), dependency parsing (Groningen, Bouma
et al. 2005), and constraint grammars together with semantic representations and
logical representations of both queries and text sentences (Evora, Saias and
Quaresma 2007). There are of course many problems with such approaches,
including structural and semantic disambiguation. However, accuracy in parsing is
improving all the time—Groningen (Bouma et al. 2005) report 88%. In addition,
there is the issue of efficiency. The Hagen (Hartrumpf 2004) group report a single-
CPU time of 5–6 months to parse the collection while Groningen (Bouma et al.
2005) mentions 17 months. In the latter case, they speed the process up dramatically
by dividing it up among processors in a Beowulf cluster.
Alongside the use of pre-defined patterns mentioned earlier, there is the use of
machine learning algorithms which of course is now widespread in all areas of
natural language processing, including QA. Examples at CLEF of tasks carried out
with machine learning include query type identification using decision trees
(Avignon, Gillard et al. 2006 and others), NE recognition (most systems), and
probable answer type recognition in a passage (Romanian Academy, Ion et al.
2009).
CLEF is multilingual, and this has opened the way for groups to experiment with
the use of cross-lingual redundancy to improve monolingual performance
(Amsterdam, Jijkoun et al. 2003, 2004; Alicante, Vicedo et al. 2004). One way in
which this can be done is to search for answers in different languages (for example,
Amsterdam when working in monolingual Dutch look in the English collection as
well) and if an answer is found (e.g. in English) this can then be searched for in the
Dutch collection. Alicante have a similar strategy.
Following on from cross-lingual redundancy is the task of cross-lingual QA
itself. They key problem here is the need for high quality machine translation in
order not to introduce noise at the translation stage. This remains something of an
unsolved problem at CLEF—inspection of the CLEF monolingual vs. cross-lingual
results (see Sect. 5) shows that cross-lingual performance is still significantly below
monolingual performance. At CLEF, there have essentially been two approaches.
The first is the translation of words using predefined ontologies or dictionaries (ITC-
irst, Negri et al. 2003; Synapse, Laurent et al. 2005, 2006; Priberam, Cassan et al.
2006; Wolverhampton, Dornescu et al. 2008; Basque Country, Agirre et al. 2009,
2010). In many cases, resources are hand-tuned to optimise performance (see
Synapse in particular). They can also be derived semi-automatically, e.g. from
aligned Wikipedia pages (Wolverhampton, Dornescu et al. 2008). Words translated
individually in this way need to be disambiguated and validated with respect to the
target corpus. ITC-irst (Negri et al. 2003) present a way of doing this by generating
all possible combinations of candidate translations for all the words in the query and
then searching for these in the document collection. The most frequently co-
occuring combination of word senses found in the collection, for the maximal
number of words in the query, is chosen as being the most likely. A similar approach
Cross-language evaluation forum 2003–2010
123

is taken by the Basque Country (Agirre et al. 2009, 2010). Priberam (Cassan et al.
2006) tackle disambiguation by using the EuroParl parallel corpus to determine
likely translations for words. These can then be used to score candidate translations
created using their dictionaries and ontologies.
The Basque Country (Agirre et al. 2009, 2010) also adopt an interesting strategy
using true cognates between languages: they take a word in Basque, convert it to
several alternative possible spellings of the equivalent word in English, and then
search for these in the collection. Any sufficiently accurate match (by a string
distance measure) is considered a likely translation. This is a very useful technique
where parallel corpora and translation dictionaries are not available for a particular
language pair.
Finally, there is the use of English as a pivot language, as adopted by Synapse
(Laurent et al. 2005). To translate a word between Portuguese and French, they first
translate to English and then from English to French. This avoids the need for bi-
lingual dictionaries in all combinations of languages.
The second approach to translation within QA is the use of machine translation at
the sentence level, e.g. to translate the entire query and then process it
monolingually in the target language (Amsterdam, Jijkoun, et al. 2004; Language
Computer Corp., Bowden et al. 2007). Language Computer Corp. are the most
spectacular example of this, since they, alone among CLEF groups, translate the
entire document collection into English and then proceed with cross-lingual QA in
an entirely monolingual fashion, still yielding excellent results.
7 Research context
In this section we address some of the relevant research directions on QA which
have been explored in the last years outside the scope of QA at CLEF, although with
connections with the CLEF topics and often influenced by the CLEF achievements.
The purpose is to highlight how the QA at CLEF initiative had significant impact on
the global research context on QA. Among the numerous research directions, we
focus on Interactive QA and on QA over structured data.
7.1 Interactive QA
The ability of a QA system to interact with the user is crucial in order to realize
successful applications in real scenarios (Webb and Webber 2009). Providing the
explanation for an answer, managing follow up questions, providing justification in
case of failure, and asking clarifications can be considered as steps forward with
respect to fact-based Question Answering. Interactive QA has been addressed, both
at CLEF and TREC, respectively in the iCLEF and the ciQA tracks.
In iCLEF 2005 (Gonzalo et al. 2005), the interactive CLEF track focused on the
problem of Cross-Language Question Answering (CL-QA) from a user-inclusive
perspective. The challenge was twofold: (i) from the point of view of Cross-
Language QA as a user task, the question was how well systems help users locate
A. Penas et al.
123

and identify answers to a question in a foreign-language document collection; (ii)
from the point of view of QA as a machine task, the question was how well
interaction with the user helps a Cross-Language QA system retrieve better answers.
In other words, the ultimate issue was to determine how the QA system can best
interact with the user to obtain details about a question that facilitate the automatic
search for an answer in the document collection. For instance, in case of ambiguity,
the system may request additional information from the user, avoiding incorrect
translations (for translation ambiguity) or incorrect inferences (for semantic
ambiguity).
At TREC 2006, the ciQA (Kelly and Lin 2007) task (complex, interactive
Question Answering) focused both on complex information needs and interactivity
in the context of Intelligence Analytics. To these purposes topics were composed by
both a template, which provided the question in a canonical form, and a narrative,
which elaborated on what the user was looking for, provided additional context, etc.
In the template, items in brackets represented ‘‘slots’’ whose instantiation varies
from topic to topic. For example:
Template: What evidence is there for transport of [drugs] from [Bonaire] to [theUnited States]?
Narrative: The analyst would like to know of efforts made to discourage narcotraffickers from using Bonaire as a transit point for drugs to the United States.Specifically, the analyst would like to know of any efforts by local authorities as wellas the international community.
As for interactivity, participants had the opportunity to deploy a fully-functional
Web-based QA system for evaluation. For each topic, a human assessor could spent
5 min interacting with each system.
Interactivity has been further explored under the perspective of the background
knowledge that the system needs in order to provide both rich and natural answers
with respect to a given question, as well as clear explanations for failures. In
(Magnini et al. 2009) it is argued that such abilities are necessarily based on a deep
analysis of the content of both question and answer, and an ontology-based
approach is proposed to represent the structure of a question–answer pair in the
context of utterance. This work focuses on aspects relevant to interactivity in a
general QA setting, including the ability to (i) consider the context of utterance of a
question, such as time and location; (ii) provide rich answers containing additional
information (e.g. justifications) with respect to the exact answer; and (iii) explain
failures when no answer is found.
7.2 QA over structured data
The explosion of data available on the Web in a structured format (e.g. DBPedia,
Freebase) has fostered the interest of the research community toward Question
Answering systems able to provide answers from such data, and to perform
reasoning on large knowledge bases. This perspective is even more interesting as
data on the Web are now being ‘‘linked’’ (linked data) by means of the use of
standard formats for exposing, sharing, and connecting pieces of data, information,
Cross-language evaluation forum 2003–2010
123

and knowledge on the Semantic Web using URIs and RDF. From this perspective,
on the one hand, QA over structured linked data opens new perspectives, as
available data can potentially cover open domain knowledge; on the other hand,
most methodologies already experimented (for instance at QA at CLEF) for the
interpretation of questions can be reused and further extended within the new
scenario.
There are several research challenges relevant to QA over structured data,
including: (i) as many of Semantic Web applications refer to one specific domain, it
is crucial to develop techniques which can be easily ported from one domain to
another; (ii) reasoning over large amount of data implies efficient algorithms as well
as the ability to merge content from different sources; (iii) question interpretation
can take advantage of the temporal and spatial context of the utterance, in order to
provide more exact answers.
Among the initiatives on QA over structured data we mention QALL-ME, a
system which takes advantage of a ontology-based representation to provide precise
and rich answers, and PowerAqua, a system tailored to manage QA over large
knowledge bases.
The QALL-ME system (Ferrandez et al. 2011) is the outcome of an European
project whose goal has been the application of open domain methodologies for
question interpretation in the context of QA applications over data represented in an
ontology. The project has realized a shared infrastructure for multilingual and
multimodal Question Answering over structured data, which has been concretely
experimented and evaluated as an application for mobile phones, and which is
available as an open source software. A relevant feature of the system is Context
Awareness, according to which all questions are anchored to a certain space and
time, meaning that every question always has a spatial and temporal context. For
instance, using deictic expressions such as ‘‘here’’ or ‘‘tomorrow’’, a question posed
at eight o’clock in Berlin may potentially mean something completely different than
the same question posed at five o’clock in Amsterdam. Deictic expressions are
solved by algorithms which recognize temporal and spatial expressions in the
question and anchor relative expressions (e.g. ‘‘during the weekend’’, ‘‘the nearest’’)
to absolute expressions (e.g. ‘‘May, 22nd’’ ‘‘Unter den Linden, Berlin’’). In addition,
users may either explicitly indicate the spatial–temporal context in the question (e.g.
‘‘Which movies are on tomorrow in Trento?’’) or let the context implicit, in which
case it will be supplied by the system by means of default information (e.g. ‘‘Which
movies are on’’ would be interpreted using ‘‘today’’ and the name of the town where
the question is uttered).
PowerAqua (Lopez et al. 2009) takes as input a natural language query and
returns answers drawn from relevant semantic sources from anywhere on the
Semantic Web. The crucial steps performed by the system are (i) the identification
of the ontologies relevant to the input question; (ii) the disambiguation of the terms
in the question against the concepts of the ontology in order to avoid potentially
incoherent constructions; and (iii) the mapping of the question into an appropriate
query based on the conceptual schema of the ontologies. What makes Power Aqua
interesting with respect to QA at CLEF is that the system makes large use of
resources (e.g. WordNet) and techniques (e.g. disambiguation, similarity) which
A. Penas et al.
123

have been largely experimented during the CLEF evaluations, as reported in Sect. 6,
highlighting its impact outside the CLEF community.
8 Conclusions
Prior to QA at CLEF, almost all QA was in English. Since the task was started in
2003, numerous groups have participated and experiments have been conducted in
many different language pairs. The result is that there are now several QA research
groups in almost all the European countries and they have sufficient expertise to
create systems which can perform complex tasks including difficult types of
questions—e.g. opinion and reason questions. In addition to numerous research
innovations within systems themselves, there have also been steps forward in the
evaluation methodology. These have included the use of several new evaluation
measures, the progress towards comparison of systems in different languages, and
the development of sophisticated tools for the data preparation.
Over the years, different trends have characterised the evolution of the QA task at
CLEF. In the first era, the emphasis was on developing basic QA techniques and
adopting them in different target languages. In the second, focus was placed on the
problems of linking questions together. These challenges included the detection of
the topic and the resolution of co-references within the sequence. In the third, focus
was switched to the direct comparison of systems between languages, a goal
enabled by the adoption of the fully parallel paragraph-aligned Aquis collection of
EU legislative documents.
Moreover, while at the beginning the aim of the exercise was to assess systems’
ability to extract an exact answer, over the years the importance of also providing a
context supporting the correctness of the answer became more and more evident.
For this reason, first short text snippets were mandatory in order to support the
response; then, entire paragraphs replaced exact answers as the required systems’
output. Returning a complete paragraph instead of an exact answer also allowed the
comparison between pure IR approaches and current QA technologies.
An additional factor which prompted the advancement of the task was the
increasing awareness of the necessity to consider potential users. This need was
addressed in ResPubliQA which was set in the legal domain and aimed at meeting
the requirements of anyone wanting to make inquiries about European legislation,
which could include lawyers, government agencies, politicians and also ordinary
citizens.
Another important output has been the multilingual test sets and their associated
gold standard answers and document collections. These are made possible by the
ingenious paradigm of back-translation which was introduced in 2003 and has been
very successfully used at CLEF ever since. Moreover, all this material is available
online allowing groups in future to re-use the data produced in order to develop and
tune their systems.5
5 Currently all the material is available at http://celct.isti.cnr.it/ResPubliQA/index.php?page=Pages/
pastCampaigns.php.
Cross-language evaluation forum 2003–2010
123

Finally, what can be concluded from the results of the QA task itself? Generally,
English factoid QA as investigated at TREC over the years is no longer worth
studying. There is enough data available for developers. Following the activity at
CLEF, performance of monolingual non-English systems has improved substan-
tially, to the extent that they are approaching that of the best English systems. Now
is the time, therefore, to look at different types of question and different task
scenarios, a process which started with ResPubliQA6 in 2009–2010.
Concerning cross-lingual systems, their performance has not shown a comparable
improvement over the years to that of monolingual ones because high-performance
machine translation remains an unsolved problem, especially where named entities
are concerned (e.g. ‘Sur les quais’ translates as ‘On the Waterfront’). Thus
translation in the QA domain warrants further investigation if multilingual barriers
to text processing are to be overcome.
In 2011, QA at CLEF entered a new era with a completely different task:
Question Answering for Machine Reading Evaluation. Noticing that traditional QA
system architectures do not permit results far beyond 60% accuracy, we understood
that any real change in the architecture requires a previous development of answer
validation/selection technologies. For this reason, the new formulation of the task
after 2010 leaves the step of retrieval aside, to focus on the development of
technologies able to work with a single document, answering questions about it and
using the reference collections as sources of background knowledge that help the
answering process.
Acknowledgments The QA evaluation campaigns at CLEF are a joint effort involving manyinstitutions and numerous people who have collaborated on the creation of the data set in the variouslanguages involved each year, and have undertaken the evaluation of the results; our appreciation andthanks (in alphabetical order) goes to: Christelle Ayache, Inaki Alegria, Lili Aunimo, Maarten de Rijke,Gregory Erbach, Corina Forascu, Valentin Jijkoun, Nicolas Moreau, Cristina Mota, Petya Osenova,Victor Peinado, Prokopis Prokopidis, Paulo Rocha, Bogdan Sacaleanu, Diana Santos, Kiril Simov, ErikTjong Kim Sang, Alessandro Vallin and Felisa Verdejo. Also, support for the TrebleCLEF Coordination,within FP7 of the European Commission, Theme ICT-1-4-1 Digital Libraries and Technology EnhancedLearning (Contract 215231) must be acknowledged for its fund for ground truth creation. This work hasbeen partially supported by the Research Network MA2VICMR (S2009/TIC-1542) and Holopedia project(TIN2010-21128-C02).
Appendix: Examples of question types
Ex. 1.1: LocationQ: Where did the Purussaurus live before becoming extinct?
A: in South America’s Amazon Basin
Context (LA081694):
Its name is Purussaurus and it is the largest species of crocodile that ever lived, a
massive-jawed creature that thundered through South America’s Amazon Basin 6
to 8 million years ago before its kind perished.
6 http://celct.isti.cnr.it/ResPubliQA.
A. Penas et al.
123

Ex. 1.2: MeasureQ: How long is the coastline of Santa Monica Bay?
A: 50 miles
Context (LA120994):
On Thursday, Wilson endorsed the Santa Monica Bay Restoration Project’s action
plan ‘‘without condition,’’ calling it a vital, ambitious and broad approach to reduce
pollution and restore the ecology of the bay, which stretches along 50 miles of Los
Angeles County coast.
Ex. 1.3: ObjectQ: What does magma consist of?
A: molten rock
Context (LA112794):
The odorless gas, more dense than air and collecting inside the floorless cabin, was
welling up from a recent intrusion of magma, or molten rock, miles below the
surface of this mountain that is popular with winter skiers and summer cyclists.
Ex. 1.3: OrganisationQ: What museum is directed by Henry Hopkins?
A: UCLA/Hammer Museum
Context (LA062394):
The story quotes UCLA/Hammer Museum Director Henry Hopkins as saying the
Codex is among works in the Hammer collection being held in escrow as a
guarantee against any financial obligation that might result from a lawsuit filed in
1990 on behalf of Joan Weiss, the niece and sole heir to the fortune of Hammer’s
wife, Frances, who died in 1989.
Ex. 1.4: PersonQ: Who is John J. Famalaro accused of having killed?
A: Denise Huber
Context (LA082094):
Arizona’s governor signed extradition documents Friday that could force house
painter John J. Famalaro to return to Orange County to face charges… Famalaro is
accused of murdering 23-year-old Denise Huber, who vanished after her car broke
down on the Corona del Mar (73) Freeway in June, 1991.
Ex. 1.5: TimeQ: When did Hernando Cortes arrive in the Aztec Empire?
A: in 1519
Context (LA112794):
When Spanish conquistador Hernando Cortes arrived in 1519, the Aztecs welcomed
him, believing he was their returning god.
Ex. 1.6: OtherQ: What is another name for the ‘‘mad cow disease’’?
A: bovine spongiform encephalopathy
Cross-language evaluation forum 2003–2010
123

Context (LA091194):
The government has banned foods containing intestine or thymus from calves
because a new scientific study suggested that they might be contaminated with the
infectious agent of bovine spongiform encephalopathy, commonly called ‘‘mad
cow disease.’’
Ex. 2: DefinitionQ: What is Amnesty International?
A: human rights group
Context (GH951214):
The human rights group Amnesty International called Wei’s trial ‘‘a mockery of
justice’’.
Ex. 3: MannerQ: How did Jimi Hendrix die?
A: drug overdose
Context (LA030994):
Hendrix Death Investigation Over: The British government said Tuesday that it
would not hold a new inquest into the death 24 years ago of rock legend Jimi
Hendrix, who died of a drug overdose at age 27.
Ex. 4: Temporal restriction by eventQ: Who was Uganda’s President during Rwanda’s war?
A: Yoweri Museveni
Context LA072894:
‘‘The complicity of Ugandan President Yoweri Museveni should not be overlooked
in the Rwandan crisis,’’ he adds.
Ex. 5: Temporal restriction by dateQ: Which city hosted the Olympic Games in 1992?
A: Barcelona
Context (LA082194):
But after the 1992 Barcelona Olympics, Henrich called Fong and announced, ‘‘Al,
I’m really jazzed. I want to train for ‘96. I know I can do it.’’
Ex. 6: Temporal restriction by time intervalQ: By how much did Japanese car exports fall between 1993 and 1994?
A: 18.3%
Context (LA053194):
Japan’s vehicle exports in 1993–94 fell 18.3% to 4.62 million, the second straight
year of decline.
Ex. 7: Closed list questionQ: Name the three Beatles that are alive
A: Paul McCartney, George Harrison and Ringo Starr
Context (LA012994-0011):
A. Penas et al.
123

Paul McCartney, George Harrison and Ringo Starr—the three surviving
Beatles—are scheduled to reunite next month to record new music for a 10-hour
video documentary, also titled ‘‘The Beatles Anthology.’’
Ex. 8: Open list questionQ: What countries are members of the Gulf Cooperation Council?
A: Saudi Arabia, Kuwait, United Arab Emirates, Qatar, Oman and Bahrain
Context (LA101394-0380):
The Gulf Cooperation Council—whose members are Saudi Arabia, Kuwait,United Arab Emirates, Qatar, Oman and Bahrain—said in a formal communique
that the allied military buildup ‘‘should continue until they are sure that Iraq no
longer poses a threat.’’
Ex. 9: Grouped questions on topic ‘‘Gulf War Syndrome’’Q1: What is Gulf War Syndrome?
A1: an inexplicable, untreatable collection of afflictions that reportedly have
touched thousands who fought in the desert
Context (LA111494):
Their short, tragic lives—chronicled neatly by their mothers in family photo
albums—are raising new fears that the mysterious Gulf War syndrome, aninexplicable, untreatable collection of afflictions that reportedly have touchedthousands who fought in the desert, is now being passed on to the next generation.
Q2: How many people have been affected by it?
A2: 11,000
Context (LA121494):
Physicians said the 1,019 cases reflected in Tuesday’s report represent a significant
sample of veterans who have sought treatment for Gulf War syndrome. Of the
697,000 who served in Operation Desert Storm, 11,000 have complained of illness.
Some 8,000 are being processed.
Ex. 10: ProcedureQ: How do you find the maximum speed of a vehicle?
Paragraph (jrc31995L0001-en, para 125):
The maximum speed of the vehicle is expressed in km/h by the figure corresponding
to the closest whole number to the arithmetical mean of the values for the speeds
measured during the two consecutive tests, which must not diverge by more than
3%. When this arithmetical mean lies exactly between two whole members it is
rounded up to the next highest number.
Ex. 11: PurposeQ: What is the aim of the Kyoto Protocol in relation to greenhouse gas emissions
for 2008-2012?
Paragraph (jrc32001Y0203_02-en, para 168):
The Kyoto Protocol, signed by the Member States and by the Community, provides
that the parties undertake to limit or reduce greenhouse gas emissions during the
Cross-language evaluation forum 2003–2010
123

period 2008-2012. For the Community as a whole, the target is to reduce greenhouse
gas emissions by 8% of their 1990 level.
Ex. 12: ReasonQ: Why are court decisions in Kazakhstan not made public?
Paragraph (jrc21994A1231_52-en, para 1330):
The process of establishing enquiry points has begun. As far as the judicial decisions
and administrative rulings are concerned they are not published in Kazakhstan
(except for some decisions made by the Supreme Court), because they are not
considered to be sources of law. To change the existing practice will require a long
transitional period.
Ex. 13: OtherQ: During a vehicle driver’s rest period, are they entitled to a bunk?
Paragraph (jrc32006R0561-en, para 139):
1. By way of derogation from Article 8, where a driver accompanies a vehicle which
is transported by ferry or train, and takes a regular daily rest period, that period may
be interrupted not more than twice by other activities not exceeding 1 h in total.
During that regular daily rest period the driver shall have access to a bunk or
couchette.
Ex. 14: OpinionQ: What did the Council think about the terrorist attacks on London?
Paragraph (jrc32006L0024-en, para 20):
On 13 July 2005, the Council reaffirmed in its declaration condemning the terrorist
attacks on London the need to adopt common measures on the retention of
telecommunications data as soon as possible.
References
Agirre, E., Ansa, O., Arregi, X., Lopez de Lacalle, M., Otegi, A., Saralegi, Z., et al. (2009). ElhuyarIXA:
Semantic relatedness and crosslingual passage retrieval. In C. Peters, G. di Nunzio, M. Kurimo, Th.
Mandl, D. Mostefa, A. Penas, & G. Roda (Eds.), Multilingual information access evaluation vol. Itext retrieval experiments, Workshop of the cross-language evaluation forum, CLEF 2009, Corfu,
Greece, 30 September–2 October. Lecture notes in computer science 6241. Springer (Revised
selected papers).
Agirre, E., Ansa, O., Arregi, X., Lopez de Lacalle, M., Otegi, A., & Saralegi, X. (2010). Document
expansion for cross-lingual passage retrieval. In M. Braschler, D. Harman, & E. Pianta (Eds.),
Notebook papers of CLEF 2010 LABs and workshops, September 22–23, 2010 Padua, Italy.
Amaral, C., Figueira, H., Martins, A., Mendes, A., Mendes, P., & Pinto, C. (2005). Priberam’s question
answering system for Portuguese. In C. Peters, F. C. Gey, J. Gonzalo, H. Muller, G. J. F. Jones, M.
Kluck, B. Magnini, & M. de Rijke (Eds.), Accessing multilingual information repositories, 6thworkshop of the cross-language evaluation forum, CLEF 2005, Vienna, Austria, September 21–23,
2005 (Revised selected papers).
Amaral, C., Cassan, A., Figueira, H., Martins, A., Mendes, A., Mendes, P., et al. (2007). Priberam’s
question answering system in QA@CLEF 2007. In C. Peters, V. Jijkoun, T. Mandl, H. Muller, D.
W. Oard, A. Penas, & D. Santos (Eds.), Advances in multilingual and multimodal informationretrieval, 8th workshop of the cross-language evaluation forum, CLEF 2007, Budapest, Hungary,
September 19–21, 2007 (Revised selected papers).
A. Penas et al.
123

Amaral, C., Cassan, A., Figueira, H., Martins, A., Mendes, A., Mendes, P., et al. (2008). Priberam’s
question answering system in QA@CLEF 2008. In C. Peters, T. Mandl, V. Petras, A. Penas, H.
Muller, D. Oard, V. Jijkoun, & D. Santos (Eds.), Evaluating systems for multilingual andmultimodal information access, 9th workshop of the cross-language evaluation forum, CLEF 2008,
Aarhus, Denmark, September 17–19, 2008 (Revised selected papers).
Bouma, G., Mur, J., van Noord, G., van der Plas, L., & Tiedemann, J. (2005). Question answering for
Dutch using dependency relations. In C. Peters, F. C. Gey, J. Gonzalo, H. Muller, G. J. F. Jones, M.
Kluck, B. Magnini, & M. de Rijke (Eds.), Accessing multilingual information repositories, 6thworkshop of the cross-language evaluation forum, CLEF 2005, Vienna, Austria, September 21–23,
2005 (Revised selected papers).
Bowden, M., Olteanu, M., Suriyentrakorn, P., d’Silva, T., & Moldovan. D. (2007). Multilingual question
answering through intermediate translation: LCC’s PowerAnswer at QA@CLEF 2007. In C. Peters,
V. Jijkoun, T. Mandl, H. Muller, D.W. Oard, A. Penas, & D. Santos (Eds.), Advances in multilingualand multimodal information retrieval, 8th workshop of the cross-language evaluation forum, CLEF
2007, Budapest, Hungary, September 19–21, 2007 (Revised selected papers).
Cassan, A., Figueira, H., Martins, A., Mendes, A., Mendes, P., Pinto, C., et al. (2006). Priberam’s
question answering system in a cross-language environment. In C. Peters, P. Clough, F. C. Gey, J.
Karlgren, B. Magnini, D. W. Oard, M. de Rijke, & M. Stempfhuber (Eds.), Evaluation ofmultilingual and multi-modal information retrieval, 7th workshop of the cross-language evaluation
forum, CLEF 2006, Alicante, Spain, September 20–22, 2006 (Revised selected papers).
Clarke, C., Cormack, G., & Lynam, T. (2001). Exploiting redundancy in question answering. In
Proceedings of the 24th annual international ACM SIGIR conference on research and developmentin information retrieval (SIGIR-2001). September 9–13, 2001, New Orleans, Louisiana. ACM 2001,
ISBN 1-58113-331-6.
Correa, S., Buscaldi, D., & Rosso, P. (2009). NLEL-MAAT at CLEF-ResPubliQA. In C. Peters, G. di
Nunzio, M. Kurimo, Th. Mandl, D. Mostefa, A. Penas, & G. Roda (Eds.), Multilingual informationaccess evaluation vol. I text retrieval experiments, workshop of the cross-language evaluation
forum, CLEF 2009, Corfu, Greece, September 30–October 2, 2010. Lecture notes in computer
science 6241. Springer (Revised selected papers).
Dornescu, I., Puscasu, G., & Orsasan, C. (2008). University of Wolverhampton at CLEF 2008. In C.
Peters, T. Mandl, V. Petras, A. Penas, H. Muller, D. Oard, V. Jijkoun, & D. Santos (Eds.),
Evaluating systems for multilingual and multimodal information access, 9th workshop of the cross-
language evaluation forum, CLEF 2008, Aarhus, Denmark, September 17–19, 2008 (Revised
selected papers).
Ferrandez, O., Spurk, C., Kouylekov, M., Dornescu, I., Ferrandez, S., Negri, M., Izquierdo, R., Tomas,
D., Orasan, C., Neumann, G., Magnini B., & Vicedo, J. L. (2011). The QALL-ME framework: A
specifiable-domain multilingual question answering architecture. Web semantics: Science, servicesand agents on the world wide web, 9 (2), Provenance in the Semantic Web, 137–145.
Ferrucci, D., Brown, E., Chu-Carroll, J., Fan, J., Gondek, D., Kalyanpur, A. A., et al. (2010). Building
Watson: An overview of the DeepQA project. AI Magazine, 31(3), 59–79.
Forner, P., Penas, A., Alegria, I., Forascu, C., Moreau, N., Osenova, P., et al. (2008). Overview of the
CLEF 2008 multilingual question answering track. In C. Peters, T. Mandl, V. Petras, A. Penas, H.
Muller, D. Oard, V. Jijkoun, & D. Santos (Eds.), Evaluating systems for multilingual andmultimodal information access, 9th workshop of the cross-language evaluation forum, CLEF 2008,
Aarhus, Denmark, September 17–19, 2008 (Revised selected papers).
Giampiccolo, D., Forner, P., Herrera, J., Penas, A., Ayache, C., Forascu, C., et al. (2007). Overview of the
CLEF 2007 Multilingual Question Answering Track. In C. Peters, V. Jijkoun, T. Mandl, H. Muller,
D.W. Oard, A. Penas, & D. Santos (Eds.), Advances in multilingual and multimodal informationretrieval, 8th workshop of the cross-language evaluation forum, CLEF 2007, Budapest, Hungary,
September 19–21, 2007 (Revised selected papers).
Gillard, L., Sitbon, L., Blaudez, E., Bellot, P., & El-Beze, M. (2006). The LIA at QA@CLEF-2006. In C.
Peters, P. Clough, F. C. Gey, J. Karlgren, B. Magnini, D. W. Oard, M. de Rijke, & M. Stempfhuber
(Eds.), Evaluation of multilingual and multi-modal information retrieval, 7th workshop of the cross-
language evaluation forum, CLEF 2006, Alicante, Spain, September 20–22, 2006 (Revised selected
papers).
Gonzalo, J., Clough, P., & Vallin, A. (2005). Overview of the CLEF 2005 interactive track. In C. Peters,
F. C. Gey, J. Gonzalo, H. Muller, G. J. F. Jones, M. Kluck, B. Magnini, & M. de Rijke (Eds.),
Cross-language evaluation forum 2003–2010
123

Accessing multilingual information repositories, 6th workshop of the cross-language evaluationforum, CLEF 2005, Vienna, Austria, September 21–23, 2005 (Revised selected papers).
Hartrumpf, S. (2004). Question answering using sentence parsing and semantic network matching. In C.
Peters, P. Clough, J. Gonzalo, G. J. F. Jones, M. Kluck, & B. Magnini (Eds.), Multilingualinformation access for text, speech and images, 5th workshop of the cross-language evaluation
forum, CLEF 2004, Bath, September 15–17, 2004, (Revised selected papers).
Herrera, J., Penas, A., & Verdejo, F. (2005). Question answering pilot task at CLEF 2004. Multilingualinformation access for text, speech and images. CLEF 2004. Vol. 3491 of lecture notes in computer
science, pp. 581–590.
Hirschman, L., & Gaizauskas. R. (2001). Natural language question answering: the view from here. In
natural language engineering, Vol. 7(4), December 2001, pp. 275–300.
Hovy, E., Gerber, L., Hermjakob, H., Lin, C., & Ravichandran, D. (2001). Toward semantics-based
answer pinpointing. In Proceedings of the DARPA human language technology conference (HLT),San Diego, CA.
Iftene, A., Trandabat, D., Pistol, I., Moruz, A. M., Husarciuc, M., Sterpu, M., & Turliuc, C. (2009).
Question answering on english and romanian languages. In C. Peters, G. di Nunzio, M. Kurimo, Th.
Mandl, D. Mostefa, A. Penas, & G. Roda (Eds.), Multilingual information access evaluation vol. itext retrieval experiments, Workshop of the cross-language evaluation forum, CLEF 2009, Corfu,
Greece, September 30–October 2, 2010. Lecture notes in computer science 6241. Springer (Revised
selected papers).
Ion, R., Stefanescu, D., Ceausu, A., Tufis, D., Irimia, E., & Barbu-Mititelu, V. (2009). A trainable multi-
factored QA system. In C. Peters, G. di Nunzio, M. Kurimo, Th. Mandl, D. Mostefa, A. Penas, & G.
Roda (Eds.), Multilingual information access evaluation vol. I text retrieval experiments, Workshop
of the cross-language evaluation forum, CLEF 2009, Corfu, Greece, September 30–October2, 2010.
Lecture notes in computer science 6241. Springer (Revised selected papers).
Jijkoun, V., & de Rijke, M. (2007). Overview of the WiQA task at CLEF 2006. In C. Peters, P. Clough, F.
C. Gey, J. Karlgren, B. Magnini, D. W. Oard, M. de Rijke, & M. Stempfhuber (Eds.), Evaluation ofmultilingual and multi-modal information retrieval, 7th workshop of the cross-language evaluation
forum, CLEF 2006, Alicante, Spain, September 20–22, 2006 (Revised selected papers).
Jijkoun, V., Mishne, G., & de Rijke, M. (2003). The University of Amsterdam at QA@CLEF2003. In C.
Peters, J. Gonzalo, M. Braschler, & M. Kluck (Eds.), Comparative evaluation of multilingualinformation access systems, 4th workshop of the cross-language evaluation forum, CLEF 2003,
Trondheim, Norway, August 21–22, 2003 (Revised selected papers).
Jijkoun, V., Mishne, G., de Rijke, M., Schlobach, S., Ahn, D., & Muller, H. (2004). The University of
Amsterdam at QA@CLEF 2004. In C. Peters, P. Clough, J. Gonzalo, G. J. F. Jones, M. Kluck, & B.
Magnini (Eds.), Multilingual information access for text, speech and images, 5th workshop of the
cross-language evaluation forum, CLEF 2004, Bath, September 15–17, 2004 (Revised selected
papers).
Kelly, D., & Lin, J. (2007). Overview of the TREC 2006 ciQA task. SIGIR Forum, 41, 1.
Lamel, L., Rosset, S., Ayache, C., Mostefa, D., Turmo, J., Comas P. (2007). Question answering on
speech transcriptions: The QAST evaluation in CLEF. In C. Peters, V. Jijkoun, T. Mandl, H. Muller,
D. W. Oard, & A. Penas, D. Santos (Eds.), Advances in multilingual and multimodal informationretrieval, 8th workshop of the cross-language evaluation forum, CLEF 2007, Budapest, Hungary,
September 19–21, 2007 (Revised selected papers).
Laurent, D., Seguela, P., & Negre, S. (2005). Cross lingual question answering using QRISTAL for CLEF
2005. In C. Peters, F. C. Gey, J. Gonzalo, H. Muller, G. J. F. Jones, M. Kluck, B. Magnini, & M. de
Rijke (Eds.), Accessing multilingual information repositories, 6th workshop of the cross-languageevaluation forum, CLEF 2005, Vienna, Austria, September 21–23, 2005 (Revised selected papers).
Laurent, D., Seguela, P., & Negre, S. (2006). Cross lingual question answer ing using QRISTAL for
CLEF 2006. In C. Peters, P. Clough, F. C. Gey, J. Karlgren, B. Magnini, D. W. Oard, M. de Rijke, &
M. Stempfhuber (Eds.), Evaluation of multilingual and multi-modal information retrieval, 7th
workshop of the cross-language evaluation forum, CLEF 2006, Alicante, Spain, September 20–22,
2006 (Revised selected papers).
Laurent, D., Seguela, P., & Negre, S. (2007). Cross lingual question answering using QRISTAL for CLEF
2007. In: C. Peters, V. Jijkoun, T. Mandl, H. Muller, D.W. Oard, A. Penas, & D. Santos (Eds.),
Advances in multilingual and multimodal information retrieval, 8th workshop of the cross-language
A. Penas et al.
123

evaluation forum, CLEF 2007, Budapest, Hungary, September 19–21, 2007 (Revised selected
papers).
Laurent, D., Seguela, P., & Negre, S. (2008). Cross lingual question answering using QRISTAL for CLEF
2008. In C. Peters, T. Mandl, V. Petras, A. Penas, H. Muller, D. Oard, V. Jijkoun, & D. Santos
(Eds.), Evaluating systems for multilingual and multimodal information access, 9th workshop of the
cross-language evaluation forum, CLEF 2008, Aarhus, Denmark, September 17–19, 2008 (Revised
selected papers).
Lopez, V., Uren, V. S., Sabou, M., & Motta, E. (2009). Cross ontology query answering on the semantic
web: An initial evaluation. In K-CAP-2009: Proceedings of the fifth international conference onknowledge capture, Redondo Beach, CA.
Magnini, B., Negri, M., Prevete, R., & Tanev, H. (2002). Is it the right answer? Exploiting web
redundancy for answer validation In Proceedings of the 40th annual meeting of the association forcomputational linguistics (ACL), Philadelphia. doi:10.3115/1073083.1073154.
Magnini, B., Romagnoli, S., Vallin, A., Herrera, J., Penas, A., Peinado, V., et al. (2003). The multiple
language question answering track at CLEF 2003. In C. Peters, J. Gonzalo, M. Braschler, & M.
Kluck (Eds.), Comparative evaluation of multilingual information access systems, 4th workshop of
the cross-language evaluation forum, CLEF 2003, Trondheim, Norway, August 21–22, 2003
(Revised selected papers).
Magnini, B., Vallin, A., Ayache, C., Erbach, G., Penas, A., de Rijke, M., Rocha, P., Simov, K., &
Sutcliffe, R. (2004). Overview of the CLEF 2004 multilingual question answering track. In C.
Peters, P. Clough, J. Gonzalo, G. J. F. Jones, M. Kluck, & B. Magnini (Eds.), Multilingualinformation access for text, speech and images, 5th workshop of the cross-language evaluation
forum, CLEF 2004, Bath, UK, September 15–17, 2004 (Revised selected papers).
Magnini, B., Giampiccolo, D., Forner, P., Ayache, C., Jijkoun, V., Osenova, P., et al. (2006). Overview of
the CLEF 2006 multilingual question answering track. In C. Peters, P. Clough, F. C. Gey, J.
Karlgren, B. Magnini, D. W. Oard, M. de Rijke, & M. Stempfhuber (Eds.), Evaluation ofmultilingual and multi-modal information retrieval, 7th Workshop of the cross-language evaluation
forum, CLEF 2006, Alicante, September 20–22, 2006 (Revised selected papers).
Magnini, B., Speranza, M., & Kumar, V. (2009). Towards interactive question answering: an ontology-
based approach. In Proceedings of the IEEE international conference on semantic computing,
September 22–24, 2010, Carnegie Mellon University, Pittsburgh, PA.
Negri, M., Tanev, H., & Magnini, B. (2003) Bridging Languages for Question Answering: DIOGENE at
CLEF-2003. In C. Peters, J. Gonzalo, M. Braschler, & M. Kluck (Eds.), Comparative evaluation ofmultilingual information access systems, 4th workshop of the cross-language evaluation forum,
CLEF 2003, Trondheim, August 21–22, 2003 (Revised selected papers).
Noguera, E., Llopis, F., Ferrandez, A., & Escapa, A. (2007). Evaluation of open-domain question
answering systems within a time constraint. In Advanced Information networking and applicationsworkshops, AINAW ‘07. 21st international conference.
Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002). BLEU: A method for automatic evaluation of
machine translation. In Proceedings of the 40th annual meeting of the association for computationallinguistics (ACL), Philadelphia, July 2002.
Penas, A., & Rodrigo, A. (2011) A Simple Measure to Assess Non-response. In Proceedings of 49thannual meeting of the association for computational linguistics—human language technologies(ACL-HLT 2011), Portland, Oregon, June 19–24, 2011.
Penas, A., Rodrigo, A., Sama, V., & Verdejo, F. (2006). Overview of the answer validation exercise 2006.
In C. Peters, P. Clough, F. C. Gey, J. Karlgren, B. Magnini, D. W. Oard, M. de Rijke, & M.
Stempfhuber (Eds.), Evaluation of multilingual and multi-modal information retrieval, 7th
workshop of the cross-language evaluation forum, CLEF 2006, Alicante, Spain, September
20–22, 2006 (Revised selected papers).
Penas, A., Rodrigo, A., & Verdejo, F. (2007). Overview of the Answer Validation Exercise 2007. In
C. Peters, V. Jijkoun, T. Mandl, H. Muller, D. W. Oard, A. Penas, V. Petras, & D. Santos,
(Eds.), Advances in multilingual and multimodal information retrieval, LNCS 5152, September
2008.
Penas, A., Forner, P., Sutcliffe, R., Rodrigo, A., Forascu, C., Alegria, I., et al. (2009). Overview of
ResPubliQA 2009: Question answering evaluation over European legislation. In C. Peters, G. di
Nunzio, M. Kurimo, Th. Mandl, D. Mostefa, A. Penas, & G. Roda (Eds.), Multilingual informationaccess evaluation vol. i text retrieval experiments, workshop of the cross-language evaluation
Cross-language evaluation forum 2003–2010
123

forum, CLEF 2009, Corfu, Greece, September 30–October 2. Lecture Notes in computer science
6241. Springer-Verlag, 2010. (Revised selected papers).
Penas, A., Forner, P., Rodrigo, A., Sutcliffe, R., Forascu, & Mota, C. (2010). Overview of ResPubliQA
2010: Question answering evaluation over european legislation. In M. Braschler, D. Harman, and E.
Pianta (Eds,), Notebook papers of CLEF 2010 LABs and workshops, September 22–23, 2010, Padua,
Italy.
Perez-Iglesias, J, Garrido, G., Rodrigo, A, Araujo, L., & Penas, A. (2009). Information retrieval baselines
for the ResPubliQA Task. In Borri, F., Nardi, A., & Peters, C. (Eds.), Cross language evaluationforum: Working notes of CLEF 2009, Corfu, Greece, September 30–October 2.
Prager, J. (2006). Open-domain question-answering, Foundations and trends in information retrieval 1(2),
91–231. http:/dx.doi.org/10.1561/1500000001.
Prager, J., Brown, E., & Coden, A. (2000). Question-answering by predictive annotation. In Proceedingsof the 23rd annual international ACM SIGIR conference on research and development ininformation retrieval, Athens.
Rodrigo, A., Penas, A., & Verdejo, F. (2008). Overview of the answer validation exercise 2008. In C.
Peters, T. Mandl, V. Petras, A. Penas, H. Muller, D. Oard, V. Jijkoun, & D. Santos (Eds.),
Evaluating systems for multilingual and multimodal information access, 9th workshop of the cross-
language evaluation forum, CLEF 2008, Aarhus, September 17–19, 2008 (Revised selected papers).
Rodrigo, A., Perez, J., Penas, A., Garrido, G., & Araujo, L. (2009). Approaching question answering by
means of paragraph validation. In C. Peters, G. di Nunzio, M. Kurimo, Th. Mandl, D. Mostefa, A.
Penas, & G. Roda (Eds.), Multilingual information access evaluation vol. I text retrievalexperiments, workshop of the Cross-Language Evaluation Forum, CLEF 2009, Corfu, Greece,
September 30–October 2, 2010. Lecture notes in computer science 6241. Springer. Revised selected
papers).
Saias, J., & Quaresma, P. (2007). The senso question answering approach to Portuguese QA@CLEF-
2007. In C. Peters, V. Jijkoun, T. Mandl, H. Muller, D. W. Oard, A. Penas, & D. Santos (Eds.),
Advances in multilingual and multimodal information retrieval, 8th workshop of the cross-language
evaluation forum, CLEF 2007, Budapest, September 19–21, 2007 (Revised selected papers).
Saias, J., & Quaresma, P. (2008) The senso question answering system at QA@CLEF 2008. In C.
Peters, T. Mandl, V. Petras, A. Penas, H. Muller, D. Oard, V. Jijkoun, & D. Santos (Eds.),
Evaluating systems for multilingual and multimodal information access, 9th workshop of the
cross-language evaluation forum, CLEF 2008, Aarhus, September 17–19, 2008 (Revised selected
papers).
Santos, D., & Cabral, L. M. (2009). GikiCLEF: Crosscultural issues in an international setting:
Asking non-English-centered questions to Wikipedia. In Borri, F., Nardi, A., & Peters, C. (Eds.),
Cross language evaluation forum: working notes of CLEF 2009, Corfu, Greece, September 30–
October 2.
Toba, H., Sari, S., Adriani, M., & Manurung, M. (2010). Contextual approach for paragraph selection in
question answering task. In M. Braschler, D. Harman, & E. Pianta (Eds.), Notebook papers of CLEF2010 LABs and workshops, September 22–23, 2010, Padua, Italy.
Vallin, A., Magnini, B., Giampiccolo, D., Aunimo, L., Ayache, C., & Osenova, P. (2005). Overview of
the CLEF 2005 multilingual question answering track. In C. Peters, F. C. Gey, J. Gonzalo, H.
Muller, G. J. F. Jones, M. Kluck, B. Magnini, & M. de Rijke (Eds.), Accessing multilingualinformation repositories, 6th workshop of the cross-language evaluation forum, CLEF 2005,
Vienna, Austria, September 21–23, 2005 (Revised selected papers).
van Rijsbergen, K. J. (1979). Information retrieval. London: Butterworth.
Vicedo, J. L., Izquierdo, R., Llopis, F., & Munoz, R. (2003). Question answering in Spanish. In C. Peters,
J. Gonzalo, M. Braschler, & M. Kluck (Eds.), Comparative evaluation of multilingual informationaccess systems, 4th workshop of the cross-language evaluation forum, CLEF 2003, Trondheim,
Norway, August 21–22, 2003 (Revised selected papers).
Vicedo, J.L., Saiz, M., & Izquierdo, R. (2004). Does english help question answering in Spanish? In C.
Peters, P. Clough, J. Gonzalo, G. J. F. Jones, M. Kluck, & B. Magnini (Eds.), Multilingualinformation access for text, speech and images, 5th workshop of the cross-language evaluation
forum, CLEF 2004, Bath, UK, September 15–17, 2004 (Revised selected papers).
Voorhees, E. M. (2000). Overview of the TREC9 question answering track. In Proceedings of the NinthText Retrieval Conference (TREC-9).
A. Penas et al.
123

Voorhees, E. M. (2002). Overview of the TREC 2002 Question answering track. In Proceedings of theeleventh text retrieval conference (TREC-11).
Voorhees, E. M., Tice, D. M. (1999). The TREC-8 question answering track evaluation. In Proceedingsof the eight text retrieval conference (TREC-8).
Webb, N., & Webber, B. (Eds.) (2009). Special issue on interactive question answering. Journal ofNatural Language Engineering, 15(1), Cambridge University Press.
Cross-language evaluation forum 2003–2010
123





























